SPSS 10.0高级教程十三:分类资料的Logistic回归分析
Spss软件之logistic回归分析

…
n
0
1
Xn01
X n02
…
1
0
X n11
X n12
…
2
0
Xn21
X n22
…
Xk X 10k X 11 k X 12k
X iMk
X n0k X n1 k X n2k
M
0
XnM1
XnM2
…
X nMk
Conditional logistic regression
用Pi表示第i层在一组危险因素作用下发病的概率, 条 件 logistic 模型可表示为
n
L
1
i1 1
M
k exp
j (X itj X i0 j )
t 1
j1
可以看出,条件logistic 回归分析只估计了表示危 险因素作用的βj值,表示匹配组效应的常数项βi0 则被自动地消去了。
Conditional logistic regression
对上述条件似然函数L取自然对数后,用非线性 迭代法求出参数的估计值bi及其标准误Sbi。回归 系数的假设检验及分析方法与非条件logistic回归 完全相同。
c1 1, c0 0,
Xj
1, 暴露
0,非暴露
ORj exp( j )
Logistic regression analysis
0,
ORj
1
无作用
ORj exp( j ), j >0, ORj 1 危险因子
0, ORj 1 保护因子
二、模型的参数估计
在logistic回归模型中,回归系数的估计通常用最大 似然法(MLE)。其基本思想是先建立一个样本 的似然函数,求似然函数达到最大值时参数的取 值,即为参数的极大似然估计值。
用SPSS做logistic回归分析解读

如何用SPSS做logistic回归分析解读————————————————————————————————作者:————————————————————————————————日期:如何用进行二元和多元logistic回归分析一、二元logistic回归分析二元logistic回归分析的前提为因变量是可以转化为0、1的二分变量,如:死亡或者生存,男性或者女性,有或无,Yes或No,是或否的情况。
下面以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进行二元logistic回归分析。
(一)数据准备和SPSS选项设置第一步,原始数据的转化:如图1-1所示,其中脑梗塞可以分为ICAS、ECAS和NCAS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NCAS转化为1、0分类,是ICAS赋值为1,否赋值为0。
年龄为数值变量,可直接输入到spss中,而性别需要转化为(1、0)分类变量输入到spss当中,假设男性为1,女性为0,但在后续分析中系统会将1,0置换(下面还会介绍),因此为方便期间我们这里先将男女赋值置换,即男性为“0”,女性为“1”。
图 1-1第二步:打开“二值Logistic 回归分析”对话框:沿着主菜单的“分析(Analyze)→回归(Regression)→二元logistic(Binary Logistic)”的路径(图1-2)打开二值Logistic 回归分析选项框(图1-3)。
如图1-3左侧对话框中有许多变量,但在单因素方差分析中与ICAS 显著相关的为性别、年龄、有无高血压,有无糖尿病等(P<),因此我们这里选择以性别和年龄为例进行分析。
在图1-3中,因为我们要分析性别和年龄与ICAS的相关程度,因此将ICAS选入因变量(Dependent)中,而将性别和年龄选入协变量(Covariates)框中,在协变量下方的“方法(Method)”一栏中,共有七个选项。
SPSS操作方法:逻辑回归

在SPSS中进行逻辑回归分析需要按照以下步骤进行:
1. 打开数据文件,确保数据文件中包含自变量和因变量。
自变量应该是分类变量,因变量应该是二元变量(例如0或1)。
2. 点击“分析”菜单,选择“回归”子菜单,然后选择“逻辑回归”选项。
3. 在“逻辑回归”对话框中,选择自变量和因变量。
您可以在“分类”选项卡中更改自变量的编码方式。
例如,您可以将自变量转换为因子变量或二分类变量。
4. 在“选项”对话框中,您可以更改输出选项和模型拟合统计量。
例如,您可以更改模型拟合统计量的输出格式和置信区间。
5. 点击“确定”按钮,SPSS将执行逻辑回归分析并生成输出结果。
下面是一个示例:
假设我们有一个数据文件,其中包含年龄、性别和是否吸烟三个变量。
我们想要分析吸烟是否影响是否患上肺癌。
1. 打开数据文件,并确保数据文件中包含年龄、性别和是否吸烟三个变量。
2. 点击“分析”菜单,选择“回归”子菜单,然后选择“逻辑回归”选项。
3. 在“逻辑回归”对话框中,选择“是否吸烟”作为因变量,“年龄”和“性别”作为自变量。
4. 在“选项”对话框中,勾选“拟合统计量”、“系数”、“标准误”、“置信区间”和“z值”复选框。
5. 点击“确定”按钮,SPSS将执行逻辑回归分析并生成输出结果。
输出结果将包括模型拟合统计量、系数、标准误、置信区间和z值等信息。
根据这些信息,我们可以评估模型拟合程度和自变量对因变量的影响程度。
SPSS做Logistic回归步骤
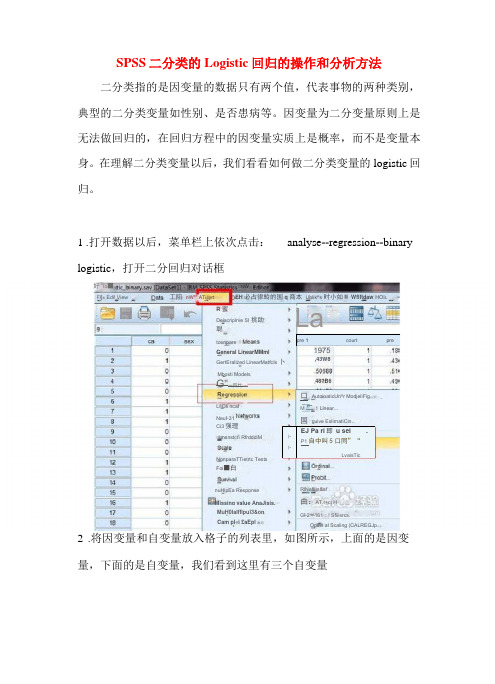
SPSS 二分类的Logistic 回归的操作和分析方法二分类指的是因变量的数据只有两个值,代表事物的两种类别, 典型的二分类变量如性别、是否患病等。
因变量为二分变量原则上是 无法做回归的,在回归方程中的因变量实质上是概率,而不是变量本 身。
在理解二分类变量以后,我们看看如何做二分类变量的logistic 回归。
1 .打开数据以后,菜单栏上依次点击: analyse --regression --binary logistic ,打开二分回归对话框2 .将因变量和自变量放入格子的列表里,如图所示,上面的是因变 量,下面的是自变量,我们看到这里有三个自变量pre 1courtpre卜 卜EJ Pa ri 即 u sei.P1自中叫5口同”“LvaisTic好 Io ■网 □N W□imsnstcri RfrdddiMNonparaTTietrtc Tests Foi ■白MuH0lalfflpul3&on Deiscriplrve SI 挑助聪LfiOli ncaf - Neuf-31 nuHlpEa ResponseMissing value AnaJisis. EH 必占律蛉的国q 商本 Ublik^s 时小如M Wflftdaw HOI LFl[« Edi! View工陷 nW"" ATiilyrtCam pl«i £aEpl 骷与Opsin al Scaling (CALREGJp..R 蜜GertEralized LinearMatfcIs 卜 Mbosti ModelsRlNafllin&af .曲:AT.r+ci HC] 2^^161;! Sfiiisrcs.tosnpareGeneral LinearMMml 48?B6Ci3强理 G"一四忙—一 3 La,43W8口 AutoioaticUn^r ModjeliFig..M 二1 Linear...国 guive EslirnatiCin...C>ep«n (lferit3 .设置回归方法,这里选择最简单的方法:enter ,它指的是将所有的 变量一次纳入到方程。
logistic spss

分类资料的回归分析------Logistic 回归例1 在一次关于公共交通的社会调查中,一个调查项目为“是坐公交车上下班还是骑自行车上下班”。
因变量1y =表示主要乘坐公交车上下班,0y =表示主要骑自行车上下班。
自变量1x 是年龄;2x 是月收入;3x 是性别,31x =表示男性,30x =表示女性。
调查对象为工薪群体,数据如下表,建立y 与自变量间的回归。
理论回归模型:011223ln,1p px x x pββββ=+++-其中13(1,...,)p p y x x ==。
获得容量为n 的样本()123,,,,1,...,i i i i x x x y i n =后可得样本回归模型:011223ln,1ii i p i ip x x x p ββββ=+++-其中13(1,...,)i i p p y x x ==,1,...,i n =。
一般情况:01122ln ...,1p p px x x pββββ=+++-其中1(1,...,)p p p y x x ==。
2.参数估计极大似然估计或者加权最小二乘估计3.系数解释从数学上来讲,与多重线形回归模型中系数的解释并无不同,即i β表示i x 改变一个单位时ln1pp-的改变量。
在实际中此改变量表示什么含义?请看例2。
例2 本例是探讨妇女使用雌激素与患子宫内膜癌的研究资料。
模型: 011l n ,1px pββ=+-优势odds :1pp- 表示某个事件的相对危险度 0x =时:1x =时:回归模型中的系数与有时比有极为密切的关系,同时与自变量的量化方法密切相关。
4.补充说明(1)关于自变量类型自变量的常见类型:连续型变量、二水平的分类变量、多水平的分类变量、等级变量。
多水平的分类变量:例如个体的血型、民族、职业、工种等等如何处理?产生哑变量,所谓哑变量就是一组取值1和0的二值分类变量,用来表示一个分类变量。
例为了了解冠心病与种族的关系,某研究所调查了100个个体,数据如下表。
(完整版)spss的logistic分析教程

Logistic回归主要分为三类,一种是因变量为二分类得logistic回归,这种回归叫做二项logistic回归,一种是因变量为无序多分类得logistic回归,比如倾向于选择哪种产品,这种回归叫做多项logistic回归。
还有一种是因变量为有序多分类的logistic回归,比如病重的程度是高,中,低呀等等,这种回归也叫累积logistic回归,或者序次logistic回归。
二值logistic回归:选择分析——回归——二元logistic,打开主面板,因变量勾选你的二分类变量,这个没有什么疑问,然后看下边写着一个协变量。
有没有很奇怪什么叫做协变量?在二元logistic回归里边可以认为协变量类似于自变量,或者就是自变量。
把你的自变量选到协变量的框框里边。
细心的朋友会发现,在指向协变量的那个箭头下边,还有一个小小的按钮,标着a*b,这个按钮的作用是用来选择交互项的。
我们知道,有时候两个变量合在一起会产生新的效应,比如年龄和结婚次数综合在一起,会对健康程度有一个新的影响,这时候,我们就认为两者有交互效应。
那么我们为了模型的准确,就把这个交互效应也选到模型里去。
我们在右边的那个框框里选择变量a,按住ctrl,在选择变量b,那么我们就同时选住这两个变量了,然后点那个a*b的按钮,这样,一个新的名字很长的变量就出现在协变量的框框里了,就是我们的交互作用的变量。
然后在下边有一个方法的下拉菜单。
默认的是进入,就是强迫所有选择的变量都进入到模型里边。
除去进入法以外,还有三种向前法,三种向后法。
一般默认进入就可以了,如果做出来的模型有变量的p值不合格,就用其他方法在做。
再下边的选择变量则是用来选择你的个案的。
一般也不用管它。
选好主面板以后,单击分类(右上角),打开分类对话框。
在这个对话框里边,左边的协变量的框框里边有你选好的自变量,右边写着分类协变量的框框则是空白的。
你要把协变量里边的字符型变量和分类变量选到分类协变量里边去(系统会自动生成哑变量来方便分析,什么事哑变量具体参照前文)。
spss logistic回归分析

Log
P 1− P
= 1.358 −1.832x1
−
2.140x3
应用Logistic回归分析时的注意事项
1. Logistic回归是乘法模型,这一点,在结果解释时需 要慎重。
对于自变量(X1,X2),OR12=EXP(β1+β2)=OR1×OR2
例:某研究调查胃癌发病的危险因素,得到“有不良饮食习 惯”相对于“无不良饮食习惯”的OR=2.6, “喜吃卤食和盐渍 食物”相对于“不吃卤食和盐渍食物”的OR=2.4。那么根据 Logistic回归,“有不良饮食习惯且喜吃卤食和盐渍食物”相 对于“无不良饮食习惯且不吃卤食和盐渍食物”的 OR=2.6×2.4=6.24,得出此结论时需要考虑:从专业知识上 是否合理?
另法:将X1、X3指定为分类变量。
另法:将X1、X3指定为分类变量。
注:变量编码发生 了变化:0→ 0.5, 1→ -0.5
与前述结果相比,X1与X3的回归系数符号发生了变化,结果解释有 所不同:病情不严重组相对于严重组,OR=4.928(病情不严重的 患者,其治愈的概率是病情严重的患者的4.928倍);新疗法组相对 于旧疗法组, OR=9.707, (接受新疗法的患者,其治愈的概率是 接受旧疗法的患者的9.707倍)。 注:对于二分类变量,可以当作连续变量处理,也可以指定为 分类变量,但要注意结果解释。
2. 通常情况下,自变量为二分类变量时,可以当作连续变 量进入模型(常用0、1或者1、2赋值),也可以通过 “categorical”来指定哑变量。但是,对多分类变量应该 通过“categorical”来指定哑变量,而不宜直接作为连续 变量处理。
多元线性回归分析与Logistic回归分析都是实际工作中 常用的方法,用于影响因素分析时,多元线性回归的因 变量是连续变量,而Logistic回归的因变量是分类变 量;两种方法的自变量可为连续变量或分类变量,当为 分类变量时,均需相应的哑变量(二分类变量例外)。
利用 SPSS 进行 Logistic 回归分析简要步骤

利用SPSS 进行Logistic 回归分析简要步骤
现实中的很多现象可以划分为两种可能,或者归结为两种状态,这两种状态分别用0
和1 表示。
如果我们采用多个因素对0-1 表示的某种现象进行因果关系解释,就可能应用到logistic 回归。
Logistic 回归分为二值logistic 回归和多值logistic 回归两类.
第一步:整理原始数据。
数据整理内容包括两个方面:一
是对各地区按照三大地带的分类结果赋值,用0、1 表示,二是将城镇人口比重转换逻辑值,变量名称为“城市化”。
第二步:打开“聚类分析”对话框。
沿着主菜单的“Analyze→Regression→Binary Logistic
K
”的路径(图8-1-3)打开二值
Logistic 回归分析选项框.
第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调
入Dependent(因变量)和Covariates(协变量)列表框中(图8-1-5)。
在本例中,将名义变
量“城市化”调入Dependent(因变量)列表框,将“人均GDP”和“中部”调入Covariates (协变量)列表框中。
在Method(方法)一栏有七个选项。
采用第一种方法,即系统默认的强迫回归方法(Enter)。
接下来进行如下4 项设置:
⒈设置Categorical(分类)选项:定义分类变量.
⒉设置Save(保存)选项,
⒊设置Options
第四步,结果解读.。
SPSS数据分析—多分类Logistic回归模型

前面我们说过二分类Logistic回归模型,但分类变量并不只是二分类一种,还有多分类,本次我们介绍当因变量为多分类时的Logistic回归模型。
多分类Logistic回归模型又分为有序多分类Logistic回归模型和无序多分类Logistic回归模型一、有序多分类Logistic回归模型有序多分类Logistic回归模型拟合的基本方法是拟合因变量水平数-1个Logistic回归模型,也称为累积多分类Logit模型,实际上就是将因变量依次分割成两个等级,对这两个等级建立二分类Logistic回归模型,无论模型的分割点在什么位置,所拟合的这n-1个回归模型的自变量系数均保持不变,改变的只有常数项,这也是累积多分类Logit模型的前提条件,也称为平行线检验。
累积多分类Logit模型的常数项是负数,和二分类Logistic回归模型的常数项符号相反下面看一个例子现在想分析人们的工作满意度,选取了一些相关变量,数据如下从数据中,可见因变量满意度satis有三个水平,因此考虑拟合有序多分类Logistic回归模型分析—回归—有序二、无序多分类Logistic回归模型前面讲的有序分类Logistic回归模型,前提为因变量为有序多分类,但是当因变量为无序多分类或者不满足平行线假定时,就需要使用无序多分类Logistic 回归模型。
无序多分类Logistic回归模型也是拟合因变量水平数-1个广义Logit模型,不同的是它需要先定义某一个水平为参照水平,其余水平和其进行对比,SPSS默认取水平最大者为参照水平。
例,通过一组数据,希望分析出不同背景人的投票倾向图中可见因变量pres92为无序多分类变量,有三个水平,考虑使用无序多分类Logistic回归模型分析—回归—多项Logistic。
SPSS Logistic回归分析及其应用 图文

寻找合适的模型
•进行logit变换:
p b0 b1x1 bp x p
logit
(
p)
ln( 1
p
p
)
b0
b1x1
bp xp
logit ( p) b0 b1x1 bp x p
其中:p为因变量取值为1(y=1)的概率,p/(1-p)称为发生比(OR)
第10页共62页模型中回归系数的含义?回归系数表示当其他自变量取值保持不变时该自变量取值增加一个单位引起发生比or自然对数值的变化量?用发生比orp1p测量自变量xi变化对发生概率的影响程度第11页共62页分析的一般步骤?变量的编码?哑变量的设置和引入设置参照类?各个自变量的单因素分析?变量的筛选?交互作用的引入?建立多个模型?选择较优的模型?模型应用条件的评价?输出结果的解释第12页共62页logistic回归的分类?二项logistic回归binaryregression?多分变量logistic回归multinominalregression第13页共62页二项logistic回归?因变量只取两个值表示一种决策一种结果的两种可能性
• 因变量呈二项分布
Logistic回归模型的估计方法
• 最大似然估计法(Maximum likelihood estimation,MLE)。最大似然估计法通过最 大化对数似然值(log likelihood)估计参数。 (对应于最小二乘法OLS)
• 最大似然估计法是一种迭代算法,它以一个 预测估计值作为参数的初始值,根据算法确 定能增大对数似然值的参数的方向和变动。 估计了该初始函数后,对残差进行检验并用 改进的函数进行重新估计,直到收敛为止 (即对数似然不再显著变化)。
详解利用SPSS进行Logistic_回归分析
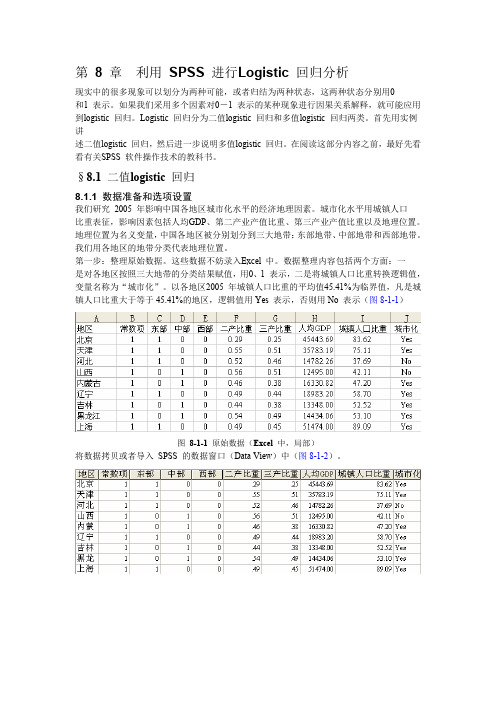
第8 章利用SPSS 进行Logistic 回归分析现实中的很多现象可以划分为两种可能,或者归结为两种状态,这两种状态分别用0和1 表示。
如果我们采用多个因素对0-1 表示的某种现象进行因果关系解释,就可能应用到logistic 回归。
Logistic 回归分为二值logistic 回归和多值logistic 回归两类。
首先用实例讲述二值logistic 回归,然后进一步说明多值logistic 回归。
在阅读这部分内容之前,最好先看看有关SPSS 软件操作技术的教科书。
§8.1 二值logistic 回归8.1.1 数据准备和选项设置我们研究2005 年影响中国各地区城市化水平的经济地理因素。
城市化水平用城镇人口比重表征,影响因素包括人均GDP、第二产业产值比重、第三产业产值比重以及地理位置。
地理位置为名义变量,中国各地区被分别划分到三大地带:东部地带、中部地带和西部地带。
我们用各地区的地带分类代表地理位置。
第一步:整理原始数据。
这些数据不妨录入Excel 中。
数据整理内容包括两个方面:一是对各地区按照三大地带的分类结果赋值,用0、1 表示,二是将城镇人口比重转换逻辑值,变量名称为“城市化”。
以各地区2005 年城镇人口比重的平均值45.41%为临界值,凡是城镇人口比重大于等于45.41%的地区,逻辑值用Yes 表示,否则用No 表示(图8-1-1)图8-1-1 原始数据(Excel 中,局部)将数据拷贝或者导入SPSS 的数据窗口(Data View)中(图8-1-2)。
图8-1-2 中国31 个地区的数据(SPSS 中,局部)第二步:打开“聚类分析”对话框。
沿着主菜单的“Analyze→Regression→Binary Logistic K”的路径(图8-1-3)打开二值Logistic 回归分析选项框(图8-1-4)。
图8-1-3 打开二值Logistic 回归分析对话框的路径对数据进行多次拟合试验,结果表明,像二产比重、三产比重等对城市化水平影响不显著。
经典实用的spss课件 十三、logistic回归模型

行参数估计。
3Leabharlann 模型结果解释与可视化解释模型系数的含义,并通过图表展示 模型的效果和变量的影响。
实战应用
案例分析 实战练习
以实际案例为例,演示如何应用Logistic回归模型 进行分类预测和决策支持。
通过实际数据和案例,进行Logistic回归模型的练 习和应用。
总结与展望
总结本次课程内容
回顾本次课程所学的知识和技能,总结关键要点。
展望下一步学习方向
探讨Logistic回归模型的延伸应用和未来发展方向。
经典实用的SPSS课件 十 三、logistic回归模型
SPSS的Logistic回归模型是一种经典且实用的统计分析方法。本课程将深入探 讨Logistic回归模型的应用,以及数据处理和模型建立的相关操作。
什么是Logistic回归模型
Logistic回归模型是一种分类模型,用于预测二分类或多分类的概率。它基于 特征变量与分类变量之间的关系,通过建立回归方程来进行预测和解释。
Logistic回归模型的应用场景
市场营销
预测客户购买某产品的概率, 帮助制定营销策略。
医学研究
预测疾病发生的概率,辅助 诊断和治疗决策。
信用风险评估
预测借款人违约的概率,辅 助风险管理和授信决策。
数据处理
数据收集与清洗
收集相关数据,并进行数据清洗,包括处理缺失值和异常值。
数据预处理
对数据进行预处理,如标准化、离散化等,以满足模型的前提条件。
建立模型
模型建立方法
选择合适的自变量,确定模型的形式,进行参数估 计。
模型评估方法
对模型进行评估,包括拟合优度、模型显著性、变 量重要性等指标。
SPSS操作
SPSS课件logistic回归分析

Logistic回归分析
Log.sav
关于考试
考试时间:下周的上课时间
每人准备一张软盘,在软盘上注明姓名、学 号
Logistic回归分析
数据背景(data13-02) 北京医科大学附属人民医院内分泌科卢纹凯教授课题。 颈总动脉中层厚度imt>0.8mm或有斑块定义为动脉硬 化,因变量type值为1;非硬化imt<0.8mm且无斑块, 因变量type值为0。糖尿病患者123例数据。研究哪 些指标可以判断糖尿病患者是否动脉硬化。自变量 AGE年龄、ALB尿白蛋白、BMI体重指数、ISI胰岛素 敏感指数、SBP收缩压、TG甘油三脂、CHO胆固醇、 DURA糖尿病程。其中尿白蛋白、甘油三脂、胆固醇 三项生化指标在回归估计过程中均使用他们的对数变 量:ALBLN、TGLN、CHOLN。
级分组资料或是计量资料,此时,可以使用logistic
回归来分析பைடு நூலகம்变量(二值变量)与自变量的关系。
三、 Logistic回归分析
Categorical 多分类变量的比较
Save 功能按钮
Option 功能按钮
Logistic回归分析
为研究急性肾衰(AFR)患者死亡的危险因素,经回顾性
调查分析,获得某医院1999~2000年中所有发生AFR的
422名患者的临床资料见数据文件logistic.sav。本资料共涉 及29个变量,分别是:sex, age, 社会支持,慢性病,手术,
肿瘤,糖尿病,动脉硬化,器官移植,cr(血肌酐),hg
(血红蛋白),肾毒性,少尿,lbp,黄疸,昏迷,辅助呼 吸,心衰,肝衰,出血,呼衰,器官衰竭,胰腺炎,dic, 败血症,感染,hbp,透析方式,死亡。其中器官衰竭、和 透析方式为多分类变量,分别有6个和4个水平,定量变量 有age,cr,hg;其余为二分类变量。
如何用SPSS做logistic回归分析解读

如何用spss17.0进行二元和多元logistic回归分析一、二元logistic回归分析二元logistic回归分析的前提为因变量是可以转化为0、1的二分变量,如:死亡或者生存,男性或者女性,有或无,Yes或No,是或否的情况。
下面以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进行二元logistic回归分析。
〔一〕数据准备和SPSS选项设置第一步,原始数据的转化:如图1-1所示,其中脑梗塞可以分为ICAS、ECAS和NCAS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NCAS转化为1、0分类,是ICAS赋值为1,否赋值为0。
年龄为数值变量,可直接输入到spss中,而性别需要转化为〔1、0〕分类变量输入到spss当中,假设男性为1,女性为0,但在后续分析中系统会将1,0置换〔下面还会介绍〕,因此为方便期间我们这里先将男女赋值置换,即男性为“0〞,女性为“1〞。
图1-1第二步:打开“二值Logistic 回归分析〞对话框:沿着主菜单的“分析〔Analyze〕→回归〔Regression〕→二元logistic 〔Binary Logistic〕〞的路径〔图1-2〕打开二值Logistic 回归分析选项框〔图1-3〕。
如图1-3左侧对话框中有许多变量,但在单因素方差分析中与ICAS 显著相关的为性别、年龄、有无高血压,有无糖尿病等〔P<0.05〕,因此我们这里选择以性别和年龄为例进行分析。
在图1-3中,因为我们要分析性别和年龄与ICAS的相关程度,因此将ICAS选入因变量〔Dependent〕中,而将性别和年龄选入协变量〔Covariates〕框中,在协变量下方的“方法〔Method〕〞一栏中,共有七个选项。
采用第一种方法,即系统默认的强迫回归方法〔进入“Enter〞〕。
接下来我们将对分类〔Categorical〕,保存〔Save〕,选项〔Options〕按照如图1-4、1-5、1-6中所示进行设置。
应用SPSS软件进行多分类Logistic回归分析

应用SPSS软件进行多分类Logistic回归分析应用SPSS软件进行多分类Logistic回归分析一、简介Logistic回归是一种常用的统计分析方法,在很多领域中都有广泛的应用。
它主要用于预测一个分类变量的可能性或概率,例如判断一个疾病的患病风险、判断学生成绩的优劣、预测金融市场的涨跌等。
本文将介绍如何使用SPSS软件进行多分类Logistic回归分析,并以一个具体案例来说明其应用。
二、SPSS软件介绍SPSS软件是统计分析的常用工具之一,它具有友好的用户界面和丰富的分析功能。
在进行Logistic回归分析时,SPSS可以帮助我们进行数据处理、模型建立、模型拟合、模型评估等步骤,并输出详细的分析结果。
三、案例描述我们假设有一份数据集,包含了500个样本和5个自变量,要根据这些自变量对样本进行多分类。
自变量包括性别、年龄、教育水平、收入和职业。
而多分类的目标变量是购买冰淇淋的偏好,包括三个分类:喜欢巧克力口味、喜欢草莓口味和喜欢香草口味。
四、数据处理首先,我们需要对数据进行处理。
SPSS可以读取各种文件格式,如Excel、CSV等。
我们将数据导入SPSS后,可以进行缺失值处理、异常值处理等预处理步骤。
这些步骤是为了保证后续的分析结果的准确性和可靠性。
五、模型建立在SPSS中,我们可以使用多分类Logistic回归模型进行建模。
它采用最大似然估计方法来估计模型参数,以便进行分类预测。
我们需要将自变量和目标变量进行指定,SPSS会自动计算出各个自变量对目标变量的系数和统计学意义。
六、模型拟合在模型拟合阶段,SPSS会对模型进行拟合优度的检验,包括卡方拟合优度检验、Hosmer-Lemeshow检验等。
这些检验可以帮助我们评估模型的拟合程度和可靠性。
如果模型的拟合程度不好,我们可以对模型进行进一步调整和改进。
七、模型评估在模型评估阶段,SPSS提供了一系列的统计指标和图表,用于评估多分类Logistic回归模型的性能。
经典实用的spss课件十三、logistic回归模型

探索回归分析的基本概念,了解逻辑回归模型的定义以及其应用场景。深入 剖析模型的原理、假设和参数估计,通过模型拟合检验和优化方法提高模型 的准确性。最后通过案例分析和实战练习巩固知识。
什么是逻辑回归模型?
逻辑回归是一种广泛应用于分类问题的统计分析方法。它通过将自变量与对 数几率相联系,用于预测离散的二分类结果。
逻辑回归模型的应用场景
医学研究
逻辑回归可用于预测疾病的患病 风险,为医生提供决策依据。
客户流失分析
逻辑回归可帮助企业预测哪些客 户可能流失,并采取措施保留他 们。
信用评分
逻辑回归可用于确定个人的信用 等级,帮助银行和金融机构做出 信贷决策。
逻辑回归模型的原理和假设
原理
逻辑回归基于最大似然估计原理,通过最大化似 然函数来估计模型参数。
模型拟合检验和优化
拟合度检验
使用拟合度统计量检验模型与实际数据的拟合程度,如对数似然比检验。
模型优化
通过改善模型的拟合度、调整变量选择等方法来提升模型的准确性和预测能力。
案例分析和实战练习
通过实际案例分析和实战练习,运用逻辑回归模型解决实际问题,加深对模型应用的理解和掌握。
假设
逻辑回归假设自变量与因变量之间的关系是线性 的,并且变量之间不存在多重共线性。
模型参数的估计和解释
1
解释变量
2
解释变量的系数表示其对因变量的影响程
度,正系数表示正向关系,负系数表示负
向关系。
3
参数估计
使用最大似然估计方法来估计模型的回归 系数。
交互作用
通过引入交互项,可以考虑多个自变量之 间的相互影响。
应用SPSS软件进行多分类Logistic回归分析

- 0. 805 0. 458 03 1. 052 0. 424 03
- 2. 188 0. 760 03
- 0. 502 0. 804 03
S td. E rro r 0. 168 0. 105
0. 346 0. 195
0. 264 0. 140
0. 393 0. 291
W a ld 22. 879 19. 148
学习阶段 性别 视力低下
初中 男 轻度 中度 重度
实际 1287 490 1123
表 5 实际和预测频数以及残差
预测 11971743 5941508
频 数 Pea rson R esidua l 01785 - 1. 125
1107. 826
0. 138
百 分 比
实际
预测
4414%
4113%
16. 9%
度, 2 代表中度, 3 代表重度; “性别”中, 1 代表男性, 2 代表女
性。SPSS10. 0 中的M u ltinom ialL og istic R eg ression 模块在运
行时会自动将各分类变量中的最后一类 (数值最大者) 作为参
考类别。 根据所建模型中的系数可估计出一个学生某种视力
96. 963
0. 000
0
991610
21415
4
S ig 01612
Ξ 现在第一军医大学攻读卫生统计学硕士学位
·548·
© 1994-2007 China Academic Journal Electronic Publishing House. All rights reserved.
0
注: 3 T h is p a ram eter is set to zero becau se it is redundan t.
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
矿产资源开发利用方案编写内容要求及审查大纲
矿产资源开发利用方案编写内容要求及《矿产资源开发利用方案》审查大纲一、概述
㈠矿区位置、隶属关系和企业性质。
如为改扩建矿山, 应说明矿山现状、
特点及存在的主要问题。
㈡编制依据
(1简述项目前期工作进展情况及与有关方面对项目的意向性协议情况。
(2 列出开发利用方案编制所依据的主要基础性资料的名称。
如经储量管理部门认定的矿区地质勘探报告、选矿试验报告、加工利用试验报告、工程地质初评资料、矿区水文资料和供水资料等。
对改、扩建矿山应有生产实际资料, 如矿山总平面现状图、矿床开拓系统图、采场现状图和主要采选设备清单等。
二、矿产品需求现状和预测
㈠该矿产在国内需求情况和市场供应情况
1、矿产品现状及加工利用趋向。
2、国内近、远期的需求量及主要销向预测。
㈡产品价格分析
1、国内矿产品价格现状。
2、矿产品价格稳定性及变化趋势。
三、矿产资源概况
㈠矿区总体概况
1、矿区总体规划情况。
2、矿区矿产资源概况。
3、该设计与矿区总体开发的关系。
㈡该设计项目的资源概况
1、矿床地质及构造特征。
2、矿床开采技术条件及水文地质条件。