Speculative Multiprocessor Cache Line Actions Using Instruction and Line History 1 Abstract
计算机术语介绍

DP(Dual Processor,双处理器) DSM(Dedicated Stack Manager,专门堆栈管理) DSMT(Dynamic Simultaneous Multithreading,动态同步多线程) DST(Depleted Substrate Transistor,衰竭型底层晶体管) DTV(Dual Threshold Voltage,双重极限电压) DUV(Deep Ultra-Violet,纵深紫外光) EBGA(Enhanced Ball Grid Array,增强形球状网阵排列) EBL(electron beam lithography,电子束平版印刷) EC(Embedded Controller,嵌入式控制器) EDEC(Early Decode,早期解码) Embedded Chips(嵌入式) EPA(edge pin array,边缘针脚阵列) EPF(Embedded Processor Forum,嵌入式处理器论坛) EPL(electron projection lithography,电子发射平版印刷)
IOPs(Integer Operations Per Second,整数操作/秒) IPC(Instructions Per Clock Cycle,指令/时钟周期) ISA(instruction set architecture,指令集架构) ISD(inbuilt speed-throttling device,内藏速度控制设备) ITC(Instruction Trace Cache,指令追踪缓存) ITRS(International Technology Roadmap for Semiconductors,国 际半导体技术发展蓝图) KNI(Katmai New Instructions,Katmai 新指令集,即 SSE) Latency(潜伏期) LDT(Lightning Data Transport,闪电数据传输总线) LFU(Legacy Function Unit,传统功能单元) LGA(land grid array,接点栅格阵列) LN2(Liquid Nitrogen,液氮) Local Interconnect(局域互连)
专业术语中英文对照表计算机专业

1、CPU3DNow!(3D no waiting,无须等待的3D处理)AAM(AMD Analyst Meeting,AMD分析家会议)ABP(Advanced Branch Prediction,高级分支预测)ACG(Aggressive Clock Gating,主动时钟选择)AIS(Alternate Instruction Set,交替指令集)ALAT(advanced load table,高级载入表)ALU(Arithmetic Logic Unit,算术逻辑单元)Aluminum(铝)AGU(Address Generation Units,地址产成单元)APC(Advanced Power Control,高级能源控制)APIC(Advanced rogrammable Interrupt Controller,高级可编程中断控制器)APS(Alternate Phase Shifting,交替相位跳转)ASB(Advanced System Buffering,高级系统缓冲)ATC(Advanced Transfer Cache,高级转移缓存)ATD(Assembly Technology Development,装配技术发展)BBUL(Bumpless Build-Up Layer,内建非凹凸层)BGA(Ball Grid Array,球状网阵排列)BHT(branch prediction table,分支预测表)Bops(Billion Operations Per Second,10亿操作/秒)BPU(Branch Processing Unit,分支处理单元)BP(Brach Pediction,分支预测)BSP(Boot Strap Processor,启动捆绑处理器)BTAC(Branch Target Address Calculator,分支目标寻址计算器)CBGA (Ceramic Ball Grid Array,陶瓷球状网阵排列)CDIP (Ceramic Dual-In-Line,陶瓷双重直线)Center Processing Unit Utilization,中央处理器占用率CFM(cubic feet per minute,立方英尺/秒)CMT(course-grained multithreading,过程消除多线程)CMOS(Complementary Metal Oxide Semiconductor,互补金属氧化物半导体)CMOV(conditional move instruction,条件移动指令)CISC(Complex Instruction Set Computing,复杂指令集计算机)CLK(Clock Cycle,时钟周期)CMP(on-chip multiprocessor,片内多重处理)CMS(Code Morphing Software,代码变形软件)co-CPU(cooperative CPU,协处理器)COB(Cache on board,板上集成缓存,做在CPU卡上的二级缓存,通常是内核的一半速度))COD(Cache on Die,芯片内核集成缓存)Copper(铜)CPGA(Ceramic Pin Grid Array,陶瓷针型栅格阵列)CPI(cycles per instruction,周期/指令)CPLD(Complex Programmable Logic Device,複雜可程式化邏輯元件)CPU(Center Processing Unit,中央处理器)CRT(Cooperative Redundant Threads,协同多余线程)CSP(Chip Scale Package,芯片比例封装)CXT(Chooper eXTend,增强形K6-2内核,即K6-3)Data Forwarding(数据前送)dB(decibel,分贝)DCLK(Dot Clock,点时钟)DCT(DRAM Controller,DRAM控制器)DDT(Dynamic Deferred Transaction,动态延期处理)Decode(指令解码)DIB(Dual Independent Bus,双重独立总线)DMT(Dynamic Multithreading Architecture,动态多线程结构)DP(Dual Processor,双处理器)DSM(Dedicated Stack Manager,专门堆栈管理)DSMT(Dynamic Simultaneous Multithreading,动态同步多线程)DST(Depleted Substrate Transistor,衰竭型底层晶体管)DTV(Dual Threshold Voltage,双重极限电压)DUV(Deep Ultra-Violet,纵深紫外光)EBGA(Enhanced Ball Grid Array,增强形球状网阵排列)EBL(electron beam lithography,电子束平版印刷)EC(Embedded Controller,嵌入式控制器)EDEC(Early Decode,早期解码)Embedded Chips(嵌入式)EPA(edge pin array,边缘针脚阵列)EPF(Embedded Processor Forum,嵌入式处理器论坛)EPL(electron projection lithography,电子发射平版印刷)EPM(Enhanced Power Management,增强形能源管理)EPIC(explicitly parallel instruction code,并行指令代码)EUV(Extreme Ultra Violet,紫外光)EUV(extreme ultraviolet lithography,极端紫外平版印刷)FADD(Floationg Point Addition,浮点加)FBGA(Fine-Pitch Ball Grid Array,精细倾斜球状网阵排列)FBGA(flipchip BGA,轻型芯片BGA)FC-BGA(Flip-Chip Ball Grid Array,反转芯片球形栅格阵列)FC-LGA(Flip-Chip Land Grid Array,反转接点栅格阵列)FC-PGA(Flip-Chip Pin Grid Array,反转芯片针脚栅格阵列)FDIV(Floationg Point Divide,浮点除)FEMMS:Fast Entry/Exit Multimedia State,快速进入/退出多媒体状态FFT(fast Fourier transform,快速热欧姆转换)FGM(Fine-Grained Multithreading,高级多线程)FID(FID:Frequency identify,频率鉴别号码)FIFO(First Input First Output,先入先出队列)FISC(Fast Instruction Set Computer,快速指令集计算机)flip-chip(芯片反转)FLOPs(Floating Point Operations Per Second,浮点操作/秒)FMT(fine-grained multithreading,纯消除多线程)FMUL(Floationg Point Multiplication,浮点乘)FPRs(floating-point registers,浮点寄存器)FPU(Float Point Unit,浮点运算单元)FSUB(Floationg Point Subtraction,浮点减)GFD(Gold finger Device,金手指超频设备)GHC(Global History Counter,通用历史计数器)GTL(Gunning Transceiver Logic,射电收发逻辑电路)GVPP(Generic Visual Perception Processor,常规视觉处理器)HL-PBGA: 表面黏著,高耐热、轻薄型塑胶球状网阵封装HTT(Hyper-Threading Technology,超级线程技术)Hz(hertz,赫兹,频率单位)IA(Intel Architecture,英特尔架构)IAA(Intel Application Accelerator,英特尔应用程序加速器)ICU(Instruction Control Unit,指令控制单元)ID(identify,鉴别号码)IDF(Intel Developer Forum,英特尔开发者论坛)IEU(Integer Execution Units,整数执行单元)IHS(Integrated Heat Spreader,完整热量扩展)ILP(Instruction Level Parallelism,指令级平行运算)IMM: Intel Mobile Module, 英特尔移动模块Instructions Cache,指令缓存Instruction Coloring(指令分类)IOPs(Integer Operations Per Second,整数操作/秒)IPC(Instructions Per Clock Cycle,指令/时钟周期)ISA(instruction set architecture,指令集架构)ISD(inbuilt speed-throttling device,内藏速度控制设备)ITC(Instruction Trace Cache,指令追踪缓存)ITRS(International Technology Roadmap for Semiconductors,国际半导体技术发展蓝图)KNI(Katmai New Instructions,Katmai新指令集,即SSE)Latency(潜伏期)LDT(Lightning Data Transport,闪电数据传输总线)LFU(Legacy Function Unit,传统功能单元)LGA(land grid array,接点栅格阵列)LN2(Liquid Nitrogen,液氮)Local Interconnect(局域互连)MAC(multiply-accumulate,累积乘法)mBGA (Micro Ball Grid Array,微型球状网阵排列)nm(namometer,十亿分之一米/毫微米)MCA(machine check architecture,机器检查体系)MCU(Micro-Controller Unit,微控制器单元)MCT(Memory Controller,内存控制器)MESI(Modified, Exclusive, Shared, Invalid:修改、排除、共享、废弃)MF(MicroOps Fusion,微指令合并)mm(micron metric,微米)MMX(MultiMedia Extensions,多媒体扩展指令集)MMU(Multimedia Unit,多媒体单元)MMU(Memory Management Unit,内存管理单元)MN(model numbers,型号数字)MFLOPS(Million Floationg Point/Second,每秒百万个浮点操作)MHz(megahertz,兆赫)mil(PCB 或晶片佈局的長度單位,1 mil = 千分之一英寸)MIPS(Million Instruction Per Second,百万条指令/秒)MOESI(Modified, Owned, Exclusive, Shared or Invalid,修改、自有、排除、共享或无效)MOF(Micro Ops Fusion,微操作熔合)Mops(Million Operations Per Second,百万次操作/秒)MP(Multi-Processing,多重处理器架构)MPF(Micro processor Forum,微处理器论坛)MPU(Microprocessor Unit,微处理器)MPS(MultiProcessor Specification,多重处理器规范)MSRs(Model-Specific Registers,特别模块寄存器)MSV(Multiprocessor Specification Version,多处理器规范版本)NAOC(no-account OverClock,无效超频)NI(Non-Intel,非英特尔)NOP(no operation,非操作指令)NRE(Non-Recurring Engineering charge,非重複性工程費用)OBGA(Organic Ball Grid Arral,有机球状网阵排列)OCPL(Off Center Parting Line,远离中心部分线队列)OLGA(Organic Land Grid Array,有机平面网阵包装)OoO(Out of Order,乱序执行)OPC(Optical Proximity Correction,光学临近修正)OPGA(Organic Pin Grid Array,有机塑料针型栅格阵列)OPN(Ordering Part Number,分类零件号码)PAT(Performance Acceleration Technology,性能加速技术)PBGA(Plastic Pin Ball Grid Array,塑胶球状网阵排列)PDIP (Plastic Dual-In-Line,塑料双重直线)PDP(Parallel Data Processing,并行数据处理)PGA(Pin-Grid Array,引脚网格阵列),耗电大PLCC (Plastic Leaded Chip Carriers,塑料行间芯片运载)Post-RISC(加速RISC,或后RISC)PR(Performance Rate,性能比率)PIB(Processor In a Box,盒装处理器)PM(Pseudo-Multithreading,假多线程)PPGA(Plastic Pin Grid Array,塑胶针状网阵封装)PQFP(Plastic Quad Flat Package,塑料方块平面封装)PSN(Processor Serial numbers,处理器序列号)QFP(Quad Flat Package,方块平面封装)QSPS(Quick Start Power State,快速启动能源状态)RAS(Return Address Stack,返回地址堆栈)RAW(Read after Write,写后读)REE(Rapid Execution Engine,快速执行引擎)Register Contention(抢占寄存器)Register Pressure(寄存器不足)Register Renaming(寄存器重命名)Remark(芯片频率重标识)Resource contention(资源冲突)Retirement(指令引退)RISC(Reduced Instruction Set Computing,精简指令集计算机)ROB(Re-Order Buffer,重排序缓冲区)RSE(register stack engine,寄存器堆栈引擎)RTL(Register Transfer Level,暫存器轉換層。
UniversityofWisconsin-Madison(

University of Wisconsin-Madison(UMW)周玉龙1101213442 计算机应用UMW简介美国威斯康辛大学坐落于美国密歇根湖西岸的威斯康辛州首府麦迪逊市,有着风景如画的校园,成立于1848年, 是一所有着超过150年历史的悠久大学。
威斯康辛大学是全美最顶尖的三所公立大学之一,是全美最顶尖的十所研究型大学之一。
在美国,它经常被视为公立的常青藤。
与加利福尼亚大学、德克萨斯大学等美国著名公立大学一样,威斯康辛大学是一个由多所州立大学构成的大学系统,也即“威斯康辛大学系统”(University of Wisconsin System)。
在本科教育方面,它列于伯克利加州大学和密歇根大学之后,排在公立大学的第三位。
除此之外,它还在本科教育质量列于美国大学的第八位。
按美国全国研究会的研究结果,威斯康辛大学有70个科目排在全美前十名。
在上海交通大学的排行中,它名列世界大学的第16名。
威斯康辛大学是美国大学联合会的60个成员之一。
特色专业介绍威斯康辛大学麦迪逊分校设有100多个本科专业,一半以上可以授予硕士、博士学位,其中新闻学、生物化学、植物学、化学工程、化学、土木工程、计算机科学、地球科学、英语、地理学、物理学、经济学、德语、历史学、语言学、数学、工商管理(MBA)、微生物学、分子生物学、机械工程、哲学、西班牙语、心理学、政治学、统计学、社会学、动物学等诸多学科具有相当雄厚的科研和教学实力,大部分在美国大学相应领域排名中居于前10名。
学术特色就学术方面的荣耀而言,威斯康辛大学麦迪逊校区的教职员和校友至今共获颁十七座诺贝尔奖和二十四座普立兹奖;有五十三位教职员是国家科学研究院的成员、有十七位是国家工程研究院的成员、有五位是隶属于国家教育研究院,另外还有九位教职员赢得了国家科学奖章、六位是国家级研究员(Searle Scholars)、还有四位获颁麦克阿瑟研究员基金。
威斯康辛大学麦迪逊校区虽然是以农业及生命科学为特色,但是令人注目,同时也是吸引许多传播科系学子前来留学的最大诱因,则是当前任教于该校新闻及传播研究所、在传播学界有「近代美国传播大师」之称的杰克·麦克劳(Jack McLauld)。
第4章习题答案

(2)SRAM 芯片和 DRAM 芯片各有哪些特点?各自用在哪些场合?
(3)CPU 和主存之间有哪两种通信方式?SDRAM 芯片采用什么方式和 CPU 交换信息?
(4)为什么在 CPU 和主存之间引入 Cache 能提高 CPU 访存效率?
(5)为什么说 Cache 对程序员来说是透明的?
(6)什么是 Cache 映射的关联度?关联度与命中率、命中时间的关系各是什么?
EEPROM (Electrically EPROM) 多模块存储器(Multi-Module Memory) 双口 RAM (Dual Port RAM) 程序访问的局部化
空间局部性(Spatial Locality) 命中时间(Hit Time) 失靶损失(Miss Penalty) Cache 槽或 Cache 行 (Slot / Line) 全相联 Cache(Fully Associative Cache) 多级 Cache(Multilevel Cache) 代码 Cache(指令 Cache) 先进先出 (First-In-First-Out,FIFO) Write Through(写直达、通过式写、直写) Write Back (写回、回写) 物理存储器(Physical Memory) 虚页号(Virtual Page number ) 物理地址(Physical address) 物理页号(Page frame) 重定位(Relocation) 页表基址寄存器(Page table base register) 修改位(Modify bit / Dirty bit) 访问方式位(Access bit) 交换(swapping) / 页面调度(paging) LRU 页(Least Recently Used Page) 分页式虚拟存储器(Paging VM) 段页式虚拟存储器(Paged Segmentation VM)
计算机术语大全(很好的哦)

计算机术语大全1、CPU3DNow!(3D no waiting,无须等待的3D处理)AAM(AMD Analyst Meeting,AMD分析家会议)ABP(Advanced Branch Prediction,高级分支预测)ACG(Aggressive Clock Gating,主动时钟选择)AIS(Alternate Instruction Set,交替指令集)ALAT(advanced load table,高级载入表)ALU(Arithmetic Logic Unit,算术逻辑单元)Aluminum(铝)AGU(Address Generation Units,地址产成单元)APC(Advanced Power Control,高级能源控制)APIC(Advanced rogrammable Interrupt Controller,高级可编程中断控制器)APS(Alternate Phase Shifting,交替相位跳转)ASB(Advanced System Buffering,高级系统缓冲)ATC(Advanced Transfer Cache,高级转移缓存)ATD(Assembly Technology Development,装配技术发展)BBUL(Bumpless Build-Up Layer,内建非凹凸层)BGA(Ball Grid Array,球状网阵排列)BHT(branch prediction table,分支预测表)Bops(Billion Operations Per Second,10亿操作秒)BPU(Branch Processing Unit,分支处理单元)BP(Brach Pediction,分支预测)BSP(Boot Strap Processor,启动捆绑处理器)BTAC(Branch Target Address Calculator,分支目标寻址计算器)CBGA (Ceramic Ball Grid Array,陶瓷球状网阵排列)CDIP (Ceramic Dual-In-Line,陶瓷双重直线)Center Processing Unit Utilization,中央处理器占用率CFM(cubic feet per minute,立方英尺秒)CMT(course-grained multithreading,过程消除多线程)CMOS(Complementary Metal Oxide Semiconductor,互补金属氧化物半导体)CMOV(conditional move instruction,条件移动指令)CISC(Complex Instruction Set Computing,复杂指令集计算机)CLK(Clock Cycle,时钟周期)CMP(on-chip multiprocessor,片内多重处理)CMS(Code Morphing Software,代码变形软件)co-CPU(cooperative CPU,协处理器)COB(Cache on board,板上集成缓存,做在CPU卡上的二级缓存,通常是内核的一半速度))COD(Cache on Die,芯片内核集成缓存)Copper(铜)CPGA(Ceramic Pin Grid Array,陶瓷针型栅格阵列)CPI(cycles per instruction,周期指令)CPLD(Complex Programmable Logic Device,複雜可程式化邏輯元件)CPU(Center Processing Unit,中央处理器)CRT(Cooperative Redundant Threads,协同多余线程)CSP(Chip Scale Package,芯片比例封装)CXT(Chooper eXTend,增强形K6-2内核,即K6-3)Data Forwarding(数据前送)dB(decibel,分贝)DCLK(Dot Clock,点时钟)DCT(DRAM Controller,DRAM控制器)DDT(Dynamic Deferred Transaction,动态延期处理)Decode(指令解码)DIB(Dual Independent Bus,双重独立总线)DMT(Dynamic Multithreading Architecture,动态多线程结构)DP(Dual Processor,双处理器)DSM(Dedicated Stack Manager,专门堆栈管理)DSMT(Dynamic Simultaneous Multithreading,动态同步多线程)DST(Depleted Substrate Transistor,衰竭型底层晶体管)DTV(Dual Threshold Voltage,双重极限电压)DUV(Deep Ultra-Violet,纵深紫外光)EBGA(Enhanced Ball Grid Array,增强形球状网阵排列)EBL(electron beam lithography,电子束平版印刷)EC(Embedded Controller,嵌入式控制器)EDB(Execute Disable Bit,执行禁止位)EDEC(Early Decode,早期解码)Embedded Chips(嵌入式)EM64T(Extended Memory 64 Technology,扩展内存64技术)EPA(edge pin array,边缘针脚阵列)EPF(Embedded Processor Forum,嵌入式处理器论坛)EPL(electron projection lithography,电子发射平版印刷)EPM(Enhanced Power Management,增强形能源管理)EPIC(explicitly parallel instruction code,并行指令代码)EUV(Extreme Ultra Violet,紫外光)EUV(extreme ultraviolet lithography,极端紫外平版印刷)FADD(Floationg Point Addition,浮点加)FBGA(Fine-Pitch Ball Grid Array,精细倾斜球状网阵包装)FBGA(flipchip BGA,轻型芯片BGA)FC-BGA(Flip-Chip Ball Grid Array,翻转芯片球形网阵包装)FC-LGA(Flip-Chip Land Grid Array,翻转接点网阵包装)FC-PGA(Flip-Chip Pin Grid Array,翻转芯片球状网阵包装)FDIV(Floationg Point Divide,浮点除)FEMMS:Fast EntryExit Multimedia State,快速进入退出多媒体状态FFT(fast Fourier transform,快速热欧姆转换)FGM(Fine-Grained Multithreading,高级多线程)FID(FID:Frequency identify,频率鉴别号码)FIFO(First Input First Output,先入先出队列)FISC(Fast Instruction Set Computer,快速指令集计算机)flip-chip(芯片反转)FLOPs(Floating Point Operations Per Second,浮点操作秒)FMT(fine-grained multithreading,纯消除多线程)FMUL(Floationg Point Multiplication,浮点乘)FPRs(floating-point registers,浮点寄存器)FPU(Float Point Unit,浮点运算单元)FSUB(Floationg Point Subtraction,浮点减)GFD(Gold finger Device,金手指超频设备)GHC(Global History Counter,通用历史计数器)GTL(Gunning Transceiver Logic,射电收发逻辑电路)GVPP(Generic Visual Perception Processor,常规视觉处理器)HL-PBGA 表面黏著,高耐热、轻薄型塑胶球状网阵封装HTT(Hyper-Threading Technology,超级线程技术)Hz(hertz,赫兹,频率单位)IA(Intel Architecture,英特尔架构)IAA(Intel Application Accelerator,英特尔应用程序加速器)IATM(Intel Advanced Thermal Manager,英特尔高级热量管理指令集)ICU(Instruction Control Unit,指令控制单元)ID(identify,鉴别号码)IDF(Intel Developer Forum,英特尔开发者论坛)IDMB(Intel Digital Media Boost,英特尔数字媒体推进指令集)IDPC(Intel Dynamic Power Coordination,英特尔动态能源调和指令集)IEU(Integer Execution Units,整数执行单元)IHS(Integrated Heat Spreader,完整热量扩展)ILP(Instruction Level Parallelism,指令级平行运算)IMM Intel Mobile Module, 英特尔移动模块Instructions Cache,指令缓存Instruction Coloring(指令分类)IOPs(Integer Operations Per Second,整数操作秒)IPC(Instructions Per Clock Cycle,指令时钟周期)ISA(instruction set architecture,指令集架构)ISD(inbuilt speed-throttling device,内藏速度控制设备)ITC(Instruction Trace Cache,指令追踪缓存)ITRS(International Technology Roadmap for Semiconductors,国际半导体技术发展蓝图)KNI(Katmai New Instructions,Katmai新指令集,即SSE)Latency(潜伏期)LDT(Lightning Data Transport,闪电数据传输总线)LFU(Legacy Function Unit,传统功能单元)LGA(land grid array,接点栅格阵列)LN2(Liquid Nitrogen,液氮)Local Interconnect(局域互连)MAC(multiply-accumulate,累积乘法)mBGA (Micro Ball Grid Array,微型球状网阵排列)nm(namometer,十亿分之一米毫微米)MCA(Machine Check Architecture,机器检查架构)MCU(Micro-Controller Unit,微控制器单元)MCT(Memory Controller,内存控制器)MESI(Modified, Exclusive, Shared, Invalid:修改、排除、共享、废弃)MF(MicroOps Fusion,微指令合并)mm(micron metric,微米)MMX(MultiMedia Extensions,多媒体扩展指令集)MMU(Multimedia Unit,多媒体单元)MMU(Memory Management Unit,内存管理单元)MN(model numbers,型号数字)MFLOPS(Million Floationg PointSecond,每秒百万个浮点操作)MHz(megahertz,兆赫)mil(PCB 或晶片佈局的長度單位,1 mil = 千分之一英寸)MIMD(Multi Instruction Multiple Data,多指令多数据流)MIPS(Million Instruction Per Second,百万条指令秒)MOESI(Modified, Owned, Exclusive, Shared or Invalid,修改、自有、排除、共享或无效)MOF(Micro Ops Fusion,微操作熔合)Mops(Million Operations Per Second,百万次操作秒)MP(Multi-Processing,多重处理器架构)MPF(Micro processor Forum,微处理器论坛)MPU(Microprocessor Unit,微处理器)MPS(MultiProcessor Specification,多重处理器规范)MSRs(Model-Specific Registers,特别模块寄存器)MSV(Multiprocessor Specification Version,多处理器规范版本)MVP(Mobile Voltage Positioning,移动电压定位)IVNAOC(no-account OverClock,无效超频)NI(Non-Intel,非英特尔)NOP(no operation,非操作指令)NRE(Non-Recurring Engineering charge,非重複性工程費用)OBGA(Organic Ball Grid Arral,有机球状网阵排列)OCPL(Off Center Parting Line,远离中心部分线队列)OLGA(Organic Land Grid Array,有机平面网阵包装)OoO(Out of Order,乱序执行)OPC(Optical Proximity Correction,光学临近修正)OPGA(Organic Pin Grid Array,有机塑料针型栅格阵列)OPN(Ordering Part Number,分类零件号码)PAT(Performance Acceleration Technology,性能加速技术)PBGA(Plastic Pin Ball Grid Array,塑胶球状网阵排列)PDIP (Plastic Dual-In-Line,塑料双重直线)PDP(Parallel Data Processing,并行数据处理)PGA(Pin-Grid Array,引脚网格阵列),耗电大PLCC (Plastic Leaded Chip Carriers,塑料行间芯片运载)Post-RISC(加速RISC,或后RISC)PPE(Power Processor Element,Power处理器元件)PPU(Physics Processing Unit,物理处理单元)PR(Performance Rate,性能比率)PIB(Processor In a Box,盒装处理器)PM(Pseudo-Multithreading,假多线程)PPGA(Plastic Pin Grid Array,塑胶针状网阵封装)PQFP(Plastic Quad Flat Package,塑料方块平面封装)PSN(Processor Serial numbers,处理器序列号)QFP(Quad Flat Package,方块平面封装)QSPS(Quick Start Power State,快速启动能源状态)RAS(Return Address Stack,返回地址堆栈)RAW(Read after Write,写后读)REE(Rapid Execution Engine,快速执行引擎)Register Contention(抢占寄存器)Register Pressure(寄存器不足)Register Renaming(寄存器重命名)Remark(芯片频率重标识)Resource contention(资源冲突)Retirement(指令引退)RISC(Reduced Instruction Set Computing,精简指令集计算机)ROB(Re-Order Buffer,重排序缓冲区)RSE(register stack engine,寄存器堆栈引擎)RTL(Register Transfer Level,暫存器轉換層。
计算机英语词汇

计算机英语词汇计算机英语词汇大全英语单词的产生是汉英两种语言双向交流的产物,一些带有中国特色的名称和概念进入了英语词汇,同时还有一些英语词汇进入了汉语,在文化环境中衍生出新的含义,形成了英语词汇的语义文化特征。
以下是店铺帮大家整理的计算机英语词汇大全,欢迎阅读与收藏。
计算机英语词汇1alu(arithmetic logic unit,算术逻辑单元)agu(address generation units,地址产成单元)bga(ball grid array,球状矩阵排列)bht(branch prediction table,分支预测表)bpu(branch processing unit,分支处理单元)brach pediction(分支预测)cmos: complementary metal oxide semiconductor,互补金属氧化物半导体cisc(complex instruction set computing,复杂指令集计算机)clk(clock cycle,时钟周期)cob(cache on board,板上集成缓存)cod(cache on die,芯片内集成缓存)cpga(ceramic pin grid array,陶瓷针型栅格阵列)cpu(center processing unit,中央处理器)data forwarding(数据前送)decode(指令解码)dib(dual independent bus,双独立总线)ec(embedded controller,嵌入式控制器)embedded chips(嵌入式)epic(explicitly parallel instruction code,并行指令代码)fadd(floationg point addition,浮点加)fcpga(flip chip pin grid array,反转芯片针脚栅格阵列)fdiv(floationg point divide,浮点除)femms:fast entry/exit multimedia state,快速进入/退出多媒体状态fft(fast fourier transform,快速热欧姆转换)fid(fid:frequency identify,频率鉴别号码)fifo(first input first output,先入先出队列)flip-chip(芯片反转)flop(floating point operations per second,浮点操作/秒)fmul(floationg point multiplication,浮点乘)fpu(float point unit,浮点运算单元)fsub(floationg point subtraction,浮点减)gvpp(generic visual perception processor,常规视觉处理器) hl-pbga: 表面黏著,高耐热、轻薄型塑胶球状矩阵封装ia(intel architecture,英特尔架构)icu(instruction control unit,指令控制单元)id:identify,鉴别号码idf(intel developer forum,英特尔开发者论坛)ieu(integer execution units,整数执行单元)imm: intel mobile module,英特尔移动模块instructions cache,指令缓存instruction coloring(指令分类)ipc(instructions per clock cycle,指令/时钟周期)isa(instruction set architecture,指令集架构)kni(katmai new instructions,katmai新指令集,即sse)latency(潜伏期)ldt(lightning data transport,闪电数据传输总线)local interconnect(局域互连)mesi(modified,exclusive,shared,invalid:修改、排除、共享、废弃)mmx(multimedia extensions,多媒体扩展指令集)mmu(multimedia unit,多媒体单元)mflops(million floationg point/second,每秒百万个浮点操作) mhz(million hertz,兆赫兹)mp(multi-processing,多重处理器架构)mps(multiprocessor specification,多重处理器规范)msrs(model-specific registers,特别模块寄存器)naoc(no-account overclock,无效超频)ni:non-intel,非英特尔olga(organic land grid array,基板栅格阵列)ooo(out of order,乱序执行)pga: pin-grid array(引脚网格阵列),耗电大post-riscpr(performance rate,性能比率)psn(processor serial numbers,处理器序列号)pib(processor in a box,盒装处理器)ppga(plastic pin grid array,塑胶针状矩阵封装)pqfp(plastic quad flat package,塑料方块平面封装)raw(read after write,写后读)register contention(抢占寄存器)register pressure(寄存器不足)register renaming(寄存器重命名)remark(芯片频率重标识)resource contention(资源冲突)retirement(指令引退)risc(reduced instruction set computing,精简指令集计算机) sec: single edge connector,单边连接器shallow-trench isolation(浅槽隔离)simd(single instruction multiple data,单指令多数据流)sio2f(fluorided silicon oxide,二氧氟化硅)smi(system management interrupt,系统管理中断)smm(system management mode,系统管理模式)smp(symmetric multi-processing,对称式多重处理架构)soi: silicon-on-insulator,绝缘体硅片sonc(system on a chip,系统集成芯片)spec(system performance evaluation corporation,系统性能评估测试)sqrt(square root calculations,平方根计算)sse(streaming simd extensions,单一指令多数据流扩展)superscalar(超标量体系结构)tcp: tape carrier package(薄膜封装),发热小throughput(吞吐量)tlb(translate look side buffers,翻译旁视缓冲器)uswc(uncacheabled speculative write combination,无缓冲随机联合写操作)valu(vector arithmetic logic unit,向量算术逻辑单元)vliw(very long instruction word,超长指令字)vpu(vector permutate unit,向量排列单元)vpu(vector processing units,向量处理单元,即处理mmx、sse等simd指令的地方)adimm(advanced dual in-line memory modules,高级双重内嵌式内存模块)amr(audio/modem riser;音效/调制解调器主机板附加直立插卡) aha(accelerated hub architecture,加速中心架构)。
PhoenixBIOS Setup Utility中英文解析

①Main:1.System time 设置时间格式为(时,分,秒)2.SYTEM DATA 设置日期3.LEGACY DISKETEE A:/B: 设置软驱4.PRIMARY MASTER/SLAVE 设置IDE1设置5.SECONDARY MASTER/SLAVE 设置IDE2设置6.keyboard-features 键盘特征【numlock 小键盘灯keyboard auto repeat rate 键盘自动重复时间keyboard auto repeat delay 键盘自动重复延迟时间】7.SYSTEM MENORY 系统内存8.EXTENDED MEMORY 扩展内存6.BOOT-time diagnostic screnn 启动时间诊断屏幕②Advanced(高级设置)1.Multiprocessor Specification 多重处理器规范 1.4 /1.1它专用于多处理器主板,用于确定MPS的版本,以便让PC制造商构建基于英特尔架构的多处理器系统。
与1.1标准相比,1.4增加了扩展型结构表,可用于多重PCI总线,并且对未来的升级十分有利。
另外,v1.4拥有第二条PCI总线,还无须PCI桥连接。
新型的SOS(Server Operating Systems,服务器操作系统)大都支持1.4标准,包括WinNTt 和Linux SMP(Symmetric Multi-Processing,对称式多重处理架构)。
如果可以的话,尽量使用1.4。
Installed o/s 安装O/S模式有IN95和OTHER两个值。
Reset Configuration Data 重设配置数据,有YES和NO两个值。
ache Memory (快取记忆体)此部份提供使用者如何组态特定记忆体区块的方法.【Memory Cache (记忆体快取)设定记忆体的状态.Enabled开启记忆体快取功能.Disabled关闭记忆体快取功能.(预设值)Cache System BIOS area (快取系统BIOS区域)控制系统BIOS区域的快取.Uncached不快取系统BIOS区域.Write Protect忽略写入/储存设定.(预设值)Cache Vedio BIOS area (快取视讯BIOS区域)控制视讯BIOS区域的快取.Uncached不快取视讯BIOS区域.Write Protect忽略写入/储存设定.(预设值)Cache Base 0-512K / 512K-640K (快取传统0-512K / 512K-640K)控制512K / 512K-640K传统记忆体的快取.Uncached不快取视讯BIOS区域.Write Through将写入快取,并同时传送至主记忆体.Write Protect忽略写入/储存设定.Write Back将写入快取,但除非必要,不传送至主记忆体.(预设Cache Extended Memory Area (快取延伸记忆体区域)控制1MB以上的系统记忆体.Uncached不快取视讯BIOS区域.Write Through将写入快取,并同时传送至主记忆体.Write Protect忽略写入/储存设定.Write Back将写入快取,但除非必要,不传送至主记忆体.(预设值)Cache A000-AFFF / B000-BFFF/ C8000-CFFF / CC00-CFFF / D000-DFFF /D400-D7FF/ D800-DBFF / DC00-DFFF / E000-E3FF / E400-F7FFDisabled不快取这个区块.(预设值)USWC CachingUncached Speculative Write Combined.】3.I/O Device Configuration输入输出选项【Serial port A:/B:串行口也就是常说的COM口设置有三个值AUTO自动,ENABLED开启,DISABLED关闭。
PhoenixBIOS Setup Utility设置图解
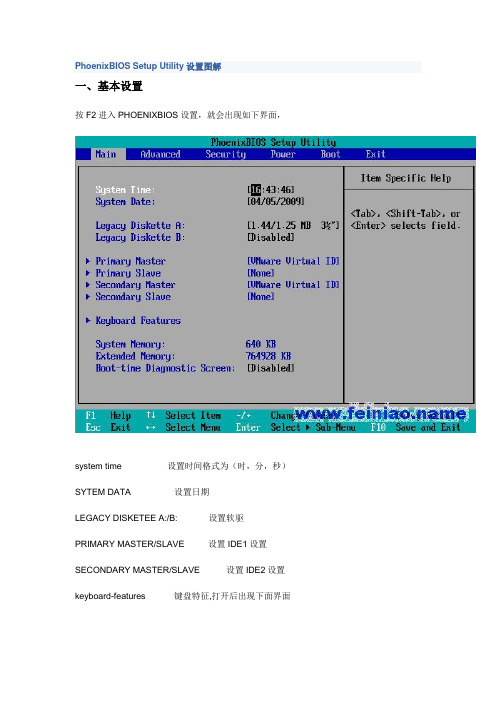
PhoenixBIOS Setup Utility设置图解一、基本设置按F2进入PHOENIXBIOS设置,就会出现如下界面,system time 设置时间格式为(时,分,秒)SYTEM DATA 设置日期LEGACY DISKETEE A:/B: 设置软驱PRIMARY MASTER/SLAVE 设置IDE1设置SECONDARY MASTER/SLAVE 设置IDE2设置keyboard-features 键盘特征,打开后出现下面界面numlock 小键盘灯keyboard auto repeat rate 键盘自动重复时间keyboard auto repeat delay 键盘自动重复延迟时间SYSTEM MENORY 系统内存EXTENDED MEMORY 扩展内存BOOT-time diagnostic screnn 启动时间诊断屏幕二、高级设置Advanced(高级设置)Multiprocessor Specification 多重处理器规范 1.4 /1.1它专用于多处理器主板,用于确定MPS的版本,以便让PC制造商构建基于英特尔架构的多处理器系统。
与1.1标准相比,1.4增加了扩展型结构表,可用于多重PCI总线,并且对未来的升级十分有利。
另外,v1.4拥有第二条PCI总线,还无须PCI桥连接。
新型的SOS(Server Operating Systems,服务器操作系统)大都支持1.4标准,包括WinNTt和Linux SMP(Symmetric Multi-Processing,对称式多重处理架构)。
如果可以的话,尽量使用1.4。
Installed o/s 安装O/S模式有IN95和OTHER两个值。
Reset Configuration Data 重设配置数据,有YES和NO两个值。
CCache Memory (快取记忆体)此部份提供使用者如何组态特定记忆体区块的方法.Memory Cache (记忆体快取)设定记忆体的状态.Enabled开启记忆体快取功能.Disabled关闭记忆体快取功能.(预设值)Cache System BIOS area (快取系统BIOS区域)控制系统BIOS区域的快取.Uncached不快取系统BIOS区域.Write Protect忽略写入/储存设定.(预设值)Cache Vedio BIOS area (快取视讯BIOS区域)控制视讯BIOS区域的快取.Uncached不快取视讯BIOS区域.Write Protect忽略写入/储存设定.(预设值)Cache Base 0-512K / 512K-640K (快取传统0-512K / 512K-640K) 控制512K / 512K-640K传统记忆体的快取.Uncached不快取视讯BIOS区域.Write Through将写入快取,并同时传送至主记忆体.Write Protect忽略写入/储存设定.Write Back将写入快取,但除非必要,不传送至主记忆体.(预设Cache Extended Memory Area (快取延伸记忆体区域)控制1MB以上的系统记忆体.Uncached不快取视讯BIOS区域.Write Through将写入快取,并同时传送至主记忆体.Write Protect忽略写入/储存设定.Write Back将写入快取,但除非必要,不传送至主记忆体.(预设值) Cache A000-AFFF / B000-BFFF/ C8000-CFFF / CC00-CFFF / D000-DFFF /D400-D7FF/ D800-DBFF / DC00-DFFF / E000-E3FF / E400-F7FFDisabled不快取这个区块.(预设值)USWC CachingUncached Speculative Write Combined.I/O Device Configuration输入输出选项Serial port A:/B:串行口也就是常说的COM口设置有三个值AUTO自动,ENABLED开启,DISABLED关闭。
通信缩写术语

计算机缩写术语完全介绍在使用计算机的过程中,你可能会碰到各种各样的专业术语,特别是那些英文缩写常让我们不知所云,下面收集了各方面的词组,希望对大家有帮助。
一、港台术语与内地术语之对照由于港台的计算机发展相对快一些,许多人都去香港或台湾寻找资料,但是港台使用的电脑专业术语与内地不尽相同,你也许曾被这些东西弄得糊里糊涂的。
---------------------------港台术语内地术语埠接口位元位讯号信号数码数字类比模拟高阶高端低阶低端时脉时钟频宽带宽光碟光盘磁碟磁盘硬碟硬盘程式程序绘图图形数位数字网路网络硬体硬件软体软件介面接口母板主板主机板主板软碟机软驱记忆体内存绘图卡显示卡监视器显示器声效卡音效卡解析度分辨率相容性兼容性数据机调制解调器---------------------------二、英文术语完全介绍在每组术语中,我按照英文字母的排列顺序来分类。
1、CPU3DNow!(3D no waiting,无须等待的3D处理)AAM(AMD Analyst Meeting,AMD分析家会议)ABP(Advanced Branch Prediction,高级分支预测)ACG(Aggressive Clock Gating,主动时钟选择)AIS(Alternate Instruction Set,交替指令集)ALAT(advanced load table,高级载入表)ALU(Arithmetic Logic Unit,算术逻辑单元)Aluminum(铝)AGU(Address Generation Units,地址产成单元)APC(Advanced Power Control,高级能源控制)APIC(Advanced rogrammable Interrupt Controller,高级可编程中断控制器)APS(Alternate Phase Shifting,交替相位跳转)ASB(Advanced System Buffering,高级系统缓冲)ATC(Advanced Transfer Cache,高级转移缓存)ATD(Assembly Technology Development,装配技术发展)BBUL(Bumpless Build-Up Layer,内建非凹凸层)BGA(Ball Grid Array,球状网阵排列)BHT(branch prediction table,分支预测表)Bops(Billion Operations Per Second,10亿操作/秒)BPU(Branch Processing Unit,分支处理单元)BP(Brach Pediction,分支预测)BSP(Boot Strap Processor,启动捆绑处理器)BTAC(Branch Target Address Calculator,分支目标寻址计算器)CBGA (Ceramic Ball Grid Array,陶瓷球状网阵排列)CDIP (Ceramic Dual-In-Line,陶瓷双重直线)Center Processing Unit Utilization,中央处理器占用率CFM(cubic feet per minute,立方英尺/秒)CMT(course-grained multithreading,过程消除多线程)CMOS(Complementary Metal Oxide Semiconductor,互补金属氧化物半导体)CMOV(conditional move instruction,条件移动指令)CISC(Complex Instruction Set Computing,复杂指令集计算机)CLK(Clock Cycle,时钟周期)CMP(on-chip multiprocessor,片内多重处理)CMS(Code Morphing Software,代码变形软件)co-CPU(cooperative CPU,协处理器)COB(Cache on board,板上集成缓存,做在CPU卡上的二级缓存,通常是内核的一半速度))COD(Cache on Die,芯片内核集成缓存)Copper(铜)CPGA(Ceramic Pin Grid Array,陶瓷针型栅格阵列)CPI(cycles per instruction,周期/指令)CPLD(Complex Programmable Logic Device,複雜可程式化邏輯元件)CPU(Center Processing Unit,中央处理器)CRT(Cooperative Redundant Threads,协同多余线程)CSP(Chip Scale Package,芯片比例封装)CXT(Chooper eXTend,增强形K6-2内核,即K6-3)Data Forwarding(数据前送)dB(decibel,分贝)DCLK(Dot Clock,点时钟)DCT(DRAM Controller,DRAM控制器)DDT(Dynamic Deferred Transaction,动态延期处理)Decode(指令解码)DIB(Dual Independent Bus,双重独立总线)DMT(Dynamic Multithreading Architecture,动态多线程结构)DP(Dual Processor,双处理器)DSM(Dedicated Stack Manager,专门堆栈管理)DSMT(Dynamic Simultaneous Multithreading,动态同步多线程)DST(Depleted Substrate Transistor,衰竭型底层晶体管)DTV(Dual Threshold Voltage,双重极限电压)DUV(Deep Ultra-Violet,纵深紫外光)EBGA(Enhanced Ball Grid Array,增强形球状网阵排列)EBL(electron beam lithography,电子束平版印刷)EC(Embedded Controller,嵌入式控制器)EDEC(Early Decode,早期解码)Embedded Chips(嵌入式)EPA(edge pin array,边缘针脚阵列)EPF(Embedded Processor Forum,嵌入式处理器论坛)EPL(electron projection lithography,电子发射平版印刷)EPM(Enhanced Power Management,增强形能源管理)EPIC(explicitly parallel instruction code,并行指令代码)EUV(Extreme Ultra Violet,紫外光)EUV(extreme ultraviolet lithography,极端紫外平版印刷)FADD(Floationg Point Addition,浮点加)FBGA(Fine-Pitch Ball Grid Array,精细倾斜球状网阵排列)FBGA(flipchip BGA,轻型芯片BGA)FC-BGA(Flip-Chip Ball Grid Array,反转芯片球形栅格阵列)FC-PGA(Flip-Chip Pin Grid Array,反转芯片针脚栅格阵列)FDIV(Floationg Point Divide,浮点除)FEMMS:Fast Entry/Exit Multimedia State,快速进入/退出多媒体状态FFT(fast Fourier transform,快速热欧姆转换)FGM(Fine-Grained Multithreading,高级多线程)FID(FID:Frequency identify,频率鉴别号码)FIFO(First Input First Output,先入先出队列)FISC(Fast Instruction Set Computer,快速指令集计算机)flip-chip(芯片反转)FLOPs(Floating Point Operations Per Second,浮点操作/秒)FMT(fine-grained multithreading,纯消除多线程)FMUL(Floationg Point Multiplication,浮点乘)FPRs(floating-point registers,浮点寄存器)FPU(Float Point Unit,浮点运算单元)FSUB(Floationg Point Subtraction,浮点减)GFD(Gold finger Device,金手指超频设备)GHC(Global History Counter,通用历史计数器)GTL(Gunning Transceiver Logic,射电收发逻辑电路)GVPP(Generic Visual Perception Processor,常规视觉处理器)HL-PBGA: 表面黏著,高耐热、轻薄型塑胶球状网阵封装HTT(Hyper-Threading Technology,超级线程技术)Hz(hertz,赫兹,频率单位)IA(Intel Architecture,英特尔架构)IAA(Intel Application Accelerator,英特尔应用程序加速器)ICU(Instruction Control Unit,指令控制单元)ID(identify,鉴别号码)IDF(Intel Developer Forum,英特尔开发者论坛)IEU(Integer Execution Units,整数执行单元)IHS(Integrated Heat Spreader,完整热量扩展)ILP(Instruction Level Parallelism,指令级平行运算)IMM: Intel Mobile Module, 英特尔移动模块Instructions Cache,指令缓存Instruction Coloring(指令分类)IOPs(Integer Operations Per Second,整数操作/秒)IPC(Instructions Per Clock Cycle,指令/时钟周期)ISA(instruction set architecture,指令集架构)ISD(inbuilt speed-throttling device,内藏速度控制设备)ITC(Instruction Trace Cache,指令追踪缓存)ITRS(International Technology Roadmap for Semiconductors,国际半导体技术发展蓝图)KNI(Katmai New Instructions,Katmai新指令集,即SSE)Latency(潜伏期)LDT(Lightning Data Transport,闪电数据传输总线)LFU(Legacy Function Unit,传统功能单元)LGA(land grid array,接点栅格阵列)LN2(Liquid Nitrogen,液氮)Local Interconnect(局域互连)MAC(multiply-accumulate,累积乘法)mBGA (Micro Ball Grid Array,微型球状网阵排列)nm(namometer,十亿分之一米/毫微米)MCA(machine check architecture,机器检查体系)MCU(Micro-Controller Unit,微控制器单元)MCT(Memory Controller,内存控制器)MESI(Modified, Exclusive, Shared, Invalid:修改、排除、共享、废弃)MF(MicroOps Fusion,微指令合并)mm(micron metric,微米)MMX(MultiMedia Extensions,多媒体扩展指令集)MMU(Multimedia Unit,多媒体单元)MMU(Memory Management Unit,内存管理单元)MN(model numbers,型号数字)MFLOPS(Million Floationg Point/Second,每秒百万个浮点操作)MHz(megahertz,兆赫)mil(PCB 或晶片佈局的長度單位,1 mil = 千分之一英寸)MIPS(Million Instruction Per Second,百万条指令/秒)MOESI(Modified, Owned, Exclusive, Shared or Invalid,修改、自有、排除、共享或无效)MOF(Micro Ops Fusion,微操作熔合)Mops(Million Operations Per Second,百万次操作/秒)MP(Multi-Processing,多重处理器架构)MPF(Micro processor Forum,微处理器论坛)MPU(Microprocessor Unit,微处理器)MPS(MultiProcessor Specification,多重处理器规范)MSRs(Model-Specific Registers,特别模块寄存器)MSV(Multiprocessor Specification Version,多处理器规范版本)NAOC(no-account OverClock,无效超频)NI(Non-Intel,非英特尔)NOP(no operation,非操作指令)NRE(Non-Recurring Engineering charge,非重複性工程費用)OBGA(Organic Ball Grid Arral,有机球状网阵排列)OCPL(Off Center Parting Line,远离中心部分线队列)OLGA(Organic Land Grid Array,有机平面网阵包装)OoO(Out of Order,乱序执行)OPC(Optical Proximity Correction,光学临近修正)OPGA(Organic Pin Grid Array,有机塑料针型栅格阵列)OPN(Ordering Part Number,分类零件号码)PAT(Performance Acceleration Technology,性能加速技术)PBGA(Plastic Pin Ball Grid Array,塑胶球状网阵排列)PDIP (Plastic Dual-In-Line,塑料双重直线)PDP(Parallel Data Processing,并行数据处理)PGA(Pin-Grid Array,引脚网格阵列),耗电大PLCC (Plastic Leaded Chip Carriers,塑料行间芯片运载)Post-RISC(加速RISC,或后RISC)PR(Performance Rate,性能比率)PIB(Processor In a Box,盒装处理器)PM(Pseudo-Multithreading,假多线程)PPGA(Plastic Pin Grid Array,塑胶针状网阵封装)PQFP(Plastic Quad Flat Package,塑料方块平面封装)PSN(Processor Serial numbers,处理器序列号)QFP(Quad Flat Package,方块平面封装)QSPS(Quick Start Power State,快速启动能源状态)RAS(Return Address Stack,返回地址堆栈)RAW(Read after Write,写后读)REE(Rapid Execution Engine,快速执行引擎)Register Contention(抢占寄存器)Register Pressure(寄存器不足)Register Renaming(寄存器重命名)Remark(芯片频率重标识)Resource contention(资源冲突)Retirement(指令引退)RISC(Reduced Instruction Set Computing,精简指令集计算机)ROB(Re-Order Buffer,重排序缓冲区)RSE(register stack engine,寄存器堆栈引擎)RTL(Register Transfer Level,暫存器轉換層。
PHOENIXBIOS设置图解教程

按F2进入PHOENIXBIOS设置,就会出现如下界面,system time设置时间格式为(时,分,秒)SYTEM DATA设置日期LEGACY DISKETEE A:/B:设置软驱PRIMARY MASTER/SLAVE设置IDE1设置SECONDARY MASTER/SLAVE设置IDE2设置keyboard-features键盘特征,打开后出现下面界面numlock小键盘灯keyboard auto repeat rate键盘自动重复时间keyboard auto repeat delay键盘自动重复延迟时间SYSTEM MENORY系统内存EXTENDED MEMORY扩展内存BOOT-time diagnostic screnn启动时间诊断屏幕Advanced(高级设置)Multiprocessor Specification多重处理器规范 1.4/1.1它专用于多处理器主板,用于确定MPS的版本,以便让PC制造商构建基于英特尔架构的多处理器系统。
与1.1标准相比,1.4增加了扩展型结构表,可用于多重PCI总线,并且对未来的升级十分有利。
另外,v1.4拥有第二条PCI总线,还无须PCI桥连接。
新型的SOS(Server Operating Systems,服务器操作系统)大都支持1.4标准,包括WinNTt和Linux SMP(Symmetric Multi-Processing,对称式多重处理架构)。
如果可以的话,尽量使用1.4。
Installed o/s安装O/S模式有IN95和OTHER两个值。
Reset Configuration Data重设配置数据,有YES和NO两个值。
CCache Memory (快取记忆体)此部份提供使用者如何组态特定记忆体区块的方法.Memory Cache (记忆体快取)设定记忆体的状态.Enabled开启记忆体快取功能.Disabled关闭记忆体快取功能.(预设值)Cache System BIOS area (快取系统BIOS区域)控制系统BIOS区域的快取.Uncached不快取系统BIOS区域.Write Protect忽略写入/储存设定.(预设值) Cache Vedio BIOS area (快取视讯BIOS区域)控制视讯BIOS区域的快取.Uncached不快取视讯BIOS区域.Write Protect忽略写入/储存设定.(预设值) Cache Base 0-512K / 512K-640K (快取传统0-512K / 512K-640K)控制512K / 512K-640K传统记忆体的快取.Uncached不快取视讯BIOS区域.Write Through将写入快取,并同时传送至主记忆体.Write Protect忽略写入/储存设定.Write Back将写入快取,但除非必要,不传送至主记忆体.(预设Cache Extended Memory Area (快取延伸记忆体区域)控制1MB以上的系统记忆体.Uncached不快取视讯BIOS区域.Write Through将写入快取,并同时传送至主记忆体.Write Protect忽略写入/储存设定.Write Back将写入快取,但除非必要,不传送至主记忆体.(预设值)Cache A000-AFFF / B000-BFFF/ C8000-CFFF / CC00-CFFF /D000-DFFF /D400-D7FF/ D800-DBFF / DC00-DFFF / E000-E3FF / E400-F7FFDisabled不快取这个区块.(预设值)USWC CachingUncached Speculative Write Combined.I/O Device Configuration输入输出选项Serial port A:/B:串行口也就是常说的COM口设置有三个值AUTO自动,ENABLED开启,DISABLED关闭。
计算机英语缩写

计算机英语缩写整理者:quetzal3DNow!(3D no waiting,无须等待的3D处理)AAM(AMD Analyst Meeting,AMD分析家会议)ABP(Advanced Branch Prediction,高级分支预测)ACG(Aggressive Clock Gating,主动时钟选择)AIS(Alternate Instruction Set,交替指令集)ALAT(advanced load table,高级载入表)ALU(Arithmetic Logic Unit,算术逻辑单元)AGU(Address Generation Units,地址产成单元)APC(Advanced Power Control,高级能源控制)APIC(Advanced rogrammable Interrupt Controller,高级可编程中断控制器)APS(Alternate Phase Shifting,交替相位跳转)ASB(Advanced System Buffering,高级系统缓冲)ATC(Advanced Transfer Cache,高级转移缓存)ATD(Assembly Technology Development,装配技术发展)BBUL(Bumpless Build-Up Layer,内建非凹凸层)BGA(Ball Grid Array,球状网阵排列)BHT(branch prediction table,分支预测表)Bops(Billion Operations Per Second,10亿操作/秒)BPU(Branch Processing Unit,分支处理单元)BP(Brach Pediction,分支预测)BSP(Boot Strap Processor,启动捆绑处理器)BTAC(Branch Target Address Calculator,分支目标寻址计算器)CBGA (Ceramic Ball Grid Array,陶瓷球状网阵排列)CDIP (Ceramic Dual-In-Line,陶瓷双重直线)Center Processing Unit Utilization,中央处理器占用率CFM(cubic feet per minute,立方英尺/秒)CMT(course-grained multithreading,过程消除多线程)CMOS(Complementary Metal Oxide Semiconductor,互补金属氧化物半导体)CMOV(conditional move instruction,条件移动指令)CISC(Complex Instruction Set Computing,复杂指令集计算机)CLK(Clock Cycle,时钟周期)CMP(on-chip multiprocessor,片内多重处理)CMS(Code Morphing Software,代码变形软件)co-CPU(cooperative CPU,协处理器)COB(Cache on board,板上集成缓存,做在CPU卡上的二级缓存,通常是内核的一半速度)COD(Cache on Die,芯片内核集成缓存)Copper(铜)CPGA(Ceramic Pin Grid Array,陶瓷针型栅格阵列)CPI(cycles per instruction,周期/指令)CPLD(Complex Programmable Logic Device,複雜可程式化邏輯元件)CPU(Center Processing Unit,中央处理器)CRT(Cooperative Redundant Threads,协同多余线程)CSP(Chip Scale Package,芯片比例封装)CXT(Chooper eXTend,增强形K6-2内核,即K6-3)Data Forwarding(数据前送)dB(decibel,分贝)DCLK(Dot Clock,点时钟)DCT(DRAM Controller,DRAM控制器)DDT(Dynamic Deferred Transaction,动态延期处理)Decode(指令解码)DIB(Dual Independent Bus,双重独立总线)DMT(Dynamic Multithreading Architecture,动态多线程结构)DP(Dual Processor,双处理器)DSM(Dedicated Stack Manager,专门堆栈管理)DSMT(Dynamic Simultaneous Multithreading,动态同步多线程)DST(Depleted Substrate Transistor,衰竭型底层晶体管)DTV(Dual Threshold Voltage,双重极限电压)DUV(Deep Ultra-Violet,纵深紫外光)EBGA(Enhanced Ball Grid Array,增强形球状网阵排列)EBL(electron beam lithography,电子束平版印刷)EC(Embedded Controller,嵌入式控制器)EDEC(Early Decode,早期解码)Embedded Chips(嵌入式)EPA(edge pin array,边缘针脚阵列)EPF(Embedded Processor Forum,嵌入式处理器论坛)EPL(electron projection lithography,电子发射平版印刷)EPM(Enhanced Power Management,增强形能源管理)EPIC(explicitly parallel instruction code,并行指令代码)EUV(Extreme Ultra Violet,紫外光)EUV(extreme ultraviolet lithography,极端紫外平版印刷)FADD(Floationg Point Addition,浮点加)FBGA(Fine-Pitch Ball Grid Array,精细倾斜球状网阵排列)FBGA(flipchip BGA,轻型芯片BGA)FC-BGA(Flip-Chip Ball Grid Array,反转芯片球形栅格阵列)FC-PGA(Flip-Chip Pin Grid Array,反转芯片针脚栅格阵列)FDIV(Floationg Point Divide,浮点除)FEMMS:Fast Entry/Exit Multimedia State,快速进入/退出多媒体状态FFT(fast Fourier transform,快速热欧姆转换)FGM(Fine-Grained Multithreading,高级多线程)FID(FID:Frequency identify,频率鉴别号码)FIFO(First Input First Output,先入先出队列)FISC(Fast Instruction Set Computer,快速指令集计算机)flip-chip(芯片反转)FLOPs(Floating Point Operations Per Second,浮点操作/秒)FMT(fine-grained multithreading,纯消除多线程)FMUL(Floationg Point Multiplication,浮点乘)FPRs(floating-point registers,浮点寄存器)FPU(Float Point Unit,浮点运算单元)FSUB(Floationg Point Subtraction,浮点减)GFD(Gold finger Device,金手指超频设备)GHC(Global History Counter,通用历史计数器)GTL(Gunning Transceiver Logic,射电收发逻辑电路)GVPP(Generic Visual Perception Processor,常规视觉处理器)HL-PBGA: 表面黏著,高耐热、轻薄型塑胶球状网阵封装HTT(Hyper-Threading Technology,超级线程技术)Hz(hertz,赫兹,频率单位)IA(Intel Architecture,英特尔架构)IAA(Intel Application Accelerator,英特尔应用程序加速器)ICU(Instruction Control Unit,指令控制单元)ID(identify,鉴别号码)IDF(Intel Developer Forum,英特尔开发者论坛)IEU(Integer Execution Units,整数执行单元)IHS(Integrated Heat Spreader,完整热量扩展)ILP(Instruction Level Parallelism,指令级平行运算)IMM: Intel Mobile Module, 英特尔移动模块Instructions Cache,指令缓存Instruction Coloring(指令分类)IOPs(Integer Operations Per Second,整数操作/秒)IPC(Instructions Per Clock Cycle,指令/时钟周期)ISA(instruction set architecture,指令集架构)ISD(inbuilt speed-throttling device,内藏速度控制设备)ITC(Instruction Trace Cache,指令追踪缓存)ITRS(International Technology Roadmap forSemiconductors,国际半导体技术发展蓝图)KNI(Katmai New Instructions,Katmai新指令集,即SSE)Latency(潜伏期)LDT(Lightning Data Transport,闪电数据传输总线)LFU(Legacy Function Unit,传统功能单元)LGA(land grid array,接点栅格阵列)LN2(Liquid Nitrogen,液氮)Local Interconnect(局域互连)MAC(multiply-accumulate,累积乘法)mBGA (Micro Ball Grid Array,微型球状网阵排列)nm(namometer,十亿分之一米/毫微米)MCA(machine check architecture,机器检查体系)MCU(Micro-Controller Unit,微控制器单元)MCT(Memory Controller,内存控制器)MESI(Modified, Exclusive, Shared, Invalid:修改、排除、共享、废弃)MF(MicroOps Fusion,微指令合并)mm(micron metric,微米)MMX(MultiMedia Extensions,多媒体扩展指令集)MMU(Multimedia Unit,多媒体单元)MMU(Memory Management Unit,内存管理单元)MN(model numbers,型号数字)MFLOPS(Million Floationg Point/Second,每秒百万个浮点操作)MHz(megahertz,兆赫)mil(PCB 或晶片佈局的長度單位,1 mil = 千分之一英寸)MIPS(Million Instruction Per Second,百万条指令/秒)MOESI(Modified, Owned, Exclusive, Shared or Invalid,修改、自有、排除、共享或无效)MOF(Micro Ops Fusion,微操作熔合)Mops(Million Operations Per Second,百万次操作/秒)MP(Multi-Processing,多重处理器架构)MPF(Micro processor Forum,微处理器论坛)MPU(Microprocessor Unit,微处理器)MPS(MultiProcessor Specification,多重处理器规范)MSRs(Model-Specific Registers,特别模块寄存器)MSV(Multiprocessor Specification Version,多处理器规范版本)NAOC(no-account OverClock,无效超频)NI(Non-Intel,非英特尔)NOP(no operation,非操作指令)NRE(Non-Recurring Engineering charge,非重複性工程費用)OBGA(Organic Ball Grid Arral,有机球状网阵排列)OCPL(Off Center Parting Line,远离中心部分线队列)OLGA(Organic Land Grid Array,有机平面网阵包装)OoO(Out of Order,乱序执行)OPC(Optical Proximity Correction,光学临近修正)OPGA(Organic Pin Grid Array,有机塑料针型栅格阵列)OPN(Ordering Part Number,分类零件号码)PAT(Performance Acceleration Technology,性能加速技术)PBGA(Plastic Pin Ball Grid Array,塑胶球状网阵排列)PDIP (Plastic Dual-In-Line,塑料双重直线)PDP(Parallel Data Processing,并行数据处理)PGA(Pin-Grid Array,引脚网格阵列),耗电大PLCC (Plastic Leaded Chip Carriers,塑料行间芯片运载)Post-RISC(加速RISC,或后RISC)PR(Performance Rate,性能比率)PIB(Processor In a Box,盒装处理器)PM(Pseudo-Multithreading,假多线程)PPGA(Plastic Pin Grid Array,塑胶针状网阵封装)PQFP(Plastic Quad Flat Package,塑料方块平面封装)PSN(Processor Serial numbers,处理器序列号)QFP(Quad Flat Package,方块平面封装)QSPS(Quick Start Power State,快速启动能源状态)RAS(Return Address Stack,返回地址堆栈)RAW(Read after Write,写后读)REE(Rapid Execution Engine,快速执行引擎)Register Contention(抢占寄存器)Register Pressure(寄存器不足)Register Renaming(寄存器重命名)Remark(芯片频率重标识)Resource contention(资源冲突)Retirement(指令引退)RISC(Reduced Instruction Set Computing,精简指令集计算机)ROB(Re-Order Buffer,重排序缓冲区)RSE(register stack engine,寄存器堆栈引擎)RTL(Register Transfer Level,暫存器轉換層。
MPC755资料

To locate any published errata or updates for this document, refer to the website at .
Contents 1. Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 2. Features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 3. General Parameters . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 4. Electrical and Thermal Characteristics . . . . . . . . . . . . 7 5. Pin Assignments . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24 6. Pinout Listings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 7. Package Description . . . . . . . . . . . . . . . . . . . . . . . . . 31 8. System Design Information . . . . . . . . . . . . . . . . . . . 36 9. Document Revision History . . . . . . . . . . . . . . . . . . . 50 10. Ordering Information . . . . . . . . . . . . . . . . . . . . . . . . 52
(计算机)英文术语完全介绍

(计算机)英文术语完全介绍二、英文术语完全介绍在每组术语中,我按照英文字母的排列顺序来分类。
1、CPU 3DNow!(3D no waiting,无须等待的3D处理) AAM(AMD Analyst Meeting,AMD分析家会议) ABP(Advanced Branch Prediction,高级分支预测)ACG(Aggressive Clock Gating,主动时钟选择) AIS(Alternate Instruction Set,交替指令集) ALAT (advanced load table,高级载入表) ALU(Arithmetic Logic Unit,算术逻辑单元) Aluminum(铝) AGU(Address Generation Units,地址产成单元) APC(Advanced Power Control,高级能源控制) APIC(Advanced rogrammable Interrupt Controller,高级可编程中断控制器) APS(Alternate Phase Shifting,交替相位跳转) ASB(Advanced System Buffering,高级系统缓冲) ATC (Advanced Transfer Cache,高级转移缓存) ATD(Assembly Technology Development,装配技术发展) BBUL(Bumpless Build-Up Layer,内建非凹凸层) BGA(Ball Grid Array,球状网阵排列) BHT(branch prediction table,分支预测表) Bops(Billion Operations Per Second,10亿操作/秒) BPU(Branch Processing Unit,分支处理单元) BP (Brach Pediction,分支预测) BSP(Boot Strap Processor,启动捆绑处理器) BTAC(Branch Target AddressCalculator,分支目标寻址计算器) CBGA (Ceramic Ball Grid Array,陶瓷球状网阵排列) CDIP (Ceramic Dual-In-Line,陶瓷双重直线) Center Processing Unit Utilization,中央处理器占用率 CFM(cubic feet per minute,立方英尺/秒) CMT(course-grained multithreading,过程消除多线程) CMOS(Complementary Metal Oxide Semiconductor,互补金属氧化物半导体) CMOV (conditional move instruction,条件移动指令) CISC (Complex Instruction Set Computing,复杂指令集计算机) CLK(Clock Cycle,时钟周期) CMP(on-chip multiprocessor,片内多重处理) CMS(Code Morphing Software,代码变形软件) co-CPU(cooperative CPU,协处理器) COB(Cache on board,板上集成缓存,做在CPU 卡上的二级缓存,通常是内核的一半速度)) COD(Cache on Die,芯片内核集成缓存) Copper(铜) CPGA(Ceramic Pin Grid Array,陶瓷针型栅格阵列) CPI(cycles per instruction,周期/指令) CPLD(Complex Programmable Logic Device,複雜可程式化邏輯元件) CPU(Center Processing Unit,中央处理器) CRT(Cooperative Redundant Threads,协同多余线程) CSP(Chip Scale Package,芯片比例封装) CXT(Chooper eXTend,增强形K6-2内核,即K6-3) Data Forwarding(数据前送) dB(decibel,分贝) DCLK(Dot Clock,点时钟) DCT(DRAM Controller,DRAM控制器) DDT(Dynamic Deferred Transaction,动态延期处理) Decode(指令解码) DIB(Dual Independent Bus,双重独立总线) DMT(Dynamic Multithreading Architecture,动态多线程结构) DP(Dual Processor,双处理器) DSM(Dedicated Stack Manager,专门堆栈管理) DSMT(Dynamic Simultaneous Multithreading,动态同步多线程) DST(Depleted Substrate Transistor,衰竭型底层晶体管) DTV(Dual Threshold Voltage,双重极限电压) DUV(Deep Ultra-Violet,纵深紫外光) EBGA(Enhanced Ball Grid Array,增强形球状网阵排列) EBL(electron beam lithography,电子束平版印刷) EC(Embedded Controller,嵌入式控制器) EDEC(Early Decode,早期解码) Embedded Chips(嵌入式) EPA(edge pin array,边缘针脚阵列) EPF (Embedded Processor Forum,嵌入式处理器论坛) EPL (electron projection lithography,电子发射平版印刷)EPM(Enhanced Power Management,增强形能源管理) EPIC (explicitly parallel instruction code,并行指令代码)EUV(Extreme Ultra Violet,紫外光) EUV(extreme ultraviolet lithography,极端紫外平版印刷) FADD (Floationg Point Addition,浮点加) FBGA(Fine-PitchBall Grid Array,精细倾斜球状网阵排列) FBGA(flipchip BGA,轻型芯片BGA) FC-BGA(Flip-Chip Ball Grid Array,反转芯片球形栅格阵列) FC-LGA(Flip-Chip Land Grid Array,反转接点栅格阵列) FC-PGA(Flip-Chip Pin Grid Array,反转芯片针脚栅格阵列) FDIV(Floationg Point Divide,浮点除) FEMMS:Fast Entry/Exit Multimedia State,快速进入/退出多媒体状态 FFT(fast Fouriertransform,快速热欧姆转换) FGM(Fine-Grained Multithreading,高级多线程) FID(FID:Frequency identify,频率鉴别号码) FIFO(First Input First Output,先入先出队列) FISC(Fast Instruction Set Computer,快速指令集计算机) flip-chip(芯片反转) FLOPs (Floating Point Operations Per Second,浮点操作/秒)FMT(fine-grained multithreading,纯消除多线程) FMUL (Floationg Point Multiplication,浮点乘) FPRs (floating-point registers,浮点寄存器) FPU(Float Point Unit,浮点运算单元) FSUB(Floationg Point Subtraction,浮点减) GFD(Gold finger Device,金手指超频设备) GHC(Global History Counter,通用历史计数器) GTL(Gunning Transceiver Logic,射电收发逻辑电路) GVPP(Generic Visual Perception Processor,常规视觉处理器) HL-PBGA: 表面黏著,高耐热、轻薄型塑胶球状网阵封装 HTT(Hyper-Threading Technology,超级线程技术) Hz(hertz,赫兹,频率单位) IA(Intel Architecture,英特尔架构) IAA(Intel Application Accelerator,英特尔应用程序加速器) ICU(Instruction Control Unit,指令控制单元) ID(identify,鉴别号码)IDF(Intel Developer Forum,英特尔开发者论坛) IEU (Integer Execution Units,整数执行单元) IHS(Integrated Heat Spreader,完整热量扩展) ILP (Instruction Level Parallelism,指令级平行运算) IMM: Intel Mobile Module, 英特尔移动模块 Instructions Cache,指令缓存 Instruction Coloring(指令分类) IOPs (Integer Operations Per Second,整数操作/秒) IPC (Instructions Per Clock Cycle,指令/时钟周期) ISA (instruction set architecture,指令集架构) ISD (inbuilt speed-throttling device,内藏速度控制设备)ITC(Instruction Trace Cache,指令追踪缓存) ITRS (International Technology Roadmap for Semiconductors,国际半导体技术发展蓝图) KNI(Katmai New Instructions,Katmai新指令集,即SSE) Latency(潜伏期) LDT(Lightning Data Transport,闪电数据传输总线) LFU(Legacy Function Unit,传统功能单元) LGA(land grid array,接点栅格阵列) LN2(Liquid Nitrogen,液氮) Local Interconnect(局域互连) MAC (multiply-accumulate,累积乘法) mBGA (Micro Ball Grid Array,微型球状网阵排列) nm(namometer,十亿分之一米/毫微米) MCA(machine check architecture,机器检查体系) MCU(Micro-Controller Unit,微控制器单元) MCT (Memory Controller,内存控制器) MESI(Modified, Exclusive, Shared, Invalid:修改、排除、共享、废弃)MF(MicroOps Fusion,微指令合并) mm(micron metric,微米) MMX(MultiMedia Extensions,多媒体扩展指令集)MMU(Multimedia Unit,多媒体单元) MMU(Memory Management Unit,内存管理单元) MN(model numbers,型号数字) MFLOPS(Million Floationg Point/Second,每秒百万个浮点操作) MHz(megahertz,兆赫) mil(PCB 或晶片佈局的長度單位,1 mil = 千分之一英寸) MIPS (Million Instruction Per Second,百万条指令/秒) MOESI (Modified, Owned, Exclusive, Shared or Invalid,修改、自有、排除、共享或无效) MOF(Micro Ops Fusion,微操作熔合) Mops(Million Operations Per Second,百万次操作/秒) MP(Multi-Processing,多重处理器架构)MPF(Micro processor Forum,微处理器论坛) MPU (Microprocessor Unit,微处理器) MPS(MultiProcessor Specification,多重处理器规范) MSRs(Model-SpecificRegisters,特别模块寄存器) MSV(MultiprocessorSpecification Version,多处理器规范版本) NAOC (no-account OverClock,无效超频) NI(Non-Intel,非英特尔) NOP(no operation,非操作指令) NRE (Non-Recurring Engineering charge,非重複性工程費用)OBGA(Organic Ball Grid Arral,有机球状网阵排列) OCPL (Off Center Parting Line,远离中心部分线队列) OLGA (Organic Land Grid Array,有机平面网阵包装) OoO(Out of Order,乱序执行) OPC(Optical Proximity Correction,光学临近修正) OPGA(Organic Pin Grid Array,有机塑料针型栅格阵列) OPN(Ordering Part Number,分类零件号码) PAT(Performance Acceleration Technology,性能加速技术) PBGA(Plastic Pin Ball Grid Array,塑胶球状网阵排列) PDIP (Plastic Dual-In-Line,塑料双重直线) PDP(Parallel Data Processing,并行数据处理) PGA (Pin-Grid Array,引脚网格阵列),耗电大 PLCC (Plastic Leaded Chip Carriers,塑料行间芯片运载) Post-RISC(加速RISC,或后RISC) PR(Performance Rate,性能比率)PIB(Processor In a Box,盒装处理器) PM (Pseudo-Multithreading,假多线程) PPGA(Plastic Pin Grid Array,塑胶针状网阵封装) PQFP(Plastic Quad Flat Package,塑料方块平面封装) PSN(Processor Serialnumbers,处理器序列号) QFP(Quad Flat Package,方块平面封装) QSPS(Quick Start Power State,快速启动能源状态) RAS(Return Address Stack,返回地址堆栈) RAW (Read after Write,写后读) REE(Rapid Execution Engine,快速执行引擎) Register Contention(抢占寄存器) Register Pressure(寄存器不足) Register Renaming (寄存器重命名) Remark(芯片频率重标识) Resource contention(资源冲突) Retirement(指令引退) RISC (Reduced Instruction Set Computing,精简指令集计算机) ROB(Re-Order Buffer,重排序缓冲区) RSE(register stack engine,寄存器堆栈引擎) RTL(Register Transfer Level,暫存器轉換層。
硬件英文表

FSUB(Floationg Point Subtraction,浮点减)
GVPP(Generic Visual Perception Processor,常规视觉处理器)
HL-PBGA: 表面黏著,高耐热、轻薄型塑胶球状矩阵封装IA(Intel Architecture,英特尔架构)
BPU(Branch Processing Unit,分支处理单元)
Brach Pediction(分支预测)
CISC(Complex Instruction Set Computing,复杂指令集计算机)
CLK(Clock Cycle,时钟周期)
COB(Cache on board,板上集成缓存)
Reset switch:重启开关
Speaker:喇叭
ห้องสมุดไป่ตู้
Printer:打印机
Scanner:扫描仪
UPS:不断电系统
IDE:集成设备电路 指IDE接口规格Integrated Device Electronics IDE接口装置泛指采用IDE接口的各种设备
SCSI:小型机系统接口 指SCSI接口规格Small Computer System Interface,SCSI接口装置泛指采用SCSI接口的各种设备
Master 主,slave 从(设备主从跳线,常见于IDE硬盘和IDE光驱)
Primary 主要的 secondary 次要的
S.M.A.R.T.:Self-Monitoring, Analysis and Reporting Technology自我监测分析和报告技术。广泛运用于硬盘
1、CPU
芯片相关简写

1、CPU3DNow!(3D no waiting,无须等待的3D处理)AAM(AMD Analyst Meeting,AMD分析家会议)ABP(Advanced Branch Prediction,高级分支预测)ACG(Aggressive Clock Gating,主动时钟选择)AIS(Alternate Instruction Set,交替指令集)ALAT(advanced load table,高级载入表)ALU(Arithmetic Logic Unit,算术逻辑单元)Aluminum(铝)AGU(Address Generation Units,地址产成单元)APC(Advanced Power Control,高级能源控制)APIC(Advanced rogrammable Interrupt Controller,高级可编程中断控制器)APS(Alternate Phase Shifting,交替相位跳转)ASB(Advanced System Buffering,高级系统缓冲)ATC(Advanced Transfer Cache,高级转移缓存)ATD(Assembly Technology Development,装配技术发展)BBUL(Bumpless Build-Up Layer,内建非凹凸层)BGA(Ball Grid Array,球状网阵排列)BHT(branch prediction table,分支预测表)Bops(Billion Operations Per Second,10亿操作/秒)BPU(Branch Processing Unit,分支处理单元)BP(Brach Pediction,分支预测)BSP(Boot Strap Processor,启动捆绑处理器)BTAC(Branch Target Address Calculator,分支目标寻址计算器)CBGA (Ceramic Ball Grid Array,陶瓷球状网阵排列)CDIP (Ceramic Dual-In-Line,陶瓷双重直线)Center Processing Unit Utilization,中央处理器占用率CFM(cubic feet per minute,立方英尺/秒)CMT(course-grained multithreading,过程消除多线程)CMOS(Complementary Metal Oxide Semiconductor,互补金属氧化物半导体)CMOV(conditional move instruction,条件移动指令)CISC(Complex Instruction Set Computing,复杂指令集计算机)CLK(Clock Cycle,时钟周期)CMP(on-chip multiprocessor,片内多重处理)CMS(Code Morphing Software,代码变形软件)co-CPU(cooperative CPU,协处理器)COB(Cache on board,板上集成缓存,做在CPU卡上的二级缓存,通常是内核的一半速度))COD(Cache on Die,芯片内核集成缓存)Copper(铜)CPGA(Ceramic Pin Grid Array,陶瓷针型栅格阵列)CPI(cycles per instruction,周期/指令)CPLD(Complex Programmable Logic Device,复杂可程式化逻辑元件)CPU(Center Processing Unit,中央处理器)CRT(Cooperative Redundant Threads,协同多余线程)CSP(Chip Scale Package,芯片比例封装)CXT(Chooper eXTend,增强形K6-2内核,即K6-3)Data Forwarding(数据前送)dB(decibel,分贝)DCLK(Dot Clock,点时钟)DCT(DRAM Controller,DRAM控制器)DDT(Dynamic Deferred Transaction,动态延期处理)Decode(指令解码)DIB(Dual Independent Bus,双重独立总线)DMT(Dynamic Multithreading Architecture,动态多线程结构)DP(Dual Processor,双处理器)DSM(Dedicated Stack Manager,专门堆栈管理)DSMT(Dynamic Simultaneous Multithreading,动态同步多线程)DST(Depleted Substrate Transistor,衰竭型底层晶体管)DTV(Dual Threshold Voltage,双重极限电压)DUV(Deep Ultra-Violet,纵深紫外光)EBGA(Enhanced Ball Grid Array,增强形球状网阵排列)EBL(electron beam lithography,电子束平版印刷)EC(Embedded Controller,嵌入式控制器)EDEC(Early Decode,早期解码)Embedded Chips(嵌入式)EPA(edge pin array,边缘针脚阵列)EPF(Embedded Processor Forum,嵌入式处理器论坛)EPL(electron projection lithography,电子发射平版印刷)EPM(Enhanced Power Management,增强形能源管理)EPIC(explicitly parallel instruction code,并行指令代码)EUV(Extreme Ultra Violet,紫外光)EUV(extreme ultraviolet lithography,极端紫外平版印刷)FADD(Floationg Point Addition,浮点加)FBGA(Fine-Pitch Ball Grid Array,精细倾斜球状网阵排列)FBGA(flipchip BGA,轻型芯片BGA)FC-BGA(Flip-Chip Ball Grid Array,反转芯片球形栅格阵列)FC-LGA(Flip-Chip Land Grid Array,反转接点栅格阵列)FC-PGA(Flip-Chip Pin Grid Array,反转芯片针脚栅格阵列)FDIV(Floationg Point Divide,浮点除)FEMMS:Fast Entry/Exit Multimedia State,快速进入/退出多媒体状态FFT(fast Fourier transform,快速热欧姆转换)FGM(Fine-Grained Multithreading,高级多线程)FID(FID:Frequency identify,频率鉴别号码)FIFO(First Input First Output,先入先出队列)FISC(Fast Instruction Set Computer,快速指令集计算机)flip-chip(芯片反转)FLOPs(Floating Point Operations Per Second,浮点操作/秒)FMT(fine-grained multithreading,纯消除多线程)FMUL(Floationg Point Multiplication,浮点乘)FPRs(floating-point registers,浮点寄存器)FPU(Float Point Unit,浮点运算单元)FSUB(Floationg Point Subtraction,浮点减)GFD(Gold finger Device,金手指超频设备)GHC(Global History Counter,通用历史计数器)GTL(Gunning Transceiver Logic,射电收发逻辑电路)GVPP(Generic Visual Perception Processor,常规视觉处理器)HL-PBGA: 表面黏著,高耐热、轻薄型塑胶球状网阵封装HTT(Hyper-Threading Technology,超级线程技术)Hz(hertz,赫兹,频率单位)IA(Intel Architecture,英特尔架构)IAA(Intel Application Accelerator,英特尔应用程序加速器)ICU(Instruction Control Unit,指令控制单元)ID(identify,鉴别号码)IDF(Intel Developer Forum,英特尔开发者论坛)IEU(Integer Execution Units,整数执行单元)IHS(Integrated Heat Spreader,完整热量扩展)ILP(Instruction Level Parallelism,指令级平行运算)IMM: Intel Mobile Module, 英特尔移动模块Instructions Cache,指令缓存Instruction Coloring(指令分类)IOPs(Integer Operations Per Second,整数操作/秒)IPC(Instructions Per Clock Cycle,指令/时钟周期)ISA(instruction set architecture,指令集架构)ISD(inbuilt speed-throttling device,内藏速度控制设备)ITC(Instruction Trace Cache,指令追踪缓存)ITRS(International Technology Roadmap for Semiconductors,国际半导体技术发展蓝图)KNI(Katmai New Instructions,Katmai新指令集,即SSE)Latency(潜伏期)LDT(Lightning Data Transport,闪电数据传输总线)LFU(Legacy Function Unit,传统功能单元)LGA(land grid array,接点栅格阵列)LN2(Liquid Nitrogen,液氮)Local Interconnect(局域互连)MAC(multiply-accumulate,累积乘法)mBGA (Micro Ball Grid Array,微型球状网阵排列)nm(namometer,十亿分之一米/毫微米)MCA(machine check architecture,机器检查体系)MCU(Micro-Controller Unit,微控制器单元)MCT(Memory Controller,内存控制器)MESI(Modified, Exclusive, Shared, Invalid:修改、排除、共享、废弃)MF(MicroOps Fusion,微指令合并)mm(micron metric,微米)MMX(MultiMedia Extensions,多媒体扩展指令集)MMU(Multimedia Unit,多媒体单元)MMU(Memory Management Unit,内存管理单元)MN(model numbers,型号数字)MFLOPS(Million Floationg Point/Second,每秒百万个浮点操作)MHz(megahertz,兆赫)mil(PCB 或晶片布局的长度单位,1 mil = 千分之一英寸)MIPS(Million Instruction Per Second,百万条指令/秒)MOESI(Modified, Owned, Exclusive, Shared or Invalid,修改、自有、排除、共享或无效)MOF(Micro Ops Fusion,微操作熔合)Mops(Million Operations Per Second,百万次操作/秒)MP(Multi-Processing,多重处理器架构)MPF(Micro processor Forum,微处理器论坛)MPU(Microprocessor Unit,微处理器)MPS(MultiProcessor Specification,多重处理器规范)MSRs(Model-Specific Registers,特别模块寄存器)MSV(Multiprocessor Specification Version,多处理器规范版本)NAOC(no-account OverClock,无效超频)NI(Non-Intel,非英特尔)NOP(no operation,非操作指令)NRE(Non-Recurring Engineering charge,非重复性工程费用)OBGA(Organic Ball Grid Arral,有机球状网阵排列)OCPL(Off Center Parting Line,远离中心部分线队列)OLGA(Organic Land Grid Array,有机平面网阵包装)OoO(Out of Order,乱序执行)OPC(Optical Proximity Correction,光学临近修正)OPGA(Organic Pin Grid Array,有机塑料针型栅格阵列)OPN(Ordering Part Number,分类零件号码)PAT(Performance Acceleration Technology,性能加速技术)PBGA(Plastic Pin Ball Grid Array,塑胶球状网阵排列)PDIP (Plastic Dual-In-Line,塑料双重直线)PDP(Parallel Data Processing,并行数据处理)PGA(Pin-Grid Array,引脚网格阵列),耗电大PLCC (Plastic Leaded Chip Carriers,塑料行间芯片运载)Post-RISC(加速RISC,或后RISC)PR(Performance Rate,性能比率)PIB(Processor In a Box,盒装处理器)PM(Pseudo-Multithreading,假多线程)PPGA(Plastic Pin Grid Array,塑胶针状网阵封装)PQFP(Plastic Quad Flat Package,塑料方块平面封装)PSN(Processor Serial numbers,处理器序列号)QFP(Quad Flat Package,方块平面封装)QSPS(Quick Start Power State,快速启动能源状态)RAS(Return Address Stack,返回地址堆栈)RAW(Read after Write,写后读)REE(Rapid Execution Engine,快速执行引擎)Register Contention(抢占寄存器)Register Pressure(寄存器不足)Register Renaming(寄存器重命名)Remark(芯片频率重标识)Resource contention(资源冲突)Retirement(指令引退)RISC(Reduced Instruction Set Computing,精简指令集计算机)ROB(Re-Order Buffer,重排序缓冲区)RSE(register stack engine,寄存器堆栈引擎)RTL(Register Transfer Level,暂存器转换层。
PHOENIX BIOS参数设置

PHOENIX BIOS参数设置一、基本设置(Main)近日很多朋友问,怎么设置光驱启动,总是说的不太明白,所以就用图解说下,直观点,BIOS有三种,AWORD、AMI、PHOENIX这里先介绍PHOENIX。
按F2进入PHOENIXBIOS设置,就会出现如下界面,system time 设置时间格式为(时,分,秒)SYTEM DATA 设置日期LEGACY DISKETEE A:/B: 设置软驱PRIMARY MASTER/SLAVE 设置IDE1设置SECONDARY MASTER/SLAVE 设置IDE2设置keyboard-features 键盘特征,打开后出现下面界面numlock 小键盘灯keyboard auto repeat rate 键盘自动重复时间keyboard auto repeat delay 键盘自动重复延迟时间SYSTEM MENORY 系统内存EXTENDED MEMORY 扩展内存BOOT-time diagnostic screnn 启动时间诊断屏幕二、高级设置(Advanced)(一)Multiprocessor Specification 多重处理器规范 1.4 /1.1它专用于多处理器主板,用于确定MPS的版本,以便让PC制造商构建基于英特尔架构的多处理器系统。
与1.1标准相比,1.4增加了扩展型结构表,可用于多重PCI总线,并且对未来的升级十分有利。
另外,v1.4拥有第二条PCI总线,还无须PCI桥连接。
新型的SOS(Server Operating Systems,服务器操作系统)大都支持1.4标准,包括WinNTt和Linux SMP(Symmetric Multi-Processing,对称式多重处理架构)。
如果可以的话,尽量使用1.4。
(二)Installed o/s 安装O/S模式有IN95和OTHER两个值。
(三)Reset Configuration Data 重设配置数据,有YES和NO两个值。
A Scalable Approach to Thread-Level Speculation

A Scalable Approach to Thread-Level SpeculationJ.Gregory Steffan,Christopher B.Colohan,Antonia Zhai,and Todd C.MowryComputer Science DepartmentCarnegie Mellon UniversityPittsburgh,PA15213steffan,colohan,zhaia,tcm@AbstractWhile architects understandhow to build cost-effective parallelmachines across a wide spectrum of machine sizes(ranging fromwithin a single chip to large-scale servers),the real challenge ishow to easily create parallel software to effectively exploit all ofthis raw performancepotential.One promising technique for over-coming this problem is Thread-Level Speculation(TLS),which en-ables the compiler to optimistically create parallel threads despiteuncertainty as to whether those threads are actually independent.In this paper,we propose and evaluate a design for supportingTLS that seamlessly scales to any machine size because it is astraightforward extension of writeback invalidation-based cachecoherence(which itself scales both up and down).Our experi-mental results demonstrate that our scheme performs well on bothsingle-chip multiprocessors and on larger-scale machines wherecommunication latencies are twenty times larger.1.IntroductionMachines which can simultaneously execute multiple parallelthreads are becoming increasingly commonplace on a wide vari-ety of scales.For example,techniques such as simultaneous mul-tithreading[23](e.g.,the Alpha21464)and single-chip multipro-cessing[16](e.g.,the Sun MAJC[21]and the IBM Power4[10])suggest that thread-level parallelism may become increasingly im-portant even within a single chip.Beyond chip boundaries,evenpersonal computers are often sold these days in two or four-processor configurations.Finally,high-end machines(e.g.,theSGI Origin[14])have long exploited parallel processing.Perhaps the greatest stumbling block to exploiting all of thisraw performance potential is our ability to automatically convertsingle-threaded programs into parallel programs.Despite the sig-nificant progress which has been made in automatically paralleliz-ing regular numeric applications,compilers have had little or nosuccess in automatically parallelizing highly irregular numeric orespecially non-numeric applications due to their complex controlflow and memory access patterns.In particular,it is the fact thatcondition)...x =hash[index1];...hash[index2]=y;...(b)Execution using thread-level speculationEpoch 1hash[10] == hash[3]RedoProcessor1Processor2Processor3Processor4Epoch 4hash[25] == hash[10]attempt_commit()..................ing cache coherence to detect a RAW dependence violation.2.1An ExampleTo illustrate the basic idea behind our scheme,we show an example of how it detects a read-after-write(RAW)dependence violation.Recall that a given speculative load violates a RAW de-pendence if its memory location is subsequently modified by an-other epoch such that the store should have preceded the load in the original sequential program.As shown in Figure2,we aug-ment the state of each cache line to indicate whether the cacheline has been speculatively loaded(SL)and/or speculatively mod-ified(SM).For each cache,we also maintain a logical timestamp (called an epoch number)which indicates the sequential ordering of that epoch with respect to all other epochs,and aflag indicating whether a data dependence violation has occurred.In the example,epoch6performs a speculative load,so the cor-responding cache line is marked as speculatively loaded.Epoch5 then stores to that same cache line,generating an invalidation con-taining its epoch number.When the invalidation is received,three things must be true for this to be a RAW dependence violation. First,the target cache line of the invalidation must be present in the cache.Second,it must be marked as having been speculatively loaded.Third,the epoch number associated with the invalidation must be from a logically-earlier epoch.Since all three conditions are true in the example,a RAW dependence has been violated; epoch6is notified by setting the violationflag.As we will show, the full coherence scheme must handle many other cases,but the overall concept is analogous to this example.In the sections that follow,we define the new speculative cache line states and the actual cache coherence scheme,including the actions which must occur when an epoch becomes homefree or is notified that a violation has occurred.We begin by describing the underlying architecture assumed by the coherence scheme.2.2Underlying ArchitectureThe goal of our coherence scheme is to be both general and scalable to any size of machine.We want the coherence mech-anism to be applicable to any combination of single-threaded or multithreaded processors within a shared-memory multiprocessor (i.e.not restricted simply to single-chip multiprocessors,etc.).For simplicity,we assume that the shared-memory architec-ture supports an invalidation-based cache coherence scheme where all hierarchies enforce the inclusion property.Figure3(a)shows Figure3.Base architecture for the TLS coherence scheme.a generalization of the underlying architecture.There may be a number of processors or perhaps only a single multithreaded processor,followed by an arbitrary number of levels of physi-cally private caching.The level of interest is thefirst level where invalidation-based cache coherence begins,which we refer to as the speculation level.We generalize the levels below the spec-ulation level(i.e.further away from the processors)as an inter-connection network providing access to main memory with some arbitrary number of levels of caching.The amount of detail shown in Figure3(a)is not necessary for the purposes of describing our cache coherence scheme.In-stead,Figure3(b)shows a simplified model of the underlying ar-chitecture.The speculation level described above happens to be a physically shared cache and is simply referred to from now on as “the cache”.Above the caches,we have some number of proces-sors,and below the caches we have an implementation of cache-coherent shared memory.Although coherence can be recursive,speculation only occurs at the speculation level.Above the speculation level(i.e.closer to the processors),we maintain speculative state and buffer specula-tive modifications.Below the speculation level(i.e.further from the processors),we simply propagate speculative coherence ac-tions and enforce inclusion.2.3Overview of Our SchemeThe remainder of this section describes the important details of our coherence scheme,which requires the following key ele-ments:(i)a notion of whether a cache line has been speculatively loaded and/or speculatively modified;(ii)a guarantee that a spec-ulative cache line will not be propagated to regular memory,and that speculation will fail if a speculative cache line is replaced;andDescriptionIESDSpESpSDescriptionReadReadExline with exclusive access.Upgrade-request:gain exclusive access to InvWritebackFlushNotifySharedRead-exclusive-speculative:return cache UpgradeSpaccess to a cache line that is already present.Invalidation-speculative:only invalidateDescriptionThe request has returned shared access.The request has returned exclusive access.The request is from a logically-later epoch.The request is from a logically-earlier epoch.(c)Responses to processor events(d)Responses to external coherence events2.6Baseline Coherence SchemeOur coherence scheme for supporting TLS is summarized by the two state transition diagrams shown in Figures4(c)and4(d). The former shows transitions in response to processor-initiated events(i.e.speculative and non-speculative loads and stores),and the latter shows transitions in response to coherence messages from the external memory system.Let usfirst briefly summarize standard invalidation-based cache coherence.If a load suffers a miss,we issue a read to the memory system;if a store misses,we issue a read-exclusive.If a store hits and the cache line is in the shared(S)state,we issue an upgrade-request to obtain exclusive access.Note that read-exclusive and upgrade-request messages are only sent down into the memory hierarchy by the cache;when the underlying coher-ence mechanism receives such a message,it generates an invalida-tion message(which only travels up to the cache from the memory hierarchy)for each cache containing a copy of the line to enforce exclusiveness.Having summarized standard coherence,we now describe a few highlights of how we extend it to support TLS. 2.6.1Some Highlights of Our Coherence SchemeWhen a speculative memory reference is issued,we transi-tion to the speculative-exclusive(SpE)or speculative-shared(SpS) state as appropriate.For a speculative load we set the SLflag,and for a speculative store we set the SMflag.When a speculative load misses,we issue a normal read to the memory system.In contrast,when a speculative store misses, we issue a read-exclusive-speculative containing the current epoch number.When a speculative store hits and the cache line is in the shared(S)state,we issue an upgrade-request-speculative which also contains the current epoch number.When a cache line has been speculatively loaded(i.e.it is in either the SpE or SpS state with the SLflag set),it is susceptible to a read-after-write(RAW)dependence violation.If a normal invalidation arrives for that line,then clearly the speculation fails. In contrast,if an invalidation-speculative arrives,then a violation only occurs if it is from a logically-earlier epoch.When a cache line is dirty,the cache owns the only up-to-date copy of the cache line and must preserve it.When a speculative store accesses a dirty cache line,we generate aflush to ensure that the only up-to-date copy of the cache line is not corrupted with speculative modifications.For simplicity,we also generate aflush when a speculative load accesses a dirty cache line(we describe later in Section2.7how this case can be optimized).A goal of this version of the coherence scheme is to avoid slow-ing down non-speculative threads to the extent possible.Hence a cache line in a non-speculative state is not invalidated when an invalidation-speculative arrives from the external memory system. For example,a line in the shared(S)state remains in that state whenever an invalidation-speculative is received.Alternatively, the cache line could be relinquished to give exclusiveness to the speculative thread,possibly eliminating the need for that specula-tive thread to obtain ownership when it becomes homefree.Since the superior choice is unclear without concrete data,we compare the performance of both approaches later in Section5.4.2.6.2When Speculation SucceedsOur scheme depends on ensuring that epochs commit their speculative modifications to memory in logical order.We imple-ment this ordering by waiting for and passing the homefree token at the end of each epoch.When the homefree token arrives,we know that all logically-earlier epochs have completely performed all speculative memory operations,and that any pending incom-ing coherence messages have been processed—hence memory is consistent.At this point,the epoch is guaranteed not to suffer any further dependence violations with respect to logically-earlier epochs,and therefore can commit its speculative modifications.Upon receiving the homefree token,any line which has only been speculatively loaded immediately makes one of the following state transitions:either from speculative-exclusive(SpE)to exclu-sive(E),or else from speculative-shared(SpS)to shared(S).We will describe in the next section how these operations can be im-plemented efficiently.For each line in the speculative-shared(SpS)state that has been speculatively modified(i.e.the SMflag is set),we must issue an upgrade-request to acquire exclusive ownership.Once it is owned exclusively,the line may transition to the dirty(D) state—effectively committing the speculative modifications to reg-ular memory.Maintaining the notion of exclusiveness is therefore important since a speculatively modified line that is exclusive(i.e. SpE with SM set)can commit its results immediately simply by transitioning directly to the dirty(D)state.It would obviously take far too long to scan the entire cache for all speculatively modified and shared lines—ultimately this would delay passing the homefree token and hurt the performance of our scheme.Instead,we propose that the addresses of such lines be added to an ownership required buffer(ORB)whenever a line be-comes both speculatively modified and shared.Hence whenever the homefree token arrives,we can simply generate an upgrade-request for each entry in the ORB,and pass the homefree token on to the next epoch once they have all completed.2.6.3When Speculation FailsWhen speculation fails for a given epoch,any specula-tively modified lines must be invalidated,and any speculatively loaded lines make one of the following state transitions:either from speculative-exclusive(SpE)to exclusive(E),or else from speculative-shared(SpS)to shared(S).In the next section,we will describe how these operations can also be implemented efficiently.2.7Performance OptimizationsWe now present several methods for improving the perfor-mance of our baseline coherence scheme.Forwarding Data Between Epochs:Often regions that we would like to parallelize contain predictable data dependences be-tween epochs.We can avoid violations due to these dependences by inserting wait–signal synchronization.After producing thefi-nal value of a variable,an epoch signals the logically-next epoch that it is safe to consume that value.Our coherence scheme can be extended to support value forwarding through regular memory by allowing an epoch to make non-speculative memory accesses while it is still speculative.Hence an epoch can perform a non-speculative store whose value will be propagated to the logically-next epoch without causing a dependence violation.Dirty and Speculatively Loaded State:As described for the baseline scheme,when a speculative load or store accesses adirty cache line we generate aflush,ensuring that the only up-to-date copy of a cache line is not corrupted with speculative modifi-cations.Since a speculative load cannot corrupt the cache line,it is safe to delay writing the line back until a speculative store oc-curs.This minor optimization is supported with the addition of the dirty and speculatively loaded state(DSpL),which indicates that a cache line is both dirty and speculatively loaded.Since it is trivial to add support for this state,we include it in the baseline scheme that we evaluate later in Section5.Suspending Violations:Recall that if a speculatively ac-cessed line is replaced,speculation must fail because we can no longer track dependence violations.In our baseline scheme,if an epoch is about to evict a speculative line from the cache,we simply let it proceed and signal a dependence violation.(Since one epoch is always guaranteed to be non-speculative,this scheme will not deadlock.)Alternatively,we could suspend the epoch un-til it becomes homefree,at which point we can safely allow the replacement to occur since the line is no longer speculative. Support for Multiple Writers:If two epochs speculatively modify the same cache line,there are two ways to resolve the sit-uation.One option is to simply squash the logically-later epoch, as is the case for our baseline scheme.Alternatively,we could al-low both epochs to modify their own copies of the cache line and combine them with the real copy of the cache line as they commit, as is done in a multiple-writer coherence protocol[3,4].To support multiple writers in our coherence scheme—thus al-lowing multiple speculatively modified copies of a single cache line to exist—we need the following two new features.First,an invalidation-speculative will only cause a violation if it is from a logically-earlier epoch and the line is speculatively loaded;this al-lows multiple speculatively modified copies of the same cache line to co-exist.Second,we must differentiate between normal invali-dations(triggered by remote stores)and invalidations used only to enforce the inclusion property(triggered by replacements deeper in the cache hierarchy).A normal invalidation will not invali-date a speculative cache line that is only speculatively modified; hence the homefree epoch can commit a speculatively modified cache line to memory without invalidating logically-later epochs that have speculatively modified the same cache line.3.Implementing Our SchemeWe now describe a potential implementation of our coherence scheme.We begin with a hardware implementation of epoch num-bers.We then give an encoding for cache line states,and describe the organization of epoch state information.Finally,we describe how to allow multiple speculative writers and how to support spec-ulation in a shared cache.3.1Epoch NumbersIn previous sections,we have mentioned that epoch numbers are used to determine the relative ordering between epochs.In the coherence scheme,an epoch number is associated with every speculatively-accessed cache line and every speculative coherence action.The implementation of epoch numbers must address sev-eral issues.First,epoch numbers must represent a partial ordering (rather than total ordering)since epochs from independent pro-grams or even from independent chains of speculation within the same program are unordered with respect to each other.We im-plement this by having each epoch number consist of two parts: a thread identifier(TID)and a sequence number.If the TIDs from two epoch numbers do not match exactly,then the epochs are unordered.If the TIDs do match,then the signed difference between the sequence numbers is computed to determine logical ordering.(Signed differences preserve the relative ordering when the sequence numbers wrap around.)The second issue is that we would like this comparison of epoch numbers to be performed quickly.At the same time,we would like to have theflexibility to have large epoch numbers (e.g.,32or even64bits),since this simplifies TLS code gener-ation when there is aggressive control speculation[19].Rather than frequently computing the signed differences between large sequence numbers,we instead precompute the relative ordering between the current epoch and other currently-active epochs,and use the resulting logically-later mask to perform simple bit-level comparisons(as discussed later in Section3.4).The third issue is storage overhead.Rather than storing large epoch numbers in each cache line tag,we instead exploit the logically-later mask to store epoch numbers just once per chip. 3.2Implementation of Speculative StateWe encode the speculative cache line states given in Figure4(a) usingfive bits as shown in Figure5(a).Three bits are used to en-code basic coherence state:exclusive(Ex),dirty(Di),and valid (Va).Two bits—speculatively loaded(SL)and speculatively mod-ified(SM)—differentiate speculative from non-speculative states. Figure5(b)shows the state encoding which is designed to have the following two useful properties.First,when an epoch becomes homefree,we can transition from the appropriate speculative to non-speculative states simply by resetting the SM and SL bits.Sec-ond,when a violation occurs,we want to invalidate the cache line if it has been speculatively modified;this can be accomplished by setting its valid(Va)bit to the AND of its Va bit with the comple-ment of its SM bit(i.e.Va=Va&!SM).Figure5(c)illustrates how the speculative state can be ar-ranged.Notice that only a small number of bits are associated with each cache line,and that only one copy of an epoch number is needed.The SL and SM bit columns are implemented such that they can beflash-reset by a single control signal.The SM bits are also wired appropriately to their corresponding Va bits such that they can be simultaneously invalidated when an epoch is squashed. Also associated with the speculative state are an epoch number,an ownership required buffer(ORB),the addresses of the cancel and violation routines,and a violationflag which indicates whether a violation has occurred.3.3Allowing Multiple WritersAs mentioned earlier in Section2.7,it may be advantageous to allow multiple epochs to speculatively modify the same cache line. Supporting a multiple writer scheme requires the ability to merge partial modifications to a line with a previous copy of the line;this in turn requires the ability to identify any partial modifications. One possibility is to replicate the SM column of bits so that there are as many SM columns as there are words(or even bytes)inDescriptionV aDiExSLSMSL Ex VaI X XE00S00D01DSpL01SpE001111SpS001111Figure5.Encoding of cache line states.Figure6.Support for combining cache lines.a cache line,as shown in Figure5(c).We will call thesefine-grain SM bits.When a write occurs,the appropriate SM bit is set. If a write occurs which is of lower granularity than the SM bits can resolve,we must conservatively set the SL bit for that cache line since we can no longer perform a combine operation on this cache line—setting the SL bit ensures that a violation is raised if a logically-earlier epoch writes the same cache line.Figure6shows an example of how we combine a speculatively modified version of a cache line with a non-speculative one.Two epochs speculatively modify the same cache line simultaneously, setting thefine-grain SM bit for each location modified.A specu-latively modified cache line is committed by updating the current non-speculative version with only the words for which thefine-grain SM bits are set.In the example,both epochs have modified thefirst location.Since epoch i+1is logically-later,its value(G) takes precedence over epoch i’s value(E).Because dependence violations are normally tracked at a cache line granularity,another potential performance problem is false violations—i.e.where disjoint portions of a line were read and written.To help reduce this problem,we observe that a line only needs to be marked as speculatively loaded(SL)when an epoch reads a location that it has not previously overwritten(i.e.the load is exposed[1]).Thefine-grain SM bits allow us to distinguish exposed loads,and therefore can help avoid false violations.3.4Support for Speculation in a Shared CacheWe would like to support multiple speculative contexts within a shared cache for three reasons.First,we want to maintain specula-tive state across OS-level context switches so that we can support TLS in a multiprogramming environment.Second,we can use multiple speculative contexts to allow a single processor to exe-cute another epoch when the current one is suspended(i.e.during a suspending violation).Finally,multiple speculative contexts al-low TLS to work with simultaneous multithreading(SMT)[23].TLS in a shared cache allows epochs from the same program to access the same cache lines with two exceptions:(i)two epochs may not modify the same cache line,and(ii)an epoch may not read the modifications of a logically-later epoch.We can enforce these constraints either by suspending or violating the appropri-ate epochs,or else through cache line replication.With the latter approach,a speculatively modified line is replicated whenever an-other epoch attempts to speculatively modify that same line.This replicated copy is obtained from the external memory system,and both copies are kept in the same associative set of the shared cache. If we run out of associative entries,then replication fails and we must instead suspend or violate the logically-latest epoch owning a cache line in the associative set.Suspending an epoch in this case must be implemented carefully to avoid deadlock.Figure5(c)shows hardware support for shared-cache specula-tion where we implement several speculative contexts.The Ex, Di,and Va bits for each cache line are shared between all specula-tive contexts,but each speculative context has its own SL and SM bits.Iffine-grain SM bits are implemented,then only one group of them is necessary per cache line(shared by all speculative con-texts),since only one epoch may modify a given cache line.The single SM bit per speculative context indicates which speculative context owns the cache line,and is simply computed as the OR ofall of thefine-grain SM bits.To determine whether a speculative access requires replication, we must compare the epoch number and speculative state bits with other speculative contexts.Since epoch number comparisons may be slow,we want to use a bit mask which can compare against all speculative contexts in one quick operation.We maintain a logically-later mask for each speculative context(shown in Fig-ure5(c))that indicates which speculative contexts contain epochs that are logically-later,thus allowing us to quickly make the com-parisons using simple bit operations[19].3.5Preserving CorrectnessIn addition to data dependences,there are a few other issues re-lated to preserving correctness under TLS.First,speculation must fail whenever any speculative state is lost(e.g.,the replacement of a speculatively-accessed cache line,the overflow of the ORB, etc.).Second,as with other forms of speculation,a speculative thread should not immediately invoke an exception if it derefer-ences a bad pointer,divides by zero,etc.;instead,it must wait un-til it becomes homefree to confirm that the exception really should have taken place,and for the exception to be precise.Third,if an epoch relies on polling to detect failed speculation and it con-tains a loop,a poll must be inserted inside the loop to avoid infinite looping.Finally,system calls generally cannot be performed spec-ulatively without special support.We will explore this issue more aggressively in future work;for now,we simply stall a speculative thread if it attempts to perform a system call until it is homefree.4.Experimental FrameworkWe evaluate our coherence protocol through detailed simula-tion.Our simulator models4-way issue,out-of-order,superscalar processors similar to the MIPS R10000[24].Register renaming, the reorder buffer,branch prediction,instruction fetching,branch-ing penalties,and the memory hierarchy(including bandwidth and contention)are all modeled,and are parameterized as shown in Ta-ble1.We simulate all applications to completion.Our baseline architecture has four tightly-coupled,single-threaded processors,each with their own primary data and instruc-tion caches.These are connected by a crossbar to a4-bank,unified secondary cache.Our simulator implements the coherence scheme defined in Section2using the hardware support described in Sec-tion3.To faithfully simulate the coherence traffic of our scheme, we model8bytes of overhead for coherence messages that contain epoch numbers.Because epoch numbers are compared lazily(and in parallel with cache accesses),they have no impact on memory access latency.The simulated execution model makes several assumptions with respect to the management of epochs and speculative threads. Epochs are assigned to processors in a round-robin fashion,and each epoch must spawn the next epoch through the use of a lightweight fork instruction.For our baseline architecture,we as-sume that a fork takes10cycles,and this same delay applies to synchronizing two epochs when forwarding occurs.Violations are detected through polling,so an epoch runs to completion before checking if a violation has occurred.When an epoch suffers a violation,we also squash all logically-later epochs.We are simulating real MIPS binaries which contain TLS in-structions.Unused coprocessor instruction encodings are used forTable1.Simulation parameters.Pipeline ParametersIssue WidthFunctional UnitsReorder Buffer SizeInteger MultiplyInteger DivideAll Other IntegerFP DivideFP Square RootAll Other FPBranch Prediction32B32KB,4-way set-assoc32KB,2-way set-assoc,2banks2MB,4-way set-assoc,4banks8for data,2for insts8B per cycle per bank10cycles Secondary CacheMinimum Miss Latency to1access per20cycles10cycles200cycles TLS primitives,and are added to the applications using gcc ASM statements.To produce this code,we are using a set of tools based on the SUIF compiler system.These tools,which are not yet com-plete,help analyze the dependencepatterns in the code,insert TLS primitives into loops,perform loop unrolling,and insert synchro-nization code.The choice of loops to parallelize and other op-timizations(described below)were made by hand,although we plan to have a fully-automatic compiler soon.We only parallelize regions of code that are not provably parallel(by a compiler).Table2shows the applications used in this study:buk is an implementation of the bucket sort algorithm;compress95per-forms data compression and decompression;equake uses sparse matrix computation to simulate an earthquake;and ijpeg per-forms various algorithms on images.The buk application has been reduced to its kernel,removing the data set generation and verification code—the other applications are run in their entirety. For compress95,certain loop-carried dependences occur fre-quently enough that we either hoist them outside of the loop or else explicitly forward them using wait-signal synchronization. 5.Experimental ResultsWe now present the results of our simulation studies.To quan-tify the effectiveness of our support for TLS,we explore the impact of various aspects of our design on the performance of the four ap-plications.Our initial sets of experiments are for a single-chip multiprocessor,and later(in Section5.5)we evaluate larger-scale machines that cross chip boundaries.5.1Performance of the Baseline SchemeTable3summarizes the performance of each application on our baseline architecture,which is a four-processor single-chip multiprocessor that implements our baseline coherence scheme. Throughout this paper,all speedups(and other statistics relative to a single processor)are with respect to the original executable (i.e.without any TLS instructions or overheads)running on a sin-gle processor.Hence our speedups are absolute speedups and not。
PhoenixBIOS Setup Utility图解

近日很多朋友问,怎么设置光驱启动,总是说的不太明白,所以就用图解说下,直观点,BIOS有三种,A WORD、AMI、PHOENIX这里先介绍PHOENIX。
按F2进入PHOENIXBIOS设置,就会出现如下界面,system time 设置时间格式为(时,分,秒)SYTEM DA TA设置日期LEGACY DISKETEE A:/B: 设置软驱PRIMARY MASTER/SLAVE 设置IDE1设置SECONDARY MASTER/SLA VE 设置IDE2设置keyboard-features 键盘特征,打开后出现下面界面numlock 小键盘灯keyboard auto repeat rate 键盘自动重复时间keyboard auto repeat delay 键盘自动重复延迟时间SYSTEM MENORY 系统内存EXTENDED MEMORY 扩展内存Advanced(高级设置)Multiprocessor Specification 多重处理器规范 1.4 /1.1它专用于多处理器主板,用于确定MPS的版本,以便让PC制造商构建基于英特尔架构的多处理器系统。
与1.1标准相比,1.4增加了扩展型结构表,可用于多重PCI 总线,并且对未来的升级十分有利。
另外,v1.4拥有第二条PCI总线,还无须PCI桥连接。
新型的SOS(Server Operating Systems,服务器操作系统)大都支持1.4标准,包括WinNTt和Linux SMP(Symmetric Multi-Processing,对称式多重处理架构)。
如果可以的话,尽量使用1.4。
Installed o/s 安装O/S模式有IN95和OTHER两个值。
Reset Configuration Data 重设配置数据,有YES和N O两个值。
CCache Memory (快取记忆体)此部份提供使用者如何组态特定记忆体区块的方法.Memory Cache (记忆体快取)设定记忆体的状态.Enabled开启记忆体快取功能.Disabled关闭记忆体快取功能.(预设值)Cache System BIOS area (快取系统BIOS区域)控制系统BIOS区域的快取.Uncached不快取系统BIOS区域.Write Protect忽略写入/储存设定.(预设值)Cache Vedio BIOS area (快取视讯BIOS区域)控制视讯BIOS区域的快取.Uncached不快取视讯BIOS区域.Write Protect忽略写入/储存设定.(预设值)Cache Base 0-512K / 512K-640K (快取传统0-512K / 512K-640K) 控制512K / 512K-640K传统记忆体的快取.Uncached不快取视讯BIOS区域.Write Through将写入快取,并同时传送至主记忆体.Write Protect忽略写入/储存设定.Write Back将写入快取,但除非必要,不传送至主记忆体.(预设Cache Extended Memory Area (快取延伸记忆体区域)控制1MB以上的系统记忆体.Uncached不快取视讯BIOS区域.Write Through将写入快取,并同时传送至主记忆体.Write Protect忽略写入/储存设定.Write Back将写入快取,但除非必要,不传送至主记忆体.(预设值) Cache A000-AFFF / B000-BFFF/ C8000-CFFF / CC00-CFFF / D000-DFFF / D400-D7FF/ D800-DBFF / DC00-DFFF / E000-E3FF / E400-F7FFDisabled不快取这个区块.(预设值)USWC CachingUncached Speculative Write Combined.I/O Device Configuration输入输出选项Serial port A:/B:串行口也就是常说的COM口设置有三个值AUTO自动,ENABLED开启,DISABLED关闭。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Speculative Multiprocessor Cache Line Actions Using Instruction and Line History1David M.Koppelman2Department of Electrical&Computer EngineeringLouisiana State University,Baton Rouge102EE Building,Baton Rouge,LA,70803U.S.A.Abstract:A technique is described for reducing miss latency in coherent-cache shared-memory parallel computers.Miss latency is reduced by speculatively invalidating and updating(copying an exclusively held line back to memory)cache lines at one proces-sor that might be needed at another processor.A line becomes a candidate for speculative invalidation when another line last accessed by the same instruction is invalidated.A line becomes a candidate for speculative updating under corresponding condi-tions.The technique can be implemented by constructing linked lists of lines for each memory access instruction.The amount of memory needed by an implementation is less than50%the size of the cache,roughly comparable to the cost of adding error-correcting memory.No time need be added to cache hits.In execution-driven simulations of such systems running programs from the Splash2suite invalidations and updates are reduced by 50%or more.Total time spent servicing misses is reduced by about20%on16-processor systems,execution time is reduced as much as20%for some benchmarks on high latency systems. Keywords:Multiprocessor,Coherent Caches,Cache Manage-ment,Instruction History,Speculative Invalidation1IntroductionThe time needed to complete shared-memory operations is a significant factor in the performance of coherent-cache shared-memory parallel computers.The messages needed to maintain cache coherence can take hundreds of cycles or more to reach distant processors.Even on the fastest systems in which messages reach their destinations in tens of cycles memory operations take much longer than the several cycles typically needed when the cache is hit[3,13,16].On systems using directory-based cache-coherence[3,13]an operation that misses the cache must wait for two or four message transit times.(The number of messages may be higher.)For example,a read miss to a memory location that is not exclusively held may be satisfied in two message delays:the message sent to the home memory and a return message containing the data. Misses can result in four message delays in the case of a write to a location which is cached elsewhere and in the case of a read miss to a location which is exclusively held(by another cache).In the former case the copies held elsewhere are invalidated,in the latter a request is made for the newly written data.(See[3,13] for details.)Cache misses that must wait four message delays will be called second-cache misses.A method is introduced here which reduces the number of second-cache misses by speculatively invalidating or updating (restoring to the shared state)cache lines.Speculative invali-dation reduces the number of write misses in which the data is cached elsewhere.Speculative updating reduces the number of read misses in which the data is exclusively held.As a result of these actions miss latency is reduced since fewer messages,on average,are needed.The choice of lines to speculatively invalidate or update is made assuming that those lines last accessed by an instruction may share the same fate.That is,if one line last-accessed by a particular instruction is invalidated,then other lines last-accessed by the instruction will likely be invalidated.The same idea is used for updating.This idea is implemented by constructing,for each active memory access instruction,a linked list of accessed lines.A line is added to the list when the access instruction operates on it.A line can belong to only one list at a time,so a subsequent access by another instruction will remove the line from thefirst list and place it on the new instruction’s list.The updating of the pointers needed to implement the linked list,as well as the speculative actions,need not be com-pleted during a cache access.Therefore,maintaining the lists adds little or nothing to the cache-hit latency.The speculative actions do add to the volume of communication;added volume is only a problem if it slows down other traffic.Execution-driven simu-lations show that the additional volume only adds a very small amount to the time needed for normal network traffic,while the overall time for shared-memory access is reduced.Other methods of reducing shared-memory access latency have been reported.Prefetching is in some ways similar to the technique described here.Software prefetch schemes use prefetch instructions,which bring data to a cache but otherwise have no effect,inserted by the programmer or compiler.(See[9,15]for prefetching on serial systems and[8,12]for parallel systems.)Soft-ware prefetching works well when the data needed can be identi-fied well enough in advance.The scheme described here does not depend upon such identification by a compiler or programmer;no changes at all need be made to object code.Prefetch instructions are not needed in hardware prefetch-ing schemes.A hardware prefetching scheme is described by Dahlgren,Dubois(in thefirst reference),and Stenstr¨o m[6,7]for parallel systems and by Chen and Baer[4]for serial systems. Blocks to be prefetched are identified by guessing the stride of memory accesses.Once determined,prefetch can occur as far in advance as needed.The effectiveness of such schemes depends upon regular access to memory and so may only work for certain programs.Other schemes attempt to determine the behavior of ac-cesses to a location[1,5,11,17].In an adaptive caching scheme described by Bennett,Carter,and Zwaenepoel,data sharing be-havior is divided into classes.In a system based on this idea,the history of memory accesses to a location would be used to deter-mine its class.A coherence mechanism appropriate to the class would then be chosen for the location.Trace driven simulations show that classes can be detected and that performance gains are possible.Cox and Fowler[5]and in a similar paper Stenstr¨o m,Brors-son,and Sandberg[17],observe that a pattern of read/invalidate/ miss observed at a line might indicate that the data is migratory, exclusively read and written over a span of time by one processor at a time.A read by a processor to such a line might fetch an exclusive copy(rather than a shared copy),anticipating a write1To appear in the proceedings of The10th International Conference on Parallel&Distributed Computing Systems,New Orleans,Louisiana,October 1997.2This work is supported in part by the Louisiana Board of Regents through the Louisiana Education Quality Support Fund,contract number LEQSF (1993-95)-RD-A-07and by the National Science Foundation under Grant No.MIP-9410435.310 LD R1, [R2]314 ADD R3,R1,R4320 MUL R5,R3,R6324 ST [R7], R5Instr. Hist. Table (IHT)Line History Table (LHT)A dd r P t r sS t a t e Executing Code Figure 1.Relationship between code,IHT,and LHT:IHT has an entryfor the two memory access instructions in illustrated code.Each entry points to linked list of lines last-accessed by the instruction,stored in LHT.A dd r S t a t P tr sExample of speculative invalidation:1)Normal invalidationmessage received from memory.2)Line invalidated and speculative in-validation initiated.3)Tail of list speculatively invalidated.4)New tail of list speculatively invalidated,list is empty,ending these invalidations.by the processor.Lebeck and Wood describe a scheme in which the cache directory (located at the memory module)observes a block’s behavior.Based on this behavior it might speculatively invalidate the block in certain caches [11].One shortcoming with these methods is that the behavior is associated with a line—one line.The behavior at a line must first be detected before any performance benefit is realized in accesses to the line.In the scheme described here behavior is associated with an instruction;once the behavior is detected the perfor-mance benefit is realized in all lines accessed by the instruction.A big improvement since the ratio of number of lines to number of instructions can be very large.Lilja describes a scheme in which the policy chosen for a write instruction,write invalidate or write update,is based upon its execution history,using software assistance [14].It is similar to the method described here in that the fate of a line is tied to the instruction that last accessed it.It is however less flexible,since only instructions that were the last to write a line could initiate an update (write back).In the method described here,a line is speculatively updated only if another line last-accessed by the same instruction is updated.This could happen long after the write executed or after some lines accessed by the write were subsequently written by other instructions.2Speculative Invalidation Hardware2.1HardwareSpeculative actions are added to multiprocessor,cached shared memory parallel systems;for some background see [3,13].Speculative invalidation and updating can be implemented by adding two tables and some control hardware to each cache andby making minor modifications to the memory controllers.The cache has two tables added,an instruction history table (IHT)and a line history table (LHT).The IHT stores the head and tail of active instructions’linked lists,as well as other data.The LHT stores the pointers needed to implement the linked list.A con-troller is used to maintain the lists and to perform the speculative actions.Each cache line has an associated LHT entry.(The LHT entry could be located on the same physical devices used for the line,however there may be cost and performance benefits when they are kept separate.)Figure 1illustrates the relationship be-tween the tables and executing code.The code fragment in the left part of the figure contains two memory access instructions;entries for the two are in the IHT in the center of the figure.The LHT in the right of the figure holds the linked list.An IHT en-try may also contain information used to determine if speculative action is warranted.Whenever a memory access instruction hits the cache,the corresponding line’s LHT entry is read.The previous and next pointers are used to remove the line from the list it was in when accessed (if any).The memory accesses instruction’s IHT index is written to the line’s LHT entry.The IHT entry for the memory access instruction and the line pointed to by the IHT entry’s head pointer are updated so that the accessed line is the new list head.Speculative actions are triggered by invalidation and update messages (sent from the memory to the cache).When an invalida-tion message is received,the target line is invalidated as usual.In addition,a process called list traversal is possibly started.First,the line’s LHT entry is read and the identity of the last-accessing instruction is determined.The IHT entry for that instruction is read.Based on information in the IHT entry a decision is made on whether to proceed with list traversal.If positive,the tail pointer is read,and the line to which it points is speculatively invalidated or updated.A line is speculatively invalidated by sending a speculative invalidation message to the home memory (containing data if the line were exclusively held).The IHT’s tail pointer is updated,and the next speculative action is scheduled.An example of specu-lative invalidation is illustrated in Figure 2.The procedure for speculative updates is similar,except lines are not removed from the list and,of course,speculative update messages are sent to memory.The data in a line that had been speculatively invalidated from the cache is treated no differently than if the memory had sent an invalidation message:a subsequent access to that location will miss the cache.A speculatively updated line is no different than one that had been copied back:to complete a write an exclusive copy would have to be re-obtained.To avoid network congestion and memory hotspots the rate of list traversal should be controlled.In the simulations,a rate was determined statically using network topology,link widths,and other data.For higher performance,the rate of list traversal could be based on the current state of the network.2.2Performance Monitoring HardwareThe effectiveness of speculative invalidation would be re-duced if a processor frequently accessed a block that it had spec-ulatively invalidated but that had not been subsequently written by another processor.Such events will be called false positives .False positives also occur when there are speculative updates tolines which are later written at the same processor,before beingread elsewhere.To reduce the number of false positives a record is kept foreach memory access instruction of the effectiveness of the spec-ulative actions using that instruction’s linked list.List traversal would not be initiated for instructions generating too many falsepositives.The damage from false positives is also reduced by limitingthe number of lines acted upon during list traversal,avoidingthe significant performance degradation that would occur on a long list of false positives.For the experiments described below,the limit was twenty for invalidation,but there was no limit forupdating.List traversal resumes if the lines remain unaccessed at the cache and an invalidation arrives for a remaining list member.2.3Hardware CostMost of the cost of the speculative hardware is in the IHT and LHT and the controller needed at the caches.The cost willbe estimated byfinding the amount of additional storage needed.Let n IHT denote the number of entries in the IHT.Letn s,n c,and n l denote the number of sets,the number of lines inthe cache,and the size of the lines at each processor,respectively. Each LHT entry contains pointers to two other LHT entries.Sincethere is one LHT entry for each cache line,the pointers need to be log2n c bits.(If n c is an integral power of two then the pointers must be1+log2n c bits,to code a null value.)The size of thelast-accessorfield must be log2n IHT bits.The line itself must store the data as well as a tag.Thesize of the line for a byte-addressable system is given by8n l+A− log2n s − log2n l bits,where A is the number of bits in an address.The ratio of the amount of storage for the LHT to the amount of storage for the line is given by2 log2n c + log2n IHT(a )0.000.200.400.600.801.00bar chol fft fmm lu oc rdx wsq S e c o n d C a c h e M i s s e s(b)0.500.600.700.800.901.001.10bar chol fft fmm lu oc rdx wsq T o t . M i s s L a t . (N o r m .)(c)0.700.750.800.850.900.951.001.05bar chol fft fmm lu oc rdx wsq E x e c . T i m e (N o r m .)Figure 4.Effect of cache size on (a )fraction of second cache misses with (shaded)and without (outline)speculative actions,(b )total miss latency,and (c )execution time.Bars normalized to conventional system.Table I :Basic Configuration ParametersSimulation Parameter System Size42=4×4mesh 212bytesTLB CapacityLRU,fully assoc.213setsCache Associativity16bytesCache Capacity1cycle full mapCompletion Buffer10cyclesn pr =6bytes (plus data)Network Interface Width4bytesHop LatencyN ,six-step”algorithm,and LU is a dense-matrix LU factoriza-tion program.Four Splash 2applications were also run,Barnes,FMM,Ocean (contiguous partitions),and Water N 2.Barnes sim-ulates particle interactions in three dimensions using the Barnes-Hut method and FMM simulates particle interactions in two di-mensions using the Adaptive Fast Multipole Method;both use tree-based data structures,though of different types.Water N 2simulates forces on water molecules and Ocean simulates oceancurrents [18].The programs were run using the base problem sizes specified in the distribution.The programs’comments spec-ify where statistics gathering might start and stop;the statistics described below are collected in those intervals.3.3ConfigurationsThe experiments tested several different parallel-computer configurations.Variations were made in network characteristics,memory timing,and cache structure.The table gives the sim-ulation parameters describing the basic configuration .The dif-ferences from the basic configuration will be noted for each ex-periment.Some parameters are explained below;see [10]for a detailed explanation of the network-and memory-related param-eters.3.4Simulated Speculative HardwareIn the implementation modeled by the experiments,specu-lative invalidation occurs at two rates:fast,for short lists,and slow,for long lists.After a speculative invalidation occurs the list length is checked;if it is less than n slow then the next ac-tion (if any)is scheduled for t a −fast cycles later.Otherwise,it is scheduled for t a −slow cycles later.The fast rate is based on the maximum amount of traffic a single link could carry (multiplied by a tuning coefficient)when one cache is in the process of list traversal and there are no other message sources.The slow rate is based on the maximum amount of traffic a single link could carry (multiplied by a tuning coefficient)when all caches are in list traversal and there are no other message sources.4Experiments4.1Basic ConfigurationThe effectiveness of speculative actions at reducing the num-ber of second-cache misses is illustrated in Figure 3for the basic configuration.There is a pair of bars,indicating misses,for each benchmark;the bar on the left is for the conventional system;the bar on the right is for systems using speculative actions.The size of the bar segments indicate the number of each type of miss.Second cache misses,outlined in bold,are labeled W-RO for a write to a block which is shared in another cache;W-RW for a write to a block which is exclusive in another cache;and R-RW for a read to a block which is exclusive in another cache.Other read and write misses are denoted R-M-1and W-M-1,respec-tively.The segment sizes are scaled so that the number of misses in the conventional system is one.As can be seen,the number of second-cache misses is reduced substantially,sometimes to less than 10%its original value.There is a diversity of miss behavior and reaction to speculative actions.While the number of second-cache misses is reduced,the total number of misses remains the same or increases only slightly,as can be seen in Figure 3.The impact on total miss time (the sum of all miss latencies)(a )lu oc rdx wsq S e c o n d C a c h e M i s s e s0.000.200.400.600.801.00bar chol fft fmm (b)0.500.600.700.800.901.001.10bar chol fft fmm lu oc rdx wsq T o t . M i s s L a t . (N o r m .)(c)0.800.850.900.951.001.05bar chol fft fmm lu oc rdx wsq E x e c . T i m e (N o r m .)Figure 5.Effect of line size on (a )fraction of second cache misses with (shaded)and without (outline)speculative actions,(b )total miss latency,and(c )execution time.Bars normalized to conventional system.(a)0.200.400.600.801.001.20bar cholfftfmmluocrdx wsqA v g . M i s s L a t . (N o r m .)(b)0.000.200.400.600.801.001.20bar chol fft fmm lu oc rdx wsqT o t . M i s s L a t . (N o r m .)(c)0.600.700.800.901.001.10bar chol fft fmm lu oc rdx wsq E x e c . T i m e (N o r m .)Figure 6.Effect of network latency on (a )average miss latency,(b )total miss latency,and (c )execution time.Bars normalized to conventional system.can be seen in Figure 4(b );(the bars for 213sets are for the basic configuration).Impact on miss time varies with how many second cache misses there were and with additional congestion caused by speculative actions.Miss time is reduced by 25%or more in four benchmarks but less than 10%in two.The impact on execution time can be seen in Figure 4(c ).Some applications,such as FMM and Water N 2show negligible improvement,others show 10%or more improvement.The small improvements are due to an increase in miss rate or a small number of second-cache misses.4.2System-Configuration EffectsSystem configuration can determine the effectiveness of speculative actions.In systems using smaller caches lines are more likely to be evicted,so there will be fewer lines to specu-latively invalidate.There is a greater chance of unrelated data sharing a line in systems with larger line sizes,possibly confound-ing speculation.Also with larger lines,an individual action uses more network and memory bandwidth.In systems having higher network latency more run time is spent waiting for accesses to complete,so reductions in miss latency have a greater impact on performance.Speculative actions can hurt performance on systems with bandwidth constraints in the network or memory system.To test the effect of cache size,experiments were performed in which the number of sets in the cache was varied from 29to 215.Figure 4(a )shows the number of second-cache misses with (shaded)and without (outline)speculative actions,scaled to the number of misses without speculative actions.Second-cache misses are only a small fraction of total misses when caches are small.With only a few second-cache misses to eliminate,specula-tive actions have almost no effect,this can be seen in Figure 4(b )and (c ).As cache sizes increases the fraction of second cache misses becomes significant,the effect of increasing the cache size beyond a certain point is small.For most of the benchmarks,the change in absolute run time between 215and 217sets was small.The number of misses encountered by Water N 2changed little above 29sets.These results show that speculative actions are not effective when the cache is small and that beyond a certain cache size,adding speculative actions will have a greater perfor-mance impact than a further increase in cache size.The effect of line size on speculative actions is shown in Figure 5.In systems using longer lines speculative actions are less effective.The impact on absolute execution time varies with benchmark.Kernels LU,FFT,and Cholesky run well with long lines (due to contiguous data)while Radix suffers greatly (due to small randomly ordered data).The others also suffer to some extent at longer line sizes.The results of varying network latency are plotted in Fig-ure 6,latency is given in CPU cycles per hop.(Since CPU clocks run faster higher than external components the numbers may ap-pear high.)As expected,speculative actions perform better on systems with higher latency.The effect is large,FFT goes from a slowdown with a 1-cycle latency to a 20%drop in execution time at 80cycles.The additional traffic due to speculative actions can congest a system with limited bandwidth.To test this memory band-width,given in cycles per access,was varied,the results are in Figure 7.On systems with the fastest memory access latency was a smaller fraction of execution time and so speculative actions had less of an effect,on systems with the slowest memory speculative actions congested the system.The best speedups were attained at middle values.On real systems memory might be banked so that latency would be high but so would bandwidth.5ConclusionsA method of speculative invalidation and updating of cache lines was ing these speculative actions,the number of second-cache misses is reduced significantly.These speculative actions have only a minor impact on miss rate.The average time needed to service cache misses is reduced by over 20%in some cases.The cost of adding this hardware is approximately the same as the cost of increasing cache size by 50%.(In systems having an ample amount of cache,increasing cache size will have little or no effect on performance,so that increasing cache size by 50%would be more cost-effective in systems with undersized caches while adding speculative actions would be the better route(a)0.400.500.600.700.800.901.00bar chol fft fmm lu oc rdx wsq A v g . M i s s L a t . (N o r m .)(b)0.400.500.600.700.800.901.001.10bar chol fft fmm lu oc rdx wsq T o t . M i s s L a t . (N o r m .)(c)0.700.750.800.850.900.951.00bar chol fft fmm lu oc rdx wsq E x e c . T i m e (N o r m .)Figure 7.Effect of non-pipelined memory latency on (a )average miss latency,(b )total miss latency,and (c )execution time.Bars normalized toconventional system.to improved performance when caches are large.)To put the cost in perspective,the added cost is roughly equivalent to the cost of adding error-correcting-code memory.The technique works best in systems with large caches and having high network latency.Performance is low on systems using small caches because lines are frequently evicted in such systems;there is less benefit in speculatively invalidating a line that will likely be evicted.In contrast,on systems using larger cache sizes,speculative actions would not be undermined by eviction.Perfor-mance is also lower on systems in which network latency is low because the penalty for a cache miss is smaller,and so avoiding second-cache misses is less worthwhile.The technique could be used in place of,or in combination with,prefetching and adaptive cache coherence schemes.The information collected in the IHT and LHT might be useful for other purposes,such as an improved line-replacement algorithm.If future systems adopt simultaneous multithreading or other schemes in which high cache miss rates can be tolerated then speculative actions will be less useful.On the other hand,there is little doubt that in future systems communication latency with respect to clock speed will be higher,favoring speculative ac-tions.6References[1]John K.Bennett,John B.Carter,and Willy Zwaenepoel,“Adaptive software cache management for distributed shared memory architectures,”ACM Computer Arch.News,vol.18,no.2,pp.125–134,May 1990.[2]Eric A.Brewer,Chrysanthos N.Dellarocas,Adrian Col-brook,and William E.Weihl,“Proteus:a high-performance parallel-architecture simulator,”in Proc.of the ACM SIG-METRICS conference,May 1992.[3]David Chaiken,Craig Fields,Kiyoshi Kurihara,and Anant Agarwal,“Directory based cache coherence in large–scale multiprocessors,”IEEE Computer,vol.23,no.6,pp.49–59,June 1990.[4]Tien-Fu Chen and Jean-Loup Baer,“Effective hardware-based data prefetching for high-performance processors,”IEEE Trans.on Computers,vol.44,no.5,pp.609-623,May 1995.[5]Cox,A.L.,and Fowler,R.J.Adaptive cache coherency for detecting migratory shared data.Proc.of the Intl.Symp.on Computer Arch.May 1993,pp.98–108.[6]Fredrik Dahlgren,Michel Dubois,and Per Stenstroem,“Se-quential hardware prefetching in shared-memory multipro-cessors,”IEEE Trans.on Parallel and Distributed Systems,vol.6,no.7,pp.733-746,July 1995.[7]Fredrik Dahlgren and Per Stenstr¨o m,“Evaluation of hardware-based stride and sequential prefetching in shared-memory multiprocessors,”IEEE Trans.on Parallel and Dis-tributed Systems,vol.7,no.4,pp.385-398.[8]Kourosh Gharachorloo,Anoop Gupta,and John L.Hen-nessy,“Two techniques to enhance the performance of mem-ory consistency models,”in Proc.of the Intl.Conference on Parallel Processing,August 1991,vol.I,pp.355–364.[9]Klaiber,A.C.,and Levy,H.M.An architecture for software-controlled data prefetching.Proc.of the Intl.Symp.on Com-puter Arch.May 1991,pp.43–53.[10]D.M.Koppelman,“Ver.L3.11Proteus Changes”Depart-ment of Electrical and Computer Engineering,Louisiana State University,(simulator documentation),/koppel/proteus/proteusl。