随机森林算法介绍及R语言实现
randomforest随机森林 参数

randomforest随机森林参数
Random Forest(随机森林)参数
Random Forest(随机森林)是一种基于决策树的集成学习(ensemble learning)方法,通过构建多个决策树,将它们拼接在一起,从而形成一个强有力的、具有良好泛化能力的决策树模型。
它非常适合做分类和回归任务。
Random Forest有如下重要参数:
1. n_estimators:决策树的数量,即构建森林时使用的树的数量,默认值为10 。
2. max_features:决策树每次生成时,所使用的最大特征数量,默认值为None,也可以设置一个整数或者浮点数。
3. min_samples_split:决策树中每个节点最少需要分割的样本数,默认值为2。
4. min_samples_leaf:决策树每个叶子节点所需要的最少样本数,默认值为1。
5. max_depth:决策树深度,即从根节点到叶子节点的最大分入数量,如果为None,则节点的深度将不受限,默认值为None。
6. bootstrap:是否有放回的采样,默认值为True,即有放回采样。
7. criterion:决策树所使用的评价准则,默认值为“gini”,也可以选择“entropy”。
8. oob_score:是否使用袋外数据来估计泛化精度,默认值为
False,即不使用袋外数据。
r语言随机森林模型怎么求出回归方程

r语言随机森林模型怎么求出回归方程全文共四篇示例,供读者参考第一篇示例:随机森林是一种强大的机器学习算法,它结合了决策树和集成学习的优势,在回归问题中也有很好的表现。
在R语言中,使用随机森林模型可以很容易地求出回归方程,下面我们就来详细介绍一下如何在R语言中求出随机森林回归方程。
1. 数据准备我们需要准备好用于建模的数据集。
数据集应该包含输入变量和目标变量,输入变量用于建立回归模型,目标变量是我们要预测的值。
在R语言中可以使用data.frame()函数将数据加载进来,确保数据集中不含有缺失值。
2. 导入随机森林库在R语言中,可以使用randomForest包来构建随机森林模型。
首先需要安装包并导入到R中,可以使用以下代码完成这一步:```install.packages("randomForest")library(randomForest)```3. 构建随机森林模型接下来,我们使用randomForest()函数来构建随机森林模型。
在函数中需要指定输入变量和目标变量,以及其他一些参数,如树的数量、节点最小样本数等。
以下是一段示例代码:这里的"data"是我们准备好的数据集,"Target"是目标变量的列名,"~ ."表示使用所有其他变量作为输入变量,"ntree"表示森林中树的数量,"mtry"表示每个节点中考虑的变量数量。
根据具体情况可以调整这些参数来优化模型。
4. 提取回归方程随机森林模型是由多个决策树组成的集合模型,因此没有明确的回归方程。
但是可以通过查看变量的重要性来理解模型的影响因素。
可以使用以下代码来查看变量的重要性:```varImpPlot(rf_model)```这个函数会返回一个图表,显示每个变量的重要性以及它们对模型的贡献程度。
可以根据这个图表来了解模型中哪些变量对预测结果具有更大的影响。
r语言 随机森林 回归 最优参数

系好安全带,伙计们!我们正在潜入令人兴奋的机器学习的世界与永远流行的随机森林回归算法。
这个坏孩子不仅能把事物分类,而且能预测数值。
准备好卷起你的袖子,加入我,当我们利用R语言的力量创建我们自己的随机森林回归模型。
嘿,我们不会停下来的——我们正在寻找最终的参数,让这个模型歌舞。
让我们在这个算法上撒点魔法释放出它的全部潜力!
让我们给R环境注入一些魔法通过召唤必要的R包随机森林回归。
我们将利用“install。
packages()”咒语来构思“随机森林”软件包,它将赋予我们构建神秘的随机森林模型所需的魔法功能。
一旦套件安全了,我们可以挥动我们的魔杖,用“ library()” 咒语在我们的 R 会话中恢复它。
现在,我们到森林的旅程随机的可能性是真正开始的!
"好,系好安全带,准备潜入随机森林的世界!一旦我们得到了随机森林包的火力,它去时间开始设计我们可怕的回归模型。
我们需要准备我们的数据集,把它分成一个训练集和一个测试集。
我们释放出“兰多姆森林()”功能的魔法,用训练数据来训练我们的模型,并通过在测试数据上作出预测来观察它的工作。
等等,还有更多!我们可以通过使用诸如交叉验证等很酷的技术来寻找我们随机森林回归模型的完美参数这就像找到宝藏图回归成功!让我们一起征服这个随机的森林!"。
R随机森林算法
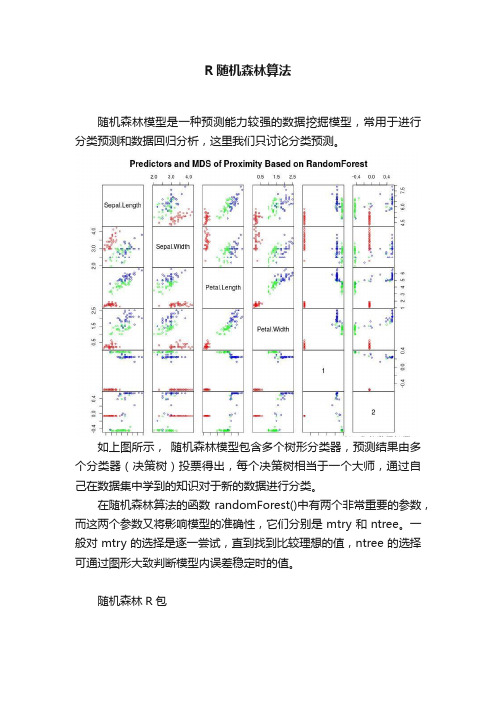
R随机森林算法随机森林模型是一种预测能力较强的数据挖掘模型,常用于进行分类预测和数据回归分析,这里我们只讨论分类预测。
如上图所示,随机森林模型包含多个树形分类器,预测结果由多个分类器(决策树)投票得出,每个决策树相当于一个大师,通过自己在数据集中学到的知识对于新的数据进行分类。
在随机森林算法的函数randomForest()中有两个非常重要的参数,而这两个参数又将影响模型的准确性,它们分别是mtry和ntree。
一般对mtry的选择是逐一尝试,直到找到比较理想的值,ntree的选择可通过图形大致判断模型内误差稳定时的值。
随机森林R包randomForest::randomForest 该包中主要涉及5个重要函数,关于这5个函数的语法和参数请见下方:randomForest():此函数用于构建随机森林模型randomForest(formula, data=NULL, ..., subset, na.action=na.fail)1. formula:指定模型的公式形式,类似于y~x1+x2+x3...;2. data:指定分析的数据集;3.ntree:指定随机森林所包含的决策树数目,默认为500;4. mtry:指定节点中用于二叉树的变量个数,默认情况下数据集变量个数的二次方根(分类模型)或三分之一(预测模型)。
一般是需要进行人为的逐次挑选,确定最佳的m值;估值过程指定m值,即随机产生m个变量用于节点上的二叉树,m的选择原则是使错误率最低。
应用bootstrap自助法在原数据集中又放回地抽取k个样本集,组成k棵决策树,每个决策树输出一个结果。
对k个决策树组成的随机森林对样本进行分类或预测:分类原则:少数服从多数;预测原则:简单平均。
oob error如何选择最优的特征个数m,要解决这个问题,我们主要依据计算得到的袋外错误率.在构建每棵树时,对训练集使用了不同的bootstrap sample(随机且有放回地抽取)。
用R实现随机森林的分类与回归

用R实现随机森林的分类与回归第五届中国R语言会议北京2012 李欣海用R实现随机森林的分类与回归Applications of Random Forest using RClassification and Regression李欣海中科院动物所邮件:lixh@//0>.主页:////.博客:////.微博:////. 第五届中国R语言会议北京2012 李欣海随机森林简介Random Forest////.an-introduction-to-data-mining-for-marketing-and-business-intelli gence/Random Forest is an ensemble classifier thatconsists of many decision trees It outputs the class that is the mode of the class'soutput by individual trees Breiman 2001 It deals with “small n large p”-problems, high-orderinteractions, correlated predictor variables.Breiman, L. 2001. Random forests. Machine Learning 45:5-32. Being cited 6500 times until 20123/25 第五届中国R语言会议北京2012 李欣海随机森林简介History////.an-introduction-to-data-mining-for-marketing-and-business-intelli gence/The algorithm for inducing a random forest was developed byLeo Breiman 2001 and Adele Cutler, and "Random Forests" istheir trademarkThe term came from random decision forests that was firstproposed by Tin Kam Ho of Bell Labs in 1995The method combines Breiman's "bagging" idea and therandom selection of features, introduced independently by Ho1995 and Amit and Geman 1997 in order to construct acollection of decision trees with controlled variation.4/25 第五届中国R语言会议北京2012 李欣海随机森林简介Tree modelsy β + β x + β x + β x + εi 0 1 1i 2 2 i 3 3i iClassification treeRegression treeCrawley 2007 The R Book p691 Crawley 2007 The R Book p6945/25 第五届中国R语言会议北京2012 李欣海随机森林简介The statistical community uses irrelevant theory,questionable conclusions?David R. Cox Emanuel Parzen Bruce HoadleyBrad EfronNO YES6/25 第五届中国R语言会议北京2012 李欣海随机森林简介Ensemble classifiers////.Tree models are simple, often produce noisy bushy or weakstunted classifiers Bagging Breiman, 1996: Fit many large trees to bootstrap-resampled versions of the training data, and classify by majority vote Boosting Freund & Shapire, 1996: Fit many large or small trees to reweighted versions of the training data. Classify by weighted majority vote Random Forests Breiman 1999: Fancier version of bagging.In general Boosting Random Forests Bagging Single TreeTrevor Hastie.7/25 第五届中国R语言会议北京2012 李欣海随机森林简介How Random Forest Works////.At each tree split, a random sample of m features is drawn, and only those m features are considered for splittingTypically m sqrtp or logp, where p is the number offeatures For each tree grown on a bootstrap sample, the error rate for observations left out of the bootstrap sample ismonitored. This is called the out-of-bag OOB error rate Random forests tries to improve on bagging by “de-correlating” the trees. Each tree has the same expectation.Trevor Hastie, p21 in Trees, Bagging, Random Forests and Boosting8/25 第五届中国R语言会议北京2012 李欣海随机森林简介R PackagesrandomForest randomForestTitle: Breiman and Cutler’s random forests for classification and regressionVersion: 4.6-6Date: 2012-01-06Author:Fortran original by Leo Breiman and Adele Cutler, R port by Andy Liawand Matthew Wiener.Implementation based on CART trees for variables of different types.Biased in favor of continuous variables and variables with many categories.partycforestBased on unbiased conditional inference trees.For variables of different types: unbiased when subsampling.黄河渭河9/25 第五届中国R语言会议北京2012 李欣海随机森林:分类# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #宁夏# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #青海# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #朱?的分布# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # ### ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #山西# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # ### ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #甘肃# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # ### ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # #陕西 ## ## ## # # # # # # # # # # ## ## ## # # ## ##### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # ### #河南## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ############ # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # #### ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ######### ## ######## ######## ### #### ### ## ######## ## ############################ ####### ########## ## #### #### #### ## ### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # ### ## ################## ## #### ######## ## ######### ###### ####### ## # ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## # ## #### ## ## #### ### ## #### ## # # ## # ##### ## ## ########### #### ##### ## ## ############ ######## ### ## ##### ###### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # ##### #### ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ###### #### ## ## ##### ##### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # ######### ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ######## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ### ###### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # #四川 # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # ### ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #湖北# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # ### ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #重庆# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # ## ## ## ## ## ## ## ## # # # # # # # # ## ## ## ## ## ## # # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # ### #湖南湖南黄河汉江岷江嘉陵江10/25 第五届中国R语言会议北京2012 李欣海随机森林:分类DataLand Foot prec_ prec_ prec_ Nestuse x y Elev Aspect Slope Pop GDP t_ann t_jan t_july yearcover print ann jan july site1 107.505 33.392 984 0.67 29.6 21 42.0 20 2.95 845 6 153 12.4 0.3 24.0 1981 金家河1 107.548 33.409 1315 0.90 19.0 14 22.5 26 1.97 869 6 157 11.3 -0.6 22.7 1981 姚家沟1 107.505 33.392 984 0.67 29.6 21 42.0 20 2.95 845 6 153 12.4 0.3 24.0 1982 金家河1 107.548 33.409 1315 0.90 19.0 14 22.5 26 1.97 869 6 157 11.3 -0.6 22.7 1982 姚家沟1 107.505 33.392 984 0.67 29.6 21 42.0 20 2.95 845 6 153 12.4 0.3 24.0 1983 金家河1 107.548 33.409 1315 0.90 19.0 14 22.5 26 1.97 869 6 157 11.3 -0.6 22.7 1983 姚家沟1 107.548 33.409 1315 0.90 19.0 14 22.5 26 1.97 869 6 157 11.3 -0.6 22.7 1984 姚家沟1 107.405 33.406 1056 0.54 11.4 21 0.0 20 0.98 892 7 161 11.4 -0.5 22.9 1984 三岔河1 107.405 33.406 1056 0.54 11.4 21 0.0 20 0.98 892 7 161 11.4 -0.5 22.9 1985 三岔河1 107.548 33.409 1315 0.90 19.0 14 22.5 26 1.97 869 6 157 11.3 -0.6 22.7 1985 姚家沟0 107.400 32.780 980 0.46 42.1 11 45.8 14 1.78 927 6 170 13.0 1.3 24.0 0 3030 107.430 32.780 1553 0.97 29.6 14 171.8 32 4.76 887 5 162 13.0 1.3 24.0 0 3040 107.460 32.780 1534 0.51 25.7 14 12.7 14 1.78 886 5 162 14.0 2.15 25.2 0 3050 107.490 32.780 996 0.72 29.4 14 76.1 20 2.97 886 5 162 12.4 0.8 23.4 0 3060 107.520 32.780 1144 0.16 9.3 14 29.3 20 1.78 956 6 175 12.4 0.8 23.4 0 3070 107.550 32.780 915 0.91 20.7 11 214.7 20 5.95 956 6 175 11.6 0.15 22.5 0 3080 107.580 32.780 930 0.13 35.7 22 153.2 29 4.76 993 7 181 11.6 0.15 22.5 0 3090 107.610 32.780 873 0.40 31.9 11 66.4 29 2.97 931 6 171 12.7 1.1 23.8 0 3100 107.640 32.780 1147 0.50 35.5 11 46.8 20 2.38 1041 7 189 12.7 1.1 23.8 0 3110 107.670 32.780 1699 0.89 21.1 14 20.5 20 1.78 1060 8 192 10.4 -0.8 21.2 0 312tableibis$use ibis$use - as.factoribis$useibis$landcover - as.factoribis$landcover0 12538 560 11/25 第五届中国R 语言会议北京2012 李欣海随机森林:分类Multicollinearity is a painVariables in the two-principal-component space-50 0 50306530643018biplotprincompibis[,2:16], corT3017 2971 306330623060 2970306130582923 2969 2924 3016 y 3057 3059 3015 3056 30143013305530123010 30112968296329662967 30093005 2877 2922 2965 30542830 2964 3008 3006 3007292129622914 30192829 2876 30522919 2920 30533048 2960 3003 2961 3050 30013021 304929983000 3002 29593022 29173004 3051278329553020 2958 2957 2875282830472913291829993023290626892641 28272737 29732836 2784 2826 3046 2956 2874 2986 3033 2735 30442867 2690 2688 2915 30452975 2974 29163024 2789 2739 2788 2740 2642 2925 2972 3041 2869 28682927 2839 27362977 2793 2741 3037 29533025 2928 2820 2791 29103030 2832 2592 2995 2640 2994 2952 28592978 2881 2930 2879 3042 2863 3039 2909 29072983 3029 2880 2990 2992 2989 3036 3043 29542931 2834 2991 2884 2996 28622982 2981 3028 2985 2833 2993 3040 28722940 3032 2878 2883 2835 2882 2786 2787 2831 2873 26442976 2886 3035 2837 2785 2790 2951 2911 28252929 2870 26932926 2866 3034 2988 2864 2848 2782 2646 2871 2692 2745 29083027 2980 2943 2987 2847 2849 2912 2824 2742 2905 2823 29972942 2895 2865 2738 28613031 2984 2979 2941 2733 2840 2841 2643 2781 2744 2858 2645 2691 2896 2838 2647 2855 27432935 3026 2933 2893 2890 2892 2891 2894 2845 2794 2796 2792 2846 2746 2748 2695 2904 2747 2694 2545 3038 27002850 2851 2749 2795 2648 2696 2699 25962897 2842 2843 2798 2885 2556 25972934 293727012844 2797 2652 2697 28572887 2932 2800 2854 2598 2856 2650 2651 26982702 2550 2750 26492888 2947 2802 2751 2852 2654 2811 2853 2653 25902939 2945 2949 2753 27042711 2938 2946 2944 2706 2948 2779 2600 2780 2364 2602 2603 2317 2639 2898 2505 2601 2764 24662936 2552 2902 2551 2717 25082755 2503 2561 2549 2502 2734 25552761 2899 2900 2822 2606 2655 2703 2605 2752 2686 2608 2513 2821 2599 2801 2507 2414 2544 28602504 2950 25542889 2901 2803 2656 2799 2778 2687 2560 2510 260723712709 2558 2456 2609 2。
李欣海:用R实现随机森林的分类与回归

YES
6/25 随机森林简介
第五届中国R语言会议 北京2012
李欣海
Ensemble classifiers
/profiles/Trevor_Hastie/
Tree models are simple, often produce noisy (bushy) or weak (stunted) classifiers.
• For each tree grown on a bootstrap sample, the error rate for observations left out of the bootstrap sample is monitored. This is called the out-of-bag (OOB) error rate.
#################################################################################
# # # #
# # # #
# # # #
# # # #
# # # #
# # # #
# # # #
# # # #
# # # #
# # # #
#
#
#
#
黄河 # # # # # #
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
#
利用随机森林构建分类模型,并用十折交叉验证。r语言教程

利用随机森林构建分类模型,并用十折交叉验证。
r语言教程在R语言中,我们可以使用`caret`包中的`train`函数进行模型的训练,并使用`caret`包的`createDataPartition`函数进行十折交叉验证。
以下是使用随机森林构建分类模型的示例代码:首先,确保你已经安装了必要的包。
如果没有,你可以使用以下命令进行安装:```r("caret")("randomForest")```然后,加载这些包:```rlibrary(caret)library(randomForest)接下来,我们需要加载数据。
假设我们有一个名为`data`的数据框,其中包含我们的特征和目标变量:```rdata <- ("your_") 请将"your_"替换为你的数据文件路径```然后,我们将使用`createDataPartition`函数进行十折交叉验证的数据分割:```r(123) 为了结果的可重复性control <- rbind(trainControl(method = "cv", number = 10), 10折交叉验证trainControl(method = "oob") 用于随机森林的外部验证)```接着,我们将使用`train`函数训练我们的模型:(123) 为了结果的可重复性rf_model <- train(target ~ ., data = data, trControl = control, method = "rf") 使用随机森林方法训练模型```最后,我们可以输出模型的详细信息:```rprint(rf_model)```以上代码演示了如何使用随机森林和十折交叉验证在R语言中构建分类模型。
请注意,你可能需要根据自己的数据和需求对代码进行一些调整。
r语言孤立森林算法

r语言孤立森林算法孤立森林(Isolation Forest)是一种用于异常检测的无监督学习算法,它能够有效地检测出数据集中的异常点。
而R语言提供了丰富的机器学习库和工具,其中就包括了实现孤立森林算法的相关函数和包。
本文将介绍如何使用R语言实现孤立森林算法,并通过一个示例来说明其应用。
一、什么是孤立森林算法孤立森林算法是一种基于树的集成学习方法,它通过构建一个随机的树结构来划分数据集,然后通过树的高度来评估数据点的异常程度。
算法的基本思想是,异常点往往比正常点更容易被随机划分到孤立的叶子节点上,因此可以通过计算数据点在树中的路径长度来判断其异常程度。
二、使用R语言实现孤立森林算法在R语言中,我们可以使用isolationForest包来实现孤立森林算法。
首先,我们需要安装和加载isolationForest包:```Rinstall.packages("isolationForest")library(isolationForest)```接下来,我们可以使用isolationForest函数来构建孤立森林模型。
该函数的主要参数包括数据集(data),树的数量(ntree)和随机数种子(seed)等。
下面是一个简单的示例:```R# 构建孤立森林模型model <- isolationForest(data, ntree = 100, seed = 123)# 打印模型信息print(model)```在构建完孤立森林模型后,我们可以使用predict函数来对新的数据进行异常检测。
该函数会返回每个数据点的异常得分,得分越高表示越异常。
下面是一个示例:```R# 对新数据进行异常检测scores <- predict(model, new_data)# 打印异常得分print(scores)```三、示例应用:检测信用卡欺诈为了说明孤立森林算法的应用,我们以信用卡欺诈检测为例进行示例。
用R实现随机森林的分类与回归
用R实现随机森林的分类与回归第五届中国R语言会议北京2012 李欣海用R实现随机森林的分类与回归Applications of Random Forest using RClassification and Regression李欣海中科院动物所邮件:lixh@//0>.主页:////.博客:////.微博:////. 第五届中国R语言会议北京2012 李欣海随机森林简介Random Forest////.an-introduction-to-data-mining-for-marketing-and-business-intelli gence/Random Forest is an ensemble classifier thatconsists of many decision trees It outputs the class that is the mode of the class'soutput by individual trees Breiman 2001 It deals with “small n large p”-problems, high-orderinteractions, correlated predictor variables.Breiman, L. 2001. Random forests. Machine Learning 45:5-32. Being cited 6500 times until 20123/25 第五届中国R语言会议北京2012 李欣海随机森林简介History////.an-introduction-to-data-mining-for-marketing-and-business-intelli gence/The algorithm for inducing a random forest was developed byLeo Breiman 2001 and Adele Cutler, and "Random Forests" istheir trademarkThe term came from random decision forests that was firstproposed by Tin Kam Ho of Bell Labs in 1995The method combines Breiman's "bagging" idea and therandom selection of features, introduced independently by Ho1995 and Amit and Geman 1997 in order to construct acollection of decision trees with controlled variation.4/25 第五届中国R语言会议北京2012 李欣海随机森林简介Tree modelsy β + β x + β x + β x + εi 0 1 1i 2 2 i 3 3i iClassification treeRegression treeCrawley 2007 The R Book p691 Crawley 2007 The R Book p6945/25 第五届中国R语言会议北京2012 李欣海随机森林简介The statistical community uses irrelevant theory,questionable conclusions?David R. Cox Emanuel Parzen Bruce HoadleyBrad EfronNO YES6/25 第五届中国R语言会议北京2012 李欣海随机森林简介Ensemble classifiers////.Tree models are simple, often produce noisy bushy or weakstunted classifiers Bagging Breiman, 1996: Fit many large trees to bootstrap-resampled versions of the training data, and classify by majority vote Boosting Freund & Shapire, 1996: Fit many large or small trees to reweighted versions of the training data. Classify by weighted majority vote Random Forests Breiman 1999: Fancier version of bagging.In general Boosting Random Forests Bagging Single TreeTrevor Hastie.7/25 第五届中国R语言会议北京2012 李欣海随机森林简介How Random Forest Works////.At each tree split, a random sample of m features is drawn, and only those m features are considered for splittingTypically m sqrtp or logp, where p is the number offeatures For each tree grown on a bootstrap sample, the error rate for observations left out of the bootstrap sample ismonitored. This is called the out-of-bag OOB error rate Random forests tries to improve on bagging by “de-correlating” the trees. Each tree has the same expectation.Trevor Hastie, p21 in Trees, Bagging, Random Forests and Boosting8/25 第五届中国R语言会议北京2012 李欣海随机森林简介R PackagesrandomForest randomForestTitle: Breiman and Cutler’s random forests for classification and regressionVersion: 4.6-6Date: 2012-01-06Author:Fortran original by Leo Breiman and Adele Cutler, R port by Andy Liawand Matthew Wiener.Implementation based on CART trees for variables of different types.Biased in favor of continuous variables and variables with many categories.partycforestBased on unbiased conditional inference trees.For variables of different types: unbiased when subsampling.黄河渭河9/25 第五届中国R语言会议北京2012 李欣海随机森林:分类# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #宁夏# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #青海# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #朱?的分布# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # ### ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #山西# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # ### ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #甘肃# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # ### ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # #陕西 ## ## ## # # # # # # # # # # ## ## ## # # ## ##### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # ### #河南## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ############ # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # #### ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ######### ## ######## ######## ### #### ### ## ######## ## ############################ ####### ########## ## #### #### #### ## ### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # ### ## ################## ## #### ######## ## ######### ###### ####### ## # ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## # ## #### ## ## #### ### ## #### ## # # ## # ##### ## ## ########### #### ##### ## ## ############ ######## ### ## ##### ###### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # ##### #### ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ###### #### ## ## ##### ##### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # ######### ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ######## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ### ###### # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # #四川 # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # ### ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #湖北# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # ### ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## #重庆# # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # ## ## ## ## ## ## ## ## # # # # # # # # ## ## ## ## ## ## # # # # ## ## ## ## # # # # # # # # # # # # # ### # # ## ## ## # # # # # # # # # # ## ## ## # # ## ## ## # # # # # # # # # # ## ## ## # ### #湖南湖南黄河汉江岷江嘉陵江10/25 第五届中国R语言会议北京2012 李欣海随机森林:分类DataLand Foot prec_ prec_ prec_ Nestuse x y Elev Aspect Slope Pop GDP t_ann t_jan t_july yearcover print ann jan july site1 107.505 33.392 984 0.67 29.6 21 42.0 20 2.95 845 6 153 12.4 0.3 24.0 1981 金家河1 107.548 33.409 1315 0.90 19.0 14 22.5 26 1.97 869 6 157 11.3 -0.6 22.7 1981 姚家沟1 107.505 33.392 984 0.67 29.6 21 42.0 20 2.95 845 6 153 12.4 0.3 24.0 1982 金家河1 107.548 33.409 1315 0.90 19.0 14 22.5 26 1.97 869 6 157 11.3 -0.6 22.7 1982 姚家沟1 107.505 33.392 984 0.67 29.6 21 42.0 20 2.95 845 6 153 12.4 0.3 24.0 1983 金家河1 107.548 33.409 1315 0.90 19.0 14 22.5 26 1.97 869 6 157 11.3 -0.6 22.7 1983 姚家沟1 107.548 33.409 1315 0.90 19.0 14 22.5 26 1.97 869 6 157 11.3 -0.6 22.7 1984 姚家沟1 107.405 33.406 1056 0.54 11.4 21 0.0 20 0.98 892 7 161 11.4 -0.5 22.9 1984 三岔河1 107.405 33.406 1056 0.54 11.4 21 0.0 20 0.98 892 7 161 11.4 -0.5 22.9 1985 三岔河1 107.548 33.409 1315 0.90 19.0 14 22.5 26 1.97 869 6 157 11.3 -0.6 22.7 1985 姚家沟0 107.400 32.780 980 0.46 42.1 11 45.8 14 1.78 927 6 170 13.0 1.3 24.0 0 3030 107.430 32.780 1553 0.97 29.6 14 171.8 32 4.76 887 5 162 13.0 1.3 24.0 0 3040 107.460 32.780 1534 0.51 25.7 14 12.7 14 1.78 886 5 162 14.0 2.15 25.2 0 3050 107.490 32.780 996 0.72 29.4 14 76.1 20 2.97 886 5 162 12.4 0.8 23.4 0 3060 107.520 32.780 1144 0.16 9.3 14 29.3 20 1.78 956 6 175 12.4 0.8 23.4 0 3070 107.550 32.780 915 0.91 20.7 11 214.7 20 5.95 956 6 175 11.6 0.15 22.5 0 3080 107.580 32.780 930 0.13 35.7 22 153.2 29 4.76 993 7 181 11.6 0.15 22.5 0 3090 107.610 32.780 873 0.40 31.9 11 66.4 29 2.97 931 6 171 12.7 1.1 23.8 0 3100 107.640 32.780 1147 0.50 35.5 11 46.8 20 2.38 1041 7 189 12.7 1.1 23.8 0 3110 107.670 32.780 1699 0.89 21.1 14 20.5 20 1.78 1060 8 192 10.4 -0.8 21.2 0 312tableibis$use ibis$use - as.factoribis$useibis$landcover - as.factoribis$landcover0 12538 560 11/25 第五届中国R 语言会议北京2012 李欣海随机森林:分类Multicollinearity is a painVariables in the two-principal-component space-50 0 50306530643018biplotprincompibis[,2:16], corT3017 2971 306330623060 2970306130582923 2969 2924 3016 y 3057 3059 3015 3056 30143013305530123010 30112968296329662967 30093005 2877 2922 2965 30542830 2964 3008 3006 3007292129622914 30192829 2876 30522919 2920 30533048 2960 3003 2961 3050 30013021 304929983000 3002 29593022 29173004 3051278329553020 2958 2957 2875282830472913291829993023290626892641 28272737 29732836 2784 2826 3046 2956 2874 2986 3033 2735 30442867 2690 2688 2915 30452975 2974 29163024 2789 2739 2788 2740 2642 2925 2972 3041 2869 28682927 2839 27362977 2793 2741 3037 29533025 2928 2820 2791 29103030 2832 2592 2995 2640 2994 2952 28592978 2881 2930 2879 3042 2863 3039 2909 29072983 3029 2880 2990 2992 2989 3036 3043 29542931 2834 2991 2884 2996 28622982 2981 3028 2985 2833 2993 3040 28722940 3032 2878 2883 2835 2882 2786 2787 2831 2873 26442976 2886 3035 2837 2785 2790 2951 2911 28252929 2870 26932926 2866 3034 2988 2864 2848 2782 2646 2871 2692 2745 29083027 2980 2943 2987 2847 2849 2912 2824 2742 2905 2823 29972942 2895 2865 2738 28613031 2984 2979 2941 2733 2840 2841 2643 2781 2744 2858 2645 2691 2896 2838 2647 2855 27432935 3026 2933 2893 2890 2892 2891 2894 2845 2794 2796 2792 2846 2746 2748 2695 2904 2747 2694 2545 3038 27002850 2851 2749 2795 2648 2696 2699 25962897 2842 2843 2798 2885 2556 25972934 293727012844 2797 2652 2697 28572887 2932 2800 2854 2598 2856 2650 2651 26982702 2550 2750 26492888 2947 2802 2751 2852 2654 2811 2853 2653 25902939 2945 2949 2753 27042711 2938 2946 2944 2706 2948 2779 2600 2780 2364 2602 2603 2317 2639 2898 2505 2601 2764 24662936 2552 2902 2551 2717 25082755 2503 2561 2549 2502 2734 25552761 2899 2900 2822 2606 2655 2703 2605 2752 2686 2608 2513 2821 2599 2801 2507 2414 2544 28602504 2950 25542889 2901 2803 2656 2799 2778 2687 2560 2510 260723712709 2558 2456 2609 2。
r语言随机森林结果解读

r语言随机森林结果解读
在R语言中,使用随机森林模型进行数据分析后,可以使用各种方法和技巧来解读模型结果。
以下是一些常用的方法和步骤:
1.查看模型摘要:使用summary()函数可以查看随机森林模型的摘
要,其中包括模型的各项指标和参数。
2.查看变量重要性:使用importance()函数可以查看每个变量在模型
中的重要性,通常用“MeanDecreaseAccuracy”和“MeanDecreaseGini”两个指标来衡量。
3.查看模型系数:使用coef()函数可以查看模型中的系数,即各个特
征对最终预测结果的影响程度。
4.查看特征重要性:可以通过特征重要性图(feature importance plot)
来查看各个特征对模型预测结果的影响程度。
使用plot(model$importance)可以生成特征重要性图。
5.查看模型预测结果:使用predict()函数可以对新的数据进行预测,
并将预测结果与实际值进行比较,以评估模型的准确性。
6.查看模型评估指标:可以使用各种评估指标来衡量模型的性能,
如准确率、精确率、召回率、F1得分等。
可以使用confusionMatrix()函数来计算混淆矩阵,从而得到各种评估指标。
7.查看模型交互式可视化:使用R中的交互式可视化工具,如shiny
包或plotly包等,可以更直观地查看模型结果,包括特征重要性图、混淆矩阵、ROC曲线等。
总之,在R语言中解读随机森林模型结果需要结合实际问题和数据集来进行深入分析和理解。
R语言实现随机森林

R语⾔实现随机森林R语⾔实现随机森林install.packages("pacman")install.packages("caret")install.packages("pROC")install.packages()install.packages("randomForest")library(randomForest)library(ggplot2)library(lattice)library(pacman)library(caret)library(pROC)library(rpart)data(iris)dim(iris)trainlist<-createDataPartition(iris$Species,p=0.7,list=FALSE)#取出百分之七⼗的iris数据trainset<-iris[trainlist,]testset<-iris[-trainlist,]#⼀部分分成训练集,另⼀部分则为测试集set.seed(2000)#⽣成2000个随机数rf.train<-randomForest(as.factor(Species)~.,data=trainset,importance=TRUE,na.action = na.pass)#因变量是Species,.表⽰其他都为⾃变量,数据来⾃trainset#importance表⽰随机森林需要给出每⼀个变量重要性的排序#na.action表⽰如何处理缺失值plot(rf.train,main = "randomforest")#画图,main表⽰设置标题#三种颜⾊代表三种鸢尾花,⿊⾊代表三种鸢尾花平均值#横轴是决策树的数⽬,纵轴是误差数rf.test<-predict(rf.train,newdata = testset,type = "class")rf.testrf.cf<-caret::confusionMatrix(as.factor(rf.test),as.factor(testset$Species))rf.test2<-predict(rf.train,newdata = testset,type="prob")roc.rf<-multiclass.roc(testset$Species,rf.test2)fit1=rpart(Species~.,data=trainset)pre2=predict(fit1,testset,type="prob")roc1<-multiclass.roc(testset$Species,pre2[,1])plot(roc1$rocs[[1]],col="red")plot(roc1$rocs[[3]],add=TRUE,col="green")#画出roc曲线,显⽰预测效果。
r语言随机森林预测模型校准曲线

r语言随机森林预测模型校准曲线R语言随机森林预测模型校准曲线一、引言在数据科学和机器学习领域,预测模型的准确性和稳健性一直备受关注。
在使用R语言进行数据分析和建模的过程中,随机森林(Random Forest)模型因其强大的预测能力和对复杂数据的适应性而备受青睐。
然而,即使模型在训练数据上表现良好,但在新数据上的泛化能力仍然是一个必须仔细考虑的问题。
为了评估模型的预测性能和稳健性,我们可以使用校准曲线( Calibration Curve)这一工具来进行全面的评估。
二、校准曲线的概念和应用1. 什么是校准曲线?校准曲线是一种用来评估预测模型的准确性和稳健性的图形化工具。
它展示了模型的预测概率和实际发生事件的概率之间的关系。
通过比较预测概率和实际概率的一致性,我们可以得出模型的校准性如何,以及是否存在过度自信或不足自信的情况。
2. 如何绘制校准曲线?在R语言中,我们可以使用相关的包(如calibrate)来生成校准曲线。
我们需要将数据划分为训练集和测试集,并在训练集上构建随机森林模型。
使用测试集的真实响应值和模型的预测概率值,来绘制校准曲线。
这个过程可以帮助我们直观地了解模型的校准性。
3. 校准曲线的解读和应用校准曲线通常是一条虚线,表示理想状态下预测概率与实际发生概率完全一致的情况。
我们希望模型的校准曲线能够尽可能地贴近这条理想曲线,表明模型的预测概率与实际概率存在良好的一致性。
如果校准曲线偏离理想状态,就需要进一步探究模型的不足之处,并采取相应的改进措施。
三、个人观点和理解随机森林模型作为一种强大的预测工具,其校准性在实际应用中显得尤为重要。
通过绘制校准曲线,我们可以直观地评估模型的预测性能,并发现模型可能存在的问题。
在实际建模过程中,不仅要关注模型的预测准确性,还要着重考虑模型的稳健性和应对新数据的能力。
校准曲线为我们提供了一个直观、深入的评估工具,有助于提高模型的可靠性和实用性。
四、总结随机森林预测模型的校准曲线是评估模型的准确性和稳健性的重要工具。
随机森林.ppt

两个重要的代码
randomForest
主要参数是ntree,mtry
Predict
第一步,随机森林的安装
随机森林是基于R语言运行,安装过程分两步: 1.ubuntu系统下首先安装R语言包。
用一行代码。 sudo apt-get install R 然后ubuntu系统就自动的帮你安装完R。 2.安装random forest 意想不到的简单。 打开终端 ,输入R,就算进入到了R语言的编码界面。 在大于号后面入
决策树的定义
Hale Waihona Puke 决策树是这样的一颗树:每个内部节点上选用一个属性进行分割 每个分叉对应一个属性值 每个叶子结点代表一个分类
A1
a11 A2
a12 c1
a21
a22
c1
c2
a13
A3
a31
a32
c2
c1
决策树框架
决策树生成算法分成两个步骤
树的生成
开始,数据都在根节点 递归的进行数据分片
0,mtry=3,proximity=TRUE,importance=TRUE) print(iris.rf) iris.pred<-predict( iris.rf,iris[ind==2,] ) table(observed=iris[ind==2,"Species"],predicted=iris.pred )
随机森林的特点
两个随机性的引入,使得随机森林不容易陷入过 拟合
两个随机性的引入,使得随机森林具有很好的抗 噪声能力
对数据集的适应能力强:既能处理离散型数据, 也能处理连续型数据,数据集无需规范化。
随机森林特征重要性计算_R语言随机森林模型中具有相关特征的变量重要性

随机森林特征重要性计算_R语言随机森林模型中具有相关特征的变量重要性随机森林(Random Forest)是一种常用的机器学习方法,可以用于特征选择和变量重要性评估。
在R语言中,可以使用randomForest包来构建随机森林模型,并计算变量的重要性。
在随机森林算法中,变量的重要性可以通过两种方式来评估:基于节点的重要性(Node Importance)和基于变量的重要性(Variable Importance)。
基于节点的重要性是通过计算每个节点在模型中的准确率改变来评估,它只对拆分节点的变量感兴趣。
可以使用varImp函数计算每个节点的重要性。
```R# 导入randomForest包library(randomForest)#构建随机森林模型model <- randomForest(Species ~ ., data = iris)#计算节点的重要性node_importance <- varImp(model)print(node_importance)```上面的代码将计算随机森林模型中每个节点的重要性,并打印结果。
基于变量的重要性是通过计算每个变量的平均节点准确率改变来评估。
可以使用importance函数计算变量的重要性。
```R#计算变量的重要性variable_importance <- importance(model)print(variable_importance)```上面的代码将计算随机森林模型中每个变量的重要性,并打印结果。
基于变量的重要性是基于基于节点的重要性的总和来计算的,通常更为常用。
例如,可以使用以下代码将变量按重要性进行排序并绘制柱状图:```R#按重要性对变量进行排序sorted_importance <- sort(variable_importance, decreasing = TRUE)#绘制柱状图barplot(sorted_importance, main = "Variable Importance",xlab = "Variables", ylab = "Importance")```上面的代码将变量按重要性进行排序,并绘制了一个柱状图来展示变量的重要性。
实验报告及分析_R中bagging回归与随机森林以及boosting回归

一、R中boosting回归这个主要用R中的mboost包中的mboost函数来实现。
但是作为铺助,还要加载party包。
函数如下mboost(formula, data = list(),baselearner = c("bbs", "bols", "btree", "bss", "bns"), ...)其中的参数需要注意formula的输入格式。
至于data也可以是数据框。
我们用决策树的boosting方法。
要注意查看formula的输入格式,参见下面的具体例子。
一个具体的例子我们使用我的电脑上自带的数据,即E:\Documents\R中的mg文本文件中的数据。
该数据无任何说明,知道它是由6个自变量和一个因变量构成。
试验如下。
> library(party)> library(mboost)> w<-read.table('mg.txt',header=T)>B1<-mboost(y~btree(x1)+btree(x2)+btree(x3)+btree(x4)+btree(x5)+btre e(x6),data=w[-1,]) #构建分类器,用除掉第一个样本的数据做训练数据。
>y0<-predict(B1,w[1,]) #用第一个样本作测试。
二、bagging回归与boosting回归想法类似,bagging回归的做法就是不断放回地对训练样本进行再抽样,对每个自助样本都建立一棵回归树,对于每一个观测,每棵树给一个预测,最后将其平均。
使用到的函数包为ipred,使用函数为bagging(),用法如下:bagging(formula, data, subset, na.action=na.rpart, ...)主要参数介绍:formula:回归方程形式data:数据集(数据框)control:对树枝的控制,使用函数rpart.control(),可以控制诸如cp值,xval等参量。
boruta算法r语言

boruta算法r语言
Boruta算法是一种基于随机森林的特征选择算法,它可以帮助我们在大量特征中快速筛选出最重要的特征,从而提高模型的性能和解释能力。
在R语言中,Boruta算法可以通过“Boruta”包来实现。
首先,我们需要使用随机森林对原始数据集进行训练,并获取每个特征的重要性指标。
然后,使用Boruta算法进行特征选择,它会根据每个特征的重要性指标和随机性生成一组假特征,与原始特征进行比较,以确定每个特征的重要性。
在使用Boruta算法时,我们需要设置一些参数,如随机森林的数量、最大深度、控制假特征数量的阈值等。
此外,还可以根据需要进行交叉验证等操作,以提高模型的泛化能力和稳定性。
总之,Boruta算法是一种非常实用的特征选择技术,在处理大规模数据时尤为重要。
只要掌握了基本的R语言编程技巧和Boruta 算法的原理,我们就可以快速地进行特征选择,并构建出高效、可解释性强的预测模型。
- 1 -。
r语言之randomforest随机森林

R语言之Random Forest随机森林什么是随机森林?随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。
随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。
“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想--集成思想的体现。
随机森林算法的实质是基于决策树的分类器集成算法,其中每一棵树都依赖于一个随机向量,随机森林的所有向量都是独立同分布的。
随机森林就是对数据集的列变量和行观测进行随机化,生成多个分类数,最终将分类树结果进行汇总。
随机森林相比于神经网络,降低了运算量的同时也提高了预测精度,而且该算法对多元共线性不敏感以及对缺失数据和非平衡数据比较稳健,可以很好地适应多达几千个解释变量数据集。
随机森林的组成随机森林是由多个CART分类决策树构成,在构建决策树过程中,不进行任何剪枝动作,通过随机挑选观测(行)和变量(列)形成每一棵树。
对于分类模型,随机森林将根据投票法为待分类样本进行分类;对于预测模型,随机森林将使用单棵树的简单平均值来预测样本的Y值。
随机森林的估计过程1)指定m值,即随机产生m个变量用于节点上的二叉树,二叉树变量的选择仍然满足节点不纯度最小原则;2)应用Bootstrap自助法在原数据集中有放回地随机抽取k 个样本集,组成k棵决策树,而对于未被抽取的样本用于单棵决策树的预测;3)根据k个决策树组成的随机森林对待分类样本进行分类或预测,分类的原则是投票法,预测的原则是简单平均。
随机森林的两个重要参数:1.树节点预选的变量个数:单棵决策树决策树的情况。
2.随机森林中树的个数:随机森林的总体规模。
随机森林模型评价因素1)每棵树生长越茂盛,组成森林的分类性能越好;2)每棵树之间的相关性越差,或树之间是独立的,则森林的分类性能越好。
随机森林算法构建模型 roc r语言

随机森林算法构建模型 roc r语言随机森林算法是一种常用的机器学习算法,可以用于分类和回归问题。
本文将介绍随机森林算法的原理和在R语言中的实现,并讨论其在模型评估中的重要指标——ROC曲线。
一、随机森林算法原理随机森林算法是基于决策树的集成学习算法。
它通过构建多个决策树,然后将它们的结果进行集成,以提高预测的准确性和鲁棒性。
具体来说,随机森林算法通过自助采样(bootstrap sampling)从原始训练集中随机选择一部分样本,用于构建每个决策树。
在构建每个决策树时,随机森林还会随机选择一部分特征,以增加模型的多样性。
这样可以减少过拟合的风险,并且使得模型更具有泛化能力。
在进行预测时,随机森林算法将所有决策树的预测结果进行投票或平均,得到最终的预测结果。
二、在R语言中实现随机森林算法在R语言中,我们可以使用randomForest包来实现随机森林算法。
下面是一个简单的示例代码:```R# 导入randomForest包library(randomForest)# 读取数据data <- read.csv("data.csv")# 划分训练集和测试集train <- data[1:500, ]test <- data[501:1000, ]# 构建随机森林模型model <- randomForest(target ~ ., data = train, ntree = 100)# 预测predictions <- predict(model, newdata = test)# 模型评估confusionMatrix(predictions, test$target)```在上述代码中,我们首先导入randomForest包,并读取了一个名为data.csv的数据集。
然后,我们将数据集划分为训练集和测试集。
接下来,使用randomForest函数构建随机森林模型,其中`target ~ .`表示使用所有特征来预测目标变量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
随机森林算法介绍及R语言实现随机森林算法介绍算法介绍:简单的说,随机森林就是用随机的方式建立一个森林,森林里面有很多的决策树,并且每棵树之间是没有关联的。
得到一个森林后,当有一个新的样本输入,森林中的每一棵决策树会分别进行一下判断,进行类别归类(针对分类算法),最后比较一下被判定哪一类最多,就预测该样本为哪一类。
随机森林算法有两个主要环节:决策树的生长和投票过程。
决策树生长步骤:1.从容量为N的原始训练样本数据中采取放回抽样方式(即bootstrap取样)随机抽取自助样本集,重复k(树的数目为k)次形成一个新的训练集N,以此生成一棵分类树;2.每个自助样本集生长为单棵分类树,该自助样本集是单棵分类树的全部训练数据。
设有M个输入特征,则在树的每个节点处从M个特征中随机挑选m(m < M)个特征,按照节点不纯度最小的原则从这m个特征中选出一个特征进行分枝生长,然后再分别递归调用上述过程构造各个分枝,直到这棵树能准确地分类训练集或所有属性都已被使用过。
在整个森林的生长过程中m将保持恒定;3.分类树为了达到低偏差和高差异而要充分生长,使每个节点的不纯度达到最小,不进行通常的剪枝操作。
投票过程:随机森林采用Bagging方法生成多个决策树分类器。
基本思想:1.给定一个弱学习算法和一个训练集,单个弱学习算法准确率不高,可以视为一个窄领域专家;2.将该学习算法使用多次,得出预测函数序列,进行投票,将多个窄领域专家评估结果汇总,最后结果准确率将大幅提升。
随机森林的优点:∙可以处理大量的输入变量;∙对于很多种资料,可以产生高准确度的分类器;∙可以在决定类别时,评估变量的重要性;∙在建造森林时,可以在内部对于一般化后的误差产生不偏差的估计;∙包含一个好方法可以估计遗失的资料,并且,如果有很大一部分的资料遗失,仍可以维持准确度;∙提供一个实验方法,可以去侦测 variable interactions;∙对于不平衡的分类资料集来说,可以平衡误差;∙计算各例中的亲近度,对于数据挖掘、侦测偏离者(outlier)和将资料视觉化非常有用;∙使用上述。
可被延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类。
也可侦测偏离者和观看资料;∙学习过程很快速。
缺点∙随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合;∙对于有不同级别的属性的数据,级别划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的。
R语言实现寻找最优参数mtry,即指定节点中用于二叉树的最佳变量个数library("randomForest")n<-length(names(train_data)) #计算数据集中自变量个数,等同n=ncol(train_dat a)rate=1#设置模型误判率向量初始值for(i in 1:(n-1)){set.seed(1234)rf_train<-randomForest(as.factor(train_data$IS_LIUSHI)~.,data=train_data,mtry =i,ntree=1000)rate[i]<-mean(rf_train$err.rate) #计算基于OOB数据的模型误判率均值print(rf_train)}rate #展示所有模型误判率的均值plot(rate)寻找最佳参数ntree,即指定随机森林所包含的最佳决策树数目set.seed(100)rf_train<-randomForest(as.factor(train_data$IS_LIUSHI)~.,data=train_data,mtry=1 2,ntree=1000)plot(rf_train) #绘制模型误差与决策树数量关系图legend(800,0.02,"IS_LIUSHI=0",cex=0.9,bty="n")legend(800,0.0245,"total",cex=0.09,bty="n")随机森林模型搭建set.seed(100)rf_train<-randomForest(as.factor(train_data$IS_LIUSHI)~.,data=train_data,mtry=1 2,ntree=400,importance=TRUE,proximity=TRUE)∙importance设定是否输出因变量在模型中的重要性,如果移除某个变量,模型方差增加的比例是它判断变量重要性的标准之一;∙proximity参数用于设定是否计算模型的临近矩阵;∙ntree用于设定随机森林的树数。
输出变量重要性:分别从精确度递减和均方误差递减的角度来衡量重要程度。
importance<-importance(rf_train)write.csv(importance,file="E:/模型搭建/importance.csv",s=T,quote=F)barplot(rf_train$importance[,1],main="输入变量重要性测度指标柱形图")box()提取随机森林模型中以准确率递减方法得到维度重要性值。
type=2为基尼系数方法importance(rf_train,type=1)varImpPlot(x=rf_train,sort=TRUE,n.var=nrow(rf_train$importance),main="输入变量重要性测度散点图")信息展示print(rf_train) #展示随机森林模型简要信息hist(treesize(rf_train)) #展示随机森林模型中每棵决策树的节点数max(treesize(rf_train));min(treesize(rf_train))MDSplot(rf_train,train_data$IS_OFF_USER,palette=rep(1,2),pch=as.numeric(train_d ata$IS_LIUSHI)) #展示数据集在二维情况下各类别的具体分布情况检测pred<-predict(rf_train,newdata=test_data)pred_out_1<-predict(object=rf_train,newdata=test_data,type="prob") #输出概率table <- table(pred,test_data$IS_LIUSHI)sum(diag(table))/sum(table) #预测准确率plot(margin(rf_train,test_data$IS_LIUSHI),main=观测值被判断正确的概率图)randomForest包可以实现随机森林算法的应用,主要涉及5个重要函数,语法和参数请见下1:randomForest()函数用于构建随机森林模型randomForest(formula, data=NULL, ..., subset, na.action=na.fail)randomForest(x, y=NULL, xtest=NULL, ytest=NULL, ntree=500,mtry=if (!is.null(y) && !is.factor(y))max(floor(ncol(x)/3), 1) else floor(sqrt(ncol(x))),replace=TRUE, classwt=NULL, cutoff, strata,sampsize = if (replace) nrow(x) else ceiling(.632*nrow(x)),nodesize = if (!is.null(y) && !is.factor(y)) 5else1,maxnodes = NULL,importance=FALSE, localImp=FALSE, nPerm=1,proximity, oob.prox=proximity,norm.votes=TRUE, do.trace=FALSE,keep.forest=!is.null(y) && is.null(xtest), corr.bias=FALSE,keep.inbag=FALSE, ...)∙formula指定模型的公式形式,类似于y~x1+x2+x3…;∙data指定分析的数据集;∙subset以向量的形式确定样本数据集;∙na.action指定数据集中缺失值的处理方法,默认为na.fail,即不允许出现缺失值,也可以指定为na.omit,即删除缺失样本;∙x指定模型的解释变量,可以是矩阵,也可以是数据框;∙y指定模型的因变量,可以是离散的因子,也可以是连续的数值,分别对应于随机森林的分类模型和预测模型。
这里需要说明的是,如果不指定y值,则随机森林将是一个无监督的模型;∙xtest和ytest用于预测的测试集;∙ntree指定随机森林所包含的决策树数目,默认为500;∙mtry指定节点中用于二叉树的变量个数,默认情况下数据集变量个数的二次方根(分类模型)或三分之一(预测模型)。
一般是需要进行人为的逐次挑选,确定最佳的m值;∙replace指定Bootstrap随机抽样的方式,默认为有放回的抽样∙classwt指定分类水平的权重,对于回归模型,该参数无效;∙strata为因子向量,用于分层抽样;∙sampsize用于指定样本容量,一般与参数strata联合使用,指定分层抽样中层的样本量;∙nodesize指定决策树节点的最小个数,默认情况下,判别模型为1,回归模型为5;∙maxnodes指定决策树节点的最大个数;∙importance逻辑参数,是否计算各个变量在模型中的重要性,默认不计算,该参数主要结合importance()函数使用;∙proximity逻辑参数,是否计算模型的临近矩阵,主要结合MDSplot()函数使用;∙oob.prox是否基于OOB数据计算临近矩阵;∙norm.votes显示投票格式,默认以百分比的形式展示投票结果,也可以采用绝对数的形式;∙do.trace是否输出更详细的随机森林模型运行过程,默认不输出;∙keep.forest是否保留模型的输出对象,对于给定xtest值后,默认将不保留算法的运算结果。
2:importance()函数用于计算模型变量的重要性importance(x, type=NULL, class="NULL", scale=TRUE, ...)∙x为randomForest对象;∙type可以是1,也可以是2,用于判别计算变量重要性的方法,1表示使用精度平均较少值作为度量标准;2表示采用节点不纯度的平均减少值最为度量标准。