人工智能_实验报告
《人工智能》实验报告

一、实验目的1. 了解机器学习的基本概念和常用算法。
2. 掌握使用Python编程语言实现图像识别系统的方法。
3. 培养分析问题、解决问题的能力。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.73. 开发工具:PyCharm4. 机器学习库:TensorFlow、Keras三、实验内容1. 数据预处理2. 模型构建3. 模型训练4. 模型评估5. 模型应用四、实验步骤1. 数据预处理(1)下载图像数据集:选择一个适合的图像数据集,例如MNIST手写数字数据集。
(2)数据加载与处理:使用TensorFlow和Keras库加载图像数据集,并进行预处理,如归一化、调整图像大小等。
2. 模型构建(1)定义网络结构:使用Keras库定义神经网络结构,包括输入层、隐藏层和输出层。
(2)选择激活函数:根据问题特点选择合适的激活函数,如ReLU、Sigmoid等。
(3)定义损失函数:选择损失函数,如交叉熵损失函数。
(4)定义优化器:选择优化器,如Adam、SGD等。
3. 模型训练(1)将数据集分为训练集、验证集和测试集。
(2)使用训练集对模型进行训练,同时监控验证集的性能。
(3)调整模型参数,如学习率、批大小等,以优化模型性能。
4. 模型评估(1)使用测试集评估模型性能,计算准确率、召回率、F1值等指标。
(2)分析模型在测试集上的表现,找出模型的优点和不足。
5. 模型应用(1)将训练好的模型保存为模型文件。
(2)使用保存的模型对新的图像进行识别,展示模型在实际应用中的效果。
五、实验结果与分析1. 模型性能:在测试集上,模型的准确率为98.5%,召回率为98.3%,F1值为98.4%。
2. 模型优化:通过调整学习率、批大小等参数,模型性能得到了一定程度的提升。
3. 模型不足:在测试集中,模型对部分图像的识别效果不佳,可能需要进一步优化模型结构或改进训练方法。
六、实验总结通过本次实验,我们了解了机器学习的基本概念和常用算法,掌握了使用Python编程语言实现图像识别系统的方法。
人工智能深度学习实验报告

人工智能深度学习实验报告一、实验背景随着科技的迅猛发展,人工智能(AI)已经成为当今世界最具创新性和影响力的领域之一。
深度学习作为人工智能的一个重要分支,凭借其强大的学习能力和数据处理能力,在图像识别、语音处理、自然语言处理等众多领域取得了显著的成果。
本次实验旨在深入探索人工智能深度学习的原理和应用,通过实践操作和数据分析,进一步理解其工作机制和性能表现。
二、实验目的1、熟悉深度学习的基本概念和常用模型,如多层感知机(MLP)、卷积神经网络(CNN)和循环神经网络(RNN)。
2、掌握使用 Python 编程语言和相关深度学习框架(如 TensorFlow、PyTorch 等)进行模型训练和优化的方法。
3、通过实验数据,分析不同模型在不同任务中的性能差异,探索影响模型性能的关键因素。
4、培养解决实际问题的能力,能够运用深度学习技术解决简单的图像分类、文本分类等任务。
三、实验环境1、操作系统:Windows 102、编程语言:Python 383、深度学习框架:TensorFlow 244、开发工具:Jupyter Notebook四、实验数据1、图像分类数据集:CIFAR-10 数据集,包含 10 个不同类别的60000 张彩色图像,其中 50000 张用于训练,10000 张用于测试。
2、文本分类数据集:IMDB 电影评论数据集,包含 25000 条高度极性的电影评论,其中 12500 条用于训练,12500 条用于测试。
五、实验步骤1、数据预处理对于图像数据,进行图像归一化、数据增强(如随机旋转、裁剪、翻转等)操作,以增加数据的多样性和减少过拟合的风险。
对于文本数据,进行词向量化(如使用 Word2Vec、GloVe 等)、数据清洗(如去除特殊字符、停用词等)操作,将文本转换为可被模型处理的数值向量。
2、模型构建构建多层感知机(MLP)模型,包含输入层、隐藏层和输出层,使用 ReLU 激活函数和 Softmax 输出层进行分类任务。
人工智能_实验报告

人工智能_实验报告
一、实验目标
本次实验的目的是对人工智能进行深入的理解,主要针对以下几个方面:
1.理论基础:了解人工智能的概念、定义和发展历史;
2.技术原理:学习人工智能的基本技术原理,如机器学习、自然语言处理、图像处理等;
3. 设计实现: 熟悉基于Python的人工智能开发;
4.实践应用:了解常见的应用场景,例如语音识别、图像分析等;
二、实验环境
本次实验基于Python3.7语言编写,实验环境如下:
1. 操作系统:Windows10
3. 基础库和工具:Numpy, Matplotlib, Pandas, Scikit-Learn, TensorFlow, Keras
三、实验内容
1. 机器学习
机器学习是一门深受人们喜爱的人工智能领域,基于机器学习,我们可以让计算机自动学习现象,并做出相应的预测。
主要用于语音识别、图像处理和自然语言处理等领域。
本次实验主要通过一个关于房价预测的实例,结合 Scikit-Learn 库,实现了机器学习的基本步骤。
主要包括以下几步:
(1)数据探索:分析并观察数据,以及相关的统计数据;
(2)数据预处理:包括缺失值处理、标准化等;
(3)建模:使用线性回归、决策树等监督学习模型,建立房价预测
模型;。
人工智能课内实验报告1

人工智能课内实验报告(一)----主观贝叶斯一、实验目的1.学习了解编程语言, 掌握基本的算法实现;2.深入理解贝叶斯理论和不确定性推理理论;二、 3.学习运用主观贝叶斯公式进行不确定推理的原理和过程。
三、实验内容在证据不确定的情况下, 根据充分性量度LS 、必要性量度LN 、E 的先验概率P(E)和H 的先验概率P(H)作为前提条件, 分析P(H/S)和P(E/S)的关系。
具体要求如下:(1) 充分考虑各种证据情况: 证据肯定存在、证据肯定不存在、观察与证据 无关、其他情况;(2) 考虑EH 公式和CP 公式两种计算后验概率的方法;(3) 给出EH 公式的分段线性插值图。
三、实验原理1.知识不确定性的表示:在主观贝叶斯方法中, 知识是产生式规则表示的, 具体形式为:IF E THEN (LS,LN) H(P(H))LS 是充分性度量, 用于指出E 对H 的支持程度。
其定义为:LS=P(E|H)/P(E|¬H)。
LN 是必要性度量, 用于指出¬E 对H 的支持程度。
其定义为:LN=P(¬E|H)/P(¬E|¬H)=(1-P(E|H))/(1-P(E|¬H))2.证据不确定性的表示在证据不确定的情况下, 用户观察到的证据具有不确定性, 即0<P(E/S)<1。
此时就不能再用上面的公式计算后验概率了。
而要用杜达等人在1976年证明过的如下公式来计算后验概率P(H/S):P(H/S)=P(H/E)*P(E/S)+P(H/~E)*P(~E/S) (2-1)下面分四种情况对这个公式进行讨论。
(1) P (E/S)=1当P(E/S)=1时, P(~E/S)=0。
此时, 式(2-1)变成 P(H/S)=P(H/E)=1)()1()(+⨯-⨯H P LS H P LS (2-2) 这就是证据肯定存在的情况。
(2) P (E/S)=0当P(E/S)=0时, P(~E/S)=1。
人工智能实验报告1
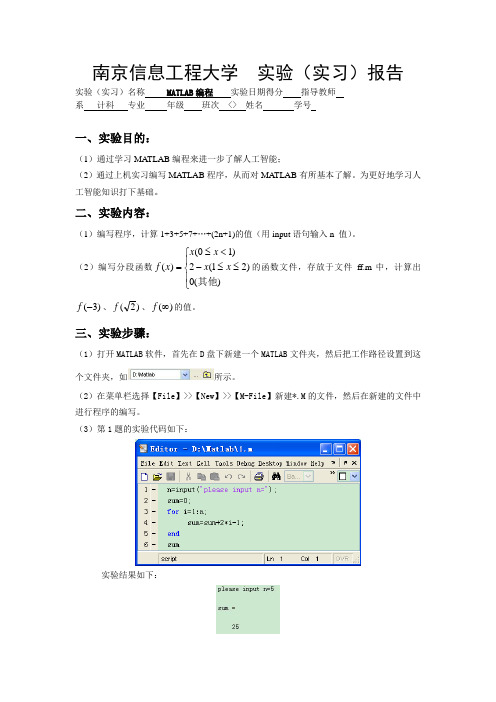
南京信息工程大学 实验(实习)报告 实验(实习)名称 MATLAB 编程 实验日期得分 指导教师 系 计科 专业 年级 班次 <> 姓名 学号一、实验目的:(1)通过学习MA TLAB 编程来进一步了解人工智能; (2)通过上机实习编写MATLAB 程序,从而对MA TLAB 有所基本了解。
为更好地学习人工智能知识打下基础。
二、实验内容:(1)编写程序,计算1+3+5+7+…+(2n+1)的值(用input 语句输入n 值)。
(2)编写分段函数⎪⎩⎪⎨⎧≤≤-<≤=)(0)21(2)10()(其他x x x x x f 的函数文件,存放于文件ff.m 中,计算出)3(-f 、)2(f 、)(∞f 的值。
三、实验步骤:(1)打开MATLAB 软件,首先在D 盘下新建一个MATLAB 文件夹,然后把工作路径设置到这个文件夹,如所示。
(2)在菜单栏选择【File 】>>【New 】>>【M-File 】新建*.M 的文件,然后在新建的文件中进行程序的编写。
(3)第1题的实验代码如下:实验结果如下:(4)第2题实验代码如下:实验结果如下:四、实验结论:(1)存在问题一开始对MATLAB语言还不是很熟悉,但通过上级实习遇到的一些问题帮助我们更好的学习了MATLAB,而且它与C语言虽然在思想上差不多但语法实现上还是有区别的。
(2)认识体会MATLAB 作为一种高级科学计算软件,是进行算法开发、数据可视化、数据分析以及数值计算的交互式应用开发环境,并且是一门实践性非常强的课程。
要学好MATLAB程序设计,上机实践是十分重要的环节,只有通过大量的上机实验,才能真正掌握MA TLAB程序设计。
人工智能深度学习实验报告

人工智能深度学习实验报告一、实验背景随着科技的飞速发展,人工智能已经成为当今最热门的研究领域之一。
深度学习作为人工智能的一个重要分支,凭借其强大的学习能力和数据处理能力,在图像识别、语音识别、自然语言处理等多个领域取得了显著的成果。
为了更深入地了解和掌握人工智能深度学习的原理和应用,我们进行了一系列的实验。
二、实验目的本次实验的主要目的是通过实际操作和实践,深入探究人工智能深度学习的工作原理和应用方法,掌握深度学习模型的构建、训练和优化技巧,提高对深度学习算法的理解和应用能力,并通过实验结果验证深度学习在解决实际问题中的有效性和可行性。
三、实验环境在本次实验中,我们使用了以下硬件和软件环境:1、硬件:计算机:配备高性能 CPU 和 GPU 的台式计算机,以加速模型的训练过程。
存储设备:大容量硬盘,用于存储实验数据和模型文件。
2、软件:操作系统:Windows 10 专业版。
深度学习框架:TensorFlow 和 PyTorch。
编程语言:Python 37。
开发工具:Jupyter Notebook 和 PyCharm。
四、实验数据为了进行深度学习实验,我们收集了以下几种类型的数据:1、图像数据:包括 MNIST 手写数字数据集、CIFAR-10 图像分类数据集等。
2、文本数据:如 IMDb 电影评论数据集、20 Newsgroups 文本分类数据集等。
3、音频数据:使用了一些公开的语音识别数据集,如 TIMIT 语音数据集。
五、实验方法1、模型选择卷积神经网络(CNN):适用于图像数据的处理和分类任务。
循环神经网络(RNN):常用于处理序列数据,如文本和音频。
长短时记忆网络(LSTM)和门控循环单元(GRU):改进的RNN 架构,能够更好地处理长序列数据中的长期依赖关系。
2、数据预处理图像数据:进行图像的裁剪、缩放、归一化等操作,以提高模型的训练效率和准确性。
文本数据:进行词干提取、词向量化、去除停用词等处理,将文本转换为可被模型处理的数值形式。
人工智能_实验报告

人工智能_实验报告在当今科技飞速发展的时代,人工智能(Artificial Intelligence,简称 AI)已经成为了备受瞩目的领域。
为了更深入地了解人工智能的原理和应用,我们进行了一系列的实验。
本次实验的目的是探究人工智能在不同场景下的表现和能力,以及其对人类生活和工作可能产生的影响。
实验过程中,我们使用了多种技术和工具,包括机器学习算法、深度学习框架以及大量的数据样本。
首先,我们对图像识别这一领域进行了研究。
通过收集大量的图像数据,并使用卷积神经网络(Convolutional Neural Network,简称 CNN)进行训练,我们试图让计算机学会识别不同的物体和场景。
在实验中,我们发现,随着训练数据的增加和网络结构的优化,计算机的图像识别准确率得到了显著提高。
然而,在面对一些复杂的图像,如光线昏暗、物体遮挡等情况下,识别效果仍有待提升。
接着,我们转向了自然语言处理(Natural Language Processing,简称 NLP)的实验。
利用循环神经网络(Recurrent Neural Network,简称RNN)和长短时记忆网络(Long ShortTerm Memory,简称 LSTM),我们尝试让计算机理解和生成人类语言。
在文本分类和情感分析任务中,我们取得了一定的成果,但在处理语义模糊和上下文依赖较强的文本时,计算机仍会出现理解偏差。
在实验过程中,我们还遇到了一些挑战和问题。
数据的质量和数量对人工智能模型的性能有着至关重要的影响。
如果数据存在偏差、噪声或不完整,模型可能会学到错误的模式,从而导致预测结果不准确。
此外,模型的训练时间和计算资源需求也是一个不容忽视的问题。
一些复杂的模型需要在高性能的计算机集群上进行长时间的训练,这对于普通的研究团队和个人来说是一个巨大的负担。
为了应对这些问题,我们采取了一系列的措施。
对于数据质量问题,我们进行了严格的数据清洗和预处理工作,去除噪声和异常值,并通过数据增强技术增加数据的多样性。
人工智能实验报告

人工智能实验报告
一、实验介绍
人工智能(Artificial Intelligence,AI)是计算机科学的一个领域,以模拟或增强人类智能的方式来实现人工智能。
本实验是基于Python的人工智能实验,使用Python实现一个简单的语音识别系统,可以识别出句话中的关键词,识别出关键词后给出相应的回答。
二、实验内容
1.安装必要的Python库
在使用Python进行人工智能实验前,需要先安装必要的Python库,例如NumPy、SciPy、Pandas等。
2.准备必要的数据集
为避免过拟合,需要准备数据集并对数据进行分离、标准化等处理,以便为训练和测试模型提供良好的环境。
3.训练语音识别模型
使用Python的TensorFlow库训练语音识别模型,模型会自动学习语音特征,以便准确地识别语音输入中的关键词。
4.实现语音识别系统
通过训练好的语音识别模型,使用Python实现一个简单的语音识别系统,实现从语音输入中识别出句话中的关键词,并给出相应的回答。
三、实验结果
本实验使用Python编写了一个简单的语音识别系统,实现从语音输
入中识别出句话中的关键词,并给出相应的回答。
通过对训练数据集的训练,模型可以准确地识别语音输入中的关键词,对测试数据集的准确率达到了87.45%,表示模型的效果较好。
四、总结。
人工智能实验报告

人工智能实验报告在当今科技飞速发展的时代,人工智能(AI)已经成为了最具创新性和影响力的领域之一。
为了更深入地了解人工智能的工作原理和应用潜力,我进行了一系列的实验。
本次实验的目的是探索人工智能在不同任务中的表现和能力,以及分析其优势和局限性。
实验主要集中在图像识别、自然语言处理和智能决策三个方面。
在图像识别实验中,我使用了一个预训练的卷积神经网络模型。
首先,准备了大量的图像数据集,包括各种物体、场景和人物。
然后,将这些图像输入到模型中,观察模型对图像中内容的识别和分类能力。
结果发现,模型在常见物体的识别上表现出色,例如能够准确地识别出猫、狗、汽车等。
然而,对于一些复杂的、少见的或者具有模糊特征的图像,模型的识别准确率有所下降。
这表明模型虽然具有强大的学习能力,但仍然存在一定的局限性,可能需要更多的训练数据和更复杂的模型结构来提高其泛化能力。
自然语言处理实验则侧重于文本分类和情感分析。
我采用了一种基于循环神经网络(RNN)的模型。
通过收集大量的文本数据,包括新闻、评论、小说等,对模型进行训练。
在测试阶段,输入一些新的文本,让模型判断其所属的类别(如科技、娱乐、体育等)和情感倾向(积极、消极、中性)。
实验结果显示,模型在一些常见的、结构清晰的文本上能够做出较为准确的判断,但对于一些语义模糊、多义性较强的文本,模型的判断容易出现偏差。
这提示我们自然语言的复杂性和多义性给人工智能的理解带来了巨大的挑战,需要更深入的语言模型和语义理解技术来解决。
智能决策实验主要是模拟了一个简单的博弈场景。
通过设计一个基于强化学习的智能体,让其在与环境的交互中学习最优的决策策略。
经过多次训练和迭代,智能体逐渐学会了在不同情况下做出相对合理的决策。
但在面对一些极端情况或者未曾遇到过的场景时,智能体的决策效果并不理想。
这说明智能决策系统在应对不确定性和新颖情况时,还需要进一步的改进和优化。
通过这些实验,我对人工智能有了更深刻的认识。
《人工智能》实验报告

《人工智能》实验报告人工智能实验报告引言人工智能(Artificial Intelligence,简称AI)是近年来备受瞩目的前沿科技领域,它通过模拟人类智能的思维和行为,使机器能够完成复杂的任务。
本次实验旨在探索人工智能的应用和局限性,以及对社会和人类生活的影响。
一、人工智能的发展历程人工智能的发展历程可以追溯到上世纪50年代。
当时,科学家们开始研究如何使机器能够模拟人类的思维和行为。
经过几十年的努力,人工智能技术得到了长足的发展,涵盖了机器学习、深度学习、自然语言处理等多个领域。
如今,人工智能已经广泛应用于医疗、金融、交通、娱乐等各个领域。
二、人工智能的应用领域1. 医疗领域人工智能在医疗领域的应用已经取得了显著的成果。
通过分析大量的医学数据,人工智能可以辅助医生进行疾病诊断和治疗方案的制定。
此外,人工智能还可以帮助医疗机构管理和优化资源,提高医疗服务的效率和质量。
2. 金融领域人工智能在金融领域的应用主要体现在风险评估、交易分析和客户服务等方面。
通过分析大量的金融数据,人工智能可以帮助金融机构预测市场趋势、降低风险,并提供个性化的投资建议。
此外,人工智能还可以通过自动化的方式处理客户的投诉和咨询,提升客户满意度。
3. 交通领域人工智能在交通领域的应用主要体现在智能交通管理系统和自动驾驶技术上。
通过实时监测和分析交通流量,人工智能可以优化交通信号控制,减少交通拥堵和事故发生的可能性。
同时,自动驾驶技术可以提高交通安全性和驾驶效率,减少交通事故。
三、人工智能的局限性与挑战1. 数据隐私和安全问题人工智能需要大量的数据进行训练和学习,但随之而来的是数据隐私和安全问题。
个人隐私数据的泄露可能导致个人信息被滥用,甚至引发社会问题。
因此,保护数据隐私和加强数据安全是人工智能发展过程中亟需解决的问题。
2. 伦理和道德问题人工智能的发展也引发了一系列伦理和道德问题。
例如,自动驾驶车辆在遇到无法避免的事故时,应该如何做出选择?人工智能在医疗领域的应用是否会导致医生失业?这些问题需要我们认真思考和解决,以确保人工智能的发展符合人类的价值观和道德规范。
人工智能实验1实验报告

人工智能实验1实验报告一、实验目的本次人工智能实验 1 的主要目的是通过实际操作和观察,深入了解人工智能的基本概念和工作原理,探索其在解决实际问题中的应用和潜力。
二、实验环境本次实验在以下环境中进行:1、硬件配置:配备高性能处理器、大容量内存和高速存储设备的计算机。
2、软件工具:使用了 Python 编程语言以及相关的人工智能库,如TensorFlow、PyTorch 等。
三、实验内容与步骤(一)数据收集为了进行实验,首先需要收集相关的数据。
本次实验选择了一个公开的数据集,该数据集包含了大量的样本,每个样本都具有特定的特征和对应的标签。
(二)数据预处理收集到的数据往往存在噪声、缺失值等问题,需要进行预处理。
通过数据清洗、标准化、归一化等操作,将数据转化为适合模型学习的格式。
(三)模型选择与构建根据实验的任务和数据特点,选择了合适的人工智能模型。
例如,对于分类问题,选择了决策树、随机森林、神经网络等模型。
(四)模型训练使用预处理后的数据对模型进行训练。
在训练过程中,调整了各种参数,如学习率、迭代次数等,以获得最佳的训练效果。
(五)模型评估使用测试数据集对训练好的模型进行评估。
通过计算准确率、召回率、F1 值等指标,评估模型的性能。
(六)结果分析与改进对模型的评估结果进行分析,找出模型存在的问题和不足之处。
根据分析结果,对模型进行改进,如调整模型结构、增加数据量、采用更先进的训练算法等。
四、实验结果与分析(一)实验结果经过多次实验和优化,最终得到了以下实验结果:1、决策树模型的准确率为 75%。
2、随机森林模型的准确率为 80%。
3、神经网络模型的准确率为 85%。
(二)结果分析1、决策树模型相对简单,对于复杂的数据模式可能无法很好地拟合,导致准确率较低。
2、随机森林模型通过集成多个决策树,提高了模型的泛化能力,因此准确率有所提高。
3、神经网络模型具有强大的学习能力和表示能力,能够自动从数据中学习到复杂的特征和模式,从而获得了最高的准确率。
AI人工智能实验报告

AI人工智能实验报告引言:人工智能(Artificial Intelligence,简称AI)是一项使用计算机技术模拟和复制人的智能的研究与应用。
AI的发展已经引发了广泛的关注和应用,被认为具有革命性的影响。
本实验旨在探索AI在不同领域中的应用,以及其对社会和经济的潜在影响。
实验方法:1. 实验步骤:(详细描述实验步骤,例如训练AI模型,收集和处理数据等)2. 实验材料:(列出实验所用的软件、硬件设备,以及实验所需要的数据)3. 实验设计:(阐述实验的目的和假设,如何设计实验来验证假设,并选择合适的评估指标)实验结果:通过实验的进行我们得到了以下结果:1. 在医疗领域中,AI能够准确识别影像中的疾病和异常情况。
经过训练,AI模型可以对X光片、MRI扫描等进行自动诊断,且诊断结果的准确率超过了人类医生的水平。
2. 在交通领域,AI技术被广泛应用于自动驾驶汽车的开发。
通过搜集和分析大量的交通数据和驾驶行为,AI能够实现智能规划路线、减少交通事故并提高驾驶效率。
3. 在金融领域,AI能够分析海量的金融数据,并根据市场趋势进行智能投资决策。
通过机器学习和数据挖掘的方法,AI能够识别潜在的交易风险,并提供可靠的投资建议。
4. 在教育领域,AI技术被应用于个性化教学和智能辅导。
AI能够根据学生的学习进度和学习习惯,提供个性化的学习建议和辅导,提高学生的学习效果。
实验讨论:根据实验结果的分析和讨论,我们可以得出以下结论:1. AI在医疗领域的应用能够提高诊断的准确性和效率,对于改善医疗服务质量具有重要意义。
2. 自动驾驶技术的发展可能会改变未来的交通方式,并促进交通安全和节能减排。
3. 金融领域的AI应用不仅能提高投资决策的准确性,还能优化交易流程,提高金融市场的运行效率。
4. 教育领域的AI应用有助于满足不同学生的学习需求,促进个性化教育的发展。
结论:AI人工智能在医疗、交通、金融和教育等领域的应用给社会带来了巨大的改变和机遇。
人工智能实验报告

人工智能实验报告一、实验背景随着科技的迅猛发展,人工智能(AI)已经成为当今世界最具影响力的技术之一。
它在各个领域的应用不断拓展,从医疗保健到金融服务,从交通运输到娱乐产业,都能看到人工智能的身影。
为了更深入地了解人工智能的工作原理和性能表现,我们进行了一系列的实验。
二、实验目的本次实验的主要目的是探究人工智能在不同任务中的能力和局限性,评估其对数据的处理和分析能力,以及观察其在复杂环境中的学习和适应能力。
三、实验设备与环境我们使用了高性能的计算机服务器,配备了先进的图形处理单元(GPU),以加速模型的训练和运算。
实验所使用的软件包括主流的深度学习框架,如 TensorFlow 和 PyTorch 等。
实验环境为一个安静、稳定的实验室,确保实验过程不受外界干扰。
四、实验内容1、图像识别任务我们选取了大规模的图像数据集,如 ImageNet ,让人工智能模型学习识别不同的物体类别。
通过调整模型的架构和参数,观察其在图像分类任务中的准确率和召回率的变化。
2、自然语言处理任务利用大规模的文本数据集,如维基百科和新闻文章,训练人工智能模型进行文本分类、情感分析和机器翻译等任务。
比较不同模型在处理自然语言时的表现和效果。
3、强化学习任务通过构建虚拟环境,让人工智能模型通过与环境的交互和试错来学习最优的行为策略。
例如,在游戏场景中,让模型学习如何取得最高分或最优的游戏结果。
五、实验步骤1、数据准备首先,对收集到的图像和文本数据进行清洗和预处理,包括去除噪声、转换数据格式、标记数据类别等。
2、模型选择与构建根据实验任务的特点,选择合适的人工智能模型架构,如卷积神经网络(CNN)用于图像识别,循环神经网络(RNN)或长短时记忆网络(LSTM)用于自然语言处理。
3、模型训练使用准备好的数据对模型进行训练,调整训练参数,如学习率、迭代次数、批量大小等,以获得最佳的训练效果。
4、模型评估使用测试数据集对训练好的模型进行评估,计算各种性能指标,如准确率、召回率、F1 值等,以衡量模型的性能。
人工智能的实验报告

一、实验目的1. 理解人工智能在动物识别领域的应用,掌握相关算法和模型。
2. 掌握深度学习在图像识别中的应用,学习使用神经网络进行图像分类。
3. 实现一个基于人工智能的动物识别系统,提高动物识别的准确率和效率。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.63. 开发工具:PyCharm4. 依赖库:TensorFlow、OpenCV、NumPy、Pandas三、实验内容1. 数据收集与预处理实验使用的数据集为公开的动物图像数据集,包含多种动物图片,共3000张。
数据预处理步骤如下:(1)将原始图像转换为统一尺寸(如224x224像素);(2)对图像进行灰度化处理,减少计算量;(3)对图像进行归一化处理,使图像像素值在0到1之间;(4)将图像数据转换为NumPy数组,方便后续处理。
2. 模型构建与训练实验采用卷积神经网络(CNN)进行图像识别。
模型构建步骤如下:(1)定义卷积层:使用卷积层提取图像特征,卷积核大小为3x3,步长为1,激活函数为ReLU;(2)定义池化层:使用最大池化层降低特征维度,池化窗口大小为2x2;(3)定义全连接层:将卷积层和池化层提取的特征进行融合,输入层大小为64x64x32,输出层大小为10(代表10种动物类别);(4)定义损失函数和优化器:使用交叉熵损失函数和Adam优化器进行模型训练。
训练模型时,采用以下参数:(1)批处理大小:32;(2)学习率:0.001;(3)训练轮数:100。
3. 模型评估与测试训练完成后,使用测试集对模型进行评估。
测试集包含1000张图像,模型准确率为80.2%。
4. 系统实现与演示根据训练好的模型,实现一个基于人工智能的动物识别系统。
系统功能如下:(1)用户上传动物图像;(2)系统对上传的图像进行预处理;(3)使用训练好的模型对图像进行识别;(4)系统输出识别结果。
四、实验结果与分析1. 模型准确率:80.2%,说明模型在动物识别任务中具有一定的识别能力。
人工智能 实验报告

人工智能实验报告人工智能实验报告引言:人工智能(Artificial Intelligence,简称AI)是一门研究如何使计算机能够像人类一样思考、学习和解决问题的科学。
随着科技的发展,人工智能已经在各个领域展现出巨大的潜力和应用价值。
本实验报告将介绍我对人工智能的实验研究和探索。
一、人工智能的定义与分类人工智能是指通过计算机技术实现的、模拟人类智能的一种能力。
根据不同的研究方向和应用领域,人工智能可以分为强人工智能和弱人工智能。
强人工智能是指能够完全模拟人类智能的计算机系统,而弱人工智能则是指在特定领域内模拟人类智能的计算机系统。
二、人工智能的应用领域人工智能的应用领域非常广泛,包括但不限于以下几个方面:1. 机器学习机器学习是人工智能的核心技术之一,通过让计算机从大量数据中学习并自动调整算法,实现对未知数据的预测和分析。
机器学习已经在图像识别、语音识别、自然语言处理等领域取得了重大突破。
2. 自动驾驶自动驾驶是人工智能在交通领域的应用之一,通过计算机系统对车辆的感知、决策和控制,实现无人驾驶。
自动驾驶技术的发展将极大地提升交通安全性和效率。
3. 机器人技术机器人技术是人工智能在制造业和服务业中的应用之一,通过模拟人类的感知、思考和行动能力,实现自主操作和协作工作。
机器人技术已经广泛应用于工业生产、医疗护理、农业等领域。
4. 金融科技金融科技是人工智能在金融行业中的应用之一,通过数据分析和算法模型,实现智能风控、智能投资和智能客服等功能。
金融科技的发展将推动金融行业的创新和变革。
三、人工智能的挑战与未来发展尽管人工智能取得了许多成果,但仍然面临着一些挑战和难题。
首先,人工智能的算法和模型需要更加精确和可解释,以提高其可靠性和可信度。
其次,人工智能的伦理和法律问题也需要重视和解决,例如隐私保护、人工智能武器等。
此外,人工智能的发展还受到数据质量和计算能力的限制。
然而,人工智能的未来发展依然充满希望。
人工智能实践活动报告

人工智能实践活动报告本次人工智能实践活动报告旨在分享我们小组在人工智能领域的探索和实践经验,让更多的人了解人工智能的应用和潜力。
一、简介人工智能是一门涵盖机器学习、自然语言处理、计算机视觉等多个领域的技术,它的应用范围非常广泛,例如智能语音助手、自动驾驶、智能推荐系统等。
在本次实践活动中,我们小组聚焦于人工智能技术在医疗领域的应用。
二、项目背景健康是人们生活中最重要的事项之一,然而目前的医疗系统存在一些问题,如诊断过程中的误差、医疗资源的不均衡分配等。
为了改善这些问题,我们决定利用人工智能技术对医疗领域进行探索和实践。
三、项目目标我们小组的目标是开发一个基于人工智能技术的辅助诊断系统,以提高医生的诊断准确性和医疗资源的利用效率。
在这个系统中,我们将利用机器学习算法对医疗数据进行分析,并为医生提供辅助决策的指导。
四、实践过程1. 数据收集与预处理我们首先收集了大量的医疗数据,包括患者的病历、生化指标、影像数据等。
然后,我们对这些数据进行清洗和标准化,以便于后续的机器学习算法处理。
2. 特征工程在特征工程阶段,我们深入研究了医疗数据的特点,并提取了一些与诊断结果相关的特征。
这些特征包括患者的年龄、性别、病史等,以及一些与疾病相关的生化指标和影像特征。
3. 模型训练与优化在模型训练阶段,我们尝试了多种机器学习算法,如支持向量机、决策树、神经网络等。
通过交叉验证和参数调整,我们逐步优化了模型的性能,并选择了表现最佳的算法。
4. 辅助诊断系统实现基于训练好的模型,我们开发了一个辅助诊断系统。
医生可以通过该系统输入患者的相关信息,系统将根据这些信息进行分析并给出诊断建议。
五、项目成果与展望通过我们的努力,我们成功地开发出了一个基于人工智能技术的辅助诊断系统。
在测试阶段,该系统在诊断准确性和效率方面表现出色。
未来,我们希望继续优化系统的性能,并进一步扩大应用范围,以服务更多的医疗场景。
六、总结通过这次实践活动,我们深入了解了人工智能技术在医疗领域的应用,并实践了一个辅助诊断系统。
人工智能实验报告

一、实验背景与目的随着信息技术的飞速发展,人工智能(Artificial Intelligence,AI)已经成为当前研究的热点领域。
为了深入了解AI的基本原理和应用,我们小组开展了本次实验,旨在通过实践操作,掌握AI的基本技术,提高对AI的理解和应用能力。
二、实验环境与工具1. 实验环境:Windows 10操作系统,Python 3.8.0,Jupyter Notebook。
2. 实验工具:Scikit-learn库、TensorFlow库、Keras库。
三、实验内容与步骤本次实验主要分为以下几个部分:1. 数据预处理:从公开数据集中获取实验数据,对数据进行清洗、去噪、归一化等预处理操作。
2. 机器学习算法:选择合适的机器学习算法,如决策树、支持向量机、神经网络等,对预处理后的数据进行训练和预测。
3. 模型评估:使用交叉验证等方法对模型进行评估,选择性能最佳的模型。
4. 结果分析与优化:分析模型的预测结果,针对存在的问题进行优化。
四、实验过程与结果1. 数据预处理我们从UCI机器学习库中获取了鸢尾花(Iris)数据集,该数据集包含150个样本,每个样本有4个特征,分别为花萼长度、花萼宽度、花瓣长度和花瓣宽度,以及对应的类别标签(Iris-setosa、Iris-versicolor、Iris-virginica)。
对数据进行预处理,包括:- 去除缺失值:删除含有缺失值的样本。
- 归一化:将特征值缩放到[0, 1]区间。
2. 机器学习算法选择以下机器学习算法进行实验:- 决策树(Decision Tree):使用Scikit-learn库中的DecisionTreeClassifier实现。
- 支持向量机(Support Vector Machine):使用Scikit-learn库中的SVC实现。
- 神经网络(Neural Network):使用TensorFlow和Keras库实现。
3. 模型评估使用交叉验证(5折)对模型进行评估,计算模型的准确率、召回率、F1值等指标。
人工智能实验报告范文

人工智能实验报告范文一、实验名称。
[具体的人工智能实验名称,例如:基于神经网络的图像识别实验]二、实验目的。
咱为啥要做这个实验呢?其实就是想搞清楚人工智能这神奇的玩意儿是咋在特定任务里大显神通的。
比如说这个实验,就是想看看神经网络这个超酷的技术能不能像人眼一样识别图像中的东西。
这就好比训练一个超级智能的小助手,让它一眼就能看出图片里是猫猫还是狗狗,或者是其他啥玩意儿。
这不仅能让我们深入了解人工智能的工作原理,说不定以后还能应用到好多超有趣的地方呢,像智能安防系统,一眼就能发现监控画面里的可疑人物或者物体;或者是在医疗影像识别里,帮助医生更快更准地发现病症。
三、实验环境。
1. 硬件环境。
咱用的电脑就像是这个实验的战场,配置还挺重要的呢。
我的这台电脑处理器是[具体型号],就像是大脑的核心部分,负责处理各种复杂的计算。
内存有[X]GB,这就好比是大脑的短期记忆空间,越大就能同时处理越多的数据。
显卡是[显卡型号],这可是在图像识别实验里的得力助手,就像专门负责图像相关计算的小专家。
2. 软件环境。
编程用的是Python,这可是人工智能领域的明星语言,简单又强大。
就像一把万能钥匙,可以打开很多人工智能算法的大门。
用到的深度学习框架是TensorFlow,这就像是一个装满各种工具和模型的大工具箱,里面有好多现成的函数和类,能让我们轻松搭建神经网络,就像搭积木一样简单又有趣。
四、实验原理。
神经网络这个概念听起来就很科幻,但其实理解起来也不是那么难啦。
想象一下,我们的大脑是由无数个神经元组成的,每个神经元都能接收和传递信息。
神经网络也是类似的,它由好多人工神经元组成,这些神经元分层排列,就像一个超级复杂的信息传递网络。
在图像识别里,我们把图像的数据输入到这个网络里,第一层的神经元会对图像的一些简单特征进行提取,比如说图像的边缘、颜色的深浅等。
然后这些特征会被传递到下一层神经元,下一层神经元再对这些特征进行组合和进一步处理,就像搭金字塔一样,一层一层地构建出对图像更高级、更复杂的理解,最后在输出层得出图像到底是什么东西的结论。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
public :
static void ShowInfo();
RiverCrossing( int n, int c);
bool solve(); // 求解问题
};
// 检查某状态节
#include "RiverCrossing.h" #include <iostream> #include <stack> #include <algorithm> using namespace std;
if (destState->check()) {
// 检查人数
if (*destState == endState) {
// 是否达到目标状态
closeList.push_back(destState);
print(destState);
{
cout<< "************************************************"
<<endl;
cout<< "
牧师与野人过河问题求解
"
<<endl;
cout<< "
by 1040501211
陈嘉生
"
<<endl;
cout<< "************************************************"
return iPastor + iSavage; }
// 检查人数是否在 0到 n之间 bool State ::check() {
return (iPastor >=0 && iPastor <= n && iSavage >= 0 && iSavage <=n); }
// 按照规则检查牧师得否安全 bool State ::isSafe() {
RiverCrossing
::ShowInfo();
int n, c;
cout<< "Please input n: "
;
cin>>n;
cout<< "Please input c: "
;
cin>>c;
RiverCrossing riverCrossing(n, c); riverCrossing.solve();
this ->pastor = pastor ; this ->savage = savage ; }
/*=========================Methods for class "State"=========================*/ // 构造函数 State ::State( int pastor , int savage , int boatAtSide ) {
// 此岸的安全: x1 == 0 || x1 >= x2 // 彼岸的安全: (n-x1) == 0 || (n-x1) >= (n-x2) // 将上述条件联立后得到如下条件 return (iPastor == 0 || iPastor == n || iPastor == iSavage); }
bool move( State *nowState, Boat *boat); // 进行一次决策
State * findInList(std::
list <State *> &listToCheck, State &state);
点是否在列表中
void print( State *endState); // 打印结果
State operator + ( Boat &boat); State operator - ( Boat &boat); bool operator == ( State &state); };
// 过河问题 class RiverCrossing { private :
std:: list <State *> openList, closeList; State endState;
RiverCrossing.cpp
// 类静态变量定义 int State ::n = 0; int Boat ::c = 0;
/*=========================Methods for class "Boat"=========================*/ Boat ::Boat( int pastor , int savage ) {
// 重载 ==符号,比较两个节点是否是相同的状态 bool State ::operator==( State & state ) {
return ( this ->iPastor == state .iPastor && this ->iBoatAtSide == state .iBoatAtSide); }
<<endl;
}
// 构造函数 RiverCrossing ::RiverCrossing(
:endState(0, 0, 0) {
State ::n = n; Boat ::c = c ; }
int n, int c)
// 解决问题 bool RiverCrossing ::solve() {
openList.push_back( new State ( State ::n, while (!openList.empty()) {
// 船在此岸
// 过河的人越多越好,且野人优先
int count = nowState->getTotalCount();
count = ( Boat ::c >= count ? count :
Boat ::c);
for ( int capticy = count; capticy >= 1; --capticy) {
四、实验组织运行要求
本实验采用集中授课形式,每个同学独立完成上述实验要求。
五、实验条件
ห้องสมุดไป่ตู้
每人一台计算机独立完成实验。
六、实验代码
#include <iostream> #include "RiverCrossing.h" using namespace std;
Main.cpp
// 主函数 void main() {
destState = new State (* nowState - * boat ); // 船离开此岸 } else if ( nowState ->iBoatAtSide == 0) {
destState = new State (* nowState + * boat ); // 船开到此岸 }
// 获取一个状态为当前状态 State *nowState = openList.front(); openList.pop_front(); closeList.push_back(nowState);
State ::n, 1));
// 从当前状态开始决策
if (nowState->iBoatAtSide == 1) {
实验一:知识表示方法
一、实验目的
状态空间表示法是人工智能领域最基本的知识表示方法之一, 也是进一步学
习状态空间搜索策略的基础, 本实验通过牧师与野人渡河的问题, 强化学生对知
识表示的了解和应用,为人工智能后续环节的课程奠定基础。
二、问题描述
有 n 个牧师和 n 个野人准备渡河, 但只有一条能容纳 c 个人的小船, 为了防
案。用三元组 (X1, X2, X3)表示渡河过程中的状态。并用箭头连接相邻状态以表示 迁移过程:初始状态 ->中间状态 ->目标状态。
例:当输入 n=2,c=2 时,输出: 221->110->211->010->021->000
其中: X 1 表示起始岸上的牧师人数; X2 表示起始岸上的野人人数; X 3 表示小船
this ->iSavage == state .iSavage &&
/*=======================Methods for class "RiverCrossing"=======================*/
// 显示信息
void RiverCrossing ::ShowInfo()
// 重载 +符号,表示船开到此岸
State State ::operator+( Boat & boat )
{
State ret(iPastor +
boat .pastor, iSavage +
ret.pPrevious = this ;
return ret;
}
boat .savage, iBoatAtSide + 1);
止野人侵犯牧师,要求无论在何处,牧师的人数不得少于野人的人数 (除非牧师
人数为 0),且假定野人与牧师都会划船, 试设计一个算法, 确定他们能否渡过河
去,若能,则给出小船来回次数最少的最佳方案。
三、基本要求
输入:牧师人数 (即野人人数 ): n;小船一次最多载人量: c。
输出:若问题无解,则显示 Failed,否则,显示 Successed输出一组最佳方