基于散列表的单片机快速查找算法
单片机的查表程序

单片机的查表程序在单片机开发过程中.一些非线性的控制过程.最适合做一个表格来.时时改变系统的参数.达到控制的目的.最常的如产生正弦的的程.就是建一个大的数组时时改变输出的8位字节送给外部DA.由DA生成一个完整的正弦波.当然了.LED显示也是一个例子.通过建一个数组来实现段码的点亮点灭.下面就是一个LED表---digits[0]#define SEG_a 0x01#define SEG_b 0x02#define SEG_c 0x04#define SEG_d 0x08#define SEG_e 0x10#define SEG_f 0x20#define SEG_g 0x40#define SEG_dot 0x80unsigned char digits[10] = {(SEG_a|SEG_b|SEG_c|SEG_d|SEG_e|SEG_f), // 0(SEG_b|SEG_c), // 1(SEG_a|SEG_b|SEG_d|SEG_e|SEG_g), // 2(SEG_a|SEG_b|SEG_c|SEG_d|SEG_g), // 3(SEG_b|SEG_c|SEG_c|SEG_f|SEG_g), // 4(SEG_a|SEG_c|SEG_d|SEG_f|SEG_g), // 5(SEG_a|SEG_c|SEG_d|SEG_e|SEG_f|SEG_g), // 6(SEG_a|SEG_b|SEG_c), // 7(SEG_a|SEG_b|SEG_c|SEG_d|SEG_e|SEG_f|SEG_g), // 8(SEG_a|SEG_b|SEG_c|SEG_d|SEG_f|SEG_g) // 9};C查表就太简单了temp2 = digits[ show_data[i] ];一句搞定,C中还有一个switch语句也是一个很好的用查表语句C51汇编就相对麻烦一点.不过MCS-51指令系统中有专用的查表指令:MOVC A,@A+DPTR和MOV A, @A+PC.MOVC A,@A+DPTR指令,DPTR作为基址寄存器时,其值为16位而且可根据需要设计,故可用于在6 4KROM范围内查表。
散列法hashing检索

15
例子: CLUSTERING OF LINEAR PROBING 0
1
设散列函数 H(k)=k MOD 11 求: 60、17、29、38在散列表中的位置。 2 3
H(60)= 60 mod 11 = 5
H(17)= 17 mod 11 = 6 H(29)= 29 mod 11 = 7 H(38)= 38 mod 11 = 5,H(38+1) mod 11 = 6 H(38+2) mod 11 = 7 H(38+3) mod 11 = 8
张三 李四 王五 一对一映射? 1 2 3 4 5 6 7
散列函数
8
例子:
由下标值 到 元素地址:
&a[i] a + i* sizeof(e); O(1). 问题: 下标值连续。要维护线序结构 变量名表
key1 Key2 hashing … keym … an
由不连续key值到元素地址:
前提:key>>P
11Leabharlann 字分析法:常常有这样的情况,关键码位数比基本区的地址码位数多, 这时可以对关键码的各位进行分析,丢掉分布不均匀的位留 下均匀的位作为地址。
key
000319426 000718309 000629443 000758615 000919697 000310329
h(key)
326 709 643 715 997 329
12
中平方法
先求出关键码的平方,然后取中间几位作为地址。
例如:关键码key=4731 47312 = 22382361。如果地址长度为3位,则可 以取第三位到第五位作为散列地址,即有 h1(4731)=382,当然也可以取4-6位,即有 h2(4731)= 823。
散列表实验报告(不同装载因子下链表法和放寻址法对比)

散列表实验报告(不同装载因子下链表法和放寻址法对比)TOC \o “1-4“ \h \z \u 1 概述22 原理介绍22.1 散列表介绍22.2 直接寻址表32.3 散列函数32.3.1 除法散列42.3.2 乘法散列42.3.3 全域散列42.4 解决碰撞问题52.4.1 链接法52.4.2 开放寻址法52.4.2.1 线性探查62.4.2.2 二次探查62.4.2.3 双重散列73 算法说明73.1 概述73.2 使用链接法解决碰撞问题83.2.1 算法思想83.2.2 伪代码描述93.2.3 算法分析与证明103.3 使用开放寻址法的双重散列解决碰撞问题123.3.1 算法思想123.3.2 伪代码描述123.3.3 算法分析与证明143.4 两个算法的比较144 实验设计与分析165 C++实现与结果分析185.1 C++实现与结果185.2 结果分析266 实验总结和感想27概述该实验报告主要是通过介绍散列表的各种技术,包括散列函数、解决碰撞的机制等技术,并对两种解决碰撞的机制:链接法和开放寻址法进行分析和证明,并通过实验分析两者在不同的规模下的运行时间和空间占用的对比,来证明在“算法说明”一章中的理论分析。
原理介绍散列表介绍散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。
也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
这个映射函数叫做散列函数,存放记录的数组叫做散列表。
它实际上是是普通数组概念的推广,因为可以对数组进行直接寻址,故可以而在O(1)时间内访问数组的任意元素。
如果存储空间允许,我们可以提供一个数组,为每个可能的关键字保留一个位置,就可以应用直接寻址技术。
基本概念若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上。
由此,不需比较便可直接取得所查记录。
称这个对应关系f为散列函数(Hash function),按这个思想建立的表为散列表。
数据结构-散列查找

例:m=1000 ,将下面4个关键字用1000去除 关键字值 % 1000
10052501 10052502 01110525 02110525
501 502 525 Hash函数值一样,显然不好 525
p的选择* : 理论分析和实践结果均证明,p应取小于或等于
m的(最大)素数。
例: H(key)=key % 997
在实际应用中,不产生冲突的散列函数极少存在。
散列技术的首要问题
采用散列技术时需要考虑两个首要问题:
如何选择使记录“分布均匀”的散列函数? 一旦发生冲突,用什么方法来解决?
还需考虑散列表本身的组织方法。
10.4.2 Hash函数的构造方法
Hash函数的选取原则:
① 计算尽可能简单 ② 函数的值域必须在Hash表长的范围内 ③ 尽可能随机性要好:是指Hash函数应当尽可能均匀地
return(sum % tableSize);//整数的除留余数法 }
一个好的字符串Hash函数
int H (char *key, int tableSize ) { int hashVal = 0;
while( *key != '\0' ) hashVal = 37* hashVal + *key++;
散列函数H:把关键字值key映射到散列表存储位置 的函数,通常用H来表示。
Address = H ( key )
装载因子:
α=n/m
m为散列表的空间大小; n为填入散列表中的记录数。
冲突
某个散列函数对于不相等的关键字计算出了相同的散列地 址,称为“发生了冲突”。发生冲突的两个关键字称为“ 同义词”。
begin
数据结构散列表

7.3 散列表的查找技术
概 述
冲突:对于两个不同关键码ki≠kj,有H(ki)=H(kj), 即两个不同的记录需要存放在同一个存储位置,ki和kj 相对于H称做同义词。
……
关 键 码 集 合
ki kj
H(ki) H ( k j)
ri
……
7.3 散列表的查找技术
散列函数
设计散列函数一般应遵循以下原则: ⑴ 计算简单。散列函数不应该有很大的计算量,否 则会降低查找效率。 ⑵ 函数值即散列地址分布均匀。函数值要尽量均匀 散布在地址空间,这样才能保证存储空间的有效利 用并减少冲突。
7.3 散列表的查找技术
1、散列函数——直接定址法
散列函数是关键码的线性函数,即:
H(key) = a key + b (a,b为常数)
例:关键码集合为{10, 30, 50, 70, 80, 90},选取的散 列函数为H(key)=key/10,则散列表为:
0 1 10 2 3 30 4 5 50 6 7 8 9 70 80 90
5 2 4 3 8 9
3 4 2 6 1 6
2 2 2 7 7 7
7.3 散列表的查找技术
3、散列函数——数字分析法
适用情况:
能预先估计出全部关键码的每一位上各种数字出现 的频度,不同的关键码集合需要重新分析。
7.3 散列表的查找技术
4、散列函数——平方取中法
对关键码平方后,按散列表大小,取中间的若干位作 为散列地址(平方后截取)。 例:散列地址为2位,则关键码123的散列地址为: (1234)2=1522756 适用情况:
Node<int> *HashSearch2(Node<int> *ht[ ], int m, int k) { j=H(k); p=ht[j]; while (p && p->data!=k) p=p->next; if (p->data= =k) return p; else { q=new Node<int>; q->data=k; q->next= ht[j]; ht[j]=q; } }
散列表查找算法 python3

散列表查找算法散列表是一种常用的数据结构,用于快速查找和插入数据。
散列表查找算法是利用散列表进行数据查找的一种算法。
1. 散列表概述散列表(Hash Table),又称哈希表,是根据关键码值(Key value)而直接进行访问的数据结构。
它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
这个映射函数叫作散列函数(Hash Function),存放记录的数组叫作散列表。
散列技术在各个领域都有广泛应用,例如数据库索引、缓存设计、密码学等。
2. 散列函数散列函数是将关键字映射为散列地址的函数。
好的散列函数能够将关键字均匀地分布在整个散列表中,减少冲突发生的概率。
常见的散列函数有以下几种:•直接定址法:直接使用关键字本身作为散列地址。
•数字分析法:对于一组数字序列,分析其规律并利用规律设计出合适的散列函数。
•平方取中法:对关键字进行平方运算后取中间若干位作为散列地址。
•折叠法:将关键字分割成若干部分,然后进行叠加求和,再取其低位作为散列地址。
•除留余数法:对关键字进行除法运算,将余数作为散列地址。
3. 冲突解决由于不同的关键字可能映射到相同的散列地址上,所以在插入数据时可能会出现冲突。
冲突解决是散列表中一个重要的问题。
常见的冲突解决方法有以下几种:•开放定址法:当发生冲突时,依次往后探测空闲位置,直到找到空闲位置或者遍历整个表。
•链地址法:将相同散列地址的元素链接在一起,形成一个链表。
•其他方法:还有一些其他的方法如再散列、公共溢出区等。
4. 散列表查找算法散列表查找算法是利用散列表进行数据查找的一种算法。
其基本思想是通过散列函数将关键字映射到对应的散列地址上,然后在该地址上查找目标值。
具体步骤如下:1.根据关键字计算其散列值,得到对应的散列地址。
2.在该地址上查找目标值,若找到则返回结果;若未找到,则根据冲突解决方法继续查找,直至找到目标值或者遍历完整个散列表。
散列表查找算法的时间复杂度通常为O(1),即平均情况下只需要一次访问就能找到目标值。
数据结构课程设计-利用散列表做一个电话号码查找系统

数据结构课程设计-利⽤散列表做⼀个电话号码查找系统【基本要求】(1)设每个记录有下列数据项:电话号码、⽤户名、地址;(2)从键盘输⼊各记录,分别以电话号码和⽤户名为关键字建⽴散列表;(3)采⽤⼀定的⽅法解决冲突;(4)查找并显⽰给定电话号码的记录;(5)查找并显⽰给定⽤户名的记录。
【选做内容】(1)系统功能的完善;(2)设计不同的散列函数,⽐较冲突率; (3)在散列函数确定的前提下,尝试各种不同类型处理冲突的⽅法,考察平均查找长度的变化。
⽤的C++开发,基本实现了3种哈希函数+3种解决冲突的⽅法。
因为要求同时有姓名散列与按号码散列,所以⽤了flag标记每次的散列类型,针对不同的要求对散列函数做了个别优化。
哈希表类的结构如下1class HashTable{2public:3 HashTable(int size = MAXSIZE-1);4 ~HashTable(){ delete[]E; delete[]tag; delete[]E2; delete[]tag2; }5int hash1(string name, int flag);//哈希函数1 除数求余法6int hash2(string tel);//哈希函数2 折叠法7int hash3(string tel);//哈希函数3 数字分析法8int solve1(int hashVal, int flag);//线性探测法解决冲突9int solve2(int hashVal, int flag);//⼆次探测法解决冲突10 Node* solve3(int hashVal, int flag);//拉链法解决冲突11 User input();//往电话薄中添加⽤户12void creat(int flag); //创建散列表13void show(int flag); //列出电话薄所有元素14void search(int flag,string at); //搜索指定⽤户15void searchByNode(int flag, string at); //拉链法搜索指定⽤户16void insert(int flag, User newUser); //插⼊17void del(int flag, string by);//删除18void save(int flag);//将电话薄保存⾄本地⽂件19int length; //要创建的电话本长度20 Node** ht;21private:22 User* E; //⽤户数组按姓名散列23 User* E2; //⽤户数组2 按电话号码散列24int* tag; //标记散列表1每个桶的存储状态 0为空 1为实25int* tag2;//标记散列表2每个桶的存储状态26int flag; //1表⽰是按姓名 2表⽰按电话号码新建的哈希表27int maxSize; //哈希表最⼤长度28int f;//⽐例因⼦主要⽤于折叠法29 };View CodeUser类的结构class User{public:string name;string tel;string address;bool operator==(const User&target){if (this->name == &&this->address == target.address&&this->tel == target.tel)return true;elsereturn false;}};哈希函数1int HashTable::hash1(string name,int flag) //除留求余法{int hashValue; long a = 0;switch (flag){case1:for (int i = 0; i < name.length(); i++)a += int(name[i]);hashValue = a%maxSize;break;case2:int temp = atof(name.c_str());hashValue = temp%maxSize;break;}return hashValue;};哈希函数2int HashTable::hash2(string tel) //折叠法--移位法{int hashValue;int temp; //移位法求和temp = atof(tel.substr(0, 3).c_str()) + atof(tel.substr(3, 3).c_str())+ atof(tel.substr(6, 3).c_str()) + atof(tel.substr(9, 2).c_str());//取计算之后的数的最后三位if (temp >= 999){char p[10];sprintf(p, "%d", temp);string lastThree = p;lastThree = lastThree.substr(lastThree.length() - 3, 3);hashValue = atof(lastThree.c_str());return hashValue;}hashValue = temp;return hashValue;};哈希函数3int HashTable::hash3(string tel)//数字分析法做哈希函数{int hashValue;hashValue = atof(tel.substr(8, 3).c_str()); //因为电话号码⼀般后4位不同return hashValue;};解决冲突的⽅法1.线性探测法int HashTable::solve1(int hashVal,int flag) //线性探查法处理冲突{int output = hashVal;switch (flag){case1:for (int j = 1; j < MAXSIZE; j++){output = (hashVal + j) % MAXSIZE;if (tag[output] == 0){tag[output] = 1;return output;}}return -1;break;case2:for (int j = 1; j < MAXSIZE; j++){output = (hashVal + j) % MAXSIZE;if (tag2[output] == 0){tag2[output] = 1;return output;}}return -1;default:break;}};2.⼆次探查法int HashTable::solve2(int hashVal, int flag) //⼆次探查法解决冲突{int i = hashVal; //i为初始桶号int k = 0; //k为探查次数int odd = 0; //odd为控制加减的标志int save; //缓存上⼀次的桶号switch (flag){case1:while (tag[i]==1){if (odd == 0){k++; save = i;i = (i + 2 * k-1) % MAXSIZE;odd = 1;}else{i = (save - 2 * k+1) % MAXSIZE;odd = 0;if (i<0){i = i + MAXSIZE;}}}return i;break;case2:while (tag2[i] == 1){if (odd == 0){k++; save = i;i = (i + 2 * k - 1) % MAXSIZE;odd = 1;}else{k++;i = (save - 2 * k + 1) % MAXSIZE;odd = 0;if (i<0){i = i + MAXSIZE;}}}return i;break;default:break;}};3.拉链法Node* HashTable::solve3(int hashVal, int flag)//拉链法解决冲突{int i = hashVal; //第i条链Node*p = ht[i]; //该链上的头指针while (p!=NULL)p = p->next;//往后遍历直到找到⼀个空节点⽤于存放userreturn p;};所有代码如下1 #include <iostream>2 #include <string>3 #include <fstream>45using namespace std;67const int MAXSIZE = 12;//默认最⼤表长89101112//存储项13class User{14public:15string name;16string tel;17string address;18bool operator==(const User&target)19 {20if (this->name == &&this->address == target.address&&this->tel == target.tel) 21return true;22else23return false;24 }25 };2627//⽤于拉链法28struct Node{29 User user;30 Node* next;31 };32class HashTable{33public:34 HashTable(int size = MAXSIZE-1);35 ~HashTable(){ delete[]E; delete[]tag; delete[]E2; delete[]tag2; }36int hash1(string name, int flag);//哈希函数1 除数求余法37int hash2(string tel);//哈希函数2 折叠法38int hash3(string tel);//哈希函数3 数字分析法39int solve1(int hashVal, int flag);//线性探测法解决冲突40int solve2(int hashVal, int flag);//⼆次探测法解决冲突41 Node* solve3(int hashVal, int flag);//拉链法解决冲突42 User input();//往电话薄中添加⽤户43void creat(int flag); //创建散列表44void show(int flag); //列出电话薄所有元素45void search(int flag,string at); //搜索指定⽤户46void searchByNode(int flag, string at); //拉链法搜索指定⽤户47void insert(int flag, User newUser); //插⼊48void del(int flag, string by);//删除49void save(int flag);//将电话薄保存⾄本地⽂件50int length; //要创建的电话本长度51 Node** ht;52private:53 User* E; //⽤户数组按姓名散列54 User* E2; //⽤户数组2 按电话号码散列55int* tag; //标记散列表1每个桶的存储状态 0为空 1为实56int* tag2;//标记散列表2每个桶的存储状态57int flag; //1表⽰是按姓名 2表⽰按电话号码新建的哈希表58int maxSize; //哈希表最⼤长度59int f;//⽐例因⼦主要⽤于折叠法60 };6162 HashTable::HashTable(int size)63 {64 maxSize = size; //⽤作除数65 E = new User[MAXSIZE];66 E2 = new User[MAXSIZE];67 tag = new int[MAXSIZE];68 tag2 = new int[MAXSIZE];69for (int i = 0; i < MAXSIZE; i++)70 {71 tag[i] = 0;72 tag2[i] = 0;73 }74 f = maxSize / 512; //⽤于折叠法产⽣的哈希值过⼤保留3位数的地址范围为0~51175 ht = new Node*[maxSize]; //存放节点的⼀维数组拉链法76 };7778int HashTable::hash1(string name,int flag) //除数求余法79 {80int hashValue; long a = 0;81switch (flag)82 {83case1:84for (int i = 0; i < name.length(); i++)85 a += int(name[i]);86 hashValue = a%maxSize;87break;88case2:89int temp = atof(name.c_str());90 hashValue = temp%maxSize;91break;9293 }94return hashValue;95 };9697int HashTable::hash2(string tel) //折叠法--移位法98 {99int hashValue;100int temp; //移位法求和101 temp = atof(tel.substr(0, 3).c_str()) + atof(tel.substr(3, 3).c_str())102 + atof(tel.substr(6, 3).c_str()) + atof(tel.substr(9, 2).c_str());103//取计算之后的数的最后三位104if (temp >= 999)105 {106char p[10];107 sprintf(p, "%d", temp);108string lastThree = p;109 lastThree = lastThree.substr(lastThree.length() - 3, 3);110 hashValue = atof(lastThree.c_str());111return hashValue;112 }113 hashValue = temp;114return hashValue;115 };116117int HashTable::hash3(string tel)//数字分析法做哈希函数118 {119int hashValue;120 hashValue = atof(tel.substr(8, 3).c_str()); //因为电话号码⼀般后4位不同121return hashValue;122 };123124int HashTable::solve1(int hashVal,int flag) //线性探查法处理冲突125 {126int output = hashVal;127switch (flag)128 {129case1:130for (int j = 1; j < MAXSIZE; j++)131 {132 output = (hashVal + j) % MAXSIZE;133if (tag[output] == 0)134 {135 tag[output] = 1;136return output;137 }138 }139return -1;140break;141case2:142for (int j = 1; j < MAXSIZE; j++)143 {144 output = (hashVal + j) % MAXSIZE;145if (tag2[output] == 0)146 {147 tag2[output] = 1;148return output;149 }150 }151return -1;152default:153break;154 }155156 };157158int HashTable::solve2(int hashVal, int flag) //⼆次探查法解决冲突159 {160int i = hashVal; //i为初始桶号161int k = 0; //k为探查次数162int odd = 0; //odd为控制加减的标志163int save; //缓存上⼀次的桶号164switch (flag)165 {166case1:167while (tag[i]==1)168 {169if (odd == 0)170 {171 k++; save = i;172 i = (i + 2 * k-1) % MAXSIZE;173 odd = 1;174 }175else176 {177 i = (save - 2 * k+1) % MAXSIZE;178 odd = 0;179if (i<0)180 {181 i = i + MAXSIZE;182 }183 }184 }185return i;186break;187case2:188while (tag2[i] == 1)189 {190if (odd == 0)191 {192 k++; save = i;193 i = (i + 2 * k - 1) % MAXSIZE;194 odd = 1;195 }196else197 {198 k++;199 i = (save - 2 * k + 1) % MAXSIZE;200 odd = 0;201if (i<0)202 {203 i = i + MAXSIZE;204 }205 }206 }207return i;208break;209default:210break;211 }212213 };214215/*216Node* HashTable::solve3(int hashVal, int flag)//拉链法解决冲突217218{219 int i = hashVal; //第i条链220221 Node*p = ht[i]; //该链上的头指针222 while (p!=NULL)223 p = p->next;//往后遍历直到找到⼀个空节点⽤于存放user 224 return p;225};226227void HashTable::searchByNode(int flag, string at)//调⽤拉链法搜索228{229 int i = hash1(at,1);230 Node** ht = new Node*[maxSize]; //存放节点的⼀维数组231 Node*p = ht[i]; //该链上的头指针232 while (p!=NULL&&p->!=at)233 {234 p = p->next;235 }236};237*/238 User HashTable::input()239 {240 User user;241 cout << "请输⼊姓名:" << endl;242 cin >> ;243 cout << "请输⼊电话号码:" << endl;244 cin >> user.tel;245 cout << "请输⼊地址:" << endl;246 cin >> user.address;247return user;248 };249250void HashTable::creat(int flag)251 {252switch (flag)253 {254case1: //按姓名哈希创建哈希表255for (int i = 0; i < length; i++)256 {257 User newUser = input();258int val = hash1(,1);259if (tag[val] == 1)260 val = solve1(val,1);//线性探测法解决冲突261 E[val] = newUser;262 tag[val] = 1;263 }264break;265case2: //按电话号码哈希创建哈希表266for (int i = 0; i < length; i++)267 {268 User newUser = input();269int val = hash1(newUser.tel,2);270if(tag2[val] == 1)271 val = solve1(val,2);//线性探测法解决冲突272 E2[val] = newUser;273 tag2[val] = 1;274 }275break;276 }277 };278void HashTable::show(int flag)279 {280switch (flag)281 {282case1:283for (int i = 0; i < MAXSIZE; i++)284 {285if (tag[i] == 1)286 cout << E[i].name << "" << E[i].tel << "" << E[i].address << " 位于: " << i << endl; 287 }288break;289case2:290for (int i = 0; i < MAXSIZE; i++)291 {292if (tag2[i] == 1)293 cout << E2[i].name << "" << E2[i].tel << "" << E2[i].address << " 位于: " << i << endl; 294 }295break;296 }297298 };299300void HashTable::search(int flag,string at) //at表⽰索引内容301 {302int i = 0;303switch (flag)304 {305case1: //调⽤线性探测法查找姓名306 i = hash1(at,1);307if (tag[i] == 1 && E[i].name != at)308 i = solve1(i, 2);309if (i < 0 || tag2[i] == 0)310 {311 cout << "查⽆此⼈!" << endl;312return;313 }314if (tag[i] == 1 && E[i].name == at)315 cout << E2[i].name << "" << E2[i].tel << "" << E2[i].address << endl;316break;317case2: //调⽤⼆次探测法查找电话号码318 i = hash2(at);319if (tag2[i] == 1&&E2[i].tel!=at)320 i = solve2(i,2);321if (i < 0||tag2[i]==0)322 {323 cout << "查⽆此⼈!" << endl;324return;325 }326if (tag2[i] == 1 && E2[i].tel==at)327 cout << E2[i].name << "" << E2[i].tel << "" << E2[i].address << endl;328break;329 }330 };331332void HashTable::insert(int flag, User newUser){333int i = -1;334switch (flag)335 {336case1:337 i = hash1(,1);338if (tag[i] == 1||E[i]==newUser)339 i = solve1(i, 1);340if (i < 0)341 {342 cout << "表满!插⼊失败!" << endl;343return;344 }345if (tag[i] == 0)346 {347 E[i] = newUser;348 tag[i] = 1;349 length++;350 cout << "插⼊成功" << endl;351 }352case2:353 i = hash1(newUser.tel,2);354if (tag2[i] == 1 || E2[i] == newUser)355 i = solve1(i, 2);356if (i < 0)357 {358 cout << "表满!插⼊失败!" << endl;359return;360 }361if (tag2[i] == 0)362 {363 E2[i] = newUser;364 tag2[i] = 1;365 length++;366 cout << "插⼊成功" << endl;367 }368default:369break;370 }371 };372373void HashTable::del(int flag, string by) //by表⽰按照何种标签进⾏删除374 {375int i = -1;376int select;//选择是否删除377switch (flag)378 {379case1: //调⽤线性探测法查找姓名380 i = hash1(by,1);381if (tag[i] == 1 && E[i].name != by)382 i = solve1(i, 2);383if (i < 0 || tag2[i] == 0)384 {385 cout << "查⽆此⼈!" << endl;386return;387 }388if (tag[i] == 1 && E[i].name == by)389 {390 cout << E2[i].name << "" << E2[i].tel << "" << E2[i].address << endl; 391 cout << "是否删除 0.删了 1.算了" << endl;392 cin >> select;393if (select == 0)394 tag[i] = 0;//伪删除395 }396break;397case2: //调⽤⼆次探测法查找电话号码398 i = hash2(by);399if (tag2[i] == 1 && E2[i].tel != by)400 i = solve2(i, 2);401if (i < 0 || tag2[i] == 0)402 {403 cout << "查⽆此⼈!" << endl;404return;405 }406if (tag2[i] == 1 && E2[i].tel == by)407 {408 cout << E2[i].name << "" << E2[i].tel << "" << E2[i].address << endl; 409 cout << "是否删除 0.删了 1.算了" << endl;410 cin >> select;411if (select == 0)412 tag2[i] = 0;//伪删除413 }414break;415 }416 };417418void HashTable::save(int flag)419 {420 fstream out1("电话薄(姓名散列).txt", ios::out);421 fstream out2("电话薄(号码散列).txt", ios::out);422switch (flag)423 {424case1:425for (int i = 0; i < maxSize; i++)426 {427if (tag[i] == 1)428 out1 << E[i].name << "" << E[i].tel << "" << E[i].address << endl; 429 }430 cout << "已存⾄电话薄(姓名散列).txt" << endl;431return;432break;433case2:434for (int i = 0; i < maxSize; i++)435 {436if (tag2[i] == 1)437 out2 << E2[i].name << "" << E2[i].tel << "" << E2[i].address << endl; 438 }439 cout << "已存⾄电话薄(号码散列).txt" << endl;440return;441break;442default:443break;444 }445446 };hashtable.h1 #include <iostream>2 #include <string>3 #include <fstream>4 #include "hashtable.h"5using namespace std;67//菜单8void menu()9 {10 cout << " ****************************" << endl;11 cout << "|| 0.建表 ||" << endl;12 cout << "|| 1.查看 ||" << endl;13 cout << "|| 2.搜索 ||" << endl;14 cout << "|| 3.添加 ||" << endl;15 cout << "|| 4.删除 ||" << endl;16 cout << "|| 5.保存 ||" << endl;17 cout << "|| 6.退出 ||" << endl;18 cout << " ****************************" << endl;1920 }2122int main()23 {24 User user;25int size;//第⼀次创建的数据量⼤⼩26int select;//主菜单选项27int select_;//⼦菜单选项28 cout << "欢迎使⽤电话簿" << endl;29 HashTable ht;30while (1)31 {32 menu();33 cin >> select;34switch (select)35 {36case0:37 cout << "第⼀次使⽤,请输⼊要新建的电话本⼤⼩:" << endl;38 cin >> size;39 ht.length = size;40 cout << "1.姓名散列 2.电话号码散列" << endl;41 cin >> select_;42 ht.creat(select_);43break;44case1:45 cout << "1.姓名散列 2.电话号码散列" << endl;46 cin >> select_;47 ht.show(select_);48break;49case2:50 cout << "1.按姓名查找 2.按电话号码查找" << endl;51 cin >> select_;52if (select_==1)53 {54 cout << "输⼊姓名" << endl;55string name;56 cin >> name;57 ht.search(1, name);58 }59else if (select_ == 2)60 {61 cout << "输⼊号码" << endl;62string tel;63 cin >> tel;64 ht.search(2, tel);65 }66else67 cout << "不合法操作" << endl;68break;69case3:70 user = ht.input();71 cout << "1.插⼊到姓名散列表 2.插⼊到电话号码散列" << endl;72 cin >> select_;73 ht.insert(select_,user);74break;75case4:76 cout << "1.根据姓名删除 2.根据电话号码删除" << endl;77 cin >> select_;78if (select_ == 1)79 {80 cout << "输⼊姓名" << endl;81string name;82 cin >> name;83 ht.del(1, name);84 }85else if (select_ == 2)86 {87 cout << "输⼊号码" << endl;88string tel;89 cin >> tel;90 ht.del(2, tel);91 }92else93 cout << "不合法操作" << endl;94break;95case5:96 cout << "1.保存姓名散列表到本地 2.保存电话号码散列表到本地" << endl;97 cin >> select_;98 ht.save(select_);99case6:100return0;101 }102 }103 }main.cpp通过这次课程设计,总结如下1. C++技艺不精,语法不熟悉,⽐如模版类与运算符重载,指针更是不⼤熟练。
(完整版)设计散列表实现通讯录查找系统

设计散列表实现通讯录查找系统#include<stdio.h>#include<stdlib.h>#include<string>#include <windows.h>#define MAXSIZE 20 //电话薄记录数量#define MAX_SIZE 20 //人名的最大长度#define HASHSIZE 53 //定义表长#define SUCCESS 1#define UNSUCCESS -1#define LEN sizeof(HashTable)typedef int Status;typedef char NA[MAX_SIZE];typedef struct{//记录NA name;NA tel;NA add;}Record;typedef struct{//哈希表Record *elem[HASHSIZE]; //数据元素存储基址int count; //当前数据元素个数int size; //当前容量}HashTable;Status eq(NA x,NA y){//关键字比较,相等返回SUCCESS;否则返回UNSUCCESS if(strcmp(x,y)==0)return SUCCESS;else return UNSUCCESS;}Status NUM_BER; //记录的个数void getin(Record* a){//键盘输入各人的信息printf("输入要添加的个数:\n");scanf("%d",&NUM_BER);for(i=0;i<NUM_BER;i++){printf("请输入第%d个记录的用户名:\n",i+1);scanf("%s",a[i].name);printf("请输入%d个记录的电话号码:\n",i+1);scanf("%s",a[i].tel);printf("请输入第%d个记录的地址:\n",i+1);scanf("%s",a[i].add); //gets(str2);??????}}void ShowInformation(Record* a)//显示输入的用户信息{int i;for( i=0;i<NUM_BER;i++)printf("\n第%d个用户信息:\n 姓名:%s\n 电话号码:%s\n 联系地址:% s\n",i+1,a[i].name,a[i].tel,a[i].add);}void Cls(Record* a){printf("*");system("cls");}long fold(NA s){//人名的折叠处理char *p;long sum=0;NA ss;strcpy(ss,s);//复制字符串,不改变原字符串的大小写strupr(ss);//将字符串ss转换为大写形式p=ss;while(*p!='\0')sum+=*p++;printf("\nsum====================%d",sum);return sum;}int Hash1(NA str){//哈希函数int m;n=fold(str);//先将用户名进行折叠处理m=n%HASHSIZE; //折叠处理后的数,用除留余数法构造哈希函数return m; //并返回模值}int Hash2(NA str){//哈希函数long n;int m;n = atoi(str);//把字符串转换成整型数.m=n%HAreturn m; //并返回模值}Status collision(int p,int &c){//冲突处理函数,采用二次探测再散列法解决冲突int i,q;i=c/2+1;while(i<HASHSIZE){if(c%2==0){c++;q=(p+i*i)%HASHSIZE;if(q>=0) return q;else i=c/2+1;}else{q=(p-i*i)%HASHSIZE;c++;if(q>=0) return q;else i=c/2+1;}}return UNSUCCESS;}void benGetTime();void CreateHash1(HashTable* H,Record* a){//建表,以人的姓名为关键字,建立相应的散列表//若哈希地址冲突,进行冲突处理benGetTime();int i,p=-1,c,pp;for(i=0;i<NUM_BER;i++){c=0;p=Hash1(a[i].name);pp=p;while(H->elem[pp]!=NULL) {pp=collision(p,c);if(pp<0){printf("第%d记录无法解决冲突",i+1);//需要显示冲突次数时输出continue;}//无法解决冲突,跳入下一循环}H->elem[pp]=&(a[i]); //求得哈希地址,将信息存入H->count++;printf("第%d个记录冲突次数为%d。
散列查找(散列表创建及平方探测)

散列查找(散列表创建及平⽅探测)编译处理时,涉及变量及属性的管理:插⼊(新变量的定义),查找(变量的引⽤)。
顺序查找 O(N) ⼆分查找 O(logN) ⼆叉树查找O(H) 平衡⼆叉树 O(logN)如何快速查找?查找的本质:已知对象找位置有序的安排对象-》全序:顺序查找半序:⼆叉树直接算出位置-》散列查找散列查找:1.计算位置。
2.解决冲突。
⼀、计算位置构造散列函数。
要求:计算简单;地址分布均匀。
数字关键词:1 直接定值。
2 除留余数 h(key)= key mod p,p<tablesize且p为素数。
3 数字分析法。
4 折叠法。
5平⽅取中法。
字符关键字:1 ASII码加和法 2 前3个字符移位法。
3 移位法。
⼆、处理冲突1. 开放地址法。
(换个位置)2.链地址法。
(同⼀位置的冲突对象放在⼀起)开放地址法⼀旦发⽣冲突,就按照某种规则起找另⼀空地址。
若发⽣了第i次冲突,试探性的将地址加di线性探测:di=i 容易产⽣聚集现象平⽅探测:di=+-i*i 有空间,但跳来跳去不⼀定能找到。
有定理显⽰,如果散列表长度是某个4k+3形式的素数时,平⽅探测就可以探查到整个散列空间。
双散列:di=i*h2(key) 对任意key,h2(key)!=0 h2(key )=p-(key mod p)再散列:把散列表扩⼤,散列表扩⼤时,需要重新计算。
代码散列表的创建:1#define MAXTABLESIZE 100000 /* 允许开辟的最⼤散列表长度 */2 typedef int Index;3 typedef Index Position;4 typedef enum { Legitimate, Empty, Deleted}EntryType;56 typedef struct HashEntry cell;// 散列表单元定义7struct HashEntry8 {9 ElementType Data; //散列表单元中的数据10 EntryType Info; // 散列表单元的信息11 };12 typedef struct Tb1Node *HashTable;//散列表定义13struct Tb1Node14 {15int TableSize; //散列表⼤⼩16 cell *cells; //散列表数组,数组是散列表单元的集合17 };18int NextPrime(int X)19 {20int i,P;21 P = (X%2==0) ? X+1:X+2; //PC从x下⼀个数奇数开始22while(P< MAXTABLESIZE) //23 {24for(i=(int) (sqrt(X));i<2;i--)//依次判断从根号x到2中是否有可以整除的25if(P%i==0) break; //说明不是素数,跳出for,26if(i==2)break; //判断是不是全都除了⼀遍,如果全都除了⼀遍,都不整除,说明是素数,跳出while 27else P=P+2; //说明不是素数,继续从下⼀个奇数p+2继续查找。
基于散列表的单片机快速查找算法

1.(1912)《基于散列表的单片机快速查找算法》源程序代码如下:. /*在IC卡计时收费系统的查找算法中用到了如下数据结构*/struct f /*刷卡记录的数据结构*/{unsigned char MemBNum; /*下1条记录的存储块号*/unsigned char CardID[4]; /*4个字节的IC卡号*/unsigned char CardType; /*1个字节的卡类型*/unsigned char FirstTime[2]; /*首次刷卡时间*/};/*为了访问的方便,定义如下联合*/union h{unsigned char Data[8]; /*8个字节的数组*/struct f Record; /*记录占8个字节*/};/*DataRec为联合类型变量*/union h idata DataRec;/*为了实现存储空间的管理,定义如下全局变量*/unsigned char MemManage[28]; /*用于存储空间管理的28个内存单元*/unsigned char NowPoint=0; /*用于存储空间管理的数组指针*//*在散列表查找算法中用到了下列函数*//*下4个函数为采用I2C总线访问24LC16的函数,由于篇幅原因在本文中未提供原码,读者可参考其它文献*//*下4个函数中参数addr为访问24LC16时用到的11位存储地址,返回值指示读写访问是否成功*/ unsigned char wrbyte(unsigned int addr,unsigned char odata); /*向24LC16中写一个字节,该字节在odata中。
*/unsigned char rdbyte(unsigned int addr,unsigned char odata); /*从24LC16中读一个字节,读到字节在odata中。
*/unsigned char wr8byte(unsigned int addr,unsigned char *mtd); /*向24LC16中写8个字节,mtd为写缓冲区首址。
设计高效查询算法的使用教程

设计高效查询算法的使用教程概述在计算机科学和信息技术领域,查询算法是一种用于从大量数据中检索所需信息的技术。
它能够帮助我们快速地找到想要的数据,提高数据处理和搜索的效率。
本教程将介绍几种常见的高效查询算法,并提供使用示例和实践指导。
目录1. 顺序查找2. 二分查找3. 散列表查找4. 树状数组5. 线段树6. 布隆过滤器1. 顺序查找顺序查找是最简单的查询算法之一,它逐个检查数据集中的元素,直到找到目标值或扫描完整个数据集。
它适用于小型数据集或无序数据集的查询。
以下是一个使用顺序查找的示例代码:```def sequential_search(arr, target):for i in range(len(arr)):if arr[i] == target:return ireturn -1```2. 二分查找二分查找是一种高效的查询算法,它要求待查找的数据集必须已经排序。
它通过将目标值与中间元素进行比较,并根据比较结果缩小搜索范围。
以下是一个使用二分查找的示例代码:```def binary_search(arr, target):low = 0high = len(arr) - 1while low <= high:mid = (low + high) // 2if arr[mid] == target:return midelif arr[mid] < target:low = mid + 1else:high = mid - 1return -1```3. 散列表查找散列表是一种采用键值对存储数据的数据结构,其中键通过哈希函数转换为索引,快速定位目标值。
散列表的优点是查询速度快,但它也存在哈希冲突的问题。
以下是一个使用散列表查找的示例代码:```class HashTable:def __init__(self):self.size = 10self.table = [[] for _ in range(self.size)]def _hash_function(self, key):return key % self.sizedef insert(self, key, value):hash_key = self._hash_function(key)self.table[hash_key].append((key, value))def search(self, key):hash_key = self._hash_function(key)for item in self.table[hash_key]:if item[0] == key:return item[1]return None```4. 树状数组树状数组(Binary Indexed Tree)是一种用于快速查询区间和的数据结构。
一种基于散列算法的数据查找方法
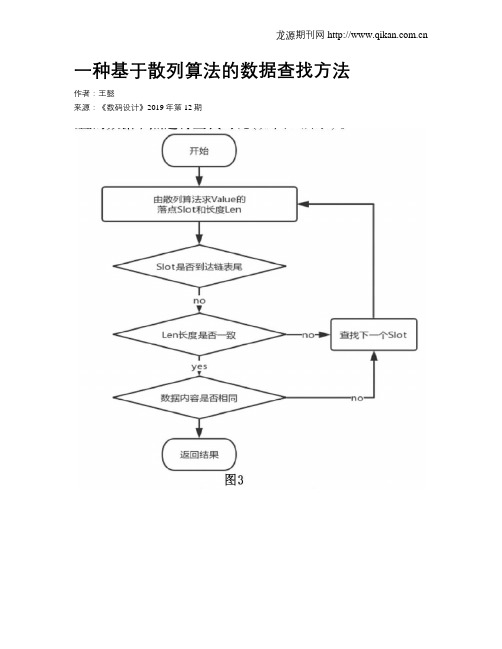
一种基于散列算法的数据查找方法作者:王懿来源:《数码设计》2019年第12期摘要:本文基于散列算法的数据查找方法是先根据数据总容量设定值N进行散列算法求值,并设置数据链表,使每个数据链表单元指向第一个存放数据的节点;再根据数据算出散列值,并将其链接至该散列值相应的数据链表单元指向的第一个数据节点,若冲突则后移。
关键词:散列算法;查找Abstract: the data search method based on hash algorithm in this paper is to evaluate the hash algorithm according to the set value of the total data capacity N, and set the data chain list, so that each data chain table element points to the node where the first data is stored. Then calculate the hash value from the data and link it to the first data node pointed to by the corresponding data chain of the hash value, or move back in case of conflict.Key words: hash algorithm; To find the1 研究背景和意義随着云计算和大数据技术的飞速发展,越来越多的企业和个人将各类信息数据外包给云存储服务提供商。
中国互联网络信息中心(CNNIC)2019年8月30日的《中国互联网络发展状况统计报告》显示中国网民规模为8.54亿。
随着职能手机的普及,移动互联网的时代也已经到来;为了实现更加智能的应用,物联网技术也逐渐被推广,随之而来的是更多实时获取的视频、音频、传感器等数据也被涌入互联网,数据量进一步暴增。
一种高效的散列查询算法

一种高效的散列查询算法
郑德舜
【期刊名称】《南京邮电大学学报(自然科学版)》
【年(卷),期】2006(026)002
【摘要】散列函数在查询算法中起着重要作用,基于此的查询算法在理论上可达到常数级时间复杂度.提出了双次线性映射散列函数,和除留余数法、平方取中法、折叠法等常用的散列函数相比,该函数具有单调性,并在一定程度上消除了堆积现象;和线性散列函数相比,该函数具有受数据分布特性影响小,易推广的特点.通过该散列函数,一个待查元素可以在有序序列中被定位到离真实位置偏差很小的范围之内.基于此提出了一种高效的查询算法.
【总页数】5页(P92-96)
【作者】郑德舜
【作者单位】南京邮电大学,通信与信息工程学院,江苏,南京,210003
【正文语种】中文
【中图分类】O211.9
【相关文献】
1.一个高效散列排序算法 [J], 贺松云;万绍俊
2.基于加权自学习散列的高维数据最近邻查询算法 [J], 彭聪;钱江波;陈华辉;董一鸿
3.网络入侵检测中高效散列模式树算法的研究 [J], 陈海涛;胡华平;张怡;龚正虎
4.一种基于散列链的高效微支付系统 [J], 程文青;郎为民;杨宗凯;谭运猛
5.基于散列技术的高效剪枝关联规则挖掘算法 [J], 彭永供;王靓明;朱敏;段隆振因版权原因,仅展示原文概要,查看原文内容请购买。
算法7.10 散列表的查找_数据结构(C语言版)(第2版)_[共3页]
![算法7.10 散列表的查找_数据结构(C语言版)(第2版)_[共3页]](https://img.taocdn.com/s3/m/b82961b1f5335a8102d220d8.png)
225 成一个单链表,链表的头指针保存在HT[1]中,同理,可以构造其他几个单链表,整个散列表的结构如图7.30所示。
图7.30 用链地址法处理冲突时的散列表
这种构造方法在具体实现时,依次计算各个关键字的散列地址,然后根据散列地址将关键字插入到相应的链表中。
7.4.4 散列表的查找
在散列表上进行查找的过程和创建散列表的过程基本一致。
算法7.10描述了开放地址法(线性探测法)处理冲突的散列表的查找过程。
下面以开放地址法为例,给出散列表的存储表示。
//- - - - -开放地址法散列表的存储表示- - - - -
#define m 20
//散列表的表长 typedef struct{
KeyType key;
//关键字项 InfoType otherinfo;
//其他数据项 }HashTable[m];
算法7.10 散列表的查找
【算法步骤】
① 给定待查找的关键字key ,根据造表时设定的散列函数计算H 0 = H (key )。
② 若单元H 0为空,则所查元素不存在。
③ 若单元H 0中元素的关键字为key ,则查找成功。
④ 否则重复下述解决冲突的过程:
● 按处理冲突的方法,计算下一个散列地址H i ;
● 若单元H i 为空,则所查元素不存在;
● 若单元H i 中元素的关键字为key ,则查找成功。
【算法描述】
#define NULLKEY 0
//单元为空的标记
int SearchHash(HashTable HT,KeyType key)。
基于散列表的单片机快速查找算法

基于散列表的单片机快速查找算法
邹继军;饶运涛
【期刊名称】《单片机与嵌入式系统应用》
【年(卷),期】2003(000)011
【摘要】由单片机构成的应用系统中,经常要用到查找算法.对静态查找表进行查找,实现起来较为容易,而对于动态查找表的查找,在单片机系统非常有限的资源内则不太好实现.针对这一情况,提出一种基于散列表的单片机快速查找算法,并结合其在IC 卡计时收费系统中的应用,详细描述算法的具体实现;阐述散列表数据结构、哈希函数和存储空间管理的设计思想,提供可在单片机上实现的算法源代码.
【总页数】3页(P7-9)
【作者】邹继军;饶运涛
【作者单位】东华理工学院;东华理工学院
【正文语种】中文
【中图分类】TP3
【相关文献】
1.基于二维地图的连通路径快速查找算法 [J], 马春艳;崔鹏;金明日
2.散列表快速查找算法在单片机系统中的应用 [J], 李晨光;杨福财
3.一种基于CAVLC解码的快速码表查找算法 [J], 黄明政;王建华;韩一石;孙运龙
4.基于 Redis 内存数据库的快速查找算法 [J], 郎泓钰;任永功
5.基于散列表的快速分组分类算法 [J], 李宾;刘淑媛;刘衍珩
因版权原因,仅展示原文概要,查看原文内容请购买。
基于DPI不对称流量的同源同宿解决方案

基于DPI不对称流量的同源同宿解决方案潘洁;高峰;刘栋;董昭;侯慧芳【摘要】在当前互联网应用分析领域,为了获得更加准确的基础数据,流量采集时需要保证每次会话流量的完整性.通过对流量不对称的起因及影响进行分析,结合业务分析的实际需要,提出同源同宿流量归并基本思路和解决方案.【期刊名称】《电信科学》【年(卷),期】2016(032)012【总页数】6页(P116-121)【关键词】不对称;同源同宿;散列算法【作者】潘洁;高峰;刘栋;董昭;侯慧芳【作者单位】中国移动通信集团设计院有限公司,北京100080;中国移动通信集团采购共享服务中心,北京100053;中国移动通信集团采购共享服务中心,北京100053;中国移动通信集团设计院有限公司,北京100080;中国移动通信集团设计院有限公司,北京100080【正文语种】中文【中图分类】TP913在互联网络工程建设中,出于负载均衡、路由安全保护等考虑,运营商一般按网状、多出口的结构进行设计和建设,导致互联网络中较多完整端到端会话(session)的上行流、下行流分布在不同的物理链路中,当不同的链路接入不同的流量采集设备时将会造成会话数据不完整,因此需要在数据分析之前对非对称流量进行同源同宿处理。
同源同宿处理是深度分组解析(deep packet inspection,DPI)应用的重要基础。
目前造成会话不完整的主要原因是网络路由不对称,这是由网络中路由器的工作特点决定的:路由器在接收到数据分组时,会根据路由协议对下一跳路由度量值(cost)进行计算,并选定一个最优路由进行数据转发,源、宿两端的路由器在路由选择时可能各自选择一条最优但不重合的路由。
最典型的情况是两个相邻路由器间有多条等价的最优路由,A→B发送数据时选择第一条路由;B→A发送数据时选择另一条路由,从而造成路由不对称。
当前大部分城域网采用双出口的结构建设,两个出口流量负荷尽量均等。
网络结构和数据流向如图1所示。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.(1912)《基于散列表的单片机快速查找算法》源程序代码如下:. /*在IC卡计时收费系统的查找算法中用到了如下数据结构*/struct f /*刷卡记录的数据结构*/{unsigned char MemBNum; /*下1条记录的存储块号*/unsigned char CardID[4]; /*4个字节的IC卡号*/unsigned char CardType; /*1个字节的卡类型*/unsigned char FirstTime[2]; /*首次刷卡时间*/};/*为了访问的方便,定义如下联合*/union h{unsigned char Data[8]; /*8个字节的数组*/struct f Record; /*记录占8个字节*/};/*DataRec为联合类型变量*/union h idata DataRec;/*为了实现存储空间的管理,定义如下全局变量*/unsigned char MemManage[28]; /*用于存储空间管理的28个内存单元*/unsigned char NowPoint=0; /*用于存储空间管理的数组指针*//*在散列表查找算法中用到了下列函数*//*下4个函数为采用I2C总线访问24LC16的函数,由于篇幅原因在本文中未提供原码,读者可参考其它文献*//*下4个函数中参数addr为访问24LC16时用到的11位存储地址,返回值指示读写访问是否成功*/ unsigned char wrbyte(unsigned int addr,unsigned char odata); /*向24LC16中写一个字节,该字节在odata中。
*/unsigned char rdbyte(unsigned int addr,unsigned char odata); /*从24LC16中读一个字节,读到字节在odata中。
*/unsigned char wr8byte(unsigned int addr,unsigned char *mtd); /*向24LC16中写8个字节,mtd为写缓冲区首址。
*/unsigned char rd8byte(unsigned int addr,unsigned char *mrd); /*从24LC16中读8个字节,mrd为读缓冲区首址。
*/unsigned char hash(unsigned char *ID); /*链地址法的散列表查找算法程序*/unsigned char hash_search(union h NowRec); /*哈希(hash)函数*/unsigned char compare(unsigned char *ID1,unsigned char *ID2); /*关键字比较函数*/ unsigned char req_mem(void); /*存储块分配函数*/void free_mem(unsigned char MemBNum); /*释放存储块函数*/unsigned char account(union h OutRec,union h InRec); /*计时消费结帐处理函数,可根据实际情况实现*//*功能:采用链地址法的散列表查找算法,包含记录的添加与删除入口参数(NowRec):待查找的记录返回值:为0表示无相同关键字记录,将输入记录添加到表尾,为1表示查找成功,结帐并删除该记录*/ unsigned char hash_search(union h NowRec){unsigned char i,result; /*result为返回的查找结果,result=0查找失败,result=1查找成功*/unsigned char NowMemBNum; /*当前访问记录的存储块号*/unsigned char NextMemBNum; /*下1条记录的存储块号*/unsigned int LastRecAddr; /*链表中上1条已访问记录的首地址或链表首地址*/unsigned int NowRecAddr; /*链表中当前访问记录的首地址*/union h ReadRec; /*从24LC16中读到的记录*/result=0;NowRecAddr=hash(NowRec.Record.CardID); /*调用哈希函数得到哈希地址*/LastRecAddr=NowRecAddr; /*初始化LastRecAddr*/rdbyte(NowRecAddr,NowMemBNum); /*读得链表的首存储块号*/NextMemBNum=NowMemBNum; /*初始化NextMemBNum*/if(NextMemBNum==0xff){result=0; /*链表为空,无相同关键字记录*//*由存储块号计算得到记录的存储首地址,添加新记录时用到*/NowRecAddr=(unsigned int)NowMemBNum*8+0x100;}else{while(1){NowMemBNum=NextMemBNum; /*保存当前要访问记录的存储块号*/LastRecAddr=NowRecAddr; /*保存上1条已访问记录的首地址或链表首地址*//*计算得到当前要访问记录的存储首地址*/NowRecAddr=(unsigned int)NowMemBNum*8+0x100;rd8byte(NowRecAddr,ReadRec.Data); /*从链表中读取1条记录,共8个字节*/NextMemBNum=ReadRec.Record.MemBNum; /*下1条记录的存储块号*/if(compare(NowRec.Record.CardID,ReadRec.Record.CardID)) /*比较卡号是否相等*/{result=1; /*相等,查找成功*/break;}if(NextMemBNum==0xff){result=0; /*已到表尾,无相同关键字记录*/break;}}}if(result==0) /*查找失败,添加新记录*/{i=req_mem(); /*请求分配存储块,返回空闲存储块号,并更新存储空间利用表*/wrbyte(NowRecAddr,i); /*新记录插入表尾,更新表尾记录的"下一条记录存储块号"字段*/ NowRecAddr=i*8+0x100; /*由存储块号计算存储首地址*/wr8byte(NowRecAddr,NowRec.Data); /*将新记录写入分配的存储块中*/}if(result==1) /*查找成功,结帐并删除记录*/{account(NowRec,ReadRec); /*根据消费时间,计算消费费用并结帐*//*从链表中删除该记录,即将下1条记录的存储块号写入上1条记录的相应字段中*/wrbyte(LastRecAddr,NextMemBNum);free_mem(NowMemBNum); /*更新存储空间利用表,释放该记录所占用的存储块*/}return result; /*返回查找结果*/}/*hash函数,入口参数为4字节卡号,返回值为计算所得哈希地址*/unsigned char hash(unsigned char *ID){unsigned char HashAddr; /*保存计算所得哈希地址*/unsigned int Sum; /*将构成卡号的4个字节按字节累加所得累加和*/Sum=0;Sum+=ID[0]; Sum+=ID[1];Sum+=ID[2]; Sum+=ID[3];HashAddr=Sum%224;return HashAddr;}/*比较两个卡号是否相同,相同返回值为1,不同返回值为0*/unsigned char compare(unsigned char *ID1,unsigned char *ID2){unsigned char i;unsigned char CompResult; /*保存卡号比较结果*/for(i=0;i<4;i++) if(ID1[i]!=ID2[i]) break;if(i==4) CompResult=1; /*卡号相同,返回值为1*/else CompResult=0; /*卡号不同,返回值为0*/return CompResult;}/*存储块分配程序,调用该程序返回空闲存储块号*/unsigned char req_mem(void){unsigned char i,temp;while(1){if(MemManage[NowPoint]==0xff){NowPoint++; /*无空闲存储块,继续搜索*/if(NowPoint==28) NowPoint=0; /*用于存储空间管理的内存单元为28个*/ }else{/*有空闲存储块,查找存储块号*/temp=0x01;for(i=0;i<8;i++){if((MemManage[NowPoint] & temp)==0) break;temp=temp<<1;}break;}}MemManage[NowPoint]|=temp; /* 该存储块已分配,置标志位*/temp=NowPoint*8+i; /* 计算得到存储块号*/return temp; /* 返回存储块号*/}/*存储块释放程序,清除标志位,释放指定存储块*/void free_mem(unsigned char MemBNum){unsigned char i,j;i=MemBNum/8; MemBNum%=8;j=0x01; j<<=MemBNum;MemManage[i]^=j; /*清除标志位,释放指定存储块*/}.。