SQL分组、排序及多表连接语句
数据库函数select查询语句的分类语法结构多表连接,DISTINCT关键字表列的别名和m。。。

数据库函数select查询语句的分类语法结构多表连接,DISTINCT关键字表列的别名和m。
数据库函数 select 查询语句SQL语句* DDL create,drop, alter* DML insert,delete,update,select* DCL grant,revoke* TCL commit; rollback;DDL修饰符:* unsigned ⾮负数* zerofill 0填充* default 默认值* null 空值约束:* primary key 主键,⾮空 + 唯⼀* unique 唯⼀键,不能有重值* not null ⾮空* auto_increment ⾃增长 int,必须是primary key主键1.SELECT 查询语句的分类语法结构多表连接案例简单查询语句从⼀个表中查询数据复杂查询语句多表连接查询(将来源于多个表的列横向叠加)*内连接 *左连接 *右连接 *全连接 * ⾃连接 *⾮等值连接复合查询(将查询结果集上下叠加)*Union*Union All *Intersect *Minus并集交集差集⼦查询* ⾮关联⼦查询 *关联⼦查询语法结构SELECT select_list # 1个或多个列名,之间⽤逗号隔开,列也称作投影[ INTO new_table ] # 结果集放⼊指定⽂件FROM [table_source] #表名[ WHERE search_condition ] #表⾏过滤条件[ GROUP BY group_by_expression ] #按照指定的列将表⾏分组,形成新的⾏[ HAVING search_condition ] #对分组后的新⾏进⾏过滤[ ORDER BY order_expression [ ASC | DESC ] ] #按照指定的1个或多个列进⾏排序,ASC=增序,DESC=降序select where⼦句常⽤的算数逻辑⽐较运算符通配运算符和优先级where⼦句对⾏记录进⾏过滤1.算数运算符:+,-,*, / 对应加,减,乘,除2.逻辑运算符:not (⾮);and (⽽且);or(或者);3.⽐较运算符:= 等于; !=或<>不等于; >⼤于; <⼩于; >=⼤于等于; <=⼩于等于;is null为空值;is not null为⾮空值;in (值列表)在值列表中not in (值列表)不在值列表中;between 低值and ⾼值(包含低值和⾼值)在低值和⾼值之间;not between 低值and ⾼值(包含低值和⾼值)不在低值和⾼值范围内;like ‘通配符’按照通配符进⾏匹配;4.常⽤通配符:% 匹配0个或任意多个字符_匹配任意1个字符5.运算符优先级各类运算符之间存在优先级,只记住括号( )的优先级最⾼即可1.查询学⽣表中性别为‘⼥’,体重超过60公⽄的学⽣的所有信息三个表查询学⽣表中性别为‘⼥’,体重超过60公⽄的学⽣的所有信息select * from stu where sex='⼥' and weight>60;2.查询学⽣表中1班或者2班中,⾝⾼超过190的学⽣select * from stu where (cno=1 or cno=2) and height>190;或者select * from stu where cno in (1,2) and height>190;3.查询学⽣表中3班学⽣⾥⾯考分在400和520之间的⼥⽣select * from stu where cno=3 and sex='⼥' and score between 400 and 520;或者select * from stu where cno=3 and sex='⼥' and (score>= 400 and score<=520);4.查询学⽣表中没有分配班级⽽且是⼥⽣的学⽣select * from stu where cno is null and sex='⼥';5.在学⽣表体重低于40公⽄且⾝⾼低于1.65⽶的学⽣,列出其姓名,⾝⾼,体重,总分以及总分占750分满分的百分⽐select sname,height,weight,score,score/750*100 from stu where height/100<1.65 and weight<40;6.在学⽣表中查找学⽣姓名,第⼆个字是‘侯’,或者第⼀个字是‘张’且名字只有两个字的学⽣select * from stu where sname like '_侯%' or sname like '张_';2mysql 常⽤的字符串数值⽇期条件判断 CASE 空值聚合关键字列的别名函数函数⽤来处理SQL语句中的数据,可以嵌⼊在SQL语句中使⽤,增加了SQL语句对数据的处理功能函数可以有0到多个参数,但是总会有⼀个返回值函数可以⽤来计算、修改、格式化输出⼆维表中的各类数据不同数据库的函数的名称和⽤法略有不同,但都会提供如:字符串处理、数值处理、⽇期处理、统计等分类的函数、⽅便⽤户处理各类数据1.字符串函数 char_length(字符串) 的长度三个字姓名的学⽣char_length(str)字符串长度计算参数str中有多少个字符,str可以是具体的⼀个字符串,也可以是表中的列1.查看字符串“中国⼈”有⼏个字(后⾯为常量from可省略select char_length('中国⼈');2.学⽣表中姓名为三个字的学⽣有哪些?select * from stu where char_length(sname)=3;或select * from stu where sname like '___';有些需求仅靠SQL语句提供的功能⽆法实现,必须依靠数据库提供的函数2.concat(str1,str2,……)拼接把参数str1和str2拼接成⼀个字符串班级+姓名把参数str1和str2拼接成⼀个字符串1.把‘我是’和‘中国⼈’拼接成⼀句话select concat('我是','中国⼈');2.学⽣表打印已分班的学⽣姓名和班级,以xxx是x班的形式打印结果select concat(sname,'是',cno,'班') 名称表from stu where cno is not null;3.substr(str,pos,len)截取把参数str字符串从第pos位起,截取len位把参数str字符串从第pos位起,截取len位字符串姓⽒1.把‘我是中国⼈’字符串从第3位起截取3位字符select substr('我是中国⼈',3,3);⼆班的同学都有什么姓⽒? (截取第⼀个字段) ⼆班同学的姓⽒select substr(sname,1,1) from stu where cno=2;4.)MySQL 数值四舍五⼊函数round(num,n),数字和⾝⾼体重bmi值四舍五⼊不要⼩数缺省为正数 0对数字num进⾏四舍五⼊运算,从第n位⼩数算起(保留⼏位)1.)15.5469,保留2位⼩数,从第2位⼩数进⾏四舍五⼊运算select round(15.5469,2);2.)计算肥胖学⽣许褚的BMI值,四舍五⼊保留2位⼩数,体重/⾝⾼^2select round(weight/(height/100*height/100),2) from stu where sname='许褚';5.)MySQL ⽇期函数year(date1) month(date1)year(date1)获取⽇期date1的年份select year(‘2019-11-27 09:00:00’);month(date1)获取⽇期date1的⽉份1.学⽣表中哪些同学是1990年出⽣的?select * from stu where year(birth)=1990;2.学⽣表中哪些同学是8⽉出⽣的?select * from stu where month(birth)=8;6.)计算时间curdate查 datediff(date1,date2) 计算年龄⽣⽇⼩于23岁curdate()获取当前⽇期curtime()获取当前时间now()获取当前的⽇期和时间datediff(date1,date2)返回date1和date2两个⽇期间隔的天数1.计算2018年6⽉1⽇和2018年元旦之间间隔的天数select datediff('2018-6-1','2018-1-1');select datediff('2019-11-29','2015-10-20'); 和静差1501天2计算学⽣表中学⽣的年龄,显⽰姓名,⽣⽇,年龄(保留2位⼩数),只显⽰⼩于23岁的同学select sname,birth,round(datediff(now(),birth)/365,2) from stu where round(datediff(now(),birth)/365,2)<23;7.MySQL 条件判断函数 if(expr,v1,v2) 分数姓名复姓if(expr,v1,v2)如果表达式expr成⽴,返回v1值否则,返回v2值1..如果学⽣⾼考分⼤于等于520,其为统招⽣,否则其为委培⽣,从学⽣表中查找,显⽰姓名,考分,类型(统招或委培)select sname,score,if(score>=520,'统招','委培') 类型 from stu;2.新来的学⽣都姓什么,需要考虑复姓(诸葛、太史、夏侯)和外号(⼤乔、⼩乔)?select sname,substr(sname,if(sname in ('⼤乔','⼩乔'),2,1),if(substr(sname,1,2) in ('诸葛','太史','夏侯'),2,1)) 姓 from stu;先从外号中筛选出⼤乔⼩乔,选出乔姓,然后截取两位名字,如果是诸葛,夏侯,太史截取两位,其他的就截取⼀位。
sql左连分组查询语句

sql左连分组查询语句SQL左连接分组查询是一种常用的数据查询语句,可以根据指定的条件对多个表进行连接,并按照指定的字段进行分组。
下面列举了10个示例,以展示SQL左连接分组查询的应用。
1. 查询每个部门的员工数量```SELECT department, COUNT(employee_id) AS employee_count FROM employeesGROUP BY department;```这个查询会返回一个结果集,其中每一行表示一个部门及其对应的员工数量。
2. 查询每个部门的平均工资```SELECT department, AVG(salary) AS average_salaryFROM employeesGROUP BY department;```这个查询会返回一个结果集,其中每一行表示一个部门及其对应的平均工资。
3. 查询每个部门的最高工资和最低工资```SELECT department, MAX(salary) AS max_salary, MIN(salary) AS min_salaryFROM employeesGROUP BY department;```这个查询会返回一个结果集,其中每一行表示一个部门及其对应的最高工资和最低工资。
4. 查询每个部门的员工数量,并按照员工数量降序排序```SELECT department, COUNT(employee_id) AS employee_count FROM employeesGROUP BY departmentORDER BY employee_count DESC;```这个查询会返回一个结果集,其中每一行表示一个部门及其对应的员工数量,并按照员工数量降序排列。
5. 查询每个部门的员工数量,并只显示员工数量大于10的部门```SELECT department, COUNT(employee_id) AS employee_count FROM employeesGROUP BY departmentHAVING employee_count > 10;```这个查询会返回一个结果集,其中每一行表示一个员工数量大于10的部门及其对应的员工数量。
SQL查询语句

WHERE ytd_sales>10000
) AS t
WHERE a.au_id=ta.au_id
AND ta.title_id=t.title_id
此例中,将SELECT返回的结果集合给予一别名t,然后再符:
<#为虚拟表,可一跨数据库创建!>
8.更改列表名显示的查询
select 字段名1 as ''A'',字段名2 as ''B'' from 表名
select "A"=字段名1,"B"=字段名2 from 表名
select 字段名1"A",字段名2"B" from 表名
Sum:计算总和
Stdev:计算统计标准偏差
Var:统计方差
13.汇总查询<Compute子句>
(1).compute:
Select 字段名列表 From 表名 [where 条件表达式] Compute 汇总表达式
Select cno,sno,degree From score Compute avg(degree)
①执行Where子句,从表中选取行;
②由Group By分组;
③执行Having子句选取满足的分组条件。
---------------------------------------{那我们如何对函数产生的值来设定条件呢?
举例来说,我们可能只需要知道哪些店的营业额有超过 $1,500。在这个情况下,
SELECT "栏位1", SUM("栏位2")
sql符号用法

sql符号用法SQL是一种用于管理关系型数据库的语言,它包含了许多符号和关键字,这些符号和关键字可以帮助我们对数据库进行查询、插入、更新和删除等操作。
下面是一些常见的SQL符号及其用法:1. SELECT:用于查询数据表中的数据。
可以通过SELECT语句来选择需要查询的列和行。
2. FROM:用于指定要从哪个表中查询数据。
3. WHERE:用于指定查询条件。
可以使用比较运算符(如=、<、>)或逻辑运算符(如AND、OR)来构建条件。
4. ORDER BY:用于对查询结果进行排序。
可以按照一个或多个列进行排序,还可以指定升序或降序排列。
5. GROUP BY:用于将结果分组。
通常会与聚合函数(如SUM、AVG)一起使用,以便对每个分组计算汇总值。
6. HAVING:与GROUP BY一起使用,用于过滤分组后的结果集合。
类似于WHERE语句,但是WHERE只能过滤行级别的数据,而HAVING可以过滤分组级别的数据。
7. JOIN:用于将两个或多个表中的数据连接在一起。
常见的JOIN类型有INNER JOIN、LEFT JOIN和RIGHT JOIN等。
8. UNION:用于将两个或多个SELECT语句返回的结果集合并在一起。
UNION要求两个结果集的列数和数据类型必须一致。
9. INSERT INTO:用于向数据表中插入新的数据。
可以指定要插入的列和值。
10. UPDATE:用于更新数据表中的数据。
可以指定要更新的列和值,还可以使用WHERE语句来过滤需要更新的行。
11. DELETE FROM:用于删除数据表中的数据。
可以使用WHERE语句来过滤需要删除的行。
以上就是SQL常见符号及其用法的介绍。
熟练掌握这些符号,可以帮助我们更加高效地管理和操作数据库。
Oracle【三表的联合查询】
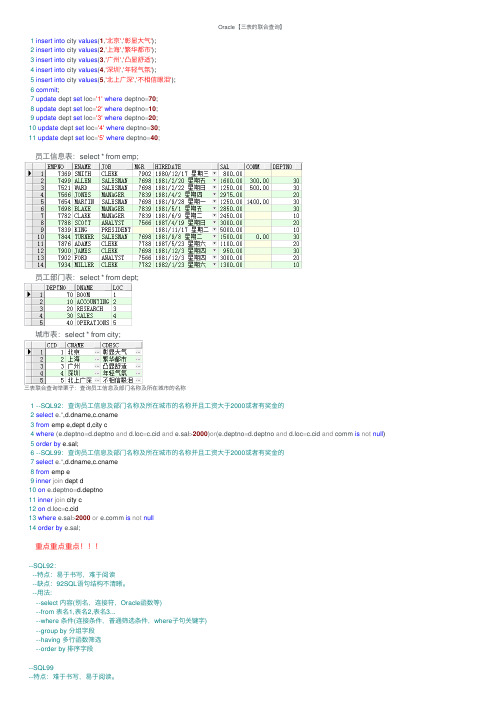
Oracle 【三表的联合查询】员⼯信息表:select * from emp;员⼯部门表:select * from dept;城市表:select * from city;三表联合查询举栗⼦:查询员⼯信息及部门名称及所在城市的名称重点重点重点!!!1 insert into city values (1,'北京','彰显⼤⽓');2 insert into city values (2,'上海','繁华都市');3 insert into city values (3,'⼴州','凸显舒适');4 insert into city values (4,'深圳','年轻⽓氛');5 insert into city values (5,'北上⼴深','不相信眼泪');6 commit ;7 update dept set loc ='1' where deptno =70;8 update dept set loc ='2' where deptno =10;9 update dept set loc ='3' where deptno =20;10 update dept set loc ='4' where deptno =30;11 update dept set loc ='5' where deptno =40;1 --SQL92:查询员⼯信息及部门名称及所在城市的名称并且⼯资⼤于2000或者有奖⾦的2 select e.*,d.dname,ame3 from emp e,dept d,city c4 where (e.deptno =d.deptno and d.loc =c.cid and e.sal >2000)or (e.deptno =d.deptno and d.loc =c.cid and comm is not null )5 order by e.sal;6 --SQL99:查询员⼯信息及部门名称及所在城市的名称并且⼯资⼤于2000或者有奖⾦的7 select e.*,d.dname,ame8 from emp e9 inner join dept d10 on e.deptno =d.deptno11 inner join city c12 on d.loc =c.cid13 where e.sal >2000 or m is not null14 order by e.sal;--SQL92:--特点:易于书写,难于阅读--缺点:92SQL 语句结构不清晰。
SQL语句大全

SQL语句参考,包含Access、MySQL以及SQL Server基础创建数据库CREATE DATABASE database-name删除数据库drop database dbname备份sql server1.创建备份数据的device2. USE master3.EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat'4.开始备份5.BACKUP DATABASE pubs TO testBack创建新表create table tabname(col1 type1 [not null] [primary key],c ol2 type2 [not null],..)根据已有的表创建新表:A:create table tab_new like tab_old (使用旧表创建新表)B:create table tab_new as select col1,col2… from tab_old d efinition only删除新表drop table tabname增加一个列Alter table tabname add column col type注:列增加后将不能删除。
DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。
添加主键Alter table tabname add primary key(col)删除主键Alter table tabname drop primary key(col)创建索引create [unique] index idxname on tabname(col….)删除索引drop index idxname注:索引是不可更改的,想更改必须删除重新建。
创建视图create view viewname as select statement删除视图drop view viewname几个简单的基本的sql语句选择:select * from table1 where 范围插入:insert into table1(field1,field2) values(value1,value 2)删除:delete from table1 where 范围更新:update table1 set field1=value1 where 范围查找:select * from table1 where field1 like ’%value1%’ ---l ike的语法很精妙,查资料!排序:select * from table1 order by field1,field2 [desc]总数:select count as totalcount from table1求和:select sum(field1) as sumvalue from table1平均:select avg(field1) as avgvalue from table1最大:select max(field1) as maxvalue from table1最小:select min(field1) as minvalue from table1几个高级查询运算词UNION 运算符UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。
SQL语言的简单应用-pt

select JH,RQ,RCYL1,RCYL,HS FROM DBA01 WHERE JH='DXX11X189'
AND RQ>='20100620'
Date型
一、SQL语句的基本语法--2、基本运算和基本函数
8)TO_CHAR(X,Y):将一个日期或数字转换为一个字符串。当 X为日期时,y为一个日期模式,当x为一个数字时,y为各种字 符串的格式模型。
deco注de意(S:CTS当,nSuElLlE,CNUTL语L,句RO中UN包D((含NV多L(个YC子YL,句0)时)/((RWOHUNEDR(ESC,TGSR,0O)U+P((SC TdSe-coRBdOYeU,N(OD(RY(CSDYCELTR+SY,BC0YS)L)等)*,10n)0ul/,l2,4O)nR)uD,l1lE),R)0,B日NYU油L子L,,R句OU必ND须(Y放CSL在*1最00后/(YCYL+YCSL
10)DISTINCT:当执行查询操作时,某些情况下可能会显示 完全相同的数据结果,而完全相同的显示结果可能是没有任何 实际意义的。此时可用DISTINCT取消完全重复的显示结果。
SELECT DISTINCT JH FROM YD_DBA09 WHERE NY >= '200901' AND NY<= '200912'
9)TO_DATE(X,Y):按照格式模型y将字符串x转换为日期
select JH "井号",DWMC,KJRQ "开井日期",CSNR "措施内容"
from DZS_YTSJ.CSXG WHERE KJRQ>='20100615'
postgresql 常用sql 语句

一、概述PostgreSQL是一种功能强大的开源关系型数据库管理系统,广泛应用于各种规模和类型的应用程序中。
在使用PostgreSQL时,熟练掌握常用的SQL语句是非常重要的,可以帮助用户更高效地管理和操作数据库。
本文将介绍PostgreSQL中常用的SQL语句,帮助读者更好地使用这一数据库管理系统。
二、连接数据库1. 连接到数据库使用以下命令可以连接到PostgreSQL数据库:```psql -U username -d database_name```其中,-U参数用于指定用户名,-d参数用于指定要连接的数据库名称。
2. 退出数据库在连接到数据库后,可以使用以下命令退出数据库:```\q```三、数据库管理1. 创建数据库使用以下命令可以在PostgreSQL中创建数据库: ```CREATE DATABASE database_name;```2. 删除数据库若要删除数据库,可以使用以下命令:```DROP DATABASE database_name;```四、表操作1. 创建表使用以下命令可以在数据库中创建表:```CREATE TABLE table_name (column1 datatype,column2 datatype,column3 datatype,...);```2. 删除表若要删除表,可以使用以下命令:```DROP TABLE table_name;```五、数据操作1. 插入数据使用以下命令可以向表中插入数据:```INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);```2. 查询数据查询表中的数据可以使用以下命令:```SELECT column1, column2, ...FROM table_nameWHERE condition;```3. 更新数据若要更新表中的数据,可以使用以下命令:```UPDATE table_nameSET column1 = value1, column2 = value2, ...WHERE condition;```4. 删除数据若要删除表中的数据,可以使用以下命令:```DELETE FROM table_nameWHERE condition;```六、数据过滤1. 按条件过滤使用WHERE子句可以对查询结果进行条件筛选,例如: ```SELECT *FROM table_nameWHERE column1 = value;```2. 模糊查询若要进行模糊查询,可以使用LIKE运算符,例如:```SELECT *FROM table_nameWHERE column1 LIKE 'value';```七、数据排序1. 升序排序若要按升序对查询结果进行排序,可以使用以下命令: ```SELECT *FROM table_nameORDER BY column1 ASC;```2. 降序排序若要按降序对查询结果进行排序,可以使用以下命令: ```SELECT *FROM table_nameORDER BY column1 DESC;```八、聚合函数1. 求和使用SUM函数可以对数据列进行求和操作,例如:```SELECT SUM(column1)FROM table_name;```2. 平均值若要计算数据列的平均值,可以使用AVG函数:```SELECT AVG(column1)FROM table_name;```3. 计数使用COUNT函数可以统计行数或满足条件的行数,例如: ```SELECT COUNT(*)FROM table_name;九、数据分组1. 分组统计若要对数据进行分组统计,可以使用GROUP BY子句,例如:```SELECT column1, COUNT(*)FROM table_nameGROUP BY column1;```2. 分组筛选若要对分组后的数据进行筛选,可以使用HAVING子句:```SELECT column1, COUNT(*)FROM table_nameGROUP BY column1HAVING COUNT(*) > 1;```十、连接表1. 内连接使用INNER JOIN可以连接两个表,并返回满足连接条件的行,例```SELECT *FROM table1INNER JOIN table2ON table1.column1 = table2.column2;```2. 左连接若要返回左表中所有行以及与其关联的右表中的行,可以使用LEFT JOIN:```SELECT *FROM table1LEFT JOIN table2ON table1.column1 = table2.column2;```十一、子查询1. 标量子查询若要返回单一值的子查询结果,可以使用标量子查询,例如:```SELECT column1,(SELECT MAX(column2) FROM table2) AS max_value FROM table1;```2. 列表子查询使用列表子查询可以返回一列多行结果,例如:```SELECT column1FROM table1WHERE column1 IN (SELECT column2 FROM table2); ```十二、索引1. 创建索引若要在表的一个或多个列上创建索引,可以使用以下命令: ```CREATE INDEX index_nameON table_name (column1, column2, ...);```2. 删除索引若要删除索引,可以使用以下命令:```DROP INDEX index_name;```十三、事务管理1. 开始事务使用以下命令可以开始一个事务:```BEGIN;```2. 提交事务若要将未提交的事务更改保存到数据库中,可以使用以下命令: ```COMMIT;```3. 回滚事务若要撤销未提交的事务更改,可以使用以下命令:```ROLLBACK;```十四、权限管理1. 授权若要授予用户对数据库或表的特定操作许可,可以使用GRANT命令:```GRANT permissionON object_nameTO user_name;```2. 撤销权限若要撤销用户对数据库或表的特定操作许可,可以使用REVOKE命令:```REVOKE permissionON object_nameFROM user_name;```3. 角色管理使用CREATE ROLE命令可以创建新角色,使用ALTER ROLE命令可以修改角色,使用DROP ROLE命令可以删除角色。
sql(三):多表查询、左右连接、组函数与分组统计

sql(三):多表查询、左右连接、组函数与分组统计⼀、多表查询之前查询都是在⼀张表上进⾏的查询,如果使⽤多张表进⾏查询,则称为多表查询。
格式如下:[sql]1. select {DISTINCT}* | 具体列名别名2. form 表名称1 别名1,表名称2 别名23. { where 条件(s) }4. {order by 排序的字段1 ASC | DESC,排序的字段2 ASC | DESC.....}1. 使⽤多表查询,同时查询emp和dept表[sql]1. SELECT * FROM emp,dept ;查询出来的结果条数是emp条数 * dept的条数。
说明在使⽤多表查询的时候会产⽣笛卡尔积。
如果表的数据越多,笛卡尔积产⽣的结果就越多,想要去掉笛卡尔积,则必须使⽤字段进⾏关联的操作。
例如,使⽤dept字段来关联:[sql]1. SELECT * FROM emp,dept2. WHERE emp.deptno=dept.deptno ;2. 如果表名过长,可以为其取别名[sql]1. SELECT * FROM emp e,dept d2. WHERE e.deptno=d.deptno ;3.⾃关联例:要求查询出每个雇员的姓名、⼯作、雇员的直接上级领导的姓名[sql]1. SELECT e.ename,e.job,m.ename2. FROM emp e,emp m3. WHERE e.mgr=m.empno ;⼆、左右连接1. (+)在左边表⽰右连接例如:[sql]1. SELECT e.empno,e.ename,d.deptno,d.dname,d.loc2. FROM emp e,dept d3. WHERE e.deptno(+)=d.deptno ;表⽰d表的deptno字段⼀定会出现,即使e表的deptno没有存在相匹配的⾏...2. (+)在右边表⽰左连接例如:[sql]1. SELECT e.empno,e.ename,d.deptno,d.dname,d.loc2. FROM emp e,dept d3. WHERE e.deptno=d.deptno(+) ;表⽰e表的deptno字段⼀定会出现,即使d表的deptno没有存在相匹配的⾏...三、SQL:1999语法(了解)格式:[sql]1. SELECT table1.column,table2.column2. FROM table1 [CROSS JOIN table2]|3. [NATURAL JOIN table2]|4. [JOIN table2 USING(column_name)]|5. [JOIN table2 ON(table1.column_name=table2.column_name)]|6. [LEFT|RIGHT|FULL OUTER JOIN table2 ON(table1.column_name=table2.column_name)];四、组函数与分组统计分组:例如,把所有男⽣分为⼀组,⼥⽣分为⼀组。
sql语句大全(详细)

sql语句大全(详细)sql语句大全(详细)数据库操作1.查看所有数据库show databases;2.查看当前使用的数据库select database();3.创建数据库create databases 数据库名 charset=utf8;4.删除数据库drop database 数据库名5.使用数据句库use database 数据库名6.查看数据库中所有表show tables;表的操作1.查看表结构desc 表名2.创建表结构的语法create table table_name(字段名数据类型可选的约束条件);demo:创建班级和学生表create table classes(id int unsigned auto_increment primary key not null, name varchar(10));create table students(id int unsigned primary key auto_increment not null, name varchar(20) default '',age tinyint unsigned default 0,height decimal(5,2),gender enum('男','女','人妖','保密'),cls_id int unsigned default 0)3.修改表–添加字段alter table 表名 add 列名类型demo:alter table students add birthday datetime;4.修改表–修改字段–重命名版alert table 表名 change 原名新名类型及约束demo:alter table syudents change birthday birth datetime not null;5.修改表–修改字段–不重命名alter table 表名 modify 列名类型及约束demo : alter table students modify birth date nout noll;6.删除表–删除字段alter table 表名 drop 列名demo :later table students drop birthday;7.删除表drop table 表名demo:drop table students;8.查看表的创建语句–详细过程show create table 表名demo : show create tabele students;查询基本使用1.查询所有列select * from 表名例:select * from classes;2.查询指定列select 列1,列2,...from 表名;例:select id,name from classes;增加说明:主键列是自动增长,但是在全列插入时需要占位,通常使用空值(0或者null) ; 字段默认值 default 来占位,插入成功后以实际数据为准1.全列插入:值的顺序与表结构字段的顺序完全一一对应此时字段名列表不用填写insert into 表名 values (...)例:insert into students values(0,’郭靖',1,'蒙古','2016-1-2');2.部分列插入:值的顺序与给出的列顺序对应此时需要根据实际的数据的特点填写对应字段列表insert into 表名 (列1,...) values(值1,...)例:insert into students(name,hometown,birthday) values('黄蓉','桃花岛','2016-3-2');上面的语句一次可以向表中插入一行数据,还可以一次性插入多行数据,这样可以减少与数据库的通信3.全列多行插入insert into 表名 values(...),(...)...;例:insert into classes values(0,'python1'),(0,'python2');4.部分列多行插入insert into 表名(列1,...) values(值1,...),(值1,...)...;例:insert into students(name) values('杨康'),('杨过'),('小龙女');修改update 表名 set 列1=值1,列2=值2... where 条件例:update students set gender=0,hometown='北京' where id=5;删除delete from 表名 where 条件例:delete from students where id=5;逻辑删除,本质就是修改操作update students set isdelete=1 where id=1;as关键字1.使用 as 给字段起别名select id as 序号, name as 名字, gender as 性别 from students;2.可以通过 as 给表起别名select s.id,,s.gender from students as s;条件语句查询where后面支持多种运算符,进行条件的处理比较运算符逻辑运算符模糊查询范围查询空判断比较运算符等于: =大于: >大于等于: >=小于等于: <=不等于: != 或 <>例1:查询编号大于3的学生select * from students where id > 3;例2:查询编号不大于4的学生select * from students where id <= 4;例3:查询姓名不是“黄蓉”的学生select * from students where name != '黄蓉';例4:查询没被删除的学生select * from students where is_delete=0;逻辑运算符andornot例5:查询编号大于3的女同学select * from students where id > 3 and gender=0;例6:查询编号小于4或没被删除的学生select * from students where id < 4 or is_delete=0;模糊查询like%表示任意多个任意字符_表示一个任意字符例7:查询姓黄的学生select * from students where name like '黄%';例8:查询姓黄并且“名”是一个字的学生select * from students where name like '黄_';例9:查询姓黄或叫靖的学生select * from students where name like '黄%' or name like '%靖';范围查询分为连续范围查询和非连续范围查询in表示在一个非连续的范围内例10:查询编号是1或3或8的学生select * from students where id in(1,3,8);between … and …表示在一个连续的范围内例11:查询编号为3至8的学生select * from students where id between 3 and 8;例12:查询编号是3至8的男生select * from students where (id between 3 and 8) and gender=1;空判断判断为空例13:查询没有填写身高的学生select * from students where height is null;注意: 1. null与’'是不同的 2. is null判非空is not null例14:查询填写了身高的学生select * from students where height is not null;例15:查询填写了身高的男生select * from students where height is not null and gender=1;优先级优先级由高到低的顺序为:小括号,not,比较运算符,逻辑运算符and比or先运算,如果同时出现并希望先算or,需要结合()使用排序排序查询语法:select * from 表名 order by 列1 asc|desc [,列2 asc|desc,...]语法说明:将行数据按照列1进行排序,如果某些行列1 的值相同时,则按照列2 排序,以此类推asc从小到大排列,即升序desc从大到小排序,即降序默认按照列值从小到大排列(即asc关键字)例1:查询未删除男生信息,按学号降序select * from students where gender=1 and is_delete=0 order by id desc;例2:查询未删除学生信息,按名称升序select * from students where is_delete=0 order by name;例3:显示所有的学生信息,先按照年龄从大–>小排序,当年龄相同时按照身高从高–>矮排序select * from students order by age desc,height desc;分页select * from 表名 limit start=0,count说明从start开始,获取count条数据start默认值为0也就是当用户需要获取数据的前n条的时候可以直接写上xxx limit n;例1:查询前3行男生信息select * from students where gender=1 limit 0,3;关于分页的一个有趣的推导公式已知:每页显示m条数据,当前显示第n页求总页数:此段逻辑后面会在python项目中实现查询总条数p1使用p1除以m得到p2如果整除则p2为总数页如果不整除则p2+1为总页数获取第n页的数据的SQL语句求解思路第n页前有n-1页所在第n页前已经显示的数据的总量是(n-1)*m由于数据的下标从0开始所以第n页前所有的网页的下标是0,1,…,(n-1)*m-1所以第n页的数据起始下标是(n-1)*m获取第n页数据的SQL语句select * from students where is_delete=0 limit (n-1)*m,m注意:在sql语句中limit后不可以直接加公式聚合函数总数count(*) 表示计算总行数,括号中写星与列名,结果是相同的例1:查询学生总数select count(*) from students;最大值max(列) 表示求此列的最大值例2:查询女生的编号最大值select max(id) from students where gender=2;最小值min(列) 表示求此列的最小值例3:查询未删除的学生最小编号select min(id) from students where is_delete=0;求和sum(列) 表示求此列的和例4:查询男生的总年龄select sum(age) from students where gender=1;–平均年龄select sum(age)/count(*) from students where gender=1;平均值avg(列) 表示求此列的平均值例5:查询未删除女生的编号平均值select avg(id) from students where is_delete=0 andgender=2;分组group bygroup by + group_concat()group_concat(字段名)根据分组结果,使用group_concat()来放置每一个分组中某字段的集合group by + 聚合函数通过group_concat()的启发,我们既然可以统计出每个分组的某字段的值的集合,那么我们也可以通过集合函数来对这个值的集合做一些操作group by + havinghaving 条件表达式:用来过滤分组结果having作用和where类似,但having只能用于group by 而where是用来过滤表数据group by + with rollupwith rollup的作用是:在最后新增一行,来记录当前表中该字段对应的操作结果,一般是汇总结果。
sql表连接查询使用方法(sql多表连接查询)

sql表连接查询使⽤⽅法(sql多表连接查询)实际的项⽬,存在多张表的关联关系。
不可能在⼀张表⾥⾯就能检索出所有数据。
如果没有表连接的话,那么我们就需要⾮常多的操作。
⽐如需要从A表找出限制性的条件来从B表中检索数据。
不但需要分多表来操作,⽽且效率也不⾼。
⽐如书中的例⼦:复制代码代码如下:SELECT FIdFROM T_CustomerWHERE FName='MIKE'这个SQL语句返回2,也就是姓名为MIKE 的客户的FId值为2,这样就可以到T_Order中检索FCustomerId等于2 的记录:复制代码代码如下:SELECT FNumber,FPriceFROM T_OrderWHERE FCustomerId=2下⾯我们详细来看看表连接。
表连接有多种不同的类型,有交叉连接(CROSS JOIN)、内连接(INNER JOIN)、外连接(OUTTER JOIN)。
(1)内连接(INNER JOIN):内连接组合两张表,并且只获取满⾜两表连接条件的数据。
复制代码代码如下:SELECT o.FId,o.FNumber,o.FPrice,c.FId,c.FName,c .FAgeFROM T_Order o JOIN T_Customer cON o.FCustomerId= c.FId注:在⼤多数数据库系统中,INNER JOIN中的INNER是可选的,INNER JOIN 是默认的连接⽅式。
在使⽤表连接的时候可以不局限于只连接两张表,因为有很多情况下需要联系许多表。
例如,T_Order表同时还需要连接T_Customer和T_OrderType两张表才能检索到所需要的信息,编写如下SQL语句即可:复制代码代码如下:SELECT o.FId,o.FNumber,o.FPrice,c.FId,c.FName,c .FAgeFROM T_Order o JOIN T_Customer cON o.FCustomerId= c.FIdINNER JOIN T_OrderTypeON T_Order.FTypeId= T_OrderType.FId(2)交叉连接(CROSS JOIN):交叉连接所有涉及的表中的所有记录都包含在结果集中。
第九节:连接查询——SQL99

第九节:连接查询——SQL99⼀、连接查询-SQL99标准 1、分类 (1)内连接:inner join (2)外连接: ①左外连接:left 【outer】 ②右外连接:right 【outer】 ③全外连接:full 【outer】 (3)交叉连接:cross 2、语法格式select 查询列表from 表1 别名【连接类型】join 表2 别名on 连接条件【where 筛选条件】【group by 分组】【having 筛选条件】【order by 排序列表】 3、⼆、SQL99 标准 1、内连接 (1)分类 等值连接 ⾮等值连接 ⾃连接 (2)语法格式select 查询列表from 表1 别名【inner】 join 表2 别名 on 连接条件where 筛选条件group by 分组列表having 分组后的筛选order by 排序列表limit ⼦句; (3)特点 ①表的顺序可以调换,可以添加排序、分组、筛选; ②内连接的结果=多表的交集,inner join 和 SQL92 语法中的等值连接效果是⼀样的,都是查询多表的交集; ③n表连接⾄少需要n-1个连接条件; ④ inner 可以省略,筛选条件放在 where 后⾯,连接条件放在 on 语句后⾯,提⾼分离性,便于阅读; 2、外连接 (1)分类 左外连接 右外连接 全外连接 (2)语法格式select 查询列表from 表1 别名left|right|full【outer】 join 表2 别名 on 连接条件where 筛选条件group by 分组列表having 分组后的筛选order by 排序列表limit ⼦句; (3)特点 ①查询的结果=主表中所有的⾏,如果从表和它匹配的将显⽰匹配⾏,如果从表没有匹配的则显⽰null ②left join 左边的就是主表,right join 右边的就是主表full join 两边都是主表 ③⼀般⽤于查询除了交集部分的剩余的不匹配的⾏; ④外连接的查询结果为主表中的所有记录,如果从表中有和它匹配的,则显⽰匹配的值,如果从表中没有和它匹配的,则显⽰ null; ⑤外连接查询结果 = 内连接结果 + 主表中有⽽从表没有的记录; ⑥全外连接 = 内连接结果 + 表1中有但表2中没有的 + 表2中有但表1中没有的; 3、交叉连接 (1)语法格式select 查询列表from 表1 别名cross join 表2 别名; (2)特点 类似于笛卡尔乘积三、案例 1、内连接 (1)等值连接 ①查询员⼯名,部门名;SELECTlast_name,department_nameFROMemployees eINNER JOIN departments dON e.`department_id` = d.`department_id` ; ②查询名字中包含 e 的员⼯名和⼯种名(添加筛选)SELECTlast_name,job_titleFROMemployees eINNER JOIN jobs jON e.`job_id` = j.`job_id`WHERE e.`last_name` LIKE '%e%' ; ③查询部门个数 > 3 的城市名和部门个数(分组+筛选)SELECTcity,COUNT(*)FROMlocations lINNER JOIN departments dON l.`location_id` = d.`location_id`GROUP BY l.`city`HAVING COUNT(*) > 3 ; ④查询哪个部门的部门员⼯个数 > 3的部门名和员⼯个数,并按个数降序(排序)SELECTdepartment_name,COUNT(*)FROMdepartments dINNER JOIN employees eON d.`department_id` = e.`department_id`GROUP BY d.`department_name`HAVING COUNT(*) > 3ORDER BY COUNT(*) DESC ; ⑤查询员⼯名、部门名、⼯种名、并按部门名排序(多表连接)SELECTlast_name,department_name,job_titleFROMemployees eINNER JOIN departments dON e.`department_id` = d.`department_id`INNER JOIN jobs jON e.`job_id` = j.`job_id`ORDER BY department_name DESC ; (2)⾮等值连接 ①查询员⼯的⼯资级别SELECTsalary,grade_levelFROMemployees eINNER JOIN job_grades jON e.`salary` BETWEEN j.`lowest_sal`AND j.`highest_sal` ; ②查询⼯资级别的个数 > 2的个数,并且按⼯资级别降序SELECTCOUNT(*),grade_levelFROMemployees eINNER JOIN job_grades jON e.`salary` BETWEEN j.`lowest_sal`AND j.`highest_sal`GROUP BY grade_levelHAVING COUNT(*) > 20ORDER BY grade_level DESC ; (3)⾃连接 ①查询员⼯的名字、上级的名字SELECTst_name,st_nameFROMemployees eINNER JOIN employees mON e.`manager_id` = m.`employee_id` ; ②查询姓名中包含字符 k 的员⼯的名字、上级的名字SELECTst_name,st_nameFROMemployees eINNER JOIN employees mON e.`manager_id` = m.`employee_id`WHERE e.`last_name` LIKE '%k%' ; 2、外连接 (1)左外连接 ①查询男朋友不在男神表的⼥神名SELECT,bo.*FROMbeauty bLEFT OUTER JOIN boys boON b.`boyfriend_id` = bo.`id`WHERE bo.id IS NULL ; ②查询哪个部门没有员⼯SELECTd.*,e.`employee_id`FROMdepartments dLEFT OUTER JOIN employees eON d.`department_id` = e.`department_id`WHERE e.`department_id` IS NULL ; (2)右外连接SELECT,bo.*FROMboys boRIGHTOUTER JOIN beauty bON b.`boyfriend_id` = bo.`id`WHERE bo.id IS NULL ; (3)全外连接(MySQL不⽀持) ①SELECT b.*, bo.*FROM beauty bFULL OUTER JOIN boys boON b.`boyfriend_id` = bo.id; 3、交叉连接 交叉连接 == 笛卡尔乘积 ①SELECT b.*, bo.*FROM beauty bCROSS JOIN boys bo;四、练习 1、查询编号 > 3 的⼥神们的男朋友信息,如果有则列出详细,如果没有,⽤null填充SELECT b.*, bo.*FROM beauty bLEFT OUTER JOIN boys bo ON b.`boyfriend_id` = bo.`id`WHERE b.`id` > 3; 2、查询哪个城市没有部门SELECTl.*,d.*FROMlocations lLEFT OUTER JOIN departments dON l.`location_id` = d.`location_id`WHERE d.`department_id` IS NULL ; 3、查询部门名为 SAL 或 IT 的员⼯信息SELECT d.*, e.*FROM departments dLEFT OUTER JOIN employees e ON e.`department_id` = d.`department_id` WHERE d.`department_name` IN ('SAL', 'IT');五、总结 SQL92 VS SQL99 ①功能:SQL99⽀持的⽐较多; ②可读性:SQL99 实现连接条件和筛选条件的分离,可读性较⾼; 七种 Join 连接。
SQL语句汇总

S Q L语句一:基本查询:(1)插入单行数据insert into 表名(列名1,列名2,列名3,……)values(值1,值2,值3……)from 表名(2)将现有表中的数据添加到新表中insert into 新表名(列名1,列名2,列名3,……)select(值1,值2,值3……)from已存在表的表名select 表名1.列名1,表名1.列名2……into 表名//不需先创建表(3)创建标识列select identity(数据类型,标识种子,标识常量)as 列名into 新表form原始表(4)使用union关键字插入多行数据insert 表名(列名1,列名2,列名3,……)select 列名1,列名2,列名3,……unionselect 列名1,列名2,列名3,……(5)更新某行数据upadate 表名set列名1=更新值,列名2=更新值……where 列名1=原始值,列名2=原始值……(6)删除数据行delete from表名where条件注意:不能删除有主键被其他表引用的行!truncate table 表名注意:此语句用来删除表中所有行,但是表的结构、列、约束等不变。
且不能用于有外键约束的表(7)限制查询返回行数及按百分比返回select TOP 行数列名1,……from 表名where条件select TOP PRECENT列名1,……from 表名where条件(8)LIKE查询select *from 表名where列名LIKE'zhang%'(9)between查询select *from 表名where列名between 数值范围(10)In查询select 列名from列名where列名(not)In('字符值1','字符值2',……)order by 列名(11)使用聚合函数查询select 聚合函数(列名)from表名where条件(12)分组查询select 列名1,聚合函数(列名)from表名group by 列名1(13)having筛选select 列名1,列名2,……from表名group by 列名,列名……having count(*)>1(14)使用distinct去除重复信息select distinct 列名from 表名(15)NULL值的判断空值运算符:is(not)NULL注意:不能用<>代替上面的语句(16)组合查询使用AND OR 运算符(17)关于IN和NOT IN查询在条件中添加语句:where 列名IN(not in)('values1'……)(18)IN 与OR 可以互换,已达到同样的效果(19)NOT 运算符NOt 即对查询条件取反注意:NULL 取反仍为NULL(20)NOT与BETWEEN组合使用列名NOT BETWEEN 40 AND 60(21)LIKE 模糊查询“%"通配符:表示任意的字符匹配,且不计字符的多少列名LIKE '计算机%'表示此列是以"计算机"开头后接任意的字符列名LIKE '%计算机'表示此列是以"计算机"结尾前面接任意多的字符列名LIKE '%计算机%'表示此列是含有"计算机"前后接任意多的字符列名LIKE '基础%计算机'表示此列是以"基础"开头,以"计算机"结尾中间可含有任意多的字符"_"通配符:表示任意一个字符的匹配,且知道列名含有的字符个数列名LIKE '计算机__'表示此列含有五个字符"[]"通配符:用于指定一系列字符,只要满足这些字符其中之一,且位置出现在[]通配符的位置的字符串就满足查询条件列名LIKE '[计生]%'表示要查是以"计"字,或是以"生"字开头的列名列名LIKE '[^计生]%'表示要查所有不以"计"字,或是以"生"字开头的列名注意:用NOT和用^能达到同样的效果(22)使用ESCAPE定义转义字符LIKE '%M%'ESCAPE ‘M’注意:上面第二个%号是实际值,不作为通配符二:连接符、数值运算和函数(1)连接符:+,||用于连接表中的两列或者多列数据,使他们作为一列供用户查找操作Select 列名1+列名2,列名4 from 表名注意:相连接的列名的数据类型应当相容,若不相容就要强制转换如下:select 列名1+CAST(列名2 AS 数据类型),列名4 from 表名另注意:若有一列名为NULL则连接后结果也为空(2)数值运算:加、减、乘、除、取余%Select 列名1*列名2,列名4 from 表名注意:相运算的两列必须是数值型,若是数据类型不同但同为数值(比如说:学号有人为char型,有的人为int型)就要强制转换如下:select 列名1+CAST(列名2 AS 数据类型),列名4 from 表名(3)函数:字符处理函数:ASCII(字符表达式),返回字符表达式最左端字符的ASCII码值CHAR(INT 型表达式),将ASCII码转换为字符。
sql连接2张表_SQL:多表查询

sql连接2张表_SQL:多表查询⼀,表的加法在原有school数据库⾥再创建⼀张跟course结构相同的表course1,可以【右击course】,【点复制表】-【选结构和顺序】,然后把course1⾥按照要求修改数据完成操作后发现course和course1 结构是⼀样的,列和列的数据类型是⼀致的,不同的是红⾊框的数据union将两张表的查询语句结合⼀起练习:将course和course1相加,⽤union⽂⽒图:加法(Union)图⼀表的加法会把表⾥重复的数据删除,只保留⼀个(图⼀);若想要保留2张表⾥重复的⾏,在Union后加all保留2张表⾥重复的⾏,在Union后加all 即可(图⼆)表的加法会把表⾥重复的数据删除,只保留⼀个图⼆⼆,表的连接School数据库⾥4张表学⽣表和成绩表之间有什么关系呢?学号关联起来,学号0001的成绩,可以通过成绩表⾥查学号0001的⾏,⼀共发现3⾏,对应是找到了学号student和score这两张表通过学号0001三门课程的成绩。
School数据库⾥四张表之间的关系4张表联结关系图交叉联结cross join:(将⼀个表的每⼀⾏ 与 另⼀表中的每⼀⾏ 合并在⼀起)交叉联结cross join表1 三⾏数据;表2 两⾏数据 交叉联结=3*2 六⾏数据典型的交叉联结 :扑克牌⽣活中典型的交叉联结13张牌(A,1,2,3,4,5,6,7,8,9,10,J,Q,K)和 四种花⾊(♠,)交叉联结 13*4=52张牌【注】:交叉联结实际业务⽤的⽐较少(耗时成本;没有实际价值),交叉联结是所有联结的基础交叉联结是所有联结的基础内联结inner join:(查找出同时存在于两张表的数据)内联结inner join左联结left join: (将左侧的表作为主表,将左表数据全部取出,右边表只选出和左边表相同列名的⾏)左联结left join右联结right join右联结right join:(将右侧表的数据全部取出,将左侧表中与右侧表相同列名的⾏取出)全联结 full join (查询结果返回左表和右表中的所有⾏。
SQLServer中常用的SQL语句

SQLServer中常⽤的SQL语句1、概述名词笛卡尔积、主键、外键数据完整性实体完整性:主属性不能为空值,例如选课表中学号和课程号不能为空参照完整性:表中的外键取值为空或参照表中的主键⽤户定义完整性:取值范围或⾮空限制,例如:性别(男⼥),年龄(0-130)表连接⾃然连接:与等值连接(a.id=b.id)相⽐,连接后的表只有⼀列id,⽽不是两列(a.id和b.id)。
半连接:与等值连接(a.id=b.id)相⽐,连接后的表只有A表的列,被B表“多次匹配”列会显⽰为⼀⾏。
左外连接:left join右外连接:right join全外连接:full join全内连接:inner joinSQL语⾔的构成DDL语⾔:数据定义,定义基本表、视图、索引;DML语⾔:数据操纵,查询、增加、修改、删除DCL语⾔:权限2、查询概述查询包括:单表查询、连接查询、带有exists的相关⼦查询、集合操作四中。
select...from常⽤语句执⾏过程3、单表查询group by 只有出现在group by⼦句中的属性,才可出现在select⼦句中。
⽤order by⼦句对查询结果按照⼀个或多个列的值进⾏升/降排列输出,升序为ASC;降序为desc,空值将作为最⼤值排序having 与 where的区别where 决定哪些元组被选择参加运算,作⽤于关系中的元组having 决定哪些分组符合要求,作⽤于分组4、连接查询连接查询包括:多表连接查询、单表连接查询(⾃连接)、外连接查询、嵌套查询4种连接条件⼀连接条件⼆连接条件中的列名称为连接字段,对应的连接字段应是可⽐的。
执⾏过程:采⽤表扫描的⽅法,在表1中找到第⼀个元组,然后从头开始扫描表2,查找到满⾜条件的元组即进⾏串接并存⼊结果表中;再继续扫描表2,依次类推,直到表2末尾。
再从表1中取第⼆个元组,重复上述的操作,直到表1中的元组全部处理完毕。
4.1 单表连接(⾃连接)⽤表别名把⼀个表定义为两个不同的表进⾏连接。
多表查询sql语句

多表查询sql语句多表查询sql语句--解锁SCOTT⽤户2 alter user scott account unlock3 --检索指定的列4 select job,ename,empno from emp;5 --带有表达是的select⼦句6 select sal*(1+0.2),sal from emp;7 --显⽰不重复的记录8 select distinct job from emp;9 --⽐较筛选 <> =10 select empno,ename,sal from emp where sal>1000;11 select empno,ename,JOB from emp;12 select empno,ename,sal from emp where sal <>all(3000,950,800);13 --特殊关键字筛选14 --like 模糊查询15 select empno,ename,job from emp where JOB like '%S';16 --IN --varchar17 select empno,ename,job from emp where job in('PRESIDENT','MANAGER','ANALYST');18 --NOT IN19 select empno,ename,job from emp where job not in('PRESIDENT','MANAGER','ANALYST') ;20 --BETWEEN -numer ,inter21 select empno,ename,sal from emp where sal between 2000 and 3000;22 --NOT BETWEEN23 select empno,ename,sal from emp where sal NOT between 2000 and 3000;24 --IS NULL/ is not null25 select * from emp where comm is NOT null;26 --逻辑筛选27 --and ,or,not 关系于 -或 --⾮28 select empno,ename,sal from emp where (sal>=2000 and sal<=3000 ;29 select empno,ename,sal from emp where sal<2000 or sal>3000 ;30 --分组查询31 select deptno,job from emp group by deptno,job order by deptno ;32 select deptno as 部门编号,avg(sal) as 平均⼯资 from emp group by deptno;33 select deptno as 部门编号,avg(sal) as 平均⼯资 from emp group by deptno having avg(sal)>2000; --group by ⼦条件 having34 --排序查询Order by; desc:逆序 asc默认35 select deptno,empno,ename from emp order by deptno,EMPNO;多表查询sql语句七种⽰例图在创建关系型数据表时,根据数据库范式的要求,为了降低数据的冗余,提供数据维护的灵活性将数据分成多个表进⾏存储,实际⼯作当中,需要多个表的信息,需要将多个表合并显⽰多表查询sql语句代码1 --内连接2 select e.empno as 员⼯编号, e.ename as 员⼯名称, d.dname as 部门3 from emp e inner join dept d on e.deptno=d.deptno;45 --左外连接6 insert into emp(empno,ename,job) values(9527,'EAST','SALESMAN');78 select e.empno,e.ename,e.job,d.deptno,d.dname from emp e left join dept d9 on e.deptno=d.deptno;10 --右外连接11 select e.empno,e.ename,e.job,d.deptno,d.dname from emp e right join dept d12 on e.deptno=d.deptno;1314 --完全连接15 select e.empno,e.ename,e.job,d.deptno,d.dname from emp e full join dept d16 on e.deptno=d.deptno;1718 --⾃然连接(共有的属性,会去除重复列)19 select empno,ename,job,dname from emp natural join dept where sal>2000;2021 事务如果不提交,会⼀直写⼊以下表空间;22 redo(记录⽇志表空间) undo(记录⽇志备份表空间)23 提交: commit 回滚: rollback2425 --右外连接过滤26 select * from emp e right join dept d on e.deptno=d.deptno27 where e.deptno is null;28 --左外连接过滤29 select * from emp e left join dept d on e.deptno=d.deptno30 where d.deptno is null;31 --全外连接过滤32 select * from emp e full join dept d on e.deptno=d.deptno33 where d.deptno is null or e.deptno is null;343536 /*⾃连接(self join)是SQL语句中经常要⽤的连接⽅式,使⽤⾃连接可以将⾃⾝表的⼀个镜像当作另⼀个表来对待,从⽽能够得到⼀些特殊的数据。
通用SQL数据库查询语句范例(多表查询)

[UNION [ALL] selectstatement][…n]
其中selectstatement为待联合的Select查询语句。
ALL选项表示将所有行合并到结果集合中。不指定该项时,被联合查询结果集合中的重复行将只保留一行。
使用TOP n [PERCENT]选项限制返回的数据行数,TOP n说明返回n行,而TOP n PERCENT时,说明n是表示一百分数,指定返回的行数等于总行数的百分之几。例如:
Select TOP 2 *FROM testtable Select TOP 20 PERCENT * FROM testtable
Select *
FROM authors AS a INNER JOIN publishers AS p
ON a.city=p.city
又如使用自然连接,在选择列表中删除authors 和publishers 表中重复列(city和state):
ON DATALENGTH(p1.pr_info)=DATALENGTH(p2.pr_info)
(一)内连接
内连接查询操作列出与连接条件匹配的数据行,它使用比较运算符比较被连接列的列值。内连接分三种:
1、等值连接:在连接条件中使用等于号(=)运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列。
Select a.au_fname+a.au_lname
FROM authors a,titleauthor ta
(Select title_id,title
FROM titles
Where ytd_sales>10000
) AS t
SQL编写规范

SQL编写规范SQL编写规范1 DML语句1. 【强制】SELECT语句必须指定具体字段名称,禁⽌写成*。
因为select *会将不该读的数据也从MySQL⾥读出来,造成⽹卡压⼒。
且表字段⼀旦更新,但model层没有来得及更新的话,系统会报错。
2. 【强制】insert语句指定具体字段名称,不要写成insert into t1 values(…),道理同上。
3. 【建议】insert into…values(XX),(XX),(XX)…。
这⾥XX的值不要超过5000个。
值过多虽然上线很很快,但会引起主从同步延迟。
4. 【建议】SELECT语句不要使⽤UNION,推荐使⽤UNION ALL,并且UNION⼦句个数限制在5个以内。
因为union all不需要去重,节省数据库资源,提⾼性能。
5. 【建议】in值列表限制在500以内。
例如select… where userid in(….500个以内…),这么做是为了减少底层扫描,减轻数据库压⼒从⽽加速查询。
6. 【建议】事务⾥批量更新数据需要控制数量,进⾏必要的sleep,做到少量多次。
7. 【强制】事务涉及的表必须全部是innodb表。
否则⼀旦失败不会全部回滚,且易造成主从库同步终端。
8. 【强制】写⼊和事务发往主库,只读SQL发往从库。
9. 【强制】除静态表或⼩表(100⾏以内),DML语句必须有where条件,且使⽤索引查找。
10. 【强制】⽣产环境禁⽌使⽤hint,如sql_no_cache,force index,ignore key,straight join等。
因为hint是⽤来强制SQL按照某个执⾏计划来执⾏,但随着数据量变化我们⽆法保证⾃⼰当初的预判是正确的,因此我们要相信MySQL优化器!11. 【强制】where条件⾥等号左右字段类型必须⼀致,否则⽆法利⽤索引。
12. 【建议】SELECT|UPDATE|DELETE|REPLACE要有WHERE⼦句,且WHERE⼦句的条件必需使⽤索引查找。
sql必知必会知识点总结

sql必知必会知识点总结SQL(Structured Query Language)是用于管理关系数据库的标准编程语言。
以下是SQL的一些核心知识点,这些知识点对于理解和使用SQL至关重要:1. 查询数据:使用`SELECT`语句从数据库表中检索数据。
```sqlSELECT column1, column2 FROM table_name;```2. 过滤数据:使用`WHERE`子句来过滤记录。
```sqlSELECT column1, column2 FROM table_name WHERE condition;```3. 排序数据:使用`ORDER BY`对查询结果进行排序。
```sqlSELECT column1, column2 FROM table_name ORDER BY column1 ASC|DESC;```4. 聚合数据:使用聚合函数如`COUNT()`, `SUM()`, `AVG()`, `MAX()`和`MIN()`来处理数据。
```sqlSELECT COUNT(column_name) FROM table_name;```5. 分组数据:使用`GROUP BY`对结果集进行分组。
通常与聚合函数一起使用。
```sqlSELECT column1, COUNT()FROM table_nameGROUP BY column1;```6. 连接表:使用`JOIN`语句连接两个或多个表。
有INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN等。
7. 插入数据:使用`INSERT INTO`语句向表中插入新行。
```sqlINSERT INTO table_name (column1, column2) VALUES (value1, value2); ```8. 更新数据:使用`UPDATE`语句来修改表中的现有记录。
```sqlUPDATE table_name SET column1=value1, column2=value2 WHERE condition;```9. 删除数据:使用`DELETE`语句从表中删除记录。
sql常用查询语句格式及例子说明

SQL常用查询语句格式及例子说明1.概述本文将介绍S Q L中常用的查询语句格式,并通过具体的例子进行说明。
通过学习本文,您将能够掌握SQ L中常用查询语句的写法和应用场景。
2.查询单个表2.1选择特定列查询特定列的语法格式如下:S E LE CT co lu mn1,col u mn2,...F R OM ta bl e_na me;示例:S E LE CT id,n am e,ageF R OM st ud en ts;2.2查询所有列查询表中所有列的语法格式如下:S E LE CT*F R OM ta bl e_na me;示例:S E LE CT*F R OM st ud en ts;2.3带条件的查询带条件的查询的语法格式如下:S E LE CT co lu mn1,col u mn2,...F R OM ta bl e_na meW H ER Ec on di ti on;示例:S E LE CT id,n am e,ageF R OM st ud en tsW H ER Ea ge>20;3.查询多个表3.1内连接查询内连接查询的语法格式如下:S E LE CT*F R OM ta bl e1I N NE RJ OI Nt ab le2O N ta bl e1.c ol um n_n a me=t ab le2.co lum n_n am e;示例:S E LE CT st ud en ts.id,st ud en ts.n am e,d e pa rt me nt s.na meF R OM st ud en tsI N NE RJ OI Nd ep ar tme n tsO N st ud en ts.d ep art m en t_id=d ep ar tme n ts.i d;3.2左连接查询左连接查询的语法格式如下:S E LE CT*F R OM ta bl e1L E FT JO IN ta bl e2O N ta bl e1.c ol um n_n a me=t ab le2.co lum n_n am e;示例:S E LE CT st ud en ts.id,st ud en ts.n am e,d e pa rt me nt s.na meF R OM st ud en tsL E FT JO IN de pa rt men t sO N st ud en ts.d ep art m en t_id=d ep ar tme n ts.i d;3.3右连接查询右连接查询的语法格式如下:S E LE CT*F R OM ta bl e1R I GH TJ OI Nt ab le2O N ta bl e1.c ol um n_n a me=t ab le2.co lum n_n am e;示例:S E LE CT st ud en ts.id,st ud en ts.n am e,d e pa rt me nt s.na meF R OM st ud en tsR I GH TJ OI Nd ep ar tme n tsO N st ud en ts.d ep art m en t_id=d ep ar tme n ts.i d;4.排序和限制结果4.1排序查询结果排序查询结果的语法格式如下:S E LE CT*F R OM ta bl e_na meO R DE RB Yc ol um n_nam e[A SC|D ES C];示例:S E LE CT id,n am e,ageF R OM st ud en tsO R DE RB Ya ge DE SC;4.2限制结果数量限制结果数量的语法格式如下:S E LE CT*F R OM ta bl e_na meL I MI Tn um be r;示例:S E LE CT*F R OM st ud en tsL I MI T10;5.分组查询5.1分组聚合查询分组聚合查询的语法格式如下:S E LE CT co lu mn1,agg r eg at e_fu nc ti on(c ol um n2)F R OM ta bl e_na meG R OU PB Yc ol um n1;示例:S E LE CT de pa rt me nt_i d,CO UN T(id)F R OM st ud en tsG R OU PB Yd ep ar tm ent_id;6.结论本文介绍了S Q L常用的查询语句格式,并通过具体的例子进行了说明。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验五SQL分组、排序及多表连接语句一、实验目的1.熟练掌握SQL分组语句;2.熟练掌握SQL排序语句;3.熟练掌握多表连接语句;二、实验内容给定一个练习数据库和相应的练习题,要求上机完成,并验证结果实验基础知识提要从数据库中检索行,并允许从一个或多个表中选择一个或多个行或列。
虽然SELECT 语句的完整语法较复杂,但是其主要的子句可归纳如下:SELECT select_listFROM table_source[ WHERE search_condition ][ GROUP BY group_by_expression ][ HA VING search_condition ][ ORDER BY order_expression [ ASC | DESC ] ]From子句中的连接类型指定从其中检索行的表,当存在多个表时用“,”分隔。
表之间可以使用连接,连接的类型如下:INNER指定返回所有相匹配的行对。
废弃两个表中不匹配的行。
如果未指定联接类型,则这是默认设置。
LEFT [OUTER]指定除所有由内联接返回的行外,所有来自左表的不符合指定条件的行也包含在结果集内。
来自左表的输出列设置为NULL。
RIGHT [OUTER]指定除所有由内联接返回的行外,所有来自右表的不符合指定条件的行也包含在结果集内。
来自右表的输出列设置为NULL。
FULL [OUTER]如果来自左表或右表的某行与选择准则不匹配,则指定在结果集内包含该行,并且将与另一个表对应的输出列设置为NULL。
除此之外,结果集中还包含通常由内联接返回的所有行。
Group By子句指定用来放置输出行的组,并且如果SELECT 子句<select list> 中包含聚合函数,则计算每组的汇总值。
指定GROUP BY 时,选择列表中任一非聚合表达式内的所有列都应包含在GROUP BY 列表中,或者GROUP BY 表达式必须与选择列表表达式完全匹配。
Having子句指定组或聚合的搜索条件。
HA VING 通常与GROUP BY 子句一起使用。
如果不使用GROUP BY 子句,HA VING 的行为与WHERE 子句一样。
Order By子句指定结果集的排序。
除非同时指定了TOP,否则ORDER BY 子句在视图、内嵌函数、派生表和子查询中无效。
ASC指定按递增顺序,从最低值到最高值对指定列中的值进行排序。
DESC指定按递减顺序,从最高值到最低值对指定列中的值进行排序。
空值被视为最低的可能值。
三、实验步骤构建以下的数据表作为实验数据内容3.1 Suppliers(供货厂商)代码描述数据类型长度约束条件SupplierID 供货厂商编号INT 4 主码CompanyName 厂名V ARCHAR 40ContactName 联系人名V ARCHAR 30ContactTitle 联系人职位V ARCHAR 30Address 地址V ARCHAR 60City 城市名V ARCHAR 15Region 地区V ARCHAR 15PostalCode 邮政编码V ARCHAR 10Country 国家V ARCHAR 15Phone 电话V ARCHAR 24Fax 传真V ARCHAR 24HomePage 主页V ARCHAR 163.2 Region(地区)代码描述数据类型长度约束条件RegionID 地区编号INT 4 主码RegionDescription 地区描述V ARCHAR 503.3 Products(产品)代码描述数据类型长度约束条件ProductID 产品编号INT 4 主码ProductName 品名V ARCHAR 40SupplierID 供货厂商编号INT 4CategoryID 所属种类号INT 4QuantityPerUnit 单位数量V ARCHAR 20UnitPrice 单价FLOAT 8UnitsInStock 库存INT 2UnitsOnOrder 定货数INT 2ReorderLevel 修订量INT 2Discontinued 是否进行BIT 13.4 Orders(定单)代码描述数据类型长度约束条件OrderID 定单编号INT 4 主码CustomerID 顾客编号V ARCHAR 5EmployeeID 职员编号INT 4OrderDate 定货日期DA TETIME 8RequiredDate 交货日期DA TETIME 8ShippedDate 载运日期DA TETIME 8ShipVia 经由数INT 4Freight 运费FLOAT 8ShipName 船名V ARCHAR 40ShipAddress 地址V ARCHAR 60ShipCity 城市V ARCHAR 15ShipRegion 地区V ARCHAR 15PostalCode 邮政编码V ARCHAR 10ShipCountry 国籍V ARCHAR 153.5 OrderDetails(定单详细信息)代码描述数据类型长度约束条件OrderID 定单编号INT 4 主码ProductID 产品编号INT 4 主码UnitPrice 单价FLOAT 8Quantity 数量INT 2Discount 折扣FLOAT 43.6 Employees(职工)代码描述数据类型长度约束条件EmployeeID 职工编号INT 4 主码LastName 姓V ARCHAR 20FirstName 名V ARCHAR 10Title 头衔V ARCHAR 30TitleOfCourtesy 性别V ARCHAR 25BirthDate 生日DA TETIME 8HireDate 受聘日期DA TETIME 8Address 地址V ARCHAR 60City 城市V ARCHAR 15Region 地区V ARCHAR 15PostalCode 邮政编码V ARCHAR 10Country 国籍V ARCHAR 15HomePhone 住宅电话V ARCHAR 24Extension 分机号V ARCHAR 4Photo 照片IMAGE 16Notes 备注V ARCHAR 16ReportsTo 直接上级号INT 4Photopath 职工照片路径V ARCHAR 2553.7 Customers(顾客)代码描述数据类型长度约束条件CustomerID 顾客编号V ARCHAR 5 主码CompanyName 公司名V ARCHAR 40ContactName 联系人名V ARCHAR 30ContactTitle 联系人头衔V ARCHAR 30Address 地址V ARCHAR 60City 城市V ARCHAR 15Region 地区V ARCHAR 15PostalCode 邮政编码V ARCHAR 10Country 国籍V ARCHAR 15Phone 电话V ARCHAR 24Fax 传真V ARCHAR 243.8 OldSuppliers(供应厂商备份表)结构与Suppliers表相同运行SQL SERVER服务管理器,确认数据库服务器开始运行。
运行企业管理器,以图示方式点击“附加数据库”,恢复db目录下的数据库文件打开查询分析器,选择刚才恢复的数据库exampleDB,输入SQL指令,获得运行结果。
任务:完成以下SQL查询语句查询顾客表(Customer)中没有设定区域的顾客编号和公司名select CustomerID,CompanyNamefrom customerswhere Region is NULL⏹统计职工表(Employees)中头衔的数量select distinct count(Title)from Employees⏹查找订单表(Orders)中顾客编号为’VICTE’和’WELLI’的的订单号和运费,并按照运费的降序排列select OrderID,Freightfrom orderswhere CustomerID in ('VICTE','WELLI') order by Freight DESC查找产品表(Products)中的平均库存总价(库存总价=单价×库存数) select avg(UnitPrice*UnitsInStock)from products查找提供产品的各个供应商编号及其供应的产品数量select SupplierID,UnitsOnOrderfrom products查找提供产品的各个供应商名称及其供应的产品数量select CompanyName,UnitsOnOrderfrom products,suppliers where products.SupplierID=suppliers.SupplierID在订单详细信息表(OrderDetails)中查找每个订单号对应的产品种类超过4种的订单号和产品种类数,并按照产品种类数升序排列select OrderID,count(ProductID)from OrderDetails group by OrderIDhaving count(ProductID)>=4 order by count(ProductID)查询客户的公司名和它所下订单的订单编号select CompanyName,OrderIDfrom customers,orderswhere customers.CustomerID=orders.CustomerID找出所有的职员姓和名以及他的直接上级的姓和名select stName CLastName,f1.FirstName CFirstName,stName RLastName,f2.FirstName RFirstNamefrom Employees f1 LEFT JOIN Employees f2 ON (f1.ReportsTo=f2.EmployeeID)使用外部连接,查找所有的职员的基本信息以及其直接上级的姓、名select f1.*,stName RLastName,f2.FirstName RFirstNamefrom Employees f1 LEFT JOIN Employees f2 ON(f1.ReportsTo=f2.EmployeeID)四. 实验结果与分析(上交实验报告)分析思考问题:1. 分析Where筛选和Having筛选的区别;having 和where 都是用来筛选用的 having 是筛选组而where是筛选记录 他们有各自的区别 1》当分组筛选的时候用having 2》其它情况用where 用having 就一定要和group by连用, 用group by不一有having (它只是一个筛选条件用的)where作用于表而Having作用于组。