网页视频抓取教程
下载网页上的新闻视频到本地

下载网页上的新闻视频到本地
下载网页上的新闻视频到本地的步骤如下:
1. 打开包含新闻视频的网页。
2. 在网页的空白处,点击鼠标右键,选择“审查元素”或者“检查”选项。
这将进入检查界面。
3. 在检查界面中,点击“Network”,再点击“Media”。
然后按F5刷新页面,刷新几次后,下面就会出现视频文件。
4. 在视频文件上点击鼠标右键,然后点击“Open in new tab”,视频文件就会在新的标签页打开。
5. 在新的标签页,将视频下载到本地即可。
此外还可以通过以下方式下载:
1. 油猴插件:一个强大的浏览器插件,可以运行各种各样的脚本。
安装好后,在知乎视频界面刷新一下,就可以看到下载按钮,直接点击下载,视频就可以保存到本地了。
2. 猫抓:一个音视频资源嗅探插件,安装后,播放网页视频的时候会自动嗅探视频资源,然后将视频文件下载到本地。
还支持多个视频批量下载。
3. AIX智能下载器:这是一个浏览器扩展,几乎可以下载任何网页中的视频。
在需要提取视频的页面上,点击插件图标,转到视频标签,就可以发现想下载的视频文件,选择下载即可。
这是针对不同视频网站的通用方法。
以上方法仅供参考,应按实际情况选择适合自己的下载方式。
Python网络爬虫中的在线视频与直播数据抓取

Python网络爬虫中的在线视频与直播数据抓取随着互联网和数字技术的快速发展,在线视频和直播已经成为人们日常娱乐和获取信息的重要方式。
Python作为一种强大的编程语言,可以用于实现网络爬虫,并能够帮助我们抓取在线视频和直播数据,为用户提供更好的观看体验和使用感受。
本文将介绍Python网络爬虫中抓取在线视频和直播数据的方法和技巧。
一、在线视频数据抓取在网络上,有许多平台提供了丰富多样的在线视频资源,如优酷、腾讯视频、爱奇艺等。
我们可以利用Python编写网络爬虫程序,来抓取这些平台上的视频数据。
1. 网页分析与解析首先,我们需要通过发送HTTP请求,获取目标网页的HTML源代码。
然后,利用Python中的解析库(如BeautifulSoup、lxml等)对源代码进行解析和提取,从而获取视频的相关信息,如标题、播放量、评论等。
2. URL拼接与下载接下来,我们需要从视频信息中提取出视频的URL链接。
有些平台可能会对视频链接进行加密或者隐藏,我们可以通过分析网页中的JavaScript脚本,来获取真实的视频链接。
获取到视频链接后,我们可以使用Python的下载库(如requests、urllib等)来进行视频的下载。
3. 视频解码与播放在下载完成后,视频文件通常是经过编码的,我们可以使用Python 的解码库(如ffmpeg、cv2等)来进行视频解码工作,并通过Python 的图形库(如opencv、pygame等)来进行视频的播放。
二、直播数据抓取与在线视频不同,直播数据是实时生成的,我们需要通过爬虫程序来实时抓取直播平台上的数据。
1. 弹幕数据抓取直播平台上,观众可以实时发送消息,这些消息通常以弹幕的形式出现在视频画面上。
我们可以通过网络爬虫程序抓取直播平台的弹幕数据,进而进行分析和处理。
2. 实时数据采集与展示除了弹幕数据,直播平台上还会提供其他实时数据,如在线观看人数、点赞数量等。
我们可以编写爬虫程序,实时获取这些数据,并通过可视化工具(如matplotlib、Tableau等)进行展示和分析。
极品!下载网页上的视频----如何快速下载视频简易教程
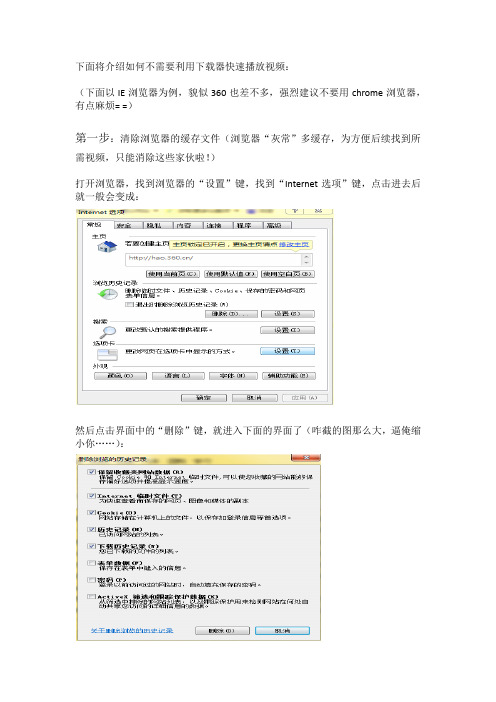
下面将介绍如何不需要利用下载器快速播放视频:(下面以IE浏览器为例,貌似360也差不多,强烈建议不要用chrome浏览器,有点麻烦= =)第一步:清除浏览器的缓存文件(浏览器“灰常”多缓存,为方便后续找到所需视频,只能消除这些家伙啦!)打开浏览器,找到浏览器的“设置”键,找到“Internet选项”键,点击进去后就一般会变成:然后点击界面中的“删除”键,就进入下面的界面了(咋截的图那么大,逼俺缩小你……):接着呢,就“直接”点击“删除键”,把缓存解决了。
(PS:也可以全勾啦,前提是如果哪天你觉得把浏览器中的东东重头再来,你就直接把能勾的选项都勾了,这样你的浏览器就能木有啥记录啦)接下来该干什么呢?第二步:去把你要下载的视频满怀激情地看一遍吧!!!到了收获的季节啦!☻第三步:再次肥到“Internet 选项”那个界面:这次我们点击“删除”键隔壁那个“设置”键进去后就会出现下面的界面:然后你就点击“查看文件”键,就会进入C盘的一个文档库里:这回你会看到大堆让人看着蛋疼的文件,甭管它,往下滑动,找到以“.flv ”为后缀的媒体文件,即视频文件(PS:那边还有mp4格式等其他XX格式的文件,咱都不要,就要flv的)。
这一栏里面就有你所需要的找的视频文件(虽然前面已经删除了缓存文件,但是还是会有一两个顽固分子,所以就一个个试吧!另外这些文件还不能直接打开,用以下步骤后就可以啦!)“复制”该视频文件,然后找一个你喜欢的地方“粘贴”(为方便建议直接在桌面粘贴)粘贴后就可以直接打开这个视频文件啦,可能不是你所要找的,肥去那一栏再粘贴里面其他的视频文件,一个个试就会发现啦!你所要下载视频的任务就完成啦,顺便给该视频重命名吧,粘贴后的默认的名字长的要死,一般人又认不出来窝!结束啦,有问题欢迎“师姐师妹”咨询,“师弟师兄”就木有这种待遇啦!!!九村支教队独家出版。
网页链接提取方法

网页链接提取方法网页链接的提取是数据采集中非常重要的部分,当我们要采集列表页的数据时,除了列表标题的链接还有页码的链接,数据采集只采集一页是不够,还要从首页遍历到末页直到把所有的列表标题链接采集完,然后再用这些链接采集详情页的信息。
若仅仅靠手工打开网页源代码一个一个链接复制粘贴出来,太麻烦了。
掌握网页链接提取方法能让我们的工作事半功倍。
在进行数据采集的时候,我们可能有提取网页链接的需求。
网页链接提取一般有两种情况:提取页面内的链接;提取当前页地址栏的链接。
针对这两种情况,八爪鱼采集器均有相关功能实现。
下面介绍一个网页链接提取方法。
一、八爪鱼提取页面内的超链接在网页里点击需要提取的链接,选择“采集以下链接地址”网页链接提取方法1二、八爪鱼提取当前地址栏的超链接从左边栏拖出一个提取数据的步骤出来(如果当前页已经有其他的提取字段,这一步可省略)点击“添加特殊字段”,选择“添加当前页面网址”。
可以看到,当前地址栏的超链接被抓取下来网页链接提取方法2而批量提取网页链接的需求,一般是指批量提取页面内的超链接。
以下是一个使用八爪鱼批量提取页面内超链接的完整示例。
采集网站:https:///search?initiative_id=tbindexz_20170918&ie=utf8&spm=a21 bo.50862.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=手表&suggest=history_1&_input_charset=utf-8&wq=&suggest_query=&source=sugg est步骤1:创建采集任务1)进入主界面,选择自定义模式网页链接提取方法32)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”网页链接提取方法43)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的商品url是这次演示采集的信息网页链接提取方法5步骤2:创建翻页循环1)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击下一页”网页链接提取方法6步骤3:商品url采集1)如图,移动鼠标选中列表中商品的名称,右键点击,需采集的内容会变成绿色,然后点击“选中全部”网页链接提取方法72)选择“采集以下链接地址”网页链接提取方法83)点击“保存并开始采集”网页链接提取方法94)根据采集的情况选择合适的采集方式,这里选择“启动本地采集”网页链接提取方法10步骤4:数据采集及导出1)选择合适的导出方式,将采集好的数据导出网页链接提取方法11通过以上操作,目标网页内的商品超链接就被批量采集下来了。
python爬取视频教程

python爬取视频教程爬取视频教程是一项非常有用和流行的技能,在这个数字化时代,互联网上存在着丰富的视频教程资源,使用Python编程语言可以方便地爬取这些视频教程并保存到本地。
以下我将介绍如何使用Python爬取视频教程。
首先,我们需要了解一些基本的爬虫概念和工具。
Python中最主要的爬虫库是requests和beautifulsoup。
requests可以发送HTTP请求并获取网页内容,beautifulsoup则可以解析网页内容。
我们还可以使用其他的第三方库来进一步处理视频,如FFmpeg、OpenCV等。
接下来,我们需要找到要爬取的目标网站。
可以选择一些专门提供视频教程的网站,如Youtube、B站等。
这些网站提供了API接口,可以方便地获取视频相关的信息。
我们可以使用requests库发送GET请求,获取返回的网页内容。
然后,我们需要在网页中找到视频的链接。
这就需要用到beautifulsoup库,它可以解析HTML文档,并提供了一些简单而强大的方法来提取并操作数据。
我们可以使用beautifulsoup 找到视频标签,并提取其中的链接信息。
接下来,我们可以使用requests库进一步获取视频的内容,并保存到本地。
在请求时,我们需要设置一些请求头(User-Agent、Referer等),以模拟浏览器行为,防止被网站屏蔽。
可以使用requests库的get方法下载视频数据,并使用Python 的文件操作将数据保存到本地文件中。
最后,如果需要进一步处理视频,如转换格式、剪辑、提取关键帧等,可以使用FFmpeg、OpenCV等库进行处理。
FFmpeg是一个强大的多媒体处理工具,可以进行视频的转码、剪辑等操作。
OpenCV是一个计算机视觉库,可以处理视频帧图像,提取关键帧等。
总结起来,使用Python爬取视频教程需要以下步骤:选择目标网站、使用requests库获取网页内容、使用beautifulsoup库解析网页内容、找到视频链接、使用requests库下载视频、(可选)使用FFmpeg、OpenCV等库进一步处理视频。
教你如何下载网页上的视频

当我们上网时肯定遇到很多你想下载的网页视频,并把其收藏起来,但是事与愿违,有些视频总是要申请账号,并且有的还要钱。
当这样的时候,我们就比较头疼了,下面给大家介绍一种下载网页视频的方法。
因为我是以chrome做例子的,所以就用到chrome和chrome cache viewer两个软件。
1.去掉电脑隐藏文件夹属性,找到路径:C:\Users\XXXXX\AppData\Local\Google\Chrome\UserData\Default\Cache(XXXXXX为用户名)将cache文件夹里面的东西全部删掉。
2.打开chrome找到自己想要找到的网页视频,点开,让其缓冲,此时,注意要打开chromecache viewer。
现在我随便找一个网页视频,就拿爱拍来说吧,爱拍上面的视屏是需要钱或者鲜花的,那么想要下载爱拍上面的视频就用到了这个方法,首先,我点开了,先缓冲着,等到放映时,我点开chrome cache viewer,,找到最大的文件,这个网页的文件就是,双击,如下图,看见URL了么,就是这个视频的地址,复制下来,在一个新的网页中输入地址,就能下载了,是不是很简单呢。
下载的时候注意,像这种对视频保护的网站,不能等到缓冲完,等到缓冲完,那个就没有了,所以要是中间的时候完成所有工作。
(注意此只限在有保护的网站)还有要是优酷上面的视频或者别的视频,如果太大的话会分成很多段,那就需要自己去耐心等待了,同时,多段的要注意,一定要等到缓冲完才能全部下载。
一般这种视频都是MP4格式的,FLV一般都是一个整体的。
怎样在无下载连接的视频网上截取一段视频

怎样在无下载连接的视频网上截取一段视频?当你看到很精彩的视频你想不想把他保存起来以后继续欣赏呢?或者是做成MP4格式放到手机里??但是目前绝大部分的视频网站由于版权、带宽等原因不提供视频下载服务,甚至想方设法把这些视频资源藏起来。
所以你无法把它们保存到自己的电脑上。
我们要怎么样才能把别人的视频文件保存到自己的电脑上呢?下面教你几招保存视频文件~~让我们来突破封锁,把在线视频搬回家,想看就看!一、WMV、ASF等格式的网络视频1、右键属性法。
第一步:打开在线视频网页,在网页播放器内点击鼠标右键,然后选择“属性”就能看到类似http://..../*.WMV”这样的地址,这就是视频地址了。
第二步:复制视频地址用下载软件下载。
如果右键被禁用,在浏览器地址栏中键入“:alert(document.oncontextmenu='')”(输入时不要输入双引号),此时会弹出个对话框,点击“确定”按钮,然后再对着你的目标视频点击鼠标右键就可以看到弹出菜单了!2、HTML源代码查询法(此方法同样适用rm格式的视频的下载。
)如果对方网站没有加密或隐藏视频资源的URL地址,就能用这个方法找到URL地址。
操作如下:第一步:在视频的播放页面,点击鼠标右键,选择“查看源文件”,系统自动用记事本程序打开网页源文件。
第二步:执行“编辑→查找”命令,然后在查找对话框中输入“.wma”,进行查找。
第三步:复制类似"http://..../*.rm"的地址或者*.rm的文件名,然后在下载软件中进行下载,对后者,需要根据当前网页的地址补全文件地址,一般是当前网页的地址加文件地址,就是这个文件的url地址。
3、迅雷法:(“网际快车”同样适用)第一步:安装并运行最新版本的迅雷,执行“工具→配置”打开配置面板,选择“监视”项,勾选右边“浏览器”下的三项。
第二步:打开在线视频网页,把鼠标移动到视频的播放页面上,会有一个“下载”字样的图标,点击即可。
如何提取网页中的视频

如何提取网页中的视频如何提取网页中的视频今天,随着移动流量大幅度降低资费,还有无处不在的WIFI,无论是学习还是娱乐观看视频已然成为生活必不可少的一部分,浏览网页看到喜欢的视频想收藏下载下来,如果数量少那简单,用浏览器的插件一键下载,如果数量多呢人工操作就显得麻烦,下面介绍一个批量快捷下载视频的工具-八爪鱼采集器,供大家愉快下载海量视频。
常见场景:1、遇到需要采集视频时,可以采集视频的地址(URL),再使用网页视频下载器下载视频。
2、当视频链接在标签中,可切换标签进行采集。
3、当视频链接在标签中,也可采集源码后进行格式化数据。
操作示例:采集要求:采集百度视频上综艺往期视频示例网址:/show/list/area-内地+order-hot+pn-1+channel-tvshow操作步骤:1、新建自定义采集,输入网址后点击保存。
注:点击打开右上角流程按钮。
2、创建循环翻页,找到采集页面中下一页按钮,点击,执行“循环点击下一页”。
在流程中的点击翻页勾选Ajax加载数据,时间设置2-3秒。
3、创建循环点击列表。
点击第一张图片,选择“选中全部”(由于标签可能不同,会导致无法选中全部,可以继续点击没被选中的图片)继续选择循环点击每个元素4、进入详情页后,点击视频标题(从火狐中可以看到视频链接在A标签中,如图所示),所以需要手动更换到相应的A标签。
手动更换为A标签:更换为A标签后,选择“选中全部”,将所有视频标题选中,此时就可以采集视频链接地址。
5、所有操作设置完毕后,点击保存。
然后进行本地采集,查看采集结果。
6、采集完成后将URL导出,使用视频URL批量下载工具将视频下载出来就完成了。
相关采集教程:网络爬虫视频教程:/tutorial/videotutorial新手入门视频采集教程:/tutorial/videotutorial/videoxsrm八爪鱼使用功能点视频教程:/tutorial/videotutorial/videognd网站数据采集实战视频教程:/tutorial/videotutorial/videoszczxpath应用示例—视频教程:/tutorial/videotutorial/xpathyinyong八爪鱼7.0文本循环采集教程,以采集腾讯视频举例:/tutorial/wbxh_7系统学习xpath—视频教程:/tutorial/xitongxpathajax点击-视频:/tutorial/ajax八爪鱼采集器URL循环-视频教程:/tutorial/urlxunhaun八爪鱼——90万用户选择的网页数据采集器。
网页视频提取工具使用方法
网页视频提取工具使用方法网页视频提取工具使用方法如今,看视频很便捷,但是提取网页中的视频大多数人还是用浏览器的扩展程序,比如Chrome、火狐的一些插件然后操作并不是很方便高效,下面介绍一个网页视频提取工具-八爪鱼采集器,能让你在短时间内批量获取网页视频。
本文以八爪鱼采集器简易模板采集提取腾讯网页视频为例。
需要采集腾讯地图关键词搜索内容的,在网页简易模式界面里点击腾讯进去之后可以看到关于腾讯的三个规则信息,我们依次直接使用就可以的。
网页视频提取工具使用方法步骤1采集腾讯视频-热播电影排行榜内容(下图所示)即打开腾讯网主页点击第三个(腾讯视频-最近热播电影排行榜)采集搜索到的内容。
1、找到腾讯视频-最近热播电影排行榜规则然后点击立即使用网页视频提取工具使用方法步骤22、下图显示的即为简易模式里面的腾讯视频-最近热播电影排行规则①查看详情:点开可以看到示例网址②任务名:自定义任务名,默认为腾讯视频-最近热播电影排行③任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组④翻页次数:设置要采集几页⑤示例数据:这个规则采集的所有字段信息网页视频提取工具使用方法步骤33、规则制作示例任务名:自定义任务名,也可以不设置按照默认的就行任务组:自定义任务组,也可以不设置按照默认的就行翻页次数:2设置好之后点击保存,保存之后会出现开始采集的按钮保存之后会出现开始采集的按钮网页视频提取工具使用方法步骤44、选择开始采集之后系统将会弹出运行任务的界面可以选择启动本地采集(本地执行采集流程)或者启动云采集(由云服务器执行采集流程),这里以启动本地采集为例,我们选择启动本地采集按钮网页视频提取工具使用方法步骤55、选择本地采集按钮之后,系统将会在本地执行这个采集流程来采集数据,下图为本地采集的效果网页视频提取工具使用方法步骤66、采集完毕之后选择导出数据按钮即可,这里以导出excel2007为例,选择这个选项之后点击确定网页视频提取工具使用方法步骤77、然后选择文件存放在电脑上的路径,路径选择好之后选择保存网页视频提取工具使用方法步骤88、这样数据就被完整的导出到自己的电脑上来了哦,点击打开excel表就可以查看了。
电脑怎么下载网页视频的方法

电脑怎么下载网页视频的方法下随着网络技术的迅速发展,使得网络及网络应用更加广泛和深入,同时也使得网络安全问题日渐突出和复杂。
面是店铺为大家整理的关于电脑怎么下载网页视频的方法,一起来看看吧!电脑怎么下载网页视频的方法1.准备工具:IE11浏览器或谷歌浏览器或360浏览器或猎豹浏览器或火狐浏览器或等等浏览器,IE6我没试过,IE8貌似也不好找。
教程就用谷歌浏览器吧,其他的大同小异。
2.进入你要下载的视频网站,并确定可以播放了。
出来后是这个样子地,会出现在浏览器的下方:4.点Network,如果你用过的话,以后就会默认到这里的点击后:可以将网址这里拉长些:5.刷新页面,也就是页面重新载入(快捷键F5),并播放视频,如果你不刷新,或者先播放视频再点开“开发者工具”是捕获不到视频地址的。
此时视频文件的地址已经暴露出来了,只需寻找了。
一般的来讲,网络上mp4文件用的是较多的,也有flv的,看好视频后缀名称就可以了。
如果你熟练了,你也可以先打开“开发者工具”在进入播放视频,一样的。
一般来讲,同一网站的视频地址都会在一个地方,下回大概还是这个位置,就不用再浪费时间寻找了。
这是我找到的地址:看到了吗?后面写着 video/mp4 mp4耶~~~如果你确定了这个站的视频是mp4的,你也可以这样:用过滤器在过滤器上写mp4,看到了吗:6.开始复制地址,准备下载,在你找到的地址上右键,选择”Copy link address”(复制链接地址):地址就这样复制成功了。
7.下载下载的方式有很多种,你可以用迅雷,旋风,浏览器等。
一.软件下载:打开迅雷软件后,新建->确定就OK了。
手机一键批量下载网页视频和图片,这款神器不得不装!

手机一键批量下载网页视频和图片,这款神器不得不装!
展开全文
现实中有很对小伙伴经常用手机看一下视频或者图片,有时候需要下载下来,图片还好说,长按基本都可以保存,但是视频下载就不那么方便了,尤其是有时候需要批量下载。
今天,“电脑那些事儿”给大家介绍一款堪称神器的手机浏览器,只有3M多的大小,却可以实现一键批量下载网页上的视频和图片,需要的小伙伴们赶紧看看吧~
视频版教程:
文字版教程:
1、下载安装河豚浏览器(安卓)
你可以自己搜索下载安装。
也可以:
2、在搜索框内输入视频或者图片的网址。
(1)下载图片:你可以点击浏览器预置的网站,也可以自己输入网址搜索。
①比如输入百度网址,然后搜索“电脑”相关图片。
点击页面下方的“提取图片和视频”。
跳转到图片下载页面,选择好想要下载的图片(也可以全选)。
②点击页面下方的“保存到手机”即可完成下载,点击“已保存图片”或者进入手机相册,可以查看已下载的图片。
(2)下载视频:方法与下载图片差不多。
①比如我们直接点击浏览器预置的头条网站,然后搜索“电脑那些事儿”发表的视频。
②进入视频页面,点击页面下方的“提取图片和视频”,跳转到视频下载页面,选择好想要下载的视频(也可以全选)。
③点击页面下方的“保存到手机”即可完成下载,点击“已保存视频”或者进入手机相册,可以查看已下载的视频。
下载网页视频的方法

下载网页视频的方法
要下载网页视频,可以使用以下方法之一:
1. 使用网页视频下载器:有许多提供网页视频下载功能的软件和浏览器插件可供选择。
安装并使用这些工具,可以轻松地下载网页视频。
2. 在浏览器中查看源代码并搜索视频链接:打开网页视频所在的网页,并使用浏览器的“查看源代码”功能。
在源代码中搜索包含视频链接的标签或关键词,然后复制该链接并在浏览器中打开。
从打开的链接中下载视频。
3. 使用视频下载网站:有一些专门的视频下载网站可以帮助您下载网页视频。
打开这些网站并根据提示粘贴视频链接或网页地址,并进行下载。
无论使用哪种方法,确保不在文中使用任何标题相同的文字,以遵循您的要求。
如何将页面blob类型的视频链接下载下来?

1.F12开启代码检查,点击代码区,CTR+F调出关键词搜索框,输入video,找到video标签,确认视频类型。如图,type为m3u8; 2.点击Network,刷新后,找到v2选项,点击后,根据RequestURL确认链接后缀带有m3u8的字符,拷贝此链接;
4.等待下面的小方格全部变色为绿色后,即可自动下载下来。
有时候访问页Leabharlann 遇到喜欢的视频会直接使用代码检查找到视频链接直接拷贝下载但是遇到video标签中的链接带有blob如图直接拷贝访问是无法下载的
如何将页面 blob类型的视频链接下载下来?
有时候访问页面遇到喜欢的视频,会直接使用代码检查,找到视频链接直接拷贝下载,但是遇到video标签中的链接带有blob(如图),直 接拷贝访问是无法下载的。我们需要按以下步骤来实现目的:
怎样在无下载连接的视频网上截取一段视频

打开在线网络播放页面,点击视频“播放”按钮,在视频缓冲前断开网络。
第二步:
再次点击“播放”按钮,让该视频连接网络,因为断网无法连接,大概几秒钟弹出“无法建立与服务器的连接”对话框。
第三步:
复制对话框中的地址,用下载软件下载视频。
三、flv格式视频文件
FLV流媒体格式是一种新的视频格式,目前非常火暴,相比以上传统格式文件,flv视频的下载,难度稍大一些。
在网页中的播放器内,点鼠标右键,选择“在RealPlayer中播放”,然后就会调用“RealPlayer”播放器(前提是你必须安装给播放软件)进行本地播放。
件”,再继续选择“剪辑属性→查看剪辑信息”,就能找该视频的URL地址了
第三步:
复制视频地址下载即可。
2:断网法
一、WMV、ASF等格式的网络视频
1、右键属性法。
第一步:
打开在线视频网页,在网页播放器内点击鼠标右键,然后选择“属性”就能看到类似http:
//..../*.WMV”这样的地址,这就是视频地址了。
第二步:
复制视频地址用下载软件下载。
如果右键被禁用,在浏览器地址栏中键入“:
alert(document.oncontextmenu='')”(输入时不要输入双引号),此时会弹出个对话框,点击“确定”按钮,然后再对着你的目标视频点击鼠标右键就可以看到弹出菜单了!
1、"专用工具:
软件名称:
xxFLV视频下载软件(点击下载)
第一步:
安装并运行维棠,在菜单中选择“工具→选项”,在弹出的“选项”窗口的“常规选项”的右边点选“在IE右键里添加下载菜单”,选择确定后,重启IE。
第二步:
在FLV视频节目所在页面空白处点击右键,选择“利用维棠下载视频”启动维棠FLV视频下载软件来分析FLV视频真实地址并开始下载FLV视频节目。
抓取在线文件的方法

抓取在线文件的方法全文共四篇示例,供读者参考第一篇示例:随着互联网的快速发展,许多人都习惯于在网络上搜索和阅读各种文档、文件。
不过,在某些情况下,我们可能需要将在线文件下载到本地存储或进行其他处理。
那么,如何有效地抓取在线文件呢?本文将介绍几种常用的方法。
一、使用浏览器下载功能最简单直接的方法就是使用浏览器自带的下载功能。
当您在浏览器中打开一个在线文件时,通常可以看到一个“下载”按钮或类似的选项,点击即可将文件下载到本地。
大多数浏览器都支持这一功能,包括Chrome、Firefox、Safari等。
二、使用在线下载工具如果您需要抓取大量的在线文件,手动一个一个点击下载可能会比较麻烦。
这时候,您可以考虑使用一些在线下载工具,如IDM (Internet Download Manager)、迅雷等。
这些工具可以帮助您批量下载文件,提高效率。
三、使用专门的下载软件除了浏览器和在线下载工具,还有一些专门的下载软件可以帮助您抓取在线文件。
wget是一款常用的命令行下载工具,支持各种协议,可以方便地下载文件。
JDownloader、Free Download Manager等软件也很受欢迎。
四、使用网页抓取工具有时候,我们可能需要抓取某个网页上的所有文件,包括图片、视频、文档等。
这时候,网页抓取工具就可以派上用场了。
可以使用HTTrack、WebCopy等工具来下载整个网站的内容。
五、编写脚本自动化下载如果您是一名程序员,还可以考虑编写脚本来自动化下载文件。
使用Python的requests库可以轻松地编写一个脚本来下载网络上的文件。
这样可以更加灵活地控制下载过程。
不过,需要注意的是,在抓取在线文件时,一定要遵守相关的法律法规,不要侵犯他人的知识产权。
在使用下载工具和软件时,也要注意安全性,避免下载恶意文件导致计算机感染病毒。
抓取在线文件有很多种方法,您可以根据具体需求选择合适的方法。
希望本文介绍的方法对您有所帮助,祝您抓取文件顺利!第二篇示例:在当今互联网时代,抓取在线文件已经成为一种常见的操作方式。
怎样在浏览器网页上下载网上视频

怎样把网上的视频下载到电脑
当我们在别人空间里、土豆网、56网、优酷网等网站看到很好看的视频,总是想把它下到自己的手机/MP4/MP5里,回去在慢慢地欣赏。
可是问题出现了!QQ空间、土豆,56,优酷里的视频不能直接下载,必需借助下载工具,真的很气人!下面我告诉大家一个简单的方法,不需要安装任何下载工具就能把你要看的视频下载到电脑上!
附截图教程!
1。
把你看的视频先缓冲完(看完也可以)。
2。
点击网页最上面一拦的‘ 工具(T)’,然后找到‘ Internet 选项(0)...’
3。
点击‘Internet 选项(0)...’ ,找到‘设置(S)’
4。
单击‘ 设置(S)’,出现下面这样的图框,找到‘查看文件(V)...’
5。
点击‘查看文件’,并在出现的图框内鼠标右键单击——排列图片(I)——大小
6。
由于视频文件比较大,会排在最前面。
找到视频文件,直接拉到桌面上就行了。
视频文件一般是FLV,MP4格式的,如下面的粉红色框内就是视频文件,不要找错了。
7。
到此基本上完毕。
FLV格式的文件MP4/MP5有的能放出来有的放不出来,建议在转换一下格式,转换成高清格式(rmvb,mp4)的。
手机转换成3GP格式。
推荐转换器:抓抓影音伴侣。
我可不是在为它做广告,它又没给我钱,我用的就是这个转换器,很方便,很好用。
下载转换器请到官网去下。
下载转换器请到官网去下。
python爬取豆瓣电影的流程

python爬取豆瓣电影的流程Python爬取豆瓣电影的流程豆瓣是一个备受关注的网站,它为我们提供了许多好看的电影资源。
我们可以使用Python来爬取豆瓣电影,学习其中的爬虫技巧,为我们的学习和工作带来更多的便利。
下面是python爬取豆瓣电影的流程:1. 安装必要的库在Python中爬取网页时,需要使用一些库来实现。
常用的一些库包括:requests: 用于发起HTTP请求和获取网页数据。
beautifulsoup4: 用于解析HTML数据,提取网页中的数据。
lxml: 解析XML和HTML数据。
pandas: 用于数据处理和分析。
以上几个库都是Python爬虫中经常使用的库,在使用前需要先使用pip安装。
2. 发起HTTP请求使用Python发起HTTP请求,可以使用requests库。
通过发送请求,可以获取网页的HTML代码,进而爬取需要的数据。
其中,requests 库提供了get()和post()方法,分别用于发起GET和POST请求。
3. 解析HTML数据获取到网页的HTML代码后,需要对数据进行解析,提取出我们需要的数据。
这一步可以使用beautifulsoup4库来完成。
使用该库,我们可以定位到HTML页面中的特定元素,例如div、span、a等。
找到需要的元素后,我们再通过一些属性或方法提取出里面的文本信息或元素标签等。
4. 筛选数据和保存数据在得到数据后,我们还需要对数据进行筛选和清洗,去掉无用的数据,仅保留我们需要的数据。
筛选后的数据可以存储到本地文件,方便我们分析和处理。
5. 程序优化在爬取网页时,通常会爬取大量数据。
这会导致程序运行时间过长,甚至会出现网络阻塞等问题。
因此,我们需要对程序进行优化,采用多线程或异步处理等方式,提高程序的效率和稳定性。
以上就是Python爬取豆瓣电影的流程。
在这个流程中,我们需要充分发挥Python的优势,利用各种库和工具,实现数据的高效爬取和处理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
网页视频抓取教程
如何采集视频教程
本教程为大家讲解如何采集页面中的视频。
常见场景:
1、遇到需要采集视频时,可以采集视频的地址(URL),再使用网页视频下载器下载视频。
2、当视频链接在标签中,可切换标签进行采集。
3、当视频链接在标签中,也可采集源码后进行格式化数据。
操作示例:
采集要求:采集百度视频上综艺往期视频
示例网址:/show/list/area-内地+order-hot+pn-1+channel-tvshow 操作步骤:
1、新建自定义采集,输入网址后点击保存。
注:点击打开右上角流程按钮。
2、创建循环翻页,找到采集页面中下一页按钮,点击,执行“循环点击下一页”。
在流程中的点击翻页勾选Ajax加载数据,时间设置2-3秒。
3、创建循环点击列表。
点击第一张图片,选择“选中全部”(由于标签可能不同,会导致无法选中全部,可以继续点击没被选中的图片)
继续选择循环点击每个元素
4、进入详情页后,点击视频标题(从火狐中可以看到视频链接在A标签中,如图所示),所以需要手动更换到相应的A标签。
手动更换为A标签:
更换为A标签后,选择“选中全部”,将所有视频标题选中,此时就可以采集视频链接地址。
5、所有操作设置完毕后,点击保存。
然后进行本地采集,查看采集结果。
6、采集完成后将URL导出,使用视频URL批量下载工具将视频下载出来就完成了。
相关采集教程:
网络爬虫视频教程/tutorial/videotutorial
网站数据采集实战视频教程
/tutorial/videotutorial/videoszcz
模拟登录并识别验证码抓取数据/tutorial/gnd/dlyzm xpath抓取网页文字/tutorial/gnd/xpath
其他采集功能点/tutorial/gnd/qitagnd
八爪鱼——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。
配置好采集任务后可关机,任务可在云端执行。
庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。
4、功能免费+增值服务,可按需选择。
免费版具备所有功能,能够满足用户的基本采集需求。
同时设置了一些增值服务(如私有云),满足高端付费企业用户的需要。