编译原理语法分析器实验报告
编译原理语法分析实验报告

编译原理语法分析实验报告编译原理语法分析实验报告引言编译原理是计算机科学中的重要课程,它研究的是如何将高级语言转化为机器语言的过程。
语法分析是编译过程中的一个关键步骤,它负责将输入的源代码转化为抽象语法树,为后续的语义分析和代码生成提供便利。
本实验旨在通过实践,加深对语法分析的理解,并掌握常见的语法分析算法。
实验环境本次实验使用的是Python编程语言,因为Python具有简洁的语法和强大的库支持,非常适合用于编译原理的实验。
实验步骤1. 词法分析在进行语法分析之前,需要先进行词法分析,将源代码划分为一个个的词法单元。
词法分析器的实现可以使用正则表达式或有限自动机等方式。
在本实验中,我们选择使用正则表达式来进行词法分析。
2. 文法定义在进行语法分析之前,需要先定义源代码的文法。
文法是一种形式化的表示,它描述了源代码中各个语法成分之间的关系。
常见的文法表示方法有巴科斯范式(BNF)和扩展巴科斯范式(EBNF)。
在本实验中,我们选择使用BNF来表示文法。
3. 自顶向下语法分析自顶向下语法分析是一种基于产生式的语法分析方法,它从文法的起始符号开始,逐步展开产生式,直到生成目标字符串。
自顶向下语法分析的关键是选择合适的产生式进行展开。
在本实验中,我们选择使用递归下降分析法进行自顶向下语法分析。
4. 自底向上语法分析自底向上语法分析是一种基于移进-归约的语法分析方法,它从输入串的左端开始,逐步将输入符号移入分析栈,并根据产生式进行归约。
自底向上语法分析的关键是选择合适的归约规则。
在本实验中,我们选择使用LR(1)分析法进行自底向上语法分析。
实验结果经过实验,我们成功实现了自顶向下和自底向上两种语法分析算法,并对比了它们的优缺点。
自顶向下语法分析的优点是易于理解和实现,可以直接根据产生式进行展开,但缺点是对左递归和回溯的处理比较困难,而且效率较低。
自底向上语法分析的优点是可以处理任意文法,对左递归和回溯的处理较为方便,而且效率较高,但缺点是实现相对复杂,需要构建分析表和使用分析栈。
编译原理实验报告

编译原理实验报告一、实验目的本次编译原理实验的主要目的是通过实践加深对编译原理中词法分析、语法分析、语义分析和代码生成等关键环节的理解,并提高实际动手能力和问题解决能力。
二、实验环境本次实验使用的编程语言为 C/C++,开发工具为 Visual Studio 2019,操作系统为 Windows 10。
三、实验内容(一)词法分析器的设计与实现词法分析是编译过程的第一个阶段,其任务是从输入的源程序中识别出一个个具有独立意义的单词符号。
在本次实验中,我们使用有限自动机的理论来设计词法分析器。
首先,我们定义了单词的种类,包括关键字、标识符、常量、运算符和分隔符等。
然后,根据这些定义,构建了相应的状态转换图,并将其转换为程序代码。
在实现过程中,我们使用了字符扫描和状态转移的方法,逐步读取输入的字符,判断其所属的单词类型,并将其输出。
(二)语法分析器的设计与实现语法分析是编译过程的核心环节之一,其任务是在词法分析的基础上,根据给定的语法规则,判断输入的单词序列是否构成一个合法的句子。
在本次实验中,我们采用了自顶向下的递归下降分析法来实现语法分析器。
首先,我们根据给定的语法规则,编写了相应的递归函数。
每个函数对应一种语法结构,通过对输入单词的判断和递归调用,来确定语法的正确性。
在实现过程中,我们遇到了一些语法歧义的问题,通过仔细分析语法规则和调整函数的实现逻辑,最终解决了这些问题。
(三)语义分析与中间代码生成语义分析的任务是对语法分析所产生的语法树进行语义检查,并生成中间代码。
在本次实验中,我们使用了四元式作为中间代码的表示形式。
在语义分析过程中,我们检查了变量的定义和使用是否合法,类型是否匹配等问题。
同时,根据语法树的结构,生成相应的四元式中间代码。
(四)代码优化代码优化的目的是提高生成代码的质量和效率。
在本次实验中,我们实现了一些基本的代码优化算法,如常量折叠、公共子表达式消除等。
通过对中间代码进行分析和转换,减少了代码的冗余和计算量,提高了代码的执行效率。
编译原理语法分析试验报告

编译原理语法分析试验报告语法分析是编译原理中的重要内容之一,主要用于对源程序进行语法检查,判断其是否符合给定的语法规则。
本次试验通过使用ANTLR工具,对C语言的子集进行了语法分析的实现。
一、实验目的:1.了解语法分析的基本概念和方法;2.使用ANTLR工具生成语法分析器;3.掌握ANTLR工具的基本使用方法;4.实现对C语言子集的语法分析。
二、实验内容:本次试验主要内容是使用ANTLR工具生成C语言子集的语法分析器,并对给定的C语言子集进行语法分析。
三、实验步骤:1.学习ANTLR工具的基本概念和使用方法;2.根据C语言子集的语法规则,编写ANTLR的语法文件(.g文件);3.使用ANTLR工具生成语法分析器;4.编写测试代码,对给定的C语言子集进行语法分析。
四、实验结果:经过以上的步骤,得到了一个完整的C语言子集的语法分析器,并且通过测试代码对给定的C语言子集进行了语法分析。
五、实验总结:通过本次实验,我对语法分析有了更深入的了解,掌握了使用ANTLR工具生成语法分析器的基本方法,同时也巩固了对C语言的基本语法规则的理解。
在实验过程中,遇到了一些问题,例如在编写ANTLR的语法文件时,对一些特殊语法规则的处理上有些困惑,但通过查阅资料和与同学的探讨,最终解决了这些问题。
本次试验对于我的学习有很大的帮助,我了解到了编译原理中的重要内容之一,也更深入地理解了语法分析的基本原理和方法。
通过实验,我发现使用ANTLR工具能够更方便地生成语法分析器,大大提高了开发效率。
总之,本次试验让我对编译原理中的语法分析有了更深入的了解,并且提高了我的编程能力和分析问题的能力。
在今后的学习和工作中,我将继续深入研究编译原理相关的知识,并应用到实际项目中。
国开电大 编译原理 实验4:语法分析实验报告

国开电大编译原理实验4:语法分析实
验报告
1. 实验目的
本实验的目的是研究和掌握语法分析的原理和实现方法。
2. 实验内容
本次实验主要包括以下内容:
- 设计并实现自顶向下的LL(1)语法分析器;
- 通过语法分析器对给定的输入串进行分析,并输出相应的分析过程;
- 编写测试用例,验证语法分析器的正确性。
3. 实验步骤
3.1 设计LL(1)文法
首先,根据实验要求和给定的语法规则,设计LL(1)文法。
3.2 构建预测分析表
根据所设计的LL(1)文法,构建预测分析表。
3.3 实现LL(1)语法分析器
根据预测分析表,实现自顶向下的LL(1)语法分析器。
3.4 对输入串进行分析
编写程序,通过LL(1)语法分析器对给定的输入串进行分析,并输出相应的分析过程和结果。
3.5 验证语法分析器的正确性
设计多组测试用例,包括正确的语法串和错误的语法串,验证语法分析器的正确性和容错性。
4. 实验结果
经过实验,我们成功设计并实现了自顶向下的LL(1)语法分析器,并对给定的输入串进行了分析。
实验结果表明该语法分析器具有较好的准确性和容错性。
5. 实验总结
通过本次实验,我们对语法分析的原理和实现方法有了更深入的了解。
同时,我们也学会了如何设计并实现自顶向下的LL(1)语
法分析器,并验证了其正确性和容错性。
这对于进一步研究编译原理和深入理解编程语言的语法结构具有重要意义。
6. 参考资料
- 《编译原理与技术》
- 课程实验文档及代码。
编译原理语法分析实验报告

编译原理语法分析实验报告编译原理实验报告一、实验目的本实验的主要目的是熟悉编译原理中的语法分析算法及相关知识,并通过实际编码实现一个简单的语法分析器。
二、实验内容1.完成一个简单的编程语言的语法定义,并用BNF范式表示;2.基于给定的语法定义,实现自顶向下的递归下降语法分析器;3.实验所用语法应包含终结符、非终结符、产生式及预测分析表等基本要素;4.实现语法分析器的过程中,需要考虑文法的二义性和优先级等问题。
三、实验步骤1.设计一个简单的编程语言的语法,用BNF范式进行表达。
例如,可以定义表达式文法为:<exp> ::= <term> { + <term> , - <term> }<term> ::= <factor> { * <factor> , / <factor> }<factor> ::= <digit> , (<exp>) , <variable><digit> ::= 0,1,2,3,4,5,6,7,8,9<variable> ::= a,b,c,...,z2. 根据所设计的语法,构建语法分析器。
首先定义需要用到的终结符、非终结符和产生式。
例如,终结符可以是+、-、*、/、(、)等,非终结符可以是<exp>、<term>、<factor>等,产生式可以是<exp> ::= <term> + <term> , <term> - <term>等。
3.实现递归下降语法分析器。
根据语法的产生式,编写相应的递归函数进行递归下降分析。
递归函数的输入参数通常是一个输入字符串和当前输入位置,输出结果通常是一个语法树或语法分析错误信息。
4.在语法分析的过程中,需要处理语法的二义性和优先级问题。
编译原理语法分析器实验报告

编译原理语法分析器实验报告班级:学号:姓名:实验名称语法分析器一、实验目的1、根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
2、本次实验的目的主要是加深对自上而下分析法的理解。
二、实验内容[问题描述]递归下降分析法:0.定义部分:定义常量、变量、数据结构。
1.初始化:从文件将输入符号串输入到字符缓冲区中。
2.利用递归下降分析法分析,对每个非终结符编写函数,在主函数中调用文法开始符号的函数。
LL(1)分析法:模块结构:1、定义部分:定义常量、变量、数据结构。
2、初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体等);3、运行程序:让程序分析一个text文件,判断输入的字符串是否符合文法定义的规则;4、利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示简单的错误提示。
[基本要求]1. 对数据输入读取2. 格式化输出分析结果2.简单的程序实现词法分析public static void main(String args[]) {LL l = new LL();l.setP();String input = "";boolean flag = true;while (flag) {try {InputStreamReader isr = newInputStreamReader(System.in);BufferedReader br = new BufferedReader(isr);System.out.println();System.out.print("请输入字符串(输入exit退出):");input = br.readLine();} catch (Exception e) {e.printStackTrace();}if(input.equals("exit")){flag = false;}else{l.setInputString(input);l.setCount(1, 1, 0, 0);l.setFenxi();System.out.println();System.out.println("分析过程");System.out.println("----------------------------------------------------------------------");System.out.println(" 步骤| 分析栈| 剩余输入串| 所用产生式");System.out.println("----------------------------------------------------------------------");boolean b = l.judge();System.out.println("----------------------------------------------------------------------");if(b){System.out.println("您输入的字符串"+input+"是该文法的一个句子");}else{System.out.println("您输入的字符串"+input+"有词法错误!");}}}}//实现各函数并且加注释三、编程并上机调试运行运行结果如下图:四、实验小结通过这次实验,我对语法分析有了更深刻的了解,对它的形成有了更清楚得认识。
编译原理 语法分析实验报告

h=copy[1]-'0';//因为状态从0开始
strcpy(copy1,LR[h]);
while(copy1[0]!=vn[k]) //获取当前k值
k++;
l=strlen(LR[h])-4;
top1=top1-l+1;
top2=top2-l+1;
y=a[top1-1];
p=goto1[y][k];
T->T*F|F
F->(E)|i
2设计及实现能够识别表达式的LR分析程序。
文法如下:
G[E]:E->E+T|T
T->T*F|F
F->(E)|i
③ 设计及实现能够识别表达式的算符优先分析程序。
文法如下:
G[E]:E->E+T|T
T->T*F|F
F->P↑F|P
P->(E)|i
④设计及实现计算表达式的计算器。
{
printf("%c",copy[i])
return 0;
i++;
}
printf("\n");
}
if(copy[0]=='r')
{ /*处理归约*/
i=0;
while(copy[i]!='#')//例 "S3#" 输出ACTION
{
printf("%c",copy[i])
return 0;
i++;
{ /*输出符号栈*/
printf("%c",b[n]);
n=n+1;
编译原理语法分析器实验报告

西安邮电大学编译原理实验报告学院名称:计算机学院****:***实验名称:语法分析器的设计与实现班级:计科1405班学号:04141152时间:2017年5月12日一.实验目的1.熟悉语法分析的过程2.理解相关文法分析的步骤3.熟悉First集和Follow集的生成二.实验要求对于给定的文法,试编写调试一个语法分析程序:要求和提示:1)可选择一种你感兴趣的语法分析方法(LL(1)、算符优先、递归下降、SLR(1)等)作为编制语法分析程序的依据。
2)对于所选定的分析方法,如有需要,应选择一种合适的数据结构,以构造所给文法的机内表示。
3)能进行分析过程模拟。
如输入一个句子,能输出与句子对应的语法树,能对语法树生成过程进行模拟;能够输出分析过程每一步符号栈的变化情况。
设计一个由给定文法生成First集和Follow集并进行简化的算法动态模拟三.实验内容1.文法:E->TE’E’->+TE’|εT->FT’T’->*FT’|εF->(E)|i:2.程序描述(LL(1)文法)本程序是基于已构建好的某一个语法的预测分析表来对用户的输入字符串进行分析,判断输入的字符串是否属于该文法的句子。
基本实现思想:接收用户输入的字符串(字符串以“#”表示结束)后,对用做分析栈的一维数组和存放分析表的二维数组进行初始化。
然后取出分析栈的栈顶字符,判断是否为终结符,若为终结符则判断是否为“#”且与当前输入符号一样,若是则语法分析结束,输入的字符串为文法的一个句子,否则出错若不为“#”且与当前输入符号一样则将栈顶符号出栈,当前输入符号从输入字符串中除去,进入下一个字符的分析。
若不为“#”且不与当前输入符号一样,则出错。
3.判断是否LL(1)文法要判断是否为LL(1)文法,需要输入的文法G有如下要求:具有相同左部的规则的SELECT集两两不相交,即:SELECT(A→?)∩SELECT(A→?)= ?如果输入的文法都符合以上的要求,则该文法可以用LL(1)方法分析。
编译原理实验报告(语法分析器)

.编译原理实验专业:13级网络工程语法分析器1一、实现方法描述所给文法为G【E】;E->TE’E’->+TE’|空T->FT’T’->*FT’|空F->i|(E)递归子程序法:首先计算出五个非终结符的first集合follow集,然后根据五个产生式定义了五个函数。
定义字符数组vocabulary来存储输入的句子,字符指针ch指向vocabulary。
从非终结符E函数出发,如果首字符属于E的first集,则依次进入T函数和E’函数,开始递归调用。
在每个函数中,都要判断指针所指字符是否属于该非终结符的first集,属于则根据产生式进入下一个函数进行调用,若first集中有空字符,还要判断是否属于该非终结符的follow集。
以分号作为结束符。
二、实现代码头文件shiyan3.h#include<iostream>#include<cstdio>#include<string>using namespace std;#define num 100char vocabulary[num];char *ch;void judge_E();void judge_EE();void judge_T();void judge_TT();void judge_F();源文件#include"shiyan3.h"void judge_E(){if(*ch==';'){cout<<"该句子符合此文法!"<<endl;int a=0;cout<<"按1结束程序"<<endl;cin>>a;if(a==1)exit(0);}elseif(*ch=='('||*ch=='i'){judge_T();judge_EE();}else{cout<<"该句子不匹配此文法!"<<endl;int a=0;cout<<"按1结束程序"<<endl;cin>>a;if(a==1)exit(0);}}void judge_EE(){if(*ch==';'){cout<<"该句子符合此文法!"<<endl;int a=0;cout<<"按1结束程序"<<endl;cin>>a;if(a==1)exit(0);}if(*ch=='+'){ch++;judge_T();judge_EE();}elseif(*ch=='#'||*ch==')')return;else{cout<<"该句子不匹配此文法!"<<endl;int a=0;cout<<"按1结束程序"<<endl;cin>>a;if(a==1)exit(0);}}void judge_T(){if(*ch==';'){cout<<"该句子符合此文法!"<<endl;int a=0;cout<<"按1结束程序"<<endl;cin>>a;if(a==1)exit(0);}if(*ch=='('||*ch=='i'){judge_F();judge_TT();}else{cout<<"该句子不匹配此文法!"<<endl;int a=0;cout<<"按1结束程序"<<endl;cin>>a;if(a==1)exit(0);}}void judge_TT(){if(*ch==';'){cout<<"该句子符合此文法!"<<endl;int a=0;cout<<"按1结束程序"<<endl;cin>>a;if(a==1)exit(0);}if(*ch=='*'){ch++;judge_F();judge_TT();}elseif(*ch==')'||*ch=='+'||*ch=='#')return;else{cout<<"该句子不匹配此文法!"<<endl;int a=0;cout<<"按1结束程序"<<endl;cin>>a;if(a==1)exit(0);}}void judge_F(){if(*ch==';'){cout<<"该句子符合此文法!"<<endl;int a=0;cout<<"按1结束程序"<<endl;cin>>a;if(a==1)exit(0);}if(*ch=='('){ch++;judge_E();if(*ch==')'){ch++;}else{cout<<"该句子不匹配此文法!"<<endl;int a=0;cout<<"按1结束程序"<<endl;cin>>a;if(a==1)exit(0);}}elseif(*ch=='i'){ch++;//cout<<*ch;}else{cout<<"该句子不匹配此文法!"<<endl;int a=0;cout<<"按1结束程序"<<endl;cin>>a;if(a==1)exit(0);}}void main(){//char *ch;cout<<"**********************欢迎使用语法分析器************************"<<endl;cout<<"请输入一个句子:"<<endl;cin.getline(vocabulary,15);ch=vocabulary;judge_E();cout<<endl;cout<<"************************结束使用,再见!**************************"<<endl;}三、运行结果四、心得体会此次实验使用的是递归子程序法,用这个方法最大的问题就是函数里的递归调用,一不小心就把人绕糊涂了。
编译原理语法分析试验报告

二、语法分析(一)实验题目编写程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析。
(二)实验内容和要求1.要求程序至少能分析的语言的内容有:1)变量说明语句2)赋值语句3)条件转移语句4)表达式(算术表达式和逻辑表达式)5)循环语句6)过程调用语句2.此外要处理:包括依据文法对句子进行分析;出错处理;输出结果的构造。
3.输入输出的格式:输入:单词文件(词法分析的结果)输出:语法成分列表或语法树(都用文件表示),错误文件(对于不合文法的句子)。
4.实现方法:可以采用递归下降分析法,LL (1)分析法,算符优先法或LR分析法的任何一种,也可以针对不同的句子采用不同的分析方法。
(三)实验分析与设计过程1.待分析的C语言子集的语法:该语法为一个缩减了的C语言文法,估计是整个C语言所有文法的60% (各种关键字的定义都和词法分析中的一样),具体的文法如下:语法:100: program -> declaiationjist101: declarationjist -> declarationjist declaration declaration102: declaiation -> vai_declaiation|fijn_declaration103: vai.declaration -> type_specifier ID;|tvpe_specifier ID [NUM];104: typ Jsp亡cifki -> mt|void|float|chai-|long|double|105: fun_declaration -> type_specifier ID (params)|compound_stmt106: paranis -> params_list|void107: paramjist ->paiam_list.paiam|paiam108: param -> type-spectifier ED|type_specifier LD[]109: compound_stmt -> {locaLdeclaiations statementjist}110: locaLdeclarations -> local_declarations var_declaration|empty111: statementjist -> statementjist statement|emptv112: statement -> epiesion_stmt|conipound_stmtselection.stmt iteration_stmt|retuin_stmt113: expression^stmt -> expression;!;114: selection_stmt -> if{expressionjstatement if(expression)statement elsestatement115: iteration_stmt -> wliile{expression)statement116: return_stmt -> return;|return expression;117: expression -> var = expression|siinple-expression118: var -> ID | ID [expression]119: suuple_expression ->additive_expression relop additive_expression|additive_expression120: relop -> <=|<|>|>=|= =|!=121: additive_expression -> additive_expression addop term | term122: addop -> + | -123: term -> term mulop factor factor124: mulop -> *|/125: factor -> (expression)|var|call|NUM126: call -> ID(aigs)127: args -> aig_list|empty128: arg_list -> arg_list,expression|expression该文法满足了实验的要求,而且多了很多的内容,相当于一个小型的文法说明:把文法标号从100到128是为了程序中便于找到原来的文法。
编译原理词法分析器语法分析器实验报告

void analyse(char Vn[],char Vt[])
{
int i,j,m,p,q,length,t,h;
char w,X;
char str[100];
opt0:
scanf("%s",str);
for(i=0;i<strlen(str);i++)
{
if(!find(str[i],Vt))
getchar();
}
}
opt3:
printf("请输入要分析的字符串,且以#结束:\n");
analyse(Vn, Vt);
printf("********************请选择***********************\n");
printf(" 1:输入字符串\n");
printf(" 2:输入新分析表\n");
{
printf("%c",str[t]); //显示剩余字符串
}
if(find(X,Vt)&& X!='#') //分析栈的栈顶元素和剩余输入串的第一个元素相比较
{
if(X==w)
{
printf("%15c匹配\n",X);
j++;
w=str[j];
goto opt1;
}
else
error();
}
else
sum=0;
while((ch>='0'&&ch<='9'))
{
sum=sum*10+ch-'0';
编译原理语法分析实验报告
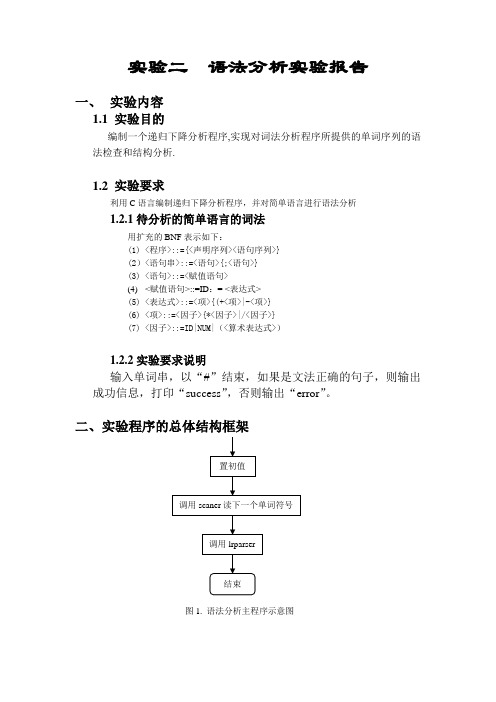
实验二语法分析实验报告一、实验内容1.1 实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析.1.2 实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析1.2.1待分析的简单语言的词法用扩充的BNF表示如下:(1) <程序>::={<声明序列><语句序列>}(2)<语句串>::=<语句>{;<语句>}(3) <语句>::=<赋值语句>(4) <赋值语句>::=ID:= <表达式>(5) <表达式>::=<项>{(+<项>|-<项>}(6) <项>::=<因子>{*<因子>|/<因子>}(7) <因子>::=ID|NUM|(<算术表达式>)1.2.2实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
二、实验程序的总体结构框架图1. 语法分析主程序示意图图2.递归下降分析程序示意图图5. expression表达式分析函数示意图图6.term分析函数示意图三、关键技术的实现方法Scanner函数定义已在实验一给出,本实验不再重复给出void Irparser(){kk=0;if(syn==1){scaner();yucu();if(syn==6){scaner();if(syn==0 && (kk==0)) cout<<"success!"<<endl;}else{if(kk!=1)cout<<"缺end!"<<endl;kk=1;}}else {cout<<"缺begin!"<<endl;kk=1;}return;}void yucu(){statement();while(syn==26){scaner();statement();}return;}void statement() {if(syn==10){scaner();if(syn==18){scaner();expression();}else{cout<<"赋值号错误"<<endl;kk=1;}}else{cout<<"语句错误"<<endl;kk=1;}return;}void expression(){term();while((syn==13)||(syn==14)){scaner();term();}return;}void term(){factor();while((syn==15)||(syn==16)){scaner();factor();}return;}void factor(){if((syn==10)||(syn==11))scaner();else if(syn==27){scaner();expression();if(syn==28)scaner();else{cout<<")错误"<<endl;kk=1;}}else{cout<<"表达式错误"<<endl;kk=1;}return;}void main(){p=0;cout<<"Please input string"<<endl;do{cin.get(ch);if(ch!=”\n”)prog[p++]=ch;}while(ch!='#');p=0;scaner();Irparser();}四、实验心得语法分析是编译过程的核心部分,它的主要功能是按照程序语言的语法规则,从由词法分析输出的源程序符号串中识别出各类语法成分,同时进行语法检查,为语义分析和代码生成做准备。
编译原理实验——语法分析器报告
组员学号姓名实验名称对各算术表达式进行语法分析实验室实验目的或要求实验目的:1、掌握语法分析器生成工具的使用和了解编译器的设计;2、了解自上而下语法分析器的构造过程;3、能够构造LR分析表,编写由该分析表驱动的语法分析器程序;4、借助语法制导翻译,可在语法分析的同时,完成对语义的翻译;5、借助语法分析,设计一个表达式的判断分析器,即从键盘上输入算术表达式,分析器将显示该表达式的正确与否。
实验原理(算法流程)实验算法流程图如下所示:开始输入表达式表达式保存到数ch第一个元素为)+-*/YCh[i]=’(’i++YNCh[i]=NULLNCh[i]是0~9i++YCh[i]是0~9Ch[i]=+ -*/)N多了+ -*/)Y其他错误NYCh[i]=* /Ni++YCh[i]=+ -*/NY多了+ -*/Ch[i]=+ -NNCh[i]=)Y少了)N错误首部多了) +-*/结束程序界面(效果图)实验结果界面:只选择几个典型的例子进行分析,可进行任意表达式输入。
1)未进行语法分析时的界面;2)输入正确的表达式(1+2)*(6-3)+1进行语法分析时的界面结果;3)输入错误的表达式1*2+(2+3并进行语法分析时的界面结果;程序界面(效果图)4)输入错误的表达式1+(+5+6)并进行语法分析时的界面结果;程序界面(效果图)程序代码 #include "stdafx.h"#include "grammer.h"#include "mfc_语法分析器.h"#include "mfc_语法分析器Dlg.h"int flag;int i,j;int length;CString string;int grammer(CString str){i=0;flag=0;char ch[MAX];length=str.GetLength();strcpy(ch,str);if(length!=0){F(ch);if(flag==0){MessageBox(NULL,"输入表达式符合文法","正确",MB_OK|MB_ICONINFORMATION);}//str=ch;//return flag;}else{MessageBox(NULL,"表达式为空","提示",MB_OK|MB_ICONW ARNING);//MessageBox(NULL,"表达式为空","提示",MB_OK|MB_ICONERROR);return -1;}return flag;}void F(char ch[]){if(ch[0]=='+'){程序代码flag=0;MessageBox(NULL,"输入表达式不符合文法0","错误",MB_OK|MB_ICONERROR); MessageBox(NULL,"开始处多了+","提示",MB_OK|MB_ICONINFORMA TION);flag=1;}elseif(ch[0]=='-'){flag=0;MessageBox(NULL,"输入表达式不符合文法0","错误",MB_OK|MB_ICONERROR);MessageBox(NULL,"开始处多了-","提示",MB_OK|MB_ICONINFORMA TION);flag=1;}elseif(ch[0]=='*'){flag=0;MessageBox(NULL,"输入表达式不符合文法0","错误",MB_OK|MB_ICONERROR);MessageBox(NULL,"开始处多了*","提示",MB_OK|MB_ICONINFORMA TION);flag=1;}elseif(ch[0]=='/'){flag=0;MessageBox(NULL,"输入表达式不符合文法0","错误",MB_OK|MB_ICONERROR);MessageBox(NULL,"开始处多了/","提示",MB_OK|MB_ICONINFORMA TION);flag=1;}elseif(ch[0]==')'){flag=0;MessageBox(NULL,"输入表达式不符合文法0","错误",MB_OK|MB_ICONERROR);MessageBox(NULL,"开始处多了)","提示",MB_OK|MB_ICONINFORMA TION);flag=1;}/*上述为对第一个字符的特殊处理*/elseif(ch[i]!=NULL){if(ch[i]=='('){i++;F(ch);程序代码if(ch[i]!=')'){if(flag==0){MessageBox(NULL,"输入表达式不符合文法1","错误",MB_OK|MB_ICONERROR);MessageBox(NULL,"少了')'","提示",MB_OK|MB_ICONINFORMATION);}flag=1;}else{i++;if(ch[i]!=NULL)T(ch);}}elseif(ch[i]<='9'&&ch[i]>='0'){while(ch[i]<='9'&&ch[i]>='0')i++;if(ch[i]!=NULL)T(ch);}else{if(flag==0){if(ch[i]!=NULL&&ch[i]!=')'){MessageBox(NULL,"输入表达式不符合文法2.1","错误",MB_OK|MB_ICONERROR);if(ch[i]==' ') MessageBox(NULL,"含有空格","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i]=='+') {MessageBox(NULL,"多了'+'号","提示",MB_OK|MB_ICONINFORMA TION);}else if(ch[i]=='-') MessageBox(NULL,"多了'-'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i]=='*') MessageBox(NULL,"多了'*'号","提示",MB_OK|MB_ICONINFORMA TION);程序代码else if(ch[i]=='/') MessageBox(NULL,"多了'/'号","提示",MB_OK|MB_ICONINFORMA TION);}else if(ch[i]==NULL){MessageBox(NULL,"输入表达式不符合文法2.2","错误",MB_OK|MB_ICONERROR);if(ch[i-1]==' ') MessageBox(NULL,"含有空格","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i-1]=='+') MessageBox(NULL,"多了最后的'+'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i-1]=='-') MessageBox(NULL,"多了最后的'-'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i-1]=='*') MessageBox(NULL,"多了最后的'*'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i-1]=='/') MessageBox(NULL,"多了最后的'/'号","提示",MB_OK|MB_ICONINFORMA TION);}else if(ch[i]!=NULL&&ch[i]==')'){MessageBox(NULL,"输入表达式不符合文法2.3","错误",MB_OK|MB_ICONERROR);if(ch[i-1]==' ') MessageBox(NULL,"含有空格","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i-1]=='(') MessageBox(NULL,"含有一对空括号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i-1]=='+') MessageBox(NULL,"多了最后的'+'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i-1]=='-') MessageBox(NULL,"多了最后的'-'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i-1]=='*') MessageBox(NULL,"多了最后的'*'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i-1]=='/') MessageBox(NULL,"多了最后的'/'号","提示",MB_OK|MB_ICONINFORMA TION);}}flag=1;}}}void T(char ch[]){if(ch[i]=='*'||ch[i]=='/')程序代码{i++;if(ch[i]!=NULL&&ch[i]!='+'&&ch[i]!='-'&&ch[i]!='*'&&ch[i]!='/')F(ch);else{if(flag==0){MessageBox(NULL,"输入表达式不符合文法3","错误",MB_OK|MB_ICONERROR);if(ch[i]==' ') MessageBox(NULL,"含有空格","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i]=='+') MessageBox(NULL,"多了'+'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i]=='-') MessageBox(NULL,"多了'-'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i]=='*') MessageBox(NULL,"多了'*'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i]=='/') MessageBox(NULL,"多了'/'号","提示",MB_OK|MB_ICONINFORMA TION);}flag=1;}}elseE(ch);}void E(char ch[]){if(ch[i]=='+'||ch[i]=='-'){i++;if(ch[i]!=NULL&&ch[i]!='+'&&ch[i]!='-'&&ch[i]!='*'&&ch[i]!='/')F(ch);else{if(flag==0){if(ch[i]!=NULL){MessageBox(NULL,"输入表达式不符合文法4.1","错误",MB_OK|MB_ICONERROR);if(ch[i]==' ') MessageBox(NULL,"含有空格","提示",MB_OK|MB_ICONINFORMA TION);程序代码else if(ch[i]=='+') MessageBox(NULL,"多了'+'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i]=='-') MessageBox(NULL,"多了'-'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i]=='*') MessageBox(NULL,"多了'*'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i]=='/') MessageBox(NULL,"多了'/'号","提示",MB_OK|MB_ICONINFORMA TION);}else if(ch[i]==NULL){MessageBox(NULL,"输入表达式不符合文法4.2","错误",MB_OK|MB_ICONERROR);if(ch[i-1]==' ') MessageBox(NULL,"含有空格","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i-1]=='+') MessageBox(NULL,"多了最后的'+'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i-1]=='-') MessageBox(NULL,"多了最后的'-'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i-1]=='*') MessageBox(NULL,"多了最后的'*'号","提示",MB_OK|MB_ICONINFORMA TION);else if(ch[i-1]=='/') MessageBox(NULL,"多了最后的'/'号","提示",MB_OK|MB_ICONINFORMA TION);}}flag=1;}}else if(ch[i]!=')'){if(flag==0){MessageBox(NULL,"输入表达式不符合文法5","错误",MB_OK|MB_ICONERROR);if(ch[i]=='('&&ch[i+2]==')') MessageBox(NULL,"含有一对多余的括号","提示",MB_OK|MB_ICONINFORMA TION);else MessageBox(NULL,"其他类型的错误","提示",MB_OK|MB_ICONINFORMA TION);}flag=1;}}实验结果分析及心得体会实验结果分析:本次实验借助语法分析,设计一个表达式的判断分析器,从键盘上输入算术表达式,分析器对该表达式的正确与否进行分析。
编译原理实验报告-语法分析

编译原理课程实验报告实验2:语法分析
三、系统设计得分
要求:分为系统概要设计和系统详细设计。
(1)系统概要设计:给出必要的系统宏观层面设计图,如系统框架图、数据流图、功能模块结构图等以及相应的文字说明。
1)系统的数据流图:
说明
说明:本语法分析器是基于上一个实验词法分析器的基础上,通过在界面写或者是导入源程序,词法分析器将源程序识别的词法单元传递给语法分析器,语法分析器验证这个词法单元组成的串是否可以由源语言的文法生成,能够输出语法分析的结果,文法的first集、follow 集和预测分析表,当然也可以以易于理解的方式报告语法错误。
2)系统框架图
本系统框架主要是三部分,一部分是词法分析,负责识别源程序的词法单元识别,并将其存
因为预测分析表实在是过于庞大,因此本处分段截取预测分析表,下面的表是接在上面表的右侧。
(3)针对一测试程序输出其句法分析结果;
测试程序:
语法分析结果:
语法分析树:
(4)输出针对此测试程序对应的语法错误报告;
带错误的测试程序:
语法错误报告:
(5)对实验结果进行分析。
总结:
本语法分析器具有强大的语法分析功能
●允许变量的连续声明,比如int a,b,c;
●允许声明的同时赋值,比如string c = “你好”;
●允许对数组的声明和引用,同时进行赋值,比如char[4] a = {‘a’,’b’,’c’,’d’};a[0] = ‘m’;
●支持多种类型的声明和赋值,比如int,short,long,flaot,double,char,string,boolean
的声明和赋值;
●允许声明和使用一个过程函数,比如:。
语法分析实验报告

语法分析实验报告一、实验目的语法分析是编译原理中的重要环节,本次实验的目的在于深入理解和掌握语法分析的基本原理和方法,通过实际操作和实践,提高对编程语言语法结构的分析能力,为进一步学习编译技术和开发相关工具打下坚实的基础。
二、实验环境本次实验使用的编程语言为 Python,使用的开发工具为 PyCharm。
三、实验原理语法分析的任务是在词法分析的基础上,根据给定的语法规则,将输入的单词符号序列分解成各类语法单位,并判断输入字符串是否符合语法规则。
常见的语法分析方法有自顶向下分析法和自底向上分析法。
自顶向下分析法包括递归下降分析法和预测分析法。
递归下降分析法是一种直观、简单的方法,但存在回溯问题,效率较低。
预测分析法通过构建预测分析表,避免了回溯,提高了分析效率,但对于复杂的语法规则,构建预测分析表可能会比较困难。
自底向上分析法主要包括算符优先分析法和 LR 分析法。
算符优先分析法适用于表达式的语法分析,但对于一般的上下文无关文法,其适用范围有限。
LR 分析法是一种功能强大、适用范围广泛的方法,但实现相对复杂。
四、实验内容(一)词法分析首先,对输入的源代码进行词法分析,将其分解为一个个单词符号。
单词符号包括关键字、标识符、常量、运算符、分隔符等。
(二)语法规则定义根据实验要求,定义了相应的语法规则。
例如,对于简单的算术表达式,可以定义如下规则:```Expression > Term | Expression '+' Term | Expression ''TermTerm > Factor | Term '' Factor | Term '/' FactorFactor >'(' Expression ')'| Identifier | Number```(三)语法分析算法实现选择了预测分析法来实现语法分析。
首先,根据语法规则构建预测分析表。
然后,从输入字符串的起始位置开始,按照预测分析表的指导进行分析。
编译原理语法分析实验报告

编译原理语法分析实验报告一、实验目的本实验主要目的是学习和掌握编译原理中的语法分析方法,通过实验了解和实践LR(1)分析器的实现过程,并对比不同的文法对语法分析的影响。
二、实验内容1.实现一个LR(1)的语法分析器2.使用不同的文法进行语法分析3.对比不同文法对语法分析的影响三、实验原理1.背景知识LR(1)分析器是一种自底向上(bottom-up)的语法分析方法。
它使用一个分析栈(stack)和一个输入缓冲区(input buffer)来处理输入文本,并通过移进(shift)和规约(reduce)操作进行语法分析。
2.实验步骤1)构建文法的LR(1)分析表2)读取输入文本3)初始化分析栈和输入缓冲区4)根据分析表进行移进或规约操作,直至分析过程结束四、实验过程与结果1.实验环境本实验使用Python语言进行实现,使用了语法分析库ply来辅助实验。
2.实验步骤1)构建文法的LR(1)分析表通过给定的文法,根据LR(1)分析表的构造算法,构建出分析表。
2)实现LR(1)分析器使用Python语言实现LR(1)分析器,包括读取输入文本、初始化分析栈和输入缓冲区、根据分析表进行移进或规约操作等功能。
3)使用不同的文法进行语法分析选择不同的文法对编写的LR(1)分析器进行测试,观察语法分析的结果。
3.实验结果通过不同的测试案例,实验结果表明编写的LR(1)分析器能够正确地进行语法分析,能够识别出输入文本是否符合给定文法。
五、实验分析与总结1.实验分析本实验通过实现LR(1)分析器,对不同文法进行语法分析,通过实验结果可以观察到不同文法对语法分析的影响。
2.实验总结本实验主要学习和掌握了编译原理中的语法分析方法,了解了LR(1)分析器的实现过程,并通过实验提高了对语法分析的理解。
六、实验心得通过本次实验,我深入学习了编译原理中的语法分析方法,了解了LR(1)分析器的实现过程。
在实验过程中,我遇到了一些问题,但通过查阅资料和请教老师,最终解决了问题,并完成了实验。
语法分析器实验报告

杭州电子科技大学班级: 12052312 专业: 计算机科学与技术实验报告【实验名称】实验二语法分析一. 实验目的编写一个语法分析程序, 实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二. 实验内容利用编程语言实现语法分析程序, 并对简单语言进行语法分析。
2.1 待分析的简单语言的语法用扩充的BNF表示如下:⑴<程序>: : =begin<语句串>end⑵<语句串>: : =<语句>{;<语句>}⑶<语句>: : =<赋值语句>⑷<赋值语句>: : =ID: =<表达式>⑸<表达式>: : =<项>{+<项> | -<项>}⑹<项>: : =<因子>{*<因子> | /<因子>⑺<因子>: : =ID | NUM | (<表达式>)2.2 实验要求说明输入单词串, 以“#”结束, 如果是文法正确的句子, 则输出成功信息, 打印“success”, 否则输出“error”。
例如:输入begin a:=9; x:=2*3; b:=a+x end #输出success!输入x:=a+b*c end #输出error测试以上输入的分析, 并完成实验报告。
2.3 语法分析程序的算法思想(1)主程序示意图如图2-1所示。
图2-1 语法分析主程序示意图(2)递归下降分析程序示意图如图2-2所示。
(3)语句串分析过程示意图如图2-3所示。
图2-3 语句串分析示意图图2-2 递归下降分析程序示意图(4)statement 语句分析程序流程如图2-4.2-5.2-6.2-7所示。
图2-4 statement 语句分析函数示意图 图2-5 expression 表达式分析函数示意图图2-7 factor 分析过程示意图三.个人心得一、 通过该实验, 主要有以下几方面收获: 二、 对实验原理有更深的理解。
(完整)编译原理实验报告(词法分析器 语法分析器)

编译原理实验报告实验一一、实验名称:词法分析器的设计二、实验目的:1,词法分析器能够识别简单语言的单词符号2,识别出并输出简单语言的基本字。
标示符。
无符号整数.运算符.和界符。
三、实验要求:给出一个简单语言单词符号的种别编码词法分析器四、实验原理:1、词法分析程序的算法思想算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号.2、程序流程图(1)主程序(2)扫描子程序3、各种单词符号对应的种别码五、实验内容:1、实验分析编写程序时,先定义几个全局变量a[]、token[](均为字符串数组),c,s( char型),i,j,k(int型),a[]用来存放输入的字符串,token[]另一个则用来帮助识别单词符号,s用来表示正在分析的字符.字符串输入之后,逐个分析输入字符,判断其是否‘#’,若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c)、int letter(char c)判断其是数字,字符还是算术符,分别为用以判断数字或字符的情况,算术符的判断可以在switch语句中进行,还要通过函数int lookup(char token[])来判断标识符和保留字。
2 实验词法分析器源程序:#include 〈stdio.h〉#include <math.h>#include <string。
h>int i,j,k;char c,s,a[20],token[20]={’0’};int letter(char s){if((s〉=97)&&(s〈=122)) return(1);else return(0);}int digit(char s){if((s〉=48)&&(s<=57)) return(1);else return(0);}void get(){s=a[i];i=i+1;}void retract(){i=i-1;}int lookup(char token[20]){if(strcmp(token,"while")==0) return(1);else if(strcmp(token,"if")==0) return(2);else if(strcmp(token,"else”)==0) return(3);else if(strcmp(token,"switch”)==0) return(4);else if(strcmp(token,"case")==0) return(5);else return(0);}void main(){printf(”please input string :\n");i=0;do{i=i+1;scanf("%c",&a[i]);}while(a[i]!=’#’);i=1;j=0;get();while(s!=’#'){ memset(token,0,20);switch(s){case 'a':case ’b':case ’c':case ’d':case ’e’:case ’f’:case 'g’:case ’h':case 'i':case ’j':case 'k’:case ’l':case 'm’:case 'n':case ’o':case ’p':case ’q’:case 'r’:case 's’:case 't’:case ’u’:case ’v’:case ’w’:case ’x':case ’y':case ’z’:while(letter(s)||digit(s)){token[j]=s;j=j+1;get();}retract();k=lookup(token);if(k==0)printf("(%d,%s)”,6,token);else printf("(%d,—)",k);break;case ’0':case ’1’:case ’2':case ’3':case '4’:case '5’:case ’6':case ’7’:case ’8’:case '9’:while(digit(s)){token[j]=s;j=j+1;get();}retract();printf(”%d,%s",7,token);break;case '+':printf(”(’+',NULL)”);break;case ’-':printf("(’-',null)");break;case ’*':printf(”('*’,null)");break;case '<':get();if(s=='=’) printf(”(relop,LE)”);else{retract();printf("(relop,LT)");}break;case ’=':get();if(s=='=’)printf("(relop,EQ)");else{retract();printf(”('=',null)”);}break;case ’;':printf(”(;,null)");break;case ' ’:break;default:printf("!\n”);}j=0;get();} }六:实验结果:实验二一、实验名称:语法分析器的设计二、实验目的:用C语言编写对一个算术表达式实现语法分析的语法分析程序,并以四元式的形式输出,以加深对语法语义分析原理的理解,掌握语法分析程序的实现方法和技术.三、实验原理:1、算术表达式语法分析程序的算法思想首先通过关系图法构造出终结符间的左右优先函数f(a),g(a)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
编译原理语法分析器实验报告西安邮电大学编译原理实验报告学院名称:计算机学院****:***实验名称:语法分析器的设计与实现班级:计科1405班学号:04141152时间:2017年5月12日把SELECT (i)存放到temp中结果返回1;1.构建好的预测分析表2.语法分析流程图一.实验结果正确运行结果:错误运行结果:二.设计技巧和心得体会这次实验编写了一个语法分析方法的程序,但是在LL(1)分析器的编写中我只达到了最低要求,就是自己手动输入的select集,first集,follow集然后通过程序将预测分析表构造出来,然后自己编写总控程序根据分析表进行分析。
通过本次试验,我能够设计一个简单的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。
还能选择最有代表性的语法分析方法,如LL(1) 语法分析程序、算符优先分析程序和LR分析分析程序。
三.源代码package com.LL1;import java.util.ArrayDeque;import java.util.Deque;/*** LL1文法分析器,已经构建好预测分析表,采用Deque实现* Created by HongWeiPC on 2017/5/12.*/public class LL1_Deque {//预测分析表private String[][] analysisTable = new String[][]{{"TE'", "", "", "TE'", "", ""},{"", "+TE'", "", "", "ε", "ε"},{"FT'", "", "", "FT'", "", ""},{"", "ε", "*FT'", "", "ε", "ε"},{"i", "", "", "(E)", "", ""}};//终结符private String[] VT = new String[]{"i", "+", "*", "(", ")", "#"};//非终结符private String[] VN = new String[]{"E", "E'", "T", "T'", "F"};//输入串strTokenprivate StringBuilder strToken = new StringBuilder("i*i+i");//分析栈stackprivate Deque<String> stack = new ArrayDeque<>();//shuru1保存从输入串中读取的一个输入符号,当前符号private String shuru1 = null;//X中保存stack栈顶符号private String X = null;//flag标志预测分析是否成功private boolean flag = true;//记录输入串中当前字符的位置private int cur = 0;//记录步数private int count = 0;public static void main(String[] args) {LL1_Deque ll1 = new LL1_Deque();ll1.init();ll1.totalControlProgram();ll1.printf();}//初始化private void init() {strToken.append("#");stack.push("#");System.out.printf("%-8s %-18s %-17s %s\n", "步骤", "符号栈", "输入串", "所用产生式");stack.push("E");curCharacter();System.out.printf("%-10d %-20s %-20s\n", count, stack.toString(), strToken.substring(cur, strToken.length()));}//读取当前栈顶符号private void stackPeek() {X = stack.peekFirst();}//返回输入串中当前位置的字母private String curCharacter() {shuru1 = String.valueOf(strToken.charAt(cur));return shuru1;}//判断X是否是终结符private boolean XisVT() {for (int i = 0; i < (VT.length - 1); i++) {if (VT[i].equals(X)) {return true;}}return false;}//查找X在非终结符中分析表中的横坐标private String VNTI() {int Ni = 0, Tj = 0;for (int i = 0; i < VN.length; i++) {if (VN[i].equals(X)) {Ni = i;}}for (int j = 0; j < VT.length; j++) {if (VT[j].equals(shuru1)) {Tj = j;}}return analysisTable[Ni][Tj];}//判断M[A,a]={X->X1X2...Xk}//把X1X2...Xk推进栈//X1X2...Xk=ε,不推什么进栈private boolean productionType() {return VNTI() != "";}//推进stack栈private void pushStack() {stack.pop();String M = VNTI();String ch;//处理TE' FT' *FT'特殊情况switch (M) {case "TE'":stack.push("E'");stack.push("T");break;case "FT'":stack.push("T'");stack.push("F");break;case "*FT'":stack.push("T'");stack.push("F");stack.push("*");break;case "+TE'":stack.push("E'");stack.push("T");stack.push("+");break;default:for (int i = (M.length() - 1); i >= 0; i--) {ch = String.valueOf(M.charAt(i));stack.push(ch);}break;}System.out.printf("%-10d %-20s %-20s %s->%s\n", (++count), stack.toString(), strToken.substring(cur, strToken.length()), X, M);}//总控程序private void totalControlProgram() {while (flag) {stackPeek(); //读取当前栈顶符号令X=栈顶符号if (XisVT()) {if (X.equals(shuru1)) {cur++;shuru1 = curCharacter();stack.pop();System.out.printf("%-10d %-20s %-20s \n", (++count), stack.toString(), strToken.substring(cur, strToken.length()));} else {ERROR();}} else if (X.equals("#")) {if (X.equals(shuru1)) {flag = false;} else {ERROR();}} else if (productionType()) {if (VNTI().equals("")) {ERROR();} else if (VNTI().equals("ε")) {stack.pop();System.out.printf("%-10d %-20s %-20s %s->%s\n", (++count), stack.toString(), strToken.substring(cur, strToken.length()), X, VNTI());} else {pushStack();}} else {ERROR();}}}//出现错误private void ERROR() {System.out.println("输入串出现错误,无法进行分析");System.exit(0);}//打印存储分析表private void printf() {if (!flag) {System.out.println("****分析成功啦!****");} else {System.out.println("****分析失败了****");}}}。