Tiny语言的词法分析器-C++版-课程设计报告
c词法分析器实验报告

c词法分析器实验报告篇一:词法分析器设计实验报告计算机与信息学院(信息工程系)编译原理实验报告专业班级课程教学班任课教实验指导教师实验地点XX ~XX学年第一学期实验一词法分析器设计一、实验目的通过本实验的编程实践,使学生了解词法分析的任务,掌握词法分析程序设计的原理和构造方法,使学生对编译的基本概念、原理和方法有完整的和清楚的理解,并能正确地、熟练地运用。
二、实验内容用 VC++/VB/JAVA 语言实现对 C 语言子集的源程序进行词法分析。
通过输入源程序从左到右对字符串进行扫描和分解,依次输出各个单词的内部编码及单词符号自身值;若遇到错误则显示“Error”,然后跳过错误部分继续显示;同时进行标识符登记符号表的管理。
以下是实现词法分析设计的主要工作:(1)从源程序文件中读入字符。
(2 (3 (4(属性值——token 的机内表示)(5)如果发现错误则报告出错 7(6三、实验流程图四、实验步骤12、编制好源程序后,设计若干用例对系统进行全面的上机测试,并通过所设计的词法分析程序;直至能够得到完全满意的结果。
3、书写实验报告;实验报告正文的内容:五、实验结果篇二:C语言词法分析器实验报告计算机科学与工程系编译原理课程设计实验报告姓名:__ ******__ 学号_ *******__ 年级专业及班级___08计算机科学与技术成绩- 1 -- 2 -- 3 -- 4 -- 5 -篇三:词法分析器实验报告实验报告实验题目:词法分析器院系班级:计科系0901班姓名学号: XX210603实验时间:XX-10-21设计。
编制并调试一个词法分析程序,加深对词法分析原理的理解。
实验要求设计出一个简单的词法分析程序,能够识别关键字(包含begin、if、end、 while、else、 then)、标识符、数字及数种符号(+、-、*、/、(、)、:、=、:=、#、>、、=、;)。
返回并打印各类字符所对应的种类编码及该字符所组成的二元组。
编译原理设计c语言的词法分析器

编译原理课程设计报告题目:学院:教师:姓名:学号:班级:评分:签字:编译原理课程设计一:设计c语言的词法分析器一、实验目的了解高级语言单词的分类,了解状态图以及如何表示并识别单词规则,掌握状态图到识别程序的编程,加深对词法原理的理解。
二、实验要求了解高级语言单词的分类,了解状态图以及如何表示并识别单词规则,掌握状态图到识别程序的编程。
三、实验设计3.1.单词分类及表示3.1.1 C语言的子集分类(1)标识符:以字母开头的字母数字串(2)整数或浮点型。
(3)保留字:for,while,do,else,if,static,int,sizeof,break,continue(4)运算符:+,-,*,/,%,>,<,=,!=,==,<=,>=,!,&,&&,||;(5)界符:"(",")",",",":",";","{","}"3.1.2单词二元组(单词分类号、单词自身值)3.2 词法分析器的设计3.2.1算法设计3.2.1.1概要设计从文件中逐个读取字符,只要这五大类的状态序列则继续读取,否则回退字符,在对应类别进行查找,输出单元二次组至另一文件夹。
3.2.1.2状态图设计3.2.2输入输出设计输入:通过文件指针从文件中一个一个读取字符输出:输出单词二元组至文件。
格式为(种别码,值)3.2.3主要函数void Getchar(FILE *fp ) //读入一个字符void GetBC(FILE *fp)//读入一个非空字符void contacat()//连接字符int letter()//判断是否为字母int digit()//判断是否为字母void retract(FILE *fp,char *c)//回退int reserve (char **k)//处理保留字int sysmbol(identifier *id)//处理标识符,查找符号表并存放位置若没有则添加int constant(constnumber *con)//存入常数表,并返回它在常数表中的位置void Tofile(int num, int val, identifier *id, constnumber *con, FILE *fw)//写到文件void WordAnalyze(char **k,char *c, char **CODE, identifier *id, constnumber *con, FILE *fp, FILE *fw)//词法分析函数四、结果测试文件输入int main(){int a=1,b=3;if(a>1)b=b-2;}输出结果:结论:程序输出结果与期望输出结果相符。
实验一词法分析器实验报告示例
词法分析器实验报告一.需求分析1.C语言关键字的子集,以文件形式保存,待判断的C语言语句以文件形式保存。
2.关键字文件包括标识符、基本字、常数、运算符和界符以及相应的种别码。
3.在计算机终端顺次输出各词法单位的种别码和值。
若为标识符,其值为该标识符在标识符表中的位置;若为常数,其值为该常数在常数表中的位置;其余值为-1。
非法输入单词的种别码为-1,值为-2。
4.“单词”定义:C语言中最小的语法单位。
“标识符”定义:用户自定义的标志符。
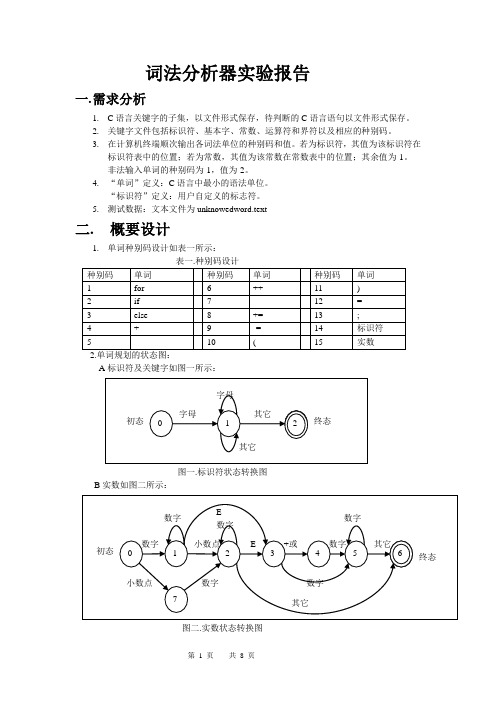
5.测试数据:文本文件为unknowedword.text二.概要设计1.单词种别码设计如表一所示:A标识符及关键字如图一所示:图一.标识符状态转换图B实数如图二所示:图二.实数状态转换图C图三.运算符状态转换图D其它与运算符雷同,此处略3. 数据结构know[N] 用来存放构成单词符号的字符串;unknow[N]用来存放待辨别的字符串;chartab[T][N] 用来存放识别出的标识符;keytab[M][N] 用来存放从文件中读入的基本字;consttab[T] 用来存放识别出的实数。
以上均设为全局变量。
4.基本操作Getchar()初始条件:unknow中读入了一串待辨别的字符串。
操作结果:从unknow读入一个字符到ch中,指向unknow的指针加1。
Getbc()初始条件:unknow中读入了一串待辨别的字符串。
操作结果:从unknow中读入不是空格的下一个字符。
Concat()初始条件:know中为字母且ch中为字母,或know中为数字(包括小数点)ch中也为数字。
操作结果:将ch中的字符连接到know中。
Isletter()初始条件:ch中已经读入了一个新的字符。
操作结果:判断ch中的字符是否字母。
Isdigit()初始条件:ch中已经读入了一个新的字符。
操作结果:判断ch中的字符是否数字。
Keyword()初始条件:已判断出know中的字符串为标识符。
C语言词法分析器实验报告

计算机科学与工程系编译原理课程设计实验报告姓名:__ ******__ 学号_ *******__ 年级专业及班级___08计算机科学与技术成绩扫描引号:扫描单词:扫描其他字符:实验环境:需要TC、VC++ 6.0等开发工具作为本次试验的环境。
fprintf(fp1,"*********************************************************\n");}int guanjz(char ch1[])//关键字和标识符判断{char ch2[32][9]={"auto","double","int","struct","break","else","long","switch","case","enum", "register","typedef","char","extern","return","union","const","float","short","unsigned","continue","for","signed","void","default","goto","sizeof","volatile","do","while","static","if"};//定义关键字集for(int i=0;i<32;i++){//逐个比对如果为关键字则返回类别i+1if(!strcmp(ch1,ch2[i]))return i+1;}return 47;//否则返回一般标识符类}。
实验三 用C语言编写TINY语言的词法分析器

实验三 用C 语言编写TINY 语言的词法分析器一、实验内容:用C 语言编写TINY 语言的词法分析器,并用该词法分析器分析某个TINY 语言源程序,将识别出的单词以二元组的形式显示到屏幕上。
二、实验目的:掌握用C 语言编写生成词法分析器的方法;三、实验要求1.写好实验预习报告;2.编写上机的C 语言描述的词法分析器和测试程序;3.写出实验结果;4.实验完后要上交实验报告;四、相关说明TINY 的单词记号分为三种典型类型:保留字、特殊符号和“其他”单词。
保留字一共8个,特殊符号包括运算符和界符:分别是四种基本的整数运算符号,两种比较符号(等号和小于),以及括号、分号和赋值号。
除赋值号是两个字符的长度以外,其余均为一个字符。
TINY 的标识符是一个或多个字母的序列。
数是一个或多个数字的序列。
TINY 的单词如下表所示:保留字特殊符号 其他 if+ 数 (一个或多个数字)then- else﹡ 标识符 (一个或多个字母) end/ repeat= until< read( write); := 除了单词之外,TINY 还要遵循以下词法规则:注释应放在花括号{……}中,且不可嵌套;代码应是自由格式;空白符由空格、制表位和新行组成。
五、实验器材硬件:PC 机一台软件:Turbo C 、LEX.EXE六、参考程序1.C 语言描述的词法分析器:shiyan3.c2.测试程序:test.txtif x<3then y:=(x+3)*4else y:=x-3end3.实验过程与实验效果如下图所示:。
编译原理课程设计报告——词法分析器

精选课程设计任务书引言 (4)第一章概述 (5)1.1设计内容 (5)1.2设计要求 (5)第二章设计的基本原理 (6)2.1 (6)2.2 (6)第三章程序设计 (7)3.1 总体方案设计 (7)3.2 各模块设计 (8)第四章程序测试 (9)4.1一般测试4.2出错处理测试第五章结论 (10)参考文献 (10)附录程序清单 (11)引言《编译原理》是国内外各高等院校计算机科学技术类专业,特别是计算机软件专业的一门重要专业课程。
该课程系统地向学生介绍编译程序的结构、工作流程及编译程序各组成部分的设计原理和实现技术。
由于该课程理论性和实践性都比较强,内容较为抽象复杂,涉及到大量的软件设计算法,因此,一直是一门比较难学的课程。
为了使学生更好地理解和掌握编译技术的基本概念、基本原理和实现方法,实践环节非常重要,只有通过上机进行程序设计,才能使学生对比较抽象的教学内容产生具体的感性认识,增强学生综合分析问题、解决问题的能力,并对提高学生软件设计水平大有益处。
编译原理涉及词法分析,语法分析,语义分析及优化设计等各方面。
词法分析阶段是编译过程的第一个阶段,是编译的基础。
这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。
词法分析程序实现这个任务。
词法分析程序可以使用 Lex 等工具自动生成。
从左到右逐个字符对构成源程序的字符串进行扫描,依据词法规则,识别出一个一个的标记(token ),把源程序变为等价的标记串序列。
执行词法分析的程序称为词法分析器,也称为扫描器。
词法分析是所有分析优化的基础,涉及的知识较少,如状态转换图等,易于实现。
本次课程设计,我的选题是词法分析, C++ 代码实现。
第一章概述1.1 设计内容对 C 语言的一个子集设计并实现一个简单的词法分析器,掌握利用状态转换图设计词法分析器的基本方法。
1.2设计要求利用该词法分析器完成对源程序字符串的词法分析。
编译原理 TINY语言 词法分析 语法分析

一、设计题目:
根据给定的 TINY 语言规范,为 TINY 语言设计编译器,要求完成 TINY 语言的词法分析和语法分析部分。
二、课题解析
词法分析 词法分析的主要任务是:输入源程序,对构成源程序的字符串扫描和分解,识别出一个个的单词,如关 键字、标识符、数字、运算符等等。 词法分析要完成的工作有:
四、相关数据结构
class Token //单词
{ int Row;//单词所在行 int Col;//单词所在列 TokenTypes Type;//单词类型 int Value//单词值
}
class TINYNode //语法树中一个单词节点 {
String Data;//单词值 List<TINYNode> Children;//子节点 }
南京信息工程大学 编译原理 课程设计 3 / 12
五、实验截图
南京信息工程大学 编译原理 课程设计 4 / 12
南京信息工程大学 编译原理 课程设计 5 / 12
六、运行结果分析
本课程设计完成了课题的要求,能够对用户输入的 YINY 源代码进行词法分析和语法分析,并能提供 检错功能,提示用户错误发生在源代码的何处。
词法分析 ..................................................................................................................................................... 3 语法分析 ..................................................................................................................................................... 3 三、算法说明 ............................................................................................................................................................. 3 四、相关数据结构 ..................................................................................................................................................... 3 五、实验截图 ............................................................................................................................................................. 4 六、运行结果分析 ..................................................................................................................................................... 6 七、收获和体会 ......................................................................................................................................................... 6 七、附录一:TINY 语言文法规范........................................................................................................................... 7 八、附录二:部分程序源代码 ................................................................................................................................. 8
C语言词法分析器实验报告

计算机科学与工程系编译原理课程设计实验报告姓名:__ ******__ 学号_ *******__ 年级专业及班级___08计算机科学与技术成绩扫描引号:扫描单词:扫描其他字符:实验环境:需要TC、VC++ 6.0等开发工具作为本次试验的环境。
fprintf(fp1,"*********************************************************\n");}int guanjz(char ch1[])//关键字和标识符判断{char ch2[32][9]={"auto","double","int","struct","break","else","long","switch","case","enum", "register","typedef","char","extern","return","union","const","float","short","unsigned","continue","for","signed","void","default","goto","sizeof","volatile","do","while","static","if"};//定义关键字集for(int i=0;i<32;i++){//逐个比对如果为关键字则返回类别i+1if(!strcmp(ch1,ch2[i]))return i+1;}return 47;//否则返回一般标识符类}总结:指导教师签名:2011年4月12日星期二。
(完整版)词法分析器(c语言实现)

词法分析c实现一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的C语言程序源代码:#include <stdio.h>#include <string.h>char prog[80],token[8],ch;int syn,p,m,n,sum;char *rwtab[6]={"begin","if","then","while","do","end"};scaner();main(){p=0;printf("\n please input a string(end with '#'):/n");do{scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(syn){case 11:printf("( %-10d%5d )\n",sum,syn);break;case -1:printf("you have input a wrong string\n");getch();exit(0);default: printf("( %-10s%5d )\n",token,syn);break;}}while(syn!=0);getch();}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;ch=prog[p++];m=0;while((ch==' ')||(ch=='\n'))ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')) { while((ch>='0')&&(ch<='9')) { sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=22;token[m++]=ch;}else{ syn=20;p--;}break;case '>':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=24;token[m++]=ch;}else{ syn=23;p--;}break;case '+': token[m++]=ch;ch=prog[p++];if(ch=='+'){ syn=17;token[m++]=ch;}else{ syn=13;p--;}break;ch=prog[p++];if(ch=='-'){ syn=29;token[m++]=ch;}else{ syn=14;p--;}break;case '!':ch=prog[p++];if(ch=='='){ syn=21;token[m++]=ch;}else{ syn=31;p--;}break;case '=':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=25;token[m++]=ch;}else{ syn=18;p--;}break;case '*': syn=15;token[m++]=ch;break;case '/': syn=16;token[m++]=ch;break;case '(': syn=27;token[m++]=ch;break;case ')': syn=28;break;case '{': syn=5;token[m++]=ch;break;case '}': syn=6;token[m++]=ch;break;case ';': syn=26;token[m++]=ch;break;case '\"': syn=30;token[m++]=ch;break;case '#': syn=0;token[m++]=ch;break;case ':':syn=17;token[m++]=ch;break;default: syn=-1;break;}token[m++]='\0';}四、结果分析:输入begin x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如下序列:(begin 1)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图5-1所示:。
TINY-C编译器的设计与实现-词法分析器的设计与实现

TINY-C编译器的设计与实现-词法分析器的设计与实现⽬录摘要: (1)⼀前⾔ (3)1.1编译系统概述 (3)1.2编译器的概述 (3)1.3TINY语⾔的概述 (4)⼆需求分析 (6)2.1 词法分析⽬的 (6)2.2 词法分析中的定义 (6)2.3 词法分析概述 (6)2.4 词法分析功能 (6)2.5词法分析的要求 (7)2.6 外部接⼝要求 (7)2.7 数据流程图 (7)2.7.1 顶层数据流程图 (7)2.7.2 第⼆层数据流程图 (7)三概要设计 (9)3.1概要设计分析 (9)3.1.1 ⽬的 (9)3.1.2 定义 (9)3.1.3 参考资料 (9)3.2 任务概述 (9)3.2.1 ⽬标 (9)3.2.2 需求概述 (10)3.3 总体设计 (10)3.3.1 词法分析的⽬标和作⽤ (10)3.3.2词法分析的数学基础和算法: (10)3.3.3 TINY编译器的词法分析的实现: (12)3.3.4词法分析器的总体结构和外部模块 (14)四详细设计与编码 (15)4.1 引⾔ (15)4.1.1 根本⽬的 (15)4.1.2 要求 (15)4.1.3 参考资料 (15)4.2 任务概述 (15)4.2.1 ⽬标 (15)4.2.2 需求概述 (15)4.3 总体设计 (15)4.3.1 需求概述 (15)4.3.2 词法分析器的结构 (15)4.4 程序设计说明 (16)4.4.1 全局模块 (19)4.4.2 词法分析模块 (22)五测试分析 (31)5.1 引⾔ (31)5.1.1编写⽬的: (31)5.1.2项⽬背景: (31)5.1.3定义: (31)5.2 任务概述 (31)5.2.1⽬标: (31)5.2.2运⾏环境: (31)5.2.3需求概述: (32)5.2.4条件与限制: (32)5.3 计划 (32)5.3.1测试⽅案: (32)5.3.2测试项⽬ (32)5.4 测试项⽬说明 (32)5.4.1 测试项⽬名称及测试内容(1) (32)5.4.2测试项⽬名称及测试内容(2) (33)5.5 评价 (34)5.5.1 软件能⼒ (34)5.5.2 缺陷和限制 (34)5.6 测试结论 (34)六总结与⼼得 (35)参考⽂献 (36)致谢........................................ 错误!未定义书签。
《C-语言的词法分析器(基于Lex)》课程设计报告

《C-语⾔的词法分析器(基于Lex)》课程设计报告《编译原理与实践》课程报告课题名称: C-语⾔的词法分析器实现(基于Lex)课题负责⼈名(学号):李恒(0643111198)同组成员名单(⾓⾊):⽆指导教师:于中华评阅成绩:评阅意见:提交报告时间:2007 年12 ⽉31⽇1. ⽬的与意义词法分析是编译原理中⼀个重要的部分。
它可将源程序读作字符⽂件并将其分为若⼲个记号,每⼀个记号都是表⽰源程序中信息单元的字符序列。
词法分析器是翻译步骤的第⼀步,它对于编译器接下来要进⾏的⼯作起着开头的作⽤,因此要想实现对C-语⾔的编译器,词法分析器必不可少。
2. 基于Parser Generator的词法分析器构造⽅法利⽤Parser Generator构造词法分析器规则,⽣成对应的c语⾔及其头⽂件。
然后进⾏编译。
3. C-语⾔词法分析的设计重要数据类型:关键字枚举:typedef enum{ENDFILE, ERROR,/* reserved words */ELSE, IF, INT, RETURN, VOID, WHILE,/* multicharacter tokens */ID, NUM,/* special symbols */PLUS, MINUS, TIMES, OVER, LT, LE, GT, GE, EQU, NEQU,ASSIGN, SEMI, COMMA, LPAREN, RPAREN, LBRKT, RBRKT, LBRC, RBRC, LCOM, RCOM}TokenType;关键字声明:digit [0-9]number {digit}+letter [a-zA-Z]identifier {letter}+newline \nwhitespace [ \t]+c-语⾔的词法规则:"else" {return ELSE;} "if" {return IF;}"int" {return INT;} "return" {return RETURN;} "void" {return VOID;} "while" {return WHILE;} "+" {return PLUS;} "-" {return MINUS;} "*" {return TIMES;} "/" {return OVER;} "<" {return LT;}"<=" {return LE;} ">" {return GT;}">=" {return GE;}"==" {return EQU;}"!=" {return NEQU;} "=" {return ASSIGN;} ";" {return SEMI;} "," {return COMMA;} "(" {return LPAREN;} ")" {return RPAREN;} "[" {return LBRKT;} "]" {return RBRKT;} "{" {return LBRC;} "}" {return RBRC;} {number} {return NUM;} {identifier} {return ID;} {newline} {lineNo++} {whitespace} {/* skip */} "/*" { char c;do{ c = input();if (c == EOF ) break;if (c == '\n' ) lineNo++;} while ( c != '/*');}{return ERROR;}重要处理程序设计:⽂件util.c执⾏输出结果的打印:void printToken(TokenType token, const char* tokenString) { switch (token){case ELSE:case IF:case INT:case RETURN:case VOID:case WHILE:fprintf(listing, "reserved word: %s\n", tokenString);break;case PLUS:fprintf(listing, "+\n");break;case MINUS:fprintf(listing, "-\n");break;case TIMES:fprintf(listing, "*\n");break;case OVER:fprintf(listing, "/\n");break;case LT:fprintf(listing, "<\n");break;case LE:fprintf(listing, "<=\n");break;fprintf(listing, ">\n"); break;case GE:fprintf(listing, ">=\n"); break;case EQU:fprintf(listing, "==\n"); break;case NEQU:fprintf(listing, "!=\n"); break;case ASSIGN: fprintf(listing, "=\n"); break;case SEMI:fprintf(listing, ";\n"); break;case COMMA: fprintf(listing, ",\n"); break;case LPAREN: fprintf(listing, "(\n"); break;case RPAREN: fprintf(listing, ")\n"); break;case LBRKT: fprintf(listing, "[\n"); break;case RBRKT: fprintf(listing, "]\n"); break;case LBRC:fprintf(listing, "{\n");case RBRC:fprintf(listing, "}\n");break;case LCOM:fprintf(listing, "/*\n");break;case RCOM:fprintf(listing, "*/\n");break;case ENDFILE:fprintf(listing,"EOF\n");break;case NUM:fprintf(listing, "NUM,val=%s\n",tokenString); break;case ID:fprintf(listing, "ID, name=%s\n",tokenString); break;case ERROR:fprintf(listing, "ERROR: %s\n",tokenString); break;default:break;}}函数getToken获取下⼀个token:TokenType getToken(void){ static int firstTime = TRUE; TokenType currentToken;if (firstTime){ firstTime = FALSE;lineNo++;yyin = source;yyout = listing;}currentToken = yylex();strncpy(tokenString,yytext,MAXTOKENLEN);if (TraceScan) {fprintf(listing, "\t%d: ", lineNo);printToken(currentToken,tokenString);}return currentToken;}4. 运⾏结果及分析输⼊⽂件如果所⽰:输出结果如图:对于输⼊的每⼀⾏进⾏词法分析,表⽰出保留字,标识符,以及终结符。
编译原理课程设计报告C-语言词法与语法分析器的实现

编译原理课程设计报告课题名称:编译原理课程设计C-语言词法与语法分析器的实现提交文档学生姓名:提交文档学生学号:同组成员名单:指导教师姓名:指导教师评阅成绩:指导教师评阅意见:..提交报告时间:年月日C-词法与语法分析器的实现1.课程设计目标(1)题目实用性C-语言拥有一个完整语言的基本属性,通过编写C-语言的词法分析和语法分析,对于理解编译原理的相关理论和知识有很大的作用。
通过编写C-语言词法和语法分析程序,能够对编译原理的相关知识:正则表达式、有限自动机、语法分析等有一个比较清晰的了解和掌握。
(2)C-语言的词法说明①语言的关键字:else if int return void while所有的关键字都是保留字,并且必须是小写。
②专用符号:+ - * / < <= > >= == != = ; , ( ) [ ] { } /* */③其他标记是ID和NUM,通过下列正则表达式定义:ID = letter letter*NUM = digit digit*letter = a|..|z|A|..|Zdigit = 0|..|9注:ID表示标识符,NUM表示数字,letter表示一个字母,digit表示一个数字。
小写和大写字母是有区别的。
④空格由空白、换行符和制表符组成。
空格通常被忽略。
⑤注释用通常的c语言符号/ * . . . * /围起来。
注释可以放在任何空白出现的位置(即注释不能放在标记内)上,且可以超过一行。
注释不能嵌套。
(3)程序设计目标能够对一个程序正确的进行词法及语法分析。
2.分析与设计(1)设计思想a.词法分析词法分析的实现主要利用有穷自动机理论。
有穷自动机可用作描述在输入串中识别模式的过程,因此也能用作构造扫描程序。
通过有穷自动机理论能够容易的设计出词法分析器。
b.语法分析语法分析采用递归下降分析。
递归下降法是语法分析中最易懂的一种方法。
它的主要原理是,对每个非终结符按其产生式结构构造相应语法分析子程序,其中终结符产生匹配命令,而非终结符则产生过程调用命令。
TINY-C编译器的设计与实现-语法分析器的设计与实现

目录摘要 (3)1。
前言 (4)2。
语法分析器的设计原理 (6)2.1 语法分析器的功能 (6)2。
2 语法分析的目标和作用 (6)2.3 构造语法分析器的步骤 (6)2。
4 上下文无关文法及分析 (7)2。
5 常用的语法分析方法和几种算法的比较 (9)2.5.1自上而下分析法 (9)2.5。
2自下而上分析法 (11)3. 语法分析器的设计和实现 (14)3。
1 TINY语言的介绍 (14)3。
2 TINY的文法生成 (14)3.3 TINY语法分析器算法的选择 (17)3。
4 TINY语言的递归下降分析程序 (20)3.5 TINY语法分析的输出 (22)3。
5.1 语法分析的输出结果 (22)3.5.2 抽象语法树的节点声明 (23)3.5。
3 语法树结构 (24)3。
6 语法分析的主要函数与核心代码 (28)3。
6。
1 语法分析器的主要文件和函数 (28)3.6.2 语法分析模块 (29)4. 测试分析 (39)4。
1 测试方法 (39)4。
2 测试计划 (39)4.3 测试项目说明 (39)4.4 测试结论 (43)5. 结论与心得 (44)参考文献 (45)致谢................................... 错误!未定义书签。
附录................................... 错误!未定义书签。
ContentsAbstract (4)1。
Preface (6)2。
Syntax analyzer principle of design (7)2。
1 Function of parsing (7)2。
2 Purpose and function of parsing (7)2.3 The of parsing analyzer structure (7)2。
4 Context—free grammar and analysis (8)2。
编译原理课程设计报告词法分析器

一.课程设计题目:词法分析器的实现二.课程设计成员三.课程设计内容和要求设计一个程序,调试、编译,实现词法分析的功能,识别各单词或字符所属类别,并显示在屏幕上。
词法分析器:逐个读入源程序字符并按照构词规则切分成一系列单词。
单词是语言中具有独立意义的最小单位,包括保留字、标识符、运算符、标点符号和常量等。
词法分析是编译过程中的一个阶段,在语法分析前进行。
也可以和语法分析结合在一起作为一遍,由语法分析程序调用词法分析程序来获得当前单词供语法分析使用。
要求:通过词法分析器能够实现以下五种类型如单词等的识别。
(1)关键字"begin","end","if","then","else","while","write","read"等,"do", "call","const","char","until","procedure","repeat"等(2)运算符:"+","-","*","/","="等(3)界符:"{","}","[","]",";",",",".","(",")",":"等(4)标识符(5)常量四.操作要求首先建立一个或多个文档,此处新建了两个文档,例:07196133.txt文本文档和zhaoxiaodong.txt文本文档,以供选择,各文本文档中都输入有不同的内容,运行程序,出现提示,输入文本文档的名称,即可对文本文档中的内容进行分析,并把分析结果输出显示在屏幕上。
编译原理课程设计-词法分析器的设计及实现(C)

词法分析器的设计一.设计说明及设计要求一般来说,编译程序的整个过程可以划分为五个阶段:词法分析、语法分析、中间代码生成、优化和目标代码生成。
本课程设计即为词法分析阶段。
词法分析阶段是编译过程的第一个阶段。
这个阶段的任务是从左到右一个字符一个字符地读入源程序,对构成源程序的字符流进行扫描和分解,从而识别出一个个单词(也称单词符号或符号)。
如保留字(关键字或基本字)、标志符、常数、算符和界符等等。
二.设计中相关关键字说明1.基本字:也称关键字,如C语言中的if , else , while , do ,for,case,break, return 等。
2.标志符:用来表示各种名字,如常量名、变量名和过程名等。
3.常数:各种类型的常数,如12,6.88,和“ABC”等。
4.运算符:如+ ,- , * , / ,%, < , > ,<= , >= 等。
5.界符,如逗点,冒号,分号,括号,# ,〈〈,〉〉等。
三、程序分析词法分析是编译的第一个阶段,它的主要任务是从左到右逐个字符地对源程序进行扫描,产生一个个单词序列,用以语法分析。
词法分析工作可以是独立的一遍,把字符流的源程序变为单词序列,输出在一个中间文件上,这个文件做为语法分析程序的输入而继续编译过程。
然而,更一般的情况,常将词法分析程序设计成一个子程序,每当语法分析程序需要一个单词时,则调用该子程序。
词法分析程序每得到一次调用,便从源程序文件中读入一些字符,直到识别出一个单词,或说直到下一个单词的第一个字符为止。
四、模块设计下面是程序的流程图五、程序介绍在程序当前目录里建立一个文本文档,取名为infile.txt,所有需要分析的程序都写在此文本文档里,程序的结尾必须以“@”标志符结束。
程序结果输出在同一个目录下,文件名为outfile.txt,此文件为自动生成。
本程序所输出的单词符号采用以下二元式表示:(单词种别,单词自身的值)如程序输出结果(57,"#")(33,"include")(52,"<")(33,"iostream") 等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(
write
)
;
:=
二、构造Tiny语言DFA
ID:letter(letter)*
Number: digit(digit)*
三、根据DFA编写词法分析器
#include<fstream>
#include<string>
#include<iostream>
usingnamespacestd;
staticintrowCounter = 1;//静态变量,用于存储行数
int temp:用于存储数字,并输出。
static intbracketExist:静态变量,标记注释是否存在。
string token, str分别用于临时存储读取的符号的字母串。
五、算法总结
建立Lex class,并读取每一行,创建Lex的实例,在Lex中处理。先判断是否在注释范围内,若是,则输出注释内容,直至产生“}”字符。若不在注释区内,则读取单个字符,根据DFA进行判断。若为符号,则当下一个字符不是符号时输出;若为数字,则继续往下读,直至下一个字符不是数字为止,输出。若为字母,继续读取,直至下一个字符不是字母,把这一串字母和预先定义的保留字比对,若是,则输出“Reserved word”,若不是,则输出“ID,name=”字样。一行处理完毕,便开始创建下一行实例,直至文件尾。
}
}
if(bracketExist ==false)
{
//数字
while(isdigit(line[i]))
{
temp = temp * 10 + line[i];
if(!isdigit(line[i + 1]))
{
output <<"\t"<< rowCounter <<": "<<"NUM, val= "<< temp -'0'<< endl;
{
if(isToken(token))
{
output <<"\t"<< rowCounter <<": "<< token << endl;
}
else
{
intj = 0;
while(token[j] !='\0')
{
output <<"\t"<< rowCounter <<": "<< token[j] << endl;
intj = 0;
remove("SampleOutput.txt");
for(j = 0; j < i; j++)
{
Lexlex(line[j]);
}
cout << endl << endl <<"Writing file completed!!"<< endl << endl << endl;
return0;
while(line[i] !='}')
{
output << line[i];//不处理,直接输出
if(line[i + 1] !=NULL)
{
i++;
}
else
break;
}
if(line[i] =='}')//注释结束
{
output << line[i]<<endl;
bracketExist =false;
实验报告
学号: 姓名: 专业:计算机科学与技术 班级:2班 第9周
课程名称
?编译原理课程设计
实验课时
8
实验项目
手工构造Tiny语言的词法分析器
实验时间
7-10周
实验目的
熟悉Tiny语言词法;构造DFA;设计数据类型、数据结构;用C++实现Tiny语言的词法分析器
实验环境
?Windows 10 专业版
returnstr;
}
voidscan(stringinputLine)
{
ofstreamoutput;
output.open("SampleOutput.txt",ios::app);
stringline =inputLine;
inti = 0;
stringstr ="";
inttemp;
stringtoken ="";
9: fact := fact * x;
9: ID, name= fact
9: :=
9: ID, name= fact
9: *
9: ID, name= x
9: ;
10: x := x - 1;
10: ID, name= x
10: :=
10: ID, name= x
10: -
10: NUM, val= 1
}
if(line[i + 1] ==NULL)
{
if(line[i] ==';')
output <<"\t"<< rowCounter <<": "<< line[i];
break;
}
}
//清空,以备下一行读取
line ="";
str ="";
temp = 0;
token ="";
output << endl;
5: read x; { input an integer }
5: Reversed Word: read
5: ID, name= x
5: ;
5: { input an integer }
6: if 0 < x then { don't compute if x <= 0 }
6: Reversed Word: if
{
token = token + line[i];
if(isdigit(line[i + 1]) || (line[i + 1] >='a'&&line[i + 1] <='z') || (line[i + 1] >='A'&&line[i + 1] <='Z') || line[i + 1] ==' '|| line[i + 1] =='{'|| line[i + 1] =='}'|| line[i + 1] ==NULL)
break;
}
else
{
output <<"\t"<< rowCounter <<": "<<"ID, name= "<< str << endl;
break;
}
}
if(line[i + 1] !=NULL)
i++;
}
str ="";
if(line[i + 1] !=NULL)
{
i++;
}
else
break;
staticboolbracketExist =false;//判断注释存在与否,false为不存在
classLex
{
public:
ofstreamoutput;
stringline ="";
Lex(stringinputLine)
{
line =inputLine;
scan(Trim(line));
stringline[50];
inti = 0;
while(getline(input, line[i]))
{
//cout << line[i] << endl;
i++;
}
input.close();
cout << endl << endl <<"Reading source file completed!!"<< endl;
output << rowCounter <<": "<< line << endl;//输出每行
while(line[i] !='\0')//根据DFA扫描并判断
{
if(line[i] =='{')//注释
{
bracketExist =true;
}
if(bracketExist ==true)
{
output <<"\t"<< rowCounter <<": ";
j++;
}
}
}
else
{
i++;
continue;