基于进化算法的本体匹配技术(英文版)(薛醒思,陈俊风,潘正祥著)思维导图
第10章知识图谱

5
2 语义网络
优点
①结构性:以节点和弧形式把事物属性 以及事物间的语义联想显式地表示出来。 ②联想性:作为人类联想记忆模型提出。 ③自然性:直观地把事物的属性及其语 义联系表示出来,便于理解,自然语言 与语义网络的转换比较容易实现。
84 语义Web源自奠基人Tim Berners-Lee 2016年图灵奖得 主万维网、语义网 之父,提出语义 Web
Web1.0
Web1.0,是以编辑为 特征,网站提供给用 户的内容是网站编辑 进行编辑处理后提供 的,用户阅读网站提 供的内容。这个过程 是网站到用户的单向 行 为 , web1.0 时 代 的 代表站点为新浪,搜 狐,网易三大门户, 强调的是文档互连。
作用
为真实世界的各个场 景直观地建模,运用 “图”这种基础性、通用 性的“语言”,“高保真” 地表达这个多姿多彩 世界的各种关系,并 且非常直观、自然、 直接和高效,不需要 中间过程的转换和处 理。
术语
①实体: 具有可区别 性且独立存在的某种 事物。 ②类别:主要指集合、 类别、对象类型、事 物的种类。 ③属性、属性值:实 体具有的性质及其取 值。 ④关系:不同实体之 间的某种联系,
11
10.2 知识图谱基本原理
10.2.1 10.2.2 10.2.3 10.2.4 10.2.5
认知智能是人工智能的高级目标 知识图谱概念 知识图谱模型 知识图谱特点 知识图谱分类
1 认知智能是人工智能的高级目标
13
2 知识图谱概念
定义
知识图谱用节点和关系 所组成的图谱。
本体概念匹配技术的研究与实现

本体概念匹配技术的研究与实现
本体概念匹配技术是指通过对概念进行语义分析和语义匹配,实现对不同本体中相似或相同概念的匹配。
其研究与实现主要包括以下几个步骤:
1. 本体构建:首先需要构建本体,即建立概念之间的关系、属性和语义等信息。
可以利用本体建模语言,如OWL (Ontology Web Language)或RDF(Resource Description Framework)来描述本体。
2. 语义分析:对于给定的本体,需要对概念进行语义分析,从而抽取出概念的语义特征。
可以利用自然语言处理技术,如词频统计、词语关联性分析等方法来进行语义分析。
3. 语义匹配:根据语义分析的结果,可以通过计算概念之间的相似度来实现语义匹配。
常用的相似度计算方法包括语义距离计算、基于语义路径的匹配等。
4. 匹配算法:根据相似度计算结果,可以采用不同的匹配算法来实现概念匹配。
常见的匹配算法有基于规则的匹配算法、基于统计学的匹配算法等。
5. 实验评估:对于实现的本体概念匹配技术,需要进行实验评估,验证其效果和性能。
可以利用已有的本体库进行实验,对匹配结果进行比对和评估。
总的来说,本体概念匹配技术的研究与实现主要包括本体构建、
语义分析、语义匹配、匹配算法和实验评估等步骤。
通过这些步骤的组合,可以实现对不同本体中相似或相同概念的匹配,从而提高信息检索、数据集成和语义推理等应用的效果和效率。
西文授权影印图书的著录及其他

h
o
r.
用逗号,
哪里没有逗号,
哪里应该空格等.西文授权
影印图书的 USMARC 的题名说明 2
4
5字段有如下
几种形式:
第 1 种,
题名 页 只 有 题 名 与 责 任 者 只 有 中 文 形
式,
封面有英文题名则 USMARC 如下:
著 录 USMARC 只 是 一 门 略 带 艺 术 性 质 的 技 能,用
摘 要:
RDA 格式的新规定及分类标引.
关键词:
授权影印图书;
RDA 格式
中图分类号:
G2
4
5.
3 文献标识码:
A 文章编号:
1
0
0
7—6
9
2
1(
2
0
2
0)
0
5—0
1
5
1—0
3
通过实践验证理论
1 用理论指导实践,
“
毛主席在«
实践论»
一文中明确指出:
我们的实
号,
将原版图书的 I
o
l
u
t
i
o
n
a
r
l
o
r
i
t
hm b
a
s
e
do
n
t
o
l
o
ya
g
g
y
/
,
ma
t
c
h
i
n
e
c
hn
i
u
e $cX
i
n
s
i
Xu
e J
un
f
e
n
e
基于知识图谱使用多特征语义融合的文档对匹配

第 54 卷第 8 期2023 年 8 月中南大学学报(自然科学版)Journal of Central South University (Science and Technology)V ol.54 No.8Aug. 2023基于知识图谱使用多特征语义融合的文档对匹配陈毅波1,张祖平2,黄鑫1,向行1,何智强1(1. 国网湖南省电力有限公司,湖南 长沙,410004;2. 中南大学 计算机学院,湖南 长沙,410083)摘要:为了区分文档间的同源性和异质性,首先,提出一种多特征语义融合模型(Multi-Feature Semantic Fusion Model ,MFSFM)来捕获文档关键字,它采用语义增强的多特征表示法来表示实体,并在多卷积混合残差CNN 模块中引入局部注意力机制以提高实体边界信息的敏感性;然后,通过对文档构建一个关键字共现图,并应用社区检测算法检测概念进而表示文档,从而匹配文档对;最后,建立两个多特征文档数据集,以验证所提出的基于MFSFM 的匹配方法的可行性,每一个数据集都包含约500份真实的科技项目可行性报告。
研究结果表明:本文所提出的模型在CNSR 和CNSI 数据集上的分类精度分别提高了13.67%和15.83%,同时可以实现快速收敛。
关键词:文档对匹配;多特征语义融合;知识图谱;概念图中图分类号:TP391 文献标志码:A 文章编号:1672-7207(2023)08-3122-10Matching document pairs using multi-feature semantic fusionbased on knowledge graphCHEN Yibo 1, ZHANG Zuping 2, HUANG Xin 1, XIANG Xing 1, HE Zhiqiang 1(1. State Grid Hunan Electric Power Company Limited, Changsha 410004, China;2. School of Computer Science and Engineering, Central South University, Changsha 410083, China)Abstract: To distinguish the homogeneity and heterogeneity among documents, a Multi-Feature Semantic Fusion Model(MFSFM) was firstly proposed to capture document keywords, which employed a semantically enhanced multi-feature representation to depict entities. A local attention mechanism in the multi-convolutional mixed residual CNN module was introduced to enhance sensitivity to entity boundary information. Secondly, a keyword co-occurrence graph for documents was constructed and a community detection algorithm was applied to represent收稿日期: 2022 −05 −15; 修回日期: 2022 −09 −09基金项目(Foundation item):湖南省电力物联网重点实验室项目(2019TP1016);电力知识图谱关键技术研究项目(5216A6200037);国家自然科学基金资助项目(72061147004);湖南省自然科学基金资助项目( 2021JJ30055) (Project (2019TP1016) supported by Hunan Key Laboratory for Internet of Things in Electricity; Project(5216A6200037) supported by key Technologies of Power Knowledge Graph; Project(72061147004) supported by the National Natural Science Foundation of China; Project(2021JJ30055) supported by the Natural Science Foundation of Hunan Province)通信作者:张祖平,博士,教授,从事大数据分析与处理研究;E-mail :***************.cnDOI: 10.11817/j.issn.1672-7207.2023.08.016引用格式: 陈毅波, 张祖平, 黄鑫, 等. 基于知识图谱使用多特征语义融合的文档对匹配[J]. 中南大学学报(自然科学版), 2023, 54(8): 3122−3131.Citation: CHEN Yibo, ZHANG Zuping, HUANG Xin, et al. Matching document pairs using multi-feature semantic fusion based on knowledge graph[J]. Journal of Central South University(Science and Technology), 2023, 54(8): 3122−3131.第 8 期陈毅波,等:基于知识图谱使用多特征语义融合的文档对匹配concepts, thus facilitating document was matching. Finally, two multi-feature document datasets were established to validate the feasibility of the proposed MFSFM-based matching approach, with each dataset comprising approximately 500 real feasibility reports of scientific and technological projects. The results indicate that the proposed model achieves an increase in classification accuracy of 13.67% and 15.83% on the CNSR and CNSI datasets, respectively, and demonstrates rapid convergence.Key words: document pairs matching; multi-feature semantic fusion; knowledge graph; concept graph识别文档对的关系是一项自然语言理解任务,也是文档查重和文档搜索工作必不可少的步骤。
进化计算(ppt)-智能科学与人工智能

基本遗传算法的构成要素
3、遗传算子 • 选择算子(selection) :又称为复制算子。按照某种策略 从父代中挑选个体进入下一代,如使用比例选择、轮盘 式选择。
• 交叉算子(crossover):又称为杂交算子。将从群体中选 择的两个个体,按照某种策略使两个个体相互交换部分 染色体,从而形成两个新的个体。如使用单点一致交叉。 • 变异算子(mutation):按照一定的概率(一般较小),改 变染色体中某些基因的值。
2018/11/28
史忠植 高级人工智能
25
遗传算法
与自然界相似,遗传算法对求解问题的本身一无 所知,它所需要的仅是对算法所产生的每个染色 体进行评价,并基于适应值来选择染色体,使适 应性好的染色体有更多的繁殖机会。 在遗传算法中,位字符串扮演染色体的作用,单 个位扮演了基因的作用,随机产生一个体字符串 的初始群体,每个个体给予一个数值评价,称为 适应度,取消低适应度的个体,选择高适应度的 个体参加操作。 常用的遗传算子有复制、杂交、变异和反转。
• 同年,DeJong完成了他的重要论文《遗传自适应系统 的行为分析》。他在该论文中所做的研究工作可看作 是遗传算法发展过程中的一个里程碑,这是因为他把 Holland的模式理论与他的计算使用结合起来。
2018/11/28 史忠植 高级人工智能 6
发展历史
• 1989 Goldberg对遗传算法从理论上,方法上 和应用上作了系统的总结。 • 1990年,Koza提出了遗传规划(Genetic Programming)的概念。(用于搜索解决特定 问题的最适计算机程序)
第十二章
进化计算 Evolutionary Computation
史忠植
中国科学院计算技术研究所
人工智能之知识图谱

图表目录图1知识工程发展历程 (3)图2 Knowledge Graph知识图谱 (9)图3知识图谱细分领域学者选取流程图 (10)图4基于离散符号的知识表示与基于连续向量的知识表示 (11)图5知识表示与建模领域全球知名学者分布图 (13)图6知识表示与建模领域全球知名学者国家分布统计 (13)图7知识表示与建模领域中国知名学者分布图 (14)图8知识表示与建模领域各国知名学者迁徙图 (14)图9知识表示与建模领域全球知名学者h-index分布图 (15)图10知识获取领域全球知名学者分布图 (23)图11知识获取领域全球知名学者分布统计 (23)图12知识获取领域中国知名学者分布图 (23)图13知识获取领域各国知名学者迁徙图 (24)图14知识获取领域全球知名学者h-index分布图 (24)图15 语义集成的常见流程 (29)图16知识融合领域全球知名学者分布图 (31)图17知识融合领域全球知名学者分布统计 (31)图18知识融合领域中国知名学者分布图 (31)图19知识融合领域各国知名学者迁徙图 (32)图20知识融合领域全球知名学者h-index分布图 (32)图21知识查询与推理领域全球知名学者分布图 (39)图22知识查询与推理领域全球知名学者分布统计 (39)图23知识查询与推理领域中国知名学者分布图 (39)图24知识表示与推理领域各国知名学者迁徙图 (40)图25知识查询与推理领域全球知名学者h-index分布图 (40)图26知识应用领域全球知名学者分布图 (46)图27知识应用领域全球知名学者分布统计 (46)图28知识应用领域中国知名学者分布图 (47)图29知识应用领域各国知名学者迁徙图 (47)图30知识应用领域全球知名学者h-index分布图 (48)图31行业知识图谱应用 (68)图32电商图谱Schema (69)图33大英博物院语义搜索 (70)图34异常关联挖掘 (70)图35最终控制人分析 (71)图36企业社交图谱 (71)图37智能问答 (72)图38生物医疗 (72)图39知识图谱领域近期热度 (75)图40知识图谱领域全局热度 (75)表1知识图谱领域顶级学术会议列表 (10)表2 知识图谱引用量前十论文 (56)表3常识知识库型指示图 (67)摘要知识图谱(Knowledge Graph)是人工智能重要分支知识工程在大数据环境中的成功应用,知识图谱与大数据和深度学习一起,成为推动互联网和人工智能发展的核心驱动力之一。
第8章进化算法ppt课件

数 应为:N fi
fi
fi
f
复制的目的在于保证那些适应度高的优良个体在 进化中生存下去,但是复制不会产生新的个体。
在整堂课的教学中,刘教师总是让学 生带着 问题来 学习, 而问题 的设置 具有一 定的梯 度,由 浅入深 ,所提 出的问 题也很 明确
设一初始种群: 含有4个个体 每个个体为一个长度为5的二进制数 对应的十进制数就是变量xi, 适应度函数设为 f ( xi ) = xi2
的操作
在整堂课的教学中,刘教师总是让学 生带着 问题来 学习, 而问题 的设置 具有一 定的梯 度,由 浅入深 ,所提 出的问 题也很 明确
8.1.2
遗传算法特点与发展
1、特点
1)对参数编码进行操作,而不是参数本身,可以模 拟生物遗传、进化机理,特别对无数值概念(只有 代码概念)的优化问题有益
2)直接以目标函数值作为搜索信息,对于待寻优的 函数无限制,应用广泛
8.1.3 遗传算法应用
函数优化、组合优化 生产调度问题、自动控制 机器人智能控制 图像处理和模式识别 人工生命 遗传程序设计 机器学习
在整堂课的教学中,刘教师总是让学 生带着 问题来 学习, 而问题 的设置 具有一 定的梯 度,由 浅入深 ,所提 出的问 题也很 明确
8.2 GA的基本理论
GA的核心思想源于:生物进化过程(从 简单到复杂,从低级向高级)本身是一个自 然的、并行发生的、稳健的优化过程。这一 优化过程的日标是对环境的自适应性,生物 种群通过“优胜劣汰”及遗传变异来达到进 化(优化)的目的。
在整堂课的教学中,刘教师总是让学 生带着 问题来 学习, 而问题 的设置 具有一 定的梯 度,由 浅入深 ,所提 出的问 题也很 明确
16.如何清晰地思考.pdf

1. 关于 Problem Solving 的 《跟波利亚学解题》 《知其所以然地学习(以算法学习为例)》 2. 关于机器学习的(机器学习和人工智能领域对于理解我们的思维方式也提供了极好的 参考) 《数学之美番外篇:平凡而又神奇的贝叶斯方法》 《机器学习与人工智能学习资源导引》 3. 关于学习,记忆与思考的 《一直以来伴随我的一些学习习惯》(一,二,三,四) 《方法论,方法论——程序员的阿喀琉斯之踵》 《学习与记忆》 《阅读与思考》 《鱼是最后一个看到水的》 《我不想与我不能》 《学习密度与专注力》 好在我并不打算零星的一本一本推荐:D 所以我就花了点时间将整个的知识体系整理了一番, 画了下面这张结构图,请按图索骥,如下(有三个版本,1. 至 xMind Share 的超链接,2. 内 嵌在该页面中的幻灯片,如果无法载入请参考 1 .3. 图片版(注:图很大,请下载浏览或打 印)) 我在前面写学习习惯的时候曾经提到: 8. 学习一项知识,必须问自己三个重要问题:1. 它的本质是什么.2. 它的第一原 则是什么.3. 它的知识结构是怎样的. 有朋友问我具体的例子,好吧,那么这张思维导图便是第三点——知识结构——的一个很 好的例子:) 1. 至 XMind Share 的超链接:/pongba/how-to-think-straight-4/ 2. 嵌入的幻灯片(如加载失败请直接点击上面的 XMind Share 超链接至 XMind 浏览): 3. 图片版(此为缩略版,完整版请至相册下载:google picasa 的 ,或 csdn 相册的)(最后 提醒一下,别忘了这幅图只是大量书籍和 Wikipedia 条目的"藏宝图",如何延伸阅读请参 考前文所述的方法)
本体的相似性网络推理框架

本体的相似性网络推理框架文贵华;江丽君【期刊名称】《东南大学学报(英文版)》【年(卷),期】2006(022)003【摘要】To properly compute the ontological similarity,an ontological similarity network-based reasoning framework is proposed.It structurally integrates extension-based approach,intension-based approach,the similarity network-based reasoning to exploit the implicit similarity,and the feedback from the context to validate the similarity measures.A new similarity measure is also presented to construct concept similarity network,which scales the similarity using the relative depth of the least common super-concept between any two concepts.Subsequently, the graph theory, instead of predefined knowledge rules, is applied to perform the similarity network-based reasoning such that the knowledge acquisition can be avoided.The framework has been applied to text categorization and visualization of high dimensional data.Theory analysis and the experimental results validate the proposed framework.%为了更恰当地计算本体相似性,提出了一种本体的相似性网络推理的集成框架.该框架集成了基于外延的方法,基于内涵的方法,计算间接相似的相似性网络推理,和检验相似性测度有效性的环境反馈.同时,提出了一种用于构造概念相似性网络的新测度,相似性网络上的推理则采用图论实现而不是预定义知识规则,这样可免去知识获取的困难.框架已经应用于文本分类和高维数据的可视化,理论分析和实验验证了相似性网络推理框架的有效性.【总页数】5页(P394-398)【作者】文贵华;江丽君【作者单位】华南理工大学计算机科学与工程学院,广州,510641;华南理工大学计算机科学与工程学院,广州,510641【正文语种】中文【中图分类】TP3因版权原因,仅展示原文概要,查看原文内容请购买。
920087-人工智能导论(第4版)-第6章 智能计算及其应用(导论)

二进制串 12...n
Gray 1 2... n
二进制编码 Gray编码
k
k
1
1
k
k k
1 1
Gray编码 二进制编码
k
k i (mod 2) i 1
17
6.2.3 编码
2. 实数编码
采用实数表达法不必进行数制转换,可直接在解的表 现型上进行遗传操作。
多参数映射编码的基本思想:把每个参数先进行二进 制编码得到子串,再把这些子串连成一个完整的染色体。
Introduction of Artificial Intelligence
第 6 章 智能计算及其应用
教材:
王万良《人工智能导论》(第4版) 高等教育出版社,2017.7
第6章 智能计算及其应用
受自然界和生物界规律的启迪,人们根据其原理模 仿设计了许多求解问题的算法,包括人工神经网络、 模糊逻辑、遗传算法、DNA计算、模拟退火算法、 禁忌搜索算法、免疫算法、膜计算、量子计算、粒 子群优化算法、蚁群算法、人工蜂群算法、人工鱼 群算法以及细菌群体优化算法等,这些算法称为智 能 计 算 也 称 为 计 算 智 能 (computational intelligence, CI)。
(4)稳定性原则: 指算法对其控制参数及问题的数 据的敏感度。
(5)生物类比原则:在生物界被认为是有效的方法
及操作可以通过类比的方法引入到算法中,有时会带
来较好的结果。
9
第6章 智能计算及其应用
6.1 进化算法的产生与发展
6.2 基本遗传算法
6.3 遗传算法的改进算法
6.4 遗传算法的应用
19
6.2.4 群体设定
2. 种群规模的确定 群体规模太小,遗传算法的优化性能不太好,易陷
智能优化理论 第8章 思维进化算法

04
思维进化算法的改进
思维进化算法的改进
1
改进的思维进化算法之一:MEA-PSO-GA
2
针对思维进化算法的趋同和异化操作带有太多的 随机性,公告板的信息不能得到充分利用,使得 效果下降,出现重复搜索。
3
借鉴粒子群优化算法(PSO)和遗传算法(GA) 的优点,提出算法的基本思想
人类思维进步速度高于生物进化速度 的原因包括向前人和优胜者学习以及 不断地探索与创新。
思维进化算法认为,趋同和异化是普遍 存在于各个领域的人们的思维活动中的 两种模式。
03
思维进化算法的描述
思维进化算法的描述
01
思维进化算法由群体、子群体、个体、公告板、环境和特征提取系统等部分组 成,其系统结构如图8.1所示。
混沌优化与思维进化算法相结合具有多方面的优势,如拓宽搜索空间、提高搜索效率等。
二者应该如何相结合?答
第8章 思维进化算法
目 录
• 思维进化算法的提出 • 思维进化算法的基本思想 • 思维进化算法的描述 • 思维进化算法的改进 • 复习思考题
01
思维进化算法的提出
思维进化算法的提出
思维进化算法(Mind-Evolution-Algorithm.MEA)是1998年由孙承意提出的一 种新的进化算法。
思维进化算法的改进
在思维进化算法子种群的产生 过程中加入类似PSO粒子移动 更新位置的行为,使得个体按
一定规则移动。
加入类似GA交叉和变异算子, 保证种群多样性,防止非成 熟收敛,避免重复搜索,提
高收敛速度。
以得分最高的个体为中心,随 机产生一个种群,对神群中个 体的 速度和位置随机进行初始
化,运用PSO算法。
思维进化算法的改进
一种基于NSGA-II算法的本体匹配技术

信息科学科技创新导报 Science and Technology Innovation Herald129①基金项目:福建省教育厅中青年项目(闽科教[2017]76号)——基于进化算法的语义传感本体集成技术的研究(项目编号:JAT171063)。
DOI:10.16660/ki.1674-098X.2017.35.129一种基于NSGA-II算法的本体匹配技术①江荔(福州职业技术学院信息技术工程系 福建福州 350108)摘 要:本体可以用于克服语义异质问题,但是直接使用不同的本体会将语义异质问题提升到更高的级别。
本体匹配过程是通过确定两个本体中的实体之间的关系,从而解决两个本体间的异质问题。
目前提出的各种本体匹配方法中,基于进化算法的本体匹配技术应用比较广泛,但是基于进化算法的本体匹配技术的效率和最后获取的本体匹配结果的质量都差强人意。
为了解决这一问题,本文在提出了一种新的基于NSGA-II的本体匹配技术。
在本文的工作中,提出了一种新的基于信息论的相似度度量技术,为本体匹配问题构建了一个多目标的优化模型,针对性地设计了一种NSGA-II算法以求解该问题。
实验结果表明我们的方案是有效的。
关键词:本体匹配技术 NSGA-II 进化算法 相似度度量技术中图分类号:TP311文献标识码:A文章编号:1674-098X(2017)12(b)-0129-02本体被认为是一种实现异质语义数据源交互的方案。
然而由于人的主观性,同一个实体(如类、属性或个体)在不同的本体中可能用不同的名称或方式来定义。
因此,直接使用不同的本体会将语义异质问题提升到更高的级别。
本体匹配过程是通过确定两个本体中的实体之间的关系,从而解决两个本体间的异质问题。
当本体规模庞大的时候,手动匹配本体是不可能的,因此人们近年来提出了各种本体匹配技术。
通过各种能够提供本体元素之间相似度数值的相似度度量技术,本体匹配技术能够识别本体中的元素是否相同。
群体进化思维导图-高清简单脑图模板-知犀思维导图
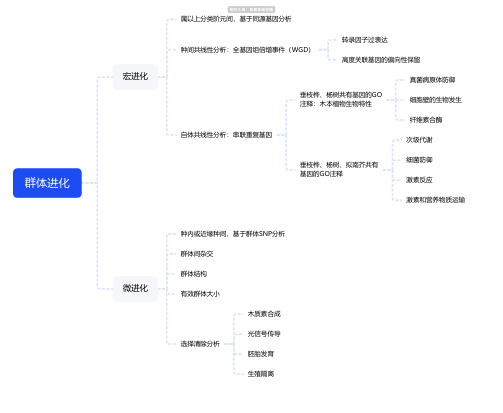
群体进化宏进化
属以上分类阶元间,基于同源基因分析
种间共线性分析:全基因组倍增事件(WGD)
转录因子过表达
高度关联基因的偏向性保留
自体共线性分析:串联重复基因
垂枝桦、杨树共有基因的GO
注释:木本植物生物特性
真菌病原体防御
细胞壁的生物发生
纤维素合酶
垂枝桦、杨树、拟南芥共有
基因的GO注释
次级代谢
细菌防御
激素反应
激素和营养物质运输微进化
种内或近缘种间,基于群体SNP分析
群体间杂交
群体结构
有效群体大小
选择清除分析
木质素合成
光信号传导
胚胎发育
生殖隔离。
使用遗传算法实现基于实例的本体映射

使用遗传算法实现基于实例的本体映射
王颖;薛醒思
【期刊名称】《福建工程学院学报》
【年(卷),期】2013(011)003
【摘要】提出了一种新颖的基于实例的本体映射方法,即通过遗传算法确定最优实例间的映射集合,并通过相似度扩散算法获取高准确率的本体映射结果.文章描述了实例相似度度量技术和upPropagation算法,给出了本体映射问题的单目标优化模型,论述了使用遗传算法求解该问题的3个关键步骤,最后通过实验验证.实验表明,采用遗传算法实现基于实例的本体映射方法,可以获取高准确率的本体映射结果.【总页数】5页(P247-251)
【作者】王颖;薛醒思
【作者单位】福建工程学院信息科学与工程学院,福建福州350118;福建工程学院信息科学与工程学院,福建福州350118
【正文语种】中文
【中图分类】TP18
【相关文献】
1.基于遗传算法的本体映射技术 [J], 薛醒思
2.基于实例的本体映射方法研究 [J], 仲志成;仲颖;郭刚
3.使用遗传算法实现K-means聚类算法的K值选择 [J], 杨芳;湛燕;田学东;郭宝兰
4.基于实例相似度的本体映射方法研究 [J], 沈亦军;吕刚
5.使用LDA构建预警情报的本体映射依据研究 [J], 刘冬瑞;潘越;郭继光
因版权原因,仅展示原文概要,查看原文内容请购买。