第八章 数据处理
疲劳裂纹扩展速率的实验数据处理

A (1-R)Kc
da/dN B
(1-R)Kc
da/dN C
(1-R)Kc
KthCF D K
(1-R)K1scc D K
(1-R)K1scc D K
A类 ; B类:Kmax<K1scc, (DK)thCF<<DKth 主要是疲劳过程; 腐蚀使(da/dN)CF Kmax>K1scc, 腐蚀 使da/dN)CF。 普遍加快,如铝 合金在淡水中。 马氏体镍在干氢中.
DKth Mpa.m1/2
8 7 6 5 4 3 2 1
低碳钢 低合金钢 不锈钢 A517-F
9301 A508C A533B
R 不同钢材的R-DKth 关系 lgda/dN
R=0.8 0 -1
0 .2
.4
.6
.8 1.0
R<0的情况:负应力存在, 对da/dN三区域的影响不同。 情况比R>0时复杂得多。
lgda/dN
8.4 疲劳裂纹扩展速率试验
0
a (mm)
D =const. R=0
Dai DK 曲线 目的:测定材料的 da/dNa DNi
一、试验原理:
Paris公式: 实验 a =a 0 R=0 D
N
lg(DK)
da/dN=C(DK)m (DK)i=f (D,ai,)
记录ai、Ni
ai=(ai+1+ai)/2
12
In general, at low frequencies, crack growth rate 在空气中,一般观察不到波形对疲劳裂纹扩展速 increase as more time is allowed for environmental 率的影响。但在腐蚀环境中,若载荷循环的拉伸 attack during the fatigue process. 部分作用慢, da/dN 一般较高。
数字采集系统-误差分析与数据处理62页PPT

第八章 误差分析与数据处理 《数据采集系统》课件
8.1 误差分析及其处理
二、去误差处理
2.随机误差的处理
随机误差的统计特性 由于随机误差的随机性,很难预期第 i 次测量数据的值,但是可用概率
8.1 误差分析及其处理 8.2 数据检验与预处理
第八章 误差分析与数据处理 《数据采集系统》课件
8.1 误差分析及其处理
一、误差分析的基本问题
1.测量误差名词术语 真值——某一物理量在一定条件下客观存在的(实际具备的)量 值。实际测量中常用“理论真值”和“约定真值”。 标称值——计量或测量器具上标注的量值。
8.1 误差分析及其处理
二、去误差处理
1.系统误差的消除
根据不同的测量目的,对测量仪器、仪表、测量条件测量方法及步骤等 进行全面分析,以发现系统误差,然后采用相应的措施来消除或减弱它。 1)从产生的来源上消除:仪器、环境、方法、人员素质等。 2)利用修正的方法来消除:通过资料、理论推导或者实验获取系统误差的 修正值,最终测量值=测量读数+修正值。如干扰很大无法消除时… 3)采用特殊方法消除:
结果之间的一致性。 误差公理——一切测量都有误差,误差存在于所有科学试验中。
第八章 误差分析与数据处理 《数据采集系统》课件
8.1 误差分析及其处理
一、误差分析的基本问题
2.测量误差的表示
1)绝对误差——示值与真值之差。它的负值称为修正值。 2)相对误差——绝对误差与真值之比。 3)引用误差——绝对误差与测量仪表量程之比。
第八章 误差分析与数据处理 《数据采集系统》课件
汇编语言王爽第三版检测点答案带目录

汇编语言王爽第三版检测点答案带目录在学习汇编语言的过程中,王爽老师的《汇编语言(第三版)》无疑是一本备受推崇的经典教材。
而对于学习者来说,检测点的答案能够帮助我们更好地巩固知识,查漏补缺。
接下来,我将为大家详细呈现这本教材中各个章节检测点的答案,并附上清晰的目录,方便大家查阅和学习。
第一章基础知识检测点 11(1)1 个 CPU 的寻址能力为 8KB,那么它的地址总线的宽度为。
答案:13 位。
因为 8KB = 8×1024 = 2^13B,所以地址总线的宽度为 13 位。
检测点 12(1)8086 CPU 有根数据总线。
答案:16 根。
(2)8086 CPU 有根地址总线。
答案:20 根。
检测点 13(1)内存地址空间的大小受的位数决定。
答案:地址总线。
(2)8086 CPU 的地址总线宽度为 20 位,其可以寻址的内存空间为。
答案:1MB。
因为 2^20 = 1048576B = 1MB。
第二章寄存器检测点 21(1)写出每条汇编指令执行后相关寄存器中的值。
mov ax,62627 AX = 62627mov ah,31H AH = 31H,AX = 31627mov al,23H AL = 23H,AX = 3123H检测点 22(1)给定段地址为 0001H,仅通过变化偏移地址寻址,CPU 的寻址范围为到。
答案:00010H 到 1000FH。
(2)有一数据存放在内存 20000H 单元中,现给定段地址为 SA,若想用偏移地址寻到此单元。
则 SA 应满足的条件是:最小为,最大为。
答案:最小为 1001H,最大为 2000H。
第三章内存访问检测点 31(1)下面的程序实现依次用内存 0:0~0:15 单元中的内容改写程序中的数据。
完成程序。
assume cs:codesgcodesg segmentdw 0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987Hstart: mov ax,0mov ds,axmov bx,0mov cx,8s: mov ax,bxmov bx+16,axadd bx,2loop smov ax,4c00hint 21hcodesg endsend start检测点 32(1)下面的程序将“Mov ax,4c00h ”之前的指令复制到内存 0:200 处。
误差和分析数据处理

第八章误差和分析数据处理一、选择题 1•以下情况产生的误差属于系统误差的是 -------------- ( ) (A)指示剂变色点与化学计量点不一致 (B)滴定管读数最后一位估测不准 (C)称样时砝码数值记错 (D)称量过程中天平零点稍有变动 2•下列表述中,最能说明系统误差小的是 (A)高精密度 (C)标准差大 ( ) (B)与已知的质量分数的试样多次分析结果的平均值一致 (D)仔细校正所用砝码和容量仪器等 一( ) (B)相对误差是绝对误差在真值中所占的百分比 (D)总体平均值就是真值 旦 --() (C)精密度是保证准确度的前提3•下列各项定义中不正确的是 ------------ (A)绝对误差是测定值与真值之差 (C)偏差是指测定值与平均值之差4•在定量分析中,精密度与准确度之间的关系是 (A)精密度高,准确度必然高 (D)准确度是保证精密度的前提5.当对某一试样进行平行测定时一( )(A)操作过程中溶液严重溅失 (D)试样不均匀 6•下列有关随机误差的论述中不正确的是 --------- (A)随机误差具有随机性 (B)随机误差具有单向性 随机误差是由一些不确定的偶然因素造成的 7•分析测定中随机误差的特点是 --------- ( ) (A)数值有一定范围 (B)数值无规律可循出现的概率相同 8•以下关于随机误差的叙述正确的是 ---------- ( (A)大小误差出现的概率相等 (B)正负误差出现的概率相等 (C)正误差出现的概率大于负误差 (D)负误差出现的概率大于正误差 9•在量度样本平均值的离散程度时,应采用的统计量是 ---------- ( ) (B)准确度高,精密度也就高 ,若分析结果的精密度很好 (B)使用未校正过的容量仪器,但准确度不好,可能的原因是 (C)称样时某些记录有错误 ( ) (C)随机误差在分析中是无法避免的 (D) (C)大小误差出现的概率相同 (D)正负误差 (A)变异系数CV (B)标准差s (C)平均值的标准差 s ; (D)全距R 10.对置信区间的正确理解是 ---------- ( ) (A) 一定置信度下以真值为中心包括测定平均值的区间 中心包括真值的范围 (C)真值落在某一可靠区间的概率 的可靠范围 11. 测定铁矿中Fe 的质量分数,求得置信度为 95%时平均值的置信区间为 35.21% ± 0.10%。
第八章 字符数据处理

8.1 字符与字符串
8.1.1 字符型数据
1.字符常量:由单引号括起的单个字符如: ' 一' , '一', 'G','?。’。 2.转义字符常量:以反斜杆’\’开头的特殊字符序列意思是把反 。 斜杆后面的字符序列转换成特定的含义.而不是原来的含义。 3.字符串常量:用双引号括起来的字符序列其长度没有限制,系统 在末尾自动加上‘\n' 以示结束。。 例如, "Ch5nJr","1 x34" 等。 4.字符变量:存放字符常量的内存变量字符变量用关键字零碎工作 来说明在定义字符变量的同时可进行初始化。。。 5.符号常量:以指定的符号代表其后的“一串字符”用于简化程序 的编写和修改。。 例如:#定义 PAI 13.14 #定义 N 10
2. 整个字符串变量一次输入输出: %s
//字符变量引用
char a[10] , b[7]="abcde" ; scanf(“%s" , a); /*键盘输入的字符串存人a数组*/ printf(“%s=%s” , “a[10]=” , a) ; /*输出常量串和a数组中的字符串*/ printf(“%s” , &b[1]); /*输出字符串:bcde*/ a 数组 存储: b 数组
3. 常用的联合使用 例 1 : putchar(getchar());等同 printf("%c",getchar()); 例 2 :作为字符输入结束的判断条件 (c=getchar())!=‘\ n'; 表示若读入的字符不为“回车” 例:每读入一个字符输出该字符直到输入一个 "回车" 止 回车" 主要部份()。 回车后 { 烧焦 c ; 才读 为 () ; (c=getchar())!=‘\ n'; printf;("%c",c) 一 以下程序执行结果正确的是: (? ) (一)计算机 计算机 (B)CCoommppuutteerr
数据处理技术

8.1测量数据预处理技术 8.1测量数据预处理技术
2) 系统校准
VR V= N NR
系统校准特别适于传感器特性随时间会发生变 系统校准特别适于传感器特性随时间会发生变 特别适于传感器特性随时间会发生 的场合。如电容式湿度传感器, 化的场合。如电容式湿度传感器,其输入输出特性 会随着时间而发生变化, 会随着时间而发生变化,一般一年以上变化会大于 精度容许值,这时可每隔一段时间(例如3个月或6 精度容许值,这时可每隔一段时间(例如3个月或6 个月),用其它精确方法测出这时的湿度值, ),用其它精确方法测出这时的湿度值 个月),用其它精确方法测出这时的湿度值,然后 把它作为校准值输入测量系统。在实际测量湿度时, 把它作为校准值输入测量系统。在实际测量湿度时, 计算机将自动用该输入值来校准以后的测量值。 计算机将自动用该输入值来校准以后的测量值。
多路开关 V0 V1 A Vn A/D CPU 前置放大器 模数转换器 计算机
8.1测量数据预处理技术 8.1测量数据预处理技术
1) 数字调零 数字调零电路如上图所示。在测量输入通道中, 数字调零电路如上图所示。在测量输入通道中, CPU分时巡回采集1 CPU分时巡回采集1路校准电路与n路传感变送器送 分时巡回采集 来的电压信号。首先是第0 路的校准信号即接地信 来的电压信号。首先是第0 理论上电压为零的信号, 放大电路、A/D转 号,理论上电压为零的信号,经放大电路、A/D转 换电路进入CPU的数值应当为零, 换电路进入CPU的数值应当为零,而实际上由于零 CPU的数值应当为零 点偏移产生了一个不等于零的数值, 点偏移产生了一个不等于零的数值,这个值就是零 然后依次采集1 点偏移值N0;然后依次采集1、2、… n路,每
计算机控制技术
吴国辉
点估计与直方图

h.
k
h
M m. k
h 176 19.56 20. 9
案例2 分析(续) 确定每组的上下限:第一组的下限,应不超过给定数据的最 小值 m ,记作 ,这里取a 80;
a
按组距20,将所给数据分成以下9个组: 80~100 100~120 160~180 180~200 240~260. 120~140 200~220 140~160 220~240
将第9组的上限260,记作 b ,应有b
M. 若出现 b M 的情况,可取 b M .
案例2 分析(续) 3. 进行频数统计,求出频率分布表 统计120个数据分别属于以上各组的个数,称属于第 i 组
的频率.
(i 1,2, ,9) 数据的个数为该组的频数,记作 fi. fi 称 ( n 是数据的总个数,这里 n 120)为第 i 组数据 n
s
总体均方差 的点估计
用样本方差
s 估计总体方差 , 即
n
2 1 ˆ s ( xi x) . n 1 i 1
练习2
试估计案例1中该车间全体工人日生产零件数的均值 方差 2 和均方差
.
解 由练习1的计算结果可知,总体均值 均方 差 的估计值分别为
,
总体方差
ห้องสมุดไป่ตู้ 2及总体
k
p
h
p /h
由图可以看出,第 个矩形的面积 内的频率,即 i 且 i i 即所有矩形面积之和等于1.
p A h p , h
i
Ai 等于数据落入第 i 组
A p
i 1 i i 1
k
k
i
1.
实验设计与数据处理第八章例题及课后习题答案doc资料
0
428
0 1.162084
492
0 1.162084
512
0
0
509
0
0
Signific ance F
7.93E-05
Lower Upper 下限 上限
95%
95% 95.0% 95.0%
465.4405 471.5595 465.4405 471.5595
5.242078 12.93644 5.242078 12.93644
0.002795085 2.593838854 0.122018
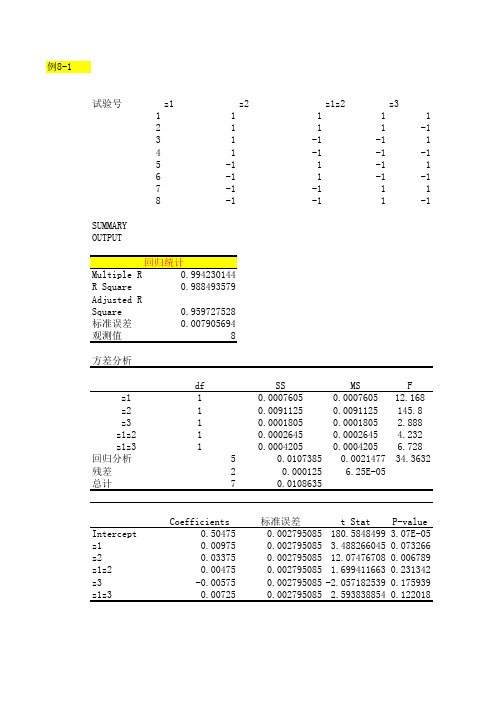
例8-2
回归方程: 由该回归方程 中偏回归系数 绝对值的大 小,可以得到 各因素和交互 作用的主次顺 序为:
y=0.50475+0.00 975z1+0.03375z 2+0.00475z1z20.00575z3+0.00 725z1z3
0 0 -41.73590203
y=468.5+9.09z1 -26.56z2+z3
标准误差
t Stat P-value
1.10193312 425.1619191 1.84E-10
1.385649972 6.55956341 0.002794
1.385649972 -19.17042163 4.36E-05
SS 0.0091125
0.001626 0.0108635
MS
F
0.0091125 33.62546
0.000271
试验号
z1 1 2 3 4 5 6 7 8 9 10 11
z2 1 1 1 1 -1 -1 -1 -1 0 0 0
z3 1 1 -1 -1 1 1 -1 -1 0 0 0
数据处理讲义第7,8章

y j
T j an
T yijk
i j k
T y a bn
因子B
B1 B2 … Bb
析是其中两个因素时的简单情况。这时,方差分析不仅 要判断各因子对指标的影响是否显著,还要考察因子各 水平之间的相互组合对指标的交互影响。这是单因子方 差分析所没有的。
第 1节
无交互作用的非重复试验的二元方差分析
如果有2个因子A、B,
因子A有a种水平,A1,A2,…,Aa; 因子B有b种水平B1,B2,…,Bb 如果因子A与因子B无交互作用(一般来说,交互作用总
子对指标的影响是否显著,以及影响的大小,从而找出最
佳条件。
回归分析中要求自变量是定量的;而方差分析中因子可以
是数量也可以是属性。
在上例中,若给定α=5%,问灯丝的配料方案对寿命有无
影响?
解:依题意 r=4,n1=7,n2=5,n3=8,n4=6,n=26 计算可得下表:
离差平方和
组间 组内 44774.6 149970.8
问灯丝的不同配料方案对灯泡的寿命有无显著影响,在这
里引申几个定义:
① 因素:对实验结果有影响的条件称为因素或因子,在这
里指的是不同配料方案的灯丝,因素可以是数量也可以是
属性,因素可根据能否人为控制,分为:可控因素,不可 控因素,例中因素为可控的;不可控的比如:油田采出水 的温度、矿化度或原油性质等;
是存在的,如果实验者根据实际经验或直观分析认为交 互作用很小时,可以忽略),在A,B的每一种组合水平 Ai×Bj上只做一次试验,共有a×b次实验。
实验结果为yij,i=1,2,…,a;j=1,2,…,b。所有
结果相互独立。二元方差分析可以解决因子A,B分别对 实验结果的影响是否显著的问题。
放射性测量数据的处理

一次测量或有限次测量平均值只能是数学期望值近似值,这么就给 测量结果带来了误差。放射性测量这种误差完全是由放射性核衰变 和探测器统计粒子统计性引发,故称为统计误差。
放射性测量数据的处理
6
第6页
第八章 射性测量数据处理与结果表述
✓以被保留数字末位为基准, ✓假如碰到它后面尾数小于5(4以下),则该尾数被舍弃; ✓假如碰到它后面尾数大于5(6以上),则末位数进1; ✓假如尾数恰为5,则要依据被保留数字末位数而定。当末尾数为奇数时,末尾
数进 1;当末尾数为偶数时,尾数5被舍弃。
放射性测量数据的处理
13
第13页
第八章 射性测量数据处理与结果表述
放射性测量数据的处理
16
第16页
第八章 射性测量数据处理与结果表述
2).几个数作乘、除运算: 各数中以有效数字位数最少数为基准,其它各数都凑成比该数多1位有效数字数 参加运算;运算结果取小数位数最少位数。 比如: 13469×34=135×102×34=4590×102=46×104
放射性测量数据的处理
放射性测量数据的处理
放射性测量数据的处理
第1页
第八章 射性测量数据处理与结果表述
➢普通只有经过几个不一样方法测量结果比较; ✓ 或即使是同一个方法,但使用不一样设备,将其测量结果进行比较。 ✓ 一旦找到了系统误差,能够对其进行校正,以降低甚至消除系统误差对测 量结果带来影响。
➢偶然误差也叫随机误差,是由不确定原因引发。
✓ 随机误差出现服从统计分布规律。 ✓ 增加测量次数,能够减小偶然误差。
放射性测量数据的处理
2
第2页
郝大海《社会调查研究方法》笔记和课后习题详解(数据处理)【圣才出品】

十万种考研考证电子书、题库、视频学习平台第八章数据处理8.1复习笔记【知识框架】【重点难点归纳】一、资料检查与校订1.资料检查资料检查是指对调查得到的原始资料质量的审查与核实,目的是确定哪些资料可以接受,十万种考研考证电子书、题库、视频学习平台哪些资料要剔除。
它主要通过对回收问卷的完整性、准确性和真实性的检查来实现。
(1)检查问卷①资料的完整性主要通过问卷填答的完整程度反映出来,资料不完整包括以下情况:a.问卷的某一页或某几页漏填;b.问卷中的一个或多个问题没有填答。
②资料的准确性主要依赖于访问实施的准确程度,即访问员(或被访者)是否按要求实施了访问(或进行了回答),答案是否按要求作了记录。
如果回收问卷中出现以下情况,就表明访问没有严格按要求实施,相应的问卷资料是不准确的:a.问卷是由不符合要求的被访者填答的;b.问卷记录的访问日期是在调查规定的截止日期以后;c.问卷记录的答案有错误。
对检查出来的有问题的问卷,基本处理原则是:能纠正就纠正,无法纠正的作废卷处理。
在实践中,资料搜集上查验出了问题,要找到该访问员让其对漏答情况给出解释,对错误的回答记录做出相应判断,也可以要求访问员重新访问。
在由研究者自行进行的检查中,如废卷数量影响到样本的代表性,就要按相同的概率抽样原则重新选择一些被访者,进行补充调查。
(2)回访①资料真实性检查一般是在资料搜集结束后,由熟悉访问员情况的分区(组)督导或专门训练的复查员通过随机抽取5%~l5%已访问过的被访者进行回访来实现的。
对被访者的回访既可以采用打电话,也可以通过邮寄回访问卷的方式进行。
十万种考研考证电子书、题库、视频学习平台②复查的内容主要是确认访问员是否按规定访问了指定的被访者,访问员在访问中是否有违规操作行为。
复查应该是标准化的,要有复查问卷和格式统一的复查记录表。
复查问卷应包括以下内容:a.复查对象的原问卷编号;b.复查的次数及时间记录;c.确认访问员是否来访过;d.确认访问员是否访问了指定的被访者;e.(如果赠送礼品)确认访问员是否已送出礼品;f.复查对象对访问员访问态度的评价;g.从原问卷中挑选一些较敏感、较难回答或事实性的题目,回访复查对象,以检验访问员是否有违规操作行为。
第八章字符数据处理

\0
§8-3 二维字符数组(续2)
将程序改为:
char str[13];
scanf(“%s”,str);
同样输入: How are You?
结果是: H o w \0
( 表示空格)。
原因是系统将w和a之间的空格作为分割符。
第八章 字符数据处理
第一节 第二节 第三节 第四节 第五节
字符与字符串 字符数组 字符串处理函数 二维字符数组 应用举例
§8-1 字符与字符串
字符型数据 字符型数据的输入输出
◆ ◆ ◆ ◆
◆
◆
getchar() getche() getch() gets() putchar() puts();
例C8_502
s a b c m n o p \0 t a b c d e f g h i \0
§8-5 应用举例(续1)
例C8_502:将一个字符串接在另一个字符串后边。 main() { char s[100],t[100]; int i,j; for(i=0;(s[i++]=getchar())!=„\n‟;); for(i=0;(t[i++]=getchar())!=„\n‟;); for(i=0;s[i++]!=„\0‟;) ; for(j=0;(s[i++]= t[j++];); puts(s); }
例C8_201
§8-3 二维字符数组
例C8_301:用多维数组存放学生姓名,并进行排序。 ◆ 多维数组赋初值 Char name[ ][10]={“ ZhangHong ”,“ WangMing ”, “ LiHua ”, “ ZhaoNing ”}; ◆ 排序 for(i=0;i<3;i++) for(j=i+1;j<4;j++) 观察 if(strcmp(name[i],name[j])>0) 内存分 { strcpy(temp,name[i]); strcpy(name[i],name[j]); 配情况 和排序 strcpy(name[j],temp); 结果。 }
八年级数学上册 第八章数据的代表教学分析与建议 北师大版 教案

北师大版八年级数学(上)第八章数据的代表教学分析与建议一、教材分析生活中,人们离不开数据,我们不仅需要收集数据,还要对数据进行加工处理,进而作出判断。
学生通过七年级的学习,对收集数据,从数据中获取信息以及数据的处理已有初步的认识和经验,而通过本章的学习,学生学会用平均数、中位数和众数等数据的代表来刻画生活中数据问题,从而提高对信息加工、数据处理的能力。
二、教学目标1、初步经历数据的收集与处理过程,发展学生初步的统计意识和数据处理能力。
2、初步经历调查、统计、研讨等活动,在活动中发展合作交流的意识与能力。
3、掌握平均数、中位数、众数的的概念;能利用科学计算器求一组数据的算术平均数。
4、知道数的差异对平均数的影响,并能用加权平均数解释现实生活中一些简单的现象;了解平均数、中位数、众数的差别,初步体会它们在不同情景中的应用。
三、本章教材的设计理念1、“平均水平”是最为常用的一个评判数据的指标,本章通过实际背景,引入了刻画“平均水平”的三个数据代表,以让学生获取一定的评判能力。
2、在现有的认知结构中,学生多是单一地用算术平均数理解一组数据的平均水平。
为此,本章先从一个学生熟悉的现实生活背景导入算术平均数、加权平均数的概念,并让学生了解权的差异对平均数的影响;在此基础上,通过一个有争议的话题,引起学生对“平均水平”的认知冲突,从而引入中位数、众数的概念,让学生多角度在认识平均;最后,通过学生的探索,让其获得利用计算器处理数据的基本技能。
3、充分注意了数据呈现方式的多样化和知识间的前后联系。
教材有意识地安排了一些例、习题,以条形统计图、扇形统计图的方式呈现数据。
这样,既加强了知识间的联系,巩固了学生对各种图表信息的识别与获取能力,同时也增加了对学生生活中见到的统计图表进行数据处理和评判的主动意识。
4、对数据的收集,本章未作为教学重点,这是考虑到一是数据收集在七年级时已进行过,二是考虑到课堂教学时间的有限性,三只考虑到以后教材中还会专门学习。
(NEW)郝大海《社会调查研究方法》(第3版)笔记和课后习题详解

目 录第一章 导 论1.1 复习笔记1.2 课后习题详解第二章 抽样设计2.1 复习笔记2.2 课后习题详解第三章 抽样实务及问题3.1 复习笔记3.2 课后习题详解第四章 题目设计方法4.1 复习笔记4.2 课后习题详解第五章 问卷设计与评估5.1 复习笔记5.2 课后习题详解第六章 资料搜集方法的选择6.1 复习笔记6.2 课后习题详解第七章 标准化访问7.1 复习笔记7.2 课后习题详解第八章 数据处理8.1 复习笔记8.2 课后习题详解第九章 调查中的其他议题9.1 复习笔记9.2 课后习题详解第一章 导 论1.1 复习笔记【知识框架】【重点难点归纳】一、调查研究概述1调查研究方法的界定从所涉及的内容看,本书介绍的调查方法是一种量化的社会研究方法。
具体说来,就是通过向被访者询问问题来搜集资料,然后对资料进行统计分析的社会研究方法;其中,询问既可以是由被访者自己填答问卷,也可以通过当面访问或电话访问进行。
对于调查方法的定义,可以从以下三点来理解:(1)询问作为调查研究的基本要素,是一个科学测量过程。
(2)选取有代表性的被访者,是调查研究成功的关键。
(3)资料的统计分析是完成调查研究的必要环节。
2.调查研究发展简史按时间顺序,调查研究的发展大体可以划分为近代和现代两个阶段。
近代调查研究主要包括行政统计和社会问题调查,而现代调查研究则主要包括民意测验、市场调查和研究性调查。
虽然存在着多种调查形式,但从内在发展脉络看,无论是在近代还是现代,始终贯穿着实地观测和统计量化两条线索,因此,了解调查研究的发展过程,要始终把握住这两条线索。
(1)近代调查研究①发展过程a.作为一种社会研究方法,调查研究肇始于近代的行政统计调查。
17世纪下半叶,一些学者和政府官员逐渐意识到,人口、土地和经济方面的统计数字,有助于了解基本国情和社会整体状况,于是出现了德国“国势学”和英国“政治算数”等不同学派的统计学。
在随后的发展中,政治算数学派的统计学逐渐取得主导地位。
数据管理规定管理要求(3篇)

第1篇第一章总则第一条为加强我国数据资源的管理,保障数据安全,促进数据资源的合理利用,根据《中华人民共和国数据安全法》、《中华人民共和国个人信息保护法》等相关法律法规,制定本规定。
第二条本规定适用于我国境内从事数据采集、存储、处理、传输、交换、应用等活动的组织和个人。
第三条数据管理应当遵循以下原则:(一)依法合规:数据管理活动必须符合国家法律法规和政策要求。
(二)安全可靠:确保数据安全,防止数据泄露、篡改、破坏等风险。
(三)开放共享:推动数据资源的开放共享,促进数据资源的合理利用。
(四)创新发展:鼓励数据管理技术创新,提高数据管理效率。
(五)协同治理:建立数据管理协同治理机制,形成全社会共同参与的良好局面。
第二章数据分类与分级第四条数据按照以下分类进行管理:(一)个人信息数据:指涉及个人身份、生理、心理、行为等信息的数据。
(二)公共数据:指政府部门、公共机构、企事业单位在履行职责过程中产生、获取和管理的,对公众开放的数据。
(三)企业数据:指企业生产经营活动中产生、获取和管理的,用于企业内部管理、决策和业务运营的数据。
(四)其他数据:指不属于上述三类数据的其他数据。
第五条数据按照以下分级进行管理:(一)一级数据:涉及国家安全、经济安全、社会稳定、公共利益等重大利益的数据。
(二)二级数据:涉及重要行业、重要领域、重要企业等数据。
(三)三级数据:涉及一般行业、一般领域、一般企业等数据。
(四)四级数据:涉及个人隐私、企业商业秘密等数据。
第三章数据采集与存储第六条数据采集应当遵循以下原则:(一)合法合规:数据采集活动必须符合国家法律法规和政策要求。
(二)最小必要:采集的数据应当限于实现特定目的所必需的范围。
(三)知情同意:采集个人信息数据时,应当告知数据主体采集的目的、范围、方式等信息,并取得数据主体的同意。
第七条数据存储应当遵循以下要求:(一)安全可靠:采取必要的安全措施,确保数据存储的安全性。
(二)分类存储:按照数据分类分级要求,对数据进行分类存储。
结构试验-第八章 试验结果处理与误差分析
例子:P255, 例8-7.
八、试验数据处理
可疑数据的鉴别 测量结果的取舍:过失误差的剔除
(3) 肖维纳(Chauvenet)准则 在n次试验中,某数据的剩余误差可能出现的次数小于 半次时,便可剔除。
1 a 2n
根据a查表8-2,得到Z(注意表8-2是a/2的概率),用Z×S做 为判据(S为子样的方差)。 见Origin例子。
八、试验数据处理
八、试验数据处理
误差理论基础
随机误差虽然由偶然因素造成,但其服从正态分布
1.0
0.8
0.6
y
0.4 0.2 0.0 -4 -2 0 2 4
x
八、试验数据处理
正态分布概率表达式
1 y e 2
2 2 2
又称高斯分布 见Origin例子:
标准差(均方差)的定义:
最大绝对误差、最大相对误差分别为:
X max f f f Z1 Z 2 ... Z n Z1 Z 2 Z n
emax f f f e1 e2 ... en Z Z 2 Z n 1
2、系统误差
3、随机误差
八、试验数据处理
误差的分类:
过失误差:严格意义不属于误差,属于错误,应尽量避免 系统误差:由仪器缺陷,环境因素,方法不精确等造成,可消
除或修正
随机误差:由预先难以预料的微小因素造成,正负误差出现的
概率相同、符合正态分布;具有抵偿性,多次测量结果的算术 平均值中,随机误差趋于零
P 250 例8-3
八、试验数据处理
误差传递公式
当规定了最终误差的范围,需要我们确定各测量量的 误差控制范围--误差的逆运算。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
回答 编 码
1,2,3,4 5,6
1 2
不会引起头痛 ,胃痛
长期喝,习惯 朋友喝/受朋友 影响 不知道
7,8
9,10 11,12 13,14,15
3
4 5 6
4.数据文档的转换
数据文档的初始形态 统计分析软件:如SAS、SPSS、MINITAB、SYSTAT、EVIEWS 数据库管理软件:如:Microsoft Excel、Lotus1-2-3和Quatro Pro
对方差进行开方,即可得到标准差。
二、单变量描述统计
4.离散趋势的常用测度指标
四分位差 把调查数据按照从小到大的顺序排列后,用三 个四分位数点( Q1 , Q2 , Q3 )将其分为四个相等部分,高四分 位数点 Q3与低四分位数点 Q1 之间的距离即为四分位差 。
QD Q3 Q1
变异系数 指调查数据的标准差与其算术平均数的比值, 也称为离散系数,主要用于比较不同类别数据的离散程度。
在实际操作中,建立回归模型的过程非常复杂,应用时必 须结合具体情况进行探讨和分析 。
例题
下表是一份数据,其中的y是保险公司职员一周平均 加班时数,x是一周新签保单数,这里希望能确立一个模 型来研究新签保单和员工加班时数之间的关系。 实例数 据
周序号 新签保单(X) 加班时数(Y)
1
2
825
215
(1)单项选择题录入----根据题项附值,题内若有其 他选项则转化为开放式问题模式录入。 (2)多项选择题录入 A多选项二分法----每个变量只有0或1取值; B多选项分类法----为多个答案分设变量。 (3)开放式问题录入 A列出答案;B合并答案;C设置编码;D选定编码。
•
你为什么喜欢喝A品牌的啤酒?
3.数据处理的前期准备
选择高效率的数据处理人员。 建立完善的工作制度。 制定科学的工作标准。
§8.2 一般数据处理流程
一、数据审核 二、后编码 三、数据录入 四、数据文档的转换 五、数据库清理 六、数据库储存
一般数据处理流程图
(1)数据审核 否
剔除或返还纠错
数据是否可 用 是 (2)后编码 (3)数 据录 入 (4)数据文档转换 (5)数据库清理
2.后编码 编码指将问卷(或调查表)中的文字信息转化为 计算机能识别的数字符号的过程,即给问卷或调 查表的每一个题目的每一个备选答案分配一个符 码,符码通常是一个数字 。 3.数据录入 指将问卷或编码表中的每一题目或变量对应的代 码读到磁盘等储存介质上,或通过键盘直接敲入 计算机中 。
数据编码与录入的处理方式:
3.5
1
3
4 5 6 7 8 9
1070
550 480 920 1350 352 670
4
2 1 3 4.5 1.5 3
10
1215
5
表
周序号 1 2 3 4 5 6 7 8 9 10 新签保单(X) 825 215 1070 550 480 920 1350 352 670 1215
计算一元回归的中间变量
众数 指数据中出现次数最多的变量值,记为 M 0 。 计算分组数据的众数: 1 M0 L i 1 2 1和 2 分别为众 L 为众数所在组的下限 , i 为众数所在组组距, 数所在组变量值的次数与下一组和上一组变量值的次数之差。
二、单变量描述统计
4.离散趋势的常用测度指标
加班时数(Y) 3.5 1 4 2 1 3 4.5 1.5 3 5 X2 680625 46225 1144900 302500 230400 846400 1822500 123904 448900 1476225 Y2 12.25 1 16 4 1 9 20.25 2.25 9 25 XY 2887.5 215 4280 1100 480 2760 6075 528 2010 6075
一、频数分布和统计图表
1.频数分布
指把总体按某一标志分组,并按一定顺序列出每个组的单位 数,所形成的总体单位在各组间的分布;也称为次数分布或 分布数列。
2.频数分布表
把总体中各个类别及其相应的频数、频率及累计频率等指标 用汇总表格的形式展示出来所形成表格。
3.编制频数分布表的一般步骤
找出数据的变动范围; 确定组数和组距; 确定组限(上限、下限)和组中值; 计算调查数据落入各组的频数和频率。
标准差 指调查数据中各变量值与其算术平均数离差平方 的算术平均数的平方根,记为 s 。 方差 指标准差的平方,记为 s 2 。 依据原始数据计算方差:
s2
x
n i 1
i
x
2
n 1
依据分组数据计算方差:
s2
x x
k i i 1
2
fi
f
i 1
k
i
1
编制频数分布表时,需要注意组数、组距及组限的确定 问题;
不同的统计图一般都有其特定的适用范围,在实际应用 时,应根据数据性质及所反映问题的需要选择适宜的统 计图。
二、单变量描述统计
1.集中趋势
指调查数据的频数分布从两边向中间集中的趋势,也称作 趋中性 。
2.离散趋势
指调查数据远离其分布中心值的程度。
注:不同处理方式分析结果将有所不同。
6.数据库储存
是否需要给数据库加入新的变量。
数据库文档通常储存在磁盘等储存介质上,另外再 用一张磁盘或其他储存介质作为备份以保证安全 。
第9章
数据分析方法
§9.1 统计分析方法Ⅰ—描述统计 §9.2 统计分析方法Ⅱ—推断统计
§9.1 统计分析方法Ⅰ—描述统计
一、频数分布和统计图表
4.统计图
是一种以点、线条、面积等方法描述和显示数据的形式,具 有直观、醒目、易于理解等特点,一般由坐标系、图形和图 例三部分组成。
5.常用的统计图有:
条形图、直方图、饼图、折线图、趋势图、态度对比图、轮 廓形象图等。
编制频数分布表及绘制统计图时应注意的问题
编制频数分布表和绘制统计图只是对调查数据进行处理 的初级阶段;
x1 x2 xn x n
x
i 1
n
i
n
加权算术平均数——根据分组数据计算
x1 f1 x2 f 2 xk f k x f1 f 2 f k
x f
i 1 k
k
i i
k
1
i
二、单变量描述统计
3.集中趋势的常用测度指标
中位数 指把一组数据按照从小到大的顺序排列后,位置 居中的变量值,记为 M e 。 计算原始数据的中位数: M e xn1 2 当 n 为奇数时: 当 n 为偶数时: M e xn 2 xn 21 2
集中趋势指标反映调查数据的共性和集中性,离散趋 势指标反映调查数据的个性和分散性。调查数据的离 散程度越高,用于描述数据集中趋势指标的代表性越 差,使用这些代表性指标进行统计分析的效果越差。
二、单变量描述统计
3.集中趋势的常用测度指标
平均数 又称均值,主要有算术平均数、调和平均数和几 何平均数等计算方法,其中以算术平均数最为常用。 简单算术平均数——根据原始数据计算
多元线性回归 非线性回归
yi 0 1 x1 2 x2 n xn i
三、多变量描述统计
应用相关与回归分析方法时应注意的问题
相关分析的目的是测定变量之间相关关系的方向和程度, 回归分析的目的是利用回归模型进行预测和控制。
进行相关分析时,不能仅凭相关系数的大小来解释变量之 间的相关程度,否则有可能会得出不切实际的结论。
5.数据库清理
目的:不让有错误的数据进入统计分析过程。 数据库清理是对数据库文件做以下检查: 编码检查 一致性检查 缺失值检查 一致性检查---为了找出超出正常范围、逻辑上不合理或极端 的数值。如一般备选答案1~5,9为缺失值,若出现8则错。 缺失值检查---是存在明显错误、不合理数据、漏填数据项。 处理方式:均值代替、 估计值代替、问卷删除、 结对删除。
i 1 i 1
三、多变量描述统计
4.回归分析
是研究因变量对自变量依赖关系的一种统计分析方法,目的 是通过自变量的给定值来估计或预测因变量的均值。 一元线性回归
y 0 1 x
一般实现步骤 绘出散点图→建立一般模型→估计方程参数→检验回 归方程的拟合优度→检验参数的显著性→检验回归方 程的显著性→分析回归方程的残差→预测
一、频数分布表和统计图法 二、单变量描述统计 三、多变量描述统计
统计分析方法的选择:
• 1、调研问题的性质 • 描述性问题----如对某电视广告接触状况的反应;对 某产品性能的评价;不同人对某品牌偏好差异等。 采用频数分析和描述统计。 • 关系性问题----如相关关系和因果关系。采用相关分 析、回归分析、方差分析等。 • 2、数据资料的性质 • 品质变量----如性别、职业等。采用列联分析、非参 数检验等。 • 数量变量----如年龄、收入、销售量、知名度等,即 等距、等比量表,或次序量表进行数学转换后。可 采用各种方法。
加入新变量
是
是否需要加入新变量 否 (6)数据库储存
一般数据处理流程图
1.数据审核
数据资料的审核是数据资料处理的第一步工作。 审核方式
资料收集过程中的审核。
资料回收后的审核。 审核的一般方法
文字资料的审核方法。 数字资料的审核方法。
常见需审核的问题:
• 问卷的某些部分填写不完整或记录字迹不清楚; • 调查对象回答差异不大; • 返回的调查问卷本身丢失几页; • 问卷的回收超过时限; • 问卷的填写人员不符合调查要求; • 问卷存在明显不一致的答案; 处理方式: • 对于样本量较少而调查对象又比较容易确认的不合 格问卷,通常采用退回现场重新调查的方式; • 对于无法退回现场,缺失值较少且缺失值不是关键 变量的少数问卷,进行填补确实值的处理; • 其他情况采用丢弃不合格问卷。