实验三.哈夫曼编码的贪心算法设计
贪心算法构造哈夫曼树

软件02 1311611006 张松彬利用贪心算法构造哈夫曼树及输出对应的哈夫曼编码问题简述:两路合并最佳模式的贪心算法主要思想如下:(1)设w={w0,w1,......wn-1}是一组权值,以每个权值作为根结点值,构造n棵只有根的二叉树(2)选择两根结点权值最小的树,作为左右子树构造一棵新二叉树,新树根的权值是两棵子树根权值之和(3)重复(2),直到合并成一颗二叉树为一、实验目的(1)了解贪心算法和哈夫曼树的定义(2)掌握贪心法的设计思想并能熟练运用(3)设计贪心算法求解哈夫曼树(4)设计测试数据,写出程序文档二、实验内容(1)设计二叉树结点数据结构,编程实现对用户输入的一组权值构造哈夫曼树(2)设计函数,先序遍历输出哈夫曼树各结点3)设计函数,按树形输出哈夫曼树代码:#include <stdio.h>#include <string.h>#include <time.h>#include <stdlib.h>typedef struct Node{ //定义树结构int data;struct Node *leftchild;struct Node *rightchild;}Tree;typedef struct Data{ //定义字符及其对应的频率的结构int data;//字符对应的频率是随机产生的char c;};void Initiate(Tree **root);//初始化节点函数int getMin(struct Data a[],int n);//得到a中数值(频率)最小的数void toLength(char s[],int k);//设置有k个空格的串svoid set(struct Data a[],struct Data b[]);//初始化a,且将a备份至bchar getC(int x,struct Data a[]);//得到a中频率为x对应的字符void prin(struct Data a[]);//输出初始化后的字符及对应的频率int n;void main(){//srand((unsigned)time(NULL));Tree *root=NULL,*left=NULL,*right=NULL,*p=NULL; int min,num;int k=30,j,m;struct Data a[100];struct Data b[100];int i;char s[100]={'\0'},s1[100]={'\0'};char c;set(a,b);prin(a);Initiate(&root);Initiate(&left);Initiate(&right);Initiate(&p);//设置最底层的左节点min=getMin(a,n);left->data=min;left->leftchild=NULL;left->rightchild=NULL;//设置最底层的右节点min=getMin(a,n-1);right->data=min;right->leftchild=NULL;right->rightchild=NULL;root->data=left->data+right->data;Initiate(&root->leftchild);Initiate(&root->rightchild);//将设置好的左右节点插入到root中root->leftchild=left;root->rightchild=right;for(i=0;i<n-2;i++){min=getMin(a,n-2-i);Initiate(&left);Initiate(&right);if(min<root->data)//权值小的作为左节点{left->data=min;left->leftchild=NULL;left->rightchild=NULL;p->data=min+root->data;Initiate(&p->leftchild);Initiate(&p->rightchild);p->leftchild=left;p->rightchild=root;root=p;}else{right->data=min;right->leftchild=NULL;right->rightchild=NULL;p->data=min+root->data;Initiate(&p->leftchild);Initiate(&p->rightchild);p->leftchild=root;p->rightchild=right;root=p;}Initiate(&p);}num=n-1;p=root;printf("哈夫曼树如下图:\n");while(num){if(num==n-1){for(j=0;j<k-3;j++)printf(" ");printf("%d\n",root->data);}for(j=0;j<k-4;j++)printf(" ");printf("/ \\\n");for(j=0;j<k-5;j++)printf(" ");printf("%d",root->leftchild->data);printf(" %d\n",root->rightchild->data);if(root->leftchild->leftchild!=NULL){root=root->leftchild;k=k-2;}else{root=root->rightchild;k=k+3;}num--;}num=n-1;Initiate(&root);root=p;printf("各字符对应的编码如下:\n");while(num){if(root->leftchild->leftchild==NULL){strcpy(s1,s);m=root->leftchild->data;c=getC(m,b);printf("%c 【%d】:%s\n",c,m,strcat(s1,"0"));}if(root->rightchild->leftchild==NULL){strcpy(s1,s);m=root->rightchild->data;c=getC(m,b);printf("%c 【%d】:%s\n",c,m,strcat(s1,"1"));}if(root->leftchild->leftchild!=NULL){strcat(s,"0");root=root->leftchild;}if(root->rightchild->leftchild!=NULL){strcat(s,"1");root=root->rightchild;}num--;}}int getMin(struct Data a[],int n){int i,t;for(i=1;i<n;i++){if(a[i].data<a[0].data){t=a[i].data;a[i].data=a[0].data;a[0].data=t;}}t=a[0].data;for(i=0;i<n-1;i++){a[i]=a[i+1];}return t;}void toLength(char s[],int k){int i=0;for(;i<k;i++)strcat(s," ");}void Initiate(Tree **root){*root=(Tree *)malloc(sizeof(Tree));(*root)->leftchild=NULL;(*root)->rightchild=NULL;}void set(struct Data a[],struct Data b[]) {int i;srand((unsigned)time(NULL));n=rand()%10+2;for(i=0;i<n;i++){a[i].data=rand()%100+1;a[i].c=i+97;b[i].data=a[i].data;b[i].c=a[i].c;if(i>=0&&a[i].data==a[i-1].data)i--;}}char getC(int x,struct Data b[]){int i;for(i=0;i<n;i++){if(b[i].data==x){break;}}return b[i].c;}void prin(struct Data a[]){int i;printf("字符\t出现的频率\n");for(i=0;i<n;i++){printf("%c\t %d\n",a[i].c,a[i].data);}}。
实验三-贪心算法

for(inti=0;i<s.length();i++){
buf.append(getEachCode(s.substring(i,i+1)));
}
returnbuf.toString();
}
publicString getEachCode(String name){
for(inti=0;i<buffer.length();i++){
if(name.equals(codes[i].name)){
returnhuffstring[i];
}
}
return"";
}
publicvoidgetCode(intn,String[] thecodes,String thebuffer){
importjava.util.Scanner;
classHuffmanCode{
Stringname;
doubleweight;
intlc,rc,pa;
publicHuffmanCode(){
name="";
weight=0;
lc=-1;rc=-1;pa=-1;
}
}
publicclassHuffman1 {
dist[j]=newdist;prev[j]=u;}}}}
(3)运行结果
3、题目三
(1)问题分析
设G=(V,E)是连通带权图,V={1,2,…,n}。构造G的最小生成树的Prim算法的基本思想是:首先置S{1},然后,只要S是V的真子集,就进行如下的贪心选择:选取满足条件i∈S,j∈V-S,且c[i][j]最小的边,将顶点j添加到S中。这个过程一直进行到S=V时为止。过程中所取到的边恰好构成G的一棵最小生成树。
L15-哈夫曼编码-贪心算法

Lecture15:Huffman CodingCLRS-16.3Outline of this LectureCodes and Compression.Huffman coding.Correctness of the Huffman coding algorithm.1Suppose that we have a character datafile that we wish to store.Thefile contains only6char-acters,appearing with the following frequencies:Frequency in’000sA binary code encodes each character as a binary string or codeword.We would like tofind a binary code that encodes thefile using as few bits as possi-ble,ie.,compresses it as much as possible.2In afixed-length code each codeword has the same length.In a variable-length code codewords may have different lengths.Here are examples offixed and vari-able legth codes for our problem(note that afixed-length code must have at least3bits per codeword).Freq in’000safixed-lengtha variable-lengthThefixed length-code requires bits to store thefile.The variable-length code uses onlybits, saving a lot of space!Can we do better?Note:In what follows a code will be a set of codewords,e.g., and3EncodingGiven a code(corresponding to some alphabet)and a message it is easy to encode the message.Just replace the characters by the codewords.Example:If the code isthen bad is encoded into010011If the code isthen bad is encoded into11001114DecodingGiven an encoded message,decoding is the process of turning it back into the original message.A message is uniquely decodable(vis-a-vis a particu-lar code)if it can only be decoded in one way.For example relative to010011is uniquely de-codable to bad.Relative to1100111is uniquely decodable to bad. But,relative to1101111is not uniquely decipher-able since it could have encoded either bad or acad. In fact,one can show that every message encoded using and are uniquely decipherable.The unique decipherability property is needed in order for a code to be useful.5Prefix-CodesFixed-length codes are always uniquely decipherable (why).We saw before that these do not always give the best compression so we prefer to use variable length codes.Prefix Code:A code is called a prefix(free)code if no codeword is a prefix of another one.Example:is a prefix code.Important Fact:Every message encoded by a prefix free code is uniquely decipherable.Since no code-word is a prefix of any other we can alwaysfind the first codeword in a message,peel it off,and continue decoding.Example:We are therefore interested infinding good(best com-pression)prefix-free codes.6Fixed-Length versus Variable-Length CodesProblem:Suppose we want to store messages made up of4characters with frequencies,,, (percents)respectively.What are thefixed-length codes and prefix-free codes that use the least space?7Fixed-Length versus Variable-Length Prefix CodesSolution:charactersfrequencyfixed-length codeprefix codeT o store100of these characters,(1)thefixed-length code requires bits,(2)the prefix code uses onlya saving.Remark:We will see later that this is the optimum (lowest cost)prefix code.8Optimum Source Coding ProblemThe problem:Given an alphabetwith frequency distributionfind a binary prefix code for that minimizes the number of bitsneeded to encode a message of charac-ters,where is the codeword for encoding,and is the length of the codeword.Remark:Huffman developed a nice greedy algorithm for solving this problem and producing a minimum-cost(optimum)prefix code.The code that it produces is called a Huffman code.9101011n2/35n1/20n4/100n3/550c/5e/45d/15b/15a/20Correspondence between Binary T rees and prefix codes.1-1correspondence between leaves and bel of leaf is frequency of character.Left edge is labeled ;right edge is labeled 1Path from root to leaf is codeword associated with character.1010111n2/35n1/20n4/100n3/550c/5e/45d/15b/15a/20Note that ,the depth of leaf in tree isequal to the length,of the codeword in code associated with thatleaf.So,The sumis the weighted externalpathlength of tree.The Huffman encoding problem is equivalent to the minimum-weight external pathlength problem:given weights ,find tree with leaves labeled that has minimum weighted exter-nal path length.11Huffman CodingStep1:Pick two letters from alphabet with the smallest frequencies and create a subtree that has these two characters as leaves.(greedy idea) Label the root of this subtree as.Step2:Set frequency. Remove and add creating new alphabet.Note that.Repeat this procedure,called merge,with new alpha-bet until an alphabet with only one symbol is left.The resulting tree is the Huffman code.12Example of Huffman CodingLet be the alphabet and its frequency distribution.In thefirst step Huffman coding merges and.1a/20c/5d/15e/45b/15n1/20Alphabet is now.13Example of Huffman Coding–ContinuedAlphabet is now. Algorithm merges and(could also have merged and).e/45 n2/35n1/2011a/20 c/5d/15b/15New alphabet is.14Example of Huffman Coding –Continued Alphabet is.Algorithm mergesand.n2/35n1/20551110e/45a/20 d/15c/5b/15New alphabet is.15Example of Huffman Coding –Continued Current alphabet is.Algorithm merges andand finishes.10111n2/35n1/20n4/100n3/550c/5e/45d/15b/15a/2016Example of Huffman Coding –Continued Huffman code is obtained from the Huffman tree.10111n2/35n1/20n4/100n3/550c/5e/45d/15b/15a/20Huffman code is,,,,.This is the optimum (minimum-cost)prefix code for this distribution.17Huffman Coding AlgorithmGiven an alphabet with frequency distribution.The binary Huffman tree is constructed using a priority queue,,of nodes,with labels(frequencies) as keys.Huffman();;the future leavesfor to Why?new node;Extract-Min();Extract-Min();;Insert();return Extract-Min()root of the treeRunning time is,as each priority queue operation takes time.18An Observation:Full TreesLemma:The tree for any optimal prefix code must be“full”,meaning that every internal node has exactly two children.Proof:If some internal node had only one child then we could simply get rid of this node and replace it with its unique child.This would decrease the total cost of the encoding.19Huffman Codes are OptimalLemma:Consider the two letters,and with the smallest fre-quencies.There is an optimal code tree in which these two let-ters are sibling leaves in the tree in the lowest level.Proof:Let be an optimum prefix code tree,and let and be two siblings at the maximum depth of the tree(must exist because is full).Assume without loss of generality that and(if this is not true,then rename these characters).Since and have the two smallest frequencies it follows that(they may be equal)and(may be equal).Because and are at the deepest level of the tree we know that and.Now switch the positions of and in the tree resulting in a differ-ent tree and see how the cost changes.Since is optimum,Therefore,,that is,is an optimum tree.By switching with we get a new tree which by a similar argu-ment is optimum.Thefinal tree satisfies the statement of the claim.20Huffman Codes are OptimalWe have just shown there is an optimum tree agrees with ourfirst greedy choice,i.e.,and are siblings, and are in the lowest level.Similarly to the proof we seen early for the fractional knapsack problem,we still need to show the optimal substructure property of Huffman coding problem.Lemma:Let be a full binary tree representing an optimal prefix code over an alphabet,where fre-quency is defined for each character.Con-sider any two characters and that appear as sib-ling leaves in,and let be their parent.Then, considering as a character with frequency,the tree represents an optimal prefix code for the alphabet.21Huffman Codes are OptimalProof:An exercise.(Hint:First write down the cost relation between,and.We then show is an op-timal prefix code tree for by contradiction(by mak-ing use of the assumption that is an optimal tree for .))By combining the results of the lemma,it follows that the Huffman codes are optimal.22。
哈夫曼编码贪心算法时间复杂度

哈夫曼编码贪心算法时间复杂度
哈夫曼编码的贪心算法时间复杂度为O(nlogn),其中n为待编
码的字符数量。
算法的主要步骤包括构建哈夫曼树和生成编码表两部分。
构建哈夫曼树的时间复杂度为O(nlogn),其中n为待编码的字
符数量。
构建哈夫曼树的过程涉及到对字符频次列表进行排序,并不断合并频次最小的两个节点,直至只剩下一个节点作为根节点。
排序的时间复杂度为O(nlogn),每次合并两个节点的时间复杂度为O(logn)。
因此,构建哈夫曼树的总时间复杂度为
O(nlogn)。
生成编码表的时间复杂度同样为O(nlogn),其中n为待编码的字符数量。
生成编码表的过程是遍历哈夫曼树的每个节点,并记录下每个字符所对应的编码。
由于哈夫曼树的每个叶子节点代表一个字符,因此遍历哈夫曼树的时间复杂度为O(n),并
且遍历过程的时间复杂度与树的高度相关,由于哈夫曼树是一个二叉树,因此树的高度为O(logn)。
因此,生成编码表的总
时间复杂度为O(nlogn)。
综上所述,哈夫曼编码的贪心算法的时间复杂度为O(nlogn)。
哈弗曼树编码实验报告
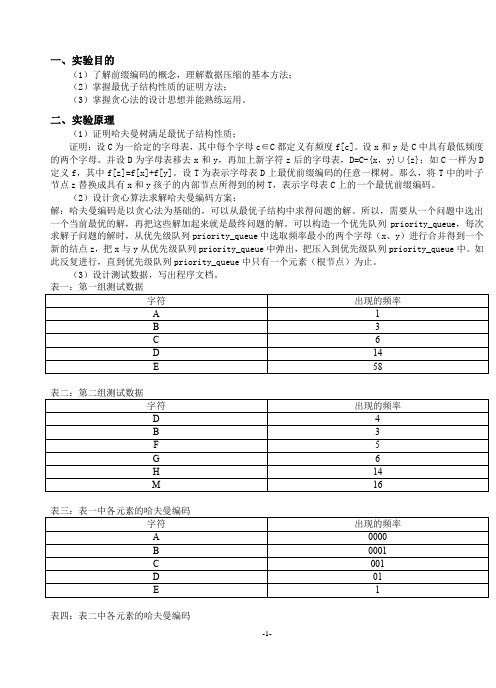
一、实验目的(1)了解前缀编码的概念,理解数据压缩的基本方法;(2)掌握最优子结构性质的证明方法;(3)掌握贪心法的设计思想并能熟练运用。
二、实验原理(1)证明哈夫曼树满足最优子结构性质;证明:设C为一给定的字母表,其中每个字母c∈C都定义有频度f[c]。
设x和y是C中具有最低频度的两个字母。
并设D为字母表移去x和y,再加上新字符z后的字母表,D=C-{x,y}∪{z};如C一样为D 定义f,其中f[z]=f[x]+f[y]。
设T为表示字母表D上最优前缀编码的任意一棵树。
那么,将T中的叶子节点z替换成具有x和y孩子的内部节点所得到的树T,表示字母表C上的一个最优前缀编码。
(2)设计贪心算法求解哈夫曼编码方案;解:哈夫曼编码是以贪心法为基础的,可以从最优子结构中求得问题的解。
所以,需要从一个问题中选出一个当前最优的解,再把这些解加起来就是最终问题的解。
可以构造一个优先队列priority_queue,每次求解子问题的解时,从优先级队列priority_queue中选取频率最小的两个字母(x、y)进行合并得到一个新的结点z,把x与y从优先级队列priority_queue中弹出,把压入到优先级队列priority_queue中。
如此反复进行,直到优先级队列priority_queue中只有一个元素(根节点)为止。
(3)设计测试数据,写出程序文档。
表四:表二中各元素的哈夫曼编码三、实验设备1台PC及VISUAL C++6.0软件四、代码#include <iostream>#include <queue>#include <vector>#include <iomanip>#include <string>#include<cctype>using namespace std;structcodeInformation{double priority;charcodeName;intlchild,rchild,parent;bool test;bool operator < (constcodeInformation& x) const {return !(priority<x.priority);} };bool check(vector<codeInformation>qa,const char c){for (int i=0 ;i<(int)(qa.size());i++){if(qa[i].codeName==c) return true;} return false;}voidaline(char c,int n){for (int i=0;i<n;i++)cout<<c;}intInputElement(vector<codeInformation>* Harffcode,priority_queue<codeInformation>* pq) {int i=1,j=1;codeInformation wk;while(i){aline('-',80);cout<<"请输入第"<<j<<"个元素的字符名称(Ascll码):"<<flush;cin>>wk.codeName;while(check(* Harffcode,wk.codeName)){cout<<"字符已存在,请输入一个其他的字符:";cin>>wk.codeName;}cout<<"请输入第"<<j<<"个元素的概率(权值):"<<flush;cin>>wk.priority;wk.lchild=wk.rchild=wk.parent=-1;wk.test=false;Harffcode->push_back(wk);pq->push(wk);j++;cout<<"1…………继续输入下一个元素信息!"<<endl;cout<<"2…………已完成输入,并开始构造哈夫曼树!"<<endl;cin>>i;if (i==2) i=0;}int count=1;j=Harffcode->size();int selectElement(vector<codeInformation>*,priority_queue<codeInformation>*);for (int k=j;k<2*j-1;k++){aline('*',80);cout<<"第"<<count<<"次合并:"<<endl;int i1=selectElement(Harffcode,pq);int i2=selectElement(Harffcode,pq);(*Harffcode)[i1].parent=(*Harffcode)[i2].parent=k;wk.lchild=wk.rchild=wk.parent=-1;wk.codeName='#';(*Harffcode).push_back(wk);wk.priority=(*Harffcode)[k].priority=(*Harffcode)[i1].priority+(*Harffcode)[i2].priority;(*Harffcode)[k].lchild=i1;(*Harffcode)[k].rchild=i2;wk.test=false;pq->push(wk); c ount++;cout<<"所合成的节点名称:#(虚节点)\t"<<"概率(权值):"<<(*Harffcode)[k].priority<<endl;}aline('*',80);return j;}voidshowChar(const char c){if(isspace(c))cout<<"#";cout<<c;}int selectElement(vector<codeInformation>*Harffcode,priority_queue<codeInformation>*qurgh){for (int i=0;i<(int)(*Harffcode).size();i++){if (((*Harffcode)[i].priority==(*qurgh).top().priority)&&((*Harffcode)[i].test==false)){cout<<"所选择的节点的信息:"<<"频率(权值):"<<setw(5)<<(*qurgh).top().priority<<"\t 名为:";showChar((*qurgh).top().codeName);cout<<endl;(*qurgh).pop();(*Harffcode)[i].test=true;return i;}}}voidhuffmanCode(vector<codeInformation>Harffcode,int n){for (int i1=0;i1<(int)Harffcode.size();i1++){cout<<"array["<<i1<<"]的概率(权值):"<<Harffcode[i1].priority<<"\t"<<"名为:";showChar(Harffcode[i1].codeName);cout<<"\t父节点的数组下标索引值:"<<Harffcode[i1].parent<<endl;}aline('&',80);for (int i=0;i<n;i++){string s=" "; int j=i;while(Harffcode[j].parent>=0){if (Harffcode[Harffcode[j].parent].lchild==j) s=s+"0";else s=s+"1";j=Harffcode[j].parent;}cout<<"\n概率(权值)为:"<<setw(8)<<Harffcode[i].priority<<" 名为:";showChar(Harffcode[i].codeName);cout<<"的符号的编码是:";for (int i=s.length();i>0;i--)cout<<s[i-1];}}voidchoise(){cout<<endl;aline('+',80);cout<<"\n1……………………继续使用该程序"<<endl;cout<<"2……………………退出系统"<<endl;}void welcome(){cout<<"\n"<<setw(56)<<"欢迎使用哈夫曼编码简易系统\n"<<endl;}int main(){welcome();system("color d1");int i=1,n;vector<codeInformation>huffTree; priority_queue<codeInformation>qpTree;while(i!=2){n=InputElement(&huffTree,&qpTree);huffmanCode(huffTree, n);choise();cin>>i;huffTree.clear();while(qpTree.empty()) qpTree.pop();}return 0;}五、实验过程原始记录( 测试数据、图表、计算等)程序测试结果及分析:图(2)输入第一组测试数据开始输入第一组测试数据,该组数据信息如表一所示。
哈夫曼编码贪心算法

哈夫曼编码贪心算法
一、哈夫曼编码
哈夫曼编码(Huffman Coding)是一种著名的数据压缩算法,也称作霍夫曼编码,由美国信息论家杰弗里·哈夫曼在1952年提出[1]。
哈夫曼编码可以有效地将资料压缩至最小,它的原理是将资料中出现频率最高的字元编码为最短的码字,而出现频率低的字元编码为较长的码字,从而显著提高了信息的保密性和容量。
二、贪心算法
贪心算法(Greedy Algorithm)是一种计算机算法,它试图找到一种满足条件的最佳解决方案,通常每一步都是做出在当前状态下最佳的选择,而不考虑将来可能发生的结果。
哈夫曼编码贪心算法是利用贪心算法来实现哈夫曼编码的。
该算法的步骤如下:
1. 首先统计出每一个字符出现的次数,并以此建立森林。
森林
中的每一棵树都用一个节点表示,每个节点的数值为字符出现的次数。
2. 从森林中挑选出两个出现次数最少的字符,将它们作为左右
子树合成一颗新的树,新树的根节点的数值为两个孩子节点的和。
3. 将新树加入森林中,并删除左右子树对应的原节点。
4. 重复上述步骤,直到森林中只剩一颗树,这颗树就是哈夫曼树。
5. 从哈夫曼树根节点出发,逐层往下搜索,左子节点编码为“0”,右子节点编码为“1”,最终得到每个字符的哈夫曼编码。
贪心算法实现Huffman编码

算法分析与设计实验报告第次实验附录:完整代码#include <iostream>#include <string>#include<stdio.h>#include <time.h>#include <iomanip>#include <vector>#include<algorithm>using namespace std;class Huffman{public:char elementChar;//节点元素int weight;//权重char s;//哈夫曼编码Huffman* parent;//父节点Huffman* leftChild;//左孩子Huffman* rightChild;//右孩子public:Huffman();Huffman(char a, int weight);bool operator < (const Huffman &m)const { return weight < m.weight;} };Huffman::Huffman(){this->s = ' ';this->elementChar = '*';//非叶子节点this->parent = this->leftChild = this->rightChild = NULL;}Huffman::Huffman(char a, int weight):elementChar(a),weight(weight) {this->s = ' ';this->elementChar = '*';//非叶子节点this->parent = this->leftChild = this->rightChild = NULL;}//递归输出哈夫曼值void huffmanCode(Huffman & h){if(h.leftChild == NULL && h.rightChild == NULL){//如果是叶子节点,输出器哈夫曼编码string s;Huffman temp = h;while(temp.parent != NULL){s = temp.s + s;temp = *temp.parent;}cout << h.elementChar << "的哈夫曼编码是:" << s << endl; return;}//左孩子huffmanCode(*h.leftChild);//右孩子huffmanCode(*h.rightChild);}int main(){int l,p=0;double q=0.0;clock_t start,end,over;start=clock();end=clock();over=end-start;start=clock();string huffmanStr;cout << "请输入一串字符序列:" << endl;cin >> huffmanStr;//得到字符串信息int i=0,j,n,m[100],h,k=0;char cha[100];n = huffmanStr.length();cout << "字符串总共有字符" << n << "个" << endl;for(int i = 0; i < n; i++){j = 0; h = 0;while(huffmanStr[i] != huffmanStr[j])j++;if(j == i){cha[k] = huffmanStr[i];cout << "字符" << cha[k] << "出现";}//如果j !=i 则略过此次循环elsecontinue;for(j = i; j < n; j++){if(huffmanStr[i] == huffmanStr[j])h++;}cout << h << "次" << endl;m[k] = h;k++;}//哈夫曼编码Huffman huffmanTemp;vector < Huffman > huffmanQueue;//初始化队列for(int i = 0; i < k; i++){huffmanTemp.elementChar = cha[i];huffmanTemp.weight = m[i];huffmanQueue.push_back(huffmanTemp);}//得到哈夫曼树所有节点int huffmanQueue_index = 0;sort(huffmanQueue.begin(), huffmanQueue.end());while(huffmanQueue.size() < 2 * k - 1){//合成最小两个节点的父节点huffmanTemp.weight = huffmanQueue[huffmanQueue_index].weight + huffmanQueue[huffmanQueue_index + 1].weight;huffmanQueue[huffmanQueue_index].s = '0';huffmanQueue[huffmanQueue_index + 1].s = '1';huffmanTemp.elementChar = '*';//将父节点加入队列huffmanQueue.push_back(huffmanTemp);sort(huffmanQueue.begin(), huffmanQueue.end());huffmanQueue_index += 2;}//把所有节点构造成哈夫曼树int step = 0;//步长while(step + 2 < 2 * k){for(int j = step + 1; j <= huffmanQueue.size(); j++){if(huffmanQueue[j].elementChar == '*' && huffmanQueue[j].leftChild == NULL && (huffmanQueue[j].weight == huffmanQueue[step].weight + huffmanQueue[step+1].weight)){huffmanQueue[j].leftChild = &huffmanQueue[step];huffmanQueue[j].rightChild = &huffmanQueue[step+1];huffmanQueue[step].parent = huffmanQueue[step+1].parent = &huffmanQueue[j]; break;}}step += 2;}//序列最后一个元素,即哈弗曼树最顶端的节点huffmanTemp = huffmanQueue.back();huffmanCode(huffmanTemp);for(l=0;l<1000000000;l++)p=p+l;end=clock();printf("The time is %6.3f",(double)(end-start-over)/CLK_TCK);return 0;}。
哈夫曼编码的贪心算法时间复杂度

哈夫曼编码的贪心算法时间复杂度哈夫曼编码的贪心算法时间复杂度在信息技术领域中,哈夫曼编码是一种被广泛应用的数据压缩技术,它利用了贪心算法的思想来设计。
贪心算法是一种在每一步都选择当前状态下最优解的方法,从而希望通过一系列局部最优解达到全局最优解。
在哈夫曼编码中,这个想法被巧妙地运用,从而有效地实现了数据的高效压缩和解压缩。
哈夫曼编码是由大名鼎鼎的大卫·哈夫曼(David A. Huffman)在1952年提出的,它通过将频率最高的字符赋予最短的编码,最低的字符赋予最长的编码,从而实现了对数据的高效压缩。
这种编码技术在通信领域、存储领域和计算机科学领域都有着广泛的应用,是一种非常重要的数据处理技术。
在哈夫曼编码的实现过程中,贪心算法的时间复杂度是非常重要的。
时间复杂度是用来衡量算法所需时间的数量级,通常使用大O记号(O(n))来表示。
对于哈夫曼编码的贪心算法来说,其时间复杂度主要取决于以下几个步骤:1. 需要对数据进行统计,以获取每个字符出现的频率。
这个步骤的时间复杂度是O(n),其中n表示字符的数量。
在实际应用中,这个步骤通常由哈希表或统计排序来实现,因此时间复杂度可以控制在O(n)的数量级。
2. 接下来,需要构建哈夫曼树。
哈夫曼树是一种特殊的二叉树,它的构建过程需要将频率最低的两个节点合并成一个新的节点,然后再对新节点进行排序。
这个过程会持续n-1次,直到所有节点都被合并到一棵树中。
构建哈夫曼树的时间复杂度是O(nlogn),其中n表示字符的数量。
3. 根据哈夫曼树生成每个字符的编码。
这个过程涉及到对哈夫曼树进行遍历,并记录下每个字符对应的编码。
由于哈夫曼树的特性,每个字符的编码可以通过从根节点到叶子节点的路径来得到。
这个步骤的时间复杂度是O(n),因为对于每个字符都需要进行一次遍历。
哈夫曼编码的贪心算法时间复杂度主要由构建哈夫曼树的步骤决定,为O(nlogn)。
这意味着在实际应用中,哈夫曼编码的运行时间随着字符数量的增加而增加,并且增长速度为nlogn的数量级。
贪心算法程序设计

贪心算法程序设计贪心算法程序设计1. 什么是贪心算法贪心算法(Greedy Algorithm)是一种常见的算法思想,它在每一步选择中都采取当前状态下的最优选择,从而希望最终达到全局最优解。
贪心算法的核心思想是局部最优解能导致全局最优解。
2. 贪心算法的基本步骤贪心算法的基本步骤如下:1. 定义问题的优化目标。
2. 将问题分解成子问题。
3. 选择当前最优的子问题解,将子问题的解合并成原问题的解。
4. 检查是否达到了问题的优化目标,如果没有达到,则回到第二步,继续寻找下一个最优子问题解。
5. 在所有子问题解合并成原问题解后,得到问题的最优解。
3. 贪心算法的应用场景贪心算法的应用非常广泛,几乎可以用于解决各种优化问题。
以下几个常见的应用场景:1. 零钱找零问题:给定一定面额的纸币和硬币,如何找零使得所需纸币和硬币的数量最小?2. 区间调度问题:给定一些活动的开始时间和结束时间,如何安排活动使得可以办理的活动数量最大?3. 背包问题:给定一些具有重量和价值的物品,如何选择物品使得背包的总价值最大?4. 最小树问题:给定一个带权无向图,如何找到一棵树,使得它的边权之和最小?5. 哈夫曼编码问题:给定一组字符和相应的频率,如何构造一个满足最低编码长度限制的二进制编码?4. 贪心算法的优缺点贪心算法的优点是简单、高效,可以快速得到一个近似最优解。
而且对于一些问题,贪心算法能够得到全局最优解。
贪心算法的缺点在于它不一定能够得到全局最优解,因为在每一步只考虑局部最优解,无法回溯到之前的选择。
5. 贪心算法的程序设计在使用贪心算法进行程序设计时,通常需要以下几个步骤:1. 定义问题的优化目标。
2. 将问题分解成子问题,并设计子问题的解决方案。
3. 设计贪心选择策略,选择局部最优解。
4. 设计贪心算法的递推或迭代公式。
5. 判断贪心算法是否能够得到全局最优解。
6. 编写程序实现贪心算法。
6.贪心算法是一种常见的算法思想,它在每一步选择中都采取当前状态下的最优选择,从而希望最终达到全局最优解。
算法分析与设计实验二贪心算法

算法分析与设计实验二贪心算法贪心算法是一种基于贪心策略的求解问题的方法,该方法在每一步都采取最优的选择,从而最终得到全局最优解。
本实验将介绍贪心算法的概念、特点以及实际应用。
1.贪心算法的概念和特点贪心算法是一种求解问题的策略,它在每一步都做出局部最优选择,以期望最终得到全局最优解。
它不考虑每一步选择的长远影响,而只关注眼前能得到的最大利益。
贪心算法有以下特点:1.1.子问题的最优解能够推导父问题的最优解:贪心算法解决的问题具有最优子结构,即问题的最优解包含其子问题的最优解。
1.2.贪心选择性质:通过选择当前最优解,可以得到局部最优解。
1.3.无后效性:当前选择的最优解不会对以后的选择产生影响。
2.实际应用2.1.背包问题背包问题是一个经典的优化问题,贪心算法可以用于解决背包问题的一种情况,分数背包问题。
在分数背包问题中,物品可以被分割成任意大小,而不仅仅是0和1两种状态,因此可以通过贪心算法求解。
2.2.最小生成树问题最小生成树问题是求解连通带权图的一种最优生成树的问题。
其中,普里姆算法和克鲁斯卡尔算法就是贪心算法的典型应用。
2.3.哈夫曼编码哈夫曼编码是一种用于对信息进行无损压缩的方法,它可以将出现频率较高的字符用较短的二进制编码表示。
贪心算法可以在构建哈夫曼树的过程中选择出现频率最低的两个字符进行合并。
3.贪心算法的设计步骤3.1.理解问题并找到最优解的子结构。
3.2.根据问题特点设计贪心策略。
3.3.利用贪心策略进行求解,并逐步推导得到全局最优解。
3.4.对求得的解进行检验,确保其满足问题的要求。
4.贪心算法的优缺点4.1.优点:贪心算法简单直观,易于实现和理解;对于一些问题,贪心算法可以得到全局最优解。
4.2.缺点:贪心算法无法保证得到问题的全局最优解;贪心策略的选择可能不唯一综上所述,贪心算法是一种基于贪心策略的求解问题的方法,通过每一步的局部最优选择,期望得到全局最优解。
贪心算法具有明显的优点和缺点,在实际应用中可以有效地解决一些问题。
贪心算法设计与应用

实验报告课程算法设计与分析实验实验名称贪心算法设计与应用第 1 页一、实验目的理解贪心算法的基本原理,掌握贪心算法设计的基本方法及其应用;二、实验内容(一)Huffman编码和译码问题:1.问题描述给定n个字符在文件中的出现频率,利用Huffman树进行Huffman编码和译码。
设计一个程序实现:1.输入含n(n<=10)个字符的字符集S以及S中各个字符在文件中的出现频率,建立相应的Huffman树,求出S中各个字符的Huffman编码。
2.输入一个由S中的字符组成的序列L,求L的Huffman 编码。
3. 输入一个二进制位串B,对B进行Huffman译码,输出对应的字符序列;若不能译码,则输出无解信息。
提示:对应10 个字符的Huffman树的节点个数<211。
2.测试数据Inputn=5字符集合S={a, b, c, d, e},对应的频率分别为a: 20b: 7c: 10d: 4e: 18字符序列L=ebcca二进制位串B=01100111010010OutputS中各个字符的Huffman编码:(设Huffman树中左孩子的权<=右孩子的权)a: 11b: 010c: 00d: 011e: 10L的Huffman 编码:10010000011B对应的字符序列: dcaeeb若输入的B=01111101001,则无解(二) 加油问题(Problem Set 1702):1.问题描述一个旅行家想驾驶汽车从城市A到城市B(设出发时油箱是空的)。
给定两个城市之间的距离dis、汽车油箱的容量c、每升汽油能行驶的距离d、沿途油站数n、油站i离出发点的距离d[i]以及该站每升汽油的价格p[i],i=1,2,…,n。
设d[1]=0<d[2]<…<d[n]。
要花最少的油费从城市A到城市B,在每个加油站应加多少油,最少花费为多少?2.具体要求Input输入的第一行是一个正整数k,表示测试例个数。
贪心算法-哈弗曼编码、汽车加油问题

1.问题描述哈夫曼编码(贪心策略)——要求给出算法思想、编码程序和译码程序,对样本数据“哈夫曼编码实验数据.dat”,要求提交符号的具体编码以及编码后的文件。
2.求解问题的贪心算法描述压缩数据由以下步骤组成:a)检查字符在数据中的出现频率。
b)构建哈夫曼树。
c)创建哈夫曼编码表。
d)生成压缩后结果,由一个文件头和压缩后的数据组成。
3.算法实现的关键技巧1.最小堆两种基本操作:插入新元素,抽取最小元素。
(1)插入新元素:把该元素放在二叉树的末端,然后从该新元素开始,向根节点方向进行交换,直到它到达最终位置。
(2)抽取最小元素:把根节点取走。
然后把二叉树的末端节点放到根节点上,然而把该节点向子结点反复交换,直到它到达最终位置。
2. 构建哈夫曼树:a)把所有出现的字符作为一个节点(单节点树),把这些树组装成最小堆;b)从该优先级队列中连续抽取两个频率最小的树分别作为左子树,右子树,将他们合并成一棵树(频率=两棵树频率之和),然后把这棵树插回队列中。
c)重复步骤b,每次合并都将使优先级队列的尺寸减小1,直到最后队列中只剩一棵树为止,就是我们需要的哈夫曼树。
3.压缩数据: 遍历输入的文本,对每个字符,根据编码表依次把当前字符的编码写入到编码结果中去。
File Header(文件头):unsigned int size; 被编码的文本长度(字符数);unsigned char freqs[ NUM_CHARS ]; 字符频率表compressed; (Bits: 压缩后的数据);4.贪心选择性质&最优子结构性质证明:即证明最优前缀码问题具有弹性选择性质和最优子结构性质.(1)贪心选择性质设C是编码字符集,C中字符c的频率为f(c)。
又设x,y是C中具有最小频率的两个字符,则存在C的最优前缀码使x,y具有相同码长且仅最后一位编码不同。
证明:设二叉树T表示C的任意一个最优前缀码。
对C左适当修改得到T“,使得在新树中,x和y是最深叶子且为兄弟。
0023算法笔记——【贪心算法】哈夫曼编码问题

0023算法笔记—-【贪心算法】哈夫曼编码问题1、问题描述哈夫曼编码是广泛地用于数据文件压缩的十分有效的编码方法。
其压缩率通常在20%~90%之间.哈夫曼编码算法用字符在文件中出现的频率表来建立一个用0,1串表示各字符的最优表示方式。
一个包含100,000个字符的文件,各字符出现频率不同,如下表所示。
有多种方式表示文件中的信息,若用0,1码表示字符的方法,即每个字符用唯一的一个0,1串表示.若采用定长编码表示,则需要3位表示一个字符,整个文件编码需要300,000位;若采用变长编码表示,给频率高的字符较短的编码;频率低的字符较长的编码,达到整体编码减少的目的,则整个文件编码需要(45×1+13×3+12×3+16×3+9×4+5×4)×1000=224,000位,由此可见,变长码比定长码方案好,总码长减小约25%。
前缀码:对每一个字符规定一个0,1串作为其代码,并要求任一字符的代码都不是其他字符代码的前缀。
这种编码称为前缀码。
编码的前缀性质可以使译码方法非常简单;例如001011101可以唯一的分解为0,0,101,1101,因而其译码为aabe。
译码过程需要方便的取出编码的前缀,因此需要表示前缀码的合适的数据结构.为此,可以用二叉树作为前缀码的数据结构:树叶表示给定字符;从树根到树叶的路径当作该字符的前缀码;代码中每一位的0或1分别作为指示某节点到左儿子或右儿子的“路标”。
从上图可以看出,表示最优前缀码的二叉树总是一棵完全二叉树,即树中任意节点都有2个儿子。
图a表示定长编码方案不是最优的,其编码的二叉树不是一棵完全二叉树.在一般情况下,若C是编码字符集,表示其最优前缀码的二叉树中恰有|C|个叶子.每个叶子对应于字符集中的一个字符,该二叉树有|C|-1个内部节点。
给定编码字符集C及频率分布f,即C中任一字符c以频率f(c)在数据文件中出现.C的一个前缀码编码方案对应于一棵二叉树T。
哈夫曼编码和译码的算法设计与实现

哈夫曼编码和译码的算法设计与实现实验名称哈夫曼编码和译码的算法设计与实现实验方案实验成绩实验日期实验室信息系统设计与仿真室I 实验操作实验台号班级姓名实验结果一、实验目的1、掌握哈夫曼编码的二叉树结构表示方法;2、编程实现哈夫曼编码译码器;3、掌握贪心算法的设计策略。
二、实验任务①从文件中读取数据,构建哈夫曼树;②利用哈夫曼树,对输入明文进行哈夫曼编码;③利用哈夫曼树,对输入编码译码为明文。
三、实验设计方案1、结构体设计Huffman树:包括字符,权,父亲下标,左孩子下标,右孩子下标#define N 29 //26个小写字母,逗号,句号和空格字符.struct treenode{ //静态链表char c; //charint w; //weightint f; //fatherint l; //left child indexint r; //right child index};struct treenode htree[2*N-1];2、自定义函数设计①函数原型声明void input(); //读取文件字符、权值数据void huffman(); //建立huffman树void getcode(int i, char *str); //得到单个字符的huffman编码void encode(char ch); //将明文进行huffman编码void decode(char *str); //将huffman编码译为明文②读取文件字符、权值数据void input(){int i;char c;int f;freopen("in.txt","r",stdin);for(i=0;i<n;i++)< p="">{c=getchar(); //接收字符scanf("%d",&f); //接收权值getchar(); //接收回车ht[i].c=c;ht[i].w=f;ht[i].l=ht[i].f=ht[i].r=-1; //初始化父亲、左右孩子下标} freopen( "CON", "r", stdin);}③建立huffman树//使用贪心法建立huffman树,每次选择权值最小的根结点void huffman(){void huffman(){int j,k,n;input();j=0;k=N;for(n=N;n<2*N-1;n++){ //建立huffman树,共合并N-1次int r=0,s=0;ht[n].l=ht[n].f=ht[n].r=-1;while(r<2){ //选择两个最小的权值结点if((ht[k].w==0 || ht[k].w>ht[j].w) && j<n){< p="">s+=ht[j].w;if(r==0) ht[n].l = j; //修改父亲、孩子下标else ht[n].r=j;ht[j].f=n;j++;}else{s+=ht[k].w;if(r==0) ht[n].l = k; //修改父亲、孩子下标else ht[n].r=k;ht[k].f=n;k++;}r++;}ht[n].w=s; //修改权值}}④根据字符下标找到字符的huffman编码//根据字符所在的下标,从叶子结点往上搜索到根节点,然后逆置得到该字符的huffman编码void getcode(int i, char *str){ int n,j,l=0;for(n=i;ht[n].f!=-1;n=ht[n].f){ //沿着父亲往上搜索int m=ht[n].f;if(n==ht[m].l)str[l++]='0'; //左孩子记为0elsestr[l++]='1'; //右孩子记为1}for(j=0;j<=(l-1)/2;j++){ //将编码逆置char t;t=str[j];str[j]=str[l-1-j];str[l-1-j]=t;}str[l]=0; // str存放huffman编码,字符串结束标记}⑤读入明文生成huffman编码void encode(char ch){int i;char str[N];for(i=0;ht[i].c!=0;i++)if(ht[i].c==ch) //找字符下标break;if (ht[i].c!=0){getcode(i,str); //得到字符的huffman编码printf("%s",str);}}⑥将huffman编码串译码为明文void decode(char *str){while(*str!='\0'){int i;for(i=2*N-2;ht[i].l!=-1;){if(*str=='0')i=ht[i].l;elsei=ht[i].r;str++;}printf("%c",ht[i].c);}}3、主函数设计思路:主函数实现实验任务的基本流程。
哈夫曼编码的贪心算法时间复杂度

哈夫曼编码是一种广泛应用于数据压缩领域的编码方式,而哈夫曼编码的贪心算法是实现这一编码方式的重要方法之一。
在本文中,我将深入探讨哈夫曼编码及其贪心算法的时间复杂度,并就此展开全面评估。
让我们简要回顾一下哈夫曼编码的基本概念。
哈夫曼编码是一种变长编码方式,通过将出现频率高的字符用较短的编码表示,而将出现频率低的字符用较长的编码表示,从而实现数据的有效压缩。
在这一编码方式中,贪心算法被广泛应用于构建哈夫曼树,以实现最优编码方案的选择。
那么,接下来我们将重点关注哈夫曼编码的贪心算法时间复杂度。
哈夫曼编码的贪心算法的时间复杂度主要取决于两个方面:构建哈夫曼树的时间复杂度和编码字符串的时间复杂度。
让我们来看构建哈夫曼树的时间复杂度。
在哈夫曼编码的贪心算法中,构建哈夫曼树的时间复杂度主要取决于构建最小堆(或最大堆)以及合并节点的操作。
在构建最小堆的过程中,需要对所有字符按照其频率进行排序,并将其依次插入最小堆中,这一操作的时间复杂度为O(nlogn)。
而在合并节点的过程中,需要不断从最小堆中取出两个频率最小的节点,并将其合并为一个新节点,然后再将新节点插入最小堆中,这一操作需要进行n-1次,所以合并节点的时间复杂度为O(nlogn)。
构建哈夫曼树的时间复杂度为O(nlogn)。
我们来看编码字符串的时间复杂度。
在使用哈夫曼编码对字符串进行编码时,需要根据构建好的哈夫曼树来进行编码,这一过程的时间复杂度主要取决于字符串的长度和哈夫曼树的深度。
由于哈夫曼树是一个二叉树,所以在最坏情况下,编码一个字符的时间复杂度为O(n),其中n为哈夫曼树的深度。
编码字符串的时间复杂度为O(kn),其中k 为字符串的长度。
哈夫曼编码的贪心算法的时间复杂度主要包括构建哈夫曼树的时间复杂度和编码字符串的时间复杂度,其中构建哈夫曼树的时间复杂度为O(nlogn),编码字符串的时间复杂度为O(kn)。
哈夫曼编码的贪心算法的时间复杂度为O(nlogn+kn)。
贪心法求哈夫曼编码

实验题目:设需要编码的字符集为{d1, d2, …, dn},它们出现的频率为{w1, w2, …, wn},应用哈夫曼树构造最短的不等长编码方案。
实验目的:(1)了解前缀编码的概念,理解数据压缩的基本方法;(2)掌握最优子结构性质的证明方法;(3)掌握贪心法的设计思想并能熟练运用。
实验内容:实验代码:#include <iostream>using namespace std;/** 霍夫曼树结构*/class HuffmanTree{public:unsigned int Weight, Parent, lChild, rChild;};typedef char **HuffmanCode;/** 从结点集合中选出权值最小的两个结点* 将值分别赋给s1和s2*/void Select(HuffmanTree* HT,int Count,int *s2,int *s1){unsigned int temp1=0;unsigned int temp2=0;unsigned int temp3;for(int i=1;i<=Count;i++){if(HT[i].Parent==0){if(temp1==0){temp1=HT[i].Weight;(*s1)=i;}else{if(temp2==0){temp2=HT[i].Weight;(*s2)=i;if(temp2<temp1){temp3=temp2;temp2=temp1;temp1=temp3;temp3=(*s2);(*s2)=(*s1);(*s1)=temp3;}}else{if(HT[i].Weight<temp1){temp2=temp1;temp1=HT[i].Weight;(*s2)=(*s1);(*s1)=i;}if(HT[i].Weight>temp1&&HT[i].Weight<temp2){temp2=HT[i].Weight;(*s2)=i;}}}}}}/** 霍夫曼编码函数*/void HuffmanCoding(HuffmanTree * HT,HuffmanCode * HC,int *Weight,int Count){int i;int s1,s2;int TotalLength;char* cd;unsigned int c;unsigned int f;int start;if(Count<=1) return;TotalLength=Count*2-1;HT = new HuffmanTree[(TotalLength+1)*sizeof(HuffmanTree)];for(i=1;i<=Count;i++){HT[i].Parent=0;HT[i].rChild=0;HT[i].lChild=0;HT[i].Weight=(*Weight);Weight++;}for(i=Count+1;i<=TotalLength;i++){HT[i].Weight=0;HT[i].Parent=0;HT[i].lChild=0;HT[i].rChild=0;}//建造霍夫曼树for(i=Count+1;i<=TotalLength;++i){Select(HT, i-1, &s1, &s2);HT[s1].Parent = i;HT[s2].Parent = i;HT[i].lChild = s1;HT[i].rChild = s2;HT[i].Weight = HT[s1].Weight + HT[s2].Weight;}//输出霍夫曼编码(*HC)=(HuffmanCode)malloc((Count+1)*sizeof(char*));cd = new char[Count*sizeof(char)];cd[Count-1]='\0';for(i=1;i<=Count;++i){start=Count-1;for(c = i,f = HT[i].Parent; f != 0; c = f, f = HT[f].Parent){if(HT[f].lChild == c)cd[--start]='0';elsecd[--start]='1';(*HC)[i] = new char [(Count-start)*sizeof(char)];strcpy((*HC)[i], &cd[start]);}}delete [] HT;delete [] cd;}/** 在字符串中查找某个字符* 如果找到,则返回其位置*/int LookFor(char *str, char letter, int count){int i;for(i=0;i<count;i++){if(str[i]==letter) return i;}return -1;}void OutputWeight(char *Data,int Length,char **WhatLetter,int **Weight,int *Count){int i;char* Letter = new char[Length];int* LetterCount = new int[Length];int AllCount=0;int Index;int Sum=0;float Persent=0;for(i=0;i<Length;i++){if(i==0){Letter[0]=Data[i];LetterCount[0]=1;AllCount++;}else{Index=LookFor(Letter,Data[i],AllCount);if(Index==-1){Letter[AllCount]=Data[i];LetterCount[AllCount]=1;AllCount++;}else{LetterCount[Index]++;}}}for(i=0;i<AllCount;i++){Sum=Sum+LetterCount[i];}(*Weight) = new int[AllCount];(*WhatLetter) = new char[AllCount];for(i=0;i<AllCount;i++){Persent=(float)LetterCount[i]/(float)Sum;(*Weight)[i]=(int)(100*Persent);(*WhatLetter)[i]=Letter[i];}(*Count)=AllCount;delete [] Letter;delete [] LetterCount;}int main(){HuffmanTree * HT = NULL;HuffmanCode HC;char Data[100];char *WhatLetter;int *Weight;int Count;cout<<"请输入一行文本数据:"<<endl;cin>>Data;cout<<endl;OutputWeight(Data,strlen(Data),&WhatLetter,&Weight,&Count); HuffmanCoding(HT, &HC, Weight, Count);cout<<"字符出现频率编码结果"<<endl;for(int i = 0; i<Count; i++){cout<<WhatLetter[i]<<" ";cout<<Weight[i]<<"%\t";cout<<HC[i+1]<<endl;}cout<<endl;system("pause");return 0;}实验结果截图:哈夫曼算法描述:(1)初始化:将初始森林的各根结点(双亲)和左右孩子指针置为-1;(2)输入叶子权:叶子在向量T的前n个分量中,构成初始森林的n个根结点;(3)合并:对森林中的树进行n-1次合并,共产生n-1个新结点,依次放入向量T的第i 个分量(n<=i<=m-1)中,每次合并的步骤是:a、在当前森林的所有结点中,选取具有最小权值和次小权值的两个结点,分别用p1和p2记住这两个根节点在向量T中的下标;b、将根为T[p1]和T[p2]的两棵树合并,使其成为新结点T[i]的左右孩子,得到一棵以新结点T[i]为根的二叉树若取pi为叶结点的权,取编码长度li为叶结点的路径长度,则∑ pi ⨯li最小的问题就是带权路径长度最小的哈夫曼树的构造问题。
实验三.哈夫曼编码的贪心算法设计

实验四 哈夫曼编码的贪心算法设计(4学时)[实验目的]1. 根据算法设计需要,掌握哈夫曼编码的二叉树结构表示方法;2. 编程实现哈夫曼编译码器;3. 掌握贪心算法的一般设计方法。
实验目的和要求(1)了解前缀编码的概念,理解数据压缩的基本方法;(2)掌握最优子结构性质的证明方法;(3)掌握贪心法的设计思想并能熟练运用(4)证明哈夫曼树满足最优子结构性质;(5)设计贪心算法求解哈夫曼编码方案;(6)设计测试数据,写出程序文档。
实验内容设需要编码的字符集为{d 1, d 2, …, dn },它们出现的频率为{w 1, w 2, …, wn },应用哈夫曼树构造最短的不等长编码方案。
核心源代码#include <>#include <>#include <>typedef struct{unsigned int weight; arent==0){min=i;break;}}for(i=1; i<=n; i++) ∑=j i k k a{if((*ht)[i].parent==0){if((*ht)[i].weight<(*ht)[min].weight)min=i;}}*s1=min;for(i=1; i<=n; i++){if((*ht)[i].parent==0 && i!=(*s1)){min=i;break;}}for(i=1; i<=n; i++){if((*ht)[i].parent==0 && i!=(*s1)){if((*ht)[i].weight<(*ht)[min].weight)min=i;}}*s2=min;}eight=w[i];(*ht)[i].LChild=0;(*ht)[i].parent=0;(*ht)[i].RChild=0;}for(i=n+1; i<=m; i++) eight=0;(*ht)[i].LChild=0;(*ht)[i].parent=0;(*ht)[i].RChild=0;}printf("\n哈夫曼树为: \n");for(i=n+1; i<=m; i++) arent=i;(*ht)[s2].parent=i;(*ht)[i].LChild=s1;(*ht)[i].RChild=s2;(*ht)[i].weight=(*ht)[s1].weight+(*ht)[s2].weight;printf("%d (%d, %d)\n",(*ht)[i].weight,(*ht)[s1].weight,(*ht)[s2].weight); }printf("\n");}arent; p!=0; c=p,p=(*ht)[p].parent) Child==c){cd[--start]='1'; eight,hc[i]);for(i=1; i<=n; i++)w+=(*ht)[i].weight*a[i];printf(" 带权路径为:%d\n",w);}void main(){HuffmanTree HT;HuffmanCode HC;int *w,i,n,wei;printf("**哈夫曼编码**\n" );printf("请输入结点个数:" );scanf("%d",&n);w=(int *)malloc((n+1)*sizeof(int));printf("\n输入这%d个元素的权值:\n",n);for(i=1; i<=n; i++){printf("%d: ",i);fflush(stdin);scanf("%d",&wei);w[i]=wei;}CrtHuffmanTree(&HT,w,n); CrtHuffmanCode(&HT,&HC,n);}实验结果实验体会哈夫曼编码算法:每次将集合中两个权值最小的二叉树合并成一棵新二叉树,n-1次合并后,成为最终的一棵哈夫曼树。
实验三哈夫曼编码

实验三哈夫曼编码一、实验目的和任务1、 理解信源编码的意义;2、 熟悉 MATLAB 程序设计;3、 掌握哈夫曼编码的方法及计算机实现;4、 对给定信源进行香农编码,并计算编码效率;二、实验原理介绍1、把信源符号按概率大小顺序排列, 并设法按逆次序分配码字的长度;12.......n p p p ≥≥≥2、在分配码字长度时,首先将出现概率 最小的两个符号的概率相加合成一个概率;3、把这个合成概率看成是一个新组合符号地概率,重复上述做法直到最后只剩下两个符号概率为止;4、完成以上概率顺序排列后,再反过来逐步向前进行编码,每一次有二个分支各赋予一个二进制码,可以对概率大的赋为零,概率小的赋为1;5、从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即相应的码字。
三、实验设备介绍1、计算机2、编程软件MATLAB6.5以上四、实验内容和步骤对如下信源进行哈夫曼编码,并计算编码效率。
12345670.200.190.180.170.150.100.01X a a a a a a a P ⎡⎤⎡⎤=⎢⎥⎢⎥⎣⎦⎣⎦(1)计算该信源的信源熵,并对信源概率进行排序;(2)首先将出现概率最小的两个符号的概率相加合成一个概率,把这个合成 概率与其他的概率进行组合,得到一个新的概率组合,重复上述做法,直到只剩下两个概率为止。
之后再反过来逐步向前进行编码,每一次有两个分支各赋予一个二进制码。
对大的概率赋“1”,小的概率赋“0”。
(3)从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即相应的码字。
(4)计算码字的平均码长得出最后的编码效率。
实验代码:。
实验三哈夫曼编码

数据结构实验报告1.实验要求1 实验目的掌握二叉树基本操作的实现方法了解赫夫曼树的思想和相关概念学习使用二叉树解决实际问题的能力利用二叉树结构实现赫夫曼编/解码器。
基本要求:1、初始化(Init):能够对输入的任意长度的字符串s进行统计,统计每个字符的频度,并建立赫夫曼树2、建立编码表(CreateTable):利用已经建好的赫夫曼树进行编码,并将每个字符的编码输出。
3、编码(Encoding):根据编码表对输入的字符串进行编码,并将编码后的字符串输出。
4、译码(Decoding):利用已经建好的赫夫曼树对编码后的字符串进行译码,并输出译码结果。
5、打印(Print):以直观的方式打印赫夫曼树(选作)6、计算输入的字符串编码前和编码后的长度,并进行分析,讨论赫夫曼编码的压缩效果。
测试数据:I love data Structure, I love Computer。
I will try my best to study data Structure.2. 程序分析2.1 存储结构用二叉树的结构建立哈夫曼树,每个节点的结构是struct HNode{int weight;int parent;int lch;int rch;string code;char data;哈夫曼树的特点:只有度为2的结点和叶子结点,所以具有n个叶子结点的哈夫曼树的结点总数为2n-1顺序存储结构:设置一个的HTree[2*n-1]数组2.2 关键算法分析关键算法一:初始化伪代码:1.将存字符串权值的数组a赋0值,字符种类n赋0值2.获取输入字符串3.遍历输入的字符串,若某个字符出现一次,则在a[i]++,i为该字符ascii码4.遍历a数组,在a[i]有值的地方给HTree[i].weight赋值为a[i],HTree[i].data赋值为ascii码为i的字符源代码:void Huffman::Init() //初始化{for(int m=0;m<256;++m)a[m]=0;cout<<"请输入想要编码的字符"<<endl;getline(cin,str);n=0;cout<<"各字符权值为:"<<endl;for(int i = 0;i!=str.size();++i)++a[str[i]];for(int i=0;i<256;++i)if(a[i]!=0){cout<<char(i)<<" "<<a[i]<<endl;n++;}HTree=new HNode[2*n-1];int j = 0;//j!=n;++j)for(int k=0;k<256;++k){if(a[k]!=0){HTree[j].weight=a[k];HTree[j].data=char(k);j++;}}}时间复杂度:若输入的字符串长度为n,则时间复杂度为O(n)关键算法二:编码:思想(不等长编码)使用频率高的字符,编码长度短;使用频率低的字符,编码长度长;利用不等长编码,可以使报文总长度较短,这也是文件压缩技术的核心。
贪心算法哈夫曼编码c语言

贪心算法哈夫曼编码c语言哈夫曼编码的贪心算法可以分为以下几步:1. 读入需要编码的字符及其出现频率,并按照频率从小到大排序。
2. 构建哈夫曼树。
首先将所有字符看成只有一个节点的树,然后取出频率最小的两棵树,将它们合并成一棵树,这棵树的频率是两棵树的频率之和。
继续取出频率最小的两棵树,重复上述过程,直到只剩下一棵树为止,这就是哈夫曼树。
3. 对哈夫曼树进行编码。
从哈夫曼树的根节点开始,往左走为0,往右走为1,一直走到叶子节点,记录下这个叶子节点代表的字符的编码。
这就是哈夫曼编码。
以下是用C语言实现的贪心算法实现:```c#include <stdio.h>#include <stdlib.h>#include <string.h>#define MAX_N 256 // 假设字符集大小为256typedef struct node {char ch; // 字符int freq; // 频率struct node *left, *right; // 左右子节点} Node;// 建立一个新的节点Node* new_node(char ch, int freq) {Node *node = (Node*)malloc(sizeof(Node));node->ch = ch;node->freq = freq;node->left = node->right = NULL;return node;}// 在nodes数组中找寻最小的两个节点void find_min_two_nodes(Node **nodes, int size, int *min1, int *min2) {*min1 = *min2 = -1;for (int i = 0; i < size; i++) {if (nodes[i] == NULL) continue;if (*min1 == -1 || nodes[i]->freq < nodes[*min1]->freq) {*min2 = *min1;*min1 = i;} else if (*min2 == -1 || nodes[i]->freq < nodes[*min2]->freq) {*min2 = i;}}}// 构建哈夫曼树Node* build_huffman_tree(char *str, int *freq, int n) {Node *nodes[MAX_N];for (int i = 0; i < n; i++) {nodes[i] = new_node(str[i], freq[i]);}int size = n;while (size > 1) {int min1, min2;find_min_two_nodes(nodes, size, &min1, &min2);Node *node = new_node(0, nodes[min1]->freq +nodes[min2]->freq);node->left = nodes[min1];node->right = nodes[min2];nodes[min1] = node;nodes[min2] = NULL;size--;}return nodes[0];}// 递归生成哈夫曼编码void gen_huffman_code(Node *root, char *code, int depth, char **table) {if (root == NULL) return;if (root->left == NULL && root->right == NULL) {code[depth] = '\0';table[root->ch] = (char*)malloc((depth + 1) * sizeof(char)); strcpy(table[root->ch], code);return;}code[depth] = '0';gen_huffman_code(root->left, code, depth + 1, table);code[depth] = '1';gen_huffman_code(root->right, code, depth + 1, table); }// 哈夫曼编码char** huffman_code(char *str, int *freq, int n) {Node *root = build_huffman_tree(str, freq, n);char **table = (char**)malloc(MAX_N * sizeof(char*)); char code[MAX_N];gen_huffman_code(root, code, 0, table);return table;}int main() {char str[] = "ABACCABB";int freq[] = {2, 3, 1, 2, 1, 1, 1, 1};int n = strlen(str);char **table = huffman_code(str, freq, n);for (int i = 0; i < n; i++) {printf("char: %c, code: %s\n", str[i], table[str[i]]);}return 0;}```输出结果:```char: A, code: 11char: B, code: 0char: A, code: 11char: C, code: 100char: C, code: 100char: A, code: 11char: B, code: 1char: B, code: 01```这就是对字符串"ABACCABB"进行哈夫曼编码的结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验四哈夫曼编码的贪心算法设计( 4 学时)
[实验目的]
1. 根据算法设计需要,掌握哈夫曼编码的二叉树结构表示方法;
2. 编程实现哈夫曼编译码器;
3. 掌握贪心算法的一般设计方法。
实验目的和要求
(1)了解前缀编码的概念,理解数据压缩的基本方法;
(2)掌握最优子结构性质的证明方法;
(3)掌握贪心法的设计思想并能熟练运用
(4)证明哈夫曼树满足最优子结构性质;
(5)设计贪心算法求解哈夫曼编码方案;
(6)设计测试数据,写出程序文档。
实验内容j
设需要编码的字符集为{d1, d2, -dn },它们出现的频率为k i a k{w1, w2, --wn},应用哈夫曼树构ki 造最短的不等长编码方案。
核心源代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct
{
unsigned int weight;// 用来存放各个结点的权值
unsigned int parent,LChild,RChild;// 指向双亲、孩子结点的指针
} HTNode, *HuffmanTree;// 动态分配数组,存储哈夫曼树
typedef char *HuffmanCode;// 动态分配数组,存储哈夫曼编码
可编辑
// 选择两个 parent 为 0,且 weight 最小的结点 s1 和 s2 void Select(HuffmanTree *ht,int n,int *s1,int *s2) {
int i,min;
for(i=1; i<=n; i++)
{
if((*ht)[i].parent==0)
{
min=i;
break;
}
}
for(i=1; i<=n; i++)
{
if((*ht)[i].parent==0)
{
if((*ht)[i].weight<(*ht)[min].weight)
min=i;
}
}
*s1=min;
for(i=1; i<=n; i++)
if((*ht)[i].parent==0 && i!=(*s1))
{
min=i;
break;
}
}
for(i=1; i<=n; i++)
{
if((*ht)[i].parent==0 && i!=(*s1))
{
if((*ht)[i].weight<(*ht)[min].weight)
min=i;
}
}
*s2=min;
}
// 构造哈夫曼树 ht,w 存放已知的 n 个权值 void CrtHuffmanTree(HuffmanTree *ht,int *w,int n) { int m,i,s1,s2;
m=2*n-1; // 总共的结点数
*ht=(HuffmanTree)malloc((m+1)*sizeof(HTNode));
for(i=1; i<=n; i++) //1--n 号存放叶子结点,初始化
{
(*ht)[i].weight=w[i];
(*ht)[i].LChild=0;
(*ht)[i].parent=0;
(*ht)[i].RChild=0;
}
for(i=n+1; i<=m; i++) // 非叶子结点的初始化
{
(*ht)[i].weight=0;
(*ht)[i].LChild=0;
(*ht)[i].parent=0;
(*ht)[i].RChild=0;
}
printf("\n 哈夫曼树为 : \n");
for(i=n+1; i<=m; i++) // 创建非叶子结点,建哈夫曼树
{ II在(*ht)[1]~(*ht)[i-1] 的范围内选择两个pare nt为0且weight最小的结点,其序号分别赋值给si、s2
Select(ht,i-1,&s1,&s2);
(*ht)[s1].parent=i;
(*ht)[s2].parent=i;
(*ht)[i].LChild=s1;
(*ht)[i].RChild=s2;
(*ht)[i].weight=(*ht)[s1].weight+(*ht)[s2].weight;
printf("%d (%d, %d)\n",(*ht)[i].weight,(*ht)[s1].weight,(*ht)[s2].weight);
}
printf("\n");
}
// 从叶子结点到根,逆向求每个叶子结点对应的哈夫曼编码
void CrtHuffmanCode(HuffmanTree *ht, HuffmanCode *hc, int n)
{
char *cd; // 定义的存放编码的空间
int a[100];
int i,start,p,w=0;
unsigned int c;
hc=(HuffmanCode *)malloc((n+1)*sizeof(char *)); // 分配 n 个编码的头指针
cd=(char *)malloc(n*sizeof(char)); // 分配求当前编码的工作空间
cd[n-1]='\0'; // 从右向左逐位存放编码,首先存放编码结束符
for(i=1; i<=n; i++) // 求 n 个叶子结点对应的哈夫曼编码
{
a[i]=0;
start=n-1; // 起始指针位置在最右边
for(c=i,p=(*ht)[i].parent; p!=0; c=p,p=(*ht)[p].parent) // 从叶子到根结点求编码{ if( (*ht)[p].LChild==c)
{
cd[--start]='1'; // 左分支标 1
a[i]++;
}
else
{
cd[--start]='0'; // 右分支标 0
a[i]++;
}
}
hc[i]=(char *)malloc((n-start)*sizeof(char)); // 为第 i 个编码分配空间strcpy(hc[i],&cd[start]); // 将 cd 复制编码到 hc
}
free(cd);
for(i=1; i<=n; i++)
printf(" 权值为 %d 的哈夫曼编码为: %s\n",(*ht)[i].weight,hc[i]);
for(i=1; i<=n; i++)
w+=(*ht)[i].weight*a[i];
printf(" 带权路径为: %d\n",w);
}
void main()
HuffmanTree HT;
HuffmanCode HC;
int *w,i,n,wei;
printf("** 哈夫曼编码 **\n" );
printf(" 请输入结点个数: " );
scanf("%d",&n);
w=(int *)malloc((n+1)*sizeof(int));
printf("\n 输入这 %d 个元素的权值 :\n",n);
for(i=1; i<=n; i++)
{
printf("%d: ",i);
fflush(stdin);
scanf("%d",&wei);
w[i]=wei;
}
CrtHuffmanTree(&HT,w,n); CrtHuffmanCode(&HT,&HC,n); }
实验结果
实验体会
哈夫曼编码算法:每次将集合中两个权值最小的二叉树合并成一棵新二叉树, n-1次合并后,成为最终的一棵 哈夫曼树。
这既是贪心法的思想:从某一个最初状态出发,根据当前的局部最优策略,以满足约束方程为条件,以 使目标函数最快(或最慢)为原则,在候选集合中进行一系列的选择,以便尽快构成问题的可行解。
每次选择两个权值最小的二叉树时,规定了较小的为左子树。
"H:\Detiug\Cpp2. exe"
3
12
24
16
合夫曼树为,
、 1 1 1 0 10 1 0 ■■ 马 ,扁弔币 丨I 壁1矗壽 合今.诅 ..舍 Q 口 U ....■ 7 2 ^UT 4 6 frH «..£y 2 9 3 15 2 1 4fc n 为为
为为为为为
刘
路耳
!■肩Bffi:BBIE 直权SS
100 10 0 1 0 10 0 »=*.»=»:in 马 r3rp J l... t Tfl _I^H n ——帛
d.帛扁弔 o =8 o- H 匕 2。