一种高效CAVLC编码结构的VLSI设计实现
基于H.264-AVC视频解码器的VLSI设计与研究

基于H.264-AVC视频解码器的VLSI设计与研究随着数字视频的快速发展,高效的视频解码器成为实现高清视频播放和视频传输的关键技术之一。
H.264/AVC编码标准以其出色的编码效率和卓越的视频质量而被广泛应用。
然而,H.264/AVC编码标准的高复杂性也给视频解码器的设计带来了巨大的挑战。
本文基于H.264/AVC视频解码器的VLSI设计与研究,旨在探索高效的视频解码器的实现方法。
首先,我们对H.264/AVC编码标准进行了详细的分析,深入了解其编码原理和算法。
然后,我们研究了H.264/AVC视频解码器的架构和各个功能模块的设计思路。
在VLSI设计方面,我们充分利用了现代集成电路技术的优势,采用了高度并行的设计策略。
我们将解码器划分为多个功能模块,包括帧内预测、帧间预测、变换与量化、熵编码和解码控制等。
每个功能模块都被设计为独立的硬件模块,并通过高速数据通路进行连接。
通过合理的模块划分和高效的数据通路设计,我们实现了高度并行的解码器结构,提高了解码性能。
此外,我们还研究了解码器的功耗和面积优化问题。
通过合理的电源规划和电路优化,我们成功降低了解码器的功耗。
同时,我们采用了紧凑的电路布局和面积优化技术,有效减小了解码器的芯片面积。
最后,我们进行了综合和布局布线,验证了设计的正确性和可行性。
实验结果表明,我们设计的H.264/AVC视频解码器具有出色的解码性能和高效的功耗面积比。
综上所述,本文基于H.264/AVC视频解码器的VLSI设计与研究,实现了高效的视频解码器。
通过合理的架构设计、高度并行的硬件实现和功耗面积优化,我们成功地提高了解码性能,并实现了低功耗和小面积的解码器。
这对于实现高清视频播放和视频传输具有重要的意义,也为视频解码器的设计和优化提供了有益的参考。
VLSI技术的基本原理与设计方法

VLSI技术的基本原理与设计方法随着科技的迅猛发展,各种电子产品在我们生活中占据着越来越重要的地位。
而所有这些电子产品都离不开一个重要的技术:VLSI技术。
VLSI指的是非常大规模集成电路技术,是目前集成电路技术的一种基本形式。
本文将对VLSI技术的基本原理和设计方法做一个简要的介绍。
一、VLSI技术的基本原理VLSI技术是基于微电子技术的一种重要形式。
它主要是将各种电子元器件(芯片、集成电路、电阻、传感器等)集成在一个小小的芯片上。
具体实现中,VLSI技术主要遵循以下三个原理:1. MOSFET(金属氧化物半导体场效应晶体管)原理当VLSI集成电路中的MOSFET晶体管导通时,电子会在它们的通道中游走。
而当晶体管截止时,电子在通道中的移动会停止。
MOSFET晶体管是VLSI集成电路的核心,它能够完成各种逻辑功能,包括与门、或门、非门等。
2. CMOS(互补金属氧化物半导体)原理CMOS原理是一种优秀的低功耗技术,其基本思想是利用PMOS(钨氧化物半导体)和NMOS(有机金属半导体)晶体管的互补特性来实现电路的全量化。
VLSI集成电路中使用CMOS电路可以实现高效和低功耗的目的。
3. 精细化工艺原理精细化工艺是指通过提高制造VLSI集成电路的工艺过程的精度和准确性,从而实现制造更加复杂的电路。
当VLSI集成电路的工艺精度和准确性越高时,芯片上的电子元器件数量就越多,电路的密度和速度也能够得到更大的提升。
二、VLSI技术的设计方法VLSI技术的设计方法是制造VLSI集成电路的重要步骤之一。
它主要包括以下几个方面:1. 电路设计VLSI集成电路的电路设计是指从电路原理图开始设计电路与芯片。
其中,电路的设计需要考虑到电路特性、电路定位、功能需求和功耗等。
当电路设计完成后,可以使用电磁仿真软件对其进行仿真,以确保电路的正常运转。
2. 物理设计物理设计是指将电路转化为动态的、几何的物理结构,这能够确保电路的顺利布局。
一种CAVLC解码器的研究与实现

Vo 1 . 31, No. 2
J u n ., 2 0 1 3
一
种C A V L C解 码 器 的 研 究 与 实 现
宋 娜, 刘剑武
( 莆 田学 院 电 子 信 息 工程 系 , 福建 莆田 3 5 1 1 0 0 )
摘 要 :熵 解 码 算 法 性 能 好 坏 是 H. 2 6 4视 频 解 码 器 性 能 高 低 的 关 键 因 素 之 一 . 基 于 上 下 文 的 自适 应 可 变 长 编 码
Re s e a r c h a n d i m pl e me nt a t i o n o f a CAVLC de c o d e r
S o n g Na , L i u J i a n w u
( D e p a r t me n t o f E l e c t r o n i c& I n f o r ma t i o n E n g i n e e r i n g , P u t i a n Un i v e r s i t y , P u t i a n 3 5 1 1 0 0 , F u j i a n , C h i n a ) Ab s t r a c t :En t r o p y d e c o d i n g a l g o r i t h m p e r f o r ma n c e i s o n e o f t h e k e y f a c t o r s o f H. 2 6 4 v i d e o d e c o d e r p e r f o r ma n c e .
0 引 言
移 动 多媒体 和物 联 网技术 的发 展如 火如 荼 , 人 们使 用移 动终 端下 载视 频 的需求 日益增 大 , 因而 对具 有较 高压缩 效率 , 并 且有更 好 网络健 壮性 的视 频压 缩标 准 的需 求更 加 迫 切. 在 现 有 的 多种 视 频 编解 码 标 准 中 , 由 I TU— T视 频编码 专 家组 和 1 s O/ I E C运 动 图像专 家组 成立 的联 合视频 小 组 J VT 开 发 的 H. 2 6 4标 准 , 满 足 了 这种对 运 动 图像 高压 缩 的需求 .H. 2 6 4 / AVC编 码标 准 是 最 有竞 争 力 的 标 准 之一 , 可应 用 在 诸 如 移 动 多媒 体通讯 、 网络流 媒体 、 视频 会议 和数 字存 储媒 体等 多种 场合 _ 】 ] .
基于FPGA的H.264AVC CAVLC熵编码的可重构设计与实现

基于FPGA的H.264/AVC CAVLC熵编码的可重构设计与实现随着数字视频技术的迅速发展,视频压缩变得越来越广泛,然而人们对视频压缩技术的要求也越来越高。
近年来国际上相继推出了MPEG-4及H.264/AVC视频压缩标准,它对未来的数字电视、无线视频等产业的发展起到了巨大的推动作用。
H.264/AVC标准是当前最主流的视频压缩标准,它具有适用范围广、能满足不同速率等优点,与先前的标准相比,编码效率有了显著提高。
H.264中包括两种熵编码:基于上下文的可变长编码(CAVLC)及基于上下文的自适应算术编码(CABAC)。
本文主要研究的是CAVLC,它能够根据之前编码的数据在相对应的码表中进行自适应的选择,找出和当前编码数据统计特性最匹配的一个码表进行编码。
动态部分可重构(Dynamic Partial Reconfiguration, DPR)是目前主流的可重构技术,也是研究的热点。
通过动态部分可重构技术实现硬件电路具有速度快、资源利用率高等优点。
本文的课题是对H.264/AVC视频编码标准中基于上下文编码算法的研究以及可重构模块的设计与实现。
主要完成的工作如下所示:(1)简要介绍了视频压缩的概念和H.264编码标准的发展历史及关键技术。
深入研究了H.264编解码过程,尤其是CAVLC编解码中的元素和实现流程。
(2)对FPGA的概念、编程技术进行了简单的回顾。
深入理解了FPGA的内部结构和设计流程。
在分析了FPGA可重构概念、原理之后,按配置方式的不同,对可重构技术进行了分类,并对它们进行了比较,指出了其中的优缺点,最终本文选择了EAPR设计方法。
(3)简要介绍了硬件描述语言及发展趋势,在此基础上用Verioog HDL 语言编写了CAVLC编解码的可重构模块,并进行了综合验证。
因为传统的查找表比较繁琐,所需的逻辑资源比较多,因此,本设计采用了基于“子表”的查找方法和与检查第一个“1”的位置相结合的方法进行查表(将表的每一列作为一个状态,然后按照不同方法继续划分),加快了查找速度、节约了资源。
CAVLC熵编码器的FPGA高效实现

mi a i n o v r eo e a i n r a ie i r o n r v r e zg z g s a n t eu s r a mo u e r s lsi h l n to f e e s p r t n a d a g e trs e e s i a c n i h p t e m d l e u t n t ee i
—
e fce y o he CA V IC odu e wih no i c e s fc fi inc ft m l t n r a e o om p a i n t ut ton i he upsr a m o l . Fia l r s ls t e m du e n ly, e u t
21 0 2年 6月 科 技 大学 学 报 ( 自然 科 学版 )
J OURNAL OF XI AN U NI DI VER SI TY
J n 2 1 u.o2
Vo _ 9 NO 3 【3 .
d i1 3 6 / .s n 1 0 — 4 0. 0 2 0 0 6 o :0. 9 9 j is . 0 1 2 0 2 1 . 3. 1
C AVLC熵 编 码器 的 F PGA 高 效 实现
初 秀 琴 , 吴 硕 , 常 方 , 贺 文 卿
( 西安 电子 科 技 大 学 电路 C AD研 究所 , 西 西 安 陕 707) 1 0 1
摘 要 :针 对 H. 6 2 4标 准 中基 于 上 下 文 自适 应 可 变长 编 码 ( AVL ) 法 运 算 复 杂度 高 、 易于 实 时 实 现 的 C C算 不 问题 , 出 了 C VI 提 A C熵 编 码 算 法 的高 效 实 现 体 系 结 构 . 设 计 实 现 了对 宏 块 数 据 经 分 解 后 的块 流 中不 同 该 类 型 数 据 块 的编 码 , 服 了传 统 方 案 中只 能处 理 一 种 类 型 数 据 块 的局 限 ; 出在 上 游 模 块 采 用 逆 锯 齿 扫 描 克 提
cavlc原理和实现

1.算法描述FFmpeg针对CA VLC做了大量的优化,主要体现在码表的构建和查找上。
本章将从CA VLC码表的构建、查找和CA VLC残差解码三部分对CA VLC熵解码算法进行分析。
1.1.CA VLC码表构建1.1.1.len和bits数组的构建H264/A VC标准中表9-5、9-7~9-10是CA VLC的码表,针对每个码表FFmpeg 定义了三个数组:xxx_len、xxx_bits和xxx_vlc,其中xxx_len存放的是对应二进制串的比特长度,xxx_bits存放的是对应二进制串的值,比如二进制串“0001 11”的len(长度)为6,bits(值)为7,xxx_vlc存放的是根据xxx_len和xxx_bits构建好的,供CA VLC最终使用的码表。
以表9-5中Nc==-1为例,表1表示的是YUV420P时的Chroma DC分量的coeff_token值。
FFmpeg针对该coeff_token表构建了两个数组chroma_dc_coeff_token_len[4*5]和chroma_dc_coeff_token_bits[4*5],如图3所示。
这两个数组的索引(key)是TotalCoeff和TrailingOnes的组合,等于((TotalCoeff<<2)| TrailingOnes)。
联合图3和表1可以看出chroma_dc_coeff_token_len和chroma_dc_coeff_token_bits数组的0号位置存放的是coeff_token为“01”的二进制串的信息,数组的4号位置存放的是coeff_token 为“000111”的二进制串的信息,其余依次类推,数组中多余的位置以0补充。
表1. Nc==-1时的coeff_token及其len和bits数组的构造原理图3. 针对Chroma DC分量的coeff_token构造的len和bits数组表9-5一共有六个表存在,需要对每个表都按照如上原理构造对应的len和bits数组(nC==-2是ChromaArrayType is equal to 2时对应的coeff_token表,目前只支持YUV420P,所以暂不考虑),表9-5中的coeff_token对应着TrailingOnes 和TotalCoeff两个元素所以它的key值是由TrailingOnes和TotalCoeff组合而成,而9-7~9-10只存在一个值,所以其len和bits数组的构造略有差异。
基于H.264帧间预测解码的研究及高效VLSI实现的开题报告

基于H.264帧间预测解码的研究及高效VLSI实现的开题报告一、研究背景和意义:随着数字媒体技术的不断发展,视频编码技术已经成为数字多媒体应用的核心技术之一,它在实现高质量数字视频传输和存储、降低视频存储成本方面发挥了重要作用。
其中,H.264/AVC编码标准作为最新一代的视频编码标准,具有高压缩比、良好的图像质量、较低的码率等优势,被广泛应用于数字视频传输和存储领域。
帧间预测是H.264/AVC编码标准中的一种重要技术,它通过利用前向和反向预测来减少帧之间的冗余数据,从而实现压缩。
解码器对H.264视频进行解码时,需要进行逆向的帧间预测过程,以还原原始图像,因此对于H.264解码器来说,实现高效的帧间预测解码是非常关键的。
本课题旨在深入研究H.264帧间预测解码技术,针对其在实现高效VLSI 设计上的难点,研究并实现一种可行的高效VLSI架构,为快速、高效的H.264视频解码提供技术支持。
二、研究内容和方法:(1)研究H.264帧间预测解码技术的原理和流程,包括前向预测、反向预测和运动估计等关键技术。
(2)分析H.264帧间预测解码技术在VLSI实现中的关键问题和难点,研究适合VLSI实现的高效算法和优化技术。
(3)根据研究结果,提出一种符合VLSI实现的高效的H.264帧间预测解码VLSI架构,并进行详细设计和验证。
(4)通过设计、仿真和验证,评估所提出的H.264帧间预测解码VLSI 架构的性能和功耗,并与其它现有实现方案进行比较和分析。
三、研究预期结果和创新点:(1)提出一种符合VLSI实现的高效的H.264帧间预测解码VLSI架构,具有优秀的性能和低功耗特性。
(2)通过本课题的研究,加深对数字视频编码和解码技术的理解,积累VLSI芯片设计实践经验,为数字媒体应用领域的技术发展贡献力量。
(3)在具体实践过程中,本课题将探索并解决H.264帧间预测解码在VLSI实现中遇到的难点和问题,为H.264视频解码器的研究提供新的思路和方法。
H264+CAVLC解码器的硬件设计与实现

西安电子科技大学硕士学位论文H.264 CAVLC解码器的硬件设计与实现姓名:高玉娥申请学位级别:硕士专业:通信与信息系统指导教师:吴成柯20080101第一章绪论3[91、分形编码【10。
121、基于神经网络的编码、小波变换和子带编码【131和模型基编码‘141等。
图像/视频编码技术真正走向实用化、产业化并得到飞速发展的重要标志之一就是一系列图像,视频编码国际标准的制订。
在国际标准化组织(IS0)、国际电工委员会(IEC)和国际电信联盟(ITU.T)等组织的协调下,对不同时期图像编码的研究成果进行了整理和加工,制订了几类通用的压缩编码国际标准(图1.1)。
这些标准代表了不同时期图像编码的发展水平,不仅极大地推动了数据压缩编码技术的实用化、产业化,同时也在一定意义上刺激了信源理论研究的进一步拓展。
图1.1图像/视频压缩编码国际标准的发展历史联合二值图像组(JBIG)【l5】制订了用于二值图像或低精度灰度图像编码的适合渐迸传输的无损压缩国际标准JBIG。
联合图像专家组(JPEG)【16】主要负责灰度和彩色静止图像编码的标准化工作。
在2000年,JPEG专家组又制订了最新的国际标准JPEG.2000[171。
活动图像专家组(MPEG)则负责制订用于数字存储的活动图像及伴音的编码标准。
1993制订了在CD.ROM、硬盘等媒介上存储CIF格式视频的MPEG.1标准,其比特率小于1.5Mbps[18】。
1995年制订了MPEG-2标型”,将比特率扩大到10~20Mbps并支持HDTV格式。
近年来又制订了应用范围更加宽广的基于视频对象编码的MPEG-4标准[201,以及用于数字图书馆的基于内容检索的MPEG.7标准【2“。
为了适应可视电话和会议电视的需要,ITu-T的可视电话专家组于1993年制订了面向ISDN传输的H.261标准(p×64kbps)(22】,在1996年和1998年又分别推出了适合低码率传输的H.263[23】及其改进版本H.263+标准剀。
CAVLC编码过程详解[熵编码] (转载)
![CAVLC编码过程详解[熵编码] (转载)](https://img.taocdn.com/s3/m/4eec1a2f2f60ddccda38a0cf.png)
CAVLC编码过程详解[熵编码] (转载)2010-03-29 18:43:00| 分类:h264 | 标签:|举报|字号大中小订阅编码过程:假设有一个4*4数据块{0, 3, -1, 0,0, -1, 1, 0,1, 0, 0, 0,0, 0, 0, 0}数据重排列:0,3,0,1,-1,-1,0,1,0……1)初始值设定:非零系数的数目(TotalCoeffs)= 5;拖尾系数的数目(TrailingOnes)= 3;最后一个非零系数前零的数目(Total_zeros)= 3;变量NC=1;(说明:NC值的确定:色度的直流系数NC=-1;其他系数类型NC值是根据当前块左边4*4块的非零系数数目(NA)当前块上面4*4块的非零系数数目(NB)求得的,见毕厚杰书P120表6.10)suffixLength = 0;i = TotalCoeffs = 5;2)编码coeff_token:查标准(BS ISO/IEC 14496-10:2003)Table 9-5,可得:If (TotalCoeffs == 5 && TrailingOnes == 3 && 0 <= NC < 2)coeff_token = 0000 100;Code = 0000 100;3)编码所有TrailingOnes的符号:逆序编码,三个拖尾系数的符号依次是+(0),-(1),-(1);即:TrailingOne sign[i--] = 0;TrailingOne sign[i--] = 1;TrailingOne sign[i--] = 1;Code = 0000 1000 11;4)编码除了拖尾系数以外非零系数幅值Levels:过程如下:(1)将有符号的Level[ i ]转换成无符号的levelCode;如果Level[ i ]是正的,levelCode = (Level[ i ]<<1) – 2;如果Level[ i ]是负的,levelCode = - (Level[ i ]<<1) – 1;(2)计算level_prefix:level_prefix = levelCode / (1<<suffixLength);查表9-6可得所对应的bit string;(3)计算level_suffix:level_suffix = levelCode % (1<<suffixLength);(4)根据suffixLength的值来确定后缀的长度;(5)suffixLength updata:If ( suffixLength == 0 )suffixLength++;else if ( levelCode > (3<<suffixLength-1) && suffixLength <6)suffixLength++;回到例子中,依然按照逆序,Level[i--] = 1;(此时i = 1)levelCode = 0;level_prefix = 0;查表9-6,可得level_prefix = 0时对应的bit string = 1;因为suffixLength初始化为0,故该Level没有后缀;因为suffixLength = 0,故suffixLength++;Code = 0000 1000 111;编码下一个Level:Level[0] = 3;levelCode = 4;level_prefix = 2;查表得bit string = 001;level_suffix = 0;suffixLength = 1;故码流为0010;Code = 0000 1000 1110 010;i = 0,编码Level结束。
上下文相关算术编码的VLSI结构设计

上下文相关算术编码的VLSI结构设计
张菁菁
【期刊名称】《湖南工程学院学报(自然科学版)》
【年(卷),期】2003(013)001
【摘要】由于上下文相关算术编码(CAE)方法的良好压缩特性,使其适用于二值形状视频对象的编码.然而CAE编码所消耗的运算资源较大,不能满足实时视频编码的要求.为了有效减少数据载入次数,提出一种高效的上下文相关算术编码(CAE)的VLSI结构.采用延迟线结构保存输入像素,使其在以后的处理中重复利用.实验结果表明,采用这种结构,有效减少了存储器的访问次数,在计算概率索引时,避免了加法操作,从而达到了利用较少的门电路实现高效编码的设计目标.
【总页数】3页(P60-61,87)
【作者】张菁菁
【作者单位】吉首大学张家界校区数学与计算机系,湖南,张家界,427000
【正文语种】中文
【中图分类】TP312
【相关文献】
1.基于上下文自适应算术编码的可重构配置信息压缩算法 [J], 伍卫国;杨志华;余国良
2.JPEG2000算术编码器的算法优化和VLSI设计 [J], 刘文松;朱恩;王健;徐龙涛;林叶
3.JPEG2000中算术编码的VLSI结构设计 [J], 乔世杰;樊炜;高勇
4.基于上下文算术编码的非三角网格拓扑压缩 [J], 刘迎;韩忠明;陈谊;黄今慧;毛明毅;李海生
5.基于上下文快速有效的自适应二进制算术编码实现 [J], 张丹
因版权原因,仅展示原文概要,查看原文内容请购买。
一种高效的H.264 CABAC解码器的VLSI结构

一种高效的H.264 CABAC解码器的VLSI结构石迎波;李云松;张建龙【期刊名称】《西安电子科技大学学报(自然科学版)》【年(卷),期】2006(033)006【摘要】提出一种H.264/AVC中基于上下文的自适应二进制算术编码(CABAC)解码器的硬件设计方法,在采用并行结构的基础上,给出了一种高效的VLSI实现方案.采用两级有限状态机结构控制宏块解码过程,并通过对残差系数存储器的定时清零解决了数据存储耗时的问题,大大降低了解码控制的复杂度,从而提高解码速度,达到每1至2个时钟解出1比特.仿真结果表明,该方案能满足H.264/AVC main profile CIF 30fps实时解码的要求.【总页数】6页(P844-848,891)【作者】石迎波;李云松;张建龙【作者单位】西安电子科技大学,综合业务网理论与关键技术国家重点实验室,陕西,西安,710071;西安电子科技大学,综合业务网理论与关键技术国家重点实验室,陕西,西安,710071;西安电子科技大学,综合业务网理论与关键技术国家重点实验室,陕西,西安,710071【正文语种】中文【中图分类】TN919.81【相关文献】1.一种高效的H.264去块效应滤波器VLSI结构设计 [J], 席迎来;王凤琴;郝重阳;周巍2.一种高效的CABAC解码器硬件结构设计 [J], 徐美华;吴明;周杰3.一种用于H.264编解码的新型高效可重构多变换VLSI结构 [J], 曹伟;洪琪;侯慧;童家榕;来金梅;闵昊;荆明娥4.高清H.264 CABAC解码器的优化设计 [J], 陈潜;杨秀芝5.宏块并行可复用的H.264帧内解码器的VLSI结构设计 [J], 兰旭光;李兴玉;温灏;王志刚因版权原因,仅展示原文概要,查看原文内容请购买。
CAVLC熵编码器的FPGA高效实现

CAVLC熵编码器的FPGA高效实现初秀琴;吴硕;常方;贺文卿【期刊名称】《西安电子科技大学学报(自然科学版)》【年(卷),期】2012(039)003【摘要】针对H.264标准中基于上下文自适应可变长编码(CAVLC)算法运算复杂度高、不易于实时实现的问题,提出了CAVLC熵编码算法的高效实现体系结构.该设计实现了对宏块数据经分解后的块流中不同类型数据块的编码,克服了传统方案中只能处理一种类型数据块的局限;提出在上游模块采用逆锯齿扫描替代锯齿扫描以省去逆序操作,在不增加上游模块运算量的同时提高了CAVLC模块的效率.现场可编程门阵列(FPGA)验证结果表明,该体系结构的编码系统时钟可达147.78 MHz,编码的首次延迟为32个时钟周期,吞吐延迟为16个时钟周期,可以满足高清、实时应用的编码要求.【总页数】6页(P100-105)【作者】初秀琴;吴硕;常方;贺文卿【作者单位】西安电子科技大学电路CAD研究所,陕西西安 710071;西安电子科技大学电路CAD研究所,陕西西安 710071;西安电子科技大学电路CAD研究所,陕西西安 710071;西安电子科技大学电路CAD研究所,陕西西安 710071【正文语种】中文【中图分类】TN919.81【相关文献】1.基于模块级流水和并行处理的CAVLC编码器实现 [J], 陆伊;杨爱良;章宇东2.H.264/AVC中CAVLC编码器的硬件实现 [J], 李程达;陈炜3.H.264/AVC中CAVLC编码器的硬件设计与实现 [J], 何腾波;盛利元;蒋文明4.CAVLC编码算法及高速熵编码器的FPGA实现 [J], 刘晓明;张续莹;李芳;陈光洪5.基于FPGA的H.264解码IP核中CAVLC熵解码模块的设计 [J], 杨炎思;王霞因版权原因,仅展示原文概要,查看原文内容请购买。
一种高性能低复杂度的CAVLC编码器设计(陶为)

第 卷 第 期 中国图象图形学报 V ol. ,No. 200 年 月 .,200Journal of Image and Graphics _________________________收稿日期: 改回日期: 第一作者简介:陶为(1986~),男。
中国科学技术大学电子科学与技术系大硕士研究生。
主要研究方向为视频编解码的超大规模集成电路设计。
E-mail :zytttw@一种高性能低复杂度的CAVLC 编码器设计陶为1) 唐建2) 郭立3)(中国科学技术大学电子科学与技术系,合肥,230027)摘 要 提出了一种应用于H.264/AVC 的高速有效的CAVLC 编码器结构。
为避免直接查找表,采用基于预处理的查找方法,优化了查找表结构;对非零系数level 编码,利用算术计算替代查找表,且通过展开和共享技术对算术表达式进行优化;码字拼接部分也作了面积上的优化。
在133MHz 的频率约束下,采用SMIC 0.18um CMOS 工艺进行逻辑综合,所需的逻辑门数为8723,能满足高清视频1920×1088-30fps 实时编码要求。
关键词 H.264/AVC 基于上下文的自适应变长编码CAVLC VLSI 结构中图法分类号:TN919.81 文献标识码:A 文章编号:1006-8961(200 ) - -A High Performance And Low Cost Implementation of CAVLC EncoderTAO Wei 1), TANG Jian 2), GUO Li 3)(Department of Electronic Science and Technology, University of Science and Technology of China, Hefei, 230027)Abstract A high speed and efficient VLSI architecture for H.264/A VC CA VLC is proposed. For the sake of avoiding mapping look-up table directly, a new look-up table algorithm based on the pre-processing greatly optimizes look-up table structure; for non-zero coefficient level coding, an approach called arithmetic compute is exploited to replace look-up table, and the arithmetic expression is optimized with technology of unfolding and share ;And some optimization of area is done in the bit-packer module. With the synthesis constraint of 133MHz, the hardware cost of the proposed design is 8723 gates based on SMIC 0.18um CMOS technology. The real-time processing requirement for H.264 video encoding on HD1920×1088-30fps can be met by the new architecture with less hardware cost. Keywords H.264/A VC, Context-based Adaptive Variable Length Coding(CA VLC), VLSI architecture1 引言H.264/AVC 是ITU-T 和MPEG 组织共同推出新一代视频压缩标准,其压缩率较以往的视频标准有显著提高,得到广泛应用。
JPEG编码器的设计与VLSI实现

JPEG编码器的设计与VLSI实现陈程俊;官俊涛;黄海【摘要】Owing to the larger information of images and videos, it is necessary to compress these information.By analyzing the Joint Photographic Experts Group (JPEG)compression standard, this paper implements a high performance whole process design of JPEG picture encoder.Firstly, the 2D discrete cosine transform(DCT), quantization and entropy coding modules were modeled using Verilog HDL language.Then, each module was simulated by Modelsim and verified by comparing with MATLAB results separately.The compared results show that all of the developed modules are correct.After that, the whole JPEG encoder was designed and verified by using standard test images.The PSNR was obtained by comparing the original image with rebuilt JPEG image.The results show that this JPEG encoder can satisfy the application requirement.Finally, the very large scale integration (VLSI)implementing of the proposed JPEG encoder was developed.The encoder was synthesized by using synopsys Design Compiler and routed and placed by using Cadence SOC Encounter under the process of smic180 nm.The physical implementation results are as follows: The total power is 460 mw at working frequency 100 MHz and the total area is 10.7 mm2.Furthermore, this design can also be used as an IP core in other image and video processing chips.%随着图片和视频的信息量变得越来越大,对这些信息进行压缩和存储十分必要,设计了一种高性能的联合图像专家组(JPEG)图像编码器.首先,采用Verilog HDL语言对JPEG中二维离散余弦变换(DCT)、量化以及熵编码等关键模块进行了建模,并对各个模块分别进行了仿真和验证,通过比较MATLAB和Modelsim的仿真结果验证所设计功能模块的正确性;在此基础上,完成了JPEG编码器的整体设计,并选取标准测试图片对其进行功能验证,通过比较原始图片和重建JPEG图像得到PSNR值,验证结果表明所设计的JPEG编码器满足应用需求;最后,对JPEG编码器进行了超大规模集成电路(VLSI)硬件实现,在SMIC180 nm工艺下,用Synopsys Design Compiler对设计进行综合,用Cadence SOC Encounter对综合后的门级网表进行布局布线,物理实现结果如下:工作在100 MHz下,芯片的功耗为460 mW,最终布局布线之后的面积为10.7 mm2.所设计的编码器可以作为IP 核应用于其他图像或者视频处理芯片之中.【期刊名称】《应用科技》【年(卷),期】2017(044)004【总页数】6页(P49-54)【关键词】JPEG;Verilog;二维离散余弦变换变换;量化;熵编码;综合;布局布线;超大规模集成电路【作者】陈程俊;官俊涛;黄海【作者单位】哈尔滨理工大学软件学院,黑龙江哈尔滨,150080;哈尔滨理工大学软件学院,黑龙江哈尔滨,150080;哈尔滨理工大学软件学院,黑龙江哈尔滨,150080【正文语种】中文【中图分类】TN47近几十年来,互联网技术和通信技术发展的十分迅速,图像和视频等信息被广泛应用于网络,由于图像和视频本身的数据冗余使得处理的数据量很大,给存储和传输带来很大的不便。
一种高效CAVLC编码结构的VLSI设计实现

一种高效CAVLC编码结构的VLSI设计实现
胡红旗;许家栋;孙景楠
【期刊名称】《计算机工程与应用》
【年(卷),期】2008(44)32
【摘要】CAVLC是H.264/AVC标准新引入的一项重要特性.通过对已有游程编码结构的分析和改进,提出了一种可满足H.264/AVC实时编码应用的高效CAVLC编码结构.该结构采用优化的数据处理顺序,提高了系统的吞吐率.同时利用算术结构设计代替查找表所需的ROM,降低了设计的硬件成本.在133MHz频率约束下采用0.18um工艺的综合结果表明,所需的逻辑门数为13114,以较少的逻辑资源实现了HD1080@30fps的实时处理.
【总页数】3页(P79-81)
【作者】胡红旗;许家栋;孙景楠
【作者单位】西北工业大学,电子信息学院,西安,710072;西北工业大学,电子信息学院,西安,710072;浙江工商大学,杭州商学院,杭州,310012
【正文语种】中文
【中图分类】TN762
【相关文献】
1.CAVLC熵编码器的FPGA高效实现 [J], 初秀琴;吴硕;常方;贺文卿
2.一种适用于H.264标准的高度并行双层流水线结构CAVLC编码器 [J], 乔飞;魏鼎力;杨华中;汪蕙
3.一种极低码率视频压缩编码算法的VLSI结构 [J], 江科;章倩苓;汤庭鳌
4.一种矢量编码器的VLSI结构 [J], 周汀;陈旭昀;章倩苓;李蔚
5.一种高效视频编码插值滤波VLSI架构设计 [J], 连晓聪;周巍;段哲民;李茸
因版权原因,仅展示原文概要,查看原文内容请购买。
VLSI后端设计实现课件
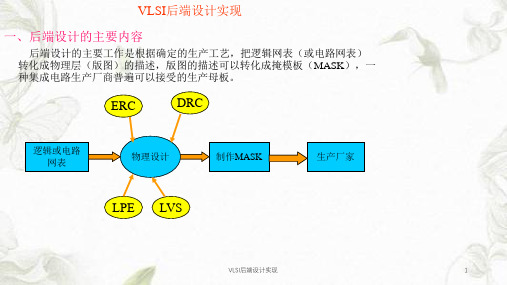
VLSI后端设计实现
10
N+
N+
Metal:金属层,信号互连,
6
电源和地。
3
P+: PMOS管的S、D
P+
P+
1 Nwell: N阱,PMOS管所在的 区域。
SiO2;氧化层,层与层之间的隔
离绝缘,栅下面叫栅氧,厚度比较 薄。其它地方叫场氧,厚度比较厚。
P型硅片(衬底)
1
1、DRC(设计规则检查)
设计规则是工艺厂家规定的对版图设计的约束,只有在满足约束条件下的版图才能转 化为合格的MASK,否则就有可能在生产中产生一系列的问题。
版图一般由三类元件组成: 晶体管(R、C、L)、连线、连接孔(含通空) 设计规则约束规定了一系列最小线宽、最小间距等的规则,主要包括: I、元件的最小尺寸规则。 II、元件的互连规则,如线宽。 III、元件的间距规则。 层内:同一层的设计规则,主要是宽度和间距。 层间:不同层间的设计规则,主要是元件层间规则和连接孔规则。
2、门阵列实现技术
门阵列是用大量同种门构成的阵列,在排列紧密的单元行之间留有布线通道。一般我 们把布线之前的门阵列称为母片,用户可以根据电路完成最终连线。
3、基于标准单元库的设计
标准单元就是经过实践验证正确的电路单元的集合。包括电路符号库、功能参数库和 版图描述库三个部分。
I 、标准单元的特性
a、包括基本单元、宏单元、I/O单元。
B
V
V
S
D
S
A
D
NMOS
PMOS
VLSI后端设计实现
14
A
V
B
V
S
一种高效地实现运动估计算法的VLSI结构

一种高效地实现运动估计算法的VLSI结构
舒清明;徐葭生
【期刊名称】《电子学报》
【年(卷),期】1995(23)5
【摘要】本文提出了一种全新的低延滞、高吞吐率、可编程的VLSI树型结构,它能十分有效地实现FSA和TSSA运动估计算法。
该结构比其它树型结构少1/3的处理单元(PE),而且PE单元的延时减少一半。
独特的ME窗缓冲结构使I/O带宽和I/O管脚大大减小,交叉流水线技术使硬件利用率可达到100%。
这些特点使得该结构适合VLSI实现。
【总页数】1页(P12)
【作者】舒清明;徐葭生
【作者单位】不详;不详
【正文语种】中文
【中图分类】TN919.8
【相关文献】
1.一种易于硬件实现的运动估计算法及其VLSI实现 [J], 赵波;杜建超;颜尧平
2.快速高效的半像素运动估计算法的VLSI实现 [J], 鲍林;李维祥
3.一种适合VLSI实现的H.264整像素运动估计算法 [J], 马涛;陈杰
4.一种支持PMVFAST运动估计算法的VLSI体系结构 [J], 黎铁军;沈承东;李思昆
5.全搜索运动估计算法的高效VLSI结构设计 [J], 曹伟;毛志刚
因版权原因,仅展示原文概要,查看原文内容请购买。
基于VLSI实现的视频编码关键算法研究的开题报告

基于VLSI实现的视频编码关键算法研究的开题报告
一、选题背景和依据
随着数字影像技术的发展,视频编码技术得到了广泛应用,例如视
频通信、视频监控、视频网站等。
在视频编码中,关键算法是决定编码
质量和压缩率的重要因素。
现代数字电路设计的特点是高度集成和低功耗,这里将研究基于VLSI实现的视频编码关键算法,以提升视频编码的速度和效率。
二、研究内容和目标
本研究将选取主流的视频编码标准H.264和H.265(HEVC)为研究对象,探究熵编码、运动估计、变换与量化等关键算法的VLSI实现方法,以提高视频编码的处理速度和视频质量。
三、研究方法和步骤
1、深入分析视频编码标准H.264和H.265,明确其编码原理和流程;
2、对比现有的视频编码器的VLSI实现方案,确定所选算法的VLSI 实现需求;
3、针对所选算法,设计适合于VLSI实现的算法优化方案,以提高
速度和纠错能力;
4、实现选定的算法,并根据实际测试数据进行优化;
5、采用FPGA等平台进行实际测试,验证所提出的算法优化方案,验证算法的可行性和可靠性。
四、预期成果和应用价值
1、实现H.264和H.265(HEVC)视频编码关键算法的VLSI实现,提高编码效率、速度和视频质量;
2、验证设计的VLSI芯片的可行性和可靠性;
3、在相关领域中推动视频编码技术的发展,有助于提高基于数字影像技术的应用质量和效率。