多文件编译
c语言多文件编译

c语言多文件编译
在C语言中,可以将一个程序的不同部分分别写在不同的文件中,然后再一起编译成一个可执行文件。
这种方式称为多文件编译。
多文件编译的一般步骤如下:
1. 将程序的不同部分分别写在不同的文件中,每个文件包含一个或多个函数的定义和声明。
2. 在一个文件中,一般是主函数所在的文件(通常命名为main.c),通过#include指令包含其他文件的头文件,以便使用其中的函数。
3. 在其他文件中,分别编写函数的定义和声明,并在文件的开头加上头文件的包含指令。
4. 使用编译器对每个文件单独进行编译,生成对应的目标文件(以.o或.obj为扩展名)。
- 在Linux平台上,可以使用gcc命令编译每个文件,如:gcc -c file1.c -o file1.o
- 在Windows平台上,可以使用MinGW或者Visual Studio 等工具进行编译。
5. 将生成的目标文件链接在一起,生成最终的可执行文件。
- 在Linux平台上,可以使用gcc命令链接目标文件,如:gcc file1.o file2.o -o executable
- 在Windows平台上,可以使用MinGW或者Visual Studio 等工具进行链接。
需要注意的是,每个文件中的函数需要正确的定义和声明,以
及合适的头文件的包含。
各个文件之间也需要保持依赖关系的正确性,确保一个文件在使用其他文件中的函数时,已经具备了被使用的函数的定义和声明。
fortran多文件编译命令

Fortran 是一种面向科学计算和工程计算的编程语言,它广泛应用于数值分析、科学计算、大气和地球物理学等领域。
在使用 Fortran 进行程序开发时,经常会遇到需要将多个源文件编译为可执行文件的情况。
本文将介绍如何使用不同编译器来编译 Fortran 多个源文件,以及对应的编译命令。
一、使用 gfortran 编译器编译 Fortran 多个源文件1. 编写多个 Fortran 源文件在进行编译之前,首先需要编写多个 Fortran 源文件,这些文件通常以 .f90 或 .f95 作为后缀。
假设我们有三个源文件分别为 m本人n.f90、sub1.f90 和 sub2.f90。
2. 使用 gfortran 进行编译使用 gfortran 进行编译时,可以通过以下命令将多个源文件编译为可执行文件:```gfortran -o program m本人n.f90 sub1.f90 sub2.f90```其中,-o 选项用于指定输出的可执行文件名,后面紧跟着可执行文件名 program,然后列出所有需要编译的源文件名。
3. 运行可执行文件编译完成后,可执行文件 program 就会生成,可以通过以下命令运行该可执行文件:```./program```二、使用 ifort 编译器编译 Fortran 多个源文件1. 编写多个 Fortran 源文件与使用 gfortran 编译器相似,使用 ifort 编译器编译 Fortran 多个源文件也需要首先编写多个源文件,这些文件的后缀通常为 .f90 或 .f95。
假设我们有三个源文件分别为 m本人n.f90、sub1.f90 和 sub2.f90。
2. 使用 ifort 进行编译使用 ifort 进行编译时,可以通过以下命令将多个源文件编译为可执行文件:```ifort -o program m本人n.f90 sub1.f90 sub2.f90```同样地,-o 选项用于指定输出的可执行文件名,后面紧跟着可执行文件名 program,然后列出所有需要编译的源文件名。
汇编多文件编程-概述说明以及解释

汇编多文件编程-概述说明以及解释1.引言1.1 概述汇编多文件编程是一种在汇编语言中使用多个文件来编写程序的技术。
在传统的汇编程序中,所有的代码都是写在一个文件中的,当程序变得庞大时,这会导致代码的可读性和可维护性变得非常困难。
汇编多文件编程通过将不同功能的代码分开存放在不同的文件中,使得程序结构更清晰,代码逻辑更容易理解。
通过合理地划分文件,我们可以将不同的功能模块独立编写,便于单独测试和调试,提高了代码的复用性和可扩展性。
在汇编多文件编程中,我们通常将主程序和不同的功能模块分别写在不同的文件中。
这些文件可以包含代码、数据和常量等信息。
通过在主程序中调用其他文件中的函数和变量,我们可以实现不同文件之间的交互和数据共享。
汇编多文件编程还可以提高代码的模块化程度,降低了编写和维护程序的难度。
它使得团队合作开发更加便捷,每个成员可以独立地编写和测试自己负责的部分,最后再进行整合。
总之,汇编多文件编程是一种有效的编程技术,它能够提高程序的可读性、可维护性和可扩展性。
通过合理地划分和组织代码,我们可以更好地编写和管理复杂的汇编程序。
在本文中,我们将介绍汇编语言的基础知识,以及如何使用多文件进行汇编编程的概念和方法。
1.2 文章结构文章结构部分的内容可以包括以下内容:文章结构部分旨在介绍本文的整体组织架构,用以引导读者了解本篇长文的内容安排和逻辑结构。
本文主要分为引言、正文和结论三个部分。
引言部分对本文的主题进行概述,并介绍文章的背景和意义。
通过简要介绍汇编多文件编程的概念和应用领域,引发读者对该主题的兴趣,并提出本文的目的和研究问题。
正文部分是本文的核心内容,主要分为两个小节:汇编语言基础和多文件编程概念。
在汇编语言基础部分,将介绍汇编语言的定义、特点和基本语法,为读者建立起对汇编语言的基本认识。
在多文件编程概念部分,将详细探讨多文件编程的原理和应用,包括多文件编程的优势、实现方法和注意事项,以及多文件编程在实际项目开发中的应用案例。
keil工程中多文件编译

keil工程中多文件编译时全局变量怎么引用
由于代码较多时为了代码的工整以及易读性,往往将代码拆分成模块,并书写头文件。
但keil中定义全局变量往往是一件头疼的事情。
关键词:static
(1)xx.h文件中基本书写的是管脚定义和函数声明,全局变量不能定义在头文件中,必须最声明在模块化的xx.c文件中,并最好初始化unsigned char i = 0;const uchar code array 【10】={……};
(2)要想在B.c文件中调用A.c中的全局变量时只需用extern再次声明下就好了。
static unsigned char i = 0;static const uchar code array【10】={……};(不能用extern unsigned char i;否则会出现multiple public definition等错误)
extern原理:通常所说的编译(build)其实分两个部分编译(compile)和链接(link)编译的单位是文件,即单个的C文件,因此即使一个变量没有定义就使用了,编译器是不会报错的,编译器认为这个变量应该是在其它文件中被定义了,先作为一个符号放这儿,等一会儿再说。
而在链接的阶段,链接器就要处理这些跨文件的符号(包括变量、函数等),
如果在其它文件中找到了,且是唯一被定义的,就把所有文件中具有全局作用域的同一符号链接为一个东西。
所以,在多个文件的情况下,如果有全局变量需要在多个文件中使用,只需要在一个文件中定义它,在其它文件中使用extern声明一下就可以了,加了extern的意思是显式的告诉编译器,这个变量是在其它文件中被定义的,在编译的时候你略过就可以了,链接器会处理好的,这样编译器就不会报错了。
altium designer 多个原理文件编译

altium designer 多个原理文件编译
在Altium Designer中,可以通过Project -> Add New to Project 来添加多个原理图文件。
首先,确保所有的原理图文件都已经添加到项目中。
然后,可以通过Project -> Options来打开项目选项对话框。
在选项对话框中,选择【Design Compiler】选项卡。
在这个选项卡中,可以选择与当前项目关联的原理图文件。
点击右上角的【Add】按钮来添加要编译的原理图文件。
添加完所有需要编译的原理图文件后,点击【OK】按钮保存设置并关闭选项对话框。
接下来,可以选择要编译的原理图文件。
在Project面板中,展开项目并展开【Design Compiler】选项卡。
将所有要编译的原理图文件勾选上。
最后,点击【Compile】按钮开始编译多个原理图文件。
编译完成后,可以在【Messages】面板中查看编译的结果和状态。
请注意,编译多个原理图文件可能会花费一些时间,具体取决于项目的大小和复杂性。
Dev-C++同时编译多个C或C++文件方法

Dev-C++同时编译多个C或C++⽂件⽅法Dev-C++同时编译多个C⽂件:考察多源代码⽂件程序的编译及头⽂件的使⽤:如果程序的函数分别放在不同的程序之中,那就必须是定义常量的#define指令对于每个⽂件都可⽤:定义⼀个***.h⽂件,存储函数原型和常量定义需⼀起编译的⽂件添加 #include "***.h"即可编译步骤:1.新建⼀个C空⽩⼯程2.将需要⼀起编译的⽂件添加⾄上述新建⼯程中3.编译运⾏即可,C++同理C/C++多⽂件编译原理在单⽂件的情况下(只有⼀个.h和.c/.cpp)我们只需编译该⽂件即可,例如:$ gcc main.c -o main但更多的情况下,⼀个⼯程需要分开为多个源⽂件,⽐如 main.c、a.c、b.c 等,那这种情况下是如何编译的呢?⾸先要在main.c 中调⽤ a.c 中的⽅法,必须包含 a.h 头⽂件,有了头⽂件中的函数声明就确保了 main.c 的函数调⽤的正确性。
好了,现在我们执⾏编译多⽂件命令:$ gcc main.c a.c b.c -o main整个编译结果是这样的:编译器先把源⽂件见 main.c a.c b.c 独⽴编译为 main.obj a.obj b.obj ⽬标⽂件,然后再把其中要⽤到的函数⽅法链接到 main.obj 来,最终打包成可执⾏⽂件 main,这就是分离编译和链接原理。
如何编译由多个c++源⽂件组成的项⽬在我写数据结构作业的时候,由于⾃⼰写了⼀些需要使⽤的数据结构,所以源⽂件有如下⼏个:Main.cpp, Stack.cpp, Stack.h, Queue.cpp, Queue.h但是当我在IDE中编写好源⽂件,想要⾃⼰来编译的时候,我发现我不会处理多个源⽂件的情况,查找资料后有如下解决⽅法:1.在同⼀语句中同时编译多个源⽂件g++ -Wall -g Main.cpp Stack.cpp Queue.cpp -o StackOut⽣成可执⾏⽂件StackOut在g++编译器中,-Wall是允许发出GCC能够提供的所有有⽤的警告的参数,-g是告诉g++产⽣能被GUN调试器使⽤的调试信息以便调试你的程序。
c语言多文件编译顺序

c语言多文件编译顺序
在进行C语言多文件编译时,需要注意文件的编译顺序。
通常情况下,需要先编译依赖其他文件的文件,再编译被依赖的文件。
例如,一个程序由两个文件main.c和func.c组成,其中func.c 中的某些函数被main.c所调用。
那么,编译的顺序应该是func.c先编译,再编译main.c。
这样才能保证程序的正确性。
在Makefile中,可以通过设置依赖关系来控制编译顺序。
例如: main.o: main.c func.h
tgcc -c main.c
func.o: func.c func.h
tgcc -c func.c
main: main.o func.o
tgcc -o main main.o func.o
在上述Makefile中,main.o和func.o分别依赖于main.c和func.c以及func.h文件,因此在编译main.o和func.o之前需要先编译它们所依赖的文件。
最后,通过将main.o和func.o链接起来,生成最终的可执行文件main。
这样,就实现了C语言多文件编译的顺序控制。
- 1 -。
keil的几种编译模式

keil的几种编译模式摘要:1.编译模式的概念2.Keil 的几种编译模式2.1 编译模式1:单文件编译2.2 编译模式2:多文件编译2.3 编译模式3:项目编译2.4 编译模式4:批量编译3.各种编译模式的优缺点4.选择合适的编译模式的建议正文:编译模式是指在编译程序时,编译器如何处理源代码的方式。
编译模式可以影响到编译的速度、可维护性以及程序的性能。
Keil 是一款广泛应用于嵌入式系统开发的集成开发环境(IDE),它提供了多种编译模式以满足不同开发者的需求。
下面我们来详细介绍一下Keil 的几种编译模式。
Keil 的编译模式主要有以下几种:1.编译模式1:单文件编译在这种模式下,Keil 只编译一个源文件。
这种模式的优点是速度快,因为编译器只需要处理一个文件。
但是,这种模式的缺点是可维护性差,因为当项目规模变大时,单个文件的修改可能会影响到整个项目。
2.编译模式2:多文件编译在这种模式下,Keil 会同时编译多个源文件。
这种模式的优点是可以提高编译速度,尤其是在大型项目中。
此外,多文件编译也有利于项目的可维护性,因为每个源文件可以独立修改。
但是,这种模式的缺点是可能会导致链接错误,因为编译器需要处理多个文件之间的依赖关系。
3.编译模式3:项目编译在这种模式下,Keil 会按照项目设置中的编译顺序和选项进行编译。
这种模式的优点是可以确保项目的正确性和一致性,因为编译器会按照预定的顺序处理文件。
但是,这种模式的缺点是编译速度可能会较慢,因为编译器需要处理整个项目。
4.编译模式4:批量编译在这种模式下,Keil 会一次性编译所有源文件。
这种模式的优点是可以大大提高编译速度,尤其是在大型项目中。
但是,这种模式的缺点是可能会导致链接错误,因为编译器需要处理所有文件之间的依赖关系。
在选择Keil 的编译模式时,开发者需要根据自己的实际需求进行权衡。
对于小型项目或者只需要修改单个文件的项目,单文件编译或者多文件编译可能是更好的选择。
Linux下makefile多文件编译

1.用mkdir指令新建一个mian目录
2.用cd指令进入main目录
3.用gedit指令分别建立main.c,sum.c,sum.h文件,并在main.c,sum.c,sum.h文件中编写程序。
4.用gedit指令建立一个makefile文件,并将以下代码写入文件中
object=main.o sum.o
实 验 报 告
【2017-2018学年第5学期】
【基本信息】
【开课部门】
【实验课程】
物联网网技术
【设课形式】
独立非独立□
【实验项目】
Linux下makefile多文件编译
【项目类型】
基础综合□ 设计□
研究创新□ 其它□
【项目学时】
5
【学生姓名】
【学 号】
【专 业】
【班 级】
【同组学生】
【实验室名】
【实验日期】
12.9
【教师对报告的最终评价及处理意见】
成绩(百分制):(涂改无效)
教师:年 月 日
【实验报告】
实验目的:
1.掌握makefile的撰写
2.掌握多文件的编译
3.掌握Linux gcc、ld的作用
4.完成C语言,main.c, sum.c sum.h三个文件;实现给定两个整数的加法运算,sum.c里封装加法函数,在main.c中完成调用。
main:$(object)
<tab>gcc -o main $(object)
main.o:main.c
<tab>gcc -c main.c
sum.o:sum.c sum.h
<tab>gcc -c sum.c
clean:
gcc 批量.c编译

gcc 批量.c编译
要批量编译多个`.c`文件,可以使用GCC编译器的命令行工具。
以下是一种常见的方法:
1. 首先,将所有需要编译的`.c`文件放置在同一个文件夹下,
例如`src`文件夹。
2. 打开终端或命令提示符,进入存放`.c`文件的文件夹。
可以
使用`cd`命令切换目录,例如:
cd /path/to/src.
3. 使用GCC编译器的命令行工具进行批量编译。
可以使用通配
符``来匹配所有`.c`文件,然后将它们一起编译。
例如,使用以下
命令编译所有`.c`文件:
gcc .c -o output.
上述命令中的`.c`表示匹配所有`.c`文件,`-o output`指定编
译输出的可执行文件名为`output`。
你也可以根据需要修改输出文
件名。
4. 执行上述命令后,GCC编译器会依次编译每个`.c`文件,并生成对应的目标文件(`.o`文件)。
最后,它会将所有目标文件链接在一起,生成一个可执行文件(`output`)。
请注意,上述方法假设你的`.c`文件之间没有相互依赖关系。
如果存在依赖关系,你可能需要按照正确的顺序编译这些文件,以确保链接时能够找到所有需要的符号。
希望以上回答能够满足你的需求。
如果你还有其他问题,请继续提问。
使用makefile编译多个文件(.c,.cpp,.h等)

使⽤makefile编译多个⽂件(.c,.cpp,.h等)有时候我们要⼀次运⾏多个⽂件,这时候我们可以使⽤Makefile◊make是什么? make是⼀个命令⼯具,是⼀个解释makefile中指令的命令⼯具。
它可以简化编译过程⾥⾯所下达的指令,当执⾏make 时,make 会在当前的⽬录下搜寻 Makefile (or makefile) 这个⽂本⽂件,执⾏对应的操作。
make 会⾃动的判别原始码是否经过变动了,⽽⾃动更新执⾏档。
◊为什么要使⽤make? 假设,现在⼀个项⽬⾥⾯包含了100个程序⽂件,如果要对这个项⽬进⾏编译,那么光是编译指令就有100条。
如果要重新进⾏编译,那么就⼜得像之前⼀样重新来⼀遍。
这样重复且繁琐的⼯作实在是让我们很不爽啊。
所以,⽤make来进⾏操作,间接调⽤gcc岂不是很⽅便?如果我们更动过某些原始码档案,则 make 也可以主动的判断哪⼀个原始码与相关的⽬标⽂件档案有更新过,并仅更新该档案。
这样可以减少重新编译所需要的时间,也会更加⽅便。
◊makefile⼜是⼲什么的? makefile其实就是⼀个⽂档,⾥⾯定义了⼀系列的规则指定哪些⽂件需要先编译,哪些⽂件需要后编译,哪些⽂件需要重新编译,它记录了原始码如何编译的详细信息! makefile⼀旦写好,只需要⼀个make命令,整个⼯程完全⾃动编译,极⼤的提⾼了软件开发的效率。
先看⼀下makefile的规则: ⽬标(target):⽬标⽂件1 ⽬标⽂件2 <Tab>gcc -o 欲建⽴的执⾏⽂件⽬标⽂件1 ⽬标⽂件2先举⼀个运⾏多个c语⾔⽂件。
⾸先下⾯是⼀个完整的 c语⾔⽂件,实现了统计⽤户输⼊的字符串中⼤⼩写字母的个数#include<unistd.h>#include<sys/types.h>#include<sys/wait.h>void test(){char str[50]={0};scanf("%s",str);int m=0;int n=0;pid_t p=fork();if(p<0){printf("fork failed");}if(p == 0){for(int i=0;i<sizeof(str);i++){if( str[i]<='Z'&& str[i]>='A'){m++;}}printf("⼤写字母⼀共有");printf("%d",m);printf("个");}if(p>0){for(int i=0;i<sizeof(str);i++){if(str[i]>='a' && str[i]<='z'){n++;}}printf("⼩写字母⼀共有");printf("%d",n);printf("个");}}int main(){test();return 0;}此时我们可以把该⽂件拆成三份,⼀份是.h⽂件,⽤来放头⽂件等信息,另外两个是.c⽂件,⼀个⽤来放main⽅法,⼀个放声明的函数,如下三图则在终端进⾏⼀下操作成功运⾏多个⽂件下⾯介绍运⾏cpp⽂件,⼤致步骤相同。
C语言多文件编译的例子

C语言多文件编译的例子在VC6.0 中新建一个工程,添加fun.c、main.c 两个源文件和fun.h 一个头文件,内容如下:fun.c1.#include2.int fun1(){3.printf('The first function!\n');4.return 0;5.}6.int fun2(){7.printf('The second function!\n');8.return 0;9.}10.int fun3(){11.printf('The third function!\n');12.return 0;13.}#include int fun1(){ printf('The first function!\n'); return 0;}int fun2(){ printf('The second function!\n'); return 0;}int fun3(){ printf('The third function!\n'); return 0;}fun.h1.#ifndef _FUN_H2.#define _FUN_H3.4.extern int fun1(void);5.extern int fun2(void);6.extern int fun3(void);7.8.#endif#ifndef _FUN_H#define _FUN_Hextern int fun1(void);extern int fun2(void);extern int fun3(void);#endifmain.c1.#include2.#include3.#include 'fun.h'4.5.int main(){6.fun1();7.fun2();8.fun3();9.10.system('pause');11.return 0;12.}#include #include #include 'fun.h'int main(){ fun1(); fun2(); fun3(); system('pause'); return 0;}对上面的每个 .c 文件都进行编译,然后链接并运行:The first function!The second function!The third function!上面的例子,函数定义放在 fun.c 文件中,在 fun.h 头文件中对函数进行声明,暴露接口,然后在主文件 main.c 中引入 fun.h。
c语言多文件编程 例子

c语言多文件编程例子摘要:1.C 语言多文件编程的概念2.多文件编程的例子3.多文件编程的优点4.多文件编程的注意事项正文:C 语言多文件编程是指在C 语言程序中,将程序划分为多个源文件进行编写和编译。
这种方式可以提高程序的可读性、可维护性和可扩展性。
下面通过一个例子来介绍C 语言多文件编程的具体实现方法。
假设我们要编写一个简单的计算器程序,该程序需要实现加法、减法、乘法和除法四种运算。
我们可以将这些运算分别放在不同的源文件中,然后在主文件中进行调用。
首先,我们需要创建一个头文件,定义这四个运算函数的声明。
头文件名为`calculator.h`,内容如下:```c#ifndef CALCULATOR_H#define CALCULATOR_Hint add(int a, int b);int subtract(int a, int b);int multiply(int a, int b);int divide(int a, int b);#endif```接下来,我们分别在四个源文件中实现这四个函数。
源文件名为`add.c`、`subtract.c`、`multiply.c`和`divide.c`,内容如下:add.c:```c#include "calculator.h"int add(int a, int b) {return a + b;}```subtract.c:```c#include "calculator.h"int subtract(int a, int b) {return a - b;}```multiply.c:```c#include "calculator.h"int multiply(int a, int b) {return a * b;}```divide.c:```c#include "calculator.h"int divide(int a, int b) {if (b == 0) {printf("Error: Division by zero");return 0;}return a / b;}```最后,在主文件`main.c`中,我们可以调用这四个函数来实现计算器的功能:```c#include "calculator.h"int main() {int a, b, result;printf("Enter two integers: ");scanf("%d %d", &a, &b);switch (a) {case 1:result = add(a, b);break;case 2:result = subtract(a, b);break;case 3:result = multiply(a, b);break;case 4:result = divide(a, b);break;default:printf("Error: Invalid input ");return 0;}printf("Result: %d", result);return 0;}```通过这个例子,我们可以看到C 语言多文件编程的优点,如程序结构清晰、易于维护等。
rust 多文件编译方法

rust 多文件编译方法Rust是一种现代的、安全的系统级编程语言,它鼓励开发者使用模块化的编程风格。
在Rust中,一个项目可以由多个文件组成,每个文件包含一个或多个模块。
这种模块化的结构有助于将代码分成更小、更易于管理的部分,并使其在多个文件之间共享。
要在Rust中进行多文件编译,你需要:1.创建模块:在Rust中,一个模块通常被定义为一个文件。
你可以在一个文件中定义一个模块,然后在其他文件中引用它。
模块定义需要使用关键字`mod`,后跟模块名称和模块的内容。
例如,我们可以在`module.rs`文件中定义一个名为`module`的模块:```rust// module.rspub mod module {pub fn print_message() {println!("Hello from module!");}}```2.导入模块:要在另一个文件中使用一个模块,你需要先导入它。
可以使用`use`关键字来导入一个模块。
例如,我们可以在`main.rs`文件中导入`module`模块,然后调用`print_message`函数:```rust// main.rsmod module;use module::module::print_message;fn main() {print_message();}```在导入模块时,需要使用双冒号`::`来指示模块的路径。
在这个例子中,我们需要指定`module::module`的路径,其中`module`是文件名。
3.构建项目:一旦你将代码分成多个文件和模块,在构建项目时,你需要告诉Rust编译器如何找到这些文件。
可以使用Cargo来管理和构建Rust项目。
创建一个名为`Cargo.toml`的文件,并添加以下内容:```toml[package]name = "my_project"version = "0.1.0"edition = "2018"[lib]name = "my_lib"path = "src/lib.rs"[[bin]]name = "my_binary"path = "src/main.rs"```在这个示例中,我们定义了一个库`my_lib`和一个可执行文件`my_binary`。
多文件程序编译连接方法

多文件程序编译连接方法一、为什么需要多文件程序编译连接在大型项目中,源代码通常包含多个函数和类。
如果把所有代码都写在一个文件中,将会导致代码量庞大、可读性差、难以维护和复用。
而将源代码分割成多个文件,每个文件只包含一个函数或类的定义和实现,可以使程序结构更加清晰,提高代码的可读性和可维护性。
此外,多文件程序编译连接还能提供代码的复用性,即不同的程序可以共享同一个源代码文件,减少了代码的冗余。
二、多文件程序的基本结构为了充分利用多文件程序的优势,需要将代码分割成多个文件,并合理组织这些文件,以确保编译时能够正确地找到所需的函数和类。
以下是多文件程序的基本结构:1.头文件(.h文件):包含函数和类的声明。
头文件通常用于定义函数的原型、类的成员和公共变量等。
每个头文件应该有相应的源代码文件与之对应。
2. 源代码文件(.cpp文件):包含函数和类的定义和实现。
一个源代码文件对应一个头文件。
3. 主程序文件(.cpp文件):包含程序的入口函数(main函数)和其他需要在程序开始执行时执行的代码。
4.编译链接时生成的目标文件(.o文件):通过编译器将源代码编译成机器码后生成的文件。
这些目标文件可以被链接器连接成可执行文件。
三、多文件程序的编译链接步骤1. 预处理:预处理器负责解析源代码文件中的预处理指令,如#include、#define等,并将处理后的代码保存到临时文件中(.i文件)。
示例命令:g++ -E main.cpp -o main.i2.编译:编译器将预处理后的代码转换成汇编代码。
每个源代码文件都会生成一个相应的汇编代码文件(.s文件)。
示例命令:g++ -S main.i -o main.s3.汇编:汇编器将汇编代码转换成可重定位的机器码,并生成目标文件。
示例命令:g++ -c main.s -o main.o。
C++命令行多文件编译(g++)
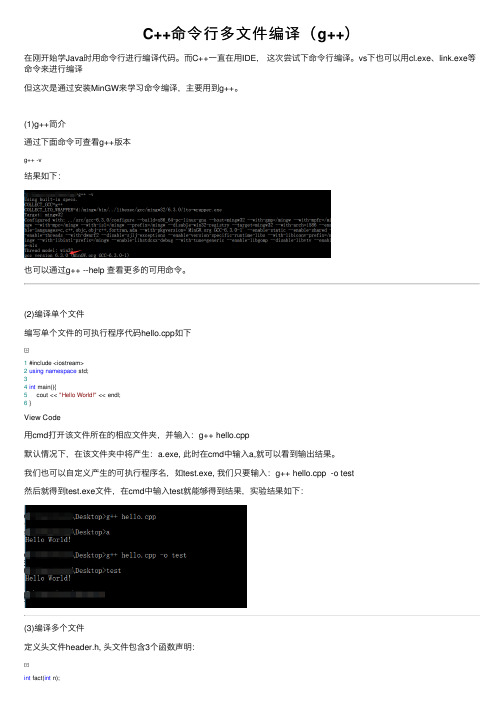
C++命令⾏多⽂件编译(g++)在刚开始学Java时⽤命令⾏进⾏编译代码。
⽽C++⼀直在⽤IDE,这次尝试下命令⾏编译。
vs下也可以⽤cl.exe、link.exe等命令来进⾏编译但这次是通过安装MinGW来学习命令编译,主要⽤到g++。
(1)g++简介通过下⾯命令可查看g++版本g++ -v结果如下:也可以通过g++ --help 查看更多的可⽤命令。
(2)编译单个⽂件编写单个⽂件的可执⾏程序代码hello.cpp如下1 #include <iostream>2using namespace std;34int main(){5 cout << "Hello World!" << endl;6 }View Code⽤cmd打开该⽂件所在的相应⽂件夹,并输⼊:g++ hello.cpp默认情况下,在该⽂件夹中将产⽣:a.exe, 此时在cmd中输⼊a,就可以看到输出结果。
我们也可以⾃定义产⽣的可执⾏程序名,如test.exe, 我们只要输⼊:g++ hello.cpp -o test然后就得到test.exe⽂件,在cmd中输⼊test就能够得到结果,实验结果如下:(3)编译多个⽂件定义头⽂件header.h, 头⽂件包含3个函数声明:int fact(int n);int static_val();int mabs(int);View Code定义函数定义⽂件func.cpp:#include "header.h"int fact(int n){int ret = 1;while(n > 1)ret *= n--;return ret;}int static_val(){static int count = 1;return ++count;}int mabs(int n){return (n > 0) ? n : -n;}View Code定义主函数⽂件main.cpp:#include <iostream>#include "header.h"using namespace std;int main(){int j = fact(5);cout << "5! is " << j << endl;for(int i=1; i<=5; ++i){cout << static_val() << "";}cout << endl;cout << "mabs(-8) is " << mabs(-8) << endl;return0;}View Code在同⼀个⽂件夹下编辑header.h,func.cpp,main.cpp后,就可以进⾏多个⽂件编译,注意到在命令⾏编译中似乎没有头⽂件什么事,头⽂件只是起到声明的作⽤,因此只需编译两个*.cpp⽂件并链接就可以。
编译多源代码文件的程序

编译多源代码文件的程序
编译多源代码文件的程序是一种用于将多个源代码文件合并成
一个可执行文件的程序。
这种程序通常用于开发大型软件项目,因为它可以将多个模块的代码组合起来,从而实现更好的代码重用和模块化设计。
编译器通常会将多个源代码文件编译成一个目标文件,然后再将目标文件链接到可执行文件中。
这个过程涉及到多个步骤,包括预处理、编译、汇编和链接等。
在编译多个源代码文件时,我们需要确保这些文件之间的依赖关系得到正确处理,以确保最终生成的可执行文件能够正常运行。
为了编译多个源代码文件,我们可以使用一些常见的工具,比如GCC、Makefile和CMake等。
这些工具可以自动化地处理代码编译和链接的过程,从而减少手动操作的复杂性和错误率。
使用这些工具,我们只需要提供源代码文件的路径和依赖关系,就可以自动生成可执行文件。
总之,编译多源代码文件的程序是一种非常重要的工具,它可以帮助我们更好地管理和维护大型软件项目,提高代码的可维护性和可重用性。
- 1 -。
VisualStudioCodeC++多文件编译运行

VisualStudioCodeC++多⽂件编译运⾏笔者在C++ PrimerPlus的学习过程中遇到了多个源⽂件编译运⾏的问题,由于笔者使⽤的是VSCode,软件本⾝并不⽀持多个源⽂件编译运⾏,可以通过⼀些⽅法来使VsCode⽀持多⽂件编译运⾏。
笔者经研究发现,有三种⽅法:分别是基于g++命令、基于Cmakelist⽅法、以及最简单的安装⼯程插件法,第⼆种⽅法可以加深对编译过程的理解和VsCode 的json配置⽂件的理解,推荐⼤家可以尝试试⼀下。
本⽂以⼀个交换函数为⽰例,演⽰了这三种⽅法。
Vscode⼯作区⽬录如下:其中各⽂件内容如下:头⽂件:void swap(int &a, int &b);主函数源码⽂件:#include<iostream>#include"swap.h"using namespace std;int main(){int val1 = 10;int val2 = 20;cout << "Before swap:\n";cout << "val1 = " << val1;cout << ", val2 = " << val2 << endl;swap(val1, val2);cout << "after swap:\n";cout << "val1 = " << val1;cout << ", val2 = " << val2 << endl;return 0;}交换函数源码⽂件:// swap.cpp#include"swap.h"void swap(int &a, int &b){int temp;temp = a;a = b;b = temp;}1.基于g++命令1.1 打开终端,点击菜单去终端的新建终端,打开终端窗⼝;1.2 g++编译多⽂件,⽣成带调试信息的可执⾏⽂件命令如下:g++ -g .\main.cpp .\swap.cpp -o main其中 -g 后⾯是两个源代码⽂件的名称,-o 后⾯是⽣成exe⽂件的名称执⾏后会⽣成⼀个exe⽂件如图所⽰:1.3 直接在终端运⾏该⽂件,命令为:.\main.exe运⾏结果如下:1.4 要想调试该函数,需要修改launch.json⽂件。
VC++6.0中如何编译运行C语言的多个源文件程序
VC++6.0中如何编译运行C语言的多个源文件程序多个源文件的编译运行在源程序过多的情况下,单个源文件往往难于检查错误,因此在程序设计时,往往是由几个人各自独立编写不同的程序,显然这些程序是不能写在一起进行编译的,这时就需要建立项目工作区来完成几个独立程序的编译,具体方法如下。
打开VC++6.0,选择“file”→“new”打开如图1所示(图1)选择“workespaces”项,并在“workespaces name”项目下输入“file”(可随意)如图2所示(图2)单击“OK”,打开如图3所示(图3)在左侧的“Workespaces”显示了新建立的工作区选择“file”→“new”打开如图9所示,在“Projects”项目下选择“W in32 ConsoleApplication”项,并在“project name”项目下输入工程名称,如“file”,选择“Add to current workespaces”项,如图4所示(图4)单击“OK”,打开如图5所示(图5)选择“An empty project”项,单击“Finish”,打开如图6所示(图6)单击“OK”,打开如图7所示(图7)在左侧的“Workespaces”显示了新建立的工程选择“file files”→“Source”→“new”,打开如图8所示(图8)点击“C++ Source File”,然后到File中输入如file1.c,最后点击OK。
以同样的方式在这个文件下建立两个文件,打开如图17所示(图8)输入源代码1和源代码2,源代码1:#include<stdio.h>int A;int main(){int power(int n);int b=3,c,d,m;printf("enter the number a and its power m:\n");scanf("%d,%d",&A,&m);c=A*b;printf("%d*%d=%d\n",A,b,c);d=power(m);printf("%d**%d=%d\n",A,m,d);return 0;}源代码2:extern A;int power(int n){int i,y=1;for(i=1;i<=n;i++)y*=A;return(y);}(注:此程序完成其他文件外部变量的使用)选择“Build”→“Build file.exe”(或按F7键),打开如图9所示(图9)在下端的输出窗口会有错误和警告的提示,如果没有错误选择“Build”→“Execute file.exe”(或按Ctrl+F5)输入13,3即可出现运行结果,如图10所示(图10)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1。
tc2.0分块编译
当程序复杂时源代码会很长,如果把全部代码放在一个源文件里,写程序,修改、加工程序都会很不方便。
程序文件很大时,装入编辑会遇到困难;在文件中找位置也不方便;对程序做了一点修改,调试前必须对整个源文件重新编译;如果不慎把已经调试确认的正确部分改了,又会带来新的麻烦。
在实践中人们体会到:应当把大软件(程序)的代码分成一些部分,分别放在一组源程序文件中,分别进行开发、编译、调试,然后把它们组合起来,形成整个软件(程序)。
C语言本身支持这种开发方式。
当我们写的程序较大时,上述问题就会反应出来,因此应当学习“大程序”的开发方法。
把一个程序分成几个源程序文件,显然这些源文件不是互相独立的。
一个源文件里可能使用其他源文件定义的程序对象(外部变量、函数、类型等),这实际上在不同源文件间形成了一种依赖关系。
这样,一个源文件里某个程序对象的定义改动时,使用这些定义的源文件也可能要做相应修改。
在生成可执行程序时,应该重新编译改动过的源文件,而没改过的源文件就不必编译了。
在连接生成可执行程序时,要把所有必要的模块装配在一起。
这些管理工作可以由人自己做,但是很麻烦。
TURBO
C集成开发环境的项目管理功能能帮助我们处理这些问题。
利用这种功能,开发大程序的工作将更加方便。
今天的各种程序开发环境都提供了类似的管理功能。
用C语言写大程序,应当把源程序分成若干个源文件。
其中有:
(1)一个或几个自定义的头文件,通常用.h 作为扩展名。
头文件里一般放:
#include预处理命令,引用系统头文件和其他头文件;
用#define定义的公共常量和宏;
数据类型定义,结构、联合等的说明;
函数原型说明,外部变量的extern说明;等等。
(2)一个或几个程序源文件,通常用.c 作为扩展名。
这些文件中放:
对自定义头文件的使用(用#include命令);
源文件内部使用的常量和宏的定义(用#define命令);
外部变量的定义;
各函数的定义,包括main函数和其他函数。
不提倡在一个.c 文件里用#include命令引入另一个.c
文件的做法。
这样往往导致不必要的重新编译,在调试程序查错时也容易引起混乱。
应该通过头文件里的函数原型说明和外部变量的extern说明,建立起函数、外部变量的定义(在某个源程序文件中)与它们的使用(可能在另一个源程序文件中)之间的联系,这是正确的做法。
使用TURBO C项目管理功能的方法是:
首先建立一个“项目文件”。
本系统中项目文件用.PRJ作为扩展名。
项目文件同样可以用编辑器建立,在这个文件中列出作为本项目组成部分的所有源程序文件的完整名字(包括扩展名),每行列一个,头文件不必列入。
源文件的次序没有关系,第一个源文件的名字将被作为最后生成的可执行程序的名字。
在启动集成开发环境后,首先装入项目文件。
用Project菜单第一个命令完成这个工作。
在此之后,编程工作的对象就是这个项目。
装入和修改源文件的方式不变。
在一个源文件初步完成后,可以用Alt-F9或菜单编译命令对它进行编译,做语法检查,生成目标模块。
这时还可能产生由于缺少必要外部定义而出现的错误。
发现这种问题,应当修改有关头文件。
在各个源文件的分别初步编译调试后,用F9或菜单的Compile/Make项命令开发环境建立可执行程序。
这时程序加工的工作对象是整个项目,如果系统发现某些目标模块不是最新的(源程序修改过),就自动对它
们重新编译,最后把目标模块连接起来,生成可执行程序。
编译中若发现源文件有错,所有的错误都将列在消息窗口,排错时系统能够对各个文件中的错误自动定位,如果被定位错误所在的文件不是当前文件,系统将自动装入相应的文件,并把亮条和光标放在正确位置。
在这个加工过程中,还可能发现模块之间的关联错误,如变量函数的名字使用和定义不一致,方式不正确,变量函数的extern说明与实际定义不一致,等等。
在Make过程中,系统利用源程序的时间信息,确定程序模块的前后时间关系,决定哪些模块需要重新编译,最后在连接时装入所有必需的模块
/*头文件f.h*/
void fun();/*函数声明*/
/*定义文件f.c*/
#include<stdio.h>
void fun()/*函数定义*/
{
printf("fun is ok");
}
/*主文件 main.c*/
#include"f.h"
int main()
{
fun();
}
C程序模块的这种构造方式带来了非常有价值的性质:封装性。
以上面的为例,main.c使用f.c模块,那么一定的角度看,f.c模块的具体实已变得无关紧要了。
f.h向main.c 所提供地操作实现了所要求的功能(必要函数原型),f.h文件的是main.c 和ball.c之间的桥梁。
即使修改了ball.c模块的具体实现方式(内部函数),只要这些修改没改变f.h中各种函数的原型,系统的其他部分就完全不需要重新编译或修改。
________________
| file_1.c |
| file_2.c |
| ... |把多个文件,如左。
将其保存为 *.prj 文件,
| ... |你可以用任何东西编辑,如tc20,vc++,pascal,记事本。
| file_n.c |但一定要记住,文件名要是*.prj形式。
这只是第一步。
----------------
打开tc20编辑框,找到project->project name这项。
输入你的 *.prj文件名。
例如,你的*.prj文件在d:\>,输入d:\*.prj
好拉:ctrl+F9,编译,ok!完成。
条件:设有一个PROJECT,包含四个文件:main.c 、func0.c 、func1.c 、incfunc.h;其中func0.c包含函数f_a()和f_b();其中func1.c包含函数f_c()和f_d(),四个函数均为整型。
其中main.c是主文件,func0.c和func1.c是包含main.c中用到的函数的两个C文件,incfunc.h是头文件。
编译前需要在main.c 、func0.c和func1.c文件中包含inc_func.h,也就是加入:#include "array.h" 语句;
inc_func.h文件内容如下(其实就是在inc_func.h文件中声明函数头;函数体在具体的func0.c和func1.c 文件中进行定义):
// 开始
#define INCFUNC_H
int f_a();
int f_b();
int f_c();
int f_d();
//结束
其他部分与编译一个文件一样。
简单概括就是,所有需要参加编译的C文件都需要包含相应的H文件;H文件要定义C文件中函数的“函数头”。
一般来说,主文件包含多个H文件,其他的C文件包含相应的H文件。
以上面的例子来说,可以用func0.h和func1.h来分别定义f_a()、f_b()和f_c()、f_d()的函数头,而 func0.c和func1.c 只须分别包含两个H文件,main.c需要同时包含两个H文件。
需要注意的是平时常用的类型所写,如:
#define uchar unsigned char
#define uint unsigned int
#define ulong unsigned long
只须在主文件main.c中定义即可,重复定义会在编译时产生很多warning。
v。