(完整word版)大数据分析系统需求
(完整word版)中国移动探索大数据和人工智能参考答案

探索大数据和人工智能参考答案1、下列选项中,不是大数据发展趋势的是?A.大数据分析的革命性方法出现B.大数据与云计算将深度融合C.大数据一体机将陆续发布D.大数据未来可能会被淘汰2、2012年7月,为挖掘大数据的价值,阿里巴巴集团在管理层设立()一职,负责全面推进“数据分享平台”战略,并推出大型的数据分享平台。
A. 首席数据官B. 首席科学家C.首席执行官D.首席架构师3、在Spark的软件栈中,用于机器学习的是A. Spark StreamingB. MllibC. GraphXD. SparkSQL4、MPP是指?A. 大规模并行处理系统B. 受限的分布式计算模型C.集群计算资源管理框架D.分布式计算编程框架5、以下哪个场景可以称为大数据场景?A.故宫游客人数B.故宫门票收入C.美团APP的定位信息D.文章内容6、以下应用没有使用你的地理位置信息的是?A. 美团B. 滴滴C. 高德地图D. Word7、Hadoop是()年诞生的?A. 1985-1985B. 1995-1996C. 2005-2006D. 2015-20168、HBASE的特点不包括哪些?A. 面向行B.稀疏性C. 多版本D.高可靠性9、整个MapReduce的过程大致分为Map、Shuffle、Combine、()?A. ReduceB. HashC. CleanD. Loading10、Flume采用了三层架构,分别为agent,collector和()A. MapB. storageC. ShuffleD. Hash11、在Spark的软件栈中,用于交互式查询的是A. SparkSQLB. MllibC. GraphXD. Spark Streaming12、下列选项中能够正确说明大数据价值密度低的是?A. 100TB数据中有50TB有效数据B. 1TB数据中有1KB有效数据C. 100PB数据中有100PB有效数据D. 10EB数据中有10EB有效数据13、IBM的()是第一个在国际象棋上战胜人类棋手的人工智能计算机。
大数据分析pdf

分布式文件系统
GFS将整个系统分为三类角色:Client(客户端)、Master (主服务器)、Chunk Server(数据块服务器)。
分布式文件系统
Hadoop是一个分布式系统基础架构,由Apache基金 会开发。用户可以在不了解分布式底层细节的情况下, 开发分布式程序,充分利用集群的威力高速运算和存储。 Hadoop实现了一个分布式文件系统(Hadoop Distri buted File System),简称HDFS。HDFS有着高容错 性的特点,并且设计用来部署在低廉的硬件上。
分布式文件系统
Google文件系统(Google File System,GFS)是一 个可扩展的分布式文件系统,用于大型的、分布式的、 对大量数据进行访问的应用。它运行于廉价的普通硬件 上,将服务器故障视为正常现象,通过软件的方式自动 容错,在保证系统可靠性和可用性的同时,大大减少了 系统的成本。
大数据包括: 交易数据和交互数据 集在内的所有数据集
大数据的技术与应用
大数据的技术与应用
1
大数据技术要解决的问题
大数据怎么用
2
大数据的相关技术
3
大数据的应用实例
大数据技术要解决的问题
Streams Real time Near time Batch
Velocity 快速的数据流转
Value
Structured Unstructured Semi-structured All the above
解决方案:
• • Hadoop(MapReduce技术) 流计算(twitter的storm和yahoo!的S4)
数据管理
数据储存
数据分析与挖掘
大数据的相关技术
信息技术行业大数据分析方案

信息技术行业大数据分析方案第一章:项目背景与目标 (2)1.1 项目概述 (2)1.2 项目目标 (3)1.3 项目意义 (3)第二章:数据采集与预处理 (4)2.1 数据源选择 (4)2.2 数据采集方法 (4)2.3 数据清洗与预处理 (4)第三章:数据存储与管理 (5)3.1 存储方案设计 (5)3.1.1 存储架构 (5)3.1.2 存储介质 (5)3.1.3 存储网络 (5)3.1.4 存储策略 (5)3.2 数据库选型与构建 (6)3.2.1 数据库类型 (6)3.2.2 数据库功能 (6)3.2.3 数据库扩展性 (6)3.2.4 数据库构建 (6)3.3 数据安全与备份 (6)3.3.1 数据加密 (6)3.3.2 访问控制 (6)3.3.3 数据备份 (7)3.3.4 备份存储 (7)第四章:数据分析方法与技术 (7)4.1 数据分析方法概述 (7)4.2 数据挖掘技术 (7)4.3 机器学习算法 (8)第五章:数据可视化与报告 (8)5.1 可视化工具选型 (8)5.2 数据可视化设计 (9)5.3 报告撰写与展示 (9)第六章:大数据分析应用场景 (10)6.1 金融行业应用 (10)6.2 医疗行业应用 (10)6.3 零售行业应用 (10)第七章:数据挖掘与决策支持 (11)7.1 决策树模型 (11)7.2 关联规则挖掘 (11)7.3 预测分析模型 (12)第八章:数据治理与合规 (12)8.1 数据治理框架 (12)8.1.1 治理策略与目标 (12)8.1.2 组织架构 (12)8.1.3 数据分类与标准 (13)8.1.4 数据质量管理 (13)8.1.5 数据安全与合规 (13)8.1.6 数据生命周期管理 (13)8.2 数据合规性检查 (13)8.2.1 法律法规梳理 (13)8.2.2 数据来源审查 (13)8.2.3 数据使用审查 (13)8.2.4 数据传输审查 (13)8.2.5 数据存储审查 (13)8.3 数据隐私保护 (13)8.3.1 隐私政策制定 (14)8.3.2 数据脱敏 (14)8.3.3 数据加密 (14)8.3.4 数据访问控制 (14)8.3.5 用户隐私培训 (14)8.3.6 隐私事件应对 (14)第九章:项目实施与进度管理 (14)9.1 项目计划与实施 (14)9.1.1 项目启动 (14)9.1.2 项目计划制定 (14)9.1.3 项目实施 (14)9.2 进度监控与调整 (15)9.2.1 进度监控 (15)9.2.2 进度调整 (15)9.3 风险管理与应对 (15)9.3.1 风险识别 (15)9.3.2 风险评估 (15)9.3.3 风险应对 (15)第十章:项目成果与展望 (16)10.1 项目成果评估 (16)10.2 项目经验总结 (16)10.3 未来发展展望 (16)第一章:项目背景与目标1.1 项目概述信息技术的迅猛发展,大数据已成为推动行业创新与发展的关键力量。
大数据分析概述

• 实时处理的要求,是区别大数据引用和传统数据仓库技术,BI技术的关键差 别之一.
Volume 数据量
PB是大数据層次的临界点. KB->MB->GB->TB->PB->EB->ZB>YB->NB->DB
大数据不仅仅是“大”
多大? PB 级
比大更重要的是 数据的复杂性, 有时甚至大数据 中的小数据如一 条微博就具有颠
大数据的4V特征 体量Volume 多样性Variety
价值密度Value
非结构化数据的超大规模和增长 •占总数据量的80~90% •比结构化数据增长快10倍到50倍 •是传统数据仓库的10倍到50倍
大数据的异构和多样性 • 很多不同形式(文本、图像、视频、机器数据) • 无模式或者模式不明显 • 不连贯的语法或句义
分布式文件系统
GFS将整个系统分为三类角色:Client(客户端)、Master (主服务器)、Chunk Server(数据块服务器)。
分布式文件系统
Hadoop是一个分布式系统基础架构,由Apache基金 会开发。用户可以在不了解分布式底层细节的情况下, 开发分布式程序,充分利用集群的威力高速运算和存储。 Hadoop实现了一个分布式文件系统(Hadoop Distri buted File System),简称HDFS。HDFS有着高容错 性的特点,并且设计用来部署在低廉的硬件上。
(完整word版)软件项目详细设计文档示例模版

(完整word版)软件项目详细设计文档示例模版XXX软件/项目/系统详细设计说明书拟制日期评审人日期批准日期编写单位或个人修订历史目录XXX软件详细设计说明书 (1)Revision Record 修订记录 (1)1 引言 (1)1。
1 编写目的 (1)1.2 背景 (1)1.3 参考资料 (1)1.4 术语定义及说明 (1)2 设计概述 (1)2。
1 任务和目标 (1)2。
1.1 需求概述 (1)2。
1。
2 运行环境概述 (1)2.1.3 条件与限制 (1)2.1.4 详细设计方法和工具 (1)3 系统详细需求分析 (1)3.1 详细需求分析 (1)3。
2 详细系统运行环境及限制条件分析接口需求分析 (2)4 总体方案确认 (2)4。
1 系统总体结构确认 (2)4.2 系统详细界面划分 (2)4.2。
1 应用系统与支撑系统的详细界面划分 (2)4.2.2 系统内部详细界面划分 (2)5 系统详细设计 (2)5。
1 系统结构设计及子系统划分 (2)5.2 系统功能模块详细设计 (3)5。
3 系统界面详细设计 (3)5.3.1 外部界面设计 (3)5.3。
2 内部界面设计 (3)5。
3.3 用户界面设计 (3)6、数据库系统设计 (3)6.1设计要求 (4)6.2 信息模型设计 (4)6。
3 数据库设计 (4)6.3。
1 设计依据 (4)6.3.2 数据库种类及特点 (4)6。
3.3 数据库逻辑结构 (4)6.3.4 物理结构设计 (4)6。
3.5 数据库安全 (4)6。
3。
6 数据字典 (4)7 非功能性设计 (4)8 (4)9 环境配置 (4)1引言1.1编写目的说明编制的目的是,大体上介绍一下软件系统中各层次中模块或子程序、以及数据库系统的设计考虑,表明此文档是主要是为编码人员提供服务,并且其他类型的项目参与人员也可以通过此文档对软件/项目有更深入了解。
1.2背景说明此软件或系统的项目背景、需求背景、开发目的等,还可以列出参与人员等相关信息。
(完整word版)福建省生态环境大数据平台概要设计v0.2

福建省生态环境大数据平台概要设计1.整体设计思想福建省生态环境大数据平台立足于福建省各种生态环境数据;通过多种渠道,采集与生态及环保有关的海量数据;采用当前最前沿的大数据技术(并行计算技术、人工智能技术),对数据等进行挖掘建模和机器学习建模,通过数据挖掘发现隐藏于其后的规律或数据间的关系,充分挖掘这些数据的价值,从而形成能实际应用于民生的新生数据;作为专家及政府的决策依据,辅助政府精细化决策,辅助专家预测将来可能有出现的环保问题;并能解决现实中真实发生的环保问题;从而改善环境,提升居民生活环境的质量,和百姓生活的福祉.平台建成后,将形成一个完整的基于大数据的生态环境数据智能化收集、智能化核算分析、智能化发布和智能化监管体系,这一平台体系可以把福建省生态环境状况,全面、直观地展现给政府部门和社会公众。
同时环保部门可以重点关注核电站周边生态环境实况。
通过可测量、可核查的生态环境数据,为福建省的生态环境现状评估、趋势预测、潜力分析、目标制定与跟踪,提供决策服务,进而实现对生态环境重点污染源、生态环境动态变化进行有效监管,并为建设生态环境交易市场体系奠定基础。
从使用者的角度看,所有的平台数据集中到统一的逻辑平面上来;平台以省、市、县分级别多视角展示生态环境实时信息,以全息,动态的地图形式全方位地展现给使用者。
平台为各类使用者提供不同的观察视角;领导能查看实时汇总信息,核辐射区大气实况;环保工作能查看各类精细报表与指标,并能搜索工作中所需要的信息。
展现方式有:电子大屏幕播放,WEB浏览,手机APP访问等三种方式。
从数据处理的角度看,平台运行后将建成以生态环境数据为中心的开放式数据中心,广泛收集来自气象,农林,海洋,交通,能源, 车联网等第三方数据,同时也给第三方输出数据并分享成果数据;为后续深度学习积累数据样本,将来平台具备很强的自我学习能力。
2.用户使用场景环保领导大屏查看全局实时信息情况,核核辐射区大气实况,查看汇总报表,指挥环境突发事件处理。
大数据毕业设计.docx

大数据毕业设计【篇一:基于hadoop数据分析系统设计(优秀毕业设计)】摘要随着云时代的来临,大数据也吸引越来越多的关注,企业在日常运营中生成、积累的用户网络行为数据。
这些数据是如此庞大,计量单位通常达到了pb、eb甚至是zb。
hadoop作为一个开源的分布式文件系统和并行计算编程模型得到了广泛的部署和应用。
本文将介绍hadoop完全分布式集群的具体搭建过程与基于hive的数据分析平台的设计与实现。
关键字hadoop,mapreduce,hiveabstract with the advent of cloud, big data also attract more and more attention, the enterprise of the generation and accumulation in the daily operation of the user network behavior data. the data is so large, the measuring unit is usually achieved the pb, eb, and even the zb. the hadoop distributed file system as an open source, and parallel computingprogramming model has been widely deployed and application. this article introduces hadoop completely distributed cluster process of concrete structures, and the design and implementation of data analysis platform based on the hive.key words hadoop,mapreduce,hive目录第一章第二章第三章3.13.23.33.43.53.6 某某企业数据分析系统设计需求分析 ...................................................... 3 hadoop简介 (4)hadoop单一部署 ...................................................................................... 7 hadoop 集群部署拓扑图 .................................................................................7 安装操作系统centos (8)hadoop基础配置 ........................................................................................... 14 ssh 免密码登录 ............................................................................................ 17 安装jdk ...................................................................................................... ... 18 安装hadoop .............................................................................................. . (19)3.6.1安装32位hadoop (19)3.6.2安装64位hadoop (28)3.73.8 hadoop优化 ................................................................................................... 32 hive安装与配置 (33)3.8.1 hive安装 (33)3.8.2 使用mysql存储metastore (33)3.8.3 hive的使用 (36)3.9 hbase安装与配置 (37)9.1 hbase安装 (37)9.2 hbase的使用 (39)3.10 集群监控工具ganglia (43)第四章 hadoop批量部署 (48)4.1 安装操作系统批量部署工具cobbler (48)4.2 安装hadoop集群批量部署工具ambari (54)第五章第六章第七章使用hadoop分析网站日志 ................................................................... 63 总结 ....................................................................................................... ..... 67 参考文献 (67)致谢........................................................................................................ . (68)第一章某某企业数据分析系统设计需求分析某某企业成立于1999年,其运营的门户网站每年产生大概2t的日志信息,为了分析网站的日志,部署了一套oracle数据库系统,将所有的日志信息都导入oracle的表中。
(完整word版)GB50174--2017《数据中心设计规范》解读

GB50174--2017《数据中心设计规范》解读GB50174--2017《数据中心设计规范》解读一、数据中心是一切信息化的基础李克强总理在政府报告中指出:新兴产业和新兴业态是竞争高地。
要实施高端装备、信息网络、集成电路、新能源、新材料、生物医药、航空发动机、燃气轮机等重大项目,把一批新兴产业培育成主导产业。
制定“互联网”行动计划,推动移动互联网、云计算、大数据、物联网等与现代制造业结合,促进电子商务、工业互联网和互联网金融健康发展,引导互联网企业拓展国际市场。
云计算、互联网、物联网、大数据等现代信息技术已成为国民经济的重要支柱。
信息化的基础是数据中心,可以说,没有数据中心就没有信息化的发展。
二、规范编制目的1、电子信息技术平均2.5年发展一代,每一代IT技术的发展都意味着其支持技术的发展,即数据中心环境要求、建筑与结构、空气调节、电气、电磁屏蔽、网络系统与布线、智能化、给水排水、消防等技术的发展,这些技术的发展需要相关技术规范的支持。
2、GB50174-2008《电子信息系统机房设计规范》于2008年发布实施,到2015年《电子信息系统机房设计规范》已运行了7年,意味着电子信息技术已发展了3代,需要规范做相应修改。
3、将《电子信息系统机房设计规范》更名为《数据中心设计规范》的主要目的是适应目前国内数据中心的建设需要以及更好地进行国际交流。
三、规范编写原则1、可实施性原则本规范在执行国家相关法律、法规和规范的基础上,注重设计方法的可操作性和可实施性,为设计人员提供实用的设计方法。
2、先进性原则《数据中心设计规范》在满足中国数据中心行业发展的前提下,吸取国外有关数据中心设计的优点,结合中国数据中心行业的具体情况,增加补充具有数据中心行业特点的相关条文规定。
主要围绕数据中心的可靠性、可用性、安全、节能、环保等方面的进行编写,具有一定的技术先进性和前瞻性。
3、科学性原则本规范提出的设计原则和方法归纳总结了国内外数据中心行业的经验,是众多行业专家经过多年实践总结出来的,是以现行有效的相关法规、标准、规范为基础,并充分考虑数据中心行业的特点和特殊性。
(完整word版)大数据案例分析

随着这个细分市场呈现三足鼎立的局面,一个问题浮出水面。郑洪峰向《中国企业家》直言,数据是这个行业最重要的资源。但是目前中航信垄断了大部分行业信息,使得飞常准必须通过购买和交换才能获得自己所需要的数据。
获益的不仅仅是农夫山泉,在农夫山泉场景中积累的经验,SAP迅速将其复制到神州租车身上。“我们客户的车辆使用率在达到一定百分比之后出现瓶颈,这意味着还有相当比率的车辆处于空置状态,资源尚有优化空间。通过合作创新,我们用SAP Hana为他们特制了一个算法,优化租用流程,帮助他们打破瓶颈,将车辆使用率再次提高了15%。”
2011年,SAP推出了创新性的数据库平台SAP Hana,农夫山泉则成为全球第三个、亚洲第一个上线该系统的企业,并在当年9月宣布系统对接成功。
胡健选择SAP Hana的目的只有一个,快些,再快些。采用SAP Hana后,同等数据量的计算速度从过去的24小时缩短到了0.67秒,几乎可以做到实时计算结果,这让很多不可能的事情变为了可能。
有了强大的数据分析能力做支持后,农夫山泉近年以30%-40%的年增长率,在饮用水方面快速超越了原先的三甲:娃哈哈、乐百氏和可口可乐。根据国家统计局公布的数据,饮用水领域的市场份额,农夫山泉、康师傅、娃哈哈、可口可乐的冰露,分别为34.8%、16.1%、14.3%、4.7%,农夫山泉几乎是另外三家之和。对于胡健来说,下一步他希望那些业务员搜集来的图像、视频资料可以被利用起来。
这种没头苍蝇的状况让农夫山泉头疼不已。在采购、仓储、配送这条线上,农夫山泉特别希望大数据获取解决三个顽症:首先是解决生产和销售的不平衡,准确获知该产多少,送多少;其次,让400家办事处、30个配送中心能够纳入到体系中来,形成一个动态网状结构,而非简单的树状结构;最后,让退货、残次等问题与生产基地能够实时连接起来。
(完整word版)大数据技术文档

第1章绪论随着计算机技术、通信网、互联网的迅速发展和日益普及,Internet上的信息量快速增长。
从海量的信息块中快速检索出用户真正需要的信息正变得很困难,信息搜索应向着具有分布式处理能力方向发展,本系统利用hadoop分布式开源框架良好的扩充能力、较低的运作成本、较高的效率和稳定性来满足需求。
现状:缺陷和不足:(1)结果主题相关度不高。
(2)搜素速度慢。
引入hadoop+nutch+solr的优点:(1)hadoop平台数据处理高效。
hadoop集群处理数据比起单机节省数倍的时间,数据量越大优势越明显,满足信息采集对数据处理的速度和质量要求。
(2)hadoop平台具有高扩展性.可以适当扩展集群数量来满足日益不断增加的数据量,而这并不会毁坏原集群的特性。
(3)安全可靠性高。
集群的数据冗余机制使得hadoop能从单点失效中恢复,即Hadoop能自动进行数据的多次备份,以确保数据不丢失,即使当某个服务器发生故障时,它也能重新部署计算任务。
(4) Nutch不仅提供抓取网页的功能,还提供了解析网页、建立链接数据库、对网页进行评分、建立solr索引等丰富的功能。
(5)通过Nutch插件机制实现了系统的可扩展性、灵活性和可维护性,提高了开发效率。
能够根据用户需求进行灵活定制抓取和解析,提高了系统使用性。
(6)通过solr集群,采用分布式索引在不同的机器上并行执行,实现检索服务器之间的信息交换.可以通过设定主题进行索引检索。
研究目标和内容本文的研究目标是全面深入分析研究分布式搜索引擎,进而优化分布式搜索引擎中的索引构建策略,内容包括:(1)深入研究hadoop分布式平台,仔细剖析hadoop中的分布式文件系统HDFS和map/Reduce编程模型。
(2)深入研究Nutch架构、相关技术与体系结构,着重研究分析Nutch插件系统的内部结构和流程;对protocol-httpclient插件进行开发支持表单登录;对 url过滤、信息解析插件进行开发,提高搜索的主题相关度;(实现用mapreduce的google的排序算法,改进系统搜索的关联度)。
(完整word版)大数据技术在电子商务中的研究

大数据技术在电子商务中的研究随着云计算、物联网、社交网络、移动互联网等新兴技术的层出不穷和持续发展,人类全面进入了大数据时代。
各种数据正在迅速膨胀、变大,逐步表现出爆炸性增长的趋势,数据的影响已经渗入到了产业、科研、教育、家庭和社会的各个层面。
随着时间的推移,人们将越来越多的意识到对数据的需求和掌握已不再局限于以往的数据挖掘和数据分析,而是为人们获得更为深刻、全面的洞察水平提供前所未有的支持。
《纽约时报》2012年2月的一篇专栏中称,“大数据”时代已经降临,在商业、经济及其他领域中,决策将日益基于数据和分析而做出,而并非基于经验和直觉1。
2012年3月,美国总统奥巴马公布了美国《大数据研究和发展计划》,标志着大数据已经成为美国的国家战略,上升为国家意志。
那么什么是大数据呢?大数据指的是在“多样的或者大量的数据中快速获取信息的水平”。
IT业界通常将大数据的特征概括为四个“V”:数据量(volume)巨大,数据类型(variety)多,数据价值(Value)大,发掘出价值的速度(Velocity)快2。
大数据和传统所说的数据库有所不同。
诞生在二十世纪七十年代的传统数据库是小型的、单一的、孤立的,基于小范围的抽样样本统计。
而大数据则要求穷尽一切相关样本,搜集尽可能全面的数据,大数据的数据集拥有的不是支离破碎的割裂数据,不是数据片段,而是完整的数据。
数据的海量与数据的完整性使大数据有着传统的数据库无法比拟的信息优势。
1大数据的重要性信息科技经过多年的发展,数据已经渗透到国家治理、国民经济、企业发展的方方面面.这些数据中隐藏着有价值的模式和信息,需要相当的时间和成本才能提取这些信息。
一些新兴的互联网公司,利用新技术大规模地收集数据,分析和预判客户行为,然后在不同的行业纵横捭阖。
而缺少数据资产、缺少强大数据分析水平的公司,则无疑将处于被颠覆的边缘。
所以大数据技术虽然发源于信息科技,但其影响力已经远远超出信息行业,正在“吞噬”和重构很多传统行业,广泛使用数据分析手段管理和优化运营的公司其实质都是一个数据公司.能够毫无疑问地说,大数据事关国计民生、产业兴衰、公司存亡。
(完整word版)H3C大数据产品技术白皮书

H3C大数据产品技术白皮书杭州华三通信技术有限公司2020年4月1 H3C大数据产品介绍 (1)1.1 产品简介 (1)1.2 产品架构 (1)1.2.1 数据处理 (2)1.2.2 数据分层 (3)1.3 产品技术特点 (4)先进的混合计算架构 (4)高性价比的分布式集群 (4)云化ETL (4)数据分层和分级存储 (5)数据分析挖掘 (5)数据服务接口 (5)可视化运维管理 (5)1.4 产品功能简介 (6)管理平面功能: (7)业务平面功能: (8)2 DataEngine HDP 核心技术 (9)3 DataEngine MPP Cluster 核心技术 (9)3.1 MPP + SharedNothing 架构 (9)3.2 核心组件 (10)3.3 高可用 (11)3.4 高性能扩展能力 (11)3.5 高性能数据加载 (12)3.6 OLAP 函数 (13)3.7 行列混合存储 (13)1 H3C大数据产品介绍1.1 产品简介H3C大数据平台采用开源社区Apache Hadoop2.0和MPP分布式数据库混合计算框架为用户提供一套完整的大数据平台解决方案,具备高性能、高可用、高扩展特性,可以为超大规模数据管理提供高性价比的通用计算存储能力。
H3C大数据平台提供数据采集转换、计算存储、分析挖掘、共享交换以及可视化等全系列功能,并广泛地用于支撑各类数据仓库系统、BI系统和决策支持系统帮助用户构建海量数据处理系统,发现数据的内在价值。
1.2 产品架构第一部分是运维管理,包括:安装部署、配置管理、主机管理、用户管HSCZEFKfl上連平frKB笹堆芒12i』」Rt巽^jpRctiuce Spjrk siremCRM SGM生产记〒曲.M-噸Hadaap2.0■1 j jET辛SEmifiKettleH3C大数据平台包含4个部分:理、服务管理、监控告警和安全管理等。
第二部分是数据ETL,即获取、转换、加载,包括:关系数据库连接Sqoop、日志采集Flume、ETL工具Kettle 。
(完整word版)信息安全技术网络安全等级保护测评要求

信息安全技术网络安全等级保护测评要求第1部分:安全通用要求编制说明1概述1.1任务来源《信息安全技术信息系统安全等级保护测评要求》于2012年成为国家标准,标准号为GB/T 28448-2012,被广泛应用于各个行业的开展等级保护对象安全等级保护的检测评估工作。
但是随着信息技术的发展,尤其云计算、移动互联网、物联网和大数据等新技术的发展,该标准在时效性、易用性、可操作性上还需进一步提高,2013年公安部第三研究所联合中国电子技术标准化研究院和北京神州绿盟科技有限公司向安标委申请对GB/T 28448-2012进行修订。
根据全国信息安全标准化技术委员会2013年下达的国家标准制修订计划,国家标准《信息安全技术信息系统安全等级保护测评要求》修订任务由公安部第三研究所负责主办,项目编号为2013bzxd-WG5-006。
1.2制定本标准的目的和意义《信息安全等级保护管理办法》(公通字[2007]43号)明确指出信息系统运营、使用单位应当接受公安机关、国家指定的专门部门的安全监督、检查、指导,而且等级测评的技术测评报告是其检查内容之一。
这就要求等级测评过程规范、测评结论准确、公正及可重现。
《信息安全技术信息系统安全等级保护基本要求》(GB/T22239-2008)(简称《基本要求》)和《信息安全技术信息系统安全等级保护测评要求》(GB/T28448-2012)(简称《测评要求》)等标准对近几年来全国信息安全等级保护工作的推动起到了重要的作用。
伴随着IT技术的发展,《基本要求》中的一些内容需要结合我国信息安全等级保护工作的特点,结合信息技术发展尤其是信息安全技术发展的特点,比如无线网络的大量使用,数据大集中、云计算等应用方式的普及等,需要针对各等级系统应当对抗的安全威胁和应具有的恢复能力,提出新的各等级的安全保护目标。
作为《基本要求》的姊妹标准,《测评要求》需要同步修订,依据《基本要求》的更新内容对应修订相关的单元测评章节。
大数据分析平台的需求报告模板

大数据分析平台的需求报告模板一、项目背景随着企业业务的不断发展和数据量的急剧增长,传统的数据分析方法已经无法满足企业对于快速、准确、全面地获取数据洞察的需求。
为了更好地支持企业的决策制定、业务优化和创新发展,建设一个高效、强大的大数据分析平台成为了当务之急。
二、目标与范围(一)目标1、整合企业内外部的各类数据,实现数据的统一管理和共享。
2、提供快速、灵活、准确的数据分析和挖掘能力,支持实时和离线分析。
3、支持多维度、可视化的数据分析展示,帮助用户直观地理解数据。
4、提升数据质量和数据安全性,确保数据的准确性、完整性和保密性。
(二)范围1、涵盖企业的业务数据、用户数据、市场数据等各类数据源。
2、包括数据采集、存储、处理、分析和展示等全流程功能。
(一)数据源1、内部数据源业务系统数据库,如销售系统、财务系统、客户关系管理系统等。
日志文件,包括服务器日志、应用程序日志等。
文档和电子表格,如 Excel 表格、Word 文档等。
2、外部数据源市场调研报告。
行业公开数据。
社交媒体数据。
(二)数据类型1、结构化数据,如关系型数据库中的表格数据。
2、半结构化数据,如 XML、JSON 格式的数据。
3、非结构化数据,如文本、图像、音频、视频等。
(三)数据量预估根据企业的业务规模和发展趋势,预估未来一段时间内的数据增长情况,以便合理规划存储和计算资源。
四、功能需求1、支持多种数据采集方式,如数据库抽取、文件导入、接口调用等。
2、能够定时自动采集数据,并对采集的数据进行初步的清洗和转换。
(二)数据存储1、具备大规模数据存储能力,支持分布式存储架构。
2、支持多种数据存储格式,如 HDFS、HBase、MySQL 等。
(三)数据处理1、提供数据清洗、转换、整合的工具和流程,确保数据的质量和一致性。
2、支持数据的聚合、分组、排序等操作。
(四)数据分析1、支持多种数据分析算法和模型,如聚类分析、回归分析、关联规则挖掘等。
2、提供数据探索和可视化分析工具,帮助用户快速发现数据中的规律和趋势。
顺德区杏坛中学学业大数据采集分析系统采购需求书
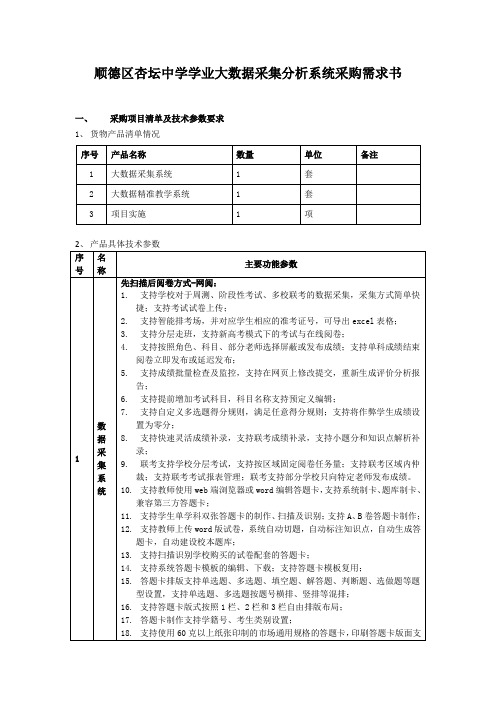
顺德区杏坛中学学业大数据采集分析系统采购需求书一、采购项目清单及技术参数要求1、货物产品清单情况1、 交货时间、地点(1) 供货要求:合同签订之日起10天内完成软件系统的供货、安装与调试,并完成对使用单位相关人员的操作与使用培训。
(2) 交货地点:佛山市顺德区杏坛中学。
2、 验收要求(1) 项目完成后,采购人员组织验收工作。
(2) 中标人应负责在项目验收时将系统的全部相关产品说明书、原厂家安装手册、技术文件、资料、及安装、验收报告等文档汇集成册交付设备使用单位和监理单位。
3、 售后服务要求(1) 卖双方在合同中约定。
质保期后,如采购人要求,中标人应长期负责有偿优惠维修。
(2) 提供标准电话技术支持(7X24小时)。
免费质保期内维修人员接到维修通知后60分钟内响应,当天到达现场,除特殊情况外,故障排除时间不超过12小时。
4、付款要求(1)验收完成后后7个工作日内支付合同总金额100%。
履约保证金按照低于中标价的3%收取,验收完成后一年内无违反合同情况下原路返还。
5、工程实施要求:(1)工程安装实施工作由中标人负责,不准分包,并实行“三包”:包质量、包工期、包施工安全。
必须是投标人自己的专业安装队伍承担工程安装,并由投标人直接进行工程全过程监管,承担工程实施过程的相关人员和施工安全负责。
(2)投标人应提供安装调试工艺流程、质量控制程序和检验方法,处理关键点、难点的对策及措施,实施前须得到采购人批准方能施行。
其内容应对所有货物的安装、调试及现场验收作出详尽安排和说明,并包括参与或派出人员人数、参与时间、责任和工作内容等。
(3)施工现场的管理投标人在工程实施全过程中应服从采购人现场代表或监理代表的统一管理和监督检查。
(4)安装现场工作和生活条件由投标人自行解决。
四、现场产品实物演示内容投标人须在开标现场调用真实平台或真实应用系统进行演示(不得使用PPT、FLASH 演示),投标人自备演示时需要的相关设备,演示时间不超过20分钟。
(完整word版)销售管理系统需求分析

《GIS设计与实现》销售管理系统需求分析报告院(系)测绘科学与技术学院班级测绘1401姓名邹斌学号1802140133日期2017.12.20指导教师庄齐枫目录一、引言 (1)1.1、编写目的 (1)1.2、销售管理系统研究的背景 (2)二、项目概述 (3)2.1、销售管理系统设计目标 (3)2.2、产品功能 (3)三、GIS数据描述 (3)3.1、E-R 图 (3)3.2、系统的总体结构图 (7)3.3、销售管理系统分层数据流图 (7)3.4、仓库管理员处理服务的用例图 (7)3.5、静态结构 (9)四、需求分析 (10)4.1、销售管理系统项目发展概括 (10)4.2、销售管理系统项目需求概括 (10)五、心得体会 (12)一、引言随着市场机制的日趋完善,商品经济化猛进发展,企业自主权不断增强,来往贸易的商品销售过程中,销售管理系统的应用不断地被企业重视,渗透到经济和社会生活的方方面面。
加之互联网环境下的信息爆炸大数据时代,通过一些新旧媒介平台开展营销手段(特别是信息时代下的线上O2O网络交易),许多企业的销售规模不断扩大,订单量越来越多,也就是说在部门人员中会累积大量的客户资料信息、商品信息、订单信息、销售数据和分析数据等,销售管理系统对于各类企业、公司的重要性愈加彰显出来。
1.1、编写目的编写销售管理系统需求分析报告的目的,是为了用户和实施方进一步明确所建系统所达到的功能和目标。
通过双方不断的讨论和交互,最终形成具有建设目标的书面材料。
经双方确认后,将作为系统实施方设计开发系统的基本需求方的软件验收标准。
同时,通过需该需求分析报告,开发方可以更加进一步了解客户的需求,经过深入细致的调研和分析,准确理解用户和项目的功能、性能、可靠性等具体要求,将用户非形式的需求表述转化为完整的需求定义,从而确定系统必须做什么,并严格按照流程及时、准确地完成系统的设计与开发,以满足用户的需求。
同时,此文档作为用户对即将开发的软件的功能要求,也是软件设计和开发者的主要依据。
(完整word版)专业公需电子商务与传统企业转型(下)

1。
以“互联网+”打造现代农业升级版,要以()思维改造传统农业发展思维。
(10。
0分)A.跳跃式B.保守C。
互联网D。
计算机技术我的答案:C√答对2.可以运用互联网提升生产能力的有自动化生产、柔性化生产、大数据运用、智能制造、个性化定制和()。
(10。
0分)A。
购买技术B。
网络营销C.提供极致服务D.以上都不是我的答案:B√答对3.构建与电子商务发展相适应的现代快递、物流配送与全流程供应链体系,构建基于“互联网+”工业产品、农产品、消费品的物流()体系。
(10.0分)A.网络化运营B.站点式运营C.区域化运营D。
一体化运营我的答案:A√答对4.以“互联网+"推进传统产业转型升级,发展绿色制造和()。
(10.0分)A.批量制造B。
规模制造C。
加工制造D。
智能制造我的答案:D√答对1.在国内可参与的共享经济有()等。
(10。
0分))A.汽车、设备、玩具、服装等的产品分享B.住房、办公室、停车位、土地等空间分享C。
智慧、知识、能力、经验等知识技能分享D。
生活服务行业的劳务分享E。
P2P、产品众筹、股权众筹等资金分享我的答案:ABCDE√答对2.一些小微企业和一些传统加工制造企业,它们很难在较短时间内用新技术来提升能力,那么有两条路径可以选择:()。
(10。
0分))A.生产商向外贸供应商转变B.组装转向技术研发C。
购买专业化技术D.建立极致化服务E.以上都不是我的答案:BD×答错1。
营销理念对企业的转型升级毫无影响,没有营销理念的生产不会被这个社会淘汰。
(10。
0分)我的答案:错误√答对2。
在互联网提升生产能力方面,就是电子商务促进企业生产能力的改造,更多的是运用互联网大数据分析技术来提升生产能力。
(10.0分)我的答案:正确√答对3.传统产业不具备电子商务或互联网的思维模式,也很容易在网上销售产品.(10.0分)我的答案:错误√答对4。
电子商务改造传统制造业,营造市场化发展氛围和生态环境,要统一思想,形成“互联网+”的共识、理念和舆论氛围,因地制宜制定发展规划和相关指导意见。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
大数据分析系统需求天津绍闻迪康科技咨询有限公司2018/5/28 仅为需求基本框架,需要根据贵公司产品、技术路线具体面议。
目录一、系统定位 (2)二、功能模块 (3)2.1爬虫系统 (3)2.1.1数据源 (3)2.1.2爬虫系统功能 (3)2.2数据处理、存储、计算系统 (4)2.2.1数据处理模块 (4)2.2.2数据存储模块 (4)2.2.3数据计算模块 (5)2.3数据分析、可视化系统 (9)2.4对外接口 (10)2.4.1会员制体系 (10)2.4.2其他 (10)2.5其他 (11)2.5.1数据痕迹 (11)2.5.2信息安全 (11)2.5.3注意事项 (11)1、系统定位从数据接入到数据应用,我们需要【大数据分析系统】包括几大功能模块:(1)爬虫系统(2)数据处理、存储、计算系统(3)数据人工智能分析、可视化系统(4)外部接口其中第(3)模块是核心,需要结合我们公司业务方向建设相关的数学模型,进行人工智能的自动分析。
爬虫系统可以从指定网站自动的进行信息的抓取,对数据库中的已有词条进行更新或新建,或者从全站按照关键词抓取信息,更新数据库中词条,爬虫搜集到的数据也需要存储到系统中。
数据库系统可以将公司现有资料分库录入系统,生成词条,词条之间相互关联,可以实现跳转,可视化查看;存储爬虫得到的数据。
数据库中的词条或者数据源大多是国外的,例如美国,日本等,涉及到的人物或者其它词条会有多种语言的表达。
系统可以结合爬虫的数据、库中本来的数据按照一定内容生成词条自身的时间轴,多库之间词条的的关系图。
系统需要与外部互联的接口,包括微信平台,天蝎系统,邮件营销平台,调查问卷分析平台。
2、功能模块2.1爬虫系统2.1.1数据源1)网站,可能是信息变化不大的静态网站,也可能是信息在实时更新的动态网站,例如博客或者论坛。
网站库不定时更新。
2)数据库,需要模拟登陆,从一些数据库中抓取数据,例如论文或者专利数据库等,可能是从国内或者国外的数据库网站中。
3)自媒体,例如Facebook,twitter等,需要从中抓取一些个人信息,例如一个人的邮箱,可能需要与公司已有的天蝎系统结合,从天蝎系统已经分析出的个人信息Excel中抓取所需信息。
(可具体商议)2.1.2爬虫系统功能1)爬虫系统需要从指定数据源网站中实时抓取信息,通过实体抽取,和数据库中的词条进行关联,自动更新数据库中已有的词条。
2)可以设定关键词,从全站以及所有数据源中抓取信息,进行数据处理后,按照词条准确匹配,存入数据库;3)可以按照用户指定的关键词在指定的网站中抓取信息,生成结果。
4)爬虫得到的信息生成的报告等可以进行导出。
数据处理在更新或增加词条时需要将抓取到的信息与词条中的属性进行匹配,将对应的信息录入。
可以是实时更新,自动匹配更新;可以是非实时的,有一定的人工干预。
由于库中数据有一大部分是国外的,有一些属性的显示方式并不唯一,需要有一定的匹配规则。
2.2数据处理、存储、计算系统2.2.1数据处理模块系统需要可以对导入系统的文档等数据和爬虫得到的数据进行数据的预处理,进行分词切词,实体抽取(可能为中英日文)。
需要可以自动增加新词条,对比现有词条实现词条的实时更新;或者也可以非实时更新可以有一定的人工干预,进行词条的半自动化增长。
处理过程需要考虑处理的规则和词条匹配的规则。
2.2.2数据存储模块存储在数据库中的数据分为几部分:1)结构化数据分词条存储在数据库中,词条分为:调研人物库,专家库,论文库,专利库,领域库,专题库,快讯库。
还需要存储词条的一些非业务属性:词条的负责人,参与人,时间周期,存储词条本身的时间轴,上传的联系痕迹等。
2)非结构化存储爬虫来的网页,文档(PDF、Word、Excel、PPT、图片、视频)图片,视频。
2.2.3数据计算模块数据库系统含有以下词条库:(1)调研人物库:生成人物简历,信息包括:∙照片,姓名。
∙基本信息:单位,语言,国别,生日,所在地,曾住地。
∙联系方式:电话传真邮箱即时通讯方式∙教育经历:时间学习单位专业学历/学位∙工作经历:时间工作单位职位备注∙官方网站:官方人物数据库社会人物数据库∙学术情况:研究领域论文情况:包括引用次数的表格和具体论文。
专利情况编写书籍参与会议表格所受奖励表格∙合作项目:次数跨度涉及单位具体合作事件∙社会活动:媒体采访政治活动来华交流∙国内外自媒体:在国外社交网站上的交友列表∙人脉关系:总结(共多少人等)姓名、职位的表格家庭情况∙调研总结及合作建议:调研总结合作建议∙原始信息来源网站∙原始文档(2)专家库:生成专家简历,包括:∙照片,姓名∙基本信息:国籍出生年月出生地语言种族∙联系方式:电话邮箱∙教育情况∙工作情况∙合作情况∙所属学会、协会或团体∙其他信息:研究领域获奖头衔∙原始文档(3)领域库:有一定的分类,信息包括:∙从事研究相关领域的人员信息:包括姓名,所在地,毕业院校,单位等∙从事相关行业的公司、机构信息:分国别进行公司介绍包括:名称,类型,地址,联系方式等∙本领域的研究成果等∙领域相关的会议,事件等信息:会议举办时间,主要参与人员,地点,名称。
∙领域相关论文资料:论文名称,发表日期,作者等。
∙领域相关:专题报告,名称,原始文件(4)专利库:信息包括:∙专利名称∙专利申请时间,国别∙专利相关领域,∙专利涉及单位或学校∙专利涉及人员(5)论文库:信息包括:∙论文题目,作者,国别∙所属领域∙发表时间∙论文原文(6)专题库:将之前写过的专题报告做整理,信息包括:∙题目,∙提交时间,∙具体报告:可以查看。
(7)快讯库:之前写过的快讯导入,或者手动添加,内容为:∙快讯标题,∙添加时间,∙领域,∙具体内容,原始文档。
系统本身包含以上几种词条库,库中数据实现可视化查看:1)以上数据首先需要从公司已有的文档中导入,自动匹配词条的属性,生成词条的可视化列表,其中词条的每一个属性作为一个标签,用户可以自己勾选需要的属性,自定义在页面中显示。
2)需要针对不同的国别对词条设置待遇、晋升机制的参考值:针对不同国家公务员,科研机构,高等院校有不同的待遇参考标准,需要在录入词条时能够人工选择,可以进行可视化对比。
3)库中数据可以进行导入导出。
4)数据库中每一个词条都要有相应的负责人,参与人,每一个词条都要有相应的创建更新时间和修改、更新浏览痕迹以及修改内容。
对于一些词条,员工可以上传关于此词条的联系痕迹,比如,专家库中,员工可以上传一些和这个专家的联系记录。
系统可以统计每个员工使用了多少词条,进行可视化查看。
系统中的存储数据主要包括结构化数据:词条数据;非结构化数据:爬虫系统爬取的或者第三方导入的网页、文档(PDF、Word、Excel、PPT、图片、视频)等。
2.3数据分析、可视化系统系统需要能够进行关联分析,生成可视化列表,主要功能为:1.库中结构化数据本身要进行关联分析,不同库中的词条会有属性能够进行相互关联,点击一个库中某一词条的相关属性可以进行跳转到另一库中的相关词条中。
2.可以根据一个关键词,从已有数据库全部词条库、库中存储的非结构化数据(爬虫数据等)中提取出来,形成关系图。
如人物关系图或者机构关系图。
若是输入人物希望包含人物的人际关系图,排出交友情况,公司,领域,会议,研究等相关信息,交友情况要根据人物共同出现的次数排序。
若是输入公司或者机构可以查看公司地点,国家,类型,建立日期公司或机构的人员,分支机构等基本情况。
若输入会议名称可以看到会议举办方,举办地点,主题,涉及领域,参会人员等。
若输入领域可以查看领域相关的科研人员,领域得到研究成果,相关论文,研究机构等。
关联需要可以查看到信息来源。
3.进行多维度分析,例如人物库中,可以生成一个人的时间轴,记录这个人的主要事件。
可以生成这个人的兴趣爱好图,家人关系图等。
行业技术机构库中可以生成主要事件的时间轴等。
4.输入两个关键词可以生成这两侧关键词之间的关系图,可以显示出多层关联,可以查看每层关联的证据。
5.可以对同一库中数据进行模糊查询,全文检索,或者按属性条件进行各种组合的筛选查询。
6.可以实现2-3同库词条的的对比,可视化展示出来。
2.4对外接口2.4.1会员制体系与微信开发对接,实现推送消息半自动化导入,系统数据库可以作为一项客户服务对用户有权限开放。
1.与公司已有的会员制微信体系的对接,系统后期作为客户可以使用的数据库商品,作为一项客户服务对用户有权限开放:需要可以把控客户的使用权限,让客户可以自动化便捷的使用数据库服务。
2. 实现推送消息半自动化导入,能够将系统抓取的数据导出,可以人工的方式导入,进行微信的推送。
2.4.2其他1.可能与公司已有天蝎系统对接,实现一定格式的文档的导入作为爬虫系统的数据源。
2.可能与外部邮件营销系统对接,记录员工发送邮件地址,记录等。
3.可能与调查问卷分析平台对接,将调查问卷的分析结果导入等。
2.5其他2.5.1数据痕迹1.系统要有内部行为记录,可以查看:员工修改记录:查看修改词条痕迹以及具体的修改内容,员工使用记录;2.有外部行为记录:记录客户的查看信息,记录用户行为,可以对客户行为进行一定的分析。
2.5.2信息安全1.系统需要注重系统中的数据信息安全,设置接口可以在文档上传到系统时将公司文档防泄密软件的加密文件解密。
2.可以在从系统传到微信或导出时将文档解密正常的查看;导出的推送报告要有隐藏的水印。
2.5.3注意事项1.系统可能分为几期开发。
2.爬虫系统需要考虑由于涉及数据源可能为海外,主要为英语和日语,国外网站会有不同的反爬机制。
3.需要驻场对接,更好的梳理了解公司业务逻辑。
4.系统完成后需要培训教程,帮助员工快速使用。