(完整版)编译原理词法分析和语法分析报告+代码(C语言版)[1]
(完整版)编译原理词法分析和语法分析报告+代码(C语言版)[1]
![(完整版)编译原理词法分析和语法分析报告+代码(C语言版)[1]](https://img.taocdn.com/s3/m/cbda17cbed630b1c58eeb512.png)
词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1待分析的简单的词法( 1)关键字:begin if then while do end所有的关键字都是小写。
( 2)运算符和界符:=+-*/<<=<>>>==;()#( 3)其他单词是标识符(ID )和整型常数( SUM ),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*( 4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID 、SUM 、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2各种单词符号对应的种别码:表 2.1各种单词符号对应的种别码单词符号种别码单词符号种别码bgin1:17If2: =18Then3<20wile4<>21do5<=22end6>23lettet( letter|digit ) *10>=24 dight dight*11=25 +13;26—14(27*15)28/16#02.3词法分析程序的功能:输入:所给文法的源程序字符串。
输出:二元组( syn,token 或 sum)构成的序列。
其中: syn 为单词种别码;token 为存放的单词自身字符串;sum 为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end # 的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1主程序示意图:主程序示意图如图3-1 所示。
其中初始包括以下两个方面:⑴ 关键字表的初值。
[工学]编译原理--词法分析_语法分析_语义分析C语言
![[工学]编译原理--词法分析_语法分析_语义分析C语言](https://img.taocdn.com/s3/m/f74ee66f7275a417866fb84ae45c3b3567ecddeb.png)
[工学]编译原理--词法分析_语法分析_语义分析C语言词法分析#include#include#includeusing namespace std;#define MAXN 20000int syn,p,sum,kk,m,n,row;double dsum,pos;char index[800],len;//记录指数形式的浮点数char r[6][10]={"function","if","then","while","do","endfunc"}; char token[MAXN],s[MAXN];char ch;bool is_letter(char c){return c>='a' && c<='z' || c>='A' && c<='Z';}bool is_digtial(char c){return c>='0' && c<='9';}bool is_dot(char c){return c==',' || c==';';}void identifier()//标示符的判断{m=0;while(ch>='a' && ch<='z' || ch>='0' && ch<='9') {token[m++]=ch;ch=s[++p];}token[m]='\\0';ch=s[--p];syn=10;for(n=0;n<6;n++)if(strcmp(token,r[n])==0){syn=n+1;break;}}void digit(bool positive)//数字的判断{len=sum=0;ch=s[p];while(ch>='0' && ch<='9'){sum=sum*10+ch-'0';ch=s[++p];}if(ch=='.'){dsum=sum;ch=s[++p];pos=0.1;while(ch>='0' && ch<='9'){dsum=dsum+(ch-'0')*pos;pos=pos*0.1;ch=s[++p];}if(ch=='e'){index[len++]=ch;ch=s[++p];if(ch=='-' || ch=='+'){index[len++]=ch;ch=s[++p];}if(!(ch>='0' && ch<='9')){syn=-1;}else{while(ch>='0' && ch<='9'){index[len++]=ch;ch=s[++p];}}}if(syn==-1 || (ch>='a' && ch<='z') || ch=='.') {syn=-1;//对数字开头的标识符进行判错。
编译原理课程设计(词法分析,语法分析,语义分析,代码生成)

#include<cstdio>#include<iostream>#include<cstdlib>#include<fstream>#include<string>#include<cmath>using namespace std;/*********************下面是一些重要数据结构的声明***************************/struct token//词法token结构体{int code;//编码int num;//递增编号token *next;};token *token_head,*token_tail;//token队列struct str//词法string结构体{int num;//编号string word;//字符串内容str *next;};str *string_head,*string_tail;//string队列struct ivan//语法产生式结构体{char left;//产生式的左部string right;//产生式的右部int len;//产生式右部的长度};ivan css[20];//语法20个产生式struct pank//语法action表结构体{char sr;//移进或归约int state;//转到的状态编号};pank action[46][18];//action表int go_to[46][11];//语法go_to表struct ike//语法分析栈结构体,双链{ike *pre;int num;//状态int word;//符号编码ike *next;};ike *stack_head,*stack_tail;//分析栈首尾指针struct L//语义四元式的数据结构{int k;string op;//操作符string op1;//操作数string op2;//操作数string result;//结果L *next;//语义四元式向后指针L *Ltrue;//回填true链向前指针L *Lfalse;//回填false链向前指针};L *L_four_head,*L_four_tail,*L_true_head,*L_false_head;//四元式链,true链,false链struct symb//语义输入时符号表{string word;//变量名称int addr;//变量地址symb *next;};symb *symb_head,*symb_tail;//语义符号链表/*********************下面是与词法分析相关的一些函数的声明***************************/void scan();//按字符读取源文件void cifa_main();//词法分析主程序int judge(char ch);//判断输入字符的类型void out1(char ch);//写入token.txtvoid out3(char ch,string word);//写入string.txtvoid input1(token *temp);//插入结点到队列tokenvoid input3(str *temp);//插入结点到队列stringvoid output();//输出三个队列的内容void outfile();//输出三个队列的内容到相应文件中/*********************下面是与语法分析相关的一些函数的声明***************************/void yufa_main();//语法分析主程序void yufa_initialize();//初始化语法分析数据结构int yufa_SLR1(int a);//语法分析主体部分int ID1(int a);//给输入字符编号,转化成action表列编号string ID10(int i);//给输入字符反编号int ID2(char ch);//给非终结状态编号,转化成go_to表列编号int ID20(char ch);//给非终结状态编号char ID21(int j);//给非终结状态反编号void add(ike *temp);//给ike分析栈链表增加一个结点void del();//给ike分析栈链表删除一个结点/*********************下面是与语义分析相关的一些函数的声明***************************/void yuyi_main(int m);//语义分析主程序void add_L_four(L *temp);//向四元式链中加一个结点void add_L_true(L *temp);//向true链中加一个结点void add_L_false(L *temp);//向false链中加一个结点void add_symb(symb *temp);//向语义符号表链中加一个结点void output_yuyi();//输出中间代码四元式和最后符号表string newop(int m);//把数字变成字符串string id_numtoname(int num);//把编号转换成相应的变量名int lookup(string m);//变量声明检查/*********************下面是一些全局变量的声明***************************/FILE *fp;//文件指针int wordcount;//标志符计数int err;//标志词法分析结果正确或错误int nl;//读取行数int yuyi_linshi;//语义临时变量string E_name,T_name,F_name,M_name,id_name,id1_name,id2_name,errword;//用于归约时名称传递和未声明变量的输出int id_num,id1_num,id2_num,id_left,id_while,id_then,id_do;//用于记录一些特殊的字符位置信息/****************************主程序开始**************************/int main(){cout<<"************************"<<endl;cout<<"* 说明:*"<<endl;cout<<"* 第一部分:词法分析*"<<endl;cout<<"* 第二部分:语法分析*"<<endl;cout<<"* 第三部分:语义分析*"<<endl;cout<<"************************"<<endl;cifa_main();//词法yufa_main();//语法output_yuyi();//语义cout<<endl;system("pause");return(0);}/****************************以上是主程序,以下是词法**************************/void cifa_main(){token_head=new token;token_head->next=NULL;token_tail=new token;token_tail->next=NULL;string_head=new str;string_head->next=NULL;string_tail=new str;string_tail->next=NULL;//初始化三个队列的首尾指针L_four_head=new L;L_four_head->next=NULL;L_four_tail=new L;L_four_tail->k=0;L_four_tail->next=NULL;L_true_head=new L;L_true_head->Ltrue=NULL;L_false_head=new L;L_false_head->Lfalse=NULL;symb_head=new symb;symb_head->next=NULL;symb_tail=new symb;symb_tail->next=NULL;yuyi_linshi=-1;id_num=0;wordcount=0;//初始化字符计数器err=0;//初始化词法分析错误标志nl=1;//初始化读取行数scan();if(err==0){char m;output();cout<<"词法分析正确完成!"<<endl<<endl<<"如果将结果保存到文件中请输入y ,否则请输入其它字母:";cin>>m;cout<<endl;if(m=='y'){outfile();cout<<"结果成功保存在token.txt和sting.txt两个文件中,请打开查看"<<endl;cout<<endl;}}void scan(){cout<<endl;system("pause");cout<<endl;char ch;string word;char document[50];int flag=0;cout<<"请输入源文件路径及名称:";cin>>document;cout<<endl;cout<<"************************"<<endl;cout<<"* 第一部分:词法分析*"<<endl;cout<<"************************"<<endl;if((fp=fopen(document,"rt"))==NULL){err=1;cout<<"无法找到该文件!"<<endl;return;}while(!feof(fp)){word="";ch=fgetc(fp);flag=judge(ch);if(flag==1)out1(ch);else if(flag==3)out3(ch,word);else if(flag==4 || flag==5 ||flag==6)continue;else{cout<<nl<<"行"<<"错误:非法字符! "<<ch<<endl;err=1;}}fclose(fp);}int judge(char ch)int flag=0;if(ch=='=' || ch=='+' || ch=='*' || ch=='>' || ch==':' || ch==';' || ch=='{' || ch=='}' || ch=='(' || ch==')') flag=1;//界符else if(('a'<=ch && ch<='z') || ('A'<=ch && ch<='Z'))flag=3;//字母else if(ch==' ')flag=4;//空格else if(feof(fp))flag=5;//结束else if(ch=='\n'){flag=6;//换行nl++;}elseflag=0;//非法字符return(flag);}void out1(char ch){int id;switch(ch){case '=' : id=1;break;case '+' : id=2;break;case '*' : id=3;break;case '>' : id=4;break;case ':' : id=5;break;case ';' : id=6;break;case '{' : id=7;break;case '}' : id=8;break;case '(' : id=9;break;case ')' : id=10;break;//界符编码default : id=0;}token *temp;temp=new token;temp->code=id;temp->num=-1;temp->next=NULL;input1(temp);return;}void out3(char ch,string word){token *temp;temp=new token;temp->code=-1;temp->num=-1;temp->next=NULL;str *temp1;temp1=new str;temp1->num=-1;temp1->word="";temp1->next=NULL;int flag=0;word=word+ch;ch=fgetc(fp);flag=judge(ch);if(flag==1 || flag==4 || flag==5 || flag==6){if(word=="and" || word=="if" || word=="then" || word=="while" || word=="do" || word=="int") {if(word=="and")temp->code=31;else if(word=="if")temp->code=32;else if(word=="then")temp->code=33;else if(word=="while")temp->code=35;else if(word=="do")temp->code=36;else if(word=="int")temp->code=37;//关键字编码input1(temp);if(flag==1)out1(ch);else if(flag==4 || flag==5 || flag==6)return;}else if(flag==1){wordcount++;temp->code=25;temp->num=wordcount;input1(temp);temp1->num=wordcount;temp1->word=word;input3(temp1);out1(ch);}else if(flag==4 || flag==5 || flag==6){wordcount++;temp->code=25;temp->num=wordcount;input1(temp);temp1->num=wordcount;temp1->word=word;input3(temp1);}return;}else if(flag==2 || flag==3)out3(ch,word);//形成字符串else{err=1;cout<<nl<<"行"<<"错误:非法字符! "<<ch<<endl; return;}}void input1(token *temp){if(token_head->next == NULL){token_head->next=temp;token_tail->next=temp;}else{token_tail->next->next=temp;token_tail->next=temp;}}void input3(str *temp){if(string_head->next == NULL){string_head->next=temp;string_tail->next=temp;}else{string_tail->next->next=temp;string_tail->next=temp;}}void output(){cout<<"token表内容如下:"<<endl;token *temp1;temp1=new token;temp1=token_head->next;while(temp1!=NULL){cout<<temp1->code;if(temp1->num == -1){cout<<endl;}else{cout<<" "<<temp1->num<<endl;}temp1=temp1->next;}cout<<"符号表内容如下:"<<endl;str *temp3;temp3=new str;temp3=string_head->next;while(temp3!=NULL){cout<<temp3->num<<" "<<temp3->word<<endl; temp3=temp3->next;}}void outfile(){ofstream fout1("token.txt");//写文件ofstream fout3("string.txt");token *temp1;temp1=new token;temp1=token_head->next;while(temp1!=NULL){fout1<<temp1->code;if(temp1->num == -1)fout1<<endl;elsefout1<<" "<<temp1->num<<endl;temp1=temp1->next;}str *temp3;temp3=new str;temp3=string_head->next;while(temp3!=NULL){fout3<<temp3->num<<" "<<temp3->word<<endl;temp3=temp3->next;}}/****************************以上是词法,以下是语法**************************/void yufa_main(){if(err==0){system("pause");cout<<endl;cout<<"************************"<<endl;cout<<"* 第二部分:语法分析*"<<endl;cout<<"************************"<<endl;yufa_initialize();//初始化语法分析数据结构token *temp;temp=new token;temp=token_head->next;int p,q;p=0;q=0;cout<<"语法分析过程如下:"<<endl;while(temp!=NULL){int w;w=ID1(temp->code);p=yufa_SLR1(w);if(p==1) break;if(p==0)temp=temp->next;if(temp==NULL) q=1;}//语法分析if(q==1)while(1){p=yufa_SLR1(17);if(p==3) break;}//最后输入$来完成语法分析}}void yufa_initialize(){stack_head=new ike;stack_tail=new ike;stack_head->pre=NULL;stack_head->next=stack_tail;stack_head->num=0;stack_head->word='!';stack_tail->pre=stack_head;stack_tail->next=NULL;//初始化栈分析链表css[0].left='Q';css[0].right="P";css[1].left='P';css[1].right="id()L;R";css[2].left='L';css[2].right="L;D";css[3].left='L';css[3].right="D";css[4].left='D';css[4].right="id:int";css[5].left='E';css[5].right="E+T";css[6].left='E';css[6].right="T";css[7].left='T';css[7].right="T*F";css[8].left='T';css[8].right="F";css[9].left='F';css[9].right="(E)";css[10].left='F';css[10].right="id";css[11].left='B';css[11].right="B and B";css[12].left='B';css[12].right="id>id";css[13].left='M';css[13].right="id=E";css[14].left='S';css[14].right="if B then M";css[15].left='S';css[15].right="while B do M";css[16].left='S';css[16].right="M";css[17].left='N';css[17].right="N;S";css[18].left='N';css[18].right="S";css[19].left='R';css[19].right="{N}";int i,j;for(i=0;i<20;i++){char *css_len;css_len=&css[i].right[0];css[i].len=strlen(css_len);}css[1].len=6;css[4].len=3;css[10].len=1;css[11].len=3;css[12].len=3;css[13].len=3;css[14].len=4;css[15].len=4;//初始化产生式for(i=0;i<46;i++){for(j=0;j<18;j++)action[i][j].sr='#';}//初始化action表for(i=0;i<46;i++){for(j=0;j<11;j++)go_to[i][j]=-1;}//初始化go_to表/****************************以下是给action表和go_to表赋初值************************/action[0][0].sr='s';action[0][0].state=2; action[1][17].sr='@';//结束action[2][1].sr='s';action[2][1].state=3; action[3][2].sr='s';action[3][2].state=4; action[4][0].sr='s';action[4][0].state=5; action[5][4].sr='s';action[5][4].state=6; action[6][11].sr='s';action[6][11].state=7; action[7][3].sr='r';action[7][3].state=4; action[8][3].sr='r';action[8][3].state=3; action[9][3].sr='s';action[9][3].state=10; action[10][0].sr='s';action[10][0].state=5; action[10][9].sr='s';action[10][9].state=13; action[11][17].sr='r';action[11][17].state=1; action[12][3].sr='r';action[12][3].state=2; action[13][0].sr='s';action[13][0].state=14; action[13][13].sr='s';action[13][13].state=23; action[13][15].sr='s';action[13][15].state=27; action[14][8].sr='s';action[14][8].state=15; action[15][0].sr='s';action[15][0].state=36; action[15][1].sr='s';action[15][1].state=41; action[16][6].sr='s';action[16][6].state=43; action[16][3].sr='r';action[16][3].state=13; action[16][10].sr='r';action[16][10].state=13; action[17][3].sr='s';action[17][3].state=19; action[17][10].sr='s';action[17][10].state=18; action[18][17].sr='r';action[18][17].state=19; action[19][0].sr='s';action[19][0].state=14; action[19][13].sr='s';action[19][13].state=23; action[19][15].sr='s';action[19][15].state=27; action[20][3].sr='r';action[20][3].state=17; action[20][10].sr='r';action[20][10].state=17; action[21][3].sr='r';action[21][3].state=18; action[21][10].sr='r';action[21][10].state=18; action[22][3].sr='r';action[22][3].state=16; action[22][10].sr='r';action[22][10].state=16; action[23][0].sr='s';action[23][0].state=31; action[24][12].sr='s';action[24][12].state=34; action[24][14].sr='s';action[24][14].state=25; action[25][0].sr='s';action[25][0].state=14; action[26][3].sr='r';action[26][3].state=14; action[26][10].sr='r';action[26][10].state=14; action[27][0].sr='s';action[27][0].state=31; action[28][12].sr='s';action[28][12].state=34; action[28][16].sr='s';action[28][16].state=29;action[30][3].sr='r';action[30][3].state=15; action[30][10].sr='r';action[30][10].state=15; action[31][7].sr='s';action[31][7].state=32; action[32][0].sr='s';action[32][0].state=33; action[33][12].sr='r';action[33][12].state=12; action[33][14].sr='r';action[33][14].state=12; action[33][16].sr='r';action[33][16].state=12; action[34][0].sr='s';action[34][0].state=31; action[35][12].sr='r';action[35][12].state=11; action[35][14].sr='r';action[35][14].state=11; action[35][16].sr='r';action[35][16].state=11; action[36][2].sr='r';action[36][2].state=10; action[36][3].sr='r';action[36][3].state=10; action[36][5].sr='r';action[36][5].state=10; action[36][6].sr='r';action[36][6].state=10; action[36][10].sr='r';action[36][10].state=10; action[37][2].sr='r';action[37][2].state=8; action[37][3].sr='r';action[37][3].state=8; action[37][5].sr='r';action[37][5].state=8; action[37][6].sr='r';action[37][6].state=8; action[37][10].sr='r';action[37][10].state=8; action[38][2].sr='r';action[38][2].state=6; action[38][3].sr='r';action[38][3].state=6; action[38][5].sr='s';action[38][5].state=39; action[38][6].sr='r';action[38][6].state=6; action[38][10].sr='r';action[38][10].state=6; action[39][0].sr='s';action[39][0].state=36; action[39][1].sr='s';action[39][1].state=41; action[40][2].sr='r';action[40][2].state=7; action[40][3].sr='r';action[40][3].state=7; action[40][5].sr='r';action[40][5].state=7; action[40][6].sr='r';action[40][6].state=7; action[40][10].sr='r';action[40][10].state=7; action[41][0].sr='s';action[41][0].state=36; action[41][1].sr='s';action[41][1].state=41; action[42][2].sr='s';action[42][2].state=45; action[42][6].sr='s';action[42][6].state=43; action[43][0].sr='s';action[43][0].state=36; action[43][1].sr='s';action[43][1].state=41; action[44][2].sr='r';action[44][2].state=5; action[44][3].sr='r';action[44][3].state=5; action[44][5].sr='s';action[44][5].state=39; action[44][6].sr='r';action[44][6].state=5;action[45][2].sr='r';action[45][2].state=9;action[45][3].sr='r';action[45][3].state=9;action[45][5].sr='r';action[45][5].state=9;action[45][6].sr='r';action[45][6].state=9;action[45][10].sr='r';action[45][10].state=9;go_to[0][0]=1;go_to[4][1]=8;go_to[4][9]=9;go_to[10][1]=12;go_to[10][2]=11;go_to[13][7]=22;go_to[13][8]=2 1;go_to[13][10]=17;go_to[15][3]=16;go_to[15][4]=38;go_to[15][5]=37;go_to[19][7]=20;go_to[19][8]=20;go_to[23][6]=24;go_to[2 5][7]=26;go_to[27][6]=28;go_to[29][7]=30;go_to[34][6]=35;go_to[39][5]=40;go_to[41][3]=42;go_to[41][4]=38;go_to[41][5]=37;go_to[4 3][4]=44;go_to[43][5]=37;/****************************action表和go_to表赋初值完毕************************/}int ID1(int i)//按action表,给输入字符编号{int j;j=-1;if(i==25) {j=0;id_num++;}//设置变量名称标志if(i==1) {j=8,id_left=id_num;}//设置产生试左边变量名称标志if(i==2) j=6;if(i==3) j=5;if(i==4) j=7;if(i==5) j=4;if(i==6) j=3;if(i==7) j=9;if(i==8) j=10;if(i==9) j=1;if(i==10) j=2;if(i==31) j=12;if(i==32) j=13;if(i==33) {j=14;id_then=L_four_tail->k+1;}//设置if语句中then位置标志if(i==35) {j=15;id_while=L_four_tail->k+1;}//设置while语句中while位置标志if(i==36) {j=16;id_do=L_four_tail->k+1;}//设置while语句中do位置标志if(i==37) j=11;return(j);}string ID10(int i)//反编号输入字符{string ch;if(i==0) ch="id";if(i==1) ch="(";if(i==2) ch=")";if(i==3) ch=";";if(i==4) ch=":";if(i==5) ch="*";if(i==6) ch="+";if(i==7) ch=">";if(i==8) ch="=";if(i==9) ch="{";if(i==10) ch="}";if(i==11) ch="int";if(i==12) ch="and";if(i==13) ch="if";if(i==14) ch="then";if(i==15) ch="while";if(i==16) ch="do";if(i==17) ch="$";return(ch);}int ID2(char ch)//按go_to表给非终结符编号{int j;j=-1;if(ch=='P') j=0;if(ch=='D') j=1;if(ch=='R') j=2;if(ch=='E') j=3;if(ch=='T') j=4;if(ch=='F') j=5;if(ch=='B') j=6;if(ch=='M') j=7;if(ch=='S') j=8;if(ch=='L') j=9;if(ch=='N') j=10;return(j);}int ID20(char ch)//给非终结符编号{int j;j=-1;if(ch=='P') j=100;if(ch=='D') j=101;if(ch=='R') j=102;if(ch=='E') j=103;if(ch=='T') j=104;if(ch=='F') j=105;if(ch=='B') j=106;if(ch=='M') j=107;if(ch=='S') j=108;if(ch=='L') j=109;if(ch=='N') j=1010;return(j);}char ID21(int j)//反编号非终结符{char ch;if(j==100 || j==0) ch='P';if(j==101 || j==1) ch='D';if(j==102 || j==2) ch='R';if(j==103 || j==3) ch='E';if(j==104 || j==4) ch='T';if(j==105 || j==5) ch='F';if(j==106 || j==6) ch='B';if(j==107 || j==7) ch='M';if(j==108 || j==8) ch='S';if(j==109 || j==9) ch='L';if(j==1010 || j==10) ch='N'; return(ch);}void add(ike *temp)//加一个结点{if(stack_head->next==stack_tail) {temp->pre=stack_head;temp->next=stack_tail;stack_head->next=temp;stack_tail->pre=temp;}else{temp->pre=stack_tail->pre; temp->next=stack_tail;stack_tail->pre->next=temp; stack_tail->pre=temp;}}void del()//删除一个结点{stack_tail->pre->pre->next=stack_tail;stack_tail->pre=stack_tail->pre->pre;}int yufa_SLR1(int w){/*cout<<"当前输入符号:"<<ID10(w)<<" ";*/int i,flag=0,state_temp;//flag错误标志,0正常移进,1错误,2归约,3结束char sr_temp;sr_temp=action[stack_tail->pre->num][w].sr;//动作state_temp=action[stack_tail->pre->num][w].state;//状态变化if(sr_temp=='#')//错误动作{flag=1;err=3;cout<<"语法分析出错!"<<endl;}else if(sr_temp=='s')//移进动作{ike *temp;temp=new ike;temp->next=NULL;temp->pre=NULL;temp->word=w;temp->num=state_temp;add(temp);cout/*<<"动作(移进):"*/<<sr_temp<<state_temp<<" "/*<<"状态转为:"<<stack_tail->pre->num<<" "<<"栈顶符号:"<<ID10(stack_tail->pre->word)*/<<endl;flag=0;}else if(sr_temp=='r')//归约动作{int p=ID2(css[state_temp].left);int q=css[state_temp].len;for(i=0;i<q;i++)del();ike *temp;temp=new ike;temp->next=NULL;temp->pre=NULL;temp->word=ID20(css[state_temp].left);temp->num=go_to[stack_tail->pre->num][p];//查go_to表add(temp);cout/*<<"动作(归约):"*/<<sr_temp<<state_temp<<" "<<css[state_temp].left<<"→"<<css[state_temp].right<<" "/*<<"状态转为:"<<stack_tail->pre->num<<" "<<"栈顶符号:"<<ID21(stack_tail->pre->word)*/<<endl;flag=2;yuyi_main(state_temp);//在产生树的同时进行语义分析}else if(sr_temp=='@')//结束动作{cout<<"END"/*<<"动作(归约):"<<sr_temp<<state_temp*/<<" "<<css[state_temp].left<<"→"<<css[state_temp].right<<" "/*<<"状态转为:"<<stack_tail->pre->num<<" "<<"栈顶符号:"<<ID21(stack_tail->pre->word)*/<<endl;flag=3;cout<<"语法分析正确完成!"<<endl;}else//其他意外情况{flag=1;err=3;cout<<"语法分析出错!"<<endl;}return(flag);}/****************************以上是语法,以下是语义**************************/void yuyi_main(int m){L *temp;int k;k=1;temp=new L;temp->op=" ";temp->op1=" ";temp->op2=" ";temp->result="";temp->next=NULL;temp->Ltrue=NULL;temp->Lfalse=NULL;if(m==4)//变量声明时加入符号表链{symb *Stemp;Stemp=new symb;id_name=id_numtoname(id_num);Stemp->word=id_name;Stemp->next=NULL;add_symb(Stemp);}if(m==5)//归约E→E+T{temp->op="+";temp->op1=E_name;temp->op2=T_name;yuyi_linshi++;//申请临时变量E_name="t"+newop(yuyi_linshi); temp->result=E_name;add_L_four(temp);//加一个四元式结点}if(m==6)//归约E→T{E_name=T_name;}if(m==7)//归约T→T*F{temp->op="*";temp->op1=T_name;temp->op2=F_name;yuyi_linshi++;//申请临时变量T_name="t"+newop(yuyi_linshi); temp->result=T_name;add_L_four(temp);//加一个四元式结点}if(m==8)//归约T→F{T_name=F_name;}if(m==9)//归约F→(E){F_name=E_name;}if(m==10)//归约F→id{id_name=id_numtoname(id_num);F_name=id_name;k=lookup(id_name);//检查变量是否声明if(k==0){err=2;errword=id_name;return;}}if(m==12)//归约B→id>id{temp->op="J>";id1_num=id_num-1;id1_name=id_numtoname(id1_num);k=lookup(id1_name);//检查变量是否声明if(k==0){err=2;errword=id1_name;return;}id2_num=id_num;id2_name=id_numtoname(id2_num);k=lookup(id2_name);//检查变量是否声明if(k==0){err=2;errword=id2_name;return;}temp->result="-1";temp->op1=id1_name;temp->op2=id2_name;add_L_four(temp);//加一个四元式结点add_L_true(temp);//加一个true链结点L *temp2;temp2=new L;temp2->op="J";temp2->op1=" ";temp2->op2=" ";temp2->result="-1";add_L_four(temp2);//加一个四元式结点add_L_false(temp2);//加一个false链结点}if(m==13)//归约M→id=E{temp->op="=";temp->op1=E_name;temp->op2=" ";id_name=id_numtoname(id_left);temp->result=id_name;add_L_four(temp);//加一个四元式结点yuyi_linshi=-1;//临时变量开始重新计数}if(m==14)//归约S→if B then M{int a;a=id_then;temp=L_true_head->Ltrue;while(temp!=NULL){temp->result="L"+newop(a);a=temp->k;temp=temp->Ltrue;}a=L_four_tail->k+1;temp=L_false_head->Lfalse;while(temp!=NULL){temp->result="L"+newop(a);temp=temp->Lfalse;}L_true_head->Ltrue=NULL;L_false_head->Lfalse=NULL;//回填并清空true链和false链}if(m==15)//归约S→while B do M{int a;a=id_do;temp=L_true_head->Ltrue;while(temp!=NULL){temp->result="L"+newop(a);a=temp->k;temp=temp->Ltrue;}a=L_four_tail->k+2;temp=L_false_head->Lfalse;while(temp!=NULL){temp->result="L"+newop(a);temp=temp->Lfalse;}L *temp1;temp1=new L;temp1->op="J";temp1->op1=" ";temp1->op2=" ";temp1->next=NULL;temp1->result="L"+newop(id_while);add_L_four(temp1);//加一个四元式结点L_true_head->Ltrue=NULL;L_false_head->Lfalse=NULL;//回填并清空true链和false链}}string newop(int m)//数字变成字符串{int shang,yushu;string chuan,chuan1;shang=m;chuan="";while(1){yushu=shang%10;chuan=chuan+char(48+yushu);shang=shang/10;if(shang==0)break;}int i;char *ch;ch=&chuan[0];chuan1="";for(i=strlen(ch)-1;i>=0;i--)chuan1=chuan1+chuan[i];return(chuan1);}void add_L_four(L *temp)//加一个四元式结点{temp->k=L_four_tail->k+1;if(L_four_head->next == NULL){L_four_head->next=temp;L_four_tail->next=temp;}else{L_four_tail->next->next=temp;L_four_tail->next=temp;}L_four_tail->k=L_four_tail->next->k;}void add_L_true(L *temp)//加一个true链结点{temp->Ltrue=L_true_head->Ltrue;L_true_head->Ltrue=temp;}void add_L_false(L *temp)//加一个false链结点{temp->Lfalse=L_false_head->Lfalse;L_false_head->Lfalse=temp;}void add_symb(symb *temp)//加一个语义符号表链结点{if(symb_head->next == NULL){temp->addr=0;symb_head->next=temp;symb_tail->next=temp;}else{temp->addr=symb_tail->next->addr+4;symb_tail->next->next=temp;symb_tail->next=temp;}}void output_yuyi(){if(err==0)//语义分析正确时的输出{cout<<endl;system("pause");cout<<endl;cout<<"************************"<<endl;cout<<"* 第三部分:语义分析*"<<endl;cout<<"************************"<<endl;cout<<"中间代码如下:"<<endl;L *temp;temp=L_four_head->next;while(temp!=NULL){。
编译原理实验词法分析语法分析

本代码只供学习参考:词法分析源代码:#include<iostream>#include<fstream>#include<string>using namespace std;string key[8]={"do","end","for","if","printf","scanf","then","while"}; string optr[4]={"+","-","*","/"};string separator[6]={",",";","{","}","(",")"};char ch;//判断是否为保留字bool IsKey(string ss) {int i;for(i=0;i<8;i++)if(!strcmp(key[i].c_str(),ss.c_str()))return true;return false;}//字母判断函数bool IsLetter(char c) {if(((c>='a')&&(c<='z'))||((c>='A')&&(c<='Z')))return true;return false;}//数字判断函数bool IsDigit(char c) {if(c>='0'&&c<='9')return true;return false;}//运算符判断函数bool IsOptr(string ss) {int i;for(i=0;i<4;i++)if(!strcmp(optr[i].c_str(),ss.c_str()))return true ;return false;}//分界符判断函数bool IsSeparator(string ss) {int i;for(i=0;i<6;i++)if(!strcmp(separator[i].c_str(),ss.c_str()))return true;return false;}void analyse(ifstream &in) {string st="";char ch;int line=1,row=0;while((in.get(ch))) {st="";if((ch==' ')||(ch=='\t')){} //空格,tab健elseif(ch=='\n') {line++;row=0; } //换行行数加一处理elseif(IsLetter(ch)) //关键字、标识符的处理{row++;while(IsLetter(ch)||IsDigit(ch)){st+=ch;in.get(ch);}in.seekg(-1,ios::cur);//文件指针(光标)后退一个字节if(IsKey(st)) //判断是否为关键字查询关键字表;cout<<st<<"\t("<<st<<","<<1<<")"<<'\t'<<'\t'<<"关键字"<<'\t'<<"("<<line<<","<<row<<")"<<endl;else //否则为标示符cout<<st<<"\t("<<st<<","<<2<<")"<<'\t'<<'\t'<<"标识符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;}elseif(IsDigit(ch)) //无符号整数处理{row++;while(IsDigit(ch)){st+=ch;ch=in.get();}in.seekg(-1,ios::cur);cout<<st<<"\t("<<st<<","<<3<<")"<<'\t'<<'\t'<<"常数"<<'\t'<<"("<<line<<","<<row<<")"<<endl;// break;}else{st="";st+=ch;if(IsOptr(st)) //运算符处理{row++;cout<<st<<"\t("<<st<<","<<4<<")"<<'\t'<<'\t'<<"运算符"<<"("<<line<<","<<row<<")"<<endl;}elseif(IsSeparator(st))//分隔符处理{ row++;cout<<st<<"\t("<<st<<","<<5<<")"<<'\t'<<'\t'<<"分界符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;}else{switch(ch){row++;case'=' : {row++;cout<<"="<<"\t("<<"="<<","<<"6"<<")"<<'\t'<<"\t关系运算符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;}case'>' :{row++;ch=in.get();if(ch=='=')cout<<">="<<'\t'<<"("<<">="<<","<<"6"<<")"<<'\t'<<"\t关系运算符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;else {cout<<">"<<"\t("<<">"<<","<<"6"<<")"<<'\t'<<"\t关系运算符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;in.seekg(-1,ios::cur);}} break;case'<' :{row++;ch=in.get();if(ch=='=')cout<<"<="<<'\t'<<"("<<"="<<","<<"6"<<")"<<"\t关系运算符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;else if(ch=='>') cout<<"<>"<<'\t'<<"("<<"<>"<<","<<"6"<<")"<<'\t'<<"\t关系运算符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;else{cout<<"<"<<"\t("<<"<"<<","<<"6"<<")"<<"\t"<<"\t关系运算符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;in.seekg(-1,ios::cur);}}break;default :{row++; cout<<ch<<'\t'<<"\t$无法识别字符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;}}}}}}int main(){ifstream in;in.open("test.txt",ios::in);cout<<"关键字-》1 标识符-》2 常数-》3 运算符-》4 分隔符-》5"<<endl;if(in.is_open()){analyse(in);in.close();system("pause");}elsecout<<"文件操作出错"<<endl;}语法分析实验源代码LL#include<iostream>using namespace std;const int MaxLen=20; //初始化栈的长度const int Length=20;//初始化数组长度char Vn[5]={'E','G','T','S','F'};//非终结符数组char Vt[8]={'i','(',')','+','-','*','/','#'};//终结符数组char ch,X;//ch读当前字符,X获取栈顶元素char strToken[Length];//存储规约表达式struct LL//ll(1)分析表的构造字初始化{char*c;};LL E[8]={"TG","TG","error","error","error","error","error","error"};LL G[8]={"error","error","null","+TG","-TG","error","error","null"};LL T[8]={"FS","FS","error","error","error","error","error","error"};LL S[8]={"error","error","null","null","null","*FS","/FS","null"};LL F[8]={"i","(E)","error","error","error","error","error","error"};class stack//栈的构造及初始化{public:stack();//初始化bool empty() const;//是否为空bool full() const;//是否已满bool get_top(char &c)const;//取栈顶元素bool push(const char c);//入栈bool pop();//删除栈顶元素void out();//输出栈中元素~stack(){}//析构private:int count;//栈长度char data[MaxLen];//栈中元素};stack::stack(){count=0;}bool stack::empty() const{if(count==0)return true;return false;}bool stack::full() const{if(count==MaxLen)return true;return false;}bool stack::get_top(char &c)const{if(empty())return false;else{c=data[count-1];return true;}}bool stack::push(const char c){if(full())return false;data[count++]=c;return true;}bool stack::pop(){if(empty())return false;count--;return true;}void stack::out(){for(int i=0;i<count;i++)cout<<data[i];cout<<'\t';}int length(char *c){int l=0;for(int i=0;c[i]!='\0';i++)l++;return l;}void print(int i,char*c)//剩余输入串的输出{for(int j=i;j<Length;j++)cout<<c[j];cout<<'\t';}void run(){bool flag=true;//循环条件int step=0,point=0;//步骤、指针int len;//长度cout<<"输入规约的字符串:"<<endl;cin>>strToken;ch=strToken[point++];//读取第一个字符stack s;s.push('#');//栈中数据初始化s.push('E');s.get_top(X);//取栈顶元素cout<<"步骤\t"<<"分析栈\t"<<"剩余输入串\t\t"<<"所用产生式\t"<<"动作"<<endl;cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<'\t'<<"初始化"<<endl;while(flag){if((X==Vt[0])||(X==Vt[1])||(X==Vt[2])||(X==Vt[3])||(X==Vt[4])||(X==Vt[5])||(X==Vt[6])) //判断是否为终结符(不包括#){if(X==ch)//终结符,识别,进行下一字符规约{s.pop();s.get_top(X);ch=strToken[point++];cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<'\t'<<"GETNEXT(I)"<<endl;}else{flag=false;}}else if(X=='#')//规约结束{if(X==ch){cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<ch<<'\t'<<"结束"<<endl;s.pop();flag=false;}else{flag=false;}}else if(X==Vn[0]) //非终结符E{for(int i=0;i<8;i++)//查分析表if(ch==Vt[i]){if(strcmp(E[i].c,"error")==0)//出错{flag=false;}else{ //对形如X->X1X2的产生式进行入栈操作s.pop();len=length(E[i].c)-1;for(int j=len;j>=0;j--)s.push(E[i].c[j]);cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<E[i].c<<'\t'<<"POP,PUSH(";for(int j=len;j>=0;j--)cout<<E[i].c[j];cout<<")"<<endl;s.get_top(X);}}}else if(X==Vn[1]) //同上,处理G{for(int i=0;i<8;i++)if(ch==Vt[i]){if(strcmp(G[i].c,"null")==0){s.pop();cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<"ε"<<'\t'<<"POP"<<endl;s.get_top(X);}else if(strcmp(G[i].c,"error")==0){flag=false;}else{s.pop();len=length(G[i].c)-1;for(int j=len;j>=0;j--)s.push(G[i].c[j]);cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<G[i].c<<'\t'<<"POP,PUSH(";for(int j=len;j>=0;j--)cout<<G[i].c[j];cout<<")"<<endl;s.get_top(X);}}}else if(X==Vn[2]) //同上处理T{for(int i=0;i<8;i++)if(ch==Vt[i]){if(strcmp(T[i].c,"error")==0){flag=false;}else{s.pop();len=length(T[i].c)-1;for(int j=len;j>=0;j--)s.push(T[i].c[j]);cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<T[i].c<<'\t'<<"POP,PUSH(";for(int j=len;j>=0;j--)cout<<T[i].c[j];cout<<")"<<endl;s.get_top(X);}}}else if(X==Vn[3])//同上处理S{for(int i=0;i<8;i++)if(ch==Vt[i]){if(strcmp(S[i].c,"null")==0){s.pop();cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<"ε"<<'\t'<<"POP"<<endl;s.get_top(X);}else if(strcmp(S[i].c,"error")==0){flag=false;}else{s.pop();len=length(S[i].c)-1;for(int j=len;j>=0;j--)s.push(S[i].c[j]);cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<S[i].c<<'\t'<<"POP,PUSH(";for(int j=len;j>=0;j--)cout<<S[i].c[j];cout<<")"<<endl;s.get_top(X);}}}else if(X==Vn[4]) //同上处理F{for(int i=0;i<7;i++)if(ch==Vt[i]){if(strcmp(F[i].c,"error")==0){flag=false;}else{s.pop();len=length(F[i].c)-1;for(int j=len;j>=0;j--)s.push(F[i].c[j]);cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<F[i].c<<'\t'<<"POP,PUSH(";for(int j=len;j>=0;j--)cout<<F[i].c[j];cout<<")"<<endl;s.get_top(X);}}}else //出错处理{flag= false;}}}int main(){cout<<"实验二"<<endl;run();system("pause");return 0;}语法实验源代码LR#include<iostream>using namespace std;const int MaxLen=20; //初始化栈的长度const int Length=20;//初始化数组长度char ch,Y;//全局变量,ch用于读当前字符,Y用于获取栈顶元素char strToken[Length];//存储规约表达式bool flag=true;//循环条件int point=0,step=1;//步骤、指针class stack//栈的构造及初始化{public:stack();//初始化bool empty() const;//是否为空bool full() const;//是否已满bool get_top(char &c)const;//取栈顶元素bool push(const char c);//入栈bool pop();void out();//输出栈中元素void out1();~stack(){}//析构private:int count;//栈长度char data[MaxLen];//栈中元素};stack l,r;//l代表符号栈,r代表状态栈stack::stack(){count=0;}bool stack::empty() const{if(count==0)return true;return false;}bool stack::full() const{if(count==MaxLen)return true;return false;}bool stack::get_top(char &c)const{if(empty())return false;else{c=data[count-1];return true;}}bool stack::push(const char c){if(full())return false;data[count++]=c;return true;}bool stack::pop(){if(empty())return false;count--;return true;}void stack::out(){for(int i=0;i<count;i++)cout<<data[i];cout<<'\t';}void stack::out1(){for(int i=0;i<count;i++)cout<<int(data[i]);cout<<'\t';}void print(int i,char*c)//剩余输入串的输出{for(int j=i;j<Length;j++)cout<<c[j];cout<<'\t';}void Goto(int i,char c)//状态转换函数,对应于表中GOTO {if(i==0){if(c=='E'){r.push(1);cout<<",GOTO(0,E)=1入栈"<<endl;}else if(c=='T'){r.push(2);cout<<",GOTO(0,T)=2入栈"<<endl;}else if(c=='F'){r.push(3);cout<<",GOTO(0,F)=3入栈"<<endl;}elseflag=false;}else if(i==4){if(c=='E'){r.push(8);cout<<",GOTO(4,E)=8入栈"<<endl;}else if(c=='T'){r.push(2);cout<<",GOTO(4,T)=2入栈"<<endl;}else if(c=='F'){r.push(3);cout<<",GOTO(4,F)=3入栈"<<endl;}elseflag=false;}else if(i==6){if(c=='T'){r.push(9);cout<<",GOTO(6,T)=9入栈"<<endl;}else if(c=='F'){r.push(3);cout<<",GOTO(6,F)=3入栈"<<endl;}elseflag=false;}else if(i==7){if(c=='F'){r.push(10);cout<<",GOTO(7,F)=10入栈"<<endl;}elseflag=false;}elseflag=false;}void Action0()//状态0时{if(ch=='i')//下一个操作符为i ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[0,i]=S5,状态5入栈"<<endl;r.push(5);l.push(ch);ch=strToken[point++];}else if(ch=='(')//下一个操作符为( ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[0,(]=S4,状态4入栈"<<endl;r.push(4);l.push(ch);ch=strToken[point++];}elseflag=false;}void Action1()//状态1{if(ch=='+')//下一个操作符为i ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[1,+]=S6,状态6入栈"<<endl;r.push(6);l.push(ch);ch=strToken[point++];}else if(ch=='#')//分析成功{flag=false;cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"Acc:分析成功"<<endl;}elseflag=false;}void Action2() //状态2{if(ch=='*')//下一个操作符为* ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[2,*]=S7,状态7入栈"<<endl;r.push(7);l.push(ch);ch=strToken[point++];}else if((ch=='+')||(ch==')')||(ch=='#'))//下一个操作符为+,),#规约{cout<<step++<<'\t';r.out1();l.out();l.pop();l.push('E');print(point-1,strToken);cout<<"r2: E→T归约";r.pop();r.get_top(Y);Goto(int(Y),'E');}elseflag=false;}void Action3()//状态3{if((ch=='+')||(ch=='*')||(ch==')')||(ch=='#'))//下一个操作符为+,*,),#规约{cout<<step++<<'\t';r.out1();l.out();l.pop();l.push('T');print(point-1,strToken);cout<<"r4: T→F归约";r.pop();r.get_top(Y);Goto(int(Y),'T');}elseflag=false;}void Action4_6_7(int x)//状态4,6,7{if(ch=='i')//下一个操作符为i ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[";cout<<x<<",i]=S5,状态5入栈"<<endl;r.push(5);l.push(ch);ch=strToken[point++];}else if(ch=='(')//下一个操作符为(,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[";cout<<x<<",(]=S4,状态4入栈"<<endl;r.push(4);l.push(ch);ch=strToken[point++];}elseflag=false;}void Action5()//状态5{if((ch=='+')||(ch=='*')||(ch==')')||(ch=='#'))//下一个操作符为+,*,),#规约{cout<<step++<<'\t';r.out1();l.out();l.pop();l.push('F');print(point-1,strToken);cout<<"r6: F→i归约";r.pop();r.get_top(Y);Goto(int(Y),'F');}elseflag=false;}void Action8()//状态8{if(ch=='+')//下一个操作符为+ ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[8,+]=S6,状态6入栈"<<endl;r.push(6);l.push(ch);ch=strToken[point++];}else if(ch==')')//下一个操作符为),移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[8,)]=S11,状态11入栈"<<endl;r.push(11);ch=strToken[point++];}elseflag=false;}void Action9()//状态9{if(ch=='*')//下一个操作符为* ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[9,*]=S7,状态7入栈"<<endl;r.push(7);l.push(ch);ch=strToken[point++];}else if((ch=='+')||(ch==')')||(ch=='#'))//下一个操作符为+,,),#规约{cout<<step++<<'\t';r.out1();l.out();l.pop();l.pop();l.pop();l.push('E');print(point-1,strToken);cout<<"r1: E→E+T归约";r.pop();r.pop();r.pop();r.get_top(Y);Goto(int(Y),'E');}elseflag=false;}void Action10()//状态10{if((ch=='+')||(ch=='*')||(ch==')')||(ch=='#'))//下一个操作符为+,*,),#规约{cout<<step++<<'\t';l.out();l.pop();l.pop();l.pop();l.push('T');print(point-1,strToken);cout<<"r3: T→T*F归约";r.pop();r.pop();r.pop();r.get_top(Y);Goto(int(Y),'T');}elseflag=false;}void Action11()//状态11{if((ch=='+')||(ch=='*')||(ch==')')||(ch=='#'))//下一个操作符为+,*,),#规约{cout<<step++<<'\t';r.out1();l.out();l.pop();l.pop();l.pop();l.push('F');print(point-1,strToken);cout<<"r5: F→(E)归约";r.pop();r.pop();r.pop();r.get_top(Y);Goto(int(Y),'F');}elseflag=false;}void run()//规约{cout<<"请输入要规约的字符串:"<<endl;cin>>strToken;cout<<"步骤\t"<<"状态栈\t"<<"符号栈\t"<<"输入串\t\t"<<"动作说明"<<endl;ch=strToken[point++];//读取第一个字符l.push('#');r.push(0);r.get_top(Y);while(flag)//循环规约{if(int(Y)==0)Action0();else if(int(Y)==1)Action1();else if(int(Y)==2)Action2();else if(int(Y)==3)Action3();else if((int(Y)==4)||(int(Y)==6)||(int(Y)==7))Action4_6_7(int(Y));else if(int(Y)==5)Action5();else if(int(Y)==8)Action8();else if(int(Y)==9)Action9();else if(int(Y)==10)Action10();else if(int(Y)==11)Action11();elseflag=false;r.get_top(Y);}}int main(){cout<<"实验三"<<endl;run();system("pause");return 0;}。
编译原理实验词法分析语法分析
本代码只供学习参考:词法分析源代码:#include<iostream>#include<fstream>#include<string>using namespace std;string key[8]={"do","end","for","if","printf","scanf","then","while"}; string optr[4]={"+","-","*","/"};string separator[6]={",",";","{","}","(",")"};char ch;//判断是否为保留字bool IsKey(string ss) {int i;for(i=0;i<8;i++)if(!strcmp(key[i].c_str(),ss.c_str()))return true;return false;}//字母判断函数bool IsLetter(char c) {if(((c>='a')&&(c<='z'))||((c>='A')&&(c<='Z')))return true;return false;}//数字判断函数bool IsDigit(char c) {if(c>='0'&&c<='9')return true;return false;}//运算符判断函数bool IsOptr(string ss) {int i;for(i=0;i<4;i++)if(!strcmp(optr[i].c_str(),ss.c_str()))return true ;return false;}//分界符判断函数bool IsSeparator(string ss) {int i;for(i=0;i<6;i++)if(!strcmp(separator[i].c_str(),ss.c_str()))return true;return false;}void analyse(ifstream &in) {string st="";char ch;int line=1,row=0;while((in.get(ch))) {st="";if((ch==' ')||(ch=='\t')){} //空格,tab健elseif(ch=='\n') {line++;row=0; } //换行行数加一处理elseif(IsLetter(ch)) //关键字、标识符的处理{row++;while(IsLetter(ch)||IsDigit(ch)){st+=ch;in.get(ch);}in.seekg(-1,ios::cur);//文件指针(光标)后退一个字节if(IsKey(st)) //判断是否为关键字查询关键字表;cout<<st<<"\t("<<st<<","<<1<<")"<<'\t'<<'\t'<<"关键字"<<'\t'<<"("<<line<<","<<row<<")"<<endl;else //否则为标示符cout<<st<<"\t("<<st<<","<<2<<")"<<'\t'<<'\t'<<"标识符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;}elseif(IsDigit(ch)) //无符号整数处理{row++;while(IsDigit(ch)){st+=ch;ch=in.get();}in.seekg(-1,ios::cur);cout<<st<<"\t("<<st<<","<<3<<")"<<'\t'<<'\t'<<"常数"<<'\t'<<"("<<line<<","<<row<<")"<<endl;// break;}else{st="";st+=ch;if(IsOptr(st)) //运算符处理{row++;cout<<st<<"\t("<<st<<","<<4<<")"<<'\t'<<'\t'<<"运算符"<<"("<<line<<","<<row<<")"<<endl;}elseif(IsSeparator(st))//分隔符处理{ row++;cout<<st<<"\t("<<st<<","<<5<<")"<<'\t'<<'\t'<<"分界符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;}else{switch(ch){row++;case'=' : {row++;cout<<"="<<"\t("<<"="<<","<<"6"<<")"<<'\t'<<"\t关系运算符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;}case'>' :{row++;ch=in.get();if(ch=='=')cout<<">="<<'\t'<<"("<<">="<<","<<"6"<<")"<<'\t'<<"\t关系运算符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;else {cout<<">"<<"\t("<<">"<<","<<"6"<<")"<<'\t'<<"\t关系运算符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;in.seekg(-1,ios::cur);}} break;case'<' :{row++;ch=in.get();if(ch=='=')cout<<"<="<<'\t'<<"("<<"="<<","<<"6"<<")"<<"\t关系运算符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;else if(ch=='>') cout<<"<>"<<'\t'<<"("<<"<>"<<","<<"6"<<")"<<'\t'<<"\t关系运算符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;else{cout<<"<"<<"\t("<<"<"<<","<<"6"<<")"<<"\t"<<"\t关系运算符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;in.seekg(-1,ios::cur);}}break;default :{row++; cout<<ch<<'\t'<<"\t$无法识别字符"<<'\t'<<"("<<line<<","<<row<<")"<<endl;}}}}}}int main(){ifstream in;in.open("test.txt",ios::in);cout<<"关键字-》1 标识符-》2 常数-》3 运算符-》4 分隔符-》5"<<endl;if(in.is_open()){analyse(in);in.close();system("pause");}elsecout<<"文件操作出错"<<endl;}语法分析实验源代码LL#include<iostream>using namespace std;const int MaxLen=20; //初始化栈的长度const int Length=20;//初始化数组长度char Vn[5]={'E','G','T','S','F'};//非终结符数组char Vt[8]={'i','(',')','+','-','*','/','#'};//终结符数组char ch,X;//ch读当前字符,X获取栈顶元素char strToken[Length];//存储规约表达式struct LL//ll(1)分析表的构造字初始化{char*c;};LL E[8]={"TG","TG","error","error","error","error","error","error"};LL G[8]={"error","error","null","+TG","-TG","error","error","null"};LL T[8]={"FS","FS","error","error","error","error","error","error"};LL S[8]={"error","error","null","null","null","*FS","/FS","null"};LL F[8]={"i","(E)","error","error","error","error","error","error"};class stack//栈的构造及初始化{public:stack();//初始化bool empty() const;//是否为空bool full() const;//是否已满bool get_top(char &c)const;//取栈顶元素bool push(const char c);//入栈bool pop();//删除栈顶元素void out();//输出栈中元素~stack(){}//析构private:int count;//栈长度char data[MaxLen];//栈中元素};stack::stack(){count=0;}bool stack::empty() const{if(count==0)return true;return false;}bool stack::full() const{if(count==MaxLen)return true;return false;}bool stack::get_top(char &c)const{if(empty())return false;else{c=data[count-1];return true;}}bool stack::push(const char c){if(full())return false;data[count++]=c;return true;}bool stack::pop(){if(empty())return false;count--;return true;}void stack::out(){for(int i=0;i<count;i++)cout<<data[i];cout<<'\t';}int length(char *c){int l=0;for(int i=0;c[i]!='\0';i++)l++;return l;}void print(int i,char*c)//剩余输入串的输出{for(int j=i;j<Length;j++)cout<<c[j];cout<<'\t';}void run(){bool flag=true;//循环条件int step=0,point=0;//步骤、指针int len;//长度cout<<"输入规约的字符串:"<<endl;cin>>strToken;ch=strToken[point++];//读取第一个字符stack s;s.push('#');//栈中数据初始化s.push('E');s.get_top(X);//取栈顶元素cout<<"步骤\t"<<"分析栈\t"<<"剩余输入串\t\t"<<"所用产生式\t"<<"动作"<<endl;cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<'\t'<<"初始化"<<endl;while(flag){if((X==Vt[0])||(X==Vt[1])||(X==Vt[2])||(X==Vt[3])||(X==Vt[4])||(X==Vt[5])||(X==Vt[6])) //判断是否为终结符(不包括#){if(X==ch)//终结符,识别,进行下一字符规约{s.pop();s.get_top(X);ch=strToken[point++];cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<'\t'<<"GETNEXT(I)"<<endl;}else{flag=false;}}else if(X=='#')//规约结束{if(X==ch){cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<ch<<'\t'<<"结束"<<endl;s.pop();flag=false;}else{flag=false;}}else if(X==Vn[0]) //非终结符E{for(int i=0;i<8;i++)//查分析表if(ch==Vt[i]){if(strcmp(E[i].c,"error")==0)//出错{flag=false;}else{ //对形如X->X1X2的产生式进行入栈操作s.pop();len=length(E[i].c)-1;for(int j=len;j>=0;j--)s.push(E[i].c[j]);cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<E[i].c<<'\t'<<"POP,PUSH(";for(int j=len;j>=0;j--)cout<<E[i].c[j];cout<<")"<<endl;s.get_top(X);}}}else if(X==Vn[1]) //同上,处理G{for(int i=0;i<8;i++)if(ch==Vt[i]){if(strcmp(G[i].c,"null")==0){s.pop();cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<"ε"<<'\t'<<"POP"<<endl;s.get_top(X);}else if(strcmp(G[i].c,"error")==0){flag=false;}else{s.pop();len=length(G[i].c)-1;for(int j=len;j>=0;j--)s.push(G[i].c[j]);cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<G[i].c<<'\t'<<"POP,PUSH(";for(int j=len;j>=0;j--)cout<<G[i].c[j];cout<<")"<<endl;s.get_top(X);}}}else if(X==Vn[2]) //同上处理T{for(int i=0;i<8;i++)if(ch==Vt[i]){if(strcmp(T[i].c,"error")==0){flag=false;}else{s.pop();len=length(T[i].c)-1;for(int j=len;j>=0;j--)s.push(T[i].c[j]);cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<T[i].c<<'\t'<<"POP,PUSH(";for(int j=len;j>=0;j--)cout<<T[i].c[j];cout<<")"<<endl;s.get_top(X);}}}else if(X==Vn[3])//同上处理S{for(int i=0;i<8;i++)if(ch==Vt[i]){if(strcmp(S[i].c,"null")==0){s.pop();cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<"ε"<<'\t'<<"POP"<<endl;s.get_top(X);}else if(strcmp(S[i].c,"error")==0){flag=false;}else{s.pop();len=length(S[i].c)-1;for(int j=len;j>=0;j--)s.push(S[i].c[j]);cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<S[i].c<<'\t'<<"POP,PUSH(";for(int j=len;j>=0;j--)cout<<S[i].c[j];cout<<")"<<endl;s.get_top(X);}}}else if(X==Vn[4]) //同上处理F{for(int i=0;i<7;i++)if(ch==Vt[i]){if(strcmp(F[i].c,"error")==0){flag=false;}else{s.pop();len=length(F[i].c)-1;for(int j=len;j>=0;j--)s.push(F[i].c[j]);cout<<step++<<'\t';s.out();print(point-1,strToken);cout<<X<<"->"<<F[i].c<<'\t'<<"POP,PUSH(";for(int j=len;j>=0;j--)cout<<F[i].c[j];cout<<")"<<endl;s.get_top(X);}}}else //出错处理{flag= false;}}}int main(){cout<<"实验二"<<endl;run();system("pause");return 0;}语法实验源代码LR#include<iostream>using namespace std;const int MaxLen=20; //初始化栈的长度const int Length=20;//初始化数组长度char ch,Y;//全局变量,ch用于读当前字符,Y用于获取栈顶元素char strToken[Length];//存储规约表达式bool flag=true;//循环条件int point=0,step=1;//步骤、指针class stack//栈的构造及初始化{public:stack();//初始化bool empty() const;//是否为空bool full() const;//是否已满bool get_top(char &c)const;//取栈顶元素bool push(const char c);//入栈bool pop();void out();//输出栈中元素void out1();~stack(){}//析构private:int count;//栈长度char data[MaxLen];//栈中元素};stack l,r;//l代表符号栈,r代表状态栈stack::stack(){count=0;}bool stack::empty() const{if(count==0)return true;return false;}bool stack::full() const{if(count==MaxLen)return true;return false;}bool stack::get_top(char &c)const{if(empty())return false;else{c=data[count-1];return true;}}bool stack::push(const char c){if(full())return false;data[count++]=c;return true;}bool stack::pop(){if(empty())return false;count--;return true;}void stack::out(){for(int i=0;i<count;i++)cout<<data[i];cout<<'\t';}void stack::out1(){for(int i=0;i<count;i++)cout<<int(data[i]);cout<<'\t';}void print(int i,char*c)//剩余输入串的输出{for(int j=i;j<Length;j++)cout<<c[j];cout<<'\t';}void Goto(int i,char c)//状态转换函数,对应于表中GOTO {if(i==0){if(c=='E'){r.push(1);cout<<",GOTO(0,E)=1入栈"<<endl;}else if(c=='T'){r.push(2);cout<<",GOTO(0,T)=2入栈"<<endl;}else if(c=='F'){r.push(3);cout<<",GOTO(0,F)=3入栈"<<endl;}elseflag=false;}else if(i==4){if(c=='E'){r.push(8);cout<<",GOTO(4,E)=8入栈"<<endl;}else if(c=='T'){r.push(2);cout<<",GOTO(4,T)=2入栈"<<endl;}else if(c=='F'){r.push(3);cout<<",GOTO(4,F)=3入栈"<<endl;}elseflag=false;}else if(i==6){if(c=='T'){r.push(9);cout<<",GOTO(6,T)=9入栈"<<endl;}else if(c=='F'){r.push(3);cout<<",GOTO(6,F)=3入栈"<<endl;}elseflag=false;}else if(i==7){if(c=='F'){r.push(10);cout<<",GOTO(7,F)=10入栈"<<endl;}elseflag=false;}elseflag=false;}void Action0()//状态0时{if(ch=='i')//下一个操作符为i ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[0,i]=S5,状态5入栈"<<endl;r.push(5);l.push(ch);ch=strToken[point++];}else if(ch=='(')//下一个操作符为( ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[0,(]=S4,状态4入栈"<<endl;r.push(4);l.push(ch);ch=strToken[point++];}elseflag=false;}void Action1()//状态1{if(ch=='+')//下一个操作符为i ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[1,+]=S6,状态6入栈"<<endl;r.push(6);l.push(ch);ch=strToken[point++];}else if(ch=='#')//分析成功{flag=false;cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"Acc:分析成功"<<endl;}elseflag=false;}void Action2() //状态2{if(ch=='*')//下一个操作符为* ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[2,*]=S7,状态7入栈"<<endl;r.push(7);l.push(ch);ch=strToken[point++];}else if((ch=='+')||(ch==')')||(ch=='#'))//下一个操作符为+,),#规约{cout<<step++<<'\t';r.out1();l.out();l.pop();l.push('E');print(point-1,strToken);cout<<"r2: E→T归约";r.pop();r.get_top(Y);Goto(int(Y),'E');}elseflag=false;}void Action3()//状态3{if((ch=='+')||(ch=='*')||(ch==')')||(ch=='#'))//下一个操作符为+,*,),#规约{cout<<step++<<'\t';r.out1();l.out();l.pop();l.push('T');print(point-1,strToken);cout<<"r4: T→F归约";r.pop();r.get_top(Y);Goto(int(Y),'T');}elseflag=false;}void Action4_6_7(int x)//状态4,6,7{if(ch=='i')//下一个操作符为i ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[";cout<<x<<",i]=S5,状态5入栈"<<endl;r.push(5);l.push(ch);ch=strToken[point++];}else if(ch=='(')//下一个操作符为(,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[";cout<<x<<",(]=S4,状态4入栈"<<endl;r.push(4);l.push(ch);ch=strToken[point++];}elseflag=false;}void Action5()//状态5{if((ch=='+')||(ch=='*')||(ch==')')||(ch=='#'))//下一个操作符为+,*,),#规约{cout<<step++<<'\t';r.out1();l.out();l.pop();l.push('F');print(point-1,strToken);cout<<"r6: F→i归约";r.pop();r.get_top(Y);Goto(int(Y),'F');}elseflag=false;}void Action8()//状态8{if(ch=='+')//下一个操作符为+ ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[8,+]=S6,状态6入栈"<<endl;r.push(6);l.push(ch);ch=strToken[point++];}else if(ch==')')//下一个操作符为),移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[8,)]=S11,状态11入栈"<<endl;r.push(11);ch=strToken[point++];}elseflag=false;}void Action9()//状态9{if(ch=='*')//下一个操作符为* ,移进{cout<<step++<<'\t';r.out1();l.out();print(point-1,strToken);cout<<"ACTION[9,*]=S7,状态7入栈"<<endl;r.push(7);l.push(ch);ch=strToken[point++];}else if((ch=='+')||(ch==')')||(ch=='#'))//下一个操作符为+,,),#规约{cout<<step++<<'\t';r.out1();l.out();l.pop();l.pop();l.pop();l.push('E');print(point-1,strToken);cout<<"r1: E→E+T归约";r.pop();r.pop();r.pop();r.get_top(Y);Goto(int(Y),'E');}elseflag=false;}void Action10()//状态10{if((ch=='+')||(ch=='*')||(ch==')')||(ch=='#'))//下一个操作符为+,*,),#规约{cout<<step++<<'\t';l.out();l.pop();l.pop();l.pop();l.push('T');print(point-1,strToken);cout<<"r3: T→T*F归约";r.pop();r.pop();r.pop();r.get_top(Y);Goto(int(Y),'T');}elseflag=false;}void Action11()//状态11{if((ch=='+')||(ch=='*')||(ch==')')||(ch=='#'))//下一个操作符为+,*,),#规约{cout<<step++<<'\t';r.out1();l.out();l.pop();l.pop();l.pop();l.push('F');print(point-1,strToken);cout<<"r5: F→(E)归约";r.pop();r.pop();r.pop();r.get_top(Y);Goto(int(Y),'F');}elseflag=false;}void run()//规约{cout<<"请输入要规约的字符串:"<<endl;cin>>strToken;cout<<"步骤\t"<<"状态栈\t"<<"符号栈\t"<<"输入串\t\t"<<"动作说明"<<endl;ch=strToken[point++];//读取第一个字符l.push('#');r.push(0);r.get_top(Y);while(flag)//循环规约{if(int(Y)==0)Action0();else if(int(Y)==1)Action1();else if(int(Y)==2)Action2();else if(int(Y)==3)Action3();else if((int(Y)==4)||(int(Y)==6)||(int(Y)==7))Action4_6_7(int(Y));else if(int(Y)==5)Action5();else if(int(Y)==8)Action8();else if(int(Y)==9)Action9();else if(int(Y)==10)Action10();else if(int(Y)==11)Action11();elseflag=false;r.get_top(Y);}}int main(){cout<<"实验三"<<endl;run();system("pause");return 0;}。
[工学]编译原理--词法分析_语法分析_语义分析C语言
![[工学]编译原理--词法分析_语法分析_语义分析C语言](https://img.taocdn.com/s3/m/adf84cd8680203d8ce2f2474.png)
[工学]编译原理--词法分析_语法分析_语义分析C语言词法分析#include<iostream>#include<cstdio>#include<cstring>using namespace std;#define MAXN 20000int syn,p,sum,kk,m,n,row; double dsum,pos;char index[800],len;//记录指数形式的浮点数char r[6][10]={"function","if","then","while","do","endfunc"}; char token[MAXN],s[MAXN];char ch;bool is_letter(char c) {return c>='a' && c<='z' || c>='A' && c<='Z';}bool is_digtial(char c) {return c>='0' && c<='9'; }bool is_dot(char c){return c==',' || c==';'; }void identifier()//标示符的判断{m=0;while(ch>='a' && ch<='z' || ch>='0' && ch<='9') {token[m++]=ch;ch=s[++p];}token[m]='\0';ch=s[--p];syn=10;for(n=0;n<6;n++)if(strcmp(token,r[n])==0){syn=n+1;break;}}void digit(bool positive)//数字的判断{len=sum=0;ch=s[p];while(ch>='0' && ch<='9'){sum=sum*10+ch-'0';ch=s[++p];}if(ch=='.'){dsum=sum;ch=s[++p];pos=0.1;while(ch>='0' && ch<='9') {dsum=dsum+(ch-'0')*pos; pos=pos*0.1;ch=s[++p];}if(ch=='e'){index[len++]=ch;ch=s[++p];if(ch=='-' || ch=='+') {index[len++]=ch;ch=s[++p];}if(!(ch>='0' && ch<='9')) {syn=-1;}else{while(ch>='0' && ch<='9'){index[len++]=ch;ch=s[++p];}}}if(syn==-1 || (ch>='a' && ch<='z') || ch=='.'){syn=-1;//对数字开头的标识符进行判错。
编译原理语法分析报告+代码

编译原理语法分析报告+代码1000字一、语法分析语法分析是编译器的重要部分,它的作用是对源程序进行分析和判断,判断源程序是否符合语法规则,把源程序划分为一个个语法单元,并建立语法树,这里介绍一种常见的语法分析方法——LR(1)分析。
1.LR(1)分析LR(1)分析是一种自底向上的语法分析方法,它是以LR语法分析机为基础的。
LR(1)分析是在扫描整个输入的基础上作出决策的,名字中的1表示当扫描到一个符号时,它会读下一个符号来做决策并且仅仅读一个符号。
2.LR(1)分析器构建构建LR(1)分析器首先需要构建LR(1)自动机,然后对其进行分析,得到一个分析表。
分析表有两个函数:action和goto。
分析表的行是状态,列是终结符或非终结符,如果分析表的项中既包含action又包含goto,那么这个表就是一个LR(1)分析表。
3.核心算法核心算法就是通过分析表进行分析,具体步骤如下:(1)创建一个栈,将一个状态push入栈。
(2)循环扫描输入,每扫描一个符号就执行一个操作,直到栈为空。
(3)在栈的顶部状态上查找action表。
如果输入符号是一个终结符,那么应该执行的动作是shift。
如果输入符号是一个结束符号,那么说明输入已经结束,执行acc(accept)操作。
(4)如果找到了一个shift,就将其作为下一个状态push入栈,并将上次扫描到的符号作为标记push入栈。
(5)否则,在栈的顶部状态上查找goto表。
在状态表中查找新状态,并将其push入栈。
常见的错误处理:(1)在action表中找不到适当的输入:语法错误,报错。
(2)在goto表中找不到适当的输入:一个状态不能在当前符号的词法单元下产生任何变化。
4.算法实现这里提供一个简单的C++代码实现。
1)自动机的结构体声明:struct Automaton {int status; // 状态编号char symbol; // 符号int go_to; // 跳转状态int move_type; // 移动类型Automaton() : status(-1), symbol(0), go_to(-1),move_type(-1) {}};2)分析表结构体声明:struct AnalyzeTable {static const int ROWS = 100; // 分析表行数static const int COLS = 100; // 分析表列数Automaton analyze_table[ROWS][COLS]; // 分析表};3)LR(1)分析器的实现:class LR1Parser {public:LR1Parser(const std::string& grammar_file); // 构造函数~LR1Parser();void parse(const std::string& input_file); // 解析函数private:std::map<char, std::vector<std::string>> productions_; // 产生式std::map<char, std::set<char>> first_; // First集合std::map<char, std::set<char>> follow_; // Follow集合AnalyzeTable analyze_table_; // 分析表};4)分析表构建函数实现:void LR1Parser::build_analyze_table() {// 对于每个项A -> α.Bβ, a,把它添加到一个集合中。
编译原理词法分析,语法分析实验报告

编译原理实验报告一.LL(1)文法分析1.设计要求(1)对输入文法,它能判断是否为LL(1)文法,若是,则转(2);否则报错并终止;(2)输入已知文法,由程序自动生成它的LL(1)分析表;(3)对于给定的输入串,应能判断识别该串是否为给定文法的句型。
2.分析该程序可分为如下几步:(1)读入文法(2)判断正误(3)若无误,判断是否为LL(1)文法(4)若是,构造分析表;(5)由总控算法判断输入符号串是否为该文法的句型。
3.流程图开始读入文法有效?是是LL(1)文法?是判断句型报错结束4.源程序/*******************************************语法分析程序作者:xxx学号:xxx********************************************/#include<stdlib.h>#include<stdio.h>#include<string.h>/*******************************************/int count=0; /*分解的产生式的个数*/int number; /*所有终结符和非终结符的总数*/char start; /*开始符号*/char termin[50]; /*终结符号*/char non_ter[50]; /*非终结符号*/char v[50]; /*所有符号*/char left[50]; /*左部*/char right[50][50]; /*右部*/char first[50][50],follow[50][50]; /*各产生式右部的FIRST和左部的FOLLOW集合*/ char first1[50][50]; /*所有单个符号的FIRST集合*/char select[50][50]; /*各单个产生式的SELECT集合*/char f[50],F[50]; /*记录各符号的FIRST和FOLLOW是否已求过*/char empty[20]; /*记录可直接推出^的符号*/char TEMP[50]; /*求FOLLOW时存放某一符号串的FIRST集合*/int validity=1; /*表示输入文法是否有效*/int ll=1; /*表示输入文法是否为LL(1)文法*/int M[20][20]; /*分析表*/char choose; /*用户输入时使用*/char empt[20]; /*求_emp()时使用*/char fo[20]; /*求FOLLOW集合时使用*//*******************************************判断一个字符是否在指定字符串中********************************************/int in(char c,char *p){int i;if(strlen(p)==0)return(0);for(i=0;;i++){if(p[i]==c)return(1); /*若在,返回1*/if(i==strlen(p))return(0); /*若不在,返回0*/}}/*******************************************得到一个不是非终结符的符号********************************************/char c(){char c='A';while(in(c,non_ter)==1)c++;return(c);}/*******************************************分解含有左递归的产生式********************************************/void recur(char *point){ /*完整的产生式在point[]中*/int j,m=0,n=3,k;char temp[20],ch;ch=c(); /*得到一个非终结符*/k=strlen(non_ter);non_ter[k]=ch;non_ter[k+1]='\0';for(j=0;j<=strlen(point)-1;j++){if(point[n]==point[0]){ /*如果‘|’后的首符号和左部相同*/ for(j=n+1;j<=strlen(point)-1;j++){while(point[j]!='|'&&point[j]!='\0')temp[m++]=point[j++];left[count]=ch;memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';m=0;count++;if(point[j]=='|'){n=j+1;break;}}}else{ /*如果‘|’后的首符号和左部不同*/ left[count]=ch;right[count][0]='^';right[count][1]='\0';count++;for(j=n;j<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';printf(" count=%d ",count);m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';count++;m=0;}}}/*******************************************分解不含有左递归的产生式********************************************/void non_re(char *point){int m=0,j;char temp[20];for(j=3;j<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';count++;m=0;}/*******************************************读入一个文法********************************************/ char grammer(char *t,char *n,char *left,char right[50][50]) {char vn[50],vt[50];char s;char p[50][50];int i,j,k;printf("\n请输入文法的非终结符号串:");scanf("%s",vn);getchar();i=strlen(vn);memcpy(n,vn,i);n[i]='\0';printf("请输入文法的终结符号串:");scanf("%s",vt);getchar();i=strlen(vt);memcpy(t,vt,i);t[i]='\0';printf("请输入文法的开始符号:");scanf("%c",&s);getchar();printf("请输入文法产生式的条数:");scanf("%d",&i);getchar();for(j=1;j<=i;j++){printf("请输入文法的第%d条(共%d条)产生式:",j,i);scanf("%s",p[j-1]);getchar();}for(j=0;j<=i-1;j++)if(p[j][1]!='-'||p[j][2]!='>'){ printf("\ninput error!");validity=0;return('\0');} /*检测输入错误*/for(k=0;k<=i-1;k++){ /*分解输入的各产生式*/if(p[k][3]==p[k][0])recur(p[k]);elsenon_re(p[k]);}return(s);}/*******************************************将单个符号或符号串并入另一符号串********************************************/void merge(char *d,char *s,int type){ /*d是目标符号串,s是源串,type=1,源串中的‘^ ’一并并入目串;type=2,源串中的‘^ ’不并入目串*/int i,j;for(i=0;i<=strlen(s)-1;i++){if(type==2&&s[i]=='^');else{for(j=0;;j++){if(j<strlen(d)&&s[i]==d[j])break;if(j==strlen(d)){d[j]=s[i];d[j+1]='\0';}}}}}/*******************************************求所有能直接推出^的符号********************************************/void emp(char c){ /*即求所有由‘^ ’推出的符号*/ char temp[10];int i;for(i=0;i<=count-1;i++){if(right[i][0]==c&&strlen(right[i])==1){temp[0]=left[i];temp[1]='\0';merge(empty,temp,1);emp(left[i]);}}}/*******************************************求某一符号能否推出‘^ ’********************************************/int _emp(char c){ /*若能推出,返回1;否则,返回0*/ int i,j,k,result=1,mark=0;char temp[20];temp[0]=c;temp[1]='\0';merge(empt,temp,1);if(in(c,empty)==1)return(1);for(i=0;;i++){if(i==count)return(0);if(left[i]==c) /*找一个左部为c的产生式*/{j=strlen(right[i]); /*j为右部的长度*/if(j==1&&in(right[i][0],empty)==1)else if(j==1&&in(right[i][0],termin)==1)return(0);else{for(k=0;k<=j-1;k++)if(in(right[i][k],empt)==1)mark=1;if(mark==1)continue;else{for(k=0;k<=j-1;k++){result*=_emp(right[i][k]);temp[0]=right[i][k];temp[1]='\0';merge(empt,temp,1);}}}if(result==0&&i<count)continue;else if(result==1&&i<count)return(1);}}}/*******************************************判断读入的文法是否正确********************************************/int judge(){int i,j;for(i=0;i<=count-1;i++){if(in(left[i],non_ter)==0){ /*若左部不在非终结符中,报错*/ printf("\nerror1!");validity=0;return(0);}for(j=0;j<=strlen(right[i])-1;j++){if(in(right[i][j],non_ter)==0&&in(right[i][j],termin)==0&&right[i][j]!='^'){ /*若右部某一符号不在非终结符、终结符中且不为‘^ ’,报错*/ printf("\nerror2!");validity=0;return(0);}}}return(1);}/*******************************************求单个符号的FIRST********************************************/void first2(int i){ /*i为符号在所有输入符号中的序号*/char c,temp[20];int j,k,m;c=v[i];char ch='^';emp(ch);if(in(c,termin)==1) /*若为终结符*/{first1[i][0]=c;first1[i][1]='\0';}else if(in(c,non_ter)==1) /*若为非终结符*/{for(j=0;j<=count-1;j++){if(left[j]==c){if(in(right[j][0],termin)==1||right[j][0]=='^'){temp[0]=right[j][0];temp[1]='\0';merge(first1[i],temp,1);}else if(in(right[j][0],non_ter)==1){if(right[j][0]==c)continue;for(k=0;;k++)if(v[k]==right[j][0])break;if(f[k]=='0'){first2(k);f[k]='1';}merge(first1[i],first1[k],2);for(k=0;k<=strlen(right[j])-1;k++){empt[0]='\0';if(_emp(right[j][k])==1&&k<strlen(right[j])-1){for(m=0;;m++)if(v[m]==right[j][k+1])break;if(f[m]=='0'){first2(m);f[m]='1';}merge(first1[i],first1[m],2);}else if(_emp(right[j][k])==1&&k==strlen(right[j])-1){temp[0]='^';temp[1]='\0';merge(first1[i],temp,1);}elsebreak;}}}}}f[i]='1';}/*******************************************求各产生式右部的FIRST********************************************/void FIRST(int i,char *p){int length;int j,k,m;char temp[20];length=strlen(p);if(length==1) /*如果右部为单个符号*/ {if(p[0]=='^'){if(i>=0){first[i][0]='^';first[i][1]='\0';}else{TEMP[0]='^';TEMP[1]='\0';}}else{for(j=0;;j++)if(v[j]==p[0])break;if(i>=0){memcpy(first[i],first1[j],strlen(first1[j]));first[i][strlen(first1[j])]='\0';}else{memcpy(TEMP,first1[j],strlen(first1[j]));TEMP[strlen(first1[j])]='\0';}}}else /*如果右部为符号串*/{for(j=0;;j++)if(v[j]==p[0])break;if(i>=0)merge(first[i],first1[j],2);elsemerge(TEMP,first1[j],2);for(k=0;k<=length-1;k++){empt[0]='\0';if(_emp(p[k])==1&&k<length-1){for(m=0;;m++)if(v[m]==right[i][k+1])break;if(i>=0)merge(first[i],first1[m],2);elsemerge(TEMP,first1[m],2);}else if(_emp(p[k])==1&&k==length-1){temp[0]='^';temp[1]='\0';if(i>=0)merge(first[i],temp,1);elsemerge(TEMP,temp,1);}else if(_emp(p[k])==0)break;}}}/*******************************************求各产生式左部的FOLLOW********************************************/ void FOLLOW(int i){int j,k,m,n,result=1;char c,temp[20];c=non_ter[i]; /*c为待求的非终结符*/ temp[0]=c;temp[1]='\0';merge(fo,temp,1);if(c==start){ /*若为开始符号*/temp[0]='#';temp[1]='\0';merge(follow[i],temp,1);}for(j=0;j<=count-1;j++){if(in(c,right[j])==1) /*找一个右部含有c的产生式*/{for(k=0;;k++)if(right[j][k]==c)break; /*k为c在该产生式右部的序号*/for(m=0;;m++)if(v[m]==left[j])break; /*m为产生式左部非终结符在所有符号中的序号*/ if(k==strlen(right[j])-1){ /*如果c在产生式右部的最后*/if(in(v[m],fo)==1){merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}else{ /*如果c不在产生式右部的最后*/for(n=k+1;n<=strlen(right[j])-1;n++){empt[0]='\0';result*=_emp(right[j][n]);}if(result==1){ /*如果右部c后面的符号串能推出^*/if(in(v[m],fo)==1){ /*避免循环递归*/merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}for(n=k+1;n<=strlen(right[j])-1;n++)temp[n-k-1]=right[j][n];temp[strlen(right[j])-k-1]='\0';FIRST(-1,temp);merge(follow[i],TEMP,2);}}}F[i]='1';}/*******************************************判断读入文法是否为一个LL(1)文法********************************************/int ll1(){int i,j,length,result=1;char temp[50];for(j=0;j<=49;j++){ /*初始化*/first[j][0]='\0';follow[j][0]='\0';first1[j][0]='\0';select[j][0]='\0';TEMP[j]='\0';temp[j]='\0';f[j]='0';F[j]='0';}for(j=0;j<=strlen(v)-1;j++)first2(j); /*求单个符号的FIRST集合*/ printf("\nfirst1:");for(j=0;j<=strlen(v)-1;j++)printf("%c:%s ",v[j],first1[j]);printf("\nempty:%s",empty);printf("\n:::\n_emp:");for(j=0;j<=strlen(v)-1;j++)printf("%d ",_emp(v[j]));for(i=0;i<=count-1;i++)FIRST(i,right[i]); /*求FIRST*/printf("\n");for(j=0;j<=strlen(non_ter)-1;j++){ /*求FOLLOW*/if(fo[j]==0){fo[0]='\0';FOLLOW(j);}}printf("\nfirst:");for(i=0;i<=count-1;i++)printf("%s ",first[i]);printf("\nfollow:");for(i=0;i<=strlen(non_ter)-1;i++)printf("%s ",follow[i]);for(i=0;i<=count-1;i++){ /*求每一产生式的SELECT集合*/ memcpy(select[i],first[i],strlen(first[i]));select[i][strlen(first[i])]='\0';for(j=0;j<=strlen(right[i])-1;j++)result*=_emp(right[i][j]);if(strlen(right[i])==1&&right[i][0]=='^')result=1;if(result==1){for(j=0;;j++)if(v[j]==left[i])break;merge(select[i],follow[j],1);}}printf("\nselect:");for(i=0;i<=count-1;i++)printf("%s ",select[i]);memcpy(temp,select[0],strlen(select[0]));temp[strlen(select[0])]='\0';for(i=1;i<=count-1;i++){ /*判断输入文法是否为LL(1)文法*/ length=strlen(temp);if(left[i]==left[i-1]){merge(temp,select[i],1);if(strlen(temp)<length+strlen(select[i]))return(0);}else{temp[0]='\0';memcpy(temp,select[i],strlen(select[i]));temp[strlen(select[i])]='\0';}}return(1);}/*******************************************构造分析表M********************************************/void MM(){int i,j,k,m;for(i=0;i<=19;i++)for(j=0;j<=19;j++)M[i][j]=-1;i=strlen(termin);termin[i]='#'; /*将#加入终结符数组*/termin[i+1]='\0';for(i=0;i<=count-1;i++){for(m=0;;m++)if(non_ter[m]==left[i])break; /*m为产生式左部非终结符的序号*/for(j=0;j<=strlen(select[i])-1;j++){if(in(select[i][j],termin)==1){for(k=0;;k++)if(termin[k]==select[i][j])break; /*k为产生式右部终结符的序号*/ M[m][k]=i;}}}}/*******************************************总控算法********************************************/void syntax(){int i,j,k,m,n,p,q;char ch;char S[50],str[50];printf("请输入该文法的句型:");scanf("%s",str);getchar();i=strlen(str);str[i]='#';str[i+1]='\0';S[0]='#';S[1]=start;S[2]='\0';j=0;ch=str[j];while(1){if(in(S[strlen(S)-1],termin)==1){if(S[strlen(S)-1]!=ch){printf("\n该符号串不是文法的句型!");return;}else if(S[strlen(S)-1]=='#'){printf("\n该符号串是文法的句型.");return;}else{S[strlen(S)-1]='\0';j++;ch=str[j];}}else{for(i=0;;i++)if(non_ter[i]==S[strlen(S)-1])break;for(k=0;;k++){if(termin[k]==ch)break;if(k==strlen(termin)){printf("\n词法错误!");return;}}if(M[i][k]==-1){printf("\n语法错误!");return;}else{m=M[i][k];if(right[m][0]=='^')S[strlen(S)-1]='\0';else{p=strlen(S)-1;q=p;for(n=strlen(right[m])-1;n>=0;n--)S[p++]=right[m][n];S[q+strlen(right[m])]='\0';}}}printf("\nS:%s str:",S);for(p=j;p<=strlen(str)-1;p++)printf("%c",str[p]);printf(" ");}}/*******************************************一个用户调用函数********************************************/void menu(){syntax();printf("\n是否继续?(y or n):");scanf("%c",&choose);getchar();while(choose=='y'){menu();}}/*******************************************主函数********************************************/void main(){int i,j;start=grammer(termin,non_ter,left,right); /*读入一个文法*/ printf("count=%d",count);printf("\nstart:%c",start);strcpy(v,non_ter);strcat(v,termin);printf("\nv:%s",v);printf("\nnon_ter:%s",non_ter);printf("\ntermin:%s",termin);printf("\nright:");for(i=0;i<=count-1;i++)printf("%s ",right[i]);printf("\nleft:");for(i=0;i<=count-1;i++)printf("%c ",left[i]);if(validity==1)validity=judge();printf("\nvalidity=%d",validity);if(validity==1){printf("\n文法有效");ll=ll1();printf("\nll=%d",ll);if(ll==0)printf("\n该文法不是一个LL1文法!");else{MM();printf("\n");for(i=0;i<=19;i++)for(j=0;j<=19;j++)if(M[i][j]>=0)printf("M[%d][%d]=%d ",i,j,M[i][j]);printf("\n");menu();}}}5.执行结果(1)输入一个文法(2)输入一个符号串(3)再次输入一个符号串,然后退出程序二.词法分析一、问题描述识别简单语言的单词符号识别简单语言的基本字、标识符、无符号整数、运算符和界符。
编译原理实验报告(词法分析+语法分析)

计算机专业类课程实验报告课程名称:编译原理学院:计算机科学与工程专业:计算机科学与技术学生姓名:***学号:*************指导教师:***日期:2015年6月5日电子科技大学计算机学院实验中心电子科技大学实验报告实验一一、实验名称:词法分析器的设计与实现二、实验学时:4三、实验内容和目的:实验内容:求n!的极小语言的源程序作为词法分析的输入程序,根据给定的文法对其进行词法分析并将单词符号与种别组成的二元式按指定格式输出到out.dyd文件中,同时将词法错误输出到error.err文件中。
其中二元式文件out.dyd 有如下要求:(1)二元式形式:单词符号⋃种别(2)每行后加上“⋃⋃⋃...⋃EOLN⋃24”(3)文件结尾加上“⋃⋃⋃...⋃EOF⋃25”出错文件error.err中错误信息格式如下:***LINE:行号⋃⋃错误性质实验目的:通过设计并实现一个词法分析器,了解和掌握词法分析程序设计的原理及相应的程序设计方法,同时提高编程能力。
四、实验原理:1、编译程序要求对高级语言编写的源程序进行分析和合成,生成目标程序。
词法分析是对源程序进行的首次分析,实现词法分析的程序为词法分析程序。
像用自然语言书写的文章一样,源程序是由一系列的句子组成的,句子是由单词符号按一定的规则构成的,而单词符号又是由字符按一定规则构成,因此,源程序实际上是由满足程序语言规范的字符按照一定的规则组合起来构成的一个字符串。
2、词法分析的功能是从左到右逐个地扫描源程序字符串,按照词法规则识别出单词符号作为输出,对识别过程中发现的词法错误,输出相关信息。
3、单词符号是程序语言最基本的语法符号,为便于语法分析,通常将单词符号分为五类(标识符,基本字,常数,运算符,界符),而本次实验中单词符号与其对应的种别如下图所示:4、状态转换图是有限有向图,是设计词法分析器的有效工具。
图中的节点代表状态,节点间的有向边代表状态之间的转换关系,有向边上标记的字符表示状态转换的条件。
编译实验报告(语法分析、词法分析)

printf("(3, %s)\n",digittp);
实
验
原
理
(
算
法
流
程
)
5、其他函数
char alphaprocess(char buffer)
char othertp [20];
othertp[0]=buffer;
othertp[1]='\0';
char *border[7]={",",";",".","(",")","{","}"}; //分格符
char *arithmetic[8]={"+","-","*","/","<",">","=","+="}; //运算符
////////////////////////////////////////////////////////////////////////////////////////
if (search(othertp,4)) do//判断字符是否是运算符
printf("(4, %s)\n",othertp);
buffer=fgetc(fp);
goto out;
if (search(othertp,5)) do //判断字符是否是分隔符
printf("(5, %s)\n",othertp);
编译原理词法分析和语法分析报告+代码(C语言版)[1]
![编译原理词法分析和语法分析报告+代码(C语言版)[1]](https://img.taocdn.com/s3/m/6a025cd1240c844769eaee6f.png)
词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图:主程序示意图如图3-1所示。
其中初始包括以下两个方面:⑴关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。
如能查到匹配的单词,则该单词为关键字,否则为一般标识符。
关键字表为一个字符串数组,其描述如下:Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,};图3-1(2)程序中需要用到的主要变量为syn,token和sum3.2 扫描子程序的算法思想:首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。
编译原理语法分析报告+代码
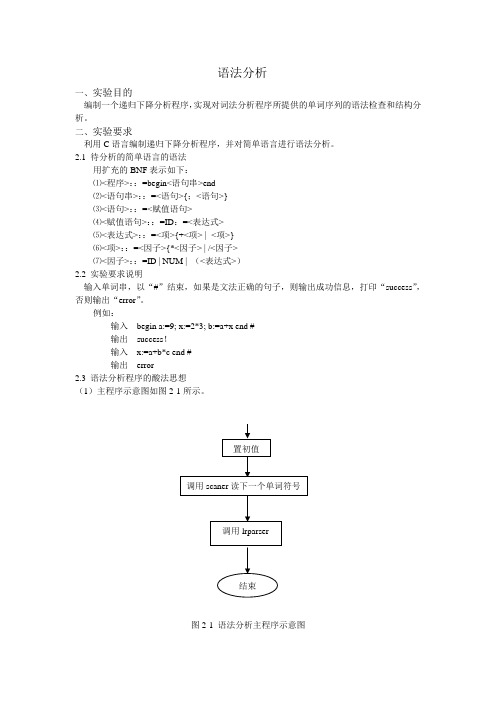
语法分析一、实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二、实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
2.1 待分析的简单语言的语法用扩充的BNF表示如下:⑴<程序>::=begin<语句串>end⑵<语句串>::=<语句>{;<语句>}⑶<语句>::=<赋值语句>⑷<赋值语句>::=ID:=<表达式>⑸<表达式>::=<项>{+<项> | -<项>}⑹<项>::=<因子>{*<因子> | /<因子>⑺<因子>::=ID | NUM | (<表达式>)2.2 实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
例如:输入begin a:=9; x:=2*3; b:=a+x end #输出success!输入x:=a+b*c end #输出error2.3 语法分析程序的酸法思想(1)主程序示意图如图2-1所示。
图2-1 语法分析主程序示意图(2)递归下降分析程序示意图如图2-2所示。
(3)语句串分析过程示意图如图2-3所示。
图2-3 语句串分析示意图图2-2 递归下降分析程序示意图(4)statement语句分析程序流程如图2-4、2-5、2-6、2-7所示。
图2-4 statement语句分析函数示意图图2-5 expression表达式分析函数示意图图2-7 factor分析过程示意图三、语法分析程序的C语言程序源代码:#include "stdio.h"#include "string.h"char prog[100],token[8],ch;char *rwtab[6]={"begin","if","then","while","do","end"};int syn,p,m,n,sum;int kk;factor();expression();yucu();term();statement();lrparser();scaner();main(){p=kk=0;printf("\nplease input a string (end with '#'): \n");do{ scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;scaner();lrparser();getch();}lrparser(){if(syn==1){scaner(); /*读下一个单词符号*/yucu(); /*调用yucu()函数;*/if (syn==6){ scaner();if ((syn==0)&&(kk==0))printf("success!\n");}else { if(kk!=1) printf("the string haven't got a 'end'!\n");kk=1;}}else { printf("haven't got a 'begin'!\n");kk=1;}return;}yucu(){statement(); /*调用函数statement();*/while(syn==26){scaner(); /*读下一个单词符号*/if(syn!=6)statement(); /*调用函数statement();*/}return;}statement(){ if(syn==10){scaner(); /*读下一个单词符号*/if(syn==18){ scaner(); /*读下一个单词符号*/ expression(); /*调用函数statement();*/ }else { printf("the sing ':=' is wrong!\n");kk=1;}}else { printf("wrong sentence!\n");kk=1;}return;}expression(){ term();while((syn==13)||(syn==14)){ scaner(); /*读下一个单词符号*/ term(); /*调用函数term();*/}return;}term(){ factor();while((syn==15)||(syn==16)){ scaner(); /*读下一个单词符号*/ factor(); /*调用函数factor(); */ }return;}factor(){ if((syn==10)||(syn==11)) scaner();else if(syn==27){ scaner(); /*读下一个单词符号*/expression(); /*调用函数statement();*/ if(syn==28)scaner(); /*读下一个单词符号*/else { printf("the error on '('\n");kk=1;}}else { printf("the expression error!\n");kk=1;}return;}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;m=0;ch=prog[p++];while(ch==' ')ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;token[m++]='\0';for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')){ while((ch>='0')&&(ch<='9')){ sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':m=0;ch=prog[p++];if(ch=='>'){ syn=21;}else if(ch=='='){ syn=22;}else{ syn=20;p--;}break;case '>':m=0;ch=prog[p++];if(ch=='='){ syn=24;}else{ syn=23;p--;}break;case ':':m=0;ch=prog[p++];if(ch=='='){ syn=18;}else{ syn=17;p--;}break;case '+': syn=13; break;case '-': syn=14; break;case '*': syn=15;break;case '/': syn=16;break;case '(': syn=27;break;case ')': syn=28;break;case '=': syn=25;break;case ';': syn=26;break;case '#': syn=0;break;default: syn=-1;break;}}四、结果分析:输入begin a:=9; x:=2*3; b:=a+x end # 后输出success!如图4-1所示:图4-1输入x:=a+b*c end # 后输出error 如图4-2所示:图4-2五、总结:通过本次试验,了解了语法分析的运行过程,主程序大致流程为:“置初值”→调用scaner 函数读下一个单词符号→调用IrParse→结束。
编译原理词法和语法分析报告+源码

词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图:主程序示意图如图3-1所示。
其中初始包括以下两个方面:⑴关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。
如能查到匹配的单词,则该单词为关键字,否则为一般标识符。
关键字表为一个字符串数组,其描述如下:Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,};图3-1(2)程序中需要用到的主要变量为syn,token和sum3.2 扫描子程序的算法思想:首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。
词法分析 编译原理 C语言版

#include "stdio.h"#include "string.h"#include "stdlib.h"#define al 10#define norw 13#define nmax 14FILE *fin;FILE *fout;char fname[al],fwname[al],a[al+1],id[al+1],sym[20];static char sword[11]={'+','-','*','/','(',')','=',',','.','#',';'};static char ssym[11][al]={"plus","minus","times","slash","lparen","rparen","eql","comma","period","neq","se micolon"};static char word[13][al]={"begin","call","const","do","end","if","odd","procedure","read","then","var","whil e","write"};//保留关键字static char wsym[13][al]={"beginsym","callsym","constsym","dosym","endsym","ifsym","oddsym","procsy m","readsym","thensym","varsym","whilesym","writesym"};//关键字类型int cc,ll,cx,num;char line[81];char ch;int getch(){if(cc==ll)//缓冲是否被读取完毕{if(feof(fin)){return -1;}ll=0;cc=0;ch=' ';while(ch!=10){if(EOF==fscanf(fin,"%c",&ch)){line[ll]=0;break;}line[ll]=ch;ll++;}// linecount++;// printf("开始分析程序的第%d行\n",linecount);// fprintf(fout,"开始分析程序的第%d行\n",linecount);}ch=line[cc];cc++;return 0;}//void error(int rowcount,int wordcount)//{//printf("!第%d行第%d个位置数字越界\n",rowcount,wordcount);//fprintf(fout,"!第%d行第%d个位置数字越界\n",rowcount,wordcount);//}int error(int n){switch(n){case 1:printf("常数说明中的“=”写成“:=”。
编译原理词法分析和语法分析报告+代码[C语言版]
![编译原理词法分析和语法分析报告+代码[C语言版]](https://img.taocdn.com/s3/m/72d7b73c02020740bf1e9b36.png)
词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:表2.1 各种单词符号对应的种别码2.3 词法分析程序的功能:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图:主程序示意图如图3-1所示。
其中初始包括以下两个方面:⑴关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。
如能查到匹配的单词,则该单词为关键字,否则为一般标识符。
关键字表为一个字符串数组,其描述如下:Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,};是图3-1(2)程序中需要用到的主要变量为syn,token和sum3.2 扫描子程序的算法思想:首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。
编译原理课程设计(词法分析,语法分析,语义分析,代码生成)

编译原理课程设计(词法分析,语法分析,语义分析,代码生成)#include<cstdio>#include<iostream>#include<cstdlib>#include<fstream>#include<string>#include<cmath>using namespace std;/************************************************/struct token// token {int code;//int num;//token *next;};token *token_head,*token_tail;//tokenstruct str// string {int num;//string word;//str *next;};str *string_head,*string_tail;//stringstruct ivan// {char left;//string right;//int len;// };ivan css[20];// 20 struct pank// action {char sr;//int state;// };pank action[46][18];//action int go_to[46][11];// go_to struct ike// {ike *pre;int num;//int word;//ike *next;};ike *stack_head,*stack_tail;// struct L//{int k;string op;//string op1;//string op2;//string result;//L *next;//L *Ltrue;//trueL *Lfalse;//false};L *L_four_head,*L_four_tail,*L_true_head,*L_false_head;//truefalse struct symb//{string word;//int addr;//symb *next;};symb *symb_head,*symb_tail;///************************************************/void scan();//void cifa_main();//int judge(char ch);// void out1(char ch);//token.txtvoid out3(char ch,string word);//string.txt void input1(token*temp);//token void input3(str *temp);//string void output();// void outfile();///************************************************/void yufa_main();//void yufa_initialize();// int yufa_SLR1(int a);// int ID1(inta);//action string ID10(int i);//int ID2(char ch);//go_toint ID20(char ch);//char ID21(int j);//void add(ike *temp);//ike void del();//ike/************************************************/void yuyi_main(int m);//void add_L_four(L *temp);// void add_L_true(L *temp);//true void add_L_false(L *temp);//false void add_symb(symb *temp);// void output_yuyi();// string newop(int m);//string id_numtoname(int num);// int lookup(string m);///************************************************/FILE *fp;//int wordcount;//int err;//int nl;//int yuyi_linshi;//stringE_name,T_name,F_name,M_name,id_name,id1_name,id2_name,errword;// int id_num,id1_num,id2_num,id_left,id_while,id_then,id_do;// /******************************************************/int main(){cout<<"************************"<<endl;cout<<"* *"<<endl;cout<<"* *"<<endl;cout<<"* *"<<endl;cout<<"* *"<<endl;cout<<"************************"<<endl;cifa_main();//yufa_main();//output_yuyi();//cout<<endl;system("pause");return(0);}/******************************************************/ void cifa_main(){token_head=new token;token_head->next=NULL;token_tail=new token;token_tail->next=NULL;string_head=new str;string_head->next=NULL;string_tail=new str;string_tail->next=NULL;//L_four_head=new L;L_four_head->next=NULL;L_four_tail=new L;L_four_tail->k=0;L_four_tail->next=NULL;L_true_head=new L;L_true_head->Ltrue=NULL;L_false_head=new L;L_false_head->Lfalse=NULL;symb_head=new symb;symb_head->next=NULL;symb_tail=new symb;symb_tail->next=NULL;yuyi_linshi=-1;id_num=0;wordcount=0;//err=0;//nl=1;//scan();if(err==0){char m;output();cout<<"!"<<endl<<endl<<" y";cin>>m;cout<<endl;if(m=='y'){outfile();cout<<"token.txtsting.txt"<<endl;cout<<endl;}}}void scan(){cout<<endl;system("pause");cout<<endl;char ch;string word;char document[50];int flag=0;cout<<":";cin>>document;cout<<endl;cout<<"************************"<<endl; cout<<"* *"<<endl;cout<<"************************"<<endl; if((fp=fopen(document,"rt"))==NULL) {err=1;cout<<"!"<<endl;return;}while(!feof(fp)){word="";ch=fgetc(fp);flag=judge(ch);if(flag==1)out1(ch);else if(flag==3)out3(ch,word);else if(flag==4 || flag==5 ||flag==6) continue;else{cout<<nl<<" "<<":! "<<ch<<endl;err=1;}}fclose(fp);}int judge(char ch){int flag=0;if(ch=='=' || ch=='+' || ch=='*' || ch=='>' || ch==':' || ch==';' || ch=='{' || ch=='}' || ch=='(' || ch==')')flag=1;//else if(('a'<=ch && ch<='z') || ('A'<=ch && ch<='Z'))flag=3;//else if(ch==' ')flag=4;//else if(feof(fp))flag=5;//else if(ch=='\n'){flag=6;//nl++;}elseflag=0;//return(flag);}void out1(char ch){int id;switch(ch){case '=' : id=1;break;case '+' : id=2;break;case '*' : id=3;break;case '>' : id=4;break;case ':' : id=5;break;case ';' : id=6;break;case '{' : id=7;break;case '}' : id=8;break;case '(' : id=9;break;case ')' : id=10;break;// default : id=0;}token *temp;temp=new token;temp->code=id;temp->num=-1;temp->next=NULL;input1(temp);return;}void out3(char ch,string word) {token *temp;temp=new token;temp->code=-1;temp->num=-1;temp->next=NULL;str *temp1;temp1=new str;temp1->num=-1;temp1->word="";temp1->next=NULL;int flag=0;word=word+ch;ch=fgetc(fp);flag=judge(ch);if(flag==1 || flag==4 || flag==5 || flag==6){if(word=="and" || word=="if" || word=="then" || word=="while" || word=="do" || word=="int"){if(word=="and")temp->code=31;else if(word=="if")temp->code=32;else if(word=="then")temp->code=33;else if(word=="while")temp->code=35;else if(word=="do")temp->code=36;else if(word=="int")temp->code=37;//input1(temp);if(flag==1)out1(ch);else if(flag==4 || flag==5 || flag==6) return;}else if(flag==1){wordcount++;temp->code=25;temp->num=wordcount;input1(temp);temp1->num=wordcount;temp1->word=word;input3(temp1);out1(ch);}else if(flag==4 || flag==5 || flag==6) {wordcount++;temp->code=25;temp->num=wordcount;input1(temp);temp1->num=wordcount;temp1->word=word;input3(temp1);}return;}else if(flag==2 || flag==3)out3(ch,word);//else{err=1;cout<<nl<<" "<<":! "<<ch<<endl; return;}}void input1(token *temp) {if(token_head->next == NULL) {token_head->next=temp;token_tail->next=temp;}else{token_tail->next->next=temp; token_tail->next=temp;}}void input3(str *temp) {if(string_head->next == NULL) {string_head->next=temp;string_tail->next=temp;}else{string_tail->next->next=temp; string_tail->next=temp;}}void output(){cout<<"token"<<endl;token *temp1;temp1=new token;temp1=token_head->next;while(temp1!=NULL){cout<<temp1->code;if(temp1->num == -1){cout<<endl;}else{cout<<" "<<temp1->num<<endl;}temp1=temp1->next;}cout<<""<<endl;str *temp3;temp3=new str;temp3=string_head->next;while(temp3!=NULL){cout<<temp3->num<<" "<<temp3->word<<endl; temp3=temp3->next;}}void outfile(){ofstream fout1("token.txt");//ofstream fout3("string.txt");token *temp1;temp1=new token;temp1=token_head->next;while(temp1!=NULL){fout1<<temp1->code;if(temp1->num == -1)fout1<<endl;elsefout1<<" "<<temp1->num<<endl;temp1=temp1->next;}str *temp3;temp3=new str;temp3=string_head->next;while(temp3!=NULL){fout3<<temp3->num<<" "<<temp3->word<<endl; temp3=temp3->next;}}/******************************************************/ void yufa_main(){if(err==0){system("pause");cout<<endl;cout<<"************************"<<endl;cout<<"* *"<<endl;cout<<"************************"<<endl;yufa_initialize();//token *temp;temp=new token;temp=token_head->next;int p,q;p=0;q=0;cout<<""<<endl;while(temp!=NULL){int w;w=ID1(temp->code);p=yufa_SLR1(w);if(p==1) break;if(p==0)temp=temp->next;if(temp==NULL) q=1;}//if(q==1)while(1){p=yufa_SLR1(17);if(p==3) break;}//$}}void yufa_initialize() { stack_head=new ike;stack_tail=new ike;stack_head->pre=NULL;stack_head->next=stack_tail; stack_head->num=0;stack_head->word='!';stack_tail->pre=stack_head; stack_tail->next=NULL;//css[0].left='Q';css[0].right="P";css[1].left='P';css[1].right="id()L;R"; css[2].left='L';css[2].right="L;D";css[3].left='L';css[3].right="D";css[4].left='D';css[4].right="id:int"; css[5].left='E';css[5].right="E+T";css[6].left='E';css[6].right="T";css[7].left='T';css[7].right="T*F";css[8].left='T';css[8].right="F";css[9].left='F';css[9].right="(E)";css[10].left='F';css[10].right="id";css[11].left='B';css[11].right="B and B"; css[12].left='B';css[12].right="id>id"; css[13].left='M';css[13].right="id=E";css[14].left='S';css[14].right="if B then M"; css[15].left='S';css[15].right="while B do M"; css[16].left='S';css[16].right="M";css[17].left='N';css[17].right="N;S";css[18].left='N';css[18].right="S";css[19].left='R';css[19].right="{N}";int i,j;for(i=0;i<20;i++){char *css_len;css_len=&css[i].right[0];css[i].len=strlen(css_len); }css[1].len=6;css[4].len=3;css[10].len=1;css[11].len=3;css[12].len=3;css[13].len=3;css[14].len=4;css[15].len=4;//for(i=0;i<46;i++){for(j=0;j<18;j++)action[i][j].sr='#';}//actionfor(i=0;i<46;i++){for(j=0;j<11;j++)go_to[i][j]=-1;}//go_to/****************************actiongo_to************************/ action[0][0].sr='s';action[0][0].state=2;action[1][17].sr='@';//action[2][1].sr='s';action[2][1].state=3;action[3][2].sr='s';action[3][2].state=4;action[4][0].sr='s';action[4][0].state=5;action[5][4].sr='s';action[5][4].state=6;action[6][11].sr='s';action[6][11].state=7;action[7][3].sr='r';action[7][3].state=4;action[8][3].sr='r';action[8][3].state=3;action[9][3].sr='s';action[9][3].state=10; action[10][0].sr='s';action[10][0].state=5; action[10][9].sr='s';action[10][9].state=13; action[11][17].sr='r';action[11][17].state=1; action[12][3].sr='r';action[12][3].state=2; action[13][0].sr='s';action[13][0].state=14; action[13][13].sr='s';action[13][13].state=23; action[13][15].sr='s';action[13][15].state=27; action[14][8].sr='s';action[14][8].state=15; action[15][0].sr='s';action[15][0].state=36; action[15][1].sr='s';action[15][1].state=41; action[16][6].sr='s';action[16][6].state=43; action[16][3].sr='r';action[16][3].state=13; action[16][10].sr='r';action[16][10].state=13; action[17][3].sr='s';action[17][3].state=19; action[17][10].sr='s';action[17][10].state=18; action[18][17].sr='r';action[18][17].state=19; action[19][0].sr='s';action[19][0].state=14; action[19][13].sr='s';action[19][13].state=23; action[19][15].sr='s';action[19][15].state=27; action[20][3].sr='r';action[20][3].state=17; action[20][10].sr='r';action[20][10].state=17; action[21][3].sr='r';action[21][3].state=18; action[21][10].sr='r';action[21][10].state=18;action[22][3].sr='r';action[22][3].state=16; action[22][10].sr='r';action[22][10].state=16; action[23][0].sr='s';action[23][0].state=31; action[24][12].sr='s';action[24][12].state=34; action[24][14].sr='s';action[24][14].state=25; action[25][0].sr='s';action[25][0].state=14; action[26][3].sr='r';action[26][3].state=14; action[26][10].sr='r';action[26][10].state=14; action[27][0].sr='s';action[27][0].state=31; action[28][12].sr='s';action[28][12].state=34; action[28][16].sr='s';action[28][16].state=29; action[29][0].sr='s';action[29][0].state=14; action[30][3].sr='r';action[30][3].state=15; action[30][10].sr='r';action[30][10].state=15; action[31][7].sr='s';action[31][7].state=32; action[32][0].sr='s';action[32][0].state=33; action[33][12].sr='r';action[33][12].state=12; action[33][14].sr='r';action[33][14].state=12; action[33][16].sr='r';action[33][16].state=12; action[34][0].sr='s';action[34][0].state=31; action[35][12].sr='r';action[35][12].state=11; action[35][14].sr='r';action[35][14].state=11; action[35][16].sr='r';action[35][16].state=11; action[36][2].sr='r';action[36][2].state=10;action[36][3].sr='r';action[36][3].state=10; action[36][5].sr='r';action[36][5].state=10; action[36][6].sr='r';action[36][6].state=10; action[36][10].sr='r';action[36][10].state=10; action[37][2].sr='r';action[37][2].state=8; action[37][3].sr='r';action[37][3].state=8; action[37][5].sr='r';action[37][5].state=8; action[37][6].sr='r';action[37][6].state=8; action[37][10].sr='r';action[37][10].state=8; action[38][2].sr='r';action[38][2].state=6; action[38][3].sr='r';action[38][3].state=6; action[38][5].sr='s';action[38][5].state=39; action[38][6].sr='r';action[38][6].state=6; action[38][10].sr='r';action[38][10].state=6; action[39][0].sr='s';action[39][0].state=36; action[39][1].sr='s';action[39][1].state=41; action[40][2].sr='r';action[40][2].state=7; action[40][3].sr='r';action[40][3].state=7; action[40][5].sr='r';action[40][5].state=7; action[40][6].sr='r';action[40][6].state=7; action[40][10].sr='r';action[40][10].state=7; action[41][0].sr='s';action[41][0].state=36; action[41][1].sr='s';action[41][1].state=41; action[42][2].sr='s';action[42][2].state=45;action[42][6].sr='s';action[42][6].state=43;action[43][0].sr='s';action[43][0].state=36;action[43][1].sr='s';action[43][1].state=41;action[44][2].sr='r';action[44][2].state=5;action[44][3].sr='r';action[44][3].state=5;action[44][5].sr='s';action[44][5].state=39;action[44][6].sr='r';action[44][6].state=5;action[44][10].sr='r';action[44][10].state=5;action[45][2].sr='r';action[45][2].state=9;action[45][3].sr='r';action[45][3].state=9;action[45][5].sr='r';action[45][5].state=9;action[45][6].sr='r';action[45][6].state=9;action[45][10].sr='r';action[45][10].state=9;go_to[0][0]=1;go_to[4][1]=8;go_to[4][9]=9;go_to[10][1]=12;go_to[10][ 2]=11;go_to[13][7]=22;go_to[13][8]=21;go_to[13][10]=17;go_to[15][3]=16;go_to[15][4]=38;go_to[15][5]=37;go_to[19][7]=20;go_t o[19][8]=20;go_to[23][6]=24;go_to[25][7]=26;go_to[27][6]=28;go_to[29][7]=30;go_to[34][6]=35;go_to[39][5]=40;go_to[41][3]=42;go_t o[41][4]=38;go_to[41][5]=37;go_to[43][4]=44;go_to[43][5]=37;/****************************actiongo_to************************/ }int ID1(int i)//action {int j;j=-1;if(i==25) {j=0;id_num++;}//if(i==1) {j=8,id_left=id_num;}//if(i==2) j=6;if(i==3) j=5;if(i==4) j=7;if(i==5) j=4;if(i==6) j=3;if(i==7) j=9;if(i==8) j=10;if(i==9) j=1;if(i==10) j=2;if(i==31) j=12;if(i==32) j=13;if(i==33) {j=14;id_then=L_four_tail->k+1;}//ifthenif(i==35) {j=15;id_while=L_four_tail->k+1;}//whilewhile if(i==36) {j=16;id_do=L_four_tail->k+1;}//whiledoif(i==37) j=11;return(j);}string ID10(int i)//{string ch;if(i==0) ch="id";if(i==1) ch="(";if(i==2) ch=")";if(i==3) ch=";";if(i==4) ch=":";if(i==5) ch="*";if(i==6) ch="+";if(i==7) ch=">";if(i==8) ch="=";if(i==9) ch="{";if(i==10) ch="}";if(i==11) ch="int";if(i==12) ch="and";if(i==13) ch="if";if(i==14) ch="then";if(i==15) ch="while"; if(i==16) ch="do";if(i==17) ch="$";return(ch);}int ID2(char ch)//go_to {int j;j=-1;if(ch=='P') j=0;if(ch=='D') j=1;if(ch=='R') j=2;if(ch=='E') j=3;if(ch=='T') j=4;if(ch=='F') j=5;if(ch=='B') j=6;if(ch=='M') j=7;if(ch=='S') j=8;if(ch=='L') j=9;if(ch=='N') j=10; return(j);}int ID20(char ch)// {int j;j=-1;if(ch=='P') j=100; if(ch=='D') j=101; if(ch=='R') j=102; if(ch=='E') j=103; if(ch=='T') j=104; if(ch=='F') j=105;if(ch=='B') j=106;if(ch=='M') j=107;if(ch=='S') j=108;if(ch=='L') j=109;if(ch=='N') j=1010;return(j);}char ID21(int j)//{char ch;if(j==100 || j==0) ch='P'; if(j==101 || j==1) ch='D'; if(j==102 || j==2) ch='R'; if(j==103 || j==3) ch='E'; if(j==104 || j==4) ch='T'; if(j==105 || j==5) ch='F'; if(j==106 || j==6) ch='B'; if(j==107 || j==7) ch='M'; if(j==108 || j==8) ch='S'; if(j==109 || j==9) ch='L'; if(j==1010 || j==10) ch='N'; return(ch);}void add(ike *temp)//{if(stack_head->next==stack_tail){temp->pre=stack_head;temp->next=stack_tail;stack_head->next=temp;stack_tail->pre=temp;}else{temp->pre=stack_tail->pre;temp->next=stack_tail;stack_tail->pre->next=temp;stack_tail->pre=temp;}}void del()//{stack_tail->pre->pre->next=stack_tail; stack_tail->pre=stack_tail->pre->pre; }int yufa_SLR1(int w){/*cout<<""<<ID10(w)<<" ";*/int i,flag=0,state_temp;//flag01,23char sr_temp;sr_temp=action[stack_tail->pre->num][w].sr;//state_temp=action[stack_tail->pre->num][w].state;// if(sr_temp=='#')//{flag=1;err=3;cout<<"!"<<endl;}else if(sr_temp=='s')//{ike *temp;temp=new ike;temp->next=NULL;temp->pre=NULL;temp->word=w;temp->num=state_temp;add(temp);cout/*<<""*/<<sr_temp<<state_temp<<" "/*<<""<<stack_tail->pre->num<<" "<<""<<ID10(stack_tail->pre->word)*/<<endl;flag=0;}else if(sr_temp=='r')//{int p=ID2(css[state_temp].left);int q=css[state_temp].len;for(i=0;i<q;i++)del();ike *temp;temp=new ike;temp->next=NULL;temp->pre=NULL;temp->word=ID20(css[state_temp].left);temp->num=go_to[stack_tail->pre->num][p];//go_toadd(temp);cout/*<<""*/<<sr_temp<<state_temp<<" "<<css[state_temp].left<<""<<css[state_temp].right<<" "/*<<""<<stack_tail->pre->num<<" "<<""<<ID21(stack_tail->pre->word)*/<<endl;flag=2;yuyi_main(state_temp);//}else if(sr_temp=='@')//{cout<<"END"/*<<""<<sr_temp<<state_temp*/<<""<<css[state_temp].left<<""<<css[state_temp].right<<" "/*<<""<<stack_tail->pre->num<<" "<<""<<ID21(stack_tail->pre->word)*/<<endl;flag=3;cout<<"!"<<endl;}else//{flag=1;err=3;cout<<"!"<<endl;}return(flag);}/******************************************************/ void yuyi_main(int m){L *temp;int k;k=1;temp=new L;temp->op=" ";temp->op1=" ";temp->op2=" ";temp->result="";temp->next=NULL;temp->Ltrue=NULL;temp->Lfalse=NULL;if(m==4)//{symb *Stemp;Stemp=new symb;id_name=id_numtoname(id_num); Stemp->word=id_name;Stemp->next=NULL;add_symb(Stemp);}if(m==5)//EE+T{temp->op="+";temp->op1=E_name;temp->op2=T_name;yuyi_linshi++;//E_name="t"+newop(yuyi_linshi); temp->result=E_name;add_L_four(temp);//}if(m==6)//ET{E_name=T_name;}if(m==7)//TT*F{temp->op="*";temp->op1=T_name;temp->op2=F_name;yuyi_linshi++;//T_name="t"+newop(yuyi_linshi); temp->result=T_name;add_L_four(temp);//}if(m==8)//TF{T_name=F_name;}if(m==9)//F(E){F_name=E_name;}if(m==10)//Fid{id_name=id_numtoname(id_num); F_name=id_name;k=lookup(id_name);//if(k==0){err=2;errword=id_name;return;}}if(m==12)//Bid>id{temp->op="J>";id1_num=id_num-1;id1_name=id_numtoname(id1_num); k=lookup(id1_name);//if(k==0){err=2;errword=id1_name;return;}id2_num=id_num;id2_name=id_numtoname(id2_num); k=lookup(id2_name);//if(k==0){err=2;errword=id2_name;return;}temp->result="-1";temp->op1=id1_name;temp->op2=id2_name;add_L_four(temp);//add_L_true(temp);//trueL *temp2;temp2=new L;temp2->op="J";temp2->op1=" ";temp2->op2=" ";temp2->result="-1";add_L_four(temp2);//add_L_false(temp2);//false}if(m==13)//Mid=E{temp->op="=";temp->op1=E_name;temp->op2=" ";id_name=id_numtoname(id_left);temp->result=id_name;add_L_four(temp);//yuyi_linshi=-1;//}if(m==14)//Sif B then M{int a;a=id_then;temp=L_true_head->Ltrue;while(temp!=NULL){temp->result="L"+newop(a);a=temp->k;temp=temp->Ltrue;}a=L_four_tail->k+1;temp=L_false_head->Lfalse;while(temp!=NULL){temp->result="L"+newop(a);temp=temp->Lfalse;}L_true_head->Ltrue=NULL;L_false_head->Lfalse=NULL;//truefalse}if(m==15)//Swhile B do M {int a;a=id_do;temp=L_true_head->Ltrue; while(temp!=NULL){temp->result="L"+newop(a); a=temp->k;temp=temp->Ltrue;}a=L_four_tail->k+2;temp=L_false_head->Lfalse; while(temp!=NULL){temp->result="L"+newop(a); temp=temp->Lfalse;}L *temp1;temp1=new L;temp1->op="J";temp1->op1=" ";temp1->op2=" ";temp1->next=NULL;temp1->result="L"+newop(id_while); add_L_four(temp1);//L_true_head->Ltrue=NULL;L_false_head->Lfalse=NULL;//truefalse }}string newop(int m)//{int shang,yushu;string chuan,chuan1;shang=m;chuan="";while(1){yushu=shang%10;chuan=chuan+char(48+yushu);shang=shang/10;if(shang==0)break;}int i;char *ch;ch=&chuan[0];chuan1="";for(i=strlen(ch)-1;i>=0;i--)chuan1=chuan1+chuan[i];return(chuan1);}void add_L_four(L *temp)//{temp->k=L_four_tail->k+1;if(L_four_head->next == NULL){L_four_head->next=temp;L_four_tail->next=temp;}else{L_four_tail->next->next=temp;L_four_tail->next=temp;}L_four_tail->k=L_four_tail->next->k; } void add_L_true(L *temp)//true{temp->Ltrue=L_true_head->Ltrue;L_true_head->Ltrue=temp;}void add_L_false(L *temp)//false {temp->Lfalse=L_false_head->Lfalse; L_false_head->Lfalse=temp;}void add_symb(symb *temp)//{if(symb_head->next == NULL){temp->addr=0;symb_head->next=temp;symb_tail->next=temp;}else{temp->addr=symb_tail->next->addr+4; symb_tail->next->next=temp;symb_tail->next=temp;}}void output_yuyi(){if(err==0)//{cout<<endl;system("pause");cout<<endl;cout<<"************************"<<endl;cout<<"* *"<<endl;cout<<"************************"<<endl;cout<<""<<endl;L *temp;temp=L_four_head->next;while(temp!=NULL){cout<<"L"<<temp->k<<": "<<temp->op<<", "<<temp->op1<<", "<<temp->op2<<","<<temp->result<<""<<endl;temp=temp->next;}cout<<""<<endl;symb *Stemp;Stemp=symb_head->next;cout<<"name"<<" type "<<" id "<<" identifer "<<"addr"<<endl;while(Stemp!=NULL){cout<<Stemp->word<<" int "<<" 25 "<<" sv "<<Stemp->addr<<endl;Stemp=Stemp->next;}}if(err==2)//{cout<<endl;system("pause");cout<<endl;cout<<"************************"<<endl; cout<<"* *"<<endl;cout<<"************************"<<endl; cout<<""<<errword<<"!"<<endl;}}string id_numtoname(int num)//{str *temp;string name;temp=string_head->next;while(temp!=NULL){if(num==temp->num){name=temp->word;break;。
编译原理词法分析,语法分析实验报告
编译原理实验报告一.LL(1)文法分析1.设计要求(1)对输入文法,它能判断是否为LL(1)文法,若是,则转(2);否则报错并终止;(2)输入已知文法,由程序自动生成它的LL(1)分析表;(3)对于给定的输入串,应能判断识别该串是否为给定文法的句型。
2.分析该程序可分为如下几步:(1)读入文法(2)判断正误(3)若无误,判断是否为LL(1)文法(4)若是,构造分析表;(5)由总控算法判断输入符号串是否为该文法的句型。
3.流程图开始读入文法有效?是是LL(1)文法?是判断句型报错结束4.源程序/*******************************************语法分析程序作者:xxx学号:xxx********************************************/#include<stdlib.h>#include<stdio.h>#include<string.h>/*******************************************/int count=0; /*分解的产生式的个数*/int number; /*所有终结符和非终结符的总数*/char start; /*开始符号*/char termin[50]; /*终结符号*/char non_ter[50]; /*非终结符号*/char v[50]; /*所有符号*/char left[50]; /*左部*/char right[50][50]; /*右部*/char first[50][50],follow[50][50]; /*各产生式右部的FIRST和左部的FOLLOW集合*/ char first1[50][50]; /*所有单个符号的FIRST集合*/char select[50][50]; /*各单个产生式的SELECT集合*/char f[50],F[50]; /*记录各符号的FIRST和FOLLOW是否已求过*/char empty[20]; /*记录可直接推出^的符号*/char TEMP[50]; /*求FOLLOW时存放某一符号串的FIRST集合*/int validity=1; /*表示输入文法是否有效*/int ll=1; /*表示输入文法是否为LL(1)文法*/int M[20][20]; /*分析表*/char choose; /*用户输入时使用*/char empt[20]; /*求_emp()时使用*/char fo[20]; /*求FOLLOW集合时使用*//*******************************************判断一个字符是否在指定字符串中********************************************/int in(char c,char *p){int i;if(strlen(p)==0)return(0);for(i=0;;i++){if(p[i]==c)return(1); /*若在,返回1*/if(i==strlen(p))return(0); /*若不在,返回0*/}}/*******************************************得到一个不是非终结符的符号********************************************/char c(){char c='A';while(in(c,non_ter)==1)c++;return(c);}/*******************************************分解含有左递归的产生式********************************************/void recur(char *point){ /*完整的产生式在point[]中*/int j,m=0,n=3,k;char temp[20],ch;ch=c(); /*得到一个非终结符*/k=strlen(non_ter);non_ter[k]=ch;non_ter[k+1]='\0';for(j=0;j<=strlen(point)-1;j++){if(point[n]==point[0]){ /*如果‘|’后的首符号和左部相同*/ for(j=n+1;j<=strlen(point)-1;j++){while(point[j]!='|'&&point[j]!='\0')temp[m++]=point[j++];left[count]=ch;memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';m=0;count++;if(point[j]=='|'){n=j+1;break;}}}else{ /*如果‘|’后的首符号和左部不同*/ left[count]=ch;right[count][0]='^';right[count][1]='\0';count++;for(j=n;j<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';printf(" count=%d ",count);m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';count++;m=0;}}}/*******************************************分解不含有左递归的产生式********************************************/void non_re(char *point){int m=0,j;char temp[20];for(j=3;j<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';count++;m=0;}/*******************************************读入一个文法********************************************/ char grammer(char *t,char *n,char *left,char right[50][50]) {char vn[50],vt[50];char s;char p[50][50];int i,j,k;printf("\n请输入文法的非终结符号串:");scanf("%s",vn);getchar();i=strlen(vn);memcpy(n,vn,i);n[i]='\0';printf("请输入文法的终结符号串:");scanf("%s",vt);getchar();i=strlen(vt);memcpy(t,vt,i);t[i]='\0';printf("请输入文法的开始符号:");scanf("%c",&s);getchar();printf("请输入文法产生式的条数:");scanf("%d",&i);getchar();for(j=1;j<=i;j++){printf("请输入文法的第%d条(共%d条)产生式:",j,i);scanf("%s",p[j-1]);getchar();}for(j=0;j<=i-1;j++)if(p[j][1]!='-'||p[j][2]!='>'){ printf("\ninput error!");validity=0;return('\0');} /*检测输入错误*/for(k=0;k<=i-1;k++){ /*分解输入的各产生式*/if(p[k][3]==p[k][0])recur(p[k]);elsenon_re(p[k]);}return(s);}/*******************************************将单个符号或符号串并入另一符号串********************************************/void merge(char *d,char *s,int type){ /*d是目标符号串,s是源串,type=1,源串中的‘^ ’一并并入目串;type=2,源串中的‘^ ’不并入目串*/int i,j;for(i=0;i<=strlen(s)-1;i++){if(type==2&&s[i]=='^');else{for(j=0;;j++){if(j<strlen(d)&&s[i]==d[j])break;if(j==strlen(d)){d[j]=s[i];d[j+1]='\0';}}}}}/*******************************************求所有能直接推出^的符号********************************************/void emp(char c){ /*即求所有由‘^ ’推出的符号*/ char temp[10];int i;for(i=0;i<=count-1;i++){if(right[i][0]==c&&strlen(right[i])==1){temp[0]=left[i];temp[1]='\0';merge(empty,temp,1);emp(left[i]);}}}/*******************************************求某一符号能否推出‘^ ’********************************************/int _emp(char c){ /*若能推出,返回1;否则,返回0*/ int i,j,k,result=1,mark=0;char temp[20];temp[0]=c;temp[1]='\0';merge(empt,temp,1);if(in(c,empty)==1)return(1);for(i=0;;i++){if(i==count)return(0);if(left[i]==c) /*找一个左部为c的产生式*/{j=strlen(right[i]); /*j为右部的长度*/if(j==1&&in(right[i][0],empty)==1)else if(j==1&&in(right[i][0],termin)==1)return(0);else{for(k=0;k<=j-1;k++)if(in(right[i][k],empt)==1)mark=1;if(mark==1)continue;else{for(k=0;k<=j-1;k++){result*=_emp(right[i][k]);temp[0]=right[i][k];temp[1]='\0';merge(empt,temp,1);}}}if(result==0&&i<count)continue;else if(result==1&&i<count)return(1);}}}/*******************************************判断读入的文法是否正确********************************************/int judge(){int i,j;for(i=0;i<=count-1;i++){if(in(left[i],non_ter)==0){ /*若左部不在非终结符中,报错*/ printf("\nerror1!");validity=0;return(0);}for(j=0;j<=strlen(right[i])-1;j++){if(in(right[i][j],non_ter)==0&&in(right[i][j],termin)==0&&right[i][j]!='^'){ /*若右部某一符号不在非终结符、终结符中且不为‘^ ’,报错*/ printf("\nerror2!");validity=0;return(0);}}}return(1);}/*******************************************求单个符号的FIRST********************************************/void first2(int i){ /*i为符号在所有输入符号中的序号*/char c,temp[20];int j,k,m;c=v[i];char ch='^';emp(ch);if(in(c,termin)==1) /*若为终结符*/{first1[i][0]=c;first1[i][1]='\0';}else if(in(c,non_ter)==1) /*若为非终结符*/{for(j=0;j<=count-1;j++){if(left[j]==c){if(in(right[j][0],termin)==1||right[j][0]=='^'){temp[0]=right[j][0];temp[1]='\0';merge(first1[i],temp,1);}else if(in(right[j][0],non_ter)==1){if(right[j][0]==c)continue;for(k=0;;k++)if(v[k]==right[j][0])break;if(f[k]=='0'){first2(k);f[k]='1';}merge(first1[i],first1[k],2);for(k=0;k<=strlen(right[j])-1;k++){empt[0]='\0';if(_emp(right[j][k])==1&&k<strlen(right[j])-1){for(m=0;;m++)if(v[m]==right[j][k+1])break;if(f[m]=='0'){first2(m);f[m]='1';}merge(first1[i],first1[m],2);}else if(_emp(right[j][k])==1&&k==strlen(right[j])-1){temp[0]='^';temp[1]='\0';merge(first1[i],temp,1);}elsebreak;}}}}}f[i]='1';}/*******************************************求各产生式右部的FIRST********************************************/void FIRST(int i,char *p){int length;int j,k,m;char temp[20];length=strlen(p);if(length==1) /*如果右部为单个符号*/ {if(p[0]=='^'){if(i>=0){first[i][0]='^';first[i][1]='\0';}else{TEMP[0]='^';TEMP[1]='\0';}}else{for(j=0;;j++)if(v[j]==p[0])break;if(i>=0){memcpy(first[i],first1[j],strlen(first1[j]));first[i][strlen(first1[j])]='\0';}else{memcpy(TEMP,first1[j],strlen(first1[j]));TEMP[strlen(first1[j])]='\0';}}}else /*如果右部为符号串*/{for(j=0;;j++)if(v[j]==p[0])break;if(i>=0)merge(first[i],first1[j],2);elsemerge(TEMP,first1[j],2);for(k=0;k<=length-1;k++){empt[0]='\0';if(_emp(p[k])==1&&k<length-1){for(m=0;;m++)if(v[m]==right[i][k+1])break;if(i>=0)merge(first[i],first1[m],2);elsemerge(TEMP,first1[m],2);}else if(_emp(p[k])==1&&k==length-1){temp[0]='^';temp[1]='\0';if(i>=0)merge(first[i],temp,1);elsemerge(TEMP,temp,1);}else if(_emp(p[k])==0)break;}}}/*******************************************求各产生式左部的FOLLOW********************************************/ void FOLLOW(int i){int j,k,m,n,result=1;char c,temp[20];c=non_ter[i]; /*c为待求的非终结符*/ temp[0]=c;temp[1]='\0';merge(fo,temp,1);if(c==start){ /*若为开始符号*/temp[0]='#';temp[1]='\0';merge(follow[i],temp,1);}for(j=0;j<=count-1;j++){if(in(c,right[j])==1) /*找一个右部含有c的产生式*/{for(k=0;;k++)if(right[j][k]==c)break; /*k为c在该产生式右部的序号*/for(m=0;;m++)if(v[m]==left[j])break; /*m为产生式左部非终结符在所有符号中的序号*/ if(k==strlen(right[j])-1){ /*如果c在产生式右部的最后*/if(in(v[m],fo)==1){merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}else{ /*如果c不在产生式右部的最后*/for(n=k+1;n<=strlen(right[j])-1;n++){empt[0]='\0';result*=_emp(right[j][n]);}if(result==1){ /*如果右部c后面的符号串能推出^*/if(in(v[m],fo)==1){ /*避免循环递归*/merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}for(n=k+1;n<=strlen(right[j])-1;n++)temp[n-k-1]=right[j][n];temp[strlen(right[j])-k-1]='\0';FIRST(-1,temp);merge(follow[i],TEMP,2);}}}F[i]='1';}/*******************************************判断读入文法是否为一个LL(1)文法********************************************/int ll1(){int i,j,length,result=1;char temp[50];for(j=0;j<=49;j++){ /*初始化*/first[j][0]='\0';follow[j][0]='\0';first1[j][0]='\0';select[j][0]='\0';TEMP[j]='\0';temp[j]='\0';f[j]='0';F[j]='0';}for(j=0;j<=strlen(v)-1;j++)first2(j); /*求单个符号的FIRST集合*/ printf("\nfirst1:");for(j=0;j<=strlen(v)-1;j++)printf("%c:%s ",v[j],first1[j]);printf("\nempty:%s",empty);printf("\n:::\n_emp:");for(j=0;j<=strlen(v)-1;j++)printf("%d ",_emp(v[j]));for(i=0;i<=count-1;i++)FIRST(i,right[i]); /*求FIRST*/printf("\n");for(j=0;j<=strlen(non_ter)-1;j++){ /*求FOLLOW*/if(fo[j]==0){fo[0]='\0';FOLLOW(j);}}printf("\nfirst:");for(i=0;i<=count-1;i++)printf("%s ",first[i]);printf("\nfollow:");for(i=0;i<=strlen(non_ter)-1;i++)printf("%s ",follow[i]);for(i=0;i<=count-1;i++){ /*求每一产生式的SELECT集合*/ memcpy(select[i],first[i],strlen(first[i]));select[i][strlen(first[i])]='\0';for(j=0;j<=strlen(right[i])-1;j++)result*=_emp(right[i][j]);if(strlen(right[i])==1&&right[i][0]=='^')result=1;if(result==1){for(j=0;;j++)if(v[j]==left[i])break;merge(select[i],follow[j],1);}}printf("\nselect:");for(i=0;i<=count-1;i++)printf("%s ",select[i]);memcpy(temp,select[0],strlen(select[0]));temp[strlen(select[0])]='\0';for(i=1;i<=count-1;i++){ /*判断输入文法是否为LL(1)文法*/ length=strlen(temp);if(left[i]==left[i-1]){merge(temp,select[i],1);if(strlen(temp)<length+strlen(select[i]))return(0);}else{temp[0]='\0';memcpy(temp,select[i],strlen(select[i]));temp[strlen(select[i])]='\0';}}return(1);}/*******************************************构造分析表M********************************************/void MM(){int i,j,k,m;for(i=0;i<=19;i++)for(j=0;j<=19;j++)M[i][j]=-1;i=strlen(termin);termin[i]='#'; /*将#加入终结符数组*/termin[i+1]='\0';for(i=0;i<=count-1;i++){for(m=0;;m++)if(non_ter[m]==left[i])break; /*m为产生式左部非终结符的序号*/for(j=0;j<=strlen(select[i])-1;j++){if(in(select[i][j],termin)==1){for(k=0;;k++)if(termin[k]==select[i][j])break; /*k为产生式右部终结符的序号*/ M[m][k]=i;}}}}/*******************************************总控算法********************************************/void syntax(){int i,j,k,m,n,p,q;char ch;char S[50],str[50];printf("请输入该文法的句型:");scanf("%s",str);getchar();i=strlen(str);str[i]='#';str[i+1]='\0';S[0]='#';S[1]=start;S[2]='\0';j=0;ch=str[j];while(1){if(in(S[strlen(S)-1],termin)==1){if(S[strlen(S)-1]!=ch){printf("\n该符号串不是文法的句型!");return;}else if(S[strlen(S)-1]=='#'){printf("\n该符号串是文法的句型.");return;}else{S[strlen(S)-1]='\0';j++;ch=str[j];}}else{for(i=0;;i++)if(non_ter[i]==S[strlen(S)-1])break;for(k=0;;k++){if(termin[k]==ch)break;if(k==strlen(termin)){printf("\n词法错误!");return;}}if(M[i][k]==-1){printf("\n语法错误!");return;}else{m=M[i][k];if(right[m][0]=='^')S[strlen(S)-1]='\0';else{p=strlen(S)-1;q=p;for(n=strlen(right[m])-1;n>=0;n--)S[p++]=right[m][n];S[q+strlen(right[m])]='\0';}}}printf("\nS:%s str:",S);for(p=j;p<=strlen(str)-1;p++)printf("%c",str[p]);printf(" ");}}/*******************************************一个用户调用函数********************************************/void menu(){syntax();printf("\n是否继续?(y or n):");scanf("%c",&choose);getchar();while(choose=='y'){menu();}}/*******************************************主函数********************************************/void main(){int i,j;start=grammer(termin,non_ter,left,right); /*读入一个文法*/ printf("count=%d",count);printf("\nstart:%c",start);strcpy(v,non_ter);strcat(v,termin);printf("\nv:%s",v);printf("\nnon_ter:%s",non_ter);printf("\ntermin:%s",termin);printf("\nright:");for(i=0;i<=count-1;i++)printf("%s ",right[i]);printf("\nleft:");for(i=0;i<=count-1;i++)printf("%c ",left[i]);if(validity==1)validity=judge();printf("\nvalidity=%d",validity);if(validity==1){printf("\n文法有效");ll=ll1();printf("\nll=%d",ll);if(ll==0)printf("\n该文法不是一个LL1文法!");else{MM();printf("\n");for(i=0;i<=19;i++)for(j=0;j<=19;j++)if(M[i][j]>=0)printf("M[%d][%d]=%d ",i,j,M[i][j]);printf("\n");menu();}}}5.执行结果(1)输入一个文法(2)输入一个符号串(3)再次输入一个符号串,然后退出程序二.词法分析一、问题描述识别简单语言的单词符号识别简单语言的基本字、标识符、无符号整数、运算符和界符。
编译原理--词法分析,语法分析,语义分析(C语言)

词法分析#include<iostream>#include<cstdio>#include<cstring>using namespace std;#define MAXN 20000int syn,p,sum,kk,m,n,row;double dsum,pos;char index[800],len;//记录指数形式的浮点数char r[6][10]={"function","if","then","while","do","endfunc"}; char token[MAXN],s[MAXN];char ch;bool is_letter(char c){return c>='a' && c<='z' || c>='A' && c<='Z';}bool is_digtial(char c){return c>='0' && c<='9';}bool is_dot(char c){return c==',' || c==';';}void identifier()//标示符的判断{m=0;while(ch>='a' && ch<='z' || ch>='0' && ch<='9'){token[m++]=ch;ch=s[++p];}token[m]='\0';ch=s[--p];syn=10;for(n=0;n<6;n++)if(strcmp(token,r[n])==0){syn=n+1;break;}}void digit(bool positive)//数字的判断{len=sum=0;ch=s[p];while(ch>='0' && ch<='9'){sum=sum*10+ch-'0';ch=s[++p];}if(ch=='.'){dsum=sum;ch=s[++p];pos=0.1;while(ch>='0' && ch<='9'){dsum=dsum+(ch-'0')*pos;pos=pos*0.1;ch=s[++p];}if(ch=='e'){index[len++]=ch;ch=s[++p];if(ch=='-' || ch=='+'){index[len++]=ch;ch=s[++p];}if(!(ch>='0' && ch<='9')){syn=-1;}else{while(ch>='0' && ch<='9'){index[len++]=ch;ch=s[++p];}}}if(syn==-1 || (ch>='a' && ch<='z') || ch=='.'){syn=-1;//对数字开头的标识符进行判错。
(完整)编译原理实验报告(词法分析器 语法分析器)

编译原理实验报告实验一一、实验名称:词法分析器的设计二、实验目的:1,词法分析器能够识别简单语言的单词符号2,识别出并输出简单语言的基本字。
标示符。
无符号整数.运算符.和界符。
三、实验要求:给出一个简单语言单词符号的种别编码词法分析器四、实验原理:1、词法分析程序的算法思想算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号.2、程序流程图(1)主程序(2)扫描子程序3、各种单词符号对应的种别码五、实验内容:1、实验分析编写程序时,先定义几个全局变量a[]、token[](均为字符串数组),c,s( char型),i,j,k(int型),a[]用来存放输入的字符串,token[]另一个则用来帮助识别单词符号,s用来表示正在分析的字符.字符串输入之后,逐个分析输入字符,判断其是否‘#’,若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c)、int letter(char c)判断其是数字,字符还是算术符,分别为用以判断数字或字符的情况,算术符的判断可以在switch语句中进行,还要通过函数int lookup(char token[])来判断标识符和保留字。
2 实验词法分析器源程序:#include 〈stdio.h〉#include <math.h>#include <string。
h>int i,j,k;char c,s,a[20],token[20]={’0’};int letter(char s){if((s〉=97)&&(s〈=122)) return(1);else return(0);}int digit(char s){if((s〉=48)&&(s<=57)) return(1);else return(0);}void get(){s=a[i];i=i+1;}void retract(){i=i-1;}int lookup(char token[20]){if(strcmp(token,"while")==0) return(1);else if(strcmp(token,"if")==0) return(2);else if(strcmp(token,"else”)==0) return(3);else if(strcmp(token,"switch”)==0) return(4);else if(strcmp(token,"case")==0) return(5);else return(0);}void main(){printf(”please input string :\n");i=0;do{i=i+1;scanf("%c",&a[i]);}while(a[i]!=’#’);i=1;j=0;get();while(s!=’#'){ memset(token,0,20);switch(s){case 'a':case ’b':case ’c':case ’d':case ’e’:case ’f’:case 'g’:case ’h':case 'i':case ’j':case 'k’:case ’l':case 'm’:case 'n':case ’o':case ’p':case ’q’:case 'r’:case 's’:case 't’:case ’u’:case ’v’:case ’w’:case ’x':case ’y':case ’z’:while(letter(s)||digit(s)){token[j]=s;j=j+1;get();}retract();k=lookup(token);if(k==0)printf("(%d,%s)”,6,token);else printf("(%d,—)",k);break;case ’0':case ’1’:case ’2':case ’3':case '4’:case '5’:case ’6':case ’7’:case ’8’:case '9’:while(digit(s)){token[j]=s;j=j+1;get();}retract();printf(”%d,%s",7,token);break;case '+':printf(”(’+',NULL)”);break;case ’-':printf("(’-',null)");break;case ’*':printf(”('*’,null)");break;case '<':get();if(s=='=’) printf(”(relop,LE)”);else{retract();printf("(relop,LT)");}break;case ’=':get();if(s=='=’)printf("(relop,EQ)");else{retract();printf(”('=',null)”);}break;case ’;':printf(”(;,null)");break;case ' ’:break;default:printf("!\n”);}j=0;get();} }六:实验结果:实验二一、实验名称:语法分析器的设计二、实验目的:用C语言编写对一个算术表达式实现语法分析的语法分析程序,并以四元式的形式输出,以加深对语法语义分析原理的理解,掌握语法分析程序的实现方法和技术.三、实验原理:1、算术表达式语法分析程序的算法思想首先通过关系图法构造出终结符间的左右优先函数f(a),g(a)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图:主程序示意图如图3-1所示。
其中初始包括以下两个方面:⑴关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。
如能查到匹配的单词,则该单词为关键字,否则为一般标识符。
关键字表为一个字符串数组,其描述如下:Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,};图3-1(2)程序中需要用到的主要变量为syn,token和sum3.2 扫描子程序的算法思想:首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。
扫描子程序主要部分流程如图3-2所示。
图3-2 四、词法分析程序的C语言程序源代码:#include <stdio.h>#include <string.h>char prog[80],token[8],ch;int syn,p,m,n,sum;char *rwtab[6]={"begin","if","then","while","do","end"}; scaner();main(){p=0;printf("\n please input a string(end with '#'):/n");do{scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(syn){case 11:printf("( %-10d%5d )\n",sum,syn);break;case -1:printf("you have input a wrong string\n");getch();exit(0);default: printf("( %-10s%5d )\n",token,syn);break;}}while(syn!=0);getch();}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;ch=prog[p++];m=0;while((ch==' ')||(ch=='\n'))ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')){ while((ch>='0')&&(ch<='9')){ sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=22;token[m++]=ch;}else{ syn=20;p--;}break;case '>':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=24;token[m++]=ch;}else{ syn=23;p--;}break;case '+': token[m++]=ch;ch=prog[p++];if(ch=='+'){ syn=17;token[m++]=ch;}else{ syn=13;p--;}break;case '-':token[m++]=ch;ch=prog[p++];if(ch=='-'){ syn=29;token[m++]=ch;}else{ syn=14;p--;}break;case '!':ch=prog[p++];if(ch=='='){ syn=21;token[m++]=ch;}else{ syn=31;}break;case '=':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=25;token[m++]=ch;}else{ syn=18;p--;}break;case '*': syn=15;token[m++]=ch;break;case '/': syn=16;token[m++]=ch;break;case '(': syn=27;token[m++]=ch;break;case ')': syn=28;token[m++]=ch;break;case '{': syn=5;token[m++]=ch;break;case '}': syn=6;token[m++]=ch;break;case ';': syn=26;token[m++]=ch;break;case '\"': syn=30;token[m++]=ch;break;case '#': syn=0;token[m++]=ch;break;case ':':syn=17;token[m++]=ch;default: syn=-1;break;}token[m++]='\0';}五、结果分析:输入begin x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如下序列:(begin 1)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图5-1所示:图5-1六、总结:词法分析的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
通过本试验的完成,更加加深了对词法分析原理的理解。
语法分析一、实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二、实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
2.1 待分析的简单语言的语法用扩充的BNF表示如下:⑴<程序>::=begin<语句串>end⑵<语句串>::=<语句>{;<语句>}⑶<语句>::=<赋值语句>⑷<赋值语句>::=ID:=<表达式>⑸<表达式>::=<项>{+<项> | -<项>}⑹<项>::=<因子>{*<因子> | /<因子>⑺<因子>::=ID | NUM | (<表达式>)2.2 实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
例如:输入begin a:=9; x:=2*3; b:=a+x end #输出success!输入x:=a+b*c end #输出error2.3 语法分析程序的酸法思想(1)主程序示意图如图2-1所示。
图2-1 语法分析主程序示意图(2)递归下降分析程序示意图如图2-2所示。
(3)语句串分析过程示意图如图2-3所示。
图2-3 语句串分析示意图图2-2 递归下降分析程序示意图(4)statement语句分析程序流程如图2-4、2-5、2-6、2-7所示。
图2-4 statement语句分析函数示意图图2-5 expression表达式分析函数示意图图2-7 factor分析过程示意图三、语法分析程序的C语言程序源代码:#include "stdio.h"#include "string.h"char prog[100],token[8],ch;char *rwtab[6]={"begin","if","then","while","do","end"};int syn,p,m,n,sum;int kk;factor();expression();yucu();term();statement();lrparser();scaner();main(){p=kk=0;printf("\nplease input a string (end with '#'): \n");do{ scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;scaner();lrparser();getch();}lrparser(){if(syn==1){scaner(); /*读下一个单词符号*/yucu(); /*调用yucu()函数;*/if (syn==6){ scaner();if ((syn==0)&&(kk==0))printf("success!\n");}else { if(kk!=1) printf("the string haven't got a 'end'!\n");kk=1;}}else { printf("haven't got a 'begin'!\n");kk=1;}return;}yucu(){statement(); /*调用函数statement();*/while(syn==26){scaner(); /*读下一个单词符号*/if(syn!=6)statement(); /*调用函数statement();*/}return;}statement(){ if(syn==10){scaner(); /*读下一个单词符号*/if(syn==18){ scaner(); /*读下一个单词符号*/ expression(); /*调用函数statement();*/ }else { printf("the sing ':=' is wrong!\n");kk=1;}}else { printf("wrong sentence!\n");kk=1;}return;}expression(){ term();while((syn==13)||(syn==14)){ scaner(); /*读下一个单词符号*/ term(); /*调用函数term();*/}return;}term(){ factor();while((syn==15)||(syn==16)){ scaner(); /*读下一个单词符号*/ factor(); /*调用函数factor(); */ }return;}factor(){ if((syn==10)||(syn==11)) scaner();else if(syn==27){ scaner(); /*读下一个单词符号*/expression(); /*调用函数statement();*/ if(syn==28)scaner(); /*读下一个单词符号*/else { printf("the error on '('\n");kk=1;}}else { printf("the expression error!\n");kk=1;}return;}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;m=0;ch=prog[p++];while(ch==' ')ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;token[m++]='\0';for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')){ while((ch>='0')&&(ch<='9')){ sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':m=0;ch=prog[p++];if(ch=='>'){ syn=21;}else if(ch=='='){ syn=22;}else{ syn=20;p--;}break;case '>':m=0;ch=prog[p++];if(ch=='='){ syn=24;}else{ syn=23;p--;}break;case ':':m=0;ch=prog[p++];if(ch=='='){ syn=18;}else{ syn=17;p--;}break;case '+': syn=13; break;case '-': syn=14; break;case '*': syn=15;break;case '/': syn=16;break;case '(': syn=27;break;case ')': syn=28;break;case '=': syn=25;break;case ';': syn=26;break;case '#': syn=0;break;default: syn=-1;break;}}四、结果分析:输入begin a:=9; x:=2*3; b:=a+x end # 后输出success!如图4-1所示:图4-1输入x:=a+b*c end # 后输出error 如图4-2所示:图4-2五、总结:通过本次试验,了解了语法分析的运行过程,主程序大致流程为:“置初值”→调用scaner 函数读下一个单词符号→调用IrParse→结束。