Xilinx PlanAhead 使用方法及心得(1.综述)
XilinxVivado的使用详细介绍(3):使用IP核--转载

XilinxVivado的使⽤详细介绍(3):使⽤IP核--转载IP核(IP Core)Vivado中有很多IP核可以直接使⽤,例如数学运算(乘法器、除法器、浮点运算器等)、信号处理(FFT、DFT、DDS等)。
IP核类似编程中的函数库(例如C语⾔中的printf()函数),可以直接调⽤,⾮常⽅便,⼤⼤加快了开发速度。
⽅式⼀:使⽤Verilog调⽤IP核这⾥简单举⼀个乘法器的IP核使⽤实例,使⽤Verilog调⽤。
⾸先新建⼯程,新建demo.v顶层模块。
(过程参考上篇⽂档)添加IP核点击Flow Navigator中的IP Catalog。
选择Math Functions下的Multiplier,即乘法器,并双击。
将弹出IP核的参数设置对话框。
点击左上⾓的Documentation,可以打开这个IP核的使⽤⼿册查阅。
这⾥直接设置输⼊信号A和B均为4位⽆符号型数据,其他均为默认值,点击OK。
稍后弹出的窗⼝,点击Generate。
⽣成的对话框直接点Ok。
综合选项中的Global表⽰只⽣成RTL代码,然后与整个⼯程⼀起参与综合,Out of context per IP表⽰⽣成后⽴即综合。
调⽤IP核选择IP Sources,展开并选择mult_gen_0 - Instantiation Template - mult_gen_0.veo,可以打开实例化模板⽂件。
如图,这段代码就是使⽤Verilog调⽤这个IP核的⽰例代码。
将⽰例代码复制到demo.v⽂件中,并进⾏修改,最终如下。
代码中声明了⽆符号型的4位变量a和b,分别赋初值7、8,作为乘数使⽤;⽆符号型的8位变量p,⽤于保存计算结果。
clk为Testbench编写的周期20ns的时钟信号;mult_gen_0 Mymult_gen_0 (...)语句实例化了mult_gen_0类型的模块对象Mymult_gen_0,并将clk、a、b、p作为参数传⼊。
fpGa_CPLD设计工具xilinxISE使用详解

1.第一章:FPGA/CPLD简介●FPGA一般是基于SRAM工艺的,其基于可编程逻辑单元通常是由查找表(LUT,look up table)和寄存器(register)组成。
其中内部的查找表通常是4输入的,查找表一般完成纯组合逻辑功能;●Xilinx可编程逻辑单元叫做slice,它由上下两部分组成,每部分都由一个register加上一个LUT组成,被称为LC(logic cell,逻辑单元),两个LC之间有一些共用逻辑,可以完成LC之间的配合工作与级连;●Altera可编程逻辑单元叫做LE(Logic Element,逻辑单元),由一个register加上一个LUT构成;Lattice的底层逻辑单元叫做PFU(programmable Function unit,可编程功能单元),它由8个LUT和9个register组成。
●Ram和dpram/spram/伪双口RAM,CAM(content addressable memory)。
Fpga中其实没有专业的rom硬件资源,实现ROM是对RAM赋初置,并且保存此初值●CAM,即内容地址储存器,在其每个存储单元都包含了一个内嵌的比较逻辑,写入cam的数据会和其内部存储的每一个数据进行比较,并返回与端口数据相同的所以内部数据的地址。
总结:RAM是一种根据地址读/写数据的存储单元;而CAM 和RAM恰恰相反,它返回的是与端口数据相匹配的内部地址。
使用很广,比如路由器中的地址交换表等等●Xilinx块ram大小是4kbit和18kbit两种结构。
Lattice块ram是9kbit●分布式ram适合用于多块小容量的ram的设计;●Dll(delay-locked loop)延迟锁定回环或者pll(phase locked loop)锁相环,可以用以完成时钟的高精度,地抖动的倍频/分频/占空比调整/移相等功能。
Xilinx主要集成的是DLL,叫做CLKDLL,在高端的FPGA中,CLKDLL的增强型模块为DCM (digital clock manager,数字时钟管理模块)。
EAPR设计初级教程

EAPR设计说明电子科技大学通信与信息工程学院杨中明 yzm520xx@DPR(Dynamic Partial Reconfiguration)在FPGA中的实现是Xilinx首先提出来的,迄今为止,也只有Xilinx提供相应的开发工具和开发流程,因此进行DPR开发不可避免要使用Xilinx的设计工具。
对于DPR设计,Xilinx曾经提出过四种设计流程:基于模块的DPR (module based),基于差异的DPR(difference based),基于比特流的DPR,然后就是EAPR。
有关前两种设计方法的详细介绍可以参考Xilinx的应用手册XAPP290.pdf。
至于第三种设计方法,Xilinx以前是有对应的一种叫Jbits的设计工具的,然而,近来却找不到相关的文档,在其官方网站上也没有该软件的下载及更新信息。
EAPR是Xilinx最近提出的一种最新的DPR设计方法,该设计方法与基于模块的DPR(module based)有些相似,但是EAPR流程与Module Based流程相比,有一下几个主要的差别:z移除了Virtex II器件局部可重配置(PR)中对于局部可重配置区域必须是整列的要求,EAPR设计流程中,允许PR区域为任意矩形区域;z总线宏使用基于SLICE来实现的Busmacro,而不是基于TBUF的Busmacro,这就使得允许使用的总线的密度更密;z EAPR流程中允许base设计中的全局信号直接穿越局部可重配置区域,而不必使用总线宏。
这一改进显著地改进了时序性能,并简化了PR设计的编译进程;z移除了需要在base设计中对AREA_GROUP RANGE进行面积约束的限制,这样就对base设计的布局布线提供了更大的灵活性;z现在的EAPR设计流程及工具支持Virtex 4及Virtex 5器件。
总之,EAPR(Early Access Partial Reconfiguration)是Xilinx提出的较新的一种动态局部可重配置设计流程(参考文档详见Xilinx的用户手册UG208.pdf),同时也是Xilinx推荐的DPR设计流程。
(完整版)XilinxSDK使用教程

Xilinx SDK使用教程本文参考Xilinx SDK软件内置的教程,打开方法:打开SDK->Help->Cheet Sheets...->Xilinx SDK Tutorials,这里有6篇文档。
本文详细介绍其中的4篇(与Application相关)如何创建一个新的软件应用1.打开SDK,切换到c/c++界面下。
(有两个界面,还有一个是Debug界面,在软件右上角处切换)2.指定一个新的硬件平台项目在SDK开发软件时,需要指定硬件平台。
(如果你打开一个现成的SDK工作空间,这一步可以省略)如果SDK工作空间中没有指定,BSP新建窗口会弹出,询问你硬件平台。
---File > New > Other > Xilinx > Hardware Platform Specification---Next, 显示新的硬件项目对话框。
---设定项目名称,以及由Vivado产生的硬件平台。
---Finish.3.创建一个独立的板级支持包(Board Support Package )---File > New > Board Support Package,打开对话框。
---指定新项目的名字(已初始一个默认的名称)---从CPU下拉列表中,选择目标处理器---从BSP OS下拉列表中,选择操作系统,默认是standalone(没有操作系统)---Finish.弹出BSP设置对话框---配置参数,生成一个BSP---OK4.创建应用项目---File > New > Application Project---指定项目名称---选择OS---选择目标硬件平台---选择目标处理器---选择编程语言---选择一个现有的BSP,或者新建一个---Next---选择一个模板,生成一个可直接运行的软件工程---Finish如何调试一个软件应用1.配置目标连接如果你想用本地设备,你可以跳过这个步骤。
华为FPGA设计高级技巧(Xilinx篇)

共62页产品名称Xilinx 篇yyyy/mm/dd日期2001/09/15日期深圳市华为技术有限公司版权所有 不得复制修订记录内部公开请输入文档编号FPGA 设计高级技巧目 录414.3 减少关键路径的逻辑级数.............................................404.2IF 语句和Case 语句揭开逻辑级数未变速度更快SRLVirtexIIXilinx篇626.3.3 专有资源的利用................................................616.3.2 Distributed RAM 代替通道计数器...................................616.3.1 Distributed RAM 代替BlockRAM ....................................616.3 如何降低芯片面积..................................................616.2.9 迂回策略为关键路径腾挪空间进行位置约束.....................................616.2.7 关键路径单独综合.......................................616.2.5 专有资源的利用................................................616.2.4 基本设计技巧..................................................616.2.3 采用BUFGS ...................................................616.2.2 对线延时比较大的netTIG 和Multi-Cycle-Path ...................606.2 如何提高芯片速度..................................................606.1 可能成为关键路径的电路.............................................606 综合运用..............................................................605.4 TimingAnalyzer 的作用...............................................595.3 FloorPlanner 的作用..................................................595.2 FPGA Editor 的作用..................................................595.1.3 正确看待map 之后的资源占用报告..................................585.1.2 布局布线策略设计方案阶段对关键电路的处理.......................585.1 布局布线..........................................................585 如何使用后端工具.......................................................574.16 LFSR 加1计数器...................................................574.15 SRL 的使用.......................................................574.14 Block SelectRAM 的使用.............................................564.13 Distributed RAM 的使用.............................................554.12 高效利用IOB ......................................................544.11 利用LUT 四输入特点减少扇出巧妙地延时................................494.7 组合逻辑和时序逻辑分离.............................................474.6流水线................................................464.5.4 综合工具与资源共享............................................464.5.3 子表达式共享..................................................454.5.2 loop 语句......................................................444.5.1 if 语句........................................................444.5 资源共享..........................................................434.4 合并if 语句赋予关键路径最高优先级............................内部公开请输入文档编号FPGA设计高级技巧627 感谢 (62)6.3.4 基本设计技巧..................................................表目录33表5 VirtexII 的DCM 分布表.................................................27表4 VirtexII乘法器速度表.......................................25表3 带奇偶校验位的Block RAM 配置表........................................24表2 VirtexII 的BlockRAM 分布表顶部上半部分58图65 15位基本型LFSR 计数器在VIRTEX 器件中的实现...........................57图64 采用Distributed RAM 实现多路加1计数器..................................55图63 输入输出寄存器移入IOB 中............................................55图62 VirtexE IOB 结构示意图...............................................54图61 采用三态电路实现电路选择............................................54图60 多路选择..........................................................53图59 扇出较小..........................................................53图58 扇出较大..........................................................52图57 组合逻辑在前..............................................52图56 组合逻辑在后..............................................49图55 Mealy 状态机的基本结构...............................................49图54 采用流水线之后的电路结构............................................48图53 采用流水线之前电路结构..............................................46图52 资源共享后一个加法器................................................45图51 资源共享前4个加法器................................................45图50 资源共享后2个加法器...............................................42图48 critical 信号只经过一级逻辑............................................42图47 critical 信号经过2级逻辑...............................................41图46 case 语句完成电路选择................................................40图45 if-else 完成多路选择..................................................39图44 并行加法电路.......................................................39图43 串行加法电路.......................................................39图42 超前进位..........................................................38图41 串行进位..........................................................37图40 No-read-on-write mode ................................................37图39 Write first mode ......................................................36图38 Read first mode ......................................................36图37 完整的单端口Block Select RAM .........................................35图36 门数增加但资源占用减少FPGA设计高级技巧关键词速度与面积压缩线延时腾挪空间摘 要以速度和面积为主题缩略语清单:ASICConfigurable Logic Block DCIDigital Clock ManagerDDRDelay-Locked Loop FPGAGeneral Routing MatrixIOBLinear Feedbak Shift RegisterLUTSum of Product SRLCustom Constraints File 参考资料清单:内部公开请输入文档编号FPGA 设计高级技巧时钟资源1 前言随着HDL 硬件描述语言综合工具及其它相关工具的推广连线等工作解脱开来极大地提高了工作效率有利就有弊现在越来越多的工程师不关心自己的电路实现形式我只要将功能描述正确工程师在用HDL 语言描述电路时或者非常模糊映射到芯片中又会是什么样子遇到问题容量更大的FPGA 器件更为要命的是更不了解与器件结构紧密相关的设计技巧工具不行导致问题迟迟不能解决导致开发成本急剧上升我们的设计规模越来越庞大几百万门的电路屡见不鲜我们所采用的器件工艺越来越先进而在对待深亚微米的器件上要更多地关注以前很少关注的线延时ASIC 设计以后也会如此此时设计技巧上有所提高而且从节约公司成本角度出发本文从澄清一些错误认识开始以速度和面积为主题本文对读者的技能基本要求是如加法器RAM 等熟悉基本的同步电路设计方法对FPGA 的结构有所了解2 综合工具与代码风格硬件描述语言和综合工具的产生然而一种不好的现象也在逐步蔓延只关注功能是否实现很少考虑电路到底是如何实现的如速度如果将设计看成是一个化学变化我们所掌握的背景知识才是参加化学反应的分子因此不能完全指望工具只有我们才是决定设计成败的关键一般包括如下两个过程前者是把行为级的描述通过一定的算法转化成门级的描述与用户约束无关通过算法映射到相应的工艺库中的器件上是映射到厂商的Gate 库中是映射到FPGA器件的单元结构中当设计代码的的风格不一样时对ASIC来说器件库一般也是GateÎÒÃDz»ÄÑÀí½âCode Style 对FPGA设计的重要性如下的16选1MUXÈçcase语句后者使用BUFT的描述图2 使用内部三态线描述的Mux2.2不同综合工具的性能不同综合工具的针对目标不一致和各综合工具的不同性能目前Design CompilerFC2Leonardo 其中DC主要是用于ASIC的综合工具其中Leonardo 是做FPGA 综合工具的先驱Synplicity公司出品但无论哪家综合工具都必须紧密结合各FPGA厂家的FPGA结构从目前来看优选Synplify 或Leonardo 综合工具到目前为止如Virtex 系列的进位链目前是这样因为综合工具一直在升级因此无法得到更好的性能则可综合出来Synplicity公司的综合工具比较优秀一点不过价格太贵导致设计性能变差若想得到更好的性能但这种基于FPGA器件的代码设计FPGA设计与ASIC设计的兼容性因此要采取恰当的风格对FPGA设计而言1. 资源共享的应用限制在同一个module里综合工具才能最大限度地发挥其资源共享综合作用这样3. Critical path所在的module与其它module分别综合对其它module采用面积优先的综合策略4. 尽可能Register所有的Output¶Ô¼ÓÔ¼Êø±È½Ï·½±ãÕâ¶Ô×ۺϷdz£ÓÐÀûËÙ¶ÈË«Ó®µÄÄ¿µÄ¾ßÌå´óС6. 一个module尽量只有一个时钟更多的代码风格verilog代码书写规范3 FPGA器件结构许多工程师在做设计时不关心自己的电路是怎么实现的并且认为至于它是如何实现的这实际是轻实现其结果是在我们的设计中人为地制造了一大堆第一个设计有20~30µ±È»Èç¹û´ó¼ÒÔÚÒ»¸ö¸ßÊÖÈëÔƵĻ·¾³Ï½øÐÐѬÌÕÎÒÃÇÔÚÇ°ÃæÌáµ½¶øÇÒ¹¤¾ß±¾ÉíÒ²²»Ò»¶¨·Ç³£ÖÇÄÜÏëÒ»ÏëÄÇôËü»¹ÓÐÓÅ»¯µÄÓàµØÂðÎÊÌâ×Ü»áÔ½À´Ô½¶àÔÚÕâÖÖÇé¿öÏÂÁ˽âÎÒÃǵÄÉè¼ÆÊÇÈçºÎʵÏÖµÄÈç½øλÁ´IOB中的register等如果没有如修改代码或者是一个非常行之有效的手段只有工具与大脑完美结合主要目的是想让读者知道了解FPGA器件结构对做好FPGA设计有多么重要可参见一书3.1器件结构对Coding Style的影响3.1.1 FPGA结构Altera 的FPGA一般的结构都是由一些CLB 的宏单元组成LUT时序单元如Altera 的FPGA和Xilinx的FPGA都采用4输入的查找表Component的延时是固定的我们知道对FPGAÈçÀûÓÃÁ˶àÉÙ¼¶µÄ²éÕÒ±íÏßÑÓʱÔò·´Ó³ÔÚCLB与CLB的互连上就需要越长的互连线在FPGA中如进位链等目的是减少对CLB数目的使用如Virtex 系列中但不占用LUT的资源可以用来实现快速进位的加法器或宽输入的函数因此就应该考虑如何更好地利用FPGA器件中的这些特点或标准单元其线延时不象FPGA那样因此深亚微米级时但更多的是与门因此3.1.3 Coding Style的对比由于器件结构的不同针对ASIC和FPGAFPGA器件的设计性能很大程度依赖于Coding ¶ÔGate Array或shandard cellÉè¼ÆÒ²²»±ØÒªÇóºÜ¸ßµÄCoding 技术66M 就很容易实现我们很少看见几十层逻辑级的设计8 级逻辑级一般只能实现到50M左右因此要达到高速和好的性能则需要好的代码风格和好的设计策略那就是提到Code Style 时往往忽略了对器件结构的了解对FPGA而言是以减少LUT的个数为主要手段不一定能提高速度和降低面积注意门数和面积不一定成正比至于为什么自然会明白可提供如下功能提供更高密度的FPGA资源xc2v40xc2v10000最高支持420M内部时钟频率和840Mb/s 的I/O支持19 种 single-ended 标准的IO 和 9种差分IO 标准VirtexII 具有XCITE 功能IOB中集成了DDR 寄存器支持可编程的sink current在RAM上 对外RAM接口性能提高400M b/s DDR-SDRAM 接口400Mb/s FCRAM 接口333Mb/sQDR-SRAM 接口600Mb/s Sigma RAM 接口567ÔöÇ¿ÁËÒÔÍùDLL 功能16个全局时钟8.15um 技术3.3 结构概述VirtexII 器件结构示意图如下3 VirtexII 结构示意图VirtexII 器件在结构上与Virtex 和VirtexE 是相似的但增加了一个专有乘法器结构在IOB 和CLB 中也有点不同3.3.1 CLBVirtexII 的CLB 与Virtex Family 和VirtexE Family 结构有点不一样在结构的安排上如下示意图Xilinx篇图4 VirtexII 的CLB结构示意图与以往不同的是4个Slice 按照如上图的阵列排布GRM在CLB中保证4个slice 之间快速的互联每列两个slice µ«Á½Áй²ÓÃÒ»¸öÒÆλÁ´3.3.2 SliceSlice基本元件包括G函数FFX一般用做D触发器另外Slice中还集成了carry logicmultiplexers等元件高性能电路图5 SLICE结构示意图内部公开请输入文档编号FPGA设计高级技巧值得大家注意的是由于设计者没有注意利用Slice中的一些高速特性或者FPGA资源实际利用率不高图6 VirtexII 的Slice 结构图VirtexII 的Slice 增加了不少的结构3.3.3 LUT每个Slice 包含两个4输入的LUT4000系列的功能也就是当做组合逻辑电路这两个功能在随后的章节会详细介绍它的4个输入G1F函数F4通过对RAM中各存储单元进行配置4输入任意组合逻辑这本身就是它原来的特点也可配置成双端口RAM1与此有关详情参见本章部分要提醒大家注意的是不管你是几输入的函数还可参见本章补充说明部分SRL从而大大节省线延时和面积如下图所示CLB的4个Slice的的SRL16移位输出可串成一个大的移位链LUT的MC15就是移位的输出作为F函数移存器的shiftin图7 SRL的移位链在使用SRL时请注意一个Shift Registers LUT只能有一个数据输出和一个数据输入VirtexII 的Slice 增加了MUXF7MUXF5F的输出可在一个CLB中实现4选一的MUXMUXFX MUXF7ÊäÈëΪFXINA输出为FX F7或F8要看Slice 具体位置用于MUX相邻两个Slice 的MUXF5的输出X1Y0两个Slice 的MUXFX可例化成MUXF6两个Slice¼´¿ÉÔÚÒ»¸öCLB中实现8选1的MUXMUXF7Òò´ËÖ»ÄÜÊÇX0Y1 这个Slice 的MUXFX可例化成MUXF7ʵÏÖ´óÓÚ8选1的MUX般工具无法直接利用该功能但通过F7可在一个CLB 中的4个Slice 实现一个16选1 的MUX用于MUX 相邻两个Slice 的F7通过MUXF8实现更宽的函数MUXF5FFF F 图8 VirtexII 的MUXFX 连接图3.3.6 Carry Logic 和Arithmetic Logic GatesArithmetic Logic Gates 包括一个XOR 和一个MULTIAND VirtexII 的Slice 结构图与基本Slice 中的进位链结构一样数据流从下往上进位链结构如下图所示图9 进位链结构示意图下图是一个采用进位链实现3bit全加器示意图图10 使用进位链实现加法器采用进位链如下图所示图11 使用进位链级联实现高速宽函数运算由于乘法器可看成累加器使用专有进位链还可实现乘法器与以往的器件不同的是如下图所示图12 VirtexII 的两个独立进位链注意3.3.7 SOPVirtexII 的每个Slice 中有一个OR 用于把Slice 中的进位链在水平方向上级联起来灵活的SOP链内部公开请输入文档编号FPGA设计高级技巧图13 VirtexII 的SOP 链上图中横向的ORCY连接成4输入的或门只是提供了4个attribute SRLOW前两者用于描述SR¿ØÖƵĸ´Î»ÊôÐÔ后两者用于描述在没有外部复位信号时configuration 或通过全局的GSR网络复位为0或为1´æ´¢µ¥Ôª½á¹¹ÈçÏÂʾÒâ14 FFX/FFY结构示意图上图的DY是G函数发生器输出信号Y在Slice 外部直接反馈进来的信号VirtexII 的Slice 结构示意图当配置成单端RAM时当配置成双端RAM时且是一端口可读可写一个VirtexII的CLB含4个Slice下面两图是Distributed RAM的应用例子图15 单端口32x1 RAM图16 双端口16x1 RAM3.4.2 Block RAMVirtexII 的Block RAM资源比以往的增加很多在整个VirtexII 系列中4列或6列的规律进行分布图17 VirtexII 的Block RAM 分布规律其中的N 等于该器件CLB的列数除以4±í2 VirtexII 的BlockRAM 分布表由于块RAM有18bit ÿ¸ö¶Ë¿Ú¿ÉÅä³ÉÈçϽṹ表3 带奇偶校验位的Block RAM 配置表VirtexII 的block RAM支持三种写模式new data is written 图18 Write first 模式Read first图19 Read first 模式NO CHANGE图20 No Change 模式关于Block RAM 更多的内容sp_block_mem.pdf3.5 乘法器资源VirtexII 系列提供有专门的乘法器结构VirtexII 的乘法器资源分布图与Block RAM 的分布图一样共用4个 开关矩阵内部公开请输入文档编号FPGA 设计高级技巧图21 乘法器与Block RAM器件中乘法器位置如下图图23 乘法器块乘法器可实现高速的低工耗的乘法器速度如下表Xilinx篇表4 VirtexII 乘法器速度表3.6 IOB一般的IOB I/Obuf存储单元包括输出寄存输入三态控制线也可以不经过寄存IOB中提供5中I/O Buf IBUF输出buf OBUFT双向buf IBUFGVirtex II 的IOB 基本结构与基本的IOB一样增加了一些IO标准和DCI功能IOB的位置有较大的改变VirtexII的所有用户IO 可配成差分信号因此5个IOB共用一个开关矩阵如下示意图图24 VirtexII的IOBVirtexII的IOB与基本的IOB结构相似I/Obuf 和输入延时线DELAY构成用于实现DDRÁ½¸ö´æ´¢µ¥ÔªÍ¨¹ýDDR MUX来实现DDRÒªÇóͨ¹ýDCM来产生DDR的正反沿时钟信号图25 VirtexII 的IOB中的DDR具体的结构如下26 VirtexII 的IOB 实际结构3.6.2 Select I/OVirtexII 的Select I/O 支持的标准有所增加每个banks 提供VRN和VRP参考电压VirtexII 提供19 种signal-ended IO 标准--LVTTL, LVCMOS (3.3V, 2.5V, 1.8V, and 1.5V)--PCI-X at 133MHz, PCI (3.3V at 33MHz and 66MHz)--GTL, GTLP--HSTL (Class I, II, III, and IV)--SSTL (3.3V and 2.5V, Class I and II)--AGP-2X提供如下的差分标准VirtexII 集成了DCI功能在芯片内部提供IO管脚的特定匹配电阻简化单板设计3.7 Clock ResourceVirtexII 的时钟资源比以往增加了很多如果想要了解更多的信息Virtex³õ¸å8个分布在芯片的顶部这些时钟管脚还可以当作普通管脚使用以顶部时钟为例由开关矩阵切换出16个时钟信号线16根时钟信号线通过8个时钟MUXÓëµ×²¿µÄ8个全局时钟信号组成全芯片的16个全局时钟信号图27 VirtexII 的Clock Pads具体的结构如下图各有一个开关矩阵8个时钟信号连到顶部的开关矩阵切换出16个时钟信号连到下面的8个时钟MUX 上28 VirtexII 的时钟在VirtexII 的器件中可以保证芯片的4个区域内最多都可以获得8个全局时钟信号在安排时钟管脚时必须考虑一下图29 VirtexII 的时钟资源分布原理3.7.2 CLK MUX在VirtexII 的器件中因此全局时钟资源可由时钟管脚BUFGMUX 的结构如下顶部Xilinx篇图30 VirtexII 的BUFGMUX该BUFGMUX 可有如下几种配置即普通的全局时钟BUFͼ31 VirtexII 的BUFGBUFGCE如下结构图图32 VirtexII 的BUFGCEBUFGMUX如下结构图内部公开请输入文档编号FPGA设计高级技巧图33 VirtexII 的BUFGCE3.7.3 DCMVirtexII 器件结构对Virtex 的DLL做了增强Digital Clock Manager DCM一般分布在芯片的底部和顶部如下画出V2250芯片的8个DCM4个在底部图34 VirtexII 250 的DCM 位置VirtexII 系列器件的DCM分布表如下表5 VirtexII 的DCM分布表VirtexII 的DCM 的符号如下35 VirtexII 的DCMDCM是对DLL的增强DLL延时锁相环通过该延时锁相环可保证DCM的输入DPS数字相移器DFS数字频率合成器DSS数字扩频本节所有内容来自个人推测3.8.1 LUT 如何配置成组合逻辑电路门数增加但资源占用减少之谜前面本文提到它的4个输入其实是RAM 的地址线它是怎么实现组合电路的呢以LUT 中的F函数为例F3F= F4F2F4F2表示非运算.or时1其它的值都是F4与门F4LUTÎÒÃÇÖ»Òª½«µØַΪ和的存储单元置为则该RAM 的功能实际就是F3与门在实际实现时111111101ͬʱF1固定接或我们可以得出结论在实际实现时都会变成4输入的组合电路对于在一个LUT 内可以实现的组合电路对LUT 而言3. 只要是在一个LUT 内实现的逻辑逻辑延时基本一样面积优化对Xilinx 而言根据上述结论如果想速度更快而不是逻辑级数则应当努力减少LUT 的个数这一点与ASIC 设计完全不一样内部公开请输入文档编号FPGA设计高级技巧图36 门数增加但资源占用减少我们知道一个LUT 只有一个输出后面的2个三输入或门要各占用一个LUTLUT 级数是2级虽然增加了一个2输入与门也是2级它只占用2个LUTÏÔÈ»ÃÅÊýÔö¼Óµ«×ÊÔ´Õ¼ÓüõÉÙµäÐÍ°¸ÀýÎÒÃÇÖ»ÒªÕÆÎÕÁ˵¥¶Ë¿ÚRAM本节以单端口RAM 为例进行说明Xilinx篇图37 完整的单端口Block Select RAM上图是一个完整的单端口RAM结构我们这里准备讲的单端口RAM是上图中的核心部分Block MemoryËüµÄдÓÐÈýÖÖ²Ù×÷ģʽRead FirstNo Change根据其输入输出信号相位关系图38 Read first mode图39 Write first mode图40 No-read-on-write mode图中可以等价看成Distributed RAM¾-³£Óöµ½ËٶȻòÃæ»ýÎÊÌâÉè¼ÆҪôËٶȲ»Âú×ãÒªÇó»òÕßÁ½Õ߶¼²»Âú×ãÉè¼ÆÒªÇó±¾ÕÂ×ÅÖØ´ÓËٶȺÍÃæ»ý½Ç¶È³ö·¢ÒÔ»ñµÃ×î¼ÑµÄЧ¹ûÓÐЩ·½·¨ÊÇÒÔÎþÉüÃæ»ýÀ´»»È¡ËÙ¶ÈÒ²ÓÐЩ·½·¨¿Éͬʱ»ñµÃËٶȺÍÃæ»ýµÄºÃ´¦Ó¦µ±ÒÀ¾Ýʵ¼ÊÇé¿ö¶ø¶¨向关键路径要时间部分为了获得更高的速度尽量压缩线延时在非关键路径上尽量优化电路结构特别提醒本文提到的一些设计技巧可能在绝大部分情况下已经失效在一些复杂电路因此是为了让大家在遇到困难时可以尝试本文所提供的设计技巧注意本章节所举的代码都采用的是VHDL语言我们认为语言是次要的另外可参见每一个VHDL信号赋值每个信号代表一条信号线能将不同的实体连接起来下面的VHDL实例为加法器的进位链电路的两种可能的描述串行进位链-- A is the addend-- B is the augend-- C is the carry-- Cin is the carry inC0 <= (A0 and B0) or((A0 or B0) and Cin);C1 <= (A1 and B1) or((A1 or B1) and C0);图41 串行进位例并行结构c1 <= g1 or (p1 and g0) or(p1 and p0 and cin);图42 超前进位显然但面积大但面积小从其实现结构来看由于进位链是FPGA的专有资源4.1.2使用圆括号处理多个加法器控制设计结构的另一种方法是使用圆括号来定义逻辑分组例图43 串行加法电路用圆括号重新构造的加法器分组如下所示Z <= (A + B) + (C + D);图44 并行加法电路上述两种方法的在速度和面积上的区别是第一种方法但整体速度慢如果信号D 是关键路径或者BD无关第二种方法但整体速度快BD的时序要求都比较苛刻4.2IF 语句和Case 语句而Case 语句生成的逻辑是并行的IF 语句可以包含一套不同的表达式通常但占用面积较大IF-Else 结构速度较慢如果对速度没有特殊要求则可用IF-Else 语句完成编解码为了避免较大的路径延时用IF 语句实现对延时要求苛刻的路径时Critical Signal有时可以将IF 和Case 语句合用用IF-Then-Else 完成8选1多路选择器MUX6to1:process(sel,in)beginif(sel= "000") then out <= in(0); elseif(sel = "001") then out <= in(1); elseif(sel = "010") then out <= in(2); elseif(sel = "011") then out <= in(3); elseif(sel = "100") thenout <= in(4);else out <= in(5); end if;end process;内部公开请输入文档编号FPGA设计高级技巧图45 if-else 完成多路选择下面的例子是用Case 语句完成8选1多路选择器的VHDL 实例Virtex 可以在单个CLB 中完成一个8选1的多路选择器因此例process( C, D, E, F, G, H, I, J, S )begin case S iswhen 000 => Z <= C;when 001 => Z <= D;when 010 => Z <= E;when 011 => Z <= F;when 100 => Z <= G;when 101 => Z <= H;when 110 => Z <= I;when others => Z <= J; end case;end process;图46 case 语句完成电路选择4.3 减少关键路径的逻辑级数在FPGA 中critical pathΪÁ˱£Ö¤ÄÜÂú×ãʱ¼äÔ¼Êø¼õÉٹؼü·¾¶ÑÓʱµÄ³£Ó÷½·¨ÊǸø×î³Ùµ½´ïµÄÐźÅ×î¸ßµÄÓÅÏȼ¶ÏÂÃæµÄʵÀýÃèÊöÁËÈçºÎ¼õÉٹؼü·¾¶ÉϵÄÂß¼-¼¶ÊýÇ°ÃæÌáµ½µÄ´®Ðмӷ¨Æ÷Ò²ÊÇÒ»¸ö°¸Àý4.3.1 通过等效电路此例中critical 信号经过了2级逻辑if (clk'event and clk ='1') then内部公开请输入文档编号FPGA设计高级技巧if (non_critical='1' and critical='1') thenout1 <= in1;elseout1 <= in2;end if;end if;图47 critical信号经过2级逻辑为了减少critical路径的逻辑级数critical信号只经过了一级逻辑图48 critical信号只经过一级逻辑注意4输入LUT特点但对ASIC而言4.3.2调整if语句中条件的先后次序设计者习惯用if语句来描述电路功能也采用有优先级概念的if语句来描述If 条件1 thenDo action1Else if 条件2 thenDo action2Else if 条件3 thenDo action3在实际情况中条件2ÔòÉÏÊöif语句无所谓谁优先是关键路径应当改成提高设计速度前面提到即便是在没有优先级的电路中例如信号置1Else if 条件2 then信号置0Else if 条件3 then信号置1Else if 条件4 then信号置0如果上述条件没有优先级我们建议合并if语句中各条件否则下面的VHDL实例说明如何使用资源共享来减少逻辑模块的数量没有资源共享时用了4个加法器完成if (...(siz = "0001")...) thencount <= count + "0001";else if (...((siz = "0010")...) thencount <= count + "0010";else if (...(siz = "0011")...) thencount <= count + "0011";else if (...(siz == "0000")...)thencount <= count + "0100";end if;利用资源共享可以节省2个加法器if (...(siz = "0000")...) thencount <= count + "0100";else if (...) thencount <= count + siz;end if;例if (select = '1') thensum<=A +B;elsesum<=C +D;end if;图49 资源共享前利用资源共享只用2个选择器和1个加法器实现if (sel ='1') thentemp1 <=A;temp2 <=B;elsetemp1 <=C;temp2 <=D;end if;sum <= temp1 + temp2;图50 资源共享后运算符占用更多的资源综合工具必须对所有的条件求值综合工具用4个加法器和一个选择器实现req²Å½¨Òé²ÉÓÃÕâÖÖ·½·¨end if;end loop;图51 资源共享前4个加法器如果信号不是关键信号这样在执行加法运算前修改代码如下for i in 0 to 3 loopif (req(i)='1') thenoffset_1 <= offset(i);end if;end loop;sum <= vsum + offset_1;图52 资源共享后一个加法器4.5.3子表达式共享一个表达式中子表达式包含2个或更多的变量应共享这些运算通过声明一个临时变量存储子表达式下面的VHDL实例描述了用相同的子表达式完成一组简单的加法运算4.5.4 综合工具与资源共享通过设置FPGA CompilerII/FPGA Express的相应选项而不需声明一个临时变量存储子表达式如下sum1 <= A + B + C;sum2 <= D + A +B;sum3 <= E + (A +B);则sum1和sum3 可共享(A +B),但与sum2不共享3. 必须在同一block中如下但与S1不可共享最好尽量自行编写共享资源代码所采用的综合工具在FPGA 阶段和转ASIC 阶段可能不同PipeliningËüµÄ»ù±¾Ë¼ÏëÊÇ°ÑÔ-À´±ØÐëÔÚÒ»¸öʱÖÓÖÜÆÚÄÚÍê³ÉµÄ²Ù×÷·Ö³É¶à¸öÖÜÆÚÍê³ÉÒò´ËÌá¸ßÁËÊý¾ÝÍÌÍÂÁ¿ËùÒÔ¶ÔFPGA 设计而言而又不耗费过多的器件资源采用流水线后必须特别考虑设计的其余部分在定义这些路径的延时约束时必须特别小心其延时为源触发器的clock-to-out 时间多级逻辑的走线延时和目的寄存器的建立时间之和采用流水线最终的结果是系统的工作频率提高了采用流水线前的电路内部公开请输入文档编号FPGA设计高级技巧process(clk, a, b, c) begin if(clk'event and clk = '1') thena_temp <= a;b_temp <= b;c_temp <= c;end if;end process;Process(clk, a_temp, b_temp, c_temp)beginif(clk'event and clk = '1') thenout <= (a_temp * b_temp) + c_temp;end if;end process;图53 采用流水线之前电路结构例Xilinx篇c_temp2 <= c_temp1;end if;end process;process(clk, mult_temp, c_temp2)beginif(clk'event and clk = '1') thenout <= mult_temp + c_temp2;end if;end process;图54 采用流水线之后的电路结构4.7组合逻辑和时序逻辑分离包含寄存器的同步存储电路和异步组合逻辑应分别在独立的进程中完成这样在综合后面积和速度指标较高Mealy状态机的基本结构如下图所示图55 Mealy状态机的基本结构内部公开请输入文档编号FPGA设计高级技巧由图可看出当前状态寄存器和输出逻辑三部分组成当前状态寄存器为时序逻辑Mealy 机可由三个进程实现例Xilinx篇。
xilinx使用步骤

Xilinx软件使用步骤目录基本操作1. 打开xilinx2. open project3. New project4. 创建新的 .vhd文件5. 建立波形文件6. 综合7. 仿真8. 下载程序到电路板中需要注意的问题1.生成顶层原理图2.建立.ucf文件3. implement时出错的原因4.仿真时的问题基本操作1. 打开xilinx图1 打开xilinx界面2. open project图2 open project图3 查找要打开的.ise文件单击打开后,出现在左侧box中。
图4 open project3. New project顶层文件类型,原理图类型选Schematic,否则选择HDL;单击下一步,通过右侧value各项目,配置器件类型,即FPGA 型号。
注意:此处配置错误的话,综合时会出现放不下或者些不进去的错误。
配置完成后,单击下一步,出现创建源文件对话框如下图所示。
不需做设置更改,直接点击下一步,出现添加现有源对话框如下图所示。
不需做任何设置,直接单击下一步,出现New project information对话框,如下图所示。
确认信息无误后,单击完成,创建的新的project即出现在主页面左侧Sources in project中,如下图所示。
4. 创建新的 .vhd文件右击主页面左侧Sources in project中xc2s200-5pq208,在右键菜单中选择New source,如下图所示;出现New source对话框;左侧选择VHDL Module,右侧输入文件名,如下图所示,单击下一步;出现define vhdl source对话框,输入端口名,输入输出类型和MSB,LSB, 如下图所示,然后单击下一步,出现信息对话框,如下图所示,确认无误后,单击完成。
然后主页面如下图所示:5. 建立波形文件在主页面,编程之后保存。
在如下图所示位置右击.vhd文件,选择new source选项。
ISE软件使用

一、软件Xilinx的软件主要是ISE, EDK, ChipScope Pro, System Generator, PlanAhead, ModelSim,如果要算上AccelDSP也凑合,不过相信国内没多少人用。
ISE是主要的逻辑设计软件,其他软件的具体实现功能都依附于ISE。
ISE有Foundation版和WebPack版。
WebPack版免费,Foundation版收费。
两者的区别是支持的器件不同。
功能是相同的。
WebPack版支持的功能可以看/ise/products/webpack_config.htm。
Foundation的话当然全支持拉,要看的话在这里/ise/logic_design_prod/foundation.htm。
说这些的目的就是,如果你的器件WebPack支持,就直接到网上下载WebPack吧,没有版权之类的后顾之忧;如果不行,Verycd上找些东西还是挺方便的。
ModelSim MX有免费的starter version,可以和ISE WebPack一起下载,安装以后在开始里面点licens_e request就可以申请starter的使用权了。
另外,可以VHDL和Verilog各申请一个,那么就可以仿真两种语言了,不过不支持mix language。
/ise/verification/mxe_details.html不过那一页说的ModelSim XE的use case不准的,XE,PE,SE的差别还是仔细看这里吧。
/xlnx/xil_ans_display.jsp?getPagePath=24506ChipScope有(好像是)60天的评估版。
/chipscopePlanAhead(稍微介绍下子,没有接触过的朋友可能不知道这是什么)PlanAhead是ISE7以后推出的软件,它的主要功能是对一个综合后的NGC/EDIF网表进行布局布线的规划。
听上去功能有点像FloorPlanner,但是功能却强大得多。
在XILINX中差分输入信号到单端信号的转换

在 XILINX 中差分输入信号到单端信号的转换
在 XILINX 中差分输入信号到单端信号的转换
设计者:sunchanghong 笔名: 海豚
sunchanghong may ,2013
Suncha nghong Beijing, china QQ:750506590 Email:haitu n200@
1/4
在 XILINX 中差分输入信号到单端信号的转换
在 XILINX 中差分输入信号到单端信号的转换
一 理论基础: 1 理论: 差分传输是一种信号传输技术,区 别于传统的一根信号线一根地线的 做法,差分传输
如图所示,在这两根线上都传输信号,这两个信号的振幅相等,相位相反,在这两根线上的 传输的信号就是差分信号。信号的接收端比较这两个电压的差值来判断发送端发送的是 0 还是 1。在电路板上,差分走线必须是等长、等宽、紧密靠近,且在同一层面的两根线。
二 XILINX FPGA 中差分信号的使用方 在一个 module 模块中讲述差分信号转换到单端信号的方法 1 在代码中的定义 module chafen( clk_p, clk_n iin_p, iin_n, qin_p, qin_n, … );
Input clk_p; Input clk_n; Input [2:0] iin_p;
IBUFDS Qin_u0 ( .I(qin_p[0]), .IB(qin_n[0]), .O(qin[0]) );
XILINX PLANAHEAD 8.2设计套件

2Mbt 差; 其静 态 电流 为 10A 4 p 意法半导体车用 3 一 i闪存
( 典型值 ) 有助于降低稳 , 意法半导体 (T c e c o i ) 出一个新的专门为 S Mio l t nc 推 r er s F 2Mbt 闪存芯片 M5B 2 。 8 W3 F 新产 压 功 耗 。此外 , MCP 7 7 具 备 关断 功 能 , 以利 用 系统 控 汽车市场 丁发的升级版 3 一 i 12 还 可
M5B 2 8 W3F采用一个 3 位宽数据总线 ,额定工作电压 2
33 .V。增 强 的 保 护 技 术 包
A 公司 1 DI 4位低功耗模数转换器
括 灵活的 软硬 件保 护 、
df y 美国模拟器件公司 ( n l e i , n, A a gD vc lc 简称 A ) o e , DI 推 Moi 操 作 模式 使用 的 安
时功耗 为4 0 3 , mw 据称功耗比同类解决方降低 了5 %。这 方 面 ,每 个 裸 片 都 含 有 一 0 D号 ,以便使用加密算法 保护存储器 ,防止软件被 种 高 S DR、低功耗和小封 装尺寸 ( F 7mm7mm的 4 8引脚 个产品 I
L C P)的组 合 使 该 器 件适 恶意篡改。 F S 合 多种 无线基 础设 施应 用 ,
器设备。 1O T 64 :02 证 的 工 厂 制造 ,采 用 S S /S19 9 0 认 2 T的 经 过大 规 模
AD 24在输 入 7 z 应用验证的先进 的制造测试技术 , 95 0MH 为汽车应用提供可靠的解 的 信 号 时 具 有 8 dBC的 决 方 案 。 3
制 逻辑 进 行 控 制 , 陶瓷 输 出 电 容 器的 稳 定性 有 助干 实 现 小 巧 品因为能够在汽车的全程温度范 围内对存储 器进行高速存取 所 而更具 成本效益 的设计 。MC 12 还具备一个用来实现绑 操 作 , 以适 合 汽 车 客 户对 传动 系 统 和 变速 器控 制 模块 的需 P 7 7
Planahead入门指导
Planahead14.1入门指南一.PlanAhead软件简介PlanAhead拥有强大的设计环境和分析工具,提供了一个按钮式的RTL到比特流(RTL-to- bitstream)的设计流程,该流程拥有全新的、增强的用户界面和项目管理功能。
此外,通过布局规划、运行多种不同实现策略,图形化浏览层层次结构,快速时序分析,以及基于模块的实现方式,让客户最大限度地利用有限的时间和设计资源实现最大的生产。
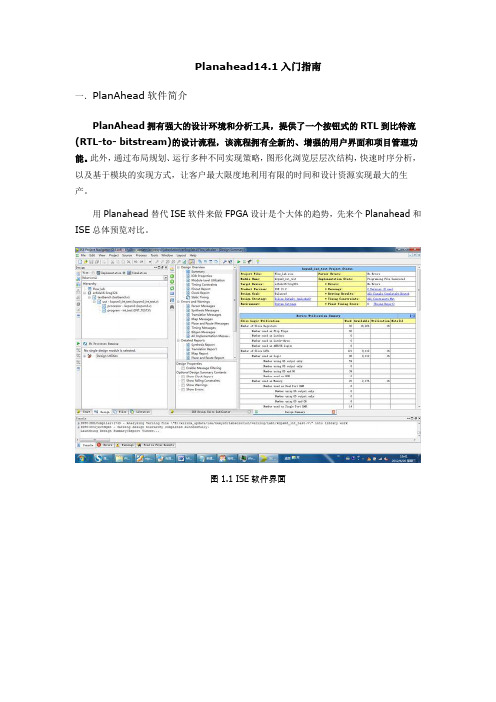
用Planahead替代ISE软件来做FPGA设计是个大体的趋势,先来个Planahead和ISE总体预览对比。
图1.1 ISE软件界面图1.2PlanAhead软件界面二.PlanAhead软件GUI设计指导2.1 软件界面图2.1PlanAhead左边工具栏上面的Project Manager用于综合管理工程文档。
Add Sources创建、管理源文件;IP Catalog创建、管理IPcore的工程设定。
Elaborate显示RTL图,并可以实现资源和功率的估计等等(在Synthesize之前,提高速度)。
(1)RTL Design与上面的Elaborate相同,都是打开RTL Design的功能。
(2)Synthesize是运行Xilinx 的XST Synthesis,综合工程。
(3)Netlist Design用来配置已经综合过的工程,包括显示综合过的RTL图,估计资源占用,配置约束,时序仿真等等。
(4)Implement执行ISE Implementation。
(5)Implemented Design观察时序和布局结果,并可以优化约束。
(6)Program and Debug按钮,用来生成烧写文件,启动ChipScope,iMPACT。
图2.2Synthesize 的下拉菜单进入到Synthesis Setting,得到图2.3。
图 2.3 Synthesis Setting 界面这里面可以选择使用的约束集合(在add sources里添加约束集合);在options里应用不同的综合选项综合。
Xilinx可编程逻辑器件设计与开发(基础篇)连载36:Spartan

Xilinx可编程逻辑器件设计与开发(基础篇)连载36:Spartan 第10章PlanAhead工具应用PlanAhead工具是Xilinx提供的一个集成的、可视化的FPGA设计工具,它可以被应用于FPGA设计过程中的不同阶段,常见的应用包括用PlanAhead进行RTL源代码的开发、I/O引脚规划、RTL网表分析、布局布线结果的分析、布局规划,还可以在PlanAhead中将Chipscope核插入设计辅助调试,从而提高性能。
也可以用PlanAhead尝试各种实现属性的不同设置,应用不同的时序约束、物理约束和布局规划技术来提高设计性能。
我们还可以将ISE的布局布线结果导入PlanAhead进行分析,定位关键路径,找到影响设计性能的真正原因,并通过添加合理的约束、尝试多种布局规划策略以提高设计性能。
PlanAhead具有以下功能。
I/O引脚规划。
RTL开发和分析。
综合和实现。
设计分析。
静态时序预估。
时序约束编辑器。
强大的布局规划。
基于块的逻辑设计。
值得一提的是,PlanAhead已经集成于ISE 11.x中,包括综合前引脚规划I/O pin planning (Pre-Synthesis)、综合后引脚规划I/O pin planning(Post-Synthesis)、综合后区域/引脚/逻辑规划Floorplan Area/IO/Logic(Post-Synthesis)和实现后时序分析/设计规划Analyze TIming/Floorplan Design(Post-ImplementaTIon),它替代了以前常用的PACE和Floorplanner 工具。
10.1 PlanAhead开发流程如图10-1所示,PlanAhead设计流程主要包含三个部分,分别是基本设计流程、实验流程和设计分析/布局规划流程。
下面分别简单介绍。
关于Xilinx ISE简单使用方法介绍
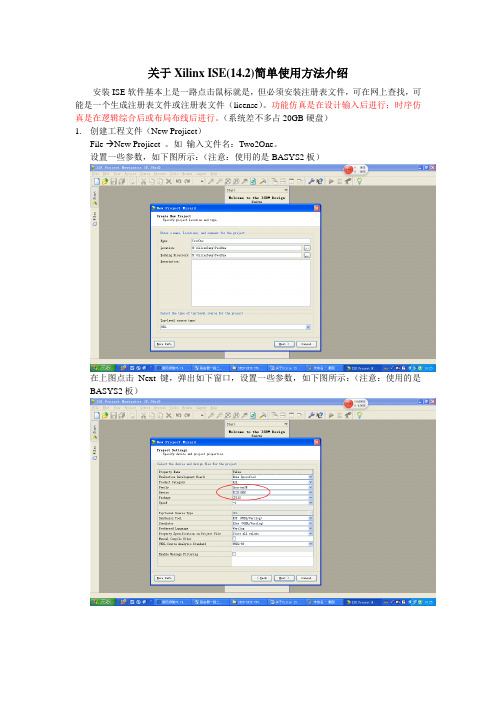
output [7:0] y_out,
);
assign y_out = flag ? x_in : 8'b00000000;
endmodule
3.程序语法检查
如下图所示:
或者:
4.创建测试文件(功能仿真数据的建立)
ProjectNew Source。如输入文件名:Two2One_tf(*.v)。
关于Xilinx ISE(14.2)简单使用方法介绍
安装ISE软件基本上是一路点击鼠标就是,但必须安装注册表文件,可在网上查找,可能是一个生成注册表文件或注册表文件(license)。功能仿真是在设计输入后进行;时序仿真是在逻辑综合后或布局布线后进行。(系统差不多占20GB硬盘)
1.创建工程文件(New Projiect)
将运行另外一个程序产生仿真波形图,如下图所示:
详细波形图:
6.管脚适配(为下载做准备)
先创建*.UCF文件
弹出窗口,点击Yes,创建.UCF文件
之后,系统会启动管脚配置程序,然后设计人员根据情况配置管脚,下图为BASYS2板管脚情况,所示:
适配后:
配置好管脚后保存好文件。
7.综合与实现
管脚分配完成之后,必须进行布局布线,如下图所示:
FileNew Projiect。如输入文件名:Two2One。
设置一些参数,如下图所示:(注意:使用的是BASYS2板)
在上图点击Next键,弹出如下窗口,设置一些参数,如下图所示:(注意:使用的是BASYS2板)
2.创建资源文件(New Source)
ProjectNew Source。如输入文件名:One2Two。
选择,如Verilog Test Fxiture,建立用于测试以上资源文件(电路)用的数据文件。建立不同时间段的输入数据,用于产生相应时段的输出波形。
xilinx软件介绍

ISE Design Suite涉及了FPGA设计的各个应用方面,包括逻辑开发、数字信号处理系统以及嵌入式系统开发等,本次设计应用了多个开发工具,在这里进行简要介绍。
1)ISE Foundation:开发集成工具
2)ChipScope Pro:在线逻辑分析仪工具
3)PlanAhead:用于布局和布线等设计分析工具
ISE Foundation软件是xilinx公司推出的FPGA/CPLD集成开发环境,不仅包括逻辑设计所需的一切,还具有简便易用的内置式工具和向导,使得I/O分配、功耗分析、时序驱动设计收敛、HDL仿真等关键步骤变得容易二直观。
ChipScope Pro软件
Xilinx公司推出了在线逻辑分析仪,通过软件方式为用户提供稳定和方便的解决方案。
该在线逻辑分析仪不仅具有逻辑分析仪的功能,而且成本低廉、操作简单,因此具有很高的实用价值。
ChipScope Pro既可以独立使用,也可以在ISE集成环境中使用,非常灵活,为用户提供方便和稳定的逻辑分析解决方案,支持Spartan和Virtex全系列FPGA芯片。
ChipScope Pro将逻辑分析器、总线分析器和虚拟I/O小型软件核直接插入到用户的设计当中,可以直接查看任何内部信号和节点,包括嵌入式硬或软处理器。
PlanAhead软件
PlanAhead工具简化了综合与布局布线之间的设计步骤,能够将大型设计划分为较小的、更易于管理的模块,并集中精力优化各个模块。
此外,还提供了一个直观的环境,为用户设计提供原理图、平面布局规划或器件图,可快速确定和改进设计的层次,以便获得更好的结果和更有效地使用资源,从而获得最佳的性能和利用率,极大地提升了整个设计的性能和质量。
添加自定义IP核基本步骤

添加自定义IP核基本步骤一、使用工具和参考链接:PlanAhead,XPS,SDK,ISE。
/blog/3987/blog/4009二、自定义IP流程简图如下:三、功能简介:本次生成的IP核只是用来控制一个LED灯根据sdk工程中对寄存器赋值来亮和灭。
四、步骤:1、使用PlanAhead创建新工程,打开PlanAhead14.4,创建新工程,输入工程名称,点击Next。
注:14.1版本存在问题,在windows系统下使用PlanAhead14.1会出现错误,建议升级至14.4。
2、 选择RTL Project ,在Do not specify sources at this time 处打钩,暂时不添加源文件。
之后,选择所使用的FPGA 型号。
之后会有工程的简单summary ,点finish 完成。
3、在工程左侧找到Add sources,添加xps工程。
然后点击红色线框所示,弹出窗口,按下图所示进行设置。
Next之后,弹出窗口,如下图所示,单击红色线框按钮,弹出如下图所示窗口,命名其为system。
然后确定!如下图所示。
点击Finish。
弹出如图所示的窗口,选择yes,(此时创建BSP)4、创建xps工程。
默认选择PLB System,点击ok。
根据自己的情况设置硬件工程,本例子中设置为单核系统,只选择了最基本的ddr,bram和串口三个。
在出现整个硬件summary之后点击finish完成设置。
5、添加自定义IP核,在Hardware中选择Create or Import Peripheral添加IP核。
如下面四个图所示,选择默认选项,在之后添加IP核名称,不能和PlanAhead以及xps工程名相同。
如下面四个图所示,之后选择PLB总线,会提示所需要的功能,包括软件reset,用户寄存器(一般都需要这个),FIFO(看需求),内存空间,中断。
本例子中只需要寄存器即可,如右上图。
之后选择默认即可,然后是添加寄存器数量,根据自己的需要添加,本例子中需要存储led灯状态,因此需要一个寄存器。
PlanAhead工具提高设计效率

独 立 的视 图可 以相 互 结合 使 用 , 从 线 拥 塞 故 障 点 , 将 具 有 大 量 连 接 并
而 允 许快 速 识别 和 浏 览关 键 设 计 对 的 P l k相 近 放 置 或 将 它 们 合 并 。 bc o 象和信息 。
可 在 P n ha l A e d环 境 中编 辑 和 a
维普资讯
D i & Dl t s { { e n Ap a n l = s g iI 殳 co
P n ha 工具提高设计效率 A ed l a
Pan ead T olm p o e De i fc c l Ah o I r v sgn Ef en y i
■ 赛灵思公 司产 品经理 Mak o s a rG o m n
设 计 问题 尤 其 涉 及 到 那 些 大 型 能 的提 高 。
制 设计 的初 始 实现 。 现 后 ,l A 实 P n— a
高性 能 计 划 , 有 效 的解 决 方 法 就 晟
虽然先进 的 FG P A综合产 品为 h a 软 件 可 以 分 析 布 局 和 时 序 结 ed
是 首 先 对 问题 详 尽 分 析 , 后将 大 几 百 万 门设 计提 供 极 高 的 自动 优 化 果 ,以改 进 用 于完 成 设 计 的布 局 规 然
问题 分 解 成 易 于 管 理 的 小 问题 。观 水 平 , 多 设计 者 仍 需 要 具 有 更 多 划 。可 以使 用来 自导入 结 果 的物 理 许
引脚、 理图殛更多 原
析设计并在实现之前解决物理方面
的 问题 。
预 期 时 间设 计 仍得 到 出乎 意 料 的 低
性能, 更别说随之而来的挫折感和压
力 。此 外 ,这 可 能还 意味 着 较 低 的
实验一 Xilinx

实验一 Xilinx_ISE 软件使用与计数器相关实验一、实验目的1.1了解并掌握采用可编程逻辑器件实现数字电路与系统的方法;1.2学习并掌握采用Xilinx_ISE 软件开发可编程器件的过程当你完成本实验项目之后,你将学会以下的功能.(1)利用ISE13.1 的软件建立一个基于XILINX FPGA开发的项目.(2)撰写一个简单的Verilog 程序,利用语法检查器(Syntax Check)来修正语法的错误(3)建立测试模板(Test Bench) 来测试你的设计.(4)加入系统所需的约束文件(.ucf)(5)完成整个设计流程.并生成可下载到实验板上的.bit文件。
(6)利用Digilent 公司Adept软件来烧录LED.bit 文件到FPGA.1.3学习使用verilog HDL描述数字逻辑电路与系统的方法;1.4掌握分层次、分模块的电路设计方法,熟悉使用可编程器件实现数字系统的一般步骤。
二、实验条件PC机Xilinx ISE13.1 软件USB下载线Digilent Adept软件(2.0或更新版)Xilinx大学计划开发板Basys2三、预习要求阅读实验原理及参考资料,了解使用Xilinx ISE13.1 软件开发Xilinx 可编程器件,设计实现所需电子系统的流程。
四、实验原理4.1 可编程器件开发流程图4.1.1 XILINX FPGA开发流程Xilinx 是全球领先的可编程逻辑完整解决方案的供应商,研发、制造并销售应用范围广泛的高级集成电路、软件设计工具以及定义系统级功能的IP(Intellectual Property)核,长期以来一直推动着FPGA技术的发展。
Xilinx的开发工具也在不断地升级,目前的ISE Project Navigator 13.x 集成了FPGA 开发需要的所有功能,其主要特点有:图4.2.1 Xilinx ISE13.1 集成开发环境•包含了Xilinx新型SmartCompile技术,可以将实现时间缩减 2.5 倍,能在最短的时间内提供最高的性能,提供了一个功能强大的设计收敛环境;•全面支持Virtex-5 系列器件(业界首款65nm FPGA);•集成式的时序收敛环境有助于快速、轻松地识别FPGA 设计的瓶颈;•可以节省一个或多个速度等级的成本,并可在逻辑设计中实现最低的总成本。
xilinx Vivado工具使用技巧

xilinx Vivado工具使用技巧综合属性在Vivado Design Suite中,Vivado综合能够合成多种类型的属性。
在大多数情况下,这些属性具有相同的语法和相同的行为。
•如果Vivado综合支持该属性,它将使用该属性,并创建反映已使用属性的逻辑。
•如果工具无法识别指定的属性,则Vivado综合会将属性及其值传递给生成的网表。
1.ASYNC_REGASYNC_REG是影响Vivado工具流中许多进程的属性。
此属性的目的是通知工具寄存器能够在D输入引脚中接收相对于源时钟的异步数据,或者该寄存器是同步链中的同步寄存器。
当遇到此属性时,Vivado综合会将其视为DONT_TOUCH属性,并在网表中向前推送ASYNC_REG属性。
此过程可确保具有ASYNC_REG属性的对象未进行优化,并且流程中稍后的工具会接收属性以正确处理它。
您可以将此属性放在任何寄存器上; 值为FALSE(默认值)和TRUE。
可以在RTL或XDC 中设置此属性。
ASYNC_REG Verilog Example:(*ASYNC_REG = “TRUE”*) reg [2:0] sync_regs;2.CLOCK_BUFFER_TYPE在输入时钟上应用CLOCK_BUFFER_TYPE以描述要使用的时钟缓冲器类型。
默认情况下,Vivado综合使用BUFG作为时钟缓冲器。
支持的值是“BUFG”,“BUFH”,“BUFIO”,“BUFMR”,“BUFR”或“无”。
CLOCK_BUFFER_TYPE属性可以放在任何顶级时钟端口上。
它可以在RTL和XDC中设置。
CLOCK_BUFFER_TYPE Verilog Example(* clock_buffer_type = “none”*) input clk1;CLOCK_BUFFER_TYPE XDC Example。
Xilinx_ISE使用教程__1

Xilinx公司软件平台介绍 公司软件平台介绍
--DSP_Tools软件
Xilinx公司推出了简化FPGA数字处理系统的集成开 发工具DSP Tools,快速、简易地将DSP系统的抽象算法 转化成可综合的、可靠的硬件系统,为DSP设计者扫清 了编程的障碍。DSP Tools主要包括System Genetator和 AccelDSP两部分,前者和Mathworks公司的Simulink实现 无缝链接,后者主要针对c/.m语言。
Slice S2
F7
F6
MUXF7 连接两个 连接两个MUXF6输出 输出
F5
Slice S1
F5
Slice S0
F6
MUXF6 连接slices S0和S1 连接 和 MUXF5连接 连接Slice内的 LUT 连接 内的
北京中教仪装备技术有限公司
Xilinx公司产品概述 公司产品概述
---FPGA内部结构(IO块)
北京中教仪装备技术有限公司
Xilinx公司产品概述 公司产品概述
---PROM产品
串行配置
并行配置
北京中教仪装备技术有限公司
Xilinx公司软件平台介绍 公司软件平台介绍
--开发工具
ISE Design Suite涉及了FPGA设计的各个应用方面, 包括逻辑开发、数字信号处理系统以及嵌入式系统开发等 FPGA开发的主要应用领域,主要包括 1 ISE Foundation 1)ISE Foundation:集成开发工具 2) EDK:嵌入式开发套件 3)DSP_TOOLs:数字信号处理开发工具 4)ChipScope Pro:在线逻辑分析仪工具 5)PlanAhead:用于布局和布线等设计分析工具
Xilinx ISE 13 笔记04 引脚约束的实现

第四引脚约束和时序约束的实现引脚约束:将顶层设计的逻辑端口和FPGA的物理引脚进行映射,步骤如下:(1)在Design面板下的View的单选按钮,将其从前面的Simulation,切换到Implementation。
(2)在Hierarchy面板窗口中,选择top文件名,右击,New Source…(3)出现New Source Wizard窗口,文件类型:Implementation Constraints File,文件名:top(4)Finish,Hierarchy中出现top.ucf文件。
(5)在Hierarchy窗口中,选择top,然后在Processes窗口下,选择User Constraints 选项,展开,选择I/O Pin Planning(PlanAhead)-Post-Synthesis选项,双击(6)出现ISE Project Navigator对话框,由于已经生成.ucf文件,选择Yes(7)出现对话框,单击OK。
(8)出现PlanAhead工具主界面(第一次等很久…),Close。
下面准备在PlanAhead软件中实现I/O引脚位置的约束,查板子原理图和引脚约束文件。
步骤如下:(1)对应每个信号行,在Site栏下,分别输入FPGA引脚的名字,然后在I/O Std 栏下,输入LVCOMS33,作为设计中所有I/O引脚的标准。
注意:也可以采用下面的方法,约束I/O引脚的位置。
如下图,在I/O Ports窗口中选中需要约束的端口,然后用鼠标将其拖拽到Package窗口所显示器件的相应的封装的位置,如此重复,知道为顶层设计的每个端口都分配了FPGA的引脚位置。
然后为每个引脚分配I/O Std为LVCMOS33。
当在FPGA映射了相应的位置后,在工具栏选择放大按钮,可以在所分配FPGA 引脚内看到“-||-”符号。
(2)保存,退出PlanAhead工具界面(3)在Hierarchy窗口中,选择top.ucf文件,然后在Processes窗口中,选择User Constraints,展开,双击Edit Constraints(Text)选项。
ISE界面介绍及使用教程VHDL

生成的测试平台test.vhd模板文件
基于VHDL语言的ISE设计流程 --对该设计进展行为仿真
删除此段代码
基于VHDL语言的ISE设计流程 --对该设计进展行为仿真
添加此段代码 用于生成rst测 试信号
基于VHDL语言的ISE设计流程 --对该设计进展行为仿真
添加此段代码 用于生成clk测 试信号
映射(Map)
适配(Fit)
布局和布线(PAR)
设计下载
CPLD设计
FPGA设计实现
计 算 机 自 动 完 成
时序收敛
ISE13.1集成开发环境介绍 --主界面介绍
源文件窗口
处理子窗口
脚本子窗口
工作区子窗口
基于VHDL语言的ISE设计流程 --一个数字系统的设计原理
外部50MHz时钟
Xcf04s-Xilinx的串行Flash芯片
xc3s500e-Xilinx的FPGA芯片
两个芯片连接在JTAG链路上
点击“Yes”按钮
基于VHDL语言的ISE设计流程 --下载设计到FPGA芯片
先不烧写设计到PROM芯片中,所以选择”Cancel”按钮
基于VHDL语言的ISE设计流程 --下载设计到FPGA芯片
输入”test”作为VHDL测试模块 的名字
点击“Next”按钮
基于VHDL语言的ISE设计流程 --对该设计进展行为仿真
点击“Next”按钮
基于VHDL语言的ISE设计流程 --对该设计进展行为仿真
点击“Finish”按钮
基于VHDL语言的ISE设计流程 --对该设计进展行为仿真
刚才的设计文件
点击“Finish”按钮
基于VHDL语言的ISE设计流程 --添加实现约束文件
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Xilinx PlanAhead 使用方法及心得(1.综述)
PlanAhead这个软件出现在ISE工具包里已经很久了。
具体是什么时候集成进去的,我也不去深究了。
但是,在ISE12里,PlanAhead的功能出现了很大的变化,不再仅仅是过去的约束软件,而是加入了RTL Design(Synthesize),Netlist Design(Implement),等传统上Project Navigator中的功能。
现在,在PlanAhead中即可进行全部的FPGA设计。
据称,Xilinx可能在14或者以后的版本中,取消Project Navigator。
那么本文就着重的说说PlanAhead的功能。
图 1 PlanAhead界面
图2所示,是PlanAhead的左边工具栏。
图 2 PlanAhead左边栏
上面的Project Manager用于综合管理工程文档。
Add Sources创建、管理源文件;IP Catalog 创建、管理IPcore的工程设定。
Elaborate显示RTL图,并可以实现资源和功率的估计等等(在Synthesize之前,提高速度)。
RTL Design与上面的Elaborate相同,都是打开RTL Design的功能。
Synthesize是运行Xilinx 的XST Synthesis,综合工程。
Netlist Design用来配置已经综合过的工程,包括显示综合过的RTL图,估计资源占用,配置约束,时序仿真等等。
Implement执行ISE Implementation。
Implemented Design观察时序和布局结果,并可以优化约束。
Program and Debug按钮,用来生成烧写文件,启动ChipScope,iMPACT。
我们再进一步展开几个执行按钮的下拉菜单。
如图3所示。
图 3 Synthesize 的下拉菜单
进入到Synthesis Setting,得到图4。
图 4 Synthesis Setting 界面
这里面可以选择使用的约束集合(在add sources里添加约束集合);在options里应用不同的综合选项综合。
进入到Create Multiple Runs里,如图5。
图 5 Create Multiple Runs界面
这里面建立的多个synthesis可以同步运行,充分利用多核cpu的优势。
而这些多个synthesis,可以是有不同的device,或者不同的Constraint sets。
下面通过一个例子说明PlanAhead如何创建工程。
图6所示是PlanAhead的启动界面。
图 6 PlanAhead界面
选择Create New Project,进入新建工程界面,如图7所示。
图7 New Project 下面是选择工程名和位置,如图8。
图8 New Project 下面是选择Design Source,如图9。
图9 Design Source
这里我们看到5个选项。
这5个选项对应着不同的设计层次。
第一个Specify RTL Sources,是导入RTL级的设计源文件,包括Verilog、VHDL代码、库,还有Xilinx IPCORE等等。
是最开始的设计文件。
第二个Specify Synthesized(Edif or NGC)netlist,是导入已经综合过的网表文件,做分析、约束和布局布线。
第三个Create an IO Planning Project,这个选项就是产生一个管脚约束文件,不做其他的事情。
即是老版本的PA做的事情。
第四个Import ISE Place& Route Results,导入已经布局布线后的工程,作分析和优化布局。
第五个Import ISE Project,直接导入ISE的工程。
我们现在选择第一个,直接设计RTL文件。
图10所示的是导入源文件的界面。
图10 Add Sources
这里我们直接导入PA的一个示例工程的源代码,位置是
ISE_DS\PlanAhead\testcases\PlanAhead_Tutorial\Projects\project_bft_core_hdl\project_bft_core _hdl.srcs\sources_1\imports,里面hdl下面的文件作为文件导入进work lib,bftLib直接作为目录导入,修改library为bftLib。
结果如图11所示。
图11 Added Sources
后面的添加IPcore直接略过,下面是添加约束文件。
约束文件的位置是
ISE_DS\PlanAhead\testcases\PlanAhead_Tutorial\Projects\project_bft_core_hdl\project_bft_core _hdl.srcs\constrs_1\imports\Sources\bft.ucf。
如图12所示。
图12 Add Constraints
然后是选择器件,我们选择Vertix-6 xc6vcx75tff784-1器件,如图13。
图13 Device
至此,工程建立完毕,显示Project Summary,如图14。
图14 Project Summary PlanAhead的界面如图15。
图15 PlanAhead
下面开始综合工程,在Synthesize右边的下拉菜单中,选择Synthesize setting,图16。
选择options右边的按钮,进入Design Run Setting,图17。
图16 Synthesize setting
图17 Design Run Settings
这里面可以配置修改XST的综合选项,还可以使用不同的综合策略来进行综合,我们这里面就不更改设置了,用它默认的配置就可以。
之后在Synthesize setting中点击RUN,执行综合。
综合完成之后,在Synthesize Completed对话框中选择Open Netlist Design,打开Netlist Design 界面。
在上面的下来菜单中选择I/O Planning,打开I/O配置页面,在下面的I/O Ports中,分配管脚。
如图18所示。
图18 I/O Planning
打开菜单栏Windows ->Report,选择XST Report,可以查看综合报告,如图19。
图19 XST Report
点击左侧的Implement,执行布局布线操作。
完成之后打开Implemented Design,查看结果。
在下面选择Timing Results,可以看到时序分析的结果。
如图20。
图20 Timing Results
点击Windows -> Device,在Device View的窗口下点击Show/Hide I/O Nets按钮。
可以查看器件间的逻辑连接情况。
如图21所示。
图21 I/O Nets
在下面的Timing Results中点击一条路径,可以在Device框中查看到对应的路径,图22。
右击path,选择Path Properties,可以查看这条路径经过的元件,图23
图22 Timing Results
图23 Path Properties
在Timing Result对话框下,点击原理图按钮,可以看到这条路径的原理图,图24。
图24。