数据结构第4章作业
数据结构课后习题(第4-5章)

【课后习题】第4章 串 第5章 数组和广义表网络工程2010级( )班 学号: 姓名:一、填空题(每空1分,共30分)1. 串有三种机内表示方法: 、 和 ,其中前两种属于顺序存储结构,第三种属于 。
2. 若n 为主串长度,m 为子串长度,则串的BF (朴素)匹配算法最坏的情况下需要比较字符的总次数为 ,T(n)= 。
3. 是任意串的子串;任意串S 都是S 本身的子串,除S 本身外,S 的其他子串称为S 的 。
4. 设数组a[1…50, 1…60]的基地址为1000,每个元素占2个存储单元,若以行序为主序顺序存储,则元素a[32,58]的存储地址为 。
5. 对于数组,比较适于采用 结构够进行存储。
6. 广义表的深度是指_______。
7. 将一个100100 A 的三对角矩阵,按行优先存入一维数组B[297]中,A 中元素66,66A 在B 数组中的位置k 为 。
注意:a i,j 的k 为 2(i-1)+j-1,(i=1时j=1,2;1<i<=n 时,j=i-1,i,i+1) 。
8. 称为空串; 称为空白串。
9. 求串T 在主串S 中首次出现的位置的操作是 ,其中 称为目标串, 称为模式。
10. 对称矩阵的下三角元素a[i,j],存放在一维数组V 的元素V[k]中(下标都是从0开始),k 与i ,j 的关系是:k= 。
11. 在n 维数组中每个元素都受到 个条件的约束。
12. 同一数组中的各元素的长度 。
13. 三元素组表中的每个结点对应于稀疏矩阵的一个非零元素,它包含有三个数据项,分别表示该元素的 、 和 。
14. 稀疏矩阵中有n 个非零元素,则其三元组有 行。
15.求下列广义表操作的结果:(1)GetHead【((a,b),(c,d))】=== ;(2)GetHead【GetTail【((a,b),(c,d))】】=== ;(3)GetHead【GetTail【GetHead【((a,b),(c,d))】】】=== ;(4)GetTail【GetHead【GetTail【((a,b),(c,d))】】】=== ;16.广义表E=(a,(b,E)),则E的长度= ,深度= ;二、判断题(如果正确,在下表对应位置打“√”,否则打“⨯”。
数据结构第四章考试题库(含答案)

第四章串一、选择题1.下面关于串的的叙述中,哪一个是不正确的()【北方交通大学 2001 一、5(2分)】A.串是字符的有限序列 B.空串是由空格构成的串C.模式匹配是串的一种重要运算 D.串既可以采用顺序存储,也可以采用链式存储2 若串S1=‘ABCDEFG’, S2=‘9898’ ,S3=‘###’,S4=‘012345’,执行concat(replace(S1,substr(S1,length(S2),length(S3)),S3),substr(S4,index (S2,‘8’),length(S2)))其结果为()【北方交通大学 1999 一、5 (25/7分)】A.ABC###G0123 B.ABCD###2345 C.ABC###G2345 D.ABC###2345E.ABC###G1234 F.ABCD###1234 G.ABC###012343.设有两个串p和q,其中q是p的子串,求q在p中首次出现的位置的算法称为()A.求子串 B.联接 C.匹配 D.求串长【北京邮电大学 2000 二、4(20/8分)】【西安电子科技大学 1996 一、1 (2分)】4.已知串S=‘aaab’,其Next数组值为()。
【西安电子科技大学 1996 一、7 (2分)】A.0123 B.1123 C.1231 D.12115.串‘ababaaababaa’的next数组为()。
【中山大学 1999 一、7】A.0 B.012121111212 C.0 D.06.字符串‘ababaabab’的nextval 为()A.(0,1,0,1,04,1,0,1) B.(0,1,0,1,0,2,1,0,1)C.(0,1,0,1,0,0,0,1,1) D.(0,1,0,1,0,1,0,1,1 )【北京邮电大学 1999 一、1(2分)】7.模式串t=‘abcaabbcabcaabdab’,该模式串的next数组的值为(),nextval 数组的值为()。
数据结构第四五六七章作业答案

数据结构第四五六七章作业答案数据结构第四、五、六、七章作业答案第四章和第五章一、填空题1.不包含任何字符(长度为0)的字符串称为空字符串;由一个或多个空格(仅空格字符)组成的字符串称为空白字符串。
2.设s=“a;/document/mary.doc”,则strlen(s)=20,“/”的位置为3。
3.子串的定位操作称为串模式匹配;匹配的主字符串称为目标字符串,子字符串称为模式。
4、串的存储方式有顺序存储、堆分配存储和块链存储5.有一个二维数组a[0:8,1:5],每个数组元素用四个相邻字节存储,内存用字节寻址。
假设存储阵列元素a[0,1]的地址为100,如果以主行顺序存储,则a[3,5]的地址为176,[5,3]的地址为208。
如果按列存储,[7,1]的地址为128,[2,4]的地址为216。
6、设数组a[1…60,1…70]的基地址为2048,每个元素占2个存储单元,若以列序为主序顺序存储,则元素a[32,58]的存储地址为8950。
7、三元素组表中的每个结点对应于稀疏矩阵的一个非零元素,它包含有三个数据项,分别表示该元素的行下标、列下标和元素值。
8、二维数组a[10][20]采用列序为主方式存储,每个元素占10个存储单元,且a[0][0]的存储地址是2000,则a[6][12]的地址是32609.已知二维数组a[20][10]按行顺序存储,每个元素占2个存储单元,a[10][5]的存储地址为1000,则a[18][9]的存储地址为116810。
已知二维数组a[10][20]按行顺序存储,每个元素占2个存储单元,a[0][0]的存储地址为1024,则a[6][18]的地址为130011,两个字符串相等。
充要条件是长度相等,相应位置的字符相同。
12、二维数组a[10][20]采用列序为主方式存储,每个元素占一个存储单元,并且a[0][0]的存储地址是200,则a[6][12]的地址是200+(12*10+6)=326。
数据结构课后习题答案第四章

第四章一、简述下列每对术语的区别:空串和空白串;串常量和串变量;主串和子串;静态分配的顺序串和动态分配的顺序串;目标串和模式串;有效位移和无效位移。
答:●空串是指不包含任何字符的串,它的长度为零。
空白串是指包含一个或多个空格的串,空格也是字符。
●串常量是指在程序中只可引用但不可改变其值的串。
串变量是可以在运行中改变其值的。
●主串和子串是相对的,一个串中任意个连续字符组成的串就是这个串的子串,而包含子串的串就称为主串。
●静态分配的顺序串是指串的存储空间是确定的,即串值空间的大小是静态的,在编译时刻就被确定。
动态分配的顺序串是在编译时不分配串值空间,在运行过程中用malloc和free等函数根据需要动态地分配和释放字符数组的空间(这个空间长度由分配时确定,也是顺序存储空间)。
●目标串和模式串:在串匹配运算过程中,将主串称为目标串,而将需要匹配的子串称为模式串,两者是相对的。
●有效位移和无效位移:在串定位运算中,模式串从目标的首位开始向右位移,每一次合法位移后如果模式串与目标中相应的字符相同,则这次位移就是有效位移(也就是从此位置开始的匹配成功),反之,若有不相同的字符存在,则此次位移就是无效位移(也就是从此位置开始的匹配失败)。
二、假设有如下的串说明:char s1[30]="Stocktom,CA", s2[30]="March 5 1999", s3[30], *p;(1)在执行如下的每个语句后p的值是什么?p=stchr(s1,'t'); p=strchr(s2,'9'); p=strchr(s2,'6');(2)在执行下列语句后,s3的值是什么?strcpy(s3,s1); strcat(s3,","); strcat(s3,s2);(3)调用函数strcmp(s1,s2)的返回值是什么?(4)调用函数strcmp(&s1[5],"ton")的返回值是什么?(5)调用函数stlen(strcat(s1,s2))的返回值是什么?解:(1) stchr(*s,c)函数的功能是查找字符c在串s中的位置,若找到,则返回该位置,否则返回NULL。
数据结构单元4练习参考答案

单元测验4一.判断题(下列各题,正确的请在前面的括号内打√;错误的打╳)(√)(1)队列是限制在两端进行操作的线性表。
(√)(2)判断顺序队列为空的标准是头指针和尾指针都指向同一个结点。
(×)(3)在链队列上做出队操作时,会改变front指针的值。
(√)(4)在循环队列中,若尾指针rear大于头指针front,其元素个数为rear- front。
(×)(5)在单向循环链表中,若头指针为h,那么p所指结点为尾结点的条件是p=h。
(√)(6)链队列在一定范围内不会出现队满的情况。
(×)(7)在循环链队列中无溢出现象。
(×)(8)栈和队列都是顺序存储的线性结构。
(×)(9)在队列中允许删除的一端称为队尾。
(×)(10)顺序队和循环队关于队满和队空的判断条件是一样的。
二.填空题(1)在队列中存取数据应遵循的原则是先进先出。
(2)队列是被限定为只能在表的一端进行插入运算,在表的另一端进行删除运算的线性表。
(3)在队列中,允许插入的一端称为队尾。
(4)在队列中,允许删除的一端称为队首(或队头)。
(5)队列在进行出队操作时,首先要判断队列是否为空。
(6)顺序队列在进行入队操作时,首先要判断队列是否为满。
(7)顺序队列初始化后,front=rear= -1 。
(8)解决顺序队列“假溢出”的方法是采用循环队列。
(9)循环队列的队首指针为front,队尾指针为rear,则队空的条件为 front == rear 。
(10)链队列LQ为空时,LQ->front->next= NULL 。
(11)设长度为n的链队列用单循环链表表示,若只设头指针,则入队操作的时间复杂度为 O(n)。
(12)设长度为n的链队列用单循环链表表示,若只设尾指针,则出队操作的时间复杂度为 0(1)。
(13)在一个链队列中,若队首指针与队尾指针的值相同,则表示该队列为空。
(14)设循环队列的头指针front指向队首元素,尾指针rear指向队尾元素后的一个空闲元素,队列的最大空间为MAXLEN,则队满标志为:front==(rear+1)%MAXLEN 。
数据结构教程李春葆课后答案第4章串

8. 采用顺序结构存储串,设计一个实现串通配符匹配的算法 pattern_index(),其中的 通配符只有‘?’ ,它可以和任一个字符匹配成功。例如,pattern_index("?re","there are") 返回的结果是 2。 解:采用 BF 算法的穷举法的思路,只需要增加对‘?’字符的处理功能。对应的算法 如下:
void maxsubstr(SqString s,SqString &t) { int maxi=0,maxlen=0,len,i,j,k; i=0; while (i<s.length) //从下标为 i 的字符开始 { j=i+1; //从 i 的下一个位置开始找重复子串 while (j<s.length) { if (s.data[i]==s.data[j]) //找一个子串,其起始下标为 i,长度为 len { len=1; for(k=1;s.data[i+k]==s.data[j+k];k++) len++; if (len>maxlen) //将较大长度者赋给 maxi 与 maxlen { maxi=i; maxlen=len; } j+=len; } else j++; } i++; //继续扫描第 i 字符之后的字符 } t.length=maxlen; //将最长重复子串赋给 t for (i=0;i<maxlen;i++) t.data[i]=s.data[maxi+i]; }
SqString CommChar(SqString s1,SqString s2) { SqString s3; int i,j,k=0; for (i=0;i<s1.length;i++) { for (j=0;j<s2.length;j++) if (s2.data[j]==s1.data[i]) break; if (j<s2.length) //s1.data[i]是公共字符 { s3.data[k]=s1.data[i]; k++; } } s3.length=k; return s3; }
数据结构(第二版)习题答案第4章

gets(s2.str);
s2.length=strlen(s2.str);
m=strcompare(s1,s2);
if(m==1) printf("s1>s2\n");
else if(m==-1) printf("s2>s1\n");
free(S);
free(T1);
free(T2);
}
【参考程序
2】:
#include<stdio.h>
#define MAXSIZE 100
typedef struct{
char str[MAXSIZE];
int length;
}seqstring;
for(k=0;k<t2.length;k++)
s->str[c+k]=t2.str[k];
else if(t1.length<t2.length)
{ for(m=s->length-1;m>i-1;m--)
s->str[t2.length-t1.length+m]=s->str[m]; //后移留空
while (i<t->length && j<p->length)
{
if(j==-1||t->str[i]==p->str[j])
{i++; j++;}
else j=next[j];
}
if (j==p->length) return (i-p->length);
数据结构第四章串习题及答案

习题四串一、单项选择题1.下面关于串的的叙述中,哪一个是不正确的?()A.串是字符的有限序列 B.空串是由空格构成的串C.模式匹配是串的一种重要运算 D.串既可以采用顺序存储,也可以采用链式存储2.串是一种特殊的线性表,其特殊性体现在()。
A.可以顺序存储 B.数据元素是一个字符C.可以链接存储 D.数据元素可以是多个字符3.串的长度是指()A.串中所含不同字母的个数 B.串中所含字符的个数C.串中所含不同字符的个数 D.串中所含非空格字符的个数4.设有两个串p和q,其中q是p的子串,求q在p中首次出现的位置的算法称为()A.求子串 B.联接 C.匹配 D.求串长5.若串S=“softwa re”,其子串的个数是()。
A.8 B.37 C.36 D.9二、填空题1.含零个字符的串称为______串。
任何串中所含______的个数称为该串的长度。
2.空格串是指__ __,其长度等于__ __。
3.当且仅当两个串的______相等并且各个对应位置上的字符都______时,这两个串相等。
一个串中任意个连续字符组成的序列称为该串的______串,该串称为它所有子串的______串。
4.INDEX(‘DATAST RUCTU RE’,‘STR’)=________。
5.模式串P=‘abaabc ac’的next函数值序列为________。
6.下列程序判断字符串s是否对称,对称则返回1,否则返回0;如 f("abba")返回1,f("abab")返回0;int f((1)__ ______){int i=0,j=0;while(s[j])(2)___ _____;for(j--; i<j && s[i]==s[j]; i++,j--);return((3)___ ____)}7.下列算法实现求采用顺序结构存储的串s和串t的一个最长公共子串。
数据结构第4单元课后练习答案

对于三个结点A,B和C,可分别组成多少 不同的无序树、有序树和二叉树?
答:(1)无序树:9棵 (2)有序树:12棵 (3)二叉树:30棵
高度为h的k叉树的特点是:第h层的节点度为 0,其余结点的度均为k。如果按从上到下, 从左到右的次序从1开始编号,则: ①各层的结点是多少? ②编号为i的结点的双亲的编号是多少? ③编号为i的结点的第m个孩子的编号是多少? ④编号为i的结点的有右兄弟的条件是什么?
写出下面得二叉树的遍历结果。
先序:ADEHFJGBCK 中序:HEJFGDABKC 后序:HJGFEDKCBA
设计算法,交换一棵二叉树中每个结点 的左、右子树。
template <class T> void BTree<T>::Exch(BTNode<T> *p){ if (p){ BTNode<T> *q=Exch(p->lchild); p->lchild=Exch(p->rchild); p->rchild=q; } }
试证明在哈夫曼算法的实施过程中,二叉树森林中的每 一棵子树都是Huffman树。
证明: 在Huffman算法进行的每一步,都会有一棵新的二叉树产生,它是合并 原来森林中根结点权值最小的两棵子树而得来的。假设此二叉树为T。 取T的根为一棵独立的子树,则它是一棵Huffman树,将此结点向下分 解,仍然得到一棵Huffman树。 此后,按照与T的形成过程相反的顺序依次分解各叶结点。由于在每次 分解时,新产生的两个叶结点在Huffman算法过程中,都是待合并子树根 结点中权值最小的,也就必然在本二叉树中是权值最小的两个叶结点。 根据前面的定理可知,T是一棵Huffman树。
数据结构与算法课程第4章的习题答案

case0: bonus=i*0.1;break;
case1: bonus=bonus1+(i-100000)*0.075;break;
case2:
case3:bonus=bonus2+(i-200000)*0.05;break;
case4:
case5:bonus=bonus4+(i-400000)*0.03;break;
第4章
4.1程序阅读题。以下程序运行结果是什么?
#includestdio.h
void main() {
int i1;
while (i15)
if (i3!2)continue;
else printf(d,i);
printf(\n);
}
结果为:2 5 8 11 14
4.2程序填空题。输出右边所示图案(共N行,N为奇数,此时N=7)。
}
注意:s、t不能定义为int,long型,因为这两种数据类型的范围都不超过21亿,无法容纳最后求的结果。
(6)求s=a+aa+aaa+…+aa...a的值,其中a是一个数字。例如2+22+222+2222+22222(此时共有5个数相加),几个数相加由键盘输入控制。
程序流程图:
程序代码:
#include<stdio.h>
bonus2=bonus1+100000*0.075;
bonus4=bonus2+200000*0.05;
bonus6=bonus4+200000*0.03;
bonus10=bonus6+400000*0.015;
数据结构试题第四章习题

习题一、单项选择题1.空串与空格字符组成的串的区别在于()。
A.没有区别B.两串的长度不相等C.两串的长度相等D.两串包含的字符不相同2.一个子串在包含它的主串中的位置是指()。
A.子串的最后那个字符在主串中的位置B.子串的最后那个字符在主串中首次出现的位置C.子串的第一个字符在主串中的位置D.子串的第一个字符在主串中首次出现的位置3.下面的说法中,只有()是正确的。
A.字符串的长度是指串中包含的字母的个数B.字符串的长度是指串中包含的不同字符的个数C.若T包含在S中,则T一定是S的一个子串D.一个字符串不能说是其自身的一个子串4.两个字符串相等的条件是()。
A.两串的长度相等B.两串包含的字符相同C.两串的长度相等,并且两串包含的字符相同D.两串的长度相等,并且对应位置上的字符相同5. 若SUBSTR(S,i,k)表示求S中从第i个字符开始的连续k个字符组成的子串的操作,则对于S=“Beijing&Nanjing”,SUBSTR(S,4,5)=()。
A.“ijing”B.“jing&”C.“ingNa”D.“ing&N”6. 若INDEX(S,T)表示求T在S中的位置的操作,则对于S=“Beijing&Nanjing”,T=“jing”,INDEX(S,T)=()。
A.2B.3C.4D.57. 若REPLACE(S,S1,S2)表示用字符串S2替换字符串S中的子串S1的操作,则对于S=“Beijing&Nanj ing”,S1=“Beijing”,S2=“Shanghai”,REPLACE(S,S1,S2)=()。
A.“Nanjing&Shanghai”B.“Nanjing&Nanjing”C.“ShanghaiNanjing”D.“Shanghai&Nanjing”8. 在长度为n的字符串S的第i个位置插入另外一个字符串,i的合法值应该是()。
A.i>0B. i≤nC.1≤i≤nD.1≤i≤n+19.字符串采用结点大小为1的链表作为其存储结构,是指()。
数据结构第4单元课后练习答案
对于三个结点A,B和C,可分别组成多少 不同的无序树、有序树和二叉树?
答:(1)无序树:9棵 (2)有序树:12棵 (3)二叉树:30棵
高度为h的k叉树的特点是:第h层的节点度为 0,其余结点的度均为k。如果按从上到下, 从左到右的次序从1开始编号,则: ①各层的结点是多少? ②编号为i的结点的双亲的编号是多少? ③编号为i的结点的第m个孩子的编号是多少? ④编号为i的结点的有右兄弟的条件是什么?
试证明在哈夫曼算法的实施过程中,二叉树森林中的每 一棵子树都是Huffman树。
证明: 在Huffman算法进行的每一步,都会有一棵新的二叉树产生,它是合并 原来森林中根结点权值最小的两棵子树而得来的。假设此二叉树为T。 取T的根为一棵独立的子树,则它是一棵Huffman树,将此结点向下分 解,仍然得到一棵Huffman树。 此后,按照与T的形成过程相反的顺序依次分解各叶结点。由于在每次 分解时,新产生的两个叶结点在Huffman算法过程中,都是待合并子树根 结点中权值最小的,也就必然在本二叉树中是权值最小的两个叶结点。 根据前面的定理可知,T是一棵Huffman树。
试证明哈夫曼算法的正确性。
定理 分裂一棵Huffman树的某个叶结点,如果产生的两个叶结点的权值 在所有叶结点权值中最小,则将生成一棵新的Huffman树。 证明: 假设二叉树T是字母表C上的一棵Huffman树,z是它的一个叶节点。在 z的下面添加两个子结点x和y,它们的权值分别是f(x)和f(y),且满足 f(z)=f(x)+f(y), f(x)和f(y)在字母表C' =C-{z}+{x,y}上的权值最小,可设新 产生的二叉树为T'。 在字母表C'上存在一棵最优二叉树T",在T"上x和y互为兄弟结点。在 T"中删除结点x和y,将字母z以及权值f(z)=f(x)+f(y)赋予x和y在T"中的父 结点,得到一棵在字母表C上的二叉树Ť。 根据引理三,可知Ť是字母表C上的最优二叉树,由于T也是字母表C上 的最优二叉树,所以WPL(Ť)= WPL(T)。 由于WPL(Ť)= WPL(T")-f(x)-f(y), WPL(T)= WPL(T')-f(x)-f(y),所以 WPL(T")=WPL(T'),即,T'是字母表C'上的最优二叉树。证毕。 补充说明:利用Huffman算法构造一棵二叉树T后,单独取出根结点和它 的两个子结点,则该子树必是一棵最优二叉树。以后,按照与T的形成过 程的相反的顺序依次分解各叶结点,直到再次构造出T,则依据上面的定 理可知T是一棵Huffman树。
《数据结构(C语言版 第2版)》(严蔚敏 著)第四章练习题答案

《数据结构(C语言版第2版)》(严蔚敏著)第四章练习题答案第4章串、数组和广义表1.选择题(1)串是一种特殊的线性表,其特殊性体现在()。
A.可以顺序存储B.数据元素是一个字符C.可以链式存储D.数据元素可以是多个字符若答案:B(2)串下面关于串的的叙述中,()是不正确的?A.串是字符的有限序列B.空串是由空格构成的串C.模式匹配是串的一种重要运算D.串既可以采用顺序存储,也可以采用链式存储答案:B解释:空格常常是串的字符集合中的一个元素,有一个或多个空格组成的串成为空格串,零个字符的串成为空串,其长度为零。
(3)串“ababaaababaa”的next数组为()。
A.012345678999 B.012121111212 C.011234223456 D.0123012322345答案:C(4)串“ababaabab”的nextval为()。
A.010104101B.010102101 C.010100011 D.010101011答案:A(5)串的长度是指()。
A.串中所含不同字母的个数B.串中所含字符的个数C.串中所含不同字符的个数D.串中所含非空格字符的个数答案:B解释:串中字符的数目称为串的长度。
(6)假设以行序为主序存储二维数组A=array[1..100,1..100],设每个数据元素占2个存储单元,基地址为10,则LOC[5,5]=()。
A.808 B.818 C.1010 D.1020答案:B解释:以行序为主,则LOC[5,5]=[(5-1)*100+(5-1)]*2+10=818。
(7)设有数组A[i,j],数组的每个元素长度为3字节,i的值为1到8,j的值为1到10,数组从内存首地址BA开始顺序存放,当用以列为主存放时,元素A[5,8]的存储首地址为()。
A.BA+141 B.BA+180 C.BA+222 D.BA+225答案:B解释:以列序为主,则LOC[5,8]=[(8-1)*8+(5-1)]*3+BA=BA+180。
数据结构-C语言-第四章作业

数据结构
练习
数据结构
设有一个二维数组A[m][n]按行优先顺序存储,假设A[0][0] 存放位置在644(10),A[2][2]存放位置在676(10),每个元素 占一个空间,问A[3][3](10)存放在什么位置?脚注(10)表示 用10进制表示。
答:设数组元素A[i][j]存放在起始地址为Loc ( i, j ) 的存储单 元中
Байду номын сангаас
练习
数据结构
设有二维数组A[10,20],其每个元素占两个字节, A[0][0]存储地址为100,若按行优先顺序存储,则 元素A[6,6]的存储地址为 352 ,按列优先顺序存储 ,元素A[6,6]的存储地址为 232 。
答:(6*20+6)*2+100=352 (6*10+6)*2+100=232
练习
数据结构
1、 设有二维数组a[6][8],每个元素占相邻的4个字节,存储 器按字节编址,已知a的起始地址是1000,试计算:
数组a的最后一个元素a[5][7]起始地址; 按行序优先时,元素a[4][6]起始地址; 按列序优先时,元素a[4][6]起始地址。
课本作业
4.5 4.8 4.10
∵ Loc ( 2, 2 ) = Loc ( 0, 0 ) + 2 * n + 2 = 644 + 2 * n + 2 = 676.
∴ n = ( 676 - 2 - 644 ) / 2 = 15
∴ Loc ( 3, 3 ) = Loc ( 0, 0 ) + 3 * 15 + 3 = 644 + 45 + 3 = 692.
《数据结构及其应用》笔记含答案 第四章_串、数组和广义表

第4章串、数组和广义表一、填空题1、零个或多个字符组成的有限序列称为串。
二、判断题1、稀疏矩阵压缩存储后,必会失去随机存取功能。
(√)2、数组是线性结构的一种推广,因此与线性表一样,可以对它进行插入,删除等操作。
(╳)3、若采用三元组存储稀疏矩阵,把每个元素的行下标和列下标互换,就完成了对该矩阵的转置运算。
(╳)4、若一个广义表的表头为空表,则此广义表亦为空表。
(╳)5、所谓取广义表的表尾就是返回广义表中最后一个元素。
(╳)三、单项选择题1、串是一种特殊的线性表,其特殊性体现在(B)。
A.可以顺序存储B.数据元素是一个字符C.可以链式存储D.数据元素可以是多个字符若2、串下面关于串的的叙述中,(B)是不正确的?A.串是字符的有限序列B.空串是由空格构成的串C.模式匹配是串的一种重要运算D.串既可以采用顺序存储,也可以采用链式存储解释:空格常常是串的字符集合中的一个元素,有一个或多个空格组成的串成为空格串,零个字符的串成为空串,其长度为零。
3、串“ababaaababaa”的next数组为(C)。
A.012345678999 B.012121111212 C.011234223456 D.01230123223454、串“ababaabab”的nextval为(A)。
A.010104101B.010102101 C.010100011 D.0101010115、串的长度是指(B)。
A.串中所含不同字母的个数B.串中所含字符的个数C.串中所含不同字符的个数D.串中所含非空格字符的个数解释:串中字符的数目称为串的长度。
6、假设以行序为主序存储二维数组A=array[1..100,1..100],设每个数据元素占2个存储单元,基地址为10,则LOC[5,5]=(B)。
A.808 B.818 C.1010 D.1020解释:以行序为主,则LOC[5,5]=[(5-1)*100+(5-1)]*2+10=818。
数据结构(C语言版)习题及答案第四章

数据结构(C语言版)习题及答案第四章习题4.1选择题1、空串与空格串是(B)。
A、相同B、不相同C、不能确定2、串是一种特殊的线性表,其特殊性体现在(B)。
A、可以顺序存储B、数据元素是一个字符C、可以链式存储D、数据元素可以是多个字符3、设有两个串p和q,求q在p中首次出现的位置的操作是(B)。
A、连接B、模式匹配C、求子串D、求串长4、设串1=“ABCDEFG”,2=“PQRST”函数trconcat(,t)返回和t串的连接串,trub(,i,j)返回串中从第i个字符开始的、由连续j 个字符组成的子串。
trlength()返回串的长度。
则trconcat(trub(1,2,trlength(2)),trub(1,trlength(2),2))的结果串是(D)。
A、BCDEFB、BCDEFGC、BCPQRSTD、BCDEFEF5、若串=“oftware”,其子串个数是(B)。
A、8B、37C、36D、94.2简答题1、简述空串与空格串、主串与子串、串名与串值每对术语的区别?答:空串是指长度为0的串,即没有任何字符的串。
空格串是指由一个或多个空格组成的串,长度不为0。
子串是指由串中任意个连续字符组成的子序列,包含子串的串称为主串。
串名是串的一个名称,不指组成串的字符序列。
串值是指组成串的若干个字符序列,即双引号中的内容。
2、两个字符串相等的充要条件是什么?答:条件一是两个串的长度必须相等条件二是串中各个对应位置上的字符都相等。
3、串有哪几种存储结构?答:有三种存储结构,分别为:顺序存储、链式存储和索引存储。
4、已知两个串:1=”fgcdbcabcadr”,2=”abc”,试求两个串的长度,判断串2是否是串1的子串,并指出串2在串1中的位置。
答:(1)串1的长度为14,串2的长度为3。
(2)串2是串1的子串,在串2中的位置为9。
5、已知:1=〃I’matudent〃,2=〃tudent〃,3=〃teacher〃,试求下列各操作的结果:trlength(1);答:13trconcat(2,3);答:”tudentteachar”trdelub(1,4,10);答:I’m6、设1=”AB”,2=”ABCD”,3=”EFGHIJK,试画出它们在各种存储结构下的结构图。
数据结构课后习题(第4-5章)

【课后习题】第4章 串 第5章 数组和广义表网络工程2010级( )班 学号: 姓名:题 号 一 二 三 四 总分 得 分一、填空题(每空1分,共30分)1. 串有三种机内表示方法: 、 和 ,其中前两种属于顺序存储结构,第三种属于 。
2. 若n 为主串长度,m 为子串长度,则串的BF (朴素)匹配算法最坏的情况下需要比较字符的总次数为 ,T(n)= 。
3. 是任意串的子串;任意串S 都是S 本身的子串,除S 本身外,S 的其他子串称为S 的 。
4. 设数组a[1…50, 1…60]的基地址为1000,每个元素占2个存储单元,若以行序为主序顺序存储,则元素a[32,58]的存储地址为 。
5. 对于数组,比较适于采用 结构够进行存储。
6. 广义表的深度是指_______。
7. 将一个100100 A 的三对角矩阵,按行优先存入一维数组B[297]中,A 中元素66,66A 在B 数组中的位置k 为 。
8. 注意:a i,j 的k 为 2(i-1)+j-1,(i=1时j=1,2;1<i<=n 时,j=i-1,i,i+1) 。
9. 称为空串; 称为空白串。
10. 求串T 在主串S 中首次出现的位置的操作是 ,其中 称为目标串, 称为模式。
11. 对称矩阵的下三角元素a[i,j],存放在一维数组V 的元素V[k]中(下标都是从0开始), 12. k 与i ,j 的关系是:k= 。
13. 在n 维数组中每个元素都受到 个条件的约束。
14. 同一数组中的各元素的长度 。
15. 三元素组表中的每个结点对应于稀疏矩阵的一个非零元素,它包含有三个数据项,分别表示该元素的 、 和 。
16.稀疏矩阵中有n个非零元素,则其三元组有行。
17.求下列广义表操作的结果:18.(1)GetHead【((a,b),(c,d))】=== ;19.(2)GetHead【GetTail【((a,b),(c,d))】】=== ;20.(3)GetHead【GetTail【GetHead【((a,b),(c,d))】】】=== ;21.(4)GetTail【GetHead【GetTail【((a,b),(c,d))】】】=== ;22.广义表E=(a,(b,E)),则E的长度= ,深度= ;二、判断题(如果正确,在下表对应位置打“√”,否则打“⨯”。
数据结构(C++版)课后答案 (王红梅)第4章 广义线性表多维数组和广义表

第 4 章广义线性表——多维数组和广义表课后习题讲解1. 填空⑴数组通常只有两种运算:()和(),这决定了数组通常采用()结构来实现存储。
【解答】存取,修改,顺序存储【分析】数组是一个具有固定格式和数量的数据集合,在数组上一般不能做插入、删除元素的操作。
除了初始化和销毁之外,在数组中通常只有存取和修改两种操作。
⑵二维数组A中行下标从10到20,列下标从5到10,按行优先存储,每个元素占4个存储单元,A[10][5]的存储地址是1000,则元素A[15][10]的存储地址是()。
【解答】1140【分析】数组A中每行共有6个元素,元素A[15][10]的前面共存储了(15-10)×6+5个元素,每个元素占4个存储单元,所以,其存储地址是1000+140=1140。
⑶设有一个10阶的对称矩阵A采用压缩存储,A[0][0]为第一个元素,其存储地址为d,每个元素占1个存储单元,则元素A[8][5]的存储地址为()。
【解答】d+41【分析】元素A[8][5]的前面共存储了(1+2+…+8)+5=41个元素。
⑷稀疏矩阵一般压缩存储方法有两种,分别是()和()。
【解答】三元组顺序表,十字链表⑸广义表((a), (((b),c)),(d))的长度是(),深度是(),表头是(),表尾是()。
【解答】3,4,(a),((((b),c)),(d))⑹已知广义表LS=(a,(b,c,d),e),用Head和Tail函数取出LS中原子b的运算是()。
【解答】Head(Head(Tail(LS)))2. 选择题⑴二维数组A的每个元素是由6个字符组成的串,行下标的范围从0~8,列下标的范围是从0~9,则存放A至少需要()个字节,A的第8列和第5行共占()个字节,若A按行优先方式存储,元素A[8][5]的起始地址与当A按列优先方式存储时的()元素的起始地址一致。
A 90B 180C 240D 540E 108F 114G 54H A[8][5] I A[3][10] J A[5][8] K A[4][9]【解答】D,E,K【分析】数组A为9行10列,共有90个元素,所以,存放A至少需要90×6=540个存储单元,第8列和第5行共有18个元素(注意行列有一个交叉元素),所以,共占108个字节,元素A[8][5]按行优先存储的起始地址为d+8×10+5=d+85,设元素A[i][j]按列优先存储的起始地址与之相同,则d+j×9+i=d+85,解此方程,得i=4,j=9。
数据结构课后题答案(第4章).
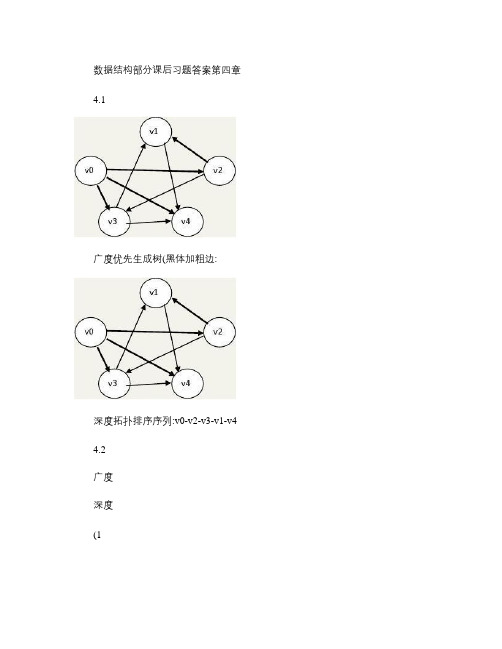
数据结构部分课后习题答案第四章4.1广度优先生成树(黑体加粗边:深度拓扑排序序列:v0-v2-v3-v1-v4 4.2广度深度(1(2加边顺序a-b b-e e-d d-f f-c4.3、如图所示为一个有6个顶点{u1,u2,u3,u4,u5,u6}的带权有向图的邻接矩阵。
根据此邻接矩阵画出相应的带权有向图,利用dijkstra 算法求第一个顶点u1到其余各顶点的最短路径,并给出计算过程。
带权有向图:4.4证明在图中边权为负时Dijkstra算法不能正确运行若允许边上带有负权值,有可能出现当与S(已求得最短路径的顶点集,归入S内的结点的最短路径不再变更内某点(记为a以负边相连的点(记为b确定其最短路径时,它的最短路径长度加上这条负边的权值结果小于a原先确定的最短路径长度,而此时a在Dijkstra算法下是无法更新的。
4.5P.198 图中的权值有负值不会影响prim和kruskal的正确性如图:KRUSKAL求解过程:4.6 Dijkstra算法如何应用到无向图?答:Dijkstra算法通常是运用在带非负权值的有向图中,但是无向图其实就是两点之间两条有向边权值相同的特殊的有向图,这样就能将Dijkstra算法运用到无向图中。
4.7用FLOYD算法求出任意两顶点的最短路径(如图A(6所示。
A(0= A(1= A(2=A(3= A(4=A(5= A(6= V1 到 V2、V3、V4、V5、V6 往返路径长度分别为 5,9,5,9,9,最长为 9,总的往返路程为 37 同理 V2 到 V1、V3、V4、V5、V6 分别为 5,8,4,4,13,最长为 13,总和 34 V3 对应分别为 9,8,12,8,9,最长为 12,总和为 46 V4 对应分别为 5,4,12,4,9,最长为 12,总和为 34 V5 对应分别为9,4,8,4,9,最长为 9,总和为 34 V6 对应分别为 9,13,9,9,9,最长为13,总和为 49 题目要求娱乐中心“距其它各结点的最长往返路程最短” ,结点V1, V5 最长往返路径最短都是 9。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第4章串作业
1 一个字符串中(任意连续字符组成的子序列)称为该串的子串。
2 空串与空格串的区别在于(空串的长度为0,空格串长度不为0 )。
3 设有两个串p和q,求p在q中首次出现的位置的运算称作(模式匹配)。
4 串时一种特殊的线性表,其特殊性体现在(操作的对象通常为串的整体)。
5 已知3个字符串分别为S=’ab…abcaabcbca…a’,S1=’caab’,S2=’bcb’,利用所学字符串基本运算的函数得到结果串为:
S3=’caabcbca…aca…a’
要求写出得到上述结果串S3所用的函数及执行算法。
i1=index(S,S1,1)
i2=index(S,S2,1)+3;
sub1=substr(S,i1,length(S)-i1+1);
sub2=substr(S,i2,length(S)-i2+1;
S3=concat(sub1, sub2);
6 如果某串的长度小于一个常数,则采用何种存储方式最节省空间?
定长顺序存储。