用Hibernate映射继承关系
Hibernate

3.Hibernate映射类型
在hbm.xml中指定的type属性值.Java属性值<--映射类型-->表字段值映射类型负责属性值和字段值之间相互转化。type可以指定两种格式:
1)Java类型 例如:ng.String
*2)Hibernate类型
字符串:string
i.清除DAO中关闭session的代码
j.测试Struts2+Hibernate程序
--根据数据表编写POJO
--定义POJO和表的映射文件 [POJO类名].hbm.xml (在hibernate.cfg.xml中采用<mapping>元素定义)
--采用Hibernate API操作
//1.按主键做条件查询
session.load(查询类型,主键值);
session.get(查询类型,主键值);
//2.添加,根据hbm.xml定义
//自动生成主键值
session.save(obj);
//3.更新,按id当条件将obj属性
//更新到数据库
session.update(obj);
//4.删除,按id当条件删除
session.delete(obj);
**4.主键生成方式
Hibernate框架提供了一些内置的主键值生成方法。使用时通过hbm.xml文件<id>元素的<generator>指定。
*1)sequence
采用指定序列生成主键值。适用Oracle数据库。
<generator class="sequence"><param name="sequence">序列名</param></generator>
Hibernate3.6(开发必看)
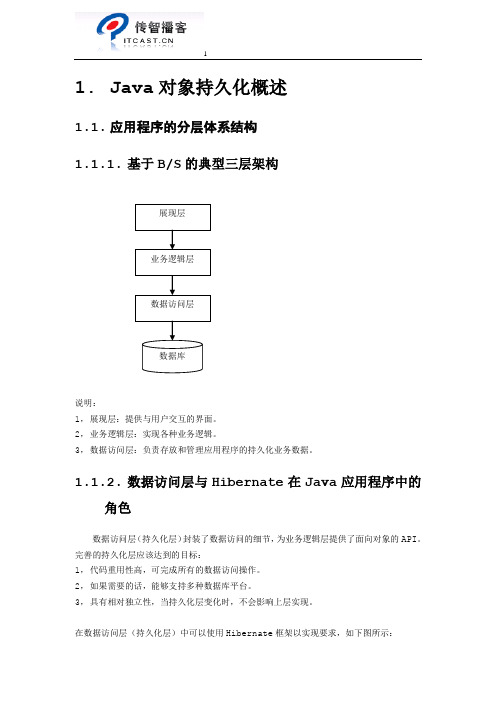
1.Java对象持久化概述1.1.应用程序的分层体系结构1.1.1.基于B/S的典型三层架构说明:1,展现层:提供与用户交互的界面。
2,业务逻辑层:实现各种业务逻辑。
3,数据访问层:负责存放和管理应用程序的持久化业务数据。
1.1.2.数据访问层与Hibernate在Java应用程序中的角色数据访问层(持久化层)封装了数据访问的细节,为业务逻辑层提供了面向对象的API。
完善的持久化层应该达到的目标:1,代码重用性高,可完成所有的数据访问操作。
2,如果需要的话,能够支持多种数据库平台。
3,具有相对独立性,当持久化层变化时,不会影响上层实现。
在数据访问层(持久化层)中可以使用Hibernate框架以实现要求,如下图所示:1.2.软件模型1.2.1.各种模型的说明概念模型:模拟问题域中的真实实体。
描述每个实体的概念和属性及实体间关系。
不描述实体行为。
实体间的关系有一对一、一对多和多对多。
关系数据模型:在概念模型的基础上建立起来的,用于描述这些关系数据的静态结构。
有以下内容组成:1,若干表2,表的所有索引3,视图4,触发器5,表与表之间的参照完整性域模型:在软件的分析阶段创建概念模型,在软件设计阶段创建域模型。
组成部分:1,具有状态和行为的域对象。
2,域对象之间的关联。
域对象(domain object):构成域模型的基本元素就是域对象。
对真实世界的实体的软件抽象,也叫做业务对象(Business Object,BO)。
域对象可代表业务领域中的人、地点、事物或概念。
域对象分为以下几种:1,实体域对象:通常是指业务领域中的名词。
(plain old java object,简单Java 对象)。
2,过程域对象:应用中的业务逻辑或流程。
依赖于实体域对象,业务领域中的动词。
如发出订单、登陆等。
3,事件域对象:应用中的一些事件(警告、异常)。
1.2.2.域对象间的关系关联:类间的引用关系。
以属性定义的方式表现。
依赖:类之间访问关系。
基于Hibernate对J2EE数据持久层设计与实现

抽象 ,具体实现 Hb ra 做得非常灵活 ,包括 int e e J C的事务、T 中的 U eTasci 、 DB JA srrnatn甚至可 o
以是 C R A 事 务。 OB
特点和优势使其在多种实现数据持久层解决方案
—
来非常觯 方匣开发人员很容易上手。 i r t H bn e ea 可以和多种应用服务器良 好集成’ 并且支持几乎所 有流行 的数据库服务器 , 为开发企业级分布式 we 应用程序提供大量的技术支持。 b 3Hb rae ient体系结构
适配器 、以及用户名和密码等, 这些属性可以在 Hbra ient e配置文件(ientegml hb ma ̄ hbraef. 或 ie t . x poet s ̄设定。另—个作用是 , Hbra rpr e) i P 在 ie t n e的 启动过程中,o fuao 类的实例首先定位映射 C ni rt n g i 文档的位置 , 从配置文件中读取这些配置信息 , 然 后创建—个 Ssin at y es Fco 对象。 o r
中成为开发 ^员首选的工具。 1O M设 计模式 R 1 M设 汁 式出现的背景 。 . OR 1 对象——关 图 l H b rae体 系结构 i en t 系映射 ( b cR li a p g简称 O M) O j t e t nM p i , e / ao n R , 是 在没 有 Hb rae的情况 下 , C成为 了 ie t n J DB 随着面向对象的软件开发方法发展而产生的。面 Jv 语言的数据库常用接 口, aa 它的效率很高 , 性能 向对象设计是当今主流的开发方法,而关系数据 很好。但是 目 , 前 随着应用系统的扩大, 数据表和 库是永久性存放数据的主流存储系统。对象和关 数据关系越来越复杂 , B J C代码变得很复杂 , D 很 系数据是业务实体的两种表现形式, 在数据库中 表现为关系数据。 性能和可靠陛。 在内存中的xg 间存在关联和继承关系,而在 C  ̄_ H b r t的出现 , i ne ea 实现了以对象关系映射的 数据库中的关系数据无法直接表达多对多关联和 方式来对数据库进行操作 ,这一过程对于开发者 继承躲 。二者之间存在着不匹配 , 导致实现数据 来 说是透 明的,ien t通过 P Ib rae t O对象 和 Hie— br 的持久性 比 较困难。 R O M是基于关系数据库的面 nt A I a e的 P 来取代复杂的 J B 开发过程,它的 DC 向对象数据持久层设计的一种良好解决方案 , 它 成功得益 于它 的体系结构的设 计。图 1 展示 了 能够为对象一关系数据库之间提供—个成功的企 Hient 的体系结构,应用程序通过持久化对象 b rae Prie t jc 来 s O s br t n 1 . i 业级映射解决方案 ,尽可能的弥补对象和关系之 (es tn bet) 访 问 Hie aeAP 而 H — b mae e t 利用 hbra.rpre 或 X pig ie tpoet s n e i MLMapn 间的差异。 1 M的优点。O M模式实现 了对象到 来配置 H b r t所使用的数据库等资源。 2 OR R i ne ea 关系型数据库中的表 的自动 的和透 明的映射 , 将 4Hb rae 口 ient接 数据从一种表示形式转换 为另一种表示形式 , 将 Hb rae ien t实现数据层持久化的原理是应 用 对象映射到关系型数据库, 并且如果对关系数据 系统通过持久化对象调用 Hb rae ien t提供的接 口, ien t的核心, 它们包括 库结构的简单改动并不会影响到面向对象代码部 持久层的各种接 口是 Hb rae
hibernate的基本用法

hibernate的基本用法Hibernate是一个开源的Java框架,用于简化数据库操作。
它为开发人员提供了一个更加简单、直观的方式来管理数据库,同时也提高了应用程序的性能和可维护性。
本文将逐步介绍Hibernate的基本用法,包括配置、实体映射、数据操作等。
一、配置Hibernate1. 下载和安装Hibernate:首先,我们需要下载Hibernate的压缩包并解压。
然后将解压后的文件夹添加到Java项目的构建路径中。
2. 创建Hibernate配置文件:在解压后的文件夹中,可以找到一个名为"hibernate.cfg.xml"的文件。
这是Hibernate的主要配置文件,我们需要在其中指定数据库连接信息和其他相关配置。
3. 配置数据库连接:在"hibernate.cfg.xml"文件中,我们可以添加一个名为"hibernate.connection.url"的属性,用于指定数据库的连接URL。
除此之外,还需要指定数据库的用户名和密码等信息。
4. 配置实体映射:Hibernate使用对象关系映射(ORM)来将Java类映射到数据库表。
我们需要在配置文件中使用"mapping"元素来指定实体类的映射文件。
这个映射文件描述了实体类与数据库表之间的对应关系。
二、实体映射1. 创建实体类:我们需要创建一个Java类,用于表示数据库中的一行数据。
这个类的字段通常与数据库表的列对应。
同时,我们可以使用Hibernate提供的注解或XML文件来配置实体的映射关系。
2. 创建映射文件:可以根据个人喜好选择使用注解还是XML文件来配置实体类的映射关系。
如果使用XML文件,需要创建一个与实体类同名的XML文件,并在其中定义实体类与数据库表之间的映射关系。
3. 配置实体映射:在配置文件中,我们需要使用"mapping"元素来指定实体类的映射文件。
Hibernate常见面试题汇总

一. H ibern ate工作使用步骤?1.读取并解析配置文件2. 读取并解析映射信息,创建Ses sionF actor y3.打开Sess sion4. 创建事务Tran satio n5.持久化操作6. 提交事务7.关闭Sess ion 8. 关闭Se sstio nFact ory 二.Hib ernat e的查询方式有几种?(1)导航对象图检索方式。
根据已经加载的对象,导航到其他对象。
(2)OID查询方式。
根据对象的O ID来查询对象。
Se ssion的get()和loa d()方法。
(3)HQL查询方式。
HQ L是面向对象的查询语言,ses sion的find()方法用于执行HQL查询语句。
可以利用Q uery接口。
Q ueryquery = se ssion.crea teQue ry(“f rom C ustom er as c wh ere c.name=: c ustom erNam e”);quer y.set Strin g(“cu stome rName”,”张三”);Listresul tList = qu ery.l ist();(4)QBC查询方式。
这种API封装了基于字符串形式的查询语句。
Crit eriacrite ria = sess ion.c reate Crite ria(U ser.c lass);Cr iteri on cr iteri on1 = Expe ssion.like(“nam e”,”T%”);Crite rioncrite rion2 = Ex pessi on.eq(age,new I ntege r(30));cr iteri a =crite ria.a dd(cr iteri on1);crit eria = cr iteri a.add(crit erion2);L ist r esult List= cri teria.list();这种查询方式使用的较少,主要是在查询中需要用户输入一系列的查询条件,如果采用HQL查询代码会比较烦。
hibernate核心,一对多,多对多映射讲解,看了就完全搞明白了

在many一方删除数据1
• 删除“五四大道”
inverse设为true,由many一方删除 从one一方去“删除”, Hibernate只是执行了 问题出在配置文件上 update语句。还是未删 没有配置set节点的inverse属性 除成功! 根本没有执行 Delete语句,数据 没有被删除!
– 配置Hibernate多对多关联,实现某OA系统项 目和人员对照关系的管理
本章目标
• 掌握单向many-to-one关联 • 掌握双向one-to-many关联 • 掌握many-to-many关联
实体间的关联
• 单向多对一
tblJd.getQx().getQxname();
• 单向一对多
TblJd jd = (TblJd)tblQx.getJds().get(0); jd.getJdname(); tblQx.getJds.add(jd);
小结
• 在租房系统中,房屋信息(Fwxx)与用户 (User)间也是多对一关系。如何配置映 射文件,使之可以通过下面的代码输出房 屋信息和发布该信息的用户名称? Fwxx fwxx = (Fwxx)super.get(Fwxx.class,1);
System.out.println( fwxx.getTitle() + "," + fwxx.getUser.getUname());
inverse是“反转”的意思,表示关联关系的控制权。 为true,表示由对方负责关联关系的添加和删除; 执行了delete语句, 为false,表示由自己负责维护关联关系。 删除成功
• 在many一方删除数据的正确做法:
hibernate框架的工作原理

hibernate框架的工作原理Hibernate框架的工作原理Hibernate是一个开源的ORM(Object-Relational Mapping)框架,它将Java对象映射到关系型数据库中。
它提供了一种简单的方式来处理数据持久化,同时也提供了一些高级特性来优化性能和可维护性。
1. Hibernate框架的基本概念在开始讲解Hibernate框架的工作原理之前,需要先了解一些基本概念:Session:Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
SessionFactory:SessionFactory是一个线程安全的对象,它用于创建Session对象。
通常情况下,应用程序只需要创建一个SessionFactory对象。
Transaction:Transaction是对数据库操作进行事务管理的接口。
在Hibernate中,所有对数据库的操作都应该在事务中进行。
Mapping文件:Mapping文件用于描述Java类与数据库表之间的映射关系。
它定义了Java类属性与数据库表字段之间的对应关系。
2. Hibernate框架的工作流程Hibernate框架主要分为两个部分:持久化层和业务逻辑层。
其中,持久化层负责将Java对象映射到数据库中,并提供数据访问接口;业务逻辑层则负责处理业务逻辑,并调用持久化层进行数据访问。
Hibernate框架的工作流程如下:2.1 创建SessionFactory对象在应用程序启动时,需要创建一个SessionFactory对象。
SessionFactory是一个线程安全的对象,通常情况下只需要创建一个即可。
2.2 创建Session对象在业务逻辑层需要进行数据访问时,需要先创建一个Session对象。
Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
2.3 执行数据库操作在获取了Session对象之后,就可以执行各种数据库操作了。
Criteria

order
ID varchar2(14)
order_number number(10)
customer_ID varchar2(14)
现在有两条HQL查询语句,分别如下:
from Customer c inner join c.orders o group by c.age;(1)
select c.ID,,c.age,o.ID,o.order_number,o.customer_ID
for(int i=0;i
System.out.println(list.get(i));
}
我们只检索了User实体的name属性对应的数据,此时返回的包含结果集的list中每个条目都是String类型的name属性对应的数据。我们也可以一次检索多个属性,如下面程序:
List list=session.createQuery(“select ,user.age from User user ”).list();
Criteria查询对查询条件进行了面向对象封装,符合编程人员的思维方式,不过HQL(Hibernate Query Lanaguage)查询提供了更加丰富的和灵活的查询特性,因此Hibernate将HQL查询方式立为官方推荐的标准查询方式,HQL查询在涵盖Criteria查询的所有功能的前提下,提供了类似标准SQL语句的查询方式,同时也提供了更加面向对象的封装。完整的HQL语句形势如下:
from User user where user.age=20 and like ‘%zx%’;
2、 实体的更新和删除:
在继续讲解HQL其他更为强大的查询功能前,我们先来讲解以下利用HQL进行实体更新和删除的技术。这项技术功能是Hibernate3的新加入的功能,在Hibernate2中是不具备的。比如在Hibernate2中,如果我们想将数据库中所有18岁的用户的年龄全部改为20岁,那么我们要首先将年龄在18岁的用户检索出来,然后将他们的年龄修改为20岁,最后调用Session.update()语句进行更新。在Hibernate3中对这个问题提供了更加灵活和更具效率的解决办法,如下面的代码:
浅析Java对象持久化:Hibernate的几种关系映射与配置

t pe y பைடு நூலகம்
/ /Hi e a e Hi e ae C n i u a b m t / b m t o fg r
nam e= ” s r pt on” de c i i cl o umn:” e crp i n” d s i to t e ”t i yp = s rng” />
to i n DTD 3 0 / . / EN” ” tp: / i e n t s ur e o g . e / h t / h b r a e.o c f r e n t
开 发 人 在 企 业 应 用 和 关 系 数 据 库 之 问 的 首 持 久 化 , 如 何 合 理 的 进 行 J a对 象 与 关 系 v a 数据 库 之 间 的 关 系映 射 是 关键 所 在 。
</i d>
<pr ope t nam e ” ry = name”
n m = a e ” n a m e ”
Q et n u si o col m n 一 ”n u a m e” t e = ’t i yp ’ rng” /> s
< P P ro e rt Y
P K i d q e to u s n i
0 缸 nS 0 0
hi e n t c fg r to b r a e on i u a i n~3. dt > 0. d”
<hi r a e o i r ton> e b n t c nfg a i u <s s i n a t r n e s o f c o y ame mys ” =” ql > <pr p r y a e-” i l c ” o e t n m - d a e t >
持久化 中间件 ,自2 0 0 5年荣获第 1 Jl 5届 ot 大奖 , 已成为 众多的 J v a a开 发人 员开发企
hbm原理

hbm原理Hibernate映射文件(HBM)原理解析HBM(Hibernate映射文件)是Hibernate框架中重要的组成部分,用于映射Java类与数据库表之间的关系。
它提供了一种将对象模型与关系模型进行转换的机制,使得开发人员可以使用面向对象的方式操作数据库。
本文将对HBM原理进行详细解析,帮助读者更好地理解和应用Hibernate框架。
一、HBM文件的基本结构HBM文件通常以.hbm.xml作为文件后缀,采用XML格式描述。
它包含了数据库表和Java类之间的映射关系及其属性信息。
一个典型的HBM文件由根元素<hibernate-mapping>包裹,内部包含了<class>、<id>、<property>等元素来定义映射关系。
1. <class>元素:用于描述Java类与数据库表之间的映射关系。
它的name属性指定了Java类的全限定名,table属性指定了对应的数据库表名。
2. <id>元素:用于定义主键映射关系。
它的name属性指定了Java 类中对应的主键属性名,column属性指定了对应的数据库列名,type属性指定了主键属性的数据类型。
3. <property>元素:用于描述普通属性的映射关系。
它的name属性指定了Java类中对应的属性名,column属性指定了对应的数据库列名,type属性指定了属性的数据类型。
二、HBM文件中的映射关系HBM文件中的映射关系有三种类型:一对一、一对多和多对多。
下面将分别进行详细介绍。
1. 一对一关系:指的是一个Java类的对象与另一个Java类的对象之间的关系。
在HBM文件中,一对一关系可以通过<one-to-one>元素来定义。
它的name属性指定了Java类中对应的属性名,class 属性指定了关联的Java类名。
2. 一对多关系:指的是一个Java类的对象与多个另一个Java类的对象之间的关系。
基于Hibernate的数据持久化应用研究

pwru o e f l,h g e f r a c b e t r 1 t o a e s s e c u c i n.U i g i ih p r om n e oj c/ e a i n lp r it ne f n to s n t, t e d v l p r a v i r t n h e e oe sc na o dw i ig
究
中图分 类号 :T 31 P 1
文献标识 码 :A
文章编号 :1 7 — 7 2 (0 85 0 7 — 3 6 1 4 9 一 2 0 )— 0 3 0
Ab ta t t b r a e e s s e c s r i e h t s o e a a o j c s n e a i n l a a a e w t i s s r c : t e n t i a p r i t n e e v c t a t r s J v b e t i r l t o a d t b s s i h t i S
H b ra e是J v 开源项 目,用户可 以在 需要时对源码 ie n t aa
这是一项烦琐 的工作,值得我们庆幸的是 tbrae t ent 解决 了 i
这一 问题 。越来越多的J v 开发人员把 H b r a e 为企业 aa ie n t 作
进行改写,对 其部分功能进行定制和拓展 。Hbrae ient 内部
L uB n L hnfn i agu i ig iZega LuBngi ‘
的 数 据 持
久
( 华东交通大学信息工程学院,江西 南昌 301) 303
( ho fIfra in Eg 。E s hn ioogU iest ,JagiNnhn 30 1) S o lo nomto n . atCiaJatn nvr iy inx acag 303 c
Hibernate_映射配置文件详解

Prepared by TongGang
hibernate.cfg.xml的常用属性
• • • • • • • • • connection.url:数据库URL ername:数据库用户名 connection.password:数据库用户密码 connection.driver_class:数据库JDBC驱动 show_sql:是否将运行期生成的SQL输出到日志以供调试。取 show_sql 值 true | false dialect:配置数据库的方言,根据底层的数据库不同产生不 dialect 同的sql语句,Hibernate 会针对数据库的特性在访问时进行 优化。 hbm2ddl.auto:在启动和停止时自动地创建,更新或删除数据 hbm2ddl.auto 库模式。取值 create | update | create-drop resource:映射文件配置,配置文件名必须包含其相 mapping resource 对于根的全路径 connection.datasource :JNDI数据源的名称
• Class:定义一个持久化类 Class: • name (可选): 持久化类(或者接 (可选): 持久化类( 可选 口)的类名 • table (可选 - 默认是类的非全限 (可选 定名): 定名): 对应的数据库表名 • discriminator-value (可选 - 默 discriminator(可选 认和类名一样): 认和类名一样): 一个用于区分不 同的子类的值,在多态行为时使用。 同的子类的值,在多态行为时使用。 它可以接受的值包括 null 和 not null。 null。
Prepared by TongGang
Hibernate 简化继承映射 外文翻译

Hibernate simplifies inheritance mappingHibernate is an object-relational mapping and persistence framework that provides a lot of advanced features, ranging from introspection to polymorphism and inheritance mapping. But mapping class hierarchies to a relational database model might prove somewhat difficult. This article covers three strategies that you can use in your everyday programming to easily map complex object models to relational database models. OverviewHibernate is a pure Java object-relational mapping and persistence framework that allows you to map plain old Java objects to relational database tables using XML configuration files. Using Hibernate can save a lot of development time on a project, since the whole JDBC layer is managed by the framework. This means that your application's data access layer will sit above Hibernate and be completely abstracted away from of the underlying data model.Hibernate has a number of advantages over other similar object-relational mapping approaches (JDO, entity beans, in-house development, and so on): it's free and open source, it has achieved a good level of maturity, it's widely used, and it has a very active community forum.To integrate Hibernate into an existing Java project, you'll need to walk through the following steps:1.Download the latest release of the Hibernate framework from the Hibernate Website. Copy the necessary Hibernate libraries (JAR files) to your application'sCLASSPATH.2.Create the XML configuration files that will be used to map your Java objects toyour database tables. (We'll describe that process in this article.)3.Copy the XML configuration files to your application's CLASSPATH.You'll notice that you don't have to modify any Java objects to support the framework. Imagine, for instance, that you needed to somehow change a database table that your Javaapplication used -- by renaming a column, for example. Once you'd changed the table, all you'd have to do to update your Java application would be to update the appropriate XML configuration file. You wouldn't need to recompile any Java code.Hibernate Query Language (HQL)Hibernate provides a query language called Hibernate Query Language (HQL), which is quite similar SQL. For those of you who prefer good old-fashioned SQL queries, Hibernate still gives you the opportunity to use them. But our supporting example will use HQL exclusively.HQL is quite simple to use. You will find all the familiar keywords you know from SQL, like SELECT, FROM, and WHERE. HQL differs from SQL in that you don't write queries directly on your data model (that is, on your tables, columns, etc.), but rather on you Java objects, using their properties and relationships.Listing 1 illustrates a basic example. This HQL code retrieves all Individuals whose firstName is "John."You can refer to the HQL reference material on the Hibernate Website if you want to learn more about HQL syntax.XML configuration filesThe core of Hibernate's functionality resides inside XML configuration files. These files must reside in your application's CLASSPATH. We placed them in the config directory of our sample code packageThe first file that we'll examine is hibernate.cfg.xml. It contains information regarding your data source (DB URL, schema name, username, password, etc.) and references to other configuration files that will contain your mapping information.The remaining XML files allow you to map Java classes against database tables. We will take a closer look at those files later, but it is important to know that their filenames follow the pattern ClassName.hbm.xml.Our supporting exampleIn this article, we'll examine a basic example that illustrates how Hibernate works and puts to good use three different strategies under which you can use Hibernate to do your object-relational mapping. Our example application will be used by an insurance company that must keep legal records of all the property rights that its customers are insured for. We've provided the full source code with this article; this code provides basic functionality from which you could build a full-fledged application, such as a Web or Swing application.Our example assumes a classic use case for this kind of application. The user would provide the search criteria for any type of customer (individual, corporation, government agency, etc.), and would then be presented with a list of all customers matching the specified criteria -- even if these are different types of customers. The user could access a more detailed view of a specific customer from that same list.In our application, a property right is represented by the Right class. A Right can either be a Lease or a Property. A Right is owned by a customer. To represent our customer, we'll use the generic class Person. A Person can either be an Individual or a Corporation. Of course, the insurance company must know the Estates to which those Rights are assigned. An Estate is a very generic term, you'll agree. So, we'll use the Land and Building classes to give our developers more comprehensive objects to work with.From this abstract, we can develop the class model shown in Figure 1:Figure 1. Complete Class ModelOur database model was designed to cover the three different strategies we'll discuss in this article. For the Right hierarchy, we'll use a single table (TB_RIGHT) and map to the correct class using the DISCRIMINATOR column. For the Person hierarchy, we'll use what we call a super table(TB_PERSON) that will share the same IDs with two othertables (TB_CORPORATION and TB_INDIVIDUAL). The third hierarchy (Estate) usestwo different tables (TB_BUILDING and TB_LAND) linked by a foreign key defined bythe combination of two columns (REF_ESTATE_ID and REF_ESTATE_TYPE).Figure 2. Complete data modelSetting up the databaseHibernate supports a wide variety of RDBMSs, and any of them should work with our sample. However, the sample code and the text of this article have been tailored for HSQLDB, a fully functional relational database written entirely in the Java language. In the sql directory of the sample code package, you will find a file named datamodel.sql. This SQL script will create the data model used in our example.Setting up the Java projectAlthough you can always build and execute the sample code using the command line, you may want to consider setting up the project in an IDE for better integration. Within the sample code package, you'll find the following directories:∙config, which contains all the sample's XML configuration files (mapping, Log4J, etc.)∙data, which contains configuration files used by HSQLDB. You will also find a batch file named startHSQLDB.bat that you may use to launch the database.∙src, contains all the sample's source code.Be sure to copy the required Java libraries and XML configuration files to you application's CLASSPATH. The code needs only the Hibernate and HSQLDB libraries in order to compile and run properly.Strategy 1: One table per subclass (Persons)In our first strategy, we'll look at how to map our Person hierarchy. You'll notice that the data model is very close to our class model. As a result, we'll use a different table for each class in the hierarchy, but all these tables must share the same primary key (we'll explain that in more detail momentarily). Hibernate will then use this primary key when it inserts new records into the database. It will also make use of this same primary key to perform JOIN operations when accessing the database.Now we need to map our object hierarchy to our table model. We have three tables (TB_PERSON, TB_INDIVIDUAL, and TB_CORPORATION). As we mentioned above, they all have a column named ID as a primary key. It's not mandatory to have a shared column name like this, but it is considered good practice -- and it makes it a lot easier to read the generated SQL queries.In the XML mapping file, shown in Listing 2, you'll notice that the two concrete classes are declared as <joined-subclass> inside the Person mapping definition. The XML element <id> is mapped to the primary key for the top-level table TB_PERSON, while the <key> elements (from each subclass) are mapped to the matching primary keys of theTB_INDIVIDUAL and TB_CORPORATION tables.Listing 2. Person.hbm.xml<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD2.0//EN""/hibernate-mapping-2.0.dtd"><hibernate-mapping><class name="eg.hibernate.mapping.dataobject.Person" table="TB_PERSON" polymorphism="implicit"><id name="id" column="ID"><generator class="assigned"/></id><set name="rights" lazy="false"><key column="REF_PERSON_ID"/><one-to-many class="eg.hibernate.mapping.dataobject.Right" /></set><joined-subclass name="eg.hibernate.mapping.dataobject.Individual"table="TB_INDIVIDUAL"><key column="id"/><property name="firstName" column="FIRST_NAME" type="ng.String" /> <property name="lastName" column="LAST_NAME" type="ng.String" /> </joined-subclass><joined-subclass name="eg.hibernate.mapping.dataobject.Corporation"table="TB_CORPORATION"><key column="id"/><property name="name" column="NAME" type="string" /><property name="registrationNumber" column="REGISTRATION_NUMBER" type="string" /></joined-subclass></class></hibernate-mapping>Saving a new instance of Individual form our Java code with Hibernate is pretty straightforward, as shown in Listing 3:In turn, Hibernate generates the two SQL INSERT requests illustrated in Listing 4. That's two requests for just one save().To access an Individual from the database, simply specify the class name in your HQL query, as shown in Listing 5.Listing 5. Invoke an HQL queryHibernate will then automatically perform the SQL JOIN to retrieve all the necessary information from both tables, as shown in Listing 6:However, when no concrete class is specified, Hibernate needs to perform an SQL JOIN, since it doesn't know which table to go through. Amongst all the retrieved table columns returned from the HQL query, an extra dynamic column will be returned as well. The clazz column is used by Hibernate to instantiate and populate the returned object. We call this class determination dynamic, as opposed to the method that we'll use in our second strategy.Listing 7 shows how to query an abstract Person given its id property, while Listing 8 shows the SQL query automatically generated by Hibernate, including the table junctions:Strategy 2: One Table per class herarchy (Rights)For our Right hierarchy, we'll use a single table (TB_RIGHT) to store the entire class hierarchy. You'll notice that the TB_RIGHT table possesses all the columns necessary to store every attribute of the Right class hierarchy. Values of the saved instances will then be saved in the table, leaving every unused column filled with NULL values. (Because it's full of "holes," we often call it a Swiss cheese table.)In Figure 3, you will notice that the TB_RIGHT table contains an additional column, DISCRIMINATOR. Hibernate uses this column to automatically instantiate the appropriate class and populate it accordingly. This column is mapped using the<discriminator> XML element from our mapping files.ConclusionIn this article, we tried to give you a fairly simple implementation example for three mapping strategies Hibernate provides. In retrospect, each strategy has its advantages and drawbacks:∙For our first strategy (one table per subclass), Hibernate will read multiple tables each time an object is instantiated and populated. That operation can produce good results if your indexes are well defined and your hierarchy isn't too deep. If that isnot the case, however, you may experience problems with overall performance.∙For our second strategy (one table per class hierarchy), you'll have to define your integrity using check constraints. This strategy might become difficult to maintain as the number of columns increases over time. On the other hand, you may choose not to use such constraints at all and rely on your application's code to manage itsown data integrity.Our third strategy (one table per concrete class) has some mapping limitations, and the underlying data model can't use referential integrity, meaning that you're notusing the relational database engine to its full potential. On the plus side, though,this strategy can be combined quite easily with the other two.Regardless of the strategy you choose, always keep in mind that you don't need to alter your Java classes in the process, meaning that there is absolutely no link between your business objects and the persistence framework. It's this degree of flexibility that is making Hibernate so popular in object-relational Java projects.Hibernate 简化继承映射Hibernate 是一个对象关系映射和持久性框架,它提供了许多高级特性,从内省到多态和继承映射。
hibernate高级用法

hibernate高级用法Hibernate是一种Java持久化框架,用于将对象转换为数据库中的数据。
除了基本的用法,Hibernate还提供了一些高级的用法,以下是一些常见的Hibernate高级用法:1、继承Hibernate支持类继承,可以让子类继承父类的属性和方法。
在数据库中,可以使用表与表之间的关系来实现继承,例如使用一对一、一对多、多对一等关系。
使用继承可以让代码更加简洁、易于维护。
2、聚合Hibernate支持聚合,可以将多个对象组合成一个对象。
例如,一个订单对象可以包含多个订单行对象。
在数据库中,可以使用外键来实现聚合关系。
使用聚合可以让代码更加简洁、易于维护。
3、关联Hibernate支持关联,可以让对象之间建立关联关系。
例如,一个订单对象可以关联一个客户对象。
在数据库中,可以使用外键来实现关联关系。
使用关联可以让代码更加简洁、易于维护。
4、延迟加载Hibernate支持延迟加载,可以在需要时才加载对象。
延迟加载可以减少数据库的负担,提高性能。
Hibernate提供了多种延迟加载的策略,例如按需加载、懒惰加载等。
5、事务Hibernate支持事务,可以确保数据库的一致性。
事务是一组数据库操作,要么全部成功,要么全部失败。
Hibernate提供了事务管理的方法,例如开始事务、提交事务、回滚事务等。
6、缓存Hibernate支持缓存,可以减少对数据库的访问次数,提高性能。
Hibernate提供了多种缓存策略,例如一级缓存、二级缓存等。
使用缓存需要注意缓存的一致性和更新问题。
7、HQL查询语言Hibernate提供了HQL查询语言,可以让开发人员使用面向对象的查询方式来查询数据库。
HQL查询语言类似于SQL查询语言,但是使用的是Java类和属性名,而不是表名和列名。
HQL查询语言可以更加灵活、易于维护。
以上是一些常见的Hibernate高级用法,它们可以帮助开发人员更加高效地使用Hibernate进行开发。
HibernateHQL--实体、属性查询,全参数绑定,引用查询

是Hibernate官方推荐的查询模式,比Criteria功能更强大。
1)实体查询:出现类名和属性名必须注意大小写区分;当不同路径下存在相同类名,需要写入在hql中写入包名;查询目标实体存在着继承关系,将查询目标的所有子类的库表记录一起返回。
String hql = “from TUser”;Query query = session.createQuery(hql);List list = query.list();2)属性查询:有时页面不需要取整个对象,而只取某个属性。
List list = session.createQuery(“select user.age from TUser user”).list();Iterator it = list.iterator();while(it.hasNext()){//返回的list中,每个条目都是一个对象数组,依次包含我们所获取的数据。
Object[] results = (Object[])it.next();System.out.println(results[0]);System.out.println(results[1]);}注:如果觉得返回数组的方式不够灵活,可以在HQL中构造对象实例。
List list = this.session.createQuery(“select new TUser(,user.age) from TUser user”).list();Iterator it = list.iterator();while(it.hasNext()){TUser user = (TUser)it.next();System.out.println(user.getName());}注:通过HQL动态构造对象实例,此时查询结果中的TUser对象只是一个Java对象,仅用于对查询结果的封装,除了在构造时赋予的属性值之外,其他属性均为未赋值状态,当我们通过session对此对象进行更新,将导致对user对象的数据库插入一条新数据,而不是更新原有对象。
Java中的ORM框架比较和选择

Java中的ORM框架比较和选择ORM(对象关系映射)框架是一种将对象模型与数据库模型进行映射的技术,它能够简化数据库访问和操作,提高开发效率。
在Java中,有许多优秀的ORM框架可供选择,如Hibernate、MyBatis、JPA等。
本文将对这些框架进行比较和选择。
1. HibernateHibernate是Java中最流行和广泛应用的ORM框架之一。
它提供了灵活的查询语言(HQL)、持久化对象的事务管理、缓存机制等功能。
Hibernate支持多种数据库,具备较好的跨数据库兼容性。
使用Hibernate的优势是可以快速简化数据库访问的代码编写,提供了丰富的关联映射、查询和继承策略等。
同时,它拥有强大的对象状态跟踪能力,对于复杂的业务逻辑处理有很好的支持。
2. MyBatisMyBatis是一种半自动化ORM框架,它使用XML或注解来配置SQL语句和映射关系。
相对于Hibernate而言,MyBatis更加灵活,可以直接编写原生SQL语句,更适合对SQL有较高要求的开发者。
MyBatis的优势在于性能和可控性方面。
它可以进行精确的SQL控制,通过手动优化SQL语句来提高数据库访问的速度。
此外,MyBatis 支持动态SQL、分页查询和一级缓存等特性,灵活满足各种不同的需求。
3. JPAJPA(Java Persistence API)是Java EE标准的ORM框架,提供了一种统一的API和规范,使开发者能够以标准的方式访问和操作数据库。
JPA实现的具体框架有很多,如Hibernate、EclipseLink等。
JPA的特点是简化了ORM的使用,提供了更加简洁和易用的代码编写方式。
它支持注解和XML配置,提供了面向对象的查询语言(JPQL)和命名查询等特性。
4. 框架选择对于选择合适的ORM框架,应根据项目需求和开发团队的技术水平来综合考虑。
如果项目规模较大、复杂度高,且需要对数据库操作进行优化,可以选择使用Hibernate框架。
hibernate uuid原理

hibernate uuid原理摘要:1.Hibernate UUID 简介2.Hibernate UUID 的生成原理3.Hibernate UUID 的应用场景4.Hibernate UUID 与数据库主键的关系5.如何自定义Hibernate UUID 生成策略正文:Hibernate 是一个广泛应用于Java 应用程序中的对象关系映射(ORM)框架。
在Hibernate 中,UUID(通用唯一标识符)被广泛应用于数据库表的主键生成。
本文将详细介绍Hibernate UUID 的原理、应用场景以及如何自定义生成策略。
1.Hibernate UUID 简介Hibernate UUID 是Hibernate 框架提供的一种生成主键的策略。
它可以生成一个32 位的、全局唯一的、时间戳无关的UUID。
UUID 由三部分组成:随机数、时间戳和命名空间。
其中,命名空间用于区分不同类型的UUID,例如:DNS、URL 等。
在Hibernate 中,我们主要关注的是随机数和时间戳。
2.Hibernate UUID 的生成原理Hibernate UUID 的生成原理主要依赖于Java 中的UUID 类。
UUID 类提供了两个静态方法:randomUUID() 和timeBasedUUID()。
randomUUID() 方法生成一个基于随机数的UUID,而timeBasedUUID() 方法生成一个基于时间戳的UUID。
Hibernate UUID 策略实际上是将这两种UUID 组合起来,生成一个新的UUID。
3.Hibernate UUID 的应用场景Hibernate UUID 主要应用于数据库表的主键生成。
在Hibernate 中,可以通过配置映射文件或使用注解来指定主键生成策略。
当使用Hibernate UUID 作为主键生成策略时,Hibernate 会自动为数据库表生成一个唯一的UUID 作为主键。
hibernate 生成数据库表的原理

hibernate 生成数据库表的原理Hibernate是一个Java持久化框架,它提供了一种方便的方式来映射Java对象到关系数据库中的表结构。
当使用Hibernate时,它可以根据预定义的映射文件或注解配置自动创建、更新和管理数据库表。
Hibernate生成数据库表的原理如下:1. 对象关系映射(Object-Relational Mapping,ORM):Hibernate使用ORM技术将Java类和关系数据库表之间建立起映射关系。
通过在实体类中定义注解或XML映射文件,Hibernate可以知道哪个Java类对应哪个数据库表以及类中的属性与表中的列之间的映射关系。
2. 元数据分析:当应用程序启动时,Hibernate会对实体类进行元数据分析。
它会扫描实体类中的注解或XML映射文件,获取实体类的名称、属性名、属性类型等信息,并根据这些信息生成相应的元数据。
3. 数据库模式生成:根据元数据,Hibernate可以自动生成数据库表的DDL语句。
它会根据实体类的名称创建表名,根据属性名创建列名,并根据属性类型确定列的数据类型、长度、约束等。
生成的DDL语句可以包括创建表、添加索引、外键约束等操作。
4. 数据库表管理:Hibernate可以根据生成的DDL语句来创建数据库表。
在应用程序启动时,Hibernate会检查数据库中是否已存在相应的表,如果不存在则创建表;如果已存在但结构与元数据不匹配,则根据需要进行表结构的更新或修改。
总的来说,Hibernate生成数据库表的原理是通过分析实体类的元数据,自动生成对应的DDL语句,并根据需要创建、更新和管理数据库表。
这种自动化的方式大大简化了开发人员的工作,提高了开发效率。
一对一的实体映射实现

(2)对数据库表的设计要求
在主动方的数据库表中应该有被动方的主键作为外键。 在主动方的数据库表中应该有被动方的主键作为外键。
(3)在映 射配置文 件中中利 用<many<manytoto-one> 标签来说 明关系 注意<many to-one>标签时 加上“unique”属性来设 <many标签时, (4)注意<many-to-one>标签时,加上“unique 属性来设 定为具有唯一性约束 具有唯一性约束。 定为具有唯一性约束
(2)命名规则:类名.hbm.xml 命名规则:类名.hbm. 本示例中的EBook hbm.xml映射文件的内容 EBook. (3)本示例中的EBook.hbm.xml映射文件的内容
9、编程基于 Hibernate的DAO组 Hibernate的DAO组 件以进行数据的访 问操作, 问操作,详细的代 码请见文档。 码请见文档。
--外键 外键” 6、 “主--外键”的实 现过程
(1)在主动方所在的持久 类中加入一个被动方类 的对象声明 (2)在主动方类的映射文 件中利用<many to<many件中利用<many-to-one> 标签表示关联关系
详细的实现过程请见后文
Web应用中实现本 一对一” 应用中实现本“ 二、在Web应用中实现本“一对一”的关联示例
一对一” 一、 “一对一”的关联映射原理 1、一对一关联的实现方案 一对一关联在hibernate hibernate中有两种方式 (1)一对一关联在hibernate中有两种方式
主键关联 唯一外键关联
主键关联的实现原理: 2、主键关联的实现原理:基于主键关联的单向一对一关联 通常使用一个特定的id生成器foreign id生成器 通常使用一个特定的id生成器foreign
Hibernate 实体类 注解 大全

@Column(name="BIRTH",nullable="false",columnDefinition="DATE")
public String getBithday() {
return birthday;
}
7、@Transient
public User getUser() {
return user;
}
9、@JoinColumn
可选
@JoinColumn和@Column类似,介量描述的不是一个简单字段,而一一个关联字段,例如.描述一个@ManyToOne的字段.
name:该字段的名称.由于@JoinColumn描述的是一个关联字段,如ManyToOne,则默认的名称由其关联的实体决定.
catalog:可选,表示Catalog名称,默认为Catalog("").
schema:可选,表示Schema名称,默认为Schema("").
3、@id
必须
@id定义了映射到数据库表的主键的属性,一个实体只能有一个属性被映射为主键.置于getXxxx()前.
4、@GeneratedValue(strategy=GenerationType,generator="")
@Entity
//继承策略。另一个类继承本类,那么本类里的属性应用到另一个类中
@Inheritance(strategy = InheritanceType.JOINED )
@Table(name="INFOM_TESTRESULT")
public class TestResult extends IdEntity{}
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
HourlyEmployee rate : double
SalariedEmployee salary : double
14.1
PDF 文件使用 "pdfFactory" 试用版本创建
第 14 章
映射继承关系
在域模型中,类与类之间除了关联关系和聚集关系,还可以存在继承关系,在图 14-1 的域模型中,Company 类和 Employee 类之间为一对多的双向关联关系(假定不允许雇员同 时在多个公司兼职) ,Employee 类为抽象类,因此它不能被实例化,它有两个具体的子类: HourlyEmployee 类和 SalariedEmployee 类。由于 Java 只允许一个类最多有一个直接的父类, 因此 Employee 类、HourlyEmployee 类和 SalariedEmployee 类构成了一颗继承关系树。
Company 类 HourlyEmployee 类 Employee 类 SalariedEmployee 类
Company.hbm.xml HourlyEmployee.hbm.xml
COMPANIES 表 HOURLY_EMPLOYEES 表
SalariΒιβλιοθήκη dEmployee.hbm.xml
SALARIED_EMPLOYEES 表
图 14-3
持久化类、映射文件和数据库表之间的对应关系
如 果 Employee 类不 是 抽象类, 即 Employee 类本 身也 能被实例化, 那么 还 需要 为 Employee 类创建对应的 EMPLOYEES 表,此时 HE 表和 SE 表的结构仍然和图 14-2 中的一 样。这意味着在 EMPLOYEES 表、HE 表和 SE 表中都定义了相同的 NAME 字段以及参照 COMPANIES 表 的 外 键 COMPANY_ID 。 另 外 , 还 需 为 Employee 类 创 建 单 独 的 Employee.hbm.xml 文件。
BusinessService 类的 findAllEmployees()方法通过 Hibernate API 从数据库中检索出所有 Employee 对象。findAllEmployees()方法返回的集和既包含 HourlyEmployee 类的实例,也包 含 SalariedEmployee 类的实例,这种查询被称为多态查询。以上程序中变量 e 被声明为 Employee 类 型 , 它 实 际 上 既 可 能 引 用 HourlyEmployee 类 的 实 例 , 也 可 能 引 用 SalariedEmployee 类的实例。 此外,从 Company 类到 Employee 类为多态关联,因为 Company 类的 employees 集合 中可以包含 HourlyEmployee 类和 SalariedEmployee 类的实例。从 Employee 类到 Company 类不是多态关联,因为 Employee 类的 company 属性只会引用 Company 类本身的实例。 数据库表之间并不存在继承关系, 那么如何把域模型的继承关系映射到关系数据模型中 呢?本章将介绍以下三种映射方式: l 继承关系树的每个具体类对应一个表: 关系数据模型完全不支持域模型中的继承关 系和多态。 l 继承关系树的根类对应一个表: 对关系数据模型进行非常规设计, 在数据库表中加
HOURLY_EMPLOYEES 表 ID <<PK>> COMPANY_ID <<FK>> NAME RATE
COMPANYS 表 ID <<PK>> NAME
SALARIED_EMPLOYEES 表 ID <<PK>> COMPANY_ID <<FK>> NAME SALARY
图 14-2 每个具体类对应一个表
图 14-1
包含继承关系的域模型
在面向对象的范畴中, 还存在多态的概念, 多态建立在继承关系的基础上。 简单的理解, 多态 是指当 一个 Java 应用 变量 被 声明 为 Employee 类时, 这 个 变量 实 际上既 可以 引 用 HourlyEmployee 类的实例, 也可以引用 SalariedEmployee 类的实例。 以下这段程序代码就体 现了多态:
List employees= businessService.findAllEmployees(); Iterator it=employees.iterator(); while(it.hasNext()){ Employee e=(Employee)it.next(); if(e instanceof HourlyEmployee){ System.out.println(e.getName()+" "+((HourlyEmployee)e).getRate()); }else System.out.println(e.getName()+" "+((SalariedEmployee)e).getSalary()); }
第 14 章
映射继承关系 ......................................................................................................................................................................... 2
14.1.1
创建映射文件
从 Company 类到 Employee 类是多态关联,但是由于关系数据模型没有描述 Employee 类和它的两个子类的继承关系,因此无法映射 Company 类的 employees 集合。例程 14-1 是 Company.hbm.xml 文件的代码,该文件仅仅映射了 Company 类的 id 和 name 属性。
继承关系树的每个具体类对应一个表................................................................3 14.1.1 创建映射文件 ............................................................................................4 14.1.2 操纵持久化对象.........................................................................................5 14.2 继承关系树的根类对应一个表............................................................................8 14.2.1 创建映射文件 ............................................................................................9 14.2.2 操纵持久化对象.......................................................................................10 14.3 继承关系树的每个类对应一个表......................................................................12 14.3.1 创建映射文件 ..........................................................................................13 14.3.2 操纵持久化对象.......................................................................................15 14.4 选择继承关系的映射方式..................................................................................16 14.5 映射多对一多态关联..........................................................................................20 14.6 小节 .....................................................................................................................22
PDF 文件使用 "pdfFactory" 试用版本创建
l
入额外的区分子类型的字段。 通过这种方式, 可以使关系数据模型支持继承关系和 多态。 继承关系树的每个类对应一个表: 在关系数据模型中用外键参照关系来表示继承关 系。 具体类是指非抽象的类,具体类可以被实例化。HourlyEmployee 类和 SalariedEmployee 类就是具体类。
例程 14-1 Company.hbm.xml
<hibernate-mapping > <class name="pany" table="COMPANIES" > <id name="id" type="long" column="ID"> <generator class="increment"/> </id> <property name="name" type="string" column="NAME" /> </class> </hibernate-mapping>