Storm:大数据流式计算及应用实践
storm的用法

storm的用法一、了解Storm大数据处理框架Storm是一个用于实时流数据处理的分布式计算框架。
它由Twitter公司开发,并于2011年发布。
作为一个开源项目,Storm主要用于处理实时数据,比如实时分析、实时计算、流式ETL等任务。
二、Storm的基本概念及特点1. 拓扑(Topology):拓扑是Storm中最重要的概念之一。
它代表了整个计算任务的结构和流程。
拓扑由一系列组件组成,包括数据源(Spout)、数据处理节点(Bolt)以及它们之间的连接关系。
2. 数据源(Spout):Spout负责从外部数据源获取数据,并将其发送给Bolt进行处理。
在拓扑中,通常会有一个或多个Spout进行数据输入。
3. 数据处理节点(Bolt):Bolt是对数据进行实际处理的模块。
在Bolt中可以进行各种自定义的操作,如过滤、转换、聚合等,根据业务需求不同而定。
4. 流组(Stream Grouping):Stream Grouping决定了从一个Bolt到下一个Bolt 之间的任务调度方式。
Storm提供了多种Stream Grouping策略,包括随机分组、字段分组、全局分组等。
5. 可靠性与容错性:Storm具有高可靠性和容错性的特点。
它通过对任务状态进行追踪、失败重试机制和数据备份等方式,确保了整个计算过程的稳定性。
6. 水平扩展:Storm可以很方便地进行水平扩展。
通过增加计算节点和调整拓扑结构,可以实现对处理能力的无缝提升。
三、Storm的应用场景1. 实时分析与计算:Storm适用于需要对大规模实时数据进行即时分析和计算的场景。
比如金融领域中的实时交易监控、电商平台中用户行为分析等。
2. 流式ETL:Storm可以实现流式ETL(Extract-Transform-Load)操作,将源数据进行抽取、转换和加载到目标系统中,并实时更新数据。
3. 实时推荐系统:通过结合Storm和机器学习算法,可以构建快速响应的实时推荐系统。
storm实验后的心得

storm实验后的心得Storm实验后的心得在进行了一系列关于Storm的实验后,我对这个分布式实时计算系统有了更加深刻的理解和认识。
通过实验,我发现Storm具有高性能、可扩展性强、容错性好等优点,适用于处理大规模的实时数据流。
下面我将就我的实验心得进行总结和分享。
我觉得Storm的高性能是它最大的优势之一。
在实验中,我通过构建拓扑结构,将数据流分成多个阶段进行处理。
通过合理的拓扑结构设计和任务划分,我成功地将计算任务分发到不同的计算节点上,实现了并行计算。
这样一来,Storm可以同时处理多个数据流,大大提高了计算效率。
Storm的可扩展性也给我留下了深刻的印象。
在实验中,我可以根据实际需求动态地增加或减少计算节点,而无需停止整个系统。
这种灵活的扩展性使得Storm能够应对不断增长的数据规模和计算需求,保证了系统的稳定性和可靠性。
Storm的容错性也是我在实验中感受到的一大优点。
在实验过程中,我模拟了计算节点的故障情况,并观察了系统的容错能力。
我发现,当一个计算节点发生故障时,Storm会自动将该节点上的任务重新分配给其他正常的节点,确保计算任务的连续性和正确性。
这种容错机制使得Storm具有很高的可靠性,在大规模分布式计算中表现出色。
Storm还具有灵活的数据处理能力。
在实验中,我可以根据实际需求设计不同的数据处理逻辑,包括数据过滤、数据转换、数据聚合等。
通过使用Storm提供的丰富的操作接口和函数库,我能够灵活地处理各种数据类型和数据流,满足不同的业务需求。
在实验过程中,我还发现Storm的学习曲线相对较陡。
由于Storm 的架构和设计思想与传统的批处理系统有很大的差异,初学者可能需要一定的时间来适应和理解Storm的工作原理。
不过,一旦掌握了Storm的基本概念和操作方式,就能够很好地利用它进行实时数据处理和分析。
总结起来,通过对Storm的实验,我深刻地认识到了这个分布式实时计算系统的优势和特点。
基于案例讲解Storm实时流计算

Storm简介 Storm的主要特点 Storm组件 Storm编程模型 Storm安装 Storm实例讲解
电商实时推荐 淘宝双十一实时销售额统计
车辆7*24小时监控
电信行业重大节假日实时保障监控
1. Storm是一个分布式的、容错的实时计算系统,它采用Clojure编写的 2. Storm可被用于“流处理”之中,实时处理消息并更新数据库 3. Storm可以进行连续查询并把结果即时反馈给客户,比如将Twitter上 的热门话题发送到客户端 4. Storm可以用来并行处理密集查询,Storm的拓扑结构是一个等待调 用信息的分布函数,当它收到一条调用信息后,会对查询进行计算,并 返回查询结果。
1.简单的编程模型。类似于MapReduce降低了并行批处理复杂性,Storm 降低了进行实时处理的复杂性。 2.可以使用各种编程语言。你可以在Storm之上使用各种编程语言。默认支 持Clojure、Java、Ruby和Python。
3.水平扩展。计算是在多个线程、进程和服务器之间并行进行的。
4.可靠的消息处理。Storm保证每个消息至少能得到一次完整处理。任务失 败时,它会负责从消息源重试消息。 5.快速。系统的设计保证了消息能得到快速的处理,使用ZeroMQ作为其底 层消息队列。 6.本地模式。Storm有一个“本地模式”,可以在处理过程中完全模拟 Storm集群。这让你可以快速进行开发和单元测试。
Bolt
可实现接口IBolt,或BaseRichbolt
主要方法:
IBolt继承了java.io.Serializable,我们在nimbus上提交了topology以后,创建出来的bolt会序列化后发送到具体 执行的worker上去。worker在执行该Bolt时,会先调用prepare方法传入当前执行的上下文execute接受一个tuple 进行处理,并用prepare方法传入的OutputCollector的ack方法(表示成功)或fail(表示失败)来反馈处理结果 cleanup 同ISpout的close方法,在关闭前调用。同样不保证其一定执行 execute 最重要的方法,用来处理自己的业务逻辑
大数据架构与应用——Storm计算平台

Apache Storm ——开发实践案例:Using check-ins to build a heat map of barsheat map of barsheat map of bars CheckinsGeocodeLookupHeatMapBuilderPersistorCheckinsGeocode LookupPersistorbuilder.setSpout("checkins", new Checkins(), 4);builder.setBolt("geocode-lookup", new GeocodeLookup(), 8);Executors and tasksbuilder.setBolt("geocode-lookup", new GeocodeLookup(), 8)Topology stream groupingsShuffle groupingdistribute outgoing tuples from one component to the next in a manner that’s random butevenly spread out.Fields groupingnsure tuples with the same values for a selectedset of fields always go to the same instance ofthe next bolt.TopologyDesign Design by breakdown into functional componentsTopology Design Design by breakdown into components at points of repartitionSimplest functional componentsvs.lowest number of repartitionsReliability?authorization flowauthorization flowAuthorizeCreditCardProcessedOrderNotificationTuple Tree—Implicit anchoring, acking, and failing Anchoringoutgoing order tuple will be automaticallyanchored to the incoming order tuple.outputCollector.emit(new Values(order)); Ackingthe tuple that was sent to it will be automatically ackedFailingthrowing a FailedException or ReportedFailed-Exception—Explicit anchoring, acking, and failing AnchoringoutputCollector.emit(tuple, new Values(order)) AckingoutputCollector.ack(tuple)FailingoutputCollector.fail(tuple);Handling failures and knowing whento retryRetriableNonretriableUnknown errorsSpout’s role in guaranteed message processingStorm调用nextTuple()获取一个新tuple.Spout使用SpoutOutputCollector向下游提供tuple.当提供tuple时, Spout通过一个messageId唯一标识这个tuple.spoutOutputCollector.emit(tuple, messageId);当tuple发送到下游bolts时,Storm开始跟踪这个tuple树. 跟踪是通过下游bolts的锚定(anchoring)和应答(acking)实现。
Storm分布式实时计算在物联网系统中的应用

事务处理过程:
程序部署:
1、生成JAR包 cd /opt/storm/jar/iot-flow-stat/source jar cfm ../iot-flow-stat.jar META-INF/MANIFEST.MF *
2、 topology发布 args[0] : topology名称 args[1] : NumWorkers args[2] : 1 表示最新,0表示最旧。 /opt/storm/apache-storm-1.0.3/bin/storm jar /opt/storm/jar/iot-flow-stat/iot-flow-
实时:数据不写磁盘,延迟低(毫秒级) 流式:不断有数据流入、处理、流出 开源:twitter开源,社区很活跃
1、简单的编程模型。类似于MapReduce降低了并行批处理复杂性, Storm降低了进行实时处理的复杂性。 2、可以使用各种编程语言。你可以在Storm之上使用各种编程语言。默 认支持Clojure、Java、Ruby和Python。 3、水平扩展。计算是在多个线程、进程和服务器之间并行进行的。
数据之间有关系(聚合等):如日志pv/uv统计、访问热点统计
N行日志
Client
N行日志
N行日志
ip
MQ
Spout
Bolt1
pv/uv
Bolt2
Storage
received
Ø 16年物联网卡流量数据通过日增量文件方式每天提供一次,流量数据当时使用 hadoop+spark(独立部署的集群,不是基于YARN)进行入库。内存消耗大、服务器 间数据交互不稳定,导致每天需要几个小时才能把全省流量数据清洗处理完入库, 流量数据整体延时在36小时到48小时左右。 Ø 17年为了缩短批量数据的时延,物联网平台与BOSS数据接口实现重大优化, BOSS提供海量物联网数据的实时订购关系、用户状态变化、流量数据(误差1M) 的实时推送。目前,归属广东移动的物联网卡活跃号码每天产生的流量话单数据大 概是48G左右。
大数据开发技术之Storm原理与实践

大数据开发技术之Storm原理与实践一、Storm简介1. 引例在介绍Storm之前,我们先看一个日志统计的例子:假如我们想要根据用户的访问日志统计使用斗鱼客户端的用大数据培训户的地域分布情况,一般情况下我们会分这几步:•取出访问日志中客户端的IP•把IP转换成对应地域•按照地域进行统计Hadoop貌似就可以轻松搞定:•map做ip提取,转换成地域•reduce以地域为key聚合,计数统计•从HDFS取出结果如果有时效性要求呢?•小时级:还行,每小时跑一个MapReduce Job•10分钟:还凑合能跑•5分钟:够呛了,等槽位可能要几分钟呢•1分钟:算了吧,启动Job就要几十秒呢•秒级:… 要满足秒级别的数据统计需求,需要•进程常驻运行;•数据在内存中Storm正好适合这种需求。
2. 特性Storm是一个分布式实时流式计算平台。
主要特性如下:•简单的编程模型:类似于MapReduce降低了并行批处理复杂性,Storm降低了实时处理的复杂性,只需实现几个接口即可(Spout实现ISpout接口,Bolt实现IBolt接口)。
•支持多种语言:你可以在Storm之上使用各种编程语言。
默认支持Clojure、Java、Ruby和Python。
要增加对其他语言的支持,只需实现一个简单的Storm通信协议即可。
•容错性:nimbus、supervisor都是无状态的, 可以用kill -9来杀死Nimbus和Supervisor进程, 然后再重启它们,任务照常进行; 当worker失败后, supervisor会尝试在本机重启它。
•分布式:计算是在多个线程、进程和服务器之间并行进行的。
•持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
•可靠的消息处理:Storm保证每个消息至少能得到一次完整处理。
任务失败时,它会负责从消息源重试消息(ack机制)。
•快速、实时:Storm保证每个消息能能得到快速的处理。
《云计算与大数据技术应用》Strom——基于拓扑的流数据实时计算框架

Storm-Yarn体系架构
Storm-Yarn体系架构
Storm-Yarn首先向Yarn Resource Manager发出请求启动一个Storm Master应用,如图中 第①步操作。
然后Storm Master在本地启动Storm Nimbus Server和Storm UI Server,如图中第②和第 ③步操作。
Flink介绍及与Storm对比
THANKS
在Topology中产生数据源的组件。通常Spout获取数据源的数据,再调用nextTuple函数,发送 数据供Bolt消费
在Topology中接收Spout的数据,再执行处理的组件。Bolt可以执行过滤、函数操作、合并、写 数据库等操作。Bolt接收到消息后调用execute函数,用户可以在其中执行相应的操作
Strom
Storm简介
Storm 是一个开源的、实时的计算平台 Storm 是非常有发展潜力的流处理系统,出现不久便在许多公司中得到使用
Storm核心组件
组件 Topology Nimbus Supervisor Worker Executor
T分组
概念
一个实时计算应用程序逻辑上被封装在Topology对象中,类似于Hadoop中的作业。与作业不同 的是,Topology会一直运行到该进程结束
负责资源分配和任务调度,类似于Hadoop中的JobTracker
负责接收Nimbus分配的任务,启动和停止管理的Worker进程,类似于Hadoop中的TaskTracker
使用Zookeeper Server维护Storm-Yarn集群中Nimbus和Supervisor之间的主从关系,如图 中第④和第⑤步操作。其中Nimbus和Supervisor分别运行在Yarn Resource Manager为其 分配的各个单独的资源容器中(Yarn Container)。
storm的原理及应用发展

Storm的原理及应用发展1. 简介Storm是一种开源的分布式实时计算系统,也被称为“流处理框架”。
它最初由Twitter开发,目前已经成为Apache软件基金会的顶级项目之一。
Storm的设计目标是提供一个高效且可靠的实时流处理框架,能够处理海量的数据并保证低延迟。
本文将介绍Storm的原理以及其应用发展的情况。
2. 原理Storm基于分布式消息驱动的编程模型,主要由三个核心组件组成:Spout、Bolt和Topology。
Spout用于从数据源获取数据并将其发送给Bolt进行处理,Bolt负责对数据进行处理和转换,而Topology则将Spout和Bolt组织成一个有向无环图(DAG),定义了数据处理的流程和数据流向。
SpoutSpout是Storm的数据源组件,可以从各种数据源中读取数据,如消息队列、数据库、文件系统等。
Spout可以以多线程的方式并行读取数据,并将读取到的数据发送给Bolt进行处理。
Spout还可以设置可靠性语义,保证数据的可靠处理。
BoltBolt是Storm的处理组件,可以对Spout发送过来的数据进行处理和转换。
Bolt可以进行计算、过滤、聚合等操作,并将处理结果发送给下一个Bolt或最终存储系统。
Bolt也可以以多线程的方式并行处理数据,提高数据处理的吞吐量。
TopologyTopology是Storm的数据处理流程描述,由多个Spout和Bolt组成的有向无环图(DAG)。
Topology定义了数据处理的流程和数据流向,可以灵活地组织数据处理逻辑。
通过调整Topology中的组件之间的关系和并发度,可以实现不同的数据处理需求。
3. 应用发展Storm作为一种高效且可靠的实时计算系统,已经在许多大规模数据处理场景中得到了广泛应用。
以下是一些Storm应用的典型案例:实时流处理Storm可以处理实时流数据,对于需要在数据到达时立即进行处理和分析的场景非常适用。
例如,电商平台可以利用Storm来实时分析用户的购买行为、即时推送个性化的推荐信息,从而提升用户体验和销售效果。
实时计算Storm 核心技术及其在报文系统中的应用

实时计算Storm 核心技术及其在报文系统中的应用摘要1随着应用创新的层出不穷和数据类型的不断丰富,企业面对的数据量急剧增长,随之而来的实时处理需求给管理者和开发人员带来了多方面的困难。
一方面,源源不断的数据流带来了硬件成本增加、难以有效管控等诸多问题;另一方面,传统的数据批处理系统无法满足实时数据处理需求,服务延迟及业务连续性不佳等问题比较严重。
为解决上述问题,作为一个优秀的实时计算框架,Storm迅速在业界得到广泛应用与认可。
本文对Storm平台特点及其背后的核心技术进行了深入剖析,并结合公司实时服务现状,特别是现有的报文系统需求,得到了一个基于Storm 的、满足高并发及业务隔离要求的原型系统,以期对下一代报文系统的设计与实现提供帮助。
目录1. Storm及报文系统概述 (1)1.1 流式数据与Storm的诞生 (1)1.2 我司实时服务现状 (2)1.3 报文系统概述 (2)2. Storm关键技术 (3)2.1 系统架构 (3)2.1.1 调度系统 (3)2.1.2 通信模型 (5)2.2 拓扑与数据流 (6)2.2.1 Topology、Spout及Bolt (6)2.2.2 数据流Grouping策略 (9)2.3 Ack机制 (10)3. Storm中的高层机制 (11)3.1 事务处理 (11)3.2 Trident API (13)3.3 DRPC (14)4. 基于Storm的报文系统初探 (14)4.1 报文系统需求分析 (14)4.2 原型系统设计 (15)4.3 原型系统实现 (17)5. 总结与展望 (20)1. Storm及报文系统概述1.1 流式数据与Storm 的诞生随着互联网的高速发展,各类数据应用层出不穷,而数据除了规模的爆炸性增长之外,新的形态也不断涌现。
流式数据便是这些新型大数据中的一类典型。
与传统数据的静态、批处理和持久化不同,流式数据是连续、无边界且瞬间性的。
大数据开发实战:Storm流计算开发
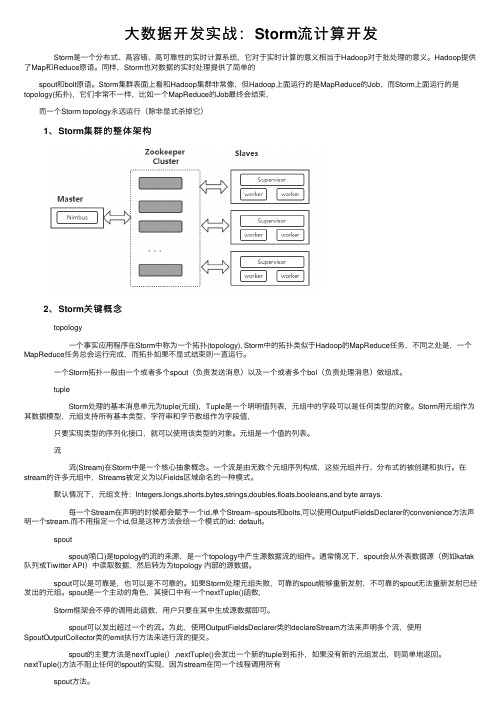
⼤数据开发实战:Storm流计算开发 Storm是⼀个分布式、⾼容错、⾼可靠性的实时计算系统,它对于实时计算的意义相当于Hadoop对于批处理的意义。
Hadoop提供了Map和Reduce原语。
同样,Storm也对数据的实时处理提供了简单的 spout和bolt原语。
Storm集群表⾯上看和Hadoop集群⾮常像,但Hadoop上⾯运⾏的是MapReduce的Job,⽽Storm上⾯运⾏的是topology(拓扑),它们⾮常不⼀样,⽐如⼀个MapReduce的Job最终会结束, ⽽⼀个Storm topology永远运⾏(除⾮显式杀掉它) 1、Storm集群的整体架构 2、Storm关键概念 topology ⼀个事实应⽤程序在Storm中称为⼀个拓扑(topology), Storm中的拓扑类似于Hadoop的MapReduce任务,不同之处是,⼀个MapReduce任务总会运⾏完成,⽽拓扑如果不显式结束则⼀直运⾏。
⼀个Storm拓扑⼀般由⼀个或者多个spout(负责发送消息)以及⼀个或者多个bol(负责处理消息)做组成。
tuple Storm处理的基本消息单元为tuple(元组),Tuple是⼀个明明值列表,元组中的字段可以是任何类型的对象。
Storm⽤元组作为其数据模型,元组⽀持所有基本类型、字符串和字节数组作为字段值, 只要实现类型的序列化接⼝,就可以使⽤该类型的对象。
元组是⼀个值的列表。
流 流(Stream)在Storm中是⼀个核⼼抽象概念。
⼀个流是由⽆数个元组序列构成,这些元组并⾏、分布式的被创建和执⾏。
在stream的许多元组中,Streams被定义为以Fields区域命名的⼀种模式。
默认情况下,元组⽀持:Integers,longs,shorts,bytes,strings,doubles,floats,booleans,and byte arrays. 每⼀个Stream在声明的时候都会赋予⼀个id,单个Stream--spouts和bolts,可以使⽤OutputFieldsDeclarer的convenience⽅法声明⼀个stream.⽽不⽤指定⼀个id,但是这种⽅法会给⼀个模式的id: default。
storm的用法和搭配

storm的用法和搭配Storm 是一个开源的、分布式的实时计算系统,具有高容错性、可伸缩性和低延迟的特点。
它在处理大规模数据流的实时计算任务中得到了广泛应用。
本文将介绍 Storm 的用法和搭配,包括 Storm 的基本概念、组件及其相互关系,并阐述Storm 与其他相关技术的结合。
一、Storm 简介与基本概念1.1 Storm 简介Storm 是一个开源分布式实时大数据处理框架,由 Twitter 公司开发并于 2011年开源发布。
它是一种高度可靠且可伸缩的实时流处理系统,可以在大规模数据集上执行复杂计算任务。
1.2 Storm 组成部分Storm 主要由以下几个组件组成:- Nimbus:负责资源分配和任务调度,是整个 Storm 集群的主节点。
- Supervisor:运行在集群工作节点上,负责启动和监控工作进程(Worker),并向 Nimbus 汇报状态信息。
- ZooKeeper:提供协调服务,用于管理Nimbus 和Supervisor 节点之间的通信。
- Topology:描述 Storm 的计算任务模型,包含多个 Spout 和 Bolt 组件构成的有向无环图。
二、Storm 的使用方法2.1 创建 Topology创建一个 Storm Topology 需要以下步骤:- 定义 Spout:Spout 是数据源,可以从消息队列、日志文件等地方获取实时数据流并发送给下游的 Bolt。
通常,你需要实现一个自定义的 Spout 类来满足应用的需求。
- 定义 Bolt:Bolt 是对接收到的数据流进行处理和转换的组件。
在 Bolt 中,你可以执行计算、过滤和聚合等操作,并将处理后的结果发送给其他 Bolt 或外部存储系统。
- 连接 Spout 和 Bolt:通过指定 Spout 和 Bolt 之间的连接关系,形成有向无环图。
2.2 配置 Topology在创建 Topology 时,还需要进行相关配置。
大数据处理中的流计算技术实践

大数据处理中的流计算技术实践随着互联网技术的飞速发展,数据产生的速度呈现爆炸式增长。
机器学习、深度学习、人工智能等技术的不断升级,大数据的处理技术也日新月异。
其中,流计算技术作为大数据处理技术的前沿,正逐步成为数据处理的重要手段。
流计算是一种针对实时数据流的计算模型,能够实时地对数据进行处理、分析、计算、交互和控制。
而流计算技术则是通过对数据的实时处理,从而实现数据流的快速处理。
根据不同的处理场景,流计算可以分为批处理和流处理两种类型。
批处理是指将数据按照时间或数量来分组处理,在确定一定批次之后再进行处理。
而流处理则是实时地对产生的数据进行处理和分析,不需要等待批次的组成。
而在大数据处理中,流计算技术可以有效地解决大数据量、高速度、高频率的数据流处理问题,实现数据的即时处理。
在实际场景中,流计算技术的应用领域十分广泛。
比如,金融领域可以通过对交易数据的实时处理,实现实时风险控制和交易监控;物流领域可以通过对物流轨迹的实时监控,实现准确的物流管理和配送控制;医疗领域可以通过对患者病情的实时监控,实现及时的诊断和治疗。
在流计算技术的实践中,Kafka-Storm-Spark Streaming是一种常用的流处理框架。
Kafka是一种高吞吐量的消息队列系统,可以将消息进行持久化存储。
Storm则是一种分布式实时计算引擎,可以对消息进行实时分析和处理。
而Spark Streaming则是将批处理框架Spark引入到流处理中,实现了高吞吐量和低延迟的实时计算需求。
当然,除了Kafka-Storm-Spark Streaming,还有其他的流计算框架可以实现数据流的实时计算。
比如,Flink是一种高吞吐量、低延迟的分布式数据流处理引擎,可以处理传统的批处理任务和流实时处理任务;Samza则是一种基于Kafka的流处理框架,可以实现低延迟和高吞吐量的实时数据处理。
总之,流计算技术的应用前景十分广阔,流计算技术也应用广泛。
大数据技术:Hadoop、Spark、Storm的功能、性能和应用场景对比分析

大数据技术:Hadoop、Spark、Storm的功能、性能和应用场景对比分析随着大数据时代的到来,越来越多的企业和机构开始重视大数据技术的应用和发展。
而在这其中,Hadoop、Spark、Storm等大数据技术已成为行业中颇具代表性和影响力的技术工具。
本文将对这三种大数据技术的功能、性能和应用场景进行对比分析。
一、HadoopHadoop是由Apache基金会研发的一款开源的分布式计算框架,主要用于大规模数据处理和分析。
Hadoop的核心组件包括HDFS、MapReduce、Yarn和Hive等。
1.功能Hadoop通过HDFS(Hadoop Distributed File System)实现了大规模数据的存储,可以存储PB级别的数据量。
同时,它通过MapReduce算法实现了基于数据的分布式计算,可以快速处理大规模数据。
再加上Yarn的资源管理,Hadoop可以实现优秀的集群管理,提高了计算的效率。
2.性能Hadoop处理数据的速度相对较慢,需要较长的计算时间。
因为它采用的是批处理模式,需要将所有数据读入内存后才能计算,所以其实时性较差。
但是在处理大规模数据时,Hadoop具有较高的效率和扩展性。
3.应用场景Hadoop的应用场景非常广泛。
例如,它可以用于搜索引擎、推荐系统、大数据分析、精准营销等领域。
在大数据分析中,Hadoop通常会和其他的数据处理工具和算法一起使用,如Hive、Pig、Spark等。
二、SparkSpark是大数据处理的另一种开源计算框架,也是由Apache基金会研发的。
与Hadoop不同,Spark的运算模型是基于内存的,因此其在处理实时数据时表现优秀。
Spark包括Spark Core、Spark SQL、Spark Streaming、GraphX和MLlib等组件。
Spark最大的特点是快速,通过内存计算,Spark可以比Hadoop 更快地处理大规模数据。
除此之外,Spark还具有强大的计算模型、易于使用的API、丰富的生态系统等特征。
《大数据实时分析Storm》培训课程(KZL)

课程名称:大数据实时分析(Storm)课程内容:一、流式实时数据处理:1. 从MapReduce到流计算2. Storm的起源及其主要特点3. 流计算在互联网和运营商中应用案例4. 其他流式数据处理系统:JStorm、Heron、Spark Streaming、Flink、GearPump二、S torm的系统模型:1. Storm流计算的典型架构实例2. 部署模式单机/分布式部署本地模式3. Storm组件:Zookeeper、nimbus、supervisor、UI三、P AXOS协议与Zookeeper初探1. PAXOS协议简介2. Zookeeper基本原理与ZAB协议3. Zookeeper的安装与使用初步4. Zookeeper演示实验四、S torm集群部署和配置1. Storm的依赖组件2. Storm的部署环境3. 部署Storm服务4. 启动Storm5. Storm的守护进程6. 部署Storm的其他节点7. 提交T opology五、S torm中的Grouping六、J ava语言补充1. 基本结构2. 类、继承与接口七、S torm的数据源编程单元:Spout1. Spout的接口与实现Spout与接口层次结构ISpout和IComponent接口接口的实现类及实例2. Spout编程示例八、S torm的数据处理编程单元:Bolt1. Bolt的接口与实现Bolt与接口层次IBolt和IComponent接口接口的实现类及实例2. Bolt程序开发示例九、K afka Spout1. Kafka简介2. Kafka集群的搭建、配置与基本操作3. Kafka High Level API与Low Level API4. High Level API5. 利用High Level API实现Kafka Spout十、消息的可靠处理1. Storm中的At Least Once2. Spout与数据的可靠性3. Bolt与数据的可靠性4. Kafka Low Level API与Kafka Spout的At Least Once机制十一、一致性事务a) Storm一致性事务的基本思路b) Google MillWheel中的Exactly Once机制c) Transactional Topologies与Trident十二、分布式RPC十三、Storm与Redisa) Redis简介与安装b) Redis的基本操作c) Jedis接口d) 从Bolt中将计算结果输出到Redis中十四、Storm与Pythona) Storm中的non-JVM语言接口b) Python简介c) 利用Python开发Storm拓扑十五、Storm实践经验选讲十六、Storm应用开发实例:一个千亿级的Storm流计算平台。
流式大数据处理的三种框架 Storm,Spark和Samza _光环大数据storm培训

流式大数据处理的三种框架 Storm,Spark和Samza _光环大数据storm培训许多分布式计算系统都可以实时或接近实时地处理大数据流。
本文将对Storm、Spark和Samza等三种Apache框架分别进行简单介绍,然后尝试快速、高度概述其异同。
许多分布式计算系统都可以实时或接近实时地处理大数据流。
本文将对三种Apache框架分别进行简单介绍,然后尝试快速、高度概述其异同。
ApacheStorm在Storm中,先要设计一个用于实时计算的图状结构,我们称之为拓扑(topology)。
这个拓扑将会被提交给集群,由集群中的主控节点(masternode)分发代码,将任务分配给工作节点(workernode)执行。
一个拓扑中包括spout 和bolt两种角色,其中spout发送消息,负责将数据流以tuple元组的形式发送出去;而bolt则负责转换这些数据流,在bolt中可以完成计算、过滤等操作,bolt自身也可以随机将数据发送给其他bolt。
由spout发射出的tuple是不可变数组,对应着固定的键值对。
ApacheSparkSparkStreaming是核心SparkAPI的一个扩展,它并不会像Storm那样一次一个地处理数据流,而是在处理前按时间间隔预先将其切分为一段一段的批处理作业。
Spark针对持续性数据流的抽象称为DStream(DiscretizedStream),一个DStream是一个微批处理(micro-batching)的RDD(弹性分布式数据集);而RDD则是一种分布式数据集,能够以两种方式并行运作,分别是任意函数和滑动窗口数据的转换。
ApacheSamzaSamza处理数据流时,会分别按次处理每条收到的消息。
Samza的流单位既不是元组,也不是Dstream,而是一条条消息。
在Samza中,数据流被切分开来,每个部分都由一组只读消息的有序数列构成,而这些消息每条都有一个特定的ID(offset)。
大数据技术与应用基础第9、10章流实时处理系统Storm、企业级、大数据流处理Apex

当提示BUILD SUCCESS则代表命令执行成功。
此时执行下面命令运行主类中的main方法,命令如下: mvn exec:java "-Dstorm.topology=storm.starter.WordCountTopology"
第10章
企业级、大数据流处理Apex
21世纪高等院校“云计算和大数据”人才培养规划教材 《大数据技术与应用基础》 人民邮电出版社
没有报错后打包解压至其他节点。 进入Web界面进行查看:http://IP:8080, 看到节点都正常即安装成功。
二、Storm安装与配置
测试Storm
Maven是现在Java社区中最强大的项目管理和项目构建工具,这里我们使用借助Maven工具。 (1)首先我们下载maven。 sudo apt-get install maven (2)Storm安装目录自带的测试案例,所以进入Storm当前目录下的examples/storm-starter。 cd /usr/local/apache-storm-0.10.0/examples/storm-starter (3)storm-starter下有一个test文件夹,接着执行如下命令。 mvn test
Apex的特点: • Apache Apex是真正的stream,消息来一个做一 个; • 更java向,让开发人员可以编写或重复使用一般 的JAVA代码; • 自动化。
内容 导航
CONTENTS
Apache Apex简介 Apache Apex开发环境配置
运行Top N Words应用
二、Apache Apex开发环境配置
二、Apache Apex开发环境配置
创建Top N words应用
基于Storm的实时大数据处理

基于Storm的实时大数据处理摘要:随着互联网的发展,需求也在不断地改变,基于互联网的营销业务生命周期越来越短,业务发展变化越来越快,许多业务数据量以指数级增长等等都要求对大量的数据做实时处理,并要求保证数据准确可靠。
面对这些挑战云计算、大数据概念应运而生,Hadoop、Storm等技术如雨后春笋般出现。
本文就当今最火的实时流数据处理系统Storm进行详细介绍。
在介绍Storm之前首先详细介绍了实时计算和分布式系统相关技术概念以便为后面内容做铺垫。
通过对Storm的基本概念、核心理念、运行机制和编程场景进行了全面的探讨,使得我们对Storm有了一个比较全面的理解和方便我们在这方面进行更进一步的学习。
关键字:Storm;实时大数据;流数据处理1概要当今世界,信息爆炸的时代,互联网上的数据正以指数级别的速度增长。
新浪微博注册用户已经超过3亿,用户日平均在线时长60min,平均每天发布超过1亿条微博[1]。
在这种背景下,云计算的概念被正式提出,立即引起了学术界和产业界的广泛关注和参与。
Google 是云计算最早的倡导者,随后各类大型软件公司都争先在“云计算”领域进行一系列的研究和部署工作。
目前最流行的莫过于Apache的开源项目Hadoop分布式计算平台,Hadoop专注于大规模数据存储和处理。
这种模型对以往的许多情形虽已足够,如系统日志分析、网页索引建立(它们往往都是把过去一段时间的数据进行集中处理),但是在实时大数据方面,Hadoop的MapReduce却显得力不从心,业务场景中需要低延迟的响应,希望在秒级别或者毫秒级别完成分析,得到响应,并希望能够随着数据量的增大而扩展。
此时,Twitter公司推出开源分布式、容错的实时流计算系统Storm,它的出现使得大规模数据实时处理成为可能,填补了该领域的空白。
Storm是一个类似于Hadoop可以处理大量数据流的分布式实时计算系统。
但是二者存在很大的区,其最主要的区别在于Storm的数据一直在内存中流转,Hadoop使用磁盘作为交换介质,需要读写磁盘。
大数据流式计算方法在气象领域的应用设想

TECHNOLOGY 技术应用一、前言随着信息时代的到来,新兴技术的应用带来了数据的爆发式增长,对各行各业带来了变革式的冲击与挑战。
在气象领域,气象观测数据的数据量也急剧增长。
这对我们提供实时气象数据服务带来了更大的挑战。
如何提供准确、高效、可靠的实时气象数据是我们需要解决的问题。
解决了这一问题,我们将更好的实现气象预报服务,更好的保障用户完成他们的工作。
大数据流式计算模式给我们提供了一条可行方案。
在电子商务领域,Storm(一个实时计算系统)已被广泛用来进行实时日志处理,这也将给我们提供宝贵的实践经验,为大数据流式计算模式在气象领域的应用提供参考。
二、背景介绍(一)大数据背景介绍大数据(Big Data),是指一些使用目前现有数据库管理工具或传统数据处理方式很难处理的大型而且复杂的数据集。
其挑战包括采集、管理、存储、检索、共享、分析和可视化。
随着信息技术的不断发展,人类产生的数据量正在与日俱增,大约每过两年就要翻上一番。
这得益于无处不在的信息感应移动设备、遥感技术、摄像头技术、无线阅读器和无线网络等技术水平的不断提升,数据采集质量的提高和采集手段的丰富,以及数据存储设备存储容量的快速增长,也使我们采集并存储更多的数据成为了可能。
大量的数据也带来了新的挑战。
采集手段的不断丰富导致了非结构化和半结构化数据的不断增长,导致使用传统的关系型数据库和办公软件统计以及可视化软件包对数据进行分析时,不光由于数据量的巨大变得处理困难,而且由于越来越多非结构化的数据也变得复杂。
虽然数据存储设备的存储容量不断提升,数据量与日俱增,而如何管理和使用这些数据逐渐成为一个新的领域,于是大数据的概念应运而生[1]。
(二)大数据计算背景介绍 大数据计算主要有批量计算和流式计算两种形态。
目前,关于大数据批量计算系统的研究和讨论相对充分,而且大数据批量计算相关技术的研究相对成熟。
但如何构建低延迟、高吞吐且持续可靠运行的大数据流式计算系统的研究成果和实践经验相对较少。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
7 Storm的数据源编程单元: Spout 7.3 Spout与数据的可靠性
7.3.1 可靠的Spout与不可靠 的Spout
7.3.2 可靠的Spout的数据项 管理
8 Storm的数据处理编程单元:Bolt
8.1 Bolt的接口与 实现
8.1.1 Bolt与接口层 次 8.1.2 IBolt和 IComponent接口 8.1.3 接口的实现类 及实例
4.1.3 本地模式
4.2 系统节点
4.2.1 Zookeeper:协调节点 4.2.2 nimbus:主控节点
4.2.3 supervisor:工作节点 4.2.4 UI:控制台节点
4.3 本章小结
5 Storm的通信模型
5.1 Thrift:可扩 展、跨语言的通信
软件框架
01
02
5.3 ZeroMQ在 Storm中的应用: 作业任务间的通信
03
04
5.2 Thrift在 Storm中的应用: 系统节点间的通信
5.4 Storm 可配置 的通信机制
5.5 本章小结
05
5 Storm的通信模 型
5.1 Thrift:可扩展、跨语言的 通信软件框架
5.1.1 Thrift的基础概念 5.1.2 基于Thrift的数据通信
5 Storm的通信模 型
2.3.2 功能
2.3.3 特色:可扩展、可 靠的分布式流式数据处 理
2 流式计算的理论与技术
2.4 其他开源流式数据处理系统
2.4.1 Yahoo S4 2.4.2 Spark Streaming 2.4.3 Facebook Puma
3 实际案例:城市道路车辆数据的实时监控分析系统
3.1 背景与需求分析
1.1.1 云计算 1.1.2 物联网
1.2 大数据下的新挑战
1.2.1 大数据及其特征 1.2.2 大数据处理的技术挑战
1.3 本章小结
第一步
第二步
第三步
2 流式计算的理论与技术
2.1 流式数据与流式实时 计算
2.3 Storm
2.5 本章小结
2.2 流式数据处理的系统 与应用
2.4 其他开源流式数据处 理系统
2 流式计算的理论 与技术
2.1 流式数据与流式实时 计算
2.1.1 流式数据 2.1.2 流式实时计算
2 流式计算的理论与技术
2.2 流式数据处理的系统与应用
2.2.1 发展与挑战 2.2.2 Hadoop 2.0生态圈
2 流式计算的理 论与技术
2.3 Storm
2.3.1 起源与发展: Twitter的开源与影响
8.2 Bolt与数据的 可靠性
8.2.1 可靠的Bolt与 不可靠的Bolt 8.2.2 可靠的Bolt的 数据项管理 8.2.3 IBasicBolt和 BaseBasicBolt
8.3 本章小结
9 StoБайду номын сангаасm的保障机制
9.1 Storm的功能性保障:多粒度的并 行化
9.1.1 并发模型 9.1.2 并行度配置 9.1.3 可插拔的自定义调度器
Config 6 . 3 . 2 To p o l o g y 构 建
示例 6 . 3 . 3 To p o l o g y 常 见
的编程模式
6.4 本章小结
7 Storm的数据源编程单元:Spout
7.1 Spout的接口与 实现
7.2 Spout的使用模 式
7.3 Spout与数据的 可靠性
7.4 本章小结
6 Stor m 的作业单元: Topol ogy
6 .3 构建To p o lo g y
6.2 Stream:组件间的 数据传递
6.1 Topology 的构成
6.2.1 概述 6.2.2 Stream Grouping:流组模式 6.2.3 自定义流组
6.3.1 To p o l o g y B u i l d e r 与
Storm:大数据流式计算及应用实践
目录
01. 第一篇 基础篇 流式数据处 理概论
02. 第二篇 系统篇 流式数据处 理系统Storm的基础原理
03. 第三篇 应用篇 基于流式数 据处理系统Storm的开发
04. 附录
第一篇 基础篇 流式数据处理概论
01
1 大数据环境下的云计算与物联网
1.1 云计算与物联网
3.1.1 背景 3.1.2 数据处理的业务需求
01
3.2 数据处理系统的架构设计与技术选型
3.2.1 架构设计
02
3.2.2 技术选型
3.3 本章小结
03
第二篇 系统篇 流式数据处理系统Storm的 基础原理
02
4 Storm的系统架构
4.1 系统架构与部署模式
4.1.1 系统架构 4.1.2 单机/分布式部署
10 Storm的高层 使用模式
10.1 分布式远程过程调用
10.1.1 概述 10.1.2 DRPC的构建与使用 10.1.3 Storm的DRPC原理
10 Storm的高层使用模式
10.2 事务型作业
10.2.1 概述 10.2.2 Transactional Topology的构建与 使用 10.2.3 Transactional Topology的编程接 口与事务型作业的实现 10.2.4 CoordinatedBolt的原理
9.2 Storm的非功能性保障:多级别的 可靠性
9.2.1 不同级别的容错机制 9.2.2 记录级容错:保障数据项不 丢失 9.2.3 记录级容错的原理:acker 任务与追踪算法
9.3 本章小结
10 Storm的高层使用模式
10.1 分布式远程 过程调用
10.3 非Java语言 的开发
10.2 事务型作业 10.4 本章小结
7 Storm的数据源编程单元: Spout
7.1 Spout的接口与实现
7.1.1 Spout与接口层次
7.1.2 ISpout和IComponent 接口
7.1.3 接口的实现类及实例
7 Storm的数据源编程单元: Spout
7.2 Spout的使用模式
7.2.1 直接连接 7.2.2 队列连接
5.2 Thrift在Storm中的应用: 系统节点间的通信
5.2.1 接口的定义与实现
5.2.2 客户端与Storm系统的 通信
5 Storm的通信模型
5.3 ZeroMQ在Storm中的应用: 作业任务间的通信
5.3.1 ZeroMQ:面向分布 式并发应用的高性能异步消 息处理库
5.3.2 Tuple与 declareOutputFields(): 数据项结构及声明