汇编语言源程序格式
第四章 汇编语言程序设计

例2:将一个十六进制数输出 算法分析: ①将十六进制数转换 成对应的字符。如果是数 字,加48H,如果是A~F, 加55。 ②利用功能调用输出。 ; 数据段
DATA
SEGMENT X DB 05H DATA ENDS
第四章
汇编语言程序格式
编写程序,将从键盘上输入一个小写英文字母, 例 3 : 编写程序 , 将从键盘上输入一个小写英文字母 , 输出 其对应的大写字母。 其对应的大写字母。
②算法分析: 使用XLAT指令查表 ③调试方法: 使用DEBUG的G命令
第四章
汇编语言程序格式
实验三: 实验三:顺序结构程序设计
1、实验目的: ① 熟练掌握汇编语言源程序的结构 ② 掌握顺序结构程序设计方法 2、实验内容: ① 使用算术运算类指令编写程序 ② 使用调整指令编写程序 ③ 使用逻辑运算指令编写程序
2
第四章
汇编语言程序格式
三、顺序结构程序设计示例
例1:编写程序完成将两个字节数据相加,并且将结果存入 编写程序完成将两个字节数据相加, 另一个单元中。 另一个单元中。 1、分析: 程序共分三个部分: ② 代码段 ① 数据段 2、设计: ① 设计数据段 DATA SEGMENT X DB 4CH Y DB 52H Z DB ? DATA ENDS
第四章
汇编语言程序格式
实验四: 实验四:分支结构程序设计
1、实验目的: 掌握分支结构程序设计方法 2、实验内容: ① 使用无符号转移指令编写程序 ② 使用有符号转移指令编写程序 ③ 使用特殊标志条件指令编写程序
12
第四章
汇编语段中有三个无符号数,分别存放在DAT,DAT+1, DAT+2字节单元中,编写一完整的源程序,找出三个数中数 值大小居中的一个,并将其存入BUF字节单元中。 DAT DB XX,XX,XX BUF DB ?
单片机指令系统习题

单⽚机指令系统习题第四章汇编语⾔程序设计第⼀节汇编语⾔源程序的格式和伪指令(⼀)学习要求1、掌握汇编语⾔源程序格式和伪指令。
2、掌握各种伪指令功能。
(⼆)内容提要⼀:汇编语⾔源程序的格式1、语句格式汇编语⾔源程序是由汇编语句(即指令)组成的。
汇编语⾔⼀般由四部分组成。
其典型的汇编语句格式如下:标号:操作码操作数;注释START:MOV A,30H ;A←(30H)(1) 标号段标号是⽤户定义的符号地址。
(2) 操作码段操作码段是每⼀语句中不可缺少的部分,也是语句的核⼼部分,⽤于指⽰计算机进⾏何种操作,汇编程序就是根据这⼀字段⽣成⽬标代码的。
(3) 操作数段指出了参与操作的数据或存放该数据的地址。
通常有⽬的操作数和源操作数之分。
(4) 注释段为了增强程序的可读性,可在某⾏指令的后⾯⽤分号起头,加上注释,⽤以说明该条指令或该段程序的功能、作⽤,以供编程⼈员参考。
此注释内容程序汇编时CPU 不予处理,不产⽣⽬标代码。
⼆:伪指令1、定位伪指令ORG(Origin)格式:[标号:] ORG mm:16位⼆进制数,代表地址。
功能:指出汇编语⾔程序通过编译,得到的机器语⾔程序的起始地址。
2、定义字节伪指令DB(Define Byte)格式:[标号:] DB X1,X2,~XnXn:单字节⼆进制、⼗进制、⼗六进制数,或以… ?括起来的字符串,数据符号。
功能:定义程序存储器从标号开始的连续单元,⽤来存放常数、字符和表格。
3、定义字伪指令DW(Define Word)格式:[标号:] DW Y1,Y2,~YnYn:双字节⼆进制、⼗进制、⼗六进制数,或以… ?括起来的字符串,数据符号。
功能:同DB,不同的是为16位数据。
4、汇编结束命令END格式:[标号:] END功能:END是汇编语⾔源程序的汇编结束标志,在它后⾯所写的指令均不予处理。
5、等值命令EQU格式:字符名称EQU 数或汇编符号功能:将⼀个数或特定的汇编符号赋予规定的字符名称。
汇编语言设计实践:第4部分 基本汇编语言

4.1 汇编语言语句种类及其格式
汇编语言的程序格式
• 完整的汇编语言源程序由段组成,段由指令语句与 伪指令语句构成
• 一个汇编语言源程序可以包含若干个代码段、数据 段、附加段或堆栈段,段与段之间的顺序可随意排 列
• 需独立运行的程序必须包含一个代码段,并指示程 序执行的起始点,一个程序只有一个起始点
• 所有的指令语句必须位于某一个代码段内,伪指令 语句可根据需要位于任一段内或段外
汇编语言的语句可以分为指令语句和伪指令语句
•指令语句——产生使CPU产生动作、可供机器
执行的机器目标代码
•伪指令语句——不产生CPU动作、在程序执行
前由汇编程序处理的说明性语句,例如,数据说明、 变量定义等等
2
一、指令语句
每一条指令语句在汇编时都要产生一个可供CPU执 行的机器目标代码,它又叫可执行语句。
指令语句的一般格式为: 标号 : 操作码
, 操作数
; 注释
一条指令语句最多可以包含4个字段 例 L1:MOV AH,0A0H ;将0A0H放入AH
3
1.标号字段
标号是可选字段,它后面必须有“:”。标号是一条 指令的符号地址,代表了该指令的第一个字节存放 地址。
注释字段可以是一条指令的后面部分,也可以是 整个语句行。
例:
LABEL1: ADD AX,BX; 功能为AX<=(AX)+(BX)
;后面的程序段将完成两次对存储器的访问
MOV AX, W_VAR1
MOV W_VAR2, AX
7
二、伪指令语句
伪指令语句又叫命令语句。 伪指令本身并不产生对应的机器目标代码。它仅 仅是告诉汇编程序对其后面的指令语句和伪指令 语句的操作数应该如何处理。
汇编 第四章伪指令及汇编语言源程序结构

MOV AL, BUF1
ADD AL, BUF2 MOV SUM, AL
;取第一个加数
;两数加 ;和放入SUM单元
3
伪指令(指 示性)语句: 提供相关辅 助信息。
指令性语句: 完成一定功 能,能翻译 成机器码。
伪指令语句
DATA SEGMENT ;DATA段定义开始 BUF1 DB 34H BUF2 DB 27H SUM DB ? DATA ENDS ;DATA段定义结束 CODE SEGMENT ;CODE段定义开始 ASSUME CS:CODE ASSUME DS:DATA ;段性质规定 START: MOV AX,DATA MOV DS,AX ;给DS赋值 MOV AL, BUF1 ;取第一个加数 ADD AL, BUF2 ;两数加 MOV SUM, AL ;和放入SUM单元 MOV AH,4CH INT 21H ;返回DOS CODE ENDS ;CODE段定义结束 END START ;源程序结束
14
二、= 等号伪指令
格式:符号名 = 表达式 功能:为常量、表达式及其他各种符号定义一个等价的符号 名,并能对所定义的符号多次重复定义,且以最后一次定义 的值为准。 例:COST = 20 M = MOV LOST = COST+10 ;30→LOST M = ADD ;M=ADD 注 : “ = ” 伪 指 令 的 格 式 和 功 能 与 EQU 类 似 。 二者区别:在同一程序中,“=”可以对一个符号重 复定义,EQU不能对同一符号重复定义。
26
三、变量、标号的分析运算和合成运算
例:DATA SEGMENT A DB ‘ABCDEF’ B DW 10 DUP(1,2DUP(2)) C DB 3,20 DUP(0) DATA ENDS ┆ MOV AX,LENGTH A ;1→AX MOV BX,LENGTH B ;10→BX MOV CX,LENGTH C ;1→CX ┆
第四章 汇编语言程序格式

.model small .data …… .code start: mov ax, @data mov ds, ax …… mov ax, 4c00h int 21h end start
9
段组定义伪操作
dseg1 dseg1 dseg2 dseg2 segment …… ends segment …… ends word public ‘data’
DATA_BYTE DATA_WORD
DB DW
10,4,10H,? 100,100H,-5,?
14
ARRAY
DB DB DW
‘HELLO’ ‘AB’ ‘AB’
ARRAY
48H 45H 4CH
4CH
4FH 41H 42H 42H 41H
PAR1 PAR2 ADDR_TABLE
DW DW DW
100,200 300,400 PAR1,PAR2
.STARTUP .EXIT [ return_value ]
13
数据定义及存储器分配伪操作:
[变量] 助记符 操作数 [ , 操作数 , … ] [ ; 注释] 助记符:DB DW DD DF DQ DT
DATA_BYTE 0AH 04H
10H
DATA_WORD 64H 00H 00H 01H FBH FFH -
12 ; (bx)=0 ; (bx)=2 ; (bx)=2
?
datagroup group data1,data2
code segment assume cs:code, ds:datagroup
; (bx)=0
程序开始和结束伪操作:
TITLE text
NAME module_name
汇编程序格式标准

Freescale 汇编语言源程序标准时间:2006-05-12 15:57:00 来源: 作者:刘玉宏Freescale 汇编语言源程序标准------------------------------------------------------此标准包括:行的长度限制可接受的字符和字符格式源程序列的分配注释格式-------------------------------------------------------行的长度:为了便于阅读和打印,Freescale使用mono-spaced字体,这种字体每个字符宽度相等.字体大小是9 point;最大行长为70个字符.示例如下:; 1 2 3 4 5 6 7;234567890123456789012345678901234567890123456789012345678901234567890 asc2hex: bsr ishex ;check for valid hex # firstbne dunA2asc ;if not just returncmp #’9’ ;check for A-F ($41-$46)bls notA2F ;skip if not A-F列表输出文件示例如下:; 1 2 3 4 5 6 7 8 9;23456789012345678901234567890123456789012345678901234567890123456789012 345678901234567890123551 C1D7 AD EA asc2hex: bsr ishex ;check for valid hex # first552 C1D9 26 0A bne dunA2asc ;if not just return553 C1DB A1 39 cmp #’9’ ;check for A-F ($41-$46)554 C1DD 23 02 bls notA2F ;skip if not A-F从以上可以看出列宽最大到93字符,因为列表输出文件并不能给读者提供更多的有用信息,因此Freescale最大用到每行93字符.-----------------------------------------------------------避免使用TAB字符TAB字符在不同的字处理软件中有不同的含义,当把源文件提交给其它文档时可能会出现问题,所以要避免使用TAB,而用多个空格代替.-----------------------------------------------------------源程序列分配源程序由标号,助记符,操作数和注释组成一行;标号在第1列开始指令助记符在第13列开始操作数在19列开始注释在31列开始;如果操作数超过了30列,注释必须和操作数的最后一个字符分开1到2个空格.如果一个标号超过11个字符,就应该另起一行,并在31列做注释.短标号也可以另起一行来突出它,这经常用在一个子程序开始处.见图3; 1 2 3 4 5 6 7;234567890123456789012345678901234567890123456789012345678901234567890 label: mne operand ;commentbrset very,long,operand ;comment can’t start in col 31veryLongLabel: ;long label on separate linenop ;instruction with no operandsshort: ;short label may use a separate linemne operand ;code to which ‘short’ refers-----------------------------------------------------------大写和小写字符源程序中协调一致的大小写可以增强可读性,并使程序变得容易理解.标号标号可以混和使用大小写,但无论在哪儿引用它都应该严格匹配其初始定义.指令助记符指令助记符,汇编指示和预处理应当使用小写字符.尽管他们可以使用大写字符,但是输入时要敲shift键,而且大写字符使读者变得不能专心阅读.各种各样得文档中指令使用大写字符仅仅是为了突出他们.有经验得程序员使用小写字符不但容易输入而且容易阅读.寄存器和位Freescale的头文件中使用大写字符定义寄存器和位.位的定义有两种方法位号(0-7)和位屏蔽码.位操作指令使用位号;逻辑操作指令使用屏蔽码方式.屏蔽码在位号前面加一个小写字母m前缀.示例见图4PTAD: equ $00 ;I/O port A data register; bit numbers for use in BCLR, BSET, BRCLR, and BRSETPTAD7: equ 7 ;bit #7PTAD6: equ 6 ;bit #6PTAD5: equ 5 ;bit #5PTAD4: equ 4 ;bit #4PTAD3: equ 3 ;bit #3PTAD2: equ 2 ;bit #2PTAD1: equ 1 ;bit #1PTAD0: equ 0 ;bit #0; bit position masksmPTAD7: equ %10000000 ;port A bit 7mPTAD6: equ %01000000 ;port A bit 6mPTAD5: equ %00100000 ;port A bit 5mPTAD4: equ %00010000 ;port A bit 4mPTAD3: equ %00001000 ;port A bit 3mPTAD2: equ %00000100 ;port A bit 2mPTAD1: equ %00000010 ;port A bit 1mPTAD0: equ %00000001 ;port A bit 0-----------------------------------------------------------标号标号可以混和使用大小写,但避免使用下划线,我们推荐使用大写字符做为多字符标号的分界.例如:VeryLongLabel代替ery_long_label标号定义并加一个冒号,尽管有很多编译器不需要这个冒号.文件和子程序头文件和子程序前面需要一个块来说明他的用途和目的,称为头图5是典型的文件头;*********************************************************************************** *********;* Title: 9S08GB60_v1r2.equ (c) FREESCALE Inc. 2003 All rights reserved. ;*********************************************************************************** *********;* Author: Jim Sibigtroth - Freescale TSPG;*;* Description: Register and bit name definitions for 9S08GB60;*;* Documentation: 9S08GB60 family Data Sheet for register and bit explanations;* HCS08 Family Reference Manual (HCS08RM1/D) appendix B for explanation of equat e files;*;* Include Files: none;*;* Assembler: Metrowerks Code Warrior 3.0 (pre-release);* or P&E Microcomputer Systems - CASMS08 (beta v4.02);*;* Revision History:;* Rev # Date Who Comments;* ----- ----------- ------ --------------------------------------------;* 1.2 24-Apr-03 J-Sib correct minor typos in comments;* 1.1 21-Apr-03 J-Sib comments and modify for CW 3.0 project;* 1.0 15-Apr-03 J-Sib Release version for 9S09GB60;*********************************************************************************** *********其中有些是必须的,有些可以省略文件名:必须,包括文件名和后缀版权声明:必须作者:必须,有些文件可能重复使用数年,有时需要帮助时可以联系他们描述:必须,但仅是摘要,更多信息应该在一个单独的文件中文档:另外一个文件,她是对这个文件的详细说明包含文件:需要时必须汇编器:汇编器的厂商和版本,非常重要版本历史:提供何时,何人,哪个文件被修改等信息图6是子程序头模板,可以根据子程序的复杂程度适当增减;****************************************************************** ;* RoutineName - expanded name or phrase describing purpose;* Brief description, typically a few lines explaining the;* purpose of the program.;*;* I/O: Explain what is expected and what is produced;*;* Calling Convention: How is the routine called?;*;* Stack Usage: (when needed) When a routine has several variables;* on the stack, this section describes the structure of the;* information.;*;* Information about routines that are called and any registers;* that get destroyed. In general, if some registers are pushed at;* the beginning and pulled at the end, it is not necessary to;* describe this in the routine header.;******************************************************************;****************************************************************** ;* GetSRec - retrieve one S-record via SCI1;* Terminal program should delay after to allow programming;* recommended delay after is TBDms, no delay after chars.;* Only header (S0), data (S1), and end (S9) records accepted;*;* Calling Convention:;* ais #-bufferLength ;# of data bytes + 4 (typ.36);* jsr GetSRec ;read S-record onto stack;* bne error ;Z=0 means record bad;*;;*; ’bufferLength’ is defined in calling program not in this;*; subroutine, calling routine must also deallocate buffer space;*; after processing the information that was returned on the stack;*;;* ais #bufferLength ;deallocate buffer space;*;* Returns: all but CCR Z-bit returned on stack (see stack map);* CCR Z-bit = 1 if valid S-record; CCR Z-bit = 0 if not valid;* S-record type @ sp+1 (1 ASCII byte) ($30, $31, or $39);* S-record size @ sp+2 (1 hex byte) (# of data bytes 0-31);* S-record addr @ sp+3 (2 hex bytes) (addr of 1st data value);* S-record data @ sp+5..sp+36 (up to 32 hex data bytes);*;* Stack map... S-record, return, and locals on stack;* | | <-sp (after local space allocated);* H:X-> | SRecCount |;* | SRecChkSum | <-sp (after jsr);* | ReturnAddr msb |;* | ReturnAddr lsb | <-sp (after rts);* | SRecTyp |;* | SRecSize |;* H:X-> | SRecAddr msb |;* | SRecAddr lsb |;* | SRecData 00 |;* | SRecData 01 | etc... (up to 32 bytes);*;* Data values are read as two ASCII characters, converted to;* hex digits, combined into 1 hex value, and stored on stack;*;* Calls: GetChar, PutChar, and GetHexByte;* Changes: A, H, and X;****************************************************************** 图7是一个复杂的头,它使用堆栈传递参数并且附加的堆栈来分配局部变量.虽然可以描述很多的细节但我们规定头的描述最好限制在3到4行.如果要求更多的细节,可以使用一个的单独的文件,而不是描述在代码文件中.调用协议是想当复杂的,因为用户必须分配传递参数的堆栈空间,堆栈内的参数包括用户填充的和本子程序返回的.当这个子程序放回后,一条BNE指令用来检查Z标志来检查本子程序是否成功得到一个S记录.当检查到一个错误或可处理的返回数据,调用程序必须处理调用前分配的传递参数的堆栈空间.堆栈的用法也非常复杂,因为本子程序在堆栈上处理信息,所以给读者提供一个堆栈信息映像来帮助读者理解这个子程序是非常重要的.这个映像展示了一个最大的块,这个块是在调用子程序之前分配的.返回地址做为JSR指令的结果也存储在堆栈上.本子程序内部分配使用的2字节局部变量必须在返回调用程序之前处理完毕.在这个子程序的头的最后调用项:列出本子程序需要调用的子程序.改变项:列出执行本子程序改变的寄存器;******************************************************************;* GetChar - wait indefinitely for a character to be received;* through SCI1 (until RDRF becomes set) then read char into A;* and return. Reading character clears RDRF. No error checking.;*;* Calling convention:;* jsr GetChar;*;* Returns: received character in A;******************************************************************图8展示一个简单的子程序头,这个头不包含堆栈信息,也不调用其它子程序,所以这些信息都不需要了.----------------------------------------------------------------注释:注释是非常重要的,大多数注释格式是以分号并从31列开始直到行尾.避免注释重复说明指令内容.例如:lda pta ;读A口数据.取而代之注释应传递这样一些信息:为什么指令在这儿,指令如何描述程序功能或系统包含的嵌入式微控制器.这是一个好的注释:lda PTAD ;check for low on bit 7 (step switch)如果注释过长不能在一行完成,那么应该在第1列单独起一行,但不宜频繁使用以防淹没代码行.如果是多行注释可以写成注释块,注释块与代码行以空注释行相分隔如下所示:;; In-line comment block. On rare occasions, an extended comment; is needed to explain some important aspect of a program. Each; line of the extended comment starts with a semicolon. A line; with nothing but a semicolon in column 1 is used above and; below the block comment to set it apart from code.;注释格式基础理论注释或空行可以使程序组成逻辑段以提高可读性.子程序头块可以标识一个子程序的开始.类似的分隔也是非常有用的.。
汇编语言程序

汇编语言程序
微处理器的指令系统决定了一台计算机能够执行的所 有操作,但其每一条指令必须以二进制表示的操作码和 操作数的形式输入到CPU中,才能被识别并执行。为了 减轻书写和记忆负担,人们提出了汇编语言——以助记 符的形式来替代每一条二进制指令。
汇编语言作为一种语言,也具有自己的语法结构, 使用者必须遵守其规则和约定才能被汇编程序识别,最 终转换为CPU的指令,交由CPU执行。这些规则和约定 包括:语句的格式、程序的格式、参数的表示、符号的 定义、内存的分配等内容,构成了汇编语言的语法。
汇编语言源程序是解决问题的语言描述,不同的问题需要用 户设计不同的方案,是一段文本文件;而汇编程序是将这一段文 本文件翻译成真正可以执行的机器语言的固定程序。两者之间的 关系如图4-1。
图4-1 源程序、汇编程序、目标程序的关系
<>
1.2 汇编语言源程序格式
下面用一个实例说明汇 CSEG SEGMENT
2.汇编程序
汇编程序(MASM)是将汇编语言源程序文件编译成目标文
件的一段程序,即是一个翻译软件,它能将汇编语言程序变成二进
制的CPU指令代码。常用的汇编程序有:ASM.EXE、MASM.EXE、
TASM.EXE等软件,经过二次扫描源程序,一一对应地形成相应
的二进制机器语言,完成汇编。
系
;返回DOS
SSEG ENDS
INT 21H CSEG ENDS
;功能调用 ;代码段定义结束
END START
;汇编结束,其后内容不再汇编
<>
汇编语言源程序格式说明:
①整个程序定义了三个段:数据段、堆栈段和代码段,这样汇 编时,能够在内存中分配了三个段(每段最大不超过64KB)的 存储空间。 ②各段空间的作用如下: 数据段:用于存放用户定义的数据变量 堆栈段:用于存储入栈与出栈的数据。 代码段:用于存储用户设计的指令代码。每条语句必须在代码 段中,指令代码是代码段所存储的内容。 ③每个段都由段名 SEGMENT开始定义,而由段名 ENDS结 束该段定义。 ④在段中每一行组成了汇编语言源程序的一条语句,每条语句 都有固定的语法格式,必须按规定的格式书写。
汇编语言程序格式及MASM

ML /Fm LI6-1.ASM
将产生LI6-1.MAP映像文件,如下:
LI6-1.MAP
Start Stop Length Name Class
00000H 00022H 00023H _TEXT CODE
汇编语言程序格式及MASM
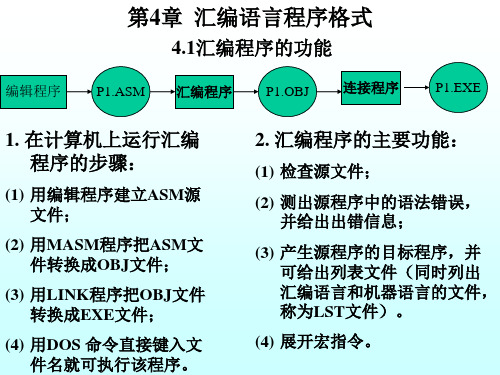
汇编语言的实现也是先利用某种编辑器编写汇编语言源程序(*.ASM),然后经过汇编得到目标模块文件(*.OBJ)、连接后形成可执行文件(*.EXE)。
1、汇编语言程序的语句格式
汇编语源程序由语句序列构成。语句一般由分隔符分成的四个部分组成,它们有两种格式:
(1)执行性语句——由硬指令构成的语句,它通常对应一条机器指令,出现在程序的代码段中:
0007 2B DA * sub bx, dx
0009 D1 E3 * shl bx, 001h
000B D1 E3 * shl bx, 001h
000D D1 E3 * shl bx, 001h
000F D1 E3 * shl bx, 001h
0011 FA * cli
0012 8E D2 * mov ss, dx
标号:硬指令助记符 操作数,操作数 ;注释
(2)说明性语句——由伪指令构成的语句,它通常指示汇编程序如何汇编源程序:
名字 伪指令助记符 参数,参数,... ;注释
◆执行性语句中,冒号前的标号反映该指令的逻辑地址;说明性语句中的名字可以是变量名、段名、子程序名或宏名等等,既反映逻辑地址又具有自身的各种属性。标号和名字很容易通过是否具有冒号来区分。
li6-1.lst
Microsoft (R) Macro Assembler Version 6.11 08/10/05 14:09:13
汇编语言程序格式

1.2汇编语言程序的段定义
DATA_SEG1 SEGMENT PARA
DATA_SEG1 ENDS
DATA_SEG2 SEGMENT PARA
…….
DATA_SEG2 ENDS
E_SEG1
SEGMENT PARA
……..
ቤተ መጻሕፍቲ ባይዱ
E_SEG1
ENDS
E_SEG2
SEGMENT PARA
……..
E_SEG2
ENDS
ENDP 说明:过程属性项省略,系统默认为NEAR,表示段内调用, FAR 过程体至少有一条返回指令RET,RET一般放在过程体的最后。 也可以使用带参数的返回语句,如RET n。
1.3汇编语言源程序过程定义
MY_CODE SEGMENT
UP_COUNT PROC NEAR
ADDCX, 1
RET
UP_COUNT ENDP
1.2 汇编语言程序的段定义
存储器是采用分段管理方式,在编制任意源程序时亦必 须按段来构造程序。按段来构造程序有两种形式:一种是完
1.
NAME TITLE EQU EXTRN PUBLIC SEG1
SEG1 SEG2
SEG2
SEGMENT PARA STACK …… ENDS SEGMENT PARA STACK ; …… ENDS
避免多模块使用不同起始地址,只有主模块使用起始地址, 否则引起程序出错。
1.4标准程序前奏
Code_SREG1 SEGMENT‘CODE’ ASSUME CS:Code_SREG1…
MAIN PROC FAR ……… RET
MAIN ENDP Code_SREG1 ENDS
END MAIN Code_G2 SEGMENT ‘CODE’
PPT-汇编语言源程序的框架结构

JMP BX ;产生多分支转移TAB: JMP SHORT A0 ;转移表JMP SHORT A1JMP SHORT A2A0: LEA DX,S0 ;各分支程序段MOV AH,9INT 21HJMP EXIT1A1: LEA DX,S1MOV AH,9INT 21H
JMP EXIT1A2:LEA DX,S2MOV AH,9INT 21HJMP EXIT1ERROR: MOV DX,OFFSET ERMOV AH,9INT 21HEXIT1: MOV AH,4CH ;返回DOSINT 21HCODE ENDSEND START
A0: LEA DX,S0 ;各分支程序段MOV AH,9INT 21HJMP EXIT1A1: LEA DX,S1MOV AH,9INT 21HJMP EXIT1A2: LEA DX,S2MOV AH,9INT 21HJMP EXIT1
ERROR: MOV DX,OFFSET ERMOV AH,9INT 21HEXIT1: MOV AH,4CH ;返回DOSINT 21HCODE ENDSEND START
图5.8 用转移表法实现多路分支旳构造框图例5.5:编程实现菜单项选择择,根据不同旳选择做不同旳事情。解:假设有3路分支,转移表中旳转移指令分别为:JMP SHORT A0、JMP SHORT A1、JMP SHORT A2;详细见图5.9所示:
参照程序:DATA SEGMENTMENU DB 0DH,0AH,"0:Chinese!"DB 0DH,0AH,"1:English!"DB 0DH,0AH,"2: German!"DB 0DH,0AH,"Please choose one to answer the following question:$"
第4章 汇编语言程序格式
WORD——从字边界(偶数地址)开始
DWORD——从双字边界(4的倍数地址)开始 PAGE——从低8位物理地址为0处开始
(2) 组合类型(combine_type)说明程序连接时的段合并方法,可以是:
PRIVATE——私有段,不与其它模块中的同名段合并——默认值 PUBLIC——公有段,连接时与其它模快中的同名段合并成一个段
4.2.1 处理机选择伪操作
.8086 . 286 . 286P . 386 . 386P 选择8086指令系统 选择80286指令系统 选择保护模式下的80286指令系统 选择80386指令系统 选择保护模式下的80386指令系统
. 486
. 486P . 586
选择80486指令系统
选择保护模式下的80486指令系统 选择Pentium指令系统
CS:CSEG,DS:DATAGROUP
START:MOV MOV ……
AX,DATAGROUP DS,AX
4.3.3 程序开始和结束伪操作
1. 开始伪操作
在程序的开始可以用NAME或TITLE作为模块的名字,NAME的格式是: NAME 模块名
如果程序中没有使用NAME伪操作,则也可使用TITLE,其格式为: TITLE text
例4.2 .MODEL SMALL .STACK 100h .DATA 例4.3 .MODEL SMALL .STACK 100h .CONST …… .DATA …… AX,@DATA DS,AX .CODE START: MOV AX,DGROUP
……
.CODE START: MOV MOV …… MOV INT END AX,4C00H 21H START
③ uninitialized data
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3.操作数项
• 指令中的操作数用来指定参与操作的数 据。对于一般指令,可以有一个或两个 操作数,也可以没有操作数;对于伪指 令和宏指令,可以根据需要有多个操作 数。操作数多于一个时,各操作数之间 用逗号分开。源自• (2) 变量•
变量在除代码段以外的其它段中定
义,后面不跟冒号。它也可以用EQU或
LABEL伪指令来定义。变量是一个可以
存放数据的存储单元的名字,即存放数
据的存储单元的地址符号名。变量用DB 、DW、DD定义,此时变量名仅表示该
数据区或存储区的第一个数据单元的首
地址。变量经常在操作数字段出现。
• 变量也有3种属性:段属性、偏移属性和类型属性。
。 • 操作数项由一个或多个表达式组成,它提供为执行所要求的操作而需
要的信息。 • 注释项用来说明程序或语句的功能。“;”为识别注释项的开始。 • 带方括号的项是可选项,需要根据具体情况而定。 • 汇编语言源程序中的每条语句一般占一行,各项之间必须用空格或制
表符作为分隔符,操作数之间用逗号分隔。
• 1.名字项 • 名字是用户按照一定规则定义的标识符,可由下列符号组成: • 字母 A~Z、a~z • 数字 0~9 • 特殊字符 ?、.、@、_、$ • 数字不能作名字项的第一个字符。而圆点仅能用作第一个字符,
• (3) 宏指令语句:就是由若干条指令语句形成的语句,一条宏指令语 句的功能相当于若干条指令语句的功能,详见第5章。
2.1.2 汇编语言语句格式
• 汇编语言源程序中的每个语句可以由4项组成,格式如下: • [名字:] 操作码 [操作数[,操作数]] [;注释] • 其中,名字项是一个符号项。 • 操作码项是一个操作码的助记符,它可以是指令、伪指令或宏指令名
可以用很多字符来说明名字,但只有前面的31个字符能被汇编程 序所识别。为了便于记忆,名字的定义应该能够见名知义,如用 BUFFER表示缓冲区、SUM表示累加和等。
• 名字有两种形式:标号或变量。指令语句中的名字通常用标号表 示,而伪指令语句中的名字通常用变量名、段名和过程名表示, 多数情况下用变量名表示。
• (1) 标号
• 标号在代码段中定义,也可以用EQU或 LABEL伪指令来定义,标号与其所代表 的指令之间用冒号分开,用来代表一条 指令所在单元的地址。标号也可以作为 过程名定义。标号经常在转移指令的操 作数字段出现,用以表示转向的目标地 址。标号在命名时,应尽量取有意义的 字符,以便程序的阅读和理解。
• 类型属性:变量的类型属性定义该变量所保留的字节 数,如BYTE(1个字节长),WORD(2个字节长) ,DWORD(4个字节长)。这一点,将在数据定义伪 指令中说明。
• 在同一个程序中,同样的标号或变量的定义只允许出 现一次,否则汇编程序会指示出错。
2.操作码项
• 操作码项可以是指令、伪指令或宏指令的助记符。助记符 表示指令语句的功能,如INC、MOV等,其符号与意义是 由系统定义的,编程时必须照写不误,既不能多写,也不 能少写,如果指令带有前缀(如REP、REPE等),则指 令前缀和指令助记符要用空格分开。
2.1.1 汇编语言语句类型
• 汇编语言源程序由语句序列构成,汇编语言程序中的语句可以分为指 令语句、伪指令语句和宏指令语句三种。
• (1) 指令语句:对应于CPU指令系统中的一条机器指令,由CPU执 行,能完成一定操作功能,能够翻译成机器代码的语句。
• (2) 伪指令语句:无对应的机器指令,不由CPU执行,只为汇编程 序在翻译汇编语言源程序时提供有关信息,并不翻译成机器代码的语 句。
第2章 汇编语言程序格式
• 2.1 汇编语言语句格式 • 2.2 伪指令 • 2.3 汇编语言源程序基本框架
2.1 汇编语言语句格式
• 同其他程序设计语言一样,汇编语言的翻 译器(汇编程序)对源程序有严格的格式 要求。这样,汇编程序才能确切翻译源程 序,形成功能等价的机器指令(目标代码 ),连接后能直接运行。汇编语言程序格 式就是汇编语言必须遵循的语法规则。
• 标号有3种属性:段属性、偏移属性和类型属性。
• 段属性:标号所代表指令单元的段起始地址,此值必 须在一个段寄存器中,而标号的段则总是在CS寄存器 中。
• 偏移属性:标号所代表指令单元的段内偏移地址,标 号的偏移地址是从段起始地址到定义标号的位置之间 的字节数。对于16位段是16位无符号数。
• 类型属性:用来指出标号是在本段内引用还是在其他 段中引用的。如是在段内引用的,则称为NEAR,转 移源和转移目标在同一个代码段中,转移时,只改变 IP值,不改变CS值;如在段外引用,则称为FAR,转 移源和转移目标在不同的代码段中,转移时,既改变 IP值,又改变CS值。
• 组成表达式的操作符有算术、逻辑、关
常用的操作符
• 算术操作符 • 逻辑与移位运算符 • 关系运算符 • 数值返回运算符 • 属性运算符
(1) 算术操作符
• 算术运算符包括:+、-、*、/、MOD(取余)。
• 运算符MOD是作除法操作,取余数,如10 MOD 3 = 1。
• 算术运算符可以用于数字表达式或地址表达式中。但 当它用于地址表达式时,只有当其结果有明确的物理 意义时才是有效的结果,例如,两个地址相乘或相除 是无意义的。在地址表达式中,可以用+或-,但也必 须注意其物理意义,例如把两个不同段的地址相加也 是无意义的。经常使用的方法是“地址±常量”来描 述指针的移动,例如,SUM+1是指SUM字节单元的 下一个字节单元的地址(注意:不是指SUM单元的 内容加1),而SUM-1则是指SUM字节单元的前一个 字节单元的地址。
• 操作数可以是常数、寄存器、标号、变 量或由表达式组成。在这里,将专门对 表达式加以说明。表达式是常数、标号 、变量、寄存器与一些操作符相组合的 序列,可以有数字表达式和地址表达式 两种。数字表达式由汇编程序根据优先 级规则计算得到一个常数值。地址表达 式由汇编程序计算得到一个地址或一个 常数值(地址间的距离长度)。
• 段属性:变量所代表数据单元的段起始地址,此值必 须在一个段寄存器中(DS、ES或SS中)。
• 偏移属性:变量所代表数据单元的段内偏移地址,变 量的偏移地址是从段的起始地址到定义变量的位置之 间的字节数。对于16位段是16位无符号数。在当前段 内给出变量的偏移值等于当前地址计数器的值,当前 地址计数器的值可以用$来表示。