postgresql维护_VACUUM
postgreSQL性能参数

postgreSQL性能参数PostgreSQL是一种强大的开源数据库管理系统,它具有可扩展性和高性能的特点。
性能参数在使用PostgreSQL来优化数据库性能和处理大量数据时起着至关重要的作用。
本篇文章将详细介绍一些常用的PostgreSQL性能参数及其作用。
1. shared_buffers: 这是控制PostgreSQL内存缓冲区大小的参数。
它指定了操作系统用于缓存数据库的页的数量。
合理设置该参数可以提高数据库的读取性能。
2. work_mem: 这个参数用于控制每个查询的内存使用量。
它指定了每个工作进程可用的内存大小。
如果查询需要排序、哈希或执行连接等操作,那么它所需的内存将由work_mem参数控制。
通过适当调整该参数,可以提高查询的性能。
3. maintenance_work_mem: 这个参数用于控制维护操作的内存使用量。
维护操作包括 VACUUM,CREATE INDEX,ALTER TABLE,REINDEX等。
合理设置maintenance_work_mem参数可以加速这些操作的执行。
4. effective_cache_size: 这个参数用于告诉PostgreSQL操作系统可以用于缓存的内存大小。
该参数的设置应该基于系统的内存大小和其他应用程序在同一服务器上的内存需求。
6. max_connections: 这个参数用于控制数据库服务器能够同时处理的最大连接数。
适当调整max_connections参数可以提高数据库的并发处理能力。
但是,需要注意的是,较大的max_connections值会增加数据库服务器的内存消耗。
7. autovacuum: 这是一个布尔参数,用于控制是否启用自动清理功能。
自动清理是PostgreSQL中的一项重要功能,它可以自动释放未使用的空间,并更新统计信息,以便查询优化器可以更好地选择查询计划。
8. wal_buffers: 这个参数用于控制WAL(Write-Ahead Logging)缓冲区的大小。
vacuum命令用法

vacuum命令用法
VACUUM是PostgreSQL数据库中用于优化表空间和回收未使用的空间的常用命令。
其基本语法如下:
VACUUM [ ( option [, ...] ) ] table_name [, ...]
其中,`option`表示可选参数,可以指定不同的选项来控制`vacuum`命令的行为。
常用的选项包括:
`--analyze`: 分析表并生成统计信息,以帮助优化查询计划。
`FULL`: 删除每页上的死元组和对活动元组进行碎片整理。
`FREEZE`: 冻结旧的txid。
`VERBOSE`: 显示执行过程中的详细信息。
`ANALYZE`: 更新查询优化器统计信息。
`DISABLE_PAGE_SKIPPING`: 禁用页面跳过策略。
`SKIP_LOCKED`: 跳过被锁定的行。
`INDEX_CLEANUP`: 删除指向死元组的索引元组。
`TRUNCATE`: 截断表并重新分配空间。
使用VACUUM命令时,可以根据需要选择不同的选项来执行不同的操作。
请注意,VACUUM命令可能需要一些时间来执行,具体取决于表的大小和系统性能。
在执行VACUUM命令时,建议关闭其他数据库连接,以避免对正在进行清理的表进行不必要的读写操作。
maintenance_work_mem的作用

maintenance_work_mem的作用maintenance_work_mem的作用1. 简介maintenance_work_mem是PostgreSQL数据库中的一个参数,它决定了执行维护任务时可用的内存量。
维护任务包括VACUUM、CREATE INDEX、ALTER TABLE等操作。
正确认识和正确设置这个参数对数据库的性能和稳定性至关重要。
2. 参数说明maintenance_work_mem的单位maintenance_work_mem的单位是kB,默认值为64MB。
可以通过修改文件或使用ALTER SYSTEM命令来更改该值。
参数值的取值范围参数值可以是任意非负整数。
较大的值可以提高维护任务的执行速度,但会消耗更多的内存资源。
3. 作用maintenance_work_mem对数据库维护任务的性能和效率起到重要的影响。
VACUUM操作VACUUM是PostgreSQL中常用的维护任务之一,它用于回收被删除或过期的行以及释放未使用的空间。
较大的maintenance_work_mem值可以使VACUUM更快地完成工作,特别是在处理大型表时。
CREATE INDEX操作CREATE INDEX操作用于创建表的索引,可以加快查询速度。
较大的maintenance_work_mem值可以加速CREATE INDEX操作,因为在创建索引时需要对数据进行排序和临时存储。
ALTER TABLE操作ALTER TABLE操作是用于修改已有表的结构,比如添加或删除列。
较大的maintenance_work_mem值可以加快ALTER TABLE操作的执行速度,尤其是当修改的表较大时。
4. 注意事项内存资源限制需要注意的是,设置过大的maintenance_work_mem值可能会导致内存不足的问题。
尤其是在同时进行多个维护任务时,需要根据数据库服务器的实际内存情况进行合理调整。
其他相关参数maintenance_work_mem的值与其他参数如shared_buffers、work_mem等也有关系。
postgres数据库维护方法和恢复

主题:postgres数据库维护方法1、首先登录服务器,用postgres用户,在/export/home/postgres下执行crontab –l命令查看bash-2.05$ crontab -l11 * * * * /export/home/postgres/vacuumdb.sh hour38 6 * * * /export/home/postgres/vacuumdb.sh daily这两行命令是根据规定时间自动运行删除优化数据库。
(其中蓝字分别代表分钟、小时、天、月、星期)crontab--操作系统的定时调度器用命令ls –al查看:bash-2.05$ ls -altotal 36608drwxr-xr-x 10 postgres postgres 512 Dec 29 09:42 .drwxr-xr-x 8 root root 512 Dec 29 09:35 ..-rw------- 1 postgres postgres 5179 Apr 14 19:55 .bash_history-rw-r--r-- 1 postgres postgres 365 Apr 10 2004 .profile-rw------- 1 postgres postgres 1575 Feb 2 18:02 .psql_historydrwxr-xr-x 2 postgres postgres 1024 Dec 29 09:31 bin-rw-r--r-- 1 postgres postgres 3088 Aug 13 2004 cptemp.lst-rw-r--r-- 1 postgres postgres 3090 Jul 27 2004 cptemp.lst.bak-rw-r--r-- 1 postgres postgres 54574 Apr 15 06:42 crontab.daily-rw-r--r-- 1 postgres postgres 1304310 Apr 15 09:16 crontab.hourdrwx------ 6 postgres postgres 512 Dec 28 16:23 datadrwxr-xr-x 3 postgres postgres 512 Apr 10 2004 docdrwxr-xr-x 5 postgres postgres 512 Apr 10 2004 includedrwxr-xr-x 2 postgres postgres 1536 Apr 10 2004 lib-rw-r--r-- 1 postgres postgres 136 Apr 10 2004 local.cshrc-rw-r--r-- 1 postgres postgres 157 Apr 10 2004 local.login-rw-r--r-- 1 postgres postgres 174 Apr 10 2004 local.profile-rw-r--r-- 1 postgres postgres 17305016 May 11 2004 logfiledrwxr-xr-x 4 postgres postgres 512 Apr 10 2004 man-rw-r--r-- 1 postgres postgres 102 May 25 2004 postgres-rw-r--r-- 1 postgres postgres 365 Dec 29 09:42 postgres.profiledrwxr-xr-x 2 postgres postgres 512 Apr 10 2004 sharedrwxr-xr-x 2 postgres postgres 512 Jul 27 2004 synOra-rwxr--r-- 1 postgres postgres 177 Jun 28 2004 vacuumdb.sh必须保证蓝字的时间戳要于当前时间基本保持一致。
PostgreSQL学习手册:数据库维护

PostgreSQL学习手册:数据库维护一、恢复磁盘空间:在PostgreSQL中,使用delete和update语句删除或更新的数据行并没有被实际删除,而只是在旧版本数据行的物理地址上将该行的状态置为已删除或已过期。
因此当数据表中的数据变化极为频繁时,那么在一段时间之后该表所占用的空间将会变得很大,然而数据量却可能变化不大。
要解决该问题,需要定期对数据变化频繁的数据表执行VACUUM操作。
VACUUM命令存在两种形式,VACUUM和VACUUM FULL,它们之间的区别见如下表格:二、更新规划器统计:PostgreSQL查询规划器在选择最优路径时,需要参照相关数据表的统计信息用以为查询生成最合理的规划。
这些统计是通过ANALYZE命令获得的,你可以直接调用该命令,或者把它当做VACUUM命令里的一个可选步骤来调用,如VACUUM ANAYLYZE table_name,该命令将会先执行VACUUM再执行ANALYZE。
与回收空间(VACUUM)一样,对数据更新频繁的表保持一定频度的ANALYZE,从而使该表的统计信息始终处于相对较新的状态,这样对于基于该表的查询优化将是极为有利的。
然而对于更新并不频繁的数据表,则不需要执行该操作。
我们可以为特定的表,甚至是表中特定的字段运行ANALYZE命令,这样我们就可以根据实际情况,只对更新比较频繁的部分信息执行ANALYZE操作,这样不仅可以节省统计信息所占用的空间,也可以提高本次ANALYZE操作的执行效率。
这里需要额外说明的是,ANALYZE是一项相当快的操作,即使是在数据量较大的表上也是如此,因为它使用了统计学上的随机采样的方法进行行采样,而不是把每一行数据都读取进来并进行分析。
因此,可以考虑定期对整个数据库执行该命令。
事实上,我们甚至可以通过下面的命令来调整指定字段的抽样率,如:ALTER TABLE testtable ALTER COLUMN test_col SET STATISTICS 200注意:该值的取值范围是0--1000,其中值越低采样比例就越低,分析结果的准确性也就越低,但是ANALYZE命令执行的速度却更快。
pg sql 术语

pg sql 术语以下是pg sql中常用的一些术语:1. 数据库集群(Database Cluster):数据库集群是多个数据库的集合,它们共享相同的配置和数据。
2. 共享内存(Shared Memory)和信号量(Semaphores):这些是操作系统级别的资源,用于在多个进程之间共享数据和控制。
3. 表空间(Tablespace):表空间是数据库中物理存储空间的一部分,用于存储表和索引等数据结构。
4. 清理(Vacuum):这是一个过程,用于删除无用的数据和释放磁盘空间。
5. 预写式日志(Write-Ahead Logging,WAL):这是PostgreSQL的一种特性,确保在事务完成之前将数据更改写入日志,从而提高数据的持久性和恢复能力。
6. 用户和角色(User and Role):在PostgreSQL中,用户和角色是相似的概念,可以用来控制对数据库的访问。
7. 热备份(Hot Standby):这是在数据库运行的情况下进行备份的方法。
通常是通过archivelog模式实现的。
8. 后台进程(Background Processes):PostgreSQL使用后台进程来处理各种任务,例如日志记录、检查点等。
9. 主从复制(Master-Slave Replication):这是PostgreSQL的一种复制模式,其中主服务器处理所有写入操作,而从服务器处理所有读取操作。
10. 流复制(Streaming Replication):这是PostgreSQL的一种复制模式,其中从服务器通过TCP流从主服务器同步数据。
这些术语是pg sql数据库管理中的重要概念,理解它们对于有效地管理和维护数据库至关重要。
postgres数据库维护方法和恢复

主题:postgres数据库维护方法1、首先登录服务器,用postgres用户,在/export/home/postgres下执行crontab –l命令查看bash-2.05$ crontab -l11 * * * * /export/home/postgres/vacuumdb.sh hour38 6 * * * /export/home/postgres/vacuumdb.sh daily这两行命令是根据规定时间自动运行删除优化数据库。
(其中蓝字分别代表分钟、小时、天、月、星期)crontab--操作系统的定时调度器用命令ls –al查看:bash-2.05$ ls -altotal 36608drwxr-xr-x 10 postgres postgres 512 Dec 29 09:42 .drwxr-xr-x 8 root root 512 Dec 29 09:35 ..-rw------- 1 postgres postgres 5179 Apr 14 19:55 .bash_history-rw-r--r-- 1 postgres postgres 365 Apr 10 2004 .profile-rw------- 1 postgres postgres 1575 Feb 2 18:02 .psql_historydrwxr-xr-x 2 postgres postgres 1024 Dec 29 09:31 bin-rw-r--r-- 1 postgres postgres 3088 Aug 13 2004 cptemp.lst-rw-r--r-- 1 postgres postgres 3090 Jul 27 2004 cptemp.lst.bak-rw-r--r-- 1 postgres postgres 54574 Apr 15 06:42 crontab.daily-rw-r--r-- 1 postgres postgres 1304310 Apr 15 09:16 crontab.hourdrwx------ 6 postgres postgres 512 Dec 28 16:23 datadrwxr-xr-x 3 postgres postgres 512 Apr 10 2004 docdrwxr-xr-x 5 postgres postgres 512 Apr 10 2004 includedrwxr-xr-x 2 postgres postgres 1536 Apr 10 2004 lib-rw-r--r-- 1 postgres postgres 136 Apr 10 2004 local.cshrc-rw-r--r-- 1 postgres postgres 157 Apr 10 2004 local.login-rw-r--r-- 1 postgres postgres 174 Apr 10 2004 local.profile-rw-r--r-- 1 postgres postgres 17305016 May 11 2004 logfiledrwxr-xr-x 4 postgres postgres 512 Apr 10 2004 man-rw-r--r-- 1 postgres postgres 102 May 25 2004 postgres-rw-r--r-- 1 postgres postgres 365 Dec 29 09:42 postgres.profiledrwxr-xr-x 2 postgres postgres 512 Apr 10 2004 sharedrwxr-xr-x 2 postgres postgres 512 Jul 27 2004 synOra-rwxr--r-- 1 postgres postgres 177 Jun 28 2004 vacuumdb.sh必须保证蓝字的时间戳要于当前时间基本保持一致。
postgres vacuum table讲解

一、介绍PostgreSQL的VACUUM命令1.1 PostgreSQL是一个开源的对象关系数据库管理系统,被广泛应用于各类企业级应用和互联网应用中。
1.2 在PostgreSQL中,VACUUM是一个重要的数据库维护命令,用于回收被删除数据所占用的存储空间,并且防止数据库的性能下降。
二、VACUUM对表的影响2.1 当一张表的数据被删除或更新时,PostgreSQL并不会立即释放被删除或更新的数据所占用的存储空间,而是将其标记为不可见。
2.2 VACUUM命令可以清理这些不可见的数据,并将存储空间彻底释放,从而提高数据库的整体性能。
2.3 正确使用VACUUM命令可以避免数据库长时间运行后性能下降的问题,保证数据库的稳定性和可靠性。
三、VACUUM的使用方法3.1 VACUUM命令可以使用两种方式执行:手动执行和自动执行。
3.2 在手动执行VACUUM时,可以对整个数据库、单个表或者单个索引执行VACUUM操作,根据具体情况选择适当的执行方式。
3.3 自动执行VACUUM可以通过配置PostgreSQL的自动化维护任务来实现,在数据库空闲时自动执行VACUUM操作,减少了手动干预的工作量。
四、VACUUM的注意事项4.1 在执行VACUUM操作时,应当避免对正在进行大量写入操作的表进行VACUUM操作,以免影响写入性能。
4.2 当数据库中存在大量删除或更新操作时,应当频繁进行VACUUM操作,及时清理不可见的数据,防止存储空间的浪费和性能的下降。
4.3 在对大型数据库进行VACUUM操作时,应当合理安排VACUUM的执行时间,避免影响数据库的正常运行。
五、VACUUM与Autovacuum的关系5.1 Autovacuum是PostgreSQL内置的自动化VACUUM系统,可以根据数据库中的写入和删除操作自动调度VACUUM任务,减少了手动维护的工作量。
5.2 通过合理配置Autovacuum的参数,可以使得数据库自动进行VACUUM操作,保持数据库的高性能和稳定性。
vacuum full 分区表

vacuum full 分区表
VACUUM FULL 是 PostgreSQL 中的一个命令,用于回收未使用的磁盘空间并优化表的性能。
当您对分区表执行 VACUUM FULL 命令时,它会扫描整个表并释放未使用的空间。
对于分区表,VACUUM FULL 会递归地应用于每个子分区,释放所有子分区中的未使用空间。
使用 VACUUM FULL 命令时需要注意以下几点:
1. 阻塞其他操作:VACUUM FULL 命令会阻塞对表的写入操作,直到命令完成。
因此,在执行 VACUUM FULL 时,应确保没有其他进程正在对表进行写操作。
2. 性能影响:VACUUM FULL 命令需要扫描整个表,对于大型表来说,这可能会耗费较长时间并占用大量系统资源。
因此,在生产环境中执行VACUUM FULL 时,应谨慎评估其对系统性能的影响。
3. 数据完整性:VACUUM FULL 命令不会影响表中的数据完整性。
它只是释放未使用的空间,并重新整理表的内部结构。
4. 备份:在执行 VACUUM FULL 之前,建议先备份表的数据,以防意外发生。
5. 分区表优化:对于分区表,除了使用 VACUUM FULL 命令外,还可以考虑使用 pg_repack 扩展进行在线重建表和索引。
这样可以避免长时间的表锁定,并允许在维护过程中进行表的读写操作。
总之,VACUUM FULL 可以用于回收分区表中的未使用空间,但需要注意其对系统性能的影响,并在执行之前进行适当的备份和评估。
postgresql日常维护和检查一-处理表、索引膨胀

postgresql⽇常维护和检查⼀-处理表、索引膨胀⼀、背景对于PostgreSQL处理MVCC(数据⽂件中新增tuple)的⽅式;相⽐其他数据库(Oracle、Mysql)⽽⾔;更容易触发表/索引膨胀。
因为update操作也会影响表膨胀的问题。
PostgreSQL 处理的⽅式是对表autovacuum,vacuum是不会降低⽔位线。
能避免表、索引膨胀。
vacuum full,reindex才会降低⽔位线。
当然通过update带来的表膨胀的情况还可以接受;PostgreSQL处理的⽅式是对表autovacuum。
所以能autovacuum的⼀般不会对表膨胀带来⼤的影响。
影响autovacuum进⾏对表回收的情况;⼤致有3种情况长事务:数据库上有长时间没有提交的事务SELECT*FROMpg_stat_activityWHERESTATE = 'Idle in transaction';未提交的2pc事务:这个特性是为分布式功能扩展的,⾮分布式的架构默认是关闭的SELECTgid,PREPARED,OWNER,DATABASE,TRANSACTION AS xminFROMpg_prepared_xactsORDER BYage( TRANSACTION ) DESC复制槽:逻辑复制、流复制都会有复制槽;复制槽的作⽤:通过记录复制的当前位置;保证备库、订阅端未接收到的数据不会在主库删除。
但是废弃的复制槽会影响表的vacuum。
这个是危害最⼤的SELECTslot_name,slot_type,DATABASE,xminFROMpg_replication_slotsORDER BYage( xmin ) DESC;⼆、监控如何知道表膨胀呢?即监控2.1、pgstattuple插件# 安装create extension pgstattuple;# 查看前5的膨胀表select oid::regclass,(pgstattuple(oid)).* from pg_class where relkind='r' order by free_space desc limit 5 offset 0;# 查看前5的索引select oid::regclass,(pgstattuple(oid)).* from pg_class where relkind='i' order by free_space desc limit 5 offset 0;2.2 bucardo发布postgres_check中包含的查询膨胀的SQL-- 表SELECTcurrent_database() AS db, schemaname, tablename, reltuples::bigint AS tups, relpages::bigint AS pages, otta,ROUND(CASE WHEN otta=0 OR sml.relpages=0 OR sml.relpages=otta THEN 0.0 ELSE sml.relpages/otta::numeric END,1) AS tbloat,CASE WHEN relpages < otta THEN 0 ELSE relpages::bigint - otta END AS wastedpages,CASE WHEN relpages < otta THEN 0 ELSE bs*(sml.relpages-otta)::bigint END AS wastedbytes,CASE WHEN relpages < otta THEN $$0 bytes$$::text ELSE (bs*(relpages-otta))::bigint || $$ bytes$$ END AS wastedsize,iname, ituples::bigint AS itups, ipages::bigint AS ipages, iotta,ROUND(CASE WHEN iotta=0 OR ipages=0 OR ipages=iotta THEN 0.0 ELSE ipages/iotta::numeric END,1) AS ibloat,CASE WHEN ipages < iotta THEN 0 ELSE ipages::bigint - iotta END AS wastedipages,CASE WHEN ipages < iotta THEN 0 ELSE bs*(ipages-iotta) END AS wastedibytes,CASE WHEN ipages < iotta THEN $$0 bytes$$ ELSE (bs*(ipages-iotta))::bigint || $$ bytes$$ END AS wastedisize,CASE WHEN relpages < otta THENCASE WHEN ipages < iotta THEN 0 ELSE bs*(ipages-iotta::bigint) ENDELSE CASE WHEN ipages < iotta THEN bs*(relpages-otta::bigint)ELSE bs*(relpages-otta::bigint + ipages-iotta::bigint) ENDEND AS totalwastedbytesFROM (SELECTnn.nspname AS schemaname,cc.relname AS tablename,COALESCE(cc.reltuples,0) AS reltuples,COALESCE(cc.relpages,0) AS relpages,COALESCE(bs,0) AS bs,COALESCE(CEIL((cc.reltuples*((datahdr+ma-(CASE WHEN datahdr%ma=0 THEN ma ELSE datahdr%ma END))+nullhdr2+4))/(bs-20::float)),0) AS otta,COALESCE(c2.relname,$$?$$) AS iname, COALESCE(c2.reltuples,0) AS ituples, COALESCE(c2.relpages,0) AS ipages,COALESCE(CEIL((c2.reltuples*(datahdr-12))/(bs-20::float)),0) AS iotta -- very rough approximation, assumes all colsFROMpg_class ccJOIN pg_namespace nn ON cc.relnamespace = nn.oid AND nn.nspname <> $$information_schema$$LEFT JOIN(SELECTma,bs,foo.nspname,foo.relname,(datawidth+(hdr+ma-(case when hdr%ma=0 THEN ma ELSE hdr%ma END)))::numeric AS datahdr,(maxfracsum*(nullhdr+ma-(case when nullhdr%ma=0 THEN ma ELSE nullhdr%ma END))) AS nullhdr2FROM (SELECTns.nspname, tbl.relname, hdr, ma, bs,SUM((1-coalesce(null_frac,0))*coalesce(avg_width, 2048)) AS datawidth,MAX(coalesce(null_frac,0)) AS maxfracsum,hdr+(SELECT 1+count(*)/8FROM pg_stats s2WHERE null_frac<>0 AND s2.schemaname = ns.nspname AND s2.tablename = tbl.relname) AS nullhdrFROM pg_attribute attJOIN pg_class tbl ON att.attrelid = tbl.oidJOIN pg_namespace ns ON ns.oid = tbl.relnamespaceLEFT JOIN pg_stats s ON s.schemaname=ns.nspnameAND s.tablename = tbl.relnameAND s.inherited=falseAND s.attname=att.attname,(SELECT(SELECT current_setting($$block_size$$)::numeric) AS bs,CASE WHEN SUBSTRING(SPLIT_PART(v, $$ $$, 2) FROM $$#"[0-9]+.[0-9]+#"%$$ for $$#$$)IN ($$8.0$$,$$8.1$$,$$8.2$$) THEN 27 ELSE 23 END AS hdr,CASE WHEN v ~ $$mingw32$$ OR v ~ $$64-bit$$ THEN 8 ELSE 4 END AS maFROM (SELECT version() AS v) AS foo) AS constantsWHERE att.attnum > 0 AND tbl.relkind=$$r$$GROUP BY 1,2,3,4,5) AS foo) AS rsON cc.relname = rs.relname AND nn.nspname = rs.nspnameLEFT JOIN pg_index i ON indrelid = cc.oidLEFT JOIN pg_class c2 ON c2.oid = i.indexrelid) AS sml order by wastedbytes desc limit 5-- 索引SELECTcurrent_database() AS db, schemaname, tablename, reltuples::bigint AS tups, relpages::bigint AS pages, otta,ROUND(CASE WHEN otta=0 OR sml.relpages=0 OR sml.relpages=otta THEN 0.0 ELSE sml.relpages/otta::numeric END,1) AS tbloat, CASE WHEN relpages < otta THEN 0 ELSE relpages::bigint - otta END AS wastedpages,CASE WHEN relpages < otta THEN 0 ELSE bs*(sml.relpages-otta)::bigint END AS wastedbytes,CASE WHEN relpages < otta THEN $$0 bytes$$::text ELSE (bs*(relpages-otta))::bigint || $$ bytes$$ END AS wastedsize,iname, ituples::bigint AS itups, ipages::bigint AS ipages, iotta,ROUND(CASE WHEN iotta=0 OR ipages=0 OR ipages=iotta THEN 0.0 ELSE ipages/iotta::numeric END,1) AS ibloat,CASE WHEN ipages < iotta THEN 0 ELSE ipages::bigint - iotta END AS wastedipages,CASE WHEN ipages < iotta THEN 0 ELSE bs*(ipages-iotta) END AS wastedibytes,CASE WHEN ipages < iotta THEN $$0 bytes$$ ELSE (bs*(ipages-iotta))::bigint || $$ bytes$$ END AS wastedisize,CASE WHEN relpages < otta THENCASE WHEN ipages < iotta THEN 0 ELSE bs*(ipages-iotta::bigint) ENDELSE CASE WHEN ipages < iotta THEN bs*(relpages-otta::bigint)ELSE bs*(relpages-otta::bigint + ipages-iotta::bigint) ENDEND AS totalwastedbytesFROM (SELECTnn.nspname AS schemaname,cc.relname AS tablename,COALESCE(cc.reltuples,0) AS reltuples,COALESCE(cc.relpages,0) AS relpages,COALESCE(bs,0) AS bs,COALESCE(CEIL((cc.reltuples*((datahdr+ma-(CASE WHEN datahdr%ma=0 THEN ma ELSE datahdr%ma END))+nullhdr2+4))/(bs-20::float)),0) AS otta,COALESCE(c2.relname,$$?$$) AS iname, COALESCE(c2.reltuples,0) AS ituples, COALESCE(c2.relpages,0) AS ipages,COALESCE(CEIL((c2.reltuples*(datahdr-12))/(bs-20::float)),0) AS iotta -- very rough approximation, assumes all colsFROMpg_class ccJOIN pg_namespace nn ON cc.relnamespace = nn.oid AND nn.nspname <> $$information_schema$$LEFT JOIN(SELECTma,bs,foo.nspname,foo.relname,(datawidth+(hdr+ma-(case when hdr%ma=0 THEN ma ELSE hdr%ma END)))::numeric AS datahdr,(maxfracsum*(nullhdr+ma-(case when nullhdr%ma=0 THEN ma ELSE nullhdr%ma END))) AS nullhdr2FROM (SELECTns.nspname, tbl.relname, hdr, ma, bs,SUM((1-coalesce(null_frac,0))*coalesce(avg_width, 2048)) AS datawidth,MAX(coalesce(null_frac,0)) AS maxfracsum,hdr+(SELECT 1+count(*)/8FROM pg_stats s2WHERE null_frac<>0 AND s2.schemaname = ns.nspname AND s2.tablename = tbl.relname) AS nullhdrFROM pg_attribute attJOIN pg_class tbl ON att.attrelid = tbl.oidJOIN pg_namespace ns ON ns.oid = tbl.relnamespaceLEFT JOIN pg_stats s ON s.schemaname=ns.nspnameAND s.tablename = tbl.relnameAND s.inherited=falseAND s.attname=att.attname,(SELECT(SELECT current_setting($$block_size$$)::numeric) AS bs,CASE WHEN SUBSTRING(SPLIT_PART(v, $$ $$, 2) FROM $$#"[0-9]+.[0-9]+#"%$$ for $$#$$)IN ($$8.0$$,$$8.1$$,$$8.2$$) THEN 27 ELSE 23 END AS hdr,CASE WHEN v ~ $$mingw32$$ OR v ~ $$64-bit$$ THEN 8 ELSE 4 END AS maFROM (SELECT version() AS v) AS foo) AS constantsWHERE att.attnum > 0 AND tbl.relkind=$$r$$GROUP BY 1,2,3,4,5) AS foo) AS rsON cc.relname = rs.relname AND nn.nspname = rs.nspnameLEFT JOIN pg_index i ON indrelid = cc.oidLEFT JOIN pg_class c2 ON c2.oid = i.indexrelid) AS sml order by wastedibytes desc limit 5三、处理表/索引膨胀使⽤pg_reorg|pg_repack、pg_squeeze或者vacuum full可以回收膨胀的空间索引膨胀会影响查询效率;处理索引膨胀的⽅法:重建索引创建新索引create index CONCURRENTLY new_index删除旧索引drop index new_index或者reindex index ... CONCURRENTLY四、避免表/索引膨胀4.1、实例级调整合理调整autovacuum参数;4.2、数据表级调整1、设置合适的autovacuum_vacuum_scale_factor, ⼤表如果频繁的有更新或删除和插⼊操作, 建议设置较⼩的autovacuum_vacuum_scale_factor来降低浪费空间,加快对表的vacuum操作频率对更新频繁的表,单独调整alter table tablename set (autovacuum_vacuum_scale_factor=0.05);2、设置表的fillfactor;对频繁更新的表;调低fillfactor参数alter table tablename set (fillfactor = 85)。
sqlite 真空vacuum sql语句

sqlite 真空vacuum sql语句
在SQLite中,使用VACUUM语句来压缩和优化数据库文件,以清理未使用的空间,并提高性能。
VACUUM语句没有参数,它只需指定要进行VACUUM操作的数据库。
以下是示例VACUUM语句的语法:
VACUUM;
当执行VACUUM语句时,SQLite将创造一个临时数据库文件,在那里将数据库中的有效数据复制过去。
然后删掉原有的数据库文件,并重命名临时数据库文件为原数据库文件的名称。
这个过程中会清理掉数据库中的未使用的空间,并优化文件的布局,以提高性能。
请注意,执行VACUUM操作将会关闭和重新打开数据库连接,因此在执行VACUUM语句之前,请确保没有正在进行的事务。
如果在执行VACUUM语句时有任何挂起的事务,将会导致错误。
此外,VACUUM操作为表和索引统计重建了一个空白的、本
地化的、零大小的数据库文件,以及根据索引的键密度来进行重新插入,这有助于更好地利用磁盘空间,并提高查询性能。
请注意,执行VACUUM操作可能需要一些时间,并且可能会导致性能瓶颈,因此建议在数据库处于空闲状态时执行VACUUM操作。
sqlite 真空vacuum sql语句

sqlite 真空vacuum sql语句SQLite中的真空(Vacuum)操作是用来优化数据库性能的一个重要操作。
它可以清理数据库中的空闲和过时的页,并重新组织存储空间,从而减少数据库文件的大小并提高查询性能。
在SQLite中,可以通过执行VACUUM命令来进行真空操作。
该命令的基本语法如下:
```
VACUUM;
```
这个命令将会扫描整个数据库文件,标记所有被删除的数据页并释放空闲的数据页。
然后,它会重建数据库文件,将所有有效的数据页移动到文件的开头,并释放尾部的空白页。
由于SQLite使用页作为存储单位,重建数据库文件可以确保数据被紧密地存储,从而提高查询性能。
需要注意的是,执行VACUUM操作将会锁定数据库文件,这意味着其他的读写操作将无法进行。
如果数据库非常大,并且执行VACUUM需要很长时间,可以考虑在非高峰期执行操作,以避免对应用程序的影响。
除了使用VACUUM命令,SQLite还提供了其他一些选项来控制真空操作。
例如,可以使用VACUUM INTO命令将数据库复制到一个新的文件中,并以新的文件替换原始文件。
这样做可以在真空操作时避免锁定原始数据库文件,允许应用程序继续进行读写操作。
除了真空操作,SQLite还提供了其他一些性能优化功能,例如自动索引、分页和增量I/O等。
开发人员可以根据具体的需求和性能瓶颈选择适合的优化方法来提升系统性能。
analyze vacuum用法

在PostgreSQL中,ANALYZE和VACUUM是两个常用的命令,用于维护和管理数据库的性能。
VACUUM用于恢复表中“死元组”占用的空间。
当记录被删除或更新(删除后插入)时,会创建一个死元组。
PostgreSQL不会从表中物理删除旧行,而是在其上放置一个“标记”,以便查询不会返回该行。
当vacuum进程运行时,这些死元组占用的空间被标记为可被其他元组重用。
ANALYZE用于分析数据库表的内容并收集有关每个表的每一列中值分布的统计信息。
PostgreSQL查询引擎使用这些统计信息来寻找最佳查询计划。
随着在数据库中插入、删除和更新行,列统计信息也会发生变化。
ANALYZE要么由DBA手动运行,要么在autovacuum后由PostgreSQL自动运行,以确保统计数据是最新的。
以上信息仅供参考,可以查阅PostgreSQL的官方文档获取更准确的信息。
PostgreSQL自动Vacuum配置方式

PostgreSQL⾃动Vacuum配置⽅式PostgreSQL的Vacuum由于以下原因需要定期执⾏。
释放,再利⽤因更新或者删除更新⽽占⽤的磁盘空间。
更新PostgreSQL 查询计划⽤的统计数据。
避免事务ID的重置⽽引起⾮常⽼的数据丢失。
VACUUM 的标准SQL⽂的执⾏和其他的对数据库的实际操作可以并⾏处理。
SELECT 、INSERT 、UPDATE 、DELETE 等命令和同通常⼀样继续能够执⾏。
但是,VACUUM处理中的时候, ALTER TABLE ADD COLUMN等等的命令不能够对表进⾏重新定义。
还有,由于执⾏VACUUM 的时候,有⼤量的I/O操作,其他的操作可能性能⽐较低,⽐如查询的反应⾮常慢。
为了较少对性能的影响,可以通过参数来调整。
autovacuum (boolean ):数据库服务器是否设置为⾃动vacuum。
默认为⾃动vacuum。
但是如果要让vacuum能够正常运转,必须使 track_counts 有效。
track_counts这个参数在 postgresql.conf配置⽂件内,或者通过命令来设置。
即使设置不是⾃动vacuum。
系统发现有防⽌事务ID的重置的必要的时候也会⾃动启动log_autovacuum_min_duration (integer ):设置执⾏时间超过多长的vacuum才输出log。
时间单位毫秒。
如果这个参数设置为0的话,所有vacuum相关的log都输出。
如果这个参数设置为-1的话,这个也是默认设置。
log的输出⽆效,也就是所有vacuum相关的log都不输出。
这个参数的设置可以修改postgresql.conf配置⽂件,也可以通过命令来设置。
autovacuum_max_workers (integer ):设置能够同时执⾏的vacuum最⼤进程数。
默认是3个。
这个参数的设置可以修改postgresql.conf配置⽂件,也可以通过命令来设置。
postgreSQL数据库的监控及数据维护操作
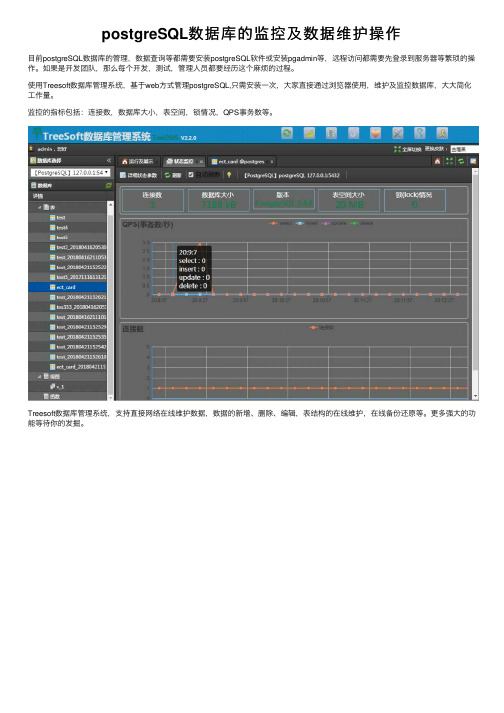
postgreSQL数据库的监控及数据维护操作⽬前postgreSQL数据库的管理,数据查询等都需要安装postgreSQL软件或安装pgadmin等,远程访问都需要先登录到服务器等繁琐的操作。
如果是开发团队,那么每个开发,测试,管理⼈员都要经历这个⿇烦的过程。
使⽤Treesoft数据库管理系统,基于web⽅式管理postgreSQL,只需安装⼀次,⼤家直接通过浏览器使⽤,维护及监控数据库,⼤⼤简化⼯作量。
监控的指标包括:连接数,数据库⼤⼩,表空间,锁情况,QPS事务数等。
Treesoft数据库管理系统,⽀持直接⽹络在线维护数据,数据的新增、删除、编辑,表结构的在线维护,在线备份还原等。
更多强⼤的功能等待你的发掘。
补充:PostgreSQL数据库性能监控⼿段之慢SQL、死锁之前接触PostgreSQL数据库甚少(此前经常使⽤mysql、db2),直⾄⼊职当前某安全公司后,发现数据库都采⽤PostgreSQL,由于负责性能测试⽅向,经常需要诊断数据库⽅⾯是否存在性能问题,于是整理了PostgreSQL设置慢SQL、查看死锁等常⽤监控⼿段。
⼀、慢SQL设置步骤1、笔者以⼯作中使⽤的docker为例,PostgreSQL版本为9.5:PostgreSQL正常安装成功后,在docker 的/var/lib/postgresql/9.5/main/postgresql.conf⽂件中,添加以下信息,保存并重启PostgreSQL数据库。
#shared_preload_libraries = '' # (change requires restart)shared_preload_libraries = 'pg_stat_statements'pg_stat_statements.max = 1000pg_stat_statements.track = top2、在 PostgreSQL库中执⾏以下SQL:CREATE EXTENSION pg_stat_statements;3、初始化信息(清除历史监控信息):select pg_stat_reset();select pg_stat_statements_reset();4、慢SQL查询(TOP 10):SELECT query, calls, total_time, (total_time/calls) as average ,rows,100.0 * shared_blks_hit /nullif(shared_blks_hit + shared_blks_read, 0) AS hit_percentFROM pg_stat_statementsORDER BY average DESC LIMIT 10;⼆、查看是否存在死锁在 PostgreSQL库中执⾏以下SQL:SELECT * FROM pg_stat_activity WHERE datname='数据库名称' and waiting='t';注:waiting等于t时为死锁以上为个⼈经验,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
PostgreSQL数据库的日常维护工作

日常数据库维护工作作者:小P来自:摘要:为了保持所安装的PostgreSQL 服务器平稳运行, 我们必须做一些日常性的维护工作。
我们在这里讨论的这些工作都是经常重复的事情,可以很容易地使用标准的Unix 工具,比如cron 脚本来实现;目录1. 综述;2. 日常清理;2.1 VACUUM;2.1.1 语法结构;2.1.2 描述;2.1.3 参数;2.1.4 为什么要用VACUUM;2.2 恢复磁盘空间;2.2.1 概述;2.2.2 VACUUM FULL;2.3 更新规划器统计;2.4 避免事务 ID 重叠造成的问题;2.5 auto-vacuum 守护进程;3. 经常重建索引;4. 日志文件维护;5. 关于本文;6. 更新日志;7. 参考文档;8. 相关文档;+++++++++++++++++++++++++++++++++++++++++++正文+++++++++++++++++++++++++++++++++++++++++++1. 综述;为了保持所安装的PostgreSQL 服务器平稳运行, 我们必须做一些日常性的维护工作。
我们在这里讨论的这些工作都是经常重复的事情,可以很容易地使用标准的Unix 工具,比如cron 脚本来实现。
不过,设置合适的脚本以及检查它们是否成功执行则是数据库管理员的责任,一件很明显的维护工作就是经常性地创建数据的备份拷贝。
如果没有最近的备份,那么您就没有从灾难中恢复的机会(比如磁盘坏了,失火,误删了表等等)。
其它主要的维护范畴的工作包括周期性的"vacuuming" (清理)数据库。
其它需要周期性注意的东西是日志文件的管理。
PostgreSQL 和其它数据库产品比较起来是低维护量的。
但是,适当在这些任务上放一些注意将更加能够确保我们的愉快工作和获取对这个系统富有成效的经验。
操作环境:PostgreSQL8.2+Ubuntu 7.042. 日常清理;2.1 VACUUM;2.1.1 语法结构;VACUUM [ FULL | FREEZE ] [ VERBOSE ] [ table ]VACUUM [ FULL | FREEZE ] [ VERBOSE ] ANALYZE [ table [ (column [, ...] ) ] ]2.1.2 描述;VACUUM 回收已删除元组占据的存储空间。
postgresql参数范围

PostgreSQL是一种开源的关系型数据库管理系统,被广泛应用于各种规模的企业和互联网应用中。
在使用PostgreSQL进行数据库管理时,经常需要根据实际需求来设置一些参数以优化数据库的性能和稳定性。
本文将介绍一些常用的PostgreSQL参数,并对它们的范围和设置方法进行详细的解释。
一、shared_buffersshared_buffers参数用于设置数据库系统中用于缓存数据页的共享内存缓冲区的大小。
在PostgreSQL中,共享内存缓冲区通常用于缓存常用的数据块,以减少对磁盘的访问,提高数据库的性能。
通常情况下,shared_buffers参数的设置范围为128MB到1/4可用内存。
二、work_memwork_mem参数用于设置排序,hash连接等运算所需的临时内存空间的大小。
在执行一些复杂的查询时,可能需要大量的临时内存空间来存储中间结果,work_mem参数可以控制每个查询所能使用的最大内存空间。
通常情况下,work_mem参数的设置范围为4MB到16MB。
三、m本人ntenance_work_memm本人ntenance_work_mem参数用于设置执行维护操作时所需的临时内存空间的大小。
执行VACUUM或CREATE INDEX等维护操作时,可能需要大量的临时内存空间来完成这些操作。
m本人ntenance_work_mem参数可以控制每个维护操作所能使用的最大内存空间。
通常情况下,m本人ntenance_work_mem参数的设置范围为16MB到1GB。
四、effective_cache_sizeeffective_cache_size参数用于指定系统中用于缓存文件系统数据的内存空间大小。
在执行I/O操作时,操作系统会尝试从内存中获取所需的数据,而不是直接从磁盘读取。
effective_cache_size参数可以控制操作系统所能使用的最大缓存空间大小。
通常情况下,effective_cache_size参数的设置范围为512MB到2GB。
sqlite 真空vacuum sql语句 -回复

sqlite 真空vacuum sql语句-回复什么是真空VACUUM SQL语句?在SQLite中,真空VACUUM是一种用于缩小数据库文件大小并重新组织其内部文件结构的命令。
通过执行VACUUM命令,可以清理数据库文件中的垃圾数据、删除未使用的空间,以及优化数据布局,从而提高数据库的性能和效率。
这个过程类似于打扫和优化硬盘上的数据文件,以确保它们能够最好地被使用。
真空VACUUM SQL语句用于在SQLite数据库中执行真空操作。
它通过执行以下步骤来实现数据库的压缩和优化:步骤1: 打开数据库首先,我们需要打开SQLite数据库文件。
在SQLite中,可以使用以下命令打开数据库:sqlite3 mydatabase.db这个命令将打开名为mydatabase.db的数据库文件,并且将进入SQLite命令行提示符模式。
步骤2: 运行真空VACUUM命令接下来,我们需要执行真空VACUUM命令来压缩和优化数据库。
在SQLite 中,真空VACUUM命令可以使用SQL语句或者命令行提示符来执行。
使用SQL语句:VACUUM;在命令行提示符中:sqlite3 mydatabase.db "VACUUM"这两种方法都会触发真空VACUUM操作,SQLite将扫描数据库文件并查找未使用的空间和垃圾数据。
它会将这些无用的数据从文件中删除,并重新组织文件结构以优化数据库的性能。
步骤3: 等待真空VACUUM完成一旦真空VACUUM命令被执行,SQLite将开始执行数据库的压缩和优化操作。
这个过程可能会花费一些时间,具体取决于数据库文件的大小和复杂性。
在操作完成前,请耐心等待。
步骤4: 关闭数据库当真空VACUUM操作完成后,您可以选择关闭SQLite数据库。
在SQLite 命令行中,可以使用以下命令关闭数据库:.quit这个命令将退出SQLite命令行提示符模式并关闭数据库。
为什么需要使用真空VACUUM SQL语句?在SQLite中,数据库文件会随着时间的推移而增长,并且在执行删除和更新操作时会留下未使用的空间和垃圾数据。
vacuum 数据库机制

VACUUM是数据库中用于清理和整理数据的一种机制。
在许多数据库系统中,包括PostgreSQL和GaussDB(DWS),VACUUM都起着重要的作用。
VACUUM的主要目的是释放未使用的空间,提高数据存储的效率。
当数据被删除或更新时,它们所占用的空间并不会立即被释放回操作系统,而是被标记为可重用。
随着时间的推移,这些未使用的空间可能会累积,导致数据库性能下降。
VACUUM操作通过清除这些未使用的空间,并将它们重新分配给其他数据,从而优化了数据库的性能。
在PostgreSQL中,VACUUM的作用具体如下:
清理和重新使用已删除或已更新的行所占用的空间。
优化数据存储,减少存储空间的浪费。
提高数据库的性能,因为清理后的数据存储更加紧凑和高效。
在GaussDB(DWS)中,VACUUM的作用与PostgreSQL类似,它通过清除旧版本数据和废旧元组来释放空间,防止数据库空间的膨胀。
VACUUM的执行过程涉及到获取共享锁、获取每个页面的死亡元组并冻结需要的元组、删除指向死亡元组的引用元组、删除死亡元组并重新分配活动元组、更新目标表的FSM和VM等步骤。
总之,VACUUM是数据库维护的重要工具,它通过清理未使用的空间来提高数据库的性能和存储效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2.5 auto-vacuum 守护进程;
3. 经常重建索引;
4. 日志文件维护;
5. 关于本文;
6. 更新日志;
7. 参考文档;
8. 相关文档;
+++++++++++++++++++++++++++++++++++++++++++
对于大多数节点而言,我们推荐的习惯是在一天中的低使用的时段安排一次整个数据库的 VACUUM, 必要时外加对更新频繁的表的更经常的清理。 (有些环境下,对那些更新非常频繁的表可能会每几分钟就 VACUUM 一次。) 如果您的集群中有多个数据库,别忘记对每个库进行清理; vacuumdb脚本可能会帮您的忙;
如果您知道自己刚删除掉一个表中大部分的行,那么我们建议使用VACUUM FULL, 这样该表的稳定态尺寸可以因为VACUUM FULL更富侵略性的方法而显著减小。 日常的磁盘空间清理,请使用 VACUUM,而不是 VACUUM FULL;
如果您有一个表,它的内容经常被完全删除,那么可以考虑用 TRUNCATE,而不是后面跟着 VACUUM 的 DELETE。 TRUNCATE 立即删除整个表的内容, 而不要求随后的 VACUUM 或者VACUUM FULL 来恢复现在没有用的磁盘空间;
2.更新 PostgreSQL 查询规划器使用的数据统计信息。
3.避免因为事务 ID 重叠造成的老旧数据的丢失。 对上面每个条件进行 VACUUM 操作的频率和范围因不同的节点而不同。 因此,数据库管理员必须理解这些问题并且开发出合适的维护策略。
建议在经常VACUUM(清理)(至少每晚一次)生产数据库, 以保证不断地删除失效的行。尤其是在增删了大量记录之后, 对受影响的表执行 VACUUM ANALYZE 命令是一个很好的习惯。例如:
很明显,那些经常更新或者删除元组的表需要比那些较少更新的表清理的更频繁一些。 所以,设置一个周期性的 cron 任务 VACUUM 那些选定的表,而忽略那些已经知道变化比较少的表. 这个方法只是在您拥有大量更新频繁的表和大量很少更新的表的时候有意义 — 清理一个小表的额外开销根本不值得担心; VACUUM 命令有两个变种:
正文
+++++++++++++++++++++++++++++++++++++++++++
1. 综述;
为了保持所安装的 PostgreSQL 服务器平稳运行, 我们必须做一些日常性的维护工作。我们在这里讨论的这些工作都是经常重复的事情, 可以很容易地使用标准的 Unix 工具,比如cron 脚本来实现。 不过,设置合适的脚本以及检查它们是否成功执行则是数据库管理员的责任, 一件很明显的维护工作就是经常性地创建数据的备份拷贝。 如果没有最近的备份,那么您就没有从灾难中恢复的机会(比如磁盘坏了,失火,误删了表等等)。
2.1.2 描述;
VACUUM 回收已删除元组占据的存储空间。 在一般的 PostgreSQL 操作里, 那些已经 DELETE 的元组或者被 UPDATE 过后过时的元组是没有从它们所属的表中物理删除的; 在完成 VACUUM 之前它们仍然存在。 因此我们有必须周期地运行 VACUUM, 特别是在常更新的表上,如果没有参数,VACUUM 处理当前数据库里每个表, 如果有参数,VACUUM 只处理那个表,简单的 VACUUM (没有FULL) 只是简单地回收空间并且令其可以再次使用;
CPU 0.00s/0.00u sec elapsed 0.00 sec.
信息: 正在清理 (vacuum) "pg_toast.pg_toast_16464"
信息: index "pg_toast_16464_index" now contains 0 row versions in 1 pages
2.1.3 参数;
FULL ------选择"完全"清理,这样可以恢复更多的空间, 但是花的时间更多并且在表上施加了排它锁。
FREEZE ---------选择激进的元组"冻结"。
VERBOSE --------- 为每个表打印一份详细的清理工作报告。
ANALYZE --------- 更新用于优化器的统计信息,以决定执行查询的最有效方法。
DETAIL: 0 dead row versions cannot be removed yet.
There were 0 unused item pointers.
0 pages contain useful free space.
0 pages are entirely empty.
0 index pages have been deleted, 0 are currently reusable.
CPU 0.00s/0.00u sec elapsed 0.00 sec.
信息: "access": found 0 removable, 0 nonremovable row versions in 0 pages
sir=# VACUUM VERBOSE ANALYZE access ;
信息: 正在清理 (vacuum) "public.access"
信息: index "access_pkey" now contains 0 row versions in 1 pages
DETAIL: 0 index row versions were removed.
其它主要的维护范畴的工作包括周期性的 "vacuuming" (清理)数据库。
其它需要周期性注意的东西是日志文件的管理。
PostgreSQL 和其它数据库产品比较起来是低维护量的。 但是,适当在这些任务上放一些注意将更加能够确保我们的愉快工作和获取对这个系统富有成效的经验。 操作环境:PostgreSQL8.2+Ubuntu 7.04
2.2 恢复磁盘空间;
2.2.1 概述;
在正常的 PostgreSQL 操作里, 对一行的UPDATE或DELETE并未立即删除旧版本的数据行。 这个方法对于获取多版本并行控制的好处是必要的: 如果一个行的版本仍有可能被其它事务看到,那么您就不能删除它。 但到了最后,不会有任何事务对过期的或者已经删除的元组感兴趣。 而它占据的空间必须为那些新的元组使用而回收, 以避免对磁盘空间增长的无休止的需求。这件事是通过运行 VACUUM 实现的。
2. 日常清理;
2.1 VACUUM;
2.1.1 语法结构;
VACUUM [ FULL | FREEZE ] [ VERBOSE ] [ table ]
VACUUM [ FULL | FREEZE ] [ VERBOSE ] ANALYZE [ table [ (column [, ...] ) ] ]
postgresql维护_VACUUM
摘要:为了保持所安装的 PostgreSQL 服务器平稳运行, 我们必须做一些日常性的维护工作。我们在这里讨论的这些工作都是经常重复的事情, 可以很容易地使用标准的 Unix 工具,比如cron 脚本来实现;
目录
1. 综述; 2. 日常清理;
CPU 0.00s/0.00u sec elapsed 0.00 sec.
信息: 正在分析 "public.access"
信息: "access": scanned 0 of 0 pages, containing 0 live rows and 0 dead rows; 0 rows in sample, 0 estimated total rows
第一种形式,叫做"懒汉 vacuum"或者只是 VACUUM, 在表和索引中标记过期的数据为将来使用;它并不试图立即恢复这些过期数据使用的空间。 因此,表文件不会缩小,并且任何文件中没有使用的空间都不会返回给操作系统。 这个变种的 VACUUM 可以和通常的数据库操作并发执行;
第二种形式是 VACUUM FULL 命令。 这个形式使用一种更加激进的算法来恢复过期的的行版本占据的空间。 任何 VACUUM FULL 释放的空间都立即返回给操作系统。 但是,这个形式的 VACUUM 命令在进行
2.3 更新规划器统计;
PostgreSQL 的查询规划器依赖一些有关表内容的统计信息用以为查询生成好的规划。 这些统计是通过ANALYZE 命令获得的,您可以直接调用这条命令, 也可以把它当做 VACUUM 里的一个可选步骤来调用。 拥有合理准确的统计是非常重要的,否则,选择了恶劣的规划很可能会降低数据库的性能; 和为了回收空间做清理一样,经常更新统计信息也是对更新频繁的表更有用。 不过,即使是更新非常频繁的表,如果它的数据的统计分布并不经常改变,那么也不需要更新统计信息。 一条简单的拇指定律就是想想表中字段的最大很最小值改变的幅度。 比如,一个包含行更新时间的 timestamp 字段将是随着行的追加和更新稳定增长最大值的; 这样的字段可能需要比那些包含访问网站的 URL 的字段更频繁一些更新统计信息。 那些 URL 字段可能改变得一样频繁,但是其数值的统计分布的改变相对要缓慢得多;