正则表达式语言 - 快速参考
正则表达式语言 - 快速参考
正则表达式语言•-•快速参考正则表达式是正则表达式引擎尝试匹配输入文本的一种模式。
•模式由一个或多个字符文本、运算符或构造组成。
字符转义正则表达式中的反斜杠字符•(\)•指示其后跟的字符是特殊字符(如下表所示),或应按原义解释该字符。
•有关更多信息,请参见正则表达式中的字符转义。
字符类字符类与一组字符中的任何一个字符匹配。
•字符类包括下表中列出的语言元素。
•有关更多信息,请参见正则表达式中的字符类。
定位点定位点或原子零宽度断言会使匹配成功或失败,具体取决于字符串中的当前位置,但它们不会使引擎在字符串中前进或使用字符。
•下表中列出的元字符是定位点。
•有关更多信息,请参见正则表达式中的定位点。
分组构造描述了正则表达式的子表达式,通常用于捕获输入字符串的子字符串。
•分组构造包括下表中列出的语言元素。
•有关更多信息,请参见正则表达式中的分组构造。
限定符限定符指定在输入字符串中必须存在上一个元素(可以是字符、组或字符类)的多少个实例才能出现匹配项。
•限定符包括下表中列出的语言元素。
•有关更多信息,请参见正则表达式中的限定符。
反向引用构造反向引用允许在同一正则表达式中随后标识以前匹配的子表达式。
•下表列出了•.NET•Framework•的正则表达式支持的反向引用构造。
•有关更多信息,请参见正则表达式中的反向引用构造。
替换构造用于修改正则表达式以启用•either/or•匹配。
•这些构造包括下表中列出的语言元素。
•有关更多信息,请参见正则表达式中的备用构造。
替换替换是替换模式中支持的正则表达式语言元素。
•有关更多信息,请参见正则表达式中的替代。
•下表中列出的元字符是原子零宽度断言。
正则表达式选项可以指定控制正则表达式引擎如何解释正则表达式模式的选项。
•其中的许多选项可以指定为内联(在正则表达式模式中)或指定为一个或多个•RegexOptions•常量。
•本快速参考仅列出内联选项。
•有关内联和•RegexOptions•选项的更多信息,请参见文章正则表达式选项。
基于JavaScript的参考文献格式快速调整

信息科学科技创新导报 Science and Technology Innovation Herald121DOI:10.16660/ki.1674-098X.2020.06.121基于JavaScript的参考文献格式快速调整①杨子江 刘黎明 陈新胜 刘廿明 蔡春梦 廖开怀 李贞铮(湖南省科学技术信息研究所 湖南长沙 410001)摘 要:实现科技查新报告撰写的自动化和智能化是查新技术的发展趋势,笔者使用JavaScript语言,利用正则表达式,完成万方导出参考文献文本字符的检测、替换、调整,在HTML网页端实现对参考文献格式的快速调整,能够减少重复性的工作,提高查新员撰写查新报告的工作效率。
关键词:科技查新 参考文献 正则表达式 JavaScript 中图分类号:TP3 文献标识码:A 文章编号:1674-098X(2020)02(c)-0121-02Abstract:To realize the automation and intelligence of scientific and technological novelty search report writing is the development trend of the new technology. The author uses JavaScript language and regular expression to complete the detection, replacement and adjustment of the text characters of the universal exported references, and realize the quick adjustment of the reference format on the HTML web end, which can reduce the repetitive work and improve the working efficiency of the novelty search report. Key Words:Novelty search;Reference documentation;Regular expression;JavaScript①作者简介:杨子江(1991—),男,汉族,湖南娄底人,本科,实习研究员,研究方向:科技查新创新与应用。
regexpreplace正则表达式

regexpreplace正则表达式全文共四篇示例,供读者参考第一篇示例:正则表达式(Regular Expression)是用来匹配字符串中字符组合的模式。
在很多编程语言中,使用正则表达式可以实现字符串的搜索、替换和匹配等操作。
在JavaScript中,我们可以使用RegExp对象来创建正则表达式,并使用test()、match()、exec()等方法来操作字符串。
而在JavaScript中,有一个非常常用的方法,就是regexpreplace方法,可以实现替换字符串中的字符。
在JavaScript中,regexpreplace方法的用法非常简单,我们只需要传入匹配规则和替换的内容即可。
例如:```javascriptconst str = "hello world";const newStr = str.replace(/hello/, "hi");console.log(newStr); // "hi world"```上面的代码中,我们传入的第一个参数是匹配规则/hello/,表示要匹配字符串中的“hello”。
第二个参数是要替换成的内容“hi”。
所以最终输出的结果是“hi world”。
regexpreplace方法还支持传入正则表达式对象作为匹配规则。
例如:在这个示例中,我们传入了一个正则表达式对象pattern,它可以匹配三组数字,每组数字之间用“-”分隔。
在替换内容中,我们使用了1、2、3来代表正则表达式中的三个分组,这样就可以将原字符串按照指定格式替换输出。
在这个示例中,我们传入一个匿名函数作为替换内容。
这个函数的第一个参数是匹配到的字符串,后面的参数是匹配到的分组和匹配到的索引。
在函数里面,我们判断了匹配到的索引,如果是第一个单词,则将其转换为大写,否则保持原样。
在实际的开发中,regexpreplace方法经常用来处理文本数据、格式化字符串或者过滤非法字符。
两个相同的字正则表达式_解释说明

两个相同的字正则表达式解释说明1. 引言1.1 概述本文将详细介绍两个相同的字正则表达式,并解释其工作原理和应用场景。
在现代信息技术领域,正则表达式是一种强大而灵活的模式匹配工具,可用于处理各种文本数据,如字符串、日志文件、邮件等。
字正则表达式是正则表达式的一种扩展形式,专门用于匹配和操作单个字符。
1.2 文章结构本文分为以下几个部分:引言、正文、字正则表达式解释说明A、字正则表达式解释说明B和结论。
在引言部分,我们将简要介绍概述、文章结构和目的。
接下来的正文将详细阐述字正则表达式的原理和功能。
字正则表达式解释说明A 和字正则表达式解释说明B将分别深入探讨两个相同的字正则表达式,并提供实际使用示例。
最后,在结论部分,我们将总结主要观点,并对比两个字正则表达式的优劣并探讨未来发展方向。
1.3 目的本文旨在帮助读者全面了解两个相同的字正则表达式及其在实际中应用的情况。
通过深入解释它们的原理和应用示例,希望读者能够掌握如何使用字正则表达式来进行字符匹配和操作,并明确了解两个字正则表达式之间的差异以及各自的优势。
这将有助于读者在实际工作中更高效地处理文本数据,并为未来的技术发展提供参考和思路。
2. 正文正文部分将详细介绍两个相同的字正则表达式。
在这一部分中,我们将分别讨论字正则表达式解释说明A和字正则表达式解释说明B。
字正则表达式是一种用于匹配和处理文本中字符序列的工具。
它可以帮助我们快速有效地搜索、替换、提取或验证符合特定模式的内容。
3. 字正则表达式解释说明A3.1 概述在本节中,我们将介绍字正则表达式解释说明A的概况。
字正则表达式解释说明A是一个功能强大且广泛应用于文本处理领域的工具。
它具有灵活多样的语法规则,能够方便地对各种复杂模式进行匹配和处理。
3.2 核心功能介绍在此部分,我们将详细阐述字正则表达式解释说明A的核心功能。
这包括但不限于以下方面:- 匹配规则:字正则表达式解释说明A提供了丰富多样的匹配规则,例如通配符、字符集合、重复次数限制等。
只匹配中文 并且不匹配英文的正则表达式

只匹配中文并且不匹配英文的正则表达式全文共四篇示例,供读者参考第一篇示例:正则表达式是一种用来描述字符串匹配模式的表达式,它可以帮助我们快速有效地处理文本数据。
在编程和数据处理的领域中,正则表达式被广泛应用于文本匹配、替换和提取等操作。
在日常工作中,我们经常需要处理多种语言的文本数据。
有时候我们可能需要只匹配中文文本,而不包括英文或其他语言的文本。
这时就需要使用一种特殊的正则表达式来实现这个目的。
在正则表达式中,中文字符的Unicode范围是[\u4e00-\u9fa5],这个范围包括了中文的全部字符。
英文字符的Unicode范围是[a-zA-Z],这个范围包括了大小写字母。
要实现只匹配中文并不匹配英文的正则表达式,我们可以通过使用Unicode的范围来实现。
下面是一个简单的只匹配中文并不匹配英文的正则表达式示例:^[\u4e00-\u9fa5]*这个正则表达式用^表示匹配字符串的开始,表示匹配字符串的结束。
[\u4e00-\u9fa5]表示匹配中文字符的范围,*表示匹配任意数量的中文字符。
这个正则表达式可以匹配任意数量的中文字符,但不匹配任何英文字符。
使用这个正则表达式可以帮助我们更方便地处理中文文本数据,过滤掉不需要的英文字符。
在实际工作中,我们可以将这个正则表达式应用在文本匹配、文本提取等操作中,从而提高工作效率。
只匹配中文并不匹配英文的正则表达式在文本处理中是非常有用的,可以帮助我们更好地处理中文文本数据。
通过学习和掌握正则表达式的基本原理和语法,我们可以更加灵活地处理各种文本数据,提高工作效率和准确性。
希望这篇文章对大家有所帮助,谢谢阅读!第二篇示例:正则表达式是一种用来描述字符串匹配模式的工具,它能够帮助我们在文本中快速地找到符合特定规则的字符串,起到筛选、替换和提取的作用。
在不同的编程语言和工具中,正则表达式都有所不同,但是它们的基本原理和语法都是相通的。
我们在日常的编程工作中经常会碰到需要匹配中文字符的情况,有时候还需要排除掉英文字符,这就需要使用特定的正则表达式来实现。
正整数正则表达

正整数正则表达一、正整数正则表达式的概念1. 啥是正则表达式呢?说白了,它就像是一种密码规则,专门用来匹配特定的字符串模式的。
对于正整数来说,正则表达式就是用来精准地找到那些只由数字组成,而且没有小数、分数、负数这些乱七八糟东西的数字。
就好比在一堆各种各样的东西里,只把那些纯粹的正整数给挑出来一样。
2. 举个例子哈,如果我们在一个文本里有很多数字,像1、2.5、-3、4之类的,正则表达式就能像一个超级智能的筛子,把1和4这样的正整数筛出来,而把2.5和 -3这种不符合要求的给过滤掉。
二、正整数正则表达式的基本形式1. 在很多编程语言里,正整数的正则表达式常见的形式是^\d+$。
这里面的 ^ 表示开始的位置,就像是起跑线一样,它告诉程序从这个地方开始检查。
\d呢,就是代表数字,这个符号就像是一个数字的小标签,只要是数字它就能识别。
最后的 + 号,表示前面的这个数字可以出现一次或者多次,就像排队一样,可以是一个数字,也可以是好几个数字连着。
最后的 $ 表示结束的位置,就像终点线,告诉程序检查到这里就结束啦。
2. 比如说,我们有一个字符串“123abc”,当用这个正则表达式去匹配的时候,它就会看到开头的123是符合要求的正整数部分,但是一看到后面的abc就知道不符合了,因为abc不是数字嘛。
再比如“45”这个字符串,它就完全符合这个正则表达式,因为从开头的4到结尾的5都是数字,而且是正整数。
三、正整数正则表达式在不同编程语言中的应用1. 在Python里呢。
Python有个re模块是专门用来处理正则表达式的。
我们可以这样写代码:首先要导入re模块,就像从一个工具盒子里拿出这个工具一样,代码是import re。
然后假如我们有一个字符串s = "123abc",我们想找出里面的正整数部分,就可以用re.findall('^\d+$', s)。
这个findall函数就会按照我们给定的正则表达式去字符串里找,然后把找到的符合要求的部分以列表的形式返回。
中文加英文括号正则

中文加英文括号正则全文共四篇示例,供读者参考第一篇示例:正则表达式是一种强大的文本匹配和处理工具,它可以帮助我们在文本中快速地找到想要的内容,并且进行相关的处理。
在正则表达式中,括号是一个非常重要的元字符,它可以用来分组匹配、提取信息,以及进行替换等操作。
在本文中,我们将介绍一些关于中文和英文括号在正则表达式中的用法和技巧。
我们来看一些关于英文括号在正则表达式中的用法。
英文括号通常用来表示一个匹配组,当我们在正则表达式中使用括号时,它们会将括号内的内容视为一个整体,以便后续的操作。
我们可以使用括号来捕获匹配的内容,便于后续提取或替换。
下面的正则表达式可以匹配一个手机号码,并使用括号将手机号码进行捕获:``` regex(\d{3})-(\d{4})-(\d{4})```在上面的正则表达式中,括号被用来分组匹配手机号的不同部分,分别为区号、中间四位数字和最后四位数字。
我们可以通过引用这些捕获组来提取或替换匹配到的内容。
可以使用`1` 来引用第一个捕获组的内容,使用`2` 来引用第二个捕获组的内容。
接着,我们来看一下中文括号在正则表达式中的用法。
中文括号和英文括号类似,在正则表达式中也可以用来分组匹配内容。
不过需要注意的是,中文括号在写正则表达式时需要特别注意编码和转义的问题,以避免出现语法错误。
下面是一个使用中文括号来匹配电话号码的正则表达式:第二篇示例:加英文括号正则表达式是一种强大的工具,可以帮助我们在文本处理中快速有效地匹配特定的模式。
在日常工作中,我们经常需要从大量的文本数据中提取特定信息,比如电话号码、邮箱地址、URL等。
使用正则表达式就可以很轻松地实现这些任务。
正则表达式是一种灵活、通用、强大的文本处理工具,在几乎所有的编程语言和文本编辑器中都能找到。
它的语法虽然看起来有些复杂,但一旦掌握基本规则,就可以轻松地编写出功能强大的匹配规则。
在本文中,我们将重点介绍中文加英文括号正则表达式的使用方法,帮助大家更好地理解和应用这一工具。
linux awk正则表达式

linux awk正则表达式Awk是一种快速数据处理和报告生成语言,通常用于文本处理和数据提取。
它支持正则表达式(Regular Expression)来查找匹配的模式,并根据找到的模式执行相应的操作。
正则表达式是一种强大的文本模式匹配工具,它可以使用特殊字符和元字符来描述文本中的模式。
在使用Awk的正则表达式之前,需要了解一些基本的正则表达式语法和常用的模式匹配技巧。
下面是一些关于Awk正则表达式的参考内容:1. 正则表达式基本语法:- 正则表达式是由普通字符(例如字母和数字)和特殊字符(例如元字符)组成的字符串。
- 元字符是特殊字符,具有特殊的含义,用于描述模式的特定部分。
- 常见的元字符有:.、*、+、?、^、$、[]、|等。
- .(点)用于匹配除换行符外的任意字符。
- *(星号)表示匹配前一个字符零次或多次。
- +(加号)表示匹配前一个字符一次或多次。
- ?(问号)表示匹配前一个字符零次或一次。
- ^(插入符)用于匹配输入行的开头。
- $(美元符)用于匹配输入行的结尾。
- [](方括号)用于指定一组字符中的任意一个。
- |(竖线)用于指定多个模式中的任意一个。
2. Awk中正则表达式的使用:- Awk中使用正则表达式进行模式匹配的语法是将正则表达式包含在斜杠(/)之间。
- 例如,/pattern/ 表示一个模式,它将匹配输入数据中的任何满足pattern的部分。
- 要在Awk中使用正则表达式,可以将模式与Awk的条件语句结合使用,如if、while等。
- 也可以在Awk的动作语句中使用正则表达式来提取匹配的部分。
3. Awk中的正则表达式操作符:- ~ 用于匹配正则表达式,例如:/pattern/ ~ $0 表示当前行是否匹配pattern。
- !~ 用于不匹配正则表达式。
- ~ /pattern/ { action } 用于在匹配pattern时执行action动作。
- 例如:/^[0-9]+$/ { print $0 } 表示如果当前行只包含数字,则输出当前行。
递增正则表达式

递增正则表达式全文共四篇示例,供读者参考第一篇示例:递增正则表达式是一种非常有用的工具,可以帮助我们在文本中快速匹配出递增的数字序列。
在很多情况下,我们需要处理一些格式化的数据,例如版本号、日期或者其它一些序列号,这时候递增正则表达式就可以发挥它的作用了。
递增正则表达式的原理很简单,它根据一定的规则匹配出递增的数字序列。
接下来,我们将给大家介绍一下递增正则表达式的基本语法和用法。
递增正则表达式的语法一般包含以下几个部分:1. 匹配开始的数字或字符;2. 包含一个或多个查找范围的数字或字符;3. 匹配递增的数字或字符;4. 包含一个或多个查找范围的数字或字符。
在这个基本语法结构下,我们就可以编写出递增正则表达式了。
如果我们需要匹配递增的整数序列,可以使用如下的正则表达式:```\d+```这个正则表达式用\d+来匹配一个或者多个数字,即整数序列。
如果我们需要匹配递增的浮点数序列,可以使用如下的正则表达式:```\d+\.\d+```这个正则表达式用\d+\.\d+来匹配一个或者多个数字加上小数点再加上一个或者多个数字,即浮点数序列。
在实际应用中,递增正则表达式可以帮助我们完成很多有用的操作。
我们可以使用递增正则表达式来提取文本中的版本号,检测文本中的日期格式是否正确,或者验证序列号的有效性等。
递增正则表达式的灵活性和实用性使得它成为了文本处理中不可或缺的工具之一。
我们还可以通过递增正则表达式来实现一些高级的操作。
如果我们需要匹配递增的数字序列,并且这个递增序列是从某个固定的起始值开始的,我们可以使用如下的正则表达式:```1\d{2}```这个正则表达式用1\d{2}来匹配以1开头的三位数字,即从100递增的整数序列。
递增正则表达式是一种非常实用的工具,可以帮助我们快速匹配出递增的数字序列,从而简化文本处理的过程。
希望以上介绍对大家有所帮助,欢迎大家在实际应用中尝试使用递增正则表达式,相信会给你带来更高效的工作体验。
apifox 正则表达式

apifox 正则表达式全文共四篇示例,供读者参考第一篇示例:正则表达式(Regular Expression)是一种强大的文本匹配工具,它可以用来检查文本符合某种模式或规则。
在网络开发中,正则表达式经常用来验证输入的数据是否符合要求,比如邮箱、手机号码、密码格式等。
在API接口测试中,正则表达式也可以帮助我们验证响应数据是否符合预期,或者从响应数据中提取我们需要的信息。
而在使用正则表达式时,我们通常会使用一些在线工具或者编程语言帮助我们快速编写和验证正则表达式。
今天我们就要介绍一款名为Apifox的在线接口测试工具,它提供了丰富的正则表达式功能,帮助开发者更方便地对接口进行测试和调试。
一、什么是Apifox?Apifox是一款基于云端的API管理工具,它的主要功能包括接口设计、调试和测试。
用户可以在Apifox中创建接口文档、定义接口参数、发送请求并查看响应数据,同时还可以对接口进行自动化测试,用于验证接口的正确性和稳定性。
在接口测试过程中,正则表达式起着非常重要的作用,可以帮助我们验证接口的基本数据格式、提取关键信息等。
二、Apifox中的正则表达式功能在Apifox中,正则表达式功能主要体现在接口测试环节。
当我们发送接口请求后,可以通过正则表达式来验证响应数据是否符合预期。
具体来说,Apifox提供了以下几种正则表达式功能:1. 正则表达式匹配验证:我们可以在接口测试中输入正则表达式,用来验证响应数据是否符合某种模式或规则。
我们可以使用正则表达式来验证邮箱、手机号码、身份证号码等格式是否正确。
2. 正则表达式提取:除了验证功能,Apifox还支持使用正则表达式提取响应数据中的信息。
我们可以通过正则表达式从响应数据中提取关键字段,比如用户名、订单号等。
3. 正则表达式替换:在接口测试中,有时我们需要对响应数据进行处理或者清理。
这时我们可以使用正则表达式来进行替换操作,比如替换敏感信息、格式化数据等。
java正则表达式

java正则表达式⼀、校验数字的表达式1 数字:^[0-9]*$2 n位的数字:^\d{n}$3 ⾄少n位的数字:^\d{n,}$4 m-n位的数字:^\d{m,n}$5 零和⾮零开头的数字:^(0|[1-9][0-9]*)$6 ⾮零开头的最多带两位⼩数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$7 带1-2位⼩数的正数或负数:^(\-)?\d+(\.\d{1,2})?$8 正数、负数、和⼩数:^(\-|\+)?\d+(\.\d+)?$9 有两位⼩数的正实数:^[0-9]+(.[0-9]{2})?$10 有1~3位⼩数的正实数:^[0-9]+(.[0-9]{1,3})?$11 ⾮零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$12 ⾮零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$13 ⾮负整数:^\d+$ 或 ^[1-9]\d*|0$14 ⾮正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$15 ⾮负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$16 ⾮正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$17 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$18 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$19 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$⼆、校验字符的表达式1 汉字:^[\u4e00-\u9fa5]{0,}$2 英⽂和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$3 长度为3-20的所有字符:^.{3,20}$4 由26个英⽂字母组成的字符串:^[A-Za-z]+$5 由26个⼤写英⽂字母组成的字符串:^[A-Z]+$6 由26个⼩写英⽂字母组成的字符串:^[a-z]+$7 由数字和26个英⽂字母组成的字符串:^[A-Za-z0-9]+$8 由数字、26个英⽂字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$9 中⽂、英⽂、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$10 中⽂、英⽂、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$11 可以输⼊含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+12 禁⽌输⼊含有~的字符:[^~\x22]+三、特殊需求表达式1 Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?4 ⼿机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$5 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$6 国内电话号码(0511-*******、021-********):\d{3}-\d{8}|\d{4}-\d{7}7 ⾝份证号(15位、18位数字):^\d{15}|\d{18}$8 短⾝份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$9 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$10 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$11 强密码(必须包含⼤⼩写字母和数字的组合,不能使⽤特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$12 ⽇期格式:^\d{4}-\d{1,2}-\d{1,2}13 ⼀年的12个⽉(01~09和1~12):^(0?[1-9]|1[0-2])$14 ⼀个⽉的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$15 钱的输⼊格式:16 1.有四种钱的表⽰形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$17 2.这表⽰任意⼀个不以0开头的数字,但是,这也意味着⼀个字符"0"不通过,所以我们采⽤下⾯的形式:^(0|[1-9][0-9]*)$18 3.⼀个0或者⼀个不以0开头的数字.我们还可以允许开头有⼀个负号:^(0|-?[1-9][0-9]*)$19 4.这表⽰⼀个0或者⼀个可能为负的开头不为0的数字.让⽤户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下⾯我们要加的是说明可能的⼩数部分:^[0-9]+(.[0-9]+)?$20 5.必须说明的是,⼩数点后⾯⾄少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$21 6.这样我们规定⼩数点后⾯必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$22 7.这样就允许⽤户只写⼀位⼩数.下⾯我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$23 8.1到3个数字,后⾯跟着任意个逗号+3个数字,逗号成为可选,⽽不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$24 备注:这就是最终结果了,别忘了"+"可以⽤"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在⽤函数时去掉去掉那个反斜杠,⼀般的错误都在这⾥25 xml⽂件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$26 中⽂字符的正则表达式:[\u4e00-\u9fa5]27 双字节字符:[^\x00-\xff] (包括汉字在内,可以⽤来计算字符串的长度(⼀个双字节字符长度计2,ASCII字符计1))28 空⽩⾏的正则表达式:\n\s*\r (可以⽤来删除空⽩⾏)29 HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (⽹上流传的版本太糟糕,上⾯这个也仅仅能部分,对于复杂的嵌套标记依旧⽆能为⼒)30 ⾸尾空⽩字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以⽤来删除⾏⾸⾏尾的空⽩字符(包括空格、制表符、换页符等等),⾮常有⽤的表达式)31 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)32 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字) 33 IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有⽤) 34 IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))20个正则表达式必知(能让你少写1,000⾏代码)正则表达式(regular expression)描述了⼀种字符串匹配的模式,可以⽤来检查⼀个串是否含有某种⼦串、将匹配的⼦串做替换或者从某个串中取出符合某个条件的⼦串等。
只让输入数字字母中文的正则-概念解析以及定义

只让输入数字字母中文的正则-概述说明以及解释1.引言概述部分的内容:在日常的软件开发和数据处理中,我们经常需要对用户输入的内容进行限制和验证,确保输入的数据符合特定要求。
而正则表达式作为一种强大的文本匹配工具,可以帮助我们快速准确地对用户输入的内容进行检查和过滤。
本文旨在介绍一种只允许输入数字、字母和中文的正则表达式。
通过使用这个正则表达式,我们可以有效地限制输入内容的范围,保证数据的可靠性和安全性。
正则表达式是一种用于描述、匹配和操作文本的字符串模式。
它使用特定的语法规则,通过组合各种字符和元字符,可以表示出一些特定的文本模式。
在本文中,我们将重点讨论如何使用正则表达式来限制用户输入的内容。
我们将分别介绍只允许输入数字、字母和中文的正则表达式,并给出相应的示例和解释。
通过理解这些正则表达式的原理和使用方法,读者可以在实际开发中根据需求进行灵活应用,确保用户输入的内容符合规定要求。
本文的目录结构如下:1. 引言1.1 概述(本节内容)1.2 文章结构1.3 目的1.4 总结2. 正文2.1 正则表达式基础知识2.2 只允许输入数字的正则表达式2.3 只允许输入字母的正则表达式2.4 只允许输入中文的正则表达式3. 结论3.1 总结3.2 展望未来通过阅读本文,读者将能够了解和掌握只让输入数字、字母和中文的正则表达式的方法,对于日常开发中处理用户输入的场景有所帮助。
接下来,我们将开始正式介绍正则表达式的基础知识,以便更好地理解和应用后续的内容。
1.2文章结构1.2 文章结构在本文中,将详细介绍正则表达式的基础知识以及如何使用正则表达式来实现只允许输入数字、字母和中文的功能。
文章将按照以下结构进行叙述:第一部分,引言,将对本文的内容进行概述。
首先介绍正则表达式的定义和作用,以及为什么我们需要一个只允许输入数字、字母和中文的正则表达式。
接着,对整篇文章的结构和目的进行说明,最后进行总结。
第二部分,正文,将逐步介绍正则表达式的基础知识以及如何编写只允许输入数字、字母和中文的正则表达式。
判断全是数字正则表达式的方法

判断全是数字正则表达式的方法判断全是数字正则表达式的方法1. 引言判断一串字符是否全是数字是一种常见的需求,在很多编程语言和软件中都会遇到。
有时候我们需要验证用户输入的是一个有效的通信,有时候我们需要保证用户输入的是一个合法的唯一识别信息号码。
无论出于什么目的,我们都需要一种方法来快速、有效地判断一个字符串中的所有字符是否都是数字。
在本文中,我将介绍一种常用的方法,使用正则表达式来判断一个字符串是否全是数字,并分享一些个人观点和理解。
2. 判断全是数字正则表达式的方法要判断一个字符串是否全是数字,我们可以使用正则表达式来进行匹配和验证。
正则表达式是一种强大的字符串模式匹配工具,它可以用来描述、查找和操作字符串中的特定模式。
在判断全是数字的场景中,我们可以使用下面的正则表达式来匹配一个全是数字的字符串:^[0-9]+$这个正则表达式的含义是:以数字0到9开头,并且以数字0到9结束,中间可以包含任意多个数字0到9。
当我们将这个正则表达式应用于一个字符串时,只有当该字符串的每一个字符都是数字时才会匹配成功,否则匹配失败。
3. 方法解析让我们详细解析一下上面的正则表达式,并说明它的工作原理。
- ^ 表示以某个模式开头,对应这个正则表达式中的数字0到9。
这个符号告诉正则表达式引擎,接下来的字符必须是字符串的开始位置。
- [0-9]+ 表示匹配一个或多个数字0到9。
方括号中的范围表示可以匹配的数字的范围,这里表示匹配0到9之间的任意一个数字。
加号+表示匹配一个或多个前面的模式,也就是匹配一个或多个数字0到9。
- $ 表示以某个模式结尾,对应这个正则表达式中的数字0到9。
这个符号告诉正则表达式引擎,接下来的字符必须是字符串的结束位置。
综合起来,这个正则表达式的作用就是匹配一个完全由数字0到9组成的字符串。
4. 个人观点和理解使用正则表达式来判断一个字符串是否全是数字是一种简洁、直观的方式。
正则表达式提供了强大、灵活的模式匹配功能,能够快速有效地满足判断全是数字的需求。
提取一段话中的文字正则

提取一段话中的文字正则全文共四篇示例,供读者参考第一篇示例:正则表达式是一种强大的工具,可以帮助我们在一段文本中提取特定的信息。
在这个前提下,我们要提取一段话中的文字,就需要用到正则表达式。
正则表达式是一种描述字符模式的符号表达式,可以在文本中进行查找、替换和匹配的操作。
在使用正则表达式提取一段话中的文字时,我们首先需要确定要提取的文字的模式。
如果要提取一段话中所有的汉字,就可以使用如下的正则表达式:[\u4e00-\u9fa5]这个正则表达式表示匹配所有的汉字。
\u4e00代表第一个汉字“一”,\u9fa5代表最后一个汉字“龥”。
通过这个正则表达式,我们就可以提取一段话中的所有汉字。
[A-Za-z]+\d+除了这些基本的提取模式外,还可以根据实际需求编写更复杂的正则表达式。
要提取一段话中所有的邮箱地址,可以使用如下正则表达式:[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}第二篇示例:正则表达式是一种强大的工具,用于在文本中查找特定模式的字符串。
通过使用正则表达式,我们可以轻松地从一段文本中提取所需的信息。
在本文中,我们将介绍如何编写正则表达式来提取一段话中的文字。
让我们来看一个简单的例子。
假设我们有一段话如下:"在这个世界上,最重要的事情就是做一个好人,善良待人,助人为乐。
"[\u4e00-\u9fa5]这个正则表达式的含义是匹配所有的汉字字符。
在这里,\u4e00表示汉字的开始范围,\u9fa5表示汉字的结束范围。
通过使用这个正则表达式,我们可以轻松地提取出我们想要的汉字字符。
"John的手机号码是************,Mary的手机号码是************。
"我们想要提取这段话中的所有手机号码,即*************"和*************"。
为了实现这个目标,我们可以编写以下正则表达式:\d{3}-\d{8}这个正则表达式的含义是匹配3位数字,然后是一个短横线,然后是8位数字。
python正则根据开头和结尾字符串获取中间字符串的方法

python正则根据开头和结尾字符串获取中间字符串的方法Python正则表达式:根据开头和结尾字符串获取中间字符串的方法在Python中,正则表达式是处理文本操作非常关键的工具。
通过正则表达式,我们可以方便地匹配和提取字符串中的特定部分,从而实现数据处理的目的。
其中,要根据开头和结尾字符串获取中间的字符串,可以使用正则表达式中的“lookbehind”和“lookahead”语法。
以下是具体的实现方法:1. 根据开头和结尾字符串生成正则表达式模式我们可以使用正则表达式模式来匹配开头和结尾字符串,并同时保留中间的部分。
例如,在文本中查找以“Hello”为开头、以“World”为结尾的字符串,可以使用如下正则表达式模式:```pythonpattern = r'(?<=Hello).*?(?=World)'```这个正则表达式模式中,使用了“lookbehind”语法“(?<=Hello)”,表示匹配以“Hello”为开头的文本。
同时,也使用了“lookahead”语法“(?=World)”,表示匹配以“World”为结尾的文本。
最后,使用“.*?”匹配开头和结尾之间的任意文本,保留中间部分。
2. 使用正则表达式模式匹配字符串在生成正则表达式模式之后,我们可以使用Python中的re模块来进行字符串匹配操作。
例如,在文本“Hello, World!”中查找以“Hello”为开头、以“World”为结尾的字符串,代码如下:```pythonimport retext = 'Hello, World!'pattern = r'(?<=Hello).*?(?=World)'match = re.search(pattern, text)if match:result = match.group(0)print(result)```在以上代码中,使用了re模块中的search()函数进行正则表达式匹配。
易语言正则表达式总结

易语⾔正则表达式总结如果查看百度百科,你会看到关于正则表达式的起源等类似官⽅语⾔的介绍。
但是,我不打算⽤这种正式的语⾔来介绍正则表达式。
我试图通过⽐较简单容易理解的语⾔来帮助刚接触正则的朋友快速⼊门!所谓正则,简单的来说就是通过各种符号来匹配相对应的⽂本,以⽅便我们快速找到⾃⼰所需要的内容!正则表达式不是易语⾔独有,前⾯说了正则是⽤特定符号匹配出特定的⽂本。
所以,⼀般的语⾔都会有正则表达式,例如php,JavaScript等。
这样来理解的话,正则就很容易理解了,如果要学习的话,就要理解正则的符号的含义,只有理解了符号特定的含义,才能将符号组合表达出来!⼀个经常使⽤的字符列表.点号匹配任何单个字符(注:点号在字符组内不算元字符)*星号表⽰之前的元素出现任意次数或0次问号前⾯元素出现0次或1次+加号前⾯元素出现1次以上-连字符注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表⽰字符的范围; 如果出现在字符组的开头,则只能表⽰连字符本⾝^脱字符表⽰开头。
注意:^在字符组的头部,将转换成排除型字符$美元符表⽰结尾。
\转义符[ ]字符组范围描述符。
[a-z]表⽰从a到z之间的任意⼀个。
\w英⽂字母和数字。
即[0-9 A-Z a-z]。
\W⾮英⽂字母和数字\s空字符,即[\t\n\r\f]。
\S⾮空字符。
\d数字,即[0-9]。
\D⾮数字。
\b词边界字符(在范围描述符外部时),表⽰为单词的分界符\B⾮词边界字符\t制表符{n}前⾯的元素字符出现n次{m,n}前⾯的元素最少出现m次,最多出现n次|选择符( )群组,⼦表达式点号.的使⽤下⾯我们⽤点号.来查找下⾯源码⽂本⾥⾯的“玖玖动⼒”星号*的使⽤还是⽤什么的源码⽂本,查找“玖玖动⼒”⽤这种⽅法匹配出来的结果是⼀样的。
后⾯的问号?和加号+的使⽤⽅法跟上⾯的都是⼀样,只是代表的次数不⼀样,⼤家注意看下就⾏,这⾥就不对这两个⼀⼀做演⽰了!下⾯简单的对连字符“-”做个演⽰:上⾯是匹配出1到9的数字.脱字符^和美元符$的使⽤^表⽰开头,如果在字符组头部,就表⽰排除字符。
js占位符正则表达式

js占位符正则表达式全文共四篇示例,供读者参考第一篇示例:在编程中,正则表达式是一种强大的工具,用于对文本进行模式匹配和搜索。
正则表达式由一些字符和特殊符号组成,描述了一个字符串的模式。
在JavaScript中,正则表达式也被广泛应用,可以用来对字符串进行检索、替换和判断等操作。
在正则表达式中,占位符是一种特殊的正则表达式,用来代表某种特定的字符或字符集。
在JavaScript中,占位符通常用来代表数字、字母、空格等常见的字符类型。
在JavaScript中,常见的占位符有以下几种:1. \d:匹配任意一个数字,相当于[0-9]。
2. \w:匹配任意一个字母、数字或下划线,相当于[a-zA-Z0-9_]。
3. \s:匹配任意一个空白字符,包括空格、制表符和换行符。
4. \b:匹配一个单词的边界。
除了上面这些基本的占位符,JavaScript还支持一些其他的占位符,可以用来匹配更复杂的模式。
可以使用^符号表示匹配字符串的开头,符号表示匹配字符串的结尾。
还可以使用.符号表示匹配任意一个字符,*表示匹配前面的字符0次或多次,+表示匹配前面的字符1次或多次,?表示匹配前面的字符0次或1次。
下面是一个简单的示例,演示如何使用占位符进行正则表达式匹配:```javascriptlet str = "Hello, my name is Alice. I am 25 years old.";let pattern = /\d+/; // 匹配一个或多个数字let result = str.match(pattern);console.log(result); // 输出:["25"]```在上面的示例中,我们定义了一个正则表达式模式\d+,用来匹配一个或多个数字。
然后通过match方法对字符串进行匹配,找到了字符串中的数字25。
除了匹配功能之外,正则表达式还可以用来替换字符串中的部分内容。
正则匹配所有文字的方法

正则匹配所有文字的方法全文共四篇示例,供读者参考第一篇示例:正则表达式是一种强大的文本匹配工具,能够帮助我们快速准确地查找符合特定模式的文字内容。
在日常的文本处理工作中,正则表达式的应用非常广泛,比如在文本编辑器、编程语言、搜索引擎等各种场景下都可以看到它的身影。
接下来,我们就来探讨一下如何使用正则表达式来匹配所有文字。
我们需要了解正则表达式中的一些基本概念。
在正则表达式中,可以使用一些特殊的符号来表示不同的匹配规则,比如"."代表匹配任意字符,"[]"代表匹配中括号内的任意一个字符,"*"代表匹配前面的字符0次或多次等等。
通过这些符号的组合和排列,我们就可以构建出一个复杂的正则表达式,用来匹配我们所需要的文字内容。
接下来,我们以一个简单的例子来说明如何使用正则表达式来匹配所有文字。
假设我们有一个包含一段文字的字符串,我们想要提取出其中的所有文字内容,不包括空格和换行符。
这时候,我们可以编写一个正则表达式来实现这个需求。
我们可以使用正则表达式"\S+"来匹配所有非空白字符的序列。
其中"\S"表示匹配任意非空白字符,"+"表示匹配前面的字符1次或多次。
通过这个正则表达式,我们可以很轻松地提取出字符串中的所有文字内容,而不受空格和换行符的干扰。
除了上面的例子,正则表达式还可以实现更复杂的匹配需求,比如匹配特定格式的日期、邮箱地址、网址等等。
只要我们了解了正则表达式的基本语法和规则,就可以根据需要自由组合和调整,来实现我们想要的文字匹配功能。
正则表达式是一种强大的工具,可以帮助我们快速准确地匹配文本内容。
通过灵活运用正则表达式,我们可以轻松地处理各种复杂的匹配需求,提高工作效率,节省时间和精力。
希望本文能够帮助大家更好地理解和应用正则表达式,在日常的文本处理工作中得心应手。
【本文总字数:417】第二篇示例:正则表达式是一种强大的文本模式匹配工具,可以用来匹配字符串中的特定模式,例如匹配所有文字。
正则表达式练习

正则表达式练习1. 分组提取/⾮捕获组分组,是正则⾥⼀个⾮常重要的概念,我们需要针对某个区域提取数据,往往需要依赖分组。
⽽分组,其实就是正则⾥()括住的部分。
(1.2)⾮捕获组针对上⾯的分组,有时候,我们并不需要捕获某个分组的内容,我们可以使⽤⾮捕获组(?:表达式),从⽽不捕获表达式部分内容到分组中。
2. 单字符或或条件是正则使⽤过程中常⽤的概念,⽐如,密码由字母或数字组成,这⾥就⽤到了或条件,⽽且,由于字母或数字都是单个字符,因此,可以使⽤[a-z0-9]这样的单字符或语法实现。
常犯错误:匹配a或b写成[a|b],此表达式实际上表⽰a或b或|,在[]内部的|表⽰其本⾝,注意区分(a|b)表⽰a或b的写法。
3. 多字符或相对单字符或条件,多字符或也是很常见的,⽐如,我们需要匹配http或ftp两个协议头的url,就需要^(http|ftp) /.+$这样的语法来实现。
(3)多字符或需求:匹配每⾏数据中以.jpg/.jpeg/.png/.gif结尾的图⽚名称(含后缀)源串:image.jpgimage.jpegimage.pngimage.gifnot_image.txtnot_image.docnot_image.xlsnot_image.ppt4. 分组引⽤前⾯介绍了分组,那某个分组在我们匹配过程中重复出现,⼜该如何处理?分组引⽤恰恰解决这个问题。
⽐如,匹配出现重复单词的⼀⾏数据,我们可以这么写(多⾏模式):/^.?(\b\S+\b).?\1.*$/m,\1表⽰引⽤前⾯分组1中匹配到的内容,也就是重复的单词内容。
5. 匹配换⾏数据“我的正则本来好好的,突然不⾏了!”这个是很多正则新⼈遇到的问题,⽽这个问题,很多时候,就是因为原来正则中的.不能匹配新数据⾥的换⾏导致的。
这时候,只需要把.改成[\s\S]这样的表达式就可以了。
这个表达式表⽰空格或⾮空格,也就是任意字符啦。
(5)匹配换⾏数据需求:分别使⽤单⾏模式和普通模式匹配id="author"的div中数据,div标签不在同⼀⾏源串:Zjmainstay预期:Zjmainstay 正则1:⾮换⾏模式 \n(\w+\b) 正则2:换⾏模式 ^(\w+\b) 题样:/r/DiScsG/16. 存在(或)(6.1)匹配多种或条件的数据,没有特殊限制需求:匹配每⾏中包含“作者”或者“读者”的数据源串:本⽂的作者是Zjmainstay本⽂有很多读者读者可以是任何⼀个地⽅的⼈这⾥的任何⼀个地⽅说明读者也能在国外什么乱七⼋糟的推理你不匹配我,凭什么要我推荐你的博客 预期:匹配本⽂的作者是Zjmainstay本⽂有很多读者读者可以是任何⼀个地⽅的⼈这⾥的任何⼀个地⽅说明读者也能在国外(6.2)匹配多种或条件的数据,有特殊限制(不使⽤环视)需求:匹配每⾏中“读者”在开头或结尾的数据源串:本⽂作者是Zjmainstay,有很多读者读者可以是任何⼀个地⽅的⼈这⾥的任何⼀个地⽅说明读者也能在国外预期:匹配本⽂作者是Zjmainstay,有很多读者读者可以是任何⼀个地⽅的⼈(6.3)匹配多种或条件的数据,有特殊限制(使⽤环视)需求:匹配每⾏中“读者”在开头或结尾的数据源串:本⽂作者是Zjmainstay,有很多读者读者可以是任何⼀个地⽅的⼈这⾥的任何⼀个地⽅说明读者也能在国外预期:匹配本⽂作者是Zjmainstay,有很多读者读者可以是任何⼀个地⽅的⼈7. 存在(与)(7.1)校验密码必须包含字母、数字和特殊字符,6-16位需求:校验密码必须包含字母、数字和特殊字符,6-16位,假定特殊字符为 -= 三个字符源串:12345123456123456123456123412345612345612345a1234a12345-1234-12345a-123a-1234a-1234a-1234a-12a-1234a-1234a-1234aaaaaaaaaaa-=-_-=-=预期:匹配a-1234a-1234a-1234a-128. 特殊限制(环视否定)(8.1)使⽤\d{1,3}匹配1-999的数据,不能以0开头需求:使⽤\d{1,3}匹配每⾏中1-999的数据,不能以0开头源串:110100999100001001预期:匹配110100999正则:(?=[0])(\d{1,3})题样:(8.2)匹配除了span标签外的所有标签需求:匹配除了内容标签外的所有内容格式标签源串:匹配我不匹配我匹配我匹配我预期:匹配匹配我匹配我匹配我正则:<(?!span).*(? 题样:/r/o70yEp/19. 替换分组使⽤(9.1)给源串每个链接加上前缀需求:给源串每个链接加上前缀源串:预期:替换得到查找:href="(?=/)/替换:href="题样:10. 分组可选(10.1)分组可选需求:判断如果单词以A开头,匹配Apple;如果单词以B开头,匹配Banana;否则匹配Empty源串:AngleAppleBananaBestEmpty预期:匹配AppleBananaEmpty正则:未想到答案题样:(10.2)分组可选与分组引⽤需求:匹配html标签的属性值,属性值可以由双引号、单引号、⽆单双引号定界源串:预期:分组匹配 I'm Zjmainstay author 2017 27 正则:=["']([\w\s']*)["'] 题样:/r/KGtpyr/111. 单字符拆分(数字)(11)匹配0.00-100.00的数值,可以有0-2位⼩数需求:匹配0.00-100.00的数值,可以有0-2位⼩数,不能以⼩数点结尾,不能以2个以上的0开头思路:(100|10-99|0-9) + 0-2⼩数位 + 排除⼩数点结尾、2个以上0开头的情况源串:10.00.009.0018.0027.036.0045.0054.0063.0072.0081.0090.0099.99100.0012.12. 贪婪模式贪婪模式,正则会优先尽可能多地匹配能匹配到的内容。
Autohotkey帮助

版本v1.1.08.01©2003-2010 Chris Mallett, portions©AutoIt Team and the AHK communitySoftware License: GNU General Public License警告:由于在AutoHotkey和AutoHotkey_L之间存在一些根本的不同。
为AutoHotkey编写的脚本在AutoHotkey_L中可能不会像预期的那样工作。
对于已知的兼容性问题和解决方案的细节,参考如下:●脚本兼容性:Unicode vs ANSI, DllCall, NumPut/Get, 其他变化。
●脚本代码文件:以UTF-8保存。
AutoHotkey,AutoHotkey_L和编译的脚本常常引发杀毒软件的误报。
更多的信息请查看FAQ 社区。
快速参考基本原理:●初学者教程●支持AutoHotkey的文本编辑器●常见问答●脚本◆命令◆变量和表达式◆函数◆对象◆交互程序调试键盘和鼠标:●热键(鼠标,遥感和键盘快捷键)●热字和自动取代●重新映射建和按钮●键,鼠标按钮和遥感控制列表其他:●DllCall●正则表达式快速参考●AutoHotkey_L特征感谢特别感谢Jonathan Bennett在1999年慷慨地将AutoIt v2作为免费软件放出使它成为我和世界上其他人的灵感和节省时间的工具。
另外,一些AutoIt v2控制台的AutoHotkey增强功能,像Window Spy和旧的脚本编译器,直接改编于AutoIt v3的源代码。
所以感谢Jon和其他AutoIt的作者。
最后,没有其他的这些个人AutoHotkey也不能成为今天的样子。
~Chris Mallett教程概述这份简介能帮助你马上开始撰写你自己的宏命令和热键。
创建一个脚本每一个脚本都是包含要被程序(AutoHotkey.exe)执行的命令的纯文本文件。
脚本也可能包含热键和热字,甚至完全由它们组成。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
“Error!”+“\u0007”中 的“\u0007”
“\b\b\b\b”中 的“\b\b\b\b”
“item1\titem2\t”中 的“item1\t”和“item2\t”
“\r\nTheseare\ntwo lines.”中的“\r\nThese”
匹配
“901” “901-” “-901-333”中的 “-333”
\A 匹配必须出现在字符串的开头。
\A\d{3}
“901” “901-”
\Z 匹配必须出现在字符串的末尾或出现在字符串末尾 的\n之前。
-\d{3}\Z
“-901-333”中的 “-333”
\z 匹配必须出现在字符串的末尾。
-\d{3}\z
\b
在字符类中,与退格键\u0008匹配。
\t
与制表符\u0009匹配。
\r
与回车符\u000D匹配。(\r与换行符\n不是等效的。)
\v
与垂直制表符\u000B匹配。
\f
与换页符\u000C匹配。
\n
与换行符\u000A匹配。
模式
匹配
\a [\b]{3,} (\w+)\t \r\n(\w+)
分组构造
说明
模式
匹配
( subexpression )
捕获匹配的子表达式并将其分配 到一个从1开始的序号中。
(\w)\1
“deep”中的“ee”
(?<name> subexpression )
将匹配的子表达式捕获到一个命 名组中。
(?
“deep”中的“ee”
<double>\w)\k<double>
(?<name1name2> subexpression )
定义平衡组定义。有关更多信 息,请参见正则表达式中的分组 构造中的“平衡组定义”部分。
(((?'Open'\()[^\(\)]*)+ ((?'Close-Open'\))[^\ (\)]*)+)*(?(Open)(?!))$
“3+2^((1-3)*(3-1))”中的“((13)*(3-1))”
(?: subexpression )
定义非捕获组。Biblioteka Write(?:Line)?
“Console.WriteLine()”中 的“WriteLine”
“Console.Write(value)”中 的“Write”
(?imnsximnsx:
subexpression )
应用或禁用subexpression中指 定的选项。有关详细信息,请参
阅正则表达式选项。
A\d{2}(?i:\w+)\b
“A12xlA12XLa12xl”中 的“A12xl”和“A12XL”
(?= subexpression )
零宽度正预测先行断言。
\w+(?=\.)
“Heis.Thedogran.Thesunis out.”中 的“is”、“ran”和“out”
字)字符之间的边界上。
的“themtheme”、“themthem”
\B 匹配不得出现在\b边界上。 返回页首
\Bend\w*\b
“endsendsendurelender”中 的“ends”和“ender”
分组构造
分组构造描述了正则表达式的子表达式,通常用于捕获输入字符串的子字符串。分组构造包括下表中列出的语言元素。有 关更多信息,请参见正则表达式中的分组构造。
{n
匹配上一个元素至少n次,但次数尽可 "\d{2,}?" “166”,“29”和“1930”
,}?
能少。
{n, 匹配上一个元素的次数介于n和m之 m}? 间,但次数尽可能少。
返回页首
"\d{3,5}?" “166”、“17668” “193024”中的“193”、“024”
反向引用构造
字符类
说明
模式
[
匹配character_group中的任何单个字 [ae]
character_group 符。默认情况下,匹配区分大小写。
]
[^ character_group ]
求反:与不在character_group中的任 何单个字符匹配。默认情况 下,character_group中的字符区分大 小写。
字符转义 字符类 定位点 分组构造 限定符 反向引用构造 替换构造 替换 正则表达式选项 其他构造
字符转义
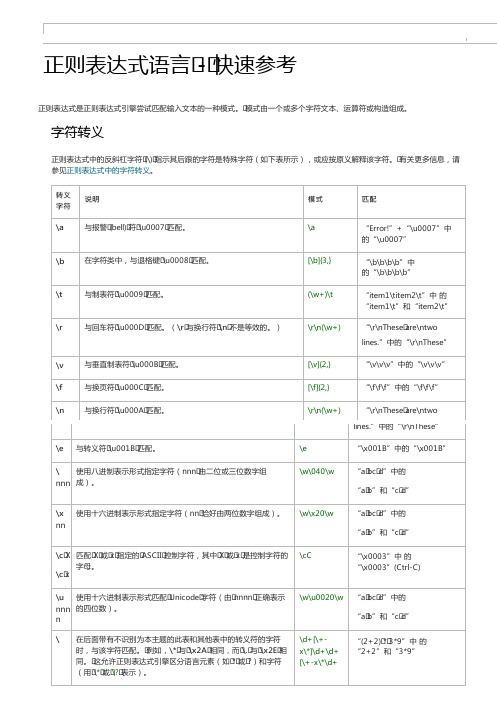
正则表达式中的反斜杠字符(\)指示其后跟的字符是特殊字符(如下表所示),或应按原义解释该字符。有关更多信息,请 参见正则表达式中的字符转义。
转义 字符
说明
\a
与报警(bell)符\u0007匹配。
模式 (\w)\1 (?<char>\w)\k<char>
匹配 “seek”中的“ee” “seek”中的“ee”
替换构造
替换构造用于修改正则表达式以启用either/or匹配。这些构造包括下表中列出的语言元素。有关更多信息,请参见正则表 达式中的备用构造。
替换构造 说明
模式
匹配
|
匹配以竖线(|)字符分隔的任何一个元素。
[^aei]
匹配 “gray”中的“a” “lane”中的“a”和“e” “reign”中的“r”、“g”和“n”
[first-last] .
\p{name} \P{name}
字符范围:与从first到last的范围中的 [A-Z] 任何单个字符匹配。
“AB123”中的“A”和“B”
限定符
限定符指定在输入字符串中必须存在上一个元素(可以是字符、组或字符类)的多少个实例才能出现匹配项。限定符包括下 表中列出的语言元素。有关更多信息,请参见正则表达式中的限定符。
限定 符
说明
模式
匹配
*
匹配上一个元素零次或多次。
\d*\.\d
“.0”,“19.9”和“219.9”
+
匹配上一个元素一次或多次。
”、“I”和“V”
定位点
定位点或原子零宽度断言会使匹配成功或失败,具体取决于字符串中的当前位置,但它们不会使引擎在字符串中前进或使用 字符。下表中列出的元字符是定位点。有关更多信息,请参见正则表达式中的定位点。
断 言
说明
^ 匹配必须从字符串或一行的开头开始。
模式 ^\d{3}
$ 匹配必须出现在字符串的末尾或出现在行或字符串 -\d{3}$ 末尾的\n之前。
反向引用允许在同一正则表达式中随后标识以前匹配的子表达式。下表列出了.NETFramework的正则表达式支持的反向 引用构造。有关更多信息,请参见正则表达式中的反向引用构造。
反向引用构造 说明
\number
后向引用。匹配编号子表达式的值。
\k<name> 返回页首
命名后向引用。匹配命名表达式的值。
"be+"
“been”中的“bee”,“bent”中的“be”
?
匹配上一个元素零次或一次。
"rai?n"
“ran”和“rain”
{n} 匹配上一个元素恰好n次。
",\d{3}"
“1,043.6”中的“,043”,“9,876,543,210”中 的“,876”、“,543”和“,210”
{n,} 匹配上一个元素至少n次。
+?
匹配上一个元素一次或多次,但次数尽可 "be+?"
“been”中的“be”,“bent”中的“be”
能少。
??
匹配上一个元素零次或一次,但次数尽可 "rai??n" “ran”和“rain”
能少。
{n}? 匹配前导元素恰好n次。
",\d{3}?"
“1,043.6”中的“,043”,“9,876,543,210”中 的“,876”、“,543”和“,210”
\p{IsCyrillic} “ДЖem”中的“Д”和“Ж”
与不在name指定的Unicode通用类别 \P{Lu} 或命名块中的任何单个字符匹配
“City”中的“i”、“t”和“y”
\w
\W \s \S \d \D 返回页首
或命名块中的任何单个字符匹配。
与任何单词字符匹配。
与任何非单词字符匹配。 与任何空白字符匹配。 与任何非空白字符匹配。 与任何十进制数字匹配。 匹配不是十进制数的任意字符。
(?! subexpression )
零宽度负预测先行断言。
\b(?!un)\w+\b
“unsuresureunityused”中 的“sure”和“used”
(?<= subexpression )
零宽度正回顾后发断言。
(?<=19)\d{2}\b
“1851199919501905 2003”中 的“99”、“50”和“05”
此文章由人工翻译。将光标移到文章的句子上,以查看原文。更多信息。
正则表达式语言-快速参考
.NET Framework 4.5
正则表达式是正则表达式引擎尝试匹配输入文本的一种模式。模式由一个或多个字符文本、运算符或构造组成。有关简单介 绍,请参见.NETFramework正则表达式。 此快速参考中的每一节都列出了可用于定义正则表达式的字符、运算符和构造的一种特定类别。
(?<! subexpression )
零宽度负回顾后发断言。
(?<!19)\d{2}\b
“1851199919501905 2003”中的“51”和“03”