Eviews 使用命令
Eviews 使用命令

· 粘贴方式
如果数据本身已在excel电子数据表格上,
也可以直接采用粘贴方式 。
粘贴方式和在window中的方式一样。
打开excel文档
三,散点图
命令: 1. 菜单:View/Graph 2. 窗口:
趋势图: Plot Y X 相关图: Scat Y X
间和日期
· Sample:方程估计是使用的样本区间 · Included observations:观察值个数,即样
本容量
· Variable:自变量,其中c表示常数项
一元线性回归模型的估计
· Coefficient:系数估计值 · Std.Error:系数估计的标准误差,即 · t-Statistic: t统计量,即 · Prob:实际显著性水平(双侧检验),即P值,
四,回归模型的估计
· 一元线性回归的OLS估计
命令: 1.菜单: Quick/Estimate Equation
2.窗口:Ls Y C X
(此时对话框中的变量次序,Y是因变量,X是自变量, C是常数项)
一元线性回归模型的估计
· 回归结果
一元线性回归模型的估计
· Dependent variable:因变量 · Method:方程估计方法 · Date:05/01/04 Time:23:20 输出结果的时
· Monthly:输入格式为2010:01 · Weekly和daily:输入格式为12:31:2011,即:
〝 月 : 日 : 年〞的形式。
· Undated or irre入数据)
命令:
1. 菜单:File/New/Workfile
eviews-操作基本命令

Eviews-操作基本命令Eviews是一种用于经济数据建模和分析的软件,可以进行数据处理、拟合模型、进行统计分析等等。
为了更好地使用Eviews进行分析,我们需要了解一些Eviews的基本命令。
以下是一些常用的Eviews操作命令。
数据清理批量修改变量名称使用rename命令可以批量修改变量的名称。
假设我们有一组包含了许多经济指标的数据,我们可以使用以下命令将某一个变量的名称由y1更改为GDP:rename(y1, GDP)创建新变量使用以下语法可以创建新变量:series newvar_name = expr其中newvar_name是新变量的名称,expr是计算新变量值的表达式。
例如,我们可以使用以下语句创建一个名为inflation的新变量,其值等于CPI变量的年度增长率:series inflation = log(CPI) - log(CPI(-1))数据筛选内置命令if用于筛选数据。
例如,假设我们有一个名为gdp的变量,我们可以使用以下语法选择其中gdp大于5000的数据:sample if gdp > 5000行列操作如果我们有一个多元素的数据,例如,一张包含多个行和列的表格,我们可以使用以下命令对其进行操作。
按行排序使用以下命令可以将数据按行排序:series gdpsum = sum(gdp)sort(gdpsum)这里我们使用了内置函数sum编写了一个名称为gdpsum的新变量,并使用sort对新变量进行排序操作。
按列计算统计量可以使用group命令按照某一列进行分组,并计算统计量。
例如,我们可以分成两个组,分别对指标A和B进行求和:group id A Bseries asum = @sum(A)series bsum = @sum(B)数据拟合和评估线性回归我们可以使用ls(least square)命令进行线性回归分析,例如:ls example_data.wf1 y x1 x2其中example_data.wf1是数据文件的路径,y是因变量,x1和x2是自变量。
eviews常用运算、函数及命令

1.常用运算:加、减、乘、除、幂例如:已知变量X 、Y,生成新变量Z在命令窗口输入:Genr Z=X + Y 加Genr Z=X – Y 减Genr Z=X * Y 乘Genr Z=X / Y 除Genr Z=X ^(3) 3次幂Genr Z=X ^(0.5) 开根号Genr Z=X ^(-1) 倒数Genr Z=X ^(2)平方以此类推……注意:*是乘,保留运算符号,不能用于设置变量名此外,还可以用括号进行复合运算,比如:Genr Z=(X + Y)*X^(3)/Y2.常用函数:对数、指数、滞后值、差分Genr Z1=LOG(X) 自然对数Ln,注意Ln(X)是错误的Genr Z2=LOG(Y)Genr Z3=EXP(X) e xGenr Z4=ABS(X) X的绝对值Genr Z5= X(-1) 滞后值:X的前一期值,注意跟倒数的区别Genr Z6= X(-2) 滞后值:X的前二期值,注意跟负二次方的区别Genr Z7= X(-3) ……Genr Z8=D( X ) X的差分,即X-X(-1)变量名必须以字母开头,后面可以跟数字,以示区别注意:D是差分,保留函数符号,不能用于设置变量名复合运算,比如:Genr Z9= EXP( X ) *((1+EXP( X ))^(-1))3.一些@开头的函数比如:@OBS(X) 返回变量X的观察值个数,其实就是n@mean(X) 返回变量X的均值@sum(X) 返回变量X的序列求和@r2 返回当前回归的R平方@dw 返回当前回归的dw值@ssr 返回当前回归的残差平方和4.常用回归命令LS Y C XLS Y C X1 X2 X3LS LOG(Y) C LOG(X1) LOG(X2)5.常用绘图命令SCA T X Y 散点图X为横轴,Y为纵轴LINE Y X1 X2 X3 折线图。
Eviews基本操作 (2)
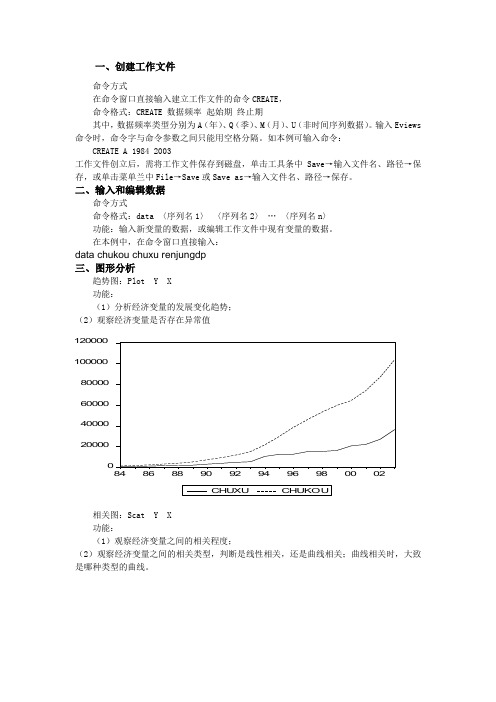
一、创建工作文件命令方式在命令窗口直接输入建立工作文件的命令CREATE , 命令格式:CREATE 数据频率 起始期 终止期 其中,数据频率类型分别为A (年)、Q (季)、M (月)、U (非时间序列数据)。
输入Eviews 命令时,命令字与命令参数之间只能用空格分隔。
如本例可输入命令:CREATE A 1984 2003工作文件创立后,需将工作文件保存到磁盘,单击工具条中Save →输入文件名、路径→保存,或单击菜单兰中File →Save 或Save as →输入文件名、路径→保存。
二、输入和编辑数据命令方式命令格式:data 〈序列名1〉 〈序列名2〉 … 〈序列名n 〉 功能:输入新变量的数据,或编辑工作文件中现有变量的数据。
在本例中,在命令窗口直接输入:data chukou chuxu renjungdp 三、图形分析趋势图:Plot Y X 功能:(1)分析经济变量的发展变化趋势; (2)观察经济变量是否存在异常值02000040000600008000010000012000084868890929496980002相关图:Scat Y X 功能:(1)观察经济变量之间的相关程度;(2)观察经济变量之间的相关类型,判断是线性相关,还是曲线相关;曲线相关时,大致是哪种类型的曲线。
20000400006000080000100000120000010000200003000040000CHUXUC H U K O U四、OLS 估计参数在主菜单命令行键入 LS Y C X单击Equation 窗口中的Resid 按钮,将显示模型的拟合图和残差图-10000-50000500010000-2000002000040000600008000010000012000084868890929496980002单击Equation 窗口中的View → Actual, Fitted, Resid → Table 按钮,可以得到拟合直线和残差的有关结果五、预测在Equation 框中选Forecast 项后,弹出Forecast 对话框,Eviews 自动计算出样本估计期内的被解释变量的拟合值,拟合变量记为chukouF ,其拟合值与实际值的对比图如下-2000002000040000600008000010000012000084868890929496980002scalar CHUKOU1 = -5719.991597 + 2.116770043*0 + 3.773129627*0区间估计coef(2) confintconfint(1)=1243-@qtdist(.975,20)*eq01.@sddep confint(2)=1243+@qtdist(.975,20)*eq01.@sddep coef(4) confint1confint1(1)=eq01.@coefs(2)-@qtdist(.975,20)*eq01.*@stderrs(2) confint1(2)=eq01.@coefs(2)+@qtdist(.975,20)*eq01.*@stderrs(2) confint1(3)=eq01.@coefs(3)-@qtdist(.975,20)*eq01.*@stderrs(3) confint1(4)=eq01.@coefs(3)+@qtdist(.975,20)*eq01.*@stderrs(3)六、非线性回归模型的估计1.倒数模型:μββ++=XY 110 在命令窗口直接依次键入GENR X1=1/X LS Y C X12.多项式模型:μβββ+++=2210X X Y 在命令窗口直接依次键入GENR X1=X GENR X2=X^2 LS Y C X1 X23.准对数模型:μββ+++=X Y ln 10 在命令窗口直接依次键入GENR lnX=LOG(X)LS Y C lnX4.双对数模型:μββ+++=X Y ln ln 10 在命令窗口直接依次键入GENR lnX=LOG(X) GENR lnY=LOG(Y)LS lnY C lnX七、异方差检验与解决办法1.X e -2相关图检验法LS Y C X 对模型进行参数估计 GENR E=RESID 求出残差序列GENR E2=E^2 求出残差的平方序列 SORT X 对解释变量X 排序SCAT X E2 画出残差平方与解释变量X 的相关图2.戈德菲尔德——匡特检验已知样本容量n=26,去掉中间6个样本点(即约n/4),形成两个样本容量均为10的子样本。
第1讲Eviews基本命令的掌握

第1讲Eviews基本命令的掌握Eviews基本命令的掌握要求:①掌握Eviews 基本操作:包括建⽴⼯作⽂件,录⼊数据,Eviews⼯作命令⽅式。
②了解并熟悉eviews基本函数的使⽤以及假设检验。
Eviews简介:见演⽰⽂档⼀、Eviews 基本操作1. 启动Eviews双击Eviews 图标,出现Eviews 窗⼝,它由以下部分组成:标题栏“Eviews ”、主菜单“⽂件,编辑,…,帮助”、命令窗⼝(空⽩处)和⼯作区域。
2.产⽣⽂件Eviews 的操作在⼯作⽂件中进⾏,故⾸先要有⼯作⽂件,然后进⾏数据输⼊、分析等等操作。
(1)读已存在⽂件:⽂件/打开/Workfile 。
(2)新建⽂件:⽂件/新建/Workfile ,出现对话框“⼯作⽂件范围”,选取或填上数据类型、起⽌时间。
填好后,得到⼀个⽆名字的⼯作⽂件,其中有:时间范围、当前⼯作⽂件样本范围、Filter、默认⽅程、系数向量C 、序列残差。
附:1Annual选项:可以⽤四位年份如Start date:1955 End date 1998,在1900年和2000年之间的年份只需要后两位即可。
Quarterly选项: 输⼊格式为: 1992:1, 65:4, 2002:3年后⾯只能跟1、2、3、4代表季度。
Monthly选项: 输⼊格式Examples: 1956:1, 1990:11年后⾯为⽉Weekly and daily选项: 在缺省状态下的格式如8:10:97即为October 8, 1997. Undated or irregular选项:为⾮⽇期数据如:Start date:1 End date 100,即为100个数的⼀个序列。
附:2保存Workfile可以⽤两种⽅法保存Workfile,第⼀种⽅法点击主窗⼝中File/SaveAs or File/Save;第⼆,Workfile窗⼝中的⼯具栏中的Save按钮即可以保存。
打开Workfile⽤File/Open/Workfile的⽅式可以打开以前保存的Workfile改变workfile的显⽰⽅式:选择View/Display Filter,或者双击workfile窗⼝中的Filter.*就会出现如下的对话框在*号后⾯填⼊你想要显⽰的变量(中间⽤空格阁开),点OK即可3.输⼊数据(1)从键盘输⼊:快速的quick/空组empty group (编辑系列) ,打开组窗⼝,产⽣⼀个⽆标题“组”;按列在表中输⼊序列名(在OBS )及其数据,每输⼊⼀个数据完,敲⼀次enter 。
Eviews简易使用方法

Eviews5.0基本操作一、启动软件包 ( 双击“Eviews ”,进入Eviews 主页) 二、建立工作文件点击file →new →workfile,在弹出的对话框中有三个选项区: (1)workfile structure type(工作文件结构类型) (2)data specification(日期设定) (3)name (名)如果选择unstructured/undataed ,则右上角会变成data range 选择区,其中输入样本容量。
如果选择balanced panel ,右上角变成panel specification 选择框,其中有4个选择框,分别要求输入频率、开始期、终止期、个体个数(面板数据中所包含的个体个数)。
相应设定完成之后点击OK 键。
出现“Workfile 对话框(子窗口)”中已有两个变量: c-----常数项resid----模型将产生的残差项三、输入(编辑)数据:法1:在命令框键入:“data y x ”( 一元)或“data y 1x 2x …”(多元)/回车;出现数据编辑框,按顺序键入数据/存盘(或最小化)。
建议使用这种方法法2:用鼠标单击“Quick ”,在出现的下拉菜单中单击“EMPTY GROUP , 输入数据,默认的变量名是SER01、SER02等等。
输入完毕,关闭GROUP 窗口,回到Workfile 窗口,对变量点击右键选rename 可以对变量名重命名如y 、x ;双击变量名可以浏览相应数据 四、作图单击“Quick/Graph/line graph ”输入y x(解释变量)五、计算描述统计量1、点击“Quick/Group statistics/Descriptive statistics/Common Sample ;2、键入y x (或y 1x 2x )/ok 。
第一章 简单线性回归模型;第二章 多元线性回归模型一、回归分析(用OLS 估计未知参数)法1:点击“Quick/Estimate Equation ”;2、在出现的估计对话框中,键入y c x/ok 法2、在命令框键入ls y c x 或ls y c 1x 2x /回车。
eviews-操作基本命令

Eviews常用命令(对于命令和变量名,不区分大小写)1.创建时间序列的工作文件a annual:create a 1952 2000s semi-annual:create s 1952 1960q quarterly:create q 1951:1 1952:3m monthly:create m 1952:01 1954:11w weekly: create w 2/15/94 3/31/94,自动认为第一天为周一,和正常的周不同。
d daily (5 day week): create d 3/15/2008 3/31/2008,和日历上周末一致,自动跳过周末。
7 daily (7 day week): create 7 3/03/2008 3/31/2008。
u undated: create u 1 33。
创建工作文件时可直接命名文件,即在create 后面直接键入“文件名”,如create myfilename a 1952 2000 或者workfile myfilename a 1952 2000系统自动生成两个序列:存放参数估计值c和残差resid。
2.创建数组(group)多个序列组合而成,以便对组中的所有变量同时执行某项操作。
数组和各个序列之间是一种链接关系,修改序列的数据、更改序列名、删除序列等操作,都会在数组中产生相应的变化。
1)创建完文件后,使用data建立数据组变量;若有word表格数据或excel数据,直接粘贴;或者用Import 从其它已有文件中直接导入数据。
data x y,…可以同时建立几个变量序列,变量值按列排列,同时在表单上出现新建的组及序列,且可以随时在组中添加新的序列。
利用组的优点:一旦某个序列的数据发生变化,会在组中和变量中同时更新;数组窗口可以直接关闭,因为工作文件中已保留了有关变量的数据。
2)通过已有序列建立一个需要的组:group mygroup x y 可以在组中直接加入滞后变量group mygroup y x(0 to -1) 3.创建标量:常数值scalar val = 10 show val 则在左下角显示该标量的值4.创建变量序列series xseries ydata x yseries z = x + yseries fit = Eq1.@coef(1) + Eq1.@coef(2) * x利用两个回归系数构造了拟合值序列5.创建变量序列genr 变量名= 表达式genr xx = x^2 genr yy = val * ygenr zz = x*y (对应分量相乘) genr zz = log(x*y) (各分量求对数) genr lnx = log(x) genr x1 = 1/xgenr Dx = D(x) genr value = 3(注意与标量的区别) genr hx = x*(x>=3)(同维新序列,小于3的值变为0,其余数值不变) 1)表达式表示方式:可以含有>,<,<>,=,<=,>=,and,or。
EViews的基本使用
EViews的基本使用一、相关性分析1.导入数据File → Open → Foreign Data as Workfile …、然后会出现下图,选择我们需要的文件打开。
在Predefined range区域可以选择Excel文件中选择表,然后点击“下一步”。
点击“完成”并可成功导入数据。
2.做相关性检验View →Covariance Analysis会出现下图:选择Correlation检验相关性,同时选择Probability确定相关性有意义。
点击“OK”3.分析结果上图是结果的一部分。
上面的数值表示两者的相关系数,下面的数值是两者相关性是否有意义的指标。
一般而言,相关系数在0.8以上我们称两者有高度相关关系,0.8到0.5之间为中度相关,小于0.5视为不相关。
另外,一般Probability的数值小于0.05,表示两者间的相关系数有意义。
二、回归分析1、用以上相同的方法导入数据;2、用以上相同的方法做各X变量间的相关性检验,确定各X变量之间不存在高度相关关系;3、回归分析在主菜单中选择Quick →Estimate Equation…输入回归方程,如方程式为Y= C+α1*X1+α2*X2+……则输入的格式为:Y(空格)C(空格)X1(空格)X2……4、分析结果以上是“沪铜和伦铜,美元指数和道琼斯指数”的回归结果。
一般先看R平方和调整R平方,表示整个模型的拟合程度,越高越好。
然后看F检验,通过F检验表示该模型在统计上有意义。
再看t检验,判断每个系数是否有意义。
一般而言,Prob.大于0.05表示有意义。
然后就可以写出回归方程。
(注:文档可能无法思考全面,请浏览后下载,供参考。
可复制、编制,期待你的好评与关注)。
Eviews中的常用函数及应用

Eviews中的常用函数及应用Eviews 常用命令 (对于命令和变量名,不区分大小写)1.创建时间序列的工作文件a annual : create a 1952 2000s semi-annual :create s 1952 1960 qquarterly : create q 1951:1 1952:3m monthly : create m 1952:01 1954:11w weekly: create w 2/15/94 3/31/94,自动认为第一天为周一,和正常的周不同。
d daily (5 day week): create d 3/15/2008 3/31/2008,和日历上周末一致,自动跳过周末。
7 daily (7 day week): create 7 3/03/2008 3/31/2008。
u undated: create u 1 33。
创建工作文件时可直接命名文件,即在create 后面直接键入“文件名”, 如create myfilename a 1952 2000 或者 workfile myfilename a 1952 2000系统自动生成两个序列:存放参数估计值c 和残差resid 。
4)回归统计函数回归统计函数是从一个指定的回归方程返回一个数。
调用方法:方程名后接.再接@函数。
如EQ1.@DW ,则返回EQ1方程的D-W 统计量。
如果在函数前不使用方程名,则返回当前估计方程的统计量。
统计函数见下面:@RESIDCOVA(I,j) 向量自回归中残差之间的协方差7.矩阵 8.常用命令:1)Cov x y :cov(,)()()/iix y x x y y n =--∑协方差矩阵。
Cor x y :22co (,)()()()()iiiir x y x x y y x x y y =----∑∑∑相关矩阵。
2)plot x y :出现趋势分析图,观察两个变量的变化趋势或是否存在异常值。
EViews 软件的常用操作

EViews软件的基本操作1 EViews的启动双击EViews6.exe,进入EViews主窗口2创建工作文件在主窗口菜单上依次点击File\New\Workfile,自动弹出创建工作文件选项卡。
在Workfile structure type选项区共有3种类型,默认状态是Dated-regular frequency类型。
在默认状态Dated-regular frequency类型下,另一选项区Date specification的默认的时间频率为Annual(年度数据),在起始栏和终止栏分别输入相应的日期1990和2004。
点击OK,在主窗口内弹出工作文件窗口。
工作文件一开始就包含了两个对象,分别为C(系数向量)和resid(残差)。
它们当前的取值分别是0 和NA(空值)。
可以通过鼠标左键双击对象名打开该对象查看其数据。
3 输入数据点击Quick \ Empty Group (Edit Series),进入数据编辑窗口,输入或粘贴数据。
注意,输入数据时最好将被解释变量y放在左起第一列,Eviews 在自动列方程时将默认左起第一列为被解释变量。
向上拖动窗口右侧的滑动条到obs的位置,输入序列名。
点击Name命令,自动弹出Object Name对话框窗口,输入文件名称(或默认为group01),关闭数据输入窗口即可;或直接关闭数据输入窗口,也会弹出提示命名序列组文件的对话框。
4 生成序列从主窗口点击Quick/Generate Series,然后在弹出的公式编辑窗口空白区输入公式LNY=LOG(Y)。
或从工作文件窗口点击Genr亦可弹出公式编辑窗口。
依次生成以下数列:LNX=LOG(X)DX=D(X)X1=X^2X2=1/XT=@TREND(1989)5 编辑数组及序列按住Ctrl 键不放,依次单击选择变量,完成后,单击鼠标右键,在弹出的快捷菜单中点击Open/as Group,弹出数组窗口,其中变量从左至右按选择变量的顺序来排列。
Eviews常用命令集解读

武汉大学实践教改项目Eviews命令集武汉大学经济学系数量经济学教研室《教改项目组》编译本命令集几乎涵盖了Eviews中所有命令,视图和过程的完整列表,我们分为基本命令,矩阵和字符串函数以及编程语言三个面加以介绍,在每一个面的列表按照字母顺序排列。
每条记录包括该命令关键词,关键词的各种用法,其功能描述和语法,在大多数记录中,我们还提供了附加参数的列表和示例。
一、基本命令addadd group过程| pool过程向组添加一个序列或者向pool中添加截面元。
语法group过程:group_name.add ser1 ser2 ser3group过程:group_name.add grp1 grp2pool过程:pool_name.add id1 id2 id3列出要添加到组中的序列名称或者序列组,或者列出要添加到pool中的截面标识符。
示例dummy.add d11 d12向组DUMMY中添加两个序列D11和D12。
countries.add us gr向pool对象COUNTRIES中添加US和GR两个截面元素。
addtextaddtext图过程在图中放置文本。
语法图过程:graph_name.addtext(options) text在addtext命令后跟随要放置到图中的文本。
选项t 顶部(在图的上部并居中)。
l 左旋转。
r 右旋转。
b 下方并居中。
x 把文本包含在框中。
要在图中放置文本,可以明确的使用座标来指定文本左上角的位置。
座标由一个数对h,v设定,单位是虚英寸。
单独的图通常是43虚英寸(散点图是33虚英寸),不管它们当前的显示大小。
座标的原点位于图的左上角。
第一个数值h指定从原点向右偏离的虚英寸距离。
第二个数值v指定从原点向下偏离的虚英寸距离。
文本的左上角将被放置在指定的座标上。
●座标可以于其他选项一起使用,但是它们必须位于选项列表的前两个位置。
座标受指定位置的其他选项控制。
●当addtext对多重图使用时,文本应用于整个图,而不是每个单独的图。
Eviews软件操作指令

EViews软件操作一、建立工作文件打开EViews主窗口;从EViews主菜单中点击File键,选择New→Workfile,则打开一个Workfile Range选择框,其中需做三项选择:①Workfile frequency;②Start date;③End date 。
根据数据的性质做①Workfile frequency;②Start date;③End date各项选择。
点击OK键。
这时会建立一个尚未命名的工作文件(Workfile:UNTITLED)。
点击name 键(起名,保存)。
二、关闭工作文件从EViews三、打开工作文件双击EViews标识,从主窗口,点击File→open→Workfile→工作文件名(工作文件名字符不得超过16个)。
四、输入数据从主窗口,点击Quick→Empty Group→用手工输入数据。
输入好数据后,对时间序列数据name(起名)→save(保存)。
也可从Ecxel中把数据粘贴到Empty Group,name→save。
注意:如果输入数据错误,如何该?从Eviews主菜单中点击Edit键。
五、用公式生成新序列从主窗口,点击Quick→Generate Series→输入计算公式。
最常用运算符号:加(+),减(-),乘(*),除(/),乘方(^),X的一阶差分(D(X),即X-X(-1)),对X取自然对数(log(X)),对X取自然对数后做一阶差分D(log(X)),下面是@函数及其含义:@SUM(X)——序列X的和@MEAN(X)——序列X的均值@ V AR(X)——序列X的方差@ SUMSQ(X)——序列X的平方和@ COV(X,Y)——序列X和序列Y协方差@ COR(X,Y)——序列X和序列Y@ R2——R2统计量@RBA R2——调整的R2统计量@ SE——回归函数的标准误差@ F——F统计量@ MOV A V(X,n)——序列X的n期移动平均,其中n为整数六、改变工作文件区间从主窗口,点击proc→structure/Resize Current Page→改变区间。
eviews操作说明

在这里选 择所使用 的时间序列 数据的频率
在这里输 入起始日期
在这里输 入终止日期
各种时间频率对应的日期格式
Annual:数据频率为年度,用四位数输入,如Start date:1980 End date 2003 冒号前表示年,冒号后表示季度。
•Quarterly:数据频率为季度,可输入为1990:1, 2000:3等,
作以前的状态。
• 剪切(Cut):删除用拖动覆盖法选定的内容并放入剪切
板。
•复制(Copy):把所选定的内容存入剪切板。 •粘贴(Paste):把复制的内容粘贴到光标所在的位置。
•清除(Delete):清除所选定的内容。 •进行(Next):执行下一个预指定操作。 •合并(Merge):把一个文件Views路径下,把选定 的对象储存到磁盘的EViews数据库中。并得到 一个关于为对象起名字的提示。如果选择了缺省 文件名,每一个对象都将按当前的名称储存。 储存为(Store As):功能和储存(Store)一 样,但通过文件对话框允许用不同名称和不同路 径保存。 命名(Name):在当前(激活)窗口中为对象 命名。
三. Eviews的基本操作
Eviews要求数据的分析处理过程必须在特定的 工作文件(Workfile)中进行,所以在录入和分 析数据之前,应创建一个工作文件。 (一)使用Workfile : 1、创建Workfile: 在主菜单中选择File/New/Workfile。会弹出 一个workfile range窗口对话框(如下图)
Eviews 使用操作说明
EViews软件包
EViews是美国GMS公司1981年发行第1版的 Micro TSP的Windows版本,通常称为计量经济 学软件包。 EViews是Econometrics Views的缩写,它的本 意是对社会经济关系与经济活动的数量规律,采 用计量经济学方法与技术进行“观察”。
Eviews的基本操作
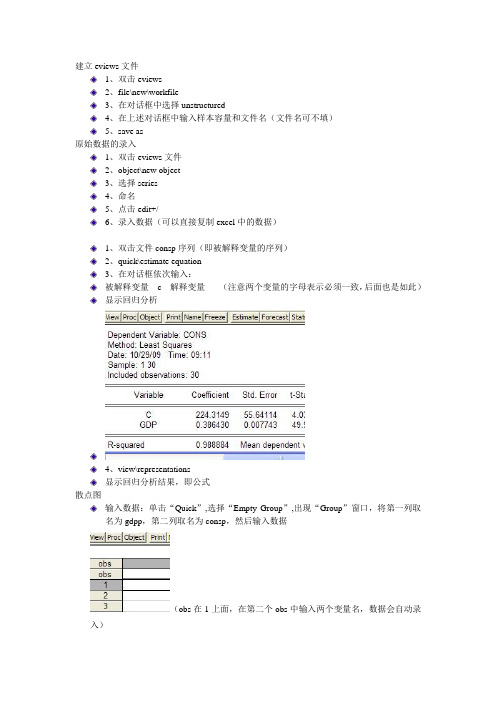
建立eviews文件
1、双击eviews
2、file\new\workfile
3、在对话框中选择unstructured
4、在上述对话框中输入样本容量和文件名(文件名可不填)
5、save as
原始数据的录入
1、双击eviews文件
2、object\new object
3、选择series
4、命名
5、点击edit+/-
6、录入数据(可以直接复制excel中的数据)
1、双击文件consp序列(即被解释变量的序列)
2、quick\estimate equation
3、在对话框依次输入:
被解释变量 c 解释变量(注意两个变量的字母表示必须一致,后面也是如此)
显示回归分析
4、view\representations
显示回归分析结果,即公式
散点图
输入数据:单击“Quick”,选择“Empty Group”,出现“Group”窗口,将第一列取
名为gdpp,第二列取名为consp,然后输入数据
(obs在1上面,在第二个obs中输入两个变量名,数据会自动录入)
(二)绘制散点图:
单击“Quick”,选择“Graph”, 在“Graph”里选择“Scatter ”,点击“OK”,出现“Series List”对话框,输入gdpp consp(有空格),点击“OK”。
出现散点图。
如下图:
如果要模型做出来,则在下图状态下
选择view——>graph——>scatter——>scattered with regression,点击ok,即出现。
Eviews操作入门输入数据-对数据进行描述统计和画图【可编辑全文】

可编辑修改精选全文完整版Eviews操作入门:输入数据,对数据进行描述统计和画图首先是打开Eviews软件,可以双击桌面上的图标,或者从windows开始菜单中寻找Eviews,打开Eviews后,可以看到下面的窗口如图F1-1。
图F1-1 Eviews窗口关于Eviews的操作可以点击F1-1的Help,进行自学。
打开Eviews后,第一项任务就是建立一个新Workfile或者打开一个已有的Workfile,单击File,然后光标放在New上,最后单击Workfile。
如图F1-2图F1-2图F1-2左上角点击向下的三角可以选则数据类型,如同F1-3。
数据类型分三类截面数据,时间序列数据和面板数据。
图F1-3图F1-2右上角可以选中时间序列数据的频率,见图F1-4。
图F1-4对话框中选择数据的频率:年、半年、季度、月度、周、天(5天一周或7天1周)或日内数据(用integer data)来表示。
对时间序列数据选择一个频率,填写开始日期和结束日期,日期格式:年:1997季度:1997:1月度:1997:01周和日:8:10:1997表示1997年8月10号,美式表达日期法。
8:10:1997表示1997年10月8号,欧式表达日期法。
如何选择欧式和美式日期格式呢?从Eviews窗口点击Options再点击dates and Frequency conversion,得到窗口F1-5。
F1-5的右上角可以选择日期格式。
图F1-5假设建立一个月度数据的workfile,填写完后点OK,一个新Workfile就建好了。
见图F1-6。
保存该workfile,单击Eviews窗口的save命令,选择保存位置即可。
图F1-6新建立的workfile之后,第二件事就是输入数据。
数据输入有多种方法。
1)直接输入数据,见F1-7在Eviews窗口下,单击Quick,再单击Empty group(edit series),直接输数值即可。
EViews常用命令简介

如何生成组
命令格式:
GROUP <组名> <对象名1>…<对象名n>
功能: 将磁盘上的序列等对象组成一个组,便 于同时对它们进行操作 条件: 工作文件中已经存在这些对象,否则建 立一个空组等待输入新的序列。
9
如何显示工作文件中的数据
命令格式: SHOW <序列名1>……<序列名n> 功能: 将磁盘上的序列等对象读入工作文件 条件: 工作文件中已经存在这些序列
命令格式: LAOD [路径] \ <工作文件名> 功能: 将磁盘上保存的工作文件读入内存 注意: 进入后不使用CREATE就必须使用LOAD 方能开始工作
6
对象名的格式
8.3制 对象包括:
序列 组 方程 图形 系统 模型等
7
如何从磁盘输入数据对象
命令格式: FETCH <对象名1>……<对象名n> 功能: 将磁盘上的序列等对象读入工作文件 条件: RAM中已经开辟工作文件区(即工作文 件已在内存)
12
如何向磁盘输出数据
命令格式: STORE <序列名1>……<序列名n> 功能: 将工作文件中的序列保存到磁盘 数据文件的扩展名为*.DB 条件: 工作文件中已经存在这些序列
13
如何进行回归分析
命令格式: LS <因变量名> <C> <自变量序列名 1>……<自变量序列名n> 功能: 进行线性回归分析 条件: 工作文件中已经存在这些序列
10
如何打印输出工作文件中的数 据
命令格式: PRINT <序列名1>……<序列名n> 功能: 将工作文件中的序列打印输出 条件: 工作文件中已经存在这些序列
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
四,回归模型的估计
一元线性回归的OLS估计
命令:
1.菜单: Quick/Estimate Equation 2.窗口:Ls
Y C X
(此时对话框中的变量次序,Y是因变量,X是自变量, C是常数项)
一元线性回归模型的估计
回归结果
一元线性回归模型的估计
Dependent variable:因变量 Method:方程估计方法 Date:05/01/04 Time:23:20 输出结果的时 间和日期 Sample:方程估计是使用的样本区间 Included observations:观察值个数,即样 本容量 Variable:自变量,其中c表示常数项
data <序列名1> <序列名2>┄<序列名n>
粘贴方式
如果数据本身已在excel电子数据表格上, 也可以直接采用粘贴方式 。 粘贴方式和在window中的方式一样。
打开excel文档
三,散点图
命令: 1. 菜单:View/Graph
2. 窗口: 趋势图: Plot Y X 相关图: Scat Y X
命令:
1. 菜单:File/New/Workfile 2. 窗口:CREATE 数据频率 起始期 终止期
工作文件的存储
保存新建的工作文件通常有两种方法。一种是 在主窗口中选择菜单File/Save 或者Save as。 另一种方法是直接单击工作文件窗口中工具栏 中的Save按扭。保存文件时,用户得给出保 存的地方和文件的名称。输入的文件名不能多 于8个字符且不得有空格,逗号和句号,文件 名输入后,点击“保存”按扭,系统会会自动 将其存储为扩展名为.wf1的工作文件。需要时 可以将文件存储为更低版本的格式。
File:有关文件的创立(New)打开(Open), 保存(Save/Save as),关闭(Close),程序 运行(Run)等,选择下拉菜单中的Exit将退 出Eviews软件。 Edit:通常情况下仅提供复制(Copy)功能, 应与粘帖(Paste)配合使用,对某些特定窗 口,如查看模型估计结果的表达式时,可对窗 口中的内容进行剪切(Cut),删除(delete) 等工作选择(Undo)表示撤消上步操作。
一元线性回归模型的估计
F-staistic: F统计量,用于检验方程的显 著性水平。
Prob(F-statistic):F检验的实际显著性 水平,即p值。
五,预测
方程窗口:forecast
Eviews 使用
ቤተ መጻሕፍቲ ባይዱ
运行Eviews
1)点击任务栏上的开始 程序 Eviews程序组 Eviews图标。 2)使用Windows 浏览器或从桌面上 “我的电脑”定位Eviews目录,双击 Eviews程序图标。 3) 双击Eviews的工作文件和数据文件。
Eviews窗口简介
9个主菜单的主要功能
Objects:提供关于对象的基本操作。包括建立 新对象(New objects)从数据库中获取/更 新对象(Fetch/update from DB),将工作 文件中的对象存储到数据库(Store to DB) 复制对象(Copy selected),重命名 (Rename),删除(Delete)。 View和procs:两者的下拉菜单的项目,随 着当前的窗口不同而改变,功能也随之变化, 主要涉及变量的多种查看方式和运算过程。
Quick:提供快速分析过程,包括常用的统计分 析方法,回归模型,时间序列模型以及各种重 要的检验。 Options:系统参数设定选项。与一般应用软 件相同,Eviews运行过程中的各种状态,如 窗口的显示模式,字体,图象,电子表格等都 有默认的格式,用户可根据需要选择Optios下 拉菜单中的项目对一些默认格式进行修改。
位于主窗口主菜单选项下面的空白行是 命令行,每次只允许键入一个操作命令。 主窗口中大面积的空白区域留给其他子 窗口显示所用,最下面的是状态行,有 程序路径,数据库和工作文件名称等相 关内容。
一,工作文件的创建
Eviews要求数据的分析处理过程必须在 特定的工作文件(Workfile)中进行, 所以在录入和分析数据之前,应创建一 个工作文件。 在主菜单中选择File/New/Workfile, 此时,屏幕出现一个工作文件定义对话 框,要求用户指定序列观测数据的的频 率和样本大小。
一元线性回归模型的估计
Coefficient:系数估计值 Std.Error:系数估计的标准误差,即 t-Statistic: t统计量,即 Prob:实际显著性水平(双侧检验),即P值, 当P值小于给定的显著性水平时,拒绝零假设。 R-squared:判定系数 Adjusted R-squared:调整后的决定系数
Annal:用四位数表示年份,如1980,2015 等.Start date输入起始年份,End date输入终 止年份。 Quarterly:输入格式为2010:1 Monthly:输入格式为2010:01 Weekly和daily:输入格式为12:31:2011,即: 〝月:日:年〞的形式。 Undated or irregular:表示其它类型的数据, 如无时间限定的数据。 (输入数据)
Window:提供各种在打开窗口中进行切换的方 式,以及关闭所有对象(Close all objects), 或关闭所有窗口(Close all) Help: Eviews的帮助选项,与一般应用软件 相同,选择Eviews Help Topics 按照索引或 目录方式在所有帮助信息中查找所需项目。下 拉菜单还提供了分类查询方式,包括对象 (object),命令(command).函数 (Function),矩阵与字符串(Matrix &String),程序(Programming)这五个方 面。
工作文件的调用
调用以前建立的工作文件可以在主窗口 菜单中依次选择File/open/workfile, 并给出相应的路径与文件名。需要特别 注意的是Eviews3.1未经汉化处理,因 此工作文件的名称以及存储路径都不能 使用汉字,否则无法被调用。
二,数据输入编辑
命令 :
1. 菜单:Objects/New object/Group 2. 窗口: