编译原理实验二语法分析器LL(1)实现
编译原理上机实验-LL(1)语法分析-C#

编译原理上机实验报告小组成员:王金名、周攀、汪国辉、澎湃、王帅、齐娟娟、刘鸳鸳一、实验目的:了解LL(1)文法分析的基本原理;提高上机实践能力;增强团队协作能力。
二、实验内容:通过LL1文法分析表分析任意一个符号串是否为某文法的句子;显示具体分析过程;打开、新建、保存分析表;保存分析结果三、实验原理:1.C#字符串处理及数组处理,这是本实验最强有力的工具;2.LL(1)文法分析的基本原理,详见教材P80 LL(1)分析器的总控算法;3.C#文件操作,C#常用控件使用。
四、实验步骤:1.构造应用程序框架,利用内置分析表实现分析符号串的最基础功能(1)使用Visual Studio 2005 新建C#语言环境的windows应用程序LL1GAnalysis;(2)将窗体的名称改成From_Main,相应的代码名称会随之更改;(3)添加texbox控件ID为textBox_input,添加listView控件,ID为listView_Result;(4)public partial class Form_Main : Form里面编写相应代码://全局变量const int Max = 100;public string[,] staticmTable ={{"","i","+","*","(",")","#"},{"S","<error>","<error>","<error>","S::=A","S::=A","<error>"},{"A","<error>","<error>","<error>","A::=BA\'","A::=BA\'","<error>"},{"A\'","A\'::=iBA\'","<error>","A\'::=ε","<error>","<error>","A\'::=ε"},{"B","<error>","<error>","<error>","B::=CB\'","B::=CB\'","<error>"},{"B\'","B\'::=ε","B\'::=+CB\'","B\'::=ε","<error>","<error>","B\'::=ε"},{"C","<error>","<error>","<error>","C::=(","C::=)A*","<error>"} };string[] VN = new string[Max]; int VNLength;string[] VT = new string[Max]; int VTLength;//以下是分析过程中要用到的公共函数public void addTolistView_Result(string step, string stack, string input, stringproduction)//分析步骤及结果显示(向listView中添加条目,并保存到string类型变量(analysisResult)作最终保存分析结果时使用{string strResultbuf = "";strResultbuf += step.PadRight(20, ' ');strResultbuf += stack.PadRight(20, ' ');strResultbuf += input.PadRight(20, ' ');strResultbuf += production.PadRight(20, ' ') + "\r\n";analysisResult += strResultbuf;ListViewItem li = new ListViewItem();li.Text = step;ListViewItem.ListViewSubItem ls = new ListViewItem.ListViewSubItem();ls.Text = stack;li.SubItems.Add(ls);ls = new ListViewItem.ListViewSubItem();ls.Text = input;li.SubItems.Add(ls);ls = new ListViewItem.ListViewSubItem();ls.Text = production;li.SubItems.Add(ls);listView_Result.Items.Add(li);}public void GetVN(string[,] table)//从分析表中获取非终结符{int i;for ( i = 1; i < table.GetLength(0);i++ ){VN[i-1] = table[i,0];}VNLength = i;}public void GetVT(string[,] table)//从分析表中获取终结符{int i;for (i = 1; i < table.GetLength(1); i++){VT[i-1] = table[0,i];}VTLength = i;}public int isVT(string str)//判断str是不是VT中的符号{int mark = 0;for (int i = 0; i < VTLength; i++){if (VT[i] == str){mark = 1;}}return mark;}public int isVN(string str)//判断str是不是VN中的符号{int mark = 0;for (int i = 0; i < VNLength; i++){if (VN[i] == str){mark = 1;}}return mark;}public string outStack(string[] Stack, int top)//栈内符号合并输出的时候用 {string str = "";for (int i = 0; i <= top; i++){str += Stack[i];}return str;}public void removeAllItems(ListView list)//清空listview Items{int itemcount = list.Items.Count;for (int i = itemcount; i > 0 ;i-- ){list.Items.RemoveAt(0);}}public string matchInTable(string[,] mt,string stacktop, string nowstr)//查表栈顶与ch 交叉处的标志并返回{int i,j;for (i = 0; i < mt.GetLength(0); i++ ){if (mt[i,0] == stacktop){break;}}for (j = 0; j < mt.GetLength(1);j++ ){if (mt[0,j] == nowstr){break;}}if (i < mt.GetLength(0)&&j<mt.GetLongLength(1)){return mt[i,j];}else{return"error! ";}}//以下是分析过程public void Start_Analysis(string[,] mTable)//开始分析并显示分析过程{tabControl_mTable.SelectTab(tabPage_Show);ShowmTable(mTable);removeAllItems(listView_Result);listView_Result.BeginUpdate();int top = -1; int step = 0;string[] Stack = new string[Max];string str = textBox_input.Text.Trim();//初始化GetVN(mTable); GetVT(mTable);top++; Stack[top] = "#";top++; Stack[top] = VN[0];str += "#";//分析while (true){if (isVT(Stack[top]) == 1)//Stack[top]是终结符,则比较栈顶符与当前符号{if (Stack[top] == str[0].ToString())//匹配当前符号{if (Stack[top] == "#")//ok{step++;addTolistView_Result(step.ToString(), outStack(Stack, top), str, "OK!");step = 0;break;}else//同时退栈{step++;addTolistView_Result(step.ToString(), outStack(Stack, top), str, ""); top--;str = str.Remove(0, 1);}}else//错误{step++;addTolistView_Result(step.ToString(), outStack(Stack, top), str,"Error!");break;}}else if (isVN(Stack[top]) == 1)//Stack[top]是非终结符,则查表{string production = matchInTable(mTable, Stack[top], str[0].ToString());if (production != "<error>"){step++;addTolistView_Result(step.ToString(), outStack(Stack, top), str, production);string probuf = "";if (production[1] == '\''){probuf = production.Remove(0, 5);}else{probuf = production.Remove(0, 4);}char[] chbuf = probuf.ToCharArray();int i = chbuf.Length - 1;string strbuf = "";Stack[top] = null;top--;while (i >= 0){if (chbuf[i] != 'ε'){if (chbuf[i] != '\''){top++;Stack[top] = strbuf.Insert(0, chbuf[i].ToString());strbuf = "";}else if (chbuf[i] == '\''){strbuf += strbuf.Insert(0, chbuf[i].ToString());}}else { break; }i--;}}else//错误production.Length != 0不在分析表中{step++;addTolistView_Result(step.ToString(), outStack(Stack, top), str, "Error!");break;}}else//错误非法字符{step++;addTolistView_Result(step.ToString(), "错误", str, "非法字符:" +str[0].ToString());break;}}//分析结束listView_Result.EndUpdate();}private void button_Start_Click(object sender, EventArgs e)//菜单及按钮开始分析(菜单项及开始按钮公用函数){string[,] mTable;if (radioButton_Staticmt.Checked){mTable = staticmTable;ShowmTable(mTable);Start_Analysis(mTable);}else if (radioButton_Createmt.Checked){if (created == 1){mTable = creamTable;ShowmTable(mTable);Start_Analysis(mTable);}else{MessageBox.Show("你还没有创建分析表,请先创建!", "错误提示",MessageBoxButtons.OK, MessageBoxIcon.Exclamation);}}else if (radioButton_Openmt.Checked){if (opened == 1){mTable = openmTable;ShowmTable(mTable);Start_Analysis(mTable);}else{MessageBox.Show("你还没有打开分析表,请先打开或创建!", "错误提示",MessageBoxButtons.OK, MessageBoxIcon.Exclamation);}}}2.实现显示分析表及新建分析表并利用该表分析句子的功能(1)添加tabControl控件ID为tabControl_mTable建立3个页面tabPage_Show显示当前分析表、tabPage_Edit新建分析表、tabPage_Open打开分析表(2)tabPage_Show中添加listView控件ID为listView_mtableshow用于显示分析表(3)tabPage_Edit中添加两个Button 控件ID分别为button_StartAdd开始添加、button_FilishAdd 完成添加;两个textBox控件ID分别为textBox_VT 、textBox_VN、分别用于获取要添加的终结符及非终结符个数;一个tableLayoutPanel控件ID为tableLayoutPanel_mTable用于根据用户输入的VT及VN的个数建立输入表(4)编辑相应代码:private void button_StartAdd_Click(object sender, EventArgs e)//新建分析表并开始输入{try{int conwidth,conheight,col, row;TextBox txb;tableLayoutPanel_mTable.Controls.Clear();conwidth = 50; conheight = 20;col = Convert.ToInt32(textBox_VT.Text)+1;row = Convert.ToInt32(textBox_VN.Text)+1;tableLayoutPanel_mTable.ColumnCount =col;tableLayoutPanel_mTable.RowCount = row;for (int i = 0; i < col;i++ ){for (int j = 0; j < row;j++ ){if (i == 0&&j==0){Label lb = new Label();lb.Text = "VN\\VT";lb.Width = conwidth;lb.ForeColor = Color.Red;tableLayoutPanel_mTable.Controls.Add(lb,i,j);}else{txb = new TextBox();txb.Width = conwidth;txb.Height = conheight;tableLayoutPanel_mTable.Controls.Add(txb,i,j);}}}}catch{MessageBox.Show("终结符或非终结符格式不对!\n请输入数字!","错误提示",MessageBoxButtons.OK, MessageBoxIcon.Exclamation);}}private void button_FilishAdd_Click(object sender, EventArgs e)//完成添加,更新分析表 {int col = tableLayoutPanel_mTable.ColumnCount;int row = tableLayoutPanel_mTable.RowCount;if (col > 1&&row>1){creamTable = new string[row, col];for (int i = 0; i < row; i++){for (int j = 0; j < row; j++){if (i == 0 && j == 0){creamTable[i, j] = "";}else{creamTable[i, j] =((TextBox)tableLayoutPanel_mTable.GetControlFromPosition(j, i)).Text.Trim();if (creamTable[i,j].Length == 0){creamTable[i, j] = "<error>";}}}}MessageBox.Show("成功更新分析表!");tabControl_mTable.SelectTab(tabPage_Show);radioButton_Createmt.Checked = true;created = 1;ShowmTable(creamTable);}else{MessageBox.Show("请先点击“开始添加”创建表格!","错误提示",MessageBoxButtons.OK, MessageBoxIcon.Exclamation);}}public void ShowmTable(string[,] mTable)//显示分析表{listView_mtableshow.Clear();ColumnHeader colHeader;ListViewItem lvi;ListViewItem.ListViewSubItem lvsi;for (int i = 1; i <= mTable.GetLength(1); i++){colHeader = new ColumnHeader();colHeader.Text = i.ToString();listView_mtableshow.Columns.Add(colHeader);}for (int i = 0; i < mTable.GetLength(0); i++){lvi = new ListViewItem();lvi.Text = mTable[i, 0];for (int j = 1; j < mTable.GetLength(1); j++){lvsi = new ListViewItem.ListViewSubItem();lvsi.Text = mTable[i, j];lvi.SubItems.Add(lvsi);}listView_mtableshow.Items.Add(lvi);}}private void miFileNew_Click(object sender, EventArgs e)//菜单新建分析表{tabControl_mTable.SelectTab(tabPage_Edit);}3.实现打开、保存分析表、保存分析结果的功能(1)添加主菜单menuStrip_Main两个Item:miFile文件、miGraAnylysis语法分析。
编译原理实验报告材料LL(1)分析报告法84481

课程编译原理实验名称实验二 LL(1)分析法实验目的1.掌握LL(1)分析法的基本原理;2.掌握LL(1)分析表的构造方法;3.掌握LL(1)驱动程序的构造方法。
一.实验内容及要求根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG(3)G->ε(4)T->FS(5)S->*FS(6)S->ε(7)F->(E)(8)F->i程序输入一以#结束的符号串(包括+*()i#),如:i+i*i#。
输出过程如下:步骤分析栈剩余输入串所用产生式1 E i+i*i# E->TG... ... ... ...二.实验过程及结果代码如下:#include<iostream>#include "edge.h"using namespace std;edge::edge(){cin>>left>>right;rlen=right.length();if(NODE.find(left)>NODE.length())NODE+=left;}string edge::getlf(){return left;}string edge::getrg(){return right;}string edge::getfirst(){return first;}string edge::getfollow(){return follow;}string edge::getselect(){return select;}string edge::getro(){string str;str+=right[0];return str;}int edge::getrlen(){return right.length();}void edge::newfirst(string w){int i;for(i=0;i<w.length();i++)if(first.find(w[i])>first.length())first+=w[i];}void edge::newfollow(string w){int i;for(i=0;i<w.length();i++)if(follow.find(w[i])>follow.length()&&w[i]!='@')follow+=w[i];}void edge::newselect(string w){int i;for(i=0;i<w.length();i++)if(select.find(w[i])>select.length()&&w[i]!='@') select+=w[i];}void edge::delfirst(){int i=first.find('@');first.erase(i,1);}int SUM;string NODE,ENODE;//计算firstvoid first(edge ni,edge *n,int x){int i,j;for(j=0;j<SUM;j++){if(ni.getlf()==n[j].getlf()){if(NODE.find(n[j].getro())<NODE.length()){for(i=0;i<SUM;i++)if(n[i].getlf()==n[j].getro())first(n[i],n,x);}elsen[x].newfirst(n[j].getro());}}}//计算followvoid follow(edge ni,edge *n,int x){int i,j,k,s;string str;for(i=0;i<ni.getrlen();i++){s=NODE.find(ni.getrg()[i]);if(s<NODE.length()&&s>-1) //是非终结符if(i<ni.getrlen()-1) //不在最右for(j=0;j<SUM;j++)if(n[j].getlf().find(ni.getrg()[i])==0){if(NODE.find(ni.getrg()[i+1])<NODE.length()){for(k=0;k<SUM;k++)if(n[k].getlf().find(ni.getrg()[i+1])==0){n[j].newfollow(n[k].getfirst());if(n[k].getfirst().find("@")<n[k].getfirst().length())n[j].newfollow(ni.getfollow());}}else{str.erase();str+=ni.getrg()[i+1];n[j].newfollow(str);}}}}//计算selectvoid select(edge &ni,edge *n){int i,j;if(ENODE.find(ni.getro())<ENODE.length()){ni.newselect(ni.getro());if(ni.getro()=="@")ni.newselect(ni.getfollow());}elsefor(i=0;i<ni.getrlen();i++){for(j=0;j<SUM;j++)if(ni.getrg()[i]==n[j].getlf()[0]){ni.newselect(n[j].getfirst());if(n[j].getfirst().find('@')>n[j].getfirst().length())return;}}}//输出集合void out(string p){int i;if(p.length()==0)return;cout<<"{";for(i=0;i<p.length()-1;i++){cout<<p[i]<<",";}cout<<p[i]<<"}";}//连续输出符号void outfu(int a,string c){int i;for(i=0;i<a;i++)cout<<c;}//输出预测分析表void outgraph(edge *n,string (*yc)[50]){int i,j,k;bool flag;for(i=0;i<ENODE.length();i++){if(ENODE[i]!='@'){outfu(10," ");cout<<ENODE[i];}}outfu(10," ");cout<<"#"<<endl;int x;for(i=0;i<NODE.length();i++){outfu(4," ");cout<<NODE[i];outfu(5," ");for(k=0;k<ENODE.length();k++){flag=1;for(j=0;j<SUM;j++){if(NODE[i]==n[j].getlf()[0]){x=n[j].getselect().find(ENODE[k]);if(x<n[j].getselect().length()&&x>-1){cout<<"->"<<n[j].getrg();yc[i][k]=n[j].getrg();outfu(9-n[j].getrlen()," ");flag=0;}x=n[j].getselect().find('#');if(k==ENODE.length()-1&&x<n[j].getselect().length()&&x>-1){cout<<"->"<<n[j].getrg();yc[i][j]=n[j].getrg();}}}if(flag&&ENODE[k]!='@')outfu(11," ");}cout<<endl;}}//分析符号串int pipei(string &chuan,string &fenxi,string (*yc)[50],int &b) {char ch,a;int x,i,j,k;b++;cout<<endl<<" "<<b;if(b>9)outfu(8," ");elseoutfu(9," ");cout<<fenxi;outfu(26-chuan.length()-fenxi.length()," "); cout<<chuan;outfu(10," ");a=chuan[0];ch=fenxi[fenxi.length()-1];x=ENODE.find(ch);if(x<ENODE.length()&&x>-1){if(ch==a){fenxi.erase(fenxi.length()-1,1);chuan.erase(0,1);cout<<"'"<<a<<"'匹配";if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}elsereturn 0;}else{if(ch=='#'){if(ch==a){cout<<"分析成功"<<endl;return 1;}elsereturn 0;}elseif(ch=='@'){fenxi.erase(fenxi.length()-1,1);if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}else{i=NODE.find(ch);if(a=='#'){x=ENODE.find('@');if(x<ENODE.length()&&x>-1)j=ENODE.length()-1;elsej=ENODE.length();}elsej=ENODE.find(a);if(yc[i][j].length()){cout<<NODE[i]<<"->"<<yc[i][j];fenxi.erase(fenxi.length()-1,1);for(k=yc[i][j].length()-1;k>-1;k--)if(yc[i][j][k]!='@')fenxi+=yc[i][j][k];if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}elsereturn 0;}}}void main(){edge *n;string str,(*yc)[50];int i,j,k;bool flag=0;cout<<"请输入上下文无关文法的总规则数:"<<endl;cin>>SUM;cout<<"请输入具体规则(格式:左部右部,@为空):"<<endl;n=new edge[SUM];for(i=0;i<SUM;i++)for(j=0;j<n[i].getrlen();j++){str=n[i].getrg();if(NODE.find(str[j])>NODE.length()&&ENODE.find(str[j])>ENODE.length()) ENODE+=str[j];}//计算first集合for(i=0;i<SUM;i++){first(n[i],n,i);}//outfu(10,"~*~");cout<<endl;for(i=0;i<SUM;i++)if(n[i].getfirst().find("@")<n[i].getfirst().length()){if(NODE.find(n[i].getro())<NODE.length()){for(k=1;k<n[i].getrlen();k++){if(NODE.find(n[i].getrg()[k])<NODE.length()){for(j=0;j<SUM;j++){if(n[i].getrg()[k]==n[j].getlf()[0]){n[i].newfirst(n[j].getfirst());break;}}if(n[j].getfirst().find("@")>n[j].getfirst().length()){n[i].delfirst();break;}}}}}//计算follow集合for(k=0;k<SUM;k++){for(i=0;i<SUM;i++){if(n[i].getlf()==n[0].getlf())n[i].newfollow("#");follow(n[i],n,i);}for(i=0;i<SUM;i++){for(j=0;j<SUM;j++)if(n[j].getrg().find(n[i].getlf())==n[j].getrlen()-1)n[i].newfollow(n[j].getfollow());}}//计算select集合for(i=0;i<SUM;i++){select(n[i],n);}for(i=0;i<NODE.length();i++){str.erase();for(j=0;j<SUM;j++)if(n[j].getlf()[0]==NODE[i]){if(!str.length())str=n[j].getselect();else{for(k=0;k<n[j].getselect().length();k++)if(str.find(n[j].getselect()[k])<str.length()){flag=1;break;}}}}//输出cout<<endl<<"非终结符";outfu(SUM," ");cout<<"First";outfu(SUM," ");cout<<"Follow"<<endl;outfu(5+SUM,"-*-");cout<<endl;for(i=0;i<NODE.length();i++){for(j=0;j<SUM;j++)if(NODE[i]==n[j].getlf()[0]){outfu(3," ");cout<<NODE[i];outfu(SUM+4," ");out(n[j].getfirst());outfu(SUM+4-2*n[j].getfirst().length()," ");out(n[j].getfollow());cout<<endl;break;}}outfu(5+SUM,"-*-");cout<<endl<<"判定结论: ";if(flag){cout<<"该文法不是LL(1)文法!"<<endl;return;}else{cout<<"该文法是LL(1)文法!"<<endl;}//输出预测分析表cout<<endl<<"预测分析表如下:"<<endl;yc=new string[NODE.length()][50];outgraph(n,yc);string chuan,fenxi,fchuan;cout<<endl<<"请输入符号串:";cin>>chuan;fchuan=chuan;fenxi="#";fenxi+=NODE[0];i=0;cout<<endl<<"预测分析过程如下:"<<endl;cout<<"步骤";outfu(7," ");cout<<"分析栈";outfu(10," ");cout<<"剩余输入串";outfu(8," ");cout<<"推导所用产生式或匹配";if(pipei(chuan,fenxi,yc,i))cout<<endl<<"输入串"<<fchuan<<"是该文法的句子!"<<endl;elsecout<<endl<<"输入串"<<fchuan<<"不是该文法的句子!"<<endl;}截屏如下:三.实验中的问题及心得这次实验让我更加熟悉了LL(1)的工作流程以及LL(1)分析表的构造方法。
编译原理实验报告《ll(1)语法分析器构造》

规则右部首符号是终结
符
.
.
{ first[r].append(1,a); break;// 添加并结束
}
if(U.find(P[i][j])!=string::npos)// 规则右部首符号是非终结符 ,形如 X:: =Y1Y2...Yk
{
s=U.find(P[i][ j]);
//cout<<P[i][ j]<<":\n";
arfa=beta=""; for( j=0;j<100&&P[j][0]!=' ';j++) {
if(P[ j][0]==U[i]) {
if(P[ j][4]==U[i])// 产生式 j 有左递归 {
flagg=1;
.
.
for(temp=5;P[j][temp]!=' ';temp++) arfa.append(1,P[
{
int i,j,r,s,tmp;
string* first=new string[n];
char a;
int step=100;// 最大推导步数
while(step--){
// cout<<"step"<<100-step<<endl;
for(i=0;i<k;i++)
{
//cout<<P[i]<<endl;
j][temp]);
if(P[ j+1][4]==U[i]) arfa.append("|");//
编译原理实验报告LL(1)分析法

编译原理实验报告LL(1)分析法课程编译原理实验名称实验二 LL(1)分析法实验目的1.掌握LL(1)分析法的基本原理;2.掌握LL(1)分析表的构造方法;3.掌握LL(1)驱动程序的构造方法。
一.实验内容及要求根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG(3)G->ε(4)T->FS(5)S->*FS(6)S->ε(7)F->(E)(8)F->i程序输入一以#结束的符号串(包括+*()i#),如:i+i*i#。
输出过程如下:步骤分析栈剩余输入串所用产生式1 E i+i*i# E->TG... ... ... ...二.实验过程及结果代码如下:#include#include "edge.h"using namespace std;edge::edge(){cin>>left>>right;rlen=right.length();if(NODE.find(left)>NODE.length()) NODE+=left;}string edge::getlf(){return left;}string edge::getrg(){return right;}string edge::getfirst(){return first;}string edge::getfollow(){return follow;}string edge::getselect(){return select;}string edge::getro(){string str;str+=right[0];return str;}int edge::getrlen(){return right.length();}void edge::newfirst(string w){int i;for(i=0;iif(first.find(w[i])>first.length())first+=w[i];}void edge::newfollow(string w){int i;for(i=0;iif(follow.find(w[i])>follow.length()&&w[i]!='@')follow+=w[i];}void edge::newselect(string w){int i;for(i=0;iif(select.find(w[i])>select.length()&&w[i]!='@') select+=w[i];}void edge::delfirst(){int i=first.find('@');first.erase(i,1);}int SUM;string NODE,ENODE;//计算firstvoid first(edge ni,edge *n,int x){int i,j;for(j=0;j{if(ni.getlf()==n[j].getlf()){if(NODE.find(n[j].getro()){for(i=0;iif(n[i].getlf()==n[j].getro())first(n[i],n,x);}elsen[x].newfirst(n[j].getro());}}}//计算followvoid follow(edge ni,edge *n,int x){int i,j,k,s;string str;for(i=0;i{s=NODE.find(ni.getrg()[i]);if(s-1) //是非终结符if(ifor(j=0;jif(n[j].getlf().find(ni.getrg()[i])==0) {if(NODE.find(ni.getrg()[i+1]){for(k=0;kif(n[k].getlf().find(ni.getrg()[i+1])==0) {n[j].newfollow(n[k].getfirst());if(n[k].getfirst().find("@")n[j].newfollow(ni.getfollow());}}else{str.erase();str+=ni.getrg()[i+1];n[j].newfollow(str);}}}}//计算selectvoid select(edge &ni,edge *n){int i,j;if(ENODE.find(ni.getro()){ni.newselect(ni.getro());if(ni.getro()=="@")ni.newselect(ni.getfollow());}elsefor(i=0;i{for(j=0;jif(ni.getrg()[i]==n[j].getlf()[0]){ni.newselect(n[j].getfirst());if(n[j].getfirst().find('@')>n[j].getfirst().length()) return;}}}//输出集合void out(string p){int i;if(p.length()==0)return;coutfor(i=0;i{cout}cout}//连续输出符号void outfu(int a,string c){int i;for(i=0;icout}//输出预测分析表void outgraph(edge *n,string (*yc)[50]) {int i,j,k;bool flag;for(i=0;i{if(ENODE[i]!='@'){outfu(10," ");cout}}outfu(10," ");coutint x;for(i=0;i{outfu(4," ");coutoutfu(5," ");for(k=0;k{flag=1;for(j=0;j{if(NODE[i]==n[j].getlf()[0]){x=n[j].getselect().find(ENODE[k]); if(x-1){cout"yc[i][k]=n[j].getrg();outfu(9-n[j].getrlen()," ");flag=0;}x=n[j].getselect().find('#');if(k==ENODE.length()-1&&x-1) {cout"yc[i][j]=n[j].getrg();}}}if(flag&&ENODE[k]!='@')outfu(11," ");}cout}}//分析符号串int pipei(string &chuan,string &fenxi,string (*yc)[50],int &b){char ch,a;int x,i,j,k; b++; cout9) outfu(8," "); else outfu(9," "); cout-1) { if(ch==a) { fenxi.erase(fenxi.length()-1,1); chuan.erase(0,1); coutfenxi.erase(fenxi.length()-1,1); if(pipei(chuan,fenxi,yc,b)) return 1;elsereturn 0;}else{i=NODE.find(ch);if(a=='#'){x=ENODE.find('@');if(x-1) j=ENODE.length()-1; elsej=ENODE.length();}elsej=ENODE.find(a);if(yc[i][j].length()){cout"-1;k--) if(yc[i][j][k]!='@')fenxi+=yc[i][j][k];if(pipei(chuan,fenxi,yc,b)) return 1; elsereturn 0;}elsereturn 0;}}}void main(){edge *n;string str,(*yc)[50];int i,j,k;bool flag=0;cin>>SUM; coutNODE.length()&&ENODE.find(str[j])>ENODE.length())ENODE+=str[j]; } //计算first集合 for(i=0;in[j].getfirst().length()){ n[i].delfirst(); break; } } } } }for(k=0;koutfu(SUM," "); cout>chuan; fchuan=chuan; fenxi="#"; fenxi+=NODE[0]; i=0; coutoutfu(7," ");coutoutfu(10," ");coutoutfu(8," ");coutif(pipei(chuan,fenxi,yc,i))coutelsecout}截屏如下:三.实验中的问题及心得这次实验让我更加熟悉了LL(1)的工作流程以及LL(1)分析表的构造方法。
编译原理实验二LL文法分析

实验2 LL(1)分析法一、实验目的通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区别和联系。
使学生了解语法分析的功能,掌握语法分析程序设计的原理和构造方法,训练学生掌握开发应用程序的基本方法。
有利于提高学生的专业素质,为培养适应社会多方面需要的能力。
二、实验要求1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。
2、如果遇到错误的表达式,应输出错误提示信息。
3、对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG|—TG(3)G->ε(4)T->FS(5)S->*FS|/FS(6)S->ε(7)F->(E)(8)F->i三、实验内容根据某一文法编制调试LL ( 1 )分析程序,以便对任意输入的符号串进行分析。
构造预测分析表,并利用分析表和一个栈来实现对上述程序设计语言的分析程序。
分析法的功能是利用LL(1)控制程序根据显示栈栈顶内容、向前看符号以及LL(1)分析表,对输入符号串自上而下的分析过程。
四、实验步骤1、根据流程图编写出各个模块的源程序代码上机调试。
2、编制好源程序后,设计若干用例对系统进行全面的上机测试,并通过所设计的LL(1)分析程序;直至能够得到完全满意的结果。
3、书写实验报告;实验报告正文的内容:写出LL(1)分析法的思想及写出符合LL(1)分析法的文法。
程序结构描述:函数调用格式、参数含义、返回值描述、函数功能;函数之间的调用关系图。
详细的算法描述(程序执行流程图)。
给出软件的测试方法和测试结果。
实验总结(设计的特点、不足、收获与体会)。
五、实验截图六、核心代码#include<iostream>#include<stdio.h>#include<stdlib.h>#include<string.h>#define MAX 20using namespace std;char A[MAX];char B[MAX];char v1[MAX] = { 'i','+','-','*','/','(',')','#'}; char v2[MAX] = {'E','G','T','S','F'};int j = 0, b = 0, top = 0;int l; //l是字符串长度class type{public:char origin;char array[7];int length;};type e, t, g,g0, g1, s, s0,s1, f, f1;type C[10][10];void print(){int a;for ( a = 0; a <= top + 1; a++)cout<<A[a];cout << "\t\t";}void print1(){int j;for (j = 0; j<b; j++)cout << " ";for (j = b; j <= l; j++)cout << B[j];cout << "\t\t\t";}int main(){int m, n, k = 0;int flag = 0,finish = 0;char ch, x;type cha;e.origin = 'E';strcpy(e.array, "TG");e.length = 2;t.origin = 'T';strcpy(t.array, "FS");t.length = 2;g.origin = 'G';strcpy(g.array, "+TG");g.length = 3;g0.origin = 'G';strcpy(g0.array, "-TG");g0.length = 3;g1.origin = 'G';g1.array[0] = '^';g1.length = 1;s.origin = 'S';strcpy(s.array, "*FS");s.length = 3;s0.origin = 'S';strcpy(s0.array, "/FS");s0.length = 3;s1.origin = 'S';s1.array[0] = '^';s1.length = 1;f.origin = 'F';strcpy(f.array, "(E)");f.length = 3;f1.origin = 'F';f1.array[0] = 'i';f1.length = 1;for (m = 0; m <= 4;m++)for (n = 0; n <= 7; n++)C[m][n].origin = 'N';/*C[0][0] = e; C[0][3] = e; C[1][2] = g0;C[1][1] = g; C[1][4] = g1; C[1][5] = g1;C[2][0] = t; C[2][3] = t;C[3][1] = s1; C[3][2] = s;C[3][4] = C[3][5] = s1;C[4][0] = f1; C[4][3] = f;*/C[0][0] = e; C[0][5] = e;C[1][1] = g; C[1][2] = g0;C[1][6] = g1; C[1][7] = g1;C[2][0] = t; C[2][5] = t;C[3][1] = s1; C[3][2] = s1;C[3][3] = s;C[3][4] = s0; C[3][6] = s1; C[3][7] = s1;C[4][0] = f1; C[4][5] = f;cout << "input,please~:";do{cin >> ch;if ((ch!='i') &&(ch!='+') &&(ch!='-') &&(ch!='*') &&(ch!='/') &&(ch!='(') &&(ch!=')') &&(ch!='#')){cout << "Error!\n";exit(1);}B[j] = ch;j++;} while (ch != '#');l = j; //l是字符串长度/* for(j=0;j<l;j++)cout<<B[j]<<endl;*/ch = B[0]; //当前分析字符A[top] = '#';A[++top] = 'E';/*'#','E'进栈*/cout << "步骤\t\t分析栈\t\t剩余字符\t\t所用字符\n"; do{x = A[top--];cout << k++;cout << "\t\t";for (j = 0; j<=7 ; j++)if (x == v1[j]){flag = 1;break;}if (flag==1){if (x == '#'){finish = 1;cout << "acc!\n";getchar();getchar();exit(1);}if (x == ch){print();print1();cout <<ch << "匹配\n";ch = B[++b];flag = 0;}else{cout<<"x:"<<x<<endl;cout<<"ch:"<<ch<<endl;print();print1();cout <<ch<< "出错\n" ;exit(1);}}else //非终结符{for (j = 0; j <= 4; j++)if (x == v2[j]){m = j;//行号break;}for (j = 0; j <= 7; j++)if (ch == v1[j]){n = j; //列号break;}cha = C[m][n];if (cha.origin != 'N'){print();print1();cout << cha.origin << "->";for (j = 0; j<cha.length; j++)cout << cha.array[j];cout << "\n";for (j = (cha.length - 1); j >= 0; j--)A[++top] = cha.array[j];if (A[top] == '^')/*为空则不进栈*/top--;}else{print();print1();cout<<"x:"<<x<<endl;cout<<"ch:"<<ch<<endl;cout<<"sign1"<<endl;cout << "Error!" << x;exit(1);}}} while (finish == 0);}。
【实验2】LL(1)文法分析器

【实验2】LL(1)⽂法分析器实验2 LL(1)⽂法分析实验题⽬:编写LL(1)⽂法分析器实验⽬的:加深对⽂法分析基本理论的理解,锻炼实现LL(1)⽂法分析器程序的实践能⼒。
要求:实现基本LL(1)⽂法的功能。
输⼊⽂法,能够求出FIRST集、FOLLOW集、预测分析表,同时,输⼊⼀串字符,输出分析过程。
⼀.需求分析1.问题的提出:语法分析是编译过程的核⼼部分,其任务是在词法分析识别单词符号串的基础上,分析并判断程序的的语法结构是否符合语法规则。
语⾔的语法结构是⽤上下⽂⽆关⽂法描述的。
因此语法分析器的⼯作的本质上就是按⽂法的产⽣式,识别输⼊符号串是否为⼀个句⼦。
对于⼀个⽂法,当给出⼀串符号时,如何知道它是不是该⽂法的⼀个句⼦,这是本设计所要解决的⼀个问题。
2.问题解决:其实要知道⼀串符号是不是该⽂法的⼀个句⼦,只要判断是否能从⽂法的开始符号出发,推导出这个输⼊串。
语法分析可以分为两类,⼀类是⾃上⽽下的分析法,⼀类是⾃下⽽上的分析法。
⾃上⽽下的主旨是,对任何输⼊串,试图⽤⼀切可能的办法,从⽂法开始符号出发,⾃上⽽下的为输⼊串建⽴⼀棵语法树。
或者说,为输⼊串寻找⼀个最左推导,这种分析过程的本质是⼀种试探过程,是反复使⽤不同产⽣式谋求匹配输⼊串的过程。
3.解决步骤:在⾃上⽽下的分析法中,主要是研究LL(1)分析法。
它的解决步骤是,⾸先接收到⽤户输⼊的⼀个⽂法,对⽂法进⾏检测和处理,消除左递归,得到LL(1)⽂法,这个⽂法应该满⾜:⽆⼆义性,⽆左递归,⽆左公因⼦。
当⽂法满⾜条件后,再分别构造⽂法每个⾮终结符的FIRST和FOLLOW集合,然后根据FIRST 和FOLLOW集合构造LL(1)分析表,最后利⽤分析表,根据LL(1)语法分析构造⼀个分析器。
LL(1)的语法分析程序包含三个部分:总控程序,预测分析表函数,先进先出的语法分析栈。
⼆.概要设计1.设计原理:所谓LL(1)分析法,就是指从左到右扫描输⼊串(源程序),同时采⽤最左推导,且对每次直接推导只需向前看⼀个输⼊符号,便可确定当前所应当选择的规则。
编译原理LL(1)语法分析实验报告

实验报实验名称 】 LL (1)语法分析【实验目的】通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区别和联系。
使了解语法分析的功能, 掌握语法分析程序设计的原理和构造方法, 训练掌握开发应用程序 的基本方法。
【 实验内容 】根据某一文法编制调试 LL ( 1 )分析程序,以便对任意输入的符号串进行分析。
构造预测分析表,并利用分析表和一个栈来实现对上述程序设计语言的分析程序。
分析法的功能是利用 LL (1)控制程序根据显示栈栈顶内容、向前看符号以及 LL(1) 分析表,对输入符号串自上而下的分析过程。
【设计思想】(1) 、LL (1)文法的定义LL(1) 分析法属于确定的自顶向下分析方法。
LL(1) 的含义是: 第一个 L 表明自顶向下分 析是从左向右扫描输入串,第 2个 L 表明分析过程中将使用最左推导, 1表明只需向右看一 个符号便可决定如何推导,即选择哪个产生式 ( 规则) 进行推导。
LL(1) 文法的判别需要依次计算 FIRST 集、FOLLOW 集和 SELLECT 集, 然后判断是否为 LL(1) 文法 ,最后再进行句子分析。
需要预测分析器对所给句型进行识别。
即在 LL(1) 分析法中,每当在符号栈的栈顶出现 非终极符时, 要预测用哪个产生式的右部去替换该非终极符; 当出现终结符时, 判断其与剩 余输入串的第一个字符是否匹配,如果匹配,则继续分析,否则报错。
LL(1) 分析方法要求 文法满足如下条件: 对于任一非终极符 A 的两个不同产生式 A ,A ,都要满足下面条件: SELECT(A ) ∩SELECT(A )=学号 20102798 实验日期 2013.04.08专业 软件工程 教师签字 姓名 薛建东 成绩( 2)、预测分析表构造LL(1) 分析表的作用是对当前非终极符和输入符号确定应该选择用哪个产生式进行推导。
它的行对应文法的非终极符,列对应终极符,表中的值有两种:一是产生式的右部的字符串,一是null 。
编译原理实验二语法分析器LL实现

编译原理实验二语法分析器L L(1)实现(总12页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--编译原理程序设计实验报告——表达式语法分析器的设计班级:计算机1306班姓名:张涛学号:实验目标:用LL(1)分析法设计实现表达式语法分析器实验内容:⑴概要设计:通过对实验一的此法分析器的程序稍加改造,使其能够输出正确的表达式的token序列。
然后利用LL(1)分析法实现语法分析。
⑵数据结构:int op=0;逆序压栈ase=(char*)malloc(100 *sizeof(char));if(!(*s).base)exit(0);(*s).top=(*s).base;(*s).stacksize=100;printf("初始化栈\n");return 0;}int pop(STack *s,char *ch) op==(*s).base){printf("弹栈失败\n");return 0;}(*s).top--;*ch=*((*s).top);printf("%c",*ch);return 1;}int push(STack *s,char ch) op-(*s).base>=(*s).stacksize){(*s).base=(char*)realloc((*s).base,((*s).stacksize+10)*sizeof(char)); if(!(*s).base)exit(0);(*s).top=(*s).base+(*s).stacksize;(*s).stacksize+=10;}*(*s).top=ch;*(*s).top++;return 1;}void LL1();int IsLetter(char ch) ode=='#';switch(state){case 0:ch=sour[i];if(Isbound(ch)){if(ERR){printf("无法识别\n");ERR=FALSE;OK=TRUE;}else if(!OK){printf("<10,%s>标识符\n",nowword);=10;[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}state=4;}else if(IsDigit(ch)){if(OK){memset(nowword,0,strlen(nowword));nowlen=0;nowword[nowlen]=ch;nowlen++;state=3;OK=FALSE;break;}else{nowword[nowlen]=ch;nowlen++;}}else if(IsLetter(ch)){if(OK){memset(nowword,0,strlen(nowword)); nowlen=0;nowword[nowlen]=ch;nowlen++;OK=FALSE;}else{nowword[nowlen]=ch;nowlen++;}}else if(Isoperate(ch)){if(!OK){printf("<10,%s>标识符\n",nowword);=10;[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}printf("<%d,%c>运算符\n",Isoperate(ch),ch); =Isoperate(ch);[10]=ch;tokenlist[m]=tokentemp;m++;}break;case 3:if(IsLetter(ch))printf("错误\n");nowword[nowlen]=ch;nowlen++;ERR=FALSE;state=0;break;}if(IsDigit(ch=sour[i])){nowword[nowlen]=ch;nowlen++;}else if(sour[i]=='.'&&flagpoint==0){flagpoint=1;nowword[nowlen]=ch;nowlen++;}else{printf("<20,%s>数字\n",nowword);i--;state=0;OK=TRUE;=20;[10]=nowword[10];tokenlist[m]=tokentemp;m++;}break;case 4:i--;printf("<%d,%c>界符\n",Isbound(ch),ch); =Isbound(ch);[10]=ch;tokenlist[m]=tokentemp;m++;state=0;OK=TRUE;break;}}printf("tokenlist值为%d\n",m);tokenlist[m+1].code='r';m++;for(t;t<m;t++){printf("tokenlist%d值为%d\n",t,tokenlist[t].code);}LL1();printf("tokenlist值为%d\n",m);if(op+1==m)printf("OK!!!");elseprintf("WRONG!!!");return 0;}void LL1(){STack s;init(&s);push(&s,'#');push(&s,'E');char ch;int flag=1;do{pop(&s,&ch);printf("输出栈顶为%c\n",ch);printf("输出栈顶为%d\n",ch);printf("当前p值为%d\n",op);if((ch=='(')||(ch==')')||(ch=='+')||(ch=='-')||(ch=='*')||(ch=='/')||(ch==10)||(ch==20)){if(tokenlist[op].code==1||tokenlist[op].code==20||tokenlist[op].code==10||tokenlist[op].code==2||to kenlist[op].code==3||tokenlist[op].code==4||tokenlist[op].code==5||tokenlist[op].code==6)op++;else{printf("WRONG!!!");exit(0);}}else if(ch=='#'){if(tokenlist[op].code==0)flag=0;else{printf("WRONG!!!@@@@@@@@@");exit(0);}}else if(ch=='E'){printf("进入E\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'R');printf("将R压入栈\n");push(&s,'T');}}else if(ch=='R'){printf("进入R\n");if(tokenlist[op].code==3||tokenlist[op].code==4){push(&s,'R');push(&s,'T');printf("将T压入栈\n");push(&s,'+');}if(tokenlist[op].code==2||tokenlist[op].code==0){}}else if(ch=='T'){printf("进入T\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'Y');push(&s,'F');}}else if(ch=='Y'){printf("进入Y\n");if(tokenlist[op].code==5||tokenlist[op].code==6){push(&s,'Y');push(&s,'F');push(&s,'*');}elseif(tokenlist[op].code==3||tokenlist[op].code==2||tokenlist[op].code==0||tokenlist[op].code==4) {}}else if(ch=='F'){printf("进入F\n");if(tokenlist[op].code==10||tokenlist[op].code==20){push(&s,10);}if(tokenlist[op].code==1){push(&s,')');push(&s,'E');push(&s,'(');}}else{printf("WRONG!!!!");exit(0);}}while(flag);}程序运行结果:(截屏)输入:((Aa+Bb)*3))#注:如需运行请将文件放置F盘,并命名为:输出:思考问题回答:LL(1)分析法的主要问题就是要正确的将文法化为LL (1)文法。
编译原理语法分析实验二表达式语法分析器的设计实现
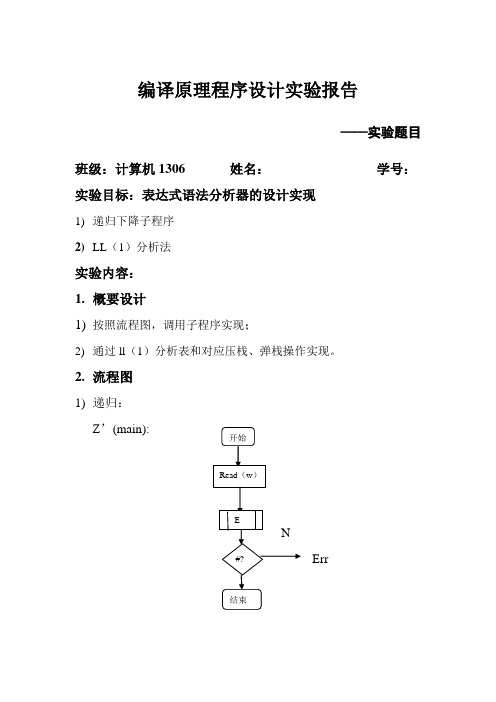
编译原理程序设计实验报告——实验题目班级:计算机1306姓名:学号:实验目标:表达式语法分析器的设计实现1) 递归下降子程序 2) LL (1)分析法实验内容: 1. 概要设计1) 按照流程图,调用子程序实现;2) 通过ll (1)分析表和对应压栈、弹栈操作实现。
2. 流程图1) 递归: Z ’(main):N Err开始Read (w ) E #? 结束E: E1:Y NY NT: T1:YNYNF :N N err Y YY N err入口 TE1 入口+? -? 出口Read(w) T出口入口 FT1 出口入口*?/?出口Read (w )T入口I ? (? Read (w )E )? Read (w )出口2) LL (1):BeginPUSH(#),PUSH(E)POP(x)x ∈VTx ∈VNx=wendW=#nyNEXT(w)yn err查LL (1)分析表空?nPUSH (i )errny逆序压栈开始构建LL(1)分析表调用函数token ()切分单词 调用*Analyse(char *token)进行分析 结束3.关键函数1)递归下降子程序void E(); //E->TX;int E1(); //X->+TX | evoid T(); //T->FYint T1(); //Y->*FY | eint F(); //F->(E) | i2)LL(1)分析法char *Find(char vn,char vt)//是否查到表char *Analyse(char *token)//分析过程int Token()//将token中数字表示成i,标识符表示成n源程序代码:(加入注释)1)递归下降子程序:#include<stdio.h>#include<iostream>#include <string.h>#include <stdlib.h>using namespace std;/********全局变量**********/char str[30];int index=0;void E();//E->TX;int E1();//X->+TX | evoid T();//T->FYint T1();//Y->*FY | eint F();//F->(E) | iFILE *fp;char cur;/*************主函数************/int main(){int len;int m;if((fp=fopen("source.txt","r"))==NULL){cout<<"can not open the source file!"<<endl;exit(1);}cur=fgetc(fp);while(cur!='#'){E();}cout<<endl;cout<<"success"<<endl;return 0;}/*************************************/void E(){T();E1();}/*************************************/int E1(){if(cur=='+'){cur=fgetc(fp);T();cout<<'+'<<" ";E1();}else if(cur=='-'){cur=fgetc(fp);T();cout<<'-'<<" ";E1();}return 0;}/************************************/void T(){F();T1();}/***********************************/int T1(){if(cur=='*'){cur=fgetc(fp);F();cout<<'*'<<" ";T1();}else if(cur=='/'){cur=fgetc(fp);F();cout<<'/'<<" ";T1();}return 0;}int F(){if((cur<='z'&&cur>='a')||(cur<='Z'&&cur>='A')||cur=='_'){for(int i=0;i<20;i++){str[i]='\0';index=0;}str[index++]=cur;cur=fgetc(fp);while((cur<='z'&&cur>='a')||(cur<='Z'&&cur>='A')||cur=='_'||(cur<='9'&&cur>='0')){str[index++]=cur;cur=fgetc(fp);}cout<<str;cout<<" ";return NULL;}else if (cur<='9'&&cur>='0'){for(int i=0;i<20;i++){str[i]='\0';index=0;}while(cur<='9'&&cur>='0'){str[index++]=cur;cur=fgetc(fp);}if(cur=='.'){str[index++]=cur;cur=fgetc(fp);while(cur<='9'&&cur>='0'){str[index++]=cur;cur=fgetc(fp);}cout<<str;cout<<" ";return NULL;}else if((cur<='z'&&cur>='a')||(cur<='Z'&&cur>='A')||cur=='_'){printf("error6\n");exit(1);}else{cout<<str;cout<<" ";return NULL;}}else if (cur=='('){cur=fgetc(fp);E();if(cur==')'){cur=fgetc(fp);return 0;}else{printf("error3\n");exit (1);}}else{printf("error4\n");exit(1);}return 0;}程序运行结果:(截屏)输入:Source.txt文本((Aa+Bb)*(88.2/3))#输出:2)LL(1)#include <iostream>#include <cstdio>#include <cstdlib>#include <cstring>#include <stack>using namespace std;struct Node1{char vn;char vt;char s[12];}MAP[22];//存储分析预测表每个位置对应的终结符,非终结符,产生式int k;char token[30];int token_index=0;charG[12][12]={"E->TR","R->+TR","R->-TR","R->e","T->FW","W->*FW","W->/FW", "W->e","F->(E)","F->i","F->n"};//存储文法中的产生式,用R代表E',W代表T',e代表空//char VN[6]={'E','R','T','W','F'};//存储非终结符//char VT[9]={'i','n','+','-','*','/','(',')','#'};//存储终结符char Select[12][12]={"(,i,n","+","-","),#","(,i,n","*","/","+,-,),#","(","i","n"};//存储文法中每个产生式对应的select集合charRight[12][8]={"->TR","->+TR","->-TR","->e","->FW","->*FW","->/FW","->e","->( E)","->i","->n"};stack<char> stak,stak1,stak2;char *Find(char vn,char vt){int i;for(i=0;i<k;i++){if(MAP[i].vn==vn&& MAP[i].vt==vt)return MAP[i].s;}return "error";}char *Analyse(char *token){char p,action[10],output[10];int i=1,j,k=0,l_act,m;while(!stak.empty())//判断栈中是否为空,若不空就将栈顶元素与分析表匹配进行相应操作stak.pop();stak.push('#');//栈底标志stak.push('E');//起始符号先入栈printf(" 步骤栈顶元素输入串推导所用产生式或匹配\n");p=stak.top();while(p!='#')//查预测分析表将栈顶元素进行匹配,若栈顶元素与输入串匹配成功则向前匹配,否则生成式反序入栈{printf("%7d ",i++);p=stak.top();//从栈中弹出一个栈顶符号,由p记录并输出stak.pop();printf("%6c ",p);for(j=0,m=0;j<token_index;j++)//将未被匹配的剩余输入串输出output[m++]=token[j];output[m]='\0';printf("%10s",output);if(p==token[k]){ if(p=='#')//若最后一个结束符号匹配说明输入表达式被接受,否则继续匹配{printf(" 接受\n");return "SUCCESS";}printf(" “%c”匹配\n",p);k++;}else{ //将未被匹配的第一个字符与find函数的结果进行比较,在预测分析表中查找相应生成式strcpy(action,Find(p,token[k]));if(strcmp(action,"error")==0){printf(" 没有可用的产生式\n");return "ERROR";}printf(" %c%s\n",p,action);int l_act=strlen(action);if(action[l_act-1]=='e')continue;for(j=l_act-1;j>1;j--)stak.push(action[j]);}}return "ERROR";}int Token(){FILE *fp;char cur;int i,j;fp=fopen("source.txt","r");cur=fgetc(fp);while(cur!=EOF)//把用字母数字表示的输入串转换为token序列的表示方法{if((cur<='z'&&cur>='a')||(cur<='Z'&&cur>='A')||cur=='_'){cur=fgetc(fp);while((cur<='z'&&cur>='a')||(cur<='Z'&&cur>='A')||cur=='_'||(cur<='9'&&cur>='0')){cur=fgetc(fp);} token[token_index++]='i';continue;}else if (cur<='9'&&cur>='0'){while(cur<='9'&&cur>='0')cur=fgetc(fp);if(cur=='.'){cur=fgetc(fp);while(cur<='9'&&cur>='0')cur=fgetc(fp);}token[token_index++]='n';continue;}else{token[token_index++]=cur;cur=fgetc(fp);continue;} }token[token_index]='#';cout<<"把文件中字符串用i表示,数字用n表示,转化后:";for(int index=0;index<=token_index;index++)cout<<token[index];cout<<endl<<endl;return 0;}int main (){int i,j,l,m;for(i=0,k=0;i<11;i++)//通过select集合生成预测分析表{l=strlen(Select[i]);for(j=0;j<l;j+=2){MAP[k].vn=G[i][0];MAP[k].vt=Select[i][j];strcpy(MAP[k].s,Right[i]);k++;}}Token();cout<<"分析过程如下:"<<endl;cout<<Analyse(token)<<endl;return 0;}程序运行结果:(截屏)输入:Source.txt文本((Aa+Bb)*(88.2/3))输出:目录第一章项目总论 ········································错误!未定义书签。
编译原理语法分析——LL(1)分析表的实现

printf("Please input your chioc : ");
ch = getche();
printf("\n");
if(ch == 'I' || ch == 'i')
{
printf("Input a string end up with \'#\':");
gets(string);
i = strlen(string);
if(string[i-1] != '#')
{
string[i] = '#';
string[i+1] = '\0';
}
AnalysisProcess();
goto re2;
}
else if(ch == 'Q' || ch == 'q')
{
Quit();
return ;
int i;
int j;
count = 0;
ch = fgetc(f);
while(!feof(f))
{
if (ch == '-')
{
if ( (ch2=fgetc(f)) == '>' )
{
count++; //累计产生式的字符数条数
}
else
{
fseek(f,-1L, 1);
}
}//if
else if( ch == '|' )
fclose(f);
}//Input
LL(1)语法分析实验报告

编译原理实验报告
(1)设计思路
输入文法规则、非终结符和终结符先求出first集合,然后根据first集合和文法规则再求出follow集合,最后求出LL(1)预测分析表,最后通过分析表识别字符串是否符合文法规则。
(2)流程图
(3)具体过程:
(a)first和follow集合的计算:
对G中每个文法符号X∈VT∪VN,构造FIRST(X)。
连续使用下述规则,直至每个FIRST集合不再增大:
a、若X∈ VT,则FIRST(X)={X};
b、若X∈ VN,且有产生式X→a…,则把a加入FIRST(X) ;若X→ε也是一条产生式,则把ε也加入
c、若X→Y…是一个产生式且Y∈ VN,则把FIRST(Y)中的所有非ε元素都加入FIRST(X)中;若X→Y1Y2…Yk是一个产生式,Y1,Y2,…,Yi-1都是非终结符,而且,对任意j(1≤j≤i-1),FIRST(Yj)都含有ε,则把FIRST(Yi)
(2)产生各个符合的FIRST集合及FOLLOW集合:
(3)构造M[A,a]
(4)输入字符串:i*(i+i)进行分析:
该字符串是文法的句型
(5)输入另一个字符串:i+i(i*i)进行分析:
该字符串不是文法的句型。
编译原理LL(1)分析实验报告

青岛科技大学LL(1)分析编译原理实验报告学生班级__________________________学生学号__________________________学生姓名________________________________年 ___月 ___日一、实验目的LL(1)分析法的基本思想是:自项向下分析时从左向右扫描输入串,分析过程中将采用最左推导,并且只需向右看一个符号就可决定如何推导。
通过对给定的文法构造预测分析表和实现某个符号串的分析,掌握LL(1)分析法的基本思想和实现过程。
二、实验要求设计一个给定的LL(1)分析表,输入一个句子,能根据LL(1)分析表输出与句子相应的语法数。
能对语法数生成过程进行模拟。
三、实验内容(1)给定表达式文法为:G(E’): E’→#E# E→E+T | T T→T*F |F F→(E)|i(2)分析的句子为:(i+i)*i四、模块流程五、程序代码#include<iostream>#include<stdio.h>#include <string>#include <stack>using namespace std;char Vt[]={'i','+','*','(',')','#'}; /*终结符*/char Vn[]={'E','e','T','t','F'}; /*非终结符*/ int LENVt=sizeof(Vt);void showstack(stack <char> st) //从栈底开始显示栈中的内容{int i,j;char ch[100];j=st.size();for(i=0;i<j;i++){ch[i]=st.top();st.pop();}for(i=j-1;i>=0;i--){cout<<ch[i];st.push(ch[i]);}}int find(char c,char array[],int n) //查找函数,返回布尔值{int i;int flag=0;for(i=0;i<n;i++){if(c==array[i])flag=1;}return flag;}int location(char c,char array[]) //定位函数,指出字符所在位置,即将字母转换为数组下标值{int i;for(i=0;c!=array[i];i++);return i;}void error(){cout<<" 出错!"<<endl;}void analyse(char Vn[],char Vt[],string M[5][6],string str){int i,j,p,q,h,flag=1;char a,X;stack <char> st; //定义堆栈st.push('#');st.push(Vn[0]); //#与识别符号入栈j=0; //j指向输入串的指针h=1;a=str[j];cout<<"步骤"<<"分析栈"<<"剩余输入串"<<" 所用产生式"<<endl;while(flag==1){cout<<h<<" "; //显示步骤h++;showstack(st); //显示分析栈中内容cout<<" ";for(i=j;i<str.size();i++) cout<<str[i]; //显示剩余字符串X=st.top(); //取栈顶符号放入X if(find(X,Vt,LENVt)==1) //X是终结符if(X==a) //分析栈的栈顶元素和剩余输入串的第一个元素相比较if (X!='#'){cout<<" "<<X<<"匹配"<<endl;st.pop();a=str[++j]; //读入输入串的下一字符}else{ cout<<" "<<"acc!"<<endl<<endl; flag=0;}else{error();break;}else{p=location(X,Vn); //实现下标的转换(非终结符转换为行下标)q=location(a,Vt); //实现下标的转换(终结符转换为列下标)string S1("NULL"),S2("null");if(M[p][q]==S1 || M[p][q]==S2) //查找二维数组中的产生式{error();break;} //对应项为空,则出错else{string str0=M[p][q];cout<<" "<<X<<"-->"<<str0<<endl; //显示对应的产生式st.pop();if(str0!="$") //$代表"空"字符for(i=str0.size()-1;i>=0;i--) st.push(str0[i]);//产生式右端逆序进栈}}}}main(){string M[5][6]={"Te" ,"NULL","NULL","Te", "NULL","NULL","NULL","+Te" ,"NULL","NULL","$", "$","Ft", "NULL","NULL","Ft", "NULL","NULL","NULL","$", "*Ft", "NULL","$", "$","i", "NULL","NULL","(E)", "NULL","NULL"}; //预测分析表j string str;int errflag,i;cout<<"文法:E->E+T|T T->T*F|F F->(E)|i"<<endl;cout<<"请输入分析串(以#结束):"<<endl;do{ errflag=0;cin>>str;for(i=0;i<str.size();i++)if(!find(str[i],Vt,LENVt)){ cout<<"输入串中包含有非终结符"<<str[i]<<"(输入错误)!"<<endl;errflag=1;}} while(errflag==1); //判断输入串的合法性analyse(Vn, Vt, M,str);return 0;}六、实验结果七、实验总结。
编译原理实验二:LL(1)语法分析器

编译原理实验⼆:LL(1)语法分析器⼀、实验要求 1. 提取左公因⼦或消除左递归(实现了消除左递归) 2. 递归求First集和Follow集 其它的只要按照课本上的步骤顺序写下来就好(但是代码量超多...),下⾯我贴出实验的⼀些关键代码和算法思想。
⼆、基于预测分析表法的语法分析 2.1 代码结构 2.1.1 Grammar类 功能:主要⽤来处理输⼊的⽂法,包括将⽂法中的终结符和⾮终结符分别存储,检测直接左递归和左公因⼦,消除直接左递归,获得所有⾮终结符的First集,Follow集以及产⽣式的Select集。
#ifndef GRAMMAR_H#define GRAMMAR_H#include <string>#include <cstring>#include <iostream>#include <vector>#include <set>#include <iomanip>#include <algorithm>using namespace std;const int maxn = 110;//产⽣式结构体struct EXP{char left; //左部string right; //右部};class Grammar{public:Grammar(); //构造函数bool isNotTer(char x); //判断是否是终结符int getTer(char x); //获取终结符下标int getNonTer(char x); //获取⾮终结符下标void getFirst(char x); //获取某个⾮终结符的First集void getFollow(char x); //获取某个⾮终结符的Follow集void getSelect(char x); //获取产⽣式的Select集void input(); //输⼊⽂法void scanExp(); //扫描输⼊的产⽣式,检测是否有左递归和左公因⼦void remove(); //消除左递归void solve(); //处理⽂法,获得所有First集,Follow集以及Select集void display(); //打印First集,Follow集,Select集void debug(); //⽤于debug的函数~Grammar(); //析构函数protected:int cnt; //产⽣式数⽬EXP exp[maxn]; //产⽣式集合set<char> First[maxn]; //First集set<char> Follow[maxn]; //Follow集set<char> Select[maxn]; //select集vector<char> ter_copy; //去掉$的终结符vector<char> ter; //终结符vector<char> not_ter; //⾮终结符};#endif 2.1.2 AnalyzTable类 功能:得到预测分析表,判断输⼊的⽂法是否是LL(1)⽂法,⽤预测分析表法判断输⼊的符号串是否符合刚才输⼊的⽂法,并打印出分析过程。
编译原理词法分析器,ll1,lr0,python实现代码[优质文档]
![编译原理词法分析器,ll1,lr0,python实现代码[优质文档]](https://img.taocdn.com/s3/m/5331c49280eb6294dd886c61.png)
elifsinOPERATOR_LIST2:
location = location +1
character = all_string[location]
ifcharacter =='=':
OPERATORTABLE.append(s + character)
Follow[Y[i]] |= First[Y[j]] -set(Epsilon)# 步骤2 FIRST(β)/~ 加入到FOLLOW(B)中。
Change =True
ifEpsilonnot inFirst[Y[j]]:
Flag =False
break
ifFlag:
if notFollow[X] <= Follow[Y[i]]:# 步骤3 β->~,把FOLLOW(A)加到FOLLOW(B)中
globalNonTermSet, TermSet, First, Follow, FirstA
forXinNonTermSet:
First[X] =set()# 初始化非终结符First集为空
forXinTermSet:
First[X] =set(X)# 初始化终结符First集为自己
Change =True
forYinGramaDict[X]:
foriinrange(len(Y)):
ifY[i]inTermSet:
continue
Flag =True
forjinrange(i +1,len(Y)):# continue
if notFirst[Y[j]] -set(Epsilon) <= Follow[Y[i]]:
编译原理 COMPILER__实验2.2-LL(1)分析法(1)

编译原理实验报告—LL(1)分析法程序班级:小组人员:实验2.2 LL(1)分析法一、实验目的:1.根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
2.本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
二、实验平台Windows + VC++6.0程序:“3-LL1.cpp”三、实验内容1.对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E→TG(2)G→+TG|-TG(3)G→ε(4)T→FS(5)S→*FS|/FS(6)S→ε(7)F→(E)(8)F→i程序功能:输入:一个以# 结束的符号串(包括+ - * /()i # ):例如:i+i*i-i/i#输出: 经完善程序目前能对所有输入串进行正确的分析.算法思想:栈用于存放文法符号,分析开始时,栈底先放一个‘#’,然后,放进文法开始符号。
同时,假定输入串之后也总有一个‘#’,标志输入串结束。
现设置一个文法分析表(见表1),矩阵M[A,a]中存放着一条关于A的产生式,指出当A面临符号a时所采用的侯选。
对任何(X,a)其中X为栈顶符号,程序每次都执行下述动作之一:✧如果X=a=‘#’,则输出分析成功,停止分析过程;✧如果X=a且不等于‘#’,则把X从栈顶逐出,让a指向下一个输入符号;✧如果X是一个非终结符,则查看分析表M.若M[A,a]中存放着关于X的一个产生式,那么首先把X从栈顶逐出,然后,把产生式的右部符号串按反序一一推进栈内,若右部符号为ε,则就什么都不进栈。
把产生式推进栈内的同时应做这个产生式相应的语义动作,例如字符i匹配成功,字符出错,相应的产生式等。
输出如下:输出每一步骤分析栈和剩余串的变化情况, 及每一步所用的产生式都明确显示出来。
运行步骤:首先在相同的路径下建一文本文档例如11.txt,将表达式写入文档内如i+i*i-i/i#;运行程序,显示界面如下,输入相应的文件名字,(输入输出文件名是自行定义)打开pp.txt文件,文法分析结果如下:错误提示:1>.输入i++i*i#,结果如下存在的问题:现在只能是遇到错误就停止,而没能实现同步符号ll(1)分析。
实行二LL1语法分析器

曲阜师范大学实验报告No. 2010416573 计算机系2010年级网络工程二班组日期2012-10-9姓名王琳课程编译原理成绩教师签章陈矗实验名称: LL(1)语法分析器实验报告【实验目的】1. 了解LL(1)语法分析是如何根据语法规则逐一分析词法分析所得到的单词,检查语法错误,即掌握语法分析过程。
2. 掌握LL(1)语法分析器的设计与调试。
【实验内容】文法:E ->TE’ ,E’-> +TE‘ | ,T-> FT’ ,T’->* FT’ | ,F-> (E ) |i针对上述文法,编写一个LL(1)语法分析程序:1. 输入:诸如i i *i 的字符串,以#结束。
2. 处理:基于分析表进行LL(1)语法分析,判断其是否符合文法。
3. 输出:串是否合法。
【实验要求】1. 在编程前,根据上述文法建立对应的、正确的预测分析表。
2. 设计恰当的数据结构存储预测分析表。
3. 在C、C++、Java 中选择一种擅长的编程语言编写程序,要求所编写的程序结构清晰、正确。
【实验环境】1.此算法是一个java 程序,要求在eclipse软件中运行2.硬件windows 系统环境中【实验分析】读入文法,判断正误,如无误,判断是否是LL(1)文法,若是构造分析表【实验程序】package llyufa;public class Accept2 {public static StringBuffer stack=new StringBuffer("#E");public static StringBuffer stack2=new StringBuffer("i+i*i+i#");public static void main(String arts[]){//stack2.deleteCharAt(0);System.out.print(accept(stack,stack2));}public static boolean accept(StringBuffer stack,StringBuffer stack2){//判断识别与否boolean result=true;o uter:while (true) {System.out.format("%-9s",stack+"");System.out.format("%9s",stack2+"\n");char c1 = stack.charAt(stack.length() - 1);char c2 = stack2.charAt(0);if(c1=='#'&&c2=='#')return true;switch (c1) {case'E':if(!E(c2)) {result=false;break outer;}break;case'P': //P代表E’if(!P(c2)) {result=false;break outer;}break;case'T':if(!T(c2)) {result=false;break outer;}break;case'Q': //Q代表T’if(!Q(c2)) {result=false;break outer;}break;case'F':if(!F(c2)) {result=false;break outer;}break;default: {//终结符的时候if(c2==c1){stack.deleteCharAt(stack.length()-1);stack2.deleteCharAt(0);//System.out.println();}else{return false;}}}if(result=false)break outer;}r eturn result;}public static boolean E(char c) {//语法分析子程序 Eb oolean result=true;i f(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("PT");}e lse if(c=='('){stack.deleteCharAt(stack.length()-1);stack.append("PT");}e lse{System.err.println("E 推导时错误!不能匹配!");result=false;}r eturn result;}public static boolean P(char c){//语法分析子程序 Pb oolean result=true;i f(c=='+') {stack.deleteCharAt(stack.length()-1);stack.append("PT+");}e lse if(c==')') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse if(c=='#') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse{System.err.println("P 推导时错误!不能匹配!");result=false;}r eturn result;}public static boolean T(char c) {//语法分析子程序 Tb oolean result=true;i f(c=='i') {stack.deleteCharAt(stack.length()-1);}e lse if(c=='(') {stack.deleteCharAt(stack.length()-1);stack.append("QF");}e lse{result=false;System.err.println("T 推导时错误!不能匹配!");}r eturn result;}public static boolean Q(char c){//语法分析子程序 Qb oolean result=true;i f(c=='+') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse if(c=='*') {stack.deleteCharAt(stack.length()-1);stack.append("QF*");}e lse if(c==')') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse if(c=='#') {stack.deleteCharAt(stack.length()-1);//stack.append("");}e lse{result=false;System.err.println("Q 推导时错误!不能匹配!");}r eturn result;}public static boolean F(char c) {//语法分析子程序 Fb oolean result=true;i f(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("i");}e lse if(c=='(') {stack.deleteCharAt(stack.length()-1);}e lse{result=false;System.err.println("F 推导时错误!不能匹配!");}r eturn result;}/* public static StringBuffer changeOrder(String s){//左右交换顺序S tringBuffer sb=new StringBuffer();f or(int i=0;i<s.length();i++){sb.append(s.charAt(s.length()-1-i));}r eturn sb;}*/}【执行结果】【小结】通过这次的实验,更深入的了解了编译原理,熟悉了语法分析器的制作和使用,了解了更多关于语言的知识,极大地提高了动手能力。
LL(1)语法分析实验报告

LL(1)语法分析实验报告一、实验目的通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,检查语法错误,进一步掌握常用的语法分析方法。
二、实验内容构造LL(1)语法分析程序,任意输入一个文法符号串,并判断它是否为文法的一个句子。
程序要求为该文法构造预测分析表,并按照预测分析算法对输入串进行语法分析,判别程序是否符合已知的语法规则,如果不符合则输出错误信息。
消除递归前的文法消除递归后的等价文法E→E+T E→TE’E→T E’→+TE’|εT→T*F T→FT’T→F T’→*FT’|εF→(E)|i F→(E)|i根据已建立的分析表,对下列输入串:i+i*i进行语法分析,判断其是否符合文法。
三、实验要求1.根据已由的文法规则建立LL(1)分析表;2.输出分析过程。
请输入待分析的字符串: i+i*i符号栈输入串所用产生式#E i+i*i# E→TE’#E’T i+i*i# T→FT’#E’T’F i+i*i# F→i#E’T’i i+i*i##E’T’ +i*i# T’→ε#E’ +i*i# E’→+TE’#E’T+ +i*i##E’T i*i# T→FT’#E’T’F i*i# F→i#E’T’i i*i##E’T’ *i# T’→*FT’#E’T’F* *i##E’T’F i# F→i#E’T’i i##E’T’ # T’→ε#E’ # E’→ε# #四、程序思路模块结构:1、定义部分:定义常量、变量、数据结构。
2、初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体等);3、运行程序:让程序分析一个text文件,判断输入的字符串是否符合文法定义的规则;4、利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示简单的错误提示。
五、程序流程图输入要分析的串判断输入串是否正确判断分析句型是否完全匹配?成功失败否是是否八、程序调试与测试结果运行后结果如下:九、实验心得递归下降分析法是确定的自上而下分析法,这种分析法要求文法是LL(1)文法。
编译原理实验二LL(1)语法分析实验报告

专题3_LL(1)语法分析设计原理与实现李若森 13281132 计科1301一、理论传授语法分析的设计方法和实现原理;LL(1) 分析表的构造;LL(1)分析过程;LL(1)分析器的构造。
二、目标任务实验项目实现LL(1)分析中控制程序(表驱动程序);完成以下描述算术表达式的 LL(1)文法的LL(1)分析程序。
G[E]:E→TE’E’→ATE’|εT→FT’T’→MFT’|εF→(E)|iA→+|-M→*|/设计说明终结符号i为用户定义的简单变量,即标识符的定义。
加减乘除即运算符。
设计要求(1)输入串应是词法分析的输出二元式序列,即某算术表达式“专题 1”的输出结果,输出为输入串是否为该文法定义的算术表达式的判断结果;(2)LL(1)分析程序应能发现输入串出错;(3)设计两个测试用例(尽可能完备,正确和出错),并给出测试结果。
任务分析重点解决LL(1)表的构造和LL(1)分析器的实现。
三、实现过程实现LL(1)分析器a)将#号放在输入串S的尾部b)S中字符顺序入栈c)反复执行c),任何时候按栈顶Xm和输入ai依据分析表,执行下述三个动作之一。
构造LL(1)分析表构造LL(1)分析表需要得到文法G[E]的FIRST集和FOLLOW集。
构造FIRST(α)构造FOLLOW(A)构造LL(1)分析表算法根据上述算法可得G[E]的LL(1)分析表,如表3-1所示:表3-1 LL(1)分析表主要数据结构pair<int, string>:用pair<int, string>来存储单个二元组。
该对照表由专题1定义。
map<string, int>:存储离散化后的终结符和非终结符。
vector<string>[][]:存储LL(1)分析表函数定义init:void init();功能:初始化LL(1)分析表,关键字及识别码对照表,离散化(非)终结符传入参数:(无)传出参数:(无)返回值:(无)Parse:bool Parse( const vector<PIS> &vec, int &ncol );功能:进行该行的语法分析传入参数:vec:该行二元式序列传出参数:emsg:出错信息epos:出错标识符首字符所在位置返回值:是否成功解析。
编译原理 语法分析程序设计(LL(1)分析法)

1.实验目的:掌握LL(1)分析法的基本原理,掌握LL(1)分析表的构造方法,掌握LL(1) 驱动程序的构造方法。
2.实验要求:实现LR分析法(P147,例4.6)或预测分析法(P121,例4.3)。
3.实验环境:一台配置为1G的XP操作系统的PC机;Visual C++6.0.4.实验原理:编译程序的语法分析器以单词符号作为输入,分析单词符号串是否形成符合语法规则的语法单位,如表达式、赋值、循环等,最后看是否构成一个符合要求的程序,按该语言使用的语法规则分析检查每条语句是否有正确的逻辑结构,程序是最终的一个语法单位。
编译程序的语法规则可用上下文无关文法来刻画。
语法分析的方法分为两种:自上而下分析法和自下而上分析法。
自上而下就是从文法的开始符号出发,向下推导,推出句子。
而自下而上分析法采用的是移进归约法,基本思想是:用一个寄存符号的先进后出栈,把输入符号一个一个地移进栈里,当栈顶形成某个产生式的一个候选式时,即把栈顶的这一部分归约成该产生式的左邻符号。
自顶向下带递归语法分析:1、首先对所以的生成式消除左递归、提取公共左因子2、在源程序里建立一个字符串数组,将所有的生成式都存在这个数组中。
3、给每个非终结符写一个带递归的匹配函数,其中起始符的函数写在main函数里。
这些函数对生成式右边从左向右扫描,若是终结符直接进行匹配,匹配失败,则调用出错函数。
如果是非终结符则调用相应的非终结符函数。
4、对输入的符号串进行扫描,从起始符的生成式开始。
如果匹配成功某个非终结符生成式右边的首个终结符,则将这个生成式输出。
匹配过程中,应该出现的非终结符没有出现,则出错处理。
5.软件设计与编程:对应源程序代码:#include <iostream.h>#include <stdio.h>#include <stack>using namespace std;struct Node1{ char vn;char vt;char s[10];}MAP[20]; //存储分析预测表每个位置对应的终结符,非终结符,产生式int k; //用R代表E',W代表T',e代表空char start='E';int len=8;charG[10][10]={"E->TR","R->+TR","R->e","T->FW","W->*FW","W->e","F->(E)","F->i"};//存储文法中的产生式char VN[6]={'E','R','T','W','F'}; //存储非终结符char VT[6]={'i','+','*','(',')','#'}; //存储终结符char SELECT[10][10]={"(,i","+","),#","(,i","*","+,),#","(","i"};//存储文法中每个产生式对应的SELECT集charRight[10][8]={"->TR","->+TR","->e","->FW","->*FW","->e","->(E)","->i"};stack <char> stak;bool compare(char *a,char *b){ int i,la=strlen(a),j,lb=strlen(b);for(i=0;i<la;i++){for(j=0;j<lb;j++){ if(a[i]==b[j])return 1; }}return 0;}char *Find(char vn,char vt){ int i;for(i=0;i<k;i++){ if(MAP[i].vn==vn && MAP[i].vt==vt){return MAP[i].s;} } return "error";}char * Analyse(char * word){ char p,action[10],output[10];int i=1,j,l=strlen(word),k=0,l_act,m;while(!stak.empty()){stak.pop();}stak.push('#');stak.push(start);printf("___________________________________________________________\n"); printf("\n 对符号串%s的分析过程\n",word);printf("-----------------------------------------------------------------------\n ");printf("\n");printf(" 步骤栈顶元素剩余输入串动作\n");printf("-----------------------------------------------------------------------\n ");p=stak.top();while(p!='#'){ printf("%7d ",i++);p=stak.top();stak.pop();printf("%6c ",p);for(j=k,m=0;j<l;j++){output[m++]=word[j];}output[m]='\0';printf("%10s",output);if(p==word[k]){ if(p=='#'){ printf(" 分析成功 \n");return "SUCCESS";}printf(" 匹配终结符%c\n",p);k++;}else{ strcpy(action,Find(p,word[k]));if(strcmp(action,"error")==0){ printf(" 没有可用的产生式\n");return "ERROR"; }printf(" 展开非终结符%c%s\n",p,action);int l_act=strlen(action);if(action[l_act-1]=='e'){continue;}for(j=l_act-1;j>1;j--){stak.push(action[j]);}}}if(strcmp(output,"#")!=0)return "ERROR";}int main (){ freopen("in.txt","r",stdin);char source[100];int i,j,flag,l,m;printf("\n***为了方便编写程序,用R代表E',W代表T',e代表空*****\n\n"); printf("该文法的产生式如下:\n");for(i=0;i<len;i++){printf(" %s\n",G[i]);}printf("___________________________________________________________\n"); printf("\n该文法的SELECT集如下:\n");for(i=0;i<len;i++){ printf(" SELECT(%s) = { %s }\n",G[i],SELECT[i]); }printf("___________________________________________________________\n"); //判断是否是LL(1)文法flag=1;for(i=0;i<8;i++){ for(j=i+1;j<8;j++){if(G[i][0]==G[j][0]){ if(compare(SELECT[i],SELECT[j])){flag=0;break;} } }if(j!=8){break;}}if(flag){printf("\n有相同左部产生式的SELECT集合的交集为空,所以文法是LL(1)文法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
编译原理程序设计实验报告——表达式语法分析器的设计班级:计算机1306班:涛学号:20133967 实验目标:用LL(1)分析法设计实现表达式语法分析器实验容:⑴概要设计:通过对实验一的此法分析器的程序稍加改造,使其能够输出正确的表达式的token序列。
然后利用LL(1)分析法实现语法分析。
⑵数据结构:int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};⑶分析表及流程图逆序压栈int IsLetter(char ch) //判断ch是否为字母int IsDigit(char ch) //判断ch是否为数字int Iskey(char *string) //判断是否为关键字int Isbound(char ch) //判断是否为界符int Isboundnum(char ch) //给出界符所在token值int init(STack *s) //栈初始化int pop(STack *s,char *ch) //弹栈操作int push(STack *s,char ch) //压栈操作void LL1(); //分析函数源程序代码:(加入注释)#include<stdio.h>#include<string.h>#include<ctype.h>#include<windows.h>#include <stdlib.h>int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};typedef struct Stack STack;int init(STack *s) //栈初始化{(*s).base=(char*)malloc(100*sizeof(char)); if(!(*s).base)exit(0);(*s).top=(*s).base;(*s).stacksize=100;printf("初始化栈\n");return 0;}int pop(STack *s,char *ch) //弹栈操作{if((*s).top==(*s).base){printf("弹栈失败\n");return 0;(*s).top--;*ch=*((*s).top);printf("%c",*ch);return 1;}int push(STack *s,char ch) //压栈操作{if((*s).top-(*s).base>=(*s).stacksize){(*s).base=(char*)realloc((*s).base,((*s).stacksize+10)*sizeof(char)); if(!(*s).base)exit(0);(*s).top=(*s).base+(*s).stacksize;(*s).stacksize+=10;}*(*s).top=ch;*(*s).top++;return 1;}void LL1();int IsLetter(char ch) //判断ch是否为字母{int i;for(i=0;i<=45;i++)if ((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))return 1;return 0;}int IsDigit(char ch) //判断ch是否为数字{int i;for(i=0;i<=10;i++)if (ch>='0'&&ch<='9')return 1;return 0;}int Isbound(char ch) //判断是否为界符{int i;for(i=0;i<2;i++)if(ch==bound[i]){return i+1;}}return 0;}int Isoperate(char ch) //判断是否为运算符{int i;for(i=0;i<4;i++){if(ch==operate[i]){return i+3;}}return 0;}int main(){FILE *fp;int q=0,m=0;char sour[200]=" ";printf("请将源文件置于以下位置并按以下方式命名:F:\\2.txt\n");if((fp=fopen("F:\\2.txt","r"))==NULL){printf("文件未找到!\n");}else{while(!feof(fp)){if(isspace(ch=fgetc(fp)));else{sour[q]=ch;q++;}}}int p=0;printf("输入句子为:\n");for(p;p<=q;p++)printf("%c",sour[p]);}printf("\n");int state=0,nowlen=0;BOOLEAN OK=TRUE,ERR=FALSE;int i,flagpoint=0;for(i=0;i<q;i++){if(sour[i]=='#')tokenlist[m].code=='#';switch(state){case 0:ch=sour[i];if(Isbound(ch)){if(ERR){printf("无法识别\n");ERR=FALSE;OK=TRUE;}else if(!OK){printf("<10,%s>标识符\n",nowword); tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}state=4;}else if(IsDigit(ch)){if(OK){memset(nowword,0,strlen(nowword)); nowlen=0;nowword[nowlen]=ch;nowlen++;state=3;OK=FALSE;break;}else{nowword[nowlen]=ch;nowlen++;}}else if(IsLetter(ch)){if(OK){memset(nowword,0,strlen(nowword));nowlen=0;nowword[nowlen]=ch;nowlen++;OK=FALSE;}else{nowword[nowlen]=ch;nowlen++;}}else if(Isoperate(ch)){if(!OK){printf("<10,%s>标识符\n",nowword);tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}printf("<%d,%c>运算符\n",Isoperate(ch),ch); tokentemp.code=Isoperate(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;}break;case 3:if(IsLetter(ch)){printf("错误\n");nowword[nowlen]=ch;nowlen++;ERR=FALSE;state=0;break;}if(IsDigit(ch=sour[i])){nowword[nowlen]=ch;nowlen++;}else if(sour[i]=='.'&&flagpoint==0){flagpoint=1;nowword[nowlen]=ch;nowlen++;}else{printf("<20,%s>数字\n",nowword);i--;state=0;OK=TRUE;tokentemp.code=20;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;}break;case 4:i--;printf("<%d,%c>界符\n",Isbound(ch),ch); tokentemp.code=Isbound(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;state=0;OK=TRUE;break;}}printf("tokenlist值为%d\n",m);int t=0;tokenlist[m+1].code='r';m++;for(t;t<m;t++){printf("tokenlist%d值为%d\n",t,tokenlist[t].code);}LL1();printf("tokenlist值为%d\n",m);if(op+1==m)printf("OK!!!");elseprintf("WRONG!!!");return 0;}void LL1(){STack s;init(&s);push(&s,'#');push(&s,'E');char ch;int flag=1;do{pop(&s,&ch);printf("输出栈顶为%c\n",ch);printf("输出栈顶为%d\n",ch);printf("当前p值为%d\n",op);if((ch=='(')||(ch==')')||(ch=='+')||(ch=='-')||(ch=='*')||(ch=='/')||(ch==10)||(ch==20)) {if(tokenlist[op].code==1||tokenlist[op].code==20||tokenlist[op].code==10||tokenlist[op].cod e==2||tokenlist[op].code==3||tokenlist[op].code==4||tokenlist[op].code==5||tokenlist[op].co de==6)op++;else{printf("WRONG!!!");exit(0);}}else if(ch=='#'){if(tokenlist[op].code==0)flag=0;else{printf("WRONG!!!");exit(0);}}else if(ch=='E'){printf("进入E\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'R');printf("将R压入栈\n");push(&s,'T');}}else if(ch=='R'){printf("进入R\n");if(tokenlist[op].code==3||tokenlist[op].code==4){push(&s,'R');push(&s,'T');printf("将T压入栈\n");push(&s,'+');}if(tokenlist[op].code==2||tokenlist[op].code==0){}}else if(ch=='T'){printf("进入T\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'Y');push(&s,'F');}}else if(ch=='Y'){printf("进入Y\n");if(tokenlist[op].code==5||tokenlist[op].code==6){push(&s,'Y');push(&s,'F');push(&s,'*');}elseif(tokenlist[op].code==3||tokenlist[op].code==2||tokenlist[op].code==0||tokenlist[op].code= =4){}}else if(ch=='F'){printf("进入F\n");if(tokenlist[op].code==10||tokenlist[op].code==20){push(&s,10);}if(tokenlist[op].code==1){push(&s,')');push(&s,'E');push(&s,'(');}}else{printf("WRONG!!!!");exit(0);}}while(flag);}程序运行结果:(截屏)输入:((Aa+Bb)*(88.2/3))#注:如需运行请将文件放置F盘,并命名为:2.txt输出:思考问题回答:LL(1)分析法的主要问题就是要正确的将文法化为LL (1)文法。