htmlparser
Python中使用HTMLParser解析html实例

Python中使⽤HTMLParser解析html实例前⼏天遇到⼀个问题,需要把⽹页中的⼀部分内容挑出来,于是找到了urllib和HTMLParser两个库.urllib可以将⽹页爬下来,然后交由HTMLParser解析,初次使⽤这个库,在查官⽅⽂档时也遇到了⼀些问题,在这⾥写下来与⼤家分享.⼀个例⼦复制代码代码如下:from HTMLParser import HTMLParserclass MyHTMLParser(HTMLParser):def handle_starttag(self, tag, attrs):print "a start tag:",tag,self.getpos()parser=MyHTMLParser()parser.feed('<div><p>"hello"</p></div>')这个例⼦⾥HTMLParser是基类,重载了他的handle_starttag⽅法,输出了⼀些信息.parser是MyHTMLParser的实例,调⽤feed⽅法开始解析函数.值得注意的是,不需要显⽰调⽤handle_starttag⽅法就会执⾏.HTMLParser⽅法的调⽤⽅式困惑了我很长时间,看了很多博⽂才恍然⼤悟,HTMLParser含有的⽅法分为两类,⼀类是需要显式调⽤的,⽽另⼀类不需显⽰调⽤.不需显式调⽤的⽅法下⾯的这些函数在解析的过程中会触发,但是默认情况下不会产⽣任何副作⽤,因⽽我们要根据⾃⼰的需求重载.1.HTMLParser.handle_starttag(tag,attrs): 解析时遇到开始标签调⽤,如<p class='para'>,参数tag是标签名,这⾥是'p',attrs为标签所有属性(name,value)列表,这⾥是[('class','para')]2.HTMLParser.handle_endtag(tag): 遇到结束标签时调⽤,tag是标签名3.HTMLPars.handle_data(data): 遇到标签中间的内容时调⽤,如<style> p {color: blue; }</style>,参数data为开闭标签间的内容.值得注意的是在形如<div><p>...</p></div>的位置,并不会在div处调⽤,⽽是只在p处调⽤当然还有其他函数,这⾥不做介绍显式调⽤的⽅法1.HTMLParser.feed(data): 参数为需要解析的html字符串,调⽤后字符串开始被解析2.HTMLParser.getpos(): 返回当前的⾏号和偏移位置,如(23,5)3.HTMLParser.get_starttag_text(): 返回当前位置最近的开始标签的内容所有的内容写完了,最后还有⼀点注意事项,HTMLParser只是⼀个简单的模块,解析html的功能并不完善,例如不能准确的分别开标签和"⾃闭标签",看下⾯代码:复制代码代码如下:from HTMLParser import HTMLParserclass MyHTMLParser(HTMLParser):def handle_starttag(self,tag,attrs):print 'begin tag',tagdef handle_startendtag(self,tag,attrs):print 'begin end tag',tagstr1='<br>'str2='<br/>'parser=MyHTMLParser()parser.feed(str1) # 输出 "begin tag br"parser.feed(str2) # 输出 "begin end br"。
HTMLParser提取网页超链接研究

Ke r s HT y wo d : ML as r; a e a ay i i f r ain e t c o P r e p g n lss; n o m t xr t n o ai
关键 词 : H ML asr T P r ;页面 解析 ; 息提 取 e 信
HTMI a s rE ta tW e a e . re x r c b P g P
LN n u A GF  ̄ e
(c ol f noma o cec n n ier g, ca nvr t o hn Q n do 2 6 o ) Sh o o fr t nSineadE gn e n O enU iesy f ia, ig a 6 Jo I i i i C
研 究的热点 D I 用 H ML a e 5对 We 。利 T P r r[ s 1 b页 面 内 容 进 行 解
析 [ 6 1 以过 滤掉垃圾信息 ,提 取出网页超链 接 ,从而获 取 ,可
有用的信息。
2 信息提 取
为了更好地实现 H ML asr T P r 提取 网页超链接 ,下面主要 e 介绍一下 H M P r r T L as 的应用以及 网页超链 接提取算法。 e
,
efc v l c e s t t e e h p ri k s a mp ra t se e n n .W e p o o e t e u e o p n s u c o l t f t ey a c s o h s y el s a n i o t n tp i W b mi ig ei n n r p s h s fo e o r e to s o a he e W e a e HT c iv b p g ML a s rp re e ta tw b p g y e l k i r e o g i s f li oma in f r u t e e eo me t P r e a s , x r c e a e h p r n n o d rt an u e u n r t o r rd v l p/iai / k一 u 0一 c bn一 3 w n d 66 1 /r e b 2 n r s d 6 1 r2- 4 - 2一 i— mo d b ej b
Python对HTML转义字符进行反转义的实现方法

Python对HTML转义字符进⾏反转义的实现⽅法什么是转义字符在 HTML 中 <、>、& 等字符有特殊含义(<,> ⽤于标签中,& ⽤于转义),他们不能在 HTML 代码中直接使⽤,如果要在⽹页中显⽰这些符号,就需要使⽤ HTML 的转义字符串(Escape Sequence),例如 < 的转义字符是 <,浏览器渲染 HTML 页⾯时,会⾃动把转移字符串换成真实字符。
转义字符(Escape Sequence)由三部分组成:第⼀部分是⼀个 & 符号,第⼆部分是实体(Entity)名字,第三部分是⼀个分号。
⽐如,要显⽰⼩于号(<),就可以写< 。
Python 转义字符串反转义⽤ Python 来处理转义字符串有多种⽅式,⽽且 py2 和 py3 中处理⽅式不⼀样,在 python2 中,反转义的模块是HTMLParser。
# Python2import HTMLParser>>> HTMLParser().unescape('param=p1&param=p2')'param=p1¶m=p2'Python3 HTMLParser 模块迁移到了 html.parser# Python3>>> from html.parser import HTMLParser>>> HTMLParser().unescape('param=p1&param=p2')'param=p1¶m=p2'到 python3.4 以后的版本,在 html 模块新增了 unescape ⽅法。
# Python3.4>>> import html>>> html.unescape('param=p1&param=p2')'param=p1¶m=p2'推荐最后⼀种写法,因为 HTMLParser.unescape ⽅法在 Python3.4 就已经被废弃掉不推荐使⽤了,意味着之后的版本会被彻底移除。
delphi htmlparser 实例

在Delphi中,可以使用开源的第三方库如"Tidy"或"Html-Tidy"来解析HTML。
这些库提供了对HTML文档进行解析、清理和转换的功能。
1.首先,你需要下载并安装Tidy库。
可以从官方网站上下载源代码或预编译
的二进制文件。
2.在Delphi中,使用以下代码示例来加载HTML文档并使用Tidy进行解析:
在上述代码中,你需要将Your HTML content here替换为你实际的HTML内容。
还可以根据需要设置其他Tidy选项,例如清理和修复HTML、显示警告信息等。
解析后的文档存储在Doc变量中,你可以根据需要进行进一步的处理。
请注意,这只是一个简单的示例,实际应用中可能需要更多的代码来处理异常情况、处理解析结果等。
此外,你还需要确保在Delphi项目中引入了Tidy库的正确路径和库文件。
正则表达式%2B_HTMLParser使用详解-2010-03-21

“勉强模式”限定符:
在限定符之后添加问号(?),则使限定符成为“勉强模式”。勉强模式的限定符,总 是尽可能少的匹配。如果之后的表达式匹配失败,勉强模式也可以尽可能少的再匹 配一些,以使整个表达式匹配成功。
限定符
{m, n}? {m, }? ??
说明
表达式尽量只匹配m次,最多重复n次。 表达式尽量只匹配m次,最多可以匹配任意次。 表达式尽量不匹配,最多匹配1次,相当于 {0, 1}?
转义符
\a \f \n \r \t \v
说明
响铃符 = \x07 换页符 = \x0C,换页符 响铃符 = \x07,换行 („\u000A‟) 回车符 = \x0D,回车 („\u000D‟) 制表符 = \x09,间隔 („\u0009‟) 垂直制表符 = \x0B
\e \x20 \u002B \x{20A060}
Java正则表达式入门 + HTMLParser使用
详解
一、 Java正则表达式入门 众所周知,在程序开发中,难免会遇到需要匹配、查找、 替换、判断字符串的情况发生,而这些情况有时又比较复杂, 如果用纯编码方式解决,往往会浪费程序员的时间及精力。 因此,学习及使用正则表达式,便成了解决这一矛盾的 主要手段。 大家都知道,正则表达式是一种可以用于模式匹配和替换的 规范,一个正则表达式就是由普通的字符(例如字符a到z) 以及特殊字符(元字符)组成的文字模式,它 用以描述在查 找文字主体时待匹配的一个或多个字符串。正则表达式作为 一个模板,将某个字符模式与所搜索的字符串进行匹配。 自从jdk1.4推出java.util.regex包,就为我们提供了很好的 JAVA正则表达式应用平台。
ESC 符 = \x1B, Escape 使用两位十六进制表示形式,可与该编号的字符匹配 使用四位十六进制表示形式,可与该编号的字符匹配 使用任意位十六进制表示形式,可与该编号的字符匹配
Jericho Html Parser使用介绍

Jericho Html Parser初探作者:SharpStillJericho作为其SourceForge上人气最高的最新Html解析框架,自然有其强大的理由。
但是由于目前中国人使用的不多,因此网上的中文教程和资料不多,所以造成了大家的学习困难。
因此,我们从学习复杂度,代码量等初学者入门指标来看看这个框架的魔力吧。
可以使用制作开源爬虫引擎。
这个例子我们以淘宝这样的购物网站作为解析实例。
淘宝网的页面分为 /go/chn/game,(类似album)和(类似video)和面还有许许多多这样的页面,我们利用Jericho Html Parser作为页面解析框架,来看一下他的威力。
这个网页解析框架的xml书写如下:Jericho Html Parser的核心的类便是Source类,source类代表了html文档,他可以从URL得到文档或者从String得到。
In certain circumstances you may be able to improve performance by calling the fullSequentialParse() method before calling any tag search methods. See the documentation of the fullSequentialParse() method for details.在其说明文档中有这样一句话,就是说如果在特定情况下可以使用fullSequentialParse()方法,提高解析速度,这个方法里的说明:Calling this method can greatly improve performance if most or all of the tags in the document need to be parsed.如果在一个类里将大部分或者所有的tag标记都解析了的话,比如我们经常需要提取出网页所有的URL或者图片链接,在这种情况下使用这种方法可以加快提取速度,但是值得注意的一点是:只有在Source对象被new出来的后面一句紧接着调用这句话有效。
使用HtmlParser解析HTML(C#版)

使⽤HtmlParser解析HTML(C#版)本⽂介绍了.net 版的⼀个HTMLParser⽹页解析开源类库(Winista.HTMLParser)的功能特性、⼯作原理和使⽤⽅法。
对于使⽤.net进⾏Web信息提取的开发⼈员进⾏了⼀次HTMLParser的初步讲解。
应⽤实例将会在⽇后的⽂中介绍,敬请关注。
⼀、背景知识HTMLParser原本是⼀个在sourceforge上的⼀个Java开源项⽬,使⽤这个Java类库可以⽤来线性地或嵌套地解析HTML⽂本。
他的功能强⼤和开源等特性吸引了⼤量Web信息提取的⼯作者。
然⽽,许多.net开发者朋友⼀直在寻找⼀种能在.net中使⽤的HTMLParser类库,笔者将介绍Winista.HTMLParser类库,对⽐于其他原本数量就⾮常少的.net版HTMLParser类库,Winista的版本的类库结构可以说更接近于原始Java版本。
该类库⽬前分为Utltimate、Pro、Lite和Community四个版本,前三个版本都是收费的。
只有Community版本可以免费下载并查看所有的源码。
当前Community最新版本1.8 下载。
该版本的类库⽂档下载。
⼆、功能和特性1.可以在任何.net语⾔中使⽤(C#,,J#等)2.可以解析⼏乎所有的Html标签,并且可以通过标签类别、属性或正则表达式来搜索标签。
有些甚⾄在Java版本中⽆法⽀持的标签也在这个版本中得到了⽀持。
3.设置可扩展的过滤器来过滤结果集中不需要的标签。
4.⾼性能的API接⼝使得你能处理许多常见的问题,如:哪些是页⾯中的外部链接?哪些是图⽚?哪些是不同的表格?页⾯中有错误的链接吗等等问题。
5.⼀个基于Http协议引擎的配置⽂件使得你能通过⼀个指定的URL地址来获得该页⾯内容。
该爬⾍可以遵循robot.txt协议⽂件来获得组织和允许访问的列表。
6.Http协议引擎能够完整地处理来⾃任何站点的反馈。
三、词法分析的⼯作原理HTMLParser的词法分析器对HTML进⾏了4级封装,从低级到⾼级的顺序为:ParserStream、Source、Page、Lexer。
基于HTML Parser的BBS信息抽取系统的设计与实现

P re 的一些基础类 , 中最 为重要 的是 P re 。P re asr 其 a sr asr
是 HT asr ML P r 的最 核心的类。og hmlasrb a s e r . t p r .en e 包对 V s o 和 F l r ii r t i e 的方法进行 了封装 , t 定义 了针对一 些常用 HT ML元素操作 的 Jv B a , a a en 简化对常用元素 的 提取操 作 。o g. t p r e . o e 包 定义 了基 础的 r h ml a s r n d s nd, o e 包括 : srcNo e e r No e a No e Ab ta t d 、R ma k d 、T g d 、 T x No e 。o g h ml as rt g 包 定义了 HT et d 等 r . t p re . s a ML P r e 进行解析 的网页 中的各种标签 【。 asr l 1
定 向采集各 BB S上开放 数据信 息源 , 将数据 经过分析 、 整理后得到作者信 息、发帖信息 、回复数 、正文 内容等 信息 , 并存人 数据 库 , 以备后 期查询 等用户 应用 。 BBS信 息抽 取 系统 主要 模 块结 构包 括 4个 : 息 信 抓取 模块 、信 息 解析 模块 、数 据库 存 储模 块 、结果 显
以 B S站点 URL为输入 , 此过程 中, B 在 加入正则 匹配方
法 , 到各个 网页 信息 , 得 交给信 息解析 模块 。信 息抓 取 模块分 为三部分 : 版块 信息抓取 部分 、帖子基 本信息 抓
取部 分 、正 文信 息抓取 部分 。
版块信息抓取部分根据输入的站点 URL 通过 HT , ML
3 2 信 息解析模块 .
HTMLParser使用详解

HTMLParser使⽤详解声明:本⼈来⾃转载/doc/8576448f6529647d27285286.html /HTMLParser具有⼩巧,快速的优点,缺点是相关⽂档⽐较少(英⽂的也少),很多功能需要⾃⼰摸索。
对于初学者还是要费⼀些功夫的,⽽⼀旦上⼿以后,会发现HTMLParser的结构设计很巧妙,⾮常实⽤,基本你的各种需求都可以满⾜。
这⾥我根据⾃⼰这⼏个⽉来的经验,写了⼀点⼊门的东西,希望能对新学习HTMLParser的朋友们有所帮助。
(不过当年⾼考本⼈语⽂只⽐及格⾼⼀分,所以⽂法⽅⾯的问题还希望⼤家多多担待)HTMLParser的核⼼模块是org.htmlparser.Parser类,这个类实际完成了对于HTML页⾯的分析⼯作。
这个类有下⾯⼏个构造函数:public Parser ();public Parser (Lexer lexer, ParserFeedback fb);public Parser (URLConnection connection, ParserFeedback fb) throws ParserException;public Parser (String resource, ParserFeedback feedback) throws ParserException;public Parser (String resource) throws ParserException;public Parser (Lexer lexer);public Parser (URLConnection connection) throws ParserException;和⼀个静态类public static Parser createParser (String html, String charset);对于⼤多数使⽤者来说,使⽤最多的是通过⼀个URLConnection或者⼀个保存有⽹页内容的字符串来初始化Parser,或者使⽤静态函数来⽣成⼀个Parser对象。
htmlparser使用指南
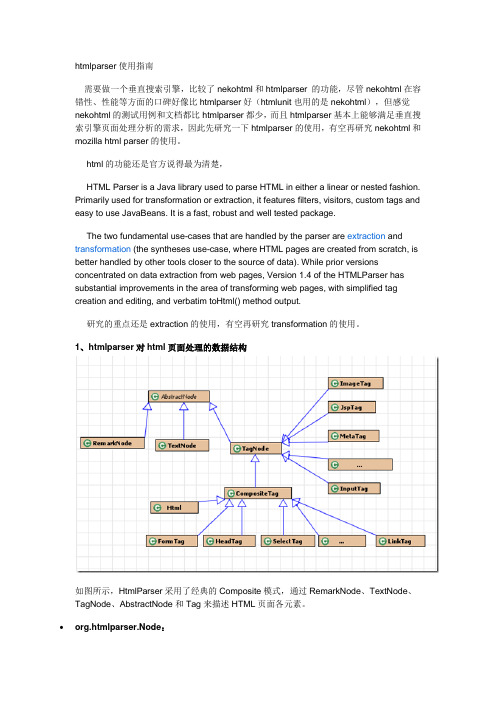
htmlparser使用指南需要做一个垂直搜索引擎,比较了nekohtml和htmlparser 的功能,尽管nekohtml在容错性、性能等方面的口碑好像比htmlparser好(htmlunit也用的是nekohtml),但感觉nekohtml的测试用例和文档都比htmlparser都少,而且htmlparser基本上能够满足垂直搜索引擎页面处理分析的需求,因此先研究一下htmlparser的使用,有空再研究nekohtml和mozilla html parser的使用。
html的功能还是官方说得最为清楚,HTML Parser is a Java library used to parse HTML in either a linear or nested fashion.Primarily used for transformation or extraction, it features filters, visitors, custom tags and easy to use JavaBeans. It is a fast, robust and well tested package.The two fundamental use-cases that are handled by the parser are extraction and transformation (the syntheses use-case, where HTML pages are created from scratch, is better handled by other tools closer to the source of data). While prior versionsconcentrated on data extraction from web pages, Version 1.4 of the HTMLParser has substantial improvements in the area of transforming web pages, with simplified tagcreation and editing, and verbatim toHtml() method output.研究的重点还是extraction的使用,有空再研究transformation的使用。
C#下解析HTML的两种方法介绍

C#下解析HTML的两种⽅法介绍在搜索引擎的开发中,我们需要对Html进⾏解析。
本⽂介绍C#解析HTML的两种⽅法。
在搜索引擎的开发中,我们需要对⽹页的Html内容进⾏检索,难免的就需要对Html进⾏解析。
拆分每⼀个节点并且获取节点间的内容。
此⽂介绍两种C#解析Html的⽅法。
⽤.WebClient下载Web Page存到本地⽂件或者String中,⽤正则表达式来分析。
这个⽅法可以⽤在Web Crawler 等需要分析很多Web Page的应⽤中。
估计这也是⼤家最直接,最容易想到的⼀个⽅法。
转⾃⽹上的⼀个实例:所有的href都抽取出来:复制代码代码如下:using System;using ;using System.Text;using System.Text.RegularExpressions;namespace HttpGet{class Class1{[STAThread]static void Main(string[] args){.WebClient client = new WebClient();byte[] page = client.DownloadData("");string content = System.Text.Encoding.UTF8.GetString(page);string regex = "href=[\\\"\\\'](http:\\/\\/|\\.\\/|\\/)?\\w+(\\.\\w+)*(\\/\\w+(\\.\\w+)?)*(\\/|\\?\\w*=\\w*(&\\w*=\\w*)*)?[\\\"\\\']";Regex re = new Regex(regex);MatchCollection matches = re.Matches(content);System.Collections.IEnumerator enu = matches.GetEnumerator();while (enu.MoveNext() && enu.Current != null){Match match = (Match)(enu.Current);Console.Write(match.Value + "\r\n");}}}}利⽤ 解析Html。
delphi htmlparser使用方法

delphi htmlparser使用方法# Delphi HTMLParser 使用方法Delphi HTMLParser 是一个强大的组件,用于解析HTML 文档,提取所需的数据,或者对HTML 文档进行操作。
以下将详细介绍Delphi HTMLParser 的使用方法。
## 一、准备工作在使用Delphi HTMLParser 之前,需要确保以下准备工作已完成:1.下载并安装Delphi HTMLParser 组件。
2.在Delphi 项目中引用HTMLParser 单元。
## 二、创建HTMLParser 实例首先,需要创建一个`THTMLParser` 类的实例:```delphiprocedure TForm1.Button1Click(Sender: TObject);varHTMLParser: THTMLParser;beginHTMLParser := THTMLParser.Create;// 其他代码end;```## 三、加载HTML 文档可以通过以下方式加载HTML 文档:1.从字符串加载:```delphiHTMLParser.LoadFromStream(TStringStream.Create("<html>...</ht ml>"));```2.从文件加载:```delphiHTMLParser.LoadFromFile("C:pathtoyourfile.html");```## 四、解析HTML 文档加载HTML 文档后,可以通过以下方法开始解析:```delphiHTMLParser.Execute;```## 五、提取数据在解析过程中,可以通过以下方式提取所需的数据:1.使用`OnElement` 事件处理标签:```delphiprocedure TForm1.HTMLParserOnElement(Sender: TObject; Tag: TTag);beginif = "div" thenMemo1.Lines.Add(Tag.OuterHTML);end;```2.使用`OnTextNode` 事件处理文本节点:```delphiprocedure TForm1.HTMLParserOnTextNode(Sender: TObject; TextNode: TTextNode);beginMemo1.Lines.Add(TextNode.Text);end;```## 六、遍历标签属性如果需要遍历标签的属性,可以使用以下代码:```delphiprocedure TForm1.HTMLParserOnElement(Sender: TObject; Tag: TTag);varI: Integer;beginfor I := 0 to Tag.AttributeCount - 1 dobeginMemo1.Lines.Add(Tag.AttributeName[I] + "=" +Tag.AttributeValue[I]);end;end;```## 七、修改HTML 文档如果需要对HTML 文档进行修改,可以在`OnElement` 事件中进行如下操作:```delphiprocedure TForm1.HTMLParserOnElement(Sender: TObject; Tag: TTag);beginif = "div" thenbeginTag.AddAttribute("class", "newClass");Tag.InnerHTML := "New Content";end;end;```## 八、保存修改后的HTML 文档将修改后的HTML 文档保存到文件或字符串:1.保存到文件:```delphiHTMLParser.SaveToFile("C:pathtoyourfile.html");```2.保存到字符串:```delphiMemo1.Text := HTMLParser.Document.OuterHTML;```以上就是Delphi HTMLParser 的使用方法。
HTMLParser-API

CssSelectorNodeFilter 接受所有支持CSS2选择器的节点.
HasAttributeFilter 接受所有否含有某个属性(还可以设置该属性的值)的节点.
HasChildFilter 接受所有含有子节点符合该Filter的节点.
RegexFilter 接受所有满足指定正则表达式的String Nodes.
StringFilter 接受所有满足指定String的String Nodes.
TagNameFilter 接受所有满足指定Tag名的TagNodes.
XorFilter 相当于一个XOR操作符,接受所有只满足其中1个Filter的节点.�
HasParentFilter 接受所有含有父节点符合该Filter的节点.
HasSiblingFilter 接受所有含有兄弟节点符合该Filter的节点.
IsEqualFilter 接受所有和某个特定的节点相同的节点.
LinkRegexFilter 接受所有linkTag标签的link值.匹配给定的正则表达式的节点.
LinkStringFilter 接受所有linkTag标签的link值,匹配给定的字符串的节.
NodeClassFilter 接受所有接受指定的类的节点.
NotFilter 接受所有不符合Filter的节点.
OrFilter 相当于一个AND操作符,接受所有满足两个Filter中任意一个的节点.
HtmlParser网络爬虫

使用 HttpClient 和 HtmlParser 实现简易爬虫这篇文章介绍了HtmlParser 开源包和HttpClient 开源包的使用,在此基础上实现了一个简易的网络爬虫(Crawler),来说明如何使用HtmlParser 根据需要处理Internet 上的网页,以及如何使用HttpClient 来简化Get 和Post 请求操作,构建强大的网络应用程序。
HttpClient 与HtmlParser 简介本小结简单的介绍一下HttpClinet 和HtmlParser 两个开源的项目,以及他们的网站和提供下载的地址。
HttpClient 简介HTTP 协议是现在的因特网最重要的协议之一。
除了WEB 浏览器之外,WEB 服务,基于网络的应用程序以及日益增长的网络计算不断扩展着HTTP 协议的角色,使得越来越多的应用程序需要HTTP 协议的支持。
虽然JAVA 类库 .net 包提供了基本功能,来使用HTTP 协议访问网络资源,但是其灵活性和功能远不能满足很多应用程序的需要。
而Jakarta Commons HttpClient 组件寻求提供更为灵活,更加高效的HTTP 协议支持,简化基于HTTP 协议的应用程序的创建。
HttpClient 提供了很多的特性,支持最新的HTTP 标准,可以访问这里了解更多关于HttpClinet 的详细信息。
目前有很多的开源项目都用到了HttpClient 提供的HTTP功能,登陆网址可以查看这些项目。
本文中使用HttpClinet 提供的类库来访问和下载Internet上面的网页,在后续部分会详细介绍到其提供的两种请求网络资源的方法:Get 请求和Post 请求。
Apatche 提供免费的HTTPClien t源码和JAR 包下载,可以登陆这里下载最新的HttpClient 组件。
笔者使用的是HttpClient3.1。
HtmlParser 简介当今的Internet 上面有数亿记的网页,越来越多应用程序将这些网页作为分析和处理的数据对象。
Htmlparser使用入门

使用Htmlparser生成Dom树一.H tmlparser简介什么是Htmlparser?顾名思义Htmlparser是一种解析分析提取Html的工具。
如果想抓取网页的数据有什么办法,正则表达式?字符串截取?但是如果网站改版这些都将不好使用。
Htmlparser可以很好的对html标签进行操作。
➢文本信息抽取,例如对html进行有效信息搜索➢链接提取,用于自动给页面的链接文本加上链接的标签➢资源提取,例如对一些图片、声音的资源的处理这样如果使用Htmlparser将Html字符串生成Dom树就可以对Dom树进行操作,也不用担心网站改版,嘿嘿,是不是很方便?二.H tmlparser生成Dom树Htmlparser中的节点分为3种:TextNode,TagNode,RemarkNode。
(1)在生成Dom树时首先需要根据url获取Html字符串,如何获取Html 字符此处不在描述(在获取Html字符串时,如果解码方式不正确将产生乱码)。
(2)新建一个XmlDocument对象,并添加根节点“root”。
(3)根据Html字符串生成一个parser对象(代码1),生成NodeFilter 对象filter(代码2)。
(4)根据parser对象的Parser(NodeFilter filter)方法可以获取到需要过滤的节点集合NodeList。
(5)接下来就可以使用递归向Xml添加Dom节点了。
循环NodeList,将节点转成ITag,判断ITag不为空并且ITag不是结束标签(IsEndTag),将ITag的标签名称(TagName)添加在Xml上还可以设置节点的属性(style、with…),再判断ITag的子字节点(Children)是否为空,如果不为空,判断ITag的FirstChild是不是TextNode节点并且节点名称不是“script"、“style”,将ITag的FirstChild文本ToPlainTextString添加在Xml节点上.获取当前ITag的子节点(Children),如果不为空递归。
基于HTMLParser的Web文献信息提取

基于HTMLParser的Web文献信息提取摘要:基于HTMLParser对网页进行解析,可抽取标签间的Link、image、meta 和title 等信息。
使用HTMLParser来提取Web文献中的题名、关键字、摘要、作者、来源等信息,清洗后存入MySql 数据库当中,以备后续数据挖掘使用。
对此进行了论述。
关键词:HTMLParser;Web文献;信息提取大量的科研项目,每年都会有数以万计的文献产生。
随之而来的问题是如此多的文献数据让人难以消化,无法从表面上看出它们所蕴涵的有用信息,更不用说有效地指导进一步的工作。
如何从大量的数据中找到真正有用的信息成为人们关注的焦点,数据挖掘技术也正是伴随着这种需求从研究走向应用。
近年来,随着Web技术的快速普及和迅猛发展,使各种信息可以以非常低的成本在网络上获得。
本文就是要利用网络爬虫技术,对Web文献进行抓取数据,构建数据仓库,以挖掘出有用的信息。
1HTMLParser简介HTMLParser是一个纯的Java写的HTML解析的库,它不依赖于其它的Java库文件,主要用于改造或提取html。
它提供了接口,支持线性和嵌套HTML文本。
在实际的项目中只需要将htmlparser.jar 导入classpath中,就可以使用Htmlparser提供的API了。
HTMLParser项目主要可以用在以下两个方面:(1)信息提取。
文本信息抽取,例如对HTML进行有效信息搜索;链接提取,用于自动给页面的链接文本加上链接的标签;资源提取,例如对一些图片、声音的资源的处理;链接检查,用于检查HTML中的链接是否有效;页面内容的监控。
(2)信息转换。
链接重写,用于修改页面中的所有超链接;网页内容拷贝,用于将网页内容保存到本地;内容检验,可以用来过滤网页上一些令人不愉快的字词;HTML信息清洗,把本来乱七八糟的HTML信息格式化;转成XML格式数据。
HTMLParser由Node、AbstractNode 和Tag 来表达HTML。
python htmlparser使用详解

python htmlparser使用详解Python HTMLParser使用详解1. 介绍HTMLParser是Python中的内置模块,用于解析HTML文件并提取其中的数据。
本文将详细介绍如何使用Python的HTMLParser模块来解析HTML文件。
2. 安装HTMLParser是Python的内置模块,无需额外安装。
3. 导入模块首先需要导入HTMLParser模块:from html.parser import HTMLParser4. 创建HTMLParser子类接下来,我们需要创建一个HTMLParser的子类,用于处理HTML 文件中的各个标签和数据。
在子类中,我们可以重写HTMLParser中的各个方法,来实现自己的逻辑。
5. 重写方法HTMLParser中的方法是根据不同的HTML标签进行调用的。
我们可以重写其中的方法来处理不同的标签和数据。
•handle_starttag(tag, attrs):处理HTML开始标签,tag表示标签名,attrs表示标签的属性。
•handle_endtag(tag):处理HTML结束标签,tag表示标签名。
•handle_data(data):处理HTML标签中的数据,data表示标签包含的数据。
•handle_comment(data):处理HTML注释,data表示注释内容。
•handle_entityref(name):处理HTML实体引用,name表示实体引用的名称。
•handle_charref(name):处理HTML字符引用,name表示字符引用的名称。
6. 解析HTML文件要使用HTMLParser解析HTML文件,首先需要读取HTML文件的内容,并将其传递给HTMLParser进行解析。
# 读取HTML文件内容with open('example.html', 'r') as f:html_content = f.read()# 创建HTMLParser子类的实例parser = MyHTMLParser()# 解析HTML文件parser.feed(html_content)7. 示例代码下面是一个简单的例子,演示了如何使用HTMLParser解析HTML 文件,并提取其中的链接:from html.parser import HTMLParserclass MyHTMLParser(HTMLParser):def handle_starttag(self, tag, attrs):if tag == 'a':for attr in attrs:if attr[0] == 'href':print(attr[1])# 读取HTML文件内容with open('example.html', 'r') as f:html_content = f.read()# 创建HTMLParser子类的实例parser = MyHTMLParser()# 解析HTML文件parser.feed(html_content)8. 总结HTMLParser模块是Python中解析HTML文件的利器,通过重写HTMLParser子类的方法,我们可以方便地提取HTML文件中的各个标签和数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
htmlparser源程序代码我们的C# 程序中经常会产生一些数据,这些数据可以使用Html 表格进行展现。
现在让我们开始写相关的C# 程序吧。
下面就是HtmlMaker.cs:01: using System;02: using System.IO;03: using ;04: using System.Data;05: using System.Drawing;06: using System.Collections.Generic;07:08: namespace Skyiv09: {10: public sealed class HtmlMaker11: {12: public bool TitleVisible { get; set; }13:14: string title;15: DataView view;16: IEnumerable<Tuple<string, string>>info;17:18: public HtmlMaker(string title, IEnumerable<Tuple<string, string>> info, DataView view)19: {20: this.title = title;21: = info;22: this.view = view;23: this.TitleVisible = true;24: }25:26: public void Save(string htmlFileName) 27: {28: using (var writer = new StreamWriter(htmlFileName))29: {30: WriteHead(writer);31: WriteTitle(writer);32: WriteInfo(writer);33: new HtmlTable(view).Write(writer); 34: WriteTail(writer);35: }36: }37:38: void WriteTitle(TextWriter writer)39: {40: if (!TitleVisible) return;41: writer.Write(" <h1>");42: WebUtility.HtmlEncode(title, writer); 43: writer.WriteLine("</h1>");44: }45:46: void WriteInfo(TextWriter writer)47: {48: if (info == null) return;49: var dt = new DataTable();50: dt.Columns.Add("Key", typeof(string)); 51: dt.Columns.Add("Value", typeof(string)); 52: foreach (var row in info)53: {54: var dr = dt.NewRow();55: dr[0] = row.Item1;56: dr[1] = row.Item2;57: dt.Rows.Add(dr);58: }59: var htmlTable = newHtmlTable(dt.DefaultView);60: htmlTable.ColumnHeadersVisible = false; 61: htmlTable.Write(writer);62: }63:64: void WriteHead(TextWriter writer)65: {66: writer.Write("<!DOCTYPE html PUBLIC \"-//W3C//DTD XHTML 1.0 Strict//EN\" ");67:writer.WriteLine("\"/TR/xhtml1/DTD/xhtm l1-strict.dtd\">");68: writer.WriteLine("<htmlxmlns=\"/1999/xhtml\">");69: writer.WriteLine("<head>");70: writer.WriteLine(" <metahttp-equiv=\"Content-Type\" content=\"text/html;charset=utf-8\" />");71: writer.Write(" <title>");72: WebUtility.HtmlEncode(title, writer);73: writer.WriteLine("</title>");74: writer.WriteLine("</head>");75: writer.WriteLine("<body>");76: }77:78: void WriteTail(TextWriter writer)79: {80: writer.WriteLine("</body>");81: writer.WriteLine("</html>");82: }83: }84: }注意上述程序第70 行表明我们生成的Html 文件是使用UTF-8 编码,这应该成为一个共识。
而在第28 行使用的StreamWriter 类默认情况也是使用UTF8Encoding 。
还有要注意第42 行和第72 行,在写入Html 文件时要使用WebUtility 类的静态方法HtmlEncode 对数据进行编码。
在第33 行和第59 行使用的HtmlTable 类的源程序HtmlTable.cs 如下所示:01: using System;02: using System.IO;03: using ;04: using System.Data;05: using System.Drawing;06:07: namespace Skyiv08: {09: sealed class HtmlTable10: {11: public int Level { get; set; }12: public bool ColumnHeadersVisible { get; set; } 13: public Color ColumnHeadersBackgroundColor { get; set; }14: public Color BackgroundColor { get; set; } 15: public Color AlternatingRowsBackgroundColor { get; set; }16:17: DataView view;18:19: public HtmlTable(DataView view)20: {21: this.view = view;22: Level = 1;23: ColumnHeadersVisible = true;24: ColumnHeadersBackgroundColor = Color.Cyan;25: BackgroundColor = Color.Azure; 26: AlternatingRowsBackgroundColor = Color.LightYellow;27: }28:29: public void Write(TextWriter writer) 30: {31: if (writer == null) return;32: if (view == null) return;33: var blank = "".PadLeft(Level * 2); 34: writer.Write(blank);35: writer.Write("<table border=\"1\" cellspacing=\"2\" cellpadding=\"2\">");36: writer.Write("<tbody");37: WriteBackgroundColor(writer, BackgroundColor);38: writer.WriteLine(">");39: if (ColumnHeadersVisible)WriteTableHead(writer);40: var rowIndex = 0;41: foreach (DataRowView row in view) WriteTableRow(writer, row, rowIndex++);42: writer.Write(blank);43: writer.WriteLine("</tbody></table>"); 44: }45:46: private void WriteBackgroundColor(TextWriter writer, Color color)47: {48: if (color == Color.Empty) return;49: writer.Write(" style=\"background-color: "); 50: writer.Write(color.ToHtmlCode());51: writer.Write("\"");52: }53:54: void WriteTableHead(TextWriter writer)55: {56: var blank2 = "".PadLeft((Level + 1) * 2);57: var blank3 = "".PadLeft((Level + 2) * 2);58: writer.Write(blank2);60: WriteBackgroundColor(writer, ColumnHeadersBackgroundColor);61: writer.WriteLine(">");62: foreach (DataColumn column inview.Table.Columns)63: {64: writer.Write(blank3);65: writer.Write("<th>");66: WebUtility.HtmlEncode(column.Caption, writer);67: writer.WriteLine("</th>");68: }69: writer.Write(blank2);70: writer.WriteLine("</tr>");71: }72:73: void WriteTableRow(TextWriter writer, DataRowView view, int rowIndex)74: {75: var blank2 = "".PadLeft((Level + 1) * 2); 76: var blank3 = "".PadLeft((Level + 2) * 2);78: writer.Write("<tr");79: if (rowIndex % 2 != 0) WriteBackgroundColor(writer, AlternatingRowsBackgroundColor);80: writer.WriteLine(">");81: foreach (var field in view.Row.ItemArray) 82: {83: writer.Write(blank3);84: writer.Write("<td>");85: WebUtility.HtmlEncode(field.ToString(), writer);86: writer.WriteLine("</td>");87: }88: writer.Write(blank2);89: writer.WriteLine("</tr>");90: }91: }92: }几点说明:第11 行的Level 字段表示这个<table> 元素在Html 文件中缩进层次,每缩进一层增加两个空格。