语种辨识
结合注意力机制和因果卷积网络的维吾尔语方言识别

第39卷第6期声学技术Vol.39, No.6引用格式:孙杰, 王宏, 吾守尔·斯拉木. 结合注意力机制和因果卷积网络的维吾尔语方言识别[J]. 声学技术, 2020, 39(6): 697-703. [SUN Jie, W ANG Hong, Wushouer Silamu. The Uyghur dialect recognition based on attention mechanism and causal convolution networks[J]. Technical Acoustics, 39(6): 697-703.] DOI: 10.16300/ki.1000-3630.2020.06.008结合注意力机制和因果卷积网络的维吾尔语方言识别孙杰1,2,王宏2,吾守尔·斯拉木1,2(1. 新疆大学信息科学与工程学院,新疆乌鲁木齐830046;2.昌吉学院,新疆昌吉831100)摘要:针对传统x-vector模型生成方言语音段级表示时,未考虑不同帧级特征对方言辨识作用不一致的问题,以及维吾尔语的黏着性特点,提出结合注意力机制和因果卷积网络的维吾尔语方言识别方法。
首先使用多层因果卷网络实现方言语音序列建模,然后采用空洞卷积核增大感受野扩展采样范围,最后使用注意力池化获取方言语音段级特征。
维吾尔语方言识别实验结果表明,所提方法较标准x-vector模型方言识别的识别准确率提升了23.19个百分点。
关键词:注意力机制;因果卷积网络;空洞卷积;维吾尔语方言;识别中图分类号:H107 文献标识码:A 文章编号:1000-3630(2020)-06-0697-07The Uyghur dialect recognition based on attention mechanismand causal convolution networksSUN Jie1,2, W ANG Hong2, Wushouer Silamu1,2(1. College of Information Science and Engineering, Xinjiang University, Urumqi 830046, Xinjiang, China;2. Changji University, Changji 831100, Xinjiang, China)Abstract:Considering that different frame features have different effects on dialect recognition when the traditional x-vector model is used to generate segment representation of dialect speech, and that Uighur language is an agglutinative language, a recognition method of Uighur dialect based on attention mechanism and causal convolution network is proposed. First, the multi-layer causal volume network is used to model the speech sequence, then the dilated convolu-tion kernel is used to expand the sampling range of the receptive field, and finally the attention pooling is used to obtain the speech segment features. The experimental results of Uyghur dialect recognition show that the accuracy of the proposed method is 23.19 percentage higher than that of the standard x-vector model.Key words: attention mechanism; causal convolution networks; dilated convolution; Uyghur dialect; recognition0 引言方言识别亦称方言分类,属于语种识别的范畴。
关于网络语音的自动语言辨识系统研究

O 引 言 自动语 言辨识 是计 算机 通过分 析处 理一 个语 音 片 段 以判别 其所属 语 种 的过 程 ,它在 多语 种的 信息 检索
和查 询 、 器 翻译 、 机 多语种 语 音识别 的前端 处 理 以及军 事领 域 中有 着很 重要 的作 用 。 以往 关于 自动语 言辨 识 的研究 多是 针对 于 电话 语 音 的 ,而研 究人 员经 常使 用 的语 音数 据 库 , 1 语 种 的 O IT ,2语 种 的 C l 如 1 G— S 1 a一 1 Fin r d以及 美 国 N S e IT组织 测评 使 用 的语 料 库 都使 用 了电话语 音 。随着 网络技 术 的快 速发展 , “ 通过 网络 传 输 的语音 日益 增 多 ,网络使 人们 多语种 之 间的交 流更
A s a tT i p p r r ot rsa h o uo t a g a e ie t c t n wi p eh s o n lh Ge nJp n s, b t c : h a e e r eer n a t i l u g d n f a o t se c e f E g s , r , a e r s p s c ma c n i i i h i ma
【国家自然科学基金】_美尔倒谱系数_基金支持热词逐年推荐_【万方软件创新助手】_20140731
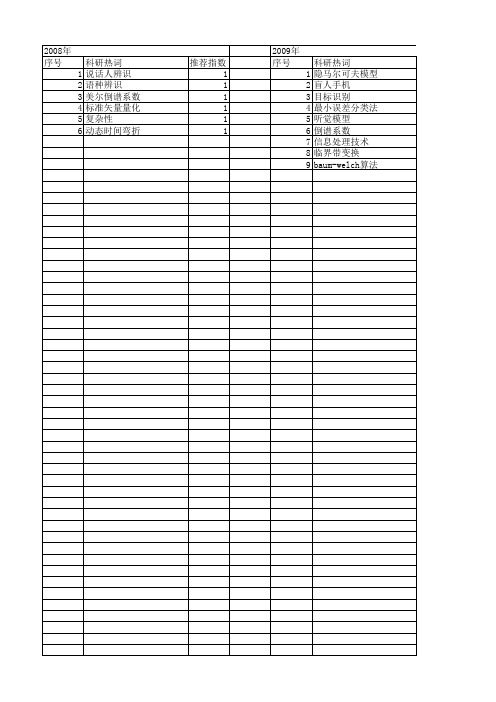
2011年 科研热词 美尔倒谱系数 频域ica 语音 美尔倒谱系数(mfcc) 线性预测系数 特征增强 录音系统 声纹 声目标识别 基音 听觉模型 共振峰 推荐指数 2 1 1 1 1 1 1 1 1 1 1 1
2012年 序号 1 2 3 4 5 6 7 8 9
科研热词 鼻音 美尔频率倒谱系数 维汉语音识别 线性预测失真度 特征组合 特征提取 多层感知器 声纹 声学模型
2008年 序号 1 2 3 美尔倒谱系数 标准矢量量化 复杂性 动态时间弯折
推荐指数 1 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9
科研热词 隐马尔可夫模型 盲人手机 目标识别 最小误差分类法 听觉模型 倒谱系数 信息处理技术 临界带变换 baum-welch算法
推荐指数 1 1 1 1 1 1 1 1 1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
科研热词 语音识别 特征提取 听觉特性 伽马啁啾 音乐流派分类 语音检测 语音控制 证据力度 美尔频率倒谱系数 空间金字塔匹配 移动机器人 法庭说话人识别 机器人控制 支持向量机 尺度不变特征转换 声音参数 听觉图像 似然比 mfcc
推荐指数 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9
科研热词 语音识别 语音特征 美尔频标倒谱系数 美尔倒谱系数 小波变换 学习矢量量化网络 图形用户界面 参数归一化 信号与信息处理
推荐指数 2 1 1 1 1 1 1 1 1
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12
推荐指数 3 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
说话人识别与语种辨识

λ
t =1
混合权值的重估公式: ① 混合权值的重估公式: 均值的重估公式: ② 均值的重估公式:
• 应用 的说话人识别过程的步骤如下: 应用VQ的说话人识别过程的步骤如下: 的说话人识别过程的步骤如下
1. 训练过程
① ② ③ ④ ① ② 从训练语音提取特征矢量,得到特征矢量集; 从训练语音提取特征矢量,得到特征矢量集; 通过LBG算法生成码本; 算法生成码本; 通过 算法生成码本 重复训练修正优化码本; 重复训练修正优化码本; 存储码本 从测试语音提取特征矢量序列 由每个模板依次对特征矢量序列进行矢量量化, 由每个模板依次对特征矢量序列进行矢量量化,计算各自的平均量 1 M 化误差: 化误差: Di = ∑ 1min[d ( X n , Yl i )] M n =1 ≤l ≤ L
10.1概述 10.1概述 10.2说话人识别方法和系统结构 10.2说话人识别方法和系统结构 10.3应用DTW的说话人确认系统 10.3应用DTW的说话人确认系统 应用DTW 10.4应用VQ的说话人识别系统 应用VQ 10.4应用VQ的说话人识别系统 10.5应用HMM的说话人识别系统 10.5应用HMM的说话人识别系统 应用HMM 10.6应用GMM的说话人识别系统 应用GMM 10.6应用GMM的说话人识别系统 10.7说话人识别中尚需进一步探索的研究课题 10.7说话人识别中尚需进一步探索的研究课题 10.8语种辨别的原理和应 10.8语种辨别的原理和应
2. 识别过程
d(Xn,Yli ) YLi , l = 1,2,....L, i = 1,2,....N Xn Yl i 是第i个码本中第 个码本矢量, 个码本中第l个码本矢量 式中 是第 个码本中第 个码本矢量,而 是待测矢量 和码矢量 之间的距离 选择平均量化误差最小的码本所对应的说话人作为系统的识别结果。 ③ 选择平均量化பைடு நூலகம்差最小的码本所对应的说话人作为系统的识别结果。
语音识别技术

基于DTW的语音识别
• DTW算法通过局部优化的方法实现加权距离和最小,即
D ( i , j ) = m in
C
∑
N
n=1
d x , y Wn i n j n ( ) ( )
(
)
∑W
n =1
N
n
Wn 为加权函数,需考虑两个因素: ⑴ 根据第n对匹配点前一步局部路径的走向来选取; ⑵ 考虑语音各部分给予不同权值,以加强某些区别特征。
• 对于孤立词(或命令)识别,DTW算法与HMM算法在相同的 环境下,识别效果相差不大。 • 优点: -可靠性强 -复杂度低 • 关于DTW理论已作介绍
基于matlab的DTW识别算 法实现
• 实验模板:”a,b,c,d,e,你好“的wav文件(8k采样, 单声道,精度8位) • DTW算法采用两步约束:
・ 说话人识别常用参数分类:
(1) 线性预测参数及其判生参数 (2) 语音频谱直接导出的参数 (3) 混合参数 (4) 其他鲁棒性参数
说话人识别与语种辨识
・ 模式匹配的方法: (1) 概率统计方法; (2) 动态时间规整方法(DTW) (3) 矢量量化方法(VQ) (4) 隐马尔可夫模型方法(HMM) (5) 人工神经网络方法(ANN)
语音识别的概述
语音识别系统的分类
分类依据 语音的发音 方式 孤立词语音 识别系 统 连接字语音 识别系 统 非特定人语 音识别系 统 说话人 词汇量的大 小 小词汇量 (10-100) 识别的方法 动态时间规 整(DTW) 矢量量化 (VQ) 隐马尔可夫 模型 (HMM ) 隐马尔可夫 模型 (HMM)、 人工神经 网络 (ANN) 应用场合
y y
yk =
Y = y1 , y2 ,L , yTy , k = 1, 2,L , Ty
语言辨识的矢量量化方法(VQ)

子包 括旅游信息 、 急服务 、 应 以及 购物 和 银 行 、 票 股
交 易 。例 如 A & T T向 处 理 9 l紧 急 呼 救 的 社 会 机 1 构 和 警 察 局 推 出 语 言 热 线 服 务 ¨ 。 图 l 明 了 两 说 个 讲 不 同语 言 的 人 是 如 何 通 过 一 个 多 语 言 话 音 系 统 进 行 交 流 。 自动 语 言辨 识 技 术 还 能 够 用 于 多 语 言 机 器 翻译 系统 的 前 端 处 理 , 当对 大 量 录 音 资 料 进 行 翻译 分 配 时 , 要 预 先 判 定 每 一 段 语 音 的 语 言 。 需 此 外 军 事 上 还 可 以 用 来 对 说 话 人 身 份 和 国 籍 进 行 监 听 或 判 别 _ 。 随 着 信 息 时 代 的 到 来 以及 国 际 因 2
( nlh 、 语 ( na n 、 斯 语 ( a i、 语 E gi ) 汉 s Ma d r ) 波 i Fr ) 法 s
( rnh 、 语 ( ema ) 北 印 度 语 ( id ) Fe c ) 德 Gr n 、 H n i 、日语 (a a ee 、 鲜 语 ( oen 、 班 牙 语 ( pns ) 泰 Jp n s) 朝 K ra ) 西 Sai 、 h
一
每 种 语 言 的 10个 持 母 语 的 人 在 实 际 的 电 话 线 路 0 上 产 生 。发 音 的 时 长 从 1秒 到 5 O秒 长 短 不 等 , 平 均 为 l. 3 4秒 。语 言 的 选 取 考 虑 了 各 种 因 素 , 时 同
个 相 对 较 新 的 领 域 。尽 管 在 某 些 方 面 , 类 似 于 其 自动 语 音识 别 、 话 人 识 别 和 声 调 检 测 ,但 所 有 这 说
基于倒谱距离窗移最小失真分割的语种辨识

摩擦 音 、 音 、 鼻 静音 , 而不 是 按 照 准确 的音 素 或 者 音
节来划 分不 同语 言 , 根 据 需 要 把每 个 大 类 分 为多 再 个小 类 . 总之 , 类别 的总 数 比每种语 言 的音素 个数 少 得多 , 样 对 语 音 的 标 注 就 变 得 相 对 简 单 一 些 . 这 此
K yw r s h dnm ro oe H M) l gaei nf a o ; u -od em n t n e od : i e a vm dl( M ; aug eti tn sbw rs g et i d k n d ic i s ao
自动语 种识 别是 指计算 机能 自动地 识别 一段 语 音属 于哪种语 言 的 技术 . 在全 球 化 的过 程 中显 得越
m dl ivl n u ea on f o n ot n t spo c,w s ar g em nao nt do oe, no igahg m uto w r a dcs.I h r et eue uh sg et i is a f v k i j o tn e
Vo . 3 No. 11 2
Ap .2 07 r 0
文 章编 号 :0 726 (07 0.160 10 .8 120 )20 1. 5
基 于 倒 谱距 离 窗移 最 小 失 真 分 割 的语 种 辨识
缪 炜 , 侯 丽敏
( 上海 大学 通信与信息 工程学 院 , 上海 20 7 ) 0 02
来越 重要 , 2 从 0世 纪 9 0年代后 , 引起 越来 越 多人 也 的关 注… .
子 中具体 包含 哪些 音 素 或 哪 些 音节 , 只需 要 判 别 它 出某段 语 音 到 底 和哪 种 语 言更 接 近 . 于 这 点 , . 基 T Ma i rn t 认 为 所 有 的语 言 都 由 4大类 组 成 , 即元 音 、
基于符号化和语言模型方法的汉语方言自动辨识

维普资讯
第 2期
Hale Waihona Puke 沈 兆 勇等 : 于 符 号 化 和 语 言 模 型 方 法 的 汉 语 方 言 自动 辨 识 基
一 a g ma { ( 。 ) r x b x\ }
汉语 方言 自动 辨识是 计算 机根 据 语 音 自动确 定 汉 语 方 言 种类 的技 术 , 在 汉 语 语 音识 别 、 息 检 它 信 索 、 游 服务 、 旅 刑侦 及军事 监 听等领 域都 具有 重要 的应 用价 值. 相对 于语种 辨识 , 汉语 方 言辨识 起步 较 晚
并且 尚处 于起步 阶段 ,0 2年 到 2 0 20 0 5年 , 台湾 的蔡 伟 和 、 加 坡 的 Lm 新 i B P等先 后 进 行 了基 于 高斯 模
究. 于 该 项 研究 刚 刚起 步 , 缺 乏 包 含语 音 标 注 的音 库 以 及成 熟 的理 论 和 方法 , 文 在借 鉴 和 改 进 鉴 还 本
T re— ars ul o rs raq io等 人提 出 的语 种 辨识 的新 方 法 I , 索 适 合 汉 语 方 言 辨识 的特 征 参 数 和 改进 后 端 C l 5探 ] 分 类器 的基 础上 , 研究 了基于 高斯 混合模 型 ( GMM) 号 化器 和 N元 语 言模 型 方法 的汉语 方 言辨 识 . 符 应
试 . 3 主 要汉 语 方 言 的 辨识 中 ,5S 料 测 试 平 均 辨 识 率 达 到 了 9. . 在 种 1 语 O7
关键词 : GMM 符 号 化 ; 言 模 型 ; 语 方 言 自动 辨 识 语 汉 中 图 分 类 号 : 9 2 3 TN 1 . 4 文献 标 识 码 :A 文 章 编 号 :1 0 — 5 3 2 0 ) 20 5 — 4 0 76 7 ( 0 6 0 — 0 40
手语辨识技术

手语辨识技术手语是十分特殊的语言,它既可以在聋人之间进行交流,也可以让人们更好的了解聋人群体。
然而,这种语言的独特性也给人们带来了一定的困扰——不是所有人都能够掌握手语,这就意味着聋人需要不断地在交流中改变方式。
在这样的情况下,手语辨识技术应运而生。
手语辨识技术是什么呢?简单来说,这是一种利用计算机视觉技术来辨识手语动作,进而通过声音或者文字的方式输出手语的技术。
这种技术可以帮助聋人更好的融入社会,也可以让普通人对手语的理解更加深入。
手语辨识技术的研究始于二十世纪八十年代,当时的技术水平还非常有限。
随着计算机技术的不断进步,现在已经有了非常成熟的手语辨识技术。
比如说,在2017年,美国一家名叫Myo的公司推出了一款手语辨识手环,通过触摸感应和肌肉传感器来判断手势,并将其转换成文字输出,从而帮助聋人更好的融入社会。
从技术原理来看,手语辨识技术可以分为两类:传统图像处理和深度学习。
传统的图像处理技术是通过对图像中的特征进行提取,并将这些特征和手语手势进行对比,从而确定手语的含义。
这种方法受到很多的限制,比如说光线、角度、距离等因素都会影响图像的质量,这会影响识别的准确率。
另一种深度学习则不同,它采用神经网络对大量数据进行训练,从而实现对手语进行辨识。
相比较传统的图像处理技术,深度学习具有更好的准确率和更高的鲁棒性。
除了技术原理之外,手语辨识技术也可以被应用在很多领域中。
比如说,在医疗领域中,手语辨识技术可以被用来识别病人的手势,从而为病人提供更好的护理服务。
在教育领域中,手语辨识技术可以为聋人学生提供更好的学习条件。
另外,在智能家居领域中,手语辨识技术也可以帮助使用者更好地控制智能设备。
当然,与其他技术一样,手语辨识技术也存在着一些问题和挑战。
比如说,在识别不同语种的手语时,手语的手势和含义可能会存在着一定的差异,这就需要更多的数据进行训练。
此外,手语辨识技术还非常依赖摄像头的质量和位置,这也限制了其在特定环境下的使用。
基于美尔倒谱系数和复杂性的语种辨识

V1 4 o. 3
・
计
算
机
工
程
20 0 8年 l O月
Oc o e 0 8 tb r 2 0
No. 9 1
Co u e gn e i g mp trEn i e rn
人 工 智能 及识 别技 术 ・
文章编号: 00- 2( 0)-00-) 10-3 8 08 9 234 文献标识码: 4 2 1- - 3 - - A
具有一定识别性能和抗噪能力 。
性预测分析 的稳定性 ,被广 泛使用的预加重 网络是一 固定 的 阶数字 系统 ,信号 方程 为
一
但 上述频域方法采 用了短 时分析方法 ,属于线性范畴 , 而语音信号作为一种典型 的非平稳信号 ,短 时分析 法仅对 各
语种 的静态特征进行 了描述 ,忽 略了说话人 的动态特征 ,而 各种实验证明 ,语音 中的动态信息是语音信号 的重要特征之
英语 、汉语 、 日 3个语种的识别效果 ,结果表 明,该方法相对于传统方法能 明显提 高语 种识另 准确性和鲁棒性 。 语 怕g
关健诃 :语种辨识 ; 复杂 性 ;标准矢量量化
La g a eI e tfc to s d 0 FCC n m p e i n u g d n i a i n Ba e n M i a d Co lxt y
P NG a , A Qu n CHE h nfn , ANG C i o g NC e- gY a u- n r
( o dc l n ie r g& Is u n s tt, n z o a z ie s y H n z o 1 0 8 Bime ia E g n e i n n t me t n t ue Ha g h uDin i v r t, a g h u3 0 1 ) r I i Un i
一般拓扑结构的非齐次隐含马尔科夫模型及其在中、英文语种辨识中的应用

Ap 0 7 r 20
一
般拓扑结构的非齐次隐含马尔科夫模型及其在 中、 英文语种辨识 中的应用
王作 英 孙 健
108) 004 f 大学电子 工程 系 北京 清华
摘 要 :为 了充分利用语 音信号 中的段 长信息 ,该文提 出了一种具有 一般 拓扑结构 的非齐次 隐含 Makv 模型 ro
fidnMa o dl MM)并将其应用于 中、 文语种辨识(ag ae D ni ai ,I ) Hd e r v k Mo e H , , 英 L n ug et ct n LD 系统。 I i f o 非齐次 H MM
既很好地描述了语音信号 的发生过程 ,又准确地利用 了状态的段长信息和语言中的上 下文连接结构信息 ,对于中、 英文语种辨识系统 ,非齐次 的 HMM 系统辨识性能好于齐次 的 HMM 模型 。而在非齐次 的 HMM 中,同段长为均 匀分布相 比, 段长分布为正态分布 时系统 的辨识性能更好 ,表明段长确实是一种重要的语种 区分信息之一 ,且正态 分布较均匀分布更接近于真实的段长分布 。
W a g Z oy n n u — ig S nJa u in
( eat et Eet nc nier g T i haU i r t B in 08, h a D pr n l r i E g e n, s gu nv sy e i 1 04 C i ) m co n i n e i, j g 0 n A s a :nodr oue uai f m t ni L n ug D nict n (I ) fc nl tei o gno s bt c I re t s d rt ni o ai ag ae et ai L D e i t ,h hmoeeu rt o nr o n I i f o i e y n Hd e ro dlH i nMakvMoe ( MM) i nrlo o g a s utr ipo o d ad s s ety h n ug d wt g eatp l i lt cues rp s .n e t i ni eagae he o c r e iu d 0 d f t l
基于GMM-UBM的语言辨识算法研究

G MM. B 的语言辨识算法 ,以期改善语言辨识系统 的性能 ,获得更好 的识别率和系统移植性. UM
1 高斯 混合 模 型
11 高 斯混 合 模型 的基 本 概 念 .
高斯混合模型 G MM 本质上是一种状态数为 l 的连续分布的隐马尔可夫模型 ( idnMa o Hd e r v k
8月
文章 编 号 :1 0 .3 2 ( 0 0 3 0 0 . 6 0 6 7 0 2 1 )0 . 0 55
基 于 GMM— M 的语 言 辨识 算 法 研 究 UB
陈业仙 。张 歆奕 .毛杰
( 邑大学 信 息工程 学院 ,广 东 江 门 5 9 2 五 2 0 0) 摘要 :运用Mal 软 件 ,以 自已建立 的语 音数据库 为基 础 ,对与文本 无 关的基 于GMM. B tb a U M的
ln u g d n i c t n s se a e n t e GMM- M d l a d i d p n e to h p a e s a g a e i e t ai y t m b s d o h i f o UB mo e n n e e d n f te s e k r i
C N Y - in Z HE e xa 。 HANG X n y。 i — iMAO Je i
(c o l f no mainE gn eig Wu i nv ri , in me 2 0 0 C ia S h o fr t n ie rn , y iest Ja g n5 9 2 . hn ) oI o U y
Mo e C H dl D MM). 。 一个 阶 G MM 可 由M 个高斯概率密度 函数加权求 和得到 。即 :
p = 岛 ) ( )∑ ( , I
语种识别算法中GSV计算的定点仿真与实现

・
60 ・ 8
计算机 工程 与设计
21 焦 02
提出 了采用 a do dl g运算来 简化 对数 似然 函数 的计 算 ,以及
GS V作 为声 学模型 ,支持 向量机 S VM 作为 区分模型 。大量仿 真测试 结果表 明 ,GS V在 整个 系统 中 占的运 算量 为 8 %左 o
右 ,是 算法硬 件 实现的瓶颈 。鉴 于此 ,对基 于 GS V的硬件 实现 方法进行 了研 究 ,提 出 了一种快 速 GS 定点计 算方 法,其 V 采 用 ado d lg运算 简化对数似然 函数 的计 算 ,完成 了语种识别的 高效定点 实现 。实验 结果表 明 ,该 定点方法 的识 别率与 浮点
展 了广 泛 的研 究 ,基 于 A RM 和 D P 开 发 的 语 音 识 别 系 统 S
音素识别器结合语言模型 的 ( aall h n eo nt nad p rl o ercg io n ep i
l g a emo e n ,P R M) 语 种 识 别 方 法 ,该 方 法 的 语 a ug d l g P L n i
( t n lDii l wi hn y tm gn e iga d Te h oo ia sa c n e ,Z e g h u4 0 0 ,Chn ) Nai a gt o a S t ig S se En ie rn n c n lgc lRe e rhCe tr h n z o 5 0 2 c ia
0 引 言
目前大部分语种 识别 方法 可归类 为基 于声 学 的方法 和 基于音素 的方法 [ 。基 于音素 方法 的典 型模 型如基 于并 行 1 ]
语种确认中基于段长的语言模型修正方法

_ 7 收H )≥’接 o 』
P S L ) <T 拒绝 H ( I Mb 0
P S L , ( IM,分另 是 目标语种 和背景语 种语言模 ( IM ) P S L ) 0 型对待测语音 s的似然 函数 。当上述似然 比大 于阈值 r时 , 接 受假设 H , n认为待测 语音 是 目标 语 种 ; 反之 , 拒绝 H , 为待 。认 测语音是背景语种 。 语种确认基线系统 的框 图如 图 l 所示 , 采用平行音素识别 器加语言模型 的结构 。系统前端是 n 个平行 音素识 别器 , 在每
L U C a g e ,W ANG S iz e ,L U Ja I hn -‘ h —h n I i ,XI S a — o g A h n h n 。
( . t e e L br o asue T h o g , n i t o e r i , h e cdm i c , ei 0 8 , h a 2 Dp. 1 S tK y ao t yo T n c e nl y I tu E c o c C i s Aa e yo S e e B i g 1 0 0 C i ; . e o a arf r d r c o st e f l t n s ne f cn s j 0 n n tf
Eet ncE gne n l r i ni r g, ̄ig u nvrt, e'g 10 8 co e i n ha U i sy B on 00 4,C ia ei i hn )
Ab t a t A n v l p r a h i p o o e o i rv si t n o n u g d l r b b l y e iin f co sa d w ih sa e s r c : o e a p o c s r p s d t mp o e e t ma i f a g a e mo e o a i t ,r vso a t r n eg t r o l p i u e o c ivn e a g a e mo e si t n s d f ra h e i gn w ln u g d l t e mai .E au t n o AL F E o p s s o s l . 4 o v l ai n C L RI ND C r u h w 1 5 % b s r l t e i rv - o e t e ai mp o e v me t n EE n sn l h n e o n t n s s m n . 3 n R o ig e p o e r c g i o y t a d 6 9 % rl t e i rv me ti R o a al l h n e o n t n s s i i e e ai mp o e n n EE n p r l o e r c g i o y — v ep i
基于CNN-BiGRU的方言语种识别

第55卷 第6期2022年6月通信技术Communications TechnologyVol.55 No.6Jun. 2022文献引用格式:付英,刘增力,汤辉.基于CNN-BiGRU的方言语种识别[J].通信技术,2022,55(6):712-719. doi:10.3969/j.issn.1002-0802.2022.06.006基于CNN-BiGRU的方言语种识别*付 英1,刘增力1,汤 辉2(1.昆明理工大学,云南 昆明 650504;2.江西省科技基础条件平台中心,江西 南昌 330003)摘 要:针对方言特征表征能力差和识别率低的问题,兼顾特征提取和模型改进两方面对不同时长的方言语种数据进行实验仿真。
首先,通过对比不同的特征提取算法,确定模型的最佳输入特征;其次,使用焦点损失代替交叉熵损失函数,对不均衡和相似度高的方言语种分配不同的权重,经实验仿真确定最优参数使模型性能达到最佳;再次,对比不同的模型在不同时长方言语种中的识别性能,实验结果显示,与基线系统相比,提出的改进模型平均识别率提升了4.09%;最后,采用语音增强方式提高模型的泛化能力和鲁棒性。
关键词:方言语种识别;焦点损失;模型改进;语音增强中图分类号:TN912.3 文献标识码:A 文章编号:1002-0802(2022)-06-0712-08Dialect Language Recognition Based on CNN-BiGRUFU Ying1, LIU Zengli1, TANG Hui2(1.Kunming University of Science and Technology, Kunming Yunnan 650504, China;2.Jiangxi Computing Center, Nanchang Jiangxi 330003, China)Abstract: Aiming at the problem of poor ability to represent dialect features and low recognition rate, this paper takes into account both feature extraction and model improvement to conduct experimental simulations on dialect language data of different durations. Firstly, the optimal input features of the model are determined through the comparison of different feature extraction algorithms. Secondly, the focal loss is used instead of the cross entropy loss function to assign different weights to the dialect languages with imbalance and high similarity, and the optimal parameters are determined by experimental simulation to optimize the performance of the model. Then, the recognition performance of different models in different dialects of different time lengths is compared. Experimental results indicate that the improved model proposed in this paper improves the average recognition rate by 4.09% compared with the baseline system. Finally, the speech enhancement is used to improve the generalization ability and robustness of the model.Keywords: dialect language recognition; focal loss; model improvement; speech enhancement0 引 言全球化的今天,不同国家不同地区的人们跨语种交流的机会越来越多,随着深度学习技术趋于成熟,语种识别研究也成为众多研究者关注的重点。
语种辨识

1语言辨识的基本概念自动语言辨识(又称语种识别),是计算机分析处理一个语音片段以判别其所属语种的技术。
随着当前全球合作的增长,各种余元之间的通信要求增加,这就对自动语言识别提出新的挑战,在机械能够懂得语言含义之前,必须辨别使用了哪种语言。
自动语言辨识的任务在于快速准确的辨识出所使用的语言,目前它已经成为通信和信息领域一个新的学科增长点。
自动语言辨识技术的学术特点在于它横跨技术的融合。
对它的研究,不仅需要掌握信息理论和技术,而且需要具有多种信息处理的手段和方法。
众所周知,语音中包含着多种信息,从语音中提取不同的信息进行处理也就形成了不同语言处理方法。
从内容上分,语音中包含着所属语言种类的信息、说话内容的语义信息和说话人个体特征,因此从识别的角度来说,我们可以利用从语音中提取的这些信息进行识别,语音信息的识别可以分为语音识别、语言辨识和说话人识别。
语音识别中要提取出包含在语音信号中的字词意思和言语内容,说话人识别则是从语音信号中获取说话人的身份,语言辨识是从语音信号中提取出包含的语言的种类(或方言的种类)。
与语音识别和说话人识别不同的是,语言辨识利用的是语音信号中的语言学信息,而不考虑语音信号中的字词意思,不考虑说话人的个性。
语种识别在信息检索和军事领域都有很重要的应用,包括自动转换服务多语言信息补偿等。
在信息服务方面, 很多信息查询中可提供多语言服务, 但一开始必须用多种语言提示用户选择用户语言。
语种辨识系统必须预先区分用户的语言种类, 以提供不同语言种类的服务。
这类典型服务的例子包括旅游信息、应急服务、以及购物和银行、股票交易。
例如 AT&T 向处理 911 紧急呼救的社会机构和警察局推出语言热线服务。
图 1 说明了两个讲不同语言的人是如何通过一个多语言话音系统进行交流。
自动语言辨识技术还能够用于多语言机器翻译系统的前端处理, 当对大量录音资料进行翻译分配时, 需要预先判定每一段语音的语言。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1语言辨识的基本概念自动语言辨识(又称语种识别),是计算机分析处理一个语音片段以判别其所属语种的技术。
随着当前全球合作的增长,各种余元之间的通信要求增加,这就对自动语言识别提出新的挑战,在机械能够懂得语言含义之前,必须辨别使用了哪种语言。
自动语言辨识的任务在于快速准确的辨识出所使用的语言,目前它已经成为通信和信息领域一个新的学科增长点。
自动语言辨识技术的学术特点在于它横跨技术的融合。
对它的研究,不仅需要掌握信息理论和技术,而且需要具有多种信息处理的手段和方法。
众所周知,语音中包含着多种信息,从语音中提取不同的信息进行处理也就形成了不同语言处理方法。
从内容上分,语音中包含着所属语言种类的信息、说话内容的语义信息和说话人个体特征,因此从识别的角度来说,我们可以利用从语音中提取的这些信息进行识别,语音信息的识别可以分为语音识别、语言辨识和说话人识别。
语音识别中要提取出包含在语音信号中的字词意思和言语内容,说话人识别则是从语音信号中获取说话人的身份,语言辨识是从语音信号中提取出包含的语言的种类(或方言的种类)。
与语音识别和说话人识别不同的是,语言辨识利用的是语音信号中的语言学信息,而不考虑语音信号中的字词意思,不考虑说话人的个性。
语种识别在信息检索和军事领域都有很重要的应用,包括自动转换服务多语言信息补偿等。
在信息服务方面, 很多信息查询中可提供多语言服务, 但一开始必须用多种语言提示用户选择用户语言。
语种辨识系统必须预先区分用户的语言种类, 以提供不同语言种类的服务。
这类典型服务的例子包括旅游信息、应急服务、以及购物和银行、股票交易。
例如AT&T 向处理911 紧急呼救的社会机构和警察局推出语言热线服务。
图1 说明了两个讲不同语言的人是如何通过一个多语言话音系统进行交流。
自动语言辨识技术还能够用于多语言机器翻译系统的前端处理, 当对大量录音资料进行翻译分配时, 需要预先判定每一段语音的语言。
随着信息时代的到来以及国际因特网的发展, 语言辨识越来越显示出其应用价值, 国际上也一直进行着卓有成效的研究和系统开发。
图1 不同语种说话人交流系统与语音处理的其他领域相比, 自动语种识别是一个相对较新的领域。
尽管在某些方面, 其类似于自动语音识别、说话人识别和声调检测, 但所有这些任务之间的差别很大。
理论上来讲, 不同语言之间的差别是多方面的, 而且差别较大。
尽管在各种层次上都可以找到这些差别( 如, 音素目录, 音素的声学实现, 词汇, 音位结构规律性和词法等等) , 由于在任何层次上都不存在可靠的算法, 因此可靠的语言辨识仍旧是一个难题。
2.语言辨识的发展自动语言辨识的研究可以追溯到20世纪70年代,与语音识别的其它方向相比较,自动语言辨识进展较为缓慢,在1993年之前的20多年里用英语发表的文献中,只能找到14篇有关自动语言辨识的研究。
这些研究的语音数据的种类覆盖了从文本的标音法和实验室语音到电话和无线电广播语音的范围。
语言的种类从3种发展到20种。
语言辨识的方法使用过每种语言的“参考语音”、基于音段和音节的马尔可夫模型、基音轮廓、共振峰矢量、声学特征、方言性的音素和韵律特征、及其原始的语音声波特征。
使用过的分类方法包括HMM、专家系统、聚类算法、二次分类、以及人工神经网络。
俄勒冈科学技术研究院的多语种电话语音数据库(简称OGI-TS)是为进行自动语言辨识研究专门设计的。
目前它是由11种语言的发音流畅的、固定词汇的语音数据所组成。
这些语言是英语(English)、波斯语(Farsi)、法语(French)、德语(German)、北印度语(Hindi)、日语(Japanese)、朝鲜语(Korean)、汉语(Chinese)、西班牙语(Spanish)、泰米尔语(Tamil)和越南语(Vietnamese)。
这些发音由每种语言的90个持母语的人在实际电话线路上产生。
发音的时长从1秒到50秒长短不等,平均13.4秒。
OGI-TS的出现重新激发了人们对自动语言辨识研究的兴趣。
1993年美国国家标准技术研究所(NIST)将OGI-TS设计为自动语言辨识评估的标准,自动语言辨识技术的研究和应用在学术界和企业界开始受到关注,一些重要的有关语音的国际学术会议上相关的学术论文数量迅速增加,并且这些会议上还设立了交流语言辨识研究的分会场。
同时,在开发相关技术产品方面开展了一些国际研究项目,国际标准化组织也就该技术研究开展了评估工作。
进入90年代中期,麻省理工的Lincoln实验室,美国电话电报公司(AT&T),俄勒冈科学技术研究院,美国国际电话电信公司(ITT),美国Rensselaer理工研究所,Locakheed- Sanders工程公司等八个开展语言辨识研究的基地也相继发布了他们的研究成果。
3语言辨识的原理自动语言辨识是属于人工智能领域的一项技术,本质上讲,语言辨识技术是一个语音信号模式识别的问题,它由训练和识别两个阶段完成。
从各种语言的训练语音中提取每种语言特征建立参考模型并存储的过程称为训练阶段;从待识别语音中提取语言特征,依据参考模型进行比较和判决,对语音段的语言种类进行判断的过程称为识别阶段。
图3.1为语言辨别系统的典型结构图,从图中可以看出,一个完整的语言辨识系统包括预处理模块、特征提取模块、模型建立模块、模式匹配模块和判决模块。
训练识别图3.1 语言辨识系统的结构框图预处理模块可以对语音信号进行转换,使之更适合计算机处理,并符合特征提取的要求,其中包括语音信号数字化,预加重和加窗处理。
特征提取则需要从经过预处理的语音信号中提取出能够反映语言特征的参数。
究竟用语音信号的哪些特征或特征变换来表征语言才是有效可靠的,这涉及到对人是如何通过听声音来识别各种语言的这一过程的理解,而这一点很难在近期得到解决。
而且,在语音信号中,通常说话人的特征、说话内容的语义信息比语言特征表现的更为明显,从这个角度而言,语言特征受到这些原因的影响更为弱化,不易提出。
多年来人们对特征参数在语言辨识系统中的有效性进行了大量的验证和研究,这些特征参数大体分为三类,线性预测系数及派生参数、由语音频谱直接导出的参数以及混合参数。
线性预测参数及其派生参数包括线性预测系数、线谱对系数、线性预测倒谱系数(LPCC )及其组合等参数;由语音频谱直接导出的参数,如基音(Pitch )及其轮廓、美尔频谱倒谱系数(MFCC ),感知线性预测(PLP )参数和口音敏感倒谱系数(ASCC)等。
需要指出的是,上述的参数不仅可用于语言辨识,它们也是说话人识别,关键字检出和连续语音识别中的常用参数,因此,现有的特征提取方法并不针对语言辨识,而是一种通用方法,这样,提取的特征也不能很好的反映各种语言独特的信息。
此外,一个面向应用的语言辨识系统会遇到许多实际的情况,比如传输信道带来的信号畸变的影响、环境背景噪声的影训练与识别环境不同带来的影响等等,这些都给语音特征参数的研究带来了挑战。
模型建立是指在训练阶段用合适的模型来表征这些特征参数,使得模型能够代表该语言的语音特性。
对模型的选择主要应从语音的类型、所期望的功能、训练和更新的难易程度以及计算量和存储量等方面综合考虑。
当前有多种模型可供选择,一般可分为模板匹配、概率生产模型和判别模型等。
按照不同的模型和特征列出如图3.2的语音辨识系统框图。
(ANN)图3.2 语音辨识系统分类模板匹配模型典型的例子有最邻模型(Nearest Neighbor,NN)模型,动态时间规整(Dynamic Time Warping,DTW)模型和矢量化(VQ)模型。
模板匹配模型的不足之处在于不能全面地反映样本分布及统计特性,适应性差,因此语言辨识应用有限。
概率统计生成模型是指采用某种概率密度函数来描述各种语言的语音特征空间的分布情况,并以该概率密度函数的一组参数作为语言的模型。
典型的有隐马尔可夫模型(HMM)、高斯混合模型(GMM)。
概率统计生产模型由于考虑了语音的统计特征,因此能较全面地反映每种语言的统计信息。
在识别阶段,用训练阶段建立的语言模型对测试语音的特征参数进行某种形式的模式匹配,从而得出相似性得分:判决模块根据该相似得分并依据特定的规则给出最终识别结果。
对于模块匹配模型,比较J模块和测试语音X的距离,距离最近的模板种类则判决为该测试语音的语言种类,即(3.1)其中,错误!未找到引用源。
为第j种语言的模板。
对于概率生成模型,判决规则为J个模型中的哪个模型对X产生的后验概率最大,就判决测试语音X属于哪种语言,即(3.2)其中,错误!未找到引用源。
为第j种语言的概率生成模型。
假定错误!未找到引用源。
,即每种语言出现的先验概率为等概率,且因P(X)对每种语言是相同的,上式可简化为(3.3)对于判决模型,判决时就是看属于哪一类可能性最大。
分类器通常具有J个输出,分别对应于J种语言模型。
给定输入语音特征序列,具有最大输出值的输出所对应的语言即为所求。
对于当J比较大时,训练具有J个输出的判别模型非常复杂,训练量也变得非常大。
因此对于多类的分类问题,常常转化为多个两类问题的组合问题,而且对于两类问题往往更适合用判别模型解决。
4.语言辨识系统的举例(基于VQ的语言辨识系统)4.1特征提取我们对语音信号进行8kHz 采样,以22.5毫秒为一帧进行参数化提取特征参数。
我们这里采用了3 种倒谱参数和相应的差分倒谱参数,每一帧计算24 维的特征向量,12维的倒谱参数和12 维的Delta 倒谱参数。
这3种倒谱参数分别为: LPCC 参数、MFCC 参数和ASCC 参数。
Delta 特征的计算如式( 1) 所示: 当i 从1 到12( 分析阶数) ,(1)上式中, dCep表示delta 特征, Cep表示倒谱, 错误!未找到引用源。
( = 0.2) 用来换算这些特征。
美尔倒谱系数又称MFCC, 是语音识别提取的另一类参数。
MFCC 不同于LPCC, 它是采用滤波器组的方法计算出来的, 这组滤波器在频率的美尔(Mel) 坐标上是等带宽的。
这是因为人类在对约1000Hz 以上的声音频率范围的感知不遵循线性关系, 而是遵循在对数频率坐标上的近似线性关系。
语音信号在经过加窗处理后变为短时信号, 用FFT 计算它的能量谱。
之后, 通过一个具有40 个滤波器( K = 40) 的滤波器组。
前13 个滤波器在1000Hz 以下是线性划分的, 后27 个滤波器在1000Hz 以上是按美尔坐标上线性划分的。
如果错误!未找到引用源。
表示第k 个滤波器的输出能量, 则美尔频率倒谱错误!未找到引用源。
在美尔刻度谱上可以采用修改的离散余弦变换(DCT) 求得:n= 1, 2, …, P (2)类取代空胞腔。