数据库第五章作业
数据库第五章习题及答案

数据库第五章习题及答案本文档为数据库第五章的习题及答案,帮助读者巩固数据库相关知识。
习题1. 数据库的优点有哪些?数据库具有以下优点: - 数据共享:多个用户可以同时访问和共享数据库中的数据。
- 数据一致性:数据库提供事务管理能力,保证了数据的一致性。
- 数据持久性:数据在数据库中是永久存储的,不会因为系统关机或程序结束而丢失。
- 数据冗余度低:数据库通过规范化设计,减少了数据的冗余性,提高了数据的存储效率。
- 数据独立性:数据库支持数据与应用程序的独立性,提高了系统的灵活性和维护性。
- 数据安全性:数据库提供了用户权限管理和数据备份机制,保证了数据的安全性。
2. 数据库的三级模式结构是什么?数据库的三级模式结构包括: - 外模式(视图层):外模式是用户所看到的数据库的子集,用于描述用户对数据库的逻辑视图。
每个用户可以有不同的外模式来满足自己的需求。
- 概念模式(逻辑层):概念模式是全局数据库的逻辑结构和组织方式,描述了数据的总体逻辑视图。
概念模式独立于具体的应用程序,是数据库管理员的角度来看待数据库的。
- 内模式(物理层):内模式是数据库的存储结构和物理组织方式,描述了数据在存储介质上的实际存储方式。
3. 数据库的完整性约束有哪些?数据库的完整性约束包括: - 实体完整性约束:确保表的主键不为空,每个实体都能够唯一标识。
- 参照完整性约束:确保外键的引用关系是有效的,即外键值必须等于被引用表中的主键值或者为空。
- 用户定义完整性约束:用户可以自定义额外的完整性约束,如检查约束、唯一约束、默认约束等。
4. 数据库的关系模型有哪些特点?数据库的关系模型具有以下特点: - 数据用二维表的形式进行组织,表由行和列组成,每一行表示一个实体,每一列表示一个属性。
- 表与表之间通过主键和外键建立关联关系,形成关系。
- 关系模型提供了一种数据独立性的设计方法,使得应用程序与数据的逻辑结构相分离,提高了系统的灵活性和可维护性。
(完整版)第五章_数据库完整性(习题)

(完整版)第五章_数据库完整性(习题)一、选择题1.完整性检查和控制的防范对象是( ),防止它们进入数据库。
安全性控制的防范对象是(),防止他们对数据库数据的存取。
A.不合语义的数据 B。
非法用户 C.不正确的数据 D.非法操作2.找出下面SQL命令中的数据控制命令().A。
GRANT MIT C.UPDATE D.SELECT3.下述SQL命令中,允许用户定义新关系时,引用其他关系的主码作为外码的是()。
A。
INSERT B。
DELETE C.REFERENCES D. SELECT4.下述SQL命令的短语中,不用于定义属性上约束条件的是()。
A.NOT NULL短语 B。
UNIQUE短语 C.CHECK短语 D。
HAVING短语二、填空题1.数据库的完整性是指数据的正确性和相容性.2.关系模型的实体完整性在CREATE TABLE中用 primary key 关键字来实现。
3.检查主码值出现不唯一和有一个为空违约情况时,则DBMS拒绝插入或修改。
4.关系模型的参照完整性在CREATE TABLE中用 foreign key关键字来实现。
5.当参照完整性检查出现违约情况时,则DBMS可以采用拒绝、级联和设置为空策略处理。
6.参照完整性的级连操作的关键字是cascade .7.在CREATE TABLE中定义属性上的约束条件,包括not null 、unique 和 check。
8.在CREATE TABLE中定义属性上的约束条件,检查列值唯一用unique 关键字。
9.关系模型的元组上的约束条件的定义,在CREATE TABLE中用check关键字来实现。
10.在Sno(学号)列上创建约束,要求Sno的值在18至22岁之间,约束名Sno_CK。
请写出对应的完整性命名子句constraintSno_CK primary key check(sno between 18 and 22)。
1.A C ;BD 2. A 3。
重庆大学数据库第五章习题

【5.1】用SQL查询请求。
(第三章关系模型中习题用SQL语句编写)1.找出所有顾客、代理商和商品不都在同一个城市,(可能有两个在同一城市)的三元组(cid,aid,pid)selectdistinct cid,aid,pidfrom agents a,customers c,products pwhere a.city<>c.city or c.city<>p.city2.取出接受顾客c002订单的代理商所在的城市select city from agents a,orders owhere a.aid=o.aid and cid='c002'3.取出曾经收到Kyoto的顾客订单的代理商所销售的所有的商品的pid值。
selectdistinct pid from orderswhere aid in(select aid from customers c,orders owhere c.cid=o.cid and cname='Kyoto')4.找出没有通过代理商a03订购过商品的顾客的cid值。
selectdistinct cid from customerswhere cid notin(select cid from orderswhere aid='a03')5.找出订购了所有商品的顾客的cid值。
select c.cid from customers c Where notexists(select pid from orders x where notexists(select*from orders y Where x.pid=y.pid and y.cid=c.cid))6.取出商品的pname和pid值,要求这些商品所在的城市和某个销售过该商品的代理商所在的城市相同。
select p.pname,p.pid from products p,agents a,orders owhere p.pid=o.pid and a.aid=o.aid and a.city=p.city7.取出同时订购了商品p01和p07的顾客的pid值。
数据库第五章作业

第五、六章练习题一、选择题1、在关系数据库设计中,子模式设计是在__________阶段进行。
[ B]A.物理设计B.逻辑设计C.概念设计D.程序设计2、设有关系R(A,B,C)的值如下:A B C2 2 32 3 43 3 5下列叙述正确的是(B)A.函数依赖A→B在上述关系中成立B.函数依赖BC→A在上述关系中成立C.函数依赖B→A在上述关系中成立D.函数依赖A→BC在上述关系中成立3、数据库设计阶段分为(D )A. 物理设计阶段、逻辑设计阶段、编程和调试阶段B. 模型设计阶段、程序设计阶段和运行阶段C. 方案设计阶段、总体设计阶段、个别设计和编程阶段D. 概念设计阶段、逻辑设计阶段、物理设计阶段、实施和调试阶段4、下列说法中不正确的是(C)。
A. 任何一个包含两个属性的关系模式一定满足3NFB. 任何一个包含两个属性的关系模式一定满足BCNFC. 任何一个包含三个属性的关系模式一定满足3NFD. 任何一个关系模式都一定有码5、设有关系模式R(A,B,C,D),F是R上成立的函数依赖集,F={B→C,C→D},则属性C的闭包C+为( C )A.BCDB.BDC.CDD.BC6、在数据库设计中,将ER图转换成关系数据模型的过程属于( B )A.需求分析阶段B.逻辑设计阶段C.概念设计阶段D.物理设计阶段7、下述哪一条不是由于关系模式设计不当而引起的?(B)A) 数据冗余B) 丢失修改C) 插入异常D) 更新异常8、下面关于函数依赖的叙述中,不正确的是(B)A) 若X→Y,X→Z,则X→YZB) 若XY→Z,则X→Z,Y→ZC) 若X→Y,Y→Z,则X→ZD) 若X→Y,Y′ Y,则X→Y′9、设U是所有属性的集合,X、Y、Z都是U的子集,且Z=U-X-Y。
下面关于多值依赖的叙述中,不正确的是(C)A) 若X→→Y,则X→→ZB) 若X→Y,则X→→YC) 若X→→Y,且Y′⊂Y,则X→→Y′D) 若Z=Φ,则X→→Y第(10)至(12)题基于以下的叙述:有关系模式A(C,T,H,R,S),基中各属性的含义是:C:课程T:教员H:上课时间R:教室S:学生根据语义有如下函数依赖集:F={C→T,(H,R)→C,(H,T)→R,(H,S)→R}10、关系模式A的码是(D)A) C B) (H,R)C)(H,T)D)(H,S)11、关系模式A的规范化程度最高达到(B)A) 1NF B) 2NF C) 3NF D) BCNF12、现将关系模式A分解为两个关系模式A1(C,T),A2(H,R,S),则其中A1的规范化程度达到(D)A) 1NF B) 2NF C) 3NF D) BCNF13、下述哪一条不属于概念模型应具备的性质?(D)A) 有丰富的语义表达能力B) 易于交流和理解C) 易于变动D) 在计算机中实现的效率高14、在下面列出的条目中,哪个(些)是当前应用开发工具的发展趋势?(D)Ⅰ.采用三层或多层Client/Server结构Ⅱ.支持Web应用Ⅲ.支持开放的、构件式的分布式计算环境A) Ⅰ和ⅡB) 只有ⅡC) 只有ⅢD) 都是15、下面所列的工具中,不能用于数据库应用系统界面开发的工具是(C)A) Visual Basic B) DelphiC) PowerDesigner D) PowerBuilder16、设关系模式R{A,B,C,D,E},其上函数依赖集F={AB→C,DC→E,D→B},则可导出的函数依赖是(A)。
数据库系统原理课后答案 第五章

5.1 名词解释(1)SQL模式:SQL模式是表和授权的静态定义。
一个SQL模式定义为基本表的集合。
一个由模式名和模式拥有者的用户名或账号来确定,并包含模式中每一个元素(基本表、视图、索引等)的定义。
(2)SQL数据库:SQL(Structured Query Language),即‘结构式查询语言’,采用英语单词表示和结构式的语法规则。
一个SQL数据库是表的汇集,它用一个或多个SQL模式定义。
(3)基本表:在SQL中,把传统的关系模型中的关系模式称为基本表(Base Table)。
基本表是实际存储在数据库中的表,对应一个关系。
(4)存储文件:在SQL中,把传统的关系模型中的存储模式称为存储文件(Stored File)。
每个存储文件与外部存储器上一个物理文件对应。
(5)视图:在SQL中,把传统的关系模型中的子模式称为视图(View),视图是从若干基本表和(或)其他视图构造出来的表。
(6)行:在SQL中,把传统的关系模型中的元组称为行(row)。
(7)列:在SQL中,把传统的关系模型中的属性称为列(coloumn)。
(8)实表:基本表被称为“实表”,它是实际存放在数据库中的表。
(9)虚表:视图被称为“虚表”,创建一个视图时,只把视图的定义存储在数据词典中,而不存储视图所对应的数据。
(10)相关子查询:在嵌套查询中出现的符合以下特征的子查询:子查询中查询条件依赖于外层查询中的某个值,所以子查询的处理不只一次,要反复求值,以供外层查询使用。
(11)联接查询:查询时先对表进行笛卡尔积操作,然后再做等值联接、选择、投影等操作。
联接查询的效率比嵌套查询低。
(12)交互式SQL:在终端交互方式下使用的SQL语言称为交互式SQL。
(13)嵌入式SQL:嵌入在高级语言的程序中使用的SQL语言称为嵌入式SQL。
(14)共享变量:SQL和宿主语言的接口。
共享变量有宿主语言程序定义,再用SQL 的DECLARE语句说明, SQL语句就可引用这些变量传递数据库信息。
《MySQL数据库原理、设计与应用》第5章课后习题答案

第五章一、填空题1.逗号或,2. 33.FLOOR(3+RAND()*(11-3+1))或FLOOR(3+RAND()*9)4.NULL5.ON DUPLICATE KEY二、判断题1.错2.对3.错4.对5.对三、选择题1. D2. B3. D4. A5. C四、简答题1.请简述DELETE与TRUNCA TE的区别。
答:①实现方式不同:TRUNCATE本质上先执行删除(DROP)数据表的操作,然后再根据有效的表结构文件(.frm)重新创建数据表的方式来实现数据清空操作。
而DELETE语句则是逐条的删除数据表中保存的记录。
②执行效率不同:在针对大型数据表(如千万级的数据记录)时,TRUNCATE清空数据的实现方式,决定了它比DELETE语句删除数据的方式执行效率更高。
③对AUTO_INCREMENT的字段影响不同,TRUNCATE清空数据后,再次向表中添加数据,自动增长字段会从默认的初始值重新开始,而使用DELETE语句删除表中的记录时,则不影响自动增长值。
④删除数据的范围不同:TRUNCATE语句只能用于清空表中的所有记录,而DELETE语句可通过WHERE指定删除满足条件的部分记录。
⑤返回值含义不同:TRUNCATE操作的返回值一般是无意义的,而DELETE语句则会返回符合条件被删除的记录数。
⑥所属SQL语言的不同组成部分:DELETE语句属于DML数据操作语句,而TRUNCA TE通常被认为是DDL数据定义语句。
2.请简述WHERE与HA VING之间的区别。
1答:①WHERE操作是从数据表中获取数据,用于将数据从磁盘存储到内存中,而HA VING是对已存放到内存中的数据进行操作。
②HA VING位于GROUP BY子句后,而WHERE位于GROUP BY 子句之前。
③HA VING关键字后可以跟聚合函数,而WHERE则不可以。
通常情况下,HA VING关键字与GROUPBY一起使用,对分组后的结果进行过滤。
国开作业数据库应用-形考任务五(第五章)09参考(含答案)

题目:以一个基本表中的允许有重复属性作为外码同另一个基本表中的主码建立联系,则这种联系为_________的联系。
选项A:1对多
选项B:多对多
选项C:1对1
选项D:多对1
答案:1对多
题目:在数据库中,数据保存在()对象中。
选项A:报表
选项B:查询
选项C:窗体
选项D:表
答案:表
题目:在购物活动中,商品实体同销售实体之间是____________联系。
选项A:1对多
选项B:多对多
选项C:1对1
选项D:多对1
答案:1对多
题目:数据字典是对系统工作流程中数据和________的描述。
选项A:字典
选项B:处理
选项C:分组
答案:处理
题目:数据库概念设计的过程中,视图设计一般有三种设计次序,以下各项中不对的是
____________。
选项A:由内向外
选项B:自顶向下
选项C:由整体到局部
选项D:由底向上
答案:由整体到局部
题目:机器实现阶段的任务是在计算机系统中建立____________,装入数据,针对各种处理要求编写出相应的应用程序。
选项A:外模式
选项B:模式
选项C:数据库模式
选项D:内模式
答案:数据库模式
题目:由概念设计进入逻辑设计时,原来实体被转换为对应的基本表或________。
选项A:流程图 C.二维表
选项B:视图
选项C:逻辑表
答案:视图
题目:由概念设计进入逻辑设计时,原来的多对多联系通常需要被转换为对应的________。
选项A:基本表 C.二维表
选项B:视图。
《第五章第三节GIS的数据库及其应用》作业设计方案-高中地理人教版选修7

《GIS的数据库及其应用》作业设计方案(第一课时)一、作业目标本作业旨在通过《GIS的数据库及其应用》的学习,使学生掌握GIS的基本概念、数据库结构以及GIS在现实生活中的应用。
通过实际操作,加深学生对GIS技术的理解,培养学生的空间思维能力和地理信息分析能力。
二、作业内容1. 理论学习:学生需认真阅读教材中关于GIS数据库的章节,了解GIS的基本概念、数据库的结构和类型,以及GIS的应用领域。
2. 知识点梳理:学生需总结出GIS数据库的主要组成部分,包括空间数据、属性数据和元数据等,并理解它们在GIS系统中的作用。
3. 案例分析:学生需选择一个与GIS数据库相关的实际案例(如城市交通规划、环境监测等),分析该案例中如何运用GIS 数据库进行数据处理和分析。
4. 实验操作:学生需利用GIS软件(如ArcGIS等)进行实际操作,完成以下任务:(1)创建简单的GIS数据库,包括空间数据和属性数据的导入和编辑;(2)运用GIS软件进行空间查询和属性查询,了解空间数据的关联性;(3)利用GIS软件进行空间分析和可视化表达,如缓冲区分析、叠加分析等。
5. 作业报告:学生需将上述内容作业设计如下:三、作业要求学生需按照以下要求完成作业:1. 理论学习和知识点梳理需结合教材内容,重点突出,条理清晰,并适当加入自己的理解和见解。
2. 案例分析需选择具有代表性的实际案例,分析过程需详实,并能够体现出GIS数据库在案例中的应用和优势。
3. 实验操作需按照步骤进行,确保每一步操作正确无误,并记录好操作过程和结果。
4. 作业报告需按照以下格式编写:- 标题:简明扼要地概括报告内容;- 正文:包括理论学习、知识点梳理、案例分析和实验操作的内容和结果;- 结论:总结GIS数据库的重要性和应用价值,以及自己在本次作业中的收获和体会。
5. 作业提交时需将报告以电子版形式发送至教师指定的邮箱或平台,并按时完成。
四、作业评价本作业的评价将从理论学习、知识点梳理、案例分析、实验操作和作业报告等多个方面进行,评价标准包括内容的准确性、条理的清晰性、操作的正确性以及报告的完整性等。
数据库第五六七章作业答案

select sno,sname,cno,grade from student join sc on student.sno=sc.sno where sdept=‘数学系’
and sno in (select sno from sc where grade>80)
on s.sno=sc.sno where grade >80 order by grade desc 13、查询哪些学生没有选课,要求列出学号、姓名和所在系
select s.sno,sname,sdept from student s left join sc on
s.sno=sc.sno where o is null
TWEEN 1 AND 5)
25、create table test_t(
col1 int, col2 char(10) not null, col3 char(10)) insert into test_t(col2) values(‘b1’) insert into test_t(col1,col2,col3) values(1,’b2’,’c2’) insert into test_t(col1,col2) values(2,’b3’)
26、删除考试成绩低于50分的学生的该门课程的选 课记录
delete from sc where grade<50 27、删除没有人选的课程记录
delete from course where cno not in
(select cno from sc) 28、删除计算机系VB成绩不及格学生的VB选课记
14、查询与VB在同一学期开设的课程的课程名和开课学期
Mysql数据库及应用(专,2020春)_第5章作业0

C.算术运算符、赋值运算符、位运算符、比较运算符、集合运算符、一元运算符等。
D.算术运算符、赋值运算符、位运算符、比较运算符、线性运算符、一元运算符等。
答案:B
8.05-8 、在MySQL数据库中,要访问任何一个对象都要通过其名称来完成,在SQL语言中,对数据库、表、变量、存储过程、函数等的定义和引用都需要通过_______来完成。
B.LOCATE
C.TRIM
D.CONCAT
答案:D
3.05-3 、可以说,表中主键约束同时具备非空约束和_______的效果。~
A.外键约束
B.默认值约束
C.检查约束
D.唯一约束
答案:D
4.05-4 、设置字段唯一约束的关键字是___________。~
A.NOT NULL
B.PRIMARY
C.FOREIGN
D.UNIQUE
答案:
5.05-5 、对用户变量赋值有两种方式,使用SET命令对用户变量进行赋值时,两种方式都可以使用,当使用SELECT语句对用户变量进行赋值时,只能使用"________”方式。
A.:
B.<
答案:A
6.05-6 、SQL是的 缩写,译为结构化查询语言.~
A.Studio Query Language
B.Structured Question Language
C.Studio Question Language
D.Structured Query Language
答案:D
7.05-7 、SQL的运算符主要有哪些?
数据库第五章习题及答案

第五章 关系数据理论一、 单项选择题1、设计性能较优的关系模式称为规范化,规范化主要的理论依据是 ( )A 、关系规范化理论B 、关系运算理论C 、关系代数理论D 、数理逻辑2、关系数据库规范化是为解决关系数据库中( )问题而引入的。
A 、插入、删除和数据冗余B 、提高查询速度C 、减少数据操作的复杂性D 、保证数据的安全性和完整性3、当关系模式R (A ,B )已属于3NF ,下列说法中( )是正确的。
A 、它一定消除了插入和删除异常B 、一定属于BCNFC 、仍存在一定的插入和删除异常D 、A 和C 都是4、在关系DB 中,任何二元关系模式的最高范式必定是( )A 、1NFB 、2NFC 、3NFD 、BCNF5、当B 属性函数依赖于A 属性时,属性A 与B 的联系是( )A 、1对多B 、多对1C 、多对多D 、以上都不是6、在关系模式中,如果属性A 和B 存在1对1的联系,则说( )A 、A B B 、B A C 、A B D 、以上都不是7、关系模式中,满足2NF 的模式,( )A 、可能是1NFB 、必定是1NFC 、必定是3NFD 、必定是BCNF8、关系模式R 中的属性全部是主属性,则R 的最高范式必定是( )A 、2NFB 、3NFC 、BCNFD 、4NF9、关系模式的候选关键字可以有( c ),主关键字有( 1个 )A 、0个B 、1个C 、1个或多个D 、多个10、如果关系模式R 是BCNF 范式,那么下列说法不正确的是( )。
A 、R 必是3NFB 、R 必是1NFC 、R 必是2NFD 、R 必是4NF11、图4.5中给定关系R ( )。
A 、不是3NFB 、是3NF 但不是2NFC 、是3NF 但不是BCNFD 、是BCNF12、设有如图4.6所示的关系R ,它是( )A 、1NFB 、2NFC 、3NFD 、4NF二、 填空题1、如果模式是BCNF ,则模式R 必定是(3NF ),反之,则( 不一定 )成立。
数据库复习 第五章 习题

第五章习题一、选择题:1.关系规范化中的删除操作异常是指①,插入操作异常是指②。
A.不该删除的数据被删除B.不该插入的数据被插入C.应该删除的数据未被删除D.应该插入的数据未被插入答案:①A ②D2.设计性能较优的关系模式称为规范化,规范化主要的理论依据是____。
A.关系规范化理论B.关系运算理论C.关系代数理论D.数理逻辑答案:A3.规范化理论是关系数据库进行逻辑设计的理论依据。
根据这个理论,关系数据库中的关系必须满足:其每一属性都是____。
A.互不相关的B.不可分解的C.长度可变的D.互相关联的答案:B4.关系数据库规范化是为解决关系数据库中____问题而引人的。
A.插入、删除异常和数据冗余B.提高查询速度C.减少数据操作的复杂性D.保证数据的安全性和完整性答案:A5.规范化过程主要为克服数据库逻辑结构中的插入异常,删除异常以及____的缺陷。
A.数据的不一致性B.结构不合理C.冗余度大D.数据丢失答案:C6.当关系模式R(A,B)已属于3NF,下列说法中____是正确的。
A.它一定消除了插入和删除异常B.仍存在一定的插入和删除异常C.一定属于BCNF D.A和C都是答案:B7.关系模型中的关系模式至少是____。
A.1NF B.2NF C.3NF D.BCNF答案:A8.在关系DB中,任何二元关系模式的最高范式必定是____。
A.1NF B.2NF C.3NF D.BCNF答案:D9.在关系模式R中,若其函数依赖集中所有候选关键宇都是决定因素,则R最高范式是____。
A.2NF B.3NF C.4 NF D.BCNF答案:C10.当B属性函数依赖于A属性时,属性A与B的联系是____。
A.1对多B.多对1 C.多对多D.以上都不是答案:B11.在关系模式中,如果属性A和B存在1对1的联系,则说____。
A.A→B B.B→A C.A↔B D.以上都不是答案:C12.候选码中的属性称为____。
数据库应用第五章选择习题

习题5一、选择题1.在Access中,可用于设计输入界面的对象是()。
A.窗体B.报表C.查询D.表2.下列不属于Access窗体的视图是()。
A.设计视图B.窗体视图C.版面视图D.数据表视图3.可以作为窗体记录源的是()。
A.表B.查询C.SELECT语句D.表、查询或SELECT语句4.在窗体设计控件组中,代表组合框的图标是()。
A. B. C. D.5.在Access数据库中,用于输入或编辑字段数据的交互控件是()。
A.文本框B.标签C.复选框D.组合框6.能够接收数值型数据输入的窗体控件是()。
A.图形B.文本框C.标签D.命令按钮7.在Access中建立了“学生”表,其中有可以存放照片的字段。
在使用向导为该表创建窗体时,“照片”字段所使用的默认控件是()。
A.图像框B.绑定对象框C.非绑定对象框D.列表框8.在Access数据库中,若要求在窗体上设置输入的数据是取自某一个表或查询中记录的数据,或者取自某固定内容的数据,可以使用的控件是()。
A.选项组控件B.列表框或组合框控件C.文本框控件D.复选框、切换按钮、选项按钮控件9.在教师信息输入窗体中,为职称字段提供“教授”“副教授”“讲师”等选项供用户直接选择,应使用的控件是()。
A.标签B.复选框C.文本框D.组合框10.要改变窗体上文本框控件的数据源,应设置的属性是()。
A.记录源B.控件来源C.筛选查阅D.默认值11.要显示格式为“页码/总页数”的页码,应当设置文本框控件的控制来源属性()。
A.[Page]/[Pages]B.=[Page]/[Pages]C.[Page]&"/"&[Pages]D.=[Page]&"/"&[Pages]12.下列属性中,属于窗体的“数据”类属性的是()。
A.记录源B.自动居中C.获得焦点D.记录选择器13.在Access数据库中,为窗体上的控件设置【Tab】键的顺序,应选择“属性表”窗格中的是()。
数据库系统基础教程第五章答案

Exercise 5.1.1 As a set:Average = 2.37 As a bag:Average = 2.48 Exercise 5.1.2Average = 218 As a bag:Average = 215 Exercise 5.1.3a As a set:161418As a bag:bore1516141615151418Exercise 5.1.3b(Ships Classes)πboreExercise 5.1.4aFor bags:On the left-hand side:Given bags R and S where a tuple t appears n and m times respectively,the union of bags R and S will have tuple t appear n + m times. Thefurther union of bag T with the tuple t appearing o times will havetuple t appear n + m + o times in the final result.On the right-hand side:Given bags S and T where a tuple t appears m and o times respectively,the union of bags R and S will have tuple t appear m + o times. Thefurther union of bag R with the tuple t appearing n times will havetuple t appear m + o + n times in the final result.For sets:This is a similar case when dealing with bags except the tuple t can only appear at most once in each set. The tuple t only appears in the result if allthe sets have the tuple t. Otherwise, the tuple t will not appear in the result. Since we cannot have duplicates, the result only has at most one copy of the tuple t.Exercise 5.1.4bFor bags:On the left-hand side:Given bags R and S where a tuple t appears n and m times respectively,the intersection of bags R and S will have tuple t appear min( n, m )times. The further intersection of bag T with the tuple t appearing otimes will produce tuple t min( o, min( n, m ) ) times in the finalresult.On the right-hand side:Given bags S and T where a tuple t appears m and o times respectively,the intersection of bags R and S will have tuple t appear min( m, o )times. The further intersection of bag R with the tuple t appearing ntimes will produce tuple t min( n, min( m, o ) ) times in the finalresult.The intersection of bags R,S and T will yield a result where tuple t appears min( n,m,o ) times.For sets:This is a similar case when dealing with bags except the tuple t can only appear at most once in each set. The tuple t only appears in the result if all the sets have the tuple t. Otherwise, the tuple t will not appear in the result.Exercise 5.1.4cFor bags:On the left-hand side:Given that tuple r in R, which appears m times, can successfully joinwith tuple s in S, which appears n times, we expect the result tocontain mn copies. Also given that tuple t in T, which appears o times,can successfully join with the joined tuples of r and s, we expect the final result to have mno copies.On the right-hand side:Given that tuple s in S, which appears n times, can successfully joinwith tuple t in T, which appears o times, we expect the result tocontain no copies. Also given that tuple r in R, which appears m times, can successfully join with the joined tuples of s and t, we expect the final result to have nom copies.The order in which we perform the natural join does not matter for bags.For sets:This is a similar case when dealing with bags except the joined tuples can only appear at most once in each result. If there are tuples r,s,t in relations R,S,T that can successfully join, then the result will contain a tuple with the schema of their joined attributes.Exercise 5.1.4dFor bags:Suppose a tuple t occurs n and m times in bags R and S respectively. In the union of these two bags R ⋃ S, tuple t would appear n + m times. Likewise, in the union of these two bags S ⋃ R, tuple t would appear m + n times. Both sides of the relation yield the same result.For sets:A tuple t can only appear at most one time. Tuple t might appear each in sets R and S one or zero times. The combinations of number of occurrences for tuple t in R and S respectively are (0,0), (0,1), (1,0), and (1,1). Only when tuple t appears in both sets R and S will the union R ⋃ S have the tuple t. The same reasoning holds when we take the union S ⋃ R.Therefore the commutative law for union holds.Exercise 5.1.4eFor bags:Suppose a tuple t occurs n and m times in bags R and S respectively. In the intersection of these two bags R ∩ S, tuple t would appear min( n,m ) times. Likewise in the intersection of these two bags S ∩ R, tuple t would appear min( m,n ) times. Both sides of the relation yield the same result.For sets:A tuple t can only appear at most one time. Tuple t might appear each in sets R and S one or zero times. The combinations of number of occurrences for tuplet in R and S respectively are (0,0), (0,1), (1,0), and (1,1). Only when tuple t appears in at least one of the sets R and S will the intersection R ∩ S have the tuple t. The same reasoning holds when we take the intersection S ∩ R.Therefore the commutative law for intersection holds.Exercise 5.1.4fFor bags:Suppose a tuple t occurs n times in bag R and tuple u occurs m times in bag S. Suppose also that the two tuples t,u can successfully join. Then in thenatural join of these two bags R S, the joined tuple would appear nm times. Likewise in the natural join of these two bags S R, the joined tuple would appear mn times. Both sides of the relation yield the same result.For sets:An arbitrary tuple t can only appear at most one time in any set. Tuples u,v might appear respectively in sets R and S one or zero times. The combinations of number of occurrences for tuples u,v in R and S respectively are (0,0), (0,1), (1,0), and (1,1). Only when tuple u exists in R and tuple v exists in S will the natural join R S have the joined tuple. The same reasoning holds when we take the natural join S R.Therefore the commutative law for natural join holds.Exercise 5.1.4gFor bags:Suppose tuple t appears m times in R and n times in S. If we take the union of R and S first, we will get a relation where tuple t appears m + n times. Taking the projection of a list of attributes L will yield a resultingrelation where the projected attributes from tuple t appear m + n times. If we take the projection of the attributes in list L first, then the projected attributes from tuple t would appear m times from R and n times from S. The union of these resulting relations would have the projected attributes of tuple t appear m + n times.For sets:An arbitrary tuple t can only appear at most one time in any set. Tuple tmight appear in sets R and S one or zero times. The combinations of number of occurrences for tuple t in R and S respectively are (0,0), (0,1), (1,0), and (1,1). Only when tuple t exists in R or S (or both R and S) will the projected attributes of tuple t appear in the result.Therefore the law holds.Exercise 5.1.4hFor bags:Suppose tuple t appears u times in R, v times in S and w times in T. On the left hand side, the intersection of S and T would produce a result where tuple t would appear min(v , w) times. With the addition of the union of R, the overall result would have u + min(v , w) copies of tuple t. On the right hand side, we would get a result of min(u + v, u + w) copies of tuple t. The expressions on both the left and right sides are equivalent.For sets:An arbitrary tuple t can only appear at most one time in any set. Tuple tmight appear in sets R,S and T one or zero times. The combinations of number of occurrences for tuple t in R, S and T respectively are (0,0,0), (0,0,1), (0,1,0), (0,1,1), (1,0,0), (1,0,1), (1,1,0) and (1,1,1). Only when tuple t appears in R or in both S and T will the result have tuple t.Therefore the distributive law of union over intersection holds.Exercise 5.1.4iSuppose that in relation R, u tuples satisfy condition C and v tuples satisfy condition D. Suppose also that w tuples satisfy both conditions C and D where w≤ min(v , w). Then the left hand side will return those w tuples. On the right hand side, σ(R) produces u tuples and σD(R) produces v tuples. However,Cwe know the intersection will produce the same w tuples in the result.When considering bags and sets, the only difference is bags allow duplicate tuples while sets only allow one copy of the tuple. The example above applies to both cases.Therefore the law holds.Exercise 5.1.5aFor sets, an arbitrary tuple t appears on the left hand side if it appears in both R,S and not in T. The same is true for the right hand side.As an example for bags, suppose that tuple t appears one time each in both R,T and two times in S. The result of the left hand side would have zero copies of tuple t while the right hand side would have one copy of tuple t.Therefore the law holds for sets but not for bags.Exercise 5.1.5bFor sets, an arbitrary tuple t appears on the left hand side if it appears in R and either S or T. This is equivalent to saying tuple t only appears when it is in at least R and S or in R and T. The equivalence is exactly the right side’s expression.As an example for bags, suppose that tuple t appears one time in R and two times each in S and T. Then the left hand side would have one copy of tuple tin the result while the right hand side would have two copies of tuple t.Therefore the law holds for sets but not for bags.Exercise 5.1.5cFor sets, an arbitrary tuple t appears on the left hand side if it satisfies condition C, condition D or both condition C and D. On the right hand side,σC (R) selects those tuples that satisfy condition C while σD(R) selects thosetuples that satisfy condition D. However, the union operator will eliminate duplicate tuples, namely those tuples that satisfy both condition C and D. Thus we are ensured that both sides are equivalent.As an example for bags, we only need to look at the union operator. If there are indeed tuples that satisfy both conditions C and D, then the right hand side will contain duplicate copies of those tuples. The left hand side, however, will only have one copy for each tuple of the original set of tuples.Exercise 5.2.1aExercise 5.2.1bExercise 5.2.1cExercise 5.2.1dExercise 5.2.1eExercise 5.2.1fExercise 5.2.1gExercise 5.2.1hExercise 5.2.1iExercise 5.2.1jExercise 5.2.1kExercise 5.2.1lExercise 5.2.1mExercise 5.2.1nExercise 5.2.2aApplying the δ operator on a relation with no duplicates will yield the same relation. Thus δ is idempotent.Exercise 5.2.2bThe result of πis a relation over the list of attributes L. Performing theLprojection again will return the same relation because the relation only contains the list of attributes L. Thus πis idempotent.LExercise 5.2.2cis a relation where condition C is satisfied by every tuple. The result of σCPerforming the selection again will return the same relation because the relation only contains tuples that satisfy the condition C. Thus σisC idempotent.Exercise 5.2.2dThe result of γis a relation whose schema consists of the groupingLattributes and the aggregated attributes. If we perform the same grouping operation, there is no guarantee that the expression would make sense. The grouping attributes will still appear in the new result. However, the aggregated attributes may or may not appear correctly. If the aggregated attribute is given a different name than the original attribute, thenwould not make sense because it contains an aggregation for an performing γLattribute name that does not exist. In this case, the resulting relation would,according to the definition, only contain the grouping attributes. Thus, γLis not idempotent.Exercise 5.2.2eThe result of τ is a sorted list of tuples based on some attributes L. If Lis not the entire schema of relation R, then there are attributes that are not sorted on. If in relation R there are two tuples that agree in all attributes L and disagree in some of the remaining attributes not in L, then it is arbitrary as to which order these two tuples appear in the result. Thus, performing the operation τ multiple times can yield a different relation where these two tuples are swapped. Thus, τ is not idempot ent.Exercise 5.2.3If we only consider sets, then it is possible. We can take π(R) and do aAproduct with itself. From this product, we take the tuples where the two columns are equal to each other.If we consider bags as well, then it is not possible. Take the case where we have the two tuples (1,0) and (1,0). We wish to produce a relation that contains tuples (1,1) and (1,1). If we use the classical operations of relational algebra, we can either get a result where there are no tuples or four copies of the tuple (1,1). It is not possible to get the desired relation because no operation can distinguish between the original tuples and the duplicated tuples. Thus it is not possible to get the relation with the two tuples (1,1) and (1,1).Exercise 5.3.1a)Answer(model) ← PC(model,speed,_,_,_) AND speed ≥ 3.00b)Answer(maker) ← Laptop(model,_,_,hd,_,_) AND Product(maker,model,_) ANDhd ≥ 100c)Answer(model,price) ← PC(model,_,_,_,price) AND Product(maker,model,_)AND maker=’B’Answer(model,price) ← Laptop(mode l,_,_,_,_,price) ANDProduct(maker,model,_) AND maker=’B’Answer(model,price) ← Printer(model,_,_,price) ANDProduct(maker,model,_) AND maker=’B’d)Answer(model) ← Printer(model,color,type,_) AND color=’true’ ANDtype=’laser’e)PCMaker(maker) ← Product(maker,_,type) AND type=’pc’LaptopMaker(maker) ← Product(maker,_,type) AND type=’laptop’Answer(maker) ← LaptopMaker(maker) AND NOT PCMaker(maker)f)Answer(hd) ← PC(model1,_,_,hd,_) AND PC(model2,_,_,hd,_) AND model1 <>model2g)Answer(model1,model2) ← PC(model1,speed, ram,_,_) ANDPC(model2,_speed,ram,_,_) AND model1 < model2h)FastComputer(model) ← PC(model,speed,_,_,_) AND speed ≥ 2.80FastComputer(model) ← Laptop(model,speed,_,_,_,_) AND speed ≥ 2.80Answer(maker) ← Product(maker,model1,_) AND Product(maker,mod el2,_) AND FastComputer(model1) AND FastComputer(model2) AND model1 <> model2i)Computers(model,speed) ← PC(model,speed,_,_,_)Computers(model,speed) ← Laptop(model,speed,_,_,_,_)SlowComputers(model) ← Computers(model,speed) ANDComputers(model1,speed1) AND speed < speed1FastestComputers(model) ← Computers(model,_) AND NOTSlowComputers(model)Answer(maker) ← Fast estComputers(model) AND Product(maker,model,_)j)PCs(maker,speed) ← PC(model,speed,_,_,_) AND Product(maker,model,_) Answer(maker) ← PCs(maker,spe ed) AND PCs(maker,speed1) ANDPCs(maker,speed2) AND speed <> speed1 AND speed <> speed2 AND speed1 <> speed2k)PCs(maker,model) ← Product(maker,model,type) AND type=’pc’Answer(maker) ← PCs(maker,model) AND PCs(maker,model1) ANDPCs(maker,model2) AND PCs(maker,model3) AND model <> model1 AND model <> model2 AND model1 <> model2 AND (model3 = model OR model3 = model1 ORmodel3 = model2)Exercise 5.3.2a)Answer(class,country) ← Classes(class,_,country,_,bore,_) AND bore ≥16b)Answer(name) ← Ships(name,_,launch ed) AND launched < 1921c)Answer(ship) ← Outcomes(ship,battle,result) AND battle=’DenmarkStrait’ AND result = ‘sunk’d)Answer(name) ← Classes(class,_,_,_,_,displacement) ANDShips(name,class,launched) AND displacement > 35000 AND launched > 1921e)Answer(nam e,displacement,numGuns) ←Classes(class,_,_,numGuns,_,displacement) AND Ships(name,class,_) ANDOutcomes (ship,battle,_) AND battle=’Guadalcanal’ AND ship=namef)Answer(name) ← Ships(name,_,_)Answer(name) ← Outcomes(name,_,_) AND NOT Answer(name)g)MoreThan One(class) ← Ships(name,class,_) AND Ships(name1,class,_) ANDname <> name1Answer(class) ← Classes(class,_,_,_,_,_) AND NOT MoreThanOne(class)h)Battleship(country) ← Classes(_,type,country,_,_,_) AND type=’bb’Battlecruiser(country) ← Classes(_,type,country,_,_,_) AND type=’bc’Answer(country) ← Battleship(country) AND Battlecruiser(country)i)Results(ship,result,date) ← Battles(name,date) ANDOutcomes(ship,battle,result) AND battle=nameAnswer(ship) ← Results(ship,result,date) AND Results(ship,_,date1) AND result=’damaged’ AND date < date1Exercise 5.3.3A nswer(x,y) ← R(x,y) AND z = zExercise 5.4.1aAnswer(a,b,c) ← R(a,b,c)Answer(a,b,c) ← S(a,b,c)Exercise 5.4.1bAnswer(a,b,c) ← R(a,b,c) AND S(a,b,c)Exercise 5.4.1cAnswer(a,b,c) ← R(a,b,c) AND NOT S(a,b,c)Exercise 5.4.1dUnion(a,b,c) ← R(a,b,c)Union(a,b,c) ← S(a,b,c)Answer(a,b,c) ← Union(a,b,c) AND NOT T(a,b,c)Exercise 5.4.1eJ(a,b,c) ← R(a,b,c) AND NOT S(a,b,c)K(a,b,c) ← R(,a,b,c) AND NOT T(a,b,c)Answer(a,b,c) ← J(a,b,c) AND K(a,b,c)Exercise 5.4.1fAnswer(a,b) ← R(a,b,_)Exercise 5.4.1gJ(a,b) ← R(a,b,_)K(a,b) ← S(_,a,b)Answer(a,b) ← J(a,b) AND K(a,b)Exercise 5.4.2aAnswer(x,y,z) ← R(x,y,z) AND x = yExercise 5.4.2bAnswer(x,y,z) ← R(x,y,z) AND x < y AND y < z Exercise 5.4.2cAnswer(x,y,z) ← R(x,y,z) AND x < yAnswer(x,y,z) ← R(x,y,z) AND y < zExercise 5.4.2dChange: NOT(x < y OR x > y)To: x ≥ y AND x ≤ yThe above simplifies to x = yAnswer(x,y,z) ← R(x,y,z) AND x = yExercise 5.4.2eChange: NOT((x < y OR x > y) AND y < z)NOT(x < y OR x > y) OR y ≥ z(x ≥ y AND x ≤ y) OR y ≥ zTo: x = y OR y ≥ zAnswer(x,y,z) ← R(x,y,z) AND x = yAnswer(x,y,z) ← R(x,y,z) AND y ≥ zExercise 5.4.2fChange: NOT((x < y OR x < z) AND y < z)NOT(x < y OR x < z) OR y ≥ zTo: (x ≥ y AND x ≥ z) OR y ≥ zAnswer(x,y,z) ← R(x,y,z) AND x ≥ y AND x ≥ zAnswer(x,y,z) ← R(x,y,z) AND y ≥zExercise 5.4.3aAnswer(a,b,c,d) ← R(a,b,c) AND S(b,c,d)Exercise 5.4.3bAnswer(b,c,d,e) ← S(b,c,d) AND T(d,e)Exercise 5.4.3cAnswer(a,b,c,d,e) ← R(a,b,c) AND S(b,c,d) AND T(d,e)Exercise 5.4.4a)Answer(rx,ry,rz,sx,sy,sz) ← R(rx,ry,rz) AND S(sx,sy,sz) AND rx = syb)Answer(rx,ry,rz,sx,sy,sz) ← R(rx,ry,rz) AND S(sx,sy,sz) AND rx < sy ANDry < szc)Answer(rx,ry,rz,sx,sy,s z) ← R(rx,ry,rz) AND S(sx,sy,sz) AND rx < syAnswer(rx,ry,rz,sx,sy,sz) ← R(rx,ry,rz) AND S(sx,sy,sz) AND ry < szd)Answer(rx,ry,rz,sx,sy,sz) ← R(rx,ry,rz) AND S(sx,sy,sz) AND rx = sye)Answer(rx,ry,rz,sx,sy,sz) ← R(rx,ry,rz) AND S(sx,sy,sz) AND rx = syAnswe r(rx,ry,rz,sx,sy,sz) ← R(rx,ry,rz) AND S(sx,sy,sz) AND ry ≥ szf)Answer(rx,ry,rz,sx,sy,sz) ← R(rx,ry,rz) AND S(sx,sy,sz) AND rx ≥ syAND rx ≥ szAnswer(rx,ry,rz,sx,sy,sz) ← R(rx,ry,rz) AND S(sx,sy,sz) AND ry ≥ sz Exercise 5.4.5aR1 := πx,y(Q R) Exercise 5.4.5bR1 := ρR1(x,z)(Q)R2 := ρR2(z,y)(Q)R3 := πx,y (R1(R1.z = R2.z)R2)Exercise 5.4.5cR1 := πx,y(Q R)R2 := σx < y(R1)。
数据库第5章习题参考答案

第5章习题解答1.选择题(1)为数据表创建索引的目的是_______。
A.提高查询的检索性能B.节省存储空间C.便于管理D.归类(2)索引是对数据库表中_______字段的值进行排序。
A.一个B.多个C.一个或多个D.零个(3)下列_______类数据不适合创建索引。
A.经常被查询搜索的列B.主键的列C.包含太多NULL值的列D.表很大(4)有表student(学号, 姓名, 性别, 身份证号, 出生日期, 所在系号),在此表上使用_______语句能创建建视图vst。
A.CREATE VIEW vst AS SELECT * FROM studentB.CREATE VIEW vst ON SELECT * FROM studentC.CREATE VIEW AS SELECT * FROM studentD.CREATE TABLE vst AS SELECT * FROM student(5)下列_______属性不适合建立索引。
A.经常出现在GROUP BY字句中的属性B.经常参与连接操作的属性C.经常出现在WHERE字句中的属性D.经常需要进行更新操作的属性(6)下面关于索引的描述不正确的是_______。
A.索引是一个指向表中数据的指针B.索引是在元组上建立的一种数据库对象C.索引的建立和删除对表中的数据毫无影响D.表被删除时将同时删除在其上建立的索引(7)SQL的视图是_______中导出的。
A.基本表B.视图C.基本表或视图D.数据库(8)在视图上不能完成的操作是_______。
A.更新视图数据B.查询C.在视图上定义新的基本表D.在视图上定义新视图(9)关于数据库视图,下列说法正确的是_______。
A.视图可以提高数据的操作性能B.定义视图的语句可以是任何数据操作语句C.视图可以提供一定程度的数据独立性D.视图的数据一般是物理存储的(10)在下列关于视图的叙述中,正确的是_______。
《数据库技术与应用》第5章 习题答案

第5章数据库完整性与安全性1.什么是数据库的完整性?什么是数据库的安全性?两者之间有什么区别和联系?解:数据库的完整性是指数据库中数据的正确性、有效性和相容性,其目的是防止不符合语义、不正确的数据进入数据库,从而来保证数据库系统能够真实的反映客观现实世界。
数据库安全性是指保护数据库,防止因用户非法使用数据库造成数据泄露、更改或破坏。
数据的完整性和安全性是两个不同的概念,但是有一定的联系: 前者是为了防止数据库中存在不符合语义的数据,防止错误信息的输入和输出,即所谓垃圾进单位、束。
静态元组①INSERT③)执行该操作,或级连(CASCADE)执行其它操作,进行违约处理以保证数据的完整性。
4.现有以下四个关系模式:供应商(供应商编号,姓名,电话,地点),其中供应商编号为主码;零件(零件编号,零件名称,颜色,重量),其中零件编号为主码;工程(工程编号,工程名称,所在地点),其中工程编号为主码;供应情况(供应商编号,零件编号,工程编号,数量),其中供应商编号,零件编号,工程编号为主码用SQL语句定义这四个关系模式,要求在模式中完成以下完整性约束条件的定义:①定义每个模式的主码;②定义参照完整性;③定义零件重量不得超过100千克。
解:CREATESCHEMASupplier_schemaCREATETABLESupplier(SnoCHAR(5)PRIMARYKEY,SnameCHAR(20)NOTNULL,PhoneCHAR(13),AddressCHAR(30));5.在关系数据库系统中,当操作违反实体完整性、参照完整性和用户自定义的完整性约束条件时,一般是如何分别进行处理的。
解:(1)按实体完整性规则自动进行检查。
包括:①检查主码值是否唯一,如果不唯一则拒绝插入或修改。
②检查主码的各个属性是否为空,只要有一个为空就拒绝插入或修改。
(2)按参照完整性检查,违约处理的策略如下:①拒绝(NOACTION)执行。
数据库系统原理与设计万常选版第五章练习题和详细答案

第五章关系数据理论一、选择题1. 为了设计出性能较优的关系模式,必须进行规范化,规范化主要的理论依据是()。
A. 关系规范化理论B. 关系代数理论C.数理逻辑D. 关系运算理论2. 规范化理论是关系数据库进行逻辑设计的理论依据,根据这个理论,关系数据库中的关系必须满足:每一个属性都是()。
A. 长度不变的B. 不可分解的C.互相关联的D. 互不相关的3. 已知关系模式R(A,B,C,D,E)及其上的函数相关性集合F={A→D,B→C ,E→A },该关系模式的候选关键字是()。
A.ABB. BEC.CDD. DE4. 设学生关系S(SNO,SNAME,SSEX,SAGE,SDPART)的主键为SNO,学生选课关系SC(SNO,CNO,SCORE)的主键为SNO和CNO,则关系R(SNO,CNO,SSEX,SAGE,SDPART,SCORE)的主键为SNO和CNO,其满足()。
A. 1NFB.2NFC. 3NFD. BCNF5. 设有关系模式W(C,P,S,G,T,R),其中各属性的含义是:C表示课程,P 表示教师,S表示学生,G表示成绩,T表示时间,R表示教室,根据语义有如下数据依赖集:D={ C→P,(S,C)→G,(T,R)→C,(T,P)→R,(T,S)→R },关系模式W 的一个关键字是()。
A. (S,C)B. (T,R)C. (T,P)D. (T,S)6. 关系模式中,满足2NF的模式()。
A. 可能是1NFB. 必定是1NFC. 必定是3NFD. 必定是BCNF7. 关系模式R中的属性全是主属性,则R的最高范式必定是()。
A. 1NFB. 2NFC. 3NFD. BCNF8. 消除了部分函数依赖的1NF的关系模式,必定是()。
A. 1NFB. 2NFC. 3NFD. BCNF9. 如果A->B ,那么属性A和属性B的联系是()。
A. 一对多B. 多对一C.多对多D. 以上都不是10. 关系模式的候选关键字可以有1个或多个,而主关键字有()。
数据库管理系统原理 第五章测验 测验答案 慕课答案 UOOC优课 课后练习 深圳大学
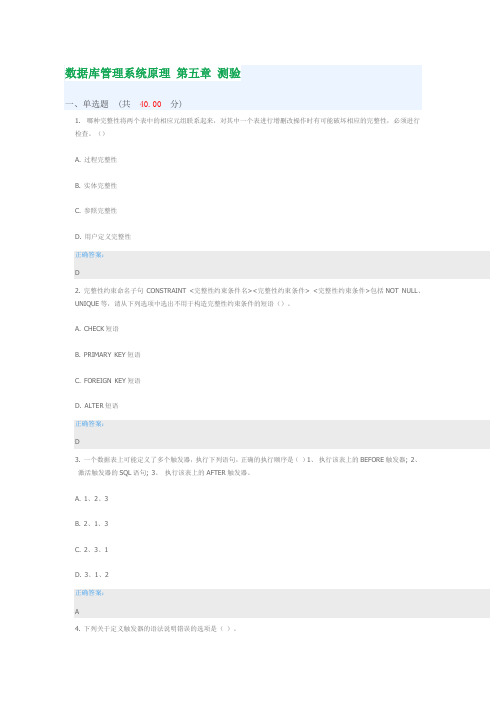
数据库管理系统原理第五章测验一、单选题(共40.00分)1. 哪种完整性将两个表中的相应元组联系起来,对其中一个表进行增删改操作时有可能破坏相应的完整性,必须进行检查。
()A. 过程完整性B. 实体完整性C. 参照完整性D. 用户定义完整性正确答案:D2. 完整性约束命名子句CONSTRAINT <完整性约束条件名><完整性约束条件> <完整性约束条件>包括NOT NULL、UNIQUE等,请从下列选项中选出不用于构造完整性约束条件的短语()。
A. CHECK短语B. PRIMARY KEY短语C. FOREIGN KEY短语D. ALTER短语正确答案:D3. 一个数据表上可能定义了多个触发器,执行下列语句,正确的执行顺序是()1、执行该表上的BEFORE触发器; 2、激活触发器的SQL语句; 3、执行该表上的AFTER触发器。
A. 1、2、3B. 2、1、3C. 2、3、1D. 3、1、2正确答案:A4. 下列关于定义触发器的语法说明错误的选项是()。
A. 表的拥有者才可以在表上创建触发器B. 触发器可以定义在基本表上,也可以定义在视图上C. 同一模式下,触发器名必须是唯一的,触发器名和表名必须在同一模式下D. 触发器只能定义在基本表上,不能定义在视图上正确答案:B二、多选题(共33.00分)1. 触发器类型()。
A. 行级触发器(FOR EACH ROW)B. 列级触发器(FOR EACH COLUMN)C. 语句级触发器(FOR EACH STATEMENT)D. 表级触发器(FOR EACH TABLE)正确答案:A C2. CREATE TABLE DEPT ( Deptno NUMERIC(2), Dname CHAR(9) UNIQUE NOT NULL)关于关键子句“ UNIQUE NOT NULL”描述正确的选项()。
A. 实体完整性B. 要求Dname列值唯一, 或者不能取空值C. 用户定义的完整性D. 要求Dname列值唯一, 并且不能取空值正确答案:C D3. 数据的安全性描述正确的选项()。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第五、六章练习题一、选择题1、在关系数据库设计中,子模式设计是在__________阶段进行。
[ B]A.物理设计 B.逻辑设计 C.概念设计 D.程序设计2、设有关系R(A,B,C)的值如下:A B C2 2 32 3 43 3 5下列叙述正确的是(B)A.函数依赖A→B在上述关系中成立B.函数依赖BC→A在上述关系中成立C.函数依赖B→A在上述关系中成立D.函数依赖A→BC在上述关系中成立3、数据库设计阶段分为( D )A. 物理设计阶段、逻辑设计阶段、编程和调试阶段B. 模型设计阶段、程序设计阶段和运行阶段C. 方案设计阶段、总体设计阶段、个别设计和编程阶段D. 概念设计阶段、逻辑设计阶段、物理设计阶段、实施和调试阶段4、下列说法中不正确的是(C)。
A. 任何一个包含两个属性的关系模式一定满足3NFB. 任何一个包含两个属性的关系模式一定满足BCNFC. 任何一个包含三个属性的关系模式一定满足3NFD. 任何一个关系模式都一定有码5、设有关系模式R(A,B,C,D),F是R上成立的函数依赖集,F={B→C,C→D},则属性C的闭包C+为( C )A.BCDB.BDC.CDD.BC6、在数据库设计中,将ER图转换成关系数据模型的过程属于( B )A.需求分析阶段B.逻辑设计阶段C.概念设计阶段D.物理设计阶段7、下述哪一条不是由于关系模式设计不当而引起的?( B)A) 数据冗余B) 丢失修改C) 插入异常D) 更新异常8、下面关于函数依赖的叙述中,不正确的是( B)A) 若X→Y,X→Z,则X→YZB) 若XY→Z,则X→Z,Y→ZC) 若X→Y,Y→Z,则X→ZD) 若X→Y,Y′ Y,则X→Y′9、设U是所有属性的集合,X、Y、Z都是U的子集,且Z=U-X-Y。
下面关于多值依赖的叙述中,不正确的是(C)A) 若X→→Y,则X→→ZB) 若X→Y,则X→→YC) 若X→→Y,且Y′⊂ Y,则X→→Y′D) 若Z=Φ,则X→→Y第(10)至(12)题基于以下的叙述:有关系模式A(C,T,H,R,S),基中各属性的含义是:C:课程T:教员H:上课时间R:教室S:学生根据语义有如下函数依赖集: F={C→T,(H,R)→C,(H,T)→R,(H,S)→R}10、关系模式A的码是(D)A) C B) (H,R)C)(H,T)D)(H,S)11、关系模式A的规范化程度最高达到(B)A) 1NF B) 2NF C) 3NF D) BCNF12、现将关系模式A分解为两个关系模式A1(C,T),A2(H,R,S),则其中A1的规范化程度达到(D)A) 1NF B) 2NF C) 3NF D) BCNF13、下述哪一条不属于概念模型应具备的性质?(D)A) 有丰富的语义表达能力B) 易于交流和理解C) 易于变动D) 在计算机中实现的效率高14、在下面列出的条目中,哪个(些)是当前应用开发工具的发展趋势?(D)Ⅰ.采用三层或多层Client/Server结构Ⅱ.支持Web应用Ⅲ.支持开放的、构件式的分布式计算环境A) Ⅰ和ⅡB) 只有ⅡC) 只有ⅢD) 都是15、下面所列的工具中,不能用于数据库应用系统界面开发的工具是(C)A) Visual Basic B) DelphiC) PowerDesigner D) PowerBuilder16、设关系模式R{A,B,C,D,E},其上函数依赖集F={AB→C,DC→E,D→B},则可导出的函数依赖是(A)。
A.AD→E B.BC→E C.DC→AB D.DB→A17、在关系模式R(A,B,C)中,有函数依赖集F={AB→C,BC→A},则R最高达到(D )。
A.第一范式B.第二范式C.第三范式D.BC范式18、下列属于逻辑结构设计阶段任务的是(C )。
A.生成数据字典 B.集成局部E-R图C.将E-R图转换为一组关系模式 D.确定数据存取方法19、关系模式R中的属性全部是主属性,则R至少是(C)范式的关系模式A、1NFB、2NFC、3NFD、BCNF20、关系模式SJP(S,J,P)中,S是学生,J是课程,P是名次。
每一个学生选修每门课程的成绩有一定的名次,每门课程中每一个名次只有一个学生(无并列)。
该关系模式属于(C)A、2NFB、3NFC、BCNFD、4NF21、ODBC中的“数据源”概念是( C )A、代表一个DBS的命名B、代表一个数据库的命名C、代表驱动器和DBMS连接命名D、代表一个磁盘的命名22、将局部E-R图集成为全局E-R图时,可能存在3类冲突,下面对这些冲突的描述中,不属于这3类冲突的是(D)A、属性冲突B、结构冲突C、命名冲突D、模式冲突23、ODBC技术中,数据源分为除了( B )以外的三种。
A、用户数据源B、网络数据源C、系统数据源D、文件数据源24、ODBC是指( C )A、对象数据为约束B、面向数据库约束C、开放式数据互联D、开放式数据库约束25、在数据库设计中,将E—R图转换成关系数据模型的过程属于(A)A、逻辑设计阶段B、需求分析阶段C、概念设计阶段D、物理设计阶段26、当关系模式R(A,B)已属于3NF,下列说法中(C )是正确的。
A、它一定消除了插入和删除异常B、一定属于BCNFC、仍存在一定的插入和删除异常D、A和B都是27、在关系模式中,如果属性A和B存在1对1的联系,则说(C )A、A→BB、B→AC、A←→BD、以上都不是28、关系数据库规范化是为解决关系数据库中(D )A、插入、删除和数据冗余B、提高查询速度C、减少数据操作的复杂性D、保证数据的安全性和完整性29、对于关系数据库,任何二元关系模式都可以达到(A )A、1NFB、2NFC、3NFD、BCNF30、概念结构设计阶段得到的结果是( B )A、数据字典描述的数据需求B、E—R图表示的概念模型C、某个DBMS所支持的数据模型D、包括存储结构和存取方法的物理结构二、填空题1、在关系数据库中,规范化关系是指_满足1NF(或属性值不可分解)2、在设计分E-R图时,由于各个子系统分别面向不同的应用,所以各个分E-R图之间难免存在冲突,这些冲突主要包括命名冲突、_属性冲突和_结构冲突三类。
3、在函数信赖中,平凡的函数信赖根据Armstrong推理规则中的___自反___律就可推出。
4、将E-R图中的实体和联系转换为关系模型中的关系,这是数据库设计过程中逻辑结构或逻辑设计阶段的任务。
5、关系模式规范化过程中,若要求分解保持函数依赖,那么模式分解一定可以达到3NF,但不一定能达到BCNF。
6、一个不好的关系模式会存在_插入异常_、_删除异常_和___数据冗余及修改异常等弊端。
7、函数依赖讨论的是属性之间的对应关系8、包含在候选码中的属性称为主属性。
9、把低级范式的关系模式,通过模式分解转换为高一级范式的关系模式的集合,这个过程称为关系模式的规范化设计。
10、在规范化设计中,消除1NF中的非主属性对码的部分函数依赖,就得到2NF,,消除2NF中的非主属性对码的传递函数依赖,就得到3NF。
三、判断题(20分)1、查询分析器是一个真正的分析工具,它不仅能执行T——SQL语句,而且对查询语句的执行进行分析,给出查询计划。
(√)2、在建立用户的登录帐号信息时,SQL SERVER会提示用户选择默认的数据库,以后用户每次连接上服务器之后,都会自动转到默认的数据库。
(√)3、SQL SERVER 在服务器和数据库级的安全级别上都设置了角色,其中角色是用户分配权限的单位。
SQL SERVER 允许用户在服务器级别上创建角色,但是为数据库安全,不允许在数据库级上建立新的角色。
(×)4、一般情况下,一个简单的数据库可以只有一个主数据文件和一个事务日志文件。
如果数据库很大,则可以设置多个次要数据文件和事务日志文件,并将它们放在不同的磁盘上。
(√)5、规则创建后,必须绑定到表中某一列或用户定义数据类型上才能生效。
(√)6、SQL SERVER 中的索引可分为索引优化与索引组合,其中索引组合不改变表中数据行的物理存储顺序,数据与索引分开存储。
(×)7、触发器就其本质而言是一种特殊的存储过程。
存储过程和触发器在数据库的开发中,在维护数据库实体完整性等方面具有不可替代的作用。
(×)8、数据库备份的类型只有两种,分别是数据库备份、事务日志备份;恢复模式只有三种:简单恢复、完全恢复和日志恢复。
(×)9、数据复制是SQL SERVER的主要功能之一。
复制有三种类型,其中对于复制不经常更改的数据,或不要求保持数据最新值(低滞后时间)的情况,合并复制是一种最好的数据复制方法。
(×)10、当关系模式已属于3NF时一定消除了所有异常。
(×)。