shell中的cut命令
shell cut用法

shell cut用法摘要:一、Shell 简介二、Shell 命令概述三、Shell cut 命令详解1.cut 命令的基本语法2.cut 命令的参数介绍3.cut 命令的实际应用案例四、总结正文:Shell 是一种用于管理Linux 系统的工具,通过Shell 命令可以实现对系统文件的快速操作。
在这些命令中,cut 命令是一个强大的文本处理工具,它可以帮助我们按照指定条件裁剪文本内容。
首先,我们来了解一下Shell 的基本概念。
Shell 是一个命令解释器,它可以接收用户输入的命令并执行。
在Linux 系统中,常用的Shell 有Bash、Zsh 等。
通过Shell,用户可以方便地管理系统资源、查看系统日志、执行程序等操作。
接下来,我们详细了解一下Shell cut 命令的使用方法。
1.cut 命令的基本语法cut 命令的基本语法如下:```cut -d 分隔符-f 字段文件```其中:- `-d`:指定分隔符,用于分割文本内容。
- `-f`:指定要提取的字段,可以是一个数字或者一个通配符。
- `文件`:指定要处理的文件。
2.cut 命令的参数介绍除了上述基本参数外,cut 命令还支持一些高级参数,如下:- `-c`:指定要提取的字符,可以是一个数字或者一个通配符。
- `-b`:指定要提取的字节,可以是一个数字或者一个通配符。
- `-n`:与`-f`类似,但指定字段时需要加数字。
- `--complement`:提取与指定条件相反的字段。
- `--delimiter`:指定分隔符,默认是空格。
3.cut 命令的实际应用案例这里我们通过一个实际案例来演示cut 命令的使用:假设有一个名为`students.txt`的文件,其中包含以下内容:```张三18 计算机科学与技术李四19 软件工程王五20 网络工程```我们可以使用以下命令按年龄分隔学生信息:```cut -d " " -f 1,3 students.txt```执行结果如下:```张三18李四19王五20```通过这个简单的例子,我们可以看到cut 命令在文本处理方面的强大功能。
shell字符串的处理(截取,连接,匹配,替换,翻转)

shell字符串的处理(截取,连接,匹配,替换,翻转)shell 字符串的处理(截取,连接,匹配,替换,翻转)本节分享下,字符串处理的内容,包括:截取,连接,匹配,替换,翻转等。
1,字符串的截取⽅法⼀:代码⽰例:echo $a|awk ’{print substr( ,1,8)}’substr是awk中的⼀个⼦函数,对第⼀个参数的进⾏截取,从第⼀个字符开始,共截取8个字符,如果不够就从第⼆个字符中补充⽅法⼆代码⽰例:echo $a|cut -b2-8cut:对标准输⼊的字符串进⾏处理cut -bn-m:以byte为单位,从第n个byte开始,取m个cut -bn,m:以byte为单位,截取第n,m个bytecut -b-n,m:以byte为单位,截取1-n,和第m个-c:以charactor为单位-d:指定分隔符,默认为tab-s:使标准输⼊中没有delimetercut -f1:截取第1个域⽅法三a=123456echo $⽅法四使⽤sed截取字符串的最后两位代码⽰例:echo $test |sed ’s//(.*/)/(../)$//’截取字符串的前2位代码⽰例:echo $test |sed ’s/^/(../)/(.*/)//’2,字符串的⽐较好像没有什么可以⽐较的3,字符串的连接$a$b或者$string4,字符串的翻转⽅法⼀:使⽤rev⽅法⼆:编写脚本实现代码⽰例:#!/usr/bin/awk -f{revline = ""for (i=1;i<=length;i++){revline = substr(,i,1) revline}}END{print revline}5,字符串的匹配grepegrepfgrep6,字符串的排序sort7,字符串的替换bash中:代码⽰例:%x=ababcd%echo $ # 只替换⼀个bbcdabcd%echo $ # 替换所有bbcdbbcdsh中:如何替换/使⽤sed替换所有匹配代码⽰例:echo $test |sed ’s/xx/yy’替换单个匹配8,得到字符串的长度:bash当中$或者expr "$VAR" : ’.*’9,判断字符串是否为数字10,得到字符串中某个字符的重复次数代码⽰例:echo $a |tr "x" "/n" | -l得到的结果需要减去1或者代码⽰例:echo $a |awk -F"x" ’{print NF-1}’11,得到字符串中某个string的重复次数12,将⼀批⽂件中的所有string替换代码⽰例:for i in file_listdovi $i <<-!:g/xxxx/s//XXXX/g:wq!done13,如何将字符串内每两个字符中间插⼊⼀个字符使⽤代码⽰例:echo $test |sed ’s/../&[insert char]/g’======================================================================================================================================概述我们⽇常应⽤中都离不开⽇志。
cut用法linux

cut用法linuxcut 命令:从文件中提取特定列cut 命令是一个强大的 Unix 工具,它允许用户从文本文件中提取特定列。
它的主要用途是在分析和处理文本数据时,如日志文件、CSV 文件或其他分隔文本文件。
命令语法cut 命令的语法如下:```cut [选项] [分隔符] [列号] [文件]```其中:选项:-d:指定分隔符,默认值为制表符(`\t`)。
-f:指定要提取的列号,以逗号分隔。
-c:指定要提取的字符范围,以逗号分隔。
分隔符:指定分隔各列的字符。
如果没有指定,则默认使用制表符(`\t`)。
列号:指定要提取的列的编号。
列号以逗号分隔,如 `1,2,5`。
文件:要处理的文件。
如果未指定,则从标准输入读取。
示例1. 使用制表符作为分隔符提取列以下命令从 `/etc/passwd` 文件中提取用户名和 UID 列:```cut -d: -f1,3 /etc/passwd```输出:```root:0daemon:1bin:2sys:3```2. 使用逗号作为分隔符提取列以下命令从一个 CSV 文件中提取姓名和年龄列,其中字段以逗号分隔:```cut -d, -f2,4 my_data.csv```输出:```John,25Jane,30```3. 指定字符范围提取字符以下命令从字符串中提取第 5 到第 10 个字符: ```cut -c5-10 "Hello, world!"```输出:```llo, w```选项-d 选项允许用户指定分隔符。
此选项对于处理使用非标准分隔符的文件非常有用。
例如,以下命令使用空格作为分隔符:```cut -d' ' -f2,3 my_data.tsv```-f 选项允许用户指定要提取的列。
列号以逗号分隔。
例如,以下命令提取第 1、3 和 5 列:```cut -d: -f1,3,5 /etc/passwd```-c 选项允许用户指定要提取的字符范围。
linuxshell字符串操作详解(长度,读取,替换,截取,连接,对比,删除,位置)

linuxshell字符串操作详解(长度,读取,替换,截取,连接,对⽐,删除,位置)1.Linux shell 截取字符变量的前8位实现⽅法有如下⼏种:1. expr substr “$a” 1 82. echo $a|awk ‘{print substr(,1,8)}’3. echo $a|cut -c1-84. echo $5. expr $a : ‘\(.\\).*’6. echo $a|dd bs=1 count=8 2>/dev/null2.按指定的字符串截取(1)第⼀种⽅法:从左向右截取最后⼀个string后的字符串${varible##*string}从左向右截取第⼀个string后的字符串${varible#*string}从右向左截取最后⼀个string后的字符串${varible%%string*}从右向左截取第⼀个string后的字符串${varible%string*}“*”只是⼀个通配符可以不要请看下⾯的例⼦:$ MYVAR=foodforthought.jpg$ echo ${MYVAR##*fo}rthought.jpg$ echo ${MYVAR#*fo}odforthought.jpg(2)第⼆种⽅法:${varible:n1:n2}:截取变量varible从n1开始的n2个字符,组成⼀个⼦字符串。
可以根据特定字符偏移和长度,使⽤另⼀种形式的变量扩展,来选择特定⼦字符串。
试着在 bash 中输⼊以下⾏:$ EXCLAIM=cowabunga$ echo ${EXCLAIM:0:3}cow$ echo ${EXCLAIM:3:7}abunga这种形式的字符串截断⾮常简便,只需⽤冒号分开来指定起始字符和⼦字符串长度。
3.按照指定要求分割:⽐如获取后缀名ls -al | cut -d “.” -f2⼩结:shell对应字符串的处理⽅法很多,根据需求灵活选择。
在做shell批处理程序时候,经常会涉及到字符串相关操作。
shell中while和print的用法 -回复

shell中while和print的用法-回复Shell中的while和print用法Shell是一种脚本语言,广泛用于Linux和Unix系统中。
它提供了一系列的命令和功能,可以对文件和数据进行处理和操作。
在Shell中,while和print是两个常用的关键字。
while用于循环执行一段代码,而print用于打印输出信息。
在本文中,我们将逐步讲解这两个关键字的用法和示例。
一、while循环的使用while循环用于执行一段代码块,只要指定的条件为真。
它的基本语法如下:while [条件]do代码块done其中,条件可以是一个命令,也可以是一个表达式。
当条件为真时,执行代码块中的语句,然后再次检查条件。
如果条件仍为真,继续执行代码块。
循环会一直进行,直到条件为假。
1.1使用命令作为条件我们首先来看一个简单的例子,使用命令作为条件。
假设我们要循环打印当前系统时间,并在循环执行一定次数后退出。
代码如下:count=0while [ count -lt 5 ]doecho "当前系统时间:(date)"count=((count+1))done在这个例子中,我们使用了一个变量count来记录循环次数。
while循环的条件是count小于5,即循环执行不超过5次。
每次循环开始时,使用`echo`命令打印出当前的系统时间,并使用`(date)`来获取系统时间的输出。
然后,我们将count的值增加1,以便循环计数。
循环执行5次后,条件不再满足,循环结束。
1.2使用表达式作为条件除了使用命令作为条件外,还可以使用表达式。
表达式通常使用关系运算符(比如`-gt`、`-lt`)和逻辑运算符(比如`&&`、` `)来进行条件判断。
假设我们有一个文本文件`data.txt`,它包含了一些数字(一行一个数字)。
我们要统计该文件中大于10的数字的数量。
代码如下:count=0while read numdoif [ num -gt 10 ]thencount=((count+1))fidone < data.txtecho "大于10的数字数量为:count"在这个例子中,我们使用`read`命令读取文件`data.txt`中的每一行数字,并将其存储到变量`num`中。
linux cut用法

linux cut用法cut 是 Linux 中一个非常实用的命令,用于从文本文件中提取信息。
它可以根据指定的字段和分隔符来切分文本,从而得到所需的信息。
以下是 cut 的一些常见用法。
1. 基础语法cut 命令的基础语法如下:```cut OPTION... [FILE]...```其中,`OPTION` 表示选项,`FILE` 表示要处理的文件名。
当没有指定文件名时,cut 命令默认从标准输入中读取数据。
例如:```$ echo "hello,world" | cut -d , -f 1hello```该命令会将字符串 "hello,world" 使用逗号 `,` 作为分隔符,提取第一个字段"hello"。
2. 指定分隔符cut 命令默认使用制表符或空格作为分隔符,但可以通过 `-d` 选项来指定其他分隔符。
例如:3. 指定字段cut 命令可以用 `-f` 选项来指定要提取的字段。
该选项后面的参数可以是字段编号,也可以是字段范围。
例如:第一个命令会提取第一个和第三个字段,即 "apple" 和 "banana"。
第二个命令会提取第二到第三个字段,即 "orange" 和 "banana"。
4. 字段排序cut 命令可以将提取的字段进行排序,使用 `-s` 选项即可。
例如:该命令会提取第三个和第一个字段(即 "banana" 和 "apple"),但会按照原来的顺序输出,不会排序。
第一个命令会删除第一个字符 "h",输出 "ello,world"。
第二个命令会删除指定的字符,输出 "elod"。
6. 结合其他命令cut 命令可以和其他命令结合使用,来达到更强大的功能。
cut用法linux

cut用法linuxcut 命令的用法cut 命令是一种从文本文件中提取特定字段或字符的实用程序。
它是一个功能强大的工具,可在各种情况下进行文本处理和数据提取。
语法```cut [选项] [分隔符] [字段列表] [文件]```选项-d (分隔符):指定用于分隔字段的分隔符。
默认分隔符为空格或制表符。
-f (字段列表):指定要提取的字段列表。
字段可以通过数字或字符范围指定。
-c (字符范围):指定要提取的特定字符范围。
-b (字节范围):指定要提取的特定字节范围。
-s (抑制空白输出):抑制空行或空白字段的输出。
字段列表字段列表可以采取以下几种形式:单个字段:指定要提取的单个字段号,例如 `-f 3`。
字段范围:使用连字符指定要提取的字段范围,例如 `-f 2-4`。
字符范围:指定要提取的字符号或范围,例如 `-c 10-15`。
字节范围:指定要提取的字节号或范围,例如 `-b 100-200`。
示例从以冒号分隔的文件中提取第二个字段:```cut -d: -f 2 file.txt```从以制表符分隔的文件中提取第一个和第三个字段: ```cut -f 1,3 file.txt```从文本文件中提取前 10 个字符:```cut -c 1-10 file.txt```从特定文件中提取 100 到 200 字节: ```cut -b 100-200 file.txt```抑制空行的输出:```cut -s -d: -f 2 file.txt```高级用法cut 命令还可以与其他命令结合使用,以实现更复杂的数据提取和处理。
与 grep 结合使用:可以将 cut 与 grep 结合使用,先过滤文本文件,然后再提取特定的字段。
与 awk 结合使用:可以将 cut 与 awk 结合使用,执行更高级的文本处理和数据提取。
与 sed 结合使用:可以将 cut 与 sed 结合使用,执行替换或删除操作,然后再提取特定的字段。
shell中cut的用法

shell中cut的用法
在shell中,`cut`命令用于以列为单位截取文本文件的数据。
它可以从一行文本中选择特定的字段,并将它们提取出来。
`cut`命令的基本用法是:
```
cut OPTION... FILE...
```
以下是一些常见的`cut`命令选项的示例用法:
1. `-c, --characters=LIST`:指定要提取的字符的位置列表。
例如,提取第1个和第3个字符:`cut -c 1,3 file.txt`。
2. `-d, --delimiter=DELIMITER`:指定字段的分隔符。
例如,使用逗号作为分隔符提取文件中的第2个字段:`cut -d ',' -f 2 file.txt`。
3. `-f, --fields=LIST`:指定要提取的字段的列表。
例如,提取文件中的第1个和第3个字段:`cut -f 1,3 file.txt`。
4. `-s, --only-delimited`:仅输出包含分隔符的行。
这对于忽略不包含分隔符的行很有用。
例如,仅提取包含逗号的行:`cut -d ',' -f 2 -s file.txt`。
5. `--complement`:反转选择,输出未被提取的字段。
例如,提取文件中的第2个字段之外的所有字段:`cut -f 2 --
complement file.txt`。
这只是`cut`命令的一小部分常用选项的示例。
要了解更多详细信息,请查看`cut`命令的文档或运行`man cut`以查看完整的帮助信息。
linux cut -c的用法

linux cut -c的用法在Linux系统中,cut是一个非常常用的命令行工具,用于对文本或数据进行切割和过滤。
其中,-c参数可以用于指定按照字符进行切割。
本文将详细介绍cut -c的用法和常见操作。
一、基本用法cut命令的基本语法如下:cut [选项] -c [数字或范围] [文件名]其中,-c参数表示按照字符进行切割,数字或范围指定要切割的字符数或范围。
文件名是要处理的文件名。
例如,要切割名为file.txt的文件,从第6个字符开始,每隔4个字符切割一次,可以使用以下命令:cut -c 6,8 file.txt这将输出file.txt中从第6个字符开始每隔4个字符的文本内容。
二、切割字符数和范围除了指定具体的数字或范围,cut命令还支持使用一些通配符进行切割。
常用的通配符有:* 数字:表示具体的字符数或范围。
* ',':表示切割的位置和数量之间用逗号隔开。
* '-':表示从某个位置开始到末尾的连续切割。
例如,要切割file.txt文件中从第6个字符开始到末尾的所有字符,可以使用以下命令:cut -c,+ file.txt这将输出file.txt中从第6个字符开始到末尾的所有字符。
三、其他选项和用法除了-c参数,cut命令还支持其他一些选项和用法,如指定切割的行数、忽略大小写等。
具体可以参考cut命令的文档或使用man cut 命令进行查看。
四、注意事项在使用cut命令时,需要注意一些特殊字符的切割方式,如空格、换行符等。
同时,也需要注意切割后的数据格式和用途,确保能够正确处理和解析。
总之,Linux cut -c命令是一个非常实用的文本处理工具,通过使用不同的参数和选项,可以实现各种复杂的文本切割和过滤操作。
通过本文的介绍,相信您已经对cut -c的用法有了更深入的了解和掌握。
Linux13:shell脚本基本命令

Linux13:shell脚本基本命令shell脚本基本命令输出命令echo输出命令echo,基本模式就是echo [选项] [输出内容]输出内容如果包含空格,则必须将内容⽤双引号括起来。
选项-e可以使输出语句⽀持反斜线转义。
加⼊退格后就不会显⽰退格符左边的⼀个字符。
ascii码表中有对应的⼋进制和⼗六进制表⽰法,所以可以表⽰对应的字符。
显⽰环境变量的值:echo ${PATH}或echo $PATH,如果⼀个变量没有被设定,那么就什么都不返回。
颜⾊输出如将abcd⽤红⾊打印:echo -e "\e[1;31m abcd \e[0m"其中\e[1的意思是开启颜⾊输出,⽽\e[0m是结束颜⾊输出,31m代表红⾊,abcd是输出内容,其他颜⾊如下:第⼀个脚本与脚本执⾏⽅式新建⼀个脚本hello.sh:#!/bin/bash#the first programecho "hello world"exit 0其中第⼀⾏是声明,不是注释,不能省略,这是在指定使⽤哪个shell,如果没有这⾏有的程序可能⽆法执⾏。
第⼆⾏#开头的是注释,第四⾏是命令。
最后⼀⾏在设置回传值,在执⾏完该脚本后,执⾏echo $?就能查看这个值,可以通过这个⾃定义错误信息。
在脚本中有需要时要重新定义⼀下PATH环境变量,以便直接使⽤⼀些外部命令⽽不是写绝对路径:PATH=/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/opt/module/jdk1.8.0_144/bin:/opt/module/hadoop-2.7.2/bin:/opt/module/hadoop-2.7.2/sbin:/root/bin export PATH执⾏shell脚本要先赋予其可rx权限:chomd 755 hello.sh然后再执⾏./hello.sh这⾥也可以⽤绝对路径执⾏。
shell cut用法

shell cut用法在Shell中,`cut`命令用于从文本中提取特定的部分。
它可以从文件的每一行中剪切字节、字符和字段,并将这些部分写入标准输出。
以下是`cut`命令的一些常见用法:1. 按字节剪切:```shellcut -b <字节范围> <文件名>```通过指定字节范围,你可以从文件中提取特定范围的字节。
2. 按字符剪切:```shellcut -c <字符范围> <文件名>```通过指定字符范围,你可以从文件中提取特定范围的字符。
3. 按字段剪切:```shellcut -f <字段范围> <文件名>```cut`命令默认以制表符(Tab)作为字段分隔符。
你可以使用`-d`选项指定自定义的分隔符。
通过指定字段范围,你可以提取文件中的特定字段。
例如,假设你有一个以逗号分隔的文件`data.csv`,你可以使用以下命令提取第一列:```shellcut -d, -f1 data.csv```这将会输出文件中的第一列数据。
4. 结合多个选项使用:```shellcut -b <字节范围> -c <字符范围> <文件名>```你可以同时使用字节和字符选项来同时指定字节和字符的范围。
5. 从标准输入中剪切:如果没有指定文件名,`cut`命令将从标准输入中读取数据,而不是从文件中读取。
你可以通过管道将数据传递给`cut`命令,例如:```shellecho "Hello, World!" | cut -c1-5```这将输出"Hello"。
这只是`cut`命令的一些基本用法示例,还有更多的选项和用法可以参考`cut`命令的文档或使用`man cut`命令查看完整的帮助文档。
Linux shell字符串截取与拼接

Linux shell字符串截取与拼接一Linux 的字符串截取很有用。
有八种方法。
假设有变量var=/123.htm1 # 号截取,删除左边字符,保留右边字符。
echo ${var#*//}其中var是变量名,# 号是运算符,*// 表示从左边开始删除第一个// 号及左边的所有字符即删除http://结果是:/123.htm.2 ## 号截取,删除左边字符,保留右边字符。
echo ${var##*/}##*/ 表示从左边开始删除最后(最右边)一个/ 号及左边的所有字符即删除/结果是123.htm3 %号截取,删除右边字符,保留左边字符echo ${var%/*}%/* 表示从右边开始,删除第一个/ 号及右边的字符结果是:4 %% 号截取,删除右边字符,保留左边字符echo ${var%%/*}%%/* 表示从右边开始,删除最后(最左边)一个/ 号及右边的字符结果是:http:5 从左边第几个字符开始,及字符的个数echo ${var:0:5}其中的0 表示左边第一个字符开始,5 表示字符的总个数。
结果是:http:6 从左边第几个字符开始,一直到结束。
echo ${var:7}其中的7 表示左边第8个字符开始,一直到结束。
结果是:/123.htm7 从右边第几个字符开始,及字符的个数echo ${var:0-7:3}其中的0-7表示右边算起第七个字符开始,3 表示字符的个数。
结果是:1238 从右边第几个字符开始,一直到结束。
echo ${var:0-7}表示从右边第七个字符开始,一直到结束。
结果是:123.htm。
注:(左边的第一个字符是用0 表示,右边的第一个字符用0-1 表示)二 Linux Shell 脚本中字符串的拼接方法如果想要在变量后面添加一个字符,可以用一下方法:$value1=home$value2=${value1}"="echo $value2把要添加的字符串变量添加{},并且需要把$放到外面。
shell cut -d 用法

shell cut -d 用法Shellcut是一个用于处理文本的命令行工具,它可以根据指定的分隔符对文本进行切割。
cut-d选项用于指定使用某个特定的分隔符对文本进行切割。
下面详细介绍cut-d的用法和示例。
一、基本用法cut命令的基本格式为:`cut[选项]<文件名>`其中,选项包含了-d和-f参数,其中-d指定分隔符,-f指定要显示的字段。
二、分隔符的使用使用cut命令时,可以通过-d选项指定一个分隔符,例如空格、制表符、逗号等。
分隔符可以是单个字符,也可以是多个字符的组合。
例如,假设有一个文本文件test.txt,内容如下:`John25Doe32Jane28`如果要以空格作为分隔符,使用以下命令:`cut-d""-f1,3test.txt`输出结果为:`JohnDoe253228`可以看到,cut命令将文本按照空格进行切割,并分别显示了第一列和第三列的内容。
三、多个分隔符的使用cut命令还支持使用多个分隔符。
可以使用-s选项指定多个分隔符的组合,例如:`cut-d,-s-f2test.txt`该命令将以逗号为分隔符,并显示第二列的内容。
四、示例下面是一些使用cut命令的示例:1.以空格为分隔符,显示文件中的前两列:`cut-d""-f1-2test.txt`输出结果为:`JohnDoe`(第一列和第二列的内容)2.以制表符为分隔符,显示文件中的前两行:`cut-d"\t"-f1test.txt`输出结果为:`John`(第一行的内容)3.以逗号为分隔符,显示文件中的第三列:`cut-d","-f3test.txt`输出结果为:`25`(第三列的内容)4.使用多个分隔符,显示文件中的第三列和第四列:`cut-d","-s-f3,4test.txt`输出结果为:`2532`(第三列和第四列的内容)五、注意事项在使用cut命令时,需要注意分隔符的正确性,以及要显示的字段范围。
shell cut用法

shell cut用法(实用版)目录1.Shell cut 用法概述2.Shell cut 的基本语法3.Shell cut 的实例分析4.Shell cut 的优点与局限性正文【1.Shell cut 用法概述】Shell cut 是 Linux 系统中一种强大的文本处理工具,它可以对文本进行剪切、复制和粘贴等操作。
Shell cut 不仅可以在命令行中使用,还可以在 Shell 脚本中使用,为用户提供了极大的便利。
【2.Shell cut 的基本语法】Shell cut 的基本语法如下:```cut -d 分隔符 -f 指定字段```其中,分隔符可以是逗号、制表符等,指定字段是指需要保留的字段。
例如,我们想要保留字段 2 和字段 4,可以使用以下命令:```cut -d "," -f 2,4```【3.Shell cut 的实例分析】假设我们有一个文本文件,内容如下:```张三,23,上海,学生李四,25,北京,教师王五,22,广州,学生```我们想要保留姓名和年龄两列,可以使用以下命令:```cut -d "," -f 1,3```执行结果如下:```张三李四王五```【4.Shell cut 的优点与局限性】Shell cut 的优点在于其强大的文本处理功能,可以满足用户的各种需求。
同时,Shell cut 具有较高的可定制性,可以根据用户的需要进行设置。
然而,Shell cut 也存在一定的局限性。
首先,它需要用户掌握一定的 Shell 命令知识,对于初学者来说可能会有一定的难度。
其次,Shell cut 的处理速度相对较慢,对于大规模文本处理可能会有所不足。
使用shell脚本进行数据可视化和表绘制的高级技巧

使用shell脚本进行数据可视化和表绘制的高级技巧在数据分析和可视化的过程中,Shell脚本是一个非常有用的工具。
它可以帮助我们自动化处理数据,并将其转换为可视化图表和表格。
本文将介绍一些高级的Shell脚本技巧,以帮助您更好地进行数据可视化和表绘制。
一、文本数据处理在使用Shell脚本进行数据可视化之前,首先需要处理原始数据。
通常,数据以文本文件的形式存储,我们需要使用Shell脚本来对其进行处理和清洗。
1. 数据提取和筛选使用Shell脚本的grep命令可以帮助我们快速提取和筛选数据。
例如,我们有一个存储学生成绩的文本文件,每一行包含了学生的姓名和成绩。
我们可以使用以下命令将所有成绩大于80分的学生提取出来:```grep "^[^ ]* [8-9][0-9]$" scores.txt```2. 数据排序和统计使用Shell脚本的sort和uniq命令可以帮助我们对数据进行排序和统计。
例如,我们有一个存储销售数据的文本文件,每一行包含了产品名称和销售额。
我们可以使用以下命令将销售额按照从高到低排序,并统计每个产品的销售总额:```sort -k2 -nr sales.txt | uniq -c```二、数据可视化处理完原始数据后,我们可以使用Shell脚本生成各种图表和表格,以便更好地呈现数据。
1. 绘制柱状图使用Shell脚本的printf命令可以帮助我们生成柱状图。
例如,我们有一个存储销售额的文本文件,每一行包含了产品名称和销售额。
我们可以使用以下命令生成柱状图:```while read linedoproduct=$(echo $line | cut -d' ' -f1)sales=$(echo $line | cut -d' ' -f2)printf "%-10s %s\n" $product $(printf "%0.s#" $(seq 1 $sales))done < sales.txt```2. 绘制饼图使用Shell脚本的awk命令可以帮助我们生成饼图。
Linux命令高级技巧使用cut和paste命令进行文本列处理和合并

Linux命令高级技巧使用cut和paste命令进行文本列处理和合并Linux命令高级技巧:使用cut和paste命令进行文本列处理和合并Linux系统是一款强大且流行的操作系统,拥有丰富的命令和功能。
在Linux环境中,处理文本列数据是一项常见的任务。
本文将介绍Linux命令中的两个高级技巧,即使用cut和paste命令进行文本列处理和合并。
一、cut命令简介及用法cut命令用于剪切文本中的列,并输出到标准输出。
cut命令的基本语法如下:```cut [OPTION]... [FILE]...```其中,OPTION是可选参数,用于指定剪切的方式。
常用的参数有:- -f:指定剪切的列数,多个列用逗号分隔。
- -d:指定列分隔符,默认为制表符(Tab)。
使用cut命令剪切单列的示例:```$ cut -f 1 data.txt```上述命令将从data.txt文件中剪切第一列,并将结果输出到标准输出。
使用cut命令剪切多列的示例:```$ cut -f 1,3 data.txt```上述命令将从data.txt文件中剪切第一列和第三列,并将结果输出到标准输出。
二、paste命令简介及用法paste命令用于合并文本中的列,并输出到标准输出。
paste命令的基本语法如下:```paste [OPTION]... [FILE]...```其中,OPTION是可选参数,用于指定合并的方式。
常用的参数有:- -d:指定列分隔符,默认为制表符(Tab)。
使用paste命令合并两列数据的示例:```$ paste file1.txt file2.txt```上述命令将file1.txt文件和file2.txt文件中的每一行按顺序合并,并将结果输出到标准输出。
使用paste命令合并多列数据的示例:```$ paste -d "," file1.txt file2.txt```上述命令将file1.txt文件和file2.txt文件中的每一行按顺序合并,并使用逗号作为列分隔符。
shell脚本--cut命令
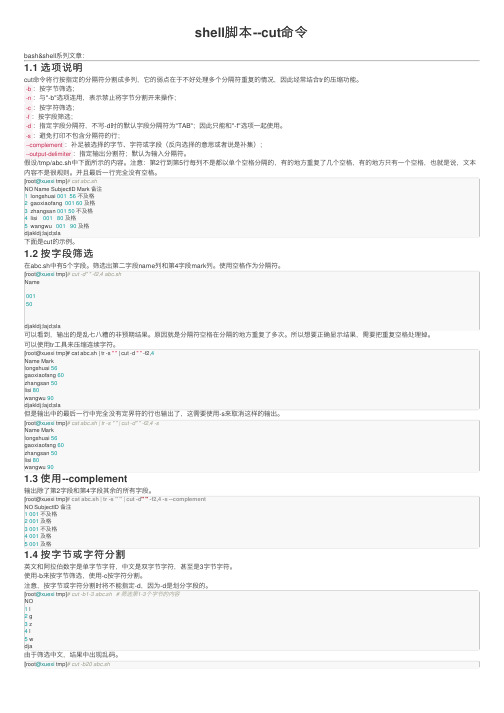
shell脚本--cut命令bash&shell系列⽂章:1.1 选项说明cut命令将⾏按指定的分隔符分割成多列,它的弱点在于不好处理多个分隔符重复的情况,因此经常结合tr的压缩功能。
-b:按字节筛选;-n:与"-b"选项连⽤,表⽰禁⽌将字节分割开来操作;-c:按字符筛选;-f:按字段筛选;-d:指定字段分隔符,不写-d时的默认字段分隔符为"TAB";因此只能和"-f"选项⼀起使⽤。
-s:避免打印不包含分隔符的⾏;--complement:补⾜被选择的字节、字符或字段(反向选择的意思或者说是补集);--output-delimiter:指定输出分割符;默认为输⼊分隔符。
假设/tmp/abc.sh中下⾯所⽰的内容。
注意:第2⾏到第5⾏每列不是都以单个空格分隔的,有的地⽅重复了⼏个空格,有的地⽅只有⼀个空格,也就是说,⽂本内容不是很规则。
并且最后⼀⾏完全没有空格。
[root@xuexi tmp]# cat abc.shNO Name SubjectID Mark 备注1 longshuai 00156不及格2 gaoxiaofang 00160及格3 zhangsan 00150不及格4 lisi 00180及格5 wangwu 00190及格djakldj;lajd;sla下⾯是cut的⽰例。
1.2 按字段筛选在abc.sh中有5个字段。
筛选出第⼆字段name列和第4字段mark列。
使⽤空格作为分隔符。
[root@xuexi tmp]# cut -d" " -f2,4 abc.shName00150djakldj;lajd;sla可以看到,输出的是乱七⼋糟的⾮预期结果。
原因就是分隔符空格在分隔的地⽅重复了多次。
所以想要正确显⽰结果,需要把重复空格处理掉。
可以使⽤tr⼯具来压缩连续字符。
[root@xuexi tmp]# cat abc.sh | tr -s " " | cut -d " " -f2,4Name Marklongshuai 56gaoxiaofang 60zhangsan 50lisi 80wangwu 90djakldj;lajd;sla但是输出中的最后⼀⾏中完全没有定界符的⾏也输出了,这需要使⽤-s来取消这样的输出。
shell中的cut命令

shell中的cut命令cut是以每一行为一个处理对象的,这种机制和sed是一样的。
(关于sed的入门文章将在近期发布)2 cut一般以什么为依据呢? 也就是说,我怎么告诉cut我想定位到的剪切内容呢? cut命令主要是接受三个定位方法:第一,字节(bytes),用选项-b第二,字符(characters),用选项-c第三,域(fields),用选项-f3 以“字节”定位,给个最简单的例子?举个例子吧,当你执行ps命令时,会输出类似如下的内容:[rocrocket@rocrocket programming]$ whorocrocket :0 2009-01-08 11:07rocrocket pts/0 2009-01-08 11:23 (:0.0)rocrocket pts/1 2009-01-08 14:15 (:0.0)如果我们想提取每一行的第3个字节,就这样:[rocrocket@rocrocket programming]$ who|cut -b 3ccc看明白了吧,-b后面可以设定要提取哪一个字节,其实-b和3之间没有空格也是可以的,但推荐有空格:)4 如果“字节”定位中,我想提取第3,第4、第5和第8个字节,怎么办?-b支持形如3-5的写法,而且多个定位之间用逗号隔开就成了。
看看例子吧:[rocrocket@rocrocket programming]$ who|cut -b 3-5,8croecroecroe但有一点要注意,cut命令如果使用了-b选项,那么执行此命令时,cut会先把-b后面所有的定位进行从小到大排序,然后再提取。
可不能颠倒定位的顺序哦。
这个例子就可以说明这个问题:[rocrocket@rocrocket programming]$ who|cut -b 8,3-5croecroecroe5 还有哪些类似“3-5”这样的小技巧,列举一下吧![rocrocket@rocrocket programming]$ whorocrocket :0 2009-01-08 11:07rocrocket pts/0 2009-01-08 11:23 (:0.0)rocrocket pts/1 2009-01-08 14:15 (:0.0)[rocrocket@rocrocket programming]$ who|cut -b -3rocrocroc[rocrocket@rocrocket programming]$ who|cut -b 3-crocket :0 2009-01-08 11:07crocket pts/0 2009-01-08 11:23 (:0.0)crocket pts/1 2009-01-08 14:15 (:0.0)想必你也看到了,-3表示从第一个字节到第三个字节,而3-表示从第三个字节到行尾。
Shell笔记:字符串提取

Shell笔记:字符串提取本文讲的字符串提取指的是从文件或某个输出中提取符合条件的列的内容,如果某个文件或输出中它的每一行的信息都是使用特定的分隔符来分割的话,就可以使用字符串的提取功能,本文涉及到的命令包括cut、printf、awk、sed等。
cut命令cut [选项] 文件名:在文件中提取符合条件的列。
选项:•-f 列号:提取第几列,提取多列只需要将列号用逗号隔开即可。
•-d 分隔符:按照指定分隔符分割列,如果分割符使用的是制表符tab,则不用特地指定分隔符,且对于cut命令来说,不能使用空格来作为分隔符。
示例:“cut -d ":" -f 1,3 /etc/passwd”表示使用分号作为分隔符分割文档后提取第一列和第三列的内容。
printf格式化输出平常使用字符串输出时使用cat或echo命令即可,printf命令只是在AWK编程中比较常用,在平常的使用中并不常用。
AWK编程中,会有print命令和printf命令,但是printf是Linux的标准输出命令,但是它默认没有输出换行符,而print在Linux命令中是没有的,且默认会自动输出换行符。
printf "输出类型和格式" 输出内容:格式化输出字符串(使用单引号或者双引号都行)。
输出类型:•%ns:输出字符串,n是数字,表示输出多少个字符。
•%ni:输出整数,n是数字,表示输出多少个数字。
•%m.nf:输出浮点数。
m和n是数字,表示输出的整数位数和小数位数。
输出格式:•\a:输出警告声音。
•\b:输出退格键。
•\f:清除屏幕。
•\n:换行。
•\r:回车。
•\t:水平制表符。
•\v:垂直制表符。
AWK命令AWK命令因为功能强大且复杂,所以通常也称为AWK编程,但是它的作用也是用来提取指定的列。
awk命令可以自动识别空格分隔的字符串(即使每列分隔的空格数不同也行),但cut命令就不可以。
awk '条件1{动作1} 条件2{动作2}...' 文件名:提取符合条件的字符串,也可以使用管道符的结果作为文件内容。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
shell中的cut命令cut是以每一行为一个处理对象的,这种机制和sed是一样的。
(关于sed的入门文章将在近期发布)2 cut一般以什么为依据呢? 也就是说,我怎么告诉cut我想定位到的剪切内容呢? cut命令主要是接受三个定位方法:第一,字节(bytes),用选项-b第二,字符(characters),用选项-c第三,域(fields),用选项-f3 以“字节”定位,给个最简单的例子?举个例子吧,当你执行ps命令时,会输出类似如下的内容:[rocrocket@rocrocket programming]$ whorocrocket :0 2009-01-08 11:07rocrocket pts/0 2009-01-08 11:23 (:0.0)rocrocket pts/1 2009-01-08 14:15 (:0.0)如果我们想提取每一行的第3个字节,就这样:[rocrocket@rocrocket programming]$ who|cut -b 3ccc看明白了吧,-b后面可以设定要提取哪一个字节,其实-b和3之间没有空格也是可以的,但推荐有空格:)4 如果“字节”定位中,我想提取第3,第4、第5和第8个字节,怎么办?-b支持形如3-5的写法,而且多个定位之间用逗号隔开就成了。
看看例子吧:[rocrocket@rocrocket programming]$ who|cut -b 3-5,8croecroecroe但有一点要注意,cut命令如果使用了-b选项,那么执行此命令时,cut会先把-b后面所有的定位进行从小到大排序,然后再提取。
可不能颠倒定位的顺序哦。
这个例子就可以说明这个问题:[rocrocket@rocrocket programming]$ who|cut -b 8,3-5croecroecroe5 还有哪些类似“3-5”这样的小技巧,列举一下吧![rocrocket@rocrocket programming]$ whorocrocket :0 2009-01-08 11:07rocrocket pts/0 2009-01-08 11:23 (:0.0)rocrocket pts/1 2009-01-08 14:15 (:0.0)[rocrocket@rocrocket programming]$ who|cut -b -3rocrocroc[rocrocket@rocrocket programming]$ who|cut -b 3-crocket :0 2009-01-08 11:07crocket pts/0 2009-01-08 11:23 (:0.0)crocket pts/1 2009-01-08 14:15 (:0.0)想必你也看到了,-3表示从第一个字节到第三个字节,而3-表示从第三个字节到行尾。
如果你细心,你可以看到这两种情况下,都包括了第三个字节“c”。
如果我执行who|cut -b -3,3-,你觉得会如何呢?答案是输出整行,不会出现连续两个重叠的c的。
看:[rocrocket@rocrocket programming]$ who|cut -b -3,3-rocrocket :0 2009-01-08 11:07rocrocket pts/0 2009-01-08 11:23 (:0.0)rocrocket pts/1 2009-01-08 14:15 (:0.0)6 给个以字符为定位标志的最简单的例子吧!下面例子你似曾相识,提取第3,第4,第5和第8个字符:[rocrocket@rocrocket programming]$ who|cut -c 3-5,8croecroecroe不过,看着怎么和-b没有什么区别啊?莫非-b和-c作用一样? 其实不然,看似相同,只是因为这个例子举的不好,who输出的都是单字节字符,所以用-b和-c没有区别,如果你提取中文,区别就看出来了,来,看看中文提取的情况:[rocrocket@rocrocket programming]$ cat cut_ch.txt星期一星期二星期三星期四[rocrocket@rocrocket programming]$ cut -b 3 cut_ch.txt����[rocrocket@rocrocket programming]$ cut -c 3 cut_ch.txt一二三四看到了吧,用-c则会以字符为单位,输出正常;而-b只会傻傻的以字节(8位二进制位)来计算,输出就是乱码。
既然提到了这个知识点,就再补充一句,如果你学有余力,就提高一下。
当遇到多字节字符时,可以使用-n选项,-n用于告诉cut不要将多字节字符拆开。
例子如下:[rocrocket@rocrocket programming]$ cat cut_ch.txt |cut -b 2����[rocrocket@rocrocket programming]$ cat cut_ch.txt |cut -nb 2[rocrocket@rocrocket programming]$ cat cut_ch.txt |cut -nb 1,2,3星星星星6 域是怎么回事呢?解释解释:)为什么会有“域”的提取呢,因为刚才提到的-b和-c只能在固定格式的文档中提取信息,而对于非固定格式的信息则束手无策。
这时候“域”就派上用场了。
(下面的讲解内容是在假设你对/etc/passwd文件的内容和组织形式比较了解的情况下进行的。
)如果你观察过/etc/passwd文件,你会发现,它并不像who的输出信息那样具有固定格式,而是比较零散的排放。
但是,冒号在这个文件的每一行中都起到了非常重要的作用,冒号用来隔开每一个项。
我们很幸运,cut命令提供了这样的提取方式,具体的说就是设置“间隔符”,再设置“提取第几个域”,就OK了!以/etc/passwd的前五行内容为例:[rocrocket@rocrocket programming]$ cat /etc/passwd|head -n 5root:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sbin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologin[rocrocket@rocrocket programming]$ cat /etc/passwd|head -n 5|cut -d : -f 1rootbindaemonadmlp看到了吧,用-d来设置间隔符为冒号,然后用-f来设置我要取的是第一个域,再按回车,所有的用户名就都列出来了!呵呵有成就感吧!当然,在设定-f时,也可以使用例如3-5或者4-类似的格式:[rocrocket@rocrocket programming]$ cat /etc/passwd|head -n 5|cut -d : -f 1,3-5root:0:0:rootbin:1:1:bindaemon:2:2:daemonadm:3:4:admlp:4:7:lp[rocrocket@rocrocket programming]$ cat /etc/passwd|head -n 5|cut -d : -f 1,3-5,7 root:0:0:root:/bin/bashbin:1:1:bin:/sbin/nologindaemon:2:2:daemon:/sbin/nologinadm:3:4:adm:/sbin/nologinlp:4:7:lp:/sbin/nologin[rocrocket@rocrocket programming]$ cat /etc/passwd|head -n 5|cut -d : -f -2root:xbin:xdaemon:xadm:xlp:x7 如果遇到空格和制表符时,怎么分辨呢?我觉得有点乱,怎么办?有时候制表符确实很难辨认,有一个方法可以看出一段空格到底是由若干个空格组成的还是由一个制表符组成的。
[rocrocket@rocrocket programming]$ cat tab_space.txtthis is tab finish.this is several space finish.[rocrocket@rocrocket programming]$ sed -n l tab_space.txtthis is tab\tfinish.$this is several space finish.$看到了吧,如果是制表符(TAB),那么会显示为\t符号,如果是空格,就会原样显示。
通过此方法即可以判断制表符和空格了。
注意,上面sed -n后面的字符是L的小写字母哦,不要看错。
(字母l、数字1还有或运算|真是难分辨啊…,看来这三个比制表符还难分辨…)8 我应该在cut -d中用什么符号来设定制表符或空格呢?悄悄的告诉你,cut的-d选项的默认间隔符就是制表符,所以当你就是要使用制表符的时候,完全就可以省略-d选项,而直接用-f来取域就可以了!放心,相信我!如果你设定一个空格为间隔符,那么就这样:[rocrocket@rocrocket programming]$ cat tab_space.txt |cut -d ' ' -f 1thisthis注意,两个单引号之间可确实要有一个空格哦,不能偷懒。
而且,你只能在-d后面设置一个空格,可不许设置多个空格,因为cut只允许间隔符是一个字符。
[rocrocket@rocrocket programming]$ cat tab_space.txt |cut -d ' ' -f 1cut: the delimiter must be a single characterTry `cut --help' for more information.9 我想将ps和cut命令配合使用时,怎么总是在最后两行出现重复现象?这个问题的具体描述是如下这样的。
当cut和ps配合时:[rocrocket@rocrocket programming]$ psPID TTY TIME CMD2977 pts/0 00:00:00 bash5032 pts/0 00:00:00 ps[rocrocket@rocrocket programming]$ ps|cut -b3P9看,最后的0重复了两次!!而且,我也试过ps ef或ps aux均有此问题。