solr技术方案
基于solr的异构数据融合检索技术

2 异构数据融合技术
异 构数据 是指数 据格式不 同, 内容不一 , 描述 不同内容 的 数据, 包括结构化数据 ( 如数据库 ) 、 半结构化数据 @ ̄ H T M L 、 X M L ) 和非结构化数据 ( 如文本、图片) 。 数据 的统一访 问的基
不 :
/ , 一、 \
XML
x m l 数据整合模 型
s o l r 搜 索 引擎 访 问 。 其代表性 的成果是E T L 集成工具, E T L 允许提取、 转换 3
解 决方案 。
关键 词 : s o l r ; 异构 数据 ; X M L ; 融合 ; 检 索
The Re t r i e va l Te c hnol ogy of He t e r oge ne ous Da t a I nt e g r a t i o n Ba s e d o n So l r
c o m m o n m e t h o d o f h e t e r o g e n e o u s d a t a i n t e g r a t i o n a n d t h e b a s i c f u n c t i o n o f S o l r w h i c h i s e n t e r p r i s e s e a r c h s e r v e  ̄ C o m b i n e d t h e X M L h e t e r o g e n e o u s d a t a i n t e g r a t i o n w i t h t h e C h i n e s e w o r d s e g m e n t a t i o n t e c h n o l o g y a n d t h e f r i e n d l y u s e r i n t e r f a c e , t h i s p a p e r b u i l t t h e h e t e r o g e n e o u s d a t a i n t e g r a t i o n r e t r i e v a l s y s t e m b a s e d o n S o l r , r e a l i z e d t h e i n d e x i n g a n d r e t r i e v a l o f X M L d o c u m e n t a n d p r o v i d e d s o l u t i o n s f o r h e t e r o g e n e o u s d a t a i n t e g r a t i o n r e t r i e v a 1 .
Solr的原理及使用

Solr的原理及使⽤1.Solr的简介Solr是⼀个独⽴的企业级搜索应⽤服务器,它对外提供类似于Web-service的API接⼝。
⽤户可以通过http请求,向搜索引擎服务器提交⼀定格式的XML⽂件,⽣成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
2.⼯作原理solr是基于Lucence开发的企业级搜索引擎技术,⽽lucence的原理是倒排索引。
那么什么是倒排索引呢?接下来我们就介绍⼀下lucence倒排索引原理。
假设有两篇⽂章1和2:⽂章1的内容为:⽼超在卡⼦门⼯作,我也是。
⽂章2的内容为:⼩超在⿎楼⼯作。
由于lucence是基于关键词索引查询的,那我们⾸先要取得这两篇⽂章的关键词。
如果我们把⽂章看成⼀个字符串,我们需要取得字符串中的所有单词,即分词。
分词时,忽略”在“、”的“之类的没有意义的介词,以及标点符号可以过滤。
我们使⽤Ik Analyzer实现中⽂分词,分词之后结果为:⽂章1:⽂章2:接下来,有了关键词后,我们就可以建⽴倒排索引了。
上⾯的对应关系是:“⽂章号”对“⽂章中所有关键词”。
倒排索引把这个关系倒过来,变成: “关键词”对“拥有该关键词的所有⽂章号”。
通常仅知道关键词在哪些⽂章中出现还不够,我们还需要知道关键词在⽂章中出现次数和出现的位置,通常有两种位置:a.字符位置,即记录该词是⽂章中第⼏个字符(优点是关键词亮显时定位快);b.关键词位置,即记录该词是⽂章中第⼏个关键词(优点是节约索引空间、词组(phase)查询快),lucene中记录的就是这种位置。
加上出现频率和出现位置信息后,我们的索引结构变为:实现时,lucene将上⾯三列分别作为词典⽂件(Term Dictionary)、频率⽂件(frequencies)、位置⽂件 (positions)保存。
其中词典⽂件不仅保存有每个关键词,还保留了指向频率⽂件和位置⽂件的指针,通过指针可以找到该关键字的频率信息和位置信息。
solr技术方案

solr技术方案Solr技术方案一用户需求以前的互动平台只能对固定表的固定字段做like这样的数据库层面的索引,性能低下,用户体验很差,很难满足业务提出的简化搜索的需求。
需求原型:以上是solr的架构图。
具体应用时需要理解一下模块的作用及配置。
RequestHandler:接受请求,分发请求。
另外也包含导入数据,如importhandler。
UpdateHandlers –处理索引请求。
Search Components:作为handlder的成员变量。
处理请求。
Facet:分类搜索Tika:apache下处理文件的一个项目。
Filter,spelling :处理字符串Http query/update Database/html importhandler 默认基本可以满足要求。
如果不够则扩展相应的handler和component。
丰富的客户端Ruby/php/java/json/javascript使用solrj以上的配置在solrconfig.xml,schema.xml中配置分词的解决办法系统提供了很多种分词方案。
StopAnalyzer,StandardAnalyzer,WhitespaceAnalyzer只是实现了数字、单词、E-mail地址、IP地址以及中文字符的分析处理,但是对于中文的分析并不好。
对于中文分词有几种解决方案。
∙P aoding: 100万汉字/s(https:///p/paoding/)∙I mdict:26万汉字/s(https:///p/imdict-chinese-analyzer/)∙I k:160万汉字/s(https:///p/ik-analyzer/)∙M mseg4j:simple 1900kb/s 准确率98%(https:///p/mmseg4j/)注:官方提供测试环境各不相同。
这里我们选择准确率最高的Mmseg4j。
而且配置起来也十分简单。
solr filtercache 原理

solr filtercache 原理Solr FilterCache 原理Solr FilterCache 是 Solr 中的一个重要组件,用于提高查询性能。
在 Solr 中,查询处理涉及多个步骤,其中之一就是过滤器缓存。
了解 FilterCache 的原理有助于更好地优化 Solr 性能。
1. 过滤器缓存概述在 Solr 中,过滤器缓存用于存储过滤器条件的结果,以便在后续查询中重复使用这些结果,而不是重新计算。
这样可以大大减少不必要的计算量,提高查询效率。
2. 过滤器缓存原理FilterCache 的核心思想是使用哈希表数据结构来存储过滤器条件的结果。
每当一个查询被执行时,Solr 会对查询中的每个过滤器条件进行哈希运算,并使用该哈希值作为键在FilterCache 中查找对应的结果。
如果找到了匹配的键,Solr 会直接使用缓存中的结果,否则会执行过滤器条件的计算,并将结果存储在 FilterCache 中,以便后续查询使用。
3. 过滤器缓存大小和策略FilterCache 的大小和策略可以通过配置来调整。
默认情况下,FilterCache 的大小是无限的,但是可以通过设置最大大小来限制其容量。
另外,Solr 还提供了多种缓存策略,例如基于最近最少使用(LRU)的策略,可以根据实际需求选择合适的策略来优化性能。
4. 过滤器缓存优化为了充分发挥 FilterCache 的优势,需要对查询进行优化。
首先,应该尽量减少不必要的过滤器条件,以减少 FilterCache 中的存储和查找开销。
其次,可以通过分析查询日志来识别经常使用的过滤器条件,并根据这些条件调整 FilterCache 的大小和策略。
此外,还可以考虑使用其他优化技术,例如分布式搜索和缓存共享等。
总之,了解Solr FilterCache 的原理有助于更好地优化Solr 性能。
通过合理配置FilterCache 的大小和策略,以及优化查询语句,可以显著提高 Solr 的查询效率。
基于solr的异构数据融合检索技术_梁艳

4 异构数据融合检索系统的设计与实现
4.1 系统架构 异构数据融合检索系统需要实现: ⑴从各数据库中提取数据信息,并转换为相应的xml文件,
即完成数据爬虫功能; ⑵采用solr对xml文件创建索引; ⑶友好的用户界面,实现响应用户的搜索请求,返回结
Key words:solr;Heterogeneous data;xml;integration;retrieval
1 背景
互联网技术的发展,使得信息数据爆炸式增长。特别是在 企业信息中,其非结构数据占到了增长数据的80%,包括PDF、 word文档,图像、音频和视频等。企业在不同的应用平台拥有不 同的检索系统,这给用户检索信息带来了诸多不便。如何构建一 个统一的检索平台,使得用户在海量的异构数据中实现统一检 索,一直是研究人员研究的热点。
果。
图3 异构数据融合检索系统框图
异构数据融合检索系统框图如图3所示,爬虫模块完成提 取数据的xml文件,实现异构数据的融合;solr索引模块需加入 中文分词功能,完成对xml文件的索引;用户界面模块需要完成 接受用户的查询请并且高亮显示,加上solr查询结果默认是以 xml文件显示的,还需要实现xml文件与原数据库的关联显示。 4.2 异构数据抓取
⑵异构性。Solr作为企业级搜索服务器,它最大的特点就 是提供了对异构系统的整合,解决了企业搜索的一大难题。Solr 它提供了基于HTTP的标准XML和JSON接口,能对XML文件直接建 立索引。solr还提供了DIH(DataImportHandler),用来从其他 的异构系统批量导入数据的批处理器。
Solr搜索技术应用实战

Solr搜索技术应用实战Solr是一个开源的搜索平台,它基于Apache Lucene构建,提供丰富的API和可扩展性,已经成为了许多开发者选择的搜索引擎。
随着数据量的增加和业务场景的多样化,Solr的应用越来越广泛。
本文将从Solr的实战应用入手,为开发者提供一些技巧和经验。
一、Solr集群搭建Solr的性能和可靠性与硬件配置和部署状态密切相关。
在生产环境中建议使用集群部署,可以分布式处理查询请求,增加搜索并发能力和容错性。
Solr集群中每个节点可以作为独立的搜索服务器,提供相同的搜索服务。
一个完整的Solr集群由多个节点组成,分为SolrCloud和非SolrCloud两种模式,SolrCloud是集群管理的一种模式,在SolrCloud模式下,Solr 集群可以更方便地进行扩容和管理。
以下是SolrCloud集群的简要步骤:1. 准备ZooKeeper,SolrCloud使用ZooKeeper进行集群管理。
2. 启动Solr节点,并与ZooKeeper进行连接。
3. 使用Solr控制台创建集合,集合分片在所有节点之间平均分配。
4. 访问SolrCloud集群的URL,进行搜索等操作。
二、Solr数据导入Solr并不能直接从数据库或文件中获取数据,需要使用数据导入扩展来实现数据导入。
Solr数据导入流程大致如下:1. 配置数据源和数据目标,Solr支持多种数据源,包括数据库、文件、RSS等。
2. 配置数据导入的转换器和分词器,将数据源的数据转化为Solr需要的格式。
3. 配置数据导入的定时策略,Solr可以定时从数据源获取数据并导入。
以下是一个Solr数据导入的示例配置文件:```<dataConfig><dataSource name=\"jdbcDataSource\" type=\"JdbcDataSource\" driver=\"com.mysql.jdbc.Driver\"url=\"jdbc:mysql:\/\/localhost:3306\/test\" user=\"root\" password=\"123456\"\/><document><entity name=\"book\" query=\"SELECT * FROM book\"><field column=\"id\" name=\"id\"\/><field column=\"title\" name=\"title\"\/><field column=\"author\" name=\"author\"\/><field column=\"description\" name=\"description\"\/><\/entity><\/document><\/dataConfig>```以上配置会将MySQL数据库中的book表的所有数据导入Solr,并映射到Solr的id、title、author和description字段中。
Solr优化案例分析

Solr优化案例分析随着umc接⼊主机的数量越来越多,每天产⽣的syslog⽇志数量也在剧增,之前⼀天产⽣的syslog数量才不到1W,随着整个集团的⽹络设备不端接⼊,导致现在每天产⽣的syslog数量⼤概在180w左右,⽽这些syslog对⽹络和PE同学排查线上⽹络设备问题⼜是⼗分重要的,他们的要求是可以提供查询最近3个⽉的syslog,保存⼀年的syslog,在7⽉份的时候,针对量不多的情况,针对mysql单表做了索引,后来⼜做了单表备份,但是查询的速度还是⽆法让⼈接受,后⾯⼜结合页⾯针对mysqlcount(*)语句做了优化:使⽤count(*)语句只是在第⼀次查询的时候查询⼀次,后⾯保存下来,在后⾯分页查询的时候,不再需要再查询总数量,即不调⽤count(*)之类的sql 语句,结果在翻页时,速度还是⽐较快,但⾸次查询的时候,还是⾮常⾮常慢,但这毕竟只是⼀个临时的解决⽅案;后⾯结合syslog搜索的业务情况,结合各种技术参考,最终选择了使⽤Solr搜索引擎来解决syslog查找慢的问题;在做压⼒测试的时候,发现性能问题:在数据量不⼤(<1000W)的时候,⽤Solr搜索是⽐较快,但随着着syslog数据量的不断增多,写索引和搜索的速度越来越不能让⼈接受,因此不得不考虑对Solr进⾏优化;⽹上了搜了⼀下Solr优化的⼤体⽅案,主要从如下两个步骤来进⾏优化:1. Solr系统层⾯;2. 索引字段优化;针对Solr系统层的优化,主要有如下的⽅法:1. 适当调⼤Solr查询缓存;2.适当增加Solr集群的切⽚;3根据查询的业务场景,适当调整索引合并的时间,等等⼀系列通⽤的做法,针对这些修改以后,发现修改前后,对查询的性能没有本质的提⾼;针对索引字段的优化,就是针对添加到Lucence中⽂档各索引字段的优化, syslog索引字段主要的字段有: id(Integer),ip(String),log_level(String),log_value(String)syslog_time(Date),要针对这些字段优索引优化,就要⾸先分析索引查找的过程,要做到字段优化索引,可以从两⽅⾯考虑,1. 减少字段索引存储量,2. 提⾼查询索引⽐较的时间,针对这两点,可以毫不犹豫的考虑把String类型的字段向Integer或Long类型之类的整型字段映射转换(整型的索引存储空间⼀般⽐字段串所占的存储索引空间要⼩;整型的查找⽐较速度⽐字段串类型要快,其实这也是数据库查找优化的⼀个⽅⾯);基于这样的考虑,ip、log_level和syslog_time可以向相应的整型映射,各个字段具体的映射⽅法如下:1. ip 地址向整形映射,这个问题⽐较好解决,在计算机⽹络协议中,在底层是会把ip地址转换成对应的⽆符号长整型,但由于java没有⽆符号这个概念,因此可以考虑把ip地址向整型或长整型做相互映射转换,但因为整型⽐长整型占⽤的字节更少,因此采⽤整型,具体转换代码如下:// 把ip地址转换成整形1.public static Long ipToInteger(String ip) {2.3.String[] ips = StringUtils.split(ip,'.');4.if (ips == null || ips.length < 4){5.throw newRuntimeException("ip地址⾮法!");6.}7.Integer integerIP = 0;8.Integer ip0= Integer.parseInteger(ips[0]);9.Integer ip1= Integer.parseInteger(ips[1]);10.Integer ip2= Integer.parseInteger(ips[2]);11.Integer ip3= Integer.parseInteger(ips[3]);12.if (ip0 > 255) {13.throw newRuntimeException("ip0地址⾮法:" + ip0);14.}15.if (ip1 > 255) {16.throw newRuntimeException("ip1地址⾮法:" + ip1);17.}18.if (ip2 > 255) {19.throw newRuntimeException("ip2地址⾮法:" + ip2);20.}21.if (ip3 > 255) {22.throw newRuntimeException("ip3地址⾮法:" + ip3);23.}24.integerIP |=( ip0 << 24) & (0xff000000);25.integerIP |=( ip1 << 16) & (0x00ff0000);26.integerIP |=( ip2 << 8) & (0x0000ff00);27.integerIP |=( ip3 << 0) & (0x000000ff);28.return integerIP ;29.}1./**2.* int类型到ip转换3.* @param integerIP4.* @return5.*/6.public static String integerToIP(IntegerintegerIP) {7.8.String ip = "";9.Integer ip0= (integerIP & 0xff000000) >>> 24;10.Integer ip1= (integerIP & 0x00ff0000) >> 16 ;11.Integer ip2= (integerIP & 0x0000ff00) >> 8;12.Integer ip3= (integerIP & 0x000000ff) >> 0;13.ip = ip0 + "." + ip1 +"." + ip2 + "." + ip3;14.return ip;15.}2. log_level 只有8种值,分别是:Emergency, Alert, Critical, Error, Warning,Notice,Informational,Debug;这个好转换,直接按下表的⽅式做相互映射即可Emergency0Alert1Critical2Error3Warning4Notice5Informational6Debug73. 把syslog_time转换成Long类型,这个更容易,java中Date类型有⼀个getTime()⽅法经过把这三个字段都转换成整型以后,索引插⼊和搜索速度都提⾼不少,特别是搜索速度有⾮常⾮常明显的提升,特别是在数据量超过2亿的时间,效果更明显到此,字段优化完毕;但此时还发现⼀个问题:⼀次查找返回的数据量太多,导致存在翻页慢的问题,例如:⼀次返回10W页数据,如果⼀下翻到第10W页,查询的速度会⾮常⾮常慢甚⾄可能出现Solr集群全部宕机的情况,这是不能接受的,因为我们页⾯上提供了翻到最后⼀⾯的功能,虽然⽤户⼀般情况下不会这么做,但万⼀不⼩点错了,整个线上Sorl集群就全部挂了,怎么办?这个问题,让我想起了mysql⾥的翻页的问题,下⾯两条SQL语句:select * from umc_syslog where syslog_time between date1 and date2 order by id limit 0, 10;select * from umc_syslog where syslog_time between date1 and date2 order by id limit 10000, 10;我们知道,第⼀条SQL语句查询的速度⾮常快,第⼆SQL语句查询的速度⾮常慢,在系统压⼒较⼤的情况下,可能会把mysql服务弄挂,根本原因在于limitstart, rows语句,mysql会在扫描时,会扫过满⾜结果的前start⾏的记录,然后才读取len⾏的数据,如果start特别⼤,会⾮常慢,在⾼性能mysql这本书中介绍了各种解决分页问题的优化,如延迟关联、阶递分页等,其中阶递分页可以在Solr中实现,但我们页⾯不允许这么做,不然早就⽤Hbase来解决了,怎么办,在⽆解决的情况下,突然发现,Solr查询中有order by排序的问题,适当⽤order by 可以很好来解决limit 分页慢的问题:假设⼀个Solr查询按id 降序排序返回,假设返回10W⾏记录,前5W条记录可以随机分页查询到,但后⾯5W条记录很难随机分页查询到,造成这个问题的原因是按id降序返回,如果适当修改⼀下查询语句,速度可能会有所提⾼,因为Solr查询每次都会返回总的记录条数,这个总的记录条数是已知的,记为total, 作如下处理:如果start ⼩于等于(total >> 1),则从前往后读;否则就从后往前读,然后,再把返回的结果逆序,显⽰即可,伪代码如下;1.if start <= (total >> 1)2.query order by id desc limit start, rows;3.else4.calculate new start as start';5.calculate new rows as rows';6.query order by asc limit start', rows';7.reverse the return data;8.end程序中相关代码:1.// 是否是按id升序查询, 默认是false2.boolean isAscend = false;3.4.// 升序或降序查询判断5.if (totalCount == 0) {6.isAscend = false;7.} else {8.if (start >= (totalCount >> 1) ) {9.isAscend = true;10.}11.}12.13.if (!isAscend) {14.realStart = start;15.realRows = rows;16.} else {17.Integer count = totalCount.intValue();18.realStart = (start + rows)>= count? 0 : (count - (start +rows));19.realRows = (start + rows)>= count? (count - start + 1) : rows;20.}21.solrQuery.setStart(realStart);22.solrQuery.setRows(realRows);23.24.if (!isAscend) {// id降序25.solrQuery.setSort("id", ORDER.desc);26.} else { // id 升序27.solrQuery.setSort("id", ORDER.asc);28.}29.30.// 逆序处理31.if (isAscend) {32.int size = syslogVOList.size();33.int left = 0;34.int right = size - 1;35.while (left < right) {36.SyslogVO leftSyslogVO =syslogVOList.get(left);37.SyslogVO rightSyslogVO =syslogVOList.get(right);38.syslogVOList.set(left, rightSyslogVO);39.syslogVOList.set(right, leftSyslogVO);40.left ++;41.right --;42.}43.}经过这个过程的处理之后,向后翻页查询的速度快了很多,⾄少不会出现宕机的现象;查询页⾯如下:在相同的条件下:优化后Solr查询的时间:优化前mysql的查询时间:其实这个技巧在mysql分页查询,数据量⾮常⼤的时候也适⽤;。
solr检索表达式

Solr是一个高性能的搜索和数据分析解决方案,提供了丰富的查询表达式和强大的查询功能,帮助用户更有效地检索数据。
以下是关于Solr检索表达式的800字回答:Solr检索表达式是一种用于指定搜索条件的语言,它允许用户使用各种运算符和函数来构建复杂的查询语句。
通过使用检索表达式,用户可以精确地匹配文档中的文本、数字、日期等数据,并应用各种过滤和排序条件。
一、基本检索表达式1. 字段名:这是最基本的检索表达式,用于指定要搜索的字段。
例如,如果要搜索名为"title"的字段,可以使用"title:"来指定该字段。
2. 文本模式:可以使用通配符(*)和正则表达式(RegEx)来匹配文本模式。
例如,"title:.*world.*"将匹配包含"world"文本模式的"title"字段。
3. 范围查询:可以使用大于(>)、小于(<)、大于等于(>=)和小于等于(<=)运算符来指定范围查询。
例如,"price:100-200"将搜索价格在100到200之间的文档。
二、高级检索表达式1. 多条件查询:可以使用逻辑运算符(AND、OR、NOT)来组合多个检索表达式。
例如,"title:example AND author:smith"将搜索标题为"example"且作者为"smith"的文档。
2. 函数查询:Solr提供了多种函数查询,如LIKE_ICASE、LIKE_LOWER、LIKE_UPPER等,用于执行不区分大小写的匹配、将文本转换为小写或大写等操作。
3. 动态参数查询:Solr支持动态参数查询,可以根据用户输入的参数动态生成查询条件。
例如,"q={query_param}"允许用户输入查询参数并生成相应的查询表达式。
Solr文档

Solr全文检索服务1企业站内搜索技术选型在一些大型门户网站、电子商务网站等都需要站内搜索功能,使用传统的数据库查询方式实现搜索无法满足一些高级的搜索需求,比如:搜索速度要快、搜索结果按相关度排序、搜索内容格式不固定等,这里就需要使用全文检索技术实现搜索功能。
1.1单独使用Lucene实现单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。
1.2使用Google或Baidu接口通过第三方搜索引擎提供的接口实现站内搜索,这样和第三方引擎系统依赖紧密,不方便扩展,不建议采用。
1.3使用Solr实现基于Solr实现站内搜索扩展性较好并且可以减少程序员的工作量,因为S olr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。
2什么是Solr什么是SolrSolr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。
Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引。
Solr搜索只需要发送 HTTP GET 请求,然后对 Solr返回Xml、json等格式的查询结果进行解析,组织页面布局。
Solr不提供构建UI 的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Solr与Lucene的区别Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
solr 引擎 分布式 同步 原理

solr引擎分布式同步原理随着互联网技术的发展,搜索引擎已经成为了互联网中不可或缺的一部分。
Solr引擎作为一款优秀的搜索引擎,以其高效、稳定、易用等特点受到了广大用户的青睐。
而在分布式环境下,Solr引擎的同步机制对于保证系统的稳定性和可靠性至关重要。
本文将详细介绍Solr引擎的分布式同步原理,帮助读者深入了解其工作机制。
一、Solr引擎概述Solr引擎是一款基于Lucene库的开源搜索引擎,提供了全文搜索、结果排序、过滤等功能。
它采用了分布式架构,可以将搜索任务分发到多个服务器上,提高了系统的可扩展性和可靠性。
Solr引擎支持多种数据存储方式,如关系型数据库、NoSQL数据库等,同时也提供了丰富的查询语言(SolrQL)和插件系统,方便用户进行定制化开发。
二、分布式同步原理在分布式环境下,为了保证各个服务器之间的数据一致性,Solr 引擎采用了以下几种同步机制:1.心跳检测:Solr引擎通过心跳检测机制,定期向其他服务器发送心跳包,确认其是否正常工作。
如果某个服务器长时间没有回复心跳包,则会被认为是故障节点,其他服务器会将其从集群中剔除。
2.消息同步:当一个服务器接收到其他服务器的请求时,它会将本地的数据更新消息发送给请求方。
请求方会接收并处理这些消息,从而实现数据的同步。
3.合并同步:当多个服务器之间存在数据差异时,它们可以通过合并同步机制将各自的数据合并成一个一致的数据副本。
这种机制可以避免数据重复和冲突,保证了数据的一致性。
4.异步更新:Solr引擎支持异步更新的机制,即数据更新操作不会立即生效,而是在后续的同步过程中被应用到所有服务器上。
这样可以提高系统的性能和响应速度,同时也能保证数据的最终一致性。
5.主从复制:Solr引擎支持主从复制机制,即一个服务器作为主节点负责处理搜索请求,而其他服务器作为从节点只负责数据同步。
这样可以减轻主节点的负担,提高系统的可扩展性和可靠性。
三、同步过程分析在分布式环境下,Solr引擎的同步过程主要包括以下几个步骤:1.请求接收:客户端向Solr集群发送搜索请求时,会将请求信息发送给主节点。
Module 16 Solr架构原理

Replica可以分布在多台
机器上,均衡索引和查询 压力。
版权所有© 2015 华为技术有限公司
第8页
2.3 SolrCloud索引 – 逻辑图
Collection:在SolrCloud中逻辑意义上的 完整的索引。它常常被划分为一个或多个 Shard,它们使用相同的Config Set。如果 Shard数超过一个,它就是分布式索引, SolrCloud让你通过Collection名称引用它, 而不需要关心分布式检索时需要使用的和 Shard相关参数。 Config Set: Solr Core提供服务必须的一 组配置文件。每个config set有一个名字。 最小需要包括solrconfig.xml 和 schema.xml ,除此之外,依据这两个文 件的配置内容,可能还需要包含其它文件。 它存储在Zookeeper中。
了解Solr其技术架构与关键流程
了解Solr组件在FusionInsight 平台中的使用
版权所有© 2015 华为技术有限公司
第2页
目录
1. Solr应用场景
什么是Solr
Solr应用场景
2. Solr架构与功能 3. Solr关键流程 4. 常用命令和参数
版权所有© 2015 华为技术有限公司
第3页
1.1 什么是Solr
Solr是一个高性能,基于Lucene的全文检索服务器,也可以作为NosQL数据使用。 Solr对Lucene进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了 可配置、可扩展,并对查询性能进行了优化,还提供了一个完善的功能管理界面。 SolrCloud是从Solr 4.0版本开始开发出的具有开创意义的分布式索引和搜索方案, 基于Solr和Zookeeper进行开发的。
solrcloud
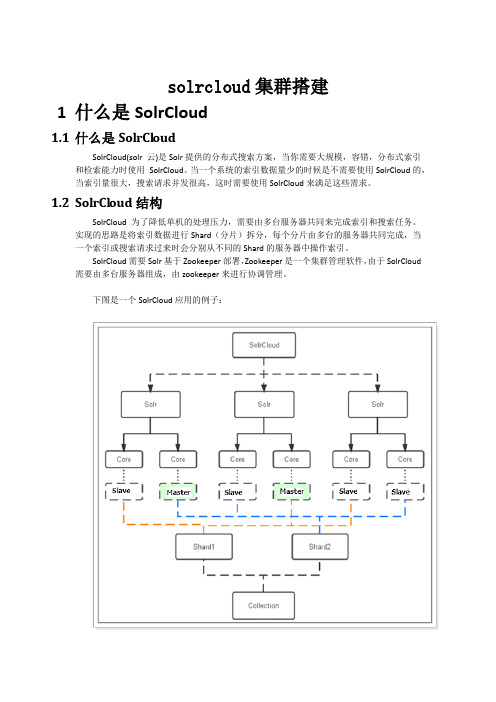
solrcloud集群搭建1什么是SolrCloud1.1什么是SolrCloudSolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用SolrCloud。
当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
1.2SolrCl oud结构SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。
实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。
SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud 需要由多台服务器组成,由zookeeper来进行协调管理。
下图是一个SolrCloud应用的例子:对上图进行图解,如下:1.2.1物理结构三个Solr实例(每个实例包括两个Core),组成一个SolrCloud。
1.2.2逻辑结构索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
1.2.2.1c ollectionCollection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。
它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。
比如:针对商品信息搜索可以创建一个collection。
collection=shard1+shard2+....+shardX1.2.2.2C ore每个Core是Solr中一个独立运行单位,提供索引和搜索服务。
Solr集群配置方案说明书

Solr集群配置方案说明书Solr集群配置方案说明书Jboss应用服务器由于版本不同,集群配置方式也不同,由于目前我们采用jboss7做为应用服务器,因此solr的服务集群方式采用jboss7的集群配置。
我们采用jboss+apache集群方式。
1.Jboss7+apache集群1.1Jboss主从服务器设置:1)下载jboss7解压后找到打开目录,找到domain/configuration/host.xml文件,如图所示:2)编辑host.xml,如果是主服务器的话,如同所示:将后面的ip改为当前机器的ip.3)从服务器的设置方式,除上述方式外,需要增加主控服务器的ip 配置,如图所示4)在配置好主从服务器的ip后,需要设置安全策略,我们增加几个用户,做主从访问控制,进入cmd模式,进入jboss安装目录下的bin目录键入add-uer命令,一个是主服务器用户名和密码,一个是从服务器用户和密码。
如下图所示:5)配好用户后我们也要将用户名策略加入到从应用服务器主控制配置中:注:value的值是base64加密1.2apache相关的配置1)编辑domain.xml,增加下面内容2)增加端口设置3)Apache配置建议采用mod_jk,配置方式跟tomcat相同.2.Solr集群配置2.1solr分发设置solr分布式部署的原理与jboss相同都是采用主从结构,下面介绍主从服务1)主服务器配置修改下面部分:注:replicateAfter : SOLR会自行在以下操作行为发生后执行复制:'commit', 'startup' 'optimize',这里我们选择commit , 即SOLR每一次接受到commit请求后,会执行复制策略。
confFiles : 待分发的配置文件,solr 也会将主服务器上的字段配置文件:schema.xml和stopwords.txt,固排文件:elevate.xml同步到辅服务器上。
Solr的应用场景分析

Solr的应用场景分析Solr是一个基于Java的搜索引擎,被广泛应用于Web搜索、文档管理、电商等各种应用场景。
本文将从Solr的特性入手,探讨其主要应用场景及其优势。
一、高效搜索引擎Solr的核心特性是高效搜索引擎,它能够处理大量的数据,并且具有快速的搜索速度。
因此,Solr适用于大型网站、Web应用程序以及企业级应用程序等各种情况下的搜索引擎。
1、电子商务在电子商务行业,Solr可以帮助电商网站提供快速、精准的搜索体验,减少用户的等待时间,促进转化率。
Solr具有高效的搜索速度以及高质量的搜索结果,可以根据用户的搜索需求,实现智能联想、拼写检查等搜索辅助功能,提高用户体验。
另外,Solr还支持基于地理位置的搜索,比如可以按照用户所在地域,展示用户附近的产品信息,大大提升用户的便利性。
2、企业应用程序在企业应用程序中,Solr也经常被用作搜索引擎,能够搜索企业内存储的各种数据,例如产品信息、客户、工程文件等。
Solr提供了高度灵活的搜索体验,用户可以通过各种搜索参数,实现快速、准确地检索所需的数据。
二、文档管理系统Solr不仅仅是一个搜索引擎,同时也是一个强大的文档管理系统,支持各种数据格式的索引和搜索。
因此,Solr可以被广泛应用于文档管理系统,帮助用户快速准确的检索所需文件。
1、数字资料库Solr可以作为数字资料库的一部分,能够实现全文检索和查询,而不仅仅是简单的关键字检索。
数字资料库包括了各种类型的文件,例如PDF文件、Microsoft Office文件、HTML文件等,Solr可以基于这些文件的内容建立索引,并实现快速准确的搜索功能。
2、知识管理系统Solr可以作为一个知识管理系统的组件,帮助企业组织内部的知识库。
当员工需要查询某种信息时,Solr可以搜索企业内多种数据源的内容,并返回相关的结果。
此外,Solr还具有自动标记、选取等功能,能够帮助企业快速实现知识共享,提高工作效率。
实现网站搜索功能的技术方案(一)

实现网站搜索功能的技术方案随着互联网的迅速发展,越来越多的企业、个人拥有自己的网站,为了提供更好的用户体验,网站搜索功能成为不可或缺的一部分。
本文将从技术的角度探讨实现网站搜索功能的技术方案,旨在为搭建高效、智能的网站搜索系统提供一些思路和参考。
一、搜索引擎的选择首先,选择适合网站规模和需求的搜索引擎是关键。
市面上有许多开源的搜索引擎可供选择,例如Elasticsearch、Solr等。
Elasticsearch是一个RESTful的分布式搜索和分析引擎,支持近实时搜索和复杂查询,适合大规模数据和高并发请求。
Solr是一个开源的全文搜索平台,具有强大的分布式搜索功能,可定制性高,适合中小型网站。
根据实际情况选择合适的搜索引擎能够为网站提供更好的搜索体验和性能。
二、数据索引与存储搜索引擎的核心功能包括数据索引和数据存储。
在实现网站搜索功能时,首先需要将网站的内容进行索引。
索引的建立可以通过爬虫程序或API接口获取网页内容,并将相关信息(例如标题、关键词、内容摘要等)提取出来。
然后,使用搜索引擎提供的API将数据进行索引,以便用户进行搜索。
在数据存储方面,搜索引擎通常采用倒排索引的方式。
倒排索引是一种将关键词与文档进行映射的数据结构,通过将关键词作为索引,可以快速地找到对应的文档。
倒排索引的存储方式可以选择传统的磁盘存储或者内存存储,根据网站数据量和性能要求进行选择。
三、搜索算法与排名策略搜索引擎在实现网站搜索功能时,还需要设计合理的搜索算法和排名策略,以提供准确、智能的搜索结果。
常见的搜索算法包括BM25、TF-IDF等。
BM25是一种基于概率的文本相似度模型,可以根据词项的频率和文档的长度计算搜索结果的相关性。
TF-IDF是一种常用的评估词语在文档中重要性的算法,通过词频和逆文档频率的乘积来衡量关键词的重要程度。
排名策略是指搜索引擎根据一定的规则对搜索结果进行排序的方法。
常见的排名策略包括页面权重、相关度评分等。
solr之~模糊查询

solr之~模糊查询有的时候,我们一开始不可能准确地知道搜索的关键字在Solr 中查询出的结果是什么,因此,Solr 还提供了几种类型的模糊查询。
模糊匹配会在索引中对关键字进行非精确匹配。
例如,有的人可能想要搜索某个前缀开始的单词(称为通配符查询),或者想要查询和关键字有一两个字母不相同的单词(称为模糊查询或编辑距离查询),或者你想要查询两个关键字,并且这两个关键字之间的距离不会大于某个最大值(称为临近查询)。
总的说来,模糊匹配是查询中的一个强大的工具。
通配符查询在Solr 中最普遍使用的模糊查询就是使用通配符。
假设你想要查询以 offic 开始的文档。
下面列举出这个查询的几个版本:•查询语句: office OR officer OR official OR officiate OR … 这个列表中的单词是所有你以 offic 开头的单词。
因为你需要找到的所有匹配都在Solr 索引中。
因此,你可以使用星号(*)作为通配符来执行相同的功能:•查询语句: offi* 匹配 office, officer, official 等等。
除了放在关键字的最后,通配符也可以放到关键字中间,例如,如果你想要同时匹配 officer 和 offer:•查询语句: off*r 匹配 offer,officer,officiator 等。
星号通配符(*)表示匹配 0 个或多个字符。
如果你只需要匹配一个字符,那么可以使用问号(?)通配符:•查询语句: off?r 匹配 offer 但是不匹配 officer。
以通配符为头进行查询在Solr 中使用通配符相当强大。
但是,使用通配符进行查询也会带来很大的开销。
一旦使用统配符的查询,那么在关键字中第一个通配符之前的部分需要在反向索引中全部查询出来。
那后,每个查询出来的结果在逐一进行检查,看是否符合查询条件。
正是因为这样,所以在统配符之前的字符越多,那么查询将会越快。
例如,使用engineer* 进行查询将不会带来很高的开销(因为这个查询在反向索引中不会找到太多的匹配),但是 e* 进行查询的开销就相当大,它将会匹配所有 e 开头的单词。
solr中文文档

</analyzer>
</fieldtype> 中文单词分词
<fieldtype name="word" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index"> <tokenizer
class="org.apache.solr.analysis.StandardTokenizerFactory"/> </analyzer>
<fieldtype name="text" class="solr.TextField" positionIncrementGap="100"> 创建索引时
<analyzer type="index">
<tokenizer
class="com.chuangs.fulltextsearch.analyzer.ChineseTokenizerFactory"
SOLR 技术文档 1. 了解 lucene 原理,全文搜索概念,参考(/category/30179) .建立
自己的索引库. 2. 了解 solr 参考(/developerworks/cn/java/j-solr1/,
override="true" />
</Context> 设置 e:/tomcat/solr 为 solr 主目录 ,建立文件夹. 3.4 将 apache-solr-1.3.0\example\solr 下所有文件复制到 e:/tomcat/solr 下 3.5 启动 tomcat -> 浏览 http://localhost:8080/solr/admin/ 能访问 Solr Admin 页面说明 Solr 服务器设置成功. 4. 为 Solr 创建索引库 4.1 在 e:/tomcat/solr 目录下新建名为 data 的文件夹,再在 data 下新建 index 名为 文件 夹 4.2 将 lucene 创建好的索引放入 e:/tomcat/solr/data/index 下 5. Solr 索引设置 5.1 在 e:/tomcat/solr /conf 下 solrconfig.xml, schema.xml <2>中的技术文档有详细说明 5.2 中文支持,如果你的索引要支持中文搜索的话,在此推荐庖丁分词,参考 (/topic/110148) schema.xml 设置如下: 中文词组分词
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Solr技术方案一用户需求以前的互动平台只能对固定表的固定字段做like这样的数据库层面的索引,性能低下,用户体验很差,很难满足业务提出的简化搜索的需求。
需求原型:业界通用的做全站搜索的基本上两种:1 选择googleAPI,百度API做。
同第三方搜索引擎绑定太死,无法满足后期业务扩展需要,而且全站的SEO做的也不是很好,对于动态的很多ajax请求需要做快照,所以暂时不采用。
2 选择现有成熟的框架。
这里我们选择使用solr。
Solr是一个基于Lucene的Java搜索引擎服务器。
Solr 提供了层面搜索、命中醒目显示并且支持多种输出格式(包括XML/XSLT 和JSON 格式)。
它易于安装和配置,而且附带了一个基于HTTP 的管理界面。
Solr已经在众多大型的网站中使用,较为成熟和稳定。
Solr 包装并扩展了Lucene,所以Solr的基本上沿用了Lucene的相关术语。
更重要的是,Solr 创建的索引与Lucene 搜索引擎库完全兼容。
通过对Solr 进行适当的配置,某些情况下可能需要进行编码,Solr 可以阅读和使用构建到其他Lucene 应用程序中的索引。
此外,很多Lucene 工具(如Nutch、Luke)也可以使用Solr 创建的索引。
这里我们主要需要以下几种功能:1 可用性及成熟性。
2 中文分词。
3 词库与同义词的管理(比如我们使用最高的:股票代码)。
4 高亮显示。
5 方便的导入数据。
6 Facet的轻松配置7 扩展性。
二Solr的体系结构体系结构Solr体系,功能模块介绍及配置。
以上是solr的架构图。
具体应用时需要理解一下模块的作用及配置。
RequestHandler:接受请求,分发请求。
另外也包含导入数据,如importhandler。
UpdateHandlers –处理索引请求。
Search Components:作为handlder的成员变量。
处理请求。
Facet:分类搜索Tika:apache下处理文件的一个项目。
Filter,spelling :处理字符串Http query/update Database/html importhandler 默认基本可以满足要求。
如果不够则扩展相应的handler和component。
丰富的客户端Ruby/php/java/json/javascript使用solrj以上的配置在solrconfig.xml,schema.xml中配置分词的解决办法系统提供了很多种分词方案。
StopAnalyzer,StandardAnalyzer,WhitespaceAnalyzer只是实现了数字、单词、E-mail 地址、IP地址以及中文字符的分析处理,但是对于中文的分析并不好。
对于中文分词有几种解决方案。
∙Paoding: 100万汉字/s(https:///p/paoding/)∙Imdict:26万汉字/s (https:///p/imdict-chinese-analyzer/)∙Ik:160万汉字/s (https:///p/ik-analyzer/)∙Mmseg4j:simple 1900kb/s 准确率98%(https:///p/mmseg4j/)注:官方提供测试环境各不相同。
这里我们选择准确率最高的Mmseg4j。
而且配置起来也十分简单。
我们只是需要在schema中配置以下fieldType即可。
<fieldType name="textComplex" class="solr.TextField"positionIncrementGap="100"><analyzer type=”index”><tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory"mode="complex" dicPath="../dic" /><filter class="solr.StopFilterFactory" ignoreCase="true"words="stopwords.txt" /></analyzer><analyzer type=”query”><tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory"mode="complex" dicPath="../dic" /><filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt"ignoreCase="true" expand="true" /><filter class="solr.StopFilterFactory" ignoreCase="true"words="stopwords.txt" /></analyzer></fieldType>三搭建方法及配置安装solr版本:V4.31. 去apache网站/solr/ 下载Solr4.32. 新建目录/usr/local/solr3. 将solr-4.3.0/dist/solr-4.3.0.war 复制到/usr/local/solr下,重命名为solr.war4. 将solr-4.3.0/example/lib/ext下的包复制到Tomcat/lib目录下5. 新建目录/usr/local/solr/solr_home 作为solr 实例的跟目录6. 将solr解压目录中的contrib,dist,example/solr/* 复制到solr_home7. 在solr_home下新建lib目录,mkdir lib8. 从dist/program/smsehome-solr/lib/拷贝除了solr-dataimporthandler-mongo-1.0.0.jar之外的jar文件,中文分词包和数据库驱动包放到lib下。
目录结构如下:└─libmmseg4j-analysis-*.jarmmseg4j-core-*.jarmmseg4j-solr-*.jarmongo-java-driver-*.jarmysql-connector-java-*-bin.jar9. 将smsehome-solr/lib/solr-dataimporthandler-mongo-1.0.0.jar导入到disc目录下10. 在solr_home下新建dic目录,mkdir dic。
11. 文件结构如下└─solr_homebin/collection1/contrib/dic/dist/lib/README.txtsolr.xmlZoo.cfg12. 拷贝发布文件data-config.xml ,solrconfig.xml ,schema.xml,solrcore.properties 到/usr/local/solr/solr_home/collection1/conf/ 目录下。
13. 修改solrcore.propertiesdb_driver=com.mysql.jdbc.Driverdb_url=jdbc:mysql://172.26.1.110:3306/smsehomedb_user=irmuserdb_passwd=irmusermongodb_host=172.26.1.110mongodb_port=27017mongodb_database=adminmongodb_username=adminmongod_password=BussINEssHome2013file_path=http://172.31.16.233:8080/smsehome-web/showPicMongo.do?uploadFileMong oId修改红色部分的配置。
以db开头的mysql数据源,以mongodb开头的时候mongodb数据源。
单机环境到此就配置好了。
打开http://ip:8080/solr/#/ 可以看到dashboard和collection1表示安装成功。
打开http://ip:8080/solr/browse可以看到索引内容为空。
集群安装与配置1下载zookeeper/并解压zookeeper。
新建zoo/data目录,用于存放zookeeper 的数据。
进入到目录zookeeper/conf 复制zoo_sample.cfg 为zoo.cfg,编辑zoo.cfg: dataDir= /zoo/dataclientPort=2181server.1=192.168.1.11:2888:3888server.2=192.168.1.12:2888:3888server.3=192.168.1.13:2888:3888dataDir设置zookeeper数据存放目录绝对路径clientPort设置Zookeeper链接端口server.i设置集群中服务器的IP及端口号,i代表第几个服务器,与之对应的,需要在zoo/data中新建myid文件,文件内容为对应的i。
集群安装:分别在192.168.1.11,192.168.1.12,192.168.1.13上安装,/zoo/data/myid文件内容分别为配置中对应的1,2,3。
2 启动zookeeper.启动zookeeper。
zkServer.sh start。
按照上面server 的顺序启动。
Server.1,server.2,server.3。
3 配置tomcat。
将上面配置好的tomcat复制3份,把相应的solr.xml文件指定到工程目录。
4 配置其中一台为JAVA_OPTS=”-Dbootstrap_confdir=/solr_home/collection1/conf-Dcollection.configName=clusterconf-DzkHost=192.168.1.11:2181,192.168.1.12:2181,192.168.1.13:2181-DnumShards=2”参数:-Dbootstrap_confdir为solr的配置文件目录-Dcollection.configName为solrCloud配置显示名-DzkHost为zookeeper服务器列表,逗号隔开-DnumShards为分片个数在其他机器分别在192.168.1.2,192.168.1.3,192.168.1.4上配置/tomcat/bin/catalina.sh(.bat windows):JAVA_OPTS=”-DzkHost=192.168.1.11:2181,192.168.1.12:2181,192.168.1.13:218 1”此处仅配置-DzkHost即可,所有solr配置均从zookeeper中获取。