编译原理课件语法制导翻译__翻译方案_SDD
合集下载
编译原理课件语法制导翻译__SDD_定义__例__表达式的解释执行
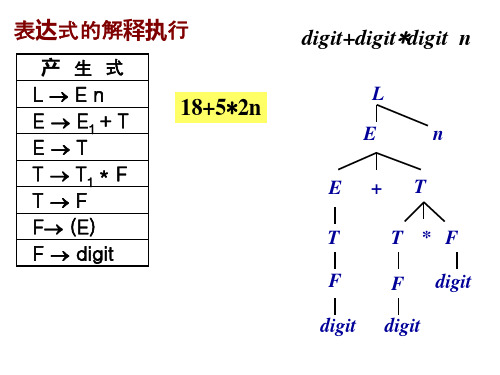
表达式的解释执行
产 生 式 LEn E E1 + T ET T T1 * F TF F (E) F digit
digit+digit*digit n
L E E T F digit +
18+5*2n
n T
T * F F digit digit
语法制导定义 SDD Syntax-Directed Definition
F.val := digit.lexval
E .val = 8
T.val = 8 F.val = 8
+
T .val = 10 T .val = 5 *
F.val = 5 F .val = 2 digit .lexval = 2
digit .lexval = 8
digit .lexval = 5
SDD与属性文法
• 副作用 • 引用透明
LEn
print (E.val)
E E1 + T E.val := E1 .val + T.val
ET
T T1 * F TF
E.val := T.val
T.val := T1.val * F.val T.val := F.val
F (E)
F digit
F.val := E.val
TF
F(E) Fdigit
翻译输入 3*5+4n 所作的动作
L E n { print (statck[top-1].val ); top = top -1; } EE1 + T { statck[top-2].val = statck[top-2].val + statck[top].val; top = top -2; } TT1 * F { statck[top-2].val = statck[top-2].val * statck[top].val; top = top -2; } { statck[top-2].val = F(E) statck[top-1].val top = top -2; }
产 生 式 LEn E E1 + T ET T T1 * F TF F (E) F digit
digit+digit*digit n
L E E T F digit +
18+5*2n
n T
T * F F digit digit
语法制导定义 SDD Syntax-Directed Definition
F.val := digit.lexval
E .val = 8
T.val = 8 F.val = 8
+
T .val = 10 T .val = 5 *
F.val = 5 F .val = 2 digit .lexval = 2
digit .lexval = 8
digit .lexval = 5
SDD与属性文法
• 副作用 • 引用透明
LEn
print (E.val)
E E1 + T E.val := E1 .val + T.val
ET
T T1 * F TF
E.val := T.val
T.val := T1.val * F.val T.val := F.val
F (E)
F digit
F.val := E.val
TF
F(E) Fdigit
翻译输入 3*5+4n 所作的动作
L E n { print (statck[top-1].val ); top = top -1; } EE1 + T { statck[top-2].val = statck[top-2].val + statck[top].val; top = top -2; } TT1 * F { statck[top-2].val = statck[top-2].val * statck[top].val; top = top -2; } { statck[top-2].val = F(E) statck[top-1].val top = top -2; }
语法制导翻译【共41张PPT】

一个属性文法称为L-属性文法,如果对于每个产生式
int T_val, R_i, R_s; int E_val;
AX1X2Xn,其中每条语义规则中的每个属性或者
是综合属性,或者是X (1jn)的一个继承属性且这 (3) E→(E(1))
val[ntop]= val[top–1]
使用标记非终结符M和N改写为
2. 函数过程A的代码(指用符号形式表示的数据和程序)
要根据当前的输入符号来决定使用哪一个产生式。
3. 与每一个产生式有关的代码,从左到右根椐产生式右部是
终结符(单词符号)、非终结符号还是语义动作,分别处 理:
保存下来,以便以后语义子程序引用这些信息。
原LR分析器的分析栈也加以扩充,存放三类信息:分析
状态、文法符号及文法符号对应的语义值。
top
sk
Xk
Xk.val
... ... ...
s1
X1
X1.val
s0
#
_
状态 文法符号 语义值
扩充后的LR分析栈
例6-3 考虑下面的语法制导定义
产生式
语义规则
9–5+2的带语义动作的分析树
设计翻译模式(根据语法制导定义)
语法制导定义是L-属性文法 保证语义动作不会引用还没有计算的属性值。
只需要综合属性的情况
为每一个语义规则建立一个包含赋值的动作,并把这个 动作放在相应的产生式右边的末尾。
例如:T T(1)*F T.val:=T(1).val*F.val
产生式 语义规则 A LM L.i:=l(A.i)
M.i:=m(L.s) A.s:=f(M.s) A QR R.i:=r(A.i) Q.i:=q(R.s) A.s:=f(Q.s)
《编译原理》教学课件-第4章 语法制导的翻译 4-3 L-属性定义

10
S { B.ps:=10 }
B {S.ht:=B.ht}
B { B1.ps:=B.ps} B1 {B2.ps:=B.ps} B2 { B.ht:=max(B1.ht,B2.ht) }
B {B1.ps:=B.ps } B1 sub {B2.ps:=shrink(B.ps)} B2 {B.ht:=disp(B1.ht,B2.ht)}
E
T
R
8 print(‘8') + T print(‘+')
R
5 print('5')
- T print(‘-')
R
经过一次深度优先遍历 得到输出:85+2-
2 print('2')
6
设计翻译方案时,必须遵守某些限制以保证当 某个动作引用一个属性时它是可用的,L属性 定义所规定的这些限制确保一个动作不会引用 一个还没有计算出来的属性
非终结符A对应的函数过程中,根据当前的输 入符号决定使用哪个产生式候选
每个产生式对应的程序代码中,按照从左到右 的次序,对于单词符号、非终结符和语义动作 分别作以下工作:
16
对于带有综合属性x的终结符X,把x的值存入为X.x 设置的变量中,然后产生一个匹配X的调用,并继 续读入一个输入符号
对于每个非终结符B,产生一个右边带有函数调用 的赋值语句c=B(b1,b2,...,bk),其中b1,b2,...,bk是为B 的继承属性设置的变量,c是为B的综合属性设置的 变量
1
例:非L-属性文法
产生式
语义规则
ALM
L.i:=l(A.i)
M.i:=m(l.s)
AQR
R.i:=r(A.i)
编译原理 第5章语法制导的翻译

属性和文法符号相关联 规则和产生式相关联
根据需要,将文法符号和某些属性相关联, 并通过语义规则来描述如何计算属性的值
E→E1+T E.code=E1.code || T.code || ‘+’ code表示了我们关心的表达式的逆波兰表示,规则说明 加法表达式的逆波兰表示由两个分量的逆波兰表示并置, 然后加上‘+’得到。
digitlexval=3
18
适用于自顶向下分析的SDD
前面的表达式文法存在直接左递归,因 此无法直接用自顶向下方法处理。 消除左递归之后,无法直接使用属性val 进行处理:
比如规则:T→FT’ T’→*FT’ T对应的项中,第一个因子对应于F, 而运算符在T’中。
19
相同表达式的不同文法的比较
38
例5.15 分析栈实现的例子
假设语法分析栈存放在一个被称为stack 的记录数组中,下标top指向栈顶;
stack[top]指向这个栈的栈顶;stack[top-1] 指向栈顶下一个位置; 如果不同的文法符号有不同的属性集合,我 们可以使用union来保存这些属性值。(归 约时,我们知道栈顶向下的各个符号分别是 什么)
语义翻译的流程
输 入 符 号 串 分 析 树 依 赖 图
语
义
规
则
的 计
实际上,编译中语义翻译的实现并不是 按图中的流程处理的;而是随语法分析 的进展,识别出一个语法结构,就对它 的语义进行分析和翻译。
算
9
5.1 语法制导定义
4.什么是语法制导定义(SDD) 上下文无关文法和属性/规则的结合;
编译原理chapter5 语法制导翻译

for 结点n所用产生式对应的每一条
语义规则 b:=f(c1,c2,…,ck ) do
精品文档
14
5.1.5 计算顺序
◆拓扑排序
一个有向非循环图的拓扑排序是图中
结点的任何顺序m1,m2,…,mk,使得
边必须是从序列中前面的结点指向后面的
结点,也就是说,如果mi→mj是mi到mj的
一条边,那么在 序列中mi必须出现在mj的
规则来计算综合属性值,即在 用哪个产生
式进行归约后,就执行那个产生式的s-属性
定义计算属性的值,从叶结点到根结点进行
计算。
5.1.3 继承属性
继承属性值是由此结点的父结点和/或兄
弟结点的某些属性值来决定的。
例5 . 3 变量说明的类性定义
int a,b,c
精品文档
11
表5.2 带有继承属性L.in的语法制导定义
精品文档
3
要求:随着语法分析,分析树逐步被构造出 来,进展到每一步,定义的文法符号的属性 值是可以计算出来的。一个重要的属性定义 类称作“L—属性”定义,满足上述要求。
精品文档
4
语
输
义
入
分
依
规
符
析
赖
则
号
树
图
的
串
计
算
图5.1 语法制导翻译的概观
精品文档
5
5.1 语法制导定义(Syntax-directed definitions) ◆语法制导定义是对上下文无关文法的推广 综◆合属属性性 继承属性 ◆依赖图 语义规则建立了属性之间的依赖关系,这些关 系可以用图来表示,这样的图称为依赖图。
语法树是常用的一种中间表示形式。
属性文法和语法制导翻译

赋值语句的语法树
assignment variable expression
在语法树中,运算符号和关键字都不在叶结 点,而是在内部结点中出现。
《编译技术》课程 北京大学信息科学技术学院
2015年春季学期
5
具体语法树 vs. 抽象语法树
if (x+y) { while (z) z=z+1 od; x =8 } else z = 7 fi $ 的具体语法树 (分析树)
北京大学信息科学技术学院 2015年春季学期 《编译技术》
第5章 语法制导翻译(2)
Syntax-Directed Translation 【第5.3, 5.4节】
回顾:语法制导定义(SDD)
为每个符号X添加相应的属性X.x,对于产生 式A->XYZ
综合属性:A.a = f (A.i, X.x, Y.y, Z.z) 继承属性:Y.i = g (A.a, X.x, Y.y, Z.z)
2015年春季学期
《编译技术》课程
北京大学信息科学技术学院
26
top
state ... X Y Z
val ... X.x Y.y Z.z
state
val ... A.a
top
... A
定义 A.a=f(X.x, Y.y, Z.z)(抽象表示)对应的动作 stack[top-2].val = f(stack[top-2].val, stack[top-1].val, stack[top].val); top = top-2;
把语义动作看成终结符号,输入 9-5+2, 其分析树见 下页,当按深度优先遍历它,执行遍历中访问的语 义动作,将输出
编译原理课件语法制导翻译翻译方案SDD

SDD的实际应用
示例 语义值的计算 类型检查的实现 解析默认参数
描述 计算表达式2+3操作得到的实际结果 检查赋值操作符两侧数值的类型是否一致 将默认参数设置为参数列表中未给出的实参
总结
协作
了解SDD,能更好地协作进行编 译程序开发。
应用
总结
SDD在通用编程语言中广泛应用, 掌握SDD将增加自己在编程方面 的实用性。
概念
定义高级语言和目标语言的一一 对应关系,保证编译器输出的目 标程序与原程序功能相同。
使用
将源程序的语法树根据SDD转化 为目标程序的语法树,完成上下 文有关的属性计算并生成目标代 码。
优点
灵活的特性、准确的语义描述和 高效的处理过程,使得编译器能 够更好地分析和翻译源程序。
语法制导定义
1
语法定义
使用一组语法制导规则将源程序的语法
语义定义
2
描述为翻译方案的形式。
通过为每个语法构造一个属性集合,并
定义每个属性的计算方法来定义程序语
3
翻译过程定义
义。
使用一组由语法定义和语义定义构成的
规则,将源程序转化为目标程序。
SDD表达式
翻译方案格式
语法制导翻译表达式的常规形式是: ⟨属性⟩→⟨表达式⟩
表达式的计算
通过本课程,你将掌握语法制导 翻译与SDD的概念、使用方法和 广泛应用领域,希望你能更好地 进行编译器程序的开发工作。
编译原理课件语法制导翻 译翻译方案SDD
本次课程将带领你深入了解语法制导翻译与S识。
语法制导翻译简介
1 定义
一种将语法和语义相结合的编译技术。
2 作用
通过定义翻译方案SDD,将高级语言的语法转化为目标语言的语法,并赋予其语义。
编译原理课件语法制导翻译__SDD_依赖图_拓扑排序__例__变量声明语句_继承属性

T type real in
L addtype ,
id3 entry
L addtype id1 entry
id2 entry
L L1, id L1.in := L.in; addtype (id.entry,L.in ) L id addtype (id.entry, L.in )
文法 ☆
real id1, id2, id3
id1.entry 1
参考
依赖图 Dependency Graph
• 语义规则的形式 b := f(c1,c2,…,ck)
可以为每一个包含过程调用的语义规则引入一 个虚综合属性 b, L E n print (E.val)
• 依赖图中为每一个属性设置一个结点, 如果属性b依赖于属性c, c1 则从属性c的结点 有一条有向边连到属性b的结点。…
如何确定属性的计算顺序? T.type 4 7 L.in 9 L.in 5 L.in addtype 8
依赖图
拓扑排序
addtype 6 id3.entry 3
addtype 10
id2.entry 2 a4 := real; a5 := a4; addtype (id3.entry, a5 ) a7 := a5; addtype (id2.entry, a7 ) a9 := a7; addtype (id1.entry, a9 )
T real
L L1, id L id
计算继承属性
D TL T int T real L L1, id
L id
D
T .type = real real
综合 属性
L.in := T.type T. type := integer T. type := real L1.in := L.in; addtype (id.entry,L.in ) addtype (id.entry,L.in )
编译原理--语法制导的翻译 ppt课件

(2)设code 为综合属性,代表各非终结符 的代码属性
type为综合属性,代表各非终结符的类型属 性
inttoreal把整型值转换为相等的实型值 vtochar将数值转换为字符串
5.3.3 给出一个SDD对x*(3*x+x*x)这样的表达式求 微分。表达式中涉及运算符+和*,变量x和常 量。假设不进行任何简化,也就是说,比如 3*x将被翻译为3*1+0*x。
ST z , R4
8.2.6 确定下列指令序列的代价。
1)
LD R0 , y
2
LD R1 , z
2
ADD R0 , R0 , R1 1
ST x , R0
2
总代价:7
3)
LD R0 , c
2
LD R1 , i
2
MUL R1 , R2 , 8 2
ST a(R1) , R0 2
总代价:8
8.3.3 假设使用栈式分配,且假设a和b都是元素大小为4字节 的数组,为下面的三地址语句生成代码。
的位数次幂值(2 length of L)
S L1.L2 S.val = L1.val +L2.val / L2.b; S L S.val = L.val; L L1 B L.val = L1.val *2 + B.val;
L.b = L1.b*2; L B L.val = B.val; L.b = 2; B 0 B.val = 0; B 1 B.val = 1;
2)三个语句序列 x = a[i] y = b[i] z = x*y
LD R1 , i MUL R1 , R1 , 4 ADD R1 , R1 , SP LD R2 , a(R1) ST x(SP) , R2 LD R3 , i MUL R3 , R3 , 4 ADD R3 , R3 , SP LD R4 , b(R3) ST y(SP) , R4 LD R5 , x(SP) LD R6 , y(SP) MUL R5 , R5 , R6 ST z(SP) ,R5
语法制导的翻译

• 属性文法没有副作用,但增加了描述的复杂度
– 比如语法分析时如果没有副作用,标识符表就必须
作为属性传递 – 可以把标识符表作为全局变量,然后通过副作用函 数来添加新标识符
• 受控的副作用
– 不会对属性求值产生约束,即可以按照任何拓扑顺
序求值,不会影响最终结果 – 或者对求值过程添加简单的约束
受控副作用的例子
计算s的综合属型a可以放在最前面将sdd转换为sdt对于产生式体中的终结符号读入符号并获取其经词法分析得到的综合属性对于非终结符号使用适当的方式调用相应函数并记录返回值l属性的sdd的实现递归下降法实现l属性sdd的例子比如code代码可能是一个上百k的串对其进行并置等运算会比较低效可以逐步生成属性的各个部分并增量式添加到最终的属性值中在各产生式中主属性是通过产生式体中各个非终结符号的主属性连接并置得到的同时还会连接一些其它的元素各非终结符号的主属性的连接顺序和它在产生式体中的顺序相同边扫描边生成属性1只需要在适当的时候发出非主属性的元素即把这些元素拼接到适当的地方假设我们在扫描一个非终结符号对应的语法结构时调用相应的函数并生成主属性l1ccodelabel如果各个函数把主属性打印出来我们处理while语句时只需要先打印labell1再调用c打印了c的代码再打印labell2再调用s打印s对于这个规则而言只需要打印labell1和labell2当然我们要求c和s的语句在相应情况下跳转到l1和l2边扫描边生成属性2l1new
上的非终结符号A的属性值由N对应的产生式所关联的 语义规则来定义
– 通过N的子结点或N本身的属性值来定义
• 继承属性(inherited attribute):结点N的属性值由N
的父结点所关联的语义规则来定义
– 依赖于N的父结点、N本身和N的兄弟结点上的属性值
– 比如语法分析时如果没有副作用,标识符表就必须
作为属性传递 – 可以把标识符表作为全局变量,然后通过副作用函 数来添加新标识符
• 受控的副作用
– 不会对属性求值产生约束,即可以按照任何拓扑顺
序求值,不会影响最终结果 – 或者对求值过程添加简单的约束
受控副作用的例子
计算s的综合属型a可以放在最前面将sdd转换为sdt对于产生式体中的终结符号读入符号并获取其经词法分析得到的综合属性对于非终结符号使用适当的方式调用相应函数并记录返回值l属性的sdd的实现递归下降法实现l属性sdd的例子比如code代码可能是一个上百k的串对其进行并置等运算会比较低效可以逐步生成属性的各个部分并增量式添加到最终的属性值中在各产生式中主属性是通过产生式体中各个非终结符号的主属性连接并置得到的同时还会连接一些其它的元素各非终结符号的主属性的连接顺序和它在产生式体中的顺序相同边扫描边生成属性1只需要在适当的时候发出非主属性的元素即把这些元素拼接到适当的地方假设我们在扫描一个非终结符号对应的语法结构时调用相应的函数并生成主属性l1ccodelabel如果各个函数把主属性打印出来我们处理while语句时只需要先打印labell1再调用c打印了c的代码再打印labell2再调用s打印s对于这个规则而言只需要打印labell1和labell2当然我们要求c和s的语句在相应情况下跳转到l1和l2边扫描边生成属性2l1new
上的非终结符号A的属性值由N对应的产生式所关联的 语义规则来定义
– 通过N的子结点或N本身的属性值来定义
• 继承属性(inherited attribute):结点N的属性值由N
的父结点所关联的语义规则来定义
– 依赖于N的父结点、N本身和N的兄弟结点上的属性值
编译原理课件语法制导翻译__SDD_例__表达式__综合属性_继承属性

T .val
依赖图 .inh T’.syn
F .val
digit .lexval *
F .val digit .lexval
inh T1’.syn ε
Production Semantic Rules T → FT’ T’.inh = F.val T.val = T’.syn T’→ *FT1’ T1’.inh = T’.inh * F.val T’.syn = T1’.syn
Production T → FT’ T’→ *FT1’ T’→ ε F → digit Semantic Rules T’.inh = F.val T.val = T’.syn T1’.inh = T’.inh * F.val T’.syn = T1’.syn T’.syn = T’.inh F.val = digit.lexval
T F T’
补充练习: 构造 3*5*7 的带 注释的语法树
digit
*
F
digit *
T’
F T’
digit
Production T → FT’ T’→ *FT1’ T’→ ε F → digit Semantic Rules T’.inh = F.val T.val = T’.syn T1’.inh = T’.inh * F.val T’.syn = T1’.syn T’.syn = T’.inh F.val = digit.lexval
6
7
Production Semantic Rules T → FT’ T’.inh = F.val T.val = T’.syn T’→ *FT1’ T1’.inh = T’.inh * F.val T’.syn = T1’.syn
编译原理 语法制导翻译

搜索方法:hash技术…
TinyC中的语法树
typedef enum {StmtK,ExpK} NodeKind; typedef enum {IfK,RepeatK,AssignK,ReadK,WriteK} StmtKind; typedef enum {OpK,ConstK,IdK} ExpKind; typedef enum {Void,Integer,Boolean} ExpType; #define MAXCHILDREN 3 typedef struct treeNode { struct treeNode * child[MAXCHILDREN]; struct treeNode * sibling; int lineno; NodeKind nodekind; union { StmtKind stmt; ExpKind exp;} kind; union { TokenType op; int val; char * name; } attr; ExpType type; /* for type checking of exps */ } TreeNode;
作为中间表示形式——分离分析与翻译
在进行语法分析的同时进行翻译存在缺
陷:
适合分析的文法可能未反映自然的语言结构 分析顺序可能与翻译顺序不一致
利用语法制导翻译方法来构造语法树
5.2.1 语法树
(抽象)语法树,压缩形式
关键字和运算符均在内部节点
链式结构会被压缩
语法树压缩例
digit.lexval:终结符只有综合属性,由词法分 析器提供 开始符号通常没有继承属性
5.1.2 综合属性
只有综合属性:S-属性定义
语法树自底向上计算属性
TinyC中的语法树
typedef enum {StmtK,ExpK} NodeKind; typedef enum {IfK,RepeatK,AssignK,ReadK,WriteK} StmtKind; typedef enum {OpK,ConstK,IdK} ExpKind; typedef enum {Void,Integer,Boolean} ExpType; #define MAXCHILDREN 3 typedef struct treeNode { struct treeNode * child[MAXCHILDREN]; struct treeNode * sibling; int lineno; NodeKind nodekind; union { StmtKind stmt; ExpKind exp;} kind; union { TokenType op; int val; char * name; } attr; ExpType type; /* for type checking of exps */ } TreeNode;
作为中间表示形式——分离分析与翻译
在进行语法分析的同时进行翻译存在缺
陷:
适合分析的文法可能未反映自然的语言结构 分析顺序可能与翻译顺序不一致
利用语法制导翻译方法来构造语法树
5.2.1 语法树
(抽象)语法树,压缩形式
关键字和运算符均在内部节点
链式结构会被压缩
语法树压缩例
digit.lexval:终结符只有综合属性,由词法分 析器提供 开始符号通常没有继承属性
5.1.2 综合属性
只有综合属性:S-属性定义
语法树自底向上计算属性
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
语法制导翻译
描述一棵语法树中结点的属性之间的 相互依赖关系 词法分析 语法分析 依赖图 输入串 语法树 语义规则计算次序 ( 拓扑排序) 树遍历
一遍扫描:在语法分析的同时完成语义规则的 计算, 无需构造实际的语法树
1. 依赖图的拓扑排序
• 依赖图 • 拓扑排序
2. 树遍历的属性计算方法
练习: 以下SDD是L-属性的吗?
产生式 语义规则
ALM
AQR
L.i := l(A.i) M.i := m(L.s) A.s := f(M.s) R.i := r(A.i) Q.i := q(R.s) A.s := f(Q.s)
• 表达式2 ☆
dependencygraph edges can go from left to right
(2) 产生式 Xj 的左边符号 X1,X2,…,Xj-l 的属性
(3) Xj 自己的属性
• S-属性文法一定是L-属性文法 表达式 ☆
Example 非L-属性文法
产生式 A BC 语义规则 A.s = B.b B.i = f ( C.c , A.s )
Fig. Syntax-directed definition of a simple desk calculator
L-属性文法 D TL 和自上而下 T int 语法分析 T real
L L1, id D T .type = real real
综T.type T. type := integer T. type := real L1.in := L.in; addtype (id.entry,L.in ) addtype (id.entry,L.in )
(a)初始状态 (b)VisitNode(S)第一次调用后 (c)VisitNode(S)第二次调用后 (d)VisitNode(S)第三次调用后 的最终状态
下面算法可对任何无循环的属性文法进行计算
While 还有未被计算的属性 do VisitNode(S) /*S是开始符号*/ procedure VisitNode(N: Node); begin if N ∈VN then /* 假设它的产生式为N→X1 X2…Xm*/ for i:=1 to m do if Xi∈VN then /* 即Xi 是非终结符 */ begin 计算 Xi 的所有能够计算的继承属性; VisitNode (Xi) end; 计算 N 的所有能够计算的综合属性 end
• 以某种次序遍历语法树,直至计算出所有属性 • 最常用的遍历方法是深度优先,从左到右的遍 历方法.如果需要的话,可使用多次遍历
例 S有继承属性a, 综合属性b X有继承属性c, 综合属性d Y有继承属性e, 综合属性f Z有继承属性h, 综合属性g
初值 S.a=0 , 输入串 xyz 的语法树如下
L .in = real
继承属性
L .in = real
,
, id2
id3
L .in = real
id1
L-属性文法
如果对于每个产生式 A→X1X2…Xn
其每个语义规则中的每个属性
或者是综合属性, 或者是Xj(1<=j<= n)的一个继承属性 , 且这个继承属性仅依赖于: (1) A的继承属性
S:a=0 , b=0 X.c=1 .d=2 x Y .e=0 Z .h=0 .f=0 .g=1 y z
产生式 语义规则 S XYZ S.b:=X.d-2 X.c=Z.g Y.e:=S.b Z.h:=S.a X.d:=2*X.c X x Y.f:=Y.e*3 Y y Z.g:=Z.h+1 Z z
3. 一遍扫描的处理方法
• 一遍扫描的处理方法
在语法分析的同时计算属性值 无需构造实际的语法树
• 自上而下分析
L-属性文法 S-属性文法
• 自下而上分析
S-属性文法和自下而上语法分析
• S-属性文法: 仅使用综合属性的属性文法
Production LEn E E1 + T ET T T1 * F TF F (E) F digit Semantic Rules L.val := E.val E.val := E1.val + T.val E.val := T.val T.val := T1.val * F.val T.val := F.val F.val := E.val F.val := digit.lexval
描述一棵语法树中结点的属性之间的 相互依赖关系 词法分析 语法分析 依赖图 输入串 语法树 语义规则计算次序 ( 拓扑排序) 树遍历
一遍扫描:在语法分析的同时完成语义规则的 计算, 无需构造实际的语法树
1. 依赖图的拓扑排序
• 依赖图 • 拓扑排序
2. 树遍历的属性计算方法
练习: 以下SDD是L-属性的吗?
产生式 语义规则
ALM
AQR
L.i := l(A.i) M.i := m(L.s) A.s := f(M.s) R.i := r(A.i) Q.i := q(R.s) A.s := f(Q.s)
• 表达式2 ☆
dependencygraph edges can go from left to right
(2) 产生式 Xj 的左边符号 X1,X2,…,Xj-l 的属性
(3) Xj 自己的属性
• S-属性文法一定是L-属性文法 表达式 ☆
Example 非L-属性文法
产生式 A BC 语义规则 A.s = B.b B.i = f ( C.c , A.s )
Fig. Syntax-directed definition of a simple desk calculator
L-属性文法 D TL 和自上而下 T int 语法分析 T real
L L1, id D T .type = real real
综T.type T. type := integer T. type := real L1.in := L.in; addtype (id.entry,L.in ) addtype (id.entry,L.in )
(a)初始状态 (b)VisitNode(S)第一次调用后 (c)VisitNode(S)第二次调用后 (d)VisitNode(S)第三次调用后 的最终状态
下面算法可对任何无循环的属性文法进行计算
While 还有未被计算的属性 do VisitNode(S) /*S是开始符号*/ procedure VisitNode(N: Node); begin if N ∈VN then /* 假设它的产生式为N→X1 X2…Xm*/ for i:=1 to m do if Xi∈VN then /* 即Xi 是非终结符 */ begin 计算 Xi 的所有能够计算的继承属性; VisitNode (Xi) end; 计算 N 的所有能够计算的综合属性 end
• 以某种次序遍历语法树,直至计算出所有属性 • 最常用的遍历方法是深度优先,从左到右的遍 历方法.如果需要的话,可使用多次遍历
例 S有继承属性a, 综合属性b X有继承属性c, 综合属性d Y有继承属性e, 综合属性f Z有继承属性h, 综合属性g
初值 S.a=0 , 输入串 xyz 的语法树如下
L .in = real
继承属性
L .in = real
,
, id2
id3
L .in = real
id1
L-属性文法
如果对于每个产生式 A→X1X2…Xn
其每个语义规则中的每个属性
或者是综合属性, 或者是Xj(1<=j<= n)的一个继承属性 , 且这个继承属性仅依赖于: (1) A的继承属性
S:a=0 , b=0 X.c=1 .d=2 x Y .e=0 Z .h=0 .f=0 .g=1 y z
产生式 语义规则 S XYZ S.b:=X.d-2 X.c=Z.g Y.e:=S.b Z.h:=S.a X.d:=2*X.c X x Y.f:=Y.e*3 Y y Z.g:=Z.h+1 Z z
3. 一遍扫描的处理方法
• 一遍扫描的处理方法
在语法分析的同时计算属性值 无需构造实际的语法树
• 自上而下分析
L-属性文法 S-属性文法
• 自下而上分析
S-属性文法和自下而上语法分析
• S-属性文法: 仅使用综合属性的属性文法
Production LEn E E1 + T ET T T1 * F TF F (E) F digit Semantic Rules L.val := E.val E.val := E1.val + T.val E.val := T.val T.val := T1.val * F.val T.val := F.val F.val := E.val F.val := digit.lexval