利用ReloadEditor制作SCORM_1.2标准教材
使用 HM VNISEdit 脚本编辑器向导

; 该脚本使用 HM VNISEdit 脚本编辑器向导产生; 安装程序初始定义常量!define PRODUCT_NAME "流氓工具箱"!define PRODUCT_VERSION "2.5"!define PRODUCT_PUBLISHER "︶ㄣ流氓‖猴孓"!define PRODUCT_WEB_SITE "http://hi.baidu.cm/amulin202"!define PRODUCT_DIR_REGKEY"Software\Microsoft\Windows\CurrentVersion\AppPaths\ResHacker.exe"!define PRODUCT_UNINST_KEY"Software\Microsoft\Windows\CurrentVersion\Uninstall\${PRODUCT_NAME}"!define PRODUCT_UNINST_ROOT_KEY "HKLM"SetCompressor lzma;添加安装类型,最多好像是可以8个,没测试过InstType "官方版"InstType "美化版";InstType /COMPONENTSONLYONCUSTOM ;关闭安装组件列表;InstType /NOCUSTOM ;删除“自定义”安装选项; ------ MUI 现代界面定义 (1.67 版本以上兼容) ------!include "MUI.nsh";!include "Sections.nsh" ;添加包含文件; MUI 预定义常量!define MUI_ABORTWARNING!define MUI_ICON"${NSISDIR}\Contrib\Graphics\Icons\modern-install.ico" ;安装程序图标!define MUI_UNICON"${NSISDIR}\Contrib\Graphics\Icons\modern-uninstall.ico" ;卸载程序图标!define MUI_HEADERIMAGE!define MUI_HEADERIMAGE_RIGHT!define MUI_HEADERIMAGE_BITMAP"${NSISDIR}\Contrib\Graphics\Header\nsis.bmp" ;这三行是定义左侧图片; 欢迎页面!insertmacro MUI_PAGE_WELCOME; 许可协议页面!insertmacro MUI_PAGE_LICENSE "D:\Monkey\NSIS\工单.txt"; 组件选择页面!insertmacro MUI_PAGE_COMPONENTS; 安装目录选择页面!insertmacro MUI_PAGE_DIRECTORY; 安装过程页面!insertmacro MUI_PAGE_INSTFILES; 安装完成页面!define MUI_FINISHPAGE_RUN "$INSTDIR\ResHacker.exe"!insertmacro MUI_PAGE_FINISH; 安装卸载过程页面!insertmacro MUI_UNPAGE_INSTFILES; 安装界面包含的语言设置!insertmacro MUI_LANGUAGE "SimpChinese"; 安装预释放文件!insertmacro MUI_RESERVEFILE_INSTALLOPTIONS; ------ MUI 现代界面定义结束 ------Name "${PRODUCT_NAME} ${PRODUCT_VERSION}"OutFile "安装程序.exe"InstallDir "$PROGRAMFILES\流氓工具箱"InstallDirRegKey HKLM "${PRODUCT_UNINST_KEY}" "UninstallString" ShowInstDetails showShowUnInstDetails showBrandingText "Hoodlum Studio"Section !主程序SectionIn RO ;SectionIn RO表示必选,用户无法修改SetOutPath "$INSTDIR" ;释放目录SetOverwrite on ;覆盖方式File "D:\Monkey\ResHacker.exe" ;源文件目录CreateDirectory "$SMPROGRAMS\流氓工具箱"CreateShortCut "$SMPROGRAMS\流氓工具箱\流氓工具箱.lnk" "$INSTDIR\ResHacker.exe"CreateShortCut "$DESKTOP\流氓工具箱.lnk""$INSTDIR\ResHacker.exe"SectionEndSectionGroup "皮肤" Skins ;定义一个组区段,区段名为皮肤,代号为SkinsSection "蓝色皮肤" a ;定义一个独立区段,该区段属当前Group下级菜单,a为该区段代号SectionIn 1 ;设置在选择第一种安装类型的时候,该区段默认选中,1在这边就是指“官方版”File "D:\Monkey\eXeScope6.50.exe"SectionEndSection /o "酷黑皮肤" b ;Section /o 表示可选安装,默认情况下,选项为被选中,用此方法来取消默认选中SectionIn 2File "D:\Monkey\MoleBox.exe"SectionEnd ;独立区段结束标志SectionGroupEnd ;组区段结束标志SectionGroup "图标" Icon ;第二个组区段,icon为该组区段的代号Section "蓝色托盘" xSectionIn 1File "D:\Monkey\RefreshIcon.exe"SectionEndSection /o "酷黑托盘" ySectionIn 2File "D:\Monkey\GetIcon.exe"SectionEndSectionGroupEndSection -AdditionalIconsWriteIniStr "$INSTDIR\${PRODUCT_NAME}.url" "InternetShortcut" "URL" "${PRODUCT_WEB_SITE}"CreateShortCut "$SMPROGRAMS\流氓工具箱\Website.lnk" "$INSTDIR\${PRODUCT_NAME}.url"CreateShortCut "$SMPROGRAMS\流氓工具箱\Uninstall.lnk" "$INSTDIR\uninst.exe"SectionEndSection -PostWriteUninstaller "$INSTDIR\uninst.exe"WriteRegStr HKLM "${PRODUCT_DIR_REGKEY}" """$INSTDIR\ResHacker.exe"WriteRegStr ${PRODUCT_UNINST_ROOT_KEY} "${PRODUCT_UNINST_KEY}" "DisplayName" "$(^Name)"WriteRegStr ${PRODUCT_UNINST_ROOT_KEY} "${PRODUCT_UNINST_KEY}" "UninstallString" "$INSTDIR\uninst.exe"WriteRegStr ${PRODUCT_UNINST_ROOT_KEY} "${PRODUCT_UNINST_KEY}" "DisplayIcon" "$INSTDIR\ResHacker.exe"WriteRegStr ${PRODUCT_UNINST_ROOT_KEY} "${PRODUCT_UNINST_KEY}" "DisplayVersion" "${PRODUCT_VERSION}"WriteRegStr ${PRODUCT_UNINST_ROOT_KEY} "${PRODUCT_UNINST_KEY}" "URLInfoAbout" "${PRODUCT_WEB_SITE}"WriteRegStr ${PRODUCT_UNINST_ROOT_KEY} "${PRODUCT_UNINST_KEY}" "Publisher" "${PRODUCT_PUBLISHER}"SectionEnd#-- 根据 NSIS 脚本编辑规则,所有 Function 区段必须放置在Section 区段之后编写,以避免安装程序出现未可预知的问题。
CLEO编辑【教程】
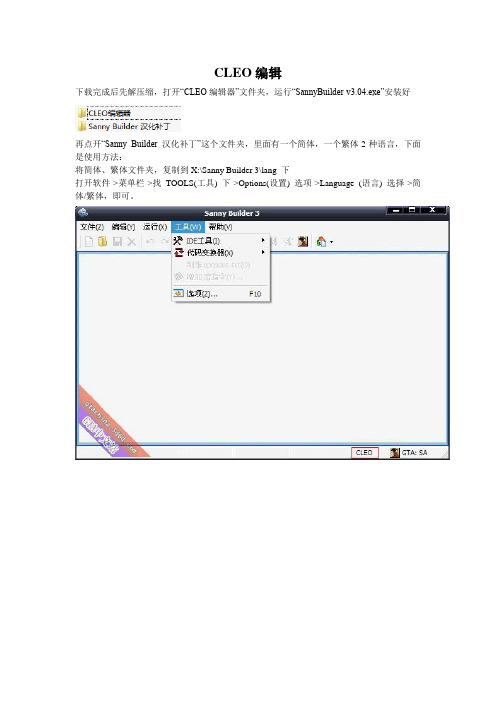
CLEO编辑下载完成后先解压缩,打开“CLEO编辑器”文件夹,运行“SannyBuilder-v3.04.exe”安装好再点开“Sanny Builder 汉化补丁”这个文件夹,里面有一个简体,一个繁体2种语言,下面是使用方法:将简体、繁体文件夹,复制到X:\Sanny Builder 3\lang 下打开软件->菜单栏->找TOOLS(工具) 下->Options(设置) 选项->Language (语言) 选择->简体/繁体,即可。
使用说明下面是cleo的使用方法的简单介绍,文字很多,下载包内有详细的说明。
怎么让CLEO横向发展,举几个例子就知道了:1、先举一个最简单的:你想在四龙赌场门前停一辆NRG500摩托车,每次打开存档都能看到它,怎么实现呢?有一个“军警车辆”CLEO,作用是把爆爆工厂里停了各种各样的警车及军车。
用Sanny Builder软件打开军警车辆CLEO的Poli_Arm_Cars.cs文件,可以看到有一大段这样的语句:$PC006 = init_parked_car_generator #BARRACKS color -1 -1 1 alarm 0 door_lock 0 0 10000 at -2141.971 -102.694 36.419 angle 270.0这是计算机语言,翻译成人话就是:在(-2141.971,-102.694,36.419)这个点上产生一辆警笛关闭的默认颜色的车头朝东的没锁门的运兵车。
“BARRACKS”是车名,想增加哪个车停放点就改成相应车名,改成NRG500就变成停放NRG500摩托了。
在刷车工具里有各种车辆的中英文名称和图片的对照。
“color -1 -1 1”表示车的颜色,这个如果不会改就不要改。
“alarm 0”表示报警器关闭,不知道有什么用。
“door_lock 0”表示没锁门,也不要改。
10000可能是生命值吧,没改过。
vscode创建代码模板的方法

vscode创建代码模板的方法(最新版2篇)目录(篇1)1.VSCode 简介2.代码模板的定义与作用3.创建代码模板的方法4.示例:创建一个简单的 HTML 代码模板5.代码模板的导入与使用6.代码模板的修改与更新7.结论正文(篇1)1.VSCode 简介Visual Studio Code(简称 VSCode)是一款免费、开源的跨平台代码编辑器,由微软开发。
它支持多种编程语言,具有丰富的插件系统和广泛的社区支持,因此受到了广大程序员的喜爱。
2.代码模板的定义与作用代码模板是一种预先定义好的代码结构,可以帮助开发者在编写代码时快速生成重复的代码段,提高编程效率。
在 VSCode 中,代码模板以`.tmpl`文件的形式存在,可以在项目中创建和导入。
3.创建代码模板的方法要在 VSCode 中创建代码模板,可以按照以下步骤进行:(1)在项目中创建一个`.tmpl`文件:在项目根目录下,右键单击并选择“新建文件”,将文件命名为`myTemplate.tmpl`。
(2)编写代码模板:在`myTemplate.tmpl`文件中,编写你想要生成的代码结构。
例如,我们可以创建一个简单的 HTML 代码模板:```html<!DOCTYPE html><html lang="zh-CN"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>{{title}}</title></head><body><h1>{{title}}</h1><p>这是一个简单的 HTML 页面。
基于SCORM标准的交互式课件的设计与开发

基于SCORM标准的交互式课件的设计与开发摘要:探讨了远程学习系统交互式课件设计、开发的主要要求,研究了SCORM标准的体系结构及其构成,提出了构建SCORM课件的优势。
重点分析了基于SCORM标准的学习管理系统开发和课件开发,详细阐述了学习管理系统的架构、SCORM的构成要素、内容包和开发关键技术。
使开发的交互式课件具有可移植、可重用、可更新、易操作的特点,更好的用于远程学习系统开展分布式训练。
关键词:交互式课件;SCORM标准;远程学习系统;SCORM课件;随着网络这种公共传递平台的普及与发展,主要包括远程学习网络的学习系统成为高等职业教育的主流发展方向,它能有效的降低学习成本,切实提高学习质量[1]。
网络学习系统中的交互式课件是这一系统的重要组成,而基于可共享内容对象参考模型(SCROM,SharableContentObjectReferenceModel)进行课件开发是其中的关键部分,它为学习人员提供的教学、教学辅导、学习测试内容集合,具有可重用、易管理、易更新、互操作等诸多优点。
1远程学习系统交互式课件的设计与开发要求针对交互式课件设计的要求,在开发过程中须遵循两个原则:一是建立课件运行的公共环境,即学习管理系统;二是建立课件的有效标准描述框架,即课件的资源描述和组织的标准。
国际上通用的SCORM标准也是基于这样的原则构建的[2]。
1.1可根据不同学习人员、学习层次进行组合高等职业教育的培训人员多种多样,培训层次分为初级、中级、高级等。
不同的培训人员和培训层次既有重叠的培训内容,又有不同的培训内容和评价体系,这就要求交互式课件具备弹性教学的能力。
根据具体需要为培训个人或团体构建简单或复杂的学习模式,将独立的各种教学组件和多种应用通过量身定制学习方案灵活重组,运用到不同的人员和层次中。
1.2满足集中培训和分散学习的不同需求集中培训依托一体化训练中心的CBT教室中进行,教师可以在CBT教室播放课件,或者在教师工作站使用课件与学生工作站进行交互。
公共语言运行库(CLR)开发系列课程(5):.NET Interop Marshalling进阶篇

.Net Interop Marshalling 进阶篇楼炉群 朱永泰 SDET SDE下载Webcast好帮手iR iReaper文件大小<=2.5Mb 可按照多种分类方式进行批量下载WMV、MP3、MP4、Zune四种格式Webcast访问iReaper主页: /iReaper h d l i加速企业解决方案部署尽在资源和利益• 用于解决方案开发的集中资源 用于解决方案开发的集中资源:资源包括指向测试工具、开发 资源包括指向测试工具 开发 人员 SDK、技术论坛、联机培训等的链接,微软全球技术支持 中心( (GTSC) )的邮件技术支持。
• 对市场调查的访问权限:您可以使用这些宝贵信息来识别您当 前的客户或未来客户的特定需求。
• 认证徽标计划:该徽标可以向客户证明您所具有的优秀技术。
• 市场营销和销售支持 h OMetro – ISV领航计划最先应用微软最新技术 提升ISV 提升 ISV竞争优势和商业价值 竞争优势和商业价值• Metro 提供了结构化的支持来帮助ISV进行新技术的评估和 部署 部署: Discover – 参与前沿技术培训 – 评估最新的微软技术及产品 Release Learn – 获取微软Beta版产品的技术支持 – 联络全球开发人员和架构师社区 – 与世界级的商务和技术社区分享最先 Develop 部署的经验收听本次课程需具备的条件• 对.NET interop有基本的了解 有基本的Level 300内容1. Interop 1 I t marshalling h lli 背景介绍 2. 字符串marshalling as a g 3. 数组marshalling背景介绍MarshallingLevel 300内容1. Interop 1 I t marshalling h lli 背景介绍 2. 字符串marshalling as a g 3. 数组marshallingLevel 300字符串本地代 本地代码• LPSTR,LPWSTR,LP , , TSTR BSTR ANSIBSTR TB • BSTR,ANSIBSTR,TB STR托管代 托管代码• String g • StringBuilderLevel 300LPString:本地代码• LPString 格式 • LPString内存相关函数CoTaskMemAlloc CoTaskMemFree C T kM F CoTaskMemRealloc• 举例:void Func(char * str)Level 300LPString:托管代码Level 300Level300DEMO在PInvoke/Reverse PInvoke 场景中使用LPSTR MarshallingBSTR:本地代码Level 300Level300BSTR:托管代码Level 300Level300DEMO在COM i/R C COM interop/Reverse Com Interop场景中使用BSTRBSTR MarshallingMarshalling杂项Level 300内容3. 数组marshalling什么是数组Level 300数组Marshal的特点Level 300数组Marshal的分类Level 300SafeArrayLevel 300DEMO在COM interop/Reverse Com Interop场景中使用SafeArrayC/C类型的数组C/C++Level 300DEMO在P/Invoke以及Reverse P/Invoke中使用c类型数组ByValArrayLevel 300DEMO ByValArray定制数组marshallingLevel 300DEMO[In],[Out], blittable [In][Out]blittable获取更多资源MSDN•MSDN中文网站•MSDN中文网络广播•MSDN中文网络广播课程预告邮件•MSDN免费中文速递邮件(MSDN Flash) •MSDN开发中心•MSDN图书中心•iReaper主页Question & Answer如需提出问题,请在此区域输入文字,并单击“问题和解答”右上方的“提问”按钮即可。
Codewarrior License制作教程(优选.)

目录第1章 Codewarrior License制作教程 (1)1.1 准备工作 (1)1.2 制作步骤 (1)1.2.1 确定FlexLm版本号 (1)1.2.2 找FEATURE (2)1.2.3 找vendor (5)1.2.4 找计算seed的关键数据 (6)1.2.5 计算ENCRYPTION_SEED (8)1.2.6 制作License生成器 (9)1.2.7 生成License (9)第1章Codewarrior License制作教程声明作者出于学习的目的撰写此文,读者需承担文章使用或传播过程中产生的一切后果,作者概不负责。
我们以飞思卡尔Codewarrior for HC08 v6.0为例,来介绍制作过程。
1.1 准备工作我们需要事先准备如下软件:z Lmtoolsz OllyICEz Calcseedz Lmcryptgui1.2 制作步骤破解Flexlm最主要的是找到4样东西:z确定Flexlm版本号z找FEATUREz找vendorz计算ENCRYPTION_SEED1.2.1确定FlexLm版本号运行Lmtools,选择Utilities标签页,点击Browse选择Codewarrior安装目录bin目录下lmgr8c.dll,然后点击Find Version,如图 1.1。
图 1.1 确定Flexlm版本号1.2.2找FEATURE运行OllyICE,界面如图 1.2。
图 1.2 OllyICE运行界面点击“文件/打开”,选择Codewarrior安装目录bin目录下IDE.exe,界面如图 1.3。
图 1.3 打开IDE.exe界面在反汇编窗口中点击右键,选择“查看”,打开模块‘LMGR8C’,如图 1.4。
图 1.4 打开模块‘LMGR8C’在反汇编窗口中点击右键,选择“查找”,打开“所有参考文本字串”,如图 1.5。
图 1.5 打开所有参考文本字串在参考文本字串窗口中点击右键,选择“查找文本”,输入“lm_ckout.c”,进行查找。
SCORM文档

SCORM( Sharable Content Object Reference Model )可共享内容对象参考模型一、 SCORM的定义SCORM是一种标准,是关于在线学习的标准,涉及学习平台(LMS)和内容(Courseware)两个方面。
通过标准的制定,学习平台和内容制作得以独立发展,由此延伸四种类型的公司:平台开发商、课件制作商、课件工具开发商、在线学习运营商。
再加上教师和学生就构成了在线学习的生态环境。
SCORM标准出现之前,内容和平台绑定很死,大大限制了在线学习的发展。
SCORM标准则解放了生产力,使得在线学习迎来一个大的发展。
二、几个重要概念LMS(学习管理系统):能够解析SCORM课件,跟踪学习者的学习记录的web系统。
Asset(原始素材):学习资源的最基本形式是asset。
asset是上传到网上并呈现给学习者的电子形式的媒体,如文本、图像、声音或任何其他一种数据。
几个asset 可以集合在一起建立新的asset。
SCO(可共享内容对象):是一个或者多个asset的集合,它可以在SCORM运行环境中与 LMS 进行数据传递。
SCO是LMS通过SCORM运行时间环境可以跟踪的最低粒度水平的学习资源。
API:是SCO与LMS之间传送的信息的一种通信机制,使用API可以开始、结束、获取、存储数据等动作。
数据模型(CAM):描述了在SCO与LMS之间传送信息数据的模型,如,跟踪信息,完成状态、停留时间等数据。
在学习者会话中,LMS必须维护来自SCO数据模型的状态信息。
而SCO需要利用这些预先定义的信息,以便在不同的LMS中重复使用。
三、 SCORM课件结构一个Scorm课件可包含任何资源文件,只需这些资源按照规范的格式进行组织。
Scorm课件一般以zip包的形式被提供,其包中包含了课件所需的图片、动画等资源。
zip包根目录下的imsmanifest.xml文件被看成为清单文件,其详细描述了该课件中的资源组织结构。
SCOM(R2)操作手册01管理区操作和配置即初装配置

S 2007( R2) 电子手册之“管理”区(初装)基本操作和配置2010年01月CoreIO技术专家Leo Huang目录【1】管理包的使用21.管理包概述22.安装并导入管理包3【2】发现待管理的设备71.发现Windows计算机82.发现网络设备143.发现Unix/Linux计算机17【3】手动安装S代理客户端21【4】卸载S客户端代理25【5】S的常规设置27【6】自创建管理包32【7】配置活动目录集成341.准备域级别和权限342.运行AD集成命令383.配置活动目录集成40【1】管理包的使用1.管理包概述管理包是拓展S管理能力的基石,是S解决方案的灵魂,在S中使用各种管理包来管理操作系统、应用程序及其它技术组件。
一个管理包(Management Pack:MP)包含了对于某一个特定技术组件的发现、监视、排错、报告、解决问题得最佳实践知识。
管理包包含了基于系统定义模型(Systems Definition Model—SDM)的系统健康模型,用来分析性能、可用性、配置与安全输入,以及相关组件的状况,来决定组件的整体状况。
可以获得微软及第三方操作系统、应用程序和设备的管理包。
微软提供了超过60个微软产品和Windows组件的管理包。
这些管理包都是由与S相同的产品开发团队所开发的。
这些管理包中的知识都来具有最可信赖的来源。
所有的微软管理包对于受许可的S用户来说,都是可以获得的。
查看微软管理包的完整列表,请访问S中的管理包目录。
众多第三方产品的管理包,例如Linux、Oracle、SAP及网络和服务器硬件,都是由微软合作伙伴所开发并提供的。
现在,共有超过100个微软合作伙伴管理包。
它们覆盖了现在公司所应用的大多数技术。
查看微软管理包的完整列表,请访问S中的管理包目录。
微软公司提供了多个工具用来为S 开发和定制管理包。
分布式应用程序设计器(Distributed Application Designer)是一个图形化向导,它可以帮助IT管理员为其IT服务快速创建安全模型与管理包。
利用ReloadEditor制作SCORM 1.2标准教材

【洪河条】利用ReloadEditor制作SCORM 1.2标准教材Reload Editor是符合IMS和SCORM标准的对课程内容的打包工具,可以在打包之前对课程内容进行SCORM标准下的策略编辑,打包好的PIF(包互换文件)可以直接导入符合SCORM标准的LMS(学习管理系统)。
目前的版本为2.02,中文的目录需要手工修改。
SCORM1.2教材制作必须要有下列组件:1、 imsmanifest.xml2、 metadata3、 SCO4、 API WrapperAPI Wrapper用复制到LMS下就可,而imsmanifest.xml、metadata可以用工具制作,至于可以和学习平台互动的SCO,可分较简单的(entry)SCO与进阶的SCO。
(一)、制作imsmanifest.xmlimsmanifest.xml是学习管理平台(LMS)在读取课程的第一个档案,如同网站的首页「index.html」一样,imsmanifest.xml的结构如下:安装工具制作imsmanifest.xml档案可以用ReloadEditor 工具来做。
可以到/editor.html网站下载ReloadEditor工具Download version 2.0.2 for Windows后进行安装制作imsmanifest.xml档案(1)、执行「开始」、「所有程序」、「Reload tools」、「Reload Editor」开启。
(2)、进入Reload Editor执行「File」、「New」、「ADL SCORM 1.2 Package」(3)、选定目录如(C:AppservWWW(4)、在右边「Organizations」上按一下鼠标右键(5)、选择「Add Organization」(6)、出现新的Organization后填入课程名称。
如Course00(7)、预览与储存,点选「工具列」上的「Preview Content Package」开启IE 浏览器观看「课程架构」。
SCORM标准及教材制作

SCORM的目标 的目标
可重复使用性(reusability) 取得容易性(accessibility) (accessibility) 互相通用性(interoperability) 耐用性(durability)
10
• Reusability(实例说明 实例说明) 实例说明
如何种植番茄 如何种植番茄 种植 Text
传统教材不具交互性: 传统教材不具交互性:
教材用在网络教学中,监控和移植效果都很差,比如学员的学习记录, 教材用在网络教学中,监控和移植效果都很差,比如学员的学习记录,分数 记录,学员资料的接口。 记录,学员资料的接口。
ADL推动SCORM,并且提出「任何符合SCORM之教材可在任何符 合SCORM之平台上操作」,可达成平台与教材间的相容与互通。
12
实时、按需组合( 实时、按需组合(
Assembled in real-time, ondemand)
随时随地提供学习和指 随时随地提供学习和指 导(To provide
learning and assistance anytime, anywhere)
什么时候用SCORM? ? 什么时候用
1、跟踪学习进度显得非常重要的时候 、 2、本部门或单位已经有符合scorm标准的 、本部门或单位已经有符合 标准的LMS 标准的 3、需要进行较多的e-learning培训 、需要进行较多的 培训 4、在整个系统或者部门间需要共享教学材料 、
任何支持SCORM RTE的LMS都可以发布并跟踪这些 都可以发布并跟踪这些SCO,而不用顾及是谁生成的; 任何支持 的 都可以发布并跟踪这些 ,而不用顾及是谁生成的; 任何支持SCORM RTE的LMS可以跟踪人意的 可以跟踪人意的SCO,知道他们何时开始,何时结束; 任何支持 的 可以跟踪人意的 ,知道他们何时开始,何时结束;
SCORM标准课件制作

SCORM标准课件制作使课件符合SCORM标准包含两⽅⾯内容:1、课件能正确导⼊平台;2、课件可以成功和平台通信。
⼀、SCORM课件导⼊:⽀持SCORM标准的平台通过读取“imsmanifest.xml”⽂件来获得课程标题、课程结构和课程地址,其中“manifest”节点是⽂件的根节点,根节点下还有两个⼦节点“organizations”和“resources”,“organizations”⾥的信息负责描述课程结构,“resources”⾥则包含了课程所⽤资源的存储位置以及类型。
有必要特别指出的是以下⼏点:1、各节点的“identifier”属性应该唯⼀;2、“organizations”节点下可以有多个“organization”节点,通过“organizations”的“default”属性指向某⼀个“organization”来决定使⽤那⼀种组织结构;3、“organization”下的“item”节点是可以嵌套的,⽤来实现课程章节的层次关系;4、“item”节点的“identifierref”属性的值为某⼀个“resource”节点的“identifier”属性的值,使某⼀章节与课程资源建⽴对应关系;5、“title”节点⾥的⽂本是课程以及章节在平台上的显⽰⽂本;6、“resource”节点的“href”属性是课程资源的存储位置。
“imsmanifest.xml”⽂件可以由⼯具⽣成,所以SCORM标准课件在导⼊⽅⾯⼀般不会出现问题,但不同平台在导⼊⼿段上并不⼀致,有些平台单纯导⼊“imsmanifest.xml”⼀个⽂件,有些平台把课程⽂件和“imsmanifest.xml”⽂件压缩成⼀个zip压缩包来整体导⼊,除了导⼊⽅式不⼀致外,“imsmanifest.xml”⽂件所⽤的编码也是⼀个需要注意的地⽅,只要能被平台正确读取即可。
⼆、SCORM课件与平台通信:任何⼀门可以跟踪的课程最起码要向平台提交课程各章节的状态(“未访问”、“未完成”、“完成”)、分数和当前位置。
scorm课件

02
CATALOGUE
scorm课件制作流程
需求分析
确定教学目标
明确课件的教学目标,以 及学生需要掌握的知识点 和技能。
确定学习内容
根据教学目标,确定需要 涵盖的学习内容,以及它 们的优先级和相关性。
确定学习方式
根据学生的特点和需求, 确定适合的学习方式,如 自主学习、合作学习等。
内容设计
内容结构
scorm课件应用平台
scorm cloud
基于云端的SCORM课件管理平台,可实现SCORM课件的上传、下载、发布、学习进度跟 踪等功能,方便企业或学校管理SCORM课件。
支持多种SCORM课件制作工具,如Adobe Captivate、Articulate Studio等,方便制作和 编辑SCORM课件。
05
CATALOGUE
scorm课件优化建议
提升学习体验
内容清晰易懂
使用简洁明了的语言,避免使用过于复杂的词汇和表达方 式。同时,确保内容结构清晰,逻辑严谨,方便学习者理 解和记忆。
视觉效果良好
合理使用图表、图像和视频等多媒体元素,以增强学习者 的学习兴趣和理解能力。同时,确保课件的排版和设计美 观大方,提高学习者的视觉舒适度。
adl scorm player
总结词
支持多种SCORM课件的播放器和跟踪器
详细描述
ADL SCORM Player是一款支持多种SCORM课件的播放器和跟踪器,它能够播放符合SCORM标准 的多媒体课件,并实时跟踪学生的学习进度和成绩,为教师和学习者提供了便捷、高效的在线学习工 具。
04
CATALOGUE
02
学习交流和讨论
提供学习者之间、学习者与教师之间的交流和讨论平台,以促进学习者
【商品说明书】vs code中文 使用手册

vs code中文使用手册嘿,编程小伙伴们! 是不是还在为找不到一款既强大又易上手的代码编辑器而苦恼呢?来来来,让我带你走进VS Code的中文世界,一起解锁高效编程的新姿势!首先,咱们得明确一点:VS Code,全称Visual Studio Code,那可是微软家的得意之作,一款免费开源、跨平台的代码编辑器,支持几乎所有主流编程语言,简直是编程界的“瑞士军刀”!一、初识VS Code,中文界面轻松上手一打开VS Code,你可能会被它的英文界面吓到,别担心,咱们这就把它变成亲切的中文! 在设置(Settings)里,找到“语言”(Language)选项,轻轻一点,中文简体安排上!瞬间,VS Code就变成了你最熟悉的模样,是不是感觉亲切多了?二、编辑器配置,个性化你的编程空间有了中文界面,接下来咱们得好好配置一下这个编辑器,让它更符合你的口味。
比如,你可以调整字体大小、颜色主题(我个人超爱“暗夜”主题,酷炫又不失沉稳),还有那些烦人的自动补全、代码格式化设置,统统可以按照你的喜好来!三、插件市场,应有尽有,让你的VS Code如虎添翼VS Code的强大,离不开它丰富的插件市场。
在这里,你可以找到各种神奇的插件,比如:GitLens,让你的Git历史记录一目了然,协作开发更顺畅;Python插件,直接支持Python代码的运行和调试,妈妈再也不用担心我的Python学习了;Code Runner,一键运行多种语言的代码,爽歪歪!安装插件超级简单,只需点击左侧的插件图标,搜索你想要的插件,然后点击“安装”即可。
是不是很简单?四、高效编程技巧,助你事半功倍掌握了VS Code的基本操作,接下来咱们聊聊如何用它来高效编程吧!多光标编辑:按住`Alt`键,然后鼠标点击或按`Ctrl+D`,就可以同时编辑多个位置的内容,效率翻倍!代码片段:自定义你的代码片段,比如常用的函数模板,下次直接调用,省时省力!终端集成:VS Code内置终端,无需切换窗口,就能执行命令、查看日志,爽歪歪!五、实战演练,让VS Code成为你的编程利器说了这么多,不如来一场实战演练吧!打开你的VS Code,选择一个你正在做的项目,或者新建一个,开始用我们刚才学到的技巧来编写代码吧!相信我,你会爱上这种流畅、高效的编程体验的!最后,我想抛出一个有争议的观点:VS Code虽然强大,但它真的适合所有人吗? 有些人可能更喜欢Sublime Text的轻盈,或者Atom的灵活。
Evolis多功能编码模块用户指南说明书

contentsforewordchapter 1 – overviewchapter 2 – featureschapter 3 – Using the reversible Mode chapter 4 – connecting a smart card encoderappendix 1appendix 2forewordThis user guide details the operation of the EvolisThisstripes, contact smart cards and contactless smart cards.Furthermore, this unique encoding module is reversible. Thus, it enables the user to flip the module over in a snap, enabling printing of the magnetic stripe side without having to use a dedicated, time-consuming and laborious system for flipping each and every card over. This feature makes it possible to speed up the full encoding process and printing cycle.chapter 1 – overviewThe encoding module is very conveniently located between thehead.Theexecuted by the other module.Itspeeds up the delivery of a ready-to-use personalized card in comparison with any traditional printer.Theoptimized throughput and efficiency.The encoding module has a motherboard with multiple connectors to link up to the contact and contactless smart card encoders. Such encoders can be placed in a dedicated area located behind the Quantum, and subsequently, be connected to the printer.chapter 2 – featuresThe encoding module has a fixed electronic component that is installed below the mechanical area.cards and a housing for contactless encoders with or without a remote antenna.In its factory configuration, the module comes with the following:lllllllllOn demand, this encoding module can be fitted with the following features:llFor maximized flexibility, the encoding module can be reconfigured within minutes and by the users themselves.Integrationdocument, and to the available extension kits and the connectors from Evolis.In compliance with the safety, quality, assembly and connections guidelines, users can customize the Quantum to their specific needs, when, for example, switching from a Mifare encoder to a device that manages HID Prox cards.chapter 3 – Using the reversible ModeThe encoding module is reversible. This means it can turn over and proceed to card encoding and printing in a single pass, without having to flip each and every card over:llFlipping the encoding module over requires that the machine be switched off, and that the power cable be disconnected to avoid any damage to the electronic boards and the encoders.3-1 replacinG the encodinG ModUleDespite the attention paid to the manufacture and quality of our products, the need to replace the encoding module may arise over the lifetime of the machine.The module can be replaced by the user with no tools needed, simply by following the instructions very carefully.Before doing anything else, please contact your Evolis dealer in order to check the advisability of replacing the encoding module. The dealer will supply a new encoding module if need be. Under these circumstances, the following procedure will need to be scrupulously carried out, in order to keep very high quality encoding, copying the properties and settings for the replacement module in the printer.to exchange the encoding module, please proceed as follows:chapter 4 – connecting a smart card encoder Connecting an encoder to the electronic board requires advanced skills.Athat the use of any connectivity accessories, other than those provided by Evolis, is totally avoided in order to prevent damages (e.g. low quality cables with substandard insulation, quality of welds and contacts, polarizing, etc.).The connectors required for integrating an encoder are provided on the motherboard of the encoding module.The following figure (top view taken from the back) shows all available connectors, as well as their purpose and type.Each connector has a reference number, stated in the technical charts, to identify each and every cable terminal.Grouped by colors, each connection item has a specific function which is highlighted in the following colors:Red :Power supplyBrown :of the smart card contact station (external DB9 connector), and of its encoder (RS232)Blue :Monitoring of the contactless smart card encoder (RS232 or TTL)Yellow :Monitoring of contact and contactless smart card encoders using the internal USB hubOrange :lectrical or electronic components required for operating the module and connecting the encoderThe plug board chart is available in Appendix 1. Please review it carefully before undertaking any intervention.Factory setting:l Flat cable between J17 and J18l Flat cable between J9 and J11l Jumper positioned between J22-1 and J22-2Thewhiteconnector.(Items colored orange)(Items colored red)Itcontact smart card from the other encoder, so that the power supply is distinct for each encoder. For example:llThe choice between these two connectors is left to the technician.(Items colored yellow)Connectingexample) may be done using one of the two ports from(Items colored brown)presence signal is performedOPTO closed :A contact smart card station can be connected in multiple ways. The most common ones are the following:case 1 - Use of an external smart card encoder. The encoder is plugged into the external DB9 (factory settings, if the printer is shipped without the encoder)This mode supports all Evolis products that come with a smart card encoder option (Pebble, Dualys, Securion)case 2 - Use of an internal smart card encoder. The smart station is connected to the encoder, and the encoder is connected to the external DB9 socketcase 3 - Use of an internal smart card encoder. The smart station is connected to the encoder, and the encoder is connected to the internal USB hubcase 1The connecting cable J17 – J18, available as a factory setting for standard modelscase 2DB9/RS232 connectioncase 3USB connection(Items colored blue)This chapter describes how to connect a contactless smart card encoder with an integrated or remote antenna.Theaddressed in the manual.J11 and J14 are directly wired to the DB9 connector (J15).The user can choose to connect one HE 14 (9-pin connector), or 2 HE10 (5-pin connector). This has no impact on features and signals.A contactless smart card station can be connected in various ways. The most common ones are the following:case 1 - Use of an internal smart card encoder with a TTL interface that requires a TTL äRS232 conversion. Output to the DB9 connectorcase 2 - Use of an internal smart card encoder that has a RS232 data interface. Output to the DB9 connectorcase 3 - Use of an internal smart card encoder with a USB interface that also powers the system. Connection to a USB port from the internal USB hubcase 1 Connecting cable J9 – J11, available as a factory setting for standardmodelscase 2DB9/RS232 connectioncase 3USB connectionappendix 1ä power supplyä contact stationappendix 2。
Arbortext editor详细教程

Arbortext® Editor™教程—关于本教程Arbortext Editor 教程介绍了关于使用Arbortext Editor 进行编辑和创作的基本概念。
本教程包括常规示例和分步练习,可以在Arbortext Editor 中尝试这些内容来进行练习。
这些练习涉及两种文档类型:DocBook 和DITA (达尔文信息类型化体系结构)。
对于这些文档类型,某些Arbortext Editor 功能会有所不同。
练习会对不同之处加以注释。
必备知识以下知识是了解本文档内容的先决条件:•熟悉操作系统及计算机•具有创作或编辑软件的经验本指南的结构本教程按以下顺序编排:•结构文档概述–结构文档概念的简介•Arbortext Editor 环境- Arbortext Editor创作环境的概述。
•使用Arbortext Editor 创作–有关基本创作任务的练习•使用DITA 主题–介绍DITA 主题文档创作方法的练习•使用DITA 映射–介绍DITA 映射文档创作方法的练习相关文档有关详细信息,请参考Arbortext Editor 帮助中心。
结构文档概述结构化文档符合定义和控制文档结构的一组规则。
XML 和HTML 是结构化文档的实例。
定义文档结构的规则集合称为“文档类型”。
在Arbortext Editor 中创作文档时,编辑器将持续检查在关联文档类型中定义的规则,并且仅允许将符合这些规则的内容插入到文档中。
DocBook 和DITA (达尔文信息类型化体系结构) 是文档类型的实例。
文档类型定义文档的以下组成部分:•可在文档中使用的标记集标记是结构化文档的基本构建块。
标记是一个容器,具有起始标记和结束标记。
标记可包含其它标记、属性和文本。
段落和列表是标记的实例。
•与各标记关联的“属性”属性提供有关标记的附加信息,属性包含在标记内部。
例如,标记可具有一个属性,用于定义标记中的信息适用于何种用户类型。
Cod e Comp r e s s i on

C o d e C o m p r e s s i o nJens Ernst University of Arizona William Evans University of Arizona Christopher W. Fraser Microsoft ResearchSteven Lucco MicrosoftTodd A. Proebsting University of ArizonaAbstractCurrent research in compiler optimization counts mainly CPU time and perhaps the first cache level or two. This view has been important but is becoming myopic, at least from a system-wide viewpoint, as the ratio of network and disk speeds to CPU speeds grows exponentially.For example, we have seen the CPU idle for most of the time during paging, so compressing pages can increase total performance even though the CPU must decompress or interpret the page contents. Another profile shows that many functions are called just once, so reduced paging could pay for their interpretation overhead.This paper describes:•Measurements that show how code compression can save space and total time in some important real-world scenarios.• A compressed executable representation that is roughly the same size as gzipped x86 programs and can be in-terpreted without decompression. It can also be com-piled to high-quality machine code at 2.5 megabytes per second on a 120MHz Pentium processor.• A compressed “wire” representation that must be de-compressed before execution but is, for example, roughly 21% the size of SPARC code when com-pressing gcc.For correspondence: {jens,todd,will}@, Dept of Com-puter Science, Gould Simpson Building, Tucson, AZ 85721. {cwfraser, steveluc}@, One Microsoft Way, Redmond, WA 98052. Originally published in Proceedings of the ACM SIGPLAN’97 Conference on Pro-gramming Language Design and Implementation (PLDI):xxx-yyy. Copyright © 1997 by the Association for Computing Machinery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permis-sions from Publications Dept, ACM Inc., fax +1 (212) 869-0481, or permis-sions@.IntroductionComputer programs are delivered to the CPU via networks, disks, and caches, all of which can be bottlenecks. In some important scenarios, it can be significantly faster to send compressed code that is then interpreted or decompressed and executed. This fact is self-evident when delivering code over 28.8kbaud modems, but it can be true for faster networks, for paging from disk, and even for cache misses if the decompressor is fast enough. We consider two im-portant bottlenecks: transmission and memory.When transmission is a bottleneck, we want the best possi-ble compression, and we can afford to expand the com-pressed program before executing. We call such codes “wire” codes because a wire is the bottleneck.When memory is a bottleneck, the code — at least seldom used code — must be stored and interpreted in compressed form. Code includes jumps and calls, so we need random access to at least the basic blocks. If some code must be compiled to run fast enough, the JIT (just in time) compila-tion rate must be very high.When both transmission and memory are bottlenecks, it may make sense to decompress a wire code into a com-pressed interpretable form.The literature on general-purpose data compression [Bell et al] offers many techniques. Our tasks have been mainly to find combinations of techniques that suit the specialized problem of compressing virtual machine (VM) code, and to determine how to generate compact automata that accu-rately predict the next VM operator or operand based on the current context, so that tokens common in the current con-text can be given the shortest encodings. This paper con-cerns only VM code, though some of the techniques clearly apply to machine-specific code as well.This paper describes two code compressors – the best that we’ve found for each of our two scenarios. The compres-sors are quite different, but both gather information aboutthe common patterns that appear in the code, and both di-vide the stream of code into several smaller streams, one holding the operators and one holding the literal operands for each operator (or class of related operators) that needs a literal operand. The compressors are:• A wire VM code that yields programs almost one-fifth the size of SPARC code.•An interpretable VM code called “Byte-coded RISC”or “BRISC,” which is roughly 30% larger than the wire format but still about the same size as non-interpretable gzipped x86 programs.We can interpret BRISC code with a typical 12x time pen-alty while cutting working set size by over 40%. Alter-nately, we can compile BRISC at over 2.5 megabytes per second, producing x86 machine code over 100 times faster than, for example, all commercial JIT compilers known to us. This high compilation rate permits us to recompile the program at each execution for clients with no local disk cache. The delivery time from the network or disk can mask some or even all of the recompilation time, and the code runs within 1.08x of the speed of fully optimized ma-chine code generated by Microsoft Visual C++ 5.0. BRISC can also trim memory requirements for large desktop appli-cations and compress programs to fit within the memory requirements of embedded systems.Both codes support client-side and server-side compilation. Server-side compilation is necessary to efficiently deliver large application programs. For example, existing JIT com-pilers must allocate registers on the client, which is expen-sive and, for the best results, super-linear in the length of the input program. By performing code optimization be-fore a program is downloaded, a mobile code system can dramatically reduce the time necessary to generate machine code on the client.Design spaceNo single code compressor suits all applications. Rather, there is a “design space” or “solution space” of related methods. The trade-offs involve addressing the issues listed below.•Should one compress using byte-codes, arithmetic coding [Witten et al], or something between? At one extreme, byte-codes are the easiest to interpret directly, and branches naturally target byte boundaries. Nibble and Huffman codes can be decoded and addressed analogously, but their units are 4-bit and 1-bit fields, so the decoding overhead is higher. At the other extreme are arithmetic codes, which can compress better by coding for sequences longer than individual symbols, but complicate direct interpretation. Arithmetic codes must be expanded before interpretation, though wehave used them successfully by decompressing a func-tion at a time.•Should the compressed representation include a dic-tionary? Dictionaries allow the compressor to emit a series of dictionary indices, but the dictionary itself must be transmitted. Dictionaries can be:•static, that is, computed exactly once and reused for all subject programs.•semi-static, that is, computed once for each subject program but then used throughout that program.•dynamic, that is, updated as the compressor and decompressor advance through the subject pro-gram.•Should the dictionary coder (if any) use move-to-front (MTF) indexing [Bentley et al; Elias]? This technique starts by replacing sequence elements with their indi-ces in a table that changes dynamically. The table’s elements are ordered such that the first element was the most recently accessed element; after each new access, the accessed element is moved to the front and all in-termediate elements are shifted down one place. A se-quence with high spatial locality tends to yield a se-quence of small indices, which should compress well.MTF coders act a bit like caching hardware, so there’s probably some interaction with register-based interme-diate codes, since registers can be regarded as a kind of cache.•Should the compressor partition its input into separate streams? Operators and operands can benefit from dif-ferent compression schemes; finer partitionings are possible.•In programs, one important class of streams can be separated by patternizing the input [Proebsting; Fraser and Proebsting]. Patternization accepts an actual pro-gram and proposes specialized instructions that might help compress that program. The patterns replace each combination of operands with wildcards. For example, the code treeFetchInt(AddrLocal[4])generates the patternsFetchInt(*)FetchInt(AddrLocal[*])FetchInt(AddrLocal[4])Regard patterns as specialized instructions. For exam-ple, the last (degenerate) pattern above is specialized to fetch the value of the local at frame offset 4. That is, 4 is “burned into” the specialized pattern. The middle pattern above takes an arbitrary offset, and the firstpattern above gets the address of the cell to fetch by popping the stack. All three push their result onto the stack.•Should the coder use finite-context or Markov model-ing, which uses the last few symbols to predict the next symbol more precisely? An “order-N” Markov model uses the last N symbols to predict the next. The degen-erate order-0 model may use frequencies but no con-text.Also, the original representation can influence the effec-tiveness of the compression techniques. In particular, should the input VM use registers or a stack? That is, should the VM resemble a conventional target machine or a stack machine? Stack machines have no register numbers to compress, but register machines permit the compiler’s front end to invest more in, say, global register allocation and thus produce code that is typically faster and smaller. Some applications can accept sub-optimal performance, but there will always exist applications that demand ambitious opti-mization.A wire codeWe use the term wire-format for codes that need not be interpreted directly but can be at least partly decompressed into an interpretable form or even compiled before they are used. Thus, for example, one can simply gzip a file of in-termediate or object code, and the result is a wire-format code. gzip typically compresses code by a factor between two and three. Yu [Yu] has recently described ways to tune general-purpose data compressors for use in software dis-tribution. His compressor outputs an average of 2.61 bits per input character, a factor of 3.07. Franz reports similar compressions using his “slim binaries” for load-time code generation [Franz and Kistler; Franz], though our numbers are not easily compared because he compresses full execu-tables, and we compress only code segments.Our wire-format code achieves a factor of 4.9. We tried a lot of techniques, but the best to date happens to be very simple: compile trees of VM code, patternize out all liter-als, form one stream for all patterns and one for containing the literal operands associated with each opcode or class of related opcodes, MTF-code each stream, and gzip the re-sulting streams in isolation. To demonstrate:1. Compile the input program into trees. For example, we compile the C codeint salt(int j, int i) {if (j > 0) {pepper(i, j); j--;}return j;}into the lcc trees:ASGNI(ADDRLP8[72],SUBI(INDIRI(ADDRLP8[72]),CNSTC[1]))LEI[1](INDIRI(ADDRLP8[68]),CNSTC[0])ARGI(INDIRI(ADDRLP8[72]))ARGI(INDIRI(ADDRLP8[68]))CALLI(ADDRGP[pepper])ASGNI(ADDRLP8[68],SUBI(INDIRI(ADDRLP8[68]),CNSTC[1]))LABELVRETI(INDIRI(ADDRLP8[68]))A full description of the lcc IR appears elsewhere [Fraser and Hanson] but is not important to the discussion here. It suffices to note that the code is stack-based, that square brackets enclose literal operands, and that the base inter-mediate code has been augmented with a few operators with the suffixes 8 and 16 to flag literals that fit in eight or sixteen bits.2. Patternize and form one stream holding the nested op-erator patterns and one for each type of operator that takes a literal operand. For example, the patternized operator stream for the sample above is:ASGNI(ADDRLP8[*],SUBI(INDIRI(ADDRLP8[*]),CNSTC[*]))LEI[*](INDIRI(ADDRLP8[*]),CNSTC[*])ARGI(INDIRI(ADDRLP8[*]))ARGI(INDIRI(ADDRLP8[*]))CALLI(ADDRGP[*])ASGNI(ADDRLP8[*],SUBI(INDIRI(ADDRLP8[*]),CNSTC[*]))LABELVRETI(INDIRI(ADDRLP8[*]))The ADDRLP8 stream is 72 72 68 72 68 68 68 68.3. Apply move-to-front coding to each stream in isolation. For example, MTF coding transforms the ADDRLP8 stream above to 0 1 0 2 2 1 1 1, using the table 72 68. Zero denotes a symbol not seen previously.4. Huffman-code all MTF indices but no MTF tables.5. gzip to produce the final, fully-compressed version of the original program. Before applying gzip, all MTF streams and tables are encoded in 1, 2, or 4-byte values (or strings for symbolic names), as appropriate. For instance, each unique instance of a particular tree is encoded as a se-quence of bytes, one per operator, emitted in prefix order. char literals are encoded as individual bytes, short literals as pairs, etc.The table below compares the size of three conventional SPARC code segments with our wire code.Conventional code Wire codeuncom-pressedGzippedlcc315,63675,92864,475gcc1,381,304380,451287,260agrep61,03615,93616,013So the wire format improves significantly over conven-tional encodings, dividing the input size by as much as 4.9 And it beats the gzipped version significantly as well, ex-cept for a small loss on the smallest input. All compilations above were done with lcc, because it was the source of the wire byte-codes. A compiler with a more ambitious optimizer would probably make the conventional code smaller, but it would probably do likewise for byte-codes too, if it were adapted to emit them.An interpretable codeOur wire format achieves unprecedented levels of code density by organizing semantically similar instruction com-ponents into separately compressed streams. This method exploits the insight that byte-stream or word-stream com-pression techniques such as Lempel-Ziv [Lempel and Ziv; Ziv and Lempel] will miss the correlation among sub-byte and sub-word quantities in instructions. Such quantities include opcodes and various types of operands. For exam-ple, LZ compression will inefficiently code simple instruc-tion semantics such as “a call instruction often follows a move instruction,” because the bits or bytes that represent opcodes are intermixed with bits or bytes that have other semantics, such as “the destination register of the move is n0.”Our wire format makes those semantics available to LZ compression by grouping opcodes and various types of operands into separate streams. Because this strategy uses LZ compression, it requires linear decompression. Some applications, such as just-in-time machine code generation or working set reduction through direct interpretation of compressed code, require a randomly addressable, compact program representation. In this section, we describe two simple techniques, operand specialization and opcode com-bination, that yield a dense, randomly addressable program representation called BRISC. These techniques exploit the same stream-separation insight as the tree compression method given above. However, instead of physically sepa-rating streams of instruction information, operand speciali-zation and opcode combination quantize the representation of these streams by packing them into a randomly accessi-ble stream of discrete byte codes. We conclude this section by presenting and analyzing measurements of a production-quality virtual machine environment (OmniVM). These measurements demonstrate that BRISC supports just-in-time code generation at 2.5MB/sec while yielding code density that is competitive with the best packaged LZ com-pression programs.Our system, called Omniware, includes a compiler that converts high-level language programs into sequences of instructions for the Omniware virtual machine (OmniVM) [Lucco, PLDI96]. OmniVM has a RISC instruction set augmented with macro-instructions for common operations such as moving and initializing blocks of data. The next section will describe how this input differs from the lcc intermediate representation used in the experiments related above. In brief, one can automatically at code generation time synthesize OmniVM RISC instructions from lcc IR and hence the two are interconvertible with respect to com-pression. However, the OmniVM programs measured in this section were highly optimized using a commercial compiler back end and so contain more information, such as register allocation decisions, than lcc IR.The Omniware system compresses fully linked executable programs containing OmniVM RISC instructions into pro-grams containing BRISC instructions. A server ships these across a network to client computers, which contain an implementation of the OmniVM. The OmniVM either in-terprets the BRISC instructions directly or converts them to native machine code. The system works on several plat-forms, including x86/NT, SPARC/Solaris 2.4, PowerPC/NT, and PowerPC/MacOS. All measurements in this section were performed on a Pentium 120MHZ proces-sor running NT 4.0. The processor was configured with 32 megabytes of memory.BRISC generationBecause we require BRISC to be interpretable, we con-strain its design to ensure that instructions occur on byte boundaries. Hence, where the split-stream compression techniques described above would use 2-3 bits per opcode, BRISC will always use 8 or 16 bits per opcode. To make up for the increased size of its opcodes, BRISC packs more information into each opcode. It does so through operand specialization and opcode combination.Operand specializationWe briefly described operand specialization in the back-ground section, as “burning in” a particular value for one or more of the fields of a patternized instruction. We now re-turn to the subject, describing operand specialization con-cretely in terms of the Omniware system. Consider the OmniVM instruction ld.iw n0,4(sp). The effect of this instruction is to load the 32-bit word at address sp+4 intoregister n0. The .iw suffix on this instruction indicates that this is the 32-bit integer version of the instruction. As it turns out, this particular instruction is the most frequently occurring instruction among our benchmark programs. To investigate possible specializations of this instruction, we patternize it into the following set of patterns (ordered from least to most general):1. ld.iw n0,4(sp)2. ld.iw *,4(sp)3. ld.iw n0,4(*)4. ld.iw n0,*(sp)5. ld.iw *,4(*)6. ld.iw *,*(sp)7. ld.iw n0,*(*)8. ld.iw *,*(*)The most general instruction pattern (8) is part of the base instruction set. When we write base instructions in patter-nized form as above, we place asterisks in all field posi-tions of the instruction, to indicate that the base instruction pattern can take on any legal field value in any field posi-tion. For example, writing the base integer register move instruction as mov.i *,*,indicates that each of the in-struction’s fields can take on any value legal for the field’s type. In the case of this mov.i instruction, both of its fields can take on any value from n0through n15, because the OmniVM has 16 integer registers.Since ld.iw n0,4(sp)is the most frequently occurring input instruction occurring in our benchmarks, it makes sense to add to our dictionary of possible instruction pat-terns some of the specialized forms of this instruction. By doing so, we avoid explicitly representing common oper-ands such as n0 or 4. The compression algorithm we de-scribe below performs operand specialization one field at a time. For example when the compressor encounters the specific instruction (1) during an input scan, it generates instruction patterns (5)-(7) as candidate dictionary entries. To arrive at a two-operand-specialized instruction pattern such as ld.iw n0,4(*), the compressor would first add ld.iw n0,*(*)or ld.iw *,4(*)to the dictionary. It would then modify the input program to reflect the pres-ence of this new instruction pattern. On a subsequent pass over the input program, the compressor could add to the dictionary a more specialized version of this instruction pattern through incorporation of another field. To denote an input instruction that has been converted to use an operand-specialized instruction pattern, we first write the instruction pattern encased in square brackets followed by a list of the literal values to be substituted into the unspecified fields (denoted by asterisks) of the instruction pattern. For exam-ple, if we have derived instruction pattern (5) from input instruction (1), then we would re-write the input instruction as [ld.iw *,4(*)]:n0,sp.Opcode combinationThe compressor also generates candidate instruction pat-terns through opcode combination. In our system, every adjacent pair of opcodes is a candidate for opcode combi-nation. For example, if the input program contains the se-quence of instructions [ld.iw n0,*(*)]:4,sp; mov.i n2,n0, the instruction pattern<[ld n0,*(*)],[mov.i ,]>would become a candidate for addition into the base instruction set. We denote with angle brackets instruction patterns resulting from opcode combination.Because BRISC is quantized, not all instruction combina-tions make sense. If a combined instruction pattern leaves a trailing sub-byte operand, the compressor can defer combi-nation until further specialization has taken place (so that the combined unspecified operands from the adjacent in-structions would pack neatly into a whole number of bytes). The compressor generates as candidate instruction patterns not only each pair of adjacent instructions <i,j>, but every possible pair consisting of a zero or one-field operand spe-cialization of i followed by a zero or one-field operand spe-cialization of j. This ensures that operand specialization won’t compete with opcode combination by further spe-cializing an instruction before the combiner has a chance to consider a less-specialized version.Opcode combination captures common code generation idioms. For example, data movement instructions such as ld.iw and mov.i frequently occur to set up parameters before call instructions. This results in a quantized version of the tree construction shown in the previous section. BRISC generation algorithmThe compressor begins with the base instruction set (cur-rently 224 instruction patterns) and adds to it to create a dictionary of frequently occurring instruction patterns. To find useful instructions to add to the dictionary, the com-pressor scans the input program several times, generating candidate instruction patterns and estimating their program size reduction P and their cost in decompressor memory usage W (W abbreviates “working set”). The program size reduction P equals the reduction in compressed program bytes that would occur if the candidate instruction pattern were added to the dictionary minus the number of bytes needed to represent the instruction pattern in the dictionary. The decompressor for BRISC uses a table of native in-struction sequences for interpretation or native code gen-eration. The compressor estimates the decompressor’s memory usage cost, W, for a dictionary entry by averaging the size in bytes of decompression table instruction se-quences for the Pentium and PowerPC 601 chips. The benefit B of an instruction pattern equals P-W (of course, in abundant memory situations we can set B equal to P).The compressor maintains a heap of candidate instructions, sorted by B. After each pass over the input program, the compressor removes the K best candidates from the heap and adds them to the dictionary. Then, the compressor modifies the input program to reflect the newly available instruction patterns. It first considers each pair of instruc-tions that can be combined by a new opcode-combined instruction pattern. On each pass, there can only be one new instruction pattern that applies to a particular pair. Af-ter it performs instruction combination, the compressor modifies all instructions in the input program that could be represented more compactly using one of the new instruc-tion patterns. To avoid undue overhead in updating the in-put program, the compressor maintains a table that maps each base instruction pattern to a list of all input program instructions matching that pattern. Similarly, to avoid gen-erating candidate instruction patterns that have already been generated, the compressor maintains a hash table of previously generated candidates, keyed by base instruction patterns and specialized field values.The compressor ceases to hunt for useful patterns after a pass that doesn’t yield at least K patterns for which B is positive. Thus the compressor uses a greedy algorithm for building the dictionary. The optimal algorithm would con-sider all possible dictionaries and their effect on compres-sion, but this would be prohibitively time-consuming. To perform dictionary encoding, the compressor uses an order-1 semi-static Markov model so that all opcodes fit within 8 bits. In other words, the compressor builds (and the decom-pressor can build, based on the dictionary) a table for each possible instruction pattern I that enumerates the instruction patterns that can follow I in the input. If more than 256 instructions can follow I, the compressor splits I into two instruction patterns. For example, the dictionary for the OmniVM program implementing lcc contains 981 in-struction patterns. Each instruction pattern has at most 244 instruction patterns that can follow it. There is a special context in the Markov model for basic block beginnings (of various types) so that the BRISC program remains inter-pretable. Once the compressor has created a dictionary, it outputs the dictionary followed by the modified input pro-gram that it has compressed during dictionary construction.A BRISC compression exampleThe Omniware C++ compiler generates the following se-quence of OmniVM instructions for the example program introduced in the wire format discussion above.enter sp,sp,24spill.i n4,16(sp)spill.i ra,20(sp)mov.i n4,n0mov.i n2,n1ble.i n4,0,$L56mov.i n1,n4 mov.i n0,n2call_pepper$L56:add.i n0,n4,-1reload.i n4,16(sp)reload.i ra,20(sp)exit sp,sp,24rjr raFor this input program, the initial dictionary is the set of base instructions it uses: {enter, spill.i, mov.i,ble.i, call, add.i, reload.i, exit, and rjr}. Be-cause this program is small, it affords little opportunity for useful instruction combination or specialization. However, we can use it to illustrate some of the steps of BRISC com-pression. We will consider just the first three instructions of the program. Applying operand specialization to these three instructions generates following candidate specializations in the first pass of the BRISC algorithm:1. [enter sp,*,*][enter *,sp,*][enter *,*,24]2. [spill.i n4,*(*)][spill.i *,16(*)][spill.i *,*(sp)]3. [spill.i ra,*(*)][spill.i *,20(*)]Note that one candidate specialization of instruction 3, spill.i *,*(sp),has already been generated by ap-plying operand specialization to instruction 2. For each instruction, the set of candidate instructions generated through operand specialization is called that instruction’s operand-specialized set. If we add the corresponding base instruction pattern to the operand-specialized set for a given input instruction i, we construct the augmented operand-specialized set of candidate instruction patterns for i. To apply opcode combination to instructions 1 and 2, we gen-erate the 16 pairs of instruction patterns that can be formed by selecting one element from instruction 1’s augmented operand-specialized set of candidates and one element from instruction 2’s augmented operand-specialized set of candi-dates:<[enter sp,*,*],[spill.i n4,*(*)]><[enter sp,*,*],[spill.i *,16(*)]><[enter sp,*,*],[spill.i *,*(sp)]><[enter *,sp,*],[spill.i n4,*(*)]>etc. Hence the total set of candidate instruction patterns generated by instructions 1 and 2 for our example program would be the 16 candidates generated through opcode com-bination and the 6 candidates generated through opcode specialization. Because the total set of base instruction patterns is only 224, however, the total number of candi-dates generated by a large program remains manageable. For example, the total number of candidates tested in com-pressing gcc-2.6.3 is 93,211. The final dictionary for gcc-。
24.配方编辑器Recipe Editor

24.配方编辑器Recipe Editor本章节说明如何使用配方编辑器Recipe Editor。
24.配方编辑器Recipe Editor (1)24.1.概要 (2)24.2.配方数据/ 扩展内存编辑器设定 (2)24.3.配方记录的设定 (4)24.1.概要Recipe Editor 可用来建立触摸屏所使用的配方数据文件,也可开启及编辑现有的配方数据文件。
此外,EasyBuilder Pro 提供另一个编辑配方数据文件的工具–配方记录,此功能需先在EasyBuilder Pro “系统参数设置”» “配方” 定义配方,再使用“配方检视元件” 来显示配方内容,以下将介绍此二种编辑器的使用方法。
24.2.配方数据/ 扩展内存编辑器设定1.从Utility Manager 点击“配方数据/扩展内存编辑器”。
2.要新增新的 .rcp 或是 .emi 文件,请点选“文件” » “开新文件”。
3.设定存取地址范围与数据格式。
设定描述存取范围填入起始地址和结束地址,以字符为单位。
选择数据格式定义完成的数据格式可储存,并于下次需要时加载。
范本将存成“dataEX.fmt” 文件并存放在EasyBuilder Pro 安装目录下。
数据格式可在数据格式区域中编辑新的数据格式。
4.点击“新增” 后,弹出数据类型编辑窗口如下,请在“描述” 字段输入数据类型的名称,并选择数据格式。
若选择“String”,需输入字符长度及设定格式类型为“ASCII” 或“Unicode”。
5.数据格式定义完成后,点选“确定” 即可编辑配方数据。
此范例的数据格式长度为13 个字符,因此可将每13 个字符长度视为一组配方来使用。
如上,第一组的“Product no.” 为address 0,”Name” 地址为address 1 ~ 10,”Store No.” 为address 11 ,”Category” 为address 12;第二组的“Product no.” 为address 13,”Name” 地址为address 14 ~ 23,”Store No.” 为address 24 ,”Category” 为address 25…依此类推。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
利用ReloadEditor制作SCORM 1.2标准教材
Reload Editor是符合IMS和SCORM标准的对课程内容的打包工具,可以在打包之前对课程内容进行SCORM标准下的策略编辑,打包好的PIF(包互换文件)可以直接导入符合SCORM标准的LMS(学习管理系统)。
目前的版本为2.02,中文的目录需要手工修改。
SCORM1.2教材制作必须要有下列组件:
1、 imsmanifest.xml
2、 metadata
3、 SCO
4、 API Wrapper
API Wrapper用复制到LMS下就可,而imsmanifest.xml、metadata可以用工具制作,至于可以和学习平台互动的SCO,可分较简单的(entry)SCO与进阶的SCO。
(一)、制作imsmanifest.xml
imsmanifest.xml是学习管理平台(LMS)在读取课程的第一个档案,如同网站的首页「index.html」一样,imsmanifest.xml的结构如下:
安装工具
制作imsmanifest.xml档案可以用ReloadEditor 工具来做。
可以到
/editor.html网站下载ReloadEditor工具Download version 2.0.2 for Windows后进行安装
制作imsmanifest.xml档案
(1)、执行「开始」、「所有程序」、「Reload tools」、「Reload Editor」开启。
(2)、进入Reload Editor执行「File」、「New」、「ADL SCORM 1.2 Package」(3)、选定目录如(C:AppservWWW
(4)、在右边「Organizations」上按一下鼠标右键
(5)、选择「Add Organization」
(6)、出现新的Organization后填入课程名称。
如Course00
(7)、预览与储存,点选「工具列」上的「Preview Content Package」
开启IE 浏览器观看「课程架构」。
(8)、按一下「工具列」的「Save」储存档案,并可用「Zip Content Package」将相关Asset及imsmanifest相关档案压缩成 .ZIP
(二)、制作Metadata
SCORM网页要记录学习组件或教材资产(Asset)的内容,以便让学习内容管理平台(LCMS)辨识,在学习组件或教材资产加入Metadata。
Metadata(诠释资料)共分9大类,分别是通用(general)、生命周期(lifecycle)、诠释资料(meta-metadata)、技术(technical)、教育(educational)、权利(rights)、关系(relation)、批注(Annotation)以及分类(Classification)等。
制作Metadata
(1)、执行「开始」、「所有程序」、「Reload tools」、「Reload Editor」开启。
(2)、进入Reload Editor执行「File」、「New」、「IMS Metadata File」,再选「IMS 1.2.2 Metadata File」出现如下画面。
(3)填入一些资料
(4)、预览与储存
填完资料后,可以点选「Tree View」卷标,观看内容。
(5)、按一下「save」储存资料(文件名:metadata.xml)
(三)、SCO制作
和学习平台互动的SCO,可分较简单的(entry)SCO与进阶的SCO。
简单的SCO只要将API加入JAVA资料就可,进阶SCO必须加入Data Model,以便和学习管理平台沟通。
简单的(entry)SCO制作
(1)先在教学目录下放APIWrapper.js与SCOFunctions.js两个档案
(2)在学习网页的<head>与</head>放入这两行
<head>
<!---------------SCORM include file---------------------->
<SCRIPT LANGUAGE="JAVASCRIPT" SRC="APIWrapper.js"></SCRIPT>
<SCRIPT LANGUAGE="JAVASCRIPT" SRC="SCOFunctions.js"></SCRIPT>
<!---------------SCORM include file---------------------->
</head>
(四)、SCORM 教材测试
可以到网站下载自测工具进行测试。
本人制作过的课程测试结果看这里:
/blog/TestLog_4_20_1324_pic.htm SCORM1.27标准的测试。