sql 逐级汇总示例(循环逐级累计法)
sql 递归累加

sql 递归累加
在SQL中,你可以使用递归查询来实现累加操作。
递归查询允许你在一个查询中引用自己,以便根据给定的条件逐级深入数据。
下面是一个示例,演示如何使用递归查询进行累加操作:
sql复制代码
WITH RecursiveSum (id, value, total) AS (
SELECT id, value, value AS total
FROM your_table
WHERE id = 1-- 起始ID
UNION ALL
SELECT t.id, t.value, t.value + r.total
FROM your_table t
INNER JOIN RecursiveSum r ON t.id = r.id + 1-- 递归关联条件
)
SELECT id, value, total
FROM RecursiveSum;
在上面的示例中,我们使用了递归查询RecursiveSum。
在第一个查询中,我们选择起始ID为1的行,并将总和初始化为该行的值。
然后,在第二个查询中,我们将递归地关联原始表your_table和RecursiveSum,并使用id列进行递增关联。
在每个递归步骤中,我们将当前行的值添加到总和中。
请注意,上述示例中的表名和列名需要根据你自己的数据结构进行调整。
sql 逐行累计求和方法

sql 逐行累计求和方法一、背景介绍在进行数据处理的时候,我们经常需要对某一列数据进行累加求和。
而在SQL中,逐行累计求和是一种非常常见的操作。
二、基本语法在SQL中,实现逐行累计求和的语法如下:SELECT SUM(column_name) OVER (ORDER BYorder_column_name) AS cumulative_sum FROM table_name;其中,SUM表示对某一列数据进行求和操作;OVER表示对整个表格进行操作;ORDER BY表示按照某一列的顺序进行排序;AS用于给结果命名。
三、具体实现步骤1. 创建测试表格首先,我们需要创建一个测试表格来演示逐行累计求和的方法。
可以使用以下SQL语句来创建一个名为test_table的表格:CREATE TABLE test_table (id INT, value INT);2. 插入测试数据接着,我们需要往test_table中插入一些测试数据。
可以使用以下SQL语句来插入10条随机生成的数据:INSERT INTO test_table (id, value) VALUES (1, 10);INSERT INTO test_table (id, value) VALUES (2, 20);INSERT INTO test_table (id, value) VALUES (3, 30);INSERT INTO test_table (id, value) VALUES (4, 40);INSERT INTO test_table (id, value) VALUES (5, 50);INSERT INTO test_table (id, value) VALUES (6, 60);INSERT INTO test_table (id, value) VALUES (7, 70);INSERT INTO test_table (id, value) VALUES (8, 80);INSERT INTO test_table (id, value) VALUES (9, 90);INSERT INTO test_table (id, value) VALUES (10, 100);3. 实现逐行累计求和接下来,我们就可以使用上文提到的SQL语法来实现逐行累计求和了。
sql 循环语句用法

在SQL 中,循环语句通常用于执行需要重复执行的任务。
然而,请注意,SQL 本身并不直接支持循环语句,因为它是一种集合型语言,旨在处理一组数据记录,而不是单个记录。
尽管如此,大多数SQL 数据库管理系统(DBMS)提供了存储过程或函数等编程构造,允许你使用条件语句和循环逻辑。
以下是几个常见的示例:1. MySQL 和MariaDB 使用WHILE 循环:```sqlDELIMITER //CREATE PROCEDURE while_loop_example()BEGINDECLARE counter INT DEFAULT 1;WHILE counter \u003c= 10 DO-- 在此处执行你的逻辑SELECT counter;SET counter = counter + 1;END WHILE;END //DELIMITER ;```2. Oracle 使用PL/SQL,它支持WHILE、FOR 和LOOP 循环:```sqlCREATE OR REPLACE PROCEDURE loop_example IScounter NUMBER := 1;BEGINLOOP-- 在此处执行你的逻辑DBMS_OUTPUT.PUT_LINE(counter);counter := counter + 1;EXIT WHEN counter \u003e 10; -- 退出循环的条件END LOOP;END;```3. SQL Server 使用T-SQL,支持WHILE 和FOR 循环:```sqlCREATE PROCEDURE while_loop_example ASBEGINDECLARE @counter INT = 1;WHILE @counter \u003c= 10BEGIN-- 在此处执行你的逻辑PRINT @counter;SET @counter = @counter + 1;END;END;```4. PostgreSQL 使用PL/pgSQL,它支持WHILE、FOR 和LOOP 循环:```sqlDO $$DECLARE counter INTEGER := 1;BEGINLOOP-- 在此处执行你的逻辑RAISE NOTICE '%', counter;counter := counter + 1;EXIT WHEN counter \u003e 10; -- 退出循环的条件END LOOP;END $$;```请注意,具体的语法和示例可能因使用的数据库管理系统而有所不同。
plsql逐条求和函数

plsql逐条求和函数
PL/SQL是一种用于编写存储过程和触发器的编程语言,可以用来编写高效的数据库程序。
如果你想在PL/SQL中编写一个逐条求和函数,可以使用下面的代码作为参考:
CREATE OR REPLACE FUNCTION sum_values (
p_min NUMBER,
p_max NUMBER
) RETURN NUMBER
AS
v_sum NUMBER;
BEGIN
v_sum := 0;
FOR i IN p_min..p_max LOOP
v_sum := v_sum + i;
END LOOP;
RETURN v_sum;
END;
这个函数接受两个参数:p_min和p_max,表示要求和的范围。
函数使用一个循环来遍历这个范围内的数字,并将它们累加起来。
最后,函数返回求和结果。
下面是如何调用这个函数的例子:
SELECT sum_values(1, 10) FROM DUAL;
这个查询将返回1到10的和,即55。
总之,使用PL/SQL编写逐条求和函数是很容易的,可以帮助你快速计算数字序列的和。
一个简单的一个sql表遍历

一个简单的一个 sql表遍历
简单的一个 sql表遍历
一般我们写储存过程或者其他sql语句的时候都会用到循环遍历数据,最常用的两种就是 1、游标 2、临时表+while
下面贴出示例代码
DECLARE @MinReLogID INT--这里的 MinReLogID 一般都是表中的主键 SELECT TOP 1 @MinReLogID= MIN(PKID) FROM APSI_OrderReplaceLog --找出最小的主键 (pkid 为主键) WHILE(@MinReLogID IS NOT NULL ) BEGIN --主要的业务逻辑 SELECT TOP 1 @MinReLogID= MIN(PKID) FROM APSI_OrderReplaceLog AND PKID>@MinReLogID--最关键的一步 找出下一个最小的主键 END
这中找最小值遍历的方式,代码较简洁,我比较喜欢用这种,就是不知道这种和其他两种对比 有什么缺点,还望
SQL集合运算参考及案例(二):树形节点数量逐级累计汇总

SQL集合运算参考及案例(⼆):树形节点数量逐级累计汇总问题描述:我们经常遇到这样⼀个问题,类似于⾯对⼀个树形结构的物料数据,需要将库存中每⼀种物料数量汇总到物料上展⽰出来;或者说组织机构是⼀棵树,我们需要统计每⼀个节点上的⼈员数量(含下级节点的累计数量)。
在此将解决的核⼼部分抽取出来。
因为是树形结构我们需要⽤到CTE的递归定义。
CTE是⼀种⼗分优雅的存在,CTE所带来最⼤的好处是代码可读性的提升,这是良好代码的必须品质之⼀。
使⽤递归CTE可以更加轻松愉快的⽤优雅简洁的⽅式实现复杂的查询。
更重要的是标准的SQL是⼯作在DB关系运算引擎上,⽽游标等⾯向过程的代码则不是,这会体现在运⾏效率上。
在定义和使⽤递归CTE时应注意:递归 CTE 定义⾄少必须包含两个 CTE 查询定义,⼀个定位点成员和⼀个递归成员。
可以定义多个定位点成员和递归成员;但必须将所有定位点成员查询定义置于第⼀个递归成员定义之前。
所有 CTE 查询定义都是定位点成员,但它们引⽤CTE 本⾝时除外。
注:最后⼀列是我们想要的值Id ParentId Qty Qty_Sum10 115212113133424 954 55--- 构造测试数据的脚本CREATE TABLE tMaterial(Id INT PRIMARY KEY, ParentId INT, Qty INT, Qty_Sum INT)INSERT INTO tMaterialSELECT1, 0, 1, 0UNION ALL SELECT2, 1, 2, 0UNION ALL SELECT3, 1, 3, 0UNION ALL SELECT4, 2, 4, 0UNION ALL SELECT5, 4, 5, 0GO传统解答:使⽤⾃定义函数、递归、游标CREATE FUNCTION fn_getQty_Sum(@Id INT)RETURNS INTASBEGINDECLARE@Qty_Sum INTSELECT@Qty_Sum= Qty FROM tMaterial WHERE Id =@IdDECLARE@OID INT, @Qty INTDECLARE cursor1 CURSOR FORSELECT t.ID from tMaterial AS t WHERE t.ParentId =@IdOPEN cursor1FETCH NEXT FROM cursor1 INTO@OIDWHILE@@FETCH_STATUS=0BEGINSET@Qty= dbo.fn_getQty_Sum(@OID)SET@Qty_Sum=@Qty_Sum+@QtyFETCH NEXT FROM cursor1 INTO@OIDENDCLOSE cursor1DEALLOCATE cursor1RETURN@Qty_SumENDUPDATE tMaterialSET Qty_Sum = dbo.fn_getQty_Sum(Id)SELECT*FROM tMaterial推荐解答1:利⽤CTE的递归和树形结构的特点,为树形结构中的所有节点增加从根节点到当前节点的“访问路径”WITH tmp AS(SELECT t1.*, CAST(CAST(t1.Id AS NVARCHAR) +'.'AS NVARCHAR(100)) AS node_pathFROM tMaterial t1WHERE t1.ParentId =0UNION ALLSELECT t1.*, CAST(t2.node_path +CAST(t1.Id AS NVARCHAR) +'.'AS NVARCHAR(100))FROM tMaterial t1JOIN tmp AS t2 ON t1.ParentId = t2.Id), T2 AS(SELECT t1.Id, t1.ParentId, t1.Qty, sum(t2.qty) AS Qty_SumFROM tmp t1JOIN tmp t2 ON t2.node_path LIKE t1.node_path +'%'GROUP BY t1.Id, t1.ParentId, t1.Qty, t1.Qty_Sum)UPDATE T1SET T1.Qty_Sum = T2.Qty_SumFROM tMaterial T1JOIN T2 ON T1.Id = T2.IdSELECT*FROM tMaterial推荐解答2:这个理解起来有点费劲,需要好好联想⼀下递归定义与表关联WITH tmp AS (SELECT t.Id tm, *FROM tMaterial tUNION ALLSELECT t2.tm tm, t1.*FROM tMaterial t1 JOIN tmp t2 ON t1.ParentId = t2.Id)SELECT tm, sum(Qty)FROM tmpGROUP BY tm。
SQL查询无限层级结构的所有下级所有上级

SQL查询无限层级结构的所有下级所有上级在SQL中实现查询无限层级结构的所有下级和所有上级,可以使用递归查询和CTE(公共表表达式)。
以一个`employees`表为例,假设该表包含了员工的id、姓名和上级id,如下所示:```CREATE TABLE employeesid INT,name VARCHAR(50),manager_id INT```为了查询所有下级可以使用递归查询,通过递归查询可以从根节点开始,不断向下查找所有层级。
以下是查询所有下级员工的SQL语句:```WITH RECURSIVE subordinates ASSELECT id, name, manager_idFROM employeesWHERE id = 1 -- 根节点的idUNIONALLSELECT e.id, , e.manager_idFROM employees eINNER JOIN subordinates s ON e.manager_id = s.idSELECT * FROM subordinates;```上述SQL语句中,使用了CTE并结合了递归查询。
`subordinates`是递归查询的子查询,首先选择根节点(id为1)作为起点,然后通过递归查询不断查找其下级员工,直到没有下级员工。
如果要查询所有上级,类似地,可以使用递归查询和CTE,但是此次是从叶子节点开始,向上查找所有上级。
以下是查询所有上级员工的SQL 语句:```WITH RECURSIVE superiors ASSELECT id, name, manager_idFROM employeesWHERE id = 6 -- 叶子节点的idUNIONALLSELECT e.id, , e.manager_idFROM employees eINNER JOIN superiors s ON e.id = s.manager_idSELECT * FROM superiors;```上述SQL语句中,`superiors`是查询所有上级的子查询,首先选择叶子节点(id为6)作为起点,然后通过递归查询不断向上查找其上级员工,直到没有上级员工。
sql写循环查询语句

sql写循环查询语句# SQL循环查询语句的编写与优化## 摘要SQL是结构化查询语言,广泛应用于数据库管理系统中。
在实际应用中,循环查询是一种常见的需求,尤其是在处理复杂的业务逻辑或需要迭代操作的情况下。
本文将介绍如何编写有效的SQL循环查询语句,涵盖了基本的循环结构、性能优化以及一些常见的应用场景。
## 引言SQL是一种专门用于管理和查询关系数据库系统中数据的语言。
在处理大规模数据集或者复杂业务逻辑时,循环查询成为一种常见的需求。
本文将围绕如何编写SQL循环查询语句展开讨论,以满足不同场景下的需求。
## 基本的循环查询结构在SQL中,循环查询通常使用`WHILE`语句来实现。
下面是一个简单的例子,演示了如何使用`WHILE`进行循环查询:```sqlDECLARE @counter INT = 1;WHILE @counter <= 10BEGIN-- 在此处编写循环内的查询逻辑PRINT 'Current Counter Value: ' + CAST(@counter AS NVARCHAR(10));-- 更新计数器SET @counter = @counter + 1;END;```上述例子中,通过`DECLARE`语句定义了一个整型变量`@counter`,然后使用`WHILE`循环进行迭代。
在循环内,可以编写具体的查询逻辑。
这个例子中,只是简单地打印计数器的值,实际应用中可以根据具体需求执行更复杂的查询。
## 性能优化尽管使用`WHILE`可以实现循环查询,但在处理大规模数据时,性能可能成为一个问题。
在这种情况下,可以考虑使用集合操作,避免使用显式的循环。
### 使用集合操作以下是一个使用集合操作的例子,以提高性能:```sql-- 使用数字表生成一个包含1到10的序列WITH Numbers AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS NumFROM master.dbo.spt_values)-- 使用JOIN实现循环SELECT n.Num, YourColumnFROM Numbers nJOIN YourTable t ON n.Num <= 10;```在上述例子中,使用了一个公共表表达式(CTE)来生成包含1到10的序列。
mssql循序渐进累加函数
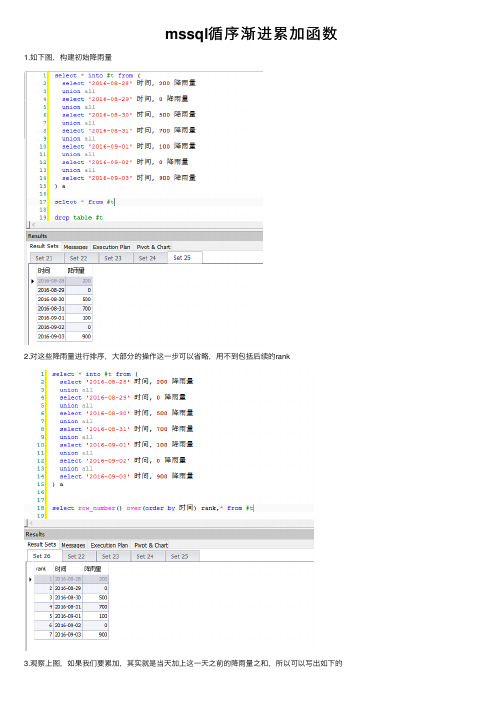
mssql循序渐进累加函数1.如下图,构建初始降⾬量2.对这些降⾬量进⾏排序,⼤部分的操作这⼀步可以省略,⽤不到包括后续的rank3.观察上图,如果我们要累加,其实就是当天加上这⼀天之前的降⾬量之和,所以可以写出如下的附上sql代码如下:SELECT row_number () OVER (ORDER BY时间) rank, *INTO #tFROM (SELECT'2016-08-28'时间, 200降⾬量UNION ALLSELECT'2016-08-29'时间, 0降⾬量UNION ALLSELECT'2016-08-30'时间, 500降⾬量UNION ALLSELECT'2016-08-31'时间, 700降⾬量UNION ALLSELECT'2016-09-01'时间, 100降⾬量UNION ALLSELECT'2016-09-02'时间, 0降⾬量UNION ALLSELECT'2016-09-03'时间, 900降⾬量) aSELECT a1.时间, a1.降⾬量, sum (a2.降⾬量) 累计降⾬量FROM #t a1 INNER JOIN #t a2 ON a2.rank <= a1.rankGROUP BY a1.时间, a1.降⾬量ORDER BY a1.时间DROP TABLE #t4.也可以不需要利⽤row_number() ⽽直接利⽤⽇期作为条件,效果跟3⼀样:代码:SELECT*INTO #tFROM (SELECT'2016-08-28'时间, 200降⾬量UNION ALLSELECT'2016-08-29'时间, 0降⾬量UNION ALLSELECT'2016-08-30'时间, 500降⾬量UNION ALLSELECT'2016-08-31'时间, 700降⾬量UNION ALLSELECT'2016-09-01'时间, 100降⾬量UNION ALLSELECT'2016-09-02'时间, 0降⾬量UNION ALLSELECT'2016-09-03'时间, 900降⾬量) aSELECT a1.时间, a1.降⾬量, sum (a2.降⾬量) 累计降⾬量FROM #t a1 INNER JOIN #t a2 ON a2.时间<= a1.时间GROUP BY a1.时间, a1.降⾬量ORDER BY a1.时间DROP TABLE #t为什么3这样写能查出来我们想要的样⼦,我们只是⽤前三天就可以看到可以观察到,⼩于8⽉28号的记录是8⽉28,⼩于8⽉29的是28和29两天,我们把这些数据捏在⼀起,就能轻松地对作为a1⽇期进⾏分组累加,最终得到⾃⼰想要的数据。
sql汇总数据操作方法

sql汇总数据操作方法SQL汇总数据操作1. 简介在数据库操作中,经常需要对数据进行汇总、统计和计算等操作。
SQL提供了多种方式来实现这些功能,本文将介绍常见的SQL汇总数据操作方法。
2. COUNT函数COUNT函数用于统计表中满足某个条件的记录数量。
SELECT COUNT(*)FROM 表名WHERE 条件;3. SUM函数SUM函数用于计算表中某个列的合计值。
SELECT SUM(列名)FROM 表名WHERE 条件;4. AVG函数AVG函数用于计算表中某个列的平均值。
SELECT AVG(列名)FROM 表名WHERE 条件;5. MAX函数和MIN函数MAX函数和MIN函数分别用于计算表中某个列的最大值和最小值。
SELECT MAX(列名)FROM 表名WHERE 条件;SELECT MIN(列名)FROM 表名WHERE 条件;6. GROUP BY子句GROUP BY子句用于对结果集进行分组,可用于汇总数据。
SELECT 列名, COUNT(*)FROM 表名WHERE 条件GROUP BY 列名;7. HAVING子句HAVING子句用于在GROUP BY子句的基础上进行进一步的过滤。
SELECT 列名, COUNT(*)FROM 表名WHERE 条件GROUP BY 列名HAVING 条件;8. WITH ROLLUPWITH ROLLUP关键字用于在使用GROUP BY进行分组后,在结果集中添加小计和总计。
SELECT 列名1, 列名2, SUM(列名3)FROM 表名WHERE 条件GROUP BY 列名1, 列名2 WITH ROLLUP;9. CASE语句CASE语句用于根据条件进行汇总和计算。
SELECT 列名,CASEWHEN 条件1 THEN 结果1WHEN 条件2 THEN 结果2ELSE 结果3ENDFROM 表名WHERE 条件;10. 总结本文介绍了SQL中常用的汇总数据操作方法,包括COUNT函数、SUM函数、AVG函数、MAX函数和MIN函数、GROUP BY子句、HAVING子句、WITH ROLLUP和CASE语句。
sql循环相加的函数

sql循环相加的函数SQL循环相加的函数是一种非常有用的功能,它可以帮助我们在数据库中对一组数据进行循环相加操作。
在本文中,我将为您详细介绍如何使用SQL编写循环相加的函数。
我们需要创建一个存储过程或函数来实现循环相加的功能。
假设我们有一个名为"numbers"的表,其中包含一列名为"value"的整数类型数据。
我们的目标是计算该列中所有值的总和。
为了实现这个目标,我们可以使用CURSOR来遍历表中的每一行,并将每行的"value"值相加到一个变量中。
下面是一个示例的SQL函数,它可以实现这个功能:```sqlCREATE FUNCTION calculate_sum() RETURNS INTBEGINDECLARE total INT DEFAULT 0;DECLARE current_value INT;-- 定义一个游标来遍历表中的每一行DECLARE cur CURSOR FOR SELECT value FROM numbers;-- 打开游标OPEN cur;-- 从游标中获取数据并循环相加loop_label: LOOP-- 从游标中获取下一行数据FETCH cur INTO current_value;-- 如果没有更多的数据,则跳出循环IF done THENLEAVE loop_label;END IF;-- 将当前行的值相加到总和中SET total = total + current_value;END LOOP;-- 关闭游标CLOSE cur;-- 返回计算得到的总和RETURN total;END;```上面的代码中,我们首先声明了一个名为"total"的变量,用于存储计算得到的总和。
然后,我们声明了一个名为"cur"的游标,用于遍历"numbers"表中的数据。
SQL构建表层次关系,递归累加数据
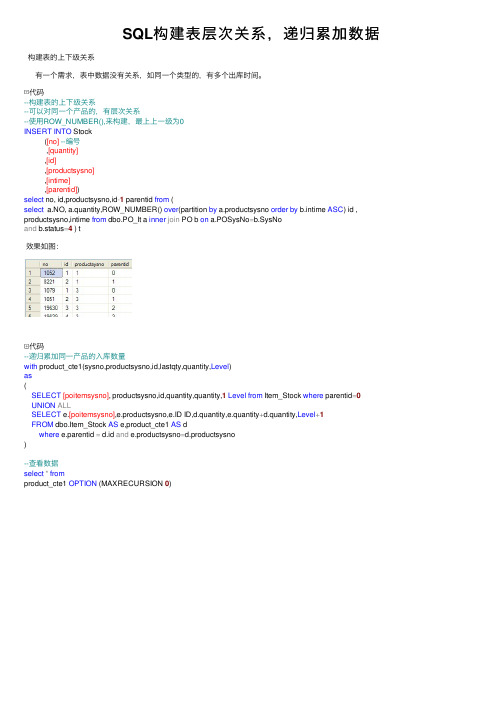
SQL构 建 表 层 次 关 系 , 递 归 累 加 数 据
构建表的上下级关系
有一个需求,表中数据没有关系,如同一个类型的,有多个出库时间。
代码 --构建表的上下级关系 --可以对同一个产品的,有层次关系 --使用ROW_NUMBER(),来构建,最上上一级为0 INSERT INTO Stock
([no] --编号 ,[quantity] ,[id] ,[productsysno] ,[intime] ,[parentid]) select no, id,productsysno,id-1 parentid from ( select a.NO, a.quantity,ROW_NUMBER() over(partition by a.productsysno order by b.intime ASC) id , productsysno,intime from dbo.PO_It a inner join PO b on a.POSysNo=b.SysNo and b.status=4 ) t
where e.parentid = d.id and e.prodelect * from product_cte1 OPTION (MAXRECURSION 0)
效果如图:
代码 --递归累加同一产品的入库数量 with product_cte1(sysno,productsysno,id,lastqty,quantity,Level) as (
SELECT [poitemsysno], productsysno,id,quantity,quantity,1 Level from Item_Stock where parentid=0 UNION ALL SELECT e.[poitemsysno],e.productsysno,e.ID ID,d.quantity,e.quantity+d.quantity,Level+1 FROM dbo.Item_Stock AS e,product_cte1 AS d
mssql sqlserver 遍历循环的新方法

mssql sqlserver 遍历循环的新方法MSSQL SQL Server 遍历循环的新方法1. 简介在MSSQL SQL Server中,遍历和循环是非常常见的操作,它们可以用于执行重复的操作或者对数据集进行逐行处理。
本文将介绍一些新的方法和技巧,来提高SQL Server中遍历循环的效率和灵活性。
2. 使用游标游标是一种用来遍历结果集的数据结构,它可以逐行处理查询结果。
使用游标可以对结果集进行一些复杂的操作,例如更新、删除或插入数据。
下面是使用游标进行循环遍历的一种常见方法:DECLARE @id INTDECLARE @name NVARCHAR(50)DECLARE db_cursor CURSOR FORSELECT id, name FROM tableOPEN db_cursorFETCH NEXT FROM db_cursor INTO @id, @nameWHILE @@FETCH_STATUS = 0BEGIN-- 在这里执行遍历循环的操作-- 例如打印ID和名称PRINT 'ID: ' + CAST(@id AS NVARCHAR(10)) + ', Name: ' + @nameFETCH NEXT FROM db_cursor INTO @id, @nameENDCLOSE db_cursorDEALLOCATE db_cursor3. 使用游标的新方法除了传统的使用游标进行遍历循环的方法之外,SQL Server还提供了一些新的方法来处理遍历循环操作,例如:使用WHILE循环使用WHILE循环可以在不使用游标的情况下进行遍历操作。
下面是一个使用WHILE循环的示例:DECLARE @id INTDECLARE @name NVARCHAR(50)DECLARE @count INTSELECT @count = COUNT(*) FROM tableSET @id = 1WHILE @id <= @countBEGINSELECT @name = name FROM table WHERE id = @id-- 在这里执行遍历循环的操作-- 例如打印ID和名称PRINT 'ID: ' + CAST(@id AS NVARCHAR(10)) + ', Name: ' + @nameSET @id = @id + 1END使用OFFSET FETCH子句SQL Server 2012及以上版本提供了OFFSET FETCH子句,它可以在查询中使用TOP关键字以及ORDER BY子句来实现分页查询。
SQL由人员汇总到部门树递归合计总数函数

SQL由⼈员汇总到部门树递归合计总数函数1、由⼈员计算出总数,在部门树(tree)按结构汇总(主⽗绑定)CREATE function [dbo].[GetEmpDepNum](@ID int)RETURNS @Tree Table (ID [int] IDENTITY (1, 1),PID Int,FID Int,SN Varchar(150), Name Varchar(150), Num Varchar(150))asbegindeclare @MaxNum int,@i int,@f int,@sNnm intInsert @Tree SELECT c1.pid,c1.fid,c1.sn,,(SELECT COUNT(*) FROM dbo.tbEmployee c2 WHERE c2.MID = c1.pid)AS sNum FROM tbDepList c1 order by FID desc,pid-- select * from @TreeBcbSELECT @MaxNum=Count(*) from @Treeset @i=1while (@i<=@MaxNum)beginselect @f=fid from @Tree where ID=@iselect @sNnm=SUM(CONVERT(int,num)) from @Tree where FID=(select fid from @Tree where ID=@i )--print 's ||'+CONVERT(varchar(100),@i)+'|'+CONVERT(varchar(100), @sNnm)if @sNnm>0beginupdate @Tree set Num =@sNnm from @Tree where PID=@fendSET @i=@i+1end--select * from @TreeBcb order by FID desc,pid--select PID, FID,CASE Num WHEN 0 THEN Name ELSE Name+' ('+Num+')' END as Name from @TreeBcb order by FID desc,pid ReturnendGO2、调⽤select PID, FID,CASE Num WHEN 0 THEN Name ELSE Name+' ('+Num+')' END as Name from dbo.GetEmpDepNum(0) order by FID ,pid。
用SQL实现统计报表中的“小计”和“合计”
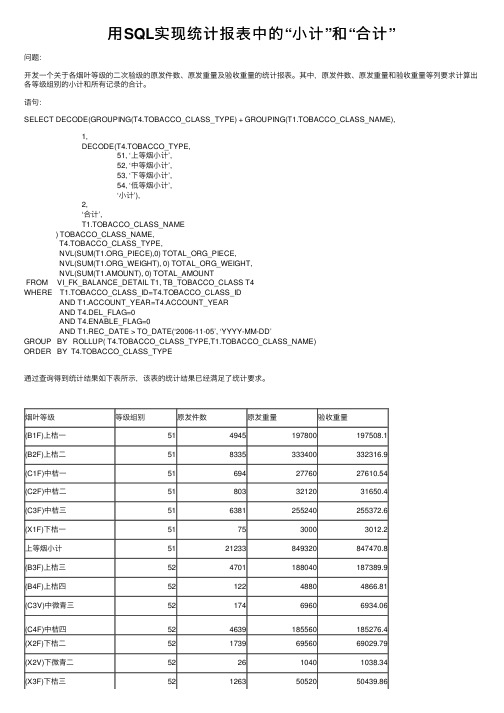
⽤SQL实现统计报表中的“⼩计”和“合计”问题:开发⼀个关于各烟叶等级的⼆次验级的原发件数、原发重量及验收重量的统计报表。
其中,原发件数、原发重量和验收重量等列要求计算出各等级组别的⼩计和所有记录的合计。
语句:SELECT DECODE(GROUPING(T4.TOBACCO_CLASS_TYPE) + GROUPING(T1.TOBACCO_CLASS_NAME),1,DECODE(T4.TOBACCO_TYPE,51, ‘上等烟⼩计’,52, ‘中等烟⼩计’,53, ‘下等烟⼩计’,54, ‘低等烟⼩计’,‘⼩计’),2,‘合计’,T1.TOBACCO_CLASS_NAME) TOBACCO_CLASS_NAME,T4.TOBACCO_CLASS_TYPE,NVL(SUM(_PIECE),0) TOTAL_ORG_PIECE,NVL(SUM(_WEIGHT), 0) TOTAL_ORG_WEIGHT,NVL(SUM(T1.AMOUNT), 0) TOTAL_AMOUNTFROM VI_FK_BALANCE_DETAIL T1, TB_TOBACCO_CLASS T4WHERE T1.TOBACCO_CLASS_ID=T4.TOBACCO_CLASS_IDAND T1.ACCOUNT_YEAR=T4.ACCOUNT_YEARAND T4.DEL_FLAG=0AND T4.ENABLE_FLAG=0AND T1.REC_DATE > TO_DATE(‘2006-11-05’, ‘YYYY-MM-DD’GROUP BY ROLLUP( T4.TOBACCO_CLASS_TYPE,T1.TOBACCO_CLASS_NAME)ORDER BY T4.TOBACCO_CLASS_TYPE通过查询得到统计结果如下表所⽰,该表的统计结果已经满⾜了统计要求。
烟叶等级等级组别原发件数原发重量验收重量(B1F)上桔⼀514945197800197508.1(B2F)上桔⼆518335333400332316.9(C1F)中桔⼀516942776027610.54(C2F)中桔⼆518033212031650.4(C3F)中桔三516381255240255372.6(X1F)下桔⼀517530003012.2上等烟⼩计5121233849320847470.8(B3F)上桔三524701188040187389.9(B4F)上桔四5212248804866.81(C3V)中微青三5217469606934.06(C4F)中桔四524639185560185276.4(X2F)下桔⼆5217396956069029.79(X2V)下微青⼆522610401038.34(X3F)下桔三5212635052050439.86中等烟⼩计5212664506560504975.1 (X4F)下桔四5310240804075.62下等烟⼩计5310240804075.62 (B3K)上杂三5400249.39低等烟⼩计5400249.39合计3399913599601356771。
sql进阶用法

sql进阶用法SQL进阶用法SQL是一种用于管理关系数据库的语言,具备了基本的查询和操作语法之后,进一步学习一些高级用法可以帮助提高数据库的性能和效率。
本文将介绍一些SQL的进阶用法,帮助你更好地运用SQL语句。
1. 子查询子查询是指在一个查询语句内嵌套另一个查询语句。
它可以作为查询条件、返回结果集或被其他查询引用。
子查询可以嵌套多层次,拥有较高的灵活性。
SELECT * FROM employees WHERE department_id IN (SEL ECT department_id FROM departments WHERE location_id = ' 1700')上述例子中,子查询在内部查询部门表中的location_id=1700的数据,然后将这些值作为外部查询的条件,返回符合条件的员工表数据。
2. 连接查询连接查询用于在多个表之间建立关联,并返回相关的联合结果集。
最常用的两种连接方式是内连接和外连接。
SELECT _id, _name, _nameFROM employees eINNER JOIN departments d ON _id = _id上述例子中,INNER JOIN将员工表和部门表按照department_id 字段进行连接,返回符合条件的结果集,包含员工的编号、姓氏和所在部门名称。
3. 窗口函数窗口函数是一种在查询结果集上进行计算的函数,它可以计算出每一行数据的相关指标,并将计算结果输出在每行数据中,比如累计求和、移动平均等。
SELECT employee_id, last_name, salary,SUM(salary) OVER (ORDER BY hire_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_sala ryFROM employees上述例子中,使用SUM函数和窗口函数实现了对员工薪水的累积求和。
sql中level的用法

sql中level的用法SQL中level的用法主要是用于分层查询和递归查询。
在分层查询中,可以通过level来确定层级关系,以便进行层级分组和聚合计算。
在递归查询中,可以利用level来控制递归深度,以及生成递归路径等。
例如,可以使用CONNECT BY语句实现分层查询,并使用level 来进行分组,如下所示:SELECT level, department_name, COUNT(*) FROM employees START WITH department_id = 10CONNECT BY PRIOR employee_id = manager_idGROUP BY level, department_name;在这个例子中,以部门ID为10的员工为起点,通过CONNECT BY 语句逐层向下查询员工信息,并用level来分组,以便计算每个部门的员工数。
另外,可以使用WITH RECURSIVE语句实现递归查询,并使用level 来控制递归深度,如下所示:WITH RECURSIVE emp_path AS (SELECT employee_id, CONCAT(employee_id) AS path, 1 AS levelFROM employees WHERE manager_id IS NULLUNION ALLSELECT e.employee_id, CONCAT(ep.path, '->',e.employee_id),ep.level + 1FROM employees e INNER JOIN emp_path epON e.manager_id = ep.employee_id AND ep.level < 3)SELECT * FROM emp_path;在这个例子中,首先以NULL为起点查询所有的顶级员工,然后递归向下查询每个员工的下属信息,并使用level来控制递归深度,以便生成员工的递归路径。
累计次数的计算方法

累计次数的计算方法在日常生活中,我们经常会遇到需要计算累计次数的情况。
比如在工作中,我们需要统计某个事件发生的次数,比如客户投诉的次数,产品销售的次数等。
在这些情况下,如何准确、快速地计算累计次数成为了一个重要的问题。
本文将介绍一种常用的计算累计次数的方法,以及相应的实例分析。
二、计算累计次数的方法计算累计次数可以采用多种方法,常用的方法包括:循环累加、数组累加、SQL查询等。
下面分别介绍这些方法的特点以及使用场景。
1. 循环累加循环累加是一种常用的计算累计次数的方法。
其基本思想是利用循环语句对每个事件进行累加,最终得到累计次数。
循环累加的步骤如下:a) 从第一个事件开始,按照一定的条件进行累加;b) 循环执行上述步骤,直到所有事件都统计完毕;c) 最终得到累计次数。
循环累加的优点是简单易懂,容易实现。
但是其缺点是效率较低,特别是在事件数量较大的情况下,循环累加的计算时间会比较长。
2. 数组累加数组累加是一种利用数组进行累计次数计算的方法。
其基本思想是先创建一个数组,用来记录每个事件的次数,然后对数组进行累加,最终得到累计次数。
数组累加的步骤如下:a) 创建一个长度为事件数量的数组,初始化为0;b) 遍历每个事件,根据事件的条件更新数组中对应的位置;c) 对数组进行累加,得到累计次数。
数组累加的优点是计算效率较高,特别是在事件数量较大的情况下,数组累加能够快速计算累计次数。
但是其缺点是需要占用较大的内存空间,特别是在事件数量较大的情况下,数组累加需要消耗大量的存储空间。
3. SQL查询SQL查询是一种利用数据库进行累计次数计算的方法。
其基本思想是利用SQL语句对事件进行统计,最终得到累计次数。
SQL查询的步骤如下:a) 写出适当的SQL语句,对事件进行统计;b) 执行SQL语句,得到累计次数。
SQL查询的优点是灵活方便,能够快速实现累计次数的计算。
但是其缺点是需要依赖数据库,特别是在事件数量较大的情况下,SQL查询会对数据库造成一定的压力。
sql 递归累加

sql 递归累加在SQL 中,递归累加可以使用递归查询来实现。
递归查询需要使用WITH RECURSIVE 语句。
假设有一个表格`numbers`,其中包含一个整数列`num`。
我们想要计算列 `num` 的累加和,可以使用递归查询来实现。
以下是一个示例:```sqlWITH RECURSIVE recursive_sum AS (SELECT num, num AS sumFROM numbersWHERE num = 1 -- 初始条件,从1开始累加UNION ALLSELECT n.num, n.num + rs.sumFROM numbers nINNER JOIN recursive_sum rs ON n.num = rs.num + 1)SELECT sumFROM recursive_sumWHERE num = (SELECT MAX(num) FROM numbers); -- 获取最大的num 对应的 sum```在上述示例中,我们首先定义了一个递归查询`recursive_sum`,它包含两个部分:1. 初始条件:选择 `num` 为 1 的行,并将 `num` 的值作为初始累加和 `sum`。
2. 递归部分:通过连接`numbers` 表格和`recursive_sum` 子查询来递归计算累加和。
在每次递归中,我们选择 `numbers` 表格中 `num` 的下一个值,并将其加上上一次递归的累加和。
我们从 `recursive_sum` 子查询中选择具有最大 `num` 值的 `sum`。
注意,递归查询可能会导致性能问题,特别是在处理大量数据时。
因此,在使用递归查询时,应谨慎考虑其性能影响。