词法分析程序实验报告
编译技术实验报告词法(3篇)

第1篇一、实验目的本次实验旨在通过实践加深对编译技术中词法分析阶段的理解,掌握词法分析的基本原理和方法,能够实现一个简单的词法分析器,并对源代码进行初步的符号化处理。
二、实验环境1. 操作系统:Windows 102. 编程语言:Java3. 开发工具:Eclipse IDE4. 实验素材:实验提供的C语言源代码三、实验原理词法分析是编译过程中的第一个阶段,其主要任务是将源代码中的字符序列转换成一系列的词法单元(Token)。
词法单元是构成源程序的基本单位,如标识符、关键字、运算符等。
词法分析的基本原理如下:1. 字符流:从源代码中逐个读取字符,形成字符流。
2. 状态转换:根据字符流中的字符,在有限状态自动机(FSM)中转换状态。
3. 词法单元生成:当状态转换完成后,生成对应的词法单元。
4. 错误处理:在分析过程中,如果遇到无法识别的字符或状态,进行错误处理。
四、实验步骤1. 设计词法分析器:根据C语言的语法规则,设计有限状态自动机,定义状态转换图。
2. 实现状态转换函数:根据状态转换图,实现状态转换函数,用于将字符流转换为词法单元。
3. 实现词法单元生成函数:根据状态转换结果,生成对应的词法单元。
4. 测试词法分析器:使用实验提供的C语言源代码,测试词法分析器的正确性。
五、实验结果与分析1. 词法分析器设计:根据C语言的语法规则,设计了一个包含26个状态的状态转换图。
状态转换图包括以下状态:- 初始状态:用于开始分析。
- 标识符状态:用于分析标识符。
- 关键字状态:用于分析关键字。
- 运算符状态:用于分析运算符。
- 数字状态:用于分析数字。
- 字符串状态:用于分析字符串。
- 错误状态:用于处理非法字符。
2. 状态转换函数实现:根据状态转换图,实现了状态转换函数。
该函数用于将字符流转换为词法单元。
3. 词法单元生成函数实现:根据状态转换结果,实现了词法单元生成函数。
该函数用于生成对应的词法单元。
词法分析程序实验报告

词法分析程序实验报告篇一:词法分析器_实验报告词法分析器实验报告实验目的:设计、编制、调试一个词法分析子程序-识别单词,加深对词法分析原理的理解。
实验要求:该程序要实现的是一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分界符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(一)实验内容(1)功能描述:对给定的程序通过词法分析器弄够识别一个个单词符号,并以二元式(单词种别码,单词符号的属性值)显示。
而本程序则是通过对给定路径的文件的分析后以单词符号和文字提示显示。
(2)程序结构描述:函数调用格式:参数含义:String string;存放读入的字符串 String str; 存放暂时读入的字符串 char ch; 存放读入的字符 int rs 判断读入的文件是否为空 char []data 存放文件中的数据 int m;通过switch用来判断字符类型,函数之间的调用关系图:函数功能:Judgement()判断输入的字符并输出单词符号,返回值为空; getChar() 读取文件的,返回值为空;isLetter(char c) 判断读入的字符是否为字母的,返回值为Boolean类型; switch (m) 判断跳转输出返回值为空;isOperator(char c)判断是否为运算符的,返回值为Boolean类型; isKey(String string)判断是否为关键字的,返回值为Boolean类型; isDigit(char c) 判断读入的字符是否为数字的,返回值为Boolean类型。
(二)实验过程记录:本次实验出错3次,第一次无法输出双运算符,于是采用双重if条件句进行判断,此方法失败,出现了重复输出,继续修改if语句,仍没有成功。
然后就采用了直接方法调用解决此问题。
对于变量的判断,开始忘了考虑字母和数字组成的变量,结果让字母和数字分家了,不过改变if语句的条件,解决了此问题。
编译原理实验词法分析实验报告

编译原理实验词法分析实验报告一、实验目的词法分析是编译过程的第一个阶段,其主要任务是从左到右逐个字符地对源程序进行扫描,产生一个个单词符号。
本次实验的目的在于通过实践,深入理解词法分析的原理和方法,掌握如何使用程序设计语言实现词法分析器,提高对编译原理的综合应用能力。
二、实验环境本次实验使用的编程语言为_____,开发工具为_____。
三、实验原理词法分析的基本原理是根据编程语言的词法规则,将输入的字符流转换为单词符号序列。
单词符号通常包括关键字、标识符、常量、运算符和界符等。
词法分析器的实现方法有多种,常见的有状态转换图法和正则表达式法。
在本次实验中,我们采用了状态转换图法。
状态转换图是一种有向图,其中节点表示状态,有向边表示在当前状态下输入字符的可能转移。
通过定义不同的状态和转移规则,可以实现对各种单词符号的识别。
四、实验步骤1、定义单词符号的类别和编码首先,确定实验中要识别的单词符号种类,如关键字(if、else、while 等)、标识符、整数常量、浮点数常量、运算符(+、、、/等)和界符(括号、逗号等)。
为每个单词符号类别分配一个唯一的编码,以便后续处理。
2、设计状态转换图根据单词符号的词法规则,绘制状态转换图。
例如,对于标识符的识别,起始状态为“起始状态”,当输入为字母时进入“标识符中间状态”,在“标识符中间状态”中,若输入为字母或数字则继续保持该状态,直到遇到非字母数字字符时结束识别,确定为一个标识符。
3、编写词法分析程序根据状态转换图,使用所选编程语言实现词法分析器。
在程序中,通过不断读取输入字符,根据当前状态进行转移,并在适当的时候输出识别到的单词符号。
4、测试词法分析程序准备一组包含各种单词符号的测试用例。
将测试用例输入到词法分析程序中,检查输出的单词符号是否正确。
五、实验代码以下是本次实验中实现词法分析器的核心代码部分:```include <stdioh>include <ctypeh>//单词符号类别定义typedef enum {KEYWORD,IDENTIFIER,INTEGER_CONSTANT,FLOAT_CONSTANT,OPERATOR,DELIMITER} TokenType;//关键字列表char keywords ={"if","else","while","for","int","float","void"};//状态定义typedef enum {START,IN_IDENTIFIER,IN_INTEGER,IN_FLOAT,IN_OPERATOR} State;//词法分析函数TokenType getToken(char token, int tokenLength) {State state = START;int i = 0;while (1) {char c = getchar();switch (state) {case START:if (isalpha(c)){state = IN_IDENTIFIER;tokeni++= c;} else if (isdigit(c)){state = IN_INTEGER;tokeni++= c;} else if (c =='+'|| c ==''|| c ==''|| c =='/'|| c =='('|| c ==')'|| c ==';'|| c ==','){state = IN_OPERATOR;tokeni++= c;} else if (c ==''){state = IN_FLOAT;tokeni++= c;} else if (c == EOF) {tokeni ='\0';tokenLength = i;return -1;} else {tokeni ='\0';tokenLength = i;return -2;}break;case IN_IDENTIFIER:if (isalpha(c) || isdigit(c)){tokeni++= c;} else {ungetc(c, stdin);tokeni ='\0';tokenLength = i;//检查是否为关键字for (int j = 0; j < sizeof(keywords) / sizeof(keywords0); j++){if (strcmp(token, keywordsj) == 0) {return KEYWORD;}}return IDENTIFIER;}break;case IN_INTEGER:if (isdigit(c)){tokeni++= c;} else if (c ==''){state = IN_FLOAT;tokeni++= c;} else {ungetc(c, stdin);tokeni ='\0';tokenLength = i;return INTEGER_CONSTANT;}break;case IN_FLOAT:if (isdigit(c)){tokeni++= c;} else {ungetc(c, stdin);tokeni ='\0';tokenLength = i;return FLOAT_CONSTANT;}break;case IN_OPERATOR: tokeni ='\0';tokenLength = i;return OPERATOR; break;}}}int main(){char token100;int tokenLength;TokenType tokenType;while ((tokenType = getToken(token, &tokenLength))!=-1) {switch (tokenType) {case KEYWORD:printf("Keyword: %s\n", token);break;case IDENTIFIER:printf("Identifier: %s\n", token);break;case INTEGER_CONSTANT:printf("Integer Constant: %s\n", token);break;case FLOAT_CONSTANT:printf("Float Constant: %s\n", token);break;case OPERATOR:printf("Operator: %s\n", token);break;case DELIMITER:printf("Delimiter: %s\n", token);break;}}return 0;}```六、实验结果对准备的测试用例进行输入,得到的词法分析结果如下:测试用例 1:```int main(){int num = 10;float pi = 314;if (num > 5) {printf("Hello, World!\n");}}```词法分析结果:```Keyword: int Identifier: main Delimiter: (Delimiter: ){Identifier: num Operator: =Integer Constant: 10;Identifier: float Identifier: pi Operator: =Float Constant: 314;Keyword: ifDelimiter: (Identifier: numOperator: >Integer Constant: 5){Identifier: printfDelimiter: (String: "Hello, World!\n" Delimiter: );}```测试用例 2:```for (int i = 0; i < 10; i++){double result = i 25;```词法分析结果:```Keyword: for Delimiter: (Keyword: int Identifier: i Operator: =Integer Constant: 0;Identifier: i Operator: <Integer Constant: 10;Identifier: i Operator: ++)Identifier: doubleIdentifier: resultOperator: =Identifier: iOperator:Float Constant: 25;}```通过对多个测试用例的分析,词法分析器能够正确识别出各种单词符号,实验结果符合预期。
词法分析实验报告代码

一、实验目的1. 理解词法分析的概念和作用。
2. 掌握词法分析器的设计和实现方法。
3. 通过实验加深对编译原理中词法分析阶段的理解。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 开发工具:PyCharm三、实验内容1. 设计一个简单的词法分析器,能够识别并输出源代码中的单词。
2. 实现词法分析器的关键功能,包括:- 字符串预处理- 单词识别- 生成词法分析表四、实验步骤1. 字符串预处理- 读取源代码字符串。
- 移除字符串中的空白字符(空格、制表符、换行符等)。
- 转义字符串中的特殊字符。
2. 单词识别- 使用正则表达式匹配单词。
- 根据正则表达式匹配结果,将单词分类为关键字、标识符、常量等。
3. 生成词法分析表- 创建一个列表,用于存储词法分析表中的每个单词及其对应的类别。
- 遍历源代码字符串,将识别出的单词添加到词法分析表中。
五、实验代码```pythonimport re# 定义词法分析表结构class Token:def __init__(self, type, value):self.type = typeself.value = value# 单词识别函数def tokenize(source_code):# 移除空白字符source_code = re.sub(r'\s+', '', source_code)# 转义特殊字符source_code = re.sub(r'\\', '\\\\', source_code)# 使用正则表达式匹配单词tokens = re.findall(r'\b\w+\b', source_code)# 生成词法分析表token_table = []for token in tokens:if re.match(r'\bint\b', token):token_table.append(Token('KEYWORD', token))elif re.match(r'\bfloat\b', token):token_table.append(Token('KEYWORD', token))elif re.match(r'\bchar\b', token):token_table.append(Token('KEYWORD', token))elif re.match(r'\bif\b', token):token_table.append(Token('KEYWORD', token))elif re.match(r'\belse\b', token):token_table.append(Token('KEYWORD', token))elif re.match(r'\breturn\b', token):token_table.append(Token('KEYWORD', token))elif re.match(r'\b\w+\b', token):token_table.append(Token('IDENTIFIER', token)) else:token_table.append(Token('CONSTANT', token)) return token_table# 主函数def main():# 读取源代码source_code = '''int main() {int a = 10;float b = 3.14;char c = 'A';if (a > b) {return a;} else {return b;}}'''# 进行词法分析token_table = tokenize(source_code)# 输出词法分析结果for token in token_table:print(f'Type: {token.type}, Value: {token.value}') if __name__ == '__main__':main()```六、实验结果运行实验代码后,输出如下:```Type: KEYWORD, Value: intType: IDENTIFIER, Value: mainType: KEYWORD, Value: (Type: KEYWORD, Value: )Type: KEYWORD, Value: intType: IDENTIFIER, Value: a Type: KEYWORD, Value: = Type: CONSTANT, Value: 10 Type: KEYWORD, Value: ; Type: KEYWORD, Value: float Type: IDENTIFIER, Value: b Type: KEYWORD, Value: = Type: CONSTANT, Value: 3.14 Type: KEYWORD, Value: ; Type: KEYWORD, Value: char Type: IDENTIFIER, Value: c Type: KEYWORD, Value: = Type: CONSTANT, Value: A Type: KEYWORD, Value: ; Type: KEYWORD, Value: if Type: IDENTIFIER, Value: ( Type: IDENTIFIER, Value: a Type: KEYWORD, Value: > Type: IDENTIFIER, Value: b Type: KEYWORD, Value: ) Type: KEYWORD, Value: { Type: KEYWORD, Value: return Type: IDENTIFIER, Value: aType: KEYWORD, Value: ;Type: KEYWORD, Value: }Type: KEYWORD, Value: elseType: KEYWORD, Value: {Type: KEYWORD, Value: returnType: IDENTIFIER, Value: bType: KEYWORD, Value: ;Type: KEYWORD, Value: }```七、实验总结通过本次实验,我们成功地设计并实现了一个简单的词法分析器,能够识别并输出源代码中的单词。
实验一词法分析实验报告1

实验一词法分析一、实验目的通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。
并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单词的内部编码与单词符号自身值。
(遇到错误时可显示“Error”,然后跳过错误部分继续显示)二、实验要求使用一符一种的分法关键字、运算符和分界符可以每一个均为一种标识符和常数仍然一类一种三、实验内容功能描述:1、待分析的简单语言的词法(1)关键字:begin if then while do end(2)运算符和界符:(3)其他单词是标识符(ID)和整型常数(NUM),通过以下正规式定义:ID=letter(letter| digit)*NUM=digit digit *(4)空格由空白、制表符和换行符组成。
空格一般用来分隔ID、NUM,运算符、界符和关键字,词法分析阶段通常被忽略。
2、各种单词符号对应的种别码图 1程序结构描述:符号界符等符号四、实验结果输入begin x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如下序列:(begin 1)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图3所示:图3输入private x:=9;if x>0 then x:=2*x+1/3; end#后经词法分析输出如下序列:(private 10)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图4所示:图4显然,private是关键字,却被识别成了标示符,这是因为图1中没有定义private关键字的种别码,所以把private当成了标示符。
输入private x:=9;if x>0 then x:=2*x+1/3; @ end#后经词法分析输出如下序列:(private 10)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图5所示图5显然,@没有在图一中定义种别,所以输出了“Error in row 1!”的报错信息。
词法分析实验报告

词法分析实验报告一、实验目的和背景词法分析是编译原理中的重要部分之一,其主要作用是将源程序中的字符序列转化为有意义的单词序列,以便于后续的处理和分析。
为了更好地理解词法分析的实现原理以及掌握相关算法和工具,本次词法分析实验旨在通过手动编写正则表达式、确定有限自动机的状态转移函数和实现词法分析程序来实现词法分析。
二、实验内容在本次实验中,我们需要完成以下任务:1.手动编写正则表达式;2.确定有限自动机的状态转移函数;3.实现词法分析程序。
三、实验过程1.手动编写正则表达式对于给定的源程序,我们首先需要根据其语法规则手动编写正则表达式。
例如,对于一个简单的算术表达式,其正则表达式可以如下所示:i. 数字(0-9):[0-9]+ii. 加号(+):\+iii. 减号(-):-iv. 乘号(*):\*v. 除号(/):/vi. 左括号(():\(vii. 右括号()):\)2.确定有限自动机的状态转移函数根据正则表达式,我们可以确定有限自动机的状态转移函数。
例如,对于上述算术表达式的正则表达式,其有限自动机的状态转移函数如下所示:i. 初始状态(S):判断下一个字符,如果是数字则进入数字状态,如果是左括号则进入左括号状态;ii. 数字状态(D):继续判断下一个字符,如果是数字则保持在数字状态,如果是运算符则输出数字记号,返回初始状态,如果是右括号则输出数字记号,返回初始状态;iii. 左括号状态(L):输出左括号记号,返回初始状态;iv. 右括号状态(R):输出右括号记号,返回初始状态。
3.实现词法分析程序根据以上的正则表达式和有限自动机的状态转移函数,我们可以编写一个简单的词法分析程序。
该程序的主要流程如下所示:i. 读取源程序的字符序列;ii. 根据有限自动机的状态转移函数,逐个字符进行状态转移;iii. 如果当前状态为接受状态,则输出相应的记号;iv. 继续进行状态转移,直至读取完整个源程序。
四、实验结果通过以上步骤,我们成功完成了对给定源程序的词法分析。
(完整word版)编译原理词法分析程序实现实验报告
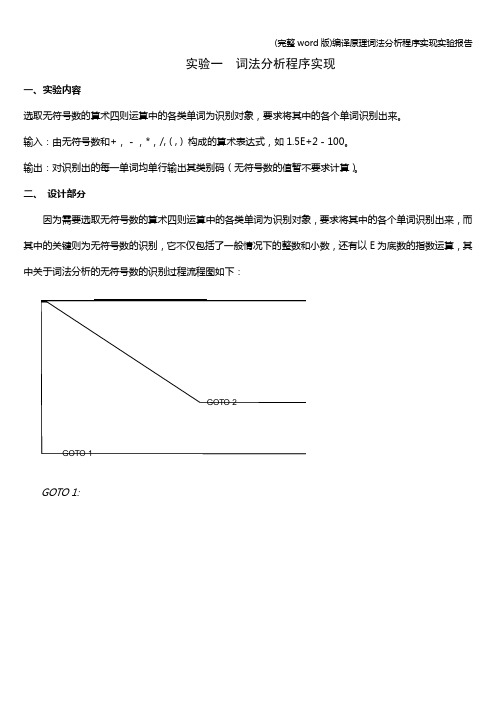
(完整word版)编译原理词法分析程序实现实验报告实验一词法分析程序实现一、实验内容选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来。
输入:由无符号数和+,-,*,/, ( , ) 构成的算术表达式,如1.5E+2-100。
输出:对识别出的每一单词均单行输出其类别码(无符号数的值暂不要求计算)。
二、设计部分因为需要选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来,而其中的关键则为无符号数的识别,它不仅包括了一般情况下的整数和小数,还有以E为底数的指数运算,其中关于词法分析的无符号数的识别过程流程图如下:GOTO 1:(完整word版)编译原理词法分析程序实现实验报告GOTO 2:三、源程序代码部分#include <stdio.h>#include<stdlib.h>#include <math.h>#define MAX 100#define UNSIGNEDNUMBER 1#define PLUS 2#define SUBTRACT 3#define MULTIPLY 4#define DIVIDE 5#define LEFTBRACKET 6#define RIGHTBRACKET 7#define INEFFICACIOUSLABEL 8#define FINISH 111int count=0;int Class;void StoreType();int Type[100];char Store[20]={'\0'};void ShowStrFile();//已经将要识别的字符串存在文件a中void Output(int a,char *p1,char *p2);//字符的输出过程int Sign(char *p);//'+''-''*''/'整体识别过程int UnsignedNum(char *p);//是否适合合法的正整数0~9int LegalCharacter(char *p);//是否是合法的字符:Sign(p)||UnsignedNum(p)||'E'||'.' void DistinguishSign(char *p);//'+''-''*''/'具体识别过程void TypyDistinguish();//字符的识别过程void ShowType();//将类别码存储在Type[100]中,为语法分析做准备void ShowStrFile()//已经将要识别的字符串存在文件a中{FILE *fp_s;char ch;if((fp_s=fopen("a.txt","r"))==NULL){printf("The FILE cannot open!");exit(0);}elsech=fgetc(fp_s);while(ch!=EOF){putchar(ch);ch=fgetc(fp_s);}printf("\n");}void StoreStr()//将文件中的字符串存储到数组Store[i] {FILE *fp=fopen("a.txt","r");char str;int i=0;while(!feof(fp)){fscanf(fp,"%c",&str);if(str=='?'){Store[i]='\0';break;}Store[i]=str;i++;}Store[i]='\0';}void ShowStore(){int i;for (i=0;Store[i]!='\0';i++)printf("%c",Store[i]);printf("\n");}void Output(int a,char *p1,char *p2){printf("%3s\t%d\t%s\t","CLASS",a,"VALUE");while(p1<=p2){printf("%c",*p1);p1++;}printf("\n");}int Sign(char *p){char ch=*p;if(ch=='+'||ch=='-'||ch=='*'||ch=='/'||ch=='('||ch==')') return 1;elsereturn 0;}int UnsignedNum(char *p){char ch=*p;if('0'<=ch&&ch<='9')return 1;elsereturn 0;}int LegalCharacter(char *p){char ch=*p;if(Sign(p)||UnsignedNum(p)||ch=='E'||ch=='.')。
词法分析报告

编译原理实验报告实验一词法分析程序的设计与实现指导教师:姓名:学号:班级:一、实验目的基本掌握计算机语言的词法分析程序的开发方法。
二、实验内容编制一个能够分析三种整数、标识符、主要运算符和主要关键字的词法分析程序。
三、实验要求1.根据以下的正规式,编制正规文法,画出状态图;标识符<字母>(<字母>|<数字字符>)*十进制整数0 | (1|2|3|4|5|6|7|8|9) (0|1|2|3|4|5|6|7|8|9)*八进制整数0 (0|1|2|3|4|5|6|7) (0|1|2|3|4|5|6|7)*十六进制整数0 (x|X) (0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f) (0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)*运算符和分隔符+ - * / > < = ( ) ;关键字if then else while do2.根据状态图,设计词法分析函数int scan( ),完成以下功能:(1)从输入流(键盘或文件)读入数据,分析出一个单词。
(2)返回单词种别(用整数表示),(3)返回单词属性(不同的属性可以放在不同的全局变量中)。
3.编写测试程序,循环调用函数scan( ),每次调用,获得一个单词的信息。
在测试程序中,打印输出单词种别、属性(注意:不要在词法分析函数scan 中打印输出!)。
四、实验环境微型计算机。
Windows 操作系统/Linux 操作系统。
编程语言:C/C++/Java/C#。
建议使用Visual C++/Netbeans/Eclipse 集成开发环境。
五、实验步骤1. 根据状态图,设计词法分析算法2. 设计函数scan( ),实现该算法3. 编制测试程序(在本试验中,可以是主函数main( ) )。
4. 调试程序:输入一组单词,检查输出结果。
六、状态图七. 测试数据:0 92+data> 0x3f00 while八.测试结果九,思考题1.词法分析能否采用空格来区分单词?答:不能,因为比如abc+bcd中没有空格,但这是三个单词。
词法分析实验报告文献

一、实验目的1. 深入理解词法分析的基本原理和过程。
2. 掌握词法分析器的设计与实现方法。
3. 熟悉C语言编程,并能够将其应用于词法分析程序的开发。
4. 培养问题分析和解决能力,提高编程技能。
二、实验原理词法分析是编译过程中的第一步,其主要任务是将源程序中的字符序列转换为一系列具有独立意义的单词符号(Token)。
词法分析器通过识别单词的构词规则,将源程序分解为一个个单词符号,为后续的语法分析和语义分析提供基础。
三、实验内容1. 词法分析器的设计本实验采用C语言实现一个简单的词法分析器,主要功能如下:- 识别并分类单词符号,包括关键字、标识符、常量、运算符和界符等。
- 对输入的源程序进行词法分析,输出每个单词符号及其对应的种别码。
- 处理词法错误,并给出错误提示。
2. 词法分析器的实现(1)数据结构- 关键字表:存储C语言中的关键字。
- 标识符表:存储用户自定义的标识符。
- 常量表:存储整型常量。
- 运算符表:存储C语言中的运算符。
- 界符表:存储C语言中的界符。
(2)主要函数- `isLetter(char c)`:判断字符是否为字母。
- `isDigit(char c)`:判断字符是否为数字。
- `alpha(char c)`:识别字母。
- `number(char c)`:识别整数。
- `anotation(char c)`:处理除号、注释以及其他特殊字符。
- `other(char c)`:处理其他字符。
(3)词法分析过程- 读取源程序中的字符。
- 根据字符类型调用相应的函数进行识别。
- 将识别出的单词符号及其种别码存储在相应的表中。
四、实验步骤1. 编写源程序,实现词法分析器。
2. 编写测试用例,对词法分析器进行测试。
3. 分析测试结果,验证词法分析器的正确性。
五、实验结果与分析1. 测试用例- 测试用例1:包含关键字、标识符、常量、运算符和界符的简单C程序。
- 测试用例2:包含错误标识符和运算符的C程序。
编译原理实验词法分析实验报告

编译技术实验报告实验题目:词法分析学院:信息学院专业:计算机科学与技术学号:姓名:一、实验目的(1)理解词法分析的功能;(2)理解词法分析的实现方法;二、实验内容PL0的文法如下‘< >’为非终结符。
‘::=’ 该符号的左部由右部定义,可读作“定义为”。
‘|’ 表示‘或’,为左部可由多个右部定义。
‘{ }’ 表示花括号内的语法成分可以重复。
在不加上下界时可重复0到任意次数,有上下界时可重复次数的限制。
‘[ ]’ 表示方括号内的成分为任选项。
‘( )’ 表示圆括号内的成分优先。
上述符号为“元符号”,文法用上述符号作为文法符号时需要用引号‘’括起。
〈程序〉∷=〈分程序〉.〈分程序〉∷= [〈变量说明部分〉][〈过程说明部分〉]〈语句〉〈变量说明部分〉∷=VAR〈标识符〉{,〈标识符〉}:INTEGER;〈无符号整数〉∷=〈数字〉{〈数字〉}〈标识符〉∷=〈字母〉{〈字母〉|〈数字〉}〈过程说明部分〉∷=〈过程首部〉〈分程序〉{;〈过程说明部分〉};〈过程首部〉∷=PROCEDURE〈标识符〉;〈语句〉∷=〈赋值语句〉|〈条件语句〉|〈过程调用语句〉|〈读语句〉|〈写语句〉|〈复合语句〉|〈空〉〈赋值语句〉∷=〈标识符〉∶=〈表达式〉〈复合语句〉∷=BEGIN〈语句〉{;〈语句〉}END〈条件〉∷=〈表达式〉〈关系运算符〉〈表达式〉〈表达式〉∷=〈项〉{〈加法运算符〉〈项〉}〈项〉∷=〈因子〉{〈乘法运算符〉〈因子〉}〈因子〉∷=〈标识符〉|〈无符号整数〉|'('〈表达式〉')'〈加法运算符〉∷=+|-〈乘法运算符〉∷=*〈关系运算符〉∷=<>|=|<|<=|>|>=〈条件语句〉∷=IF〈条件〉THEN〈语句〉〈字母〉∷=a|b|…|X|Y|Z〈数字〉∷=0|1|2|…|8|9实现PL0的词法分析三、实验分析与设计PL0词法分析程序是一个独立的过程,其功能是为语法语义分析提供单词,把输入的字符串形式的源程序分割成一个个单词符号传递给语法语义分析。
2021年编译原理实验报告词法分析程序的设计

试验2 词法分析程序设计一、试验目掌握计算机语言词法分析程序开发方法。
二、试验内容编制一个能够分析三种整数、标识符、关键运算符和关键关键字词法分析程序。
三、试验要求1、依据以下正规式, 编制正规文法, 画出状态图;标识符<字母>(<字母>|<数字字符>)*十进制整数0 | ((1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)*)八进制整数0(1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)*十六进制整数0x(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)*运算符和界符+ - * / > < = ( ) ;关键字if then else while do2、依据状态图, 设计词法分析函数int scan( ), 完成以下功效:1)从文本文件中读入测试源代码, 依据状态转换图, 分析出一个单词,2)以二元式形式输出单词<单词种类, 单词属性>其中单词种类用整数表示:0: 标识符1: 十进制整数2: 八进制整数3: 十六进制整数运算符和界符, 关键字采取一字一符, 不编码其中单词属性表示以下:标识符, 整数因为采取一类一符, 属性用单词表示运算符和界符, 关键字采取一字一符, 属性为空3、编写测试程序, 反复调用函数scan( ), 输出单词种别和属性。
四、试验环境PC微机DOS操作系统或Windows 操作系统Turbo C 程序集成环境或Visual C++ 程序集成环境五、试验步骤1、依据正规式, 画出状态转换图;2、依据状态图, 设计词法分析算法;观察状态图, 其中状态2、4、7、10(右上角打了星号)需要回调一个字符。
申明部分变量和函数:ch: 字符变量, 存放最新读进源程序字符。
strToken: 字符串变量, 存放组成单词符号字符串。
词法分析程序实验报告

词法分析程序实验报告词法分析程序实验报告一、实验目的1. 理解词法分析器的基本功能2. 理解词法规则的描述方法3. 理解状态转换图及其实现4. 能够编写简单的词法分析器二、实验要求给出单词序列对应的状态识别。
单词符号State 对应的值单词符号State 对应的值function 1 = 18if 2 < 20else 3 <= 21for 4 != 22then 5 > 23while 6 >= 24do 7 == 25 endfunction 8 ; 26letter(letter|digit)* 10 ( 27digit digit* 11 ) 28+ 13 { 29- 14 } 30* 15 # 0/ 162、主程序流程图N程序开始初始化输入源程序调用scanner()函数,识别单词序列输出单词序列Y结束输入串结束?三、识别单词的状态转换图Scanner()函数流程图变量初始化忽略空格和换行num 读取常数state=11Token[]读入关键字、标识符关键字?判断关键字 statestate=10判断运算符和分界符 state 其余符号 state=-1 ReturnNY{)(;其他其他===其他!其他</* - + 非数字数字数字开始空格或换行字母0 1返回’10’或关键字234 返回’11’567 8返回’13’ 返回’14’ 返回’15’ 返回’16’ 910111213 14 1516171819 20 >=222425返回’20’返回’21’返回’-1’返回’22’ 返回’23’ 返回’24’返回’18’返回’25’ 返回’26’ 返回’27’ 返回’28’ 返回’29’} #2. 分析直接转向法和表驱动法的优缺点状态转换图的实现通常有两种方法:状态转换表和直接转向法(1) :状态转换表法又称数据中心,是把状态转换图看作一种数据结构,由控制程序控制字符在其上运行,从而完成词法分析。
实现词法分析实验报告

实现词法分析实验报告一、实验目的本次实验的目的是通过编写代码实现一个简单的词法分析器,可以对一段输入的代码进行词法分析,识别出其中的各种标识符、关键字、常数和运算符等。
二、实验原理词法分析是编译过程中的第一个阶段,它负责将源代码按照规定的规则划分为一个个的单词(Token),每个单词代表一个最基本的语法单元。
在词法分析中,我们通过预先定义好的正则表达式规则来描述各个单词类型,并自动从源代码中提取出这些单词。
本次实验采用基于正则表达式的文法描述方式,针对不同的单词类型,使用不同的正则表达式来匹配。
通过遍历源代码字符串,逐一尝试匹配各个正则表达式,从而实现对单词的划分。
在匹配过程中,我们使用一个状态机来记录当前的匹配状态,以便处理不同的情况。
三、实验过程1. 定义Token的数据结构,包括单词类型和单词值两个字段。
使用枚举类型来表示所有的单词类型,如关键字、标识符、常数等。
2. 编写正则表达式的匹配函数,用于判断给定的字符串是否符合某个模式。
在这个函数中,使用系统提供的正则表达式库或者手动实现正则表达式匹配算法。
3. 设计一个状态机,用于记录当前匹配的状态。
状态机的状态包括开始、正在匹配、匹配成功和匹配失败等。
在状态机中,根据当前字符和当前状态进行不同的处理。
4. 在状态机中,当一个完整的Token被匹配出时,根据其类型和值创建一个Token对象,并将其添加到Token列表中。
5. 将源代码字符串按照换行符划分成多行,逐行进行处理。
对于每一行,调用状态机进行匹配,将得到的Token添加到Token列表中。
6. 输出Token列表,观察结果。
四、实验结果经过实验,我们成功实现了一个简单的词法分析器。
通过对输入的代码进行词法分析,我们可以得到每个单词的类型和值。
在本次实验中,我们测试了一段C语言代码,并成功提取出其中的关键字、标识符、常数和运算符等。
五、实验总结本次实验让我初步了解了词法分析的原理和过程。
词法分析实验报告心得(3篇)

第1篇一、实验背景词法分析是编译原理中的一项基本任务,它将源程序中的字符序列转换成一系列具有独立意义的记号(Token)。
本次实验旨在通过词法分析实验,加深对词法分析过程的理解,掌握词法分析器的实现方法,并提高编程能力。
二、实验目的1. 理解词法分析的基本概念和过程。
2. 掌握词法分析器的实现方法。
3. 提高编程能力,为后续编译原理的学习打下基础。
三、实验内容本次实验采用Java语言编写词法分析器,实现了对C语言源程序的词法分析功能。
具体实验内容包括:1. 定义词法分析器类,包含状态转移表、符号表等数据结构。
2. 设计状态转移函数,实现字符序列到Token的转换。
3. 实现词法分析器的入口函数,接收源程序字符串,输出Token序列。
四、实验步骤1. 创建词法分析器类,定义状态转移表、符号表等数据结构。
2. 设计状态转移函数,根据输入字符和当前状态,输出下一个状态和对应的Token。
3. 实现词法分析器的入口函数,接收源程序字符串,初始化状态和位置指针,遍历源程序字符序列。
4. 在遍历过程中,根据状态转移函数输出Token,并更新状态和位置指针。
5. 当遇到输入字符串结束时,输出剩余的Token,并结束词法分析过程。
五、实验心得1. 词法分析是编译过程中的第一步,它将源程序中的字符序列转换成具有独立意义的Token,为后续的语法分析和语义分析提供基础。
2. 在实现词法分析器时,需要仔细分析源程序中的字符序列,确定状态转移表和符号表的内容。
这有助于提高词法分析器的准确性和效率。
3. 在编写状态转移函数时,要考虑各种可能的输入情况,确保能够正确处理各种字符序列。
同时,要注意状态转移函数的健壮性,避免出现错误。
4. 在实现词法分析器时,需要关注数据结构的组织方式。
合理的数据结构可以提高程序的可读性和可维护性。
5. 通过本次实验,我深刻体会到编程的乐趣和挑战。
在实现词法分析器过程中,我不断学习新的知识,提高了解决问题的能力。
词法分析器实验报告_5

一、实验目的1.1总体目的1.1.1 掌握词法分析的基本原理;1.1.2.理解词法分析在编译程序过程中的作用;1.1.3.熟悉关键字表等相关的数据结构与单词的分类方法.1.1.4.加深对编译原理的理解,掌握词法分析器的实现方法和技术,同时,将JA V A 的理论知识结合实际,锻炼编程技术,强调良好的程序设计风格。
1.2程序目的利用JAVA语言针对C语言编制一个一遍扫描的编译程序。
从文件中识别出各个单词, 识别出所取的单词的类型, 并且对代码中的词法错误进行提示。
二、实验内容根据编译原理中的词法分析原理, 利用Java语言针对C语言编写一个词法分析程序: 输入: 打开一个C语言程序的源代码文件, 将其读入程序输入框。
处理: 对输入框中的代码进行词法分析,分离出关键字、标识符、数值、运算符和界符。
输出:在词法分析结果表中输出每个单词所在行号、类型以及它所对应的编码。
其中, 编码是自定义的,一种类型对应一组编码。
词法分析结果显示在词法分析错误信息栏, 提示错误个数、错误所在行号, 并对某些词法错误原因进行说明。
三、实验需求针对C语言程序代码进行词法分析器, 从指定文件中读入预分析的源程序, 从左至右扫描源程序的字符串, 按照词法规则(正则文法规则)识别出一个个正确的单词, 并转换成该单词相应的二元式(种别码、属性值)以便之后进行语法分析使用。
同时, 按照给定的规则, 识别出单词符号作为输出, 发现其中的语法错误, 不同类别的字符通过相应的函数模块来分析识别, 使程序能够正确识别文法所规定的任何组织形式的字符组合, 将所有的分析状态显示在词法分析器中。
最后在错误分析栏中显示该文件中C语言代码的词法错误个数、错误所在行, 并对错误原因进行说明。
四、主要数据结构介绍4.1关键字编码4.2标识符统一编码1004.3数值统一编码2004.4界符编码4.5运算符编码4.6全局变量含义int row: 语法错误出现的所在列数int line: 语法错误出现的所在行数int err: 语法错误的个数int begin: 当前程序扫描在字符串中的开始位置int end: 当前程序扫描在字符串中的结束位置4.7局部变量定义int i: 选择第i 个字符进行检测 int state: 单词类型判断标志 int N: 文件长度char c: 当前遍历的字符 string str: 输入字符串 int flag: 退出标志五、主要模块算法介绍5.1总体流程介绍说明: state 为输入字符状态标志, 根据输入字符不同类型选择不同处理。
编译原理实验词法分析实验报告

编译原理实验词法分析实验报告一、实验目的词法分析是编译过程中的第一个阶段,其主要任务是从输入的源程序中识别出具有独立意义的单词符号,并将其转换为内部编码形式。
本次实验的目的是通过设计和实现一个简单的词法分析程序,深入理解词法分析的基本原理和方法,提高对编程语言语法结构的认识和编程能力。
二、实验原理词法分析的基本原理是根据编程语言的词法规则,使用有限自动机或正则表达式等技术来识别单词符号。
在本次实验中,我们采用了状态转换图的方法来设计词法分析器。
状态转换图是一种用于描述有限自动机的图形表示方法,它由状态节点和有向边组成。
每个状态节点表示自动机的一个状态,有向边表示状态之间的转换条件。
当输入字符与当前状态的转换条件匹配时,自动机将从当前状态转换到下一个状态。
当到达一个终态时,表示识别出了一个单词符号。
三、实验环境本次实验使用了 Python 编程语言,并在 PyCharm 集成开发环境中进行开发和调试。
四、实验内容1、定义单词符号的种类和编码关键字:如`if`、`else`、`while` 等标识符:由字母、数字和下划线组成,且以字母或下划线开头常数:包括整数和浮点数运算符:如`+`、``、``、`/`等分隔符:如`(){},;`等2、设计状态转换图根据单词符号的定义,设计了相应的状态转换图,用于识别不同类型的单词符号。
例如,对于标识符的识别,从起始状态开始,当输入字符为字母或下划线时,进入标识符状态,继续输入字母、数字或下划线,直到遇到非标识符字符为止,此时到达终态,识别出一个标识符。
3、实现词法分析程序使用 Python 语言实现了基于状态转换图的词法分析程序。
程序首先读取输入的源程序文本,然后逐个字符进行处理,根据当前状态和输入字符进行状态转换,当到达终态时,输出识别出的单词符号及其编码。
4、进行测试编写了一些测试用例,包括包含各种单词符号的源程序代码。
运行词法分析程序对测试用例进行分析,检查输出结果是否正确。
编译原理词法分析程序设计实验报告

编译原理词法分析程序设计实验报告【实验目的】1.了解词法分析的主要任务。
2.熟悉编译程序的编制。
【实验内容】根据某文法,构造一基本词法分析程序。
找出该语言的关键字、标识符、整数以及其他一些特殊符号,给出单词的种类和值。
【实验要求】1.构造一个小语言的文法类C小语言文法(以EBNF表示)<程序>::=<分程序>{<分程序>} .<分程序>::=<标识符>’(’<变量说明部分>{,<变量说明部分>}’)’<函数体><变量说明部分>::=int<标识符>{,<标识符>}<函数体>::=’{’[<变量说明部分>;]<语句序列>’}’<语句序列>::=<语句序列>;<语句>|<语句><语句>::=<赋值语句>|<条件语句>|<循环语句>|<函数调用语句><赋值语句>::=<标识符>=<表达式><表达式>::=[+|-]<项>{<加法运算符><项>}<项>::=<因子>{<乘法运算符><因子>}<因子>:=<标识符>|<无符号整数><加法运算符>::= +|-<乘法运算符>::= *|/<条件语句>::=if<条件>’{’<语句序列>’}’[else’{’<语句序列>’}’]<条件>::=<表达式><关系运算符><表达式><关系运算符>::= ==|!=|>|<|>=|<=<循环语句>::=for’(’<表达式>;<条件>;<表达式>’)’ ’{’<语句序列>’}’<函数调用语句>::=<标识符>’(’<标识符>{,<标识符>}|<空>’)’<标识符>::=<字母>{<字母>|<数字>}<无符号整数>::=<数字>{<数字>}<字母>::=a|b|c|…|X|Y|Z<数字>::=0|1|2|…|8|9单词分类情况关键字:int if else for标识符:以字母开头的字母和数字的组合关系运算符:==|!=|>|<|>=|<=加法运算符:+|-乘法运算符:*|/界符:,;{ } ( )2.设计单词的输出形式,单词的种类和值的表示方法种别码单词值如:1 int3.编写词法分析程序cffx.c实现基本的词法分析器,能够分析关键字、标识符、数字、运算符(需要有“==”或“:=”之类需要超前搜索的运算符)以及其他一些符号。
词法分析程序实验报告

词法分析程序实验报告词法分析程序实验报告班级:2013211306 学号:2013211321 姓名:严浩⼀)实验⽬的:(1)掌握词法分析程序的实现⽅法和技术:利⽤c语⾔描述了⼀个词法分析器,旨在对于词法分析的过程站在计算机的⾓度进⾏了解与体会。
(2)加深对有限⾃动机模型的理解:语法分析的过程就是⼀个对所碰到的单词符号进⾏⾃动机模拟的过程,碰到⼀个⾃⼰需要的字符就进⾏状态转换,并最终到达终⽌状态,即完成了⼀个运⽤源语⾔进⾏分析的过程。
(3)理解词法分析在编译程序中的作⽤:其主要任务是从左到右逐个字符的对源程序进⾏扫描,按照源语⾔的语法规则识别出⼀个个的单词符号,把识别出来的单词符号存⼊符号表中,并产⽣⽤于词法分析的记号序列。
(4)⽤c语⾔对⼀个简单语⾔的⼦集编制⼀个⼀遍扫描的编译程序,以加深对编译原理的理解,掌握编译程序的实现⽅法和技术。
⼆)实验环境Windows8.1 Cfree三)实验总结:1.⼀开始想⽤数组来存储每⼀⾏的字符串,后来发现极其不⽅便,尤其是当你要连接两段字符串的时候,所以后来改成了⽤链表来存储每⼀⾏的字符串,但每个单词还是⽤字符数组来存。
2.忘记了在扫描完⼀个单词后,指针要回退,否则会漏读字符,所以后来有加上了retract()函数。
3.⼀开始把运算符也当做单词,后来发现后,⽤总单词数减去运算符以及标点数才得到正确的单词数。
4.书上的伪代码不完整,只对⼀部分运算符进⾏了处理,像‘&’‘|’‘“’等都没有处理,还需要⾃⼰补充。
四)源代码:#include#include#include#include#define lensizeof(struct Node)struct Node{char data;struct Node *nextp;};struct Node *head,*p;//头指针和操作⽤的指针char token[255];//字符数组,存放读取的字符串intnum = 0;//⾮字符串单词数char * key[] = {"auto","double","int","struct","break","else","long", "switch","case","enum","register","typedef","char", "extern","return","union","const","float","short","unsigned", "continue","for","signed","void","default","goto", "sizeof","volatile","do","if","while","static" };//关键字查询表void get_char(){//读取字符C = p -> data;p = p ->nextp;}void get_nbc(){//.⼀直扫描,直到⾮空while(C == ' '){get_char();}}void concat(){// 将字符连接size_t i;i = strlen(token);token[i] = C;token[i + 1] = '\0';}int letter(char ch){//判断是否为字符returnisalpha((int) ch);}int digit(char ch){//判断是否为数字returnisdigit((int) ch);}void retract(){//指针回退struct Node *l;l = head ->nextp;while(l ->nextp != p){l = l ->nextp;}p = l;}for(keyjudge = 0; keyjudge<= 31 ; keyjudge ++){if(strcmp( key[keyjudge] , token) == 0){ returnkeyjudge;}}return 255;}//扫描缓冲区函数定义voidscaner(){int c;int j = 0;for( j = 0 ; j < 30 ; j ++){token[j] = '\0';}get_char();get_nbc();if(letter(C))//处理字符{while((letter(C)) || (digit(C)))//以字母开头的字母数字串{ concat(); //字符放⼊token数组中get_char(); //指针再往后读⼀个字符}retract(); //当出现除字母,数字外的字符时,指针回退c = reserve(); //字母数字串与保留字匹配if(c != 255)printf("(%s,-)\n",key[c]); //输出保留字记号else{printf("(%s,%d)\n",token, notkey);}}else if(digit(C)){while(digit(C))}retract();printf("(num,%d)\n",atoi(token)); }else{num ++;switch(C){case'+':get_char();if(C == '+')printf("(++,-)\n");else if(C == '=')printf("(+=,-)\n");else{retract();printf("(+,-)\n");}break;case'-':get_char();if(C == '-')printf("(--,-)\n");else if(C == '=')printf("(-=,-)\n");else if(C == '>')printf("(->,-)\n");else{retract();printf("(-,-)\n");}printf("(*=,-)\n"); else{retract();printf("(*,-)\n");}break;case'/':get_char();if(C == '/'){get_char(); printf("注释为:"); while(C != '\n'){printf("%c",C); get_char();}printf("\n");}else if(C == '*'){get_char(); printf("注释为:"); while(C != '*'){printf("%c",C); get_char();}printf("\n");get_char();}printf("(/=,-)\n"); break;}else{retract();printf("(/,-)\n");}break;case'%':get_char();if(C == '=')printf("%s\n","(%=,-)"); else{retract();printf("%s\n","(%,-)"); }break;case'<':get_char();if(C == '=')printf("(relop,LE)\n"); else{retract();printf("(relop,LT)\n"); }break;case'>':get_char();if(C == '=')printf("(relop,GE)\n");retract();printf("(relop,GT)\n"); }break;case'=':get_char();if(C == '=')printf("(relop,EQ)\n"); else{retract();printf("(assign-op,-)\n"); }break;case'!':get_char();if(C == '=')printf("(relop,NE)\n"); else{retract();printf("(logic,NOT)\n"); }break;case'&':get_char();if(C == '&')printf("(logic,AND)\n"); else{retract();printf("(&,-)\n");}case'|':get_char();if(C == '|')printf("(logic,OR)\n");else{retract();printf("(|,-)\n");}break;case'\n': printf("(enter-op,-)\n");break; case';': printf("(;,-)\n");break; case':': printf("(:,-)\n");break;case'{': printf("({,-)\n");break;case'}': printf("(},-)\n");break;case'(': printf("((,-)\n");break;case')': printf("(),-)\n");break;case'[': printf("([,-)\n");break;case']': printf("(],-)\n");break;case'.': printf("(.,-)\n");break;case',': printf("(,,-)\n");break;case'?': printf("(?,-)\n");break;default: printf("error"); break;}}}//主函数int main() {intrownum = 0;intbytenum = 0;int word = 0;head = (struct Node*)malloc(len);//头结点空间head -> data = ' ';head ->nextp = NULL;p = head;while(1){//以⾏为单位,读⼊代码,进⾏处int i = 0;char temp[260];// 假定每⾏字符数不超260gets(temp);if(temp[0] == '$')//如果读到第⼀字符为$,则做终⽌处理break; rownum ++;p ->nextp = (struct Node*)malloc(len);p = p ->nextp;while( temp[i] != '\0' && i < 260 ){p -> data = temp[i];p ->nextp = (struct Node*)malloc(len);if(!(p ->nextp)){printf("Error,don't have enough memory.\n");exit(1);}p = p ->nextp;i ++;bytenum ++;}p -> data = '\n';p ->nextp = NULL;}//扫描缓冲区,计算字符数和⾏数p=head->nextp;//指向本⾏C语⾔代码第⼀个字符while(p->nextp!=NULL) //循环直到本⾏打印结束,并计算单词数{printf("%c",p->data);p=p->nextp; //从头⾄尾遍历链表}printf("\n"); //显⽰最后⼀个回车p = head ->nextp;while( p ->nextp != NULL){scaner();//进⾏词法分析word++;if( reserve() == 255)}printf("This program has:%d lines. \n",rownum);printf("Besides note,there are %d words.\n",word - num);printf("There are %d bytes.\n",bytenum + rownum);//输出提⽰信息system("Pause"); return 0;}五)实验结果:。
2021年编译原理实验报告词法分析程序

编译原理试验汇报(一)----词法分析程序【目要求】经过设计编制调试一个具体词法分析程序, 加深对词法分析原理了解。
并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词词法分析方法。
【题目分析】本试验以用户指定想编译以C语言编写文件作为词法分析程序输入数据。
在进行词法分析中, 先自文件头开始以行为单位扫描程序, 将该行字符读入预先设定一个数组缓冲区中, 然后对该数组字符逐词分割, 进行词法分析, 将每个词分割成关键字、标识符、常量和运算符四种词种, 最终产生四个相对应表, 即关键字表、标识符表、常量表和运算符表, 它们以文件形式进行存放。
除此之外, 还产生一个编译后文件, 它指定了每个词在四个表中位置。
【试验过程】下面就词法分析程序汉字件和关键变量进行说明:文件:cpile.c 主程序文件key.txt 关键字文件operation.txt 运算符文件id.txt 标识符文件const.txt 常量文件after_com.txt 编译后产生文件关键变量:FILE *sfp,*nfp,*ifp,*kfp,*cfp,*pfp;char ib[50][20] 标识符表(动态生成)char cb[50][10] 常量表(动态生成)char kb[44][10] 关键字表(预先定义好)char pb[36][5] 运算符表(预先定义好)关键子函数名:int number(char s[],int i); 数字处理函数int letter(char s[],int i); 字符处理函数int operation(char s[],int i); 运算符处理函数void seti (char s[]); 标识符建立函数void setc (char s[]); 常量建立函数void cfile(char s1[], char s2[],int m); 将词和词所在表中位置写入编译后文件 void error1(char s[]); 字符处理犯错汇报void error2(char s[]); 标识符处理犯错汇报void error3(char s[]); 运算符处理犯错汇报void openall(); 打开全部文件void writeall(); 将四个表写入文件void closeall(); 关闭全部文件下面简明分析一下词法分析程序运行步骤:【程序调试】现有源程序a.c清单以下:#include <stdio.h>int main(int argc, char *argv[]) {char ch;int i;ch='a';ch=ch+32 ;i=ch;printf("%d id %c\n",i,ch);/*打印*/ return 0;}运行词法分析程序后, 显示以下结果: after_com.txt文件:#[p--2]include[i--0]<[p--14]stdio.h[i--1]>[p--16]int[k--2]main[i--2]([p--7]int[k--2]argc[i--3],[p--6]char[k--0]*[p--9]argv[i--4]][p--21])[p--8]{[p--23]char[k--0]ch[i--5];[p--13]int[k--2]i[i--6];[p--13]ch[i--5]=[p--15]'[p--19]a[i--7]'[p--19];[p--13]ch[i--5]=[p--15]ch[i--5]+[p--10]32[c--0];[p--13]i[i--6]=[p--15]ch[i--5];[p--13]printf[k--33] ([p--7]"[p--1]d[i--8]id[i--9]%[p--4]c[i--10]\[p--20]n[i--11]"[p--1],[p--6]i[i--6],[p--6]ch[i--5])[p--8];[p--13]return[k--28]0[c--1];[p--13]}[p--25]key.txt 关键字文件:0 char1 short2 int3 unsigned4 long5 float6 double7 struct8 union9 void10 enum11 signed12 const13 volatile14 typedef15 auto16 register17 static18 extem19 break20 case21 continue22 default23 do24 else25 for26 goto27 if28 return29 switch30 while31 sizeof32 txt33 printf34 FILE35 fopen36 NULL37 fclose38 exit39 r40 read41 close42 w43fprintfid.txt 标识符文件:0 include1 stdio.h2 main3 argc4 argv5 ch6 i7 a8 d9 id10 c11 noperation.txt 运算符文件:0 !1 "2 #3 $4 %5 &6 ,7 (8 )9 *10 +11 -12 :13 ;14 <15 =16 >17 ?18 [19 '20 \21 ]22 .23 {24 ||25 }26 !=27 >=28 <=29 ==30 ++31 --32 &&33 /*34*/const.txt 常量文件:0 3210结果完全正确。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
词法分析程序实验报告
一、实验目的
1. 理解词法分析器的基本功能
2. 理解词法规则的描述方法
3. 理解状态转换图及其实现
4. 能够编写简单的词法分析器
二、实验要求
2、主程序流程图
三、识别单词的状态转换图Scanner()函数流程图
2. 分析直接转向法和表驱动法的优缺点
状态转换图的实现通常有两种方法:状态转换表和直接转向法(1) :状态转换表法又称数据中心,是把状态转换图看作一种数据结构,由控制程序控制字符在其上运行,从而完成词法分析。
优点是程序短,但是占存储空间多,
(2)直接转向法又称程序中心法,是把状态转换图看成一个流程图,从状态转换图的初态开始,对它的每一个状态节点都编写一段相应的程序。
源程序如下
#include<stdio.h>
#include<string.h>
char ch;//扫描哪一个字符
char stoken[100];//扫描到的单词序列
char token[10];//存储已扫描到的单词
int p,m,n;
int state;//词法分析时进入哪一个状态
int row;//用于标注哪一行不能识别
long int num;
char
*key[8]={"function","if","else","for","then","while","do","endfunction"};//定义好的能识别的关键字
void scanner()
{
for(n=0;n<10;n++) //变量初始化
token[n]=NULL;
m=0;
ch=stoken[p];
p++;
while(ch == ' '||ch == '\n')//跳过空格或是换行符
{
ch=stoken[p];
p++;
}
if(ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z')
{
m = 0;
while(ch >= 'a' && ch <= 'z' || ch >= '0' && ch <= '9' || ch >= 'A' && ch <= 'Z')
{
token[m++] = ch;
ch = stoken[p++];//扫描下一个
}
ch = stoken[--p];
state = 10;
for(n = 0; n < 8; n++)
if(strcmp(token, key[n])== 0)
{
state = n + 1;
break;
}
}
else
if(ch >= '0' && ch <= '9')//是数字
{
num = 0;
while(ch >= '0' && ch <= '9')//可能是多位数字
{
num = num * 10 + ch - '0';
ch =stoken[p++];
}
ch = stoken[--p];
state = 11;
}
else
switch(ch)
{
case '<':
m = 0;
token[m++] = ch;
ch = stoken[p++];
if(ch == '=')
{
state = 21;
token[m++] = ch;
}
else
{
state = 20;
ch = stoken[--p];
}
break;
case '>':
m = 0;
token[m++] = ch;
ch = stoken[p++];
if(ch == '=')
{
state = 24;
token[m++] = ch;
}
else
{
state = 23;
ch = stoken[--p];
}
break;
case'=':
m=0;
token[m++]=ch;
ch = stoken[p++];
if(ch=='=')
{
state = 25;
token[m++]=ch;
}
else
{
state=18;
ch = stoken[--p];
}
break;
case'!':
m=0;
token[m++]=ch;
ch = stoken[p++];
if(ch == '=')
{
state=22;
token[m++]=ch;
}
else
{
state = -1;
}
break;
case'+':
state=13;
token[0]=ch;
break;
case'-':
state=14;
token[0]=ch;
break;
case'*':
state=15;
token[0]=ch;
break;
case'/':
state=16;
token[0]=ch;
break;
case';':
state=26;
token[0]=ch;
break;
case'(':
state=27;
token[0]=ch;
break;
case')':
state=28;
token[0]=ch;
break;
case'{':
state=29;
token[0]=ch;
break;
case'}':
state=30;
token[0]=ch;
break;
case '#':
state = 0;
token[0] = ch;
break;
default:
state=-1;
break;
}
}
main()
{
p=0;
row=1;
printf("请输入要分析的单词:\n");
while(ch!='#')
{
scanf("%c",&ch);
stoken[p++]=ch;
}
printf("词法分析如下:\n");
p=0;
do
{
scanner();
switch(state)
{
case 11:
printf("\n(%d, %d)",num,state);
break;
case -1:
printf("\n不能识别 %d",row);
break;
default:
printf("\n(%s, %d)",token,state);
break;
}
}
while(state!=0);
}。