linux高可用集群配置(linux6.0)
linux 高可用方案

linux 高可用方案引言:在当今的互联网时代,高可用性已经成为许多企业和组织追求的目标。
无论是电子商务网站、金融系统还是公共服务平台,对系统的稳定性和可靠性要求越来越高。
而在实现高可用性的方案中,Linux操作系统扮演着重要角色。
本文将探讨一些常见的Linux高可用方案,以帮助读者了解和选择适合自己的解决方案。
一、负载均衡负载均衡是提高系统可用性的一种常见方法。
通过将系统的负载分布到多个节点上,实现资源的合理利用和性能的提升。
在Linux中,有许多负载均衡器可供选择,如Nginx、HAProxy等。
这些负载均衡器可以根据不同的算法将请求分发到不同的后端服务器上,使得整个系统的负载得到均衡,同时还可以实现故障转移和冗余备份。
二、集群集群是一种将多台服务器组合在一起以提供高性能和高可用性的解决方案。
在集群中,多个节点可以并行工作,共享数据和负载。
Linux 的集群方案有很多种,如Pacemaker、Keepalived等。
这些方案通过实时监测节点的状态和资源的可用性,可以在单个节点故障时实现快速切换和恢复,保证系统的持续稳定运行。
三、主从复制主从复制是一种数据同步的方法,通过将数据从主节点复制到多个从节点,实现数据冗余和备份。
在Linux中,MySQL数据库的主从复制是一种常见的解决方案。
通过将一个节点配置为主节点,其他节点配置为从节点,可以实现数据的实时同步和读写分离。
当主节点发生故障时,可以快速切换到其中一个从节点,从而实现高可用性。
四、存储冗余存储冗余是一种通过数据备份和冗余来提高系统可用性的方法。
在Linux中,有多种存储冗余方案可供选择,如RAID(独立冗余磁盘阵列)技术。
RAID技术通过将多个硬盘组合在一起,实现数据的分布式存储和备份,从而提高数据的安全性和可用性。
不同的RAID级别可提供不同的数据冗余和读写性能。
五、监控和故障检测监控和故障检测是保障系统高可用性的重要环节。
在Linux中,有许多监控和故障检测工具可供选择,如Nagios、Zabbix等。
Linux系统的高可用性和冗余设计原则

Linux系统的高可用性和冗余设计原则Linux操作系统作为一种开源的操作系统,被广泛应用于各种服务器和系统中。
高可用性与冗余设计是保障系统稳定性和可靠性的重要因素。
本文将探讨Linux系统的高可用性和冗余设计原则。
一、高可用性的原则高可用性是指系统能够持续正常运行,不间断地提供服务。
在Linux系统中,实现高可用性的原则主要包括以下几个方面:1. 避免单点故障:单点故障是指当系统中某个关键组件或设备出现故障时,整个系统无法正常工作。
为避免单点故障,可以采取冗余设计,将关键组件进行冗余部署。
2. 负载均衡:负载均衡是通过将任务或服务分摊到多个服务器上,实现系统资源的合理利用,提高系统的处理能力和对故障的容错能力。
常见的负载均衡技术包括DNS轮询、反向代理和集群等。
3. 快速故障恢复:当系统出现故障时,快速恢复是保障系统高可用性的关键。
通过实时监控系统状态,及时发现并处理故障,采取自动化的故障恢复机制,可以有效减少系统的停机时间。
4. 数据备份和恢复:合理的数据备份策略可以确保数据的安全性和完整性。
将关键数据进行定期备份,并测试恢复过程,以确保在数据丢失或系统故障情况下,能够迅速恢复数据。
二、冗余设计的原则冗余设计是指在系统中添加冗余部件或组件,以提高系统的可靠性和可用性。
在Linux系统中,常见的冗余设计原则包括以下几个方面:1. 硬件冗余:通过使用多个相同的硬件设备,如磁盘阵列、双电源等,来实现硬件级别的冗余。
当一个设备发生故障时,其他设备可以接管工作,从而保证系统的连续性。
2. 网络冗余:通过使用多条网络链路或网络设备,如交换机、防火墙等,来保障网络的高可用性和冗余性。
当某个网络设备或链路发生故障时,其他设备或链路可以提供继续的网络连接。
3. 高可用性集群:通过将多个服务器组成集群,实现资源的共享和故障的容错。
利用集群管理软件可以实现自动的故障转移和负载均衡,提高系统的可靠性和可用性。
4. 容灾和备份:将关键数据备份到远程地点或云存储中,以便在主服务器发生故障或灾难时进行灾备恢复。
如何搭建高可用性服务器集群

如何搭建高可用性服务器集群在当今互联网时代,服务器集群已经成为许多企业和网站保证高可用性和性能的重要手段。
搭建高可用性服务器集群可以有效地提高系统的稳定性和可靠性,确保用户能够随时访问网站或应用程序。
本文将介绍如何搭建高可用性服务器集群,以帮助读者更好地理解和应用这一技术。
一、搭建高可用性服务器集群的意义搭建高可用性服务器集群的主要目的是提高系统的稳定性和可靠性,确保系统能够在面对各种故障和攻击时保持正常运行。
通过将多台服务器组成集群,可以实现负载均衡、故障转移和容灾备份,从而降低单点故障的风险,提高系统的可用性和性能。
二、搭建高可用性服务器集群的步骤1. 硬件准备:首先需要准备多台服务器,这些服务器可以是物理服务器或虚拟服务器,需要保证服务器的配置相对均衡,以实现负载均衡的效果。
此外,还需要网络设备如交换机、路由器等来连接服务器,确保服务器之间可以互相通信。
2. 网络配置:在搭建服务器集群之前,需要对网络进行合理的规划和配置。
可以采用专用的网络子网来连接服务器,确保服务器之间的通信稳定和安全。
同时,还需要配置防火墙和安全策略,保护服务器免受网络攻击。
3. 软件安装:选择合适的服务器集群软件,常用的有Nginx、Apache、Tomcat等,根据实际需求和系统环境进行安装和配置。
在安装软件时,需要注意版本的兼容性和稳定性,确保软件能够正常运行并实现负载均衡和故障转移。
4. 配置负载均衡:负载均衡是服务器集群的重要组成部分,可以通过软件或硬件来实现。
常用的负载均衡算法有轮询、加权轮询、最小连接数等,根据实际情况选择合适的算法进行配置,确保服务器能够均衡地分担请求负载。
5. 配置故障转移:故障转移是保证服务器集群高可用性的关键技术,可以通过心跳检测、自动切换等方式实现。
在配置故障转移时,需要考虑服务器的健康状态和故障恢复时间,确保系统能够在出现故障时快速切换到备用服务器,保证服务的连续性。
6. 容灾备份:除了故障转移,还需要进行容灾备份,即定期备份数据和配置文件,以防止数据丢失和系统崩溃。
利用Linux操作系统进行服务器集群管理

利用Linux操作系统进行服务器集群管理在当今信息时代,服务器集群已经成为现代企业中不可或缺的一部分。
而要有效地管理服务器集群,利用Linux操作系统是一个明智的选择。
本文将介绍如何利用Linux操作系统进行服务器集群管理。
一、服务器集群管理的基本概念服务器集群是由多台服务器组成的,旨在提高系统的可靠性、可用性和性能。
服务器集群管理的核心目标是促进集群中服务器的协同工作以提供高负载、高性能和高可用性的服务。
二、Linux操作系统简介Linux操作系统是一个免费且开源的操作系统,具有出色的稳定性和安全性,广泛应用于服务器领域。
Linux操作系统提供了一系列工具和命令,用于管理集群中的多台服务器。
三、服务器集群管理工具1. SSH(Secure Shell)SSH是一种网络协议,可用于在两个网络设备之间进行加密通信。
通过SSH,管理员可以在远程终端登录服务器,执行管理操作。
2. Shell脚本Shell脚本是一种在Linux操作系统中编写的可执行脚本,用于批量执行一系列命令。
管理员可以编写Shell脚本来进行服务器集群管理任务,如自动化安装软件、配置系统参数等。
3. rsyncrsync是一种高效的文件复制工具,可用于在服务器之间同步文件和目录。
管理员可以使用rsync命令将文件从一台服务器复制到集群中的其他服务器,实现数据的同步和备份。
4. PacemakerPacemaker是一个开源的高可用性集群管理软件,可用于监控和管理服务器集群中的资源。
通过配置Pacemaker,管理员可以实现自动故障切换和负载均衡等功能。
四、利用Linux操作系统进行服务器集群管理的步骤1. 安装Linux操作系统首先,管理员需要在每台服务器上安装Linux操作系统。
可以选择适合企业需求的Linux发行版,如Ubuntu、CentOS等。
2. 配置SSH登录在每台服务器上,管理员需要配置SSH服务,以便能够通过SSH 协议远程登录服务器。
Linux高性能计算集群 Beowulf集群
Linux高性能计算集群 -- Beowulf集群/page/hardware_linux.html1 集群1.1 什么是集群简单的说,集群(cluster)就是一组计算机,它们作为一个整体向用户提供一组网络资源。
这些单个的计算机系统就是集群的节点(node)。
一个理想的集群是,用户从来不会意识到集群系统底层的节点,在他/她们看来,集群是一个系统,而非多个计算机系统。
并且集群系统的管理员可以随意增加和删改集群系统的节点。
1.2 为什么需要集群集群并不是一个全新的概念,其实早在七十年代计算机厂商和研究机构就开始了对集群系统的研究和开发。
由于主要用于科学工程计算,所以这些系统并不为大家所熟知。
直到Linux集群的出现,集群的概念才得以广为传播。
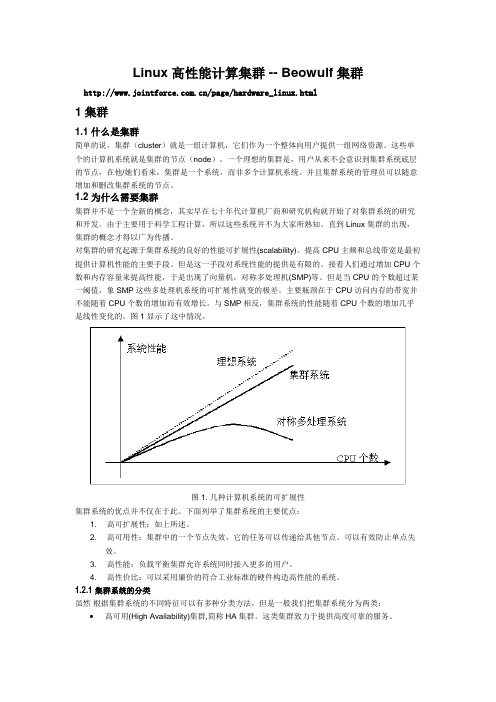
对集群的研究起源于集群系统的良好的性能可扩展性(scalability)。
提高CPU主频和总线带宽是最初提供计算机性能的主要手段。
但是这一手段对系统性能的提供是有限的。
接着人们通过增加CPU个数和内存容量来提高性能,于是出现了向量机,对称多处理机(SMP)等。
但是当CPU的个数超过某一阈值,象SMP这些多处理机系统的可扩展性就变的极差。
主要瓶颈在于CPU访问内存的带宽并不能随着CPU个数的增加而有效增长。
与SMP相反,集群系统的性能随着CPU个数的增加几乎是线性变化的。
图1显示了这中情况。
图1. 几种计算机系统的可扩展性集群系统的优点并不仅在于此。
下面列举了集群系统的主要优点:1.高可扩展性:如上所述。
2.高可用性:集群中的一个节点失效,它的任务可以传递给其他节点。
可以有效防止单点失效。
3.高性能:负载平衡集群允许系统同时接入更多的用户。
4.高性价比:可以采用廉价的符合工业标准的硬件构造高性能的系统。
1.2.1 集群系统的分类虽然根据集群系统的不同特征可以有多种分类方法,但是一般我们把集群系统分为两类:∙高可用(High Availability)集群,简称HA集群。
Linux平台Apache高可用双机集群Tomcat负载均衡集群配置手册

Linux平台Apache双机高可用集群+ Tomcat负载均衡集群配置手册在这个配置手册中,使用的操作系统和软件清单如下:操作系统:RedHat Enterprise Linux AS4 U4 64bit(安装时最好选择完全安装)软件:jdk-1_5_0_15-linux-amd64.binTomcat5.5.26httpd-2.0.63.tar.gzjakarta-tomcat-connectors-jk2-src-current.tar.gzipvsadm-1.24.tar.gzlibnet.tar.gzheartbeat-2.1.3-3.el4.centos.x86_64.rpmheartbeat-pils-2.1.3-3.el4.centos.x86_64.rpmheartbeat-stonith-2.1.3-3.el4.centos.x86_64.rpm因为是linux操作系统,所以在安装软件时请使用对应自己操作系统内核的软件,这是整个集群成功的第一步。
本配置手册中的软件都是对应RedHat Enterprise Linux AS4 U4 64bit 这个版本的软件。
jdk-1_5_0_15-linux-amd64.binJAVA环境包使用的是64位1.5版Tomcat版本为公司指定的5.5版本Apache为2.0.63版jakarta-tomcat-connectors-jk2-src-current.tar.gz是连接Apache和Tomcat的连接插件,具体可以去Tomcat网站上查找下载ipvsadm-1.24.tar.gzlibnet.tar.gz这两个是用于2台Apache服务器虚拟一个IP地址使用heartbeat-2.1.3-3.el4.centos.x86_64.rpmheartbeat-pils-2.1.3-3.el4.centos.x86_64.rpmheartbeat-stonith-2.1.3-3.el4.centos.x86_64.rpm这3个软件是用于2台Apache服务器之间的心跳检测结构图Apache1以以以以以Tomcat1Tomcat2Apache22台Tomcat服务器使用Tomcat软件可以自己做集群,2台Apache服务器需要其他的软件实现虚拟服务器功能,工作站访问虚拟IP地址访问2台Apache服务器,再通过Apache服务器访问Tomcat服务器第3 页总13 页1.安装JAVA环境包1)输入命令:./ jdk-1_5_0_15-linux-amd64.bin执行完毕后,会在当前目录下生成一个JDK-1.5.0_15的文件夹2)在 /usr/local/下新建一个名字为JAVA文件夹,将个JDK-1.5.0_15的文件夹拷入到该文件夹下3)设置环境变量。
使用Linux构建高可用性服务器集群(两篇)

引言概述:随着互联网和信息技术的不断发展,对服务器的可用性和稳定性要求越来越高。
构建高可用性服务器集群是一种常用的解决方案,它可以提高系统的稳定性、可靠性和可恢复能力。
在本文中,将探讨如何使用Linux操作系统构建高可用性服务器集群的具体步骤和注意事项。
正文内容:一、搭建集群环境1. 硬件准备a. 选择适当的服务器硬件配置,包括CPU、内存、硬盘等。
b. 使用网络交换机和数据中心的网络设备连接服务器。
2. 安装Linux操作系统a. 选择适合的Linux发行版,如CentOS、Ubuntu等。
b. 使用网络安装或光盘安装的方式安装Linux操作系统。
3. 配置网络环境a. 设置静态IP地址和子网掩码。
b. 配置DNS服务器和网关。
二、搭建高可用性服务1. 安装和配置负载均衡器a. 选择合适的负载均衡器软件,如Nginx、HAProxy等。
b. 配置负载均衡器的监听端口、后端服务器列表和负载均衡算法。
2. 安装和配置分布式存储系统a. 选择适合的分布式存储系统,如GlusterFS、Ceph等。
b. 配置分布式存储系统的卷和副本数。
3. 配置服务器高可用性a. 使用Linux的高可用性解决方案,如Pacemaker、Keepalived等。
b. 配置集群节点的互相监控和故障切换。
4. 设置共享存储a. 配置分布式文件系统或网络文件系统,如NFS、iSCSI 等。
b. 挂载共享存储到各个服务器上。
5. 配置数据库的高可用性a. 使用数据库的主从复制或集群模式,如MySQL的主从复制、Galera Cluster等。
b. 配置自动故障切换和数据同步。
三、监控和管理集群1. 配置监控系统a. 选择适合的监控系统,如Zabbix、Nagios等。
b. 配置监控项、触发器和报警方式,以及集群节点的自动发现和监控。
2. 设置日志管理a. 配置集群节点的日志收集和存储,如使用ELK (Elasticsearch、Logstash、Kibana)等。
如何配置高可用的服务器集群

如何配置高可用的服务器集群在当今互联网时代,服务器集群已经成为很多公司和组织建设稳定和高可用性网络基础设施的关键组成部分。
本文将介绍如何配置高可用的服务器集群,以保证系统的稳定性和持续性服务。
一、背景概述服务器集群是指将多台服务器组成一个集群群体,通过技术手段将多台服务器组织起来,以实现高可用、负载均衡、资源共享等目标。
通过配置高可用的服务器集群,可以有效地提高系统的可用性,避免单点故障,提供更好的服务质量和用户体验。
二、服务器硬件配置1. 选购适用的服务器硬件:选择性能强劲、稳定可靠的服务器硬件设备,例如高配置的处理器、大容量的内存、高速的存储设备等。
2. 多台服务器配置成集群:将多台服务器通过高速局域网连接起来,搭建一个服务器集群。
同时确保服务器之间互相通信的稳定性和高速性。
三、服务器软件配置1. 操作系统选择:选择一种支持服务器集群配置的操作系统,例如Linux、Windows Server等。
2. 配置负载均衡:通过负载均衡技术,将请求均匀地分发到服务器集群的各个节点上,避免单一节点过载。
常见的负载均衡技术包括硬件负载均衡器、软件负载均衡器等。
3. 数据同步与备份:配置服务器集群的数据同步和备份机制,确保数据的一致性和持久性。
常见的数据同步和备份技术包括数据库同步、文件同步、冗余数据备份等。
4. 故障检测与自动切换:配置故障检测机制,当某个服务器节点发生故障时,能够自动将请求切换到其他正常的节点上,保证系统的持续性服务。
常见的故障检测与自动切换技术包括心跳检测、故障转移、故障恢复等。
四、网络配置1. 内外网环境隔离:为服务器集群配置内外网环境隔离,确保内网服务器集群对外部网络的访问安全性和稳定性。
2. 高速网络接入:配置高速网络接入,以提供稳定的网络带宽和网络传输速度。
3. 配置域名解析:为服务器集群配置域名解析,使用户可以通过域名访问服务器集群,提高访问效率和用户体验。
五、安全保护1. 配置防火墙:为服务器集群配置防火墙,限制对服务器的非法访问和攻击。
中标麒麟高级服务器操作系统软件V6.0技术指标

中标麒麟高级服务器操作系统软件技术指标中标软件有限公司技术指标类别技术参数核心参数Kernel 2.6.32-358Gnome: gnome-desktop-2.28.2-11 X:xorg-x11-server-Xorg-1.13.0-11 Glibc: glibc-2.12-1.107GCC: gcc-4.4.7-3标准符合度按照CMMI5标准研发符合POSIX标准CGL5.0LSB4.1架构支持Intel x86、x86-64AMD x86、x86-64MIPS、SPARC国产CPU平台支持:龙芯、飞腾、神威等(申威内核版本是2.6.28)功能介绍系统核心支持能力CPU支持数量(最多):x86:32个逻辑CPUx86-64:160(4096理论值)个逻辑CPU内存支持(最大):x86:16GBx86-64:2TB(64TB理论值)虚拟内存支持(单进程最大值):x86:3GBx86-64:128TB最大文件大小:Ext3:2TBExt4:16TBGFS2:100TBXFS:100TB文件系统最大支持:(Ext3、Ext4):16TBGFS2:100TBXFS:100TB支持双核及多核处理器支持并优化NUMA体系架构可扩展性:支持2048终端设备安装提供中文化的图形操作界面符合常用操作习惯,提供详细的帮助信息支持多种安装方式,可采用光盘安装,网络安装,硬盘安装等支持大规模“一键式“快速安装部署中文处理支持多种中文输入法,如汉语拼音输入法等采用i18n(国际化)技术和标准支持最新国家标准字符集(如:GB18030-2005)应用支持提供国家级第三方评测机构对中标麒麟高级服务器操作系统上的兼容测试报告:兼容Oracle Database 11g兼容Weblogic Server 9.2兼容WebSphere Application Server 7.0硬件兼容:提供厂商认证的兼容测试报告:兼容国外厂商:HP、IBM、NetApp等兼容国内厂商:浪潮、曙光、联想、宝德、长城等软件兼容:数据库软件:Oracle、IBM、SYBASE、PostgreSQL、Mysql、人大金仓、达梦、神通等中间件软件:Oracle、IBM、东方通、中创、金蝶、Apache、普元、中和威等系统工具提供图形化软件包升级工具,支持远程和本地在线升级提供图形化核心参数调整工具提供数据库辅助安装工具提供中间件辅助安装工具提供运维监控管理软件,实现业务系统统一管理,包括:系统运行状况软硬件资源统一升级部署管理数据备份实时监控等功能支持基于本地网络和异地网络的数据备份工具支持计划任务、增量差分备份基于B/S架构的配置管理支持对备份结果进行短信、邮件通知提供图形化的SELinux、防火墙以及VPN的配置管理工具提供常用的系统工具:VsFtpd图形配置工具;日志查看工具系统运行图形分析工具(LKST、KSar等)内核崩溃转储工具(Kdump)安全特性支持安全控制集中管理,支持安全管理模式切换,包括:实现Root权限的限制基于双因子认证体系的身份鉴别核心数据加密存储特权用户管理进程级最小权限支持基于角色的访问控制多级安全(即禁止上读下写)网络安全防护细粒度的安全审计安全保密箱安全删除等多项安全功能支持基于SELinux的多种安全策略支持支持加密文件系统支持安全集中管理工具,包括:认证授权安全策略管理网络防护管理自动化数据防护设备管理审计等功能虚拟化支持提供对VMware、Hyper-V、KVM、Xen、VirtualBox等的虚拟化支持提供虚拟化管理工具实现单机、多机环境下的虚拟机的创建、配置与管理备份恢复支持对整个已安装操作系统及数据分区的镜像备份和恢复HA集群支持支持中标麒麟高可用集群软件产品:对业务系统提供多层次保护负载过大或服务异常时可以根据策略进行智能切换开发工具提供丰富的开发工具和完整的Linux开发环境集成Eclipse开发环境,C/C++(CDT)和Java(JDT)开发工具包集成Qt开发框架及基于Qt的KDE开发框架支持GCC包含的C、C++、Objective C、Chill、Fortran和java等相应支持库(libstdc++、libgcj、...等)支持Python, Perl,Shell,Ruby,PHP等脚本语言。
服务器集群如何搭建高可用性服务器环境

服务器集群如何搭建高可用性服务器环境随着互联网的快速发展,服务器的高可用性变得越来越重要。
在传统的单一服务器架构下,一旦服务器出现故障,就会导致整个系统不可用,给业务带来严重影响。
为了提高系统的稳定性和可靠性,搭建高可用性的服务器集群环境成为了一种常见的解决方案。
本文将介绍如何搭建高可用性服务器环境,以确保系统在面对故障时能够保持正常运行。
一、什么是服务器集群服务器集群是指将多台服务器通过网络连接在一起,共同对外提供服务的一种架构模式。
在服务器集群中,每台服务器都可以独立对外提供服务,当其中一台服务器发生故障时,其他服务器可以接管其工作,确保系统的持续运行。
通过服务器集群的方式,可以提高系统的可用性、负载均衡能力和扩展性。
二、搭建高可用性服务器环境的必要性1. 提高系统的稳定性:通过服务器集群,可以将系统的负载分散到多台服务器上,避免单点故障导致整个系统不可用。
2. 提高系统的可靠性:当一台服务器发生故障时,其他服务器可以接管其工作,确保系统的持续运行,减少业务中断时间。
3. 提高系统的性能:通过负载均衡技术,可以将请求分发到不同的服务器上,提高系统的并发处理能力,提升用户体验。
4. 便于系统的扩展:在业务需求增长时,可以通过增加服务器的方式来扩展系统的容量,满足业务的发展需求。
三、搭建高可用性服务器环境的步骤1. 选择合适的硬件设备:在搭建服务器集群时,首先需要选择合适的硬件设备,包括服务器、网络设备、存储设备等。
硬件设备的选择应考虑系统的性能需求、可扩展性和可靠性等因素。
2. 配置网络环境:在搭建服务器集群时,需要配置好网络环境,确保服务器之间可以互相通信。
可以使用专用网络设备或者虚拟网络技术来实现服务器之间的通信。
3. 安装操作系统和软件:在服务器集群中,每台服务器都需要安装相同的操作系统和软件环境,以确保系统的一致性。
可以选择常见的操作系统如Linux、Windows Server等,并安装相应的服务软件如Nginx、Apache等。
Linux系统RabbitMQ高可用集群安装部署文档

Linux系统RabbitMQ⾼可⽤集群安装部署⽂档RabbitMQ⾼可⽤集群安装部署⽂档架构图1)RabbitMQ集群元数据的同步RabbitMQ集群会始终同步四种类型的内部元数据(类似索引):a.队列元数据:队列名称和它的属性;b.交换器元数据:交换器名称、类型和属性;c.绑定元数据:⼀张简单的表格展⽰了如何将消息路由到队列;d.vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性;2)集群配置⽅式cluster:不⽀持跨⽹段,⽤于同⼀个⽹段内的局域⽹;可以随意的动态增加或者减少;节点之间需要运⾏相同版本的 RabbitMQ 和 Erlang。
节点类型RAM node:内存节点将所有的队列、交换机、绑定、⽤户、权限和 vhost 的元数据定义存储在内存中,好处是可以使得像交换机和队列声明等操作更加的快速。
Disk node:将元数据存储在磁盘中,单节点系统只允许磁盘类型的节点,防⽌重启 RabbitMQ 的时候,丢失系统的配置信息。
解决⽅案:设置两个磁盘节点,⾄少有⼀个是可⽤的,可以保存元数据的更改。
Erlang Cookieerlang Cookie 是保证不同节点可以相互通信的密钥,要保证集群中的不同节点相互通信必须共享相同的 Erlang Cookie3)搭建RabbitMQ集群所需要安装的组件a.Jdk 1.8b.Erlang运⾏时环境c.RabbitMq的Server组件1、安装yum源⽂件2、安装Erlang# yum -y install erlang3、配置java环境 /etc/profileJAVA_HOME=/usr/local/java/jdk1.8.0_151PATH=$JAVA_HOME/bin:$PATHCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar4、安装配置rabbitmq# tar -xf rabbitmq-server-generic-unix-3.6.15.tar -C /usr/local/# mv /usr/local/rabbitmq_server-3.6.15/ /usr/local/rabbitmq5、配置RabbitMQ环境变量/etc/profileRABBITMQ_HOME=/usr/local/rabbitmqPATH=$PATH:$ERL_HOME/bin:/usr/local/rabbitmq/sbin# source /etc/profile6、修改主机配置⽂件/etc/hosts192.168.2.208 rabbitmq-node1192.168.2.41 rabbitmq-node2192.168.2.40 rabbitmq-node3各个主机修改配置⽂件保持⼀致# /root/.erlang.cookie7、后台启动rabbitmq# /usr/local/rabbitmq/sbin/rabbitmq-server -detached添加⽤户# rabbitmqctl add_user admin admin给⽤户授权# rabbitmqctl set_user_tags admin administrator# rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"启⽤插件,可以使⽤rabbitmq管理界⾯# rabbitmq-plugins enable rabbitmq_management查看⽤户列表# rabbitmqctl list_users查看节点状态# rabbitmqctl status查看集群状态# rabbitmqctl cluster_status查看插件# rabbitmq-plugins list添加防⽕墙规则/etc/sysconfig/iptables-A INPUT -m state --state NEW -m tcp -p tcp --dport 27017 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 28017 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 15672 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 5672 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 25672 -j ACCEPT8、添加集群node节点,从节点执⾏(⽬前配置2个节点)# rabbitmqctl stop_app# rabbitmqctl join_cluster --ram rabbit@rabbitmq-node2或者# rabbitmqctl join_cluster rabbit@rabbitmq-node2# rabbitmqctl change_cluster_node_type ram启动节点#rabbitmqctl start_app9、删除集群node 节点删除1. rabbitmq-server -detached2. rabbitmqctl stop_app3. rabbitmqctl reset4. rabbitmqctl start_app设置镜像队列策略在web界⾯,登陆后,点击“Admin--Virtual Hosts(页⾯右侧)”,在打开的页⾯上的下⽅的“Add a new virtual host”处增加⼀个虚拟主机,同时给⽤户“admin”和“guest”均加上权限1、2、# rabbitmqctl set_policy -p hasystem ha-allqueue "^" '{"ha-mode":"all"}' -n rabbit"hasystem" vhost名称, "^"匹配所有的队列, ha-allqueue 策略名称为ha-all, '{"ha-mode":"all"}' 策略模式为 all 即复制到所有节点,包含新增节点,则此时镜像队列设置成功.rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]-p Vhost:可选参数,针对指定vhost下的queue进⾏设置Name: policy的名称Pattern: queue的匹配模式(正则表达式)Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-modeha-mode:指明镜像队列的模式,有效值为 all/exactly/nodesall:表⽰在集群中所有的节点上进⾏镜像exactly:表⽰在指定个数的节点上进⾏镜像,节点的个数由ha-params指定nodes:表⽰在指定的节点上进⾏镜像,节点名称通过ha-params指定ha-params:ha-mode模式需要⽤到的参数ha-sync-mode:进⾏队列中消息的同步⽅式,有效值为automatic和manualpriority:可选参数,policy的优先级注以上集群配置完成⾼可⽤HA配置Haproxy 负载均衡,keepalived实现健康检查HA服务安装配置解压⽂件# tar -zxf haproxy-1.8.17.tar.gz查看内核版本# uname –r# yum -y install gcc gcc-c++ make切换到解压⽬录执⾏安装# make TARGET=3100 PREFIX=/usr/local/haproxy # make install PREFIX=/usr/local/haproxy创建配置⽂件相关⽬录# mkdir /usr/local/haproxy/conf# mkdir /var/lib/haproxy/# touch /usr/local/haproxy/haproxy.cfg# groupadd haproxy# useradd haproxy -g haproxy# chown -R haproxy.haproxy /usr/local/haproxy# chown -R haproxy.haproxy /var/lib/haproxy配置⽂件globallog 127.0.0.1 local2chroot /var/lib/haproxypidfile /var/run/haproxy.pidmaxconn 4000user haproxygroup haproxydaemon# turn on stats unix socketstats socket /var/lib/haproxy/stats#---------------------------------------------------------------------defaultsmode httplog globaloption httplogoption dontlognulloption http-server-closeoption redispatchretries 3timeout http-request 10stimeout queue 1mtimeout connect 10stimeout client 1mtimeout server 1mtimeout http-keep-alive 10stimeout check 10smaxconn 3000#监控MQ管理平台listen rabbitmq_adminbind 0.0.0.0:8300 server rabbitmq-node1 192.168.2.208:15672 server rabbitmq-node2 192.168.2.41:15672 server rabbitmq-node3 192.168.2.40:15672#rabbitmq_cluster监控代理listen rabbitmq_local_clusterbind 0.0.0.0:8200#配置TCP模式mode tcpoption tcplog#简单的轮询balance roundrobin#rabbitmq集群节点配置 server rabbitmq-node1 192.168.2.208:5672 check inter 5000 rise 2 fall 2 server rabbitmq-node2 192.168.2.41:5672 check inter 5000 rise 2 fall 2 server rabbitmq-node3 192.168.2.40:5672 check inter 5000 rise 2 fall 2 #配置haproxy web监控,查看统计信息listen private_monitoringbind 0.0.0.0:8100mode httpoption httplogstats enablestats uri /statsstats refresh 30s#添加⽤户名密码认证stats auth admin:admin启动haproxy服务# /usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/conf/haproxy.cfg#Keepalived 源码安装软件包路径 /usr/local/src安装路径 /usr/local/keepalived配置⽂件/etc/keepalived/keeplived.conf# tar -zxf keepalived-2.0.10.tar.gz#安装依赖包# yum -y install openssl-devel libnl libnl-devel libnfnetlink-devel# ./configure --prefix=/usr/local/keepalived && make && make install创建keepalived配置⽂件⽬录#mkdir /etc/keepalived拷贝配置⽂件到/etc/keepalived⽬录下# cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/复制keepalived脚本到/etc/init.d/ ⽬录# cp /usr/local/src/keepalived-2.0.10/keepalived/etc/init.d/keepalived /etc/init.d/拷贝keepalived脚本到/etc/sysconfig/ ⽬录# cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/建⽴软连接# ln -s /usr/local/keepalived/sbin/keepalived /sbin/添加到开机启动# chkconfig keepalived on查看服务状况# systemctl status keepalivedKeepalived启动# systemctl start keepalivedmaster 配置⽂件#Master :global_defs {notification_email {134********m@}notification_email_from 134********m@smtp_server 127.0.0.1smtp_connect_timeout 30router_id NGINX_DEVEL}vrrp_script chk_haproxy {script "/usr/local/keepalived/check_haproxy.sh"interval 2weight 2fall 3rise 2}vrrp_instance haproxy_1 {state MASTERinterface ens33virtual_router_id 104priority 150advert_int 1mcast_src_ip 192.168.2.41authentication {auth_type PASSauth_pass 1111}track_interface {ens33}track_script {check_haproxy.sh}virtual_ipaddress {192.168.33.110}}#virtual_server 192.168.2.110 80 {# delay_loop 6 # 设置健康检查时间,单位是秒# lb_algo wrr # 设置负载调度的算法为wlc# lb_kind DR # 设置LVS实现负载的机制,有NAT、TUN、DR三个模式# nat_mask 255.255.255.0# persistence_timeout 0# protocol TCP# real_server 192.168.220.128 80 { # 指定real server1的IP地址# weight 3 # 配置节点权值,数字越⼤权重越⾼#TCP_CHECK {# connect_timeout 10# nb_get_retry 3# delay_before_retry 3# connect_port 80# }# }# }}#Slave :global_defs {notification_email {134********m@}notification_email_from 134********m@smtp_server 127.0.0.1smtp_connect_timeout 30router_id NGINX_DEVEL}vrrp_script chk_haproxy {script "/usr/local/keepalived/check_haproxy.sh"interval 2weight 2fall 3rise 2}vrrp_instance haproxy_2 {state SLAVEinterface ens33virtual_router_id 104priority 150advert_int 1mcast_src_ip 192.168.2.208authentication {auth_type PASSauth_pass 1111}track_interface {ens33}track_script {check_haproxy.sh}virtual_ipaddress {192.168.2.246}}#virtual_server 192.168.2.110 80 {# delay_loop 6 # 设置健康检查时间,单位是秒# lb_algo wrr # 设置负载调度的算法为wlc# lb_kind DR # 设置LVS实现负载的机制,有NAT、TUN、DR三个模式# nat_mask 255.255.255.0# persistence_timeout 0# protocol TCP# real_server 192.168.220.128 80 { # 指定real server1的IP地址# weight 3 # 配置节点权值,数字越⼤权重越⾼#TCP_CHECK {# connect_timeout 10# nb_get_retry 3# delay_before_retry 3# connect_port 80# }# }# }}haproxy检测#!/bin/bashHaproxyStatus=`ps -C haproxy --no-header | wc -l`if [ $HaproxyStatus-eq 0 ];then/etc/init.d/haproxy startsleep 3if [ `ps -C haproxy --no-header | wc -l ` -eq 0 ];then/etc/init.d/keepalived stopfifi。
如何在Linux上搭建高可用Web服务器集群

如何在Linux上搭建高可用Web服务器集群在互联网时代,Web服务器扮演着极为重要的角色。
为了确保Web 服务的高可用性和性能,很多组织和企业选择搭建高可用Web服务器集群。
本文将介绍如何在Linux操作系统上搭建高可用Web服务器集群。
一、概述高可用Web服务器集群是指通过将多台服务器连接在一起,以实现负载均衡和容错机制,从而提供稳定、可靠和高性能的Web服务。
在集群中,多台服务器相互协作,共同处理用户请求,从而提高系统的吞吐量和健壮性。
二、硬件和网络配置1. 服务器硬件需求:每台服务器需要具备足够的内存、处理器和存储空间,以适应高负载的请求。
2. 网络要求:服务器之间需要良好的网络互连,可以通过交换机或者路由器实现。
3. IP地址规划:为每个服务器分配一个唯一的IP地址,并为集群分配一个虚拟IP地址,用户请求将通过虚拟IP地址访问集群。
三、软件配置1. 安装操作系统:在每台服务器上安装相同的Linux操作系统,如CentOS、Ubuntu等。
确保操作系统版本和硬件架构一致。
2. 安装Web服务器软件:在每台服务器上安装相同版本的Web服务器软件,如Apache、Nginx等。
确保配置文件一致。
3. 安装负载均衡软件:选择一种负载均衡软件,如Nginx、HAProxy等,安装在其中一台服务器上。
负载均衡软件将负责将用户请求分发给其他服务器。
4. 配置集群参数:在负载均衡软件的配置文件中,指定集群中其他服务器的IP地址和端口号,以及设置检测服务器健康状态的机制。
四、高可用和容错机制1. 心跳检测:负载均衡软件可以通过心跳检测机制监测集群中服务器的健康状况。
如果某台服务器故障或者不可用,负载均衡软件将自动将请求转发给其他可用服务器。
2. 会话保持:为了确保用户会话的一致性,在集群中使用会话保持机制。
可以通过在负载均衡软件中设置会话保持规则,将同一用户的请求始终转发到同一台服务器上。
3. 数据同步:如果Web应用程序有状态或者需要保持数据一致性,可以使用数据同步机制,确保集群中的服务器具有相同的数据副本。
高可用集群解决方案

高可用集群解决方案
《高可用集群解决方案》
在当今数字化时代,企业对于系统的稳定性和可用性要求越来越高。
为了保障业务的正常运行,高可用集群解决方案成为了企业的迫切需求。
高可用集群是一种通过将多台服务器进行集群化部署,实现故障转移和负载均衡的方式,以提高系统的稳定性和可用性。
高可用集群解决方案通常包括硬件和软件两个层面的技术。
在硬件方面,企业可以通过在多台服务器上部署相同的硬件设备,以实现冗余备份和故障转移。
同时,还可以借助负载均衡器来分担服务器的负载,提高系统的性能和稳定性。
在软件方面,高可用集群解决方案会使用一些特定的软件工具来实现故障检测、故障转移和数据同步等功能,从而保障整个系统的稳定性和可用性。
对于企业来说,选择合适的高可用集群解决方案非常重要。
首先,企业需要根据自身的业务需求和数据规模来选择适合的集群解决方案。
其次,企业还需考虑集群解决方案的成本和部署难度,以确保自身能够承受并维护这样的解决方案。
最后,企业还需考虑解决方案的可扩展性和未来的升级计划,以确保投资的长期有效性。
总的来说,高可用集群解决方案是企业保障系统稳定性和可用性的重要手段。
通过合理选择和部署适合自身业务需求的集群
解决方案,企业可以确保系统随时可用,从而提高业务的竞争力和用户体验。
linux服务器集群的详细配置

linux服务器集群的详细配置一、计算机集群简介计算机集群简称集群是一种计算机系统, 它通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计算工作;在某种意义上,他们可以被看作是一台计算机;集群系统中的单个计算机通常称为节点,通常通过局域网连接,但也有其它的可能连接方式;集群计算机通常用来改进单个计算机的计算速度和/或可靠性;一般情况下集群计算机比单个计算机,比如工作站或超级计算机性能价格比要高得多;二、集群的分类群分为同构与异构两种,它们的区别在于:组成集群系统的计算机之间的体系结构是否相同;集群计算机按功能和结构可以分成以下几类:高可用性集群 High-availability HA clusters负载均衡集群 Load balancing clusters高性能计算集群 High-performance HPC clusters网格计算 Grid computing高可用性集群一般是指当集群中有某个节点失效的情况下,其上的任务会自动转移到其他正常的节点上;还指可以将集群中的某节点进行离线维护再上线,该过程并不影响整个集群的运行;负载均衡集群负载均衡集群运行时一般通过一个或者多个前端负载均衡器将工作负载分发到后端的一组服务器上,从而达到整个系统的高性能和高可用性;这样的计算机集群有时也被称为服务器群Server Farm; 一般高可用性集群和负载均衡集群会使用类似的技术,或同时具有高可用性与负载均衡的特点;Linux虚拟服务器LVS项目在Linux操作系统上提供了最常用的负载均衡软件;高性能计算集群高性能计算集群采用将计算任务分配到集群的不同计算节点而提高计算能力,因而主要应用在科学计算领域;比较流行的HPC采用Linux操作系统和其它一些免费软件来完成并行运算;这一集群配置通常被称为Beowulf集群;这类集群通常运行特定的程序以发挥HPC cluster的并行能力;这类程序一般应用特定的运行库, 比如专为科学计算设计的MPI 库集群特别适合于在计算中各计算节点之间发生大量数据通讯的计算作业,比如一个节点的中间结果或影响到其它节点计算结果的情况;网格计算网格计算或网格集群是一种与集群计算非常相关的技术;网格与传统集群的主要差别是网格是连接一组相关并不信任的计算机,它的运作更像一个计算公共设施而不是一个独立的计算机;还有,网格通常比集群支持更多不同类型的计算机集合;网格计算是针对有许多独立作业的工作任务作优化,在计算过程中作业间无需共享数据;网格主要服务于管理在独立执行工作的计算机间的作业分配;资源如存储可以被所有结点共享,但作业的中间结果不会影响在其他网格结点上作业的进展;三、linux集群的详细配置下面就以WEB服务为例,采用高可用集群和负载均衡集群相结合;1、系统准备:准备四台安装Redhat Enterprise Linux 5的机器,其他node1和node2分别为两台WEB服务器,master作为集群分配服务器,slave作为master的备份服务器;所需软件包依赖包没有列出:2、IP地址以及主机名如下:3、编辑各自的hosts和network文件mastervim /etc/hosts 添加以下两行vim /etc/sysconfig/networkHOSTNAME= slavevim /etc/hosts 添加以下两行vim /etc/sysconfig/network HOSTNAME= node1vim /etc/hosts 添加以下两行vim /etc/sysconfig/network HOSTNAME= node2vim /etc/hosts 添加以下两行vim /etc/sysconfig/networkHOSTNAME= 注:为了实验过程的顺利,请务必确保network文件中的主机名和hostname命令显示的主机名保持一致,由于没有假设DNS服务器,故在hosts 文件中添加记录;4、架设WEB服务,并隐藏ARPnode1yum install httpdvim /var//html/添加如下信息:This is node1.service httpd startelinks 访问测试,正确显示&nbs隐藏ARP,配置如下echo 1 >> /proc/sys/net/ipv4/conf/lo/arp_ignoreecho 1 >> /proc/sys/net/ipv4/conf/all/arp_ignore echo 2 >> /proc/sys/net/ipv4/conf/lo/arp_announce echo 2 >> /proc/sys/net/ipv4/conf/all/arp_announce ifconfig lo:0 netmask broadcast uproute add -host dev lo:0node2yum install httpdvim /var//html/添加如下信息:This is node2.service httpd startelinks 访问测试,正确显示隐藏ARP,配置如下echo 1 >> /proc/sys/net/ipv4/conf/lo/arp_ignore echo 1 >> /proc/sys/net/ipv4/conf/all/arp_ignore echo 2 >> /proc/sys/net/ipv4/conf/lo/arp_announce echo 2 >> /proc/sys/net/ipv4/conf/all/arp_announceifconfig lo:0 netmask broadcast uproute add -host dev lo:0mastervim /var//html/添加如下内容:The service is bad.service httpd startslavevim /var//html/添加如下内容:The service is bad.service httpd start5、配置负载均衡集群以及高可用集群小提示:使用rpm命令安装需要解决依赖性这一烦人的问题,可把以上文件放在同一目录下,用下面这条命令安装以上所有rpm包:yum --nogpgcheck -y localinstall .rpmmastercd /usr/share/doc/ cp haresources authkeys /etc/cd /usr/share/doc/ cp /etccd /etcvim开启并修改以下选项:debugfile /var/log/ha-debuglogfile /var/log/ha-logkeepalive 2deadtime 30udpport 694bcast eth0增加以下两项:node node vim haresources增加以下选项:ldirectord::/etc/为/etc/authkeys文件添加内容echo -ne "auth 1\n1 sha1 "注意此处的空格 >> /etc/authkeysdd if=/dev/urandom bs=512 count=1 | openssl md5 >> /etc/authkeys &nbs更改key文件的权限chmod 600 /etc/authkeysvim /etc/修改如下图所示:slave 注:由于slave的配置跟master配置都是一样的可以用下面的命令直接复制过来,当然想要再练习的朋友可以自己手动再配置一边;scp root:/etc/{,haresources} /etc/输入的root密码scp root:/etc/ /etc输入的root密码6、启动heartbeat服务并测试master & slaveservice heartbeat start这里我就我的物理机作为客户端来访问WEB服务,打开IE浏览器这里使用IE浏览器测试,并不是本人喜欢IE,而是发现用google浏览器测试,得出的结果不一样,具体可能跟两者的内核架构有关,输入,按F5刷新,可以看到三次是2,一次是1,循环出现;7、停止主服务器,再测试其访问情况masterifdown eth0再次访问,可以看到,服务器依然能够访问;。
高可用集群方案

高可用集群方案随着信息技术的不断发展,对系统的可用性要求也越来越高。
高可用集群方案作为一种解决方案,可以提供系统的高可用性和可靠性,以确保系统在任何时间段内都能正常运行。
一、什么是高可用集群方案?高可用集群方案是一种系统设计方法,通过将多个服务器组成一个集群并运行相同的应用程序或服务来提高系统的可用性。
在高可用集群中,当一个服务器出现故障或不可用时,其他服务器将接管其工作,以保持系统的连续性和稳定性。
二、为什么需要高可用集群方案?1. 提高系统的可用性:高可用集群方案可以有效降低系统故障对业务的影响。
当一个服务器发生故障时,其他服务器可以继续提供服务,确保系统的连续性和稳定性。
2. 提高系统的性能:通过将工作负载分发到不同的服务器上,高可用集群方案可以提高系统的性能和处理能力。
当系统负载较高时,可以动态调整服务器的数量和配置,以提供更好的服务质量。
3. 实现系统的容错性:高可用集群方案可以通过冗余和备份机制来实现系统的容错性。
当一个服务器发生故障时,其他服务器可以接管其工作,并保证数据的一致性和完整性。
三、高可用集群方案的核心技术1. 负载均衡:负载均衡是高可用集群方案的核心技术之一。
通过在集群中的服务器之间分配和平衡工作负载,可以提高系统的性能和可用性。
常见的负载均衡技术包括软件负载均衡和硬件负载均衡。
2. 心跳检测:心跳检测是高可用集群方案的另一项重要技术。
通过定期发送心跳包来检测服务器的状态,一旦发现服务器故障,集群中的其他服务器将接管其工作。
常见的心跳检测技术包括基于网络的心跳检测和基于硬件的心跳检测。
3. 数据复制:数据复制是高可用集群方案的必备技术之一。
通过将数据在集群中的多个节点之间进行复制和同步,可以实现数据的冗余和备份,保证数据的一致性和可靠性。
四、常见的高可用集群方案1. 主备集群:主备集群是最常见的高可用集群方案之一。
在主备集群中,有一个主服务器负责提供服务,而其他备份服务器则处于备份状态。
如何配置一个高可用服务器集群

如何配置一个高可用服务器集群高可用服务器集群是一种为了提高系统的可用性和灵活性而采用的解决方案。
它通过将多个服务器组成一个集群,实现负载均衡、故障转移和自动切换等功能,确保系统在面临服务器故障时仍能正常运行。
本文将详细介绍如何配置一个高可用服务器集群,以实现数据的持续可靠性和稳定性。
一、概述高可用服务器集群主要由主服务器和备份服务器组成。
主服务器用于处理用户请求和数据存储,备份服务器则在主服务器发生故障时接管其功能,从而实现故障转移。
在集群中,主服务器和备份服务器之间通过心跳信号进行通信,并通过监控主服务器的状态实现自动切换功能。
二、硬件配置在配置高可用服务器集群时,首先需要选择适合的硬件设备。
服务器的选择需要考虑其处理能力、存储容量、网络带宽和系统扩展性。
建议使用品牌服务器,并配置高性能的CPU和充足的内存,以保证系统的运行效率。
此外,还需要选择可靠的存储设备,例如RAID阵列,以提供数据的冗余备份和故障恢复能力。
三、软件配置1.操作系统选择在配置高可用服务器集群时,选择合适的操作系统非常重要。
常用的操作系统有Linux(如CentOS、Ubuntu)和Windows Server。
Linux具有开源、稳定、安全、高效的优势,而Windows Server则适用于Microsoft环境和一些特定的应用场景。
根据实际需求和运行环境选择适合的操作系统。
2.负载均衡器配置负载均衡器是高可用服务器集群的核心组件之一。
它能够将用户请求均匀地分发给各个服务器,从而实现请求的负载均衡。
常用的负载均衡器软件有Nginx、HAProxy和F5 BIG-IP等。
在配置负载均衡器时,需要考虑负载均衡策略、健康检查、会话保持等功能,并合理配置相关参数。
3.数据库配置数据库是应用系统的核心数据存储和管理组件。
在高可用服务器集群中,数据库也需要进行相应的配置。
常见的数据库软件有MySQL、PostgreSQL和Oracle等。
使用Linux构建高可用性服务器集群(一)2024

使用Linux构建高可用性服务器集群(一)引言概述:Linux作为一种自由开放源代码的操作系统,以其稳定性、安全性和灵活性,成为构建高可用性服务器集群的理想选择。
本文将介绍如何使用Linux构建高可用性服务器集群,从搭建基础环境到实现负载均衡和故障恢复,为大家提供全面的指导。
正文内容:一、设计服务器集群架构1. 定义业务需求和目标2. 设计数据中心拓扑结构3. 确定服务器规模和类型4. 划分子网和IP地址分配5. 设计高可用性策略和故障恢复计划二、搭建基础环境1. 安装Linux操作系统2. 配置网络连接和网络设备3. 安装并配置必要的软件依赖4. 配置硬件负载均衡设备5. 配置防火墙和安全策略三、实现负载均衡1. 选择合适的负载均衡算法2. 配置负载均衡器3. 部署并配置Web服务器集群4. 测试负载均衡效果5. 监控和调整负载均衡配置四、实现故障恢复1. 配置故障检测和自动切换机制2. 设置错误恢复和容错机制3. 配置服务器冗余和故障切换策略4. 测试故障恢复效果5. 监控和调整故障恢复配置五、优化性能和可靠性1. 配置服务器缓存和高速存储2. 使用文件系统和文件管理进行优化3. 调整网络参数和传输协议4. 实施安全性控制和访问限制5. 定期评估和更新服务器集群的性能和可靠性总结:通过本文的指导,您可以了解如何使用Linux构建高可用性服务器集群。
设计集群架构、搭建基础环境、实现负载均衡和故障恢复,以及优化性能和可靠性,都是构建高可用性服务器集群的重要步骤。
准确地计划和配置每个环节,可以提高服务器集群的稳定性和可靠性,确保业务的连续性和高性能。
集群的概念 高可用集群

集群的概念高可用集群集群是指由多个计算机或服务器组成的一个组,这些计算机或服务器通过网络互相通信和协调工作,以达到提高系统性能、可靠性和可扩展性的目的。
集群的主要特点是共享资源、分布式处理和负载均衡。
集群的出现是为了满足对大规模计算和存储的需求,通过将多个节点连接在一起,形成一个强大的计算资源整体,实现任务的分布式处理和数据的并行处理。
高可用集群是指在集群中配置了冗余的硬件和软件,以提高系统的可用性和可靠性。
当一个节点发生故障时,系统会自动切换到其他可用的节点上,保证服务的连续性,不会因为单个节点的故障而导致整个集群的停机。
高可用集群主要有以下几个重要组成部分和技术:1. 心跳检测:集群中的节点通过网络定期发送心跳信号以检测其他节点的状态,当某个节点长时间没有响应时,集群会判断该节点发生故障,并进行相应的处理。
2. 资源共享:高可用集群中的节点共享同一份数据,可以通过网络访问和操作这些数据。
当有节点发生故障时,其他节点可以接管这些数据,以保证服务的连续性。
3. 故障切换:当一个节点发生故障时,高可用集群会自动将服务切换到其他可用节点上,尽可能减少服务中断的时间。
切换过程中可能需要进行一些状态同步和资源分配的操作。
4. 资源负载均衡:高可用集群可以根据各个节点的负载情况,自动调整任务的分配和资源的利用,以保证集群的性能和吞吐量。
这可以通过监控节点的负载情况和性能指标来实现。
5. 数据备份与恢复:高可用集群中的数据一般都会进行备份,以防止数据丢失或发生故障时能够及时恢复。
备份可以通过同步或异步的方式进行。
高可用集群在很多领域都有广泛的应用,比如互联网服务、金融系统、电信系统等。
它可以提高系统的可用性和可靠性,减少服务中断的时间,提高用户的满意度和体验。
在实际应用中,高可用集群的配置和管理是一个复杂的过程。
需要考虑硬件和软件的可靠性,网络的稳定性,以及各个节点之间的通信和协调问题。
同时还需要进行故障的监控和诊断,及时发现和处理故障,保证集群的正常运行。
Linux下高可用性集群配置

Linux下高可用集群方案很多,本文介绍的是性价比比较高的一种: 使用Heartbeat 2.0配置Linux高可用性集群。
一、准备工作你首先需要两台电脑,这两台电脑并不需要有相同的硬件(或者内存大小等),但如果相同的话,当某个部件出现故障时会容易处理得多。
接下来您需要决定如何部署。
你的集群是通过Heartbeat 软件产生在两台电脑之间心跳信号来建立的。
为了传输心跳信号,需要在节点之间存在一条或多条介质通路(串口线通过modem电线,以太网通过交叉线,等等)。
现在可以开始配置硬件了。
既然想要获得高可用性(HA),那么您很可能希望避免单点失效。
在本例中,可能是您的null modem线/串口,或者网卡(NIC)/ 交叉线。
因此便需要决定是否希望为每个节点添加第二条串口null modem连线或者第二条NIC/交叉线连接。
我使用一个串口和一块额外的网卡来作为heartbeat的通路,这是因为我只有一条null modem线和一块多余的网卡,并且认为有两种介质类型传输heartbeat信号比较好。
硬件配置完成之后,便需要安装操作系统以及配置网络(我在本文中使用的是RedHat)。
假设您有两块网卡,那么有一块应该配置用于常规网络用途,另一块作为集群节点之间的专用网络连接(通过交叉线)。
例如,假设集群节点有如表-1下的IP地址:表-1集群节点的IP地址输入如下命令检查您的配置:ifconfig这将显示您的网卡及其配置。
也可以使用命令“netstat –nr”来获得网络路由信息。
如果一切正常,接下来要确定可以来两个节点之间通过所有接口ping通对方。
如果使用了串口,便需要检测其连接情况。
把一个节点作为接收者,输入命令:cat </dev/ttyS0在另一个节点上,输入:echo hello >/dev/ttyS0应该可以在接收节点上看到该文本。
如果正常的话交换这两个节点的角色再作一次,否则有可能是使用了错误的设备文件。
高可用性Linux集群构建

高可用性Linux集群构建目录Pacemaker, Corosync 和PCS 搭建高可用性负载均衡Linux 集群(1)1. 高可用性的概念: (1)2. 构建环境 (2)3. 构建步骤 (3)3.1 安装pacemaker, corosync 和pcs (3)3.2 设置hostname (3)3.3 修改/etc/hosts,增加以下两行 (3)3.4 修改防火墙设置,打开2224和80端口 (3)3.5 给hacluster用户设置密码,这个是pcs管理的用户。
(3)3.6 设置pcsd 自动启动 (3)3.7 把所有以上步骤在node2机器上运行一次,注意第二步hostname为node2 (4)3.8 添加集群节点(可以运行在node1或者node2任意一台机器,不用重复运行) (4)3.9 安装httpd(下一步替换Nignx) (4)3.10 修改httpd配置文件 (4)3.11 设置httpd 自动启动 (4)3.12 写一个简单html (5)3.13 在node2上重复3.9-3.12步,注意第上一步的node名称(5)3.14 添加集群约束 (5)3.15 设置集群开机自动启动 (5)3.16 在node2 上重复3.15. (6)4. 验证集群 (6)4.1打开浏览器访问 http://172.25.73.120 (6)5. 集群管理工具Pcs (7)Pacemaker, Corosync和PCS 搭建高可用性负载均衡Linux 集群1.高可用性的概念:●一种机制来定义哪些系统可以被用作集群节点●哪些服务或者应用可以在节点间作失效切换(fail-over)●节点间内部相互通信的方式●当失效的节点控制相同的集群资源的情况下,防止资源的冲突●防止集群裂脑(split-brain)发生●Fence机制或者更加复杂的I/O fence机制●提供集群合作管理的机制本文档的构架环境是用的2台VirtualBox虚拟机,安装的CentOS7 64位操作系统。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
集群之高可用一、定义为保证集群整体服务的高可用,考虑计算硬件和软件的容错性。
如果高可用性群集中的某个节点发生了故障,那么将由另外的节点代替它。
整个系统环境对于用户是一致的。
上一个章节,我们在讲述lvs的时候提过LVS是有一个主控服务器+几台realserver组成的,所以这个主控服务器就是其核心部分,如果这台电脑出问题了,那么realserver性能再强悍也是白搭,所以在现实中主控服务器通常是双机的,以便一台出鼓掌的时候另外一台可以继续接替其工作。
这里我就将主控服务器用heartbeat来做成高可用HA来实现其功能。
下来我就总结如何将主控服务器做成HA二、实验环境两台主机名为desktop3和desktop4的redhat6虚拟机desktop3:192.168.1.111desktop4:192.168.1.112VIP:192.168.1.220三、安装软件1.分别在两台电脑上拷贝上如下的软件heartbeat-3.0.4-1.el6.x86_64.rpm heartbeat-libs-3.0.4-1.el6.x86_64.rpm heartbeat-devel-3.0.4-1.el6.x86_64.rpm ldirectord-3.9.2-1.2.x86_64.rpm2.分别在两台电脑上安装上述的软件[[root@server102 heart]# heart]# yum localinstall --nogpgcheck * -y //安装此路径下的所有软件包并解决依赖关系[root@server103 untitled folder]# yum localinstall -y --nogpgcheck *3.将server102主机的配置文件拷贝到/etc/ha.d目录下[root@server102 heart]# cd /usr/share/doc/heartbeat-3.0.4/[root@server102 heartbeat-3.0.4]# lsapphbd.cf authkeys AUTHORS ChangeLog COPYING COPYING.LGPL ha.cf haresources README[root@server102 heartbeat-3.0.4]# cp ha.cf haresources authkeys /etc/ha.d/4.对server102主机的ha.cf配置文件进行配置[root@server102 heartbeat-3.0.4]# cd /etc/ha.d/[root@server102 ha.d]# lsauthkeys ha.cf harc haresources rc.d README.config resource.d sh[root@server102 ha.d]#vim ha.cf //对ha.cf文件进行下列的编辑debugfile /var/log/ha-debuglogfile /var/log/ha-loglogfacility local0keepalive 1deadtime 5warntime 4initdead 10udpport 694bcast eth0auto_failback onwatchdog /dev/watchdognode node ping 10.10.10.253 //网关respawn hacluster /usr/lib64/heartbeat/ipfailapiauth ipfail gid=haclient uid=hacluster说明:1.debugfile /var/log/ha-debug:调取日志文件,取默认值2.logfile /var/log/ha-log:系统运行日志文件,取默认值3.logfacility local0:日志等级,取默认值4.keepalive 1:心跳频率,自己设定。
1表示1秒;200ms则表示200毫秒5.deadtime 5:节点死亡时间阀值,就是从节点在过了5秒后还没有收到心跳就认为主节点已经死亡。
6.warntime 4:发出警告的时间,自己设定7.initdead 10:守护进程首次启动后应该等待120秒后再启动主服务器上的资源8.udpport 694:心跳信息传递的UDP端口,使用端口694进行bcast和ucast通信,取默认值9.#baud 19200:串口波特率,与serial一起使用;默认可以屏蔽10.#serial /dev/ttyS0:采用串口来传递心跳信息。
默认是屏蔽掉的11.bcast eth0:采取UDP广播来通知心跳12.#mcast eth0 225.0.0.1 694 1 0:采用udp多播来通知心跳13.#ucast eth0 192.168.1.2:采用网卡eth0的udp单播来通知心跳(9-13选一种形式进行广播就可以了)14.auto_failback on:当主节点恢复后,是否自动切回15.#stonith baytech /etc/ha.d/conf/stonith.baytech:stonith是用来保证共享存储环境中的数据完整性16.watchdog /dev/watchdog:watchdog可以让系统出现故障一份子后重启该机器,这个功能可以帮助服务器在确实停止心跳后能够重新恢复心跳。
如果使用该特性,则修改系统中/etc/modprobe.conf中添加如下行:options softdog nowayout=0这样在系统启动的时候,在内核中装入“softdog”内核模块,用来生成实际的设备文件/dev/watchdog17. node :主节点名称,与uname –n保持一致,排在第一的默认为主节点18. node :副节点名称,与uname –n保持一致19. ping 10.10.10.253respawn hacluster /usr/lib64/heartbeat/ipfailapiauth ipfail gid=haclient uid=hacluster默认的heartbeat并不检测除本身之外的其他任何服务,也不检测网络状况。
所以当网络中断时,并不会进行Load Balancer和Backup之间的切换。
可以通过设置ipfail插件,设置“ping nodes”来解决这一问题,但不能使用一个集群节点作为ping的节点。
5. 对server102主机设置watchdog[root@server102 ha.d]# modprobe softdog //设置watchdog[root@server102 ha.d]# ll /dev/watchdog //已经生成了watchdogcrw-rw----. 1 root root 10, 130 Dec 8 06:07 /dev/watchdog[root@server102 ha.d]# vim /etc/rc.local//设置开机自动加载开门狗到模块,在两台机子上都要设置touch /var/lock/subsys/localmodprobe softdog6对server102的资源文件(/etc/ha.d/haresources)进行配置[root@server102 ha.d]# vim haresources IPaddr::192.168.1.220/24/eth0 httpd这个文件中定义了实现集群所需的各个软件的启动脚本,这些脚本必须放在/etc/init.d或者/etc/ha.d/resource.d目录里。
IPaddr的作用是启动Virutal IP,他是HeartBeart自带的一个脚本;httpd是apache服务的启动脚本7.对server102的认证文件(/etc/ha.d/authkeys)进行配置[root@server102 ha.d]# vim authkeysauth 3#1 crc#2 sha1 HI!3 md5 Hello![root@server102 ha.d]# chmod 600 authkeys //文件的权限必须是6008,将server102上配置好的文件拷贝到server103上前面都是主心跳server102上的配置,现在我们将上述的配置文件全部拷贝到server103上[root@server102 ha.d]# scp ha.cf haresources authkeys server103:/etc/ha.d/root@server103's password:ha.cf 100% 10KB 10.3KB/s 00:00haresources 100% 5961 5.8KB/s 00:00authkeys 100% 643 0.6KB/s 00:009. 设置主服务器和备份服务器时间同步虽然Heartbeat不要求在两个服务器上使系统钟同步主要和备份服务器,但是系统时钟应该在的几十秒之内,否则在高可用性服务的环境下会产生故障。
在在两个系统启动Heartbeat之前,你应该人工检查并且放置系统时间(使用date命令)。
关于一种更好的长期的解决的方法你应该在两个系统上使用NTP软件同步钟。
10.开启心跳服务分别在主备心跳上启动heartbeat 服务:service heartbeat start分别查看日志,是否有报错,服务正常的话station3 上多了个eth0:0 接口,若没有出现,请等待一会,再使用ifconfig 查看,若还是没有eth0:0 接口出现,检查配置文件是否正确!若停止desktop3上的heartbeat 服务,则desktop4 会接管,并产生一个eth0:0 接口!补充知识1.ipfail前面我们在总结ha.cf文件时候提到过一个ipfail,这个具体是做什么用的呢?respawn hacluster /usr/lib64/heartbeat/ipfail从前文我们知道respawn是列出将要执行和监控的命令,这里我们列出的是ipfail,ipfail插件的用途是检测网络故障,并作出合理的反应,默认的heartbeat并不检测除本身之外的其他任何服务,也不检测网络状况。
所以当网络中断时,并不会进行Load Balancer和Backup之间的切换。
可以通过设置ipfail插件,设置“ping nodes”来解决这一问题,但不能使用一个集群节点作为ping的节点。
为了实现这样的功能ipfail使用ping节点或者ping节点组,这些节点在集群中作为“哑”节点出现。
如果HA节点间可以相互通信ipfail便可以可靠地检测到其中一个网络连接失效的情况,并作出补救。