区位码、国标码与机内码的转换
机内码和区位码的转换方法

机内码和区位码的转换方法
机内码和区位码之间的转换方法可用玛法泽型编码转换方法实施。
玛法泽型编码转换方法利用了四位的4进制码,将机内码的每四
位码看成一个整体,结合其他2个权重,依次做8次右移操作,得到
区位码的每一位值。
操作执行过程:
1. 将机内码的每四位用单独的变量(以X1,X2,X3,X4等为例)来
表示;
2. 分别计算X1,X2,X3,X4对应的权重,以其乘积表示,权重为(8,4,2,1);
3. 将X1,X2,X3,X4按序表示出8位权重和值,8位权重和值可以
用1个变量(以Y为例)表示,Y的每一位的值只与X1到X4其中的一位值有关;
4. Y的每一位分别从右至左取出,按位反码,得到了区位码。
区位码、汉字交换码和汉字机内码的概念和关系

区位码,汉字交换码和汉字机内码的概念是什么?它们之间有什么关系?区位码:1981年国家颁布了GB2312汉字标准共有6763个,其中一级3755,二级3008,还有682非汉字字符。
并为每个字符规定了标准编码,便于在计算机内部相互转换。
作为GB2312标准只是定义了一张94×94的二维表。
其中行为区号,列为位号。
这样可以利用区号和位号来找到其中的汉字。
这种编码就是我们所说的区位码。
比如陈(1934) 区号:19 位号:34,为了处理与存储的方便,每个汉字的区号和位号在计算机内部分别用一个字节来表示区位码无法于汉字进行通信,因为ASCII码中规定了OOH-1F作为控制码使用,这样就发生了冲突。
由于计算机不是中国人发明的所以只能听从于国际标准ISO2022规定区号和位号都加上32(20H),这样就防止冲突。
经过加上32以后的编码称为国际交换码陈-区号:19+32= 5100010011+00100000=00110011位号:34+32=6600100010+00100000=01000010即5166 16进制3342由于文本中通常混合使用汉字和西文字符,汉字信息如果不予以特别标识,就会与单字节的ASCII码混淆。
此问题的解决方法之一是将一个汉字看成是两个扩展ASCII码,使表示GB2312汉字的两个字节的最高位都为1。
这种高位为1的双字节汉字编码即为GB2312汉字的机内码,简称为“内码”.00110011最高位变为1则从33变为B301000010最高位变为1则从42变为C2这样一来,陈的机内码应该为B3C2这里要说明的是不管你是采用什么样的输入法输入汉字,其汉字的机内码都是相同的。
如果要从一个汉字的机内码转换为区位码,其实就是相反的方向进行运算.。
汉字区位码、国标码(交换码)和机内码转换方法

汉字区位码、国标码(交换码)和机内码转换方法一般换算全部用十六进制。
机内码、国际码是十六进制的,区位码是十进制的。
具体换算步骤:(H表示十六进制,D表示十进制)1.将四位区号分为两部分,两位数为一组。
2.把这两个数字转换成十六进制,用公式计算。
国际码=区位码(十六进制)+2020H机内码=国际码+8080H例如:某汉字的区位码是2534。
则25D=19H,34D=22H则国际码=1922H+2020H=3952H,机内码=3952H+8080H=B9D2H 1、转换关系:【设转为十六进制的区位码为区位码I;转换原因在第3点】•区位码I=区位码的区码(前两位)和位码(后两位)分别转十六进制再按原顺序组合起来•国标码•=区位码I+2020H 【2020H不拆分】•机内码=国标码+8080H【8080H不拆分】•机内码=区位码I+A0A0H【A0A0H不拆分】注意:区位码是十进制表示,由区(行)和位(列)组成一个二维结构,所以转换过程需要将区位码拆分后分别转十六进制。
2、例子:•将“江”的区位码2913转为机内码【末尾D代表十进制,末尾H代表十六进制】:1、2913D中区和位分别转十六进制:29D=1DH,13D=DH2、国标码=区位码+2020H=1D0DH+2020H=3D2DH3、机内码=国标码+8080H=3D2DH+8080H=BDADHor 机内码=区位码+A0A0H=1D0DH+A0A0H=BDADH3、扩展【扩展内容主要与为什么要加2020H或8080H这些有关】:区位码:每个汉字都有唯一的定位码,定位码一个字节,定位码一个字节,总共占用两个字节。
国标码:。
共7445个字符,其中一级3755个,二级3008个,图形符号682个【一级汉字按拼音排序,二级用部首排序】,全部国家标准代码被放置在94个区域中,每个区域中有94个矩阵。
每个字节占用8位,主要使用7位编码(高位为0)。
- 为啥要将区位码转为国标码?汉字编码之前,已经有了标准的ASCII,开发者只沿用了ASCII中32个控制字符其他ASCII被覆盖。
汉字国标码,机内码和区位码的不同

汉字国标码,机内码和区位码的不同汉字是中华文化的瑰宝,是中华民族的文化符号。
在现代社会中,汉字的应用范围越来越广泛,汉字输入也成为人们日常生活中不可或缺的一部分。
汉字输入需要用到汉字国标码、机内码和区位码,这三种码制虽然都是用来表示汉字的,但它们之间存在着不同,下面我们就来一一探究。
一、汉字国标码汉字国标码是由国家标准化委员会制定的一种汉字编码体系,也称为GB码或GB2312码。
它是在1980年提出的,是我国第一个汉字编码标准,其编码范围包括了6763个常用汉字和682个生僻字,共计7445个汉字。
汉字国标码采用两字节表示一个汉字,每个字节的取值范围是0xA1~0xFE,共计94个字符,其中0xA1~0xA9和0xF7~0xFE 是用来表示第一字节的,0xA1~0xFE是用来表示第二字节的。
汉字国标码的优点是编码规范,兼容性好,适用范围广,能够兼容各种操作系统和软件程序,因此在汉字输入中得到了广泛应用。
但其缺点也比较明显,就是字符集太小,不支持繁体字和一些特殊符号。
二、机内码机内码是计算机内部使用的一种二进制编码体系,也称为ASCII 码。
它是由美国信息交换标准委员会在1963年制定的,其编码范围包括了128个字符,包括了英文字母、数字、标点符号和控制字符等。
机内码采用一个字节表示一个字符,每个字节的取值范围是0~127。
机内码的优点是编码简单,易于处理,因此在计算机内部得到广泛应用。
但其缺点也很明显,就是只支持英文字母等ASCII字符,不支持汉字和其他语言的字符。
三、区位码区位码是中国大陆地区常用的一种汉字编码体系,也称为GB码。
它是在1956年由中国科学院信息处理研究室提出的,是我国第一个汉字编码标准。
区位码采用一个字节表示一个汉字,其中第一个字节表示该汉字所在的区,第二个字节表示该汉字在该区的位置。
区号取值范围是0xA1~0xFE,共计94个区,每个区号包含了94个位置码,位置码取值范围也是0xA1~0xFE。
国标码区位码说明

1.国标码:“国家标准信息交换用汉字编码”(GB2312-80标准),简称国标码。
国标码是二字节码, 用两个七位二进制数编码表示一个汉字。
2.区位码:为了使每一个汉字有一个全国统一的代码,区位码是国家规定的94*94的一个方阵,其中每行叫做一个区,每列叫做一个位,组合起来就组成了区位码,我们可以在相关网站查询某个汉字的区位码,例如汉字“我”的区位码是46 50 ,标识“我”在46区,50位。
3.机内码:机内码是在计算机中存储的汉子编码。
三者之间的关系。
国标码=16进制的区位码+2020H机内码=国标码+8080H例如“我”的的区位码是46 50 这是10进制的转化为16进制:2E32H所以“我”的国标码:2E32H+2020H=4E52H所以“我”机内码:4E52H+8080H=CED2(其实就是把二进制国标码的最高位置1,注意看E和2都没有变化)机内码转化为2进制就可以再计算机中存储,这里面转化为10进制可以输出。
CED2的10进制为:52946,这里我们打开记事本,按住alt建,输入52946即可以看见“我”,因为52946是“我”的机内码的10进制。
这里面有两个问题:1.为什么不用区位码直接表示国标码,为要加上2020H?2.机内码为什么要在国标码的基础上加上8080H,而不是直接只用国标码作为机内码?这里我先解决第二个问题,国标码就是由2个ASCII码组成,为什么呢(这里简单介绍一下,后面会详细说明)?因为在英文中只有26个字母,所以用一个字节就可以表示了,用一个字节的话可以表示2^8个符号,就是256个符号,绰绰有余啊,于是外国人制订了规范,规定0-127(00000000-01111111)个字符他们用了,用来表示英文字符和一些符号,就是ASCII码,但是汉字有很多,256个根本就不够,于是国家就用两个ASCII来表示一个汉字,就是2个字节标识一个汉字,例如“保”的区位码为:1703,所以国标码为:1703的10进制+2020H=3123H,然而:31H 和23H在ASCII中式有值的,31H在ASCII中表示数字1,23H表示的是“#”(这个可以在网上查询),那么如果我以国标码作为机内码的话,如果内存中有两个字节为31H和23H,那么到底是表示汉字“保”呢?还是字符1#呢?这样就有了歧义,但是解决办法就有了,0-127不是被英文字符占了吗?那么我就用127之后的来表示不就可以了吗?于是我把汉字的两个字节每个字节机上128(16进制就是80H),于是问题解决了,汉字“保”的机内码变为:3123H+8080H=B2A3H(10进制就是45475),打开记事本按住alt+45475看看是不是“保”,这样就不会和英文的ASCII冲突了。
对汉字进行传输,处理和存储时使用汉字的

对汉字进行传输,处理和存储时使用汉字的
在计算机中,对汉字进行传输、处理和存储时使用汉字的()。
A.字形码B.国标码C.输入码D.机内码
参考答案D解析:显示或打印汉字时使用汉字的字形码,在计算
机内部时使用汉字的机内码。
汉字机内码、国标码和区位码三者之间的关系为:区位码(十进制)的两个字节分别转换为十六进制后加20H得到对应的国标码;机内码是汉字交换码(国标码)两个字节的最高位分别加1,即汉字交换码(国标码)的两个字节分别加80H得到对应的机内码;区位码(十进制)的两个字节分别转换为十六进制后加A0H得到对应的机内码。
计算机处理汉字信息的前提条件是对每个汉字进行编码,这些编码统称为汉字编码。
汉字信息在系统内传送的过程就是汉字编码转换的过程。
汉字交换码:汉字信息处理系统之间或通信系统之间传输信息时,对每一个汉字所规定的统一编码,我国已指定汉字交换码的国家标准“信息交换用汉字编码字符集——基本集”,代号为GB2312—80,又称为“国标码”。
国标码:所有汉字编码都应该遵循这一标准,汉字机内码的编码、汉字字库的设计、汉字输入码的转换、输出设备的汉字地址码等,都以此标准为基础。
GB2312—80就是国标码。
该码规定:一个汉字用
两个字节表示,每个字节只有7位,与ASCII码相似。
考点3文字编码知识梳理典型例题及训练解析
考点三文字编码基础再现1、ASCII码ASCII码全称为“美国国家信息交换标准代码”,通常用来对英文字符进行编码。
该编码使用7位二进制数,共可以表示128个字符。
一个ASCII码存储时占用1字节,存储ASCII时在最高位加“0”。
ASCII码中的数字、字母按顺序依次排列。
2、汉字编码汉字在计算机内采用二进制编码,我国最早采用的汉字编码是GB2312。
每个汉字用2个字节进行编码,每个字节的最高位用“1”填充。
汉字的输入码(外码):是利用汉字相关特征对指定汉字进行编制的输入代码,包括:音码、形码、音形结合码、自然码、流水码等。
汉字的输出码(字形码):用来存储汉字的字体形状汉字的交换码:计算机系统间交换汉字通常采用GB2312标准。
处理码又称内码,用UltraEdit或WinHex工具软件观察内码时,ASCII码只占1个字节,汉字占2个字节。
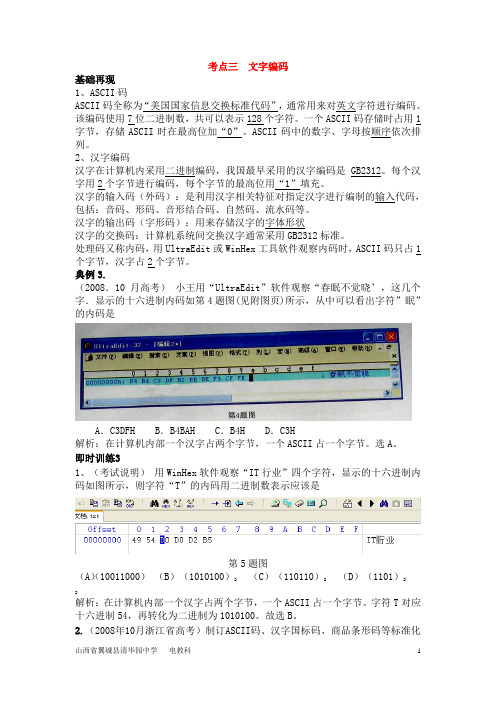
典例3.(2008.10月高考)小王用“UltraEdit”软件观察“春眠不觉晓’,这几个字.显示的十六进制内码如第4题图(见附图页)所示,从中可以看出字符”眠”的内码是A.C3DFH B.B4BAH C.B4H D.C3H解析:在计算机内部一个汉字占两个字节,一个ASCII占一个字节。
选A。
即时训练31、(考试说明)用WinHex软件观察“IT行业”四个字符,显示的十六进制内码如图所示,则字符“T”的内码用二进制数表示应该是第5题图(A)(10011000)2(B)(1010100)2(C)(110110)2(D)(1101)2解析:在计算机内部一个汉字占两个字节,一个ASCII占一个字节。
字符T对应十六进制54,再转化为二进制为1010100。
故选B。
2.(2008年10月浙江省高考)制订ASCII码、汉字国标码、商品条形码等标准化编码主要是为了信息表达的A.自由化 B.规范化 C.形象化 D.通俗化解析:考查信息标准化编码的意义,故选B。
3.(2009年3月浙江省高考)汉字点阵是一种用黑白两色点阵来表示汉字字形的编码,一个16×16点阵字模的存储容量为A.1字节B.16字节C.32字节D.64字节解析:一个点阵对应二进制1位(比特,bit或b),16×16÷8=32字节。
浙江省计算机高考复习(第6课)常用信息的编码

(3)汉字字形码
在计算机系统中,要显示或打印任何字符、汉字都 是由点阵式的字模组成。
16*16的点阵的汉字
字形码:
为了使计算机能识别和存储字模,就必须对字模进 行数字化,把字模中的每一个点都用二进制数表示,即 用“1”表示黑点,用“0”表示白点。这种数字化的字 模点阵代码就是字形码。
精品课程
常用信息的编码
计算机内部均采用二进制数来表示各种信息。要想使输 入设备输入的数字、字符、标点符号和文字等信息能被计算 机所识别,必须将其转换为相应的二进制编码。
目前常用的编码有:
BCD码、ASCII码、汉字编码和奇偶校验码等。
BCD码(了解)
用四位二进制数码来表示一个十进制数。 规则:选用0000-1001来表示0-9的十个数符。 如: (365)10=(0011 0110 0101)BCD 11001.11B= (25.75)10 =(0010 0101.0111 0101)BCD
练习3:某计算机系统中采用奇校验,若字符‘A’在
传送到目的地时为“11000010”,传输过程是否出错?
计算机能否发现?
奇偶校验码只能发现一位或者奇数位错误,而且不能纠 正错误。
汉字地址码:
指出汉字模信息在汉字库中存放的逻辑地址的编码。
三、奇偶校验码
校验码:具有发现或纠正传送过程中出现的错误的编码。
最常用、最简单的校验方法就是奇偶校验,一般以 一个字节为单位加奇偶校验位。 奇校验: 确保被传输的数据中‘1’的个数是奇数个。
偶校验:
确保被传输的数据中‘1’的个数是是偶数个。
国标码、机内码、区位码、ASCⅡ

国标码、机内码、区位码国家标准代码:国标码国家标准代码,简称国标码。
是中华人民共和国的中文常用汉字编码集,亦为新加坡采用。
国家标准强制标准冠以“GB”,推荐标准冠以“GB/T”,国标码是一个四位十六进制数。
现时中华人民共和国官方强制使用GB 18030标准,但较旧的计算机仍然使用GB 2312。
“GB”在计算机领域中常常表示GB 2312-80或GB 18030-2005。
两者是汉语编码系统的标准,在中国大陆和新加坡用于简体中文。
机内码:国标码是不可能在计算机内部直接采用的,于是,;汉字的机内码采用变形国标码,其变换方法为:将国标码的每个字节都加上128,即将两个字节的最高位由0改1,其余7位不变,如:由上面我们知道,“保”字的国标码为3123H,前字节为00110001B,后字节为00100011B,高位改1为10110001B和10100011B 即为B1A3H,因此,“保”字的机内码就是B1A3H。
区位码1980年,为了使每一个汉字有一个全国统一的代码,我国颁布了第一个汉字编码的国家标准:GB2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础,也是目前国内所有汉字系统的统一标准。
区位码是一个四位的十进制数,每个区位码都对应着一个唯一的汉字或符号,但因为十六进制数我们很少用到,所以大家常用的是区位码,它的前两位叫做区码,后两位叫做位码。
ASCⅡ目前计算机中用得最广泛的字符集及其编码,是由美国国家标准局(ANSI)制定的ASCII 码(American Standard Code for Information Interchange,美国标准信息交换码),它已被国际标准化组织(ISO)定为国际标准,称为ISO 646标准。
适用于所有拉丁文字字母,ASCII码有7位码和8位码两种形式。
简介因为1位二进制数可以表示(2^1)2种状态:0、1;而2位二进制数可以表示(2^2)4种状态:00、01、10、11;依次类推,7位二进制数可以表示(2^7)128种状态,每种状态都唯一地编为一个7位的二进制码,对应一个字符(或控制码),这些码可以排列成一个十进制序号0~127。
汉字的编码

汉字的编码1.汉字信息的交换码汉字信息交换码简称交换码,也叫国标码。
规定了7 445个字符编码,其中有682个非汉字图形符和6763个汉字的代码。
有一级常用字3 755个,二级常用字3 008个。
两个字节存储一个国标码。
国标码的编码范围是2121 H一7E7EH。
区位码和国标码之间的转换方法是将一个汉字的十进制区号和十进制位号分别转换成十六进制数,然后再分别加上20H,就成为此汉字的国标码:汉字国标码=区号(十六进制数)+20H位号(十六进制数)+ 20H而得到汉字的国标码之后,我们就可以使用以下公式计算汉字的机内码:汉字机内码=汉字国标码+8080H2.汉字偷入码汉字输人码也叫外码,都是由键盘上的字符和数字组成的。
目前流行的编码方案有全拼输人法、双拼输入法、自然码输人法和五笔输人法等。
3.汉字内码汉字内码是在计算机内部对汉字进行存储、处理的汉字代码,它应能满足存储、处理和传输的要求。
一个汉字输人计算机后就转换为内码。
内码需要两个字节存储,每个字节以最高位置‘1”作为内码的标识。
4.汉字字型码汉字字型码也叫字模或汉字输出码。
在计算机中,8个二进制位组成一个字节,它是度量空间的基本单可见一个16 x 16点阵的字型码需要16 x 16/8=32字节存储空间。
汉字字型通常分为通用型和精密型两类。
5.汉字地址码汉字地址码是指汉字库中存储汉字字型信息的逻辑地址码。
它与汉字内码有着简单的对应关系,以简化内码到地址码的转换。
6.各种汉字代码之间的关系汉字的输人、处理和输出的过程,实际上是汉字的各种代码之间的转换过程。
如图1- 1表示了这些汉字代码在汉字信息处理系统中的位置及它们之间的关系.。
汉字的国标码机内码区位码区别

汉字的国标码机内码区位码区别文字编码系列--汉字的国标码,机内码,区位码(gbcode查出的是区位码)1.国标码:“国家标准信息交换用汉字编码”(GB2312-80标准),简称国标码。
国标码是二字节码, 用两个七位二进制数编码表示一个汉字。
2.区位码:为了使每一个汉字有一个全国统一的代码,区位码是国家规定的94*94的一个方阵,其中每行叫做一个区,每列叫做一个位,组合起来就组成了区位码,我们可以在相关网站查询某个汉字的区位码,例如汉字“我”的区位码是46 50 ,标识“我”在46区,50位。
3.机内码:机内码是在计算机中存储的汉子编码。
三者之间的关系。
国标码=16进制的区位码+2020H机内码=国标码+8080H例如“我”的的区位码是46 50 这是10进制的转化为16进制:2E32H(46==2E,50==32)所以“我”的国标码:2E32H+2020H=4E52H所以“我”机内码:4E52H+8080H=CED2(其实就是把二进制国标码的最高位置1,注意看E和2都没有变化)机内码转化为2进制就可以再计算机中存储,这里面转化为10进制可以输出。
CED2的10进制为:52946,这里我们打开记事本,按住alt建,输入52946即可以看见“我”,因为52946是“我”的机内码的10进制。
这里面有两个问题:1.为什么不用区位码直接表示国标码,为要加上2020H?2.机内码为什么要在国标码的基础上加上8080H,而不是直接只用国标码作为机内码?这里我先解决第二个问题,国标码就是由2个ASCII码组成,为什么呢(这里简单介绍一下,后面会详细说明)?因为在英文中只有26个字母,所以用一个字节就可以表示了,用一个字节的话可以表示2^8个符号,就是256个符号,绰绰有余啊,于是外国人制订了规范,规定0-127(00000000-01111111)个字符他们用了,用来表示英文字符和一些符号,就是ASCII码,但是汉字有很多,256个根本就不够,于是国家就用两个ASCII来表示一个汉字,就是2个字节标识一个汉字,例如“保”的区位码为:1703,所以国标码为:1703的10进制+2020H=3123H,然而:31H 和23H在ASCII中式有值的,31H在ASCII中表示数字1,23H表示的是“#”(这个可以在网上查询),那么如果我以国标码作为机内码的话,如果内存中有两个字节为31H和23H,那么到底是表示汉字“保”呢?还是字符1#呢?这样就有了歧义,但是解决办法就有了,0-127不是被英文字符占了吗?那么我就用127之后的来表示不就可以了吗?于是我把汉字的两个字节每个字节机上128(16进制就是80H),于是问题解决了,汉字“保”的机内码变为:3123H+8080H=B2A3H(10进制就是45475),打开记事本按住alt+45475看看是不是“保”,这样就不会和英文的ASCII冲突了。
区位码国标码机内码转换问题

国标码并不等于区位码,它是由区位码稍作转换得到,其转换方法为:先将十进制区码和位码转换为十六进制的区码和位码,;这样就得了一个与国标码有一个相对位置差的代码,;再将这个代码的第一个字节和第二个字节分别加上20H,就得到国标码。
如:“保”字的国标码为3123H,它是经过下面的转换得到的:1703D->1103H->+20H->3123H。
输入码、区位码、国标码与机内码国家标准局1980年颁布的《信息交换用汉字编码字符集"基本集》(代号为GB2312 80)规定的汉字交换码作为国家标准汉字编码。
GB2312 80中共有7445个字符符号:汉字符号6763个一级汉字3755个(按汉语拼音字母顺序排列)二级汉字3008个(按部首笔划顺序排列)非汉字符号682个GB2312 80规定,我们知道,键盘是当前微机的主要输入设备,;输入码就是使用英文键盘输入汉字时的编码。
目前,我国已推出的输入码有数百种,但用户使用较多的约为十几种,按输入码编码的主要依据,大体可分为顺序码、音码、形码、音形码四类,如“保”字,用全拼,输入码为码为“BAO”,用区位码,输入码为“1703”,用五笔字型则为“WKS”。
计算机只识别由0、1组成的代码,ASCII码是英文信息处理的标准编码,汉字信息处理也必须有一个统一的标准编码。
汉字交换码(国标码)主要用于汉字信息交换,我国国家标准局于1981年5月颁布了《信息交换用汉字编码字符集——基本集》,代号为GB2312-80,共对6763个汉字和682个图形字符进行了编码,其编码原则为:汉字用两个字节表示,每个字节用七位码(高位为0),;所有的国标码汉字及符号组成一个94行94列的二维代码表中。
在此方阵中,每一行称为一个"区",每一列称为一个"位"。
这个方阵实际上组成一个有94个区(编号由01到94),每个区有94个位(编号由01到94)的汉字字符集。
刨根究底字符编码之六——简体汉字编码中区位码、国标码、内码、外码、字形码的区别及关系

刨根究底字符编码之六——简体汉字编码中区位码、国标码、内码、外码、字形码的区别及关系简体汉字编码中区位码、国标码、内码、外码、字形码的区别及关系GB2312、GBK、GB18030等GB类汉字编码⽅案的具体实现⽅式是怎样的?区位码是什么?国标码是什么?内码、外码、字形码⼜是什么意思?它们是如何转换的,⼜为什么要这样转换?下⾯以GB2312为例来加以说明(由于GBK、GB18030是以GB2312为基础扩展⽽来,因此编码实现⽅式与GB2312⼀样)。
⼀、区位码1.整个GB2312字符集分成94个区,每区有94个位,每个区位上只有⼀个字符,即每区含有94个汉字或符号,⽤所在的区和位来对字符进⾏编码(实际上就是字符编号、码点编号),因此称为区位码(或许叫“区位号”更为恰当)。
换⾔之,GB2312将包括汉字在内的所有字符编⼊⼀个94 * 94的⼆维表,⾏就是“区”、列就是“位”,每个字符由区、位唯⼀定位,其对应的区、位编号合并就是区位码。
⽐如“万”字在45区82位,所以“万”字的区位码是:45 82(注意,GB类汉字编码为双字节编码,因此,45相当于⾼位字节,82相当于低位字节)。
2.GB2312字符集中:1)01~09区(682个):特殊符号、数字、英⽂字符、制表符等,包括拉丁字母、希腊字母、⽇⽂平假名及⽚假名字母、俄语西⾥尔字母等在内的682个全⾓字符;2)10~15区:空区,留待扩展;3)16~55区(3755个):常⽤汉字(也称⼀级汉字),按拼⾳排序;4)56~87区(3008个):⾮常⽤汉字(也称⼆级汉字),按部⾸/笔画排序;5)88~94区:空区,留待扩展。
⼆、国标码(交换码)1.为了避开ASCII字符中的不可显⽰字符0000 0000 ~ 0001 1111(⼗六进制为0 ~ 1F,⼗进制为0 ~ 31)及空格字符0010 0000(⼗六进制为20,⼗进制为32)(⾄于为什么要避开、⼜为什么只避开ASCII中0~32的不可显⽰字符和空格字符,后⽂有解释),国标码(⼜称为交换码)规定表⽰汉字的范围为(0010 0001,0010 0001) ~ (0111 1110,0111 1110),⼗六进制为(21,21) ~ (7E,7E),⼗进制为(33,33) ~ (126,126)(注意,GB类汉字编码为双字节编码)。
区位码和机内码的换算

区位码和机内码的换算区位码和机内码是计算机中常用的字符编码系统。
区位码是一种用于汉字输入和排序的编码方式,而机内码则是计算机内部使用的二进制编码方式。
区位码是汉字在计算机中的输入和排序时所采用的编码方式。
它是按照汉字的笔画以及首尾部分的部首进行编码的。
每个汉字都有一个唯一的区位码,由此可以快速地找到一个汉字在字库中的位置。
例如,汉字“中”的区位码为“D4C2”。
机内码是计算机内部使用的二进制编码方式。
由于计算机内部的处理单元只能识别二进制编码,所以在计算机内部使用二进制编码对字符进行表示和处理。
常见的机内码有ASCII码(美国标准信息交换码)和Unicode码(通用字符集)。
ASCII码是一个7位的编码方式,可以表示128个字符,包括英文字母、数字和一些特殊符号。
而Unicode码则是一个16位的编码方式,可以表示几乎所有的字符,包括世界上各种语言文字和符号。
区位码和机内码之间的换算是将汉字字符在区位码和机内码之间进行相互转换。
一般来说,区位码可以通过查表的方式转换为机内码,而机内码则可以通过编码算法将其转换为区位码。
在计算机中,常常需要将汉字字符转换为机内码进行处理。
这时可以通过查找汉字编码表,根据汉字的区位码找到对应的机内码。
而当需要将机内码转换为区位码时,则需要使用编码算法,根据机内码的特定规律进行转换。
区位码和机内码的换算在汉字处理和编程开发中扮演着重要的角色。
它们的相互转换能够使汉字在计算机中得到正确的处理和显示,同时也方便开发人员进行字符串的处理和操作。
总之,区位码和机内码在计算机中起着重要的作用。
了解和掌握区位码和机内码的换算原理,对于正确处理汉字字符以及进行编程开发都具有指导意义。
通过掌握区位码和机内码的转换方法,可以更好地进行字符处理和编码操作,提高计算机应用的效率和准确性。
计算机+计算题公式梳理(答-2-23)

计算题公式梳理1.总线带宽计算:总线带宽(M B/s)=(数据线宽度/8)(B)×总线工作频率(MHz)2.存储容量= 磁盘面数(磁头数)⨯磁道数(柱面数)⨯扇区数⨯512字节B3.CPU访问内存空间大小是由CPU的地址线宽为n决定,那么CPU的寻址大小是2n(B)平均存取时间T=寻道时间5ms+旋转等待时间+数据传输时间0.01ms/扇区平均等待时间为盘片旋转一周所需时间的一半4.内存地址编码4.1容量=末地址-首地址+14.2末地址=容量+首地址-15.点阵字存储计算:点阵/8(例:24*24/8,单位B)6.光驱数据传输速率:倍速*150KB/s7.进制转换7.1十转非十:整数(短除求余倒取),小数(乘进制,取整,顺取)7.2非十转十:按权展开求和(权*基数n-1)7.32与8关系:一位8进制转为3位2进制,3位2进制转为一位8进制(421法)7.42与16:一位16进制转为4位2进制,4位2进制转为一位16进制(8421法)8.二进制算术运算8.1加法:逢二进一8.2减法:借一位算二9.二进制逻辑运算9.1逻辑或:有1得1,全0得0 逻辑加V9.2逻辑与:有0得0,全1得1 逻辑乘9.3异或:相同时为0,不同时为110.无符号整数表示:0-[2n-1]11.有符号整数原码表示:[-2n-1+1,+2n-1-1]12.有符号整数补码表示:[-2n-1,+2n-1-1]13.有符号整数二进制原码:该十进制的八位二进制原码,正数最高位置0,负数最高位置114.有符号整数二进制补码:该十进制的八位二进制原码后,反码,末尾+115.每类IP地址可用主机数量:2主机号二进制位数-216.ASCII编码计算:A(65,41H),a(97,61H),两者相差32(20H)0(48,30H),空格(32,20H)17.汉字的区位码、国标码、机内码17.1国标码=区位码+2020H17.2机内码=国标码+8080H17.3机内码=区位码+A0A0H18.灰度图像亮度计算:亮度数量=2n ,亮度取值范围=0~2n-119.彩色图像颜色种类:颜色种类=2n+m+k20.数字图像:数据量(B)=图像水平分辨率×图像垂直分辨率×像素深度(b)/821.波形声音的码率(kb/s)=取样频率(kHz)×量化位数(b)×声道数若B 则÷8存储=时间X码率声音压缩比例=压缩前码率/压缩倍数22.压缩编码以后的码率=压缩前的码率/ 压缩倍数23.单元格引用23.1相对引用:复制公式,插入行和列,删除行和列,目标单元格公式会变;移动公式时,目标单元格公式不会变;23.2绝对引用:插入行和列,删除行和列,目标单元格公式会变;复制公式,移动公式时,目标单元格公式不会变;23.3混合引用:针对上面两者各自规则引用。
区位码、国标码、机内码对应关系

整个编码字符集应被表达为包含128(一个字节的低七位即27=128)个组,其中每个组表示256(28=256)个平面。每一平面包含256行,每行有256个字位。四个字节共32位足以包容世界上所有的字符,同时也符合现代处理系统的体系结构。
第一个平面(00组中的00平面)称为基本多文种平面,它包含字母文字、音节文字及表意文字等。它分成四个区:
2. 汉字国标交换码和机内码
西文处理系统的交换码和机内码均为ASCII,用一个字节表示,一般只用低七位。1981年我国在国标GB2312-80制定了汉字交换码也称为国标交换码(简称国标码)。在国标码中,一个汉字用两个字节表示,每个字节也只用其中的七位,每个字节的取值范围和94个可打印的ASCII字符的取值范围相同(21H-7EH),涵盖了一、二级汉字和符号。为了避免ASCII码和国标码同时使用时产生二义性问题,大部分汉字系统一般都采用将国标码每个字节高位置“1”作为汉字机内码。这样既解决了汉字机内码与西文机内码之间的二义性,又使汉字机内码与国标码具有极简单的对应关系。区位码、国标码和机内码之间的关系可以概括为(区位码的十六进制表示) 2020H=国标码,国标码 8080H=机内码,以汉字“大”为例,“大”字的区内码为2083,将其转换为十六进制表示为1453H,加上2020H得到国标码3473H,再加上8080H得到机内码为B4F3H。
字模点阵的信息量是很大的,占用存储空间也很大,以16×16点阵为例,每个汉字占用32(2×16=32)个字节,两级汉字大约占用256KB。因此,字模点阵只能用来构成“字库”,而不能用于机内存储。字库中存储了每个汉字的点阵代码,当显示输出时才检索字库,输出字模点阵得到字形。
⑴A区:代码位置0000H—4DFFH(19903个字位)用于字母文字、音节文字及各种符号。
区位码、国标码与机内码的转换方法

区位码、国标码与机内码的转换关系方法为了使每一个汉字有一个全国统一的代码,1980年,我国颁布了第一个汉字编码的国家标准:GB2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础,也是目前国内所有汉字系统的统一标准。
由于国标码是四位十六进制,为了便于交流,大家常用的是四位十进制的区位码。
所有的国标汉字与符号组成一个94×94的矩阵。
在此方阵中,每一行称为一个"区",每一列称为一个"位",因此,这个方阵实际上组成了一个有94个区(区号分别为1到94)、每个区内有94个位(位号分别为1到94)的汉字字符集。
一个汉字所在的区号和位号简单地组合在一起就构成了该汉字的"区位码"。
在汉字的区位码中,高两位为区号,低两位为位号。
区位码、国标码与机内码的转换关系方法:1. 区位码先转换成十六进制数表示机内码、国际码是十六进制的,区位码是十进制的,一般换算全部用十六进制,特别注意:区位码从十进制转换为十六进制是两位两位分别转换的。
两区位码改写成十六进制,XX是区码,OO是位码H代表十六进制,区位码为XXOOH。
2. 国际码=区位码(十六进制)+2020H将区位码转换为国标码。
将XXOOH加2020H得到的就是国标码3. 机内码=国际码+8080H国标码转换成机内码。
将所得到的国标码加8080H,就可得机内码。
如:某汉字的区位码是2534。
则25D=19H,34D=22H国际码=1922H+2020H=3952H机内码=3952H+8080H=B9D2H以汉字“大”为例,“大”字的区位码为2083解:1、区号为20,位号为832、将区位号2083转换为十六进制表示为1453H3、1453H+2020H=3473H,得到国标码3473H4、3473H+8080H=B4F3H,得到机内码为B4F3H。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
精品课件
➢ (1)区位码先转换成十六进制数表示 ➢ (2)(区位码的十六进制表示)+2020H
=国标码; ➢ (3)国标码+8080H=机内码
精品课件
➢ 举例:以汉字“大”为例,“大”字的区 内码为2083
➢ 解:1、区号为20,位号为83 ➢ 2、将区位号2083转换为十六进制表示为
1453H ➢ 3、1453H+2020H=3473H,得到国标码
3473H ➢ 4、3473Fra bibliotek+8080H=B4F3H,得到机内码为
区位码、国标码与机内码 的转换关系方法
精品课件
国标码:所有汉字编码都应该遵循这一标准,汉字机内码的编码 、汉字字库的设计、汉字输入码的转换、输出设备的汉字地址码等, 都以此标准为基础。GB 2312—80就是国标码。该码规定:一个汉字 用两个字节表示,每个字节只有7位,与ASCII码相似。
区位码:将GB 2312—80的全部字符集组成一个94×94的方阵,每一 行称为一个“区”,编号为0l~94;每一列称为一个“位”,编号为 0l~94,这样得到GB 2312—80的区位图,用区位图的位置来表示的 汉字编码,称为区位码。
B4F3H
精品课件