The Pre-Image Problem in Kernel Methods
基于改进KCF的多目标人员检测与动态跟踪方法

基于改进KCF 的多目标人员检测与动态跟踪方法刘毅, 庞大为, 田煜(中国矿业大学(北京) 机电与信息工程学院,北京 100089)摘要:针对煤矿巷道光照不足、目标尺度变化剧烈、目标容易被遮挡和矿灯干扰等因素,导致对于井下的目标检测和跟踪存在成功率和准确度低的问题,提出一种基于改进核相关滤波(KCF )算法的多目标人员检测与动态跟踪方法,为避免井下复杂环境中由于光照不均引起检测失败,在改进的KCF 算法中引入SSD 检测算法,以提升对多目标人员检测能力。
① 读取待跟踪视频序列,使用经过井下数据集训练后的SSD 算法检测图像中的目标,若没有发现目标则继续读取下一帧。
② 将检测到的目标放入跟踪器中,对图像进行预处理,通过比较将所有的检测框按照设定的阈值进行打分,并根据分值从高到低依次排列,高分的检测结果直接输出,低分的检测结果用于滤除不良信息,以提升检测速度。
③ 通过KCF 跟踪预测目标M 帧后清空跟踪器,再重新进行目标检测。
通过检测算法和跟踪算法的叠加,保证对目标的持续跟踪能力。
实验结果表明:① 该方法最后的损失值稳定在1.675附近,检测结果较为稳定。
② 经过训练后的SSD 算法识别精度较训练前的SSD 算法识别精度提高了52.7%。
③ 该方法对矿井人员检测成功率、跟踪准确率分别为87.9%,88.9%,均高于其他4种算法(KCF 、CSRT 、TLD 及MIL )的检测成功率、跟踪准确率。
④ 该方法在重叠阈值较低时具有较高成功率,直至重叠阈值大于0.8时,成功率大幅下降,这是因为矿井中环境多样,想要完全符合标注的框有一定难度。
实际应用结果表明:在井下煤矿巷道光照不足、目标尺度变化剧烈、容易被遮挡和受矿灯干扰等复杂环境中,该方法具有较高的适用性。
关键词:矿井;多目标检测;目标跟踪;核相关滤波;SSD 中图分类号:TD67 文献标志码:AMulti object personnel detection and dynamic tracking method based on improved KCFLIU Yi, PANG Dawei, TIAN Yu(School of Mechanical Electronic & Information Engineering, China University of Mining and Technology-Beijing,Beijing 100089, China)Abstract : Factors such as insufficient illumination in coal mine roadways, drastic changes in object scale,easy obstruction of objects, and interference from mining lights lead to low success rate and accuracy in underground object detection and tracking. In order to solve the above problems, a multi object personnel detection and dynamic tracking method based on improved kernel correlation filter (KCF) algorithm is proposed.The method can avoid detection failure due to uneven lighting in complex underground environments. The SSD detection algorithm is introduced into the improved KCF algorithm to enhance the capability to detect multiple object personnel. ① The method reads the video sequence to be tracked, uses the SSD algorithm trained on the underground dataset to detect the object in the image. The method continues reading the next frame if no object is found. ② The method places the detected object into the tracker, preprocesses the image, scores all detection收稿日期:2023-06-05;修回日期:2023-08-30;责任编辑:王晖,郑海霞。
CSP共空间模式的介绍

Common Spatial Pattern(s) algorithm算法.The CSP paradigm is based on the design of the Berlin Brain-Computer Interface (BBCI) [1], more comprehensively described in [2], which is mainly controlled by (sensori-)motor imagery. The features exploited by this paradigm in its original form are Event-Related Synchronization and Desynchronization [3] localized in the (sensori-)motor cortex, but the paradigm is not restricted to these applications. CSP was originally introduced in [5] and first applied to EEG in [6].Due to its simplicity, speed and relative robustness, CSP is the bread-and-butter实用的paradigm for oscillatory振荡processes, and if nothing else, can be used to get a quick estimate of whether the data contains information of interest or not. Like para_bandpower, CSP uses log-variance features over a single non-adapted frequency range (which may have multiple peaks), and neither temporal structure时间结构(variations) in the signal is captured捕捉, nor are interactions 相互作用between frequency bands. The major strength of the paradigm 范式is its adaptive spatial filter自适应空间滤波器, which is computed计算using the CSP algorithm.The paradigm is implemented实施as a standard sequence of signal (pre-)processing (spatial/spectral光谱filtering), feature extraction, and machine learning. The first preprocessing预处理step is frequency filtering, followed by an adaptively learned spatial filter (which is the defining propery定义的性能of the paradigm), followed by log-variance feature extraction and finally a (usually simple) machine learning step applied to the log-variance features. The spatial filtering projects the channels of the original signal down to a small set of (usually 4-6) surrogate代理channels, where the (linear) mapping is optimized线性映射被优化such that the variance in these channels is maximally informative w.r.t. to the prediction预测task. The CSP filters can be obtained from the per-class signal covariance matrices协方差矩阵by solving a generalized eigenvalue problem广义特征值问题(of the form [V,D]=eig(Cov1,Cov1+Cov2)). CSP can also be applied to independent components to rate评价their importance or for better artifact 工件robustness鲁棒性. A wide range of classifiers分类can be used with CSP features, the most commonly used one being LDA狄利克雷/一个集合概率模型. There exists a large corpus语料库of CSP variants and extensions变换与拓展, mostly to give better control over spectral filtering, including multiband多波段的CSP (para_multiband_csp), Spectrally Weighted CSP (para_speccsp)光谱加权CSP, Invariant CSP, Common Spatio-Spectral Patterns (CSSP), Common Sparse Spectral Spatial Pattern (CSSSP), Regularized CSP,【不变的CSP,普通的时空光谱模式(CSSP),普通的稀疏频谱空间格局(CSSP),正则CSP】and several others. A more advanced (but also computationally 计算more costly) paradigm范式than CSP is the Dual-Augmented Lagrange Paradigm双增强拉格朗日范式(para_dal/para_dal_hf). The length of the data epoch数据纪元and the choice of a frequency band (defaulting默认to motor imagery time scales时间尺度and frequency ranges) are the parameters参数that are most commonly tuned to调谐the task, both of which can also be found via a small parameter 参数search.Some application areas include detection of major brain rhythm modulations主要的大脑节奏调制(e.g. alpha, beta), for example related to relaxation/stress, aspects of workload, sensori-motor imagery, visual processing vs. idling and other idle-rhythm-related questions, or emotion recognition视觉处理与空转和其他空闲的节奏相关的问题,或情感识别。
人工智能词汇

常用英语词汇 -andrew Ng课程average firing rate均匀激活率intensity强度average sum-of-squares error均方差Regression回归backpropagation后向流传Loss function损失函数basis 基non-convex非凸函数basis feature vectors特点基向量neural network神经网络batch gradient ascent批量梯度上涨法supervised learning监察学习Bayesian regularization method贝叶斯规则化方法regression problem回归问题办理的是连续的问题Bernoulli random variable伯努利随机变量classification problem分类问题bias term偏置项discreet value失散值binary classfication二元分类support vector machines支持向量机class labels种类标记learning theory学习理论concatenation级联learning algorithms学习算法conjugate gradient共轭梯度unsupervised learning无监察学习contiguous groups联通地区gradient descent梯度降落convex optimization software凸优化软件linear regression线性回归convolution卷积Neural Network神经网络cost function代价函数gradient descent梯度降落covariance matrix协方差矩阵normal equations DC component直流重量linear algebra线性代数decorrelation去有关superscript上标degeneracy退化exponentiation指数demensionality reduction降维training set训练会合derivative导函数training example训练样本diagonal对角线hypothesis假定,用来表示学习算法的输出diffusion of gradients梯度的弥散LMS algorithm “least mean squares最小二乘法算eigenvalue特点值法eigenvector特点向量batch gradient descent批量梯度降落error term残差constantly gradient descent随机梯度降落feature matrix特点矩阵iterative algorithm迭代算法feature standardization特点标准化partial derivative偏导数feedforward architectures前馈构造算法contour等高线feedforward neural network前馈神经网络quadratic function二元函数feedforward pass前馈传导locally weighted regression局部加权回归fine-tuned微调underfitting欠拟合first-order feature一阶特点overfitting过拟合forward pass前向传导non-parametric learning algorithms无参数学习算forward propagation前向流传法Gaussian prior高斯先验概率parametric learning algorithm参数学习算法generative model生成模型activation激活值gradient descent梯度降落activation function激活函数Greedy layer-wise training逐层贪心训练方法additive noise加性噪声grouping matrix分组矩阵autoencoder自编码器Hadamard product阿达马乘积Autoencoders自编码算法Hessian matrix Hessian矩阵hidden layer隐含层hidden units隐蔽神经元Hierarchical grouping层次型分组higher-order features更高阶特点highly non-convex optimization problem高度非凸的优化问题histogram直方图hyperbolic tangent双曲正切函数hypothesis估值,假定identity activation function恒等激励函数IID 独立同散布illumination照明inactive克制independent component analysis独立成份剖析input domains输入域input layer输入层intensity亮度/灰度intercept term截距KL divergence相对熵KL divergence KL分别度k-Means K-均值learning rate学习速率least squares最小二乘法linear correspondence线性响应linear superposition线性叠加line-search algorithm线搜寻算法local mean subtraction局部均值消减local optima局部最优解logistic regression逻辑回归loss function损失函数low-pass filtering低通滤波magnitude幅值MAP 极大后验预计maximum likelihood estimation极大似然预计mean 均匀值MFCC Mel 倒频系数multi-class classification多元分类neural networks神经网络neuron 神经元Newton’s method牛顿法non-convex function非凸函数non-linear feature非线性特点norm 范式norm bounded有界范数norm constrained范数拘束normalization归一化numerical roundoff errors数值舍入偏差numerically checking数值查验numerically reliable数值计算上稳固object detection物体检测objective function目标函数off-by-one error缺位错误orthogonalization正交化output layer输出层overall cost function整体代价函数over-complete basis超齐备基over-fitting过拟合parts of objects目标的零件part-whole decompostion部分-整体分解PCA 主元剖析penalty term处罚因子per-example mean subtraction逐样本均值消减pooling池化pretrain预训练principal components analysis主成份剖析quadratic constraints二次拘束RBMs 受限 Boltzman 机reconstruction based models鉴于重构的模型reconstruction cost重修代价reconstruction term重构项redundant冗余reflection matrix反射矩阵regularization正则化regularization term正则化项rescaling缩放robust 鲁棒性run 行程second-order feature二阶特点sigmoid activation function S型激励函数significant digits有效数字singular value奇怪值singular vector奇怪向量smoothed L1 penalty光滑的L1 范数处罚Smoothed topographic L1 sparsity penalty光滑地形L1 稀少处罚函数smoothing光滑Softmax Regresson Softmax回归sorted in decreasing order降序摆列source features源特点Adversarial Networks抗衡网络sparse autoencoder消减归一化Affine Layer仿射层Sparsity稀少性Affinity matrix亲和矩阵sparsity parameter稀少性参数Agent 代理 /智能体sparsity penalty稀少处罚Algorithm 算法square function平方函数Alpha- beta pruningα - β剪枝squared-error方差Anomaly detection异样检测stationary安稳性(不变性)Approximation近似stationary stochastic process安稳随机过程Area Under ROC Curve/ AUC Roc 曲线下边积step-size步长值Artificial General Intelligence/AGI通用人工智supervised learning监察学习能symmetric positive semi-definite matrix Artificial Intelligence/AI人工智能对称半正定矩阵Association analysis关系剖析symmetry breaking对称无效Attention mechanism注意力体制tanh function双曲正切函数Attribute conditional independence assumptionthe average activation均匀活跃度属性条件独立性假定the derivative checking method梯度考证方法Attribute space属性空间the empirical distribution经验散布函数Attribute value属性值the energy function能量函数Autoencoder自编码器the Lagrange dual拉格朗日对偶函数Automatic speech recognition自动语音辨别the log likelihood对数似然函数Automatic summarization自动纲要the pixel intensity value像素灰度值Average gradient均匀梯度the rate of convergence收敛速度Average-Pooling均匀池化topographic cost term拓扑代价项Backpropagation Through Time经过时间的反向流传topographic ordered拓扑次序Backpropagation/BP反向流传transformation变换Base learner基学习器translation invariant平移不变性Base learning algorithm基学习算法trivial answer平庸解Batch Normalization/BN批量归一化under-complete basis不齐备基Bayes decision rule贝叶斯判断准则unrolling组合扩展Bayes Model Averaging/ BMA 贝叶斯模型均匀unsupervised learning无监察学习Bayes optimal classifier贝叶斯最优分类器variance 方差Bayesian decision theory贝叶斯决议论vecotrized implementation向量化实现Bayesian network贝叶斯网络vectorization矢量化Between-class scatter matrix类间散度矩阵visual cortex视觉皮层Bias 偏置 /偏差weight decay权重衰减Bias-variance decomposition偏差 - 方差分解weighted average加权均匀值Bias-Variance Dilemma偏差–方差窘境whitening白化Bi-directional Long-Short Term Memory/Bi-LSTMzero-mean均值为零双向长短期记忆Accumulated error backpropagation积累偏差逆传Binary classification二分类播Binomial test二项查验Activation Function激活函数Bi-partition二分法Adaptive Resonance Theory/ART自适应谐振理论Boltzmann machine玻尔兹曼机Addictive model加性学习Bootstrap sampling自助采样法/可重复采样Bootstrapping自助法Break-Event Point/ BEP 均衡点Calibration校准Cascade-Correlation级联有关Categorical attribute失散属性Class-conditional probability类条件概率Classification and regression tree/CART分类与回归树Classifier分类器Class-imbalance类型不均衡Closed -form闭式Cluster簇/ 类/ 集群Cluster analysis聚类剖析Clustering聚类Clustering ensemble聚类集成Co-adapting共适应Coding matrix编码矩阵COLT 国际学习理论会议Committee-based learning鉴于委员会的学习Competitive learning竞争型学习Component learner组件学习器Comprehensibility可解说性Computation Cost计算成本Computational Linguistics计算语言学Computer vision计算机视觉Concept drift观点漂移Concept Learning System /CLS观点学习系统Conditional entropy条件熵Conditional mutual information条件互信息Conditional Probability Table/ CPT 条件概率表Conditional random field/CRF条件随机场Conditional risk条件风险Confidence置信度Confusion matrix混杂矩阵Connection weight连结权Connectionism 连结主义Consistency一致性/相合性Contingency table列联表Continuous attribute连续属性Convergence收敛Conversational agent会话智能体Convex quadratic programming凸二次规划Convexity凸性Convolutional neural network/CNN卷积神经网络Co-occurrence同现Correlation coefficient有关系数Cosine similarity余弦相像度Cost curve成本曲线Cost Function成本函数Cost matrix成本矩阵Cost-sensitive成本敏感Cross entropy交错熵Cross validation交错考证Crowdsourcing众包Curse of dimensionality维数灾害Cut point截断点Cutting plane algorithm割平面法Data mining数据发掘Data set数据集Decision Boundary决议界限Decision stump决议树桩Decision tree决议树/判断树Deduction演绎Deep Belief Network深度信念网络Deep Convolutional Generative Adversarial NetworkDCGAN深度卷积生成抗衡网络Deep learning深度学习Deep neural network/DNN深度神经网络Deep Q-Learning深度Q 学习Deep Q-Network深度Q 网络Density estimation密度预计Density-based clustering密度聚类Differentiable neural computer可微分神经计算机Dimensionality reduction algorithm降维算法Directed edge有向边Disagreement measure不合胸怀Discriminative model鉴别模型Discriminator鉴别器Distance measure距离胸怀Distance metric learning距离胸怀学习Distribution散布Divergence散度Diversity measure多样性胸怀/差别性胸怀Domain adaption领域自适应Downsampling下采样D-separation( Directed separation)有向分别Dual problem对偶问题Dummy node 哑结点General Problem Solving通用问题求解Dynamic Fusion 动向交融Generalization泛化Dynamic programming动向规划Generalization error泛化偏差Eigenvalue decomposition特点值分解Generalization error bound泛化偏差上界Embedding 嵌入Generalized Lagrange function广义拉格朗日函数Emotional analysis情绪剖析Generalized linear model广义线性模型Empirical conditional entropy经验条件熵Generalized Rayleigh quotient广义瑞利商Empirical entropy经验熵Generative Adversarial Networks/GAN生成抗衡网Empirical error经验偏差络Empirical risk经验风险Generative Model生成模型End-to-End 端到端Generator生成器Energy-based model鉴于能量的模型Genetic Algorithm/GA遗传算法Ensemble learning集成学习Gibbs sampling吉布斯采样Ensemble pruning集成修剪Gini index基尼指数Error Correcting Output Codes/ ECOC纠错输出码Global minimum全局最小Error rate错误率Global Optimization全局优化Error-ambiguity decomposition偏差 - 分歧分解Gradient boosting梯度提高Euclidean distance欧氏距离Gradient Descent梯度降落Evolutionary computation演化计算Graph theory图论Expectation-Maximization希望最大化Ground-truth实情/真切Expected loss希望损失Hard margin硬间隔Exploding Gradient Problem梯度爆炸问题Hard voting硬投票Exponential loss function指数损失函数Harmonic mean 调解均匀Extreme Learning Machine/ELM超限学习机Hesse matrix海塞矩阵Factorization因子分解Hidden dynamic model隐动向模型False negative假负类Hidden layer隐蔽层False positive假正类Hidden Markov Model/HMM 隐马尔可夫模型False Positive Rate/FPR假正例率Hierarchical clustering层次聚类Feature engineering特点工程Hilbert space希尔伯特空间Feature selection特点选择Hinge loss function合页损失函数Feature vector特点向量Hold-out 留出法Featured Learning特点学习Homogeneous 同质Feedforward Neural Networks/FNN前馈神经网络Hybrid computing混杂计算Fine-tuning微调Hyperparameter超参数Flipping output翻转法Hypothesis假定Fluctuation震荡Hypothesis test假定考证Forward stagewise algorithm前向分步算法ICML 国际机器学习会议Frequentist频次主义学派Improved iterative scaling/IIS改良的迭代尺度法Full-rank matrix满秩矩阵Incremental learning增量学习Functional neuron功能神经元Independent and identically distributed/独Gain ratio增益率立同散布Game theory博弈论Independent Component Analysis/ICA独立成分剖析Gaussian kernel function高斯核函数Indicator function指示函数Gaussian Mixture Model高斯混杂模型Individual learner个体学习器Induction归纳Inductive bias归纳偏好Inductive learning归纳学习Inductive Logic Programming/ ILP归纳逻辑程序设计Information entropy信息熵Information gain信息增益Input layer输入层Insensitive loss不敏感损失Inter-cluster similarity簇间相像度International Conference for Machine Learning/ICML国际机器学习大会Intra-cluster similarity簇内相像度Intrinsic value固有值Isometric Mapping/Isomap等胸怀映照Isotonic regression平分回归Iterative Dichotomiser迭代二分器Kernel method核方法Kernel trick核技巧Kernelized Linear Discriminant Analysis/KLDA核线性鉴别剖析K-fold cross validation k折交错考证/k 倍交错考证K-Means Clustering K–均值聚类K-Nearest Neighbours Algorithm/KNN K近邻算法Knowledge base 知识库Knowledge Representation知识表征Label space标记空间Lagrange duality拉格朗日对偶性Lagrange multiplier拉格朗日乘子Laplace smoothing拉普拉斯光滑Laplacian correction拉普拉斯修正Latent Dirichlet Allocation隐狄利克雷散布Latent semantic analysis潜伏语义剖析Latent variable隐变量Lazy learning懒散学习Learner学习器Learning by analogy类比学习Learning rate学习率Learning Vector Quantization/LVQ学习向量量化Least squares regression tree最小二乘回归树Leave-One-Out/LOO留一法linear chain conditional random field线性链条件随机场Linear Discriminant Analysis/ LDA 线性鉴别剖析Linear model线性模型Linear Regression线性回归Link function联系函数Local Markov property局部马尔可夫性Local minimum局部最小Log likelihood对数似然Log odds/ logit对数几率Logistic Regression Logistic回归Log-likelihood对数似然Log-linear regression对数线性回归Long-Short Term Memory/LSTM 长短期记忆Loss function损失函数Machine translation/MT机器翻译Macron-P宏查准率Macron-R宏查全率Majority voting绝对多半投票法Manifold assumption流形假定Manifold learning流形学习Margin theory间隔理论Marginal distribution边沿散布Marginal independence边沿独立性Marginalization边沿化Markov Chain Monte Carlo/MCMC马尔可夫链蒙特卡罗方法Markov Random Field马尔可夫随机场Maximal clique最大团Maximum Likelihood Estimation/MLE极大似然预计/极大似然法Maximum margin最大间隔Maximum weighted spanning tree最大带权生成树Max-Pooling 最大池化Mean squared error均方偏差Meta-learner元学习器Metric learning胸怀学习Micro-P微查准率Micro-R微查全率Minimal Description Length/MDL最小描绘长度Minimax game极小极大博弈Misclassification cost误分类成本Mixture of experts混杂专家Momentum 动量Moral graph道德图/正直图Multi-class classification多分类Multi-document summarization多文档纲要One shot learning一次性学习Multi-layer feedforward neural networks One-Dependent Estimator/ ODE 独依靠预计多层前馈神经网络On-Policy在策略Multilayer Perceptron/MLP多层感知器Ordinal attribute有序属性Multimodal learning多模态学习Out-of-bag estimate包外预计Multiple Dimensional Scaling多维缩放Output layer输出层Multiple linear regression多元线性回归Output smearing输出调制法Multi-response Linear Regression/ MLR Overfitting过拟合/过配多响应线性回归Oversampling 过采样Mutual information互信息Paired t-test成对 t查验Naive bayes 朴实贝叶斯Pairwise 成对型Naive Bayes Classifier朴实贝叶斯分类器Pairwise Markov property成对马尔可夫性Named entity recognition命名实体辨别Parameter参数Nash equilibrium纳什均衡Parameter estimation参数预计Natural language generation/NLG自然语言生成Parameter tuning调参Natural language processing自然语言办理Parse tree分析树Negative class负类Particle Swarm Optimization/PSO粒子群优化算法Negative correlation负有关法Part-of-speech tagging词性标明Negative Log Likelihood负对数似然Perceptron感知机Neighbourhood Component Analysis/NCA Performance measure性能胸怀近邻成分剖析Plug and Play Generative Network即插即用生成网Neural Machine Translation神经机器翻译络Neural Turing Machine神经图灵机Plurality voting相对多半投票法Newton method牛顿法Polarity detection极性检测NIPS 国际神经信息办理系统会议Polynomial kernel function多项式核函数No Free Lunch Theorem/ NFL 没有免费的午饭定理Pooling池化Noise-contrastive estimation噪音对照预计Positive class正类Nominal attribute列名属性Positive definite matrix正定矩阵Non-convex optimization非凸优化Post-hoc test后续查验Nonlinear model非线性模型Post-pruning后剪枝Non-metric distance非胸怀距离potential function势函数Non-negative matrix factorization非负矩阵分解Precision查准率/正确率Non-ordinal attribute无序属性Prepruning 预剪枝Non-Saturating Game非饱和博弈Principal component analysis/PCA主成分剖析Norm 范数Principle of multiple explanations多释原则Normalization归一化Prior 先验Nuclear norm核范数Probability Graphical Model概率图模型Numerical attribute数值属性Proximal Gradient Descent/PGD近端梯度降落Letter O Pruning剪枝Objective function目标函数Pseudo-label伪标记Oblique decision tree斜决议树Quantized Neural Network量子化神经网络Occam’s razor奥卡姆剃刀Quantum computer 量子计算机Odds 几率Quantum Computing量子计算Off-Policy离策略Quasi Newton method拟牛顿法Radial Basis Function/ RBF 径向基函数Random Forest Algorithm随机丛林算法Random walk随机闲步Recall 查全率/召回率Receiver Operating Characteristic/ROC受试者工作特点Rectified Linear Unit/ReLU线性修正单元Recurrent Neural Network循环神经网络Recursive neural network递归神经网络Reference model 参照模型Regression回归Regularization正则化Reinforcement learning/RL加强学习Representation learning表征学习Representer theorem表示定理reproducing kernel Hilbert space/RKHS重生核希尔伯特空间Re-sampling重采样法Rescaling再缩放Residual Mapping残差映照Residual Network残差网络Restricted Boltzmann Machine/RBM受限玻尔兹曼机Restricted Isometry Property/RIP限制等距性Re-weighting重赋权法Robustness稳重性 / 鲁棒性Root node根结点Rule Engine规则引擎Rule learning规则学习Saddle point鞍点Sample space样本空间Sampling采样Score function评分函数Self-Driving自动驾驶Self-Organizing Map/ SOM自组织映照Semi-naive Bayes classifiers半朴实贝叶斯分类器Semi-Supervised Learning半监察学习semi-Supervised Support Vector Machine半监察支持向量机Sentiment analysis感情剖析Separating hyperplane分别超平面Sigmoid function Sigmoid函数Similarity measure相像度胸怀Simulated annealing模拟退火Simultaneous localization and mapping同步定位与地图建立Singular Value Decomposition奇怪值分解Slack variables废弛变量Smoothing光滑Soft margin软间隔Soft margin maximization软间隔最大化Soft voting软投票Sparse representation稀少表征Sparsity稀少性Specialization特化Spectral Clustering谱聚类Speech Recognition语音辨别Splitting variable切分变量Squashing function挤压函数Stability-plasticity dilemma可塑性 - 稳固性窘境Statistical learning统计学习Status feature function状态特点函Stochastic gradient descent随机梯度降落Stratified sampling分层采样Structural risk构造风险Structural risk minimization/SRM构造风险最小化Subspace子空间Supervised learning监察学习/有导师学习support vector expansion支持向量展式Support Vector Machine/SVM支持向量机Surrogat loss代替损失Surrogate function代替函数Symbolic learning符号学习Symbolism符号主义Synset同义词集T-Distribution Stochastic Neighbour Embeddingt-SNE T–散布随机近邻嵌入Tensor 张量Tensor Processing Units/TPU张量办理单元The least square method最小二乘法Threshold阈值Threshold logic unit阈值逻辑单元Threshold-moving阈值挪动Time Step时间步骤Tokenization标记化Training error训练偏差Training instance训练示例/训练例Transductive learning直推学习Transfer learning迁徙学习Treebank树库algebra线性代数Tria-by-error试错法asymptotically无症状的True negative真负类appropriate适合的True positive真切类bias 偏差True Positive Rate/TPR真切例率brevity简洁,简洁;短暂Turing Machine图灵机[800 ] broader宽泛Twice-learning二次学习briefly简洁的Underfitting欠拟合/欠配batch 批量Undersampling欠采样convergence收敛,集中到一点Understandability可理解性convex凸的Unequal cost非均等代价contours轮廓Unit-step function单位阶跃函数constraint拘束Univariate decision tree单变量决议树constant常理Unsupervised learning无监察学习/无导师学习commercial商务的Unsupervised layer-wise training无监察逐层训练complementarity增补Upsampling上采样coordinate ascent同样级上涨Vanishing Gradient Problem梯度消逝问题clipping剪下物;剪报;修剪Variational inference变分推测component重量;零件VC Theory VC维理论continuous连续的Version space版本空间covariance协方差Viterbi algorithm维特比算法canonical正规的,正则的Von Neumann architecture冯· 诺伊曼架构concave非凸的Wasserstein GAN/WGAN Wasserstein生成抗衡网络corresponds相切合;相当;通讯Weak learner弱学习器corollary推论Weight权重concrete详细的事物,实在的东西Weight sharing权共享cross validation交错考证Weighted voting加权投票法correlation互相关系Within-class scatter matrix类内散度矩阵convention商定Word embedding词嵌入cluster一簇Word sense disambiguation词义消歧centroids质心,形心Zero-data learning零数据学习converge收敛Zero-shot learning零次学习computationally计算(机)的approximations近似值calculus计算arbitrary任意的derive获取,获得affine仿射的dual 二元的arbitrary任意的duality二元性;二象性;对偶性amino acid氨基酸derivation求导;获取;发源amenable 经得起查验的denote预示,表示,是的标记;意味着,[逻]指称axiom 公义,原则divergence散度;发散性abstract提取dimension尺度,规格;维数architecture架构,系统构造;建筑业dot 小圆点absolute绝对的distortion变形arsenal军械库density概率密度函数assignment分派discrete失散的人工智能词汇discriminative有辨别能力的indicator指示物,指示器diagonal对角interative重复的,迭代的dispersion分别,散开integral积分determinant决定要素identical相等的;完整同样的disjoint不订交的indicate表示,指出encounter碰到invariance不变性,恒定性ellipses椭圆impose把强加于equality等式intermediate中间的extra 额外的interpretation解说,翻译empirical经验;察看joint distribution结合概率ennmerate例举,计数lieu 代替exceed超出,越出logarithmic对数的,用对数表示的expectation希望latent潜伏的efficient奏效的Leave-one-out cross validation留一法交错考证endow 给予magnitude巨大explicitly清楚的mapping 画图,制图;映照exponential family指数家族matrix矩阵equivalently等价的mutual互相的,共同的feasible可行的monotonically单一的forary首次试试minor较小的,次要的finite有限的,限制的multinomial多项的forgo 摒弃,放弃multi-class classification二分类问题fliter过滤nasty厌烦的frequentist最常发生的notation标记,说明forward search前向式搜寻na?ve 朴实的formalize使定形obtain获取generalized归纳的oscillate摇动generalization归纳,归纳;广泛化;判断(依据不optimization problem最优化问题足)objective function目标函数guarantee保证;抵押品optimal最理想的generate形成,产生orthogonal(矢量,矩阵等 ) 正交的geometric margins几何界限orientation方向gap 裂口ordinary一般的generative生产的;有生产力的occasionally有时的heuristic启迪式的;启迪法;启迪程序partial derivative偏导数hone 怀恋;磨property性质hyperplane超平面proportional成比率的initial最先的primal原始的,最先的implement履行permit同意intuitive凭直觉获知的pseudocode 伪代码incremental增添的permissible可同意的intercept截距polynomial多项式intuitious直觉preliminary预备instantiation例子precision精度人工智能词汇perturbation不安,搅乱theorem定理poist 假定,假想tangent正弦positive semi-definite半正定的unit-length vector单位向量parentheses圆括号valid 有效的,正确的posterior probability后验概率variance方差plementarity增补variable变量;变元pictorially图像的vocabulary 词汇parameterize确立的参数valued经估价的;可贵的poisson distribution柏松散布wrapper 包装pertinent有关的总计 1038 词汇quadratic二次的quantity量,数目;重量query 疑问的regularization使系统化;调整reoptimize从头优化restrict限制;限制;拘束reminiscent回想旧事的;提示的;令人联想的( of )remark 注意random variable随机变量respect考虑respectively各自的;分其他redundant过多的;冗余的susceptible敏感的stochastic可能的;随机的symmetric对称的sophisticated复杂的spurious假的;假造的subtract减去;减法器simultaneously同时发生地;同步地suffice知足scarce罕有的,难得的split分解,分别subset子集statistic统计量successive iteratious连续的迭代scale标度sort of有几分的squares 平方trajectory轨迹temporarily临时的terminology专用名词tolerance容忍;公差thumb翻阅threshold阈,临界。
存在于英语短语

存在于英语短语存在于的英语短语大家会经常用到吗?下面是店铺给大家整理的存在于英语短语,供大家参阅!存在于英语短语1该日志服务与其它服务一起被部署到服务器上并作为存在于welcome.jsp文件中的代码的一部分。
This log service is deployed to the server together with the other services, as part of the codethat exists in the welcome.jsp file.现在,您将利用一个Ajax 类型的构架,存在于backorderadmin.jsp 的功能的子集来创建这个Web页面。
Now, create the Web page that you will implement, using an Ajax-styled architecture, a subset of the functionality that exists in backorderadmin.jsp.例如,WebSphereApplicationServer系统管理组件的大多数实现类都存在于com.ibm.ws.sm之类的包中;For example, most implementation classes for the WebSphere Application Server systemmanagement component are in packages such as com.ibm.ws.WebSphereApplicationServer连接管理组件的实现类存在于com.ibm.ws.j2c之类的包中,等等。
sm; implementation classes for the WebSphere Application Server connection managementcomponent are in packages such as com.ibm.ws. j2c, and so on.其它解析器本该存在于docutils.parsers层次结构下,但现在尚未提供这些解析器。
复杂网络上的演化博弈及其学习机制与演化动态综述

第3期2021年5月阅江学刊YuejiangAcademicJournalNo.3May2021㊃经济观察㊃复杂网络上的演化博弈及其学习机制与演化动态综述王先甲摘要:博弈论是在完全理性假设下研究多人相互作用的选择理论,演化博弈是在有限理性假设下研究群体在相互作用过程中基于个体学习与选择的群体特征演化动态理论,网络上的演化博弈是研究结构化群体的演化博弈理论㊂本文回顾了基于完全理性的博弈论,在对有限理性新的理解的基础上介绍了演化博弈理论的发展历程,着重论述了复杂网络理论与演化博弈理论交叉衍生的复杂网络上的演化博弈的研究现状与发展趋势,特别分析和总结了演化博弈中最基本㊁最核心的个体学习机制与群体演化动态特征,由此揭示演化博弈中从个体微观行为到群体宏观特征的演化机理㊂关键词:博弈论;演化博弈;复杂网络;复杂网络上的演化博弈;学习机制;演化动态中图分类号:F224.32㊀㊀文献标识码:A㊀㊀文章分类号:1674⁃7089(2021)03⁃0070⁃15基金项目:国家自然科学基金项目 复杂网络上演化博弈合作形成机理与控制策略 (71871171);国家自然科学基金重点项目 学习机制下群体博弈行为演化与管理实验 (72031009)作者简介:王先甲,博士,武汉大学经济与管理学院教授㊁博士生导师㊂㊀㊀一㊁引㊀言微观经济学主要研究完全理性假设基础上的个体选择㊂古典经济学把消费者问题和生产者问题分别看成独立的个体优化选择问题,消费者与生产者之间通过无形的市场相互联系㊂直到1959年,Debreu在著作中建立一般均衡理论,①把消费者与生产者纳入一个经济系统内,通过他们的相互作用确定市场均衡㊂这种思想和分析框架与Nash建立博弈论的思想与框架几乎完全一致㊂这种看起来十分完美的一般均衡理论至少存在两个弱点:一是仍然以完全理性为前提假设;二是无法展示市场均衡的形成过程,因为它本质上是消费者和生产者同时决策形成的㊂虽然存在这些弱点,却产生了一大进步,那就是经济07①DebreuG,TheoryofValue,NewHaven:YaleUniversityPress,1959.. All Rights Reserved.王先甲:复杂网络上的演化博弈及其学习机制与演化动态综述学界从此不太排斥用博弈论研究多个个体间的相互作用了㊂然而,多个个体相互作用通常是一个过程,并且每个个体无法预期作用过程的未来,这使得基于完全理性的决策失去了基础,因为对未来的不可知性使决策者不知道怎样进行理性选择㊂因此,多个个体在相互作用过程中对未来预期未知时如何选择就成为需要研究的重要问题㊂演化博弈为开展这类问题的研究提供了分析工具㊂演化博弈在有限理性假设下探讨群体在相互作用过程中的个体行为选择规则及群体行为演化㊂也就是说,在群体相互作用过程中个体是按某种规则进行选择而不是按完全理性假设来选择㊂既然群体博弈是一个过程,那么个体的行为选择也可能是一个过程,个体会在这个过程中不断学习以便选择对自己更有利的行为㊂因此,个体选择行为时所依据的规则本质上就是通过某种学习机制确定的㊂每个个体选择自己的行为后形成群体整体的状态(也称系统状态),群体状态刻画了群体在相互作用过程中不同时刻的特征,不同时刻状态间的关系一般称为状态转移(也称为演化动态,有时也将演化动态理解为状态转移过程的极限)㊂当组成群体的个体间具有某种特殊联系时,该群体被称为结构化群体㊂因为网络是描述结构化群体的基本工具,且结构关系会发生各种复杂的变化,所以在研究结构化群体的相互作用过程时,复杂网络上的演化博弈就成为观注的重点㊂本文试图对复杂网络上的演化博弈等相关问题的研究状况与发展趋势进行简要的回顾与总结㊂㊀㊀二、博弈论发展历程回顾博弈论是研究理性决策者之间竞争与合作关系的数学方法,其分析范围较广,几乎包括社会科学领域所有的基本问题㊂①实际上,竞争与合作行为一直伴随着人类的发展㊂一般认为最早涉及人类博弈行为的著作是2000多年以前中国春秋时期的‘孙子兵法“,②记录战争艺术的著作‘三国演义“也是研究博弈行为的智慧结晶㊂但这些相对零星的研究成果只是展现了人类博弈行为的某个侧面,尚未从科学意义上对人类博弈行为进行定量分析㊂最早采用定量方法分析人类博弈行为的研究发生在经济学领域,Cournot㊁Bertrand㊁Edgeworth分别探讨了寡头产量竞争㊁寡头价格竞争和垄断竞争㊂③经典儿童文学名著‘爱丽丝漫游仙境“的作者Dodgson(后来更名为LewisCarroll)也是一位数学家,他用零和博弈研究政治问题㊂④这些工作成功地在人类特定领域的博弈行为研究中引入了定量方法,但是还不能算是正式的博弈论研究工作㊂Zermelo开启了博弈论的第一个正式的研究工作,⑤他除了建立集合论公理体系框架之外,还首次用博弈论研究了国际象棋㊂博弈论研17①②③④⑤MyersonR,GameTheory:AnalysisofConflict,Cambridge:HarvardUniversityPress,1991.SunT,TheArtofWar,TranslatedbyClearyT,Boston&London:Shambala,1988.CournotA,RecherchessurlesPrincipesMathématiquesdelathéoriedesRichesses,Paris:Hachette,1838.BertrandJ,Théoriemathématiquedelarichessesociale ,JournaldesSavants,vol.68(1883),pp.499-508.EdgeworthF, Lateoriapuradelmonopoli ,GiornaledegliEconomisti,vol.40(1897),pp.13-31.BlackD, Lewiscarrollandthetheoryofgames ,AmericanEconomicReview,vol.59,no.2(2001),pp.206-210.DodgsonCL,ThePrinciplesofParliamentaryRepresentation,London:Harrison,1884.ZermeloE, Übereineanwendungdermengenlehreaufdietheoriedesschachspiels ,InHobsonEW,LoveAEH,eds.,ProceedingsoftheFifthInternationalCongressofMathematicians,vol.II,Cambridge:CambridgeUniversityPress,1913,pp.501-504.. All Rights Reserved.阅江学刊:2021年第3期究的第一个里程碑式的工作应该是由VonNeumann完成的,他于1928年比较完整地给出了零和博弈模型及其解的概念,①后来的主要研究者实际上都受到这一工作的启发㊂VonNeumann和Morgenstern建立了决策理论的公理体系㊁零和博弈与非零和博弈的分析框架,并将其运用于经济学研究,但是他们的理论局限于矩阵博弈㊂博弈论更一般的模型和解的概念及其分析框架是由Nash建立的,他对多人相互作用关系给出了更一般的描述并提出了Nash均衡解概念㊂Nash的研究工作和思想在很大程度上受到VonNeumann的影响,但在适应范围和分析框架方面又有本质的拓展,使博弈论最终成为研究多人相互作用行为的一般工具㊂Nash在20世纪50年代发表的关于博弈论的几篇著名论文奠定了非合作博弈的理论基础㊂②然而,由于Nash的研究工作以完全信息为基础,具有极强的数学理论性且不能处理经济学中几乎无处不在的不确定性信息问题,所以最初并未被经济学界所接受㊂Harsanyi于1977年在著作中建立了一套解释和描述多人相互作用中的不完全信息理论,③提出了BaysianNash均衡解概念和不完全信息非合作博弈论㊂但是Nash和Harsanyi的研究只能处理静态的非合作博弈,即博弈各方只能同时进行一次行为选择,不能处理多人相互作用过程的动态博弈问题㊂Selten㊁Kreps㊁Wilson建立了多阶段动态非合作博弈理论,④提出了子博弈完美Nash均衡概念和 颤抖手 精炼均衡概念㊂由于在非合作博弈研究中的杰出工作,Nash㊁Harsanyi和Selten三人在1994年被授予诺贝尔经济学奖㊂Tucker于1950年发现囚徒困境现象,⑤为非合作博弈的研究提供了典型原型,也揭示了博弈论与决策理论的重要区别,决策理论研究单人在理性假设下的决策行为,决策主体寻求的是能使自身偏好最优的行为选择,而在Nash的博弈论框架下理性人的行为出现了一种由囚徒困境所表征的特点,即个体理性与集体理性的冲突㊂实际上,囚徒困境现象在实践中广泛存在,Cournot的数量竞争模型也是囚徒困境㊂这种十分简单的博弈模型却导致博弈出现了几个不同的发展方向,其中一个是合作博弈㊂虽然VonNeumann和Morgenstern建立了合作博弈的基本框架,但是合作博弈的研究在20世纪50年代中期到60年代中后期才有了较快的发展,这一时期经济学界正在怀疑Nash提出的非合作博弈,因为它不能处理不完全信息而产生了可应用性问题㊂合作博弈按效用的可转移性可以分为效用可转移型和效用不可转移型,Aumann较早研究了效用不可转移合作博弈,⑥随后关27①②③④⑤⑥VonNeumannJ, Zurtheoriedergesellschaftsspiele ,MathematischeAnnalen,vol.100,no.1(1928),pp.295-320.VonNeumannJ,MorgensternO,TheoryofGamesandEconomicBehavior,Princeton:PrincetonUniversityPress,1944.NashJF,Bargainingproblem ,Econometrica,vol.18,no.2(1950),pp.155-162.NashJF, Non-cooperativegames ,AnnalsofMathematics,vol.54,no.2(1951),pp.286-295.NashJF, Two-personcooperativegames ,Econometrica,vol.21,no.1(1953),pp.128-140.HarsanyiJC,RationalBehaviorandBargainingEquilibriuminGamesandSocialSituations,Cambridge:CambridgeUniversityPress,1977.SeltenR, Reexaminationoftheperfectnessconceptforequilibriumpointsinextensivegame ,InternationalGameTheory,vol.4,no.1(1975),pp.25-55.KrepsD,WilsonR, Sequentialequilibrium ,Economietrica,vol.50,no.4(1982),pp.863-894.TuckerAW,ATwo-personDilemma,Unpublishednotes,StanfordUniversity,1950.AumannRJ, Thecoreofacooperativegamewithoutsidepayment ,TransactionsoftheAmericanMathematicalSociety,vol.98,no.3(1961),pp.539-552.. All Rights Reserved.王先甲:复杂网络上的演化博弈及其学习机制与演化动态综述于效用不可转移合作博弈的研究虽然并不多但依然沿用Aumann的框架㊂自VonNeumann和Morgenstern构建效用可转移合作博弈的框架以来,合作博弈基于特征函数,主要研究联盟成员如何合理有效地分配收益㊂围绕合理有效地在联盟中分配收益问题建立解概念及公理体系是合作博弈理论发展的中心㊂1953年Gillies引入了核(Core)作为合作博弈解的概念,①这个解概念具有给出的分配方案对任何子结盟没有诱导性的特性,但它不是单值的而是集值的㊂在合作博弈中集值解概念为数不少,Aumann和Mascher提出的合作博弈协商集解概念是集值的,②Peleg的内核(Kernel)解概念㊁Maschler的预核(Prekernel)解概念等都是集值解概念㊂③而Shapley在1953年提出了一个著名的单值解概念,④称为Shapley值,这个解概念可解释为每个个体得到的收益是其所有可能的边际贡献的平均值,并且Shapley用一组公理完全刻画了这个单值解概念㊂单值解概念还包括Schmeidler的核仁(Nucleolus)(它的表示形式虽然是集合,但由于采用字典序定义,实际上是一个单值解概念)㊁Tijs的τ值和平均字典值解概念㊂⑤Peleg和Sudhölter是合作博弈解概念公理化分析的集大成者㊂⑥在合作博弈研究中,Shapley的研究工作被认为是开创性的,被统称为关于稳定分配(匹配)与市场设计的研究,他与Roth一起获得2012年诺贝尔经济学奖㊂当前,博弈论几乎在所有涉及多智能体(包括人和生物)的领域得到了发展和应用㊂Aumann和Hart㊁Young和Zamir出版了四本博弈论手册,⑦堪称博弈论全书,这套博弈论手册共分80个专题对博弈论进行了较详细的论述㊂㊀㊀三、演化博弈论的发展历程回顾尽管在过去几十年里,博弈论得到了长足发展,但仍然存在一些缺陷㊂第一,经典博弈论(包括合作博弈与非合作博弈)假设参与人是完全理性的㊂在决策理论意义下,一个决策者是理性的是指他可以选择与自己偏好一致的最优决策(行为)㊂而在博弈论意义下,参与人是理性的是指参与人选择的策略(行为)在博弈中不被严格占优㊂这个定义是一种否定表示形式,它并未告诉人们直接选择什么㊂第二,以Nash均衡为基础来定义解概念给出了多人相互关系中所有参与人共同的合理的理性预期,虽然它在本质上是所有37①②③④⑤⑥⑦GilliesD,SomeTheoremsonN-personGames,Princeton:PrincetonUniversityPress,1953.AumannRJ,MaschlerM, Thebargainingsetforcooperativegame ,AdvancesinGameTheory,vol.52(1964),pp.443-476.PelegB,Vorob evNN,TóthLF, Onthekernelofcomstant-sumsimplegameswithhomogeneousweights ,IllinoisJournalofMathematics,vol.10(1966),pp.39-48.MaschlerM,PelegB,ShapleyLS, Thekernelandbargainingsetforconvexgames ,InternationalJournalofGameTheory,vol.1,no.1(1971),pp.73-93.ShapleyLS, Avalueforn-persongames ,InTuckerAW,KuhnHW,eds.,ContributionstotheTheoryofGames,vol.II,Princeton:PrincetonUniversityPress,1953,pp.307-317.SchmeidlerD, Thenucleolusofacharacteristicfunctiongame ,SiamJournalonAppliedMathematiics,vol.17(1969),pp.1163-1170.TijsSH, Boundsforthecoreofagameandtheτ-value InMoeschlinO,PallaschkeD,eds.,GameTheoryandMathematicalEconomics,Amsterdam:North-Holland,1981,pp.123-132.PelegB,SudhölterP,IntroductiontotheTheoryofCooperativeGames,Boston:KluwerAcademicPublishers,2007.AumannRJ,HartS,HandbookofGameTheorywithEconomicApplications,vol.1,Amsterdam:North-Holland,1992.AumannRJ,HartS,HandbookofGameTheorywithEconomicApplications,vol.2,Amsterdam:North-Holland,1994.AumannRJ,HartS,HandbookofGameTheorywithEconomicApplications,vol.3,Amsterdam:North-Holland,2002.YoungHP,ZamirS,HandbookofGameTheorywithEconomicApplications,vol.4,Amsterdam:North-Holland,2015.. All Rights Reserved.阅江学刊:2021年第3期参与人的选择互为最优反应的结果,却无法给出这种基于最优反应的均衡的形成过程,也不能讨论均衡的稳定性㊂第三,多重均衡问题导致经常无法排除明显不合理的均衡,进而影响参与人做出最终选择㊂第四,对合作的理解存在分歧㊂合作博弈将合作理解为结盟,而非合作博弈把合作理解为参与人选择对他人有利的策略(行为)㊂第五,无法反映参与人的学习过程㊂演化博弈虽然源于生物学,但是之所以被列入博弈论的范畴,正是因为它在一定程度上回答了上述五个问题㊂㊀㊀(一)有限理性完全理性假设是经典博弈论和经典经济学理论的基石,也是它们遭受质疑的首要问题㊂与完全理性相对立的是有限理性㊂理性本质上是讨论人在决策时选择行为的依据或原则㊂亚当∙斯密最早在其著作‘国富论“中提出经济人概念,后来被约翰∙穆勒等人总结为经济人假设,经济人假设指出人总是做出使自己利益最大化的决策㊂VonNeumann和Morgenstern建立的经典决策理论中以完全理性假设作为决策者或博弈参与人的行为选择原则,这里的完全理性假设与经济人假设是一致的㊂美国经济学家Arrow很可能是最早提出有限理性概念的学者,①他认为,人的行为是有意识理性的,但这种理性又是有限的㊂Simon一直是有限理性概念的倡导者,②他认为,人类的认知能力在心理上存在临界极限,决策中的推理活动需要足够的能力来支撑,而人类只有有限能力,决策中需要大量的信息,而能获得的信息是有限的㊂因此,决策者并非总是可以实现其最优决策,即决策者的决策是在有限理性下的决策㊂自从Simon认为有限理性是建立决策理论的基石以来,③不少学者总结了对各种有限理性进行解释和描述的模型㊂④大多数学者认为,决策者在决策过程中可以通过不断学习提高有限的知识水平㊁有限的推理能力㊁有限的信息处理能力,从而使有限理性得到不断改善㊂Thaler获得2017年诺贝尔经济学奖的工作就是通过探索有限理性展示人格特质如何系统地影响个人决策与市场㊂⑤虽然关于有限理性的多项研究成果已经获得了几届诺贝尔经济学奖,但是人们仍然认为,对有限理性的理解仅限于局部的㊁定性的分析,决策论学者㊁博弈论学者㊁经济学学者并未形成共识㊂人们对有限理性与完全理性有如下理解:当决策者面对决策问题时,如果决策者对当前和未来的信息结构和偏好结构具有完全知识,他将按完全理性假设确定的决策规则选择行为,否则,他将按其他规则选择行为㊂根据有限知识㊁有限信息㊁有限推47①②③④⑤ArrowKJ, Rationalchoicefunctionsandordings ,Economica,vol.26,no.102(1959),pp.121-127.SimonHA, Abehavioralmodelofrationalchoice ,QuarterlyJournalofEconomics,vol.69,no.1(1955),pp.99-118.[美]赫伯特㊃西蒙:‘现代决策理论的基石“,杨砺㊁徐立译,北京:北京经济学院出版社,1989年,第1页㊂SimonHA, Boundedrationalityandorganizationallearning ,OrganizationScience,vol.2,no.1(1991),pp.125-134.SeltenR,Featuresofexperimentallyobservedboundedrationality ,EuropeanEconomicReview,vol.42,no.3(1998),pp.413-436.ArthurWB, Designingeconomicagentsthatactlikehumanagents:Abehavioral-approachtoboundedrationality ,AmericanEconomicReview,vol.81,no.2(1991),pp.353-359.WallKD, Amodelofdecision-makingunderboundedrationality ,JournalofEconomicBehavior&Organization,vol.20,no.3(1993),pp.331-352.BoardR,Polynomiallyboundedrationality ,JournalofEconomicTheory,vol.63,no.2(1994),pp.246-270.SamuelsonL,Boundedrationalityandgametheory ,QuarterlyReviewofEconomicsandFinance,vol.36,no.s1(1996),pp.17-35.ThalerRH,Misbehaving:TheMakingofBehavioralEconomics,NewYork:W.W.Norton&Co.,2015.. All Rights Reserved.王先甲:复杂网络上的演化博弈及其学习机制与演化动态综述理能力确定的规则做出行为选择,称为有限理性下的选择㊂本质上,有限理性出现的原因是决策者不能完全掌握信息结构和偏好结构㊂决策者在有限理性假设下做出行为选择所依据的规则应该有利于改善他的收益㊂这样就可以连续统一地解释完全理性假设和有限理性假设下的选择行为㊂决策者可以通过各种途径改善知识㊁信息和推理能力,从而改善有限理性,改善的标志是决策者的收益提高了㊂决策者面临决策问题将以改善收益为目的,不断增进对信息结构与偏好结构的理解,从而使理性的有限性得到改善,直到对信息结构和偏好结构完全掌握,就能够按照完全理性确定的规则选择行为了㊂引入学习的观点具有必然性,因为决策者会通过不断学习改善理性的有限性并适时调整策略㊂如果将这种通过不断学习更新有限理性并调整策略的特征置入群体相互关系中,那么群体成员通过随机配对进行反复博弈㊁学习㊁调整策略,最终会显示出个体(类型或策略)适应性㊂这种思路与达尔文自然选择思想形成的生物进化理论的分析框架几乎完全相同,人类与生物的很多行为(比如竞争与合作)具有相似性,二者的学习方式完全可能互相启示㊂于是,生物学家Maynard和Price借鉴了研究生物种群群体状态进化和稳定机制的方法来分析人类的行为,将生物进化理论的思想引入博弈论,提出了演化博弈思想和演化稳定均衡策略的概念㊂这种起源于生物进化理论的博弈分析方法就被称为演化博弈论㊂㊀㊀(二)演化博弈论的发展历程回顾实际上,演化博弈思想最早应该源于Fisher在1930年开展的研究工作,①但遗憾的是他没有给出演化博弈的形式化表示与分析框架㊂Maynard和Price首先提出了源于生物学的演化博弈,并给出其形式化表示,②后经Taylor㊁Jonker㊁Selten发展而成㊂③演化博弈将生物学中的演化概念用于解释生物或人的选择行为是有限理性假设下基于规则的选择过程,并将群体博弈描述成一个过程,在动态系统稳定与博弈论的Nash均衡之间建立起联系,使得展现Nash均衡的实现过程成为可能㊂Weibull对1995年之前的演化博弈论研究进展进行了系统的总结㊂④作为研究生物认识的方法,演化博弈关注个体的行为表现特征而非生物组织内在的基因特征㊂于是,演化博弈形成的基础被认为是生物特征学的三个基本原则,即个体异质性㊁适应性和自然选择㊂表现型由基因库的多样性保障,表现型的成功生存可以用适应性测量,自然选择决定了更适应的表现型比更不适应的表现型在下一代繁殖中有更多的数量㊂变异(突变)是由偶然因素引起的,多数突变者因表现型行为不适应环境而被淘汰,少数突变者将因新的表现型更适应环境而生存㊂Maynard和Price提出了演化博弈解的概念,⑤即演化稳定均衡(策略)㊂演化稳定策略有如下性质:对己方而言,对手以小概率57①②③④⑤FisherRA,TheGeneticalTheoryofNaturalSelection,Oxford:ClarendonPress,1930.MaynardSJ,PriceGR, Thelogicofanimalconflict ,Nature,vol.246,no.5427(1973),pp.15-18.TaylorPD,JonkerLB, Evolutionarystablestrategiesandgamedynamics ,MathematicalBiosciences,vol.40,no.1(1978),pp.145-156.SeltenR, Evolutionarystabilityinextensivetwo-persongames ,MathematicalSocialSciences,vol.5,no.3(1983),pp.269-363.WeibullJW,EvolutionaryGameTheory,Cambridge:TheMITPress,1995.MaynardSJ,PriceGR, Thelogicofanimalconflict ,Nature,vol.246,no.5427(1973),pp.15-18.. All Rights Reserved.阅江学刊:2021年第3期选择变异策略时,演化稳定策略严格占优于变异策略㊂从传统的博弈论观点来理解就是:对己方而言,如果对手在演化稳定策略和变异策略之间随机选择并以很小的概率选择该变异策略时,演化稳定策略严格占优于变异策略㊂从生物学观点来理解就是:如果演化稳定策略种群被变异策略种群中的一小部分入侵,演化稳定策略种群在抵御该小变异种群过程中比变异种群有更强大的生存能力,表明演化稳定策略种群在抵御变异策略种群时具有稳定性㊂演化稳定策略还可以解释为:对己方而言,演化稳定策略对抗任何变异策略得到的收益严格大于该变异策略得到的收益㊂根据演化稳定策略的定义,可以证明演化稳定策略也是Nash均衡策略㊂由于Nash均衡策略是互为最优反应策略,所以也可以认为演化稳定策略是对任意策略的严格意义下的最优反应策略㊂由于可以将演化稳定策略理解成Nash均衡策略的一种精炼,所以它成为解决多重Nash均衡的一种方法㊂演化动态将演化稳定策略与生物演化(进化)巧妙地联系起来,演化动态描述了演化过程中个体改变策略的规则,包括演化系统结构㊁个体特征㊁策略的更新规则㊂它反映了基于适应性和学习性选择进化的本质㊂从数学上讲,演化动态是系统历史在当前时刻的动态映射㊂在复制(演化)动态关系下,可以证明渐近稳定点与演化稳定策略是等价的㊂①这样就把有限理性下某种演化动态的演化稳定策略与完全理性下的Nash均衡策略有机联系了起来㊂基于这一思想,Maynard建立了演化博弈的分析框架,②可以说是演化博弈的奠基之作㊂演化动态是演化博弈的核心概念,演化动态可分成确定性演化动态和随机性演化动态,一般来讲,对任何确定性演化动态都可以构造相应的随机演化动态㊂㊀㊀四、复杂网络上的演化博弈发展现状与发展趋势㊀㊀(一)复杂网络理论复杂网络理论是用网络工具研究由多个基本单元通过复杂相互作用构成的复杂系统的方法㊂主要研究不同网络拓扑模型及其统计特性㊁复杂网络形成机制㊁复杂网络上的动力学行为规律㊂由于现实中存在大量的复杂相互作用关系,复杂网络被认为是对大量真实复杂相互作用关系系统在结构关系上的拓扑抽象㊂复杂网络以网络为描述工具,于是,网络理论自然成为研究复杂网络的基础㊂网络理论起源于图论,③图论源于数学家Euler在1736年访问加里宁格勒时发现的七座桥散步问题㊂图论是研究图的各种性质的学问㊂图是由节点的集合和连接节点的边的集合构成的二元组,节点代表个体,边代表个体之间的相互作用关系㊂网络是被赋予某种特定意义的图㊂网络理论是研究具有特定意义的有限个体相互作用关系的工具㊂最简单的复杂网络是规则网络,主要包括格网络㊁全局耦合网络和最邻近耦合网络㊂④67①②③④PetersH,GameTheory:AMulti-leveledApproach,Berlin:SpringerVerlag,2008.MaynardSJ,EvolutionandtheTheoryofGames,Cambridge:CambridgeUniversity,1982.段志生:‘图论与复杂网络“,‘力学进展“,2008年第6期,第702-712页㊂PercM,JordanJJ,RandDG,etal, Statisticalphysicsofhumancooperation ,PhysicsReports,vol.687(2017),pp.1-51.. All Rights Reserved.王先甲:复杂网络上的演化博弈及其学习机制与演化动态综述复杂网络的复杂性主要利用结构复杂性来刻画,比如高聚类系数㊁短路径长度的小世界现象及度分布呈现幂律特征的无标度特性等,典型的复杂网络主要有随机网络㊁WS小世界网络和BA无标度网络等㊂Erdos等提出了随机网络(也称ER随机图)的概念㊂①ER随机网络模型假设网络中有N个节点,将任意两个节点以概率p进行连接,可以生成一个由N个节点构成的平均度为p(N-1)的网络,该网络的节点度满足泊松分布㊂Erdos等建立了随机网络理论并开创了基于图论的复杂网络理论的系统性研究㊂②Milgram发现了小世界现象,③由他的社会调查以及 小世界实验 可以推断地球上任意两个人之间的平均度为6(称为6度分离),表明任意两个社会成员之间总是可以通过一条相对较短的路径实现相互连接㊂Watts和Strogatz发现了这种小世界现象的结构特征,④并提出了WS小世界网络(简称WS模型)㊂这种网络有一种看上去很复杂但遵循一定规则的结构,即对于节点数给定(N)的最邻近耦合网络,把网络中任一条边以概率p断开并重新连接到另一个随机挑选的节点上,但是不允许出现重复或自连接的情况,此时概率p与网络结构有如下关系:当p=0时,该网络仍然为最邻近耦合网络;当p=1时,该网络变为特殊ER随机网络;当0<p<1时,随着p的增大,节点度之间的异质性随之增大,同时网络中可能会出现孤立簇㊂这种现象与随机重新连接性可能会破坏网络的连通性有关㊂为了保证网络连通性,Newman和Watts对WS小世界网络模型进行了修改,⑤提出了NW小世界网络(简称NW模型)㊂在NW模型中,从一个最邻近的环形网格中以概率p随机选取一对节点建立新连接,要求任何两个节点间最多只存在一条边㊂这种用随机添加新边取代WS模型中随机重新连接的方法有效地保证了网络连通性㊂NW小世界网络与WS小世界网络的基本特征是具有较大的簇系数和较小的最短平均距离,因此统称为小世界网络㊂Barabasi和Albert发现了一种具有特殊度分布特性的网络结构,⑥即极少数节点的度较大而大量节点的度较小,提出用BA无标度网络来刻画这种特性㊂BA无标度网络的生成规则为:从一个有m0个初始节点的全局连通网络开始,每次增加一个新节点,从已有节点中随机选择m(mɤm0)个节点与之连接,新节点与已有节点的相连概率与已有节点的度成正比,网络生成过程中不允许重复连接㊂这种BA无标度网络的主要特征是节点度满足幂率分布且幂率函数具备标度不变性㊂BA无标度网络可以用来描述不断增长和择优开放的现实世界㊂BA无标度网络和小世界网络一起揭示了现实世界形形色色的复杂网络具有普遍的㊁非平凡的结构特性㊂77①②③④⑤⑥ErdosP,RényiA, Onrandomgraphs ,PublicationesMathematicae,vol.6,no.4(1959),pp.290-297.ErdosP,RényiA, Ontheevolutionofrandomgraphs ,PublicationsoftheMathematicalInstituteoftheHungarianAcademyofScience,vol.5,no.1(1960),pp.17-61.MilgramS, Thesmallworldproblem ,PsychologyToday,vol.2,no.1(1967),pp.185-195.WattsDJ,StrogatzSH, Collectivedynamicsof small-world networks ,Nature,vol.393,no.6684(1998),pp.440-442.NewmanME,WattsDJ, Scalingandpercolationinthesmall-worldnetworkmodel ,PhysicalReviewE,vol.60,no.6(1999),pp.7332-7342.BarabasiAL,AlbertR, Emergenceofscalinginrandomnetworks ,Science,vol.286,no.5439(1999),pp.509-512.. All Rights Reserved.。
SOINN绍介_E

90 secs 4 hours
70 days
Test time(Approx. 6000imgs)
2 days
Without time to extract features
14
15
We have many modalities.
16
17
Modalities of SOINN Robot
150
100 50 KDE-SOINN : Local Kernel 0
10000 20000 30000 40000 50000 60000 70000 80000 90000 100000
サンプル数
32
実験 : 計算時間(前頁の拡大図)
1000 900 800 700 600 500 400 300 200
• SOINN works best with internet:
– Google Drive, finance, distribution, climate/environment, education, medicine, etc.
7
Mate Tea Cup …??
8
SOINN + internet
3
Self-organizing Incremental Neural Network (SOINN)
Noise is eliminated. Pattern is recognized.
4
SOINN applet demo
5
6
SOINN Algorithm
SOINN has vast possibilities
SOINN
Self-organizing Incremental Neural Network
基于各向异性高斯核图像边缘和角点检测

(MIPS体系结构剖析,编程与实践)第4章 MIPS 异常和中断处理文库

(MIPS体系结构剖析,编程与实践)第4章 MIPS 异常和中断处理文库.txt小时候觉得父亲不简单,后来觉得自己不简单,再后来觉得自己孩子不简单。
越是想知道自己是不是忘记的时候,反而记得越清楚。
第四章 MIPS 异常和中断处理MIPS 异常和中断处理(Exception and Interrupt handling)任何一个CPU都要提供一个详细的异常和中断处理机制。
一个软件系统,如操作系统,就是一个时序逻辑系统,通过时钟,外部事件来驱动整个预先定义好的逻辑行为。
这也是为什么当写一个操作系统时如何定义时间的计算是非常重要的原因。
大家都非常清楚UNIX提供了一整套系统调用(System Call)。
系统调用其实就是一段EXCEPTION处理程序。
我们可能要问:为什么CPU要提供Excpetion 和 Interrupt Handling呢?*处理illegal behavior, 例如,TLB Fault, or, we say, the Page fault; Cache Error;* Provide an approach for accessing priviledged resources, for example, CP0 registers. As we know, for user level tasks/processes, they are runningwith the User Mode priviledge and are prohibilited to directly control CPO. CPU need provide a mechanism for them to trap to kernel mode and then safely manipulate resources that are only availablewhen CPU runs in kernel mode.* Provide handling for external/internal interrupts. For instance, the timer interrupts and watch dog exceptions. Those two interrupt/exceptions are very important for an embedded system applicances.Now let's get back to how MIPS supports its exception and interrupt handling.For simplicty, all information below will be based on R7K CPU, which is derived from the R4k family.* The first thing for understanding MIPS exception handling is: MIPS adopts **Precise Exceptions** mechanisms. What that means? Here is the explaination from the book of "See MIPS Run": "In a precise-exception CPU, on any exception we get pointed at one instruction(the exception victim). All instructions preceding the exception victim in executionsequence are complete; any work done on the victim and on any subsequent instructions (BNN NOTE: pipeline effects) has no side effects that the software need worry about. The software that handles exceptions can ignore all the timing effects of the CPU's implementations"上面的意思其实很简单:在发生EXCEPTION之前的一切计算行为会**FINISH**。
专业英文字汇
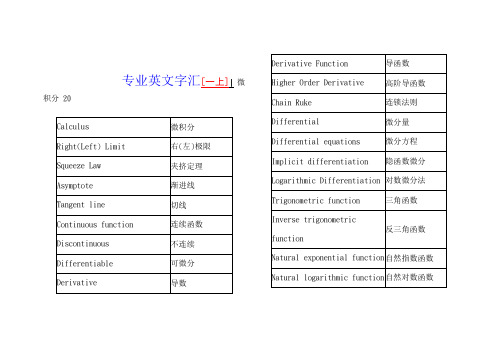
Trigonometric function
三角函数
Inverse trigonometric function
反三角函数
Naturalexponentialfunction
自然指数函数
Naturallogarithmicfunction
自然对数函数
物理实习30
dynaห้องสมุดไป่ตู้ics
动力学
kinematics
扇区
security
安全性
starvation
饥饿
statement
叙述
subalgorithm
子算法
subprogram
子程序
subroutine
子程序
syntax
语法
Unicode
万国码
variable
变数
whitespace
空白
frame
韧体
message
讯息
RAM
随机存取内存
ethernet
资料列
information
信息
router
路由器
network
网络
internet
因特网
recursive
递回
broadcast
广播
modem
调制解调器
register
缓存器
header
标头
compile
编译
compiler
编译器
tree
树
robot
机器人
monitor
屏幕
bandwidth
频宽
hacker
IBM Rational统一流程
Kernel Ridge Mixed Model(核回归混合模型)1.0说明书

Package‘KRMM’October12,2022Type PackageTitle Kernel Ridge Mixed ModelVersion1.0Author Laval Jacquin[aut,cre]Maintainer Laval Jacquin<************************>Description Solves kernel ridge regression,within the the mixed model framework,for the lin-ear,polynomial,Gaussian,Laplacian and ANOV A kernels.The model compo-nents(i.e.fixed and random effects)and variance parameters are estimated using the expectation-maximization(EM)algorithm.All the estimated components and parame-ters,e.g.BLUP of dual variables and BLUP of random predictor effects for the linear ker-nel(also known as RR-BLUP),are available.The kernel ridge mixed model(KRMM)is de-scribed in Jacquin L,Cao T-V and Ahmadi N(2016)A Unified and Comprehensi-ble View of Parametric and Kernel Methods for Genomic Prediction with Applica-tion to Rice.Front.Genet.7:145.<doi:10.3389/fgene.2016.00145>.Depends R(>=3.3.0)Imports stats,MASS,kernlab,cvTools,robustbaseLicense GPL-2|GPL-3Encoding UTF-8LazyData trueRoxygenNote5.0.1NeedsCompilation noRepository CRANDate/Publication2017-06-0317:46:04UTCR topics documented:KRMM-package (2)EM_REML_MM (4)Kernel_Ridge_MM (5)Predict_kernel_Ridge_MM (8)Tune_kernel_Ridge_MM (10)Index141KRMM-package Kernel Ridge Mixed ModelDescriptionSolves kernel ridge regression,within the the mixed model framework,for the linear,polynomial, Gaussian,Laplacian and ANOV A kernels.The model components(i.e.fixed and random effects) and variance parameters are estimated using the expectation-maximization(EM)algorithm.All the estimated components and parameters,e.g.BLUP of dual variables and BLUP of random predictor effects for the linear kernel(also known as RR-BLUP),are available.The kernel ridge mixed model (KRMM)is described in Jacquin L,Cao T-V and Ahmadi N(2016)A Unified and Comprehensible View of Parametric and Kernel Methods for Genomic Prediction with Application to Rice.Front.Genet.7:145.DetailsThis package solves kernel ridge regression for various kernels within the following mixed model framework:Y=X*Beta+Z*U+E,where X and Z correspond to the design matrices of pre-dictors withfixed and random effects respectively.The functions provided with this package are Kernel_Ridge_MM,Tune_kernel_Ridge_MM,Predict_kernel_Ridge_MM and EM_REML_MM. Author(s)Laval Jacquin Maintainer:Laval Jacquin<************************>ReferencesJacquin et al.(2016).A unified and comprehensible view of parametric and kernel methods for genomic prediction with application to rice(in peer review).Robinson,G.K.(1991).That blup is a good thing:the estimation of random effects.Statistical science,53415-32Foulley,J.-L.(2002).Algorithme em:théorie et application au modèle mixte.Journal de la Sociétéfrançaise de Statistique143,57-109Examples##Not run:library(KRMM)###SIMULATE DATAset.seed(123)p=200N=100beta=rnorm(p,mean=0,sd=1.0)X=matrix(runif(p*N,min=0,max=1),ncol=p,byrow=TRUE)#X:covariates(i.e.predictors)f=X%*%beta#f:data generating process(i.e.DGP)E=rnorm(N,mean=0,sd=0.5)Y=f+E#Y:observed response datahist(f)hist(beta)Nb_train=floor((2/3)*N)###======================================================================######CREATE TRAINING AND TARGET SETS FOR RESPONSE AND PREDICTOR VARIABLES######======================================================================###Index_train=sample(1:N,size=Nb_train,replace=FALSE)###Covariates(i.e.predictors)for training and target setsPredictors_train=X[Index_train,]Response_train=Y[Index_train]Predictors_target=X[-Index_train,]True_value_target=f[-Index_train]#True value(generated by DGP)we want to predict###=================================================================================######PREDICTION WITH KERNEL RIDGE REGRESSION SOLVED WITHIN THE MIXED MODEL FRAMEWORK######=================================================================================####Linear kernelLinear_KRR_model_train=Kernel_Ridge_MM(Y_train=Response_train,Matrix_covariates_train=Predictors_train,method="RR-BLUP")f_hat_target_Linear_KRR=Predict_kernel_Ridge_MM(Linear_KRR_model_train,Matrix_covariates_target=Predictors_target)#Gaussian kernelGaussian_KRR_model_train=Kernel_Ridge_MM(Y_train=Response_train,Matrix_covariates_train=Predictors_train,method="RKHS",rate_decay_kernel=5.0)f_hat_target_Gaussian_KRR=Predict_kernel_Ridge_MM(Gaussian_KRR_model_train,Matrix_covariates_target=Predictors_target)#Graphics for RR-BLUPdev.new(width=30,height=20)par(mfrow=c(3,1))plot(f_hat_target_Linear_KRR,True_value_target)plot(Linear_KRR_model_train$Gamma_hat,xlab="Feature(i.e.covariate)number",ylab="Feature effect(i.e.Gamma_hat)",main="BLUP of covariate effects based on training data") hist(Linear_KRR_model_train$Gamma_hat,main="Distribution of BLUP of4EM_REML_MM covariate effects based on training data")#Compare prediction based on linear(i.e.RR-BLUP)and Gaussian kerneldev.new(width=30,height=20)par(mfrow=c(1,2))plot(f_hat_target_Linear_KRR,True_value_target)plot(f_hat_target_Gaussian_KRR,True_value_target)mean((f_hat_target_Linear_KRR-True_value_target)^2)mean((f_hat_target_Gaussian_KRR-True_value_target)^2)##End(Not run)EM_REML_MM Expectation-Maximization(EM)algorithm for the restricted maximumlikelihood(REML)associated to the mixed modelDescriptionEM_REML_MM estimates the components and variance parameters of the following mixed model;Y=X*Beta+Z*U+E,using the EM-REML algorithm.UsageEM_REML_MM(Mat_K_inv,Y,X,Z,init_sigma2K,init_sigma2E,convergence_precision,nb_iter,display)ArgumentsMat_K_inv numeric matrix;the inverse of the kernel matrixY numeric vector;response vectorX numeric matrix;design matrix of predictors withfixed effectsZ numeric matrix;design matrix of predictors with random effectsinit_sigma2K,init_sigma2Enumeric scalars;initial guess values,associated to the mixed model varianceparameters,for the EM-REML algorithmconvergence_precision,nb_iterconvergence precision(i.e.tolerance)associated to the mixed model varianceparameters,for the EM-REML algorithm,and number of maximum iterationsallowed if convergence is not reacheddisplay boolean(TRUE or FALSE character string);should estimated components be displayed at each iterationValueBeta_hat Estimatedfixed effect(s)Sigma2K_hat,Sigma2E_hatEstimated variance componentsAuthor(s)Laval Jacquin<************************>ReferencesFoulley,J.-L.(2002).Algorithme em:théorie et application au modèle mixte.Journal de la Sociétéfrançaise de Statistique143,57-109Kernel_Ridge_MM Kernel ridge regression in the mixed model frameworkDescriptionKernel_Ridge_MM solves kernel ridge regression for various kernels within the following mixed model framework:Y=X*Beta+Z*U+E,where X and Z correspond to the design matrices of predictors withfixed and random effects respectively.UsageKernel_Ridge_MM(Y_train,X_train=as.vector(rep(1,length(Y_train))),Z_train=diag(1,length(Y_train)),Matrix_covariates_train,method="RKHS",kernel="Gaussian",rate_decay_kernel=0.1,degree_poly=2,scale_poly=1,offset_poly=1,degree_anova=3,init_sigma2K=2,init_sigma2E=3,convergence_precision=1e-8,nb_iter=1000,display="FALSE")ArgumentsY_train numeric vector;response vector for training dataX_train numeric matrix;design matrix of predictors withfixed effects for training data (default is a vector of ones)Z_train numeric matrix;design matrix of predictors with random effects for training data(default is identity matrix)Matrix_covariates_trainnumeric matrix of entries used to build the kernel matrixmethod character string;RKHS,GBLUP or RR-BLUPkernel character string;Gaussian,Laplacian or ANOV A(kernels for RKHS regression ONLY,the linear kernel is automatically built for GBLUP and RR-BLUP andhence no kernel is supplied for these methods)rate_decay_kernelnumeric scalar;hyperparameter of the Gaussian,Laplacian or ANOV A kernel(default is0.1)degree_poly,scale_poly,offset_polynumeric scalars;parameters for polynomial kernel(defaults are2,1and1re-spectively)degree_anova numeric scalar;parameter for ANOV A kernel(defaults is3)init_sigma2K,init_sigma2Enumeric scalars;initial guess values,associated to the mixed model varianceparameters,for the EM-REML algorithm(defaults are2and3respectively) convergence_precision,nb_iternumeric scalars;convergence precision(i.e.tolerance)associated to the mixedmodel variance parameters,for the EM-REML algorithm,and number of max-imum iterations allowed if convergence is not reached(defaults are1e-8and1000respectively)display boolean(TRUE or FALSE character string);should estimated components be displayed at each iterationDetailsThe matrix Matrix_covariates_train is mandatory to build the kernel matrix for model estimation, and prediction(see Predict_kernel_Ridge_MM).ValueBeta_hat Estimatedfixed effect(s)Sigma2K_hat,Sigma2E_hatEstimated variance componentsVect_alpha Estimated dual variablesGamma_hat RR-BLUP of covariates effects(i.e.available for RR-BLUP method only) Author(s)Laval Jacquin<************************>ReferencesJacquin et al.(2016).A unified and comprehensible view of parametric and kernel methods for genomic prediction with application to rice(in peer review).Robinson,G.K.(1991).That blup is a good thing:the estimation of random effects.Statistical science,53415-32Foulley,J.-L.(2002).Algorithme em:théorie et application au modèle mixte.Journal de la Sociétéfrançaise de Statistique143,57-109Examples##Not run:library(KRMM)###SIMULATE DATAset.seed(123)p=200N=100beta=rnorm(p,mean=0,sd=1.0)X=matrix(runif(p*N,min=0,max=1),ncol=p,byrow=TRUE)#X:covariates(i.e.predictors) f=X%*%beta#f:data generating process(i.e.DGP)E=rnorm(N,mean=0,sd=0.5)Y=f+E#Y:observed response datahist(f)hist(beta)Nb_train=floor((2/3)*N)###======================================================================######CREATE TRAINING AND TARGET SETS FOR RESPONSE AND PREDICTOR VARIABLES######======================================================================###Index_train=sample(1:N,size=Nb_train,replace=FALSE)###Covariates(i.e.predictors)for training and target setsPredictors_train=X[Index_train,]Response_train=Y[Index_train]Predictors_target=X[-Index_train,]True_value_target=f[-Index_train]#True value(generated by DGP)we want to predict###=================================================================================### ###PREDICTION WITH KERNEL RIDGE REGRESSION SOLVED WITHIN THE MIXED MODEL FRAMEWORK### ###=================================================================================####Linear kernelLinear_KRR_model_train=Kernel_Ridge_MM(Y_train=Response_train,Matrix_covariates_train=Predictors_train,method="RR-BLUP")f_hat_target_Linear_KRR=Predict_kernel_Ridge_MM(Linear_KRR_model_train,Matrix_covariates_target=Predictors_target)#Gaussian kernelGaussian_KRR_model_train=Kernel_Ridge_MM(Y_train=Response_train,Matrix_covariates_train=Predictors_train,method="RKHS",rate_decay_kernel=5.0)f_hat_target_Gaussian_KRR=Predict_kernel_Ridge_MM(Gaussian_KRR_model_train,Matrix_covariates_target=Predictors_target)#Graphics for RR-BLUPdev.new(width=30,height=20)par(mfrow=c(3,1))plot(f_hat_target_Linear_KRR,True_value_target)plot(Linear_KRR_model_train$Gamma_hat,xlab="Feature(i.e.covariate)number",ylab="Feature effect(i.e.Gamma_hat)",main="BLUP of covariate effects based on training data") hist(Linear_KRR_model_train$Gamma_hat,main="Distribution of BLUP ofcovariate effects based on training data")#Compare prediction based on linear(i.e.RR-BLUP)and Gaussian kernelpar(mfrow=c(1,2))plot(f_hat_target_Linear_KRR,True_value_target)plot(f_hat_target_Gaussian_KRR,True_value_target)mean((f_hat_target_Linear_KRR-True_value_target)^2)mean((f_hat_target_Gaussian_KRR-True_value_target)^2)##End(Not run)Predict_kernel_Ridge_MMPredict function for Kernel_Ridge_MM objectDescriptionPredict the value(s)for a vector or a design matrix of covariates(i.e.features)UsagePredict_kernel_Ridge_MM(Model_kernel_Ridge_MM,Matrix_covariates_target,X_target=as.vector(rep(1,dim(Matrix_covariates_target)[1])),Z_target=diag(1,dim(Matrix_covariates_target)[1]))ArgumentsModel_kernel_Ridge_MMa Kernel_Ridge_MM objectMatrix_covariates_targetnumeric matrix;design matrix of covariates for target dataX_target numeric matrix;design matrix of predictors withfixed effects for target data(default is a vector of ones)Z_target numeric matrix;design matrix of predictors with random effects for target data(default is identity matrix)DetailsThe matrix Matrix_covariates_target is mandatory to build the kernel matrix(with Matrix_covariates_train from Model_kernel_Ridge_MM)for prediction.Valuef_hat Predicted value for target data,i.e.f_hat=X_target*Beta_hat+Z_target*U_targetwhere U_target=K_target_train*alpha_train and alpha_train is the BLUP of al-pha for the model,i.e.alpha_train=Cov(alpha,Y_train)*Var(Y_train)^-1*(Y_train-E[Y_train])Author(s)Laval Jacquin<************************>Examples##Not run:library(KRMM)###SIMULATE DATAset.seed(123)p=200N=100beta=rnorm(p,mean=0,sd=1.0)X=matrix(runif(p*N,min=0,max=1),ncol=p,byrow=TRUE)#X:covariates(i.e.predictors)10Tune_kernel_Ridge_MMf=X%*%beta#f:data generating process(i.e.DGP)E=rnorm(N,mean=0,sd=0.5)Y=f+E#Y:observed response datahist(f)hist(beta)Nb_train=floor((2/3)*N)###======================================================================######CREATE TRAINING AND TARGET SETS FOR RESPONSE AND PREDICTOR VARIABLES######======================================================================###Index_train=sample(1:N,size=Nb_train,replace=FALSE)###Covariates(i.e.predictors)for training and target setsPredictors_train=X[Index_train,]Response_train=Y[Index_train]Predictors_target=X[-Index_train,]True_value_target=f[-Index_train]#True value(generated by DGP)we want to predict###=================================================================================### ###PREDICTION WITH KERNEL RIDGE REGRESSION SOLVED WITHIN THE MIXED MODEL FRAMEWORK### ###=================================================================================### Gaussian_KRR_model_train=Kernel_Ridge_MM(Y_train=Response_train,Matrix_covariates_train=Predictors_train,method="RKHS",rate_decay_kernel=5.0)###Predict new entries for target set and measure prediction errorf_hat_target_Gaussian_KRR=Predict_kernel_Ridge_MM(Gaussian_KRR_model_train,Matrix_covariates_target=Predictors_target)plot(f_hat_target_Gaussian_KRR,True_value_target)##End(Not run)Tune_kernel_Ridge_MM Tune kernel ridge regression in the mixed model frameworkDescriptionTune_kernel_Ridge_MM tunes the rate of decay parameter of kernels,by K-folds cross-validation, for kernel ridge regressionUsageTune_kernel_Ridge_MM(Y_train,X_train=as.vector(rep(1,length(Y_train))), Z_train=diag(1,length(Y_train)),Matrix_covariates_train,method="RKHS",kernel="Gaussian",rate_decay_kernel=0.1,degree_poly=2,scale_poly=1,offset_poly=1,degree_anova=3,init_sigma2K=2,init_sigma2E=3,convergence_precision=1e-8,nb_iter=1000,display="FALSE",rate_decay_grid=seq(0.1,1.0,length.out=10),nb_folds=5,loss="mse")Argumentsrate_decay_gridGrid over which the rate of decay is tuned by K-folds cross-validation nb_folds Number of folds,i.e.K=nb_folds(default is5)loss mse(mean square error)or cor(correlation)(default is mse)Y_train numeric vector;response vector for training dataX_train numeric matrix;design matrix of predictors withfixed effects for training data (default is a vector of ones)Z_train numeric matrix;design matrix of predictors with random effects for training data(default is identity matrix)Matrix_covariates_trainnumeric matrix of entries used to build the kernel matrixmethod character string;RKHS,GBLUP or RR-BLUPkernel character string;Gaussian,Laplacian or ANOV A(kernels for RKHS regression ONLY,the linear kernel is automatically built for GBLUP and RR-BLUP andhence no kernel is supplied for these methods)rate_decay_kernelnumeric scalar;hyperparameter of the Gaussian,Laplacian or ANOV A kernel(default is0.1)degree_poly,scale_poly,offset_polynumeric scalars;parameters for polynomial kernel(defaults are2,1and1re-spectively)degree_anova numeric scalar;parameter for ANOV A kernel(defaults is3)init_sigma2K,init_sigma2Enumeric scalars;initial guess values,associated to the mixed model varianceparameters,for the EM-REML algorithm(defaults are2and3respectively)convergence_precision,nb_iternumeric scalars;convergence precision(i.e.tolerance)associated to the mixedmodel variance parameters,for the EM-REML algorithm,and number of max-imum iterations allowed if convergence is not reached(defaults are1e-8and1000respectively)display boolean(TRUE or FALSE character string);should estimated components be displayed at each iterationValuetuned_model the tuned model(a Kernel_Ridge_MM object)expected_loss_gridthe average loss for each rate of decay tested over the gridoptimal_h the rate of decay minimizing the average lossAuthor(s)Laval Jacquin<************************>Examples##Not run:library(KRMM)###SIMULATE DATAset.seed(123)p=200N=100beta=rnorm(p,mean=0,sd=1.0)X=matrix(runif(p*N,min=0,max=1),ncol=p,byrow=TRUE)#X:covariates(i.e.predictors)f=X%*%beta#f:data generating process(i.e.DGP)E=rnorm(N,mean=0,sd=0.5)Y=f+E#Y:response datahist(f)hist(beta)Nb_train=floor((2/3)*N)###======================================================================######CREATE TRAINING AND TARGET SETS FOR RESPONSE AND PREDICTOR VARIABLES######======================================================================###Index_train=sample(1:N,size=Nb_train,replace=FALSE)###Covariates(i.e.predictors)for training and target setsPredictors_train=X[Index_train,]Response_train=Y[Index_train]Predictors_target=X[-Index_train,]True_value_target=f[-Index_train]#True value(generated by DGP)we want to predict###=======================######Tuned Gaussian Kernel######=======================###Tuned_Gaussian_KRR_train=Tune_kernel_Ridge_MM(Y_train=Response_train,Matrix_covariates_train =Predictors_train,method= RKHS ,rate_decay_grid=seq(1,10,length.out=10),nb_folds=5,loss= mse ) Tuned_Gaussian_KRR_model_train=Tuned_Gaussian_KRR_train$tuned_modelTuned_Gaussian_KRR_train$optimal_hTuned_Gaussian_KRR_train$rate_decay_gridTuned_Gaussian_KRR_train$expected_loss_griddev.new()plot(Tuned_Gaussian_KRR_train$rate_decay_grid,Tuned_Gaussian_KRR_train$expected_loss_grid,type="l",main="Tuning the rate of decay(for Gaussian kernel)with K-folds cross-validation")###Predict with tuned modelf_hat_target_tuned_Gaussian_KRR=Predict_kernel_Ridge_MM(Tuned_Gaussian_KRR_model_train,Matrix_covariates_target=Predictors_target)mean((f_hat_target_tuned_Gaussian_KRR-True_value_target)^2)cor(f_hat_target_tuned_Gaussian_KRR,True_value_target)##End(Not run)Index∗packageKRMM-package,2EM_REML_MM,4Kernel_Ridge_MM,5KRMM-package,2Predict_kernel_Ridge_MM,8Tune_kernel_Ridge_MM,1014。
英文科技论文写作-经典常用例句

经典常用例句目录经典常用例句 (1)目录 (1)说明 (5)常用动词 (5)一、中性词 (5)1.(文章等)给出、研究、建立、提出、提供 (5)2.由...得到、得出、得到(结论等).. (6)3.集中、侧重、强调、注重、聚焦、着重、投精力于 (6)4.用、使用、使用、采用、采取 (6)5.构造、形成、构成、由...构成、由...组成.. (7)6.覆盖、包括 (8)7.包含、包括、涉及 (8)8.认为、发现、观察 (9)9.基于、建立在...基础上. (9)10.在于 (10)11.放、置于 (10)12.影响 (10)13.考虑、考虑到 (10)14.回到、追溯、回归、回顾 (11)15.寻求、打算 (11)16.确定、决定、作决定 (11)17.刻画、描述、表述、描绘、叙述、陈述 (11)18.指示、显示、表明、指出、指明、标明 (11)19.意味着、推断、暗示、建议 (12)20.描述、刻画、理解 (12)21.需要指出的是、需要强调的是、需要注意的是 (12)22.推荐、建议、劝告 (12)23.展示、表现、展现 (13)24.控制、管理、监管、安排 (13)25.使得 (13)26.扩展、拓展、扩张 (13)27.改变、变更、变化、修改 (13)28.贡献、占据、捐献 (14)29.持续、维持 (14)30.近似、逼近 (14)31.接近、接触、进入 (14)32.成为 (14)33.趋势、趋向、潮流、发展(变化)方向 (14)二、褒义词 (14)1.保证、确保、担保 (14)3.证明、证实、演示、例证 (15)4.尽、尽量、尽力、尽可能的 (15)5.努力、尝试 (16)6.给出、提出、提供、给予、供给 (16)7.能、使能、能够、有能力 (16)8.增加、增长、增强、加强 (17)9.胜过、超过、比...多 (17)10.水平、有水平、高水平 (17)11.有、享有、允许有、拥有、具有、带有 (18)12.(对...)起作用、有效、运行(执行)良好 .. (19)13.优化 (19)14.支持、赞成、推荐、喜欢、更喜欢 (19)15.期待、期望、指望、有望、有希望 (19)16.提高、改进、有利于、发展、健康运行 (20)17.进行、执行、实现、贯彻、完成 (20)18.解决、克服、突破、避免 (21)19.使...简单(容易)、简洁、简便、方便、简单 . (22)20.优点、利益、好处 (22)21.有价值、具有理论价值、使用价值(工程使用、价值) (22)常用名词 (23)一、中性词 (23)I.单纯性名词 (23)II.动词的名词形式 (23)III.动名词 (23)二、褒义词 (23)I.单纯性名词 (23)II.动词的名词形式 (23)III.动名词 (23)三、贬义词 (23)I.单纯性名词 (23)II.动词的名词形式 (24)III.动名词 (24)常用连词 (24)一、比、象、如、连(联) (24)1.象、如、例如、正如 (24)2.联系、相关、联合、连接、关联、关系 (24)3.相似、类似、和...一样(相似). (24)4.比、比较、对比 (25)5.比...好,优于、超过、比...高、不亚于. (27)6.比...差、不如、不比...好、比...少 (27)二、因为、为了、所以、目标、观点、角度 (28)1.因为、由于、鉴于、归功于、归因于 (28)2.因此,所以 (29)4.目标、目的 (29)5.从...观点来看、从...角度讲、在...意义下、以...意义来看 .. (30)常用短语/习语、常用副词/介词 (30)1.在...的前沿,在...领域.. (30)2.在...框架内. (30)3.事先、预先、先于、在...以前、先前的、在前的 (30)4.适合于、适用于、可行的 (30)5.重要的、有用的、本质的、关键的、有益的、作为工具的 (31)6.剩余的、其余的、剩下的 (31)7.详细的、详细地 (31)8.以...(速度、顺序、尺寸、步长、字体等等). (32)9.就...而言、从...方面来看、在...方面.. (32)10.倾向于、易于 (32)11.可接受的、能接受的 (32)12.直接的、直截了当的、显然的、平凡的、容易的 (32)13.可利用的、可获得的、空闲的 (32)14.上(半)部分、下(半)部分、左(右)上部、左(右)下部 (33)15.稍微的(地)、稍稍的(地)、稍许 (33)16.显然、明显的 (33)17.大量的、丰富的 (33)18.怎样、怎么 (33)19.无论如何...、不管如何...、无论何事 (34)语法及特殊结构、用法 (34)1.现在分词的用法 (34)2.过去分词的用法 (36)3.不定式的用法:作宾语、作后置定语 (37)4.缩写、略写、省略句 (38)5.特殊符号的用法 (39)6.特殊句式 (39)7.(特殊)语法结构:独立主格结构、虚拟语气等等 (40)负面表述 (42)一、否定形式 (42)1.Not及No的形式否定 (42)2.介词意义否定 (43)3.动词意义否定 (43)4.短语意义否定 (43)5.形容词短语意义否定 (44)6.形容词、副词及其比较级意义否定 (44)7.前缀及后缀否定 (45)8.连词意义否定 (45)二、贬义动词 (46)1.出现、发生、遇到、遭遇 (46)2.牵扯、牵涉、卷入、包含 (47)3.阻止 (47)4.导致、引起、招致、受困于 (47)5.掩盖、遮住、隐瞒、隐藏 (48)6.欺骗、被骗 (48)7.忽略、忽视、省略、避免 (48)8.除...外、除...外(还有). (49)9.排除、去除、删除、去掉、移动 (49)10.降低、减少、退化、恶化、减小 (49)11.失败、失效、舍弃 (50)12.歪曲、曲解、扭曲 (50)13.滥用、混淆、盲目 (50)14.要求、需要、必需、必需品、必须 (50)三、贬义短语、名词、形容词、介词、连词 (52)1.不便,麻烦,繁重 (52)2.破费、昂贵、在损害...的情况下、以损害...为代价.. (52)3.冒险、风险 (52)4.挑战 (52)5.缺点、缺陷、局限、不利条件 (53)6.困难、麻烦、障碍、损失(不利结果) (53)7.苛刻的、苛求的、受限的、有限的 (54)8.差、差的、最差、最差的 (54)9.尽管、不管、不论 (54)四、矛盾(常用于反证法) (55)五、区别、不同、和...不同.. (55)图、表、例 (55)1.图 (55)2.表 (56)3.例 (56)文章的结尾部分 (56)1.经验、教训 (56)2.总结、概括、报告、结论 (56)3.将来的工作(研究)、开放性的问题 (57)4.附录 (57)5.感谢、感激 (57)6.(文献)引用、参考 (58)专业知识 (59)一、控制 (59)二、测量 (59)三、神经网络 (59)1.数据及其处理 (59)2.神经网络的结构和算法 (60)3.神经网络的训练 (61)4.神经网络训练的偏差和精度 (61)5.神经网络训练的收敛性(稳定) (62)6.神经网络的逼近性能和特点 (63)数学常用语 (63)1.向量、空间、系统的维数 (63)2.微分、求导、初等变换、可微的(可导的)、导数 (63)3.解方程、给出...的解 (64)4.张成向量空间、取秩 (64)5.距离、度量 (64)6.平方根 (64)7.区间 (64)8.精度、准确性、精确性 (64)9.前提、前提条件、充要条件 (64)10.在...情况/条件/背景/前提下、背景、情况、前提.. (65)11.满足条件、满足要求、条件成立、结论成立 (66)12.可能性、概率、百分比 (66)13.(作)差、距离、差值 (67)14.带入、替代 (67)15.迭代 (68)16.划分、分类、分组、分解 (68)17.逐步、逐点、逐渐 (68)18.等价、等于 (68)19.收敛、收敛速度 (69)20.有限步内 (69)21.计算、计算量 (69)说明1.“经典常用例句”在其注释中包含“经典短语、经典搭配”等;2. 这些例句均摘自“美国(或英国)原版外文材料(论文或图书)”,完全值得信赖和模仿。
实时操作系统

Real-Time Systems,28,237±253,2004#2004Kluwer Academic Publishers.Manufactured in The Netherlands. Real-Time Operating SystemsJOHN A.STANKOVICUniversity of VirginiaR.RAJKUMARCarnegie Mellon University1.IntroductionReal-time operating systems(RTOSs)provide basic support for scheduling,resource management,synchronization,communication,precise timing,and I/O.RTOSs have evolved from single-use specialized systems to a wide variety of more general-purpose operating systems(such as real-time variants of L inux).We have also seen an evolution from RTOSs which are completely predictable and support safety-critical applications to those which support soft real-time applications.Such support includes the concept of quality of service(QoS)for open real-time systems,often applied to multimedia applications as well as large,complex distributed real-time systems.Researchers in real-time operating system have developed new ideas and paradigms that enhance traditional operating systems to be more ef®cient and predictable.Some of these ideas are now found in traditional operating systems and many other ideas are found in the wide variety of RTOS on the market today.The RTOS market includes many proprietary kernels, composition-based kernels,and real-time versions of popular OSs such as Linux and Windows-NT.Many industry standards have been in¯uenced by RTOS research including POSIX real-time extensions,Real-Time Speci®cation for Java,OSEK(automotive RTOS standard),Ada83and Ada95.This paper provides an overview of the architectures, principles,paradigms,and new ideas developed in RTOS research over the past20years. The paper concentrates on research done within the context of complete RTOSs.Note that much more research on RTOSs has been accomplished and published as speci®c aspects on RTOS.For example,real-time synchronization and memory management research has many exciting results.Also,many ideas found in the companion paper on real-time scheduling can be found in various RTOSs as well.2.RTOS Taxonomy and ArchitecturesReal-time operating systems emphasize predictability,ef®ciency,and include features to support timing constraints.Several general categories of real-time operating systems exist:small,proprietary kernels(commercially available as well as homegrown kernels), real-time extensions to commercial timesharing operating systems such as Unix and238STANKOVIC AND RAJKUMAR Linux,component-based kernels,QoS-based kernels,and(largely)University-based research kernels.2.1.Small,Fast,Proprietary KernelsThe small,fast,proprietary kernels come in two varieties:homegrown1and commercial offerings.2Both varieties are often used for small embedded systems when very fast and highly predictable execution must be guaranteed.The homegrown kernels are usually highly specialized to the application.The cost of uniquely developing and maintaining a homegrown kernel,as well as the increasing quality of the commercial offerings is signi®cantly reducing the practice of generating homegrown kernels.In addition, component-based OSs(see Section2.3)are also reducing the need for homegrown kernels.For both varieties of proprietary kernels,to achieve speed and predictability,the kernels are stripped down and optimized versions of timesharing operating systems.To reduce the run-time overheads incurred by the kernel and to make the system fast,the kernel:*has a fast context switch,*has a small size(with its associated minimal functionality),*responds to external interrupts quickly(sometimes with a guaranteed maximum latency to post an event but,generally,no guarantee is given as to when processing of the event will be completed;this later guarantee can sometimes be computed if priorities are assigned correctly),*minimizes intervals during which interrupts are disabled,*provides®xed or variable sized partitions for memory management(i.e.,no virtual memory)as well as the ability to lock code and data in memory,*provides special sequential(often memory-based)®les that can accumulate data at a fast rate.To deal with timing requirements,the kernel*supports multi-tasking,*provides a priority-based preemptive scheduling mechanism,*provides bounded execution time for most primitives,*maintains a high-resolution real-time clock,REAL-TIME OPERATING SYSTEMS239 *provides for special alarms and timeouts,*supports real-time queuing disciplines such as earliest deadline®rst and primitives for jamming a message into the front of a queue,*provides primitives to delay processing by a®xed amount of time and to suspend/ resume execution.In general,the kernels also perform multi-tasking and inter-task communication and synchronization via standard primitives such as mailboxes(message queues),events, signals,mutexes,and semaphores.While all these latter features are designed to be fast, ``fast''is a relative term and not suf®cient when dealing with real-time constraints. Nevertheless,many real-time system designers use these features as a basis upon which to build real-time systems.This has been effective in small embedded applications such as instrumentation,communication front-ends,intelligent peripherals and many areas of process control.Since these applications are simple,it is relatively easy to show that all timing constraints are met.Consequently,the kernels provide exactly the minimal functionality that is needed.However,as applications become more complex,it becomes more and more dif®cult to craft a solution based on priority-driven scheduling where all timing,computation time,resource,precedence,and value requirements are mapped to a single priority for each task.In these situations,demonstrating predictability can be rather dif®cult.2.2.Real-Time Extensions to Commercial Operating SystemsA second approach to real-time operating systems is the extension of commercial products,for example,extending Unix to RT-Unix(Furht et al.,1991),Linux to RT-Linux(FSLLabs;Niehaus,KURT;RedIce Linux),or POSIX to RT-POSIX,or MACH to RT-MACH(Tokuda et al.,1990),or CHORUS to a real-time version(CHORUS system). The real-time version of commercial operating systems are generally slower and less predictable than the proprietary kernels,but have greater functionality and better software development environmentsÐvery important considerations in many large or complex applications.Another signi®cant advantage is that they are based on a set of familiar interfaces(standards)that facilitate portability.For Unix,since many variations of Unix have evolved,an IEEE standardization effort,called POSIX,has de®ned a common set of user-level interfaces for operating systems.The effort has focussed on eleven important real-time related functions:timers,priority scheduling,shared memory,real-time®les, semaphores,interprocess communication,asynchronous event noti®cation,process memory locking,asynchronous I/O,synchronous I/O,and threads.Various problems exist when attempting to convert a non real-time operating system to a real-time version.These problems can exist both at the system interface as well as in the implementation.For example,in Unix,interface problems exist in process scheduling due to the nice and setpriority primitives and its round-robin scheduling policy.In addition, the timer facilities are too coarse,memory management(of some versions)contains no240STANKOVIC AND RAJKUMAR method for locking pages into memory,and interprocess communication facilities do not support fast and predictable communication often resulting in different forms of priority inversion(Sha et al.,1990).The implementation problems include intolerable overhead, excessive latency in responding to interrupts,partly but very importantly,due to the non-preemptability of the kernel,and internal FIFO queues.These and other problems can and have been solved to result in a real-time operating system that is used for both real-time and non real-time processing.However,because the underlying paradigm of timesharing systems still exists,application developers must be careful not to use certain non real-time features that might insidiously impact the real-time tasks.Real-time capabilities can be added to operating systems in multiple ways.It is illustrative to study how many real-time versions of Linux have been created and commercialized in recent years.These versions can be grouped into the following categories.*Compliant kernels:In this approach,an existing real-time operating system is modi®ed such that L inux binaries can be run without any modi®cation.Essentially, the functionality and semantics of Linux system calls need to be appropriately emulated under the native operating system.For example,L ynxOS from L ynuxWorks adopts this approach.*Dual kernels:In this approach,a hard but thin real-time kernel sits below the native operating system(such as Linux or FreeBSD),and traps all accesses to and interrupts from the underlying hardware.The thin kernel schedules several hard real-time tasks co-located with it,and runs the native OS as its lowest priority task.As a result,native applications can be run without change,while hard real-time tasks can get excellent performance and predictability.A means of(non-real-time)communication is also provided between the thin real-time kernel and the native non-real-time kernel for data exchange purposes.The downside of this approach is that there is no memory protection between the real-time tasks and the native/thin kernels.As a result,the failure of any real-time task can lead to a complete system crash.The thin real-time kernel also needs to have its own set of device drivers for real-time functionality.RT-Linux(FSLLabs)is an example of this approach.*Core kernel modi®cations:In this approach,changes are made to the core of a non-real-time kernel in order to make it predictable and deterministic enough so as to behave as a real-time ing®xed-priority scheduling with a O(1)scheduler, employing high-resolution timers,making the kernel preemptive(so that a lower priority process in the kernel space due to an ongoing system call can be preempted by a higher priority process that becomes eligible to run),support for priority inheritance protocols to minimize priority inversion,making interrupt handlers schedulable using kernel threads,the use of periodic processes,replacing FIFO queues with priority queues and optimizing long paths through the kernel are typical means of accomplishing this goal.TimeSys L inux(based on CMU's L inux/RK (Oikawa and Rajkumar,1999)discussed in Section2.5.5)and to a smaller extent MontaVista Linux fall under this category.REAL-TIME OPERATING SYSTEMS241 *The Resource kernel approach:In this approach,the kernel is extended to provide support for resource reservations in addition to the traditional®xed-priority preemptive scheduling approach.The latter approach can run into problems when a relatively high-priority process overruns its expected execution time or even goes into an in®nite loop.Resource kernels support and enforce resource reservation,such that no misbehaving task can directly impact the timing behavior of another task.CMU's Linux/RK and its commercial cousin,TimeSys Linux,and fall into this category. ponent-BasedKernelsA number of systems such as OS-Kit(Ford et al.,1997),Coyote(Bhatti et al.,1999), PURE(Beuche et al.,1999),2K(Kon et al.,1998),MMLite(Helander and Forin,1998), and Pebble(Gabber et al.,1999)have a common intent to deal with operating system construction through composition.They de®ne OS components that can be selectively included to compose an RTOS that can be tailored to the application(s)at hand.OS-Kit provides a set of operating system components that can be combined to con®gure an operating system.However,it does not supply any rules to help build an operating system.Coyote is focussed on communication protocols,and its ability for re-con®guration might be adopted for operating system and embedded application areas. PURE is explicitly concerned with providing operating system components for con®guration and composition of operating systems for embedded applications.PURE uses an object-oriented methodology to provide different components for con®guration and customization of operating systems for embedded applications.2K emphasizes adaptability issues to allow applications to be as customizable as possible.2K is also concerned with component-based software for small mobile devices,or personal digital assistants(PDAs).To explore the concepts of a component-based RTOS,consider two component-based RTOSs in more detail.MML ite is an object-based,modular system architecture that provides a menu of components for use at compile-time,link-time,or runtime to construct a wide range of applications.A component in MML ite consists of one or more objects.Multiple objects can reside in a single namespace.When an object needs to send a message to an object in another namespace for the®rst time,a proxy object is created in the sending object's namespace that transparently handles the marshaling of parameters.A unique aspect of MMLite is its focus on support for transparently replacing components while these components are in use(mutation).MML ite uses COM interfaces, which in turn support dynamic recon®gurability on a per-object and per-component basis. However,COM does not provide protection between the components.The base menu of the MMLite system contains components for heap management,dynamic on-demand loading of new components,machine initialization,timer and interrupt drivers,scheduler, threads and synchronization,namespaces,®le system,network,and virtual memory. These components are typically very small(500±3000bytes on the386architecture), although the network component is much larger(84,832bytes on386).The resulting MMLite system can be quite small:the base system is26Kbytes on386,and20Kbytes242STANKOVIC AND RAJKUMAR on the ARM architecture.It is not clear to what extent MML ite provides users with the ability to easily select components that the MMLite developers write,and to what extent users themselves de®ne and utilize their own new components.Although there has been an apparent emphasis on developing minimal-sized components(in number of bytes), analysis tools regarding the runtime performance of components due to namespace resolution and the creation and loading of proxy objects is lacking.Pebble is a new operating system designed to be an ef®cient application-speci®c operating system and to support component-based applications.It also supports complex embedded applications.As an operating system,it adopts a microkernel architecture with a minimal privileged-mode nucleus that is only responsible for switching between protection domains.The OS functionality is provided by user-level components(servers), which can be replaced,augmented,or layered.The programming model is client/server; client components(applications)request services from system components(servers). Examples of system components are the interrupt dispatcher,scheduler,portal manager, device driver,®le system,virtual memory,and so on.The Pebble kernel and its essential components(interrupt dispatcher,scheduler,portal manager,real-time clock,console driver,and idle task)need approximately560Kbytes of ponents are like processes,where each one executes in its own protection domain(PD).In Pebble,a PD includes a page table and a set of portals.Portals provide communication between PDs.For example,if there is a portal from PD1to PD2,then a thread executing in PD1can invoke a speci®c service(entry point)of PD2.Therefore, components communicate through transferring threads from one PD to another using portals.The PD concept together with the portal concept can be understood as a component infrastructure.While Pebble PDs provide the means to isolate the components,portals provide the means for components to communicate with each other.Instantiation and management of portals are performed by an operating system component,Portal Manager.For instance,the instantiation process involves the registration of a server(any system or application component)in a portal and the request of a client for that portal.In Pebble,it is possible to dynamically load and to replace system components to ful®ll applications requirements.2.4.QoS-BasedKernelsQoS research has been extensive,®rst as applied to networking then to general distributed computing.More recently,QoS has been applied to soft real-time systems.In these systems,a guarantee is given that a certain amount of resources is assigned to a task or application.In other cases,there are differentiated guarantees meaning that certain classes of tasks are guaranteed resources compared to another class of tasks.For example, tasks dealing with the control of the plant may be required to obtain twice the resources than tasks reporting the results to a command center.The resources being controlled may just be the CPU or a set of resources.Many research results exist for developing algorithms to control the guarantees.Sometimes,these algorithms are implemented as monitors on top of an RTOS.In other cases,the algorithms may be implemented asREAL-TIME OPERATING SYSTEMS243 middleware(Brandt et al.,1998).The algorithms differ in their approach and utilize many different techniques such as fair-share scheduling(Jeffay et al.,1998),proportional scheduling(Stoica et al.,1996),rate-based scheduling(Jeffay,2001),reservations,and feedback control.In this paper,we are more interested in RTOS that incorporate QoS support such as RT Mach(Tokuda et al.,1990)and Rialto(Jones et al.,1996,1997).Both of these RTOSs allow users to negotiate with the RTOS for a certain amount of resources.RT-Mach employs reservations to support QoS.RT-Mach supports multimedia applications and both real-time and non-real-time tasks.Rialto allows for multiple,independent applications to co-exist.A system-wide planner reasons about the resource allocations between applications.This is similar to the reservation and admission control type work discussed above,but here,independent applications are supported on a single platform. Rialto also has support for overload and for re-negotiation of guarantees.2.5.Research KernelsMany past and current University-based research-oriented real-time operating systems have been developed.These projects addressed many of the following research issues including:*identifying the need for new approaches which challenge the basic assumptions made by timesharing operating systems and developing those new paradigms;*developing real-time process models:*some systems use the standard process model both to program with and at execution time,*some systems use the process model to program with but translate into a different run-time model to help support predictability and on-line guarantees, *some systems use real-time threads;*developing real-time synchronization primitives such as those that support priority inheritance and priority ceiling protocols;*developing solutions that facilitate timing analysis of both the initial system and upon modi®cations(the real-time scheduling algorithms play a large role here);*strongly emphasizing predictability not only of the kernel but also providing good support for application-level predictability;*retaining signi®cant amounts of application semantics at run time;*developing support for fault tolerance;244STANKOVIC AND RAJKUMAR *investigating object-oriented approaches;*providing support for multiprocessor and distributed real-time systems including end-to-end timing constraints;*developing support for QoS;*attempting to de®ne a real-time micro-kernel;*providing support for real-time programming languages such as the Real-Time Speci®cation of Java(JSR-00001).We survey several research projects as representative of a much wider set of work in the®eld.2.5.1.MARSThe MARS kernel(Damm et al.,1989;Kopetz et al.,1989)offers support for controlling a distributed application based entirely on the passage of time(rather than asynchronous events)from the environment.Emphasis is placed on an a priori static analysis to demonstrate that all the timing requirements are met.An important feature of this system is that¯ow control on the maximum number of events that the system handles is automatic and this fact contributes to the predictability analysis.This system is based on a paradigm,that is,the time-triggered model,that is different than what is found in timesharing systems.The scheduling approach is static and table-driven.Support for distributed real-time systems includes a hardware-based clock synchronization algorithm and a TDMA-like protocol to guarantee timely message delivery.A number of extensions to the original work have added¯exibility to handle more dynamic situations.The time-triggered approach advocated in MARS has seen success in the automotive industry and in several other safety-critical application domains.2.5.2.SPRINGThe Spring kernel(Stankovic and Ramamritham,1995;Stankovic et al.,1999)contains real-time support for multiprocessors and distributed systems.A novel aspect of the kernel is the dynamic planning-based scheduling of tasks that arrive dynamically.Such tasks are subject to admission control and dynamically acquire reservations for resources. This takes tasks'time and resource constraints into account and avoids the need to a priori compute worst-case blocking times.Safety-critical tasks are dealt with through static table-driven scheduling.The kernel also embodies a re¯ective architecture (Stankovic and Ramamritham,1995)that retains a signi®cant amount of application semantics at run time.This approach provides a high degree of¯exibility along withREAL-TIME OPERATING SYSTEMS245 support for graceful degradation.These planning and application semantic features are integrated to provide direct support for achieving both application-and system-level predictability.The kernel also uses global replicated memory to achieve predictable distributed communication.The abstractions provided by the Kernel include dynamic guarantees,reservations,planning,and end-to-end timing support.Spring,like MARS, presents a new paradigm for real-time operating systems,but unlike MARS it strives for a more¯exible combination of off-line and on-line techniques.Concepts of admission control,re¯ection and reservations found in the Spring kernel have been used by many other systems.2.5.3.ARTSThe ARTS kernel(Tokuda and Merger,1989)provides a distributed real-time computing environment that works in conjunction with the static priority-driven preemptive scheduling paradigm.The kernel supports the notion of real-time objects and real-time threads.Each real-time object is time-encapsulated.This is enforced by a time fence mechanism which provides a run-time check that ensures that the slack time is greater than the worst-case execution time for an object invocation about to be performed.If it is, the operation proceeds,else it is aborted.Each real-time thread can have a value function, timing constraints,worst-case execution time,phase,and delay value associated with it. Communication(object invocation)proceeds in a request±accept±reply fashion,but does not address deadlines for messages.A real-time transport protocol has been developed. The ARTS kernel is also tied to various tools that a priori analyze the system-wide schedulability of the system.2.5.4.HARTOSThe hexagonal architecture for real-time systems(HARTS)consists of multiple sites connected by a hexagonal mesh network.Each site may be a uniprocessor or multiprocessor and contains an intelligent network processor.The intelligent network processor handles much of the low-level communication functions.An experimental operating system called HARTOS(Kandlur et al.,1992)is a distributed real-time kernel running on HARTS.On each site,HARTOS runs in conjunction with the commercial uniprocessor OS,pSOS.Hence,by itself,HARTOS is not a full operating system.Rather, HARTOS focusses on interprocess communication,thereby providing some support for distributed real-time systems.In particular,HARTOS supports message send and receive, non-queued event signals,reliable streams,and message scheduling that provides a best-effort approach in delivering a message by its deadline.Support for fault-tolerant routing, clock synchronization,and for replicated processes are also planned.246STANKOVIC AND RAJKUMAR 2.5.5.RKIn extensions to Real-Time Mach,Mercer et al.(1994)added the notion of processor reservations based on the Liu and Layland periodic task model of each task obtaining C i units of time every T i units of time.Rajkumar et al.(1998)generalized this concept to the notion of a resource kernel,which is de®ned as one which provides guaranteed,timely and enforced access for applications to system resources.In addition,scheduling policies could be changed within the OS without affecting any guarantees.Resources that could be guaranteed access to can include CPU cycles(Rajkumar et al.,1988),disc bandwidth (Molano et al.,1997;Saewong and Rajkumar,2003),network bandwidth(Ghosh and Rajkumar,2002)or memory space(Easwaran and Rajkumar,2004).Resource reservations on multiple resources could also be combined to form a resource set to which one or more applications could be bound.An application bound to a resource set essentially has access to a``virtual machine''that comprises a time-or space-multiplexed subset of the underlying physical resources.This virtualization also enabled the binding of binary images to be bound to arbitrarily sized reservations(w/o access to source).An interesting variation of the priority inversion problem occurs when processes bound to two(or more)different reservations need to share a resource(such as the X-windows server).Solutions to this problem are also based on variants of priority inheritance and led to reservation inheritance protocols(de Niz et al.,2001).Counter-intuitive as it may seem,the reservation model of guaranteeing and enforcing C i units of time every T i units of time is not just useful for periodic tasks.It can also act as a traf®c shaper to aperiodic tasks in the exact same spirit of a deferrable(Sprunt et al., 1989)or sporadic server(Strosnider et al.,1995).3.ParadigmsReal-time operating systems utilize various paradigms.Key concepts found in these paradigms include:hard and soft real-time guarantees,admission control,re¯ection, reservations,and resource kernels.Many of these key concepts work together in achieving the overarching paradigm presented by a particular kernel.3.1.HardandSoft Real-Tim e GuaranteesIn general,the smaller,more deterministic kernels provide support for hard deadline systems.Here all the inputs and system details are known,and careful design and analysis can result in meeting hard deadline requirements.In performing the analysis it is also possible to carefully account for the kernel overheads.Safety-critical hard real-time systems also typically employ comfortable margins on resource utilization(such as ensuring that total utilization on a resource does not exceed50±60%).The larger,more dynamic,more probabilistic kernels provide support for soft real-time systems.Here quality of service guarantees are de®ned and shown to be met in aREAL-TIME OPERATING SYSTEMS247 probabilistic sense.We sometimes®nd hierarchical real-time scheduling or partitioned scheduling to handle different classes of tasks.3.2.Admission ControlAdmission control is a function that decides if new work entering the system should be admitted or not.The key ingredients of admission control include a model of the state of system resources,knowledge about the incoming request,the exact algorithm to make the admission control decision,and policies for the actions to take upon admission and upon rejection.First consider hard real-time systems.Many hard real-time systems are statically scheduled and operate in highly deterministic fashion.This facilitates the timing analysis required of these systems and there is no notion of admission control.But,many hard real-time systems operate in dynamic environments where static scheduling is too costly or rigid.What is required is a solution that enables on-line careful timing analysis and dynamic scheduling.A solution provided in the Spring kernel (Stankovic and Ramamritham,1989,1995)included the synergistic combination of admission control,resource reservation,and re¯ection;so this concept already exists in the hard real-time domain.Here the model of the state of the system is a detailed timeline that identi®es the start and®nish time(based on a worst-case execution time model)for each admitted task on each resource that it requires.Signi®cant re¯ective information is known about each incoming task because they are pre-analyzed for a particular real-time system;there are no general purpose on-the-¯y tasks created.The re¯ective information known about the requested work includes the worst-case execution time,shared data required by this task,precedence constraints,importance level,which tasks communicate with this task,deadline,etc.The algorithm is a heuristic that schedules the task on the detailed time line along with all the previously admitted tasks in such a manner that if successful,all the tasks will meet their deadlines.See Zho et al.(1987)for a detailed description of the algorithm.If the task is admitted,it has been assigned a very speci®c time-slice(although it may actually execute early under certain conditions).If it is not admitted,then a separate policy is invoked to decide what action to take.Typical actions include:try a simpler version of the task if any exists,or if the deadline is far away try to schedule the task on another node,or if the deadline is close then just reject this task. These policies can be modi®ed based on the importance of the task.The low-level details of the entire guaranteed schedule are available to the application.A large amount of application semantic information is pushed into the kernel(via the compiler and a special system description language).For example,the process control block(PCB)contains,in addition to the typical information,worst case execution times,deadline information, precedence requirements,a communication graph,fault-tolerance information,etc. Work on supporting QoS for audio and video has also used admission control and reservations.In many systems,various amounts and types of re¯ective information are also used.The typical model of the system has been utilizations identi®ed independently for multiple resources such as CPU,network bandwidth,disc,and memory.The precise admission control algorithm has varied from system to system,but it is usually based on。
制作爆米花的英语小作文

制作爆米花的英语小作文Title: The Art of Making Popcorn。
Popcorn, a timeless snack loved by people of all ages, holds a special place in the realm of culinary delights.Its humble yet irresistible allure has captured the hearts and taste buds of millions worldwide. In this essay, we embark on a journey to explore the art of making popcorn, from its origins to modern-day techniques.First and foremost, let us delve into the history of popcorn. Originating from the Americas, popcorn has been enjoyed for centuries by indigenous peoples. Archaeological evidence suggests that popcorn was not only consumed as a snack but also used in ceremonies and festivities. Its discovery by European explorers in the 16th century led to its introduction to the rest of the world, where it quickly gained popularity.The process of making popcorn is both simple andfascinating. It all starts with the humble popcorn kernel, a tiny seed with immense potential. When exposed to heat, the moisture inside the kernel turns into steam, creating pressure. Eventually, the pressure becomes too much for the kernel to contain, causing it to explode and transform into the fluffy treat we know and love.Traditionally, popcorn was made using a variety of methods, including popping kernels over an open flame or in a covered pot. However, with advancements in technology, new methods have emerged, making popcorn preparation more convenient and efficient. One such method is using a popcorn machine, which evenly heats the kernels and ensures a consistent popping experience.In recent years, microwave popcorn has become increasingly popular due to its convenience and ease of preparation. Simply placing a pre-packaged bag of kernels in the microwave results in a quick and delicious snack in a matter of minutes. However, some purists argue that the traditional stovetop method yields superior taste and texture, as it allows for greater control over the poppingRegardless of the method chosen, the key to making perfect popcorn lies in selecting high-quality kernels and using the right amount of heat. Overheating can lead to burnt popcorn, while underheating may result in unpopped kernels. Finding the perfect balance is essential for achieving that ideal crunchy texture and satisfying flavor.In addition to the classic buttered popcorn, there are countless variations and flavor combinations to explore. From sweet and savory to spicy and tangy, the possibilities are endless. Experimenting with different seasonings, such as caramel, cheese, or chili powder, can elevate the humble popcorn into a gourmet delight.Moreover, popcorn is not only a delicious snack but also a versatile ingredient in various culinary creations. Its light and airy texture make it an ideal addition totrail mixes, granola bars, and even desserts like popcorn balls and cakes. Its gluten-free and whole grain nature also makes it a healthier alternative to traditional snackIn conclusion, the art of making popcorn is a timeless tradition that continues to evolve with time. Whether enjoyed at home during movie nights or served at social gatherings and events, popcorn never fails to bring people together and create cherished memories. So, the next time you indulge in a bowl of freshly popped popcorn, take a moment to appreciate the history, craftsmanship, and sheer joy that this beloved snack brings into our lives.。
OracleEBSR12(12.1.3)InstallationLinux(64bit)

OracleEBSR12(12.1.3)InstallationLinux(64bit)Oracle EBS R12 (12.1.3) Installation Linux(64 bit)ContentsObjective. 31 Download & Unzip. 3Download. 3Unzip. 3MD5 Checksums. 42 Pre-Install Task. 5Disk Space. 5Specific Software Requirements. 5RPM (6)JDK. 8OS User & Group. 113 Installation process. 12Export Display. 12./rapidwiz. 12Add Env parameter to .bash_profile file. 26Set Start and Stop shell for APP and DB. 27Default DB & Apps password. 27R12 Directory Structure. 284 After Installation process. 29Register for ZHS license. 29Patch( also for some application and database bugs). 305 After Installation process(Chinese Version). 32安装和升级前 (32)安装和升级时 (33)安装和升级后 (33)6 Upgrade to 12.1.3. 36Download patch 9239090. 36Documents. 36Installation process. 377 After Upgrade. 39Autoconfig. 39Preclone. 408 Issues & Solutions. 40ObjectiveStep by Step instructions to install Oracle Applications R12(12.1.1) on Oracle Enterprise Linux 5 are described in this article. This is a single node installation, meaning that the database, all product directories and AD core directories, and all servers (concurrent processing, forms, and Web) are installed on a single node under one common APPL_TOP.The database node and the Applications node can be installed on the same machine. This type of installation is generally used for small systems or for demonstration purposes. More commonly, the database node is installed on one machine, and the Applications node on another machine. This provides improved manageability, scalability, and performance.This document will take Linux 64 bit platform as example. And my hardware configuration isItem ConfigurationCPU 2 * Intel(R) Xeon(R) X56702.93GHzRAM 6 GDisk Space/u01 300 GB/u02 200 GB/ 100 GB1 Download & UnzipDownload(NOTE: Choose proper platform and 32 bit/64 bit download files)Download Tips:Use the following command for Batch download, firstly collect all URLs required and put it in a text file, say download.txt, one URL on a line wget -i download.txt(-i means Read URLs from file.)UnzipCreate stage area - for downloaded installation pack, just unzip all zip files under stage area directory StageR12, eg.unzip B53824-01_1of4.zip -d /u02/ StageR12unzip B53824-01_2of4.zip -d /u02/ StageR12… …After unzip, File Path in StageR12 like following,Also create a directory to store patch files, then as follows showing:MD5 ChecksumsStrongly suggest you perform MD5 check against the stage area.The md5 checksums for the staged directory structure can be used to validate the software integrity. Do this by running the md5sum program against the stage area using the oracle created checksum file. Note for can observe you have any problem with your stage ornot(Corrupted zip etc)MD5 Checksums for R12.1.1 Rapid Install Media (Doc ID 802195.1)2 Pre-Install TaskDisk SpaceFile System Space Requirements for Standard InstallationNode Space Required35 GB (50 GB on HP-UX Itanium)Applications node file system(includes OracleAS 10.1.2 OracleHome, OracleAS 10.1.3 OracleHome, COMMON_TOP,APPL_TOP,and INST_TOP)55 GBDatabase node file system (Freshinstall)208 GB (210 GB on HP-UX Itanium)Database node file system (VisionDemo Database)Stage area(unzipped files)47 GBThe total space required for a standard system (not including the stage area) is 85 GB for a fresh install with a production database, and 233 GB for a fresh install with a Vision Demo database.You can use below Unix command to check disk spacedf –hSpecific Software RequirementsThe following maintenance tools must be installed on machine, and their locations specified both in the PATH of the account that runs Rapid Install and in the PATH of the accounts that will own the database tier and application tier file systems.Operating System Required Maintenance ToolsLinux x86ar, gcc, g++, ld, ksh, make, X DisplayServerLinux x86-64ar, gcc, g++, ld, ksh, make, X DisplayServerHP-UX Itanium ar, cc, aCC, make, X Display ServerHP-UX PA-RISC ar, cc, aCC, make, X Display ServerIBM AIX on Power Systems (64-bit)ar, cc, aCC, make, X Display ServerMicrosoft Windows Server (32-bit)ar, cc, ld, linkxlC, make, X DisplayServerSun Solaris SPARC (64-bit)ar, ld, make, X Display ServerRPMPer Note: 761566.1First, you should check your Linux Kernel, to determine your linux version, enter:uname –rSo my Linux is Linux 6, For Linux 6, Required Packages isGA (6.0) or higher of Oracle Linux 6 is requiredopenmotif21-2.1.30-11.EL6.i686 (32-bit)1xorg-x11-libs-compat-6.8.2-1.EL.33.0.1.i386 (32-bit)The following packages must be installed from the Oracle Linux 6 distribution media:binutils-2.20.51.0.2-5.11gcc-4.4.4-13.el16.x86_64gcc-c++-4.4.4-13.el16.x86_64glibc-2.12-1.7.el6.i686 (32-bit)glibc-2.12-1.7.el6.x86_64glibc-common-2.12-1.7.el6.x86_64glibc-devel-2.12-1.7.el6.i686 (32-bit)glibc-devel-2.12-1.7.el6.x86_64libgcc-4.4.4-13.el6.i686libgcc-4.4.4-13.el6.x86_64libstdc++-devel-4.4.4-13.el6.i686libstdc++-devel-4.4.4-13.el6.x86_64libstdc++-4.4.4-13.el6.i686libstdc++-4.4.4-13.el6.x86_64make-3.81-19.el6.x86_64gdbm-1.8.0-36.el6.i686gdbm-1.8.0-36.el6.x86_64libXp-1.0.0-15.1.el6.i686libXp-1.0.0-15.1.el6.x86_64libaio-0.3.107-10.el6.i686libaio-0.3.107-10.el6.x86_64libgomp-4.4.4-13.el6.x86_64sysstat-9.0.4-11.el6.x86_64util-linux-ng-2.17.2-6.el6.x86_64unzip-5.52-3.0.1.el5.x86_642compat-libstdc++-296-2.96-144.el6.i686compat-libstdc++33-3.2.3-69.el6.i686Additionally, the following RPMs are required for the database tier running 11gR2 (users must upgrade the bundled 11gR1 DB to 11gR2 either before or after installing 12.1) on the database tier:compat-libstdc++-33-3.2.3-69.el6.x86_64elfutils-libelf-devel-0.148.1-el6.x86_64kernel-uek-headers-2.6.32-100.28.5.el6.x86_64libaio-devel-0.3.107-10.el6.x86_64unixODBC-2.2.14-11.el6.i686unixODBC-devel-2.2.14-11.el6.i686unixODBC-2.2.14-11.el6.x86_64unixODBC-devel-2.2.14-11.el6.x86_64xorg-x11-utils-7.4-8Note:1: The openmotif package version must be 2.1.30 (for example, openmotif-2.3.3-1 is not supported).2: This unzip package (available from EL 5 distribution) is only required for purposes of running Rapid Install to unzip the required EBS files as part of the installation.Be sure you have above rmp on your system, you can use below command to check whether RPM packages are installed or notrpm -qa --queryformat "%{NAME}-%{VERSION}.%{RELEASE} (%{ARCH})\n" | grep gccq = querya = allWhat’s the RPM:The Red Hat Package Manager (RPM) is a toolset used tobuild and manage software packages on UNIX systems. Distributed withthe Red Hat Linux distribution and its derivatives (CentOS is 100%compatible rebuild of the Rehat Enterprise Linux).The RPM files represent application or package that you can install onLinux system.JDKJDK 6 is bundled with Oracle E-Business Suite version 12.1.1. You do NOT need to install the JDK separately./etc/hostsFor Oracle Linux 4, 5 and 6, and Red Hat Enterprise Linux 4 and 5:Verify that the /etc/hosts file is formatted as follows:127.0.0.1 localhost.localdomain localhost[ip_address] [node_name].[domain_name] [node_name]/etc/sysconfig/networkVerify that the /etc/sysconfig/network file is formatted as follows:HOSTNAME=[node_name].[domain_name]/etc/sysconfig/networking/profiles/default/networkIf the /etc/sysconfig/networking/profiles/default/network file exists, remove it.If you changed any files in the previous steps, restart the system./etc/sysctl.confEdit the /etc/sysctl.conf file to configure your kernel settings. After editing the file, use the "sysctl -p" command or restart the system to invoke the new settings.Note: If the current value for any parameter is higher than the value listed in the following table, then do not change the value of that parameter.The following table lists the kernel settings for Oracle Linux 4, 5 and 6, Red Hat Enterprise Linux AS/ES 4 and 5, and SUSE Linux Enterprise Server 9 and 10:1: set using the following entry in the /etc/sysctl.conf file: kernel.sem = 256 32000 100 1422: On the server running the EBS Database, this kernel parameter must be the lesser of half the size of the physical memory (in bytes) and 42949672953: values recommended for the local port range may need to be adjusted according to the specific needs of the user's environment in order to avoid port conflicts./etc/security/limits.confOpen the /etc/security/limits.conf file and change the existing values for "hard" and "soft" parameters as follows. Restart the system after making changes.Note: If the current value for any parameter is higher than the value listed in this document, then do not change the value of that parameter.* hard nofile 65535* soft nofile 4096* hard nproc 16384* soft nproc 2047/etc/resolv.confAdd or update the following entries to these minimum settings in the/etc/resolv.conf file on each server node:options attempts:5options timeout:15OS Library Patch for Oracle HTTP Server(on Oracle Linux 5, RHEL 5 and Oracle Linux 6 only)Download and apply the patch 6078836 from My Oracle Support to fix an issue with the Oracle HTTP Server (missing libdb.so.2) bundled with the E-Business Suite technology stack.Note that this patch (which includes a required operating system library) must be applied before installing Oracle E-Business Suite. Without this patch, after installation, HTTP Server cannot start.Link to Motif library in Oracle Application Server 10.1.2 (on Oracle Linux 5 and RHEL 5 only)Perform the following command (as root on your system) to update a required link to a Motif library prior to relinking or patching the 10.1.2 Application Server Oracle Home:# unlink /usr/lib/libXtst.so.6# ln -s /usr/X11R6/lib/libXtst.so.6.1 /usr/lib/libXtst.so.6OS User & GroupGenerally for PROD instance, we need create two OS user for installation, one user is used to manage DB, the other is used to manage Apps.Since our instance is a TEST instance, so for simple, we just create one user to manage DB and Apps, Here we use ‘oracle’ as user, use ‘oinstall’ as group.# groupadd oinstall -g 2000# useradd -g oinstall -u 2000 oracle# chown -R oracle:oinstall /u01/oraclechown changes the user and/or group ownership of each given file.-R, operate on files and directories recursively3 Installation processExport DisplayTo ensure we have a graphical installation process, we can export server to our local linux which have X window system. If your server have installed X window, then you can ignore this step.(ptian) ptian- env | grep ALTDISPLAYALTDISPLAY=:50(First, in our local linux, Check our local linux’s host and port)(ptian) ptian- ssh admin@admin@'s password:Last login: Thu May 31 21:32:49 2012 from 10.182.114.9(SSH to server which we intend to install EBS)[admin@bej301441 ~]$ export DISPLAY=:50./rapidwizIf you intend to use standard installation mode, you need login as root user.[root@bej301441 rapidwiz]#cd /u02/StageR12/startCD/Disk1/rapidwiz[root@bej301441 rapidwiz]# ./rapidwizRapid Install Wizard is validating your file system......4 dvd labels foundRapid Install Wizard will now launch the Java Interface.....NextNext, then no need to fill the Email, Next againDefault Oracle EBS PortsPort numbers can be modified during installation or may be automatically incremented by x during installation where x is a number 1 to 100 (typical less than 10). Port number ranges are often a grouping of 3, 4, 5, or 6 contiguous ports in the specified range.Another case, for fresh installation, as follows:Note the languages and character set chosen, as follows:Then for Vision Demo or Fresh install, will pop up below to checkWill spend almost 3 hours belowAdd Env parameter to .bash_profile file.bash_profile is a bash shell that is started when login.For DB user, Modify /.bash_profile, add your DB env file path into it, eg.. /u01/oracle/mc3yd213/db/tech_st/11.1.0/mc3yd213_bej301441.envFor Apps user, Modify /.bash_profile, add your Apps env file path into it, eg.u01/oracle/mc3yd213/apps/apps_st/appl/APPSmc3yd213_bej301441.envSet Start and Stop shell for APP and DBCreate stopAPP.sh and startAPP.sh under APP owner home (like /home/applmgr) to stop and start EBS, as follows: stopAPP.sh file:source .appadstpall.sh apps/appsstartAPP .sh file:source .appadstrtal.sh apps/appsAslo change owner to applmgr of stopAPP.sh and startAPP .sh.Create stopDB.sh and stopDB.sh under oracle owner home (like /home/oracle) to stop and start EBS, as follows: stopDB.sh file:source .oraaddlnctl.sh stop PRODstartDB.sh file:source .oraaddlnctl.sh start PRODaddbctl.sh startAslo change owner to oracle of stopDB.sh and startDB .sh.Then we can use these four files to stop/start the DB/APP。
空气炸锅煮玉米花的流程

空气炸锅煮玉米花的流程Using an air fryer to cook popcorn may not be the traditional method, but it can be a fun and convenient way to enjoy this popular snack. 空气炸锅煮爆米花可能不是传统的方法,但这可以是一种有趣又方便的方式来享受这种受欢迎的零食。
First, prepare the corn kernels by placing them in a bowl and adding a small amount of oil and some salt. Mix well to ensure that the kernels are evenly coated. 首先,准备爆米花粒,将它们放在一个碗里,加入少量的油和一些盐。
充分搅拌确保玉米粒均匀地涂上油和盐。
Then, preheat the air fryer to the recommended temperature, whichis typically around 400°F (200°C). T his will ensure that the popcorn kernels cook evenly and quickly. 接下来,将空气炸锅预热到建议的温度,通常约为400°F(200°C)。
这将确保爆米花粒均匀快速地煮熟。
Once the air fryer is preheated, transfer the seasoned corn kernels into the air fryer basket and spread them out in a single layer. It's important not to overcrowd the basket to ensure that each kernelhas enough room to pop evenly. 一旦空气炸锅预热,将调味后的玉米粒倒入炸篮中,并将它们铺开成一层。
操作系统英文版课后习题答案整理

1.1What are the three main purposes of an operating system?(1)帮助执行用户程序(2)管理软硬件资源(3)为用户提供操作接口(4)组织用户更好地使用计算机1.2 List the four steps that are necessary to run a program on a completely dedicated machine. Preprocessing > Processing > Linking > Executing.答:(1)预约计算机时间(2)手动把程序加载到内存(3)加载起始地址并开始执行(4)在电脑的控制台监督和控制程序的执行1.6 Define the essential properties of the following types of operating systems:a. Batchb. Interactivec. Time sharingd. Real timee. Networkf. Distributed答:A.批处理系统:成批处理作业,用户脱机工作,单、多道程序运行,适合处理需要很少交互的大型工件; B.交互式系统:交互性,及时性 C.分时系统:同时性,交互性,及时性,独立性D.实时系统:对时间有严格要求,外部事件驱动方式,响应及时,容错-双机备份,可靠性高,通常为特殊用途提供专用系统 E、网络操作系统:网络通信,可实现无差错的数据传输;共享软硬件;网络管理(比如安全控制);网络服务 F、分布式系统:多台分散的计算机经互联网连接而成的系统,处理器不共享内存和一个时钟,每个处理器有自己的内存,它们通过总线互相交流。
1.7 We have stressed the need for an operating system to make efficient use of the computing hardware. When is it appropriate for the operating system to forsake this principle and to“waste” resources? Why is such a system not really wasteful?答:单用户系统,它应该最大化地为用户使用,一个GUI(图形化用户接口)可能会浪费CPU周期,但是它优化了用户和系统的交互。
Ubuntu 12.04 Virutal Machine User Manual

User Manual of the Pre-built Ubuntu12.04Virutal MachineCopyright c 2006-2014Wenliang Du,Syracuse University.The development of this document is/was funded by three grants from the US National Science Foundation: Awards No.0231122and0618680from TUES/CCLI and Award No.1017771from Trustworthy Computing.Permission is granted to copy,distribute and/or modify this document under the terms of the GNU Free Documentation License,Version1.2or any later version published by the Free Software Foundation.A copy of the license can be found at /licenses/fdl.html.1OverviewUsing VirtualBox,we have created a pre-built virtual machine(VM)image for UbuntuLinux(version 12.04).This VM can be used for all our SEED labs that are based on Linux.In this document,we describe the configuration of this VM,and give an overview of all the software tools that we have installed.The VM is available online from our SEED web page.Updating the VM is quite time-consuming,because not only do we need to udpate the VM image,we have to make sure that all our labs are consistent with the newly built VM.Therefore,we only plan to update our VM image once every two years,and of course update all our labs once the VM is changed.2VM Configurations2.1Configuration of the VMThe main configuration of this VM is summarized in the following.If you are using VirtualBox,you can adjust the configuration according to the resources of your host machine(e.g.,you can assign more memory to this VM if your host machine has enough memory):•Operating system:Ubuntu12.04with the Linux kernel v3.5.0-37-generic.•Memory:1024M RAM.•Disk space:Maximum80G disk space.We have created two accounts in the VM.The usernames and passwords are listed in the following:er ID:root,Password:seedubuntu.Note:Ubuntu does not allow root to login directly from the login window.You have to login asa normal user,and then use the command su to login to the root account.er ID:seed,Password:dees2.2Network setupCurrently the“Network connection”is set to“NAT”,i.e.,your VM is put in a private network,which uses your host machine as the router.The VMs in such a setting can connect to the Internet via the NAT mechanism,and they are not visible to the outside(their IP addresses are not routable from the outside,e.g., VirtualBox assigns10.0.2.15to each VM under NAT configuration).This setting is sufficient for most of our SEED labs.If you want your VMs to be visible to the outside(e.g.,you want to host a HTTP server in a VM, and you want to access it through the Internet),then,you can refer to the instruction“Network Configu-ration in VirtualBox for SEED Labs”under the following link:/˜wedu/ seed/Documentation/Ubuntu11_04_VM/VirtualBox_MultipleVMs.pdf.The instruction was written for Ubuntu11.04,however,it also works for the updated Ubuntu12.04Virtual Machine as well.3Libraries and Software3.1Libraries and Applications InstalledBesides the packages coming with the Ubuntu12.04installation,the following libraries and applications are additionally installed using the"apt-get install"command.libnet1,libnet1-dev,libpcat-dev,libpcap-dev,libattr1-dev,vim,apache2,php5,libapache2-mod-php5,mysql-server,wireshark,bind9,nmap,netwox/netwag,openjdk-6-jdk,snort,xpdf,vsftpd,telnetd,zsh,ssh,dpkg-dev,openssl,The libcap 2.21and libpcap1.2.0have been compiled and installed from the source down-loaded from the Internet.3.2Softwares configurationNetlib/netwox/wox is a network toolbox;netwag is a GUI of netwox.They can be foundin/usr/bin/.The ICMP spoofing bug of netwox has beenfixed.It should be noted that running netwox/netwag requires the root privilege.Wireshark.Wireshark is a network protocol analyzer for Unix and Windows.It is located in/usr/bin/. Wireshark requires the root privilege to run.Nmap.Nmap is a free security scanner for network exploration and hacking.It is located in/usr/bin/. Some functions of nmap require root privilege.Firefox extensions.Firefox is installed by default in Ubuntu12.04.We have installed some useful extensions,including LiveHTTPHeaders,Tamper Data,and Firebug.They can be launched in the “Tools”menu in Firefox.Elgg web application.Elgg is a very popular open-source web application for social network,and we use it as the basis for some of Web security labs.It should be noted that to access Elgg,the apache2http server and the MySQL database server must be running.Collabtive web application.For some labs,especially those related to web security,we need a non-trivial web application.For that purpose,we have installed the Collabtive web application.Several versionsof Collabtive are installed;most of them were modified from the original version to introduce different vulnerabilities.It should be noted that to access Collabtive,the apache2http server and the MySQL database server must be running.Java.We have installed openjdk-6-jdk,the OpenJDK Development Kit(JDK)6for Java.The com-mands javac and java are available to compile and run java source code.4Pre-Installed ServersSome of the SEED labs may need additional services that are not installed or enabled in the standard Ubuntu distribution.We have included them in our pre-built VM.Note:You need root privilege to start a server.4.1The MySQL ServerThe database server MySQL is installed.It can be started by running"service mysql start".Cur-rently,there are two accounts in the MySQL server.The usernames and passwords are listed below.1.root:seedubuntu2.apache:apache(web applications use this account to connect to the mysql server)You can access the MySQL database server by running the client-side application/usr/bin/mysql. The following is a simple demo on how to use mysql.$mysql-u root-pseedubuntumysql>show databases;mysql>use db_name;mysql>show tables;mysql>select username,user_email from table_name;mysql>quit4.2The Apache2Http ServerThe apache2http server was installed using"apt-get install".It can be started by issuing the "service apache2start"command.The apache2server is configured to listen on both80and 8080ports.All the web pages hosted by the server can be located under the/var/www/directory.For each SEED lab that uses the apache2http server,we have created one or several URLs.Basically, in the pre-built VM image,we use Apache server to host all the web sites used in the lab.The name-based virtual hosting feature in Apache could be used to host several web sites(or URLs)on the same machine.A configurationfile named default in the directory"/etc/apache2/sites-available"contains the necessary directives for the configuration.The following is a list of URLs that we have pre-configured; their corresponding directories are also listed:/var/www/CSRF/Collabtive//var/www/CSRF/Attacker//var/www/SQL/Collabtive//var/www/XSS/Collabtive//var/www/SOP//var/www/SOP/attacker//var/www/SOP/Collabtive/:8080/var/www/SOP/Configuring DNS.The above URL is only accessible from inside of the virtual machine,because we have modified the/etc/hostsfile to map each domain name to the virtual machine’s local IP address (127.0.0.1).You may map any domain name to a particular IP address using the/etc/hosts.For example you can map to the local IP address by appending the following entry to/etc/hostsfile:Therefore,if your web server and browser are running on two different machines,you need to modify the/etc/hostsfile on the browser’s machine accordingly to map the target domain name to the web server’sIP address.4.3Other ServersDNS server The DNS server bind9is installed.It can be started by running"service bind9 start".The configurationfiles are under/etc/bind/.Ftp server.The vsftpd(very secure ftp daemon)server is installed.It can be started by running "service vsftpd start".Telnet server.The telnetd server is installed.It can be started by running"service openbsd-inetd start".SSH server.The openssh server is installed.It can be started by running"service ssh start".5Miscellanious ConfigurationTime zone Currently the time zone is set to be New York,adjust that to the time zone of your location. Display resolution In order to adjust the display resolution in VirtualBox,we have installed guest addi-tions from the terminal(not from the menu in VirtualBox).This is done with the following3commands: sudo apt-get install virtualbox-ose-guest-utilssudo apt-get install virtualbox-ose-guest-x11sudo apt-get install virtualbox-ose-guest-dkmsAfter installing the required additions,you can adjust the display resolution at“System Settings→Dis-plays→Monitor”.6Configure Your VM securely6.1Change the passwordFor the sake of security and your own convenience,we suggest that you change the account password.To change the Ubuntu’s account password.You need to login as root and issue the"passwd username" command.To change MySQL’s root password.You can do it as following:$mysql-u root-pseedubuntuOnce in the prompt do this:mysql>update user set User=’NewRootName’,Password=’NewPassword’where user=’root’;mysql>flush privileges;6.2Configure automatically start serviceIt’s more convenient to start some commonly used service automatically during the system boot up,although most people do not want to start some server that they do not use.Currently,most of the service(except the Apache and MySQL servers)we need for SEED labs are configured not to start automatically.You can use chkconfig to get the current configuration.You can also use chkconfig to modify the configuration.For example,to start the server XYZ automatically during the system bootup,run"chkconfig XYZ on".。
最新 人脸识别和视频分析的若干新方法

2
• 无监督学习
在无监督学习算法或“聚类算法”中并没有显式的教师。系统 对输人样本自动形成“聚类”(cluster)或“自然的”组织。
• 有监督学习
在有监督学习中,存在一个教师信号,对训练样本集中的每个 输入样本能提供类别标记和分类代价,并寻找能降低总体代价的 方向。
• FRVT2006测试结果:
测试条件 图像质量 测试 人数 测试图 像数 错误拒绝率FRR(%)
FAR=0. 01 2.0
2.8 8.5 26.0 22.0
FAR=0.1 1.1
2.2 2.6 11.7
FAR=1 0.7
2.0 1.3 5.0 6.0
超高分辨率 受控光照
高分辨率 低分辨率 非受控光照 超高分辨率 高分辨率
336
263 3600 0* 335 257
7496
14365 108000 5402 7192
13.3
现有的最好的产品远不能满足视频监控的需要。
8
原象学习的工作进展
• 人脸的光照、姿势问题可以归结为非线性问题。 1) PCA,LDA线性分析的工具; 2)核分析方法可以在高维空间将非线性数据线性 化。 • KPCA+Pre-image 学习 求解高维空间表达像在原始样本空间的对应表达
Wei-Shi Zheng, JianHuang Lai and Pong C Yuen,Penalized Pre-image Learning in Kernel Principal Component Analysis, IEEE Transactions on Neural Networks (TNN), vol. 21, no. 4, pp. 551-570, 2010. WS Zheng and Jh Lai, Regularized Locality Preserving Learning of Pre-Image Problem in Kernel Principal Component Analysis, Volume 2 , pp. 456 - 459, ICPR, 20-24 Aug. 2006. HongKong. WS Zheng, JH Lai and PC Yuen, Weakly Supervised Learning on Pre-image Problem in Kernel Methods, Volume 2 , pp. 711 – 715, ICPR, 20-24 Aug. 2006. HongKong.
NVIDIA cuDNN 最佳实践指南:3D卷积函数优化说明书

Best PracticesTable of ContentsChapter 1. Introduction (1)Chapter 2. Best Practices For Medical Imaging (2)2.1. Recommended Settings In cuDNN While Performing 3D Convolutions (2)2.1.1. cuDNN 8.x.x (2)2.1.2. cuDNN 7.6.x (3)Chapter 3. Medical Imaging Performance (5)Chapter 4. Medical Imaging Limitations (6)Chapter 1.IntroductionATTENTION: These guidelines are applicable to 3D convolution and deconvolution functionsstarting in NVIDIA® CUDA® Deep Neural Network library™ (cuDNN) v7.6.3.This document provides guidelines for setting the cuDNN library parameters to enhance the performance of 3D convolutions. Specifically, these guidelines are focused on settings such as filter sizes, padding and dilation settings. Additionally, an application-specific use-case, namely, medical imaging, is presented to demonstrate the performance enhancement of 3D convolutions with these recommended settings.Specifically, these guidelines are applicable to the following functions and their associated data types:‣cudnnConvolutionForward()‣cudnnConvolutionBackwardData()‣cudnnConvolutionBackwardFilter()For more information, see the cuDNN Developer Guide and cuDNN API.Chapter 2.Best Practices For MedicalImagingTo optimize your performance in your model, ensure you meet the following general guidelines:LayoutThe layout is in NCHW format.Filter sizeThe filter size is Tx1x1, Tx2x2, Tx3x3, Tx5x5, where T is a positive integer. There areadditional limits for the value of T in wgrad and strided dgrad.StrideArbitrary for forward and backward filter; dgrad/deconv: 1x1x1 or 2x2x2 with 2x2x2 filter. DilationThe dilation is 1x1x1.PlatformThe platform is Volta, Turing, and Ampere with input/output channels divisible by 8.Batch/image sizecuDNN will fallback to non-Tensor Core kernel if it determines that the workspace required is larger than 256MB of GPU memory. The workspace required depends on many factors.For the Tensor Core kernels, the workspace size generally scales linearly with output tensor size. Therefore, this can be mitigated by using smaller image sizes or minibatch sizes.2.1. Recommended Settings In cuDNNWhile Performing 3D ConvolutionsThe following tables show the specific improvements that were made in each release.2.1.1. cuDNN 8.x.xRecommended settings while performing 3D convolutions for cuDNN 8.x.x.2.1.2.cuDNN 7.6.xRecommended settings while performing 3D convolutions for cuDNN 7.6.x.1NHWC /NCHW corresponds to NDHWC /NCDHW in 3D convolution.2With CUDNN_TENSOROP_MATH_ALLOW_CONVERSION pre-Ampere. Default TF32 math in Ampere.3NHWC/NCHW corresponds to NDHWC/NCDHW in 3D convolution. 4With NCHW <> NHWC format transformation.5FP16: CUDNN_TENSOROP_MATH6FP32: CUDNN_TENSOROP_MATH_ALLOW_CONVERSION7An arbitrary positive value.8padding = filter // 2Chapter 3.Medical ImagingPerformanceThe following table shows the average speed-up of unique cuDNN 3D convolution calls for each network that satisfies the conditions in Best Practices For Medical Imaging. The end-to-end training performance will depend on a number of factors, such as framework overhead, kernel run time, and model architecture type.Chapter 4.Medical ImagingLimitationsYour application will be functional but slow if the model has:‣Channel counts lower than 32 (gets worse the lower it is)‣Data gradients for convolutions with strideIf the above is in the network, use cuDNNFind to get the best option.NoticeThis document is provided for information purposes only and shall not be regarded as a warranty of a certain functionality, condition, or quality of a product. NVIDIA Corporation (“NVIDIA”) makes no representations or warranties, expressed or implied, as to the accuracy or completeness of the information contained in this document and assumes no responsibility for any errors contained herein. NVIDIA shall have no liability for the consequences or use of such information or for any infringement of patents or other rights of third parties that may result from its use. This document is not a commitment to develop, release, or deliver any Material (defined below), code, or functionality.NVIDIA reserves the right to make corrections, modifications, enhancements, improvements, and any other changes to this document, at any time without notice. Customer should obtain the latest relevant information before placing orders and should verify that such information is current and complete.NVIDIA products are sold subject to the NVIDIA standard terms and conditions of sale supplied at the time of order acknowledgement, unless otherwise agreed in an individual sales agreement signed by authorized representatives of NVIDIA and customer (“Terms of Sale”). NVIDIA hereby expressly objects to applying any customer general terms and conditions with regards to the purchase of the NVIDIA product referenced in this document. No contractual obligations are formed either directly or indirectly by this document.NVIDIA products are not designed, authorized, or warranted to be suitable for use in medical, military, aircraft, space, or life support equipment, nor in applications where failure or malfunction of the NVIDIA product can reasonably be expected to result in personal injury, death, or property or environmental damage. NVIDIA accepts no liability for inclusion and/or use of NVIDIA products in such equipment or applications and therefore such inclusion and/or use is at customer’s own risk. NVIDIA makes no representation or warranty that products based on this document will be suitable for any specified use. Testing of all parameters of each product is not necessarily performed by NVIDIA. It is customer’s sole responsibility to evaluate and determine the applicability of any information contained in this document, ensure the product is suitable and fit for the application planned by customer, and perform the necessary testing for the application in order to avoid a default of the application or the product. Weaknesses in customer’s product designs may affect the quality and reliability of the NVIDIA product and may result in additional or different conditions and/or requirements beyond those contained in this document. NVIDIA accepts no liability related to any default, damage, costs, or problem which may be based on or attributable to: (i) the use of the NVIDIA product in any manner that is contrary to this document or (ii) customer product designs.No license, either expressed or implied, is granted under any NVIDIA patent right, copyright, or other NVIDIA intellectual property right under this document. Information published by NVIDIA regarding third-party products or services does not constitute a license from NVIDIA to use such products or services or a warranty or endorsement thereof. Use of such information may require a license from a third party under the patents or other intellectual property rights of the third party, or a license from NVIDIA under the patents or other intellectual property rights of NVIDIA.Reproduction of information in this document is permissible only if approved in advance by NVIDIA in writing, reproduced without alteration and in full compliance with all applicable export laws and regulations, and accompanied by all associated conditions, limitations, and notices.THIS DOCUMENT AND ALL NVIDIA DESIGN SPECIFICATIONS, REFERENCE BOARDS, FILES, DRAWINGS, DIAGNOSTICS, LISTS, AND OTHER DOCUMENTS (TOGETHER AND SEPARATELY, “MATERIALS”) ARE BEING PROVIDED “AS IS.” NVIDIA MAKES NO WARRANTIES, EXPRESSED, IMPLIED, STATUTORY, OR OTHERWISE WITH RESPECT TO THE MATERIALS, AND EXPRESSLY DISCLAIMS ALL IMPLIED WARRANTIES OF NONINFRINGEMENT, MERCHANTABILITY, AND FITNESS FOR A PARTICULAR PURPOSE. TO THE EXTENT NOT PROHIBITED BY LAW, IN NO EVENT WILL NVIDIA BE LIABLE FOR ANY DAMAGES, INCLUDING WITHOUT LIMITATION ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, PUNITIVE, OR CONSEQUENTIAL DAMAGES, HOWEVER CAUSED AND REGARDLESS OF THE THEORY OF LIABILITY, ARISING OUT OF ANY USE OF THIS DOCUMENT, EVEN IF NVIDIA HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. Notwithstanding any damages that customer might incur for any reason whatsoever, NVIDIA’s aggregate and cumulative liability towards customer for the products described herein shall be limited in accordance with the Terms of Sale for the product.VESA DisplayPortDisplayPort and DisplayPort Compliance Logo, DisplayPort Compliance Logo for Dual-mode Sources, and DisplayPort Compliance Logo for Active Cables are trademarks owned by the Video Electronics Standards Association in the United States and other countries.HDMIHDMI, the HDMI logo, and High-Definition Multimedia Interface are trademarks or registered trademarks of HDMI Licensing LLC.OpenCLOpenCL is a trademark of Apple Inc. used under license to the Khronos Group Inc.TrademarksNVIDIA, the NVIDIA logo, and cuBLAS, CUDA, CUDA Toolkit, cuDNN, DALI, DIGITS, DGX, DGX-1, DGX-2, DGX Station, DLProf, GPU, JetPack, Jetson, Kepler, Maxwell, NCCL, Nsight Compute, Nsight Systems, NVCaffe, NVIDIA Ampere GPU architecture, NVIDIA Deep Learning SDK, NVIDIA Developer Program, NVIDIA GPU Cloud, NVLink, NVSHMEM, PerfWorks, Pascal, SDK Manager, T4, Tegra, TensorRT, TensorRT Inference Server, Tesla, TF-TRT, Triton Inference Server, Turing, and Volta are trademarks and/or registered trademarks of NVIDIA Corporation in the United States and other countries. Other company and product names may be trademarks of the respective companies with which they are associated.Copyright© 2019-2020 NVIDIA Corporation. All rights reserved.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
I. INTRODUCTION N RECENT years, there has been a lot of interest in the study of kernel methods [2]–[4]. The basic idea is to map the data in the input space to a feature space via some nonlinear map , and then apply a linear method there. It is now well-known that the computational procedure depends only on in the feature space (where the inner products1 ), which can be obtained efficiently from a suitable kernel function . Besides, kernel methods have the important computational advantage that no nonconvex nonlinear optimization is involved. Thus, the use of kernels provides elegant nonlinear generalizations of many existing linear algorithms. A well-known example in supervised learning is the support vector machines (SVMs). In unsupervised learning, the kernel idea has also led to methods such as kernel-based clustering algorithms [5], [6], kernel independent component analysis [7], and kernel principal component analysis (PCA) [8]. While the mapping from input space to feature space is of primary importance in kernel methods, the reverse mapping from feature space back to input space (the pre-image problem) is also useful. Consider for example the use of kernel PCA for pattern denoising. Given some noisy patterns, kernel PCA first applies linear PCA on the -mapped patterns in the feature space, and then performs denoising by projecting them onto the subspace defined by the leading eigenvectors. These projections, however, are still in the feature space and have to be mapped back to the input space in order to recover the denoised patterns. Another example is in visualizing the clustering solu-
Abstract—In this paper, we address the problem of finding the pre-image of a feature vector in the feature space induced by a kernel. This is of central importance in some kernel applications, such as on using kernel principal component analysis (PCA) for image denoising. Unlike the traditional method in [1] which relies on nonlinear optimization, our proposed method directly finds the location of the pre-image based on distance constraints in the feature space. It is noniterative, involves only linear algebra and does not suffer from numerical instability or local minimum problems. Evaluations on performing kernel PCA and kernel clustering on the USPS data set show much improved performance. Index Terms—Kernel principal component analysis (PCA), multidimensional scaling (MDS), pre-image.
I
tion of a kernel-based clustering algorithm. Again, this involves finding the pre-images of, say, the cluster centroids in the feature space. More generally, methods for finding pre-images can be used as reduced set methods to compress a kernel expansion (which is a linear combination of many feature vectors) into one with fewer terms, and this can offer significant speed-ups in many kernel applications [9], [10]. However, the exact pre-image typically does not exist [1], and one can only settle for an approximate solution. But even this is nontrivial as the dimensionality of the feature space can be infinite. Schölkopf et al. [10] (and later in [1]) cast this as a nonlinear optimization problem, which, for particular choices of kernels (such as the Gaussian kernel2), can be solved by a fixed-point iteration method. However, as mentioned in [1], this method suffers from numerical instabilities. Moreover, as in any nonlinear optimization problem, one can get trapped in a local minimum and the pre-image obtained is, thus, sensitive to the initial guess. On the other hand, a method for computing the pre-images using only linear algebra has also been proposed [9], though it only works for polynomial kernels of degree two. While the inverse of typically does not exist, there is usually a simple relationship between feature-space distance and input-space distance for many commonly used kernels [11]. In this paper, we use this relationship together with the idea in multidimensional scaling (MDS) [12] to address the pre-image problem. The resultant procedure is noniterative and involves only linear algebra. Our exposition in the sequel will focus on the pre-image problem in kernel PCA. However, this can be applied equally well to other kernel methods, such as kernel -means clustering, as will be experimentally demonstrated in Section IV. The rest of this paper is organized as follows. Brief introduction to the kernel PCA is given in Section II. Section III then describes our proposed method. Experimental results are presented in Section IV, and the last section gives some concluding remarks. A preliminary version of this paper has appeared in [13]. II. KERNEL PCA A. PCA in the Feature Space In this section, we give a short review on the kernel PCA. For clarity, centering of the -mapped patterns will be explicitly performed in the following. . Kernel PCA Given a set of patterns performs the traditional linear PCA in the feature space corre. Analogous to linear PCA, it insponding to the kernel volves the following eigen decomposition