识别图片文字如何实现
图片文字识别的步骤

图片文字识别的步骤
在工作中整理图片资料,我们如何实现图片文字识别?相信很多朋友上班的工作就是整理图片资料,因为没有好的办法,只能手动整理,整理起来很麻烦,现在小编给大家分享一个方法,学会了这个方法,以后就不用那么麻烦了。
操作步骤:
1.下载一个迅捷OCR文字识别软件,打开软件,关闭提示窗。
2.在软件上方有一行功能导航栏,点击“快速识别”功能。
3.在软件下方修改文件的输出目录。
4.点击“添加文件”,把需要识别的文件添加进去。
5.点击软件右下角的“一键识别”按钮,开始识别图片。
6.点击操作下方的“打开文件”,便可看到识别成功的图片文字。
到这里图片文字识别的步骤就分享完了,希望可以帮助有需要的朋友们。
迅捷OCR文字识别:https:///ocr。
文字识别ocr的操作方法

文字识别ocr的操作方法
文字识别(OCR)的操作方法如下:
1. 打开文字识别软件或在线平台。
2. 选择要识别的图片或文档,可以通过导入文件或拍摄照片的方式进行。
3. 点击识别按钮,软件将会分析图片中的文字,并将其转换为可编辑的文本格式。
4. 对识别后的文本进行校对和编辑,确保准确性和完整性。
5. 保存识别后的文本,可以选择保存到本地或导出到其他应用程序中使用。
6. 根据需要,可以对识别后的文本进行进一步处理,如翻译、整理或转换格式等操作。
以上就是文字识别(OCR)的一般操作方法,具体操作可能会因软件或平台而有所不同,但基本步骤大致相似。
图片字体识别怎么做

图片字体识别怎么做
关于图片字体识别这个问题,可能很多朋友都不知道还有这样的功能,一张图片上文字太多,想要提取出来,使用一款识别软件可以省去很多不必要的麻烦,而且还可以提升工作效率。
捷速OCR文字识别软件的特点:
精准识别文字信息:软件采用先进的OCR识别技术,高达99%的识别精度轻松实现文档数字化。
完美还原文档格式:软件可一键读取文档,完美还原文档的逻辑结构和格式无需重新录入和排版。
自动解析图文版面:软件对图文混排的文档具有自动分析功能,将文字区域划分出来后自动进行识别。
首先打开百度搜索“捷速ocr文字识别软件”,将ocr软件下载安装在电脑上。
打开ocr软件的主页面,选择软件上方的功能,点击极速识别按钮。
选择过想要的识别选项后,可以开始图片文件进入,如果是多个文件夹可以进行添加文件夹进入软件中,或者直接拖拽都是可以的。
完成文件添加后,根据自己的需要选择识别文字的格式,例如docx、doc、txt 等格式问题。
然后点击开始识别即可,识别完成后,点击打开文件,其实就会出现识别的文字。
不会的朋友相信看过这篇文章后,图片字体识别怎么做已不是难题了,收藏吧,防止以后需要的时候找不到!。
如何快速识别图片里的文字?用这个方法从此告别扫描仪
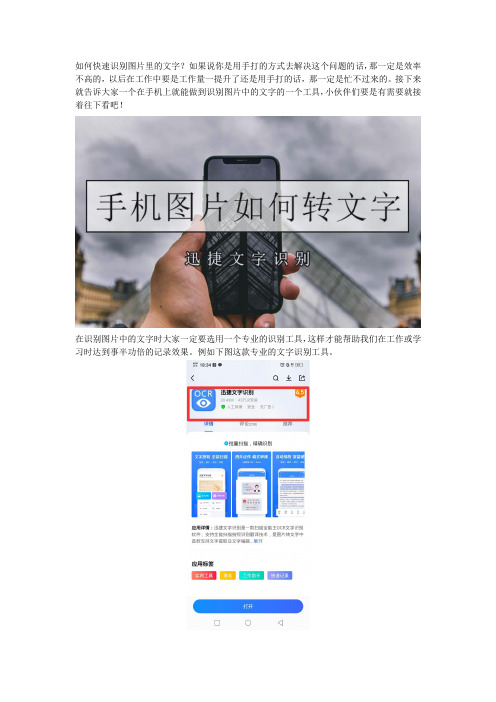
如何快速识别图片里的文字?如果说你是用手打的方式去解决这个问题的话,那一定是效率不高的,以后在工作中要是工作量一提升了还是用手打的话,那一定是忙不过来的。
接下来就告诉大家一个在手机上就能做到识别图片中的文字的一个工具,小伙伴们要是有需要就接着往下看吧!
在识别图片中的文字时大家一定要选用一个专业的识别工具,这样才能帮助我们在工作或学习时达到事半功倍的记录效果。
例如下图这款专业的文字识别工具。
在手机上安装好之后,我们将迅捷文字识别打开,根据主页面点击选择使用【上传图片识别】这个功能,接着就能看到下图中的所示的选项了,在手机相册中点击选择需要识别的图片,将它导入到迅捷文字识别中,接着完成图片裁剪后在右上角进行保存。
随后耐心等待几秒钟就能图片中的文字就能识别完成了,在识别完成后我们可以选择下图中所示的这些功能,比如使用校对功能提升识别结果的准确度,完成了校对之后记得在右上角点击按钮进行保存哦!
在弹出的识别记录标题中命名识别结果文件后就能完成本次识别了!将手机里的图片识别出文字只用这个方法就足够了,三个步骤轻轻松松搞定,小伙伴们要是有需要可以试试这个迅捷文字识别哦!。
java实现图片文字识别的两种方法

java实现图⽚⽂字识别的两种⽅法⼀、使⽤tesseract-ocr 1. 上下载安装包安装和简体中⽂训练⽂件 window64位安装包:tesseract-ocr-w64-setup-v4.1.0.20190314.exe 简体中⽂训练⽂件:chi_sim.traineddata 约40M 2. 将训练⽂件chi_sim.traineddata放⼊安装⽬录下的tessdata⽬录中 3. 配置环境变量,在path变量中加⼊tesseract安装⽬录,例如C:\Program Files\Tesseract-OCR 4. 添加系统环境变量TESSDATA_PREFIX,值为训练⽂件的⽬录,例如C:\Program Files\Tesseract-OCR\tessdata5. 使⽤java调⽤命令⾏执⾏转换,命令格式例如:F:\pic> tesseract6.png 66 -l chi_sim 即:在F:\pic⽬录下使⽤tesseract命令利⽤chi_sim训练⽂件把6.png⽂件转换成66.txt⽂件⼆、使⽤tess4j 1. 使⽤maven下载所需jar包:<dependency><groupId>net.java.dev.jna</groupId><artifactId>jna</artifactId><version>4.1.0</version></dependency><dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>3.4.0</version><exclusions><exclusion><groupId>com.sun.jna</groupId><artifactId>jna</artifactId></exclusion></exclusions></dependency> 2.下载简体中⽂训练⽂件:chi_sim.traineddata 3.使⽤如下代码调⽤//加载待读取图⽚File imageFile = new File("F://pic.png");//创建tess对象ITesseract instance = new Tesseract();//设置训练⽂件⽬录instance.setDatapath("F://tessdata");//设置训练语⾔instance.setLanguage("chi_sim");//执⾏转换String result = instance.doOCR(imageFile);。
提取文字方法

提取文字方法
提取文字可以使用光学字符识别(OCR)技术。
OCR技术将图像中的文字转化为计算机可识别的文本。
以下是一种常用的OCR方法:
1.图像预处理:
-对图像进行灰度化处理,将彩色图像转换为黑白图像。
-对图像进行二值化处理,将图像中的文字部分变为黑色,背景部分变为白色。
-对图像进行去噪处理,去除图像中的干扰线、噪点等。
2.文字分割:
-对图像中的文字进行分割,将每个字符或字符块单独提取出来。
-使用边缘检测、连通区域分析等方法来实现字符分割。
3.字符识别:
-对每个字符进行特征提取,如形状、纹理等特征。
-对每个字符的特征进行分类识别,可以使用机器学习、深度学习等方法。
4.文本识别和整理:
-对提取出的字符进行后处理,如去除冗余字符、拼接字符等,恢复成完整的文本。
-对文本进行格式化、校正、整理等处理。
需要注意的是,OCR技术对图像质量要求较高,如图像清晰度、光照条件等。
此外,不同语种的文字可能需要使用不同的OCR模型和方法。
如何将图片中的文字提取出来

现在的生活和工作越来越便捷化,电脑和手机用到的也越来越多。
而在我们的生活和工作中有很多资料都是以图片的形式存在的,那么我们使用什么方法可以将图片中的文字提取出来呢?今天小编就教给大家两种图片转文字的方法。
方法一:手机自带扫描工具现在越来越多的手机自带图片转文字功能,我们就以小米手机为例吧!小米手机中的扫一扫功能除了可以扫描二维码之外,还可以拍照购物,连接别人分享的WiFi,更值得一提的是还可以提取图片中的文字。
具体的怎样操作的?跟着小编看一下吧!我们每个人的手机上有很多软件,首先就是要找到我们小米手机自带的“扫一扫”工具。
找到该工具之后,点击进入。
因为扫一扫支持多种功能,所以我们需要点击【扫文档】。
扫文档的时候,我们可以直接扫描手机内保存的图片,也可以直接拍照进行识别。
小编大概在电脑上拍了一段文字,之后我们需要点击【识别文字】,这样就可以将图片中的文字给提取出来了。
方法二:电脑端工具手机虽然携带比较方便,但是在办公中,我们还是更加喜欢使用电脑。
电脑上的【迅捷OCR文字识别软件】一样可以将图片中的文字提取出来,OCR软件是我们在办公中很常用的一个工具。
支持图片转文字的功能也是很多的,具体的操作步骤给大家看一下。
首先,打开我们电脑上的迅捷OCR文字识别软件,在该工具的页面中,我们可以看到有多种功能。
其中极速识别、OCR文字识别都是支持图片转文字的功能。
我们就先选【极速识别】功能吧!进入到【极速识别】功能的页面后,先给该功能添加图片文件。
即点击【上传图片】。
在上传图片的时候,我们可以看到该功能支持的图片格式,如PNG、JPG、BMP格式的图片。
之后我们需要修改一下文件的【导出目录】,如果我们电脑上C盘存放的文件过多了,我们就可以存放到D盘或其它地方。
修改好之后,直接点击【开始识别】就好了。
好了,以上的两种方法都可以将图片中的文字提取出来。
大家可以根据个人的需求进行操作啊!喜欢的话,记得分享一下哦!。
文字识别流程-概述说明以及解释

文字识别流程-概述说明以及解释1.引言在1.1 概述部分,我们将介绍文字识别流程的概述。
文字识别是一种通过计算机技术将文本信息从图像或者手写的形式转换成可编辑和可搜索的文本的过程。
它的主要目标是将图像中的文字提取出来,并且准确地识别出每个字符的内容。
为了实现文字识别,通常需要经过以下几个主要步骤:预处理、检测和定位、分割和识别。
首先,在预处理阶段,我们会对输入的图像进行一系列的处理操作,如去噪、灰度化、二值化等,以提高图像的质量和文字的清晰度。
接下来,在检测和定位阶段,我们会使用各种图像处理算法和模型来检测图像中的文字区域并进行定位。
这一步骤的目的是识别出文字所在的位置,为后续的字符分割和识别做准备。
然后,在分割阶段,我们会将定位到的文字区域进行分割,将每个字符单独提取出来。
这一过程可以采用基于像素的方法,如投影法、连通区域等,也可以使用基于深度学习的方法,如卷积神经网络等。
最后,在识别阶段,我们会将每个字符送入一个文字识别模型中,模型将对每个字符进行识别,并输出识别结果。
常用的文字识别模型包括传统的基于特征工程的方法,如支持向量机、随机森林等,以及基于深度学习的方法,如卷积神经网络、循环神经网络等。
通过上述的文字识别流程,我们可以实现从图像到文本的转换,极大地提高了文字信息的利用效率和可操作性。
文字识别在许多领域中都有着广泛的应用,如自动化办公、图书馆数字化、车牌识别等。
随着技术的不断进步和发展,文字识别将会在未来得到更广泛的应用和进一步的改进。
1.2 文章结构本文将分为三个主要部分来探讨文字识别的流程。
首先,在引言部分将概述文字识别的定义、文章的结构以及目的。
接着,在正文部分将深入探讨文字识别的定义,包括文字识别的概念和原理,以及文字识别在不同领域的应用场景。
最后,在结论部分将总结文字识别的重要性,并对其未来发展进行展望。
在正文部分中,我们将详细介绍文字识别的定义和原理。
文字识别是指利用计算机技术对图像或文档中的文字进行自动识别和提取的过程。
wps怎么进行图片文字识别?

要在WPS Office中进行图片文字识别,你可以按照以下步骤进行操作:
1. 打开WPS文字(WPS Writer)或者WPS表格(WPS Spreadsheets)。
2. 在打开的文档中,插入或者打开包含文字的图片。
3. 选中图片,然后在菜单栏中找到“图片工具”、“格式”或者“插入”等选项,具体位置可能会在不同版本的WPS Office中稍有不同。
4. 在图片工具或者格式选项中,寻找文字识别或OCR功能。
在一些版本的WPS Office中,可以在“图片工具”栏或者“格式”栏中找到文字识别的图标或者选项。
5. 点击文字识别或OCR功能,WPS Office会对图片中的文字进行识别并转换成可编辑的文本。
识别的效果会显示在图片周围或者一个新的弹出窗口中。
6. 完成识别后,你可以对识别出的文字进行编辑、复制、粘贴等操作,方便你进行后续的处理或者编辑工作。
请注意,WPS Office的文字识别功能可能因版本不同而略有差异,如果你在操作过程中无法找到相关选项,建议你参考WPS Office的官方帮助文档或者联系官方技术支持获取详细的操作指引。
VBA中的图像识别和文字识别方法

VBA中的图像识别和文字识别方法在Visual Basic for Applications (VBA)中,图像识别和文字识别是非常有用的功能。
通过使用图像识别和文字识别方法,我们可以自动化识别和处理图像和文字数据,提高工作效率。
本文将介绍在VBA中实现图像识别和文字识别的方法和技巧。
一、图像识别方法1. 使用VBA的相关库和引用:为了实现图像识别功能,我们需要使用VBA的相关库和引用。
其中一个常用的库是Microsoft Office,它包含了一些用于图像处理的对象和方法。
我们可以通过在VBA编辑器中选择“工具”>“引用”来添加所需的库和引用。
2. 使用图像处理对象:在VBA中,可以使用图像处理对象来操作和处理图像数据。
例如,可以使用“Shape”对象来获取图像对象,并使用其属性和方法进行图像的截取、调整大小等操作。
可以使用“Picture”对象来载入和保存图像数据。
3. 使用图像识别算法:在VBA中,我们可以使用一些图像处理和识别算法来实现图像识别功能。
例如,可以使用基于像素点颜色的算法来进行颜色识别,可以使用基于图像特征的算法来进行形状识别等。
根据具体的需求,选择合适的算法来实现图像识别功能。
4. 图像识别的应用:图像识别方法可以应用于许多领域,例如在电子表格中自动识别和处理图像数据、在文档中自动提取图像信息等。
通过使用图像识别方法,我们可以大大提高工作效率和准确性。
二、文字识别方法1. 使用VBA的相关库和引用:为了实现文字识别功能,我们同样需要使用VBA的相关库和引用。
其中一个常用的库是Microsoft Office,它包含了一些用于文本处理的对象和方法。
同样,我们可以通过在VBA编辑器中选择“工具”>“引用”来添加所需的库和引用。
2. 使用文本处理对象:在VBA中,可以使用文本处理对象来操作和处理文本数据。
例如,可以使用“Range”对象来获取单元格中的文本数据,并使用其属性和方法进行文本的查找、替换等操作。
手机如何实现拍照识别图片文字并翻译

手机如何实现拍照识别图片文字并翻译
手机上可以帮助我们拍照识别图片上的文字?还能将识别出来的文字给全部翻译成英文?下面我们就来一起手机上是如何实现拍照识别图片文字并翻译。
工具:手机、PDF阅读器
操作方法:
1、首先,我们打开手机,在手机上下载安装一个可以拍照识别翻译文字的软件,
然后打开运行。
2、熟悉一下操作,找到小功能里面的拍照识别文字。
3、点击拍照识别文字,然后将需要的识别的文字给拍下来,上传上去后软件会
自动开始上面的文字。
4、然后点击翻译,下面是中文翻译成英文的结果。
以上就是手机上如何实现拍照就能识别和翻译文字的方法,如果有需要拍照识别和翻译文字的朋友可以了解一下。
怎么拍照识别文字?什么软件可以识别照片中文字?

怎么拍照识别文字?什么软件可以识别照片中文字?
随着科技时代的发展,大家对手机软件的使用越来越多,很多功能的软件都可以方便我们的生活,以前大家需要从书本或者图片上提取文字,都只能用人工的方式打出来。
现在很多手机软件都可以直接扫描识别,很快就能把图片上的文字识别保存,方便大家的生活和工作,那么怎么拍照识别文字?什么软件可以识别照片中文字?一起来了解一下吧!
推荐使用软件:迅捷文字识别
一、首先为大家分享的迅捷文字识别软件,是一款多功能识别APP,可以实现拍图识字,表格识别,图片转word识别,导入图片识别,导入PDF识别等功能。
这些功能在工作中非常实用,可以快速帮很多工作者完成图片提取文字,整理资料时可以加快工作效率。
二、我们马上就来看看如何用该软件实现拍照识别文字,打开手机上安装好的迅捷文字识别APP,点击打开后进入到软件首页,第一个选项就是拍照识字,我们点击该选项进入到手机相机页面,我们直接用相机对准要识别的文字页面进行拍摄。
三、拍摄完成后调整要识别的画面,拖动四个角调整画面,然后点击下一步,这时候软件就会开始自动识别,很快的速度就可以把图片中的文字识别出来,然后大家在软件页面下方的文档选项中,可以找到已经识别好的文字文档,导出保存即可。
为大家总结了怎么拍照识别文字?什么软件可以识别照片中文字?的基本内容,这款软件的几大功能都很好用,图片识别文字的速度快,而且准确率也高,希望今天整理的内容对大家有所帮助。
如何扫描识别图片中文字

如何扫描识别图片中的文字?
经常需要识别图片文字的上班族都有方法,如何扫描识别图片中的文字?职场新手是不会的,上班族也可也学习一下,这里就教大家如何扫描识别文字。
1、首先要在百度或者下载站去搜索捷速OCR文字识别软件,熟悉操作后接着识别图片中的文字。
2、工具安装好就可以打开,打开可以添加PDF,PNG,JPG,BMP 格式的文件,这里添加图片文件。
3、文件少的话可以添加文件,文件多的话还是添加文件夹,设置下要识别的格式,这里设置TXT格式,识别效果也设置下。
4、这里可以看到识别状态,操作是开始识别,删除等,这里点击开始识别或者一键识别就可以开始识别了。
5、这里是进度条,可以查看的,识别的时候不能操作,需要等一下时间。
6、图片中的文字识别好之后就可以打开文件了,直接打开就可以,电脑都可以查看TXT文件。
如何扫描识别图片中的文字就是这样,OCR还有更多功能,这里只是简单了介绍下,迅捷PDF阅读器APP也可以扫描识字,里面新增了PDF文件转换Word,对这个干兴趣的可以去试试。
手机上怎样实现拍照一键识别图片文字

手机上怎样实现拍照一键识别图片文字
虽说好记性不如烂笔头,可遇到喜欢的图片文字一个字一个字的去抄写,确实有些麻烦了,这里小编就教大家一个拍照一键识别图片文字的方法。
工具:手机、迅捷文字识别APP
操作方法;
1.首先,打开我们的手机,我们需要在手机上的应用市场上下载一个可以识别图片文字的小工具。
2.然后在手机上打开这个文字识别的工具,简单了解一下界面,点击拍照识别,然后再点击立即使用。
3.接着将需要识别的文字给拍摄下来,再点击立即识别。
4. 然后这个工具就会开始别识别处理图片上的文字,等一会文字就会被识别出来了。
5.最后点击下方的校对,可以查看一下识别的出来的效果。
事实证明这个文字识别的工具识别出来的效果还是不错的,有需要的朋友可以去手机上了解一下。
ocr工作原理

ocr工作原理OCR(Optical Character Recognition,光学字符识别)是一种将印刷体字符转换为可编辑文本的技术。
它利用计算机视觉和模式识别技术,通过扫描和解析图像中的字符,将其转化为计算机可识别的文本。
OCR的工作原理可以分为以下几个步骤:1. 图像预处理:首先,将原始图像进行预处理,包括去除噪声、调整图像的亮度和对比度等。
这一步骤旨在提高图像的质量,使得后续的字符识别更加准确。
2. 文字定位:在预处理后的图像中,需要确定文字的位置。
通过分析图像中的像素密度和连通性,可以将文字区域与其他区域进行区分。
常用的方法包括边缘检测、连通区域分析等。
3. 字符分割:在确定了文字的位置后,需要将文字分割成单个字符。
这一步骤旨在解决多个字符连在一起的问题。
常用的方法包括基于投影的字符分割、基于连通区域的字符分割等。
4. 特征提取:对于每个单独的字符,需要提取其特征以便于后续的识别。
常用的特征包括字符的形状、纹理、边缘等。
特征提取可以使用各种算法和技术,如灰度共生矩阵、方向梯度直方图等。
5. 字符识别:在特征提取后,可以使用机器学习或模式识别算法对字符进行识别。
常用的方法包括模板匹配、神经网络、支持向量机等。
这些算法通过比较字符的特征与预先训练好的模型或模板进行匹配,从而确定字符的类别。
6. 后处理:在字符识别后,可能会出现一些错误或不完整的识别结果。
为了提高准确性,可以进行后处理操作,如纠正错误、合并断开的字符等。
后处理可以使用规则或统计方法来修正识别结果。
总结起来,OCR的工作原理是通过图像预处理、文字定位、字符分割、特征提取、字符识别和后处理等步骤,将印刷体字符转换为可编辑文本。
这项技术在各种场景中都有广泛的应用,如扫描文档转换、自动化数据输入、图书数字化等。
随着计算机视觉和机器学习的发展,OCR的准确性和速度不断提高,为我们的生活和工作带来了便利。
文字识别的方法

文字识别的方法文字识别是一种基于计算机视觉的技术,旨在将印刷或手写文本转换成可编辑、可搜索的数字化文本。
在数字化时代,文字识别技术越来越成为必不可少的工具,广泛应用于各种领域,如文档管理、图书馆数字化、车牌识别、人脸识别和自然语言处理等。
现代文字识别技术主要采用以下三种方法:1. 基于模板匹配的方法:模板匹配技术是一种识别手写数字和字母的简单而有效的方法。
这种方法的基本思想是构建一个模板库,包含许多数字和字母的模板。
在识别过程中,将输入的数字或字母与模板进行匹配,找到最相似的模板即可确定其识别结果。
该方法适用于识别清晰且噪声较少的图像,但对于大量变化或噪声较大的数据则表现不佳。
2. 基于特征提取的方法:特征提取是一种将输入图像转换成特征向量的技术,其目的是为了获得图像中的关键信息,以便于后续的分类、识别等任务。
在文字识别中,特征提取主要包括局部二值模式(LBP)、方向梯度直方图(HOG)、尺度不变特征变换(SIFT)等技术。
这些特征抽取技术可以使得图像中的文字形状、纹理和颜色等特点尽可能地被保存,提高识别准确率。
3. 基于深度学习的方法:深度学习是一种模拟人脑神经网络的机器学习方法,其主要特点是对数据学习高层次的抽象特征,可以在大量数据集上进行训练,并能够自动发现关键特征,从而在文字识别方面得到较好的应用。
在深度学习中常用的神经网络包括卷积神经网络(CNN)、循环神经网络(RNN)等模型。
通过搭建合适的神经网络结构,将图像中的像素点进行卷积运算,得到卷积特征,并进行下采样或池化操作,进一步提取模型的抽象特征。
最后将该特征向量送入全连接层,得到该模型对文字图片的分类结果。
总之,随着科技的不断进步,文字识别技术将会得以广泛应用,提升社会的信息化水平,提高人们的生活质量和工作效率。
电脑图片中的文字怎么识别提取出来
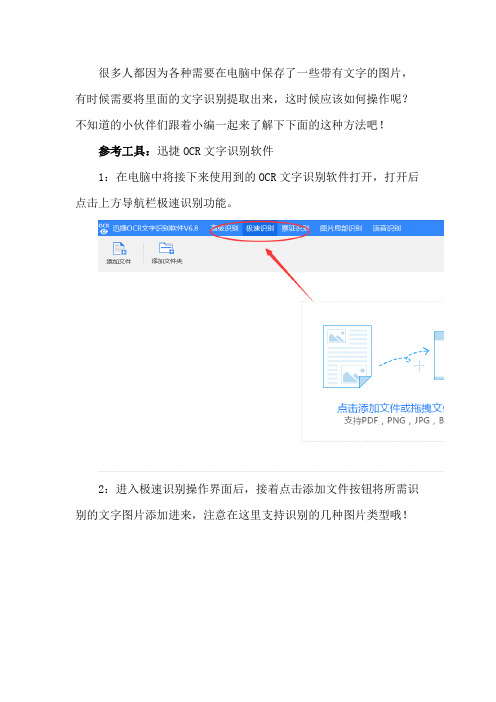
参考工具:迅捷OCR文字识别软件
1:在电脑中将接下来使用到的OCቤተ መጻሕፍቲ ባይዱ文字识别软件打开,打开后点击上方导航栏极速识别功能。
2:进入极速识别操作界面后,接着点击添加文件按钮将所需识别的文字图片添加进来,注意在这里支持识别的几种图片类型哦!
如果你的电脑中也保存了一些文字图片,并且想要将里面的文字识别提取出来,不妨尝试下上述的方法吧!
3:图片添加进来会跳转到另一个界面,将识别格式更改为TXT,识别效果根据自己需的需要选择其中一个就好了。
4:更改完之后先不要着急识别,在界面左下角这里设置一下文件输出位置,方便待会识别结束后的查找。
5:上述步骤全都完成以后就可以点击开始识别按钮了,软件会自动去识别。
6:等到识别过程结束以后,就可以点击打开文件按钮查看结果了。
ocr识别原理

ocr识别原理OCR(Optical Character Recognition)是一种光学字符识别技术,它能够将图像中的文字转换成可编辑的文本。
OCR识别原理主要是通过图像处理和模式识别技术来实现的,下面我们将详细介绍OCR的识别原理。
首先,OCR识别原理的第一步是图像预处理。
在这一步中,图像会经过一系列的处理,包括灰度化、二值化、去噪等操作,以便于后续的文字识别。
灰度化是将彩色图像转换为灰度图像,这样可以减少处理的复杂度;而二值化则是将灰度图像转换为黑白图像,以便于文字的分割和识别;去噪操作则是为了去除图像中的杂色和噪声,使得文字更加清晰。
其次,OCR识别原理的第二步是文字分割。
在这一步中,图像中的文字会被分割成单个的字符或单词。
文字分割是OCR识别的关键步骤之一,它需要通过一系列的算法和模型来实现,包括边缘检测、连通域分析、投影法等。
通过文字分割,可以将图像中的文字从背景中分离出来,为后续的文字识别提供准备。
接着,OCR识别原理的第三步是特征提取。
在这一步中,文字的特征会被提取出来,以便于后续的模式识别。
文字的特征包括大小、形状、笔画等,通过对这些特征的提取和描述,可以将文字转换成计算机可识别的数据,为后续的文字识别和匹配提供支持。
最后,OCR识别原理的最后一步是模式识别。
在这一步中,计算机会通过比对文字的特征和已知的字符模式来识别文字。
模式识别是OCR识别的核心步骤,它需要依靠大量的样本数据和训练模型来实现。
通过模式识别,计算机可以将图像中的文字转换成可编辑的文本,实现文字的识别和提取。
综上所述,OCR识别原理主要包括图像预处理、文字分割、特征提取和模式识别四个步骤。
通过这些步骤的处理和分析,OCR技术可以实现图像中文字的准确识别和转换,为人们的生活和工作带来便利。
希望本文的介绍可以帮助大家更好地了解OCR识别原理,进一步应用和发展这一技术。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
前几天晚上去朋友上班的地方等他一起下班,等了好久都不见他下来,问他怎么了?原来是工作上遇到不会的任务了。
不知道识别图片文字怎样操作?我也是对他佩服的五体投地,还在一点一点的研究怎样操作呢!就不会问问有没有人会操作的嘛!看来还是由我出马吧!今天特意总结识别图片文字的具体操作分享给大家,希望大家不要像我朋友一样遇到这样的工作任务而手足无措吧!
步骤一:在我们工作的时候,电脑是很少关闭的,所以我们只需要打开我们需要借助的工具就可以了。
如果大家的电脑上没有这样的工具的话,可以在百度里搜索迅捷OCR文字识别软件并下载安装到我们的电脑里。
步骤二:在识别图片文字的工具中,我们需要在左侧的功能栏中选择我们需要的功能,不错,今天我们需要用到的就是OCR文字识别功能,在OCR文字识别的功能中我们还需要选择一下具体的一个操作功能。
如“单张快速识别”功能。
步骤三:进入到单张快速识别的页面中,我们就可以对该功能添加图片。
即点击“上传图片”就可以了。
步骤四:将我们需要的图片文件添加成功后,还要对导出格式进行修改一下的,因为有的时候是需要TXT格式的。
而有的时候我们是需要word格式的。
步骤五:导出格式修改后,有的时候我们是还需要对导出目录进行更改一下的。
因为可能我们电脑上的某盘东西存满了,所以需要保存到别的盘里。
步骤六:最后,我们只需要点击一下“开始识别”就搞定啦!
是不是很简单的?大家有没有想要操作一下的冲动呢?没事的小伙伴可以试着学学哟,说不定在工作中就可以用的到了。