一种多线程检测死锁方法 vc
避免死锁的几种方式

避免死锁的几种方式最近项目中用到一些多线程的知识,涉及到一个线程需要锁住多个资源的情况,这就会涉及到多线程的死锁问题。
特此总结一下死锁产生的方式有好几种,并不是只有一个线程涉及多个锁才会出现死锁的情况,单个锁也有可能出现死锁。
1、第一种常见的情况是加锁之后没有解锁。
有可能是lock之后真的忘了unlock,这种比较少见也容易发现。
但是有时候程序并不是跟我们预想的一样一帆风顺的走完流程,可能是在lock和unlock之间的代码出现了异常退出,这样就造成了加锁之后没有解锁,后续程序对该锁的请求无法实现,导致死锁等待。
解决方法:在c++语言中,就是利用所谓的Autolock局部对象,在该对象的构造函数中lock,在析构函数中unlock,因为是在栈中创建的对象,系统会自动执行析构函数,即使程序异常退出也会执行析构函数从而释放资源。
2、第二种是同一个线程中对同一个资源多次调用lock函数。
有的互斥锁对象没有线程所有权属性,比如windows下的信号量Semaphores ,即一个线程获得某个信号量后,在他释放该信号量之前,他不能再次进入信号量保护的区域。
如果信号量的计数只有1,同一个线程调用WaitForSingleObject两次,程序就会阻塞在第二次调用处造成死锁。
3、第三种情况就是我们通常所说的情况。
有两个线程,线程1和线程2,有两个锁A和B,线程1持有A然后等待B,与此同时线程1持有B然后等待A。
两个线程都不释放拥有的锁,也都获取不到等待的锁。
避免死锁一般针对的是第三种情况。
1、尽量不在同一个线程中同时锁住两个临界资源,不过如果业务要求必须这样,那就没办法。
2、有一种可行的办法是,多个线程对多个锁的加锁顺序一样,这样就不会发生死锁,比如线程1线程A资源加锁,再对B资源加锁,线程2也使用相同的顺序,就不会产生死锁。
3、还有一种可行的方案是一次性获取所有需要获取的锁,如果不能一次性获取则等待。
我想了一下linux下可以用pthread_mutex_trylock函数来实现:4、还有一种方法是使用待定超时机制,如果等待一个锁太久没得到,就释放自己拥有的所有锁,避免死锁。
软件测试中的线程安全测试方法

软件测试中的线程安全测试方法随着软件应用的复杂性不断增加,多线程程序的开发变得越来越常见。
然而,由于线程安全性问题可能导致程序崩溃、数据损坏或信息泄露,线程安全测试在软件测试中变得非常重要。
本文将介绍一些常用的线程安全测试方法,以确保软件在多线程环境下的正确运行。
一、静态分析静态分析是一种通过检查源代码、字节码或二进制文件来寻找潜在线程安全问题的方法。
静态分析工具可以识别可能导致线程安全问题的代码片段,例如共享变量的错误使用、互斥锁的错误使用等。
通过使用这些工具,测试人员可以在代码编译阶段发现潜在的线程安全问题,并及时修复。
二、动态测试动态测试是一种通过运行软件来识别线程安全问题的方法。
在动态测试中,测试人员会创建多个并发线程,模拟真实的多线程环境。
测试人员使用各种测试用例来触发并发访问共享资源的场景,并观察系统的行为。
通过动态测试,测试人员可以发现在特定并发场景下可能出现的线程安全问题,例如竞态条件、活锁和死锁等。
三、模型检测模型检测是一种通过对软件模型进行形式化分析来验证线程安全性的方法。
在模型检测中,测试人员将软件模型定义为一组状态和状态转换规则,并指定线程安全性属性。
模型检测工具会自动分析模型,查找可能导致线程安全问题的状态转换序列,从而验证系统是否满足线程安全性属性。
模型检测可以帮助测试人员发现一些难以通过传统测试方法发现的线程安全问题。
四、代码审查代码审查是一种通过检查代码来发现线程安全问题的方法。
在代码审查中,测试人员仔细阅读源代码,分析代码中的共享变量、锁使用、同步机制等关键部分。
通过代码审查,测试人员可以发现一些容易被忽视的线程安全问题,例如未正确保护共享变量、锁的错误使用等。
代码审查是一种有效的人工方法,可以与其他线程安全测试方法相结合使用。
总结起来,软件测试中的线程安全测试方法包括静态分析、动态测试、模型检测和代码审查。
这些方法可以相互补充,帮助测试人员发现并解决软件中的线程安全问题。
软件测试中的多线程测试方法

软件测试中的多线程测试方法在当今软件开发的环境中,多线程应用程序的使用越来越广泛。
多线程可以提高程序的性能和响应速度,但也会带来一系列的挑战和难题。
因此,多线程测试方法在软件测试中变得至关重要。
本文将介绍一些常用的多线程测试方法,以帮助测试人员更好地保证多线程应用程序的质量和稳定性。
一、并发测试并发测试是一种测试方法,用于验证多个线程同时执行时程序的表现。
它可以用于检测并发访问共享资源时是否会出现数据竞争、死锁、活锁等问题。
并发测试的主要目标是测试程序对并发访问的处理能力,以及在不同负载条件下的性能和稳定性。
在进行并发测试时,可以考虑以下几个方面:1. 设计合适的测试用例:测试用例应包含多个并发线程,并重点关注可能引发竞争条件的场景,例如同时写入共享资源等。
2. 模拟真实场景:尽可能接近真实的并发环境,包括使用真实的并发线程数、数据量和负载条件。
3. 监控并发线程:通过监控并发线程的状态和执行情况,及时发现潜在的问题和异常。
4. 分析测试结果:对测试结果进行统计和分析,检测是否存在数据竞争、死锁、活锁等问题,并及时修复。
二、线程安全测试线程安全是指多个线程同时访问共享资源时,不会导致任何不正确的结果。
线程安全问题常常是由于对共享资源访问的同步不当导致的。
为了保证程序的正确性和稳定性,线程安全测试是不可或缺的一部分。
线程安全测试的关键是发现和复现线程安全问题。
以下是一些常用的线程安全测试方法:1. 压力测试:通过模拟大量并发线程对共享资源进行频繁访问,观察是否出现数据不一致、误处理等问题。
2. 代码静态分析:通过静态代码分析工具,检测代码中潜在的线程安全问题,如数据竞争、死锁等。
3. 动态检测工具:利用动态检测工具对程序进行监控和分析,发现线程安全问题的发生点,并定位问题的原因。
4. 边界测试:通过在极限边界条件下进行测试,例如极大数据量的并发读写,来验证程序的稳定性和线程安全性。
三、性能测试多线程应用程序的性能测试至关重要。
数据库中死锁的检测与解决方法

数据库中死锁的检测与解决方法死锁是数据库中常见的并发控制问题,指的是两个或多个事务在互相等待对方释放资源或锁的状态,导致所有事务无法继续执行的情况。
数据库中的死锁会导致资源浪费、系统性能下降甚至系统崩溃。
因此,死锁的检测与解决方法是数据库管理中非常重要的一环。
1. 死锁的检测方法死锁的检测旨在及时发现死锁并采取措施进行解决。
以下是几种常见的死锁检测方法。
1.1 死锁检测图算法死锁检测图算法是通过构建资源分配图以及等待图来检测死锁。
资源分配图以资源为节点,以事务与资源之间的分配关系为边;等待图以事务为节点,以事务之间等待请求关系为边。
如果存在一个循环等待的环,那么就可以判断系统中存在死锁。
可以采用深度优先搜索或广度优先搜索的算法遍历图,查找是否存在环。
1.2 超时监控方法超时监控方法是通过设定一个时间阈值,在事务等待资源的过程中进行计时。
如果某个事务等待资源的时间超过阈值,系统将判断该事务可能存在死锁,并采取相应的措施解锁资源。
1.3 等待图算法等待图算法是通过分析等待图来检测死锁。
等待图的构建是以事务为节点,以资源之间的竞争关系为边。
如果图中存在一个有向环,那么就可以判断系统中存在死锁。
2. 死锁的解决方法一旦死锁被检测到,必须采取措施加以解决。
以下是几种常见的死锁解决方法。
2.1 死锁剥夺死锁剥夺是通过终止一个或多个死锁事务来解决死锁。
首先需要选择一个死锁事务,然后终止该死锁事务并释放其所占用的资源。
这种方法会造成一些事务的回滚,需要谨慎操作。
2.2 死锁预防死锁预防是通过对资源的分配与释放进行约束,从而避免死锁的发生。
例如,可以采用事务串行化,即每次只允许一个事务执行;或者采用事务超时,即设定一个时间阈值,如果事务等待时间超过阈值,则自动结束事务。
2.3 死锁检测与恢复死锁检测与恢复是在发生死锁后,通过死锁检测算法找到死锁并进行恢复。
方法可以是终止一个或多个死锁事务,也可以是通过资源抢占来解除死锁。
C#多线程Lock锁

C#多线程Lock锁1.概念 临界区:⼀块代码在时间⽚段⾥,只能有⼀个线程访问。
Lock 关键字:将语句标记为临界区,上锁,执⾏语句,释放锁。
互斥锁(Mutex):访问的代码块被暂⽤,那线程就睡觉去了,等着被叫醒⼲活。
⾃旋锁:访问的代码块被暂⽤,那么该线程就⼀直在这块等着,砸门,敲门,骂街⼀个劲的让在锁⾥的线程快点出来,在外等的线程要急着进去。
⾃旋锁不能执⾏长时间的任务。
跟着急上厕所⼀样的。
object.ReferenceEquals⽅法是肯定是引⽤判等,判断该代码块是不是被锁定了。
// lock (1) int 不是lock 语句要求的引⽤类型// (object)1 跟本就没有锁住,线程交叉,数据混乱。
数据在线程中交叉⽤。
最后抛错了// null System.ArgumentNullException:“Value cannot be null.” Monitor 直接报错了// thisLock 私有静态只读内存中独⼀份,且不会被更改,所以每次线程来查看是否代码块被锁住,⽤的就是object.ReferenceEquals⽅法// 对象类中有个区块存放锁信息,再根据Lock() 中的对象地址判断是不是同⼀块地址。
如果是同⼀块地址那么就是互斥锁,只能⼀个线程进⼊// 如果对⽐值为false 那么就认为不是互斥锁,其他线程也可以进⼊操作。
static void TestThreadLockThis(){TestLockThis TestLockThis = new TestLockThis();//在t1线程中调⽤LockMe,并将deadlock设为true(将出现死锁)Thread t1 = new Thread(TestLockThis.LockMethod); = " ⼦线程执⾏";t1.Start(true);Thread.Sleep(100); = "主线程来也";//在主线程中lock c1lock (TestLockThis){//调⽤没有被lock的⽅法TestLockThis.NotLockMethod();//调⽤被lock的⽅法,并试图将deadlock解除TestLockThis.LockMethod(false);}}public class TestLockThis{private bool deadlocked = true;private static readonly object lockobject = new object();//这个⽅法⽤到了lock,我们希望lock的代码在同⼀时刻只能由⼀个线程访问public void LockMethod(object o){//lock (this) //整个类被锁住,必须等待⼦线程t1 执⾏完,才能让主线程执⾏lock (lockobject) //互斥锁,该代码块被锁住,主线程可以访问这个类的NotLockMethod(),⼦线程t1⼀直在执⾏所以等待⼦线程执⾏完后//主线程将其设置为 deadlocked =false;{while (deadlocked){deadlocked = (bool)o;Console.WriteLine($"I am locked 是{}");Thread.Sleep(600);}}}//所有线程都可以同时访问的⽅法public void NotLockMethod(){Console.WriteLine($"I am not locked 是{}");}}Lock(this) 是将这个类锁定,刚开始线程t1 访问到LockMethod 后,发现是Lock(this),只有t1线程能进⼊,后来主线程睡眠醒了后访问lock这个类被锁,所以进不去。
操作系统十大算法之死锁检测算法

cout<<"进程循环等待队列:";
p=flag; //存在进程循环等待队列的那一进程
//进程循环等待队列中的所有进程是table表中的这一行是1的进程,只是顺序要再确定
t=1;
while(t){
cout<<p<<" ";
for(j=0;j<max_process+1;j++){
}
return 1;
}
//检测
void check()
{
int table[MAXQUEUE][MAXQUEUE];
int table1[MAXQUEUE][MAXQUEUE];
int i,j,k;
int flag,t,p;
int max_process;
}
else{
while(!feof(fp)){
fscanf(fp,"%d %d",&occupy[occupy_quantity].resource,&occupy[occupy_quantity].process);
occupy_quantity++;
}
}
cout<<"请输入进程等待表文件的文件名:"<<endl;
if(occupy[i].process>max_process){
max_process=occupy[i].process;
}
}
for(i=0;i<wait_quantity;i++){
MySQL的死锁检测和解决方法

MySQL的死锁检测和解决方法死锁是多线程并发访问数据库时常见的一种问题。
当多个线程在同一时间争夺数据库资源时,如果每个线程都持有一部分资源并且等待其他线程释放自己所需要的资源,就有可能导致死锁的发生。
在MySQL数据库中,死锁是一种严重的问题,会导致系统的性能下降甚至无法响应。
1. 死锁的原因和模拟场景死锁的发生有多种原因,最常见的是由于事务并发执行时的资源争夺引起的。
下面通过模拟场景来说明死锁的发生原因。
假设有两个用户同时对表中的数据进行操作,用户A执行一个更新数据的事务,将表中的一行数据的值由1改为2,同时用户B执行另一个更新数据的事务,将同一行数据的值由2改为3。
用户A和用户B几乎同时执行,由于数据更新是需要加锁的操作,在用户A执行过程中,这一行数据被加上了锁,用户B在更新同一行数据时,也试图对这一行数据加锁。
由于这两个事务都需要等待对方释放资源,因此就造成了死锁的发生。
2. MySQL死锁的检测方法MySQL提供了两种检测死锁的方法,分别是等待图和超时机制。
等待图方法是通过检查事务中的锁依赖关系,来判断是否存在死锁。
如果存在循环等待的情况,即每个事务都在等待下一个事务释放资源,那么就可以判断为发生了死锁。
超时机制是通过设置一个等待超时时间来检测死锁。
当一个事务在等待某个资源的时间超过了设定的等待时间,系统会判断发生了死锁,并进行相应的处理。
3. MySQL死锁的解决方法MySQL提供了多种解决死锁的方法,包括调整事务隔离级别、优化查询语句、控制并发度等。
首先,可以尝试调整事务隔离级别来解决死锁问题。
MySQL提供了四种事务隔离级别,分别是读未提交、读已提交、可重复读和串行化。
不同的隔离级别对于事务并发执行时的锁的获取和释放规则不同,因此可以通过调整隔离级别来减少死锁的发生。
其次,可以优化查询语句来避免死锁。
死锁的发生与事务并发执行中对数据库资源的争夺有关,而查询语句是最常用的访问数据库资源的方式。
操作系统中的死锁检测

死锁的检测【 4 】 . 关于 j a v a多线程程序 中的死锁检测, 无 论是静态
方 法【 5 ' 6 】 还是 动态方法[ 7 , 8 1 ,过去都 已经做 过大量研 究.
而且 目前 已经有 比较成熟 的工具可 以直接检查 i a v a 程
序 中的死锁,如 i s t a c k 、 l o c k s t a t 等.由于操作系统代码
l 引言
为了充分发挥 c p u 多核的性能, 并发程序设计 已 经十分广 泛,但是开 发并 发程序面 临很 多挑 战,死锁 就是其 中的一 个. 在设备驱 动错 误 中有 1 9 %的错误是
由于并 发导致 的【 l J ,在 这些并发 错误 中 7 2 %( 6 7 / 9 3 )  ̄
 ̄
图 2描述 了本文采用的获得锁 持有者算法: ( 1 )当进程加锁的时候, 将 i a , l o c kt y pe ,r e s o u r c e
_ —
图1 描述 了本文采用 的死锁检测算法 : ( 1 )每 隔一 定时间( s e a r c hc y c l e指 定) 检 查锁 持有
计 算 机 系 统 应 用
部分介绍如何获 得锁 的等待 者. 第 5部分根据第 3 、4 部分的结果判 断是否形成循环等待 图. 第 6部分是实 验 结果.第 7部分将对论文进行总结.
任何源程序和库 函数. s y s t e mt a p既可 以在 函数 的入 口处进行探测, 也可 以在 函数 的出 口处进行探测.若在加锁 函数 退出的地 方进行 探测,那 么就可 以获得锁 的持有者信 息,因为 只有成功获得锁,进程( 本论文对线程与进程不区分对 待) 才能从加锁 函数中退 出,否则便处于等待状态 . 为 了 唯一 标 识 进 程 加 锁 和 解 锁 操 作 ,使 用 由进 程 号 ( p 、锁类型( 1 o c kt y p e ) 、资源地址( r e s o u r c ea d d r ) 组
程序中死锁检测的方法和工具

程序中死锁检测的方法和工具翟宇鹏;程雪梅【摘要】死锁一直都是并发系统中最重要的问题之一,对死锁检测的研究一直都在不断地进行着.模型检测方法是一种重要的自动验证技术,越来越多地被用在验证软硬件设计是否规范的工作中.针对死锁检测的问题进行综述,统计已有的死锁检测方法的文献资料并给出统计结果.然后对搜集出来的文献进行分析,介绍许多动态以及静态的死锁检测方法.最后介绍两种常用的模型检测工具,提出使用模型检测工具进行死锁检测的思路与方法,并证实这种方法的可行性.【期刊名称】《现代计算机(专业版)》【年(卷),期】2017(000)003【总页数】5页(P41-44,53)【关键词】死锁检测;模型检测;文献计量分析【作者】翟宇鹏;程雪梅【作者单位】四川大学计算机学院,成都610065;四川大学计算机学院,成都610065【正文语种】中文随着计算机行业的不断发展,软件规模和复杂度也在不断扩大,软件故障已成为计算机系统出错和崩溃的主要因素。
死锁[1]是分布式系统以及集成式系统中的最重要的问题之一,也是影响软件安全的主要因素。
死锁会导致程序无法正常运行或终止,甚至导致系统崩溃,带来不必要的损失。
同时,死锁的运行状态空间过大,难于重现和修正等问题使其成为软件领域的难题之一,因此,如何有效地检测死锁,提高软件的可靠性和安全性,成为急需解决的问题。
本文针对10年内国内外各知名数据库中与死锁检测以及模型检测相关的论文进行查询、筛选、分类、比较、整理等,然后对整理好的论文进行总结,分析出死锁检测的方法并进行罗列比较,以及模型检测的工具以及方法,从而再将二者结合,找出模型检测工具在死锁检测里的应用。
对搜索出来的412篇论文的不同方向进行了计量分析,并对统计的数据进行了描述,以及通过计量分析来找出这方面研究领域的热点。
因为近10年的论文更能体现出研究的正确方向,所以对于论文时间进行分析,得知最近10年每年论文发表量随着时间在平缓地增多,可知对于这方面问题的研究总体保持在增长的状态。
判断死锁的公式(一)

判断死锁的公式(一)判断死锁的公式在计算机科学领域,死锁是指多个进程或线程因争夺系统资源而产生的一种阻塞现象,导致系统无法前进。
为了判断是否发生死锁,提出了一些公式和算法。
下面列举了几个常用的判断死锁的公式:1. 死锁必要条件死锁的发生需要满足以下四个条件: - 互斥条件:每个资源只能同时被一个进程或线程占用。
- 占有和等待条件:已经获得资源的进程可以等待其他资源,同时阻塞其他进程对已获得资源的访问。
- 不可抢占条件:已分配给进程的资源不能被强制性地抢占,只能由占有资源的进程释放。
- 循环等待条件:存在一个进程资源的循环等待链,每个进程都在等待下一个进程所占有的资源。
如果以上四个条件同时满足,就有可能发生死锁。
2. 死锁检测算法死锁检测算法可以根据系统资源的状态来判断是否发生死锁。
其中最著名的算法是银行家算法(Banker’s algorithm),其公式如下:Available: 各资源的可用数量Max: 各进程对各资源的最大需求Allocation: 各进程已分配到的资源数量Need = Max - Allocation: 各进程尚需的资源数量Work = AvailableFinish[i] = false,对所有进程i初始化为falsewhile (存在一个未标记完成的进程P){if (Need[P] <= Work){Work += Allocation[P]Finish[P] = true}P = 下一个未标记完成的进程}该算法通过判断系统是否存在一个安全序列来确定是否发生死锁。
3. 死锁预防公式死锁预防是在系统设计阶段采取措施,避免死锁的发生。
其中一个常用的公式是银行家公式(Banker’s formula),用于计算进程对资源的最大需求量。
公式如下:Need[i, j] = Max[i, j] - Allocation[i, j]其中,Need[i, j]表示进程i对资源j的最大需求量,Max[i, j]表示进程i对资源j的最大需求量,Allocation[i, j]表示进程i已分配到的资源j的数量。
使用JVisualVM进行性能分析
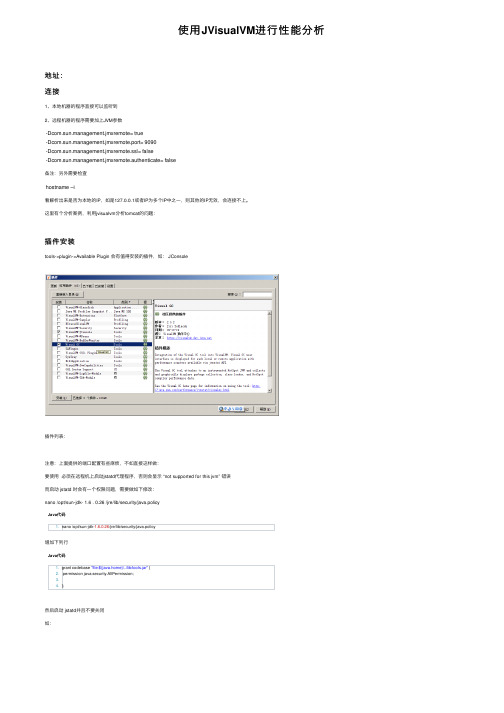
使⽤JVisualVM进⾏性能分析地址:连接1、本地机器的程序直接可以监听到2、远程机器的程序需要加上JVM参数-Dcom.sun.management.jmxremote= true-Dcom.sun.management.jmxremote.port= 9090-Dcom.sun.management.jmxremote.ssl= false-Dcom.sun.management.jmxremote.authenticate= false备注:另外需要检查hostname –i看解析出来是否为本地的IP,如是127.0.0.1或者IP为多个IP中之⼀,则其他的IP⽆效,会连接不上。
这⾥有个分析案例,利⽤jvisualvm分析tomcat的问题:插件安装tools->plugin->Available Plugin 会有值得安装的插件,如: JConsole插件列表:注意:上⾯提供的端⼝配置有些⿇烦,不如直接这样做:要使⽤必须在远程机上启动jstatd代理程序,否则会显⽰ “not supported for this jvm” 错误⽽启动 jstatd 时会有⼀个权限问题,需要做如下修改:nano /opt/sun-jdk- 1.6 . 0.26 /jre/lib/security/java.policyJava代码1. nano /opt/sun-jdk-1.6.0.26/jre/lib/security/java.policy增加下列⾏Java代码1. grant codebase "file:${java.home}/../lib/tools.jar" {2. permission java.security.AllPermission;3.4. };然后启动 jstatd并且不要关闭如:Threads查看线程的运⾏情况,运⾏、停⽌、睡眠、等待,根据这些结合实际程序运⾏的逻辑分析。
多线程 读写锁 c语言

多线程读写锁c语言在C语言中,可以使用POSIX线程库(也称为Pthreads)来实现多线程编程。
读写锁是Pthreads库提供的一种同步机制,用于控制多个线程对共享资源的访问。
读写锁可以分为两种类型:读锁和写锁。
多个线程可以同时持有读锁,但是只能有一个线程可以持有写锁。
当一个线程持有写锁时,其他线程无法获取读锁或写锁,直到该线程释放锁。
下面是一个使用读写锁的示例程序:```c#include <stdio.h>#include <stdlib.h>#include <pthread.h>#define NUM_THREADS 5pthread_rwlock_t rwlock = PTHREAD_RWLOCK_INITIALIZER;int shared_data = 0;void *reader(void *arg) {pthread_rwlock_rdlock(&rwlock); // 获取读锁int data = shared_data;printf("Reader %ld read data: %d\n", pthread_self(), data);pthread_rwlock_unlock(&rwlock); // 释放读锁return NULL;}void *writer(void *arg) {pthread_rwlock_wrlock(&rwlock); // 获取写锁shared_data = 1;printf("Writer %ld wrote data: %d\n", pthread_self(), shared_data);pthread_rwlock_unlock(&rwlock); // 释放写锁return NULL;}int main() {pthread_t threads[NUM_THREADS];int i;for (i = 0; i < NUM_THREADS; i++) {if (i % 2 == 0) {pthread_create(&threads[i], NULL, reader, NULL);} else {pthread_create(&threads[i], NULL, writer, NULL);}}for (i = 0; i < NUM_THREADS; i++) {pthread_join(threads[i], NULL);}pthread_rwlock_destroy(&rwlock);return 0;}```在上面的示例中,我们创建了5个线程,其中3个线程作为读者,2个线程作为写者。
死锁的定位分析方法

死锁的定位分析方法
死锁是多线程并发编程中的一种常见问题,发生在多个线程因争夺有限的资源而无法继续执行的情况。
以下是一些常用的方法用于定位和分析死锁问题:
1. 日志分析:通过分析应用程序的日志来查找死锁发生的线索。
查看线程的执行顺序、锁请求和释放操作,以及资源的分配情况,可能可以发现死锁的原因。
2. 调试工具:使用调试工具,如调试器或性能分析器,来观察线程的执行状态和资源的使用情况。
调试工具可以帮助你跟踪线程的执行路径和资源的分配情况。
3. 可视化工具:使用可视化工具来展示线程、锁和资源之间的关系。
通过可视化的方式可以更直观地了解线程之间的依赖关系,从而更容易发现死锁问题。
4. 静态分析工具:使用静态分析工具对代码进行分析,以检测潜在的死锁问题。
静态分析可以帮助你找出代码中可能导致死锁的部分,从而更早地发现和解决问题。
5. 代码审查:通过代码审查的方式检查代码中是否存在可能引发死锁的情况。
例如,检查是否有线程对多个资源进行了串行化的访问,或者是否有未正确释放的锁。
6. 模型检查:使用模型检查工具对并发程序进行形式化验证,以发现潜在的死
锁情况。
模型检查工具通常会基于并发程序的形式化模型进行分析,并生成验证结果。
以上方法可以帮助你定位和分析死锁问题,但请注意死锁问题可能是复杂的,并且可能需要根据具体情况采用不同的方法来解决。
java定位死锁的三种方法(jstack、Arthas和Jvisualvm)

java定位死锁的三种⽅法(jstack、Arthas和Jvisualvm)⽬录死锁死锁发⽣的原因死锁发⽣的条件1:通过jstack定位死锁信息1.2:查看死锁线程的pid2:通过Arthas⼯具定位死锁3. 通过 Jvisualvm 定位死锁死锁的预防总结死锁死锁:是指两个或两个以上的进程在执⾏过程中,因争夺资源⽽造成的⼀种互相等待的现象,若⽆外⼒作⽤,它们都将⽆法推进下去。
死锁发⽣的原因死锁的发⽣是由于资源竞争导致的,导致死锁的原因如下:系统资源不⾜,如果系统资源充⾜,死锁出现的可能性就很低。
进程(线程)运⾏推进的顺序不合适。
资源分配不当等。
死锁发⽣的条件死锁的发⽣的四个必要条件:1. 互斥条件:⼀个资源每次只能被⼀个进程使⽤。
2. 占有且等待:⼀个进程因请求资源⽽阻塞时,对已获得的资源保持不放。
3. 不可强⾏占有:进程(线程)已获得的资源,在未使⽤完之前,不能强⾏剥夺。
4. 循环等待条件:若⼲进程(线程)之间形成⼀种头尾相接的循环等待资源关系。
这四个条件是死锁的必要条件,只要系统发⽣死锁,这些条件必然成⽴,⽽只要上述条件之⼀不满⾜,就不会发⽣死锁。
1:通过jstack定位死锁信息1.1:编写死锁代码Lock lock1 = new ReentrantLock();Lock lock2 = new ReentrantLock();ExecutorService exectuorService = Executors.newFixedThreadPool(2);exectuorService.submit(() -> {lock1.lock();try{Thread.sleep(1000);}catch(Exception e){}try{}finally{lock1.unlock();lock2.unlock();}});exectuorService.submit(() -> {lock2.lock();try{Thread.sleep(1000);}catch(Exception e){}try{}finally{lock1.unlock();lock2.unlock();}});1.2:查看死锁线程的pidjps查看死锁的线程pid使⽤ jstack -l pid 查看死锁信息通过打印信息我们可以找到发⽣死锁的代码是在哪个位置"DestroyJavaVM" #13 prio=5 os_prio=31 tid=0x00007f9a1d8fe800 nid=0xd03 waiting on condition [0x0000000000000000]ng.Thread.State: RUNNABLELocked ownable synchronizers:- None"pool-1-thread-2" #12 prio=5 os_prio=31 tid=0x00007f9a1d8fe000 nid=0xa703 waiting on condition [0x000070000ff8e000]ng.Thread.State: WAITING (parking)at sun.misc.Unsafe.park(Native Method)- parking to wait for <0x0000000795768cd8> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209)at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)at mbda$main$1(SlideTimeUnit.java:63)at com.coco.util.SlideTimeUnit$$Lambda$2/565760380.run(Unknown Source)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at ng.Thread.run(Thread.java:748)Locked ownable synchronizers:- <0x0000000795768d08> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)- <0x0000000795a9e4e0> (a java.util.concurrent.ThreadPoolExecutor$Worker)"pool-1-thread-1" #11 prio=5 os_prio=31 tid=0x00007f9a2082c800 nid=0xa803 waiting on condition [0x000070000fe8b000]ng.Thread.State: WAITING (parking)at sun.misc.Unsafe.park(Native Method)- parking to wait for <0x0000000795768d08> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209)at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)at mbda$main$0(SlideTimeUnit.java:49)at com.coco.util.SlideTimeUnit$$Lambda$1/596512129.run(Unknown Source)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at ng.Thread.run(Thread.java:748)Locked ownable synchronizers:- <0x0000000795768cd8> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)- <0x0000000795a9ba28> (a java.util.concurrent.ThreadPoolExecutor$Worker)"Service Thread" #10 daemon prio=9 os_prio=31 tid=0x00007f9a2082c000 nid=0x4103 runnable [0x0000000000000000]ng.Thread.State: RUNNABLELocked ownable synchronizers:- None"C1 CompilerThread3" #9 daemon prio=9 os_prio=31 tid=0x00007f9a1e021800 nid=0x3f03 waiting on condition [0x0000000000000000] ng.Thread.State: RUNNABLE2:通过Arthas⼯具定位死锁2.1: 下载好Arthas的jar,然后运⾏有⼀个 thread -b 就可以查看到死锁信息[arthas@4182]$ thread -b"pool-1-thread-2" Id=12 WAITING on java.util.concurrent.locks.ReentrantLock$NonfairSync@2cb8a9a3 owned by "pool-1-thread-1" Id=11at sun.misc.Unsafe.park(Native Method)- waiting on java.util.concurrent.locks.ReentrantLock$NonfairSync@2cb8a9a3at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209)at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)at mbda$main$1(SlideTimeUnit.java:63)at com.coco.util.SlideTimeUnit$$Lambda$2/565760380.run(Unknown Source)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at ng.Thread.run(Thread.java:748)Number of locked synchronizers = 2- java.util.concurrent.ThreadPoolExecutor$Worker@6433a2- java.util.concurrent.locks.ReentrantLock$NonfairSync@3a855d13 <---- but blocks 1 other threads!3. 通过 Jvisualvm 定位死锁Jvisualvm 是⼀种⾃带的可视化⼯具,往往在在本地执⾏。
线程死锁的解决方法

线程死锁的解决方法
线程死锁是多线程编程中常见的问题,指两个或多个线程互相持有对方所需的资源,导致彼此都无法继续执行。
线程死锁的解决方法如下:
1. 避免嵌套锁:在使用多个锁的情况下,避免嵌套锁,尽量使用一种锁。
如果必须使用多个锁,尝试按照相同的顺序获取锁。
2. 使用超时机制:在获取锁的过程中,设置超时时间,如果超时还未获得锁,则放弃对锁的请求,避免因等待锁而陷入死锁。
3. 避免无限等待:通过使用try-lock等非阻塞锁,避免在等待锁的过程中陷入无限等待的状态。
4. 死锁检测:在程序运行时,使用死锁检测工具检测是否存在死锁情况,及时解决。
5. 合理设计线程间的依赖关系:通过合理的设计线程间的依赖关系,避免出现不合理的循环依赖。
以上是线程死锁的解决方法,针对不同的场景,可以采用不同的解决方法。
在实际开发中,要注意多线程编程的注意事项,避免出现线程死锁等问题。
- 1 -。
cycledetectinglockfactory用法-概述说明以及解释

cycledetectinglockfactory用法-概述说明以及解释1.引言1.1 概述在多线程编程中,控制线程之间的并发访问是至关重要的。
为了避免死锁和其他并发访问问题,我们需要使用适当的锁机制来确保线程安全。
cycledetectinglockfactory是一个用于检测和防止死锁的工厂类,它提供了一种先进的锁机制。
通过cycledetectinglockfactory,我们可以轻松创建具有循环检测功能的锁对象,以避免因线程之间互相持有锁而导致的死锁情况。
这种锁机制可以有效减少程序中出现的并发访问问题,提高程序的稳定性和性能。
本文将介绍cycledetectinglockfactory的简介、使用方法和优势,帮助读者更好地理解并正确应用这一先进的锁机制。
1.2 文章结构本文将首先介绍cycledetectinglockfactory的概念和背景,包括其作用和原理。
接着将详细讲解cycledetectinglockfactory的使用方法,包括如何初始化和调用该工厂类来创建锁。
然后将探讨cycledetectinglockfactory相比于传统锁的优势和特点,以及在实际应用中的应用场景和效果。
最后,通过总结cycledetectinglockfactory的应用,展望未来cycledetectinglockfactory的发展方向,并给出作者的一些思考和建议。
通过以上结构,读者将能够全面了解和掌握cycledetectinglockfactory的用法和作用,进而可以更好地应用和推广该工具。
1.3 目的本文的目的是介绍cycledetectinglockfactory的用法,帮助读者了解如何有效地利用该工具来管理锁以避免死锁和循环依赖的问题。
通过对cycledetectinglockfactory的简介、使用方法和优势进行全面介绍,使读者能够更好地理解该工具的价值和作用,从而在实际开发中更加灵活和高效地运用它。
数据库事务管理中的死锁检测与解决方法

数据库事务管理中的死锁检测与解决方法死锁是在多并发环境下,当两个或多个事务互相等待对方释放资源时变成无限等待状态的情况。
死锁会导致系统资源浪费,同时也会影响系统的性能和可用性。
在数据库事务管理中,死锁的发生是常见的,因此采取适当的死锁检测与解决方法是至关重要的。
1. 死锁检测方法1.1 死锁定位在死锁检测之前,首先需确定是否存在死锁。
一种常用的方法是通过等待图(Wait-for Graph)来检测死锁。
等待图是用来表示多个事务之间资源的竞争关系,当等待图中存在环路时,就意味着存在死锁。
1.2 系统资源监控监控数据库系统的资源使用情况,包括锁、事务等。
通过定期获取数据库系统的资源信息,可以发现死锁的发生情况。
1.3 死锁检测算法常见的死锁检测算法有:图算法、等待-图算法、死锁定时调度算法等。
其中图算法和等待-图算法较为常用,可以通过构建资源使用和等待的有向图来检测死锁。
2. 死锁解决方法2.1 死锁避免死锁避免是通过合理地预防死锁的发生,使得系统在运行时避免出现死锁。
这种方法主要基于资源请求和资源释放的顺序,通过对事务的资源请求进行动态分配和回收,避免死锁的发生。
常见的死锁避免算法有银行家算法和证据排斥检验算法。
2.2 死锁检测与解除如果死锁的避免方法不能满足需求,系统可能还是会发生死锁。
这时需要采取死锁检测和解除的方法。
常见的解除死锁的方式有回滚事务和剥夺资源。
回滚事务是指撤销某个或某些事务的执行,放弃已经占有的资源,以解除死锁。
而资源剥夺是指系统强制终止某个事务,然后再释放其所占有的资源,以解除死锁。
2.3 死锁超时处理死锁超时处理是通过设置一个死锁最大等待时间来处理死锁。
当一个事务遇到死锁时,如果等待超过设定的时间仍未解锁,系统会检测到死锁,并按照事先设定的处理方式来解锁。
3. 实践建议3.1 合理设计操作顺序在设计数据库应用时,应该尽量避免事务之间出现循环等待的情况。
在对资源进行请求时,需要明确资源请求的顺序,避免出现互相等待资源的情况。
多线程保证线程安全的方法

多线程保证线程安全的方法多线程编程中,线程安全是一个重要的问题。
如果多个线程同时访问共享数据,可能会导致数据的不一致性或者错误的结果。
为了保证线程的安全,需要采取一系列的保护措施来避免竞态条件(race condition)、死锁(deadlock)等问题的发生。
本文将介绍一些常见的多线程保证线程安全的方法。
1. 互斥锁(Mutex):互斥锁是最常见的保证线程安全的方法之一、当线程要访问共享数据时,先锁定互斥锁,其他线程要访问同一份数据时需要等待互斥锁被释放。
互斥锁一次只能被一个线程占有,从而避免了多个线程同时访问共享数据的问题。
2. 读写锁(ReadWrite Lock):在一些场景下,多个线程只读取共享数据而不修改它们。
这种情况下,可以使用读写锁来提高性能。
读写锁允许多个线程同时读取共享数据,但在有写操作时,会阻塞其他线程的读和写操作,从而保证数据的一致性。
3. 原子操作(Atomic Operations):原子操作是指能够在单个步骤中完成的操作,不会被其他线程中断。
在多线程编程中,可以使用原子操作保证共享数据的连续性。
例如,Java提供了原子类(如AtomicInteger、AtomicLong等)来保证整数操作的原子性。
4. 同步代码块(Synchronized Block):通过使用synchronized关键字修饰一个代码块,可以将其变成互斥区域,即在同一时间只允许一个线程执行该代码块。
线程进入synchronized代码块时会自动获得锁,执行完代码块后会释放锁,其他线程才能继续执行。
这样可以保证在同一时间只有一个线程执行临界区(即使用共享数据的代码段)。
5. 同步方法(Synchronized Method):可以使用synchronized关键字修饰方法,使其成为同步方法。
同步方法与同步代码块类似,只是作用范围更大,锁定的是整个方法。
多个线程在执行同步方法时,会对该对象的锁进行争夺,并且只有一个线程能够执行同步方法。
vc6.0开发多线程程序基础教程

1、HANDLE CreateThread(LPSECURITY_ATTRIBUTES lpThreadAttributes,
DWORD dwStackSize,
LPTHREAD_START_ROUTINE lpStartAddress,
该函数用于结束线程的挂起状态,执行线程。 4、VOID ExitThread(DWORD dwExitCode);
该函数用于线程终结自身的执行,主要在线程的执行函数中被调用。其中参数dwExitCode用来设置线程的退出码。 5、BOOL TerminateThread(HANDLE hThread,DWORD dwExitCode);
在MultiThread2Dlg.h文件中添加线程函数声明: void ThreadFunc(int integer);
注意,线程函数的声明应在类CMultiThread2Dlg的外部。
在类CMultiThread2Dlg内部添加protected型变量: HANDLE hThread;
::SetDlgItemText(AfxGetMainWnd()->m_hWnd,IDC_TIME,strTime);
Sleep(1000);
}
}
该线程函数没有参数,也不返回函数值。只要m_bRun为TRUE,线程一直运行。
双击IDC_STARTቤተ መጻሕፍቲ ባይዱ钮,完成该按钮的消息函数: void CMultiThread1Dlg::OnStart()
{
Beep(200,50);
Sleep(1000);
}
}
双击IDC_START按钮,完成该按钮的消息函数: void CMultiThread2Dlg::OnStart()
C++ Core dump问题定位方法

命令解释如下: 参数 crash:用于捕获 Coredump; pn:用于指定所需监视的进程名称; o(小写字母):用于指示所捕获 Core dump 文件输出目录; 由于 Core dump 写入的是出现问题时内存的信息,因此输出的 dump 文 件可能会比较大从几 M 到几 G 不定,根据当时出现问题的具体情况,因此在指 定 Core dump 输出目录时,最好指定在空间比较大的磁盘下。当执行 adplus 后,在“o”参数指定的路径下,可以看到多了一个目录,一般目录名称为:” Crash_Mode__Date_01-18-2010__Time_18-49-4343”,即 Crash 开头,后接 Core dump 产生的日期、时间。里面会有“ADPlus_report.txt”、“PID-3324__ DGISPOWERMODEL.EXE__Date_01-18-2010__Time_19-11-2424.log ” 、 “Process_List.txt”三个文件,记录了程序运行时的进程信息等,可以用记事本 打开查看。 当发生 Core dump 后,这个目录下就会多三个以“.dmp”为后缀名的文 件文件(一般是三个,有时也可能只有一个)。三个文件一般两个里面有包含 “1st”、一个包含“2nd”的字样,这个是跟 windows 系统异常捕获机制分为 两阶段处理有关,具体可以 Google 下,不具体解释。这三个文件就是 Core
WaitForSingleObject(thread1, INFINITE);
return 0; }
该程序分别启动两个线程,线程 1 和线程 2 由于都在等待对方设置信号量为 FLASE,后退出线程,互相等待导致死锁。
这时抓取 Core dump 的方法跟上面提到的一样,不同的是,这时只需要抓 取内存的快照,不需要一开始就运行 adplus,只要在发现有线程死锁现象时运 行 adplus,并把-crash 参数改为-hang,即可。