基于Google Web API的中文训练库自动获取方法研究
google api 用法

google api 用法Google API(Application Programming Interface)是谷歌提供的一组开发者工具和功能,用于与谷歌服务进行交互和访问。
谷歌提供了多个API,包括地图API、语音识别API、人工智能API等等。
这些API可以被开发者用来构建各种应用,从地图应用到语音助手,都可以使用谷歌API来实现。
使用Google API之前,首先需要创建一个开发者账号,并获取API密钥,该密钥用于验证开发者的身份和授权访问谷歌服务。
接下来,我们将介绍一些常用的Google API以及其用法。
1. Google Maps API:Google Maps API是用于在自己的网站或应用中嵌入地图功能的API。
可以使用Google Maps API来实现地理定位、地点搜索、路线规划等功能。
开发者可以使用HTML、JavaScript和CSS来定制地图的外观和交互方式。
2. Google Translate API:Google Translate API可以将文本翻译成多种语言。
可以使用这个API来开发翻译应用,让用户能够快速翻译文本到其他语言。
通过调用Translate API提供的接口,可以实现自动翻译功能。
3. Google Calendar API:Google Calendar API可以让开发者读取、写入和修改Google日历中的事件。
可以使用Calendar API来创建和管理用户的日程安排,可以实现日历应用、待办事项管理等功能。
4. Google Drive API:Google Drive API可以让开发者访问和操作用户的Google Drive云存储空间。
可以使用Drive API来上传、下载、删除和修改用户的文件,可以实现文件管理应用、在线协作编辑等功能。
5. Google Cloud Speech-to-Text API:Google Cloud Speech-to-Text API可以将语音转换为文本。
google search api 用法

google search api 用法
Google Search API 是一种开发工具,可以让开发者通过编程
方式访问和使用 Google 搜索引擎的功能。
以下是使用 Google Search API 的一般步骤:
1. 注册并获取 API 密钥:在 Google 开发者控制台创建一个项目,并启用 "Google 搜索 API"。
然后生成一个 API 密钥,用
于验证 API 请求。
2. 配置 API 请求:使用 API 密钥构建 API 请求 URL。
可以指
定搜索关键字、搜索类型、结果过滤器、排序等参数。
3. 发送 API 请求:使用编程语言的 HTTP 请求库发送 API 请求。
4. 处理 API 响应:将 API 响应解析为可用的数据格式(例如JSON 或 XML),并提取所需的信息。
需要注意的是,Google Search API 当前是一个付费服务,并
且有一定的使用限制。
在开发时要遵守相关的使用条款和限制,以确保正常使用服务。
google api 用法

google api 用法摘要:1.Google API 简介2.Google API 的使用方法3.Google API 的优点和局限性正文:【Google API 简介】Google API,即Google 应用程序接口,是Google 提供的一种让开发者能够使用Google 服务和功能的编程接口。
通过Google API,开发者可以在自己的应用程序或网站中集成Google 的服务,如搜索、地图、翻译等。
Google API 为开发者提供了丰富的工具和资源,使得开发者可以更加高效地开发和优化应用程序。
【Google API 的使用方法】使用Google API 需要遵循以下几个步骤:1.创建Google API 项目首先,需要在Google Cloud Platform 上创建一个API 项目。
在创建过程中,需要选择API 的类型、名称和版本,并为项目设置相关的权限和配置。
2.获取API 密钥创建API 项目后,需要获取API 密钥。
API 密钥是用于验证API 请求的重要信息,通常包括一个API 密钥ID 和一个API 密钥密钥。
在编写代码时,需要将API 密钥添加到请求头中,以确保API 请求的有效性。
3.编写代码在获取API 密钥后,可以使用编程语言(如Python、Java 等)编写代码,调用Google API。
在编写代码时,需要遵循Google API 的文档和规范,确保API 请求的正确性。
4.测试API在编写代码的过程中,需要对API 进行测试,以确保API 请求的有效性和返回结果的准确性。
Google API 提供了在线的API 测试工具,方便开发者进行API 测试。
【Google API 的优点和局限性】Google API 具有以下优点:1.丰富的服务和功能Google API 提供了丰富的服务和功能,如搜索、地图、翻译等,为开发者提供了更多的选择和可能性。
2.高效和灵活Google API 具有高效的性能和灵活的配置,可以满足不同应用程序和网站的需求。
使用glove训练中文语料

使用glove训练中文语料【原创版】目录1.介绍 glove 模型2.准备中文语料3.使用 glove 训练中文语料4.评估模型效果5.总结正文1.介绍 glove 模型glove 是一种用于词向量学习的深度学习模型,它可以通过大规模的文本语料库来学习词汇的表示。
glove 模型采用预训练和微调的方式,可以快速地将文本转换为密集的词向量表示,从而实现文本相似度计算、词义消歧等自然语言处理任务。
2.准备中文语料为了使用 glove 训练中文语料,首先需要准备一份大规模的中文文本语料库。
常见的中文语料库有维基百科、新闻数据、论坛对话等。
在准备语料库时,需要进行分词、去停用词、词干提取等预处理操作,以提高模型的训练效果。
3.使用 glove 训练中文语料使用 glove 训练中文语料时,需要将预处理后的中文文本输入到glove 模型中进行训练。
glove 模型支持多种训练方式,如监督学习、半监督学习和无监督学习。
在训练过程中,需要设置合适的参数,如学习率、批次大小、迭代次数等,以获得最佳的模型效果。
4.评估模型效果在训练完成后,需要对模型的效果进行评估。
常见的评估方法有均方误差 (MSE)、余弦相似度 (Cosine Similarity) 等。
通过评估模型效果,可以了解模型在训练集和测试集上的表现,从而判断模型是否具有良好的泛化能力。
5.总结本文介绍了如何使用 glove 模型训练中文语料。
通过准备大规模的中文文本语料库,并使用 glove 模型进行训练,可以获得词向量表示。
最后,通过评估模型效果,可以了解模型在自然语言处理任务中的表现。
Web环境下自动获取汉、维语料库

并根据正文 内容信 息相似 性提 取 网页正文。对提取 出的正文进行句子切分 , 分别 创建句子 级的汉 、 维语料库 , 以后创建 句子级 的 为
汉维双语平行语 料库服务。
关键 词
中图分类号
双语 平行 语料库 双语平行句对 正文提取
T3 1 P 9 文献标识 码 A
A OMAT C AC I I CHI S D U GHUR C P SL B AR UT I QU R NG NE E AN I OR U I R Y
I W EB ENVI N RONM E NT
J n in T ru ba i S y a b l t Ta h nw i i gZj ugnIrhm ai nA u mi i S e g e a i d i n
一个基于Web的自动汉语例句检索系统

一个基于Web的自动汉语例句检索系统司宪策,孙茂松sxc@sms@June11,2007Abstract例句收集是语言学研究中的常见工作,本文介绍了一个基于Web的自动汉语例句检索系统。
此系统可以从Web批量下载例句语料,并且提供句子级别的去重。
句子可以按照是否存在关键词歧义而分为可靠和不可靠集合,在尽量保留所有句子的情况下强调质量较好的句子。
对于两个关键词在同一句子中出现的情况,系统可以给出同现位置的统计,从而有助于词汇搭配和使用习惯的研究。
内置的术语定义粗提取功能通过正则文法来提取对关键词的定义。
最后给出了一个在实际研究中应用的例子AbstractCollecting sample sentences is a common task in dictionary composing and linguistic research.This paper introduced a web based automatic Chinese sam-ple sentence retrieval system.The system can download sentences from the web,and remove duplicated items when needed.Retrieved sentences can be classi-fied as reliable or not reliable based on word segmentation ambiguity,emphasizesentences with good quality while trying to preserve all of them.The systemcan help studying word cooccurences by showing distribution of the distancesbetween two words when they appeared in the same sentence.Enbeddedfiltercanfind definitions to given term by regular expression heuristics.Finally a realworld application is demostrated.1引言词汇对应例句的收集是词典编纂和语言学研究中经常进行的一个工作。
E n i g m a 算 法 详 解

成为专业程序员路上用到的各种优秀资料、神器及框架本文是鄙人工作这几年随手收集整理的一些自认为还不错的资料,成长的道理上需要积累,这么长时间了,是时候放出来分享下了,或许能帮助到你。
欢迎点赞,让更多人看到,让福利普照。
因为本文以后不会更新,但项目依旧会更新。
所以,更好的做法是,请到GitHub上Star:stanzhai-be-a-professional-programmer成为一名专业程序员的道路上,需要坚持练习、学习与积累,技术方面既要有一定的广度,更要有自己的深度。
笔者作为一位tool mad,将工作以来用到的各种优秀资料、神器及框架整理在此,毕竟好记性不如烂键盘,此项目可以作为自己的不时之需。
本人喜欢折腾,记录的东西也比较杂,各方面都会有一些,内容按重要等级排序,大家各取所需。
这里的东西会持续积累下去,欢迎Star,也欢迎发PR给我。
技术站点必看书籍大牛博客GitHub篇工具篇平台工具常用工具第三方服务爬虫相关(好玩的工具)安全相关Web服务器性能-压力测试工具-负载均衡器大数据处理-数据分析-分布式工具Web前端语言篇C游戏开发相关日志聚合,分布式日志收集RTP,实时传输协议与音视频技术站点在线学习:Coursera、edX、Udacity?-way to explore国内老牌技术社区:OSChina、博客园、CSDN、51CTO 免费的it电子书:ITeBooks - Free Download - Big Library在线学习:UdemyCrowd-sourced code mentorship. and Practicecoding with fun programming challenges - CodinGameDevStore:开发者服务商店MSDN:微软相关的官方技术集中地,主要是文档类必看书籍SICP(Structureand Interpretation of Computer Programs)深入理解计算机系统代码大全2人件人月神话软件随想录算法导论(麻省理工学院出版社)离散数学及其应用设计模式编程之美黑客与画家编程珠玑The Little SchemerSimply Scheme_Introducing_Computer_ScienceC++ PrimeEffective C++TCP-IP详解Unix 编程艺术技术的本质软件随想录计算机程序设计艺术职业篇:程序员的自我修养,程序员修炼之道,高效能程序员的修炼《精神分析引论》弗洛伊德《失控》《科技想要什么》《技术元素》凯文凯利程序开发心理学天地一沙鸥搞定:无压力工作的艺术大牛博客云风(游戏界大牛): 云风的Tian (binghe)R大【干货满满】RednaxelaFX写的文章-回答的导航帖陈皓-左耳朵耗子:酷壳 - CoolShellJeff Atwood(国外知名博主): CodingHorror阮一峰(黑客与画家译者,Web):RuanYiFeng’s Personal Website廖雪峰(他的Python、Git教-程不少人都看过):HomeGitHub篇Awesome:这是个Awesome合集,常见的资料这里面都能找到Awesome2:类似第一个Awesome杂七杂八、有用没用的Awesome合集非常不错的语言类学习资料集合:Awesomenessawesome-ios-uiawesome-android-uiAwesome-MaterialDesi gnawesome-public-datasetsawesome-AppSec(系统安全)awesome-datascience书籍资料free-programming-books中文版免费的编程中文书籍索引《程序员编程艺术—面试和算法心得》GoBooksPapersLearning)深入学习(Deep Learning)资料Docker资料合集学习使用StromHadoopInternalsSparkInternals大数据时代的数据分析与数据挖掘in DatabasesDataScience blogs日志:每个软件工程师都应该知道的有关实时数据的统一概念AndroidCode PathAndroidLearn NotesPHP类库框架,资料集合优秀项目Design开源项目Android开源项目分类汇总前端 Node.jsGuide的中文分支Angular2学习资料AngularJS应用的最佳实践和风格指南React-Native学习指南七天学会NodeJSnode.js中文资料导航Nodejs学习路线图如何学习nodejs工作,工具系统管理员工具集合ProGitNginx开发从入门到精通Google全球 IP 地址库收集整理远程工作相关的资料Colorschemes for hackers游戏开发工具集,MagicTools开发者工具箱, free-for-devGitHub秘籍Git风格指南Bast-App平台工具常用工具Mac下的神兵利器asciinema:- 免费在线作图,实时协作Origami: 次世代交互设计神器百度脑图:百度脑图第三方服务DnsPod:一个不错的只能DNS服务解析提供商DigitalOcean:海外的云主机提供商,价格便宜,磁盘是SSD的,用过一段时间整体上还可以,不过毕竟是海外的,网速比较慢。
中文文本语料获取的方式

中文文本语料获取的方式中文文本语料获取是一项重要的自然语言处理技术,它可以为机器学习、自然语言处理等领域提供丰富的数据支持。
本文将分步骤介绍中文文本语料的获取方式。
第一步:爬取网页语料爬取网页语料是一种较为常见的中文文本语料获取方式。
首先,我们需要确定要爬取的网站和网页内容。
然后,使用Python编写爬虫程序,根据网页结构和标签,提取出网页中的文本内容。
最后,将提取出的文本内容进行清洗,去除掉网页中的HTML标签、JavaScript代码等无用内容,得到纯文本语料。
第二步:使用现有的中文语料库现有的中文语料库数量众多,常见的有THUOCL中文词库、SogouQ中文文本库等。
这些语料库均经过整理、清洗、标注等处理,为研究人员提供了大量可靠的中文文本语料,而且可以直接下载和使用。
研究人员可以根据实际需要,选择相应的语料库进行下载和使用。
第三步:手动标注文本数据手动标注文本数据是一种相对繁琐的中文文本语料获取方式,但是这种方式可以获得更准确、更质量的文本数据。
通过手动标注文本数据,我们可以获得文本分类、实体识别、情感分析等所需的中文文本语料。
在实际操作中,研究人员需要结合自身的研究目的和知识体系,对文本内容、标注方式等方面进行详细规划和设计。
第四步:使用深度学习模型自动生成文本数据随着深度学习技术的快速发展,自动生成文本数据的技术也得到了广泛应用。
基于深度学习的文本生成模型可以自动学习和生成大量的中文文本,为研究人员提供了丰富的语料数据。
但是需要注意的是,使用深度学习模型自动生成的文本数据仍需要进行人工校对和清洗,以确保其质量和准确性。
总结:中文文本语料获取是自然语言处理中的一项重要技术,其应用范围广泛,如情感分析、智能客服、机器翻译等。
本文介绍了几种中文文本语料获取的方式,研究人员可以根据自身需要选择相应的方式进行使用。
同时,我们也要注意保护语料数据的隐私性和版权问题,严格遵守相关法律法规。
基于Google Web API的网页获取技术研究

【 关键词 l 网页获取 ,og bA I搜 索引擎 : Goe l We P,
1 概 述 .
当人们提及 网页的获取 .首先想到的是利用各个搜索引擎 提供 的搜索服务来获取所需的网页。 一般情况下 。 在浏览器中打 开 C ol 或其他搜索引擎搜索有用的网页。 oge 然而 , 如果需要收集 大量 同一 主题的网页 。 并建立一个 网页存储库 。 为下一步的处理 ( 如趋势分析、 网页内容挖掘等 ) 做准备时 , 各搜索引擎所提供的 服务就不 能满足需求 了。 开发一个 网络机器人收集需要的网页 .固然是个很好 的主 意。 但是 , 开发一个具有独立版权并性能良好 的网络机器人所要 花费的巨大精力和巨额资金是大多数人不能 承受 的。本文介绍 通过在 J V A A应用程序中集成 C o We P ,实现搜索 U L o出 bA I R
格 式 并 打 印 出来 。 而 C oe o ̄
和获 取 网页 。 经过 测 试 , 这 种 投 入 极 少 的 情 况 下 . 统 消耗 很 31 建 一 个 搜 索 在 系 .创
c  ̄ e于 2 0 , o 02年 4月 l 1日发布 了其 We P bA I的 bt e a测 试版本。 通过  ̄ol We P . ge bA I软件开发人员可 以在 自己的应用 程序 中检索到 G o e索引的数 以百亿计的网页 。G o 遵循 的 o o出 是 SA O P协 议 和 WS L规则 . 以使 用 C ol We P 开 发 应 D 所 o ̄ bA I e
G olS a og emh类 封装 了 C ol We P 的 主 要 接 口 它 通 e oge bA I 过 SA O P提 供 了搜 索 和存 储 网页 的功能 。G oh er og S a h类 的 e d Sac (方 法 用 于 通 过 G ol 执 行 搜 索 。eK y ) 法 则 用 于 oerh ) o ̄e st e(方 设 置 用 户 获 得 的授 权码 。 于 所有 的搜 索 . 个 属 性 的设 置 是 强 对 这 制性 的。 搜索的关键词 即查询词是由 st urSr g ) eQ eytn (设置的。 l 查 询 词 可 以是 一 个 词 , 个 短 语 , 一 个 简 短 的句 子 。 一 或是 先 创 建 一 个 G olSac ogeerh类 的 实 例 ,然 后 调用 该类 的 dS a h ) o er (方法 。该方法 执行搜索并返 回一 个 c o ̄ erh e c og S acR . e si类 的实 例 。G ol erh eu ut o g S acR sh封 装 了通 过 调 用 c ol We e og b e A I 索 所 返 回 的 所 有 结 果 。得 到 搜 索 结 果 后 , 调 用 G o . P搜 可 o Sac R sh类 的 tS lg ) 法 , 返 回 的结 果 转 换 成 字 符 串 erh eu otn (方 r 把
google api 用法

1111
1. Google Maps API:用于在应用程序中嵌入 Google 地图。
你可以显示地图、标注地点、获取地理位置信息、规划路线等。
2. Google Translate API:用于翻译文本。
你可以将文本发送到 API 进行翻译,并接收翻译后的结果。
3. Google Search API:用于在应用程序中集成 Google 搜索功能。
你可以执行搜索查询并获取搜索结果。
4. Google Analytics API:用于与 Google Analytics 数据交互。
你可以获取网站分析数据,如访问量、用户行为等。
5. Google Cloud Storage API:用于管理和操作 Google Cloud Storage 中的数据。
你可以上传、下载、删除文件等。
要使用 Google API,你需要注册 Google API 控制台账号,并创建相应的 API 密钥。
然后,你可以按照 API 的文档和规范来使用相应的 API 。
需要注意的是,Google API 可能会有使用限制和计费政策,请在使用前仔细阅读相关文档和政策。
此外,一些 API 可能需要你的应用程序在 Google 开发者控制台中进行配置和审核。
这只是对一些常见 Google API 的简要介绍,具体的用法和功能可能因 API 而异。
如果你有特定的 API 需求,请参考相应的 API 文档以获取更详细的信息和示例。
基于 Web 的中英文术语自动抽取技术

作者签名: 日 期:
导师签名: 日 期:
摘
要
摘
要
术语广泛的存在于科技文档中,如何提取、分析、理解以至翻译这些术语 成为现在自然语言处理的一个研究方向。随着当今世界信息量的急剧增加和国 际交流的日益频繁,计算机网络技术迅速普及和发展,语言障碍愈加明显和严 重,对机器翻译的潜在需求也越来越大。双语术语散落在这些海量的互联网文 本数据中,靠人工进行检测和提取是不可想象的。本文所要解决机器翻译中如 何快速地对网络文本进行处理,从中抽取出较为准确的术语中英文互译候选, 以减轻人工筛选的工作量。 目前,双语术语的研究一般是运用句法分析或者引入双语词典的方法,实 现句子对齐,而后从对齐的句子运用算法,抽取互译词。而本文的基本思路是 在无监督的情况下,利用网络上大量存在的中英文术语互译信息,达到自动抽 取中英文术语候选的目的。我们通过对互联网上大量文本信息的观察,选取一 类符合规则的文本,针对文本建立一个语言模板,运用网络爬虫,抓取网页生 成网络文本语料库;而后,在 MapReduce 架构下对网络文本语料进行处理,抽 取符合该语言模板规定的大量中英文词对;对抽取出来的大量中英文双语术语 候选进行预处理,过滤掉部分噪声;对预处理后的数据运用多种优化的 LCS 算 法加以抽取,生成中英文双语术语互译词典,并对结果加以评测。 本文的研究工作主要包括在以下几个方面: 1. 在 MapReduce 架构下,对抓取的文本语料库数据快速处理,以获得所需 文本数据资源。 2. 设计了一套无监督的双语术语自动抽取软件系统,能较为及时准确地发 现并更新术语库。 3. 基于 LCS 算法提出并建立了两种将规则和统计的方法相结合的双语术语 自动抽取模型。 4 用 CRFs 辅助优化 LCS 算法, 对比试验结果, 分析 CRFs 分词对 LCS 算法 的影响。 关键词: 术语 自动抽取 机器翻译 中文信息处理 自然语言处理
gpt key获取

gpt key获取【1】GPT简介GPT,全称为Generative Pre-trained Transformer,是一种基于深度学习的自然语言处理技术。
它采用了一种预先训练的方式,利用大规模语料库来学习语言模式,从而能够生成自然流畅的文字。
GPT技术在许多领域都有广泛的应用,如机器翻译、文本生成、对话系统等。
【2】GPT Key的获取方法要使用GPT技术,首先需要获取一个GPT Key。
GPT Key是用于访问GPT API的凭证,只有拥有GPT Key,才能使用GPT生成文本。
获取GPT Key的方法如下:1.访问GPT官方网站(https:///)注册账号,完成注册后,系统会自动生成一个GPT Key。
2.如果您是通过第三方平台使用GPT,如Google Colab、Hugging Face 等,需要先申请GPT API Key,然后在平台设置中进行授权。
3.使用GPT Key时,请注意保管好您的Key,不要泄露给他人,以免造成不必要的损失。
【3】GPT Key的使用注意事项1.合理使用GPT Key,不要滥用。
GPT API的使用是有流量限制的,超出限制将会导致Key被暂停使用。
2.在使用GPT Key时,要确保网络环境稳定和安全,防止Key被非法使用。
3.尊重知识产权,不要使用GPT Key进行侵权行为。
4.遵循道德规范,不要使用GPT Key制作或传播不良信息。
【4】总结GPT Key是访问GPT API的重要凭证,获取和使用GPT Key的方法和注意事项如上所述。
拥有了GPT Key,我们可以充分利用GPT技术在各种场景下生成高质量的文字,为我们的工作和生活带来便利。
api自动抓取导入数据库的方法

api自动抓取导入数据库的方法下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!API自动抓取数据并导入数据库的方法随着信息技术的发展,许多应用程序和服务都依赖于从第三方API(应用程序编程接口)获取数据。
基于Web的中英术语翻译获取方法研究

沈 阳航 空 工 业 学 院 学 报
第2 7卷
到术 语翻译 所在 的 网 页 ; 2 如何 识 别并 抽 取 该 () 术语 相 应 的 翻 译 。术 语 翻 译 获 取 来 源 主 要 是
板 从大 量 网页 中批量 抽 取双语 术语 。模式 匹配法 是 自动 构 造 大 规 模 双 语 词 典 的 一 种 有 效 方 法 。 G iogC o等 提 出 了一 种 基 于 中文 网页建 立 uhn a
中 图 分 类 号 :P 9 T 31 文献标识码 : A
当今科 学技 术 发 展 1新 月 异 , 个 学 科 都 拥 3 每
有 大量专 业术 语 。术语 是表 达一 个专业 领 域知识 的核心 词汇 。术语 翻译 是将 一种 语言术 语 翻译 为
业领 域 , 包含 很 多专业 新术 语 和惯用 语 , 因而具 有
双语 词典 、 双语 对 照词 汇表 、 语对 照 网站等 。因 双
翻译 正确 率 。另 外 , 管 本 文论 述 的是 中英 术语 尽
翻译 获取 问题 , 际 上 该 方 法 同样 可 应 用 于 其它 实 语 种 的术语 翻 译获 取 。
此可 以利用 We 双语 资 源进 行术 语 翻译 , 术 b上 将 语 翻译 问题 转 变 为 在 We b中获 取对 应 目标 语 言 翻译 的 过 程 。其 研 究 目标 是 给 定 一 个 源 语 言 术
题。
展 的定 位搜 索 技术 , 利用 G ol oge搜索 得 到包 含 术
语 翻译 的词 汇表 类 型 网 页 摘要 , 直接 从 网页 摘 要
术语 翻译 最简 单 的方式 是直 接查 找各种 专业
词典 。但 专业 词 典 的词 汇量 总 是 有 限 , 别是 不 特 能 及时 吸纳补 充 新 术语 , 造成 大 量 未 登 录 术语 词
基于Web的双语平行语料库自动获取系统

基于Web的双语平行语料库自动获取系统摘要:例如:进行统一中文网页编码,...我们通过观察统计发现在那些具有URL命名相似性的双语网站中,URL的pathname与base...对于对应的英文词ei在英文句子中存在多个的中文词cj...关键词:中文,词,中文词类别:专题技术来源:牛档搜索()本文系牛档搜索()根据用户的指令自动搜索的结果,文中内涉及到的资料均来自互联网,用于学习交流经验,作品其著作权归原作者所有。
不代表牛档搜索()赞成本文的内容或立场,牛档搜索()不对其付相应的法律责任!基于Web的双语平行语料库自动获取系统1叶莎妮吕雅娟刘群中国科学院计算技术研究所智能信息重点实验室{yeshani, lvyajuan,liuqun,}摘要:利用互联网上存在的海量多语言文本资源,通过网页的内容分析和链接分析,实现了一个双语语料挖掘的自动获取系统。
首先,介绍了系统框架和主要模块;其次,详细描述了各个模块的实现与创新技术;最后,给出下一步工作的展望。
本系统为获取真实的中英平行语料库提供了有效的途经。
关键词:双语语料; 网页挖掘; 平行网页A Bilingual Corpus Automatic AcquisitionSystem Based on WebAbstract: Implemented a bilingual corpus automatic acquisition system by taking advantage of an abundance of multilingual corpus in the World Wide Web, and analyzing their content and links. First, introduced system framework and main modules; second, described every module and technology innovations in detail. A prospect for the next step was given at last. This system provided an effective way for achieving Chinese-English parallel corpus.Keywords: Bilingual Text; Parallel Corpora; Web Mining;1. 引言语料库的建设是统计学习方法的重要基础,近年来,语料库资源对于自然语言处理研究的巨大价值已经得到越来越多的认可。
谷歌natural language api的用法

谷歌natural language api的用法
谷歌自然语言处理(Natural Language Processing, NLP)API 是一项提供文本分析和语义理解功能的服务。
它可以帮助开发者处理和分析文本数据,并提取其中的实体、情感、关键词等信息。
以下是谷歌自然语言处理API的基本用法:
1、创建项目并启用API:在谷歌云平台上创建一个项目,并启用自然语言处理API。
2、获取API密钥:生成一个API密钥,用于访问自然语言处理API。
3、安装客户端库:选择适合你编程语言环境的谷歌自然语言处理API的客户端库,并在项目中进行安装。
4、调用API:使用API密钥和客户端库,在你的应用程序中调用自然语言处理API的各种功能。
主要功能包括:
实体识别(Entity Recognition):识别文本中的命名实体,并将其分类为事物、地点、人名、日期等不同类型。
情感分析(Sentiment Analysis):分析文本的情感倾向,判断其中的情绪是积极的、消极的还是中性的。
语法分析(Syntax Analysis):分析句子的语法结构,提取出词汇、短语和句子之间的关系。
文本分类(Text Classification):将文本按照预定义的类别进行分类,如新闻、体育、科技等。
关键词提取(Entity Recognition):从文本中提取出最具代表性和重要性的关键词。
文本摘要(Text Summarization):自动提取文本的主要内容,并生成简洁的摘要。
借助Google文件提取文本
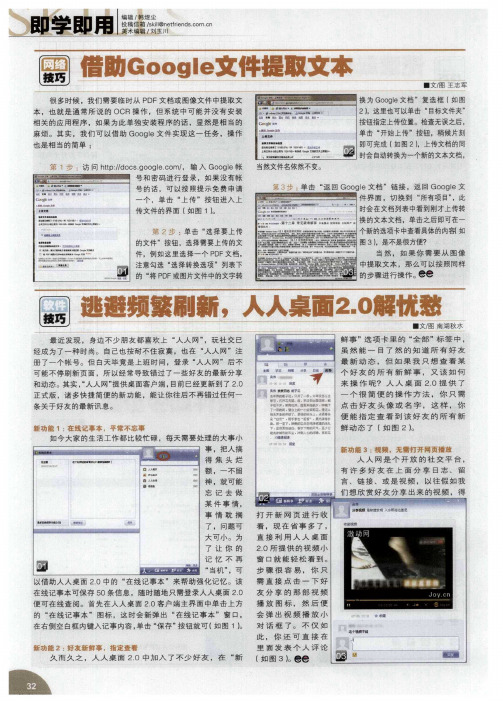
借助9 9 _文件耀取 本 9 g9
很 多 时候 ,我 们 需 要 临 时从 P DF文 档 或 图像 文 件 中提 取 文
■ 文 , 王 志 军 图
换为 G o l o ge文档 ” 复选 框 ( 图 如
神 。就可 能 忘 记 去 做
们 想 欣 赏 好 友 分 享 出 来 的 视 频 ,得 打 开 新 网 页 进 行 收 看 ,现 在 省事 多 了 , 直 接 利 用 人 人 桌 面
2 0所 提 供 的 视 频 小 .
某件事情。 事 情 耽 搁
了 ,问题 可
i 曩 t ^ t I目
时会 自动转换 为一个新 的文本文档 . 当然文件名依然不 变。 第 3步 : 击 “ 回 Go ge文 档 ”链 接 .返 回 Go ge文 单 返 oi o l 件 界 面 ,切 换 到 “ 所有项 目” ,此 时会在 文档列 表 中看 到刚 才上传转
麻 烦。其 实 ,我 们可 以借助 Go ge文件 实现 这一任务 ,操作 ol 也是相当的简单 :
■丽
如今 大 家 的生 活 工 作 都 比较 忙 碌 。每 天 需 要 处 理 的 大 事 小 事 ,把人 搞
得Байду номын сангаас焦 头 烂
额 ,一不 留
…
∞H ■ I
∞ H
人 人 网 是 个 开 放 的 社 交 平 台。
有 许 多 好 友 在 上 面 分 享 日 志 、 留 言 、链 接、或 是 视频 ,以往 假 如我
sg o l.o , 输 入 Go ge帐 o gec m/ ol 号 和 密 码 进行 登 录 ,如 果 没 有 帐 号 的话 。可 以 按 照提 示 免费 申请
google翻译API公开测试

据说之前google官方是有免费提供翻译API的,但后来在google开放平台升级后google transalte API便不再提供免费服务了,不知道是怎么回事(据说是因为有站长滥用= =)。
虽然除了google的翻译之外像是必应、百度、有道、金山等都提供免费的翻译接口(比如我之前写的多译就是利用这些API写成的),但却发现貌似在翻译文本的时候google的翻译似乎要更准确些,所以google的翻译还是很不错的。
当前google官方提供的google translate api已经不再提供免费服务,而且收费也很高的样子,所以还是自己做一个google 翻译API接口吧,即没有数量限制也可以免费使用google的翻译服务。
google翻译API接口地址:/api/translate.php使用方式GET参数:from 可选翻译的语言to 可选目标语言text 必选翻译内容from和to参数是可选的,默认值为auto,当两个值都是auto的时候会将要翻译的语言翻译成英语。
返回的数据格式为json查询出错时返回[]正确查询时返回{“from”:”翻译语言”,“to”:”目标语言”,“src”:”要翻译的内容”,“res”:”翻译后的内容”}各国语言的代码if(empty($argv[2]))$from="auto";if(empty($argv[3]))$to="auto";$url="/api/translate.php?from=$from&to=$to&text=$argv[1]"; $curl=curl_init();curl_setopt($curl,CURLOPT_URL,$url);curl_setopt($curl,CURLOPT_RETURNTRANSFER,1);$data=curl_exec($curl);curl_close($curl);$json=json_decode($data);echo $json->{'res'}."\n";?>。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
库 的方法 。通过实验 , 初步实现中文训 练库 的 自动建立 。
关 键 词 中 文 网 页 自动 分 类 中图分类号 T 33 P 9
Re e r h o i e e Tr i i g Co p r t m ai q ii o s a c f Ch n s a n n r o a Au o t Ac u st n c i M e h d Ba e n Go g e W e I t o d o o l s b AP
Hu Y a Zha g So g a n n n y ng
( c o l f o ue S in ea dT c n lg , h nv r t o eh oo y W u a 4 0 7 ) S h o mp t ce c n eh oo y Wu a U i s y f c n lg , h oC r n e i T n 30 0
1 引 言
网 页文 本分 类是 数 据 挖掘 方 面 一个 热点 研 究
用相关 词组将 进一 步被 用来 收集更 多训 练库样 本 , 文献 [ ] 出 了类 的 概 念 可 以用 类 的名 字 和 它 的 2给
相 关词 组 表 示 , 出 了一 种 叫 HC F H e 提 Q (i r—C n o一
Ke or s a t ma i ca s c t n Ofc ie e we a e ,c r o a o g e we yw d u o t ls i ai h n s b p g s o r ,g c i f o p l b API
Cl s m be T 3 3 a s Nu r P 9
维普资讯
总第 23期 2 20 0 8年第 5期
计算机与数字工程
Co mpue tr& Diia gne rn gtlEn i e i g
Vo . 6 No 5 13 . 8
基 于 G ol We P 的 中 文 训 练 库 og bA I e 自动 获 取 方 法 研 究
样本 , 分析 检索到 的 We 档来 发 现相 关词 组 , b文 利
此我们 给 出 了训 练库 自动获 取的基 本思 想 :
收稿 日期 :0 7年 l 月 2 20 1 7日, 修回 日期 : 0 2 8年 1月 2 0 2日 作者简介 : 胡燕, , 女 副教授, 硕士生导师 , 研究方向: 人工智能。张颂扬 , , 男 硕士研究生 , 研究方向 : 人工智能 、 数据挖掘。
胡 燕 张颂 扬
武汉 407 ) 30 0 ( 武汉 理 工 大学 计 算 机 科 学 与技 术 学 院
摘
要
主要研 究中文训练库 自动获取方法 , 出基 于 G ol We P 的方法 收集训练样本 , 提 og bA I e 然后给出 自动获取训 练
训练库 G ol We P oge bA I
其 中, t ) W(, 为词 t d 在文本 d中的权重 , t td 为 而 f ,) (
图 2 数 据 结构 类 的 类 层 次
词t 在文本 d中的词频 , Ⅳ为训练文本 的总数 ,, n 为训 练文本集 中出现 t 的文本数 , 分母为归一化因子 。
n c s ay c r o a a d gie a w a O a q r r o a a t m ai Thr g xp rme s,p ei n r i e e ta nn c r o a a t — e e s r o p r n v y t c uieco p r u o t c. ou h e e i nt r lmi a y Ch n s r i ig o r u o p m ai Se t b ihe t i sa ls d. c
此本文将 对 训练库 自动 获取 的方法进 行研 究 。 针 对手工 建立 训练库 的缺 点 , 们提 出 了基于 我 G g hA I o l We P 的方法 , G ol e 向 oge的索引数 据库 发
计 算机 学科 的相 关课程
出检索请 求 , 回得 到检 索 结 果 , 返 自动保 存 搜 索 到 的 网页 , 初步 实现 了 中文 训练库 自动 建立过 程 。
△ 塑丝垫
]
图 1 计算机学科训练库分类类别
2 训 练 库 自动获 取 的基 本 思 想
文献 [ ]给 出 了基 于 网络 方 法来 收 集 必 要 的 1
cp — u r e t Q ey—Fr uai ) 假 设 给 出的 话 题 都 是 om l o , tn 有层次 的且 尽 力把 所 有 类 按层 次 组 成 训练 库 。 由
数据 结 构
一 一 一
方向, 但是 大部分 的分类 方法 都预先 假设 训练 库 已
经建 成 , 训练库 的建 立 过程 很 少 有 人去 研 究 , 而 目 前 已有 的训 练库都 是手工 建立 的 , 手工建 立训练 库
不但浪 费时 间 , 工作 量很 大 , 更新 速度也 很慢 , 且 因
Abs r c Ths p p r su is a t mai o p r c u st n me d,i p o o e o ge W e Ia p o c o c l c ta t i a e t d e u o t c r o a a q i i  ̄o c io t r p s s a Go l b AP p r a h t o l t n e
维普资讯
第3 6卷 (0 8 第 5期 20 )
计 算 机 与 数 字 工 程
9
关于权重的汁算, 本文选取了常用的 T — D 公式: F IF
W( , )=f td lo ( / 0 0 ) td t , ):l N n + . 1 ( :g