编译原理笔记8 自上而下语法分析-带回溯的自顶向下分析技术
编译原理语法分析-自顶向下

实例分析
1
子规则匹配
根据语法规则,递归地匹配输入的源代码,构建语法树。
2
构建语法树
通过逐步匹配子规则,将语法树逐渐构建起来,形象地表示复杂的程序结构。
3
解释分析结果
对语法树进行解释,执行语义分析和生成中间分析方法,通过递归嵌套和预测分析,将复杂的源代码转换成易于处理的 语法树。
自顶向下分析算法
1 概述
自顶向下分析算法从目标语言的最高级别规则开始,逐步向下查找并匹配规则,构建语 法树。
2 递归下降分析
递归下降分析是自顶向下分析的一种常见方法,它通过递归调用子规则来分析输入的源 代码。
3 LL(1)分析
LL(1)分析是一种基于预测的自顶向下分析方法,它使用一个预测分析表来确定下一步要 采取的动作。
编译原理语法分析-自顶 向下
语法分析是编译器的重要组成部分,它负责将输入的源代码转换成语法树以 进行后续分析和解释。本节将介绍自顶向下的语法分析算法及其挑战。
语法分析概述
1 什么是语法分析
语法分析是编译器的第二个阶段,负责验证 输入的源代码是否符合语言的规范语法。
2 为什么需要语法分析
语法分析可以检查和纠正源代码中的语法错 误,以确保程序的正确性和可读性。
问题和挑战
1 二义性文法
当文法存在多个解释时,会导致语法分析的 困扰和歧义。需要通过合适的方法解决二义 性。
2 左递归文法
左递归文法会导致递归下降分析算法进入无 限循环,需要通过消除左递归来解决。
改进方法
1 消除二义性文法
通过重写或修改文法规则,消除存在二义性 的产生式。
2 消除左递归文法
通过改写产生式,消除文法中的左递归问题, 使得递归下降分析算法不会陷入无限循环。
第四章 编译原理语法分析--自上而下

消除左递归 (P69.)
(1)直接左递归:文法存在产生式 A→Aα。 (2)间接左递归:文法不存在产生式 A→Aα, 但存在推导 A + Aα。
消除直接左递归的方法:引入新的非终结符号A‘,将 关于A的如下产生式 A→Aα|β (α非ε且β不以A打头) 替换为 A →βA‘ A‘ →αA‘|ε 注意:不要掉了 A‘ →ε
4
自上而下分析法的思想(P66.)
从文法的开始符号出发,逐步向下推导,不断替换和展开非 终结符,去匹配输入符号串(终结符号串、句子),即寻找输入 串的最左推导,推出句子,(---自上而下的实质) 并按与最左推导相对应的顺序,从文法的开始符号(根结)出 发,自上而下从左到右地建立输入串的语法分析树。---其末 端节点正好与输入符号串相同
3
4.2 自上而下分析法面临的问题
. 本小节首先通过例子P67:
说明自上而下分析的思想 认识自上而下分析时所遇到的主要困难
自上而下分析的主要困难是P66-68 : 文法的左递归性,可能使分析陷入无限循环 回溯的不确定性,要求将已完成的工作推倒重来 为解决这些问题,使得自上而下分析是确定的,考 虑要消除文法左递归和避免回溯。 最后构造确定的有效的自上而下分析器:递归下降 分析器
2
4.1 语法分析器的功能(P66.)
语法分析是编译程序的核心部分。
语法分析是在词法分析识别出单词符号的基础上, 分析并判定(即识别)一串单词符号(称为输入串) 的语法结构是否符合语法规则,是否是文法的一个 句子。
分析判定的方法:
建立输入串α的从文法开始符号S出发的推导 S α1 … αn α 即建立以开始符号S为根的与输入串α相匹配(即α 中的各个符号为叶结点)的语法树
编译原理自上而下语法分析

编译原理
基本架构(1)
变量: sym:当前符号 函数:advance( ):读输入串下一符号 对于每个非终结符号U→α 1|α 2|…|α n处理的方法如下: P(U) {
if sym ∈FIRST(α1 )then P(α1) //处理α1的程序部分 else if sym ∈FIRST(α2 )then P(α2) //处理α2的程序部分 … else if sym ∈FIRST(αn )then P(αn) else if sym ∈FOLLOW(U)then return //处理空产生式情况 else error }
编译原理
间接左递归举例
S→Qc|c Q→Rb|b R→Sa|a 以上文法不含直接左递归,但S,Q,R 都是左递归的,因为: S=>Qc =>Rbc =>Sabc Q =>Rb =>Sab =>Qabc R =>Sa =>Qca =>Rbca
编译原理
消除文法的左递归
前提:如果一个文法不含回路(形如P⇒+ P 的推导),也不含以ε 为右部的产生式, 那么可以通过执行消除文法左递归的算 法消除文法的一切左递归(改写后的文 法可能含有以ε 为右部的产生式)。
FIRST(u)包含了u对应的字的所有可能的首终结符号。 FOLLOW(U)表示了句型中可能紧跟再U后面的终结符号。
编译原理
FIRST(α) 构造算法
对于X∈(VN∪VT),FIRST(X)
的构造 1:若XVT,则FIRST(X)={X} 2:若XVN,且有产生式X→a…, a VT ,则a FIRST(X);如果X→ ,那么 FIRST(X)。 3:若有产生式X→ Y…,Y VN ,则FIRST(Y)\ {} ⊏ FIRST(X); 如果有产生式X→Y1Y2…YK,其中Y1,Y2,Yi-1 VN且Y1Y2…Yi-1 => * , 则FIRST(Yi) \ {} ⊏ FIRST(X);若Y1Y2…YK => * ,则 FIRST(X)。
编译原理-自上而下的语法分析

高效性
由于从文法的最顶端开始分析, 一旦发现不匹配,就可以立即终 止当前分支的搜索,避免不必要 的计算,提高了编译器的效率。
易于处理左递归文
法
自上而下的分析方法可以很方便 地处理含有左递归的文法,而左 递归是许多实际编程语言的重要 特征。
局限性
无法处理左边界问题
自上而下的分析方法在处理某些含有左边界的文法时可能 会遇到问题,因为这种方法会优先匹配最左边的符号,而 左边界问题需要从右往左匹配符号。
案例三
在编译器优化中,自上而下的语法分析被用 于识别和修改源代码中的冗余和低效的语法 成分。例如,在C编译器的实现中,自上而 下的语法分析可以用于优化循环结构,减少 不必要的循环次数,提高程序的执行效率。
自上而下的语法分析还可以用于代码生成和 代码生成器的实现。通过识别和解析源代码 中的语法成分,可以生成更高效、更安全的 机器代码或字节码,提高程序的执行效率和
安全性。
THANKS
感谢观看
详细描述:递归下降分析算法易于理解,每个产生式规 则对应一个函数,函数的实现相对简单明了。
详细描述:对于每个产生式规则,需要编写相应的递归 函数,可能会导致代码冗余。
移入-规约分析算法
总结词
基于栈的算法
详细描述
移入-规约分析算法是一种自上而下的语法分 析算法,它将目标语句从左到右依次读入, 并根据文法的产生式规则进行移入或规约操 作,直到找到目标语句的语法结构。
词法分析
词法分析是编译过程的第一步,也称为扫描或词法扫描。它的任务是从左 到右读取源代码,将其分解成一个个的记号或符号。
词法分析器通常使用正则表达式或有限自动机来识别和生成记号,这些记 号可以是关键字、标识符、运算符、标点符号等。
编译原理 语法分析——自下而上分析
显然这是一个最右推导。
规范归约是关于是一个最右推导的逆过程
最左归约
规范推导
由规范推导推出的句型称为规范句型。
三峡大学计算机系602
S
a A c Be
A
bd
b S
S
a A c Be
Ab
d
S
aA
c Bea A
d
三峡大学计算机系602
c Be
5.1.3 符号栈的使用和分析树的表示
栈是语法分析的一种基本数据结构。’#’作 为栈底符号
e
dBB
b
cccc
bAAAAAAA
aaaaaaaaaS
三峡大学计算机系602
S
a A c Be
A
bd
b 分析树和语法树不一定一致。 自下而上分析过程:边输入单词符号,边 归约。 核心问题:识别可归约串
三峡大学计算机系602
5.1.2 规范归约
定义:令G是一个文法,S是文法的开始符 号,假定是文法G的一个句型,如果有
E
E* E- E E+E i
i
i
返回
E ( E)
E+ E
i
i
三峡大学计算机系602
句子i+i-i*(i+i)的归约过程是: (1) i+i-i*(i+i) (2) E+i-i*(i+i) (3) E+E-i*(i+i) (4) E-i*(i+i) (5) E-E*(i+i) (6) E-E*(E+i) (7) E-E*(E+E) (8) E-E*(E) (9) E-E*E (10) E-E (11) E
三峡大学计算机系602
编译原理语法分析_自上而下__分析过程-FirstFollowSelect

G1: S → pA |qB A → a | cA B → b | dB 输入串 pca G2: S → Ap | Bq A → a | cA B → b | dB 输入串 cap
FIRST 集
FIRST集 / 开始符号集 / 终结首符集
* a…, a∈VT} FIRST(α) = {a|α * ε, 则规定 ε∈FIRST(α) 若α
G: S→ AB A→aA |ε B→bA |ε
自上而下语法分析面临的问题
G: S → cAd A → a|ab 输入串 cabd
- 回溯 Backtrack S
c A d
S
c A d a b
a A→ α1 |α2 |…|αn 如何决定用哪个候选式替换A? 不确定分析: 带回溯 (试探) 确定分析 : 不带回溯
练习: 求 First 集
G: S → ABC A → aA |ε B → bB |b C → cC |c First(S) = { a, b }
First(A) = { a, ε }
First(B) = { b}
First(C) = { c}
例: 自上而下语法分析
G5: E → TE' E'→ +TE'|ε T → FT' T'→ *FT'|ε F → (E) | i 输入串 i+i
Select 集
SELECT集 选择集合
给定上下文无关文法的产生式A→α, * ε, • 若α SELECT(A→α) = FIRST(α) * ε, • 若α SELECT(A→α) = (FIRST(α)-{ε})∪FOLLOW(A)
自上而下的语法分析

非终结符
初值 第1次扫描 第2次扫描
M
未定
T
B
D
未定
是
未定
是
未定
是
是
SELECT(T→Ba)={d,e,b,a,ε} SELECT(T→ε) = {d,e,b,a,#} 这两者的交集不为 ∅ 。 故该文法不是 LL(1) 文法。
5.5.2 LL(1)分析一般过程
给定文法: S → aSbS|ε 。求符号串 ab 的 LL(1) 分析过程。
* FIRST(A)= {a|A = a…,且 a∈VT } >
求FIRST集合
G: M T B D
文法规则
→ TB → Ba|ε → Db|eT|ε → d|ε
第一遍 第二遍 第三遍
M T T B B B D D
→ TB → Ba →ε → Db → eT →ε →d →ε
F(M)={ } F(T)={ } F(T)={ε} F(B)={ } F(B)={e} F(B)={e,ε} F(D)={d} F(D)={d,ε}
G2[S]: S→Ap S→Bq A→cA A→a B→dB B→b FIRST(Ap) = { a,c } FIRST(Bq) = { b,d } FIRST(S) = FIRST(Ap) ∪FIRST(Bq) = { a,b,c,d }
SБайду номын сангаас
A p
G3[S]: S→aA S→d A→bAS A→ε
FOLLOW(B)=FOLLOW(B)∪{a}={#,a} FOLLOW(D)=FOLLOW(D)∪{b}={b} FOLLOW(T)=FOLLOW(T)∪FOLLOW(B)={d,e,b,#}∪{#,a} ={d,e,b,a,#}
编译原理与技术 自顶向下分析

ab
选用产 生式(2)
匹配失败!
输入串 x a
y$
2024/7/7
《编译原理与技术》讲义
15
自顶向下分析
试探分析法 e.g.2 文法G1: (1)S x A y (2)A ab (3)A a
S$ xA
a
输入串 xay$
终结符叶 子a与输
的分析过程。 入符a匹
配
输入串 x a
选用产生 式(1)
可以考虑(除 b外的)任一 符号c。可以 与之“匹配”!
20
自顶向下分析
预测分析法
提左因子变换的一般形式
A 1 | 2 |…| n A
i不含相同前缀, 不含前缀
提左因子变换后:
A A’ | A’ 1 | 2 |…| n
2024/7/7
《编译原理与技术》讲义
21
自顶向下分析
预测分析法
自顶向下分析
分析树的建立
从根(开始符号)出发,从上而下,从左自右为 输入串建立分析树
为输入串寻找一个最左推导
e.g.1 文法G0如下 S A B C A a 输入串 abc$ $-串结束符
B b
C c
2024/7/7
《编译原理与技术》讲义
1
自顶向下分析
e.g.1 文法G0:
S$
S A B C
S$
AB
C
$
a
a b c$
2024/7/7
《编译原理与技术》讲义
4
自顶向下分析
e.g.1 文法G0: S A B C A a B b C c
S$ ABC a
终结符叶子 与当前符号
匹配?
2024/7/7
编译原理语法分析_自上而下__确定的自上而下分析-预测分析方法

*
(
→TE'
)
→ε
#
→ε →ε
T T' F
→FT' →ε →*FT' →(E) →ε
→i
构造预测分析表
对每个终结符或"#", 用a表示. • 若a∈SELECT(A→α), 把A→α放入M[A,a]中 • 把所有无定义的M[A,a] 标上出错标记(或空白) • 产生式的左部可以不写入表中
E E' T →FT' T' F →i i →TE' + →+TE' →FT' →ε →*FT' →(E) →ε →ε * ( →TE' ) →ε # →ε
预测分析方法
G': E → TE' E'→ +TE'|ε T → FT' T'→ *FT'|ε F → (E) | i
E
T F i T' ε + F E' T E' T' ε ε
E E'T E'T'F
E' E'T+ E'T E'T'F
E'T' i E'T' E'
E'T' i
E'T'
#i+i#
SELECT集合 E→TE' (,i E'→+TE' + E'→ε T → FT' T'→ *FT' ),# (,i *
推出 FIRST ε 集 E N (,i E' Y + ,ε T N (,i T' Y * ,ε F N (,i
编译原理语法分析—自上而下分析

对文法G的任何符号串=X1X2…Xn构造集 合FIRST()。
1. 置FIRST()=FIRST(X1)\{};
2. 若对任何1ji-1,FIRST(Xj), 则把FIRST(Xi)\{}加至FIRST()中; 特别是,若所有的FIRST(Xj)均含有, 1jn,则把也加至FIRST()中。显 然,若=则FIRST()={}。
T→T*F | F
F→(E) | i
经消去直接左递归后变成:
E→TE E→+TE | T→FT T→*FT | F→(E) | i
(4.2)
例如文法G(S): S→Qc|c Q→Rb|b R→Sa|a
虽没有直接左递归,但S、Q、R都是左递归的
SQcRbcSabc
(4.3)
一个文法消除左递归的条件: 不含以为右部的产生式 不含回路。
即A的任何两个不同候选 i和 j FIRST(i)∩FIRST( j)=
当要求A匹配输入串时,A就能根据它所面临的第
一个输入符号a,准确地指派某一个候选前去执
行任务。这个候选就是那个终结首符集含a的。
提取公共左因子:
假定关于A的规则是 A→ 1 | 2 | …| n | 1 | 2 | … | m (其中,每个 不以开头)
*
特别是,若S A ,则规定
#FOLLOW(A)
构造不带回溯的自上而下分析的文法条件
1. 文法不含左递归,
2. 对于文法中每一个非终结符A的各个产生式 的候选首符集两两不相交。即,若
A→ 1| 2|…| n 则 FIRST( i)∩FIRST( j)= (ij)
3. 对文法中的每个非终结符A,若它存在某个 候选首符集包含,则
1)算符优先分析法:按照算符的优先关系和结 合性质进行语法分析。适合分析表达式。
《编译原理》第四章-自上而下分析

自上而下分析中出现的问题
回溯 当最终报告分析不成功时,我们难于知 道出错的确切位置. 带回溯的自上而下的分析效率较低,代 价极高.
4.3
LL(1)分析法
直接左递归的消除 直接消除: 假定非终结符P的规则为 P→P︱ 其中,不以P开头 那么我们可以把P的规则改写为如下的非直接 左递归形式: P→P’ P→P’︱ (为空字) 两种形式是等价的,也就是说,从P推出的符号 串是相同的.
语法分析的方法
Ways of Parsing
分析的目的就是为了得到从开始符S到一 个输入串u的推导: S 1 1 … n (=u) 所以,以下有两种推导方法: 由顶向下 (Top Down) : 从文法的开始 符号出发,向下推导,推出句子. 由底向上 (Bottom Up) : 从输入串开始, 逐步进行‚归约‛,直至归约到文法的开 始符号.
直接左递归,和非直接左递归的消除方法均在必须掌握 之列。这里我们切不可被形式描述消除左递归的算法吓 倒,多做几个例题后再来理解是很有好处的:
[例4。3]: 考虑文法:SQc|c Q Rb|b R Sa|a 消除左递归。 解:将终结符排序为R、Q、S。对于R不存在直接左递归。 把R带入到Q中有关的候选式: Q Sab|ab|b 现在Q同样不含直接左递归,把它带入S的有关候选式: S Sabc|abc|bc|c 经消除S的直接左递归后我们们得到整个文法 S abcS’|bcS’|cS’ S’ abcS’| Q Sab|ab|b R Sa|a 由于关于Q,R的规则式多余的则可化简
一个文法G的预测分析表M不含 多重定义入口,当且仅当该文法 是LL(1)的。 如果G是左递归和二义的,那么, M至少含有一个多重定义入口
编译原理笔记8 自上而下语法分析-带回溯的自顶向下分析技术
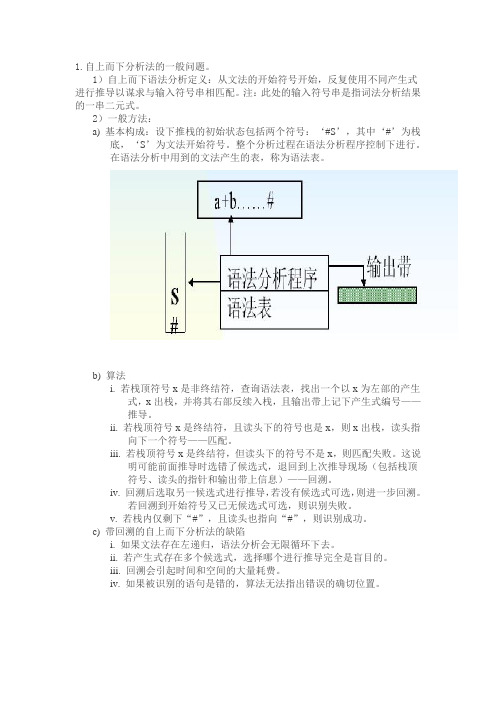
1.自上而下分析法的一般问题。
1)自上而下语法分析定义:从文法的开始符号开始,反复使用不同产生式进行推导以谋求与输入符号串相匹配。
注:此处的输入符号串是指词法分析结果的一串二元式。
2)一般方法:
a) 基本构成:设下推栈的初始状态包括两个符号:‘#S’,其中‘#’为栈
底,‘S’为文法开始符号。
整个分析过程在语法分析程序控制下进行。
在语法分析中用到的文法产生的表,称为语法表。
b) 算法
i. 若栈顶符号x是非终结符,查询语法表,找出一个以x为左部的产生
式,x出栈,并将其右部反续入栈,且输出带上记下产生式编号——
推导。
ii. 若栈顶符号x是终结符,且读头下的符号也是x,则x出栈,读头指向下一个符号——匹配。
iii. 若栈顶符号x是终结符,但读头下的符号不是x,则匹配失败。
这说明可能前面推导时选错了候选式,退回到上次推导现场(包括栈顶
符号、读头的指针和输出带上信息)——回溯。
iv. 回溯后选取另一候选式进行推导,若没有候选式可选,则进一步回溯。
若回溯到开始符号又已无候选式可选,则识别失败。
v. 若栈内仅剩下“#”,且读头也指向“#”,则识别成功。
c) 带回溯的自上而下分析法的缺陷
i. 如果文法存在左递归,语法分析会无限循环下去。
ii. 若产生式存在多个候选式,选择哪个进行推导完全是盲目的。
iii. 回溯会引起时间和空间的大量耗费。
iv. 如果被识别的语句是错的,算法无法指出错误的确切位置。
编译原理之自顶向下语法分析方法(25页)

间接左递归 若 PP α S→Aa A→Sb A→b
2021/8/25
5
消除左递归
消除直接左递归 形如:P → P α| β α非, β不以P打头
改写为:P → βP’ P’ → αP’|
2021/8/25
6
消除左递归
例:E → E+T|T T →T*F|F F →(E)| i
G[ E]: (1) E → TE’ (2) E’ → +TE’| (3) T → FT’ (4) T’ → *FT’ | (5) F → (E)|i
A →Bb|b
2021/8/25
10
回溯问题
例:S →iEtS|iEtSeS|a
E→b
判断句子ibtaea
提取左公因子:A →αβ1|αβ2
变为:
A →αA’
A’ →β1 |β2
若A →αβ1|αβ2 |…|αβn|r
变为:
A →αA’|r
A’ →β1 |β2|…|βn
2021/8/25
11
例:S →iEtS|iEtSeS|a
2021/8/25
Procedure E’; IF sym=‘+’ then Begin advance; T;E’ End;
Procedure T’; IF sym=‘*’ then Begin advance; F;T’ End;
14
3非递归的预测分析方法(LL(1))
一、总控程序 Input
24
非LL(1)文法的改造
消除左递归 提左公因子
2021/8/25
25
22
三、LL(1)文法:
一个文法G,若它的分析表M不含多重定义入 口,则称为LL(1)文法。
《编译原理》第4章自上而下语法分析

• 需要反复试探。
•问题1:回溯(P67)
x
S A y
• 例1:设有文法 (1) S xAy (2) A **|* 现有输入串:x*y 其分析过程如右:
•消除回溯
• 方法是:反复 “提取公共左因子”,使得文法 的每个非终结符号的各个候选式的首终结符集 两两不相交,来避免回溯。 设产生式为: A→δ α1|δ α2|…|δ αn
替换为:
Aδ A' A' α1|α2|…|αn
• 例3:有如下两个产生式:
<IF语句> if E then S1 else S2; <IF语句> if E then S1;
First(A1) = {a} First(A2) = {c} First(B1) = {b} First(B2) = {d}
• 在右边给定的文法中,A 的候选式有两个,其首终 结符集为: First(A1) = {*} First(A2) = {*} 相交,就会产生回溯
(1) S xAy
(2) A **|*
结论:能够从开始符号出发推导出给定的输入串,
因此,是句子。
• 常用的语法分析方法:
根据建立语法分析树的方法来分,有两大类,分四小类:
自顶向下分析法: 从文法的开始符号出发,向下推导(使用最左推 导) ,尽可能使用各种产生式,推导出与输入串 匹配的句子,从而建立语法树。
自底向上分析法: 从输入符号串开始,逐步进行归约(最右推导的 逆过程),直至归约到文法的开始符号,从而建 立语法树。 具体分类:
编译原理-自下而上的语法分析

自上而下的语法分析
特点
从高层次的文法规则开始,通过不断展开和推导,直到生成目标字符串。
优点
易于理解和实现,可以生成详细的错误报告。
自下而上的语法分析
1
自底向上的语法分析方法概述
通过以输入的标记为起点,逐步推导文法规则,直到生成目标字符串。
2
LR语法分析
一种常用的自底向上的语法分析方法,通过构建一个LR分析表进行推导。
3
LALR语法分析
是LR语法分析的一种变体,通过合并相同状态来降低分析表的复杂度。
自下而上的语法分析的优点和局限性
优点
适用于大型文法,能够处理更广泛的语言结构。
局限性
分析过程复杂,容易产生冲突,需要较大的存储空 间。
自下而上的语法分析的实现
词法分分析器的生成
根据文法规则,构建分析表或语法分析器的数据结构。
语法制导翻译的实现
在语法分析过程中,将源代码转换为目标代码。
自下而上的语法分析的应用
1
编译器中的语法分析
语法分析是编译器中的重要组成部分,用于将源代码转换为中间代码或目标代码。
2
解析器生成器
自下而上的语法分析技术被广泛应用于解析器生成器中,用于自动生成语法分析 器。
结论
自下而上的语法分析是编译原理中重要的一环,虽然实现复杂,但却具有广 泛的应用价值。
编译原理-自下而上的语 法分析
编译原理是研究程序在计算机上的自动翻译过程,语法分析是其中的重要步 骤。自下而上的语法分析是一种常用的语法分析方法。
语法分析的定义和目的
1 定义
语法分析是编译器中的一个阶段,用于验证 和分析程序语法的正确性。
2 目的
语法分析的目的是将源代码转换为语法树, 为后续的编译过程提供基础。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.自上而下分析法的一般问题。
1)自上而下语法分析定义:从文法的开始符号开始,反复使用不同产生式进行推导以谋求与输入符号串相匹配。
注:此处的输入符号串是指词法分析结果的一串二元式。
2)一般方法:
a) 基本构成:设下推栈的初始状态包括两个符号:‘#S’,其中‘#’为栈
底,‘S’为文法开始符号。
整个分析过程在语法分析程序控制下进行。
在语法分析中用到的文法产生的表,称为语法表。
b) 算法
i. 若栈顶符号x是非终结符,查询语法表,找出一个以x为左部的产生
式,x出栈,并将其右部反续入栈,且输出带上记下产生式编号——
推导。
ii. 若栈顶符号x是终结符,且读头下的符号也是x,则x出栈,读头指向下一个符号——匹配。
iii. 若栈顶符号x是终结符,但读头下的符号不是x,则匹配失败。
这说明可能前面推导时选错了候选式,退回到上次推导现场(包括栈顶
符号、读头的指针和输出带上信息)——回溯。
iv. 回溯后选取另一候选式进行推导,若没有候选式可选,则进一步回溯。
若回溯到开始符号又已无候选式可选,则识别失败。
v. 若栈内仅剩下“#”,且读头也指向“#”,则识别成功。
c) 带回溯的自上而下分析法的缺陷
i. 如果文法存在左递归,语法分析会无限循环下去。
ii. 若产生式存在多个候选式,选择哪个进行推导完全是盲目的。
iii. 回溯会引起时间和空间的大量耗费。
iv. 如果被识别的语句是错的,算法无法指出错误的确切位置。