Gibbons_bigtable-updated
btop用法 -回复

btop用法-回复[btop用法]是一个技术类的工具,用于检测服务器或网络设备的性能和负载情况。
btop是基于终端的实时系统监控工具,可以跟踪和显示系统的性能指标,如CPU使用率、内存使用率、网络流量等。
本文将一步一步详细介绍btop的安装、使用以及常见用法。
第一步:安装btop首先,在Linux系统中打开终端。
在命令行中输入以下命令来安装btop:sudo apt-get updatesudo apt-get install btop这将更新包管理器,并从软件源中安装btop软件。
第二步:启动btop在终端中输入以下命令来启动btop:btopbtop将会在终端中显示一个实时的系统监控界面。
第三步:btop界面介绍启动btop后,你将看到一个由各种指标组成的实时监控界面。
界面的下半部分是一个表格,显示了服务器的各项性能指标。
顶部是一个菜单栏,显示了不同的功能选项。
在表格中,你可以看到CPU的使用率、内存使用率、磁盘使用率、网络接口的传输速率等指标。
这些指标以百分比、数据传输速率或数据大小的形式显示。
在菜单栏中,你可以选择查看不同的功能选项。
比如,你可以使用方向键浏览不同的进程,按下空格键暂停或恢复监控,按下小写r键重置监控数据等。
第四步:使用btop的常见用法接下来,我们将介绍btop的常见用法,以帮助你更好地使用这个实用工具。
1. 查看进程信息:使用方向键上下浏览进程列表,可以查看进程的PID、CPU使用率、内存使用量等信息。
2. 暂停监控:按下空格键可以暂停监控数据的更新。
这对于查看某个特定进程的详细信息非常有用。
3. 排序进程:按下P键可以按照CPU使用率或内存使用量对进程进行排序。
这可以帮助你找到系统中占用资源最多的进程。
4. 杀死进程:选中某个进程,按下小写k键可以杀死该进程。
这在遇到死锁或者进程占用过多资源时非常有用。
5. 查看系统信息:按下大写I键可以查看系统的详细信息,包括系统的内核版本、处理器型号、操作系统等。
bigtable数据库简介

BigTable数据库概况摘要Bigtable是一个分布式的结构化数据存储系统,它被设计用来处理海量数据,通常是分布在数千台普通服务器上的PB级的数据。
Google的很多项目使用Bigt able存储数据,包括Web索引、Google Earth、GoogleFinance。
这些应用对Bigtable提出的要求差异非常大,无论是在数据量上(从URL 到网页到卫星图像)还是在响应速度上(从后端的批量处理到实时数据服务)。
尽管应用需求差异很大,但是,针对Google的这些产品,Bigtable还是成功的提供了一个灵活的、高性能的解决方案。
本论文描述了Bigtable的特点、发展史、目前应用现状、数据库存储技术、存储架构及查询、更新技术。
1 介绍BigTable是非关系的数据库,是一个稀疏的、分布式的、持久化存储的多维度排序Map。
Bigtable的设计目的是可靠的处理PB级别的数据,并且能够部署到上千台机器上。
Bigtable已经实现了下面的几个目标:适用性广泛、可扩展、高性能和高可用性,且已经在超过60个Google的产品和项目上得到了应用,包括Goog le Analytics、Google Finance、Orkut、Personalized Search、Writely和Google Earth。
这些产品对Bigtable提出了迥异的需求,有的需要高吞吐量的批处理,有的则需要及时响应,快速返回数据给最终用户。
它们使用的Bigtable集群的配置也有很大的差异,有的集群只有几台服务器,而有的则需要上千台服务器、存储几百TB的数据。
在很多方面,Bigtable和数据库很类似。
它使用了很多数据库的实现策略。
并行数据库和内存数据库已经具备可扩展性和高性能,但是Bigtable提供了一个和这些系统完全不同的接口。
Bigtable不支持完整的关系数据模型。
与之相反,Bigtable为客户提供了简单的数据模型,利用这个模型,客户可以动态控制数据的分布和格式,用户也可以自己推测底层存储数据的位置相关性。
bigtable工作原理

bigtable工作原理Google Bigtable 是一种高性能,可扩展的分布式存储系统,用于存储结构化数据。
它的工作原理如下:1. 数据模型:Bigtable 的数据模型是一个由行键 (Row key),列族 (Column family),列限定符 (Column qualifier) 和时间戳(Timestamp) 组成的多维稀疏矩阵。
每一条数据都通过唯一的行键进行标识,列族用于组织相似的列,列限定符用于唯一标识每一个独立的列,时间戳用于版本控制。
2. 存储结构:Bigtable 将数据按行键的字典顺序进行排序,并将其分布存储在多个物理机器上的不同存储节点中。
数据以列族为单位进行存储,每个列族都可以包含成千上万个列限定符。
每行中的列限定符按照字典顺序存储。
3. 分布式存储和负载均衡:Bigtable 将数据分布在多个存储节点上,以实现数据的高可用性和负载均衡。
它使用一致性哈希算法将行键映射到不同的存储节点上,这样可以实现数据的横向扩展和高性能访问。
4. 数据索引:Bigtable 使用一个称为 SSTable (Sorted String Table) 的文件格式来存储数据。
SSTable 包括一个内存索引和一个磁盘索引,用于加快数据的查找和读取。
内存索引存储在内存中,而磁盘索引存储在多个存储节点上的本地磁盘上。
5. 数据访问:通过行键,列族和时间戳来访问数据。
Bigtable使用 Bigtable API 来进行数据的读取和写入。
在读取数据时,Bigtable 可以根据时间戳来获取最新的数据或指定特定的时间戳获取历史数据。
在写入数据时,Bigtable 使用批量写入和乐观并发控制来处理并发写入操作,以保证数据的一致性和可靠性。
总体来说,Bigtable 利用分布式存储和索引技术,将大规模结构化数据存储在分布式文件系统中,并通过多节点的负载均衡和分布式计算来保证数据的高可用性和性能。
Big Table

Google's BigTable 原理首先,BigTable 从2004 年初就开始研发了,到现在为止已经用了将近8个月。
(2005年2月)目前大概有100个左右的服务使用BigTable,比如:Print,Search History,Maps和Orkut。
根据Google的一贯做法,内部开发的BigTable是为跑在廉价的PC机上设计的。
BigTable 让Google在提供新服务时的运行成本降低,最大限度地利用了计算能力。
BigTable 是建立在GFS ,Scheduler ,Lock Service 和MapReduce 之上的。
每个Table都是一个多维的稀疏图sparse map。
Table 由行和列组成,并且每个存储单元cell 都有一个时间戳。
在不同的时间对同一个存储单元cell有多份拷贝,这样就可以记录数据的变动情况。
在他的例子中,行是URLs ,列可以定义一个名字,比如:contents。
Contents 字段就可以存储文件的数据。
或者列名是:”language”,可以存储一个“EN”的语言代码字符串。
为了管理巨大的Table,把Table根据行分割,这些分割后的数据统称为:Tablets。
每个Tablets 大概有100-200 MB,每个机器存储100个左右的Tablets。
底层的架构是:GFS。
由于GFS是一种分布式的文件系统,采用Tablets的机制后,可以获得很好的负载均衡。
比如:可以把经常响应的表移动到其他空闲机器上,然后快速重建。
Tablets在系统中的存储方式是不可修改的immutable 的SSTables,一台机器一个日志文件。
当系统的内存满后,系统会压缩一些Tablets。
由于Jeff在论述这点的时候说的很快,所以我没有时间把听到的都记录下来,因此下面是一个大概的说明:压缩分为:主要和次要的两部分。
次要的压缩仅仅包括几个Tablets,而主要的压缩时关于整个系统的压缩。
Bigtable结构化数据的分布式存储系统

Bigtable结构化数据的分布式存储系统摘要Bigtable是设计用来管理那些可能达到很大大小(比如可能是存储在数千台服务器上的数PB的数据)的结构化数据的分布式存储系统。
Google的很多项目都将数据存储在Bigtable 中,比如网页索引,google 地球,google金融。
这些应用对Bigtable提出了很多不同的要求,无论是数据大小(从单纯的URL到包含图片附件的网页)还是延时需求。
尽管存在这些各种不同的需求,Bigtable成功地为google的所有这些产品提供了一个灵活的,高性能的解决方案。
在这篇论文中,我们将描述Bigtable所提供的允许客户端动态控制数据分布和格式的简单数据模型,此外还会描述Bigtable的设计和实现。
1.导引在过去的2年半时间里,我们设计,实现,部署了一个称为Bigtable的用来管理google 的数据的分布式存储系统。
Bigtable的设计使它可以可靠地扩展到成PB的数据以及数千台机器上。
Bigtable成功的实现了这几个目标:广泛的适用性,可扩展性,高性能以及高可用性。
目前,Bigtable已经被包括Google分析,google金融,Orkut,个性化搜索,Writely 和google地球在内的60多个google产品和项目所使用。
这些产品使用Bigtable用于处理各种不同的工作负载类型,从面向吞吐率的批处理任务到时延敏感的面向终端用户的数据服务。
这些产品所使用的Bigtable集群也跨越了广泛的配置规模,从几台机器到存储了几百TB数据的上千台服务器。
在很多方面,Bigtable都类似于数据库:它与数据库采用了很多相同的实现策略。
目前的并行数据库和主存数据库已经成功实现了可扩展性和高性能,但是Bigtable提供了与这些系统不同的接口。
Bigtable并不支持一个完整的关系数据模型,而是给用户提供了一个可以动态控制数据分布和格式的简单数据模型,允许用户将数据的局部性属性体现在底层的数据存储上。
bigtable名词解释

bigtable名词解释## Bigtable Glossary.### Bigtable Terminology.Bigtable.A distributed, scalable NoSQL database from Google Cloud.Designed for storing large amounts of structured data.Provides low latency, high throughput, and strong consistency guarantees.Cells.The basic unit of data in Bigtable.Consists of a row key, column family, column qualifier,timestamp, and value.Row Keys.Unique identifiers for each row in a Bigtable table.Used to retrieve rows efficiently.Column Families.Groups of related columns in a Bigtable table.Provide a way to organize data and improve performance.Column Qualifiers.Additional identifiers within a column family.Used to distinguish between different values within a column family.Timestamps.Indicate when a cell was modified.Allow for versioning of data.Value.The actual data stored in a cell.Can be any type of data, such as text, numbers, or images.Tables.Collections of rows in Bigtable.Defined by a schema that specifies the row key type and column family structure.Clusters.Groups of nodes that host Bigtable data.Provide fault tolerance and scalability.Zones.Physical locations where Bigtable clusters are deployed.Offer data redundancy and availability.### Bigtable Capabilities.High Performance.Fast reads and writes.Can handle large amounts of data (petabytes).Strong Consistency.Ensures that all writes are immediately visible to all readers.Scalability.Can be scaled up or down to meet changing data needs.Durability.Data is replicated across multiple nodes for redundancy.Protects against data loss in the event of hardware failures.Flexibility.Supports a variety of data types and data models.Can be used for a wide range of applications.## Bigtable术语解释。
bigtable浅析

bigtable浅析Bigtable 是⼀个⽤来管理结构化数据的分布式存储系统,具有很好的伸缩性,能够在⼏千台应⽤服务器上处理PB数量级数据。
⾕歌有许多项⽬都把数据存储在Bigtable中,包括web indexing,Google Earth, and Google Finance. 这些应⽤对Bigtable的侧重点不同,但是他们都是海量数据和实时性的应⽤。
尽管需求变化多端,Bigtable很好的提供了⼀个灵活多变,⾼性能额解决⽅案。
1. INTRODUCTION在很多⽅⾯Bigtable都与数据库类似:他们有同样的实现策略。
并⾏数据库和主存数据库都具有⾼伸缩性和⾼性能的特点。
但是Bigtable 提供了⼀种不同的接个⼝。
Bigtable不⽀持完全的关系数据模型;相反,它给客户端提供了⼀种简单的数据模型,这种数据模型⽀持对数据分布和格式的动态控制,并且允许客户端推出底层存储中数据的分布特性。
Bigtable的数据可以使⽤任意字符的⾏列进⾏索引,Bigtable也把数据当作不可解释的字符串(uninterpreted strings),尽管客户端常常把不同形式的结构化、半结构化的数据序列化形成这些字符。
客户端可以控制通过进⾏选择模式控制数据的位置。
最后⼀点,调整Bigtable的模式参数能让客户端动态控制是从内存还是硬盘提供数据。
2. DATA MODEL⼀个Bigtable 集群是⼀系列运⾏Bigtable软件的进程。
每⼀个集群都有⼀组tables。
Bigtable中的表是稀疏的、分布式、持久的多维有序map。
其数据有三个维度:⾏、列、时间戳。
(row:string, column:string, time:int64) → string我们称由⼀个特定⾏键、列键、时间戳指定的部分为⼀个单元(cell)。
多⾏组合起来形成负载平衡的基本单元,多列组合起来形成访问控制和资源分配的基本单元。
考虑这样⼀个具体的列⼦:⼀个⼤量⽹页和相关信息的集合,该集合会被⼤量不同的应⽤利⽤。
BigTable

1 什么是BigTableBigtable是一个为管理大规模结构化数据而设计的分布式存储系统,可以扩展到PB级数据和上千台服务器。
很多google的项目使用Bigtable存储数据,这些应用对Bigtable提出了不同的挑战,比如数据规模的要求、延迟的要求。
Bigtable能满足这些多变的要求,为这些产品成功地提供了灵活、高性能的存储解决方案。
Bigtable看起来像一个数据库,采用了很多数据库的实现策略。
但是Bigtable 并不支持完整的关系型数据模型;而是为客户端提供了一种简单的数据模型,客户端可以动态地控制数据的布局和格式,并且利用底层数据存储的局部性特征。
Bigtable将数据统统看成无意义的字节串,客户端需要将结构化和非结构化数据串行化再存入Bigtable。
下文对BigTable的数据模型和基本工作原理进行介绍,而各种优化技术(如压缩、Bloom Filter等)不在讨论范围。
2 BigTable的数据模型Bigtable不是关系型数据库,但是却沿用了很多关系型数据库的术语,像table (表)、row(行)、column(列)等。
这容易让读者误入歧途,将其与关系型数据库的概念对应起来,从而难以理解论文。
Understanding HBase and BigTable 是篇很优秀的文章,可以帮助读者从关系型数据模型的思维定势中走出来。
本质上说,Bigtable是一个键值(key-value)映射。
按作者的说法,Bigtable 是一个稀疏的,分布式的,持久化的,多维的排序映射。
先来看看多维、排序、映射。
Bigtable的键有三维,分别是行键(row key)、列键(column key)和时间戳(timestamp),行键和列键都是字节串,时间戳是64位整型;而值是一个字节串。
可以用(row:string, column:string, time:int64)→string来表示一条键值对记录。
Bigtable个人报告

双语例句
分布式结构化数据表:Bigtable
1. 2. 3. 4. 5. 6.
双语例句
分布式结构化数据表:Bigtable
1. 2. 3. 4. 5. 6.
双语例句
分布式结构化数据表:Bigtable
1. 2. 3. 4. 5. 6.
双语例句
分布式结构化数据表:Bigtable
1. 2. 3. 4. 5. 6.
双语例句
分布式结构化数据表:Bigtable
1. 2. 3. 4. 5. 6.
双语例句
分布式结构化数据表:Bigtable
1. 2. 3. 4. 5. 6.
双语例句
分布式结构化数据表:Bigtable
1. 2. 3. 4. 5. 6.
双语例句
分布式结构化数据表:Bigtable
1. 2. 3. 4. 5. 6.
t8
双语例句
数据模型
注:由于规模的问题,单个的大表不利于数据处理,因此
Bigtable将一个表分成了多个子表,每个子表包含多个行。 子表是Bigtable中数据划分和负载均衡的基本单位。
双语例句
数据模型:列
Bigtable并不是简单地存储所有的列关键字,而是将其组织成所谓的列 族(Column Family),每个族中的数据都属于同一个类型,并且同族的 数据会被压缩在一起保存。引入了列族的概念之后,列关键字就采用下述的 语法规则来定义: 族名:限定词(family:qualifier) 族名必须有意义,限定词则可以任意选定 图中,内容(Contents)、锚点(Anchor)都是不同的族。而 和my.look.ca则是锚点族中不同的限定词 族同时也是Bigtable中访问控制(Access Control)基本单元,也
BigTable简介
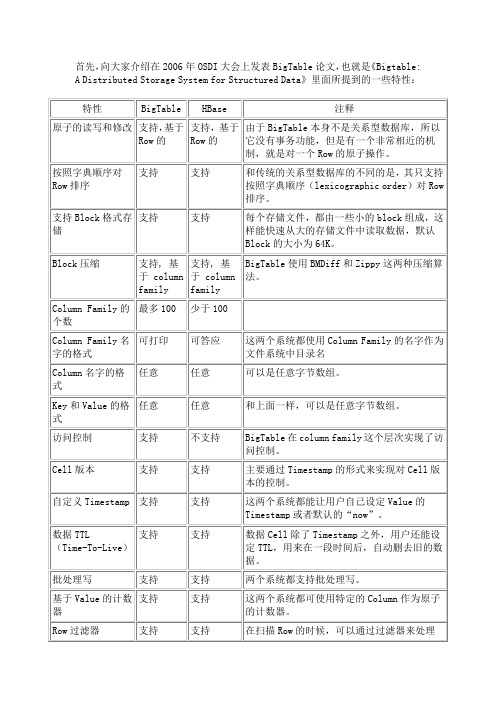
首先,向大家介绍在2006年OSDI大会上发表BigTable论文,也就是《Bigtable: A Distributed Storage System for Structured Data》里面所提到的一些特性:I.新特性在2009的LADIS大会上,Google院士jeff dean有一个非常精彩的Talk,称为“Design Lessons and Advice from Building Large Scale Distributed Systems”,在这次Talk中他提到了很多BigTable的新特性:表2. 在LADIS 2009大会上的Talk中提到的特性No CommentsPosted in PaaS相关技术, YunTable开发日记, 《云计算核心技术剖析》, 云计算II.Bigtable:一个分布式的结构化数据存储系统15 Jul为了方便部分博友和我自己,我特地将BigTable的中文版论文转载到人云亦云,原文地址在Google Labs,译者为alex。
III.摘要Bigtable是一个分布式的结构化数据存储系统,它被设计用来处理海量数据:通常是分布在数千台普通服务器上的PB级的数据。
Google 的很多项目使用Bigtable存储数据,包括Web索引、Google Earth、Google Finance。
这些应用对Bigtable提出的要求差异非常大,无论是在数据量上(从URL到网页到卫星图像)还是在响应速度上(从后端的批量处理到实时数据服务)。
尽管应用需求差异很大,但是,针对Google的这些产品,Bigtable还是成功的提供了一个灵活的、高性能的解决方案。
本论文描述了Bigtable提供的简单的数据模型,利用这个模型,用户可以动态的控制数据的分布和格式;我们还将描述Bigtable 的设计和实现。
IV. 1 介绍在过去两年半时间里,我们设计、实现并部署了一个分布式的结构化数据存储系统—在Google,我们称之为Bigtable。
bigtable的工作原理

bigtable的工作原理Bigtable是一种基于分布式的、高性能、高可扩展性的结构化数据存储系统。
其工作原理如下:1. 数据模型:Bigtable使用了一种简单的数据模型,类似于一个稀疏、多维的有序映射,每个单元格都由一个行键、列族、列限定符和时间戳唯一标识。
2. 数据存储:Bigtable将数据存储在一系列的分区中,每个分区称为一个tablet,在物理上分布在不同的服务器节点上。
每个tablet包含一部分行键的数据。
3. 数据分布:为了实现数据的负载均衡和高可扩展性,Bigtable使用一种称为一致性哈希的分布式哈希算法,将行键映射到不同的tablet中。
这样可以确保数据在节点之间均匀分布,并且在添加或删除节点时可以减少数据迁移。
4. 数据索引:为了快速定位数据,Bigtable使用了两级索引结构。
第一级索引基于行键的前缀进行分片,每个分片称为一个LSM树(Log-Structured Merge Tree)。
第二级索引将每个LSM树的最后一个分片的信息存储在一个称为索引表的数据结构中。
5. 数据写入:当写入数据时,Bigtable将数据按照行键的顺序写入到内存中的一个写缓冲区中。
当缓冲区满时,数据会被刷新到磁盘上的SSTable(Sorted Strings Table)文件中。
6. 数据读取:当读取数据时,Bigtable首先查找索引表确定数据的位置。
然后根据存储在内存中和磁盘上的数据文件,以及可能的日志文件,来获取请求的数据。
由于多个版本的数据可以存在于不同的存储层中,Bigtable可以根据指定的时间戳或者时间范围返回对应的数据。
总之,Bigtable通过将数据划分为多个tablet,并使用分布式哈希算法进行负载均衡,利用两级索引结构进行快速定位,在写入和读取数据时采用合适的缓冲和数据组织策略,实现了高性能和高可扩展性。
Bigtable 结构化数据的分布式存储系统 下

Bigtable 结构化数据的分布式存储系统下2010-10-20【google论文四】Bigtable:结构化数据的分布式存储系统(下)搜索2010-10-1622:36:43阅读0评论0字号:大中小订阅转载请注明:作者phylips@bmy 7.性能评价我们建立了一个N个tablet服务器的Bigtable集群来丈量Bigtable伴随着N的变化的性能和可扩展性。
Tablet服务器配置成由含有1G内存400GIDE硬盘的1786个机器组成的GFScell写进。
N个客户端为这些测试天生工作负载。
(我们使用与tablet服务器相同数目的客户端来保证客户端不会成为瓶颈)。
每个机器有一个双核Opteron2GHz芯片,供运行的进程使用的足够的物理内存,一个gigabit以太网链路。
机器通过一个两级树状交换机网络连接,根节点总体带宽接近100-200Gbps。
所有机用具有相同的主机配置,因此任意两个机器间的往返时间小于1ms。
Tablet服务器和master,测试客户端,GFS服务器都运行在相同的机器集合上。
每个机器运行一个GFS服务器。
另外这些机器要么运行一个tablet服务器要么运行一个客户端进程,或者一些其他同时使用这些机器的job的进程。
R是测试集中Bigtable行关键字的个数,通过对它的取值进行选择使得每个tablet服务器每个基准测试读写接近1G的数据。
顺序写基准测试使用0-R-1作为行关键字。
这个行关键字空间又被划分为相同大小的10N个相同大小的区间。
这些区间通过一个中心调度器分配给N个客户端,当客户端处理完分配给它的前一个区间后就继续分配给它下一个区间处理{分配是动态的,中心调度器维护一个未分配集合,当发现某个客户端完成后,就给它下一个区间,而不是每个客户端一开始就分配了10个固定区间}。
这种动态分配有助于减轻客户端机器上的其他进程造成的性能影响。
在每个行关键字下我们写一个字符串,这个字符串是随机天生的,因此也是未压缩的。
bigtable应用场景

bigtable应用场景
Bigtable作为一款分布式的键值存储系统,主要适用于需要处理大
规模数据并且需要高吞吐量和低延迟的应用场景。
以下是一些常见的Bigtable应用场景:
1. Web搜索引擎:Google采用Bigtable作为其搜索引擎的基础架构。
Bigtable可以支持海量的数据索引与查询,快速地返回搜索结果。
2. 社交网络:社交网络需要存储大量的用户信息、关系以及内容。
Bigtable可以帮助社交网络快速存储和检索这些信息,同时保证高并发
和低延迟。
3. 日志和事件处理:Bigtable可以很好地处理海量的日志和事件数据。
例如需要处理大量用户的访问日志以及业务的日志信息。
4. 物联网:物联网设备可以生成大量的传感器数据,包括温度、湿度、位置等信息。
通过Bigtable,可以很容易地存储和分析这些数据。
5. 金融服务:金融服务需要处理大量的交易数据以及用户资产信息。
Bigtable可以很好地管理这些数据,并且提供高可用性和数据安全保障。
总之,任何需要处理大规模数据且需要快速存储和检索的应用场景都
可以考虑使用Bigtable。
glab使用方式

glab使用方式Glab 是一个基于命令行的 Git 客户端工具,它提供了一系列命令来简化和增强 Git 的使用体验。
下面是一些常用的 Glab 使用方式的详细介绍:1. 安装 Glab:- 在 macOS 上,你可以使用 Homebrew 进行安装:`brew install glab`- 在 Windows 上,你可以从 Glab 的 GitHub 仓库下载可执行文件并添加到系统路径中- 在 Linux 上,你可以从 Glab 的 GitHub 仓库下载可执行文件并添加到系统路径中2. 登录到 GitLab:- 在命令行中运行 `glab auth login` 命令- 输入你的 GitLab 服务器地址- 输入你的 GitLab 用户名和密码进行身份验证3. 创建和管理仓库:- 创建一个新仓库:`glab repo create <repo-name>` - 克隆一个仓库到本地:`glab repo clone <repo-name>`- 列出仓库:`glab repo list`- 删除一个仓库:`glab repo delete <repo-name>`4. 创建和管理分支:- 创建一个新分支:`glab branch create <branch-name>`- 切换到一个分支:`glab branch switch <branch-name>`- 查看分支列表:`glab branch list`- 删除一个分支:`glab branch delete <branch-name>`5. 进行代码提交和合并:- 添加文件到暂存区:`glab mr create`- 提交代码到仓库:`glab mr submit`- 查看合并请求列表:`glab mr list`- 合并一个合并请求:`glab mr merge <merge-request-id>`6. 查看和管理问题:- 创建一个新问题:`glab issue create`- 列出问题:`glab issue list`- 更新问题状态:`glab issue update <issue-id> --state <state>`这些只是 Glab 提供的一些常用命令和功能,你可以通过运行 `glab --help` 命令来查看更多的命令和选项。
gcp big query语句

gcp big query语句BigQuery是Google Cloud Platform(GCP)提供的一种快速、可扩展的企业级数据仓库解决方案。
它支持使用SQL语句进行数据查询和分析。
以下是一个示例的BigQuery SQL语句:sql.SELECT.product_id,。
COUNT() as total_purchases.FROM.`project_id.dataset_name.table_name`。
WHERE.purchase_date BETWEEN '2022-01-01' AND '2022-12-31'。
GROUP BY.product_id.ORDER BY.total_purchases DESC.LIMIT.10;这个SQL语句的作用是从指定的数据集中查询产品ID及其对应的购买次数,并按购买次数降序排列,最后返回前10个结果。
让我来解释一下这个SQL语句的各个部分:`SELECT`子句用于指定要查询的字段,这里选择了产品ID和购买次数,并使用`COUNT()`函数统计购买次数并起别名为`total_purchases`。
`FROM`子句用于指定要查询的数据表,这里使用了`project_id.dataset_name.table_name`来指定数据集、数据表。
`WHERE`子句用于筛选符合条件的数据行,这里使用了`purchase_date BETWEEN '2022-01-01' AND '2022-12-31'`来筛选出指定日期范围内的数据。
`GROUP BY`子句用于对查询结果进行分组,这里按产品ID进行分组。
`ORDER BY`子句用于对查询结果进行排序,这里按购买次数降序排列。
`LIMIT`子句用于限制返回结果的数量,这里限制为返回前10个结果。
当你在GCP的BigQuery中执行这个SQL语句时,它将会返回符合条件的产品ID及其对应的购买次数,并按购买次数降序排列的前10个结果。
缘起:BigTable

缘起:BigTableGoogle的三篇论⽂,Google File System,MapReduce以及Big Table可以说是整个⼤数据领域的三驾马车,这⾥,我们简单介绍下这三驾马车基本都是⼲哈的,重点解读下Bigtable: A Distributed Storage System for Structured Data。
2003年的GFS:GFS是⼀个可扩展的分布式⽂件系统,主要解决传统单机⽂件系统中磁盘⼩,数据存储⽆冗余等问题;2004年的MapReduce:MapReduce是⼀个基于分布式⽂件系统(例如,GFS)的分布式计算框架,主要⽤来处理⼤规模数据集;2006年的BigTable:BigTable是⼀个⽤来管理结构化数据的分布式存储系统,其本质上⼀个分布式KV存储系统。
BigTable是个啥?BigTable是Google内部⽤来管理结构化数据的分布式存储系统,BigTable可以轻易地扩展到上千台机器,BigTable具有以下优点:1. 适⽤场景⼴泛:从需要⾼吞吐量的批处理作业到低延迟的⽤户数据服务,BigTable都可以胜任。
2. 可伸缩:集群规模可⽔平扩展,BigTable部署规模可以⼩到3~5台,⼤到数千台,从⽽⽀撑不同的数据量;3. ⾼性能:性能这个,想必不⽤我BB了吧,各位看官,你们怎么看呢?4. ⾼可⽤:BigTable是主从结构,不会产⽣单点故障;底层是GFS,数据冗余备份;这还不具有⾼可⽤嘛与关系型数据库不同,BigTable并不⽀持完整的关系数据模型,也就是说,BigTable是⼀个NoSQL数据库,BigTable为⽤户提供了⼀个简单的数据模型,该模型主要有以下两个特点:1. 客户端可以对数据的布局和格式动态控制;这点与关系型数据库有很⼤的差别,关系型数据库中,表创建完成后,表中存储的数据格式基本就固定了,列的数量及格式都⽆法再改变了,BigTable则不同,BigTable的列可以动态增加,完全由客户端控制。
谷歌BigTable数据库

谷歌BigTable数据库Bigtable包括了三个主要的组件:链接到客户程序中的库、一个Master服务器和多个Tablet服务器。
针对系统工作负载的变化情况,BigTable可以动态的向集群中添加(或者删除)Tablet服务器。
Master服务器主要负责以下工作:为Tablet服务器分配Tablets、检测新加入的或者过期失效的Table服务器、对Tablet服务器进行负载均衡、以及对保存在GFS上的文件进行垃圾收集。
除此之外,它还处理对模式的相关修改操作,例如建立表和列族。
每个Tablet服务器都管理一个Tablet的集合(通常每个服务器有大约数十个至上千个Tablet)。
每个Tablet服务器负责处理它所加载的Tablet的读写操作,以及在Tablets过大时,对其进行分割。
和很多Single-Master类型的分布式存储系统【17.21】类似,客户端读取的数据都不经过Master服务器:客户程序直接和Tablet服务器通信进行读写操作。
由于BigTable的客户程序不必通过Master服务器来获取Tablet的位臵信息,因此,大多数客户程序甚至完全不需要和Master服务器通信。
在实际应用中,Master服务器的负载是很轻的。
一个BigTable集群存储了很多表,每个表包含了一个Tablet的集合,而每个Tablet包含了某个范围内的行的所有相关数据。
初始状态下,一个表只有一个Tablet。
随着表中数据的增长,它被自动分割成多个Tablet,缺省情况下,每个Tablet的尺寸大约是100MB到200MB。
我们使用一个三层的、类似B+树[10]的结构存储Tablet的位臵信息(如图4)。
第一层是一个存储在Chubby中的文件,它包含了Root Tablet的位臵信息。
Root Tablet包含了一个特殊的METADATA表里所有的Tablet 的位臵信息。
METADATA表的每个Tablet包含了一个用户Tablet的集合。
一种No SQL数据库-Google Big Table的综述

一种No SQL数据库-Google Big Table的综述赵小溪经管会计 201411036022摘要本文对一种主流No SQL数据库,即Google的BigTable进行了综述。
对其实现细节进行了表述,深入了解了BigTable的架构,介绍了其读写操作,并提出了其存在的几个问题并给出了解决办法。
对BigTable进行了总结和展望。
并对No SQL数据库的发展现状和趋势作了简单介绍。
引言出现于1998年的No SQL是Carlo Strozzi开发的一个轻量、开源、不提供SQL功能的关系数据库。
在2009年,Johan Oskarsson发起了一次关于分布式开源数据库的讨论,来自Rackspace(全球三大云计算中心之一)的Etic Evans再次提出了No SQL的概念,这时的No SQL 主要指非关系型、分布式、不提供ACID的数据库设计模式。
2009年在亚特兰大举行的no:sql(east)讨论会是一个里程碑,会上对No SQL最普遍的解释是非关系型的,强调键一—值对存储和文档数据库的优点,而不是单纯的关系型数据库。
No SQL是Not Only SQL的简写,其含义是“不仅是结构化查询”,是不同于传统的关系型数据库的数据库管理系统的统称。
No SQL与SQL的最显著的区别是No SQL不使用SQL作为查询语言,其数据存储不需要固定的表格模式,也避免使用SQL的JOIN操作,具有水平可扩展性。
CAP、BASE和最终一致性是No SQL数据库存在的3大基石。
No SQL存储满足了数据存储的横向伸缩性的需求。
No SQL以其运行在PC服务器集群上,突破了性能瓶颈,没有过多的需求,支持者源于社区,弹性扩展,大数据量,灵活的数据模型,经济效率高等特点为大数据的存储、传输与处理创造了生态环境,并逐渐走向成熟并广泛应用。
Big Table作为一种非关系型数据库,是一个稀疏的、分布式的、持久化存储的多维度排序映射。
bigtable阅后感

bigtable阅后感regionserver会在zookeeper指定⽬录创建⼀个特定的⽂件夹和⽂件,hmaster监视这个服务器⽬录,发现regionserver.并创建⼀个独占的排他锁。
这个锁只能⾃⼰享⽤。
若regionserver挂掉,会丢失锁,之后,若之前创建的⽂件还存在。
regionserver会重新尝试创建独占排他锁,如果尝试成功,可以对外继续提供服务。
若创建失败,regionserver进程就⾃杀,不再对外提供服务。
根据业务需求:有的需要极⼤的吞吐量,有的需要及时响应客户端的访问。
bigtable集群配置:有的集群只有⼏台服务器,有的则需要上千台。
bigtable使⽤了很多数据库的实现策略,它不⽀持完整的关系数据模型。
但提供了⼀个简单的数据模型,客户可以使⽤这个模型来动态控制数据的分布和格式。
⽤数据库的语⾔来说,就是数据没有schema,⽤户需要⾃⼰定义schema.bigtable将数据都视为字符串,通常把结构化或半结构化的数据存储在这些字符串。
bigtable是⼀个稀疏的,分布式的,持久化存储的多维度排序map。
map的索引是⾏关键字,列关键字,时间戳(rowkey:String,column:String,timestamp:int64)->String。
map中的每个value都是⼀个未解析的字节数组。
webtable:使⽤反向url(com.baidu.www)作为关键字,⽹页的属性作为列族,⽹页的内容存放在列content:中,并⽤获取该⽹页的时间戳(获取时间不同,存储多个版本的⽹页数据)来作为标识。
⾏键:⾏键可以是任何字符串(最⼤64kb,10byte-100byte是常⽤的),⽤户对同⼀⾏键中的数据的读写都是原⼦性的(不管读写这⼀⾏中多少个不同的列)。
bigtable通过⾏键的字典序来组织数据,每个⾏都可以作为⼀个分区region,region是数据分布和负载均衡的最⼩调整单位。
bigtable中文翻译

{中是译者评论,程序除外}大表:结构化数据的分布式存储系统Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C。
Hsieh, Deborah A。
Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E。
Gruberffay,jeff,sanjay,wilsonh,kerr,m3b,tushar, kes,gruberg@google。
comGoogle, Inc。
摘要Bigtable是设计用来分布存储大规模结构化数据的分布式存储系统,从设计上它可以扩展到上2^50字节,分布存储在几千个普通服务器上。
Google的很多项目使用Bigtable来存储数据,包括网页查询,google earth和google金融。
这些应用程序对Bigtable的要求大不相同:数据大小(从URL到网页到卫星图象)不同,反应速度不同(从后端的大批处理到实时数据服务)。
对于不同的要求,Bigtable都成功的提供了灵活高效的服务。
在本文中,我们将描述Bigtable的数据模型。
这个数据模型让用户动态地控制数据的分布和结构,我们还将描述Bigtable的设计和实现。
1、介绍在过去两年半里,我们设计,实现并部署了一个称为Bigtable结构化数据的分布式存储系统。
Bigtable的设计使它能够管理2^50 bytes(petabytes)数据,并可以部署到上千台机器上。
Bigtable 完成了以下目标:应用广泛、可扩展、高性能和高可用性。
包括google analytics, google finance, orkut{Orkut是Google公司推出的社会性网络服务。
通过这一服务,用户可以在互联网上建立一个虚拟社会关系网},personalized search,writely和google earth在内的60多个产品都使用Bigtable。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Appeared in OSDI’06
Slides adapted from a reading group presentation by Erik Paulson, U. Washington October 2006
Google Scale
• Lots of data
• Column family:qualifier. Family is heavyweight, qualifier lightweight
• Column-oriented physical store- rows are sparse!
• Lookup, insert, delete API • Each read or write of data under a single row key is atomic
1000-byte values per server per second
16
Aggregate rate
17
Application at Google
18
Lessons learned
• Only implement some of the requirements, since the last is probably not needed • Many types of failure possible • Big systems need proper systems-level monitoring • Value simple designs
4
Chubby
• {lock/file/name} service • Coarse-grained locks, can store small amount of data in a lock • 5 replicas, need a majority vote to be active • Also an OSDI ’06 Paper
5
Data model: a big map
• <Row,
Column, Timestamp> triple for key
• Each value is an uninterpreted array of bytes
• Arbitrary “columns” on a row-by-row basis
Tablet Insert Insert Memtable (sorted) apple_two_E boat
Delete
Insert Delete Insert
SSTable SSTable (sorted) (sorted)
13
Compactions
• Minor compaction – convert a full memtable into an SSTable, and start a new memtable
19Biblioteka Google Bigtable
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber
– Popular compression scheme: (1) long common strings across a large window, (2) standard compression across small 16KB windows
• Bloom Filters on locality groups – avoid searching SSTable
6
BigTable vs. Relational DB
• • • • No table-wide integrity constraints No multi-row transactions Uninterpreted values: No aggregation over data Immutable data ala Versioning DBs
Tablet aardvark
Tablet
apple
apple_two_E
boat
SSTable SSTable
SSTable SSTable
10
Finding a tablet
• Client library caches tablet locations • Metadata table includes log of all events pertaining to each tablet
– Can specify: keep last N versions or last N days
• C++ functions, not SQL (no complex queries) • Clients indicate what data to cache in memory • Data stored lexicographically sorted: Client control locality by the naming of rows & columns
7
SSTable
• Immutable, sorted file of key-value pairs • Chunks of data plus an index
– Index is of block ranges, not values – Index loaded into memory when SSTable is opened – Lookup is a single disk seek
– Avoid mingling data, i.e. page contents and page metadata – Can keep some locality groups all in memory
• Can compress locality groups (10:1 typical)
12
Editing/Reading a table
• Mutations are committed to a commit log (in GFS) • Then applied to an in-memory version (memtable) • For concurrency, each memtable row is copy-on-write • Reads applied to merged view of SSTables & memtable • Reads & writes continue during tablet split or merge
• Firm believers in the End-to-End argument • 450,000 machines (NYTimes estimate, June’06)
2
Building Blocks
• • • • Scheduler (Google WorkQueue) Google File System Chubby Lock service Two other pieces helpful but not required
• Alternatively, client can load SSTable into mem
64K block 64K block 64K block SSTable
Index
8
Tablet
• Contains some range of rows of the table • Unit of distribution & load balance • Built out of multiple SSTables
11
Servers
• Tablet servers manage tablets, multiple tablets per server. Each tablet is 100-200 MBs
– Each tablet lives at only one server – Tablet server splits tablets that get too big
• Master responsible for load balancing and fault tolerance
– Use Chubby to monitor health of tablet servers, restart failed servers – GFS replicates data. Prefer to start tablet server on same machine that the data is already at
– Reduce memory usage – Reduce log traffic on restart
• Merging compaction
– Reduce number of SSTables – Good place to apply policy “keep only N versions”
• Major compaction
– Merging compaction that results in only one SSTable – No deletion records, only live data
14
Locality Groups
• Group column families together into an SSTable
– Sawzall – MapReduce
• BigTable: Build a more application-friendly storage service using these parts