语法分析报告
编译原理语法分析实验报告

编译原理语法分析实验报告第一篇:编译原理语法分析实验报告实验2:语法分析1.实验题目和要求题目:语法分析程序的设计与实现。
实验内容:编写语法分析程序,实现对算术表达式的语法分析。
要求所分析算术表达式由如下的文法产生。
E→E+T|E-T|TT→T*F|T/F|F F→id|(E)|num实验要求:在对输入表达式进行分析的过程中,输出所采用的产生式。
方法1:编写递归调用程序实现自顶向下的分析。
方法2:编写LL(1)语法分析程序,要求如下。
(1)编程实现算法4.2,为给定文法自动构造预测分析表。
(2)编程实现算法4.1,构造LL(1)预测分析程序。
方法3:编写语法分析程序实现自底向上的分析,要求如下。
(1)构造识别所有活前缀的DFA。
(2)构造LR分析表。
(3)编程实现算法4.3,构造LR分析程序。
方法4:利用YACC自动生成语法分析程序,调用LEX自动生成的词法分析程序。
实现(采用方法1)1.1.步骤:1)对文法消除左递归E→TE'E'→+TE'|-TE'|εT→FT'T'→*FT'|/FT'|εF→id|(E)|num2)画出状态转换图化简得:3)源程序在程序中I表示id N表示num1.2.例子:a)例子1 输入:I+(N*N)输出:b)例子2 输入:I-NN 输出:第二篇:编译原理实验报告编译原理实验报告报告完成日期 2018.5.30一.组内分工与贡献介绍二.系统功能概述;我们使用了自动生成系统来完成我们的实验内容。
我们设计的系统在完成了实验基本要求的前提下,进行了一部分的扩展。
增加了声明变量类型、类型赋值判定和声明的变量被引用时作用域的判断。
从而使得我们的实验结果呈现的更加清晰和易懂。
三.分系统报告;一、词法分析子系统词法的正规式:标识符(|)* 十进制整数0 |(1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)* 八进制整数0(1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)* 十六进制整数0x(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)* 运算符和分隔符 +| * | / | > | < | = |(|)| <=|>=|==;对于标识符和关键字: A5—〉 B5C5 B5—〉a | b |⋯⋯| y | z C5—〉(a | b |⋯⋯| y | z |0|1|2|3|4|5|6|7|8|9)C5|ε综上正规文法为: S—〉I1|I2|I3|A4|A5 I1—〉0|A1 A1—〉B1C1|ε C1—〉E1D1|ε D1—〉E1C1|εE1—〉0|1|2|3|4|5|6|7|8|9 B1—〉1|2|3|4|5|6|7|8|9 I2—〉0A2 A2—〉0|B2 B2—〉C2D2 D2—〉F2E2|ε E2—〉F2D2|εC2—〉1|2|3|4|5|6|7 F2—〉0|1|2|3|4|5|6|7 I3—〉0xA3 A3—〉B3C3 B3—〉0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f C3—〉(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)|C3|εA4—〉+ |-| * | / | > | < | = |(|)| <=|>=|==; A5—〉 B5C5 B5—〉a | b |⋯⋯| y | z C5—〉(a | b |⋯⋯| y | z |0|1|2|3|4|5|6|7|8|9)C5|ε状态图流程图:词法分析程序的主要数据结构与算法考虑到报告的整洁性和整体观感,此处我们仅展示主要的程序代码和算法,具体的全部代码将在整体的压缩包中一并呈现另外我们考虑到后续实验中,如果在bison语法树生成的时候推不出目标的产生式时,我们设计了报错提示,在这个词的位置出现错误提示,将记录切割出来的词在code.txt中保存,并记录他们的位置。
语法分析实验报告(1)

语法分析实验报告一.实验目的1. 在语法分析器原理学习和词法分析器实验基础上,自行实现一个高级语言语法分析器,通过实验能够把原理和实现方法应用到如描述语言语法分析等词法分析器的设计中去。
2. 利用c语言编制递归下降分析程序,并对简单语言进行语法分析。
二.实验原理1. 待分析的简单语言的语法:0.txt:ghy.txt2. TEST语法规则:(1)<program>::={<declaration_list><statement_list>}(2) <declaration_list>::=<declaration_list><declaration_stat>|ε(3) <declaration_stat>::=int ID;(4) <statement_list>::=<statement_list><statement>|ε(5)<statement>::=<if_stat>|<while_stat>|<for_stat>|<compound_stat>|<expression_stat>(6) <if_stat>::=if(<expression>)<statement>[else<statement>](7) <while_stat)::=while(<expr>)<statement>(8)<for_stat>::=for(<expression>;<expression>;<expression>)<statement>(9) <write_stat>::=write<expression>(10) <read_stat>::=read<ID>(11) <compound_stat>::={<statement_list>}(12) <expression_stat>::=<exxprssion>;|;(13) <expression>::=ID=<bool_expr>|<bool_expr>(14)<bool_expr>::=<additive_expr>|<additive_expr>(<|>|<=|>=|==|!=)<additive_expr >(15) <additive_expr>::=<term>{+|-)<term>}(16) <term>::=<factor>{*|/)<factor>)(17) <factor>::=(<expression>)|ID|NUM三.实验步骤:1.用VC++编辑、编译和运行教材P221~230的语法分析程序。
语法调研结论总结范文

一、调研背景随着我国教育事业的不断发展,语言教学在基础教育阶段占据了越来越重要的地位。
语法作为语言教学的重要组成部分,其教学效果直接影响着学生的语言运用能力。
为了深入了解当前语法教学的现状,探讨有效的语法教学方法,提高语法教学效果,我们开展了一次全面的语法调研。
二、调研方法本次调研采用问卷调查、课堂观察、访谈等多种方法,对全国范围内的部分中小学进行了全面调研。
调研对象包括教师、学生及家长,以确保调研结果的全面性和客观性。
三、调研结果与分析1. 教师教学现状(1)教师对语法教学重视程度较高,普遍认为语法是语言学习的基础。
(2)教师教学方法较为传统,主要依靠讲解和练习,缺乏创新。
(3)教师对学生的语法错误关注度高,但对学生的语法运用能力培养不足。
2. 学生学习现状(1)学生对语法学习兴趣不高,认为语法枯燥乏味。
(2)学生在语法知识掌握方面存在较大差异,部分学生掌握较好,部分学生掌握较差。
(3)学生在语法运用能力方面存在不足,不能灵活运用所学语法知识。
3. 家长关注现状(1)家长普遍关注孩子的语法学习,认为语法是孩子语言能力的重要组成部分。
(2)家长对语法教学效果不满意,认为教师教学方法单一,缺乏针对性。
四、结论与建议1. 结论本次调研结果显示,我国中小学语法教学存在以下问题:教师教学方法单一,学生兴趣不高,家长对教学效果不满意。
这些问题严重影响着语法教学的效果,亟待改进。
2. 建议(1)教师应转变教学观念,注重启发式教学,激发学生学习兴趣。
(2)教师应创新教学方法,结合多媒体技术,提高课堂教学效果。
(3)教师应关注学生个体差异,因材施教,提高学生的语法运用能力。
(4)学校应加强教师培训,提高教师的专业素养和教学能力。
(5)家长应积极配合学校,关注孩子的语法学习,为孩子创造良好的学习环境。
总之,通过本次调研,我们对我国中小学语法教学现状有了更加深入的了解。
在今后的工作中,我们将以此次调研结果为依据,不断改进语法教学方法,提高语法教学效果,为培养具有良好语言能力的学生而努力。
编译原理语法分析实验报告
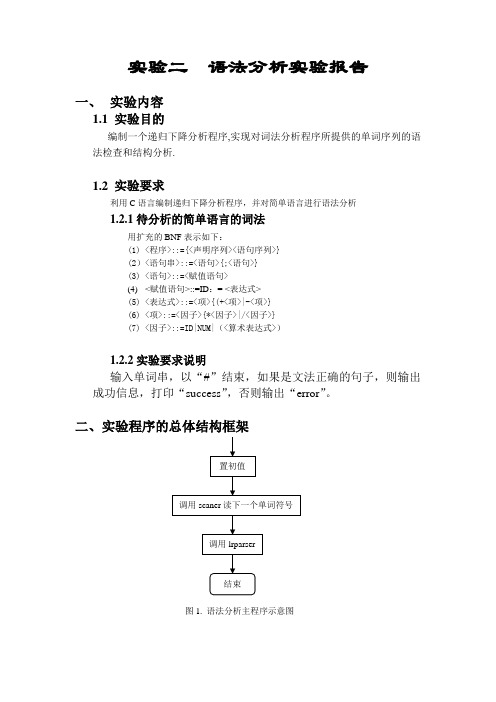
实验二语法分析实验报告一、实验内容1.1 实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析.1.2 实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析1.2.1待分析的简单语言的词法用扩充的BNF表示如下:(1) <程序>::={<声明序列><语句序列>}(2)<语句串>::=<语句>{;<语句>}(3) <语句>::=<赋值语句>(4) <赋值语句>::=ID:= <表达式>(5) <表达式>::=<项>{(+<项>|-<项>}(6) <项>::=<因子>{*<因子>|/<因子>}(7) <因子>::=ID|NUM|(<算术表达式>)1.2.2实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
二、实验程序的总体结构框架图1. 语法分析主程序示意图图2.递归下降分析程序示意图图5. expression表达式分析函数示意图图6.term分析函数示意图三、关键技术的实现方法Scanner函数定义已在实验一给出,本实验不再重复给出void Irparser(){kk=0;if(syn==1){scaner();yucu();if(syn==6){scaner();if(syn==0 && (kk==0)) cout<<"success!"<<endl;}else{if(kk!=1)cout<<"缺end!"<<endl;kk=1;}}else {cout<<"缺begin!"<<endl;kk=1;}return;}void yucu(){statement();while(syn==26){scaner();statement();}return;}void statement() {if(syn==10){scaner();if(syn==18){scaner();expression();}else{cout<<"赋值号错误"<<endl;kk=1;}}else{cout<<"语句错误"<<endl;kk=1;}return;}void expression(){term();while((syn==13)||(syn==14)){scaner();term();}return;}void term(){factor();while((syn==15)||(syn==16)){scaner();factor();}return;}void factor(){if((syn==10)||(syn==11))scaner();else if(syn==27){scaner();expression();if(syn==28)scaner();else{cout<<")错误"<<endl;kk=1;}}else{cout<<"表达式错误"<<endl;kk=1;}return;}void main(){p=0;cout<<"Please input string"<<endl;do{cin.get(ch);if(ch!=”\n”)prog[p++]=ch;}while(ch!='#');p=0;scaner();Irparser();}四、实验心得语法分析是编译过程的核心部分,它的主要功能是按照程序语言的语法规则,从由词法分析输出的源程序符号串中识别出各类语法成分,同时进行语法检查,为语义分析和代码生成做准备。
LL(1)语法分析实验报告

编译原理实验报告
(1)设计思路
输入文法规则、非终结符和终结符先求出first集合,然后根据first集合和文法规则再求出follow集合,最后求出LL(1)预测分析表,最后通过分析表识别字符串是否符合文法规则。
(2)流程图
(3)具体过程:
(a)first和follow集合的计算:
对G中每个文法符号X∈VT∪VN,构造FIRST(X)。
连续使用下述规则,直至每个FIRST集合不再增大:
a、若X∈ VT,则FIRST(X)={X};
b、若X∈ VN,且有产生式X→a…,则把a加入FIRST(X) ;若X→ε也是一条产生式,则把ε也加入
c、若X→Y…是一个产生式且Y∈ VN,则把FIRST(Y)中的所有非ε元素都加入FIRST(X)中;若X→Y1Y2…Yk是一个产生式,Y1,Y2,…,Yi-1都是非终结符,而且,对任意j(1≤j≤i-1),FIRST(Yj)都含有ε,则把FIRST(Yi)
(2)产生各个符合的FIRST集合及FOLLOW集合:
(3)构造M[A,a]
(4)输入字符串:i*(i+i)进行分析:
该字符串是文法的句型
(5)输入另一个字符串:i+i(i*i)进行分析:
该字符串不是文法的句型。
语法分析实验报告

语法分析实验报告一、实验目的语法分析是编译原理中的重要环节,本次实验的目的在于深入理解和掌握语法分析的基本原理和方法,通过实际操作和实践,提高对编程语言语法结构的分析能力,为进一步学习编译技术和开发相关工具打下坚实的基础。
二、实验环境本次实验使用的编程语言为 Python,使用的开发工具为 PyCharm。
三、实验原理语法分析的任务是在词法分析的基础上,根据给定的语法规则,将输入的单词符号序列分解成各类语法单位,并判断输入字符串是否符合语法规则。
常见的语法分析方法有自顶向下分析法和自底向上分析法。
自顶向下分析法包括递归下降分析法和预测分析法。
递归下降分析法是一种直观、简单的方法,但存在回溯问题,效率较低。
预测分析法通过构建预测分析表,避免了回溯,提高了分析效率,但对于复杂的语法规则,构建预测分析表可能会比较困难。
自底向上分析法主要包括算符优先分析法和 LR 分析法。
算符优先分析法适用于表达式的语法分析,但对于一般的上下文无关文法,其适用范围有限。
LR 分析法是一种功能强大、适用范围广泛的方法,但实现相对复杂。
四、实验内容(一)词法分析首先,对输入的源代码进行词法分析,将其分解为一个个单词符号。
单词符号包括关键字、标识符、常量、运算符、分隔符等。
(二)语法规则定义根据实验要求,定义了相应的语法规则。
例如,对于简单的算术表达式,可以定义如下规则:```Expression > Term | Expression '+' Term | Expression ''TermTerm > Factor | Term '' Factor | Term '/' FactorFactor >'(' Expression ')'| Identifier | Number```(三)语法分析算法实现选择了预测分析法来实现语法分析。
首先,根据语法规则构建预测分析表。
然后,从输入字符串的起始位置开始,按照预测分析表的指导进行分析。
编译原理语法分析实验报告

编译原理语法分析实验报告一、实验目的本实验主要目的是学习和掌握编译原理中的语法分析方法,通过实验了解和实践LR(1)分析器的实现过程,并对比不同的文法对语法分析的影响。
二、实验内容1.实现一个LR(1)的语法分析器2.使用不同的文法进行语法分析3.对比不同文法对语法分析的影响三、实验原理1.背景知识LR(1)分析器是一种自底向上(bottom-up)的语法分析方法。
它使用一个分析栈(stack)和一个输入缓冲区(input buffer)来处理输入文本,并通过移进(shift)和规约(reduce)操作进行语法分析。
2.实验步骤1)构建文法的LR(1)分析表2)读取输入文本3)初始化分析栈和输入缓冲区4)根据分析表进行移进或规约操作,直至分析过程结束四、实验过程与结果1.实验环境本实验使用Python语言进行实现,使用了语法分析库ply来辅助实验。
2.实验步骤1)构建文法的LR(1)分析表通过给定的文法,根据LR(1)分析表的构造算法,构建出分析表。
2)实现LR(1)分析器使用Python语言实现LR(1)分析器,包括读取输入文本、初始化分析栈和输入缓冲区、根据分析表进行移进或规约操作等功能。
3)使用不同的文法进行语法分析选择不同的文法对编写的LR(1)分析器进行测试,观察语法分析的结果。
3.实验结果通过不同的测试案例,实验结果表明编写的LR(1)分析器能够正确地进行语法分析,能够识别出输入文本是否符合给定文法。
五、实验分析与总结1.实验分析本实验通过实现LR(1)分析器,对不同文法进行语法分析,通过实验结果可以观察到不同文法对语法分析的影响。
2.实验总结本实验主要学习和掌握了编译原理中的语法分析方法,了解了LR(1)分析器的实现过程,并通过实验提高了对语法分析的理解。
六、实验心得通过本次实验,我深入学习了编译原理中的语法分析方法,了解了LR(1)分析器的实现过程。
在实验过程中,我遇到了一些问题,但通过查阅资料和请教老师,最终解决了问题,并完成了实验。
编译原理LL(1)语法分析实验报告

学号 E 专业计算机科学与技术姓名万学进实验日期2010-5-11教师签字成绩实验报告【实验名称】 LL(1)语法分析【实验目的】通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区别和联系。
使了解语法分析的功能,掌握语法分析程序设计的原理和构造方法,训练掌握开发应用程序的基本方法。
【实验内容】根据某一文法编制调试 LL ( 1 )分析程序,以便对任意输入的符号串进行分析。
构造预测分析表,并利用分析表和一个栈来实现对上述程序设计语言的分析程序。
分析法的功能是利用LL(1)控制程序根据显示栈栈顶内容、向前看符号以及LL(1)分析表,对输入符号串自上而下的分析过程。
【设计思想】(1)定义部分:定义常量、变量、数据结构。
(2)初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体、数组、临时变量等);(3)控制部分:从键盘输入一个表达式符号串;(4)利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示错误信息。
【实验要求】1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。
2、如果遇到错误的表达式,应输出错误提示信息。
3、对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)S->TE(2)E->+TE|$(3)T->FM(4)M->*FM|$(5)F->(E)|i#【流程图】【源代码】#include<>#include<>int vnNum,grammarNum,vtNum=6;int order;int count=1;charGrammar[20][10],BlankTerminate[20][2] ;char First[5][4]={'S','(','i','\0','E','+','$','\0','T','(','i','\0','M','*','$','\0','F','(','i','\0'}; charFollow[5][6]={'S',')','#','\0','\0',' \0','E',')','#','\0','\0','\0','T','+',')','#','\0','\0','M','+',')','#','\0','\0','F','*','+',')','#','\0'};char Select[8][4]={'(','i','\0','\0','+','\0','\0','\0',')','#','\0','\0', '(','i','\0','\0','*','\0','\0','\0','+',')','#','\0','(','\0','\0','\0','i','\0','\0','\0'};int IndiBlanket[6][7];char VT[10]={'i','+','*','(',')','#'};typedef struct {char *base;char *top;int stacksize;}AnalStack;AnalStack S;int ScanGrammar(){FILE *fp=fopen("文法.txt","r"); FILE *tp;char singleChar,nextChar;int i=0,j=0;while(!feof(fp)){fscanf(fp,"%c",&singleChar);if(singleChar=='#'){Grammar[i][j]='\0';break;}if(singleChar=='\n'){Grammar[i][j]='\0';i++;j=0;continue;}if(singleChar=='-'){tp=fp;fscanf(tp,"%c",&nextChar);if(nextChar=='>'){fp=tp;continue;}}if(singleChar=='|'){Grammar[i+1][0]=Grammar[i][0];Grammar[i][j]='\0';i++;j=1;continue;}Grammar[i][j]=singleChar;j++;}// printf("输入的文法:\n");for(int k=0;k<=i;k++){j=0;while(Grammar[k][j]!='\0'){if(j==1){// printf("->");}//printf("%c",Grammar[k][j]);j++;}// printf("\n");}// printf("%d\n",i);fclose(fp);return i;}int Fill(char gi,char sij,int grammarOrder){int i,j;for(i=0;i<vnNum;i++){if(First[i][0]==gi)break;}j=0;while(VT[j]!='\0'){if(VT[j]==sij)break;j++;}IndiBlanket[i][j]=grammarOrder;return 0;}int Indicate(){int i,j;for(i=0;i<vnNum;i++){for(j=0;j<vtNum;j++){IndiBlanket[i][j]=-1;}}for(i=0;i<=grammarNum;i++){j=0;while(Select[i][j]!='\0'){Fill(Grammar[i][0],Select[i][j],i );j++;}}printf("预测分析表如下:\n");for(i=0;i<vnNum;i++){for(j=0;j<vtNum;j++){printf("%3d",IndiBlanket[i][j]);}printf("\n");}return 0;}int Terminate_$(int grammarNum){int j=0;int count;for(int i=0;i<=grammarNum;i++){BlankTerminate[i][1]='0';}BlankTerminate[0][0]=Grammar[0][0];if(Grammar[0][1]=='$'){BlankTerminate[0][1]='1';}count=1;for(i=1;i<=grammarNum;i++){for(j=0;j<count;j++){if(Grammar[i][0]==BlankTerminate[ j][0]){if(Grammar[i][1]=='$'){BlankTerminate[j][1]='1';break;}}}if(j==count){BlankTerminate[count][0]=Grammar[i][0 ];if(Grammar[i][1]=='$'){BlankTerminate[count][1]='1';}count++;}}count--;// printf("$的终结符表:\n");/*for(i=0;i<j;i++){printf("%c:%c\n",BlankTerminate[i][0],BlankTerminate[i][1]);}*/return count;}AnalStack InitStack(){=(char *)malloc(100*sizeof(char));if(!exit(1);=;=100;*='#';++;*='S';return S;}int Print(char AnalStr[],int i,int sign){int startpos=i;printf("%d\t",count);count++;char *p=;while(p!=+2){printf("%c",*p);p++;}printf("\t");while(AnalStr[i]!='\0'){printf("%c",AnalStr[i]);i++;}printf("\t\t");if(sign==0){int j=0;while(Grammar[order][j]!='\0'){printf("%c",Grammar[order][j]);if(j==0)printf("->");j++;}printf("\n");}if(sign==1){printf("%c匹配\n",AnalStr[startpos]);}return 0;}int Push(char topChar,char curChar,int sign,int ii,char AnalStr[]){int i,j;for(i=0;i<vnNum;i++){if(First[i][0]==topChar)break;}j=0;while(VT[j]!='\0'){if(VT[j]==curChar)break;j++;}order=IndiBlanket[i][j];Print(AnalStr,ii,sign);j=1;while(Grammar[order][j]!='\0'){j++;}j--;while(j!=0){if(Grammar[order][j]!='$'){++;*=Grammar[order][j];}j--;}return 0;}int Analysis(){int i=0;int sign=0;int count=1;char curChar;InitStack();char AnalStr[10]={'\0'};printf("输入产生式:\n");scanf("%s",&AnalStr);printf("步骤\t分析栈\t剩余输入串\t产生式\n");while(AnalStr[i]!='\0'){sign=0;curChar=AnalStr[i];char *p=;char topChar=*p;;if(topChar<'A'||topChar>'Z'){if(topChar==curChar){sign=1;Print(AnalStr,i,sign);i++;continue;}else{printf("Analysis ERROR!\n");return 0;}}if(topChar=='#'){if(topChar==curChar){Print(AnalStr,i,sign);break;}else{return 0;}}else{Push(topChar,curChar,sign,i,AnalS tr);}}printf("预测分析成功!\n");return 0;}int main(){int i,m;grammarNum=ScanGrammar();vnNum=Terminate_$(grammarNum); // printf("Select集:\n");for(i=0;i<=grammarNum;i++){m=0;while(Select[i][m]!='\0'){// printf("%c",Select[i][m]);m++;}// printf("\n");}Indicate();Analysis();return 0;}【运行结果】。
LL(1)语法分析实验报告

LL(1)语法分析实验报告一、实验目的通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,检查语法错误,进一步掌握常用的语法分析方法。
二、实验内容构造LL(1)语法分析程序,任意输入一个文法符号串,并判断它是否为文法的一个句子。
程序要求为该文法构造预测分析表,并按照预测分析算法对输入串进行语法分析,判别程序是否符合已知的语法规则,如果不符合则输出错误信息。
消除递归前的文法消除递归后的等价文法E→E+T E→TE’E→T E’→+TE’|εT→T*F T→FT’T→F T’→*FT’|εF→(E)|i F→(E)|i根据已建立的分析表,对下列输入串:i+i*i进行语法分析,判断其是否符合文法。
三、实验要求1.根据已由的文法规则建立LL(1)分析表;2.输出分析过程。
请输入待分析的字符串: i+i*i符号栈输入串所用产生式#E i+i*i# E→TE’#E’T i+i*i# T→FT’#E’T’F i+i*i# F→i#E’T’i i+i*i##E’T’ +i*i# T’→ε#E’ +i*i# E’→+TE’#E’T+ +i*i##E’T i*i# T→FT’#E’T’F i*i# F→i#E’T’i i*i##E’T’ *i# T’→*FT’#E’T’F* *i##E’T’F i# F→i#E’T’i i##E’T’ # T’→ε#E’ # E’→ε# #四、程序思路模块结构:1、定义部分:定义常量、变量、数据结构。
2、初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体等);3、运行程序:让程序分析一个text文件,判断输入的字符串是否符合文法定义的规则;4、利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示简单的错误提示。
五、程序流程图输入要分析的串判断输入串是否正确判断分析句型是否完全匹配?成功失败否是是否八、程序调试与测试结果运行后结果如下:九、实验心得递归下降分析法是确定的自上而下分析法,这种分析法要求文法是LL(1)文法。
语法分析实验报告

一、实验目的1. 了解语法分析的基本概念和原理。
2. 掌握语法分析的方法和步骤。
3. 提高对自然语言处理领域中语法分析技术的理解和应用能力。
二、实验内容1. 语法分析的基本概念语法分析是指对自然语言进行结构分析,将句子分解成词、短语和句子成分的过程。
通过语法分析,可以了解句子的结构、语义和语用信息。
2. 语法分析方法语法分析方法主要有两种:句法分析和语义分析。
(1)句法分析:句法分析是指根据语法规则,对句子进行分解和组合的过程。
常见的句法分析方法有:词法分析、短语结构分析、句法分析。
(2)语义分析:语义分析是指对句子进行分析,以揭示句子所表达的意义。
常见的语义分析方法有:词汇语义分析、句法语义分析、语用语义分析。
3. 语法分析步骤(1)词法分析:将句子中的单词进行分类,提取词性、词义和词形变化等特征。
(2)短语结构分析:将词法分析得到的词组进行分类,提取短语结构、短语成分和短语关系等特征。
(3)句法分析:根据短语结构分析的结果,将句子分解成句子成分,分析句子成分之间的关系。
(4)语义分析:根据句法分析的结果,分析句子所表达的意义。
三、实验过程1. 实验环境:Python 3.8,NLTK(自然语言处理工具包)。
2. 实验步骤:(1)导入NLTK库。
(2)加载句子数据。
(3)进行词法分析,提取词性、词义和词形变化等特征。
(4)进行短语结构分析,提取短语结构、短语成分和短语关系等特征。
(5)进行句法分析,分解句子成分,分析句子成分之间的关系。
(6)进行语义分析,揭示句子所表达的意义。
四、实验结果与分析1. 词法分析结果实验句子:“我喜欢吃苹果。
”词性标注:我/代词,喜欢/动词,吃/动词,苹果/名词。
2. 短语结构分析结果实验句子:“我喜欢吃苹果。
”短语结构:主语短语(我),谓语短语(喜欢吃苹果)。
3. 句法分析结果实验句子:“我喜欢吃苹果。
”句子成分:主语(我),谓语(喜欢),宾语(吃苹果)。
4. 语义分析结果实验句子:“我喜欢吃苹果。
编译原理算符优先算法语法分析实验报告

编译原理算符优先算法语法分析实验报告实验报告:算符优先算法的语法分析一、实验目的本次实验旨在通过算符优先算法对给定的文法进行语法分析,实现对给定输入串的分析过程。
通过本次实验,我们能够了解算符优先算法的原理和实现方式,提升对编译原理的理解和应用能力。
二、实验内容1.完成对给定文法的定义和构造2.构造算符优先表3.实现算符优先分析程序三、实验原理算符优先算法是一种自底向上的语法分析方法,通过构造算符优先表来辅助分析过程。
算符优先表主要由终结符、非终结符和算符优先关系组成,其中算符优先关系用1表示优先关系,用2表示不优先关系,用0表示无关系。
算符优先分析程序的基本思路是:根据算符优先关系,依次将输入串的符号压栈,同时根据优先关系对栈内符号进行规约操作,最终判断输入串是否属于给定文法。
四、实验步骤1.定义和构造文法在本次实验中,我们假设给定文法如下:1)E->E+T,T2)T->T*F,F3)F->(E),i2.构造算符优先表根据给定文法,构造算符优先表如下:+*()i#+212112*222112(111012222122i222222#1112203.实现算符优先分析程序我们可以用C语言编写算符优先分析程序,以下是程序的基本框架:```c#include <stdio.h>//判断是否为终结符int isTerminal(char c)//判断条件//匹配符号int match(char stack, char input)//根据算符优先关系表进行匹配//算符优先分析程序void operatorPrecedence(char inputString[]) //定义栈char stack[MAX_SIZE];//初始化栈//将#和起始符号入栈//读入输入串//初始化索引指针//循环分析输入串while (index <= inputLength)//判断栈顶和输入符号的优先关系if (match(stack[top], inputString[index])) //栈顶符号规约} else//符号入栈}//计算新的栈顶}//判断是否成功分析if (stack[top] == '#' && inputString[index] == '#')printf("输入串符合给定文法!\n");} elseprintf("输入串不符合给定文法!\n");}```五、实验结果经过实验,我们成功实现了算符优先算法的语法分析。
编译原理语法分析实验报告

编译原理语法分析实验报告编译原理实验报告二、语法分析(一) 实验题目编写程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析。
(二) 实验内容和要求1. 要求程序至少能分析的语言的内容有:1) 变量说明语句2) 赋值语句3) 条件转移语句4) 表达式(算术表达式和逻辑表达式)5) 循环语句6) 过程调用语句2. 此外要处理:包括依据文法对句子进行分析;出错处理;输出结果的构造。
3. 输入输出的格式:输入:单词文件(词法分析的结果)输出:语法成分列表或语法树(都用文件表示),错误文件(对于不合文法的句子)。
4. 实现方法:可以采用递归下降分析法,LL(1)分析法,算符优先法或LR分析法的任何一种,也可以针对不同的句子采用不同的分析方法。
(三) 实验分析与设计过程1. 待分析的C语言子集的语法:该语法为一个缩减了的C语言文法,估计是整个C语言所有文法的60%(各种关键字的定义都和词法分析中的一样),具体的文法如下:语法:100: program -> declaration_list101: declaration_list -> declaration_list declaration | declaration 102: declaration -> var_declaration|fun_declaration103: var_declaration -> type_specifier ID;|type_specifier ID[NUM]; 104: type_specifier -> int|void|float|char|long|double|105: fun_declaration -> type_specifier ID (params)|compound_stmt 106: params -> params_list|void107: param_list ->param_list,param|param108: param -> type-spectifier ID|type_specifier ID[]109: compound_stmt -> {local_declarations statement_list}110: local_declarations -> local_declarations var_declaration|empty 111: statement_list -> statement_list statement|empty11编译原理实验报告112: statement -> epresion_stmt|compound_stmt|selection_stmt|iteration_stmt|return_stmt113: expression_stmt -> expression;|;114: selection_stmt -> if{expression)statement|if(expression)statement else statement115: iteration_stmt -> while{expression)statement116: return_stmt -> return;|return expression;117: expression -> var = expression|simple-expression118: var -> ID |ID[expression]119: simple_expression ->additive_expression relop additive_expression|additive_expression 120: relop -> <=|<|>|>=|= =|!=121: additive_expression -> additive_expression addop term | term 122: addop -> + | -123: term -> term mulop factor | factor124: mulop -> *|/125: factor -> (expression)|var|call|NUM126: call -> ID(args)127: args -> arg_list|empty128: arg_list -> arg_list,expression|expression该文法满足了实验的要求,而且多了很多的内容,相当于一个小型的文法说明:把文法标号从100到128是为了程序中便于找到原来的文法。
ll 1 语法分析实验报告

ll 1 语法分析实验报告语法分析实验报告一、引言语法分析是编译器中的重要步骤之一,它负责将输入的源代码转化为语法树或抽象语法树,以便后续的语义分析和代码生成。
本实验旨在通过实现一个简单的LL(1)语法分析器,加深对语法分析原理和算法的理解。
二、实验目的1. 理解LL(1)语法分析的原理和算法;2. 掌握使用LL(1)文法描述语言的方法;3. 实现一个简单的LL(1)语法分析器。
三、实验环境本实验使用C++编程语言,开发环境为Visual Studio。
四、实验步骤1. 设计LL(1)文法在开始实现LL(1)语法分析器之前,我们需要先设计一个LL(1)文法。
LL(1)文法是一种满足LL(1)分析表构造要求的文法,它能够保证在语法分析过程中不会出现二义性或回溯。
通过仔细分析待分析的语言的语法规则,我们可以设计出相应的LL(1)文法。
2. 构造LL(1)分析表根据设计的LL(1)文法,我们可以构造出对应的LL(1)分析表。
LL(1)分析表是一个二维表格,其中的行表示文法的非终结符,列表示文法的终结符。
表格中的每个元素表示在某个非终结符和终结符的组合下,应该进行的语法分析动作。
3. 实现LL(1)语法分析器基于构造的LL(1)分析表,我们可以开始实现LL(1)语法分析器。
分析器的主要工作是根据输入的源代码和LL(1)分析表进行分析,并输出语法树或抽象语法树。
五、实验结果与分析经过实验,我们成功实现了一个简单的LL(1)语法分析器,并对一些简单的语言进行了分析。
实验结果表明,我们设计的LL(1)文法和LL(1)分析表能够正确地进行语法分析,没有出现二义性或回溯。
六、实验总结通过本次实验,我们深入学习了LL(1)语法分析的原理和算法,并通过实现一个简单的LL(1)语法分析器加深了对其的理解。
实验过程中,我们发现LL(1)文法的设计和LL(1)分析表的构造是实现LL(1)语法分析器的关键。
同时,我们也意识到LL(1)语法分析器在处理复杂的语言时可能会面临一些困难,需要进一步的研究和优化。
LL(1) 语法分析实验 (4学时)——学实验报告

大学实验报告
No. 2
课程编译原理成绩教师签章
实验名称:LL(1) 语法分析实验(4学时)
一、实验目的:
1. 了解LL(1)语法分析是如何根据语法规则逐一分析词法分析所得到的单词,检查语法错误,即掌握语法分析过程。
2. 掌握LL(1)语法分析器的设计与调试
二、实验内容:
文法:E→TE’,E’→+TE’|ε,T→FT’,T’→*FT’|ε,F→(E) | i
针对上述文法,编写一个LL(1)语法分析程序:
1. 输入:诸如i+i*i 的字符串,以#结束。
2. 处理:基于分析表进行LL(1)语法分析,判断其是否符合文法。
3. 输出:串是否合法。
三、实验要求:
1. 在编程前,根据上述文法建立对应的、正确的预测分析表。
2. 设计恰当的数据结构存储预测分析表。
3. 任选C/C++/Java中的一种作为编程语言,要求所编程序结构清晰。
四、实验环境:
系统要求:WindowsXP系统
内存:256M以上
软件支持:Microsoft Visual C++6.0
开发语言:C++
五、实验分析:
1.通过文法:E→TE’,E’→+TE’|ε,T→FT’,T’→*FT’|ε,F→(E) | i 产生
六、实验过程:
七、实验结论:。
语法分析实验报告(实验二)

编译原理语法分析实验报告软工082班兰洁4一、实验容二、实验目的三、实验要求四、程序流程图●主函数;●scanner();●irparser()函数●yucu() /*语句串分析*/●statement()/*语句分析函数*/●expression()/*表达式分析函数*/●term()/*项分析函数*/●factor()/*因子分析函数*/五、程序代码六、测试用例七、输出结果八、实验心得一、实验容:编写为一上下文无关文法构造其递归下降语法分析程序,并对任给的一个输入串进行语法分析检查。
程序要求能对输入串进行递归下降语法分析,能判别程序是否符合已知的语法规则,如果不符合(编译出错),则输出错误信息。
二、实验目的:构造文法的语法分析程序,要求采用递归下降语法分析方法对输入的字符串进行语法分析,实现对词法分析程序所提供的单词序列的语法检查和结构分析,进一步掌握递归下降的语法分析方法。
三、实验要求:利用C语言编制递归下降分析程序,并对Training语言进行语法分析。
1.待分析的Training语言语法。
用扩充的表示如下:<程序>-->function<语句串>endfunc<语句串>--><语句>{;<语句>}<语句>→<赋值语句><赋值语句>→ID→<表达式><表达式>→<项>{+<项>|-<项>}<项>→<因子>{*<因子>|/<因子>}<因子>→ID|NUM|(<表达式>)备注:实验当中我对程序进行了扩展,增加了程序识别if条件判断语句,while循环语句的功能2.实验要求说明输入单词串以“#”结束,如果是文确的句子,则输出成功信息,打印“success”,否则输出“error”。
LL(1)语法分析实验报告

实验报告姓名:***学号:**********班级:惠普开发142学校:青岛科技大学Mail:****************电话:178****6475教师:宮生文实验报告:实验名称:LL(1)语法分析实验目的和要求编制一个能识别由词法分析给出的单词符号序列是否是给定文法的正确句子(程序),输出对输入符号串的分析过程。
实验内容和步骤:一、实验内容对于这个实验,总共用了三个函数,即主函数、输出分析栈函数、输出剩余串函数。
在主函数中,还要构造预测分析表。
二、实验步骤1、基于实验的内容,构造程序所需的模块2、根据已建构的模块,写出各个模块的相应程序代码3、在主函数中调用模块来完成所要得到的效果在本程序中,首先使用了结构体类型定义来定义产生式,用字符串数组存放分析栈、剩余串、终结符和非终结符,用二维数组存放预测分析表,利用指针对栈中数据进行读取。
在本程序中,总共用了三个函数,即主函数、输出分析栈函数、输出剩余串函数。
在主函数中,还要构造预测分析表,对输入的字符串进行分析,调用另外两个函数。
实验代码如下:#include<stdio.h>#include<stdlib.h>#include<string.h>#include<dos.h>char A[20];/*分析栈*/char B[20];/*剩余串*/char v1[20]={'i','+','*','(',')','#'};/*终结符*/char v2[20]={'E','G','T','S','F'};/*非终结符*/int j=0,b=0,top=0,l;/*L为输入串长度*/typedef struct type/*产生式类型定义*/{char origin;/*大写字符*/char array[5];/*产生式右边字符*/int length;/*字符个数*/}type;type e,t,g,g1,s,s1,f,f1;/*结构体变量*/type C[10][10];/*预测分析表*/void print()/*输出分析栈*/{int a;/*指针*/for(a=0;a<=top+1;a++)printf("%c",A[a]);printf("\t\t");}/*print*/void print1()/*输出剩余串*/{int j;for(j=0;j<b;j++)/*输出对齐符*/printf(" ");for(j=b;j<=l;j++)printf("%c",B[j]);printf("\t\t\t");}/*print1*/void main(){int m,n,k=0,flag=0,finish=0;char ch,x;type cha;/*用来接受C[m][n]*//*把文法产生式赋值结构体*/e.origin='E';strcpy(e.array,"TG");e.length=2;t.origin='T';strcpy(t.array,"FS");t.length=2;g.origin='G';strcpy(g.array,"+TG");g.length=3;g1.origin='G';g1.array[0]='^';g1.length=1;s.origin='S';strcpy(s.array,"*FS");s.length=3;s1.origin='S';s1.array[0]='^';s1.length=1;f.origin='F';strcpy(f.array,"(E)");f.length=3;f1.origin='F';f1.array[0]='i';f1.length=1;for(m=0;m<=4;m++)/*初始化分析表*/for(n=0;n<=5;n++)C[m][n].origin='N';/*全部赋为空*//*填充分析表*/C[0][0]=e;C[0][3]=e;C[1][1]=g;C[1][4]=g1;C[1][5]=g1;C[2][0]=t;C[2][3]=t;C[3][1]=s1;C[3][2]=s;C[3][4]=C[3][5]=s1;C[4][0]=f1;C[4][3]=f;printf("提示:本程序只能对由'i','+','*','(',')'构成的以'#'结束的字符串进行分析,\n"); printf("请输入要分析的字符串:");do/*读入分析串*/{scanf("%c",&ch);if ((ch!='i') &&(ch!='+') &&(ch!='*')&&(ch!='(')&&(ch!=')')&&(ch!='#')){printf("输入串中有非法字符\n");exit(1);}B[j]=ch;j++;}while(ch!='#');l=j;/*分析串长度*/ch=B[0];/*当前分析字符*/A[top]='#'; A[++top]='E';/*'#','E'进栈*/printf("步骤\t\t分析栈\t\t剩余字符\t\t所用产生式\n");do{x=A[top--];/*x为当前栈顶字符*/printf("%d",k++);printf("\t\t");for(j=0;j<=5;j++)/*判断是否为终结符*/if(x==v1[j]){flag=1;break;}if(flag==1)/*如果是终结符*/{if(x=='#'){finish=1;/*结束标记*/printf("acc!\n");/*接受*/getchar();getchar();exit(1);}/*if*/if(x==ch){print();print1();printf("%c匹配\n",ch);ch=B[++b];/*下一个输入字符*/flag=0;/*恢复标记*/}/*if*/else/*出错处理*/{print();print1();printf("%c出错\n",ch);/*输出出错终结符*/exit(1);}/*else*/}/*if*/else/*非终结符处理*/{for(j=0;j<=4;j++)if(x==v2[j]){m=j;/*行号*/break;}for(j=0;j<=5;j++)if(ch==v1[j]){n=j;/*列号*/break;}cha=C[m][n];if(cha.origin!='N')/*判断是否为空*/{print();print1();printf("%c-",cha.origin);/*输出产生式*/for(j=0;j<cha.length;j++)printf("%c",cha.array[j]);printf("\n");for(j=(cha.length-1);j>=0;j--)/*产生式逆序入栈*/A[++top]=cha.array[j];if(A[top]=='^')/*为空则不进栈*/top--;}/*if*/else/*出错处理*/{print();print1();printf("%c出错\n",x);/*输出出错非终结符*/exit(1);}/*else*/}/*else*/}while(finish==0);}/*main*/三、实验过程记录:实验截图:当输入内容不匹配或输入内容非法时要退出程序,此时若不关闭已经打开的文件可能导致文件内容受到破坏;解决方法是给error()函数设置一个文件指针变量参数FILE* fp,在退出程序之前通过fp关闭文件四、实验总结:通过本次实验我锻炼了自己的上机操作能力及编程能力,并对理论知识有了进一步的了解。
语法分析器实验报告

语法分析器实验报告实验报告:语法分析器的设计与实现摘要:语法分析器是编译器的一个重要组成部分,主要负责将词法分析器输出的词法单元序列进行分析和解释,并生成语法分析树。
本实验旨在设计与实现一个基于上下文无关文法的语法分析器,并通过实现一个简单的编程语言的解释器来验证其功能。
1.引言在计算机科学中,编译器是将高级程序语言转化为机器语言的一种工具。
编译器通常由词法分析器、语法分析器、语义分析器、中间代码生成器、优化器和目标代码生成器等多个模块组成。
其中,语法分析器负责将词法分析器生成的词法单元序列进行进一步的分析与解释,生成语法分析树,为后续的语义分析和中间代码生成提供基础。
2.设计与实现2.1上下文无关文法上下文无关文法(CFG)是指一类形式化的语法规则,其中所有的产生式规则都具有相同的左部非终结符,且右部由终结符和非终结符组成。
语法分析器的设计与实现需要依据给定的上下文无关文法来进行,在本实验中,我们设计了一个简单的CFG,用于描述一个名为"SimpleLang"的编程语言。
2.2预测分析法预测分析法是一种常用的自顶向下的语法分析方法,它利用一个预测分析表来决定下一步的推导选择。
预测分析表的构造依赖于给定的上下文无关文法,以及文法的FIRST集和FOLLOW集。
在本实验中,我们使用了LL(1)的预测分析法来实现语法分析器。
2.3语法分析器实现在实现语法分析器的过程中,我们首先需要根据给定的CFG构造文法的FIRST集和FOLLOW集,以及预测分析表。
接下来,我们将词法分析器输出的词法单元序列作为输入,通过不断地匹配输入符号与预测分析表中的预测符号,进行语法分析和推导。
最终,根据CFG和推导过程,构建语法分析树。
3.实验结果与分析通过实验发现,自顶向下的预测分析法在对简单的编程语言进行语法分析时具有较高的效率和准确性。
语法分析器能够正确地识别输入程序中的语法错误,并生成相应的错误提示信息。
语法分析器实验报告

杭州电子科技大学班级: 12052312 专业: 计算机科学与技术实验报告【实验名称】实验二语法分析一. 实验目的编写一个语法分析程序, 实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二. 实验内容利用编程语言实现语法分析程序, 并对简单语言进行语法分析。
2.1 待分析的简单语言的语法用扩充的BNF表示如下:⑴<程序>: : =begin<语句串>end⑵<语句串>: : =<语句>{;<语句>}⑶<语句>: : =<赋值语句>⑷<赋值语句>: : =ID: =<表达式>⑸<表达式>: : =<项>{+<项> | -<项>}⑹<项>: : =<因子>{*<因子> | /<因子>⑺<因子>: : =ID | NUM | (<表达式>)2.2 实验要求说明输入单词串, 以“#”结束, 如果是文法正确的句子, 则输出成功信息, 打印“success”, 否则输出“error”。
例如:输入begin a:=9; x:=2*3; b:=a+x end #输出success!输入x:=a+b*c end #输出error测试以上输入的分析, 并完成实验报告。
2.3 语法分析程序的算法思想(1)主程序示意图如图2-1所示。
图2-1 语法分析主程序示意图(2)递归下降分析程序示意图如图2-2所示。
(3)语句串分析过程示意图如图2-3所示。
图2-3 语句串分析示意图图2-2 递归下降分析程序示意图(4)statement 语句分析程序流程如图2-4.2-5.2-6.2-7所示。
图2-4 statement 语句分析函数示意图 图2-5 expression 表达式分析函数示意图图2-7 factor 分析过程示意图三.个人心得一、 通过该实验, 主要有以下几方面收获: 二、 对实验原理有更深的理解。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
思考题3:如果在语法分析中遇到了语法错误,是应该中断语法分析呢,还是应该进行适当处理后继续语法分析,你是怎么处理的?
五、实验体会
包括收获、心得体会、存在的问题及解决问题的方法、建议等
(2)在手工构造的文法的基础上实现LL(1)( LR(1))分析,给出其语法分析表的生成程序(对应不同的语法分析方法产生不同的分析表)及其数据结构和查找算法。
(3)给出错误处理方法,错误的位置及类型等。
(4)对字符串代码进行语法分析,并输出其语法分析结果。
三、实验结果
要求:将实验获得的结果进行描述,基本内容包括:
(1)针对某测试程序输出其语法分析结果;
(2)输出针对此测试程序对应的语法错误报告;
注:其中的测试样例自行产生。
四、实验中遇到的问题总结
主要阐述两方面的问题
(一)实验过程中遇到的问题如何解决的?
着重从实验内容的实现、上机实践以及结果分析方面进行阐述。
(二)思考题的思考与分析
思考题1:给出在生成语法分析表时所遇到的困难,以及是如何处理的?
《编译原理》课程
实验报告
哈尔滨工程大学软件学院
2015年5月
实验2:语法分析
一、实验目的
1.巩固对语法分析的基本功能和原理的认识。
2.通过对语法分析表的自动生成加深语法分析表的认识。
3.理解并处理语法分析中的异常和错误。
二、实验内容
要求:对如下工作进展开描述
(1)掌握语法分析程序的总体框架,并将其实现。