第讲-SPSS探索和交叉表分析PPT课件
第五章交叉表分析ppt课件

资 金是运 动的价 值,资 金的价 值是随 时间变 化而变 化的, 是时间 的函数 ,随时 间的推 移而增 值,其 增值的 这部分 资金就 是原有 资金的 时间价 值
第7步:设置交叉表的显示。
资 金是运 动的价 值,资 金的价 值是随 时间变 化而变 化的, 是时间 的函数 ,随时 间的推 移而增 值,其 增值的 这部分 资金就 是原有 资金的 时间价 值
计算性别与英语四级的卡方值的效应量和统计检验力。 ➢ 第一步:效应量克莱姆V系数为0.279。 ➢ 第二步:根据Cohen(1992) 对克莱姆V系数效应量大小
的评定表(查询表5- 2),效应量0.279,很接近0.30,为 中效应量。 ➢ 第三步:根据克莱姆V系数值的大小和自由度查表确定统计 检验力。这里卡方检验为中效应量,总自由度为(2-1)* (2-1)=1,总体N为286,查询表5-3统计检验力表,可 知统计检验力为大约0.99,即99%左右。 由以上计算可知,在本例中,统计量检验显著(P小于0.05 ,拒绝原假设),并且是中效应量。此时说明统计结论(拒 绝原假设的结论)的可靠性尚可,基本可以认同此结论(拒 绝原假设)
总之,在本例中,统计量检验显著(P小于0.05,拒绝原 假设),并且是小效应量。此时说明统计结论的可靠性较低, 还需进一步的研究资料佐证此结论,研究结果推广时要慎重。
资 金是运 动的价 值,资 金的价 值是随 时间变 化而变 化的, 是时间 的函数 ,随时 间的推 移而增 值,其 增值的 这部分 资金就 是原有 资金的 时间价 值
二、品质相关性检验:是指两个或两个以上的 分类变量(顺序变量)之间相关性程度的假设 检验。原假设 为:所观测的两个分类变量之间 的相关性为0。备择假设 为:所观测的两个分 类变量之间的相关性显著。
spss(13.0)教程PPT课件

Frequencies过程
例 某地101例健康男子血清总胆固醇值测定结果如下, 请绘制频数表、直方图,计算均数、标准差、变异系数CV、 中位数M、p2.5和p97.5(卫统第三版p233 1.1题)。
4.77 3.37 6.14 3.95 3.56 4.23 4.31 4.71 5.69 4.12 4.56 4.37 5.39 6.30 5.21 7.22 5.54 3.93 5.21 4.12 5.18 5.77 4.79 5.12 5.20 5.10 4.70 4.74 3.50 4.69 4.38 4.89 6.25 5.32 4.50 4.63 3.61 4.44 4.43 4.25 4.03 5.85 4.09 3.35 4.08 4.79 5.30 4.97 3.18 3.97 5.16 5.10 5.86 4.79 5.34 4.24 4.32 4.77 6.36 6.38 4.88 5.55 3.04 4.55 3.35 4.87 4.17 5.85 5.16 5.09 4.52 4.38 4.31 4.58 5.72 6.55 4.76 4.61 4.17 4.03 4.47 3.40 3.91 2.70 4.60 4.09 5.96 5.48 4.40 4.55 5.38 3.89 4.60 4.47 3.64 4.34 5.18 6.14 3.24 4.90 3第.2065页/共94页
重点介绍 重点介绍 重点介绍 重点介绍 重点介绍
• 数据的预分析 • 数据的简单描述 • 绘制直方图
• 按题目要求进行统计分析 • 保存和导出分析结果
• 保存文件 • 导出分析结果
第17页/共94页
数据文件管理
• 编辑数据文件 • 定义新变量 • 直接定义新变量 • 从原有变量计算新变量-Transform菜单 • 数据的录入 • 直接录入 • 数据录入技巧
SPSSPPT学习课件PPT课件

地位欲 .818** .001 12
1.000 . 12
从表中可看出,权威主义和地位欲的相关系数为0.818, 这表明权威主义越高的人地位欲也越高。权威主义与地位 欲不相关的假设检验值为0.001,否定假设,即权威主义与 地位欲是相关的。
2021/6/22
1
11
第11页/共128页
(三)、有序变量的Kendall分析实例
2、非参相关分析
如果数据不满足正态分布的条件,应使用Spearman 和Kendall 相关分析方法
1)Spearman相关系数是Pearson相关系数的非参形式,是根据数 据的秩而不是根据实际值计算的。它适合有序数据或不满足正态分 布假设的等间隔数据。计算时,必须对连续变量值排秩,对离散变 量排序。其计算公式为:
2021/6/22
1
12
第12页/共128页
自己动手啊!!!
链接
实践8-1
下列数据为12 位学生的体重与 血压,现要了解 学生的体重与血 压是否相关。
数据文件见 “课堂练 习”8章中的 “相关1.sav”
编号
1 2 3 4 5 6 7 8 9 10 11 12
体重
68 48 56 60 83 56 62 59 77 58 75 64
表8-1 连续变量相关分析实例数据表
观测 号 体重(克) 鸡冠重(毫克)
1 2 3 4 5 6 7 8 9 10 83 72 69 90 90 95 90 91 75 70 56 42 18 84 56 10 90 68 31 48
7
2021/6/22
1
4
第4页/共128页
1、分析步骤
1)
输入数据,依次单击分析—相 关—双变量相关,打开主对话框
SPSS入门讲义 ppt课件

SPSS软件的特点
①集数据录入、资料编辑、数据管理、统 计分析、报表制作、图形绘制为一体。从 理论上说,只要计算机硬盘和内存足够大, SPSS可以处理任意大小的数据文件,无论 文件中包含多少个变量,也不论数据中包 含多少个案例
医学课件
4
②统计功能囊括了《教育统计学》中所有的项 目,包括常规的集中量数和差异量数、 相关 分析、回归分析、方差分析、卡方检验、t检 验和非参数检验;也包括近期发展的多元统计 技术,如多元回归分析、聚类分析、判别分析、 主成分分析和因子分析等方法,并能在屏幕 (或打印机)上显示(打印)如正态分布图、直方 图、散点图等各种统计图表。从某种意义上讲, SPSS软件还可以帮助数学功底不够的使用者学 习运用现代统计技术。使用者仅需要关心某个 问题应该采用何种统计方法,并初步掌握对计 算结果的解释,而不需要了解其具体运算过程, 可能在使用手册的帮助下定量分析数据。
医学课件 2
目前,世界上最著名的数据分析软件是SAS和 SPSS。SAS由于是为专业统计分析人员设计的, 具有功能强大,灵活多样的特点,为专业人士 所喜爱。而SPSS是为广大的非专业人士设计, 它操作简便,好学易懂,简单实用,因而很受 非专业人士的青睐。此外,比起SAS软件来, SPSS主要针对着社会科学研究领域开发,因而 更适合应用于教育科学研究,是国外教育科研 人员必备的科研工具。1988年,中国高教学会 首次推广了这种软件,从此成为国内教育科研 人员最常用的工具。
医学课件 47
示例1
某物质在处理前与处理后分别抽样分析其 含脂率如下 处理前(Xi) 0.19 0.18 0.21 0.30 0.41 0.12 0.27 处理后(Yi) 0.15 0.13 0.07 0.24 0.19 0.06 0.08 0.12
SPSS超级完整版教程PPT课件

▪ 按观察单位(按行输入)输入数据 将光标移 动要输入的观察单位,单击鼠标,将该观察单 位标记,输入变量的第一个值,按“Tab” 或 “”键,输入第二个数据。
▪ 按单元格输入数据 将光标移动到想要输入的
单元格,单击鼠标,输入变量值,按回车键。
2020/1/1也0 可按此法修改变量第一值章 。绪论
35
▪ 定义变量名标签是对变量名做进一步说明。
▪ 如果变量名已经说明了变量的内涵,则不必设置 变量名标签。如性别、血型、name,等
▪ 有时,变量名不能明确表示该变量的含义。如
date_in。变量名标签设置为“入院时间”。
▪ 变量标签不受字符位数的限制,可以用英文或中 文表示。
▪ 在统计分析的输出结果中,可显示变量的英文或 中文标签,使输出结果的可读性更好。
4
4
2 王武 1 65 10/25/200 11/28/200 0
4
4
3 陈杉 2 39 12/14/200 01/13/200 0
4
5
4 李思 2 30 11/22/200 12/29/200 1
4
4
5 欧阳山 1 57 12/01/200 01/15/200 2
4
5
6
赵杉
2020/1/10
2 13 10/01/200 11/18/200 1
▪ 本例的性别分别用数值1和2表示男性、女性。这 时的1和2已经没有数值大小的含义,故可以定义 为字符变量,测量类型为Nominal。但为了操作 方便和某些统计分析,还是经常把它定义为数值 变量,默认测量类型为Scale。
▪ 单击变量窗口左下方的Data 2020/窗1/1口0 转为数据窗口。 第一章 绪论
2020/1/10
第十四章 交叉表分析法(课件)
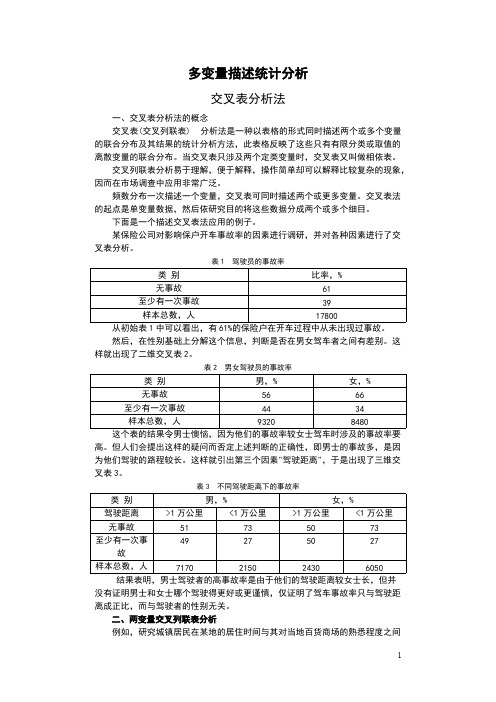
多变量描述统计分析交叉表分析法一、交叉表分析法的概念交叉表(交叉列联表) 分析法是一种以表格的形式同时描述两个或多个变量的联合分布及其结果的统计分析方法,此表格反映了这些只有有限分类或取值的离散变量的联合分布。
当交叉表只涉及两个定类变量时,交叉表又叫做相依表。
交叉列联表分析易于理解,便于解释,操作简单却可以解释比较复杂的现象,因而在市场调查中应用非常广泛。
频数分布一次描述一个变量,交叉表可同时描述两个或更多变量。
交叉表法的起点是单变量数据,然后依研究目的将这些数据分成两个或多个细目。
下面是一个描述交叉表法应用的例子。
某保险公司对影响保户开车事故率的因素进行调研,并对各种因素进行了交叉表分析。
表1 驾驶员的事故率类别比率,%无事故61至少有一次事故39样本总数,人17800从初始表1中可以看出,有61%的保险户在开车过程中从未出现过事故。
然后,在性别基础上分解这个信息,判断是否在男女驾车者之间有差别。
这样就出现了二维交叉表2。
表2 男女驾驶员的事故率类别男,%女,%无事故5666至少有一次事故4434样本总数,人93208480这个表的结果令男士懊恼,因为他们的事故率较女士驾车时涉及的事故率要高。
但人们会提出这样的疑问而否定上述判断的正确性,即男士的事故多,是因为他们驾驶的路程较长。
这样就引出第三个因素"驾驶距离",于是出现了三维交叉表3。
表3 不同驾驶距离下的事故率类别男,%女,%驾驶距离>1万公里<1万公里>1万公里<1万公里无事故51735073至少有一次事49275027故样本总数,人7170215024306050结果表明,男士驾驶者的高事故率是由于他们的驾驶距离较女士长,但并没有证明男士和女士哪个驾驶得更好或更谨慎,仅证明了驾车事故率只与驾驶距离成正比,而与驾驶者的性别无关。
二、两变量交叉列联表分析例如,研究城镇居民在某地的居住时间与其对当地百货商场的熟悉程度之间的关系,对“居住时间”和“熟悉程度”这两个变量进行交叉列联分析。
Spss实用统计分析PPT课件

单击Statistics按钮,打开OLAP Cubes:Statistics对话框
对话框左边的统计量清单框中,列出供选择使用的各种统计量。右边Cell Statistics框,接纳用户选择的统计量,凡选入的统计量在输出的分层报告表的 单元格里显示他们的值。
第28页/共84页
单击Title按钮,打开OLAP Cubes:Title话框
频数分析
Descriptives Statistics Descriptives…
统计描述
(描述性统计)
Explore…
数据探索
Crosstabs…
交叉表,或列联表
Compare Means
Ratio… Means…
比率统计 均值比较
(均值比较)
One-Sample T Test…
单样本T检验
Independent-Sample T Test… 独立样本T检验
Categorize Variables… Rank Cases…
Into Same Variable… Into Defferent Variable…
Automatic Recode… Create Time Series… Replace Missing Values
Run Pending Transforms
下面我们将列出所有的统计分析功能:
第12页/共84页
子菜单
用途说明
OLAP Cubes…
层分析报告
Reports(统计报告)
Case Summaries
观测量概述
Report Summaries in Rows 行概述报告
Report Summaries in Colums 列概述报告
使用SPSS统计软件基础课件演示教程PPT

SPSS中的t检验
在SPSS中进行t检验,用于比较两个样本或群体的均值是否存在显著差异。
SPSS中的方差分析
通过SPSS进行方差分析,用于比较多个样本或群体之间的均值差异。
SPSS中的非参数检验
学习在SPSS中执行非参数检验,用于比较中位数、百分位数等非正态分布数 据。
SPSS中的描述性统计分析
使用SPSS进行描述性统计分析,包括计算均值、标准差和百分位数。
SPSS中的频数分析
通过SPSS进行频数分析,了解变量的分布情况和频率。
SPSS中的中心趋势和离散程度 分析
通过SPSS计算变量的中心趋势和离散程度,包括平均值、中位数、方差和标 准差。
SPSS中的相关分析
进一步探索SPSS中的因子分析,包括因子旋转、解释和解读因子载荷。
SPSS中的线性回归分析
使用SPSS进行线性回归分析,预测和建立变量之间的线性关系模型。
SPSS中的因子分析
探索SPSS中的因子分析,识别变量之间的潜在维度和关联性。
SPSS中的聚类分析
利用SPSS进行聚类分析,将相似的观测或样本进行自动分类和分组。
SPSS中的判别分析
在SPSS中进行判别分析,探索如何预测和分类观测到不同群体。
SPSS中的贡献率分析
通过SPSS进行贡献率分析,了解不同变量对整体方差的贡献程度。
SPSS中的交叉表分析
利用SPSS进行交叉表分析,了解不同变量之间的关联性和交互作用。
SPSS中的多维尺度分析
在SPSS中执行多维尺度分析,将多个变量转化为少数几个维度进行分析和可视化。
SPSS中的因子分析进阶
使用SPSS统计软件基础课 件演示教程PPT
spss基本操作PPT课件

2020/1/10
26
2.2.7 缺失值(Missing)的处理
当数据中存在明显错误或明显不合 理的数据以及存在漏填数据项时,统计 上通称为数据为不完全数据或缺失数据。
SPSS中说明缺失数据的基本方法是 指定用户缺失值。用户缺失值可以是:
o 对字符型或数值型变量,用户缺失值可以是1至 3个特定的离散值(Discrete missing values);
数据编辑窗口中的数据通常以SPSS数据文 件的形式保存在计算机磁盘上,其文件扩展名 为.sav。
数据编辑窗口由窗口主菜单、工具栏、数 据编辑区、系统状态显示区组成。
2020/1/10
5
标题栏
菜单栏
工 具 栏
2020/1/10
输
入
数据显示区:
数
变量名
据
观察序号
栏
数据编辑器的构成
状态栏
6
菜单表
功能
主窗口菜单及功能 解释
17
2020/1/10
频数数据的组织方式
职称 1 1 1 2 2 2 3 3 3 4 4 4
年龄段 1 2 3 1 2 3 1 2 3 1 2 3
人数 0 15 8 10 20 2 20 10 1 35 2 0
18
2.2 SPSS数据的结构和定义方法
SPSS数据的结构包括变量名、类型、宽度、列宽
• 数值型 (1)标准型(Numeric) (2)科学记数法型(Scientific Notation) (3)逗号型(Comma) (4)圆点型(Dot) (5)美元符号型(Dollar) (6)用户自定义型(Custom Currency)
• 字符型(String) • 日期型(Date)
第五章SPSS交叉表分析

第三个表格:性别与英语四级的卡方检验表
皮尔逊卡方检验的卡方值为22.292,显著值Sig 值为0.000<0.05,应拒绝原假设,即认为性别与 英语四级通过情况之间不独立的,两变量之间存在 着关联。
换句话说,男女性别在英语四级通过情况上存在 差异。结合前面的交叉表的计数人数,认为女生在 四级通过人数比例显著大于男生。
第四个表格:性别与考研意向类型的交叉表 (略)。
第五个表格:性别与考研意向类型的卡方检 验表。
在性别与考研意向类型的卡方检验表中,皮尔逊卡 方检验的卡方值为2.857,显著性Sig值为0.240> 0.05,接受原假设,认为性别与考研意向类型之间 是独立的。即,男女学生在考研意向上不存在差异。
第5步:输出复式条形图和分布表。选中“ 显示簇状条形图”复选框。
第6步:统计量选择。点击【统计】按钮, 弹出“交叉表:统计”的对话框
第7步:设置交叉表的显示。点击“单元格”
第8步:设置输出格式。 点击“格式”
第9步:在主对话框中点击【确定】按钮,提 交执行。
第10步:结果分析。
第一个表格:统计摘要表。(略) 第二个表格:精神焦虑与患胃病情况的交叉表。
第2步:启动分析过程。点击【分析】 【描述统计】【交叉表】菜单命令。
第3步:设置分析变量。
选择 “专业承诺”变量选入“行:”变量框中。 选择“学习兴趣”、“学习成绩”变量选入“列: ”变量框中。 此外,在“层1/1”框内,将性别变量从左边选择到 分层变量框内。
在左下角,选中“显示簇状条形图”。
第六个表格:性别与消费倾向类型的交叉表。 (省略)
第七个表格:性别与消费倾向类型的卡方检验 表。(省略)
具体分析,由同学们思考。
在实际应用中,大部分测量数据都是获得原始数 据,即获得每个作答的具体信息,在SPSS录入的 数据集中,一个被试占一行记录。当然,有时也 会获得的是计数数据,例如统计满意度调查,或 者简要汇总某些教育信息时。
第七章SPSS的相关分析PPT课件

2024/10/14
25
基本操作步骤
• 菜单选项:analyze->correlate->partial
选择参与分析的 变量
选择一个或多个 控制变量
option选项:
– zero-order correlations:输出简单相关系数
20• 将家庭常住人口数作为控制变量,对家庭收入与计划购房面积做偏相 关分析
• 利用住房状况调查数据,分析家庭收入和计划购买的住房面积之间的 关系
• 两变量均为定距变量,采用简单相关系数
2024/10/14
21
偏相关分析
• 研究商品的需求量和价格、消费者收入之间的关系. – 需求量和价格之间的相关关系包含了消费者收入对商品需求量的 影响;同时收入对价格也产生影响,并通过价格变动传递到对商 品需求量的影响中
相关分析 须面对的 四个问题
关系的 强度如何
※这种关系 是否为因果
关系
这种关系 能否从样本推
到总体
2024/10/14
9
相关系数
• 相关系数以数值的方式精确地反映了两个变量间线性相关的强弱程度 • 利用相关系数进行变量间线性关系的分析的步骤
1. 计算样本相关系数r – 相关系数r的取值在-1~+1之间 – R>0表示两变量存在正的线性相关关系;r<0表示两变量存在负的
线性相关关系 – R=1表示两变量存在完全正相关;r=-1表示两变量存在完全负相
关;r=0表示两变量不相关 – |r|>0.8表示两变量有较强的线性关系; |r|<0.3表示两变量之间的
线性关系较弱 2. 对样本来自的两总体是否存在显著的线性关系进行推断
2024/10/14
spss教程--spss19.0基础知识讲解 ppt课件

• Variables
变量定义窗口和数据编辑
ppt课件 窗口转换
22
1.6.5 Data菜单
• Define Variable Properties 定义变量属性
• Set Measurement Level for 设置未知测量级别
Unknown
• Copy Data Properties • New Custom Attribute • Define Dates • Define Multiple Response
数据汇总 正交设计 复制数据集 分割文件 选择观测量 观测量加权
ppt课件
25
1.6.6 Transform菜单
• Compute Variable
通过计算建立新变量
• Count Values within Case 依据观测量计数
s
• Shift Values
生成滞后数据
• Recode into Same Variabl 变量重新赋值给同一变量
出结果进行常规的编辑整
理,窗口内容可以直接保
存,保存文件的扩展名为
“*.spv”。
ppt课件
12
1.5.3 语句窗口
• 选择菜单栏中的【File(文件)】→【New(新建)】→ 【Syntax(语法)】命令,新建一个SPSS的语句文 件,如下图所示。
• 选择菜单栏中的【File(文件)】→【Open(打开)】 →【Syntax(语法)】命令,打开一个保存的语句文 件。
ppt课件
20
• Insert Cases 插入观测量
• Find
查找
• Find Next
查找下一个
• Replace
第4章 SPSS基本统计分析 ppt课件[1]
![第4章 SPSS基本统计分析 ppt课件[1]](https://img.taocdn.com/s3/m/c93560f72b160b4e777fcf20.png)
12
▪(1)quartiles:计算四分 位数25%(QL)、50%(中位 数)、75%(QU)
▪(2)cut points for n equal groups: N等份
▪(3)percentile:自定义 百分位点
2020/10/28
13
▪ 4.1.4 频数分析的应用举例:P83 ▪ 分析人均住房面积分布情况 ▪ 以户口为标志进行比较
▪ 我们可以如此设定我们的假设:
▪ 零假设:高级中学学生在对大学教育的重要性的变化 上是分成了大小相等的组的。
▪ 研究假设:高级中学学生在对大学教育的重要性的变 化上是分成了大小不相等的组的。
2020/10/28
32
2020/10/28
33
2020/10/28
34
▪ 自由度df=k-1=3-1=2
2020/10/28
16
▪ 4.2 计算基本描述统计量
▪ 4.2.1.1 集中趋势统计量
▪ 均值(mean)、中位数(median)、众数(mode)、均值 标准误差(standard error of mean)
x
1 n
n i 1
xi
Me2(n1) 4
S.E.ofn.M xean
MeL 2020/10/282
2020/10/28
2
精品资料
▪ 4.1.1 频数分析的目的和基本任务 ▪ 目的 ▪ 粗略把握变量值的分布状况。 ▪ 例:研究被调查者的特征(如:性别、年龄、收入) ▪ 研究被调查者对某个问题的总体看法(如:教学方式、
选修课程) ▪ 研究被调查者某方面的状态(如:购买家电的类型、居
民月支出状况) ▪ 采用的方法 ▪ 计算频分布表:包括计算频数、累计频数、百分比、累
spss入门基本操作ppt课件

7
1.1.3 输入数据 在Data View中输入相应的数据,一个单元格输入一个数据, Group中输入1代表患者,2代表健康人。
22
1.4.2 导出分析结果 文件倒是保存了,但问题还没有完全解决:我们从来写文章什么的 都用的是文字处理软件,尤其是WORD,可WORD不能直接读取 SPO格式的文件,怎么办呢?没关系,SPSS提供了将结果导出为纯 文本格式或网页格式的功能,在结果浏览窗口中选择菜单 File==>Export,系统会弹出Exprot Output对话框如下
4
让我们把要做的事情理理顺:首先要做的肯定是打开计算机(废 话),然后进入Windows,在进入SPSS后,具体工作流程如下: 将数据输入SPSS,并存盘以防断电。 进行必要的预分析(分布图、均数标准差的描述等),以确定应 采用的检验方法。 按题目要求进行统计分析。 保存和导出分析结果。 下面就按这几步依次讲解。
好,到这里,就象我们刚开始所说的一样,你实际上已经完全掌握了 SPSS的基本使用方法。我们以后将要做的工作就是“百尺竿头,更进 一步”,将从下一章开始详细介绍SPSS各个模块的精确用法,使大家 能尽快的从SPSS新手向SPSS高手过度。
25
§1.5 打开其他格式的数据文件
1.5.1 直接打开
SPSS现在可以直接读入许多格式的数据文件,其中就包括EXCEL各 个版本的数据文件。选择菜单File==>Open==>Data或直接单击快 捷工具栏上的“”按钮,系统就会弹出Open File对话框,单击“文 件类型”列表框,在里面能看到直接打开的数据文件格式,分别是:
第十三章-数据分析:SPSS的使用ppt课件

(一)条形图的类型
(二)设置图表中的数据 ⒈ 个案组摘要 ⒉ 各个变量的摘要 ⒊ 个案值
(三)定义条形图的特性
三、线形图
LOGO
(一)线形图的类型
(二)设置图表中的数据 ⒈ 个案组摘要 ⒉ 各个变量的摘要 ⒊ 个案值
(三)定义条形图的特性
五、散点图
LOGO
❖ 散点图是有两个变量所确定的点在坐标系中的分布来反映变 量之间关系的统计图。使用散点图可以对变量分布特征作初 步的判断,如变量的分布是否具有等方差性等等。
进行描述分析的一般步骤如下: 选择菜单:【分析】→【描述统计】→【描述】
⒈ 【将标准化得分另存为变量】: 将计算的标准化值保存为新变量。
⒉ 【选项】: 选择可选统计量和显示顺序
LOGO
LOGO
(三)探索分析
探索过程(Explore)可以进一步检测数据,进而直观 地观测各组数据的分布,并可对数据进行正态性与同方差 的检验。
LOGO
⒉ 选择排序变量
从左侧的源变量窗口中选择一个或多个变量,通过单 击中间的箭头按钮,使之进入到排序依据窗口中。如果选 择的是多个变量,系统先按选择的第一个变量排序,第一 个变量值相等时,按第二个变量排序,以此类推。
⒊ 选择排序规则
排序规则中包括两个选项: ① 升序:按升序顺序排序。 ② 降序:按降序顺序排序。
LOGO
(六)个案选择
⒈ 打开选择个案对话框
【数据】→【选择个案】
⒉ 确定选择个案的方法
LOGO
⒊ 确定未被选中的个案的处理方法
该栏中包括两个选项: ① 【过滤】:生成过滤变量的选项。 ② 【删除】:删除未选个案的选项。
⒋ 输出选择结果
LOGO
(七)其他功能
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2021
10Βιβλιοθήκη Levene检验对数据进行方差齐次性检验时,不 强求数据必须服从正态分布,它先计算出各个观测 值减去组内均值的差,然后再通过这些差值的绝对 值进行单因素方差分析。如果得到显著性水平小于 0.05,那么就可以拒绝方差相同的假设。
2021
11
6. SPSS中实现过程
研究问题 表5.1给出两个天津、济南两个城市某年个月份的平 均气温,根据对天津平均气温和济南平均气温进行 探索性统计分析,研究天津平均气温和济南平均气 温的基本特征。
2021
15
Q-Q图,图中斜线表示正态分布的理论值,而
“○”表示数据实际值,当数据确实是正态分
布时,数据实际值应该在理论线上或者附近,
没有明显的偏离,如果出现明显偏离,就好像
图中情况,说明数据不202是1 正态分布。
16
箱式图(Boxplots),是利用最小值、25%分位 数、中位数、75%分位数和最大值五个数绘制而 成,可以描述数据分布的特征。
1 定义和计算公式
定义:调用此过程可对变量进行更为深入详尽 的描述性统计分析,故称之为探索分析。它在一般 描述性统计指标的基础上,增加有关数据其他特征 的文字与图形描述,显得更加细致与全面,有助于 用户思考对数据进行进一步分析的方案。
2021
4
2. 探索分析的内容包括下面几个方面
• 检查数据是否有错误:过大或过小的数据均 有可能是奇异值、影响点或错误数据。要找出这样 的数据,并分析原因,然后决定是否从分析中删除 这些数据。因为奇异值和影响点往往对分析的影响 较大,不能真实反映数据的总体特征。
2021
12
用于从左侧的变量列 表中选入因变量,一
般为连续变量
用于从左侧的变量列 表中选入因子变量,
一般为分类变量
用于从左侧的变量列表中选
入标签变量,用以在结果里
标识观测个案。
2021
13
计算并输出比均值和中 位数更为定的数据中心
估计值,包括4个: Hubers、Andrews、 Hampels和Tukeys
在实际应用中,应该根据数据的特点决定使用哪种集中趋势描 述统计量,均值的特点是易受极端值影响,因此如果数据中有 特别大或特别小的值时,不推荐使用均值,应该使用中位数作 为集中趋势统计量。
2021
1
离散趋势的描述统计量:全距、样本方差、样本标准差
全距(Range)也称极差,定义是:,是一个比较粗糙的描述离 散趋势的描述统计量,通过排序就可以获得,它只能说明数据 的分布范围,而不能准确刻画数据离中心的程度,因此实际中 不常用。由于全距涉及距离,因此,只适合间隔尺度变量计算。
偏度是描述数据分布对称性的统计量,如果数据关于中心(均 值)的分布是对称的,此时称为分布对称或偏度为0,如果数 据大部分分布在中心左边,小部分分布在中心右边,说明此时 中心右边有偏大的值,即右边的值距离中心远,左边值距离中 心近,这样右边的少数距离能够“抵消”左边的多数距离。此 时,偏度为正,称为正偏或右偏分布,反之称为负偏或左偏分 布
茎叶图(Stem-and-leaf),是根据数据数值绘 制的图形,类似直方图,但更精细。
Q-Q图(Q-Q plots),检验数据是否服从正态分 布。
离散趋势的描述统计量刻画了数据离中心的分散程度,也把此 类统计量成为分布尺度(Scale)统计量,尺度越大,就越分散, 从另一个角度讲,数据越分散,离中心远的数据越多,中心的 代表性就越差,因此,也可以认为离散趋势的描述统计量是刻 画集中趋势的代表性的统计量。
2021
2
分布形态的描述统计量 :偏度和峰
描述和频率分析回顾
集中趋势的描述统计量 :均值、中位数、众数 ,代表了数据的 集中位置
均值(Mean) :代表中心值或平均值的描述统计量,只适用 于间隔尺度变量计算
中位数(Median)是将数据排序后,排在第n/2位置上的案 例所对应的数值,由于中位数只是进行排序,因此间隔尺度和 顺序尺度变量都可以计算中位数,而名义尺度变量不能计算中 位数。
2021
7
4.正态分布检验
常用的正态分布检验是Q-Q图。
2021
8
5.方差齐次性检验
对数据分析不仅需要进行正态分布检验,有时 候还需要比较各个分组的方差是否相同,这就要进 行方差齐次性检验。
例如,在进行独立右边的T检验之前,就需要 事先确定两个数据的方差是否相同。
2021
9
如果通过分析发现各个方差不同,还需要对数 据进行方差分析,那么就需要对数据进行转换使得 方差尽可能相同。在探索分析中可以使用Levene检 验。
峰度大于0,说明数据分布比标准正态分布更陡峭; 峰度小于0,说明数据分布不如标准正态分布陡峭; 等于0,说明数据分布陡峭程度和标准正态分布相当。
值得指出的是,在经济学和金融学中得到的数据,很多都具有 “尖峰后尾”的特点,即峰度大于0,偏度也大于0,在处理 这类数据时,要特别小心
2021
3
5.1 探 索 分 析
2021
5
• 对数据规律的初步观察:通过初步观察获得 数据的一些内部规律,例如,两个变量间是否线性 相关。
2021
6
3.探索分析的考察方法
探索分析一般通过数据文件在分组与不分组的 情况下,获得常用统计量和图形。
一般以图形方式输出,直观帮助用户确定奇异 值、影响点、进行假设检验,以及确定用户要使用 的某种统计方式是否合适。
主要用来判别数据中有 无明显异常值
选中此项会输出含有:均值,中位数、 5%修整均数、标准误、方差、最小 值、最大值、全距、峰度系数、峰度 系数标准误、偏度系数及偏度系数标
准误
输出5个最大值与最小值,包 括观测量的标签
2021
14
箱式图,图由箱体部分和线组成,
箱体上沿为数据75%分位数,下沿为 数据25%分位数,箱体中间的横线表 示50%分位数,即中位数,箱体上方 和下方横线之间的细线长度为1.5倍箱 体长度,超出横线范围用“●”表示的 称为离群点(Outlier),其值在1.5倍 箱体长度到3倍箱体长度之间,而超出 横线用“*”表示的成为极端值 (Extreme Value),其值在3倍箱体 长度以上,记号上的数值表示其案例编 号。从箱式图可以看出,数据有一些离 群点和极端值,呈现右偏分布。