linux下的静态库与动态库的区别,Gdb调试段错误,自动生成Makefile
linux静态库的通俗理解

linux静态库的通俗理解说到Linux静态库,首先我们需要明白什么是库(Library)。
在程序开发中,往往会使用到一些常用的函数文件,例如输入输出、字符串操作等。
而这些函数文件的代码被编译成了二进制代码,并将这些函数放在一起组成一个库文件。
当我们需要调用这些函数时,只需要在程序中引用这个库文件,就可以直接使用其中的函数了。
这些库文件包括动态库和静态库两种。
那么什么是静态库呢?静态库是一种静态链接库,也被称为静态链接库。
静态库和动态库最大的不同之处在于,它们是在编译时链接到程序中的。
也就是说,在程序运行之前,静态库的代码已经全部被复制到了程序中。
在运行期间,程序会调用静态库中的函数,而不是再次加载。
相对于动态库,静态库有以下几个优点:1.移植性更好:静态库在编译时已经被链接到程序中,不需要引用外部库,因此更加便于移植到其他系统中。
3.更容易控制版本:静态库在编译时已经被链接到程序中,在运行时不会受到环境变量的影响,因此更容易控制版本。
静态库的使用方法相对简单,下面简要介绍一下:1.创建静态库文件:使用ar命令将多个.o文件打包成一个.a文件,例如:ar rcs libtest.a test1.o test2.o test3.o其中,r表示将test1.o、test2.o、test3.o文件打包成libtest.a文件,c表示在没有libtest.a文件时自动创建它,s表示为库添加索引。
2.使用静态库文件:在程序中引用静态库文件,例如:gcc -o program program.c -L./ -ltest其中-L./表示在当前目录查找库文件,-ltest表示使用名为libtest.a的静态库文件。
1.静态库不能与动态库同时使用:由于静态库已经被编译到程序中,如果同时使用动态库,可能会出现重复定义的问题。
3.静态库体积相对较大:由于静态库已经被编译到程序中,所以会增加程序的体积。
综上所述,静态库是一种很常用的库文件形式,在程序开发中是非常必要的。
静态链接库和动态链接库的区别及优缺点

静态链接库和动态链接库的区别及优缺点动态链接库和静态链接库的区别本⽂参考了以下博客:1. /gamecreating/article/details/55041522. /left_la/article/details/120985453. /augusdi/article/details/6460415静态连接库就是把(lib)⽂件中⽤到的函数代码直接链接进⽬标程序,程序运⾏的时候不再需要其它的库⽂件;动态链接就是把调⽤的函数所在⽂件模块(DLL)和调⽤函数在⽂件中的位置等信息链接进⽬标程序,程序运⾏的时候再从DLL中寻找相应函数代码,因此需要相应DLL⽂件的⽀持。
静态链接库与动态链接库都是共享代码的⽅式,如果采⽤静态链接库,则⽆论你愿不愿意,lib 中的指令都全部被直接包含在最终⽣成的 EXE ⽂件中了。
但是若使⽤ DLL,该 DLL 不必被包含在最终 EXE ⽂件中,EXE ⽂件执⾏时可以“动态”地引⽤和卸载这个与 EXE 独⽴的 DLL ⽂件。
静态链接库和动态链接库的另外⼀个区别在于静态链接库中不能再包含其他的动态链接库或者静态库,⽽在动态链接库中还可以再包含其他的动态或静态链接库。
动态库就是在需要调⽤其中的函数时,根据函数映射表找到该函数然后调⼊堆栈执⾏。
如果在当前⼯程中有多处对dll⽂件中同⼀个函数的调⽤,那么执⾏时,这个函数只会留下⼀份拷贝。
但是如果有多处对lib⽂件中同⼀个函数的调⽤,那么执⾏时,该函数将在当前程序的执⾏空间⾥留下多份拷贝,⽽且是⼀处调⽤就产⽣⼀份拷贝。
静态链接库与静态链接库调⽤规则总体⽐较如下:1、静态链接库(⽐较简单):⾸先,静态链接库的使⽤需要库的开发者提供⽣成库的.h头⽂件和.lib⽂件。
⽣成库的.h头⽂件中的声明格式如下:extern "C" 函数返回类型函数名(参数表);在调⽤程序的.cpp源代码⽂件中如下:#include "../lib.h"#pragma comment(lib,"..//debug//libTest.lib") //指定与静态库⼀起链接其次因为静态链接库是将全部指令都包含⼊调⽤程序⽣成的EXE⽂件中。
[转]Linux下g++编译与使用静态库(.a)和动态库(.os)(+修正与解释)
![[转]Linux下g++编译与使用静态库(.a)和动态库(.os)(+修正与解释)](https://img.taocdn.com/s3/m/47ddbe06773231126edb6f1aff00bed5b9f37370.png)
[转]Linux下g++编译与使⽤静态库(.a)和动态库(.os)(+修正与解释)在windows环境下,我们通常在IDE如VS的⼯程中开发C++项⽬,对于⽣成和使⽤静态库(*.lib)与动态库(*.dll)可能都已经⽐较熟悉,但是,在linux环境下,则是另⼀套模式,对应的静态库(*.a)与动态库(*.so)的⽣成与使⽤⽅式是不同的。
刚开始可能会不适应,但是⽤多了应该会习惯这种使⽤,因为步骤上并没有VS下配置那么繁琐。
下⾯就分别总结下linux下⽣成并使⽤静态库与动态库的⽅法:(由于是C++项⽬,所以编译器⽤的g++,但是与gcc的使⽤是相通的)⾸先是准备⼯作,把我们需要封装成库⽂件的函数的头⽂件与源⽂件写好,如下://myAPI.hint ADD(int a, int b);int MINUS(int a, int b);//myAPI.cpp#include "myAPI.h"int ADD(int a, int b){return a + b;}int MINUS(int a, int b){return a - b;}接下来准备⼀个测试⽤的主函数源⽂件://main.cpp#include "myAPI.h"#include <iostream>int main(){std::cout << "1 + 1 = " << ADD(1, 1) << std::endl;std::cout << "1 - 1 = " << MINUS(1, 1) << std::endl;return0;}重要说明:linux下⽤⽣成静态库的命令 ar 处理 myAPI.o ⽂件⽣成静态库⽂件,⽣成的库⽂件应遵循规范,及linux下库⽂件加“lib”前缀。
linux动态库和静态库调用方法

linux动态库和静态库调用方法
在Linux操作系统中,动态库和静态库的调用方法如下:
1. 动态库(Shared Library):动态库在程序运行时被载入内存,可以被多个程序同时使用,节省内存空间。
在Linux中,动态库一般存放在/usr/lib或/lib目录下。
调用方法:在程序中使用extern "C"来声明函数接口,然后通过dlopen(), dlsym()等函数来动态调用动态库中的函数。
2. 静态库(Static Library):静态库在程序编译时被包含进可执行程序中,每个程序都有一份自己的库副本。
静态库一般存放在/usr/lib或/lib目录下。
调用方法:在程序中直接使用静态库中的函数,不需要额外的调用方法。
只需要在编译时使用"-l"选项指定要链接的库名,例如"gcc -o test test.c -lmylib"。
需要注意的是,对于动态库和静态库的使用,一般建议优先使用动态库,因为这样可以节省内存空间,并且可以在不停止程序运行的情况下更新库文件。
第1页/ 共1页。
linux静态库和动态库
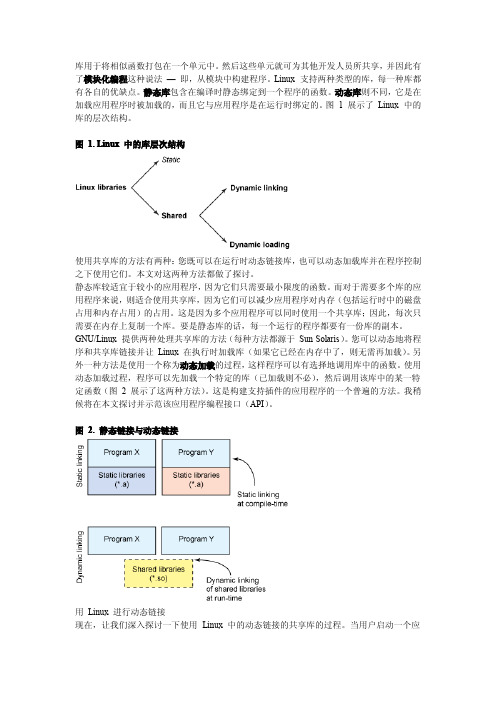
库用于将相似函数打包在一个单元中。
然后这些单元就可为其他开发人员所共享,并因此有了模块化编程这种说法—即,从模块中构建程序。
Linux支持两种类型的库,每一种库都有各自的优缺点。
静态库包含在编译时静态绑定到一个程序的函数。
动态库则不同,它是在加载应用程序时被加载的,而且它与应用程序是在运行时绑定的。
图1展示了Linux中的库的层次结构。
图 1.Linux中的库层次结构使用共享库的方法有两种:您既可以在运行时动态链接库,也可以动态加载库并在程序控制之下使用它们。
本文对这两种方法都做了探讨。
静态库较适宜于较小的应用程序,因为它们只需要最小限度的函数。
而对于需要多个库的应用程序来说,则适合使用共享库,因为它们可以减少应用程序对内存(包括运行时中的磁盘占用和内存占用)的占用。
这是因为多个应用程序可以同时使用一个共享库;因此,每次只需要在内存上复制一个库。
要是静态库的话,每一个运行的程序都要有一份库的副本。
GNU/Linux提供两种处理共享库的方法(每种方法都源于Sun Solaris)。
您可以动态地将程序和共享库链接并让Linux在执行时加载库(如果它已经在内存中了,则无需再加载)。
另外一种方法是使用一个称为动态加载的过程,这样程序可以有选择地调用库中的函数。
使用动态加载过程,程序可以先加载一个特定的库(已加载则不必),然后调用该库中的某一特定函数(图2展示了这两种方法)。
这是构建支持插件的应用程序的一个普遍的方法。
我稍候将在本文探讨并示范该应用程序编程接口(API)。
图 2.静态链接与动态链接用Linux进行动态链接现在,让我们深入探讨一下使用Linux中的动态链接的共享库的过程。
当用户启动一个应用程序时,它们正在调用一个可执行和链接格式(Executable and Linking Format,ELF)映像。
内核首先将ELF映像加载到用户空间虚拟内存中。
然后内核会注意到一个称为.interp 的ELF部分,它指明了将要被使用的动态链接器(/lib/ld-linux.so),如清单1所示。
linux库学习

Linux和Unix静态库,动态库和共享库 (1)linux下的静态库和动态库的编译 (2)Linux和Unix静态库,动态库和共享库库可以有三种使用的形式:静态、共享和动态。
静态库的代码在编译时就已连接到开发人员开发的应用程序中,而共享库只是在程序开始运行时才载入,在编译时,只是简单地指定需要使用的库函数。
动态库则是共享库的另一种变化形式。
动态库也是在程序运行时载入,但与共享库不同的是,使用的库函数不是在程序运行开始,而是在程序中的语句需要使用该函数时才载入。
动态库可以在程序运行期间释放动态库所占用的内存,腾出空间供其它程序使用。
由于共享库和动态库并没有在程序中包括库函数的内容,只是包含了对库函数的引用,因此代码的规模比较小。
已经开发的大多数库都采取共享库的方式。
ELF格式的可执行文件使得共享库能够比较容易地实现,当然使用旧的a.out模式也可以实现库的共享。
Linux系统中目前可执行文件的标准格式为ELF格式。
GNU库的使用必须遵守Library GNU Public License(LGPL许可协议)。
该协议与GNU许可协议略有不同,开发人员可以免费使用GNU库进行软件开发,但必须保证向用户提供所用的库函数的源代码。
系统中可用的库都存放在/usr/lib和/lib目录中。
库文件名由前缀lib和库名以及后缀组成。
根据库的类型不同,后缀名也不一样。
共享库的后缀名由.so和版本号组成,静态库的后缀名为.a。
采用旧的a.out格式的共享库的后缀名为.sa。
libname.so.major.minorlibname.a这里的name可以是任何字符串,用来唯一标识某个库。
该字符串可以是一个单字、几个字符、甚至一个字母。
数学共享库的库名为libm.so.5,这里的标识字符为m,版本号为5。
libm.a 则是静态数学库。
X-Windows库名为libX11.so.6,这里使用X11作为库的标识,版本号为6。
动态库与静态库的异同

动态库与静态库的异同、生成和使用详解
分类:基于Linux的C/C++程序开发2012-12-05 11:11 501人阅读评论(0) 收藏举报生成和调用静态库与动态库静态库与动态库的区别静态库和动态库
下面表格实例中,实现了把test模块分别生成动态库(libtest.so)和静态库(libtest.a),并使用了生成的库。
详情和注解如下:
注解:
test.c -----测试功能模块的c文件
test.h -----测试功能模块的头文件
main.c -----include“test.h”的主函数文件
-share -----该选项指定生成动态连接库(让连接器生成T类型的导出符号表,有时候也生成弱连接W类型的导出符号),不用该标志外部程序无法连接。
相当于一个可执行文件。
-fPCI -----表示编译为位置独立的代码,不用此选项的话编译后的代码是位置相关的所以动态载入时是通过代码拷贝的方式来满足不同进程的需要,而不
能达到真正代码段共享的目的。
注解A:在使用到这些公用函数的源程序中包含这些公用函数的原型声明,然后在用gcc 命令生成目标文件时指明静态库名,gcc 将会从静态库中
将公用函数连接到目标文件中。
注意,gcc 会在静态库名前加上前缀lib,然后追加扩展名.a 得到的静态库文件名来查找静态库文件。
Linux软件库

Linux软件库一、静态库和动态库静态库:在编译过程中的链接阶段,静态库会被编译到程序(例如C 或Rust)中。
每个客户程序都有属于自己的一份库的拷贝。
然而静态库有一个显而易见的缺点——当库需要进行一定改动时(例如修复一个bug),静态库必须重新链接一次。
动态库:动态库首先会在程序编译中的链接阶段被标记,但是客户程序和库代码在运行之前仍然没有联系,且库代码不会进入到客户程序中。
无论该客户程序是由静态编译语言(如C)编写,还是由动态解释语言(如Python)编写,系统的动态加载器都会把一个共享库和正在运行的客户程序进行连接。
因此,动态库不需要麻烦客户程序便可以进行更新。
最后,多个客户程序可以共享同一个动态库的单一副本。
二、配置软件仓库1、挂载命令:通过挂载我们可以访问到我们需要的资源。
挂载命令格式:mount 资源路径挂载路径卸载命令格式:umount 资源路径2、yum命令yum repolist //列仓库yum list //列软件yum clean all //清缓存yum -y install 软件名... //安装软件并且安装依赖yum -y remove 软件名 //卸载软件,只删除原软件,不删除依赖3、rpm命令rpm -q 软件名//模糊查找一个软件是否已安装rpm -ivh 软件名-版本信息.rpm... //安装软件不安装依赖,添加ivh选项在安装中,看起来会舒服一点rpm -e 软件名... //卸载软件三、构建库静态库和动态库在构建和发布的步骤上有一些细节的不同。
静态库需要三个步骤,而动态库需要增加两个步骤即一共五个步骤。
额外的步骤表明了动态库的动态方法具有更多的灵活性。
让我们先从静态库开始。
1、将库的源文件编译成目标模块% gcc -c primes.c2、将对象进行归档% ar -cvq libprimes.a primes.o3、发布构件库% sudo cp libprimes.a /usr/local/lib动态库构建:1、对动态库进行打包:% gcc primes.c -c -fpic2、将对象创建单个文件库% gcc -shared -Wl,-soname,libshprimes.so -o libshprimes.so.1 primes.o3、将文件放到目标目录% sudo cp libshprimes.so.1 /usr/local/lib4、链接共享库和物理文件% sudo ln --symbolic libshprimes.so.1 libshprimes.so 5、发布动态库% sudo ldconfig。
Linux静态库、共享库、动态库

1. 静态库1.1. 静态库的概念静态库就是一些目标文件的集合,以.a 结尾。
静态库在程序链接的时候使用,链接器会将程序中使用到函数的代码从库文件中拷贝到应 用程序中。
一旦链接完成,在执行程序的时候就不需要静态库了。
由于每个使用静态库的应用程序都需要拷贝所用函数的代码,所以静态链接的文件会比较 大。
1.2. 静态库的创建和使用创建静态库: 创建 libvector.a 的静态库中提供以下向量函数: // addvec.c void addvec(int* x, int* y, int*z, int n) { int i=0; for(; i< n;++i) z[i] = x[i] + y[i]; } // multvec.c void multvec(int*x, int* y, int* { int i = 0; for(; i < n; ++i) z[i] = x[i] * y[i]; } 使用 AR 工具创建静态库文件: #gcc –c addvec.c multvec.c #ar rcs libbector.a addvec.o multvec.o 其中 ar 中的 rcs 的意思是: r 表明将模块加入到静态库中,c 表示创建静态库,s 表示 生产索引。
z, int n)使用静态库 编写一个应用,调用 addvec 库中的函数: /* main2.c */ #include <stdio.h>int x[2] = {1, 2}; int y[2] = {3, 4}; int z[2]={0};int main() { addvec(x, y, z, 2); printf("z = [%d %d]\n", z[0], z[1]); return 0; } 编译-链接-运行程序: #gcc –c main2.c #gcc –static –o p2 main2.o ./libvector.a #./p2 Z = [4 6]注 1:-static 参数告诉编译器驱动程序,链接器应该构建一个完全的可执行目标文件,它可 以加载到存储器并运行,在加载时无需进一步的链接---即一次性静态链接完毕,不允许存在动 态链接。
linux 静态库和动态库的区别

linux 静态库和动态库的区别来源:/uid-22212707-id-3143983.html库从本质上来说是一种可执行代码的二进制格式,可以被载入内存中执行。
库分静态库和动态库两种。
静态库和动态库的区别1. 静态函数库这类库的名字一般是libxxx.a;利用静态函数库编译成的文件比较大,因为整个函数库的所有数据都会被整合进目标代码中,他的优点就显而易见了,即编译后的执行程序不需要外部的函数库支持,因为所有使用的函数都已经被编译进去了。
当然这也会成为他的缺点,因为如果静态函数库改变了,那么你的程序必须重新编译。
2. 动态函数库这类库的名字一般是libxxx.so;相对于静态函数库,动态函数库在编译的时候并没有被编译进目标代码中,你的程序执行到相关函数时才调用该函数库里的相应函数,因此动态函数库所产生的可执行文件比较小。
由于函数库没有被整合进你的程序,而是程序运行时动态的申请并调用,所以程序的运行环境中必须提供相应的库。
动态函数库的改变并不影响你的程序,所以动态函数库的升级比较方便。
linux系统有几个重要的目录存放相应的函数库,如/lib /usr/lib。
静态库的使用静态库的操作工具:gcc和ar 命令。
编写及使用静态库(1)设计库源码pr1.c 和pr2.c[root@billstone make_lib]# cat pr1.cvoid print1(){printf("This is the first lib src!\n");}[root@billstone make_lib]# cat pr2.cvoid print2(){printf("This is the second src lib!\n");}(2) 编译.c 文件[bill@billstone make_lib]$ cc -O -c pr1.c pr2.c[bill@billstone make_lib]$ ls -l pr*.o-rw-rw-r-- 1 bill bill 804 4 月15 11:11 pr1.o-rw-rw-r-- 1 bill bill 804 4 月15 11:11 pr2.o(3) 链接静态库为了在编译程序中正确找到库文件,静态库必须按照lib[name].a 的规则命名,如下例中[name]=pr.[bill@billstone make_lib]$ ar -rsv libpr.a pr1.o pr2.oa - pr1.oa - pr2.o[bill@billstone make_lib]$ ls -l *.a-rw-rw-r-- 1 bill bill 1822 4 月15 11:12 libpr.a [bill@billstone make_lib]$ ar -t libpr.apr1.opr2.o(4) 调用库函数代码main.c[bill@billstone make_lib]$ cat main.cint main(){print1();print2();return 0;}(5) 编译链接选项-L 及-l 参数放在后面.其中,-L 加载库文件路径,-l 指明库文件名字.[bill@billstone make_lib]$ gcc -o main main.c -L./ -lpr[bill@billstone make_lib]$ ls -l main*-rwxrwxr-x 1 bill bill 11805 4 月15 11:17 main-rw-rw-r-- 1 bill bill 50 4 月15 11:15 main.c (6)执行目标程序[bill@billstone make_lib]$ ./mainThis is the first lib src!This is the second src lib![bill@billstone make_lib]$动态库的使用编写动态库(1)设计库代码[bill@billstone make_lib]$ cat pr1.cint p = 2;void print(){printf("This is the first dll src!\n");}[bill@billstone make_lib]$(2)生成动态库[bill@billstone make_lib]$ gcc -O -fpic -shared -o dl.so pr1.c[bill@billstone make_lib]$ ls -l *.so-rwxrwxr-x 1 bill bill 6592 4 月15 15:19 dl.so[bill@billstone make_lib]$动态库的隐式调用在编译调用库函数代码时指明动态库的位置及名字, 看下面实例[bill@billstone make_lib]$ cat main.cint main(){print();return 0;}[bill@billstone make_lib]$ gcc -o tdl main.c ./dl.so[bill@billstone make_lib]$ ./tdlThis is the first dll src![bill@billstone make_lib]$当动态库的位置活名字发生改变时, 程序将无法正常运行; 而动态库取代静态库的好处之一则是通过更新动态库而随时升级库的内容.动态库的显式调用显式调用动态库需要四个函数的支持, 函数dlopen 打开动态库, 函数dlsym 获取动态库中对象基址, 函数dlerror 获取显式动态库操作中的错误信息, 函数doclose 关闭动态库.[bill@billstone make_lib]$ cat main.c#include <dlfcn.h>int main(){void *pHandle;void (*pFunc)(); // 指向函数的指针int *p;pHandle = dlopen("./d1.so", RTLD_NOW); // 打开动态库if(!pHandle){printf("Can't find d1.so \n");exit(1);}pFunc = (void (*)())dlsym(pHandle, "print"); // 获取库函数print 的地址if(pFunc)pFunc();elseprintf("Can't find function print\n");p = (int *)dlsym(pHandle, "p"); // 获取库变量p 的地址if(p)printf("p = %d\n", *p);elseprintf("Can't find int p\n");dlclose(pHandle); // 关闭动态库return 0;}[bill@billstone make_lib]$ gcc -o tds main.c –ld1 –L.此时还不能立即./tds,因为在动态函数库使用时,会查找/usr/lib、/lib目录下的动态函数库,而此时我们生成的库不在里边。
动态库与静态库

动态库与静态库什么叫库?库(Library)说⽩了就是⼀段编译好的⼆进制代码,加上头⽂件就可以供别⼈使⽤。
⼀种情况是某些代码需要给别⼈使⽤,但是我们不希望别⼈看到源码,就需要以库的形式进⾏封装,只暴露出头⽂件。
另外⼀种情况是,对于某些不会进⾏⼤的改动的代码,我们想减少编译的时间,就可以把它打包成库,因为库是已经编译好的⼆进制了,编译的时候只需要 Link ⼀下,不会浪费编译时间。
静态库:静态库即静态链接库(Windows 下的 .lib,Linux 和 Mac 下的 .a)。
之所以叫做静态,是因为静态库在编译的时候会被直接拷贝⼀份,复制到⽬标程序⾥,这段代码在⽬标程序⾥就不会再改变了。
静态库的好处很明显,编译完成之后,库⽂件实际上就没有作⽤了。
⽬标程序没有外部依赖,直接就可以运⾏。
当然其缺点也很明显,就是会使⽤⽬标程序的体积增⼤。
动态库:动态库即动态链接库(Windows 下的 .dll,Linux 下的 .so,Mac 下的 .dylib)。
与静态库相反,动态库在编译时并不会被拷贝到⽬标程序中,⽬标程序中只会存储指向动态库的引⽤。
等到程序运⾏时,动态库才会被真正加载进来。
动态库的优点是,不需要拷贝到⽬标程序中,不会影响⽬标程序的体积,⽽且同⼀份库可以被多个程序使⽤(因为这个原因,动态库也被称作共享库)。
同时,编译时才载⼊的特性,也可以让我们随时对库进⾏替换,⽽不需要重新编译代码。
动态库带来的问题主要是,动态载⼊会带来⼀部分性能损失,使⽤动态库也会使得程序依赖于外部环境。
如果环境缺少动态库或者库的版本不正确,就会导致程序⽆法运⾏(Linux 下喜闻乐见的 lib notfound 错误)。
C语言的动态函数库和静态函数库的生成和使用(linux环境下)

C语⾔的动态函数库和静态函数库的⽣成和使⽤(linux环境下)软件开发往往是⼀个⼗分庞⼤的⼯程.需要消耗⼤量的脑⼒.借助别⼈已经开发好的库,往往能提⾼效率,下⾯将介绍如何开发和使⽤共享的库⽂件.使⽤别⼈已经开发好的库,就像是我们想要建造⼀辆汽车⼗分困难,但是如果汽车的各⼤部件都已经存在并且可以获得,我们要做的⼯作就是组装,组装过程⼀定⽐设计这些部件要轻松.函数库分为两种静态(static)函数库和动态(shared)函数库.两者都是函数的集合.区别:在编译的时候会把静态函数库的内容加到⽬标程序中,⽬标程序具有函数库的代码;⽽动态函数库是在执⾏的时候才把函数库中的函数加到⽬标中,⽬标程序中并没有函数库的代码.Linux下⾯的库⽂件动态: xxxx.so静态: xxxx.aWindows下⾯的库⽂件动态: xxxx.dll静态: xxxx.lib常见C语⾔的库LibpngLibjpegLibmysql等1.使⽤gcc编译⼀个动态库⽂件和使⽤⼀个动态库Gcc -shared 源⽂件 -o ⽬标⽂件其中-shared表⽰编译的结果是⼀个动态库⽂件,⽬标⽂件常常命名为libxxx.so.例如,建⽴⼀个⽂件test.c和test.h的⽂件.Test.c:#include <stdio.h>int print(){printf("hello this is lib");}Test.hint print();使⽤gcc -shared test.c -o libtest.so (编译的结果最好使⽤lib开头,调⽤的时候可以省略)⽣成了⽂件libtest.so的动态函数库(-shared表⽰⽣成动态函数库,-o表⽰⽣成的⽬标⽂件).写⼀个程序(在call.c)⽤来调⽤这个函数库中的print()#include "libtest.h"int main(){print();return0;}编译的时候命令gcc call.c -ltest -L. -o c其中-lxx表⽰调⽤动态函数库,libtest.so,如果库⽂件的格式不是libxx.so,也可以使⽤-l xxx.so-L. 表⽰这个函数库在当前⽂件夹下⾯如果把libtest.so复制到/usr/lib或者/usr/local/lib下⾯,可以使⽤命令gcc call.c -ltest -o c不需要使⽤-L.参数.如果直接运⾏./c会出现错误#./c: error while loading shared libraries: libtest.so: cannot open shared object file: No such file or directory原因:虽然已经把函数库放到系统库⽬录或者告知函数库在当前,但是系统会⾃动去/etc/ld.so.cache中去查找已经记录的函数库,并不是去⽂件夹下搜索.所以想要使⽤函数库,还需要使⽤命令ldconfig去搜索函数库添加到系统ld.so.cache中.如果在当前的路径下,可以把当前路径添加到/etc/ld.so.conf中,然后运⾏ldconfig,就可以把当前的⽂件添加到ache中.也可以修改临时的系统库变量LD_LIBRARY_PATH.在终端中使⽤命令export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:../(shell命令,可以使⽤echo $LD_LIBRARY_PATH来查看变量,关闭终端在打开就需要重新配置了)之后,就可以运⾏了.#./c#hello this is libldconfig是动态链接库管理命令.如果想详细了解,可以去仔细查看ldconfig的命令的相关细节.还有⼀个命令ldd,他是查看程序需要什么样的动态库.#ldd clinux-gate.so.1 => (0xb77bd000)libtest.so => not foundlibc.so.6 => /lib/i386-linux-gnu/libc.so.6 (0xb75fc000)/lib/ld-linux.so.2 (0xb77c0000)2.编译成静态库⽂件并使⽤我们使⽤上⾯⽤到的例⼦libtest.c和libtest.h,call.c.⾸先把libtest.c编译成静态的函数库.Gcc -c libtest.c把libtest.c编译成libtest.o,和不加-c的区别是,-c不进⾏链接ar crv libtest.a libtest.oAr是把⽂件⽣成静态库.详细参考man ar编译⽬标程序Gcc call.c libtest.a -o c然后就可以使⽤./c运⾏了.因为静态库在编译的时候就加⼊了程序中,所以⽬标编译之后,就不需要xxx.a⽂件了.虽然,相⽐之下静态库⽐较简单,但是采⽤静态库的代码往往很⼤.。
VS中Debug和Realease、及静态库和动态库的区别整理

VS中Debug和Realease、及静态库和动态库的区别整理⼀、Debug和Realease区别产⽣的原因Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序。
Release 称为发布版本,它往往是进⾏了各种优化,使得程序在代码⼤⼩和运⾏速度上都是最优的,以便⽤户很好地使⽤。
Debug 和 Release 的真正区别,在于⼀组编译选项。
Debug 版本参数含义/MDd /MLd 或 /MTd 使⽤ Debug runtime library(调试版本的运⾏时刻函数库)/Od 关闭优化开关/D "_DEBUG" 相当于 #define _DEBUG,打开编译调试代码开关(主要针对assert函数)/ZI创建 Edit and continue(编辑继续)数据库,这样在调试过程中如果修改了源代码不需重新编译GZ 可以帮助捕获内存错误Release 版本参数含义/MD /ML 或 /MT 使⽤发布版本的运⾏时刻函数库/O1 或 /O2 优化开关,使程序最⼩或最快/D "NDEBUG" 关闭条件编译调试代码开关(即不编译assert函数)/GF 合并重复的字符串,并将字符串常量放到只读内存,防⽌被修改Debug 和 Release 并没有本质的界限,他们只是⼀组编译选项的集合,编译器只是按照预定的选项⾏动。
⼆、Debug和Realease区别的表现I. 内存分配问题1. 变量未初始化。
下⾯的程序在debug中运⾏的很好。
thing * search(thing * something)BOOL found;for(int i = 0; i < whatever.GetSize(); i++){if(whatever[i]->field == something->field){ /* found it /found = TRUE;break;} / found it */}if(found)return whatever[i];elsereturn NULL;⽽在release中却不⾏,因为debug中会⾃动给变量初始化found=FALSE,⽽在release版中则不会。
C语言静态库与动态库的区别[权威资料]
![C语言静态库与动态库的区别[权威资料]](https://img.taocdn.com/s3/m/1a97bb9703d276a20029bd64783e0912a2167cea.png)
C语言静态库与动态库的区别本文档格式为WORD,感谢你的阅读。
最新最全的学术论文期刊文献年终总结年终报告工作总结个人总结述职报告实习报告单位总结演讲稿C语言静态库与动态库的区别静态库与动态库的区别是什么呢?一起来看看下面的相关内容吧!更多内容请关注!区别1:在目标文件链接成可执行文件阶段,库函数(库函数本身有一个代码段)链接进可执行文件(代码段)中,占了很大的内存空间。
而使用动态库时,只是在链接时做了一个printf的标记,当可执行程序运行时才会加载这段printf(从库路径中加载动态链接库.so文件),这样就节省了可执行程序的空间,只有在运行这段很短的时间会占用可执行程序的空间。
可以做个测试,写一个输出hello world的小程序,一般是Linux下gcc中是默认是使用动态库的,可以看到可执行程序a.out的大小只有7千多k,而使用静态库,链接后生成可执行程序时把printf也链接到了可执行程序中,这时候可执行程序就有700多K了。
区别2:使用动态库对库的依赖性太强,一般发布的话需要库文件(库文件要放在相应的库路径中)也发布。
、静态链接库对库的依赖性不会有那么强。
静态库就像房车,出门旅游不用依赖住房,但是房车占空间;动态库就像小车,出门旅游依赖要住酒店,但是小车省空间。
实际上使用动态库在运行的时候加载printf也会占用可执行程序,在运行时占用可执行程序的空间其实是跟静态库是一样的。
但是试想:一个可执行程序a.out中有多个文件(如a应用程序,b应用程序,c文件程序),a,b,c都需要调用printf。
使用静态库时,链接时就链接了三份printf,运行时就加载三份printf,产生多分副本,白白浪费内存。
而使用动态库时,链接时,只是将printf的标记链接进了可执行程序a,out,运行时printf只用加载一份,a调用时就是调用这一份printf,b调用时也是调用这一份printf。
-------这才是动态库相对于静态库真正的优势!【相关阅读】C语言与JAVA的区别C语言C语言是一门通用计算机编程语言,应用广泛。
动态库&静态库

}
return 0;
}
end====================================================
下面是测试程序的 makefile
begin====================================================
//声明函数
int w_log(char *str);
#endif
end=====================================================
下面是all.h 中w_log 函数的实现
begin=====================================================
1)$gcc -fPIC -o libtest.o -c lib_test.c
2)$gcc -shared -o libtest.so libtest.o
也可以直接使用一条命令gcc -fPIC -shared -o libtest.so lib_test.c
动态库调用方式一:
下面就是静态调用刚才生成的 libcommonso.so 动态库了
以下是测试程序:
begin=====================================================
//./test.c
int main(int argc, char *argv[])
4) 使用静态链接库
$nm libtest.a //nm工具可以打印出库中的涉及到的所有符号,库既可以是静态的也可以是动态的。nm列出的符号有很多, 常见的有三种,一种是在库中被
[转]linux静态链接库与动态链接库详解[复制链接]
![[转]linux静态链接库与动态链接库详解[复制链接]](https://img.taocdn.com/s3/m/10bf45e5951ea76e58fafab069dc5022aaea4635.png)
[转]linux静态链接库与动态链接库详解[复制链接]/thread-1281954-1-1.html一顺便说说了哦通常情况下,对函数库的链接是放在编译时期(compile time)完成的.所有相关的对象文件(object file)与牵涉到的函数库(library)被链接合成一个可执行文件(executable file).程序在运行时,与函数库再无瓜葛,因为所有需要的函数已拷贝到自己门下。
所以这些函数库被成为静态库(static libaray),通常文件名为"libxxx.a"的形式.其实,我们也可以把对一些库函数的链接载入推迟到程序运行的时期(runtime).这就是如雷贯耳的动态链接库(dynamic link library)技术.二动态链接库的特点与优势首先让我们来看一下,把库函数推迟到程序运行时期载入的好处:1.可以实现进程之间的资源共享。
什么概念呢?就是说,某个程序的在运行中要调用某个动态链接库函数的时候,操作系统首先会查看所有正在运行的程序,看在内存里是否已有此库函数的拷贝了。
如果有,则让其共享那一个拷贝;只有没有才链接载入。
这样的模式虽然会带来一些“动态链接”额外的开销,却大大的节省了系统的内存资源。
C的标准库就是动态链接库,也就是说系统中所有运行的程序共享着同一个C标准库的代码段.2.将一些程序升级变得简单。
用户只需要升级动态链接库,而无需重新编译链接其他原有的代码就可以完成整个程序的升级。
Windows 就是一个很好的例子。
3.甚至可以真正坐到链接载入完全由程序员在程序代码中控制。
程序员在编写程序的时候,可以明确的指明什么时候或者什么情况下,链接载入哪个动态链接库函数。
你可以有一个相当大的软件,但每次运行的时候,由于不同的操作需求,只有一小部分程序被载入内存。
所有的函数本着“有需求才调入”的原则,于是大大节省了系统资源。
比如现在的软件通常都能打开若干种不同类型的文件,这些读写操作通常都用动态链接库来实现。
动态库和静态库

gcc -o main -Ldir -ltest main.c
查看动态库
在库文件夹下,可以查看动态库文件的依赖 关系
#ldd libadd.so
在当前文件夹下可以查看可执行文件的信息
#file hello 可以看hello文件使用的是动态库
创建库示例
/*main.c*/ #include<stdio.h> main() { int x=5; int y=6; printf(“x+y=%d\n”,add(x,y)); }
共享库:编译时,只是在生成的可执行程序中简 单的指定需要使用的库函数信息,程序运行过程 中需要利用库函数。
动态库:共享库的一种变化形式,目前大多采用 共享库的方式。
函数库分类
也就是说: 静态库在程序编译时会被连接到目标代码中,程
序运行时将不再需要该静态库。 动态库在程序编译时并不会被连接到目标代码中,
创建库示例
/*add.c*/ add(int x,int y) { int result; result=x+y; return result; }
创建静态库示例
1. #gcc add.c -c -o add.o //生成一 个二进制内容的.o文件,只进行前三步编译
2. #ar -cr libadd.a add.o //静态库 生成了,而且文件名必须以lib开头
#LD_LIBRARY_PATH=$PWD #export LD_LIBRARY_PATH
编译时指定路径
#gcc -o cacul -Wl,-rpath,. -L -lalg caculation.c
3. #gcc main.c -L. –ladd -static o ok //把库文件和.o文件生成可执行文 件ok
静态库和动态库

8月27号回顾:Linux Unix的简介gcc 的用法预处理命令今天:静态库和共享库(动态库)C语言的错误处理环境变量在程序中的处理(环境表)由于项目比较复杂,代码数量非常庞大,可以把代码打包成库文件,提供库文件和头文件即可。
库文件分成两种:静态库和共享库(动态库),静态库和共享库都是代码的归档文件。
在使用静态库时,把静态库复制到目标文件中,导致目标文件比较大;使用共享库时,把函数的地址放到目标文件中。
静态库和共享库的优缺点:静态库的优点:目标文件是独立于库文件,运行速度稍快。
缺点:目标文件太大,不利于代码的修改,扩展和复用共享库的优点:目标文件比较小,修改,扩展和复用比较方便。
缺点:目标文件必须和共享库文件同时存在,代码才能正常运行。
运行速度稍慢。
开发多半使用共享库。
使用了静态库的步骤:一.创建静态库文件(.a)1写源程序add.c保存退出2编译源文件,得到.o文件(gcc -c)3创建静态库文件:ar -r libXX.a add.o //把add.o文件加入到libxx.a库中注:lib 开头.a结束是静态库的命名规范,XX叫库名创建静态库文件后,还需要提供.h文件。
二.使用静态库1写调用源程序text.c ,保存退出2编译text.c ,只编译不连接(gcc -c)3连接text.o 和静态库文件连接方式有三种:A直接连接gcc text.o libXX.aB 配置环境变量LIBRARY_PA TH,把库文件所在路径放入其中,然后:gcc text.o -lXXC gcc text.o -lXX -L所在路径(双L,推荐)自己总结:写.c文件(add.c)编译不连接gcc -c 得到.o 文件(add.o)创建库文件ar -r libXX.a add.o写调用的源程序.c 文件(text.c)编译不连接gcc -c text.c 得到.o文件(text.o)连接text.o和静态库gcc text.o libXX.a运行产生的a.out文件使用共享库的步骤:一.创建共享库1写源程序add.c ,保存退出2编译gcc -c -fpic add.c (不写-fpic也行)3生成共享库gcc -shared add.o -olibXX.so注:共享库也需要提供头文件二.使用共享库和静态库方式一样注:连接成功后。
[VIP专享]Linux下Gcc生成和使用静态库和动态库详解
![[VIP专享]Linux下Gcc生成和使用静态库和动态库详解](https://img.taocdn.com/s3/m/1ea3480e804d2b160b4ec0d8.png)
=> /lib/libc.so.6 (0×40021000)/lib/ld-linux.so.2 => /lib/ld- linux.so.2 (0×40000000) 可以看到 ln 命令依赖于 libc 库和 ld-linux 库
1.7 可执行程序在执行的时候如何定位共享库文件 当系统加载可执行代码时候,能够知道其所依赖的库的名字,但是还需要知道绝对路径。 此时就需要系统动态载入器(dynamic linker/loader) 对于 elf 格式的可执行程序,是由 ld-linux.so*来完成的,它先后搜索 elf 文件的 DT_RPATH 段—环境变量 LD_LIBRARY_PATH—/etc/ld.so.cache 文件列表— /lib/,/usr/lib 目录找到库文件后将其载入内存 如:export LD_LIBRARY_PATH=’pwd’ 将当前文件目录添加为共享目录
1) B2Ak+22+12=+15+c51mc+=5m=2c111++m+12+21+++2=12=2+1+2+1+2+2+22+32k+1+2
Linux 下 Gcc 生成和使用静态库和动态库详解
一、基本概念 1.1 什么是库 在 windows 平台和 linux 平台下都大量存在着库。 本质上来说库是一种可执行代码的二进制形式,可以被操作系统载入内存执行。 由于 windows 和 linux 的平台不同(主要是编译器、汇编器和连接器的不同),因此二者 库的二进制是不兼容的。 本文仅限于介绍 linux 下的库。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
linux下的静态库与动态库的区别1.什么是库在windows平台和linux平台下都大量存在着库。
本质上来说库是一种可执行代码的二进制形式,可以被操作系统载入内存执行。
由于windows和linux的本质不同,因此二者库的二进制是不兼容的。
2.库的种类linux下的库有两种:静态库和共享库(动态库)。
二者的不同点在于代码被载入的时刻不同。
静态库的代码在编译过程中已经被载入可执行程序,因此体积较大。
共享库的代码是在可执行程序运行时才载入内存的,在编译过程中仅简单的引用,因此代码体积较小。
3.库存在的意义库是别人写好的现有的,成熟的,可以复用的代码,你可以使用但要记得遵守许可协议。
现实中每个程序都要依赖很多基础的底层库,不可能每个人的代码都从零开始,因此库的存在意义非同寻常。
共享库的好处是,不同的应用程序如果调用相同的库,那么在内存里只需要有一份该共享库的实例。
4.库文件是如何产生的在linux下静态库的后缀是.a,它的产生分两步Step 1.由源文件编译生成一堆.o,每个.o里都包含这个编译单元的符号表Step 2.ar命令将很多.o转换成.a,成文静态库动态库的后缀是.so,它由gcc加特定参数编译产生。
例如:$ gcc -fPIC -c *.c $ gcc -shared -Wl,-soname, libfoo.so.1 -o libfoo.so.1.0 *. 5.库文件是如何命名的,有没有什么规范在linux下,库文件一般放在/usr/lib /lib下,静态库的名字一般为libxxxx.a,其中xxxx是该lib的名称动态库的名字一般为libxxxx.so.major.minor,xxxx是该lib的名称,major是主版本号,minor是副版本号6.如何知道一个可执行程序依赖哪些库ldd命令可以查看一个可执行程序依赖的共享库,例如# ldd /bin/lnlibc.so.6=> /lib/libc.so.6 (0×40021000)/lib/ld-linux.so.2=> /lib/ld- linux.so.2 (0×40000000)可以看到ln命令依赖于libc库和ld-linux库Gdb调试段错误1.段错误是什么段错误是指访问的内存超出了系统给这个程序所设定的内存空间,例如访问了不存在的内存地址、访问了系统保护的内存地址、访问了只读的内存地址等等情况。
2.段错误产生的原因访问不存在的内存地址#include<stdio.h>#include<stdlib.h>void main(){int *ptr = NULL;*ptr = 0;}访问系统保护的内存地址#include<stdio.h>#include<stdlib.h>void main(){int *ptr = (int *)0;*ptr = 100;}访问只读的内存地址#include<stdio.h>#include<stdlib.h>#include<string.h>void main(){char *ptr = "test";strcpy(ptr, "TEST");}#include<stdio.h>栈溢出#include<stdlib.h>void main(){main();}3.使用gcc和gdb 调试1 dumm y_function (void)2 {3 unsigned char *ptr = 0x00;4 *ptr = 0x00;5 }67 int m ain (void)8 {9 dumm y_function ();1011 return 0;12 }调试步骤1、为了能够使用gdb调试程序,在编译阶段加上-g参数gcc -g -o test test.c2、使用gdb命令调试程序:3、进入gdb后,运行程序:4、完成调试后,输入q命令退出gdb:适用场景1、仅当能确定程序一定会发生段错误的情况下使用。
2、当程序的源码可以获得的情况下,使用-g参数编译程序。
3、一般用于测试阶段,生产环境下gdb会有副作用:使程序运行减慢,运行不够稳定,等等。
4、即使在测试阶段,如果程序过于复杂,gdb也不能处理。
自动生成Makefile对于一个UNIX/Linux下C程序员来说,一个比较麻烦的工作就是写自己的Makefile。
可能你有如下经验:写一个简单的C程序,自己多写几行gcc命令就把程序变成可执行的了;写一个稍微复杂点的程序,源文件个数可能在30个左右,还是写一行行的gcc命令就麻烦了,你可能想到写个makefile,你可能也在这样做着;但你某一天会发现你写的这个Makefile可能不是一个所有UNIX/Linux类操作系统下通用的Makefile,比如某人下载了你的程序去他自己电脑上可能make不了。
这样,你就有必要了解并学会运用autoconf和automake了。
autoconf是一个用于生成可以自动地配置软件源代码包以适应多种UNIX类系统的shell 脚本的工具。
由autoconf生成的配置脚本在运行的时候不需要用户的手工干预;通常它们甚至不需要手工给出参数以确定系统的类型。
相反,它们对软件包可能需要的各种特征进行独立的测试。
在每个测试之前,它们打印一个单行的消息以说明它们正在进行的检测,以使得用户不会因为等待脚本执行完毕而焦躁。
因此,它们在混合系统或者从各种常见UNIX 变种定制而成的系统中工作的很好。
你也省了工作,没必要维护文件以储存由各个UNIX 变种、各个发行版本所支持的特征的列表。
automake是一个从文件Makefile.am自动生成Makefile.in的工具。
每个Makefile.am 基本上是一系列make的宏定义(make规则也会偶尔出现)生成的Makefile.in,服从GNU Makefile标准。
为了生成Makefile.in,automake需要perl。
但是由automake创建的发布完全服从GNU标准,并且在创建中不需要perl。
在开始使用autoconf和automake之前,首先确认你的系统安装有GNU的如下软件:1. automake2. autoconf3. m44. perl5. 如果你需要产生共享库(shared library)则还需要GNU Libtool介绍方法之前大家看一下下面这个图,先记下autoconf和automake工作的几个步骤:步骤解释如下:1、由你的源文件通过autoscan命令生成configure.scan文件,然后修改configure.scan 文件并重命名为configure.in2、由aclocal命令生成aclocal.m43、由autoconf命令生成configure4、编辑一个Makefile.am文件并由automake命令生成Makefile.in文件5、运行configure命令生成Makefileautomake支持三种目录层次:flat、shallow和deep。
一个flat包指的是所有文件都在一个目录中的包。
为这类包提供的Makefile.am不需要SUBDIRS这个宏。
这类包的一个例子是termutils。
对应咱们程序员来说:就是所有源文件及自己写的头文件都位于当前目录里面,且没有子目录。
一个deep包指的是所有的源代码都被储存在子目录中的包;顶层目录主要包含配置信息。
GNU cpio是这类包的一个很好的例子,GNU tar也是。
deep包的顶层Makefile.am将包括宏SUBDIRS,但没有其它定义需要创建的对象的宏。
对应咱们程序员来说:就是所有源文件及自己写的头文件都位于当前目录的一个子目录里面,而当前目录里没有任何源文件。
一个shallow包指的是主要的源代码储存在顶层目录中,而各个部分(典型的是库)则储存在子目录中的包。
automake本身就是这类包(GNU make也是如此,它现在已经不使用automake)。
对应咱们程序员来说:就是主要源文件在当前目录里,而其它一些实现各部分功能的源文件各自位于不同目录。
前两个层次的程序编辑方法非常简单,按照上述步骤一步步即可。
而第三种层次shallow 稍微复杂一点,但这是我们经常写程序用到的结构。
下面以一个例子说明shallow层次结构的源文件如何自动生成Makefile文件。
例子源程序结构如下:hello是我们的工作目录,hello目录下有main.c源文件和comm、tools、db、network、interface等五个目录。
comm目录下有comm.c和comm.h源文件及头文件,tools 目录下有tools.c和tools.h,同样其它目录分别有db.c、db.h、network.c、network.h、interface.c、interface.h等一些源文件。
按照如下步骤来自动生成Makefile吧:1、进入hello目录,运行autoscan命令,命令如下:cd helloautoscan2、ls会发现多了一个configure.scan文件。
修改此文件,在AC_INIT宏之后加入AM_INIT_AUTOMAKE(hello, 1.0),这里hello是你的软件名称,1.0是版本号,即你的这些源程序编译将生成一个软件hello-1.0版。
然后把configure.scan文件的最后一行AC_OUTPUT宏填写完整变成AC_OUTPUT(Makefile),表明autoconf和automake 最终将生成Makefile文件。
最后把configure.scan文件改名为configure.in。
最终configure.in文件内容如下:# -*- Autoconf -*-# Process this file with autoconf to produce a configure script.AC_PREREQ(2.60)AC_INIT(FULL-PACKAGE-NAME, VERSION, BUG-REPORT-ADDRESS)AM_INIT_AUTOMAKE(client, 1.0)AC_CONFIG_SRCDIR([client.c])#AC_CONFIG_HEADER([config.h]) # 如果这行不注释掉会有问题为什么我也不知道# Checks for programs.AC_PROG_CC# Checks for libraries.# Checks for header files.AC_CHECK_HEADERS([netdb.h netinet/in.h strings.h sys/socket.h unistd.h])# Checks for typedefs, structures, and compiler characteristics.AC_HEADER_TIME# Checks for library functions.AC_HEADER_STDCAC_FUNC_SELECT_ARGTYPESAC_CHECK_FUNCS([bzero gethostbyname select socket])AC_OUTPUT(Makefile)3、运行aclocal命令,ls会发现多了一个aclocal.m4文件。