车牌字符分割算法研究
基于底色分辨和分段属性的车牌字符分割

文章编号:1002—8692(2008)S1-0137—03H de o apldieation照e嘲!a基于底色分辨和分段属性的车牌字符分割木论文陈箫枫,潘保昌,郑胜林,赵全友(广东工业大学信息工程学院,广东广州510006)【摘要】根据车牌有多种颜色不利分割字符的问题,提出一种分辨底色并用分段属性来进行字符分割的算法。
算法中,采用直方图平滑曲线的特征来分辨白底黑字和黑底白字的车牌区域图像,统一为白底黑字,根据二值图像纵向投影平滑曲线。
求其分段属性,分析中心线距离、间隙、宽度等,来分割出车牌的字符。
将该算法应用到车牌识别系统中.实验效果比较好。
【关键词J车牌字符分割;底色分辨;分段属性;直方图;投影曲线【中图分类号】TP391.41【文献标识码】AL i cens e Pl at e C har a ct e r Segm ent at i on B a se d o nB ac kgr oundC ol orD i s t i ngui s h i ng and Segm ent A t t r i but esC H EN X i ao—f eng,PAN B ao-c ha ng,ZH EN G Shen g—l i n,ZH A O Q uan-you(D ept.of I nfor m at i on E ngi neer i ng,G uangd ong U n i ver s i ty of T ec hnol og y,G ua ngzhou510006,C hi n a)【A b st r act l A c cor di ng t o t he pr obl em of char act e r se gm ent at i on di s advant a ge abo ut m uhi col or of hc ens e pl at e,明al gor i t hm of cha r act er segm ent at i on w i t h ba c kgr ound col ordi s t i ngui s hi ng a nd s egm e nt a tt r ibut es ar e put f or w a r d.I n t he al gor i t h m,hi st o gr a m sm oot h cu r v e f eat u r es ar e use d t o di s t i ngui s h l i cens e pl at e r egi o nal i m age s bet w e en w hi t e ba ckgr ound a nd bl ack bac kgr ound,t hen t he i m age i s uni f i ed t o w hi t e ba c kgr ound a nd bl ack char ac t e r s.The s egm e nt a tt r ibut es ar e cal cul at ed w i t h t he i m a ge l ongi tudi nal pr oj ect i on sm oot h cu r ve,an d t he m i d l i ne di st an ce,spa ce。
车牌识别实验报告

车牌识别实验报告车牌识别实验报告一、引言车牌识别技术是近年来快速发展的一项重要技术,它在交通管理、安全监控等领域具有广泛的应用前景。
本文将介绍一次车牌识别实验的过程和结果,以及对该技术的评估和展望。
二、实验目的本次实验的目的是通过使用计算机视觉技术,实现对车辆车牌的自动识别。
通过该实验,我们希望验证车牌识别技术的准确性和可行性,并评估其在实际应用中的效果。
三、实验方法1. 数据收集我们采集了一组包含不同类型和风格的车牌图像数据,包括普通车辆、摩托车和电动车等。
这些数据来源于不同的场景,包括白天、夜晚和恶劣天气等条件下的拍摄。
2. 图像预处理为了提高车牌识别的准确性,我们对采集到的图像进行了预处理。
首先,我们使用图像处理算法对图像进行了去噪处理,去除了图像中的干扰信息。
然后,我们对图像进行了灰度化处理,将彩色图像转化为灰度图像,以便后续的处理。
3. 特征提取在进行车牌识别之前,我们需要从图像中提取出车牌的特征。
我们使用了一种基于边缘检测的方法,通过检测图像中的边缘来提取车牌的轮廓。
然后,我们根据车牌的形状和大小,进一步筛选出可能的车牌区域。
4. 字符分割在车牌识别中,字符分割是非常关键的一步。
我们使用了一种基于连通区域的方法,将车牌图像中的字符分割出来。
通过分析字符之间的间隔和相对位置,我们可以更准确地识别出每个字符。
5. 字符识别最后一步是对分割出的字符进行识别。
我们使用了一种基于深度学习的方法,训练了一个字符识别模型。
通过将字符图像输入到模型中,我们可以得到对应的字符标签,从而实现对车牌的识别。
四、实验结果经过实验,我们得到了一组车牌识别的结果。
在测试数据集上,我们的识别准确率达到了90%以上。
尤其是在白天和晴朗天气下,识别效果更加出色。
然而,在夜晚和雨天等恶劣条件下,识别准确率有所下降。
五、实验评估尽管我们的车牌识别系统取得了较好的结果,但仍存在一些问题和改进空间。
首先,恶劣天气条件下的识别准确率较低,需要进一步优化算法来提高鲁棒性。
车牌的定位与字符分割 报告

车牌的定位与分割实验报告一实验目的针对交通智能系统所拍摄的汽车图片,利用设定的算法流程,完成对汽车车牌部分的定位,分割车牌部分,并完成字符的分割,以便于系统的后续分析及处理。
二实验原理详见《车牌的定位与字符分割》论文。
三概述1一般流程车牌自动识别技术大体可分为四个步骤:图像预处理、车牌定位与分割、车牌字符的分割和车牌字符识别。
而这四个步骤又可归结为两大部分:车牌分割和车牌字符识别。
图1-1为车牌自动识别技术的一般流程图。
2本实验的流程(1)图像预处理:图像去噪(2)车牌的定位:垂直边缘检测(多次)形态学处理的粗定位合并邻近区域结合车牌先验知识的精确定位(3)车牌预处理:车牌直方图均衡化倾斜校正判定(蓝底白字或者黄底黑字)归一化、二值化(4)字符的分割:垂直投影取分割阈值确定各个字符的左右界限(结合字符宽度、间隔等先验知识)分割字符四实验过程4.1图像预处理4.1.1图像去噪一般的去噪方法有:空间域上的均值滤波和中值滤波;频率域上的巴特沃斯滤波器。
图4-1是各滤波器处理椒盐噪声的效果。
a.被椒盐噪声污染的图片 b.均值滤波的效果图 c.中值滤波的效果图 d.BLPF的效果图图4-1 各滤波器处理椒盐噪声的仿真可见,中值滤波对椒盐噪声的处理效果极好,而一般所拍摄的图片上最多的便是孤立的污点,所以此处以中值滤波为主进行去噪。
图4-2是采用中值滤波处理实际汽车图片的效果。
a.原始图像b.灰度图像c.中值滤波后的图像图4-2 中值滤波处理实际汽车图片的效果很显然,经过中值滤波后去除了原图上的部分污点。
4.1.2图像复原由于通常情况下都不知道点扩展函数,所以我们采用基于盲解卷积的图像复原策略。
图4-3~4-7图是函数进行盲解卷积的实验结果,其中图4-3是图像cameraman 的模糊图像。
图4-3 模糊图像在盲解卷积处理中,选择适当大小的矩阵对恢复图像的效果很重要。
PSF的大小比PSF的值更重要,所以首先指定一个有代表性的全1矩阵作为初始PSF。
车牌字符分割新方法

有时, 小黑点区域会比较小, 在字符区域粗分割时就已经被 除去了。 然后, 重新对该字符块链表从头到尾进行搜索, 当满足以下 两种条件之一: 条件一:
2.CD123H2.@H2.CD1(I -.123H-./H-.1(I
(CC ) (CD ) (CE ) (CJ )
小 于 -.123, 就需要进行字符区域扩展, 以该车牌中普通字符区 域的宽度平均值为其宽度, 以其左坐标为基准, 调整其右坐标。 如果第七字符区域不存在时,需要通过第六字符区域的右 坐标,加上车牌中普通字符间间距平均值得到第七字符区域的 左坐标, 再按上面的方法得到其字符区域宽度和另一水平坐标。 如果第一和二字符区域需要进行字符区域扩展,可采用相似的 方法进行字符区域扩展,只是以该字符候选块的右坐标作为基 准。 其它字符区域若缺损, 可以根据该以上方法依次实现字符区 域扩展。 图 E (5)为经过字符区域分裂和合并后的车牌字符分割图 像, 可以看出该车牌缺损第六和七字符, 需要进行字符区域扩展, 扩展后的字符区域局部二值化车牌字符分割图像如 图 E (/) 所 示, 已经将缺损的第六和七字符扩展为单个完整的字符区域了。
图C
字符区域粗分割
CFC 第三字符定位 第二和三字符间间距较大, 且第三字符为 由图 C 可以看出,
普通字符, 但两个字符间有一个小黑点区域, 需要先除去这个小 黑点区域。对字符候选块链表进行搜索, 当满足以下条件:
-G123H-./H-G1(I 2.123H2.@H2.1(I 2.123H2.:H2.1(I -.123H-.@H-.1(I -.123H-.:H-.1(I
Q*SKTUQ*UQ*S)N Q*$SKTUQ*$UQ*$S)N Q-SKTUQ-UQ-S)N K*SKTUK*UK*S)N K*!’SKTUK*!’UK*!’S)N V$W V!W V’W V&W V#W
一种改进的汽车牌照字符分割算法及MATLAB实现
引言上世纪以来,随着科学技术的日新月异,人们的生活发生了巨大的变化,尤其是自动化交通工具的普及使人们享受到了前所未有的便捷,但是交通发展的同时也带来很多问题,因而人们一直在探索利用现有的技术使交通更加顺畅、安全。
智能交通系统(Intel-ligent Transportation System,ITS)是人们提出的一种有效地解决交通问题的方案,而车牌识别(License Plate Recognition,LPR)是ITS 中的关键技术之一,同时作为一项单独的技术,车牌识别在公共安全、交通管理等部门有着极其重要地应用前景。
本文所探讨的针对我国汽车牌照的字符分割算法正是车牌识别系统的基础与关键之所在,因为只有正确地分割字符才能保证后期正确地识别车牌号码完成指定的功能。
应用的广泛性也决定了该算法具有一定的难度,对于我国来讲,汽车牌照图字符分割算法存在许多难点,如:1)在大部分实际应用中都要求算法速度快,从而能够实时地对车辆进行识别以及时地反馈车牌信息,对信息做进一步处理,所以算法执行效率必须很好以满足实时化的要求。
2)有些车辆车牌存在严重的干扰(如褪色,污损),车牌周围有各种装饰物等。
3)车牌本身信息较为复杂,既有汉字也有英文字母与数字。
基于上述考虑,本论文中的算法流程简单,思路清晰、明了,以垂直投影法[1]基础,利用先验知识大大增加了对汽车牌照图像的处理准确性,本算法先将图像二值化图,所处理的数据量小,未对图像进行大量复杂的运算,有利于算法简单、高效实现。
1字符分割算法1)首先对提取好的汽车牌照灰度图像进行二值化,图像在二值化后所要处理的数据量大大减少,本算法采用全局阙值法[2],在MATLAT 中采用im2bw 函数实现[3],阙值参数为0.7,待处理图像及其二值化效果如图1、2所示。
2)在车牌二值化之后之后对各个字符进行分割以便进一步对其进行识别。
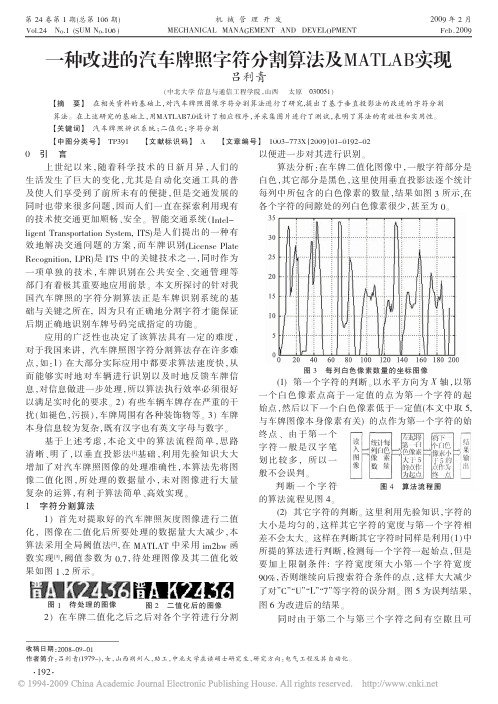
算法分析:在车牌二值化图像中,一般字符部分是白色,其它部分是黑色,这里使用垂直投影法逐个统计每列中所包含的白色像素的数量,结果如图3所示,在各个字符的间隙处的列白色像素很少,甚至为0。
人工智能技术在车牌识别中的应用研究进展

人工智能技术在车牌识别中的应用研究进展引言:车牌识别是人工智能技术在交通监控和管理上的重要应用之一。
随着信息技术的快速发展,车辆管理和交通安全成为城市发展的重要组成部分。
在这个背景下,人工智能技术的进步为车牌识别提供了更高效、准确和智能化的解决方案。
本文将介绍人工智能技术在车牌识别中的应用研究进展,包括车牌定位、车牌字符分割和车牌识别算法等方面。
一、车牌定位技术的研究进展车牌定位是车牌识别的第一步,其目标是通过图像处理技术找到图像中的车牌位置。
近年来,基于深度学习的车牌定位方法取得了显著的进展。
深度学习能够自动学习和提取图像中的特征,从而提高了车牌定位的准确性和鲁棒性。
例如,YOLO算法可以快速而准确地定位多个车牌,其目标检测精度优于传统的基于边缘和颜色信息的方法。
二、车牌字符分割技术的研究进展车牌字符分割是车牌识别的关键步骤,其目标是将车牌上的字符从车牌图像中分离出来。
传统的字符分割方法主要利用模板匹配、局部阈值和形态学操作等技术。
然而,这些方法对光照变化、车牌样式和分割效果的不确定性具有较强的敏感性。
近年来,基于深度学习的车牌字符分割方法得到了广泛应用。
例如,采用卷积神经网络结构的方法可以自动学习并提取车牌字符的特征,从而提高了字符分割的准确性和鲁棒性。
三、车牌识别算法的研究进展车牌识别算法是整个车牌识别系统的核心部分,其目标是对车牌字符进行识别并输出正确的车牌号码。
传统的车牌识别算法主要基于机器学习和模式识别方法,例如支持向量机、隐马尔可夫模型和k最近邻算法等。
然而,这些传统方法对光照变化、遮挡和干扰等因素具有较强的敏感性。
近年来,基于深度学习的车牌识别算法取得了显著的进展。
深度学习模型可以自动学习和提取车牌字符的特征,从而大大提高了识别准确度。
例如,采用卷积神经网络结构的方法可以实现端到端的车牌识别,并且能够处理大量车辆和复杂场景下的车牌识别任务。
四、人工智能技术在车牌识别中的应用挑战与展望尽管人工智能技术在车牌识别中取得了显著的进展,但仍然存在一些挑战和问题。
车牌字符分割算法研究

1 绪论1.1 背景介绍为了实现车牌字符识别,通常要经过车牌位置检测、车牌字符分割和字符识别三个关键步骤。
车牌位置检测是根据车牌字符目标区域的特点,寻找出最符合车牌特征的区域。
车牌字符分割就是在车牌图像中找出所有字符的上下左右边界,进而分割出每个车牌字符。
在实际应用中,车牌字符分割的效果对车牌字符识别正确率会产生很大的影响,由于车牌图像亮度不均、尺度变化、透视失真、字符不完整等因素,使图像质量存在较大差异,进而影响图像分割的效果,因此车牌字符分割这一技术仍然具有很大的研究意义。
在实际的监控场景中,车牌图像的透视失真通常是由于拍摄视角的变化或车辆位置的移动,相机光轴偏离车牌平面的法线方向造成的。
由于车牌图像在整幅图像中占有较小的比例,所以车牌图像几何校正主要工作是校正车牌图像的旋转和剪切失真。
旋转投影法和直线拟合法是两种主要的偏斜校正方法。
旋转投影法是为了获取垂直倾斜角,即将车牌图像穷举逐个角度进行剪切变换,然后统计垂直投影数值为0的点数,得到最大值对应的角度。
这种方法受背景区域的干扰比较大。
另一种方法是直线拟合车牌字符的左边界点从而获得垂直倾斜角,该方法为直线拟合法。
该方法并没有逐个角度对车牌图像进行剪切变换,从左边界点拟合出的直线通常不能真正用来代表车牌的垂直倾斜方向,检测出的角度存在较大误差,且字符左侧噪声对角度检测干扰太大,鲁棒性较差。
因此找到一种更准确和迅速的车牌垂直倾斜矫正方法是十分重要的。
通过得到最小的字符投影点坐标方差,得到另一种车牌垂直矫正方法。
首先将车牌字符图像进行水平校正,根据字符的区域的上下边界,将车牌字符进行粗分割。
然后将剪切变换后的字符点进行垂直偷用。
当得到投影点最想左边方差时,便能导出两类剪切角闭合表达是,最后便是确定垂直投影的倾斜角并对此进行校正。
投影法是目前最常用的车牌分割算法之一,其算法简单并且计算复杂度低。
该方法的核心思想是将车牌图像进行水平投影和垂直投影,利用峰谷特征来定位车牌字符的上下左右边界。
汽车牌照定位与字符分割的研究及实现

1.2.1 车牌定位技术研究现状及发展趋势
车牌定位技术是 LPR 系统研究的重点和难点。采集车辆图像过程中一般都有
1
汽车牌照定位与字符分割的研究及实现
各种背景干扰,能够正确分割字符的前提是从图像中准确地分割出牌照区域,这 也是 LPR 系统能否在实际中应用的基础。 目前的车牌定位算法中,主要是分析车牌所共有的部分特征,根据这些特征 来确定车牌区域的位置。车牌几何形状特征及相应的分析方法主要有[2-8]: (1)灰度变化特征:水平/垂直扫描时,牌照区域的像素灰度值按照一定的规 律进行波动;(2)颜色特征:原始车牌区域内部颜色和外部颜色差异的特征;(3) 投影特征:对车辆图像的水平/垂直扫描后其投影直方图中,牌照所对应的区域具 有一定规律的峰谷分布;(4)边缘特征:牌照区域有许多的边缘信息,使用相应的 算子将边缘信息提取出后,再通过边缘投影直方图来确定边缘的信息;(5)几何特 征:主要有车牌的长度、宽度以及长宽比例在一定的范围之内,或者可以通过牌照 的面积在一定的范围之内。利用以上这些特征均可以确定车牌的位置。 目前,车辆牌照的定位方法有基于彩色图像牌照区域字符和背景的颜色差异 特征进行定位,也有基于灰度图像牌照区域字符几何纹理特征进行定位,还有其 它结合了牌照区的颜色差异和字符纹理两种特征的方法定位,另外还有的是基于 数学形态学、神经网络、遗传算法、灰度聚类等牌照定位方法[9]。
作者签名: 导师签名:
日期: 日期:
年 年
月 月
日 日
中南民族大学硕士学位论文
第1章
1.1 问题的提出
绪论
车牌识别技术(License Plate Recognition, LPR )是智能交通管理系统的 重要组成部分,主要用于识别车牌号码。 LPR 技术在实际生活中主要应用于高速 公路实现无人收费功能、道路行车的流量监控、交通违规车辆的监控等。特别是 在各种场合实现无人收费功能的系统中,为了提高车辆的运行效率, LPR 技术将 代替人工的管理方式实现无人自动管理的功能, 因此,对 LPR 技术的研究和系统的 开发具有重要的现实意义和和实用价值。 车牌定位、字符分割、字符识别是 LPR 系统的三大关键技术。同时也是车牌 本身的几何形状特征与图像处理技术[1]的很好结合,车牌定位与字符分割在 LPR 系统中用到的数学知识主要有数学形态学、神经网络、小波分析等。对车牌定位 与字符分割的研究主要包括:图像预处理、车牌定位、车牌倾斜校正、车牌字符 分割及字符分割结果输出等。如图 1.1 所示为系统的流程框图:
车牌识别系统中的字符分割技术研究

(. l g fCo ue ce c n c oo eAn u ies 1 l e o mp trS in e a d Teh lg , h iUnv r W,Hee 3 0 9 Co e i fi2 0 3 ,Chn ;. p rme to mp trE gn eigW u u ia De at n fCo ue n i er , h 2 n Vo ain l l g f nomaina dTeh oo y W u u 2 1 0 , ia ct a Col eo fr t n c n lg , o e I o h 4 0 3 Chn )
h t :w t / ww.n s e.n p/ d z. t n c T l 8— 5 - 60 6 5 99 4 e: 6 5 1 5 9 9 3 + 6 0 6
车牌识别系统中的字符分割技术研究
陈 利1 , 2
(. 徽 大 学 计 算 机 科 学 与 技 术 学 院 , 1 安 安徽 合 肥 2 0 3 ;. 湖 信 息 技 术 职 业 学 院 计 算 机 工 程 系 . 3 0 9 2芜 安徽 芜 湖 2 10 ) 4 0 3
sm pe a la ,betrr a—tm e faursa g i l nd ce n te e l i e t e nd hih—a c r c o esng c u a y ofpr c si .
摘要 : 牌 字符 分 割 是 车 牌 识 别 系统 的三 大关 键技 术之 一 。 车 准确 的 字符 分 割 , 能 提 高字 符识 别的 准 确 率 , 既 又能提 高识 别 的速 度 。 针
对 车牌 图像 背 景复 杂 、 照 多 变 、 光 干扰 较 多的 情 况 , 章在 车 牌 区 域预 处理 的基 础上 提 出 了一 种 基 于先 验 知 识 的 垂 直 投 影 字 符 分 割 文 方 法 。 实验 结 果表 明该 算 法 简洁 、 时性 好 、 实 处理 正 确 率 高 , 到 了实 用 的标 准 。 达
车牌识别系统中车牌定位与字符分割的研究

车牌识别系统中车牌定位与字符分割的研究一、本文概述随着科技的发展和智能交通系统的普及,车牌识别系统已经成为了现代交通管理的重要组成部分。
车牌识别系统的核心在于准确、快速地实现车牌的定位与字符分割。
本文旨在深入探讨车牌识别系统中车牌定位与字符分割的关键技术,并分析其在实际应用中的挑战与解决方案。
本文将对车牌识别系统的基本框架进行概述,介绍车牌定位与字符分割在其中的地位和作用。
接着,本文将详细阐述车牌定位技术的发展历程和现状,包括基于颜色、纹理、形状等特征的定位方法,以及近年来兴起的深度学习技术在车牌定位中的应用。
同时,本文还将对字符分割技术的研究现状进行梳理,包括基于投影分析、边缘检测、形态学处理等方法的字符分割算法。
在此基础上,本文将重点分析车牌定位与字符分割在实际应用中面临的挑战,如复杂背景下的车牌定位不准确、字符粘连或断裂导致的分割失败等问题。
针对这些问题,本文将提出相应的解决方案,如通过改进算法提高定位精度、采用多特征融合的方法提高字符分割的鲁棒性等。
本文将通过实验验证所提方法的有效性,并对实验结果进行分析和讨论。
本文还将展望车牌识别系统的未来发展趋势,探讨新技术在车牌定位与字符分割中的应用前景。
通过本文的研究,旨在为车牌识别系统的优化和改进提供有益的参考和借鉴。
二、车牌定位技术研究车牌定位技术是车牌识别系统的关键环节,它涉及从复杂的背景中准确提取出车牌区域。
随着计算机视觉和图像处理技术的不断发展,车牌定位技术也取得了显著的进步。
早期的车牌定位主要基于车牌的颜色和边缘特征。
由于中国车牌通常为蓝底白字,因此可以通过颜色过滤来初步提取出可能的车牌区域。
随后,利用边缘检测算法(如Canny边缘检测)来进一步细化车牌的轮廓,从而实现车牌的粗定位。
然而,这种方法受光照条件、车牌污损等因素影响较大,定位准确性有待提高。
为了克服颜色和边缘特征方法的局限性,研究人员开始尝试基于纹理和形状特征的车牌定位方法。
结合垂直投影法与固定边界分割的车牌字符分割算法(附源码和详细解析)

结合垂直投影法与固定边界分割的车牌字符分割算法(附源码和详细解析)上⼀篇博⽂简单有效的车牌定位算法(附源码和详细解析),详细介绍了数学形态学处理车牌粗定位与蓝⾊像素统计、⾏列扫描的车牌精确定位算法。
没有看的朋友可以先看上⼀篇博⽂。
这次,在牌照字符的分割上,我结合了⽬前使⽤最多的投影法和车牌固定边界的多阈值分割算法。
它的⼤致实现过程如下:第⼀步先对上⼀节粗定位完牌照的只有⿊⽩两⾊的图像bg2实施伪彩⾊标记。
第⼆步获取标记区域各连通块的尺⼨参数,⽤作下⼀步遍历的索引。
第三步投影得直⽅图,取⼀个分割阈值,划分出背景和字符的范围,也就是在直⽅图histrow(histcol)中区分⾕底点和上升点。
第四步分析峰⾕,得到例如最⼤峰中⼼距等参数。
最后⼀步,根据上⼀步求得的参数分割字符。
具体分割流程图如下图:图5-1 字符分割流程图⼀、车牌区域彩⾊标记与特征提取 对粗定位车牌后的⼆值图像作连通区域4邻域的伪彩⾊标记的⽬的是为了⽅便计算出车牌区域的⾯积、宽⾼度以及车牌框架的⼤⼩、区域开始和结束的⾏列位置等区域特征参数,是为后续的车牌投影分析操作作预准备。
在这⼀步骤中,⾸先以4领域⼤⼩为模块对⼆值图像作区域标记,给每块连通区域块标记上序数,获取图像中连通区域的块数和图像矩阵L,初步计算出各连通区域的框架⼤⼩,然后再根据车牌的先验知识设置亮度⾼度的合理阈值筛选出真正车牌区域的连通域,记录下该连通域的序数,最后对车牌区域块作区域特征提取,获取车牌的框架⼤⼩、宽⾼度、宽⾼⽐例以及开始位置点的⾏、列数等参数。
在MATLAB中对车牌号码为粤A6ZC93和粤AC609Z两车辆的车牌粗定位⼆值图像作伪彩⾊标记效果如下图:(a)粤A6ZC93 (b)粤AC609Z图5-2 区域标记与特征参数提取⼆、车牌预处理(1) 基于Radon变换的倾斜校正 从车体侧⾯拍摄的车辆图像中提取出来的牌照会出现⾓度的倾斜,为了后续操作的⽅便,需要进⾏⾓度的校正。
图像处理中的数学形态学算法在车牌识别中的应用

图像处理中的数学形态学算法在车牌识别中的应用随着车辆数量的不断增加,车牌识别技术在交通管理、安防监控、停车场管理等领域中扮演着重要的角色。
而在车牌识别技术中,数学形态学算法作为一种重要的图像处理工具,具有很高的应用价值。
本文将重点探讨数学形态学算法在车牌识别中的应用,以及其在该领域中的优势和挑战。
一、数学形态学算法简介数学形态学算法是一种基于形状和结构分析的图像处理方法,其基本原理是利用集合论中的膨胀和腐蚀运算来分析图像中的形状和结构特征。
其中,膨胀操作可以扩张图像中的目标物体,而腐蚀操作可以收缩图像中的目标物体。
这些基本的形态学操作可以通过组合和重复应用来提取图像中的目标物体,并进行形状分析和特征提取。
二、数学形态学算法在车牌识别中的应用1. 车牌定位车牌识别的第一步是车牌的定位,即从整个图像中准确定位车牌的位置。
数学形态学算法可以通过腐蚀和膨胀操作来消除图像中的噪声,提取出车牌的边界信息。
通过应用腐蚀和膨胀操作,可以得到一系列形状和尺寸各异的区域,而其中包含车牌的区域往往具有明显的矩形或正方形特征。
因此,通过对这些区域进行形态学分析和筛选,可以有效地定位车牌的位置。
2. 车牌字符分割车牌字符分割是车牌识别的关键步骤之一,其中车牌上的字符需要被正确分割出来以方便后续的字符识别。
数学形态学算法可以通过腐蚀和膨胀操作来分离车牌上的字符,消除字符之间的干扰。
通过应用腐蚀操作,可以收缩车牌上的字符区域,使得字符之间的间隔增大;而通过应用膨胀操作,则可以扩张字符区域,使得字符之间的间隔变小。
通过选择合适的腐蚀和膨胀操作的组合方式,可以有效地实现车牌字符的分割。
3. 车牌字符识别车牌字符识别是车牌识别的最后一步,其中车牌上的字符需要被分析和识别出来。
数学形态学算法可以通过应用开运算和闭运算操作来修复和增强字符区域的形态特征,从而提高字符识别的准确性。
开运算可以消除字符区域之外的噪声,平滑字符区域的边界;而闭运算则可以填充字符区域中的空洞,增强字符区域的连通性。
车牌定位与车牌字符识别算法的研究与实现

车牌定位与车牌字符识别算法的研究与实现一、本文概述随着智能交通系统的快速发展,车牌识别技术作为其中的核心组成部分,已经得到了广泛的应用。
车牌定位与车牌字符识别作为车牌识别技术的两大关键环节,对于实现自动化、智能化的交通管理具有重要意义。
本文旨在探讨和研究车牌定位与车牌字符识别的相关算法,并通过实验验证其有效性和可行性。
本文首先对车牌定位算法进行研究,分析了基于颜色、纹理和边缘检测等特征的车牌定位方法,并对比了各自的优缺点。
随后,本文提出了一种基于深度学习的车牌定位算法,通过训练卷积神经网络模型实现对车牌区域的准确定位。
在车牌字符识别方面,本文介绍了传统的模板匹配、支持向量机(SVM)和深度学习等识别方法,并对各种方法的性能进行了比较。
在此基础上,本文提出了一种基于卷积神经网络的字符识别算法,通过训练模型实现对车牌字符的准确识别。
本文通过实验验证了所提出的车牌定位与车牌字符识别算法的有效性和可行性。
实验结果表明,本文提出的算法在车牌定位和字符识别方面均具有较高的准确率和鲁棒性,为车牌识别技术的实际应用提供了有力支持。
本文的研究不仅对车牌识别技术的发展具有重要意义,也为智能交通系统的进一步推广和应用提供了有益参考。
二、车牌定位算法的研究与实现车牌定位是车牌字符识别的前提和基础,其主要任务是在输入的图像中准确地找出车牌的位置。
车牌定位算法的研究与实现涉及图像处理、模式识别等多个领域的知识。
车牌定位算法的研究主要集中在两个方面:一是车牌区域的粗定位,即从输入的图像中大致找出可能包含车牌的区域;二是车牌区域的精定位,即在粗定位的基础上,通过更精细的处理,准确地确定车牌的位置。
在车牌粗定位阶段,常用的方法包括颜色分割、边缘检测、纹理分析等。
颜色分割主要利用车牌特有的颜色信息,如中国的车牌一般为蓝底白字,通过颜色空间的转换和阈值分割,可以大致找出可能包含车牌的区域。
边缘检测则主要利用车牌边缘的灰度变化信息,通过算子如Canny、Sobel等检测边缘,从而定位车牌。
车牌字符识别的三种算法的比对

摘要摘要车牌识别技术是智能交通系统中的重要组成部分,它在违章抓拍,不停车收费,停车场管理以及重要场所过往车辆的实时登记等方面都有重要的作用。
论文从车牌字符识别的理论出发,基于MATLAB语言对现有的模板匹配,神经网络,基于向量机(SVM)等方法在字符识别过程中的优缺点以及识别率进行系统的研究。
论文的主要工作如下:1.针对车牌图片的预处理包括去噪,增强,分割,提取字符等等;2.构建模板匹配,神经网络,基于向量机(SVM)字符识别的相关测试数据;3.分别实现模板匹配字符识别算法,神经网络字符识别算法,基于向量机(SVM)字符识别算法,并做相应识别率的实验,将三者的实验结果进行比对;4.基于MATLAB GUI做三种算法系统的界面。
关键词:车牌识别模板匹配神经网络向量机识别率ABSTRACTABSTRACTLicense plate recognition technology is the intelligent transportation system an important part of it illegal to capture, no parking, parking management, and an important place in the past, real-time vehicle registration and other aspects important role. Papers from the license plate character recognition theory, MATLAB language based on the existing template matching, neural network, based on vector machines (SVM) and other methods in the process of character recognition and the recognition rate of the advantages and disadvantages of the system. The main work is as follows:1.Pre-treatment, including the license plate image denoising, enhancement,segmentation, extraction of character, etc.2.Construction of template matching, neural network, based on the vectormachine (SVM) test data related to character recognition;3.Respectively, to achieve template matching algorithm for character recognition,neural network character recognition algorithm based on vector machines (SVM) algorithm for character recognition, and recognition rate accordingly experiment, the three sides to compare the experimental results;4.Do three algorithms based on MATLAB GUI interface of the system.Keywords: License Plate Recognition Template matching Neural network Vector Recognition rate目录 i目录第一章序言 (1)1.1课题研究背景以及意义 (1)1.2本文主要的研究内容 (1)第二章车牌图像的预处理 (5)2.1图像的平滑处理 (5)2.1.1 平滑处理的理论 (5)2.1.2 平滑处理的实现 (6)2.2图像的二值化处理 (7)2.2.1 二值化处理的理论 (7)2.2.2 二值化处理的实现 (7)2.3二值图像的形态学运算 (8)2.3.1形态学运算的理论 (8)2.4对字符进行分割 (10)2.4.1 字符分割的理论 (10)2.4.2 字符分割的实现 (11)第三章基于模板匹配算法的车牌字符识别算法 (13)3.1模板匹配算法的理论背景 (13)3.2模板匹配算法的实现及识别率的研究 (16)3.3本章小结 (19)第四章基于神经网络算法的车牌字符识别算法 (21)4.1神经网络算法的理论背景 (21)4.2神经网络算法的实现及识别率的研究 (27)4.3本章小结 (33)第五章基于向量机(SVM)算法的车牌字符识别算法 (35)5.1向量机(SVM)算法的理论背景 (35)ii 目录5.1.1 SVM的基本原理 (35)5.1.2 SVM中核函数的选择 (35)5.1.3 SVM的多类决策问题 (36)5.1.4 SVM算法描述 (38)5.2向量机(SVM)算法的实现以及识别率的研究 (39)5.2.1 车牌字符图像的预处理 (39)5.2.2 车牌字符特征的选取 (39)5.2.3 车牌字符SVM的构造 (39)5.2.3 实验过程中相关函数及参数的选定 (40)5.2.4 实验过程中的相关结果 (41)5.3本章小结 (43)第六章总结与展望 (45)致谢 (47)参考文献 (49)第一章序言 1第一章序言1.1课题研究背景以及意义目前,我国的经济正在飞速的发展,综合实力也在与日俱增,城市化进程也在加快,国内各大城市交通管理能力将面临重大考验。
复杂背景下车牌定位与字符分割算法研究的开题报告

复杂背景下车牌定位与字符分割算法研究的开题报告一、研究背景与目的近年来,随着汽车数量的不断增加,车牌识别技术也得到了广泛应用。
车牌识别系统可以实现自动地对车辆进行登记、监控和管理,能够有效提高交通安全性和管理水平。
而车牌识别系统的关键技术就是车牌定位与字符分割,其准确率和效率直接影响整个系统的性能和可靠性。
然而,在一些复杂的场景下,如光照不均、目标遮挡、倾斜变形等情况,车牌定位和字符分割的准确率会明显下降,这就对算法的鲁棒性提出了更高的要求。
因此,本文旨在研究适用于复杂场景下的车牌定位与字符分割算法,提高车牌识别系统的性能,实现快速、准确、稳定的车牌识别。
二、研究内容与方法车牌定位是车牌识别系统的关键步骤,其主要目的是从图像中确定车牌的位置和朝向。
常用的车牌定位方法包括基于颜色、基于形状和基于深度学习等方法。
然而,这些方法在一些具有复杂背景的场景下,例如夜间和弱光环境,效果较差。
因此,本文将探索利用多种信息融合的深度学习方法,提高车牌定位的鲁棒性和准确率。
车牌字符分割是车牌识别系统中的另一个重要环节,其主要任务是将车牌上的字符分割出来,方便后续的字符识别。
当前常用的车牌字符分割方法主要包括基于边缘检测和基于图像处理技术的方法。
然而,这些方法在面对复杂背景的情况下,往往难以达到较高的分割准确率。
因此,本文将尝试综合使用基于深度学习和图像处理的方式来实现车牌字符的可靠分割。
三、论文进展计划第一阶段,阅读相关文献,研究车牌定位和字符分割的相关算法,了解深度学习的基本概念和方法,研究多种信息融合的技术,包括颜色、形状、纹理等。
第二阶段,实现车牌定位和字符分割的算法,并测试其性能。
针对测试结果进行分析和评价,进一步改进算法,提高其鲁棒性和准确率。
第三阶段,将车牌定位和字符分割算法应用于实际场景,收集大量样本,对算法进行综合性能测试,并与现有算法进行比较和评估。
第四阶段,编写论文,并对研究结果进行总结和展望。
车牌字符分割方法的研究的开题报告

车牌字符分割方法的研究的开题报告一、选题背景和意义随着城市化进程的不断加快,车辆数量急剧增加,交通状况也日益复杂,如何实现车辆识别以及智能调度已经成为一个重要议题。
而在车辆识别中,车牌字符分割是一个至关重要的环节,它对于正确、快速地识别车牌号码具有决定性的影响。
因此,对于车牌字符分割方法的研究具有重要的实际意义。
二、研究内容和目标本次研究旨在提出一种基于图像处理技术的车牌字符分割方法,通过对车牌图像进行预处理、二值化、特征提取等步骤,最终得到分割后的车牌字符,并能够在不同的场景中进行有效的应用。
具体而言,研究内容包括:1.车牌图像预处理,例如去除噪声、调整图像亮度等。
2.车牌图像二值化,将彩色车牌图像转化为黑白二值图像。
3.车牌字符分割,通过特征提取和分类算法,对车牌字符进行有效分割。
4.车牌字符分割方法的实现,编写计算机程序,对不同场景的车牌图像进行测试和验证。
三、研究方法本研究将采用以下方法:1.对现有的车牌字符分割方法进行调研和分析,了解其优缺点,并提出本方法的改进策略。
2.针对车牌字符分割的特征进行深入研究,包括颜色、形状、边缘等方面。
3.设计和实现车牌字符分割的算法流程,可以采用基于统计学算法或者深度学习算法。
4.评价本文提出的车牌字符分割方法的准确度、鲁棒性和效率。
四、研究的创新性和可行性本研究的创新性和可行性在于:1.针对车牌识别中的字符分割环节进行深入、系统的研究,提出了适应不同条件的车牌字符分割方法,对解决车牌识别难题具有重要意义。
2.本研究提出的车牌字符分割方法融合了图像处理、特征提取和分类算法等多种技术,具有较强的实用性和可行性。
3.本研究实现的车牌字符分割方法在实验中具有较好的分割效果,可以为车辆识别和智能交通系统的发展提供基础技术支持。
五、论文框架本文拟从以下几个方面进行论述:1.绪论,介绍车牌字符分割的背景和意义,调研国内外相关研究现状,并提出本次研究的目标和内容。
2.相关技术介绍,对车牌字符分割所涉及的图像处理、特征提取和分类算法等技术进行介绍和分析。
基于垂直投影法的车牌字符分割算法设计

毕业论文(设计)学院: 计算机科学学院专业: 软件工程年级: 题目:基于垂直投影法的车牌字符分割算法设计学生姓名: 学号:指导教师姓名: 职称:年月XXXX大学本科毕业论文(设计)原创性声明本人郑重声明:所呈交的论文是本人在导师的指导下独立进行研究所取得的研究成果。
除了文中特别加以标注引用的内容外,本论文不包含任何其他个人或集体已经发表或撰写的成果作品。
本人完全意识到本声明的法律后果由本人承担。
作者签名:年月日目录摘要 (1)Abstract (1)第一章绪论 (1)1.1车牌识别技术的背景 (1)1.2 车牌识别系统的工作原理 (2)1.3 国内外研究 (3)1.4 本文主要内容 (3)第二章基本理论介绍 (3)2.1 数字图像处理技术 (3)2.1.1 bmp位图 (4)2.1.2 RGB编码方式 (4)2.1.3二值图像 (4)2.1.4 Otsu算法 (4)2.1.5灰度图像 (5)2.1.6 中值滤波 (5)第三章车牌图像的预处理 (5)3.1车牌图像的灰度化 (5)3.2车牌图像的二值化 (5)3.3 去噪处理 (6)3.3.1去除车牌边框 (7)3.3.2去除车牌图像中的圆点 (8)第四章车牌字符分割算法 (8)4.1传统垂直投影的车牌字符分割算法 (8)4.2 改进的垂直投影的车牌字符分割算法 (9)第五章系统实现 (10)第六章总结与展望 (13)6.1 总结 (13)6.2 展望 (13)致谢 (14)参考文献 (15)基于垂直投影法的车牌字符分割算法设计摘要:车牌识别系统在现代社会有着广泛应用,而车牌字符分割是其中的一项关键技术。
本文针对车牌字符分割算法做了较为深入的研究。
首先,要想正确的分割车牌图像,必须得到质量较好的车牌二值化图像。
所以,本文对车牌字符分割的预处理部分进行较为深入的研究,尤其是车牌图像二值化后的去噪处理。
传统投影法对车牌图像要求比较高,容易受到噪声的影响,从而造成分割字符的粘连与断裂。
汽车车牌自动定位与字符分割

I=imread('Car.jpg'); %读入图片figure(1),imshow(I); %显示出图片[y,x,z]=size(I);myI=double(I); %转化数据为双精度型%%%%%%%%%%% RGB to HIS %%%%%%%%tic % 测定算法执行的时间,开始计时%%%%%%%%%%% 统计分析%%%%%%%%%%%%%%%%=========== Y 方向=============Blue_y=zeros(y,1);for i=1:yfor j=1:xif((myI(i,j,1)<=30)&&((myI(i,j,2)<=62)&&(myI(i,j,2)>=51))&&((myI(i,j,3)<=142)&&(myI(i,j,3) >=119)))% 蓝色RGB的灰度范围Blue_y(i,1)= Blue_y(i,1)+1; % 蓝色象素点统计endendend[temp MaxY]=max(Blue_y); % Y方向车牌区域确定PY1=MaxY;while ((Blue_y(PY1,1)>=5)&&(PY1>1))PY1=PY1-1;endPY2=MaxY;while ((Blue_y(PY2,1)>=5)&&(PY2<y))PY2=PY2+1;endIY=I(PY1:PY2,:,:);%======================% X 方向%======================Blue_x=zeros(1,x); % 进一步确定X方向的车牌区域for j=1:xfor i=PY1:PY2if((myI(i,j,1)<=30)&&((myI(i,j,2)<=62)&&(myI(i,j,2)>=51))&&((myI(i,j,3)<=142)&&(myI(i,j,3) >=119)))Blue_x(1,j)= Blue_x(1,j)+1;endendendPX1=1;while ((Blue_x(1,PX1)<3)&&(PX1<x))PX1=PX1+1;endPX2=x;while ((Blue_x(1,PX2)<8)&&(PX2>PX1))PX2=PX2-1;end%======对车牌区域的修正=========PX1=PX1-2; %PX2=PX2+2;Plate=I(PY1:PY2,PX1-2:PX2+2,:);%======像素点数在X、Y方向上的统计并且显示数量统计图t=toc; % 读取计时figure(2),plot(Blue_x);gridfigure(3),plot(Blue_y);gridfigure(4),imshow(IY);figure(5),imshow(Plate);%======字符分割并且分别显示IA=I(PY1:PY2,PX1-2:PX1+12,:);figure(6),imshow(IA);IB=I(PY1:PY2,PX1+ 12:PX1+26,:);figure(7),imshow(IB);IC=I(PY1:PY2,PX1+28:PX1+44,:);figure(8),imshow(IC);ID=I(PY1:PY2,PX1+44:PX1+56,:);figure(9),imshow(ID);IE=I(PY1:PY2,PX1+58:PX1+70,:);figure(10),imshow(IE);IF=I(PY1:PY2,PX1+70:PX1+84,:);figure(11),imshow(IF);IG=I(PY1:PY2,PX1+84:PX2+2,:);figure(12),imshow(IG);%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 字符分割模块算法% 定位剪切后的彩色车牌图像--灰度--二值化--统一到黑底白字--去除上下边框% --切割出最小范围--滤波--形态学处理--分割出7个字符% 去除上下边框算法:% 1.黑白跳变小于阈值则被视为背景;2.连续白线大于某阈值则该白线被认为是背景% 3.单行白色大于阈值则被认为是背景,考虑FLAG的值;% 4.做完以上处理后,上边1/2 中搜索连续两条黑线,认为该黑线以上为背景;在下边1/2 中搜索连续两条黑线,认为该黑线以下为背景% 归一化为40*20 ,商用系统程序中归一化为32*16 ,此处仅演示作用function [d]=lpcseg(jpg)I=imread('car1.jpg');I1=rgb2gray(I);I2=edge(I1,'robert',0.15,'both');se=[1;1;1];I3=imerode(I2,se);se=strel('rectangle',[25,25]);I4=imclose(I3,se);I5=bwareaopen(I4,2000);[y,x,z]=size(I5);myI=double(I5);ticwhite_y=zeros(y,1);for i=1:yfor j=1:xif(myI(i,j,1)==1)white_y(i,1)= white_y(i,1)+1;endendend[temp MaxY]=max(white_y);PY1=MaxY;while ((white_y(PY1,1)>=5)&&(PY1>1))PY1=PY1-1;endPY2=MaxY;while ((white_y(PY2,1)>=5)&&(PY2<y))PY2=PY2+1;endIY=I(PY1:PY2,:,:);white_x=zeros(1,x);for j=1:xfor i=PY1:PY2if(myI(i,j,1)==1)white_x(1,j)= white_x(1,j)+1;endendendPX1=1;while ((white_x(1,PX1)<3)&&(PX1<x))PX1=PX1+1;endPX2=x;while ((white_x(1,PX2)<3)&&(PX2>PX1))PX2=PX2-1;endPX1=PX1-1;PX2=PX2+1;dw=I(PY1:PY2-8,PX1:PX2,:);t=toc;figure(1),subplot(3,2,1),imshow(dw),title('定位剪切后的彩色车牌图像')imwrite(dw,'dw.jpg');[filename,filepath]=uigetfile('dw.jpg','输入一个定位裁剪后的车牌图像');jpg=strcat(filepath,filename);a=imread(jpg);%figure(1);subplot(3,2,1),imshow(a),title('1.定位剪切后的彩色车牌图像')b=rgb2gray(a);imwrite(b,'2.车牌灰度图像.jpg');figure(1);subplot(3,2,2),imshow(b),title('2.车牌灰度图像')g_max=double(max(max(b)));g_min=double(min(min(b)));T=round(g_max-(g_max-g_min)/3); % T 为二值化的阈值[m,n]=size(b);d=(double(b)>=T); % d:二值图像imwrite(d,'3.车牌二值图像.jpg');figure(1);subplot(3,2,3),imshow(d),title('3.车牌二值图像')% 旋转rotate=0;d=imread('3.车牌二值图像.jpg');bw=edge(d);[m,n]=size(d);theta=1:179;% bw 表示需要变换的图像,theta 表示变换的角度% 返回值r 表示的列中包含了对应于theta中每一个角度的Radon 变换结果% 向量xp 包含相应的沿x轴的坐标[r,xp]=radon(bw,theta);i=find(r>0);[foo,ind]=sort(-r(i));k=i(ind(1:size(i)));[y,x]=ind2sub(size(r),k);[mm,nn]=size(x);if mm~=0 && nn~=0j=1;while mm~=1 && j<180 && nn~=0i=find(r>j);[foo,ind]=sort(-r(i));k=i(ind(1:size(i)));[y,x]=ind2sub(size(r),k);[mm,nn]=size(x);j=j+1;endif nn~=0if x % Enpty matrix: 0-by-1 when x is an enpty array.x=x;else % 可能x 为空值x=90; % 其实就是不旋转endd=imrotate(d,abs(90-x)); % 旋转图像rotate=1;endendimwrite(d,'4.Radon 变换旋转后的二值图像.jpg');figure(1),subplot(3,2,4),imshow(d),title('4.Radon 变换旋转后的二值图像')% 统一到白底黑字[m,n]=size(d);% flag=0 表示原来就是白底黑字,否则表示原来是黑底白字flag=0;c=d([round(m/3):m-round(m/3)],[round(n/3):n-round(n/3)]);if sum(sum(c))/m/n*9>0.5d=~d;flag=1;end% 对反色后的图像预处理,整列几乎为白的认为是背景if flag==1for j=1:nif sum(sum(d(:,j)))/m>=0.95d(:,j)=0;endend% 对以上处理后的图像再处理% 在左边1/2 处找连续两条黑线,认为该黑线左边为背景;在右边1/2 处找连续两条黑线,认为该黑线右边是背景% 左边1/2jj=0;for j=1:round(n/2)if sum(sum(d(:,[j:j+0])))==0jj=j;endendd(:,[1:jj])=0;% 右边1/2for j=n:-1:round(n/2)if sum(sum(d(:,[j-0:j])))==0jj=j;endendd(:,[jj:n])=0;endimwrite(d,'5.统一成黑底白字.jpg');figure(1),subplot(3,2,5),imshow(d),title('5.背景色统一成黑底白字') figure(2),subplot(5,1,1),imshow(d),title('5.黑底白字的二值车牌图像')% 去除上下边框% STEP 1 黑白跳变小于阈值则被视为背景% 上面2/5y1=10; % y1: 跳变阈值for i=1:round(m/5*2)count=0;jump=0;temp=0;for j=1:nif d(i,j)==1temp=1;elsetemp=0;endif temp==jumpcount=count;elsecount=count+1;endjump=temp;endif count<y1d(i,:)=0;endend% 下面2/5for i=3*round(m/5):mcount=0;jump=0;temp=0;for j=1:nif d(i,j)==1elsetemp=0;endif temp==jumpcount=count;elsecount=count+1;endjump=temp;endif count<y1d(i,:)=0;endendimwrite(d,'6.黑白跳变小于某阈值的行则被视为背景.jpg');figure(2),subplot(5,1,2),imshow(d),title('6.黑白跳变小于某阈值的行则被视为背景')% STEP 2 单行白色大于阈值则被认为是背景,考虑FLAG 的值% 上面2/5y2=round(n/2); % y2: 阈值for i=1:round(m/5*2)if flag==0temp=sum(d(i,:));y2=round(n/2);if temp>y2d(i,:)=0;endelsetemp=m-sum(d(i,:));y2=m-round(n/2);if temp<y2d(i,:)=0;endendend% 下面2/5for i=round(3*m/5):mif flag==0temp=sum(d(i,:));y2=round(n/2);if temp>y2d(i,:)=0;endelsetemp=m-sum(d(i,:));y2=m-round(n/2);if temp<y2endendendimwrite(d,'7.单行白色点总数大于某阈值则该行被认为是背景.jpg');figure(2),subplot(5,1,3),imshow(d),title('7.单行白色点总数大于某阈值则该行被认为是背景') % STEP 3 单行白色大于阈值则被认为是背景,考虑FLAG 的值% 上面2/5y2=round(n/2); % y2: 阈值for i=1:round(m/5*2)if flag==0temp=sum(d(i,:));y2=round(n/2);if temp>y2d(i,:)=0;endelsetemp=m-sum(d(i,:));y2=m-round(n/2);if temp<y2d(i,:)=0;endendend% 下面2/5for i=round(3*m/5):mif flag==0temp=sum(d(i,:));y2=round(n/2);if temp>y2d(i,:)=0;endelsetemp=m-sum(d(i,:));y2=m-round(n/2);if temp<y2d(i,:)=0;endendendimwrite(d,'8.单行白色点总数大于某阈值则该行被认为是背景.jpg');figure(2),subplot(5,1,4),imshow(d),title('8.单行白色点总数大于某阈值则该行被认为是背景') % STEP 4 做完以上处理后,上边1/2 中搜索连续两条黑线,认为该黑线以上为背景;% 在下边1/2 中搜索连续两条黑线,认为该黑线以下为背景% 上边1/2for i=1:round(m/2)if sum(sum(d([i,i+0],:)))==0ii=i;endendd([1:ii],:)=0;% 下边1/2for i=m:-1:round(m/2)if sum(sum(d([i-0:i],:)))==0ii=i;endendd([ii:m],:)=0;imwrite(d,'9.搜索上下两条黑线后的结果.jpg');figure(2),subplot(5,1,5),imshow(d),title('9.搜索上下两条黑线后的结果')% 反旋转if rotate==1d=imrotate(d,-abs(x-90));endimwrite(d,'10.反旋转去毛刺后.jpg');figure(3),subplot(3,2,1),imshow(d),title('10.反旋转去毛刺后')% 切割处最小范围d=qiege(d);e=d;imwrite(d,'11.切割处最小范围.jpg');figure(3),subplot(3,2,2),imshow(d),title('11.切割处最小范围')figure(3),subplot(3,2,3),imshow(d),title('11.均值滤波前')% 滤波h=fspecial('average',3);d=im2bw(round(filter2(h,d)));imwrite(d,'12.均值滤波后.jpg');figure(3),subplot(3,2,4),imshow(d),title('12.均值滤波后')% 某些图像进行操作% 膨胀或腐蚀% se=strel('square',3); % 使用一个3X3的正方形结果元素对象对创建的图像进行膨胀% 'line'/'diamond'/'ball'...se=eye(2); % eye(n) returns the n-by-n identity matrix 单位矩阵[m,n]=size(d);if bwarea(d)/m/n>=0.365d=imerode(d,se);elseif bwarea(d)/m/n<=0.235d=imdilate(d,se);endimwrite(d,'13.膨胀或腐蚀处理后.jpg');figure(3),subplot(3,2,5),imshow(d),title('13.膨胀或腐蚀处理后')% 寻找连续有文字的块,若长度大于某阈值,则认为该块有两个字符组成,需要分割d=qiege(d);[m,n]=size(d);figure,subplot(2,1,1),imshow(d),title(n)k1=1;k2=1;s=sum(d);j=1;while j~=nwhile s(j)==0j=j+1;endk1=j;while s(j)~=0 && j<=n-1j=j+1;endk2=j-1;if k2-k1>=round(n/6.5)[val,num]=min(sum(d(:,[k1+5:k2-5])));d(:,k1+num+5)=0; % 分割endend% 再切割d=qiege(d);% 切割出7 个字符y1=10;y2=0.25;flag=0;word1=[];while flag==0[m,n]=size(d);left=1;wide=0;while sum(d(:,wide+1))~=0wide=wide+1;endif wide<y1 % 认为是左侧干扰d(:,[1:wide])=0;d=qiege(d);elsetemp=qiege(imcrop(d,[1 1 wide m]));[m,n]=size(temp);all=sum(sum(temp));two_thirds=sum(sum(temp([round(m/3):2*round(m/3)],:)));if two_thirds/all>y2flag=1;word1=temp; % WORD 1endd(:,[1:wide])=0;d=qiege(d);endend% 分割出第二个字符[word2,d]=getword(d);% 分割出第三个字符[word3,d]=getword(d);% 分割出第四个字符[word4,d]=getword(d);% 分割出第五个字符[word5,d]=getword(d);% 分割出第六个字符[word6,d]=getword(d);% 分割出第七个字符[word7,d]=getword(d);subplot(5,7,1),imshow(word1),title('1');subplot(5,7,2),imshow(word2),title('2');subplot(5,7,3),imshow(word3),title('3');subplot(5,7,4),imshow(word4),title('4');subplot(5,7,5),imshow(word5),title('5');subplot(5,7,6),imshow(word6),title('6');subplot(5,7,7),imshow(word7),title('7');[m,n]=size(word1);% 商用系统程序中归一化大小为32*16,此处演示word1=imresize(word1,[40 20]);word2=wordprocess(word2);word3=wordprocess(word3);word4=wordprocess(word4);word5=wordprocess(word5);word6=wordprocess(word6);word7=wordprocess(word7);subplot(5,7,15),imshow(word1),title('1');subplot(5,7,16),imshow(word2),title('2');subplot(5,7,17),imshow(word3),title('3');subplot(5,7,18),imshow(word4),title('4');subplot(5,7,19),imshow(word5),title('5');subplot(5,7,20),imshow(word6),title('6');subplot(5,7,21),imshow(word7),title('7');imwrite(word1,'14.字符分割归一化后1.jpg'); imwrite(word2,'14.字符分割归一化后2.jpg'); imwrite(word3,'14.字符分割归一化后3.jpg'); imwrite(word4,'14.字符分割归一化后4.jpg'); imwrite(word5,'14.字符分割归一化后5.jpg'); imwrite(word6,'14.字符分割归一化后6.jpg'); imwrite(word7,'14.字符分割归一化后7.jpg');%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%clcword='';word(1)=wordrec(word1);word(2)=wordrec(word2);word(3)=wordrec(word3);word(4)=wordrec(word4);word(5)=wordrec(word5);word(6)=wordrec(word6);word(7)=wordrec(word7);clcsave I 'word1' 'word2' 'word3' 'word4' 'word5' 'word6' 'word7'clearload I;load bp net;word='';word(1)=wordrec(word1);word(2)=wordrec(word2);word(3)=wordrec(word3);word(4)=wordrec(word4);word(5)=wordrec(word5);word(6)=wordrec(word6);word(7)=wordrec(word7);word=strcat('识别结果:',word);subplot(5,3,14),imshow([]),title(word,'fontsize',24)% 该子程序用于切割出最小范围function e=qiege(d)[m,n]=size(d);top=1;bottom=m;left=1;right=n; % initwhile sum(d(top,:))==0 && top<=mtop=top+1;endwhile sum(d(bottom,:))==0 && bottom>=1bottom=bottom-1;endwhile sum(d(:,left))==0 && left<=nleft=left+1;endwhile sum(d(:,right))==0 && right>=1right=right-1;enddd=right-left;hh=bottom-top;e=imcrop(d,[left top dd hh]);% 分割字符function [word,result]=getword(d)word=[];flag=0;y1=8;y2=0.5;% if d==[]% word=[];% elsewhile flag==0[m,n]=size(d);wide=0;while sum(d(:,wide+1))~=0 && wide<=n-2wide=wide+1;endtemp=qiege(imcrop(d,[1 1 wide m]));[m1,n1]=size(temp);if wide<y1 && n1/m1>y2d(:,[1:wide])=0;if sum(sum(d))~=0d=qiege(d); % 切割出最小范围else word=[];flag=1;endelseword=qiege(imcrop(d,[1 1 wide m]));d(:,[1:wide])=0;if sum(sum(d))~=0;d=qiege(d);flag=1;else d=[];endendend%endresult=d;%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 该子程序用于字符归一化处理function d=wordprocess(d)[m,n]=size(d);%top 1/3, bottom 1/3for i=1:round(m/3)if sum(sum(d([i:i+0],:)))==0ii=i;d([1:ii],:)=0;endendfor i=m:-1:2*round(m/3)if sum(sum(d([i-0:i],:)))==0ii=i;d([ii:m],:)=0;endendif n~=1d=qiege(d);end% d=..这个可以通过训练过程设置大小% d=imresize(d,[32 16]); % 商用系统程序中归一划大小为:32*16d=imresize(d,[40 20]);%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 编号:A-Z 分别为1-26; 0-9 分别为27-36;% 京津沪渝港澳吉辽鲁豫冀鄂湘晋青皖苏% 赣浙闽粤琼台陕甘云川贵黑藏蒙桂新宁% 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59% 60 61 62 63 64 65 66 67 68 69 70% 使用BP 网络function word=wordrec(xx)% clear% clcload bp net;xx=im2bw(xx);xx=double(xx(:)); % 使用阈值将图像转换为二进制图像a=sim(net,xx); % 归一划为:32*16,则xx=512*1;[val,num]=max(a);if num<=26word=char(double('A')+num-1);elseif num<=36word=char(double('0')+num-1-26);elseswitch numcase 37word='京';case 38word='津';case 39word='沪';word='渝'; case 41word='港'; case 42word='澳'; case 43word='吉'; case 44word='辽'; case 45word='鲁'; case 46word='豫'; case 47word='冀'; case 48word='鄂'; case 49word='湘'; case 50word='晋'; case 51word='青'; case 52word='皖'; case 53word='苏'; case 54word='赣'; case 55word='浙'; case 56word='闽'; case 57word='粤'; case 58word='琼'; case 59word='台'; case 60word='陕'; case 61word='甘';word='云';case 63word='川';case 64word='贵';case 65word='黑';case 66word='藏';case 67word='蒙';case 68word='桂';case 69word='新';case 70word='宁';endend。
《2024年基于深度学习的车牌检测识别系统研究》范文

《基于深度学习的车牌检测识别系统研究》篇一一、引言随着人工智能和深度学习技术的快速发展,车牌检测识别系统在智能交通、安防监控、自动驾驶等领域得到了广泛应用。
本文旨在研究基于深度学习的车牌检测识别系统,通过分析其原理、方法及实现过程,为相关领域的研究和应用提供参考。
二、车牌检测识别系统的基本原理车牌检测识别系统主要基于计算机视觉和深度学习技术,通过对图像或视频进行处理和分析,实现车牌的准确检测和识别。
该系统主要包括车牌检测、车牌定位、字符分割和字符识别等几个步骤。
1. 车牌检测:通过图像处理技术,从大量图像中筛选出包含车牌的图像。
2. 车牌定位:在检测到的图像中,通过颜色、形状、纹理等特征,定位出车牌的具体位置。
3. 字符分割:将车牌图像中的字符进行分割,以便进行后续的字符识别。
4. 字符识别:通过深度学习算法对分割后的字符进行识别,最终得到车牌号码。
三、深度学习在车牌检测识别中的应用深度学习在车牌检测识别系统中发挥着重要作用,主要包括卷积神经网络(CNN)和循环神经网络(RNN)的应用。
1. 卷积神经网络(CNN):CNN具有强大的特征提取能力,可以自动学习图像中的特征,从而提高车牌检测和识别的准确率。
在车牌检测和定位阶段,CNN可以提取车牌的形状、颜色等特征,实现准确的车牌定位。
2. 循环神经网络(RNN):RNN在字符分割和字符识别方面具有优势。
通过训练RNN模型,可以实现对字符的精确分割和高效识别。
此外,RNN还可以处理序列数据,因此在处理车牌号码这种具有时序特性的数据时具有较好的效果。
四、车牌检测识别系统的实现方法基于深度学习的车牌检测识别系统实现过程主要包括数据集准备、模型训练和系统测试三个阶段。
1. 数据集准备:收集包含各种场景、光照条件、车牌类型等多样化的图像数据,并进行标注,以便用于模型训练。
2. 模型训练:使用卷积神经网络和循环神经网络构建车牌检测识别模型,通过大量训练数据对模型进行训练,提高模型的准确率和鲁棒性。
基于语义分割的车牌识别技术研究

基于语义分割的车牌识别技术研究一、前言车牌识别技术是智能交通系统的重要组成部分,它可以对车辆实现自动识别、记录和管理,有效地提升交通安全和治理效率。
随着人工智能技术的不断发展,基于语义分割的车牌识别技术受到了越来越多的关注。
本文将从技术原理、算法流程、实验结果等方面分析基于语义分割的车牌识别技术。
二、技术原理车牌识别技术的主要原理是通过图片识别技术对车辆的牌照信息进行自动识别。
其核心技术是图像处理技术和模式识别技术。
基于语义分割的车牌识别技术是在传统车牌识别技术的基础上,利用深度学习技术,通过语义分割算法实现对车牌图像中字符的分割,从而提高了车牌识别的准确率和鲁棒性。
语义分割是计算机视觉领域中的一个重要问题,它的主要目标是将图像中的像素进行有意义的分类,然后将其分组成不同的目标区域。
针对车牌识别,语义分割技术主要是将车牌图像中的字符区域与车牌背景区域进行分割,以进行后续的字符识别。
三、算法流程基于语义分割的车牌识别技术主要的算法流程如下:1. 图像预处理:对输入的车牌图像进行预处理,包括图像降噪、增强等。
2. 物体检测:通过物体检测技术对车牌区域进行检测和定位。
3. 语义分割:对车牌区域进行语义分割,将字符与背景进行分离。
4. 字符识别:对分割出来的字符进行识别,得到车牌的文字信息。
5. 数据库查询:将识别出来的车牌信息与数据库进行比对,完成车牌的信息识别和管理。
四、实验结果针对基于语义分割的车牌识别技术,相关研究者进行了大量的实验。
其中,在字符分割方面主要考虑了像素预测精度、字符定位精度、字符分割精度三个方面的评价,而在字符识别方面主要考虑了识别准确率、鲁棒性等指标。
通过多组实验数据的对比发现,基于语义分割的车牌识别技术的识别准确率、鲁棒性等指标均优于传统的车牌识别技术。
其中,使用U-Net、FC-DenseNet等深度学习模型实现的语义分割技术在车牌分割方面显示出了很好的效果。
五、结论基于语义分割的车牌识别技术是目前车牌识别领域的研究热点。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1 绪论
1.1 背景介绍
为了实现车牌字符识别,通常要经过车牌位置检测、车牌字符分割和字符识别三个关键步骤。
车牌位置检测是根据车牌字符目标区域的特点,寻找出最符合车牌特征的区域。
车牌字符分割就是在车牌图像中找出所有字符的上下左右边界,进而分割出每个车牌字符。
在实际应用中,车牌字符分割的效果对车牌字符识别正确率会产生很大的影响,由于车牌图像亮度不均、尺度变化、透视失真、字符不完整等因素,使图像质量存在较大差异,进而影响图像分割的效果,因此车牌字符分割这一技术仍然具有很大的研究意义。
在实际的监控场景中,车牌图像的透视失真通常是由于拍摄视角的变化或车辆位置的移动,相机光轴偏离车牌平面的法线方向造成的。
由于车牌图像在整幅图像中占有较小的比例,所以车牌图像几何校正主要工作是校正车牌图像的旋转和剪切失真。
旋转投影法和直线拟合法是两种主要的偏斜校正方法。
旋转投影法是为了获取垂直倾斜角,即将车牌图像穷举逐个角度进行剪切变换,然后统计垂直投影数值为0的点数,得到最大值对应的角度。
这种方法受背景区域的干扰比较大。
另一种方法是直线拟合车牌字符的左边界点从而获得垂直倾斜角,该方法为直线拟合法。
该方法并没有逐个角度对车牌图像进行剪切变换,从左边界点拟合出的直线通常不能真正用来代表车牌的垂直倾斜方向,检测出的角度存在较大误差,且字符左侧噪声对角度检测干扰太大,鲁棒性较差。
因此找到一种更准确和迅速的车牌垂直倾斜矫正方法是十分重要的。
通过得到最小的字符投影点坐标方差,得到另一种车牌垂直矫正方法。
首先将车牌字符图像进行水平校正,根据字符的区域的上下边界,将车牌字符进行粗分割。
然后将剪切变换后的字符点进行垂直偷用。
当得到投影点最想左边方差时,便能导出两类剪切角闭合表达是,最后便是确定垂直投影的倾斜角并对此进行校正。
投影法是目前最常用的车牌分割算法之一,其算法简单并且计算复杂度低。
该方法的核心思想是将车牌图像进行水平投影和垂直投影,利用峰谷特征来定位车牌字符的上下左右边界。
但是车牌的噪声、边框等因素容易影响到投影的峰谷
位置,并且对于存在较严重质量退化的图像处理困难。
为了进一步改善字符分割效果,通常将形态学分析、连通体分析和投影法三者相结合,并应用到车牌字符分割。
Anagnostopoulos等人提出用SCW方法对车牌的图像进行分割,并通过在水平方向和垂直方向的投影曲线标准差对车牌字符进行分割。
张云刚等人利用车牌的先验知识并结合Hough 变换提出了一种新的车牌字符分割算法,该方法的特点是为了消除噪声的影响提出了一种全新的图像预处理方法。
其主要步骤为首先进行分段,其次水平分割方法利用的是Hough 变换拟合,该方法能够有效的消除上下车牌边框的影响,当图像中的车牌旋转角度较大并且存在光照不均的影响时其分割效果也都很好。
然后将车牌先验知识应用于垂直投影法的字符左右边界确定中。
该方法的优点是能够消除字符间隔区域和垂直边框的影响。
但是车牌的噪声等干扰因素容易影响到投影的峰谷位置,并且对于存在较严重质量退化的图像处理困难。
因此,通常将形态学分析、连通体分析和投影法三者相结合,并应用到车牌字符分割。
Nomura等人为了处理断裂的车牌字符碎片,通过竖直投影将其检测出来并合并属于同一个字符的碎片,利用形态学粗化和细化方法将重叠和粘连的字符连通体分离。
Chang等人为使车牌字符切分更有效,利用连通体的组合规则验证所有可能的字符集合,并取得了非常好的效果。
近年来,更多新颖的车牌字符分割算法问世。
Jiao为了验证是否得到真正的车牌把预定义的车牌格式和待选字符进行匹配,使用动态规划的方法来进一步验证匹配的效果。
Fan等人以对垂直投影的水平投影分析为基础,将车牌字符分割与识别两个步骤作为一个整体的统计推断问题。
能够将车牌字符的分割与识别同时进行,车牌字符的识别模块的设计性能很大程度地影响字符分割的效果。
Franc 和Hlavac通过隐马尔可夫链将车牌图像与相应的车牌字符分割建立起随机关系,把车牌字符分割表示为最大后验估计问题。
Naito等人提出了假设检验方法,并以置信度为依据对可能的字符组合进行排队。
王兴玲利用车牌规定的字符组合方式和大小比例关系,提出了基于模板匹配的最大类间方差车牌字符分割算法。
并将设计的字符模板与车牌区域滑动匹配并进行分类,车牌的最佳匹配位置和字符的分割边界是通过最大类间方差的判决准则进行确定的。
中国大陆的车牌有统一的制定规则,所有的车牌字符所对应的高度和宽度是相等的(可将字符“1”认为与其它字符的宽度是相同的),并且字符的间距与字符大
小比例关系是确定不变的。
为此,本文以投影分析法为基础,通过设计变长模板与车牌区域滑动匹配,从而完成车牌字符分割。
首先根据车牌边框和字符排列规则将车牌图像进行旋转和剪切校正。
为了确定车牌图像中字符的上下边界,将车牌图像沿水平方向进行投影,利用预先设计好的不同长度方波模板对其进行匹配,根据相关系数得到最佳匹配的方波。
最后,将车牌图像沿垂直方向进行投影,根据车牌字符的宽度与字符间隔长度的比例关系,设计一组长度不同的方波模板。
为了获取字符的左右边界,可以将该模板与垂直投影进行匹配。
该方法以车牌字符的水平和垂直投影特性为依据,可以自适应地解决光线照射不均匀、透视失真、尺度变化、以及背景干扰等问题,具有较好的稳定性,抗干扰能力较强。
1.2 车牌字符的格式
依据国家对机动车号牌的相关规定,可以总结出车牌的特点。
按照车牌颜色的特点,有白字蓝底白边框、黑字黄底黑边框、红字或者黑字白底黑边框三种类型车牌。
也可以从字符排列角度进行分类,包括但单行七字符的车牌和上下两行字符车牌。
为了对车牌照进行识别,研究人员总结出车牌识别的先验知识,包括车牌的尺寸、字符大小、结构特征等。
车牌样本图像如图1-1所示
图1-1 车牌样本图像
车牌照的先验知识具有如下内容:
(1)车牌是一个高度为409mm,宽度为90mm的长方形,其高宽比例为4.45:1。
(2)车牌字符的高度为90mm,宽度为45mm,宽高比为2:1。
(3)车牌的边框宽度为1.5mm,字符间隙是12mm。
车牌边框线的宽度和。