人工智能十大算法总结
人工智能十大算法总结

人工智能十大算法总结人工智能(Artificial Intelligence,简称AI)是一门涉及模拟和复制人类智能的科学和工程学科。
在人工智能的发展过程中,算法起着至关重要的作用。
算法是用来解决问题的一系列步骤和规则。
下面是人工智能领域中十大重要的算法总结。
一、回归算法回归算法用于预测数值型数据的结果。
常见的回归算法有线性回归、多项式回归、岭回归等。
这些算法通过建立数学模型来找到输入和输出之间的关系,从而进行预测。
二、决策树算法决策树算法是一种基于树形结构的模型,可用于分类和回归问题。
它将数据集拆分成决策节点和叶节点,并根据特征的属性进行分支。
决策树算法易于理解和解释,并且可以处理非线性关系。
三、支持向量机算法支持向量机算法用于分类和回归分析。
它通过在特征空间中构造一个超平面来将样本划分为不同的类别。
支持向量机算法具有高维特征空间的能力和较强的泛化能力。
四、聚类算法聚类算法用于将相似的数据点分组到一起。
常见的聚类算法有K均值聚类、层次聚类等。
聚类算法能够帮助我们发现数据中的模式和结构,从而对数据进行分析和处理。
五、人工神经网络算法人工神经网络是一种类似于生物神经系统的模型。
它由大量的节点和连接组成,可以模拟人脑的学习和推理过程。
人工神经网络算法可以用于分类、识别、预测等任务。
六、遗传算法遗传算法模拟生物进化的原理,通过模拟选择、交叉和变异等操作来寻找最优解。
遗传算法常用于求解复杂优化问题,如旅行商问题、背包问题等。
七、贝叶斯网络算法贝叶斯网络是一种概率图模型,用于表示变量之间的依赖关系。
贝叶斯网络算法可以用于推断和预测问题,如文本分类、诊断系统等。
它具有直观、可解释性强的特点。
八、深度学习算法深度学习是一种基于神经网络的算法,具有多层次的结构。
它可以通过无监督或监督学习来进行模型训练和参数优化。
深度学习算法在图像识别、语音识别等领域取得了显著的成果。
九、马尔科夫决策过程算法马尔科夫决策过程是一种基于状态转移的决策模型。
人工智能算法与应用工作总结

人工智能算法与应用工作总结在当今数字化和信息化的时代,人工智能作为一项引领科技发展的关键技术,正以前所未有的速度改变着我们的生活和工作方式。
人工智能算法作为其核心组成部分,为各种应用场景提供了强大的支持和创新的解决方案。
在过去的一段时间里,我们在人工智能算法与应用方面进行了深入的研究和实践,取得了一定的成果,也遇到了一些挑战。
以下是对这段时间工作的详细总结。
一、人工智能算法的研究与发展在算法研究方面,我们主要聚焦于深度学习算法,特别是卷积神经网络(CNN)和循环神经网络(RNN)及其变体。
CNN 在图像识别、目标检测等领域表现出色,通过多层卷积和池化操作,能够自动提取图像中的特征,大大提高了识别准确率。
例如,在我们的一个项目中,利用改进的 CNN 算法对_____公司的产品缺陷进行检测,成功将检测准确率从传统方法的80%提高到了95%以上,显著减少了次品的流出。
RNN 及其变种,如长短期记忆网络(LSTM)和门控循环单元(GRU),则在处理序列数据,如自然语言处理、时间序列预测等方面具有优势。
我们运用 LSTM 算法对股票价格进行预测,通过对历史数据的学习和分析,能够提前捕捉到价格的趋势变化,为投资决策提供了有价值的参考。
此外,我们还关注了强化学习算法的研究和应用。
强化学习通过智能体与环境的不断交互和试错,学习到最优的策略。
在机器人控制、游戏AI 等领域有着广泛的应用前景。
我们利用强化学习算法训练机器人完成复杂的任务,如在特定环境中的自主导航和物品抓取,取得了较好的效果。
二、人工智能算法的应用领域(一)医疗健康在医疗领域,人工智能算法发挥了重要作用。
我们利用图像识别算法对医学影像,如 X 光、CT 扫描等进行分析,帮助医生更准确地检测疾病。
例如,通过训练的深度学习模型能够快速识别肿瘤的位置和大小,为早期诊断和治疗提供了支持。
同时,在药物研发方面,利用算法对大量的药物分子结构和生物活性数据进行挖掘和分析,加速了新药的研发进程。
人工智能的不同算法

人工智能的不同算法
人工智能的算法类型主要包括以下几种:
1. 机器学习算法:基于数据样本的学习和建模,通常需要大量的训练数据。
常见的机器学习算法包括决策树、支持向量机、神经网络、随机森林等。
2. 深度学习算法:一种特殊的机器学习算法,基于神经网络,对数据进行层层处理和学习以提取更高级别的抽象特征,适用于处理大规模图像、语音、文本等数据。
典型的深度学习算法有卷积神经网络、循环神经网络等。
3. 自然语言处理算法:用于处理自然语言数据的算法,如文本分类、机器翻译、情感分析等。
典型的自然语言处理算法有词向量模型、循环神经网络等。
4. 强化学习算法:一种用于训练智能体进行决策和行动的算法,通过不断试错和奖惩来优化行为策略。
典型的强化学习算法包括Q学习、策略梯度等。
5. 计算机视觉算法:用于处理和分析图像和视频数据的算法,如目标检测、图像分割、人脸识别等。
典型的计算机视觉算法有卷积神经网络、循环神经网络等。
以上信息仅供参考,如需获取更多详细信息,建议查阅人工智能领域相关书籍或咨询人工智能领域专业人士。
10种常见AI算法

10种常见AI算法
1.神经网络:
神经网络(Neural Network, NN)是一种模拟人脑神经细胞的处理过
程的算法。
它将大量的小单元连接成一个整体,以完成一定的任务,可以
实现自学习,也可以实现复杂的计算。
神经网络可以进行深度学习,在深
度学习中,神经网络被用来作为机器学习的架构。
它可以实现回归,分类,分析等功能。
常见的神经网络算法包括反向传播,神经网络模型,递归神
经网络(RNN),循环神经网络(CNN),生成对抗网络(GAN)和
Dropout等。
2.决策树:
决策树(Decision Tree)是一种有效可视化的机器学习算法,而且
对于大量的数据也有效。
它可以将数据转换为树状的决策图,用于进行分
析和预测。
它可以很好的处理离散的数据,也可以处理连续的数据,并且
可以训练出有用的模型。
常见的决策树算法有ID3,C4.5,CART和CHAID 等。
3.贝叶斯方法:
贝叶斯方法是一种基于概率的统计学方法,它可以为用户提供一种可
能性的估计。
它可以用来估算给定的事件发生的概率,其中包括有关特定
情况未来事件发生的概率的评估。
它的基本思想是采用贝叶斯定理来推断
和评估可能性,并做出正确的决策。
经典人工智能算法综述

经典人工智能算法综述一、专家系统专家系统是人工智能领域最早的知识工程技术之一,该技术首次在20世纪70年代末提出。
专家系统利用专家知识来解决特定问题,主要包括知识表示、知识推理和知识获取等方面。
专家系统常常包括知识库、推理机、用户接口等组成部分,通过模拟专家的经验和知识,来完成推理和决策。
专家系统在医疗、金融、制造等领域得到了广泛的应用,例如Dendral系统是一个专家系统,用于分析气相色谱质谱仪的输出数据以确定化合物的结构。
二、遗传算法遗传算法是一种模仿自然进化过程的搜索优化算法,它通过模拟自然选择、交叉和变异等进化过程来搜索问题的最优解。
遗传算法最早是由美国的约翰·霍兰德于20世纪60年代提出的。
遗传算法主要包括编码、选择、交叉、变异等操作,通过不断进化生成适应度更高的解,从而找到问题的最优解。
遗传算法在优化问题、机器学习、数据挖掘等领域得到了广泛的应用,例如在大规模旅行商问题、神经网络权值优化等问题上展现出了优势。
三、模糊逻辑模糊逻辑是一种用于表示不确定性、模糊性信息的逻辑系统,它在20世纪70年代被提出。
模糊逻辑将传统的逻辑二元关系扩展到了模糊的多值逻辑关系,使得不确定性、模糊性信息能够得到有效的处理。
模糊逻辑主要包括模糊集合理论、模糊关系、模糊推理等内容,被广泛应用于人工智能、控制系统、信息检索等领域。
例如在智能控制系统中,模糊逻辑被用于建模、推理,实现了对复杂系统的精确控制。
四、人工神经网络人工神经网络是一种模仿生物神经网络结构和功能的计算模型,它借鉴了大脑中的神经元和突触结构。
人工神经网络可以通过学习来自动地调整网络的连接权值,从而实现对信息的处理和识别。
人工神经网络于20世纪50年代被提出,并在之后得到了不断的改进和发展。
人工神经网络在模式识别、控制系统、金融预测等领域展现出了优势,例如AlphaGo就是基于深度神经网络的围棋程序,击败了世界冠军。
五、规则学习规则学习是指利用训练数据自动学习出数据中的规则并进行预测和决策的技术。
人工智能技术常用算法

人工智能技术常用算法
一、机器学习算法
1、数据类:
(1)K最近邻算法(KNN):KNN算法是机器学习里最简单的分类算法,它将每个样本都当作一个特征,基于空间原理,计算样本与样本之间的距离,从而进行分类。
(2)朴素贝叶斯算法(Naive Bayes):朴素贝叶斯算法是依据贝叶斯定理以及特征条件独立假设来计算各类别概率的,是一种贝叶斯决策理论的经典算法。
(3)决策树(Decision Tree):决策树是一种基于条件概率知识的分类和回归模型,用通俗的话来讲,就是基于给定的数据,通过计算出最优的属性,构建一棵树,从而做出判断的过程。
2、聚类算法:
(1)K-means:K-means算法是机器学习里最经典的聚类算法,它会将相似的样本分到一起,从而实现聚类的目的。
(2)层次聚类(Hierarchical clustering):层次聚类是一种使用组织树(层次结构)来表示数据集和类之间关系的聚类算法。
(3)谱系聚类(Spectral clustering):谱系聚类算法是指,以频谱图(spectral graph)来表示数据点之间的相互关系,然后将数据点聚类的算法。
三、深度学习算法
1、卷积神经网络(Convolutional Neural Network):卷积神经网络是一种深度学习算法。
13种ai智能算法

13种ai智能算法以下是13种常见的AI智能算法:1.K-近邻算法(K-Nearest Neighbors,KNN):根据周围K个最近邻的类别来预测未知数据的类别。
K值的选择和距离度量方式对结果影响较大。
2.决策树算法(Decision Trees):通过将数据集划分为若干个子集,并根据每个子集的特征进行进一步的划分,从而构建一棵树状结构。
决策树的分支准则通常基于信息增益或信息熵等指标。
3.随机森林算法(Random Forests):通过构建多个决策树,并对它们的预测结果进行投票来预测未知数据的类别。
随机森林算法能够提高预测的准确性和稳定性。
4.梯度提升树算法(Gradient Boosting Trees,GBRT):通过迭代地添加新的决策树来优化损失函数,从而逐步提高预测的准确性。
梯度提升树算法通常能够处理非线性关系和解决过拟合问题。
5.支持向量机算法(Support Vector Machines,SVM):通过将数据映射到高维空间中,并寻找一个超平面将不同类别的数据分隔开来。
SVM算法通常用于分类和回归任务。
6.线性回归算法(Linear Regression):通过拟合一个线性模型来预测连续数值型数据的目标变量。
线性回归算法可以解决回归问题,即预测数值型目标变量。
7.逻辑回归算法(Logistic Regression):通过拟合一个逻辑函数来预测离散二元型数据的目标变量。
逻辑回归算法可以解决分类问题,即预测离散二元型目标变量。
8.朴素贝叶斯算法(Naive Bayes):基于贝叶斯定理和特征条件独立假设来预测未知数据的类别。
朴素贝叶斯算法通常用于文本分类和垃圾邮件过滤等任务。
9.集成学习算法(Ensemble Learning):通过将多个学习模型(如决策树、SVM等)的预测结果进行集成,从而提高预测的准确性和稳定性。
常见的集成学习算法有Bagging和Boosting两种类型。
10.决策树桩算法(Decision Stump):通过对每个特征进行一次划分来构建一个单层决策树,从而简化决策树的构建过程。
AI必知的十大深度学习算法

AI必知的十大深度学习算法深度学习算法在如今的人工智能领域中扮演着重要的角色。
它们能够模拟人脑的神经网络结构,以逐渐改进和提升机器对复杂问题的理解能力。
在本文中,我们将介绍AI必知的十大深度学习算法。
一、感知机算法感知机算法是人工神经网络的基础。
它模拟了神经网络中的神经元处理信息的方式。
该算法基于线性可分的概念,能够将不同样本进行分类。
感知机算法的流程包括权重初始化、输出计算、误差计算和权重更新。
二、反向传播算法反向传播算法是深度学习中最重要的算法之一。
通过使用链式法则,它能够从输出端逆向传播误差,并更新神经网络中的权重。
这种算法的有效性使得神经网络能够逐层学习和提升。
三、卷积神经网络(CNN)卷积神经网络是一种专门用于处理图像和语音等数据的深度学习算法。
它使用了卷积和池化等操作,能够自动提取输入数据中的重要特征。
卷积神经网络在图像分类、目标检测等任务中表现出色。
四、循环神经网络(RNN)循环神经网络是一种能够处理序列数据的深度学习算法。
相较于传统神经网络,RNN能够引入时间维度信息,使得模型能够记忆和利用过去的状态。
这使得它在语言模型、机器翻译等任务中取得较好的效果。
五、长短期记忆网络(LSTM)长短期记忆网络是对RNN的改进版本。
它通过引入“门”的概念,能够更好地解决传统RNN中梯度消失和梯度爆炸的问题。
LSTM的结构使得它能够更好地处理长时间依赖性问题。
六、生成对抗网络(GAN)生成对抗网络由生成器和判别器组成。
生成器试图生成与真实数据相似的数据,而判别器则试图将它们与真实数据区分开来。
通过两者之间的对抗训练,GAN能够生成逼真的新数据,如图像、音频等。
七、自编码器自编码器是一种无监督学习的算法。
它试图将输入数据编码成低维表示,并通过解码器进行重构。
自编码器能够学习到输入数据的关键特征,具有数据降维和去噪能力。
八、深度信念网络(DBN)深度信念网络是一种多层的生成模型。
它由多个受限玻尔兹曼机组成,能够学习到数据分布的概率模型。
人工智能十大算法总结(精选五篇)

人工智能十大算法总结(精选五篇)第一篇:人工智能十大算法总结5-1 简述机器学习十大算法的每个算法的核心思想、工作原理、适用情况及优缺点等。
1)C4.5 算法:ID3 算法是以信息论为基础,以信息熵和信息增益度为衡量标准,从而实现对数据的归纳分类。
ID3 算法计算每个属性的信息增益,并选取具有最高增益的属性作为给定的测试属性。
C4.5 算法核心思想是ID3 算法,是ID3 算法的改进,改进方面有:1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;2)在树构造过程中进行剪枝3)能处理非离散的数据4)能处理不完整的数据C4.5 算法优点:产生的分类规则易于理解,准确率较高。
缺点:1)在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
2)C4.5 只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
2)K means 算法:是一个简单的聚类算法,把n 的对象根据他们的属性分为k 个分割,k < n。
算法的核心就是要优化失真函数J,使其收敛到局部最小值但不是全局最小值。
其中N 为样本数,K 是簇数,rnk b 表示n 属于第k 个簇,uk 是第k 个中心点的值。
然后求出最优的uk优点:算法速度很快缺点是,分组的数目k 是一个输入参数,不合适的k 可能返回较差的结果。
3)朴素贝叶斯算法:朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。
算法的基础是概率问题,分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。
朴素贝叶斯假设是约束性很强的假设,假设特征条件独立,但朴素贝叶斯算法简单,快速,具有较小的出错率。
在朴素贝叶斯的应用中,主要研究了电子邮件过滤以及文本分类研究。
4)K 最近邻分类算法(KNN)分类思想比较简单,从训练样本中找出K个与其最相近的样本,然后看这k个样本中哪个类别的样本多,则待判定的值(或说抽样)就属于这个类别。
人工智能十大流行算法通俗易懂讲明白

人工智能十大流行算法通俗易懂讲明白
答:
一、决策树算法
决策树指的是一种通过“进行检索和选择操作,以识别特定情况的最
佳策略”而产生的技术。
它由一棵树结构组成,其中的每个节点代表了一
些决策,每个分支代表了一种可能的结果,而叶子节点则代表了最后的结论。
这种算法使用的主要思想是在每个节点选择最佳决策,以帮助机器学
习模型获得最佳结果。
二、回归分析
回归分析算法是一种用来探索特定结果的数学方法,是机器学习的重
要方法之一、其目的是通过分析变量之间的关系,以及变量与输出值之间
的关系,来预测输出值,解决相关问题。
它有不同的类型,包括线性回归,逻辑回归和多项式回归。
三、K-means聚类
K-means聚类算法是一种聚类算法,它通过用一定数量的聚类中心对
数据进行分组。
它先随机选取聚类中心,然后计算每个数据点到聚类中心
的距离,将其分配到最近的聚类中心,然后更新聚类中心的位置,使它们
更加接近其分配的数据点,最终实现聚类。
四、支持向量机
支持向量机(SVM)是一种有监督的机器学习模型,它将数据集中的
数据点投射到一个高维特征空间中,构建出一个最大边界的模型。
人工智能算法详解

人工智能算法详解人工智能(Artificial Intelligence,AI)是一门研究如何使计算机能够模拟人类智能的学科。
而人工智能算法则是实现人工智能的关键。
本文将详细介绍几种常见的人工智能算法,并分析其原理和应用。
一、机器学习算法机器学习是人工智能的核心领域之一,其通过构建数学模型和算法,使计算机能够从数据中学习和改进。
在机器学习中,有三种常见的算法:监督学习、无监督学习和强化学习。
1. 监督学习算法监督学习算法是在给定输入和输出样本的情况下,通过构建模型来预测新的输入对应的输出。
其中,常用的监督学习算法有决策树、支持向量机和神经网络等。
决策树通过构建树状结构来进行分类或回归;支持向量机通过找到一个超平面来划分数据集;神经网络则是模拟人脑神经元的工作原理,通过多层神经元进行学习和预测。
2. 无监督学习算法无监督学习算法是在没有给定输出样本的情况下,通过对数据进行聚类或降维,发现数据的内在结构和规律。
常见的无监督学习算法有K-means聚类、主成分分析和自组织映射等。
K-means聚类通过寻找数据集中的K个聚类中心,将数据点分配到最近的聚类中心;主成分分析则是将高维数据转化为低维表示,保留数据的主要信息;自组织映射是一种无监督学习的神经网络,通过自组织和竞争机制实现数据的聚类和映射。
3. 强化学习算法强化学习算法是通过试错的方式,通过与环境的交互来学习最优策略。
强化学习的核心是智能体(Agent)通过观察状态、采取行动并得到奖励来进行学习。
常见的强化学习算法有Q-learning、深度强化学习等。
Q-learning是一种基于值函数的强化学习算法,通过不断更新状态-动作对的价值来学习最优策略;深度强化学习则是将深度神经网络与强化学习相结合,通过神经网络来学习和预测最优策略。
二、深度学习算法深度学习是机器学习的一个分支,其模拟人类大脑神经网络的结构和工作原理。
深度学习算法通过多层神经网络来学习和预测。
十大人工智能经典算法

十大人工智能经典算法随着人工智能技术的快速发展,越来越多的算法被提出并应用于各种领域。
本文将为您介绍十大人工智能经典算法,帮助您了解这些算法的基本概念、应用场景和优缺点。
一、线性回归算法线性回归算法是一种预测连续值的算法,通过对自变量和因变量之间的关系进行建模,来预测因变量的取值。
该算法广泛应用于金融、医疗、交通等领域。
优点是简单易行,缺点是对于非线性关系的数据处理效果较差。
二、逻辑回归算法逻辑回归算法是一种用于分类问题的算法,通过将连续值转换为二分类问题,来进行分类预测。
该算法广泛应用于欺诈检测、信用评分等领域。
优点是简单易行,缺点是对于多分类问题需要多次建模。
三、朴素贝叶斯算法朴素贝叶斯算法是一种基于贝叶斯定理的分类算法,通过计算已知类别的样本数据,来预测新样本的类别。
该算法广泛应用于垃圾邮件过滤、情感分析等领域。
优点是简单高效,缺点是对于特征之间关联性较强的数据效果较差。
四、决策树算法决策树算法是一种基于树结构的分类和回归算法,通过递归地将数据集划分为更小的子集,来构建决策树模型。
该算法广泛应用于金融、医疗、安全等领域。
优点是简单直观,缺点是对于连续型特征和缺失值处理效果较差。
五、随机森林算法随机森林算法是一种基于决策树的集成学习算法,通过构建多棵决策树并综合它们的预测结果,来提高分类和回归的准确率。
该算法广泛应用于金融、医疗、推荐系统等领域。
优点是准确率高,缺点是计算复杂度较高六、支持向量机算法支持向量机算法是一种基于统计学习理论的分类算法,通过找到能够将不同类别的样本点最大化分隔的决策边界,来进行分类预测。
该算法广泛应用于人脸识别、文本分类等领域。
优点是对于非线性问题具有较强的处理能力,缺点是对于大规模数据集计算效率较低。
七、K最近邻算法K最近邻算法是一种基于实例的学习算法,通过找到与新样本点最相近的K个已知类别的样本点,来进行分类预测。
该算法广泛应用于文本分类、图像识别等领域。
优点是简单高效,缺点是需要较大的存储空间和计算量。
AI人工智能的10种常用算法

AI人工智能的10种常用算法
一、决策树
决策树是一种基于树结构的有监督学习算法,它模拟从一组有既定条
件和结论的例子中学习的方法,它用来预测未知数据,也可以说是一种使
用规则中的优先算法,最终输出一个根据训练集结果所构建的规则树,由
根节点到叶子节点
其次,决策树可以帮助分析出未知数据的特征,通过提取出有代表性
的与结果有关的特征来构建决策树,也就是上面所说的有监督学习算法,
它可以根据训练集的特征到达其中一个结论,也可以找出未知数据的规律。
二、BP神经网络
BP神经网络是一种以“反向传播”为基础的神经网络算法,也可以
说是一种深度学习算法,它结合了神经网络和梯度下降法的思想。
BP神
经网络采用神经网络的结构,通过多层神经元对数据进行处理,每一层神
经元代表每一层的特征,并将经过神经元层层处理的结果反馈回到前面的层,同时通过梯度下降法来调整每一层神经元的权重,最终得到模型的输出。
三、K-近邻
K-近邻算法是一种基于实例的学习,也可以说是一种无监督学习算法。
人工智能的25种算法和应用场景

人工智能的25种算法和应用场景人工智能(Artificial Intelligence,简称AI)是指通过模拟人类智能行为的方法和技术使机器能够像人类一样感知、理解、学习、推理和决策的能力。
在人工智能领域,算法是实现智能的核心元素之一。
下面将介绍人工智能的25种算法及其应用场景。
1. 逻辑回归算法:逻辑回归算法是一种用于解决分类问题的算法,常用于金融风控、电商推荐等场景。
2. 决策树算法:决策树算法通过将数据集划分为一系列的分类条件,用于解决分类和回归问题。
应用场景包括医学诊断、客户流失预测等。
3. 随机森林算法:随机森林算法是一种基于决策树的集成学习方法,通过组合多个决策树来提高模型的准确性与鲁棒性。
常用于信用评分、疾病预测等领域。
4. 支持向量机算法:支持向量机算法是一种用于解决分类和回归问题的算法,可处理线性和非线性问题。
应用场景包括语音识别、图像识别等。
5. 隐马尔可夫模型算法:隐马尔可夫模型算法用于描述具有潜在不可观察状态的动态过程。
应用场景包括语音识别、自然语言处理等。
6. K均值聚类算法:K均值聚类算法将数据分为K个不重叠的簇,常用于客户分群、图像分割等领域。
7. 线性回归算法:线性回归算法用于解决回归问题,通过拟合一个线性模型来预测目标变量的值。
应用场景包括股票价格预测、销售预测等。
8. K最近邻算法:K最近邻算法基于样本之间的距离度量来进行分类,常用于图像识别、推荐系统等。
9. 神经网络算法:神经网络算法模拟人脑的神经网络结构,通过多层的神经元进行学习与预测。
应用场景包括人脸识别、自动驾驶等。
10. 深度学习算法:深度学习算法是一种基于多层神经网络的机器学习方法,通过学习多层次的特征表示来实现智能。
应用领域包括自然语言处理、图像识别等。
11. 遗传算法:遗传算法模拟物种遗传和进化过程,通过优胜劣汰的机制来搜索最优解。
常用于布局优化、参数优化等。
12. 蚁群算法:蚁群算法模拟蚂蚁觅食的行为,通过信息素的传递和挥发来搜索最优解。
人工智能十大算法总结

人工智能十大算法总结
一,深度学习
深度学习(Deep Learning)是一种流行的机器学习技术,它利用多层神经网络对复杂的数据进行分析和处理。
它是目前实现最为成功的人工智能算法之一,在图像识别、语音识别、自然语言处理等领域取得了显著的成果。
深度学习算法的基础是深度神经网络,该算法可构建具有记忆和泛化能力的神经网络,并在获得训练数据后进行学习,从而自动提取特征并完成相应的预测任务。
深度学习一般在大数据集上进行训练,具有良好的特征提取能力以及在预测任务上的表现。
二、卷积神经网络
卷积神经网络(ConvolutionalNN)是一种特殊的深度学习算法,它优化了传统的神经网络的计算效率。
该算法将一系列卷积层和池化层组合构建而成,并将每层输出与下一层输入相连,以实现特定的功能。
三、支持向量机
支持向量机(SVM)是一种非常流行的机器学习算法,它主要用于分类和回归任务,用来在可用数据中学习模型参数。
SVM的优势在于可以有效地使用少量的样本数据进行训练,并且可以实现非线性、非平稳的分类和回归。
四、随机森林
随机森林(Random Forest)是一种常用的机器学习算法,它利用随机森林来构建决策树模型,以实现分类和回归任务。
十大人工智能经典算法中的应用

十大人工智能经典算法中的应用以下是十大人工智能经典算法中的一些应用:1. 决策树:广泛应用于分类和回归问题。
决策树通过递归地将数据集划分成越来越小的子集,生成一个易于理解和使用的决策规则集合。
在金融、医疗、商业等领域有广泛应用。
2. 随机森林:是一种集成学习算法,通过构建多个决策树并结合它们的预测结果来提高分类和回归任务的准确性和稳定性。
随机森林在处理高维特征和大规模数据集方面表现优秀,广泛应用于自然语言处理、推荐系统和计算机视觉等领域。
3. 逻辑回归:主要用于分类问题,通过将线性回归和逻辑函数结合,将连续的输出值转化为二分类的逻辑值。
逻辑回归在市场营销、信用评分和生物信息学等领域有广泛应用。
4. 支持向量机:主要用于分类和回归问题,通过找到能够将不同类别的数据点最大化分隔的决策边界来实现分类或回归。
支持向量机在文本分类、图像识别和自然语言处理等领域有广泛应用。
5. 神经网络:是一种模拟人脑神经元网络的算法,通过训练和学习来识别模式和解决问题。
神经网络在语音识别、图像识别、自然语言处理和机器翻译等领域有广泛应用。
6. 贝叶斯分类器:基于贝叶斯定理的分类算法,通过计算给定特征下类别的条件概率来进行分类。
贝叶斯分类器在垃圾邮件过滤、文本分类和情感分析等领域有广泛应用。
7. K-最近邻算法:一种基于实例的学习算法,通过将新数据点与已知数据点进行比较,找到最接近的邻居并使用它们的类别信息来预测新数据点的类别。
K-最近邻算法在文本分类、图像识别和推荐系统等领域有广泛应用。
8. 聚类算法:通过将相似的数据点聚集在一起形成多个聚类,从而实现数据的无监督学习。
聚类算法在市场细分、客户分群和图像分割等领域有广泛应用。
9. 主成分分析:一种降维技术,通过找到数据中的主要成分并将其余成分作为噪声去除,实现数据的压缩和简化。
主成分分析在特征选择、数据可视化等领域有广泛应用。
10. 关联规则学习:用于发现数据集中项之间的有趣关系。
人工智能不同场景常用算法

人工智能不同场景常用算法
人工智能的不同场景常用的算法有很多种,以下是一些常见的算法:
1. 决策树算法:用于分类和预测问题,如预测客户购买偏好。
2. 随机森林算法:用于分类和预测问题,如预测信用卡欺诈。
3. 支持向量机算法:用于分类和回归问题,如电影评分预测。
4. 朴素贝叶斯算法:用于分类问题,如邮件分类。
5. 逻辑回归算法:当预测目标是概率时,值域需要满足大于等于0,小于等于1的条件,这个时候单纯的线性模型无法满足要求,因为当定义域不在某个范围之内时,值域也会超出规定区间。
以上信息仅供参考,如有需要,建议查阅人工智能相关书籍或咨询专业人士。
人工智能常用的29种算法

人工智能常用的29种算法1. 线性回归(Linear Regression)2. 逻辑回归(Logistic Regression)3. 支持向量机(Support Vector Machine)4. 决策树(Decision Tree)5. 随机森林(Random Forest)6. K近邻算法(K-Nearest Neighbor)7. K均值算法(K-Means)8. 神经网络(Neural Network)9. 朴素贝叶斯(Naive Bayes)10. AdaBoost算法11. 梯度下降算法(Gradient Descent)12. 隐马尔科夫模型(Hidden Markov Model)13. PCA(Principal Component Analysis)14. LDA(Linear Discriminant Analysis)15. ARIMA自回归滑动平均模型16. LSTM(Long Short-Term Memory)17. GRU(Gated Recurrent Unit)18. 反向传播算法(Backpropagation)19. 遗传算法(Genetic Algorithm)20. 蚁群算法(Ant Colony Algorithm)21. 贪心算法(Greedy Algorithm)22. 色彩聚类算法(Color Clustering Algorithm)23. 图像识别算法(Image Recognition Algorithm)24. 文本分类算法(Text Classification Algorithm)25. 改进的粒子群算法(Improved Particle Swarm Optimization)26. 强化学习算法(Reinforcement Learning)27. 协同过滤算法(Collaborative Filtering Algorithm)28. 局部敏感哈希算法(Local Sensitive Hashing)29. 非负矩阵分解算法(Non-negative Matrix Factorization)。
AI人工智能的10种常用算法
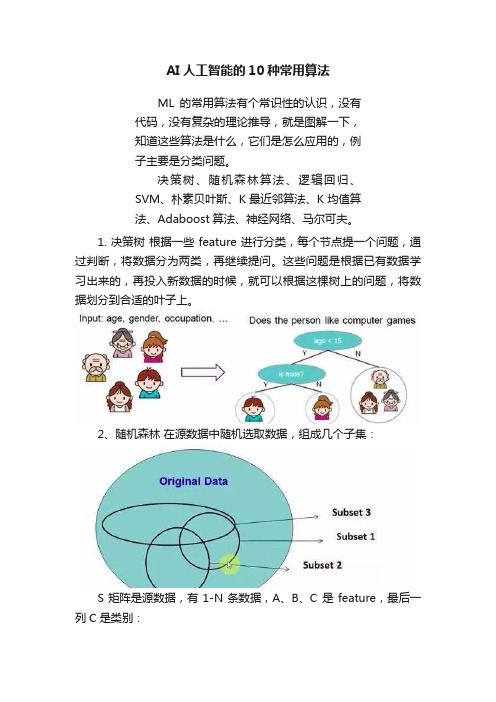
AI人工智能的10种常用算法ML的常用算法有个常识性的认识,没有代码,没有复杂的理论推导,就是图解一下,知道这些算法是什么,它们是怎么应用的,例子主要是分类问题。
决策树、随机森林算法、逻辑回归、SVM、朴素贝叶斯、K最近邻算法、K均值算法、Adaboost算法、神经网络、马尔可夫。
1. 决策树根据一些 feature 进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。
这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
2、随机森林在源数据中随机选取数据,组成几个子集:S矩阵是源数据,有1-N条数据,A、B、C 是feature,最后一列C是类别:由S随机生成M个子矩阵:这M个子集得到 M 个决策树:将新数据投入到这M个树中,得到M个分类结果,计数看预测成哪一类的数目最多,就将此类别作为最后的预测结果。
3、逻辑回归当预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。
所以此时需要这样的形状的模型会比较好:那么怎么得到这样的模型呢?这个模型需要满足两个条件“大于等于0”,“小于等于1”大于等于0 的模型可以选择绝对值,平方值,这里用指数函数,一定大于0;小于等于1 用除法,分子是自己,分母是自身加上1,那一定是小于1的了。
再做一下变形,就得到了 logistic regressions 模型:通过源数据计算可以得到相应的系数了:最后得到 logistic 的图形:4、SVM 要将两类分开,想要得到一个超平面,最优的超平面是到两类的 margin 达到最大,margin就是超平面与离它最近一点的距离,如下图,Z2>Z1,所以绿色的超平面比较好。
将这个超平面表示成一个线性方程,在线上方的一类,都大于等于1,另一类小于等于-1:点到面的距离根据图中的公式计算:所以得到total margin的表达式如下,目标是最大化这个margin,就需要最小化分母,于是变成了一个优化问题:举个例子,三个点,找到最优的超平面,定义了 weight vector=(2,3)-(1,1):得到weight vector为(a,2a),将两个点代入方程,代入(2,3)另其值=1,代入(1,1)另其值=-1,求解出 a 和截矩 w0 的值,进而得到超平面的表达式。
人工智能数据挖掘十大经典算法

数据挖掘十大经典算法一、C4.5C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法。
C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;2)在树构造过程中进行剪枝;3)能够完成对连续属性的离散化处理;4)能够对不完整数据进行处理。
C4.5算法有如下优点:产生的分类规则易于理解,准确率较高。
其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
1、机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。
树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。
2、从数据产生决策树的机器学习技术叫做决策树学习,通俗说就是决策树。
3、决策树学习也是数据挖掘中一个普通的方法。
在这里,每个决策树都表述了一种树型结构,他由他的分支来对该类型的对象依靠属性进行分类。
每个决策树可以依靠对源数据库的分割进行数据测试。
这个过程可以递归式的对树进行修剪。
当不能再进行分割或一个单独的类可以被应用于某一分支时,递归过程就完成了。
另外,随机森林分类器将许多决策树结合起来以提升分类的正确率。
决策树是如何工作的?1、决策树一般都是自上而下的来生成的。
2、选择分割的方法有好几种,但是目的都是一致的:对目标类尝试进行最佳的分割。
3、从根到叶子节点都有一条路径,这条路径就是一条―规则4、决策树可以是二叉的,也可以是多叉的。
对每个节点的衡量:1)通过该节点的记录数2)如果是叶子节点的话,分类的路径3)对叶子节点正确分类的比例。
有些规则的效果可以比其他的一些规则要好。
由于ID3算法在实际应用中存在一些问题,于是Quilan提出了C4。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
5-1 简述机器学习十大算法的每个算法的核心思想、工作原理、适用
情况及优缺点等。
1)C4.5 算法:
ID3 算法是以信息论为基础,以信息熵和信息增益度为衡量标准,从而实现对数据的归纳分类。
ID3 算法计算每个属性的信息增益,并选取具有最高增益的属性作为给定的测试属性。
C4.5 算法核心思想是ID3 算法,是ID3 算法的改进,改进方面有:
1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
2)在树构造过程中进行剪枝
3)能处理非离散的数据
4)能处理不完整的数据
C4.5 算法优点:产生的分类规则易于理解,准确率较高。
缺点:
1)在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
2)C4.5 只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
2)K means 算法:
是一个简单的聚类算法,把n 的对象根据他们的属性分为k 个分割,k < n。
算法的核心就是要优化失真函数J,使其收敛到局部最小值但不是全局最小值。
其中N 为样本数,K 是簇数,rnk b 表示n 属于第k 个簇,uk 是第k 个中心点的值。
然后求出最优的uk
优点:算法速度很快
缺点是,分组的数目k 是一个输入参数,不合适的k 可能返回较差的结果。
3)朴素贝叶斯算法:
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。
算法的基础是概率问题,分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。
朴素贝叶斯假设是约束
性很强的假设,假设特征条件独立,
但朴素贝叶斯算法简单,快速,具有较小的出错率。
在朴素贝叶斯的应用中,主要研究了电子邮件过滤以及文本分类研究。
4)K 最近邻分类算法(KNN)
分类思想比较简单,从训练样本中找出K个与其最相近的样本,然后看这k个样本中哪个类别的样本多,则待判定的值(或说抽样)就属于这个类别。
缺点:
1)K 值需要预先设定,而不能自适应
2)当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K 个邻居中大容量类的样本占多数。
该算法适用于对样本容量比较大的类域进行自动分类。
5)EM 最大期望算法
EM 算法是基于模型的聚类方法,是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量。
E步估计隐含变量,M步估计其他参数,交替将极值推向最大。
EM 算法比K-means 算法计算复杂,收敛也较慢,不适于大规模数据集和高维数据,但比K-means 算法计算结果稳定、准确。
EM 经常用在机器学习和计算机视觉的数据集聚(Data Clustering)领域。
6)PageRank 算法
是google 的页面排序算法,是基于从许多优质的网页链接过来的网页,必定还是优质网页的回归关系,来判定所有网页的重要性。
(也就是说,一个人有着越多牛X 朋友的人,他是牛X 的概率就越大。
)
优点:完全独立于查询,只依赖于网页链接结构,可以离线计算。
缺点:1)PageRank 算法忽略了网页搜索的时效性。
2)旧网页排序很高,存在时间长,积累了大量的in-links,拥有最新资讯的新网页排名却很低,因为它们几乎没有in-links。
7)AdaBoost
Adaboost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。
将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。
整个过程如下所示:
1. 先通过对N 个训练样本的学习得到第一个弱分类器;
2. 将分错的样本和其他的新数据一起构成一个新的N 个的训练样本,通过对这个样本的学习得到第二个弱分类器;
3. 将和都分错了的样本加上其他的新样本构成另一个新的N个的训练样本,通过对这个样本的学习得到第三个弱分类器;
4. 如此反复,最终得到经过提升的强分类器。
目前AdaBoost 算法广泛的应用于人脸检测、目标识别等领域。
8)Apriori 算法
Apriori 算法是一种挖掘关联规则的算法,用于挖掘其内含的、未知的却又实际存在的数据关系,其核心是基于两阶段频集思想的递推算法。
Apriori 算法分为两个阶段:1)寻找频繁项集
2)由频繁项集找关联规则
算法缺点:
1)在每一步产生侯选项目集时循环产生的组合过多,没有排除不应该参与组合的元素;
2)每次计算项集的支持度时,都对数据库中的全部记录进行了一遍扫描比较,需要很大的I/O 负载。
9)SVM 支持向量机
支持向量机是一种基于分类边界的方法。
其基本原理是(以二维数据为例):如果训练数据分布在二维平面上的点,它们按照其分类聚集在不同的区域。
基于分类边界的分类算法的目标是,通过训练,找到这些分类之间的边界(直线的――称为线性划分,曲线的――称
为非线性划分)。
对于多维数据(如N 维),可以将它们视为N 维空间中的点,而分类边界就是N 维空间中的面,称为超面(超面比N维空间少一维)。
线性分类器使用超平面类型的边界,非线性分类器使用超曲面。
支持向量机的原理是将低维空间的点映射到高维空间,使它们成为线性可分,再使用线性划分的原理来判断分类边界。
在高维空间中是一种线性划分,而在原有的数据空间中,是一种非线性划分。
SVM 在解决小样本、非线性及高维模式识别问题中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
10)CART 分类与回归树
是一种决策树分类方法,采用基于最小距离的基尼指数估计函数,用来决定由该子数据集生成的决策树的拓展形。
如果目标变量是标称的,称为分类树;如果目标变量是连续的,称为回归树。
分类树是使用树结构算法将数据分成离散类的方法。
优点
1)非常灵活,可以允许有部分错分成本,还可指定先验概率分布,可使用自动的成本复杂性剪枝来得到归纳性更强的树。
2)在面对诸如存在缺失值、变量数多等问题时CART 显得非常稳健。