一种面向动态链状数据结构的指针定值引用链算法
数据结构中linklist的理解

数据结构中linklist的理解LinkList(链表)的理解。
在数据结构中,链表(LinkList)是一种基本的数据结构,它由一系列节点组成,每个节点包含数据和指向下一个节点的指针。
链表是一种线性数据结构,它可以用来表示一系列元素的顺序。
与数组不同,链表中的元素在内存中不是连续存储的,而是通过指针相互连接起来的。
这种特性使得链表具有一些独特的优势和应用场景。
链表的基本结构。
链表由节点组成,每个节点包含两部分,数据和指针。
数据部分用来存储元素的值,指针部分用来指向下一个节点。
链表的第一个节点称为头节点,最后一个节点称为尾节点,尾节点的指针指向空值(NULL)。
链表的分类。
链表可以分为单向链表、双向链表和循环链表三种基本类型。
单向链表,每个节点只包含一个指针,指向下一个节点。
双向链表,每个节点包含两个指针,分别指向前一个节点和后一个节点。
循环链表,尾节点的指针指向头节点,形成一个闭环。
不同类型的链表适用于不同的场景,选择合适的链表类型可以提高数据操作的效率。
链表的优势。
链表相对于数组有一些明显的优势:插入和删除操作高效,由于链表中的元素不是连续存储的,插入和删除操作可以在常数时间内完成,而数组中的插入和删除操作需要移动大量元素,时间复杂度为O(n)。
动态扩展,链表的大小可以动态调整,不需要预先分配固定大小的内存空间。
链表的应用场景。
由于链表的优势,它在一些特定的应用场景中得到了广泛的应用:LRU缓存,链表可以用来实现LRU(Least Recently Used)缓存淘汰算法,当缓存空间不足时,链表可以高效地删除最久未使用的元素。
大整数运算,链表可以用来表示大整数,实现大整数的加减乘除运算。
图论算法,在图论算法中,链表常常用来表示图的邻接表,用于表示图中的顶点和边的关系。
链表的实现。
链表的实现可以使用指针或者引用来表示节点之间的关系。
在C语言中,可以使用指针来表示节点之间的连接关系;在Java等语言中,可以使用引用来表示节点之间的连接关系。
数据结构--第二章考试题库(含答案)

第2章线性表一选择题1.下述哪一条是顺序存储结构的优点?()【北方交通大学 2001 一、4(2分)】A.存储密度大 B.插入运算方便 C.删除运算方便 D.可方便地用于各种逻辑结构的存储表示2.下面关于线性表的叙述中,错误的是哪一个?()【北方交通大学 2001 一、14(2分)】A.线性表采用顺序存储,必须占用一片连续的存储单元。
B.线性表采用顺序存储,便于进行插入和删除操作。
C.线性表采用链接存储,不必占用一片连续的存储单元。
D.线性表采用链接存储,便于插入和删除操作。
3.线性表是具有n个()的有限序列(n>0)。
【清华大学 1998 一、4(2分)】A.表元素 B.字符 C.数据元素 D.数据项 E.信息项4.若某线性表最常用的操作是存取任一指定序号的元素和在最后进行插入和删除运算,则利用()存储方式最节省时间。
【哈尔滨工业大学 2001二、1(2分)】A.顺序表 B.双链表 C.带头结点的双循环链表 D.单循环链表5.某线性表中最常用的操作是在最后一个元素之后插入一个元素和删除第一个元素,则采用()存储方式最节省运算时间。
【南开大学 2000 一、3】A.单链表 B.仅有头指针的单循环链表 C.双链表 D.仅有尾指针的单循环链表6.设一个链表最常用的操作是在末尾插入结点和删除尾结点,则选用( )最节省时间。
A. 单链表B.单循环链表C. 带尾指针的单循环链表D.带头结点的双循环链表【合肥工业大学 2000 一、1(2分)】7.若某表最常用的操作是在最后一个结点之后插入一个结点或删除最后一个结点。
则采用()存储方式最节省运算时间。
【北京理工大学 2000一、1(2分)】A.单链表 B.双链表 C.单循环链表 D.带头结点的双循环链表8. 静态链表中指针表示的是(). 【北京理工大学 2001 六、2(2分)】A.内存地址 B.数组下标 C.下一元素地址 D.左、右孩子地址9. 链表不具有的特点是()【福州大学 1998 一、8 (2分)】A.插入、删除不需要移动元素 B.可随机访问任一元素C.不必事先估计存储空间 D.所需空间与线性长度成正比10. 下面的叙述不正确的是()【南京理工大学 1996 一、10(2分)】A.线性表在链式存储时,查找第i个元素的时间同i的值成正比B. 线性表在链式存储时,查找第i个元素的时间同i的值无关C. 线性表在顺序存储时,查找第i个元素的时间同i 的值成正比D. 线性表在顺序存储时,查找第i个元素的时间同i的值无关11. 线性表的表元存储方式有((1))和链接两种。
2022年南京航空航天大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)

2022年南京航空航天大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)一、选择题1、用数组r存储静态链表,结点的next域指向后继,工作指针j指向链中结点,使j沿链移动的操作为()。
A.j=r[j].nextB.j=j+lC.j=j->nextD.j=r[j]->next2、从未排序序列中依次取出一个元素与已排序序列中的元素依次进行比较,然后将其放在已排序序列的合适位置,该排序方法称为()排序法。
A.插入B.选择C.希尔D.二路归并3、链表不具有的特点是()。
A.插入、删除不需要移动元素B.可随机访问任一元素C.不必事先估计存储空间D.所需空间与线性长度成正比4、向一个栈顶指针为h的带头结点的链栈中插入指针s所指的结点时,应执行()。
A.h->next=sB.s->next=hC.s->next=h;h->next=sD.s->next=h-next;h->next=s5、已知有向图G=(V,E),其中V={V1,V2,V3,V4,V5,V6,V7}, E={<V1,V2>,<V1,V3>,<V1,V4>,<V2,V5>,<V3,V5>, <V3,V6>,<V4,V6>,<V5,V7>,<V6,V7>},G的拓扑序列是()。
A.V1,V3,V4,V6,V2,V5,V7B.V1,V3,V2,V6,V4,V5,V7C.V1,V3,V5,V2,V6,V7D.V1,V2,V5,V3,V4,V6,V76、已知字符串S为“abaabaabacacaabaabcc”,模式串t为“abaabc”,采用KMP算法进行匹配,第一次出现“失配”(s!=t)时,i=j=5,则下次开始匹配时,i和j的值分别()。
A.i=1,j=0 B.i=5,j=0 C.i=5,j=2 D.i=6,j=27、循环队列放在一维数组A中,end1指向队头元素,end2指向队尾元素的后一个位置。
【微计算机信息】_路由协议_期刊发文热词逐年推荐_20140722
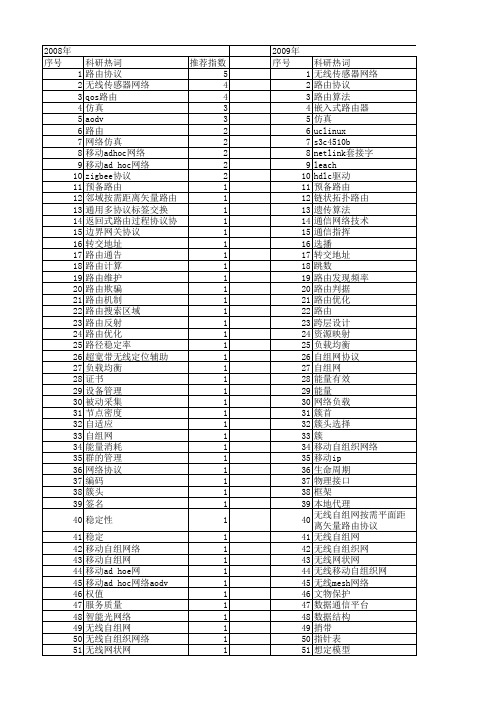
快速重路由 开放式最短路径优先协议 并行性 平均时延 带宽探测 实时性 定向扩散 多跳 多路径路由 多路径传输 多路径 多点中继机制 多协议标记交换 外地代理 哈希算法 及时响应 动态配置算法 加权累计传输时间 功率自寻优 分组传送率 分簇路由 分簇协议 出入度 低功耗 任播 临时按序路由算法 zigbee技术 sleach rstree rarp qos p2p网络 osr协议 ospf路由协议 omnet++ ns2 mina maodv leach协议 dsr路由协议 dm-chord chord路由协议 cc2430 asn.1 amr
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97
无线mesh网络 数据融合 改进 收敛性 捎带 按需路由 按需距离矢量路由协议 按需距离矢量路由 性能分析 性能 微处理器 延迟休假队列 对等网 密钥管理 实时通信 完全网状连接 安全 多跳通信 多路径路由 多约束最短路径优先 多约束 多播路由 多播组成员管理 多径 协议欺骗 匿名 动态维护 动态源路由协议 动态源路由 分群算法 分簇算法 分层多跳无线网 低功耗 tora opnet odv ns2 mpls vpn mipv6 mesh路由 libpcap libnet icmp dsr协议 dhcpv6 cbha协议 bgp aomdv aodvjr ad"hoc无线网络 ad hoc网络
链状双重独立编码结构例题

链状双重独立编码结构例题链状双重独立编码结构通常指的是一种数据结构,其中包含链表和双重独立编码。
链表是一种数据结构,由节点的集合组成,每个节点包含数据和指向下一个节点的引用。
双重独立编码(Dual Link Coding)通常表示在一个数据结构中使用两个独立的引用,分别指向前一个节点和后一个节点。
以下是一个简单的链状双重独立编码结构的示例题:考虑一个存储学生信息的系统,每个学生有姓名和学号。
设计一个链状双重独立编码结构,使得可以按学号和姓名进行快速的检索和插入操作。
在这个结构中,每个节点应包含学生的姓名、学号,以及两个指针,一个指向前一个节点,另一个指向后一个节点。
struct Student {string name;int studentId;Student* prev;Student* next;};上述C++结构体定义了一个学生信息节点,包含姓名、学号以及两个指针 prev 和 next 分别指向前一个节点和后一个节点。
下面是一个使用这个结构体创建链表的简单示例:#include <iostream>using namespace std;int main() {// 创建节点Student* student1 = new Student{"Alice", 101, nullptr, nullptr};Student* student2 = new Student{"Bob", 102, nullptr, nullptr};Student* student3 = new Student{"Charlie", 103, nullptr, nullptr};// 连接节点形成链表student1->next = student2;student2->prev = student1;student2->next = student3;student3->prev = student2;// 输出链表中的学生信息Student* current = student1;while (current != nullptr) {cout << "Name: " << current->name << ", Student ID: " << current->studentId << endl;current = current->next;}// 释放内存delete student1;delete student2;delete student3;return 0;}这个示例创建了三个学生节点,并使用双向引用连接它们,形成了一个链状双重独立编码结构。
定义区块链的四种方法

引言我们了解了区块链的主要功能,并讨论了信任和完备性与软件系统之间的关系,但是对于“区块链”(blockchain)这个术语,你可能还缺乏一个明确的定义我们会给出一个区块链的临时定义,并在接下来的课程中一直贯彻这个定义来辅助你的学习。
而在本节内容最后我们会阐明,为什么对所有权的管理是一个意义非凡的区块链应用场景。
术语在接下来的讨论中,“区块链”这个术语会被如下使用:一种数据结构一种算法一个完整的技术方案一般应用场景下的完全去中心化的端到端系统1.区块链是什么?区块链是一种数据结构在计算机科学和软件工程学中,数据结构指的是计算机存储和组织数据的方式。
我们可以将其类比为一栋建筑的平面图。
在平面图中会根据功能需要把空间划分为墙壁、楼板以及楼梯等部分。
当“区块链”作为一种数据结构被使用的时候,其实是指将数据整合进一个个“区块”当中。
“区块”可以看成是一本书当中的某一页,而一个个区块连接起来后便成为了一个链条,因此称之为区块链。
在一本书中,每一页都包含了存储信息的单词和句子,并且书中所有的信息都被存放在了不同的页中,而不是只放在一个单独的巨大页面里。
同时,书中的每一页都通过页码标注来确定其位置,并且与前后页相连接。
对于一本书而言,我们可以通过检查其中页码的连续性来判断是否存在内容缺失。
同时,这种连续性也意味着每一页上的信息之间也是具有一定顺序的,而信息的顺序是一个被广泛应用的重要细节。
回到“区块链”的概念中,数据“区块”形成的链状结构是通过一个特殊的编码系统来实现的,只是这个编码系统与一本书当中按顺序编写的方法大不相同。
2.区块链是什么?区块链是一种算法在软件工程中,我们称算法是让计算机完成任务的一系列逻辑指令,这些指令经常包含着数据结构。
当我们把“区块链”作为一种算法来考虑的时候,意思是在一个完全去中心化的端到端系统中,将大量区块链特有的数据妥善协调组织的算法,类似于一种完美的民主投票方法。
3.区块链是什么?区块链是一个完整技术方案当我们把“区块链”作为一个完整的技术方案提出来的时候,“区块链”就是指将区块链数据结构、区块链算法、密码学以及安全技术都打包到一起,来实现一个完整的技术方案,用以保证完全去中心化的端到端系统的完备性。
JAVA语言选择题40道:内存优化.Tex

1.以下哪种Java数据类型用于最小化内存使用,存储一个字符?o A. Stringo B. charo C. into D. double答案: B解析: char是Java中占用最小内存(2字节)的数据类型,用于存储单个字符。
2.在C语言中,以下哪种方法能有效减少内存使用?o A. 使用全局变量而非局部变量o B. 使用静态变量而非动态分配o C. 尽可能使用long代替into D. 不释放不再使用的动态内存答案: B解析: 静态变量在数据段中分配内存,程序运行期间不会释放,相比动态分配的局部变量,静态变量可以减少频繁的内存分配和释放,节省内存。
3.当在C语言中使用数组时,哪种方法可以减少内存使用?o A. 使用malloc动态分配数组o B. 使用一维数组替代多维数组o C. 使用double数据类型替代into D. 使用定长数组替代动态数组答案: D解析: 定长数组在编译时分配内存,相比使用malloc动态分配的数组,它可以避免运行时的内存分配,减少内存使用和管理开销。
4.在Java中,哪种对象可以在减少内存使用方面提供帮助?o A. Stringo B. StringBuffero C. StringBuildero D. ArrayList答案: B解析: StringBuffer在修改字符串时不会创建新的对象,相比String和StringBuilder,它能有效减少在多线程环境下修改字符串时的内存使用。
5.如何在C语言中释放一个使用malloc分配的数组?o A. 使用free函数o B. 使用delete操作符o C. 不需要释放o D. 使用free函数的数组版本答案: A解析: C语言中,释放动态分配的内存使用free函数。
没有特定的数组版本,释放的是指向数组开始的指针。
6.Java中,哪种方法可以用来检测内存泄漏?o A. 使用System.gc()o B. 使用IDE的内存分析工具o C. 使用编译器检查o D. 使用free函数答案: B解析: Java的IDE如Eclipse, IntelliJ IDEA等,提供了专门的内存分析工具来检测和分析内存泄漏。
2022年南京航空航天大学金城学院计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)

2022年南京航空航天大学金城学院计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)一、选择题1、哈希文件使用哈希函数将记录的关键字值计算转化为记录的存放地址,因为哈希函数是一对一的关系,则选择好的()方法是哈希文件的关键。
A.哈希函数B.除余法中的质数C.冲突处理D.哈希函数和冲突处理2、若需在O(nlog2n)的时间内完成对数组的排序,且要求排序是稳定的,则可选择的排序方法是()。
A.快速排序B.堆排序C.归并排序D.直接插入排序3、单链表中,增加一个头结点是为了()。
A.使单链表至少有一个结点B.标识表结点中首结点的位置C.方便运算的实现D.说明单链表是线性表的链式存储4、在用邻接表表示图时,拓扑排序算法时间复杂度为()。
A.O(n)B.O(n+e)C.O(n*n)D.O(n*n*n)5、在下列表述中,正确的是()A.含有一个或多个空格字符的串称为空格串B.对n(n>0)个顶点的网,求出权最小的n-1条边便可构成其最小生成树C.选择排序算法是不稳定的D.平衡二叉树的左右子树的结点数之差的绝对值不超过l6、已知关键字序列5,8,12,19,28,20,15,22是小根堆(最小堆),插入关键字3,调整后的小根堆是()。
A.3,5,12,8,28,20,15,22,19B.3,5,12,19,20,15,22,8,28C.3,8,12,5,20,15,22,28,19D.3,12,5,8,28,20,15,22,197、下列关于无向连通图特性的叙述中,正确的是()。
Ⅰ.所有的顶点的度之和为偶数Ⅱ.边数大于顶点个数减1 Ⅲ.至少有一个顶点的度为1A.只有Ⅰ B.只有Ⅱ C.Ⅰ和Ⅱ D.Ⅰ和Ⅲ8、下述二叉树中,哪一种满足性质:从任一结点出发到根的路径上所经过的结点序列按其关键字有序()。
A.二叉排序树B.哈夫曼树C.AVL树D.堆9、每个结点的度或者为0或者为2的二叉树称为正则二叉树。
c++虚函数和动态束定总结

c++虚函数和动态束定总结
C++中的虚函数和动态绑定是面向对象编程中非常重要的概念,它们在实现多态性和继承性方面起着关键作用。
让我来从多个角度全面总结一下这两个概念。
首先,我们来看虚函数。
在C++中,通过在基类的成员函数声明前加上关键字`virtual`来定义虚函数。
当派生类继承并重写这个虚函数时,可以实现多态性,即同一个函数调用可以根据对象的实际类型来执行不同的函数体。
这样的设计使得程序更加灵活和可扩展,能够更好地适应变化和复杂的需求。
虚函数的存在使得基类指针可以在运行时指向派生类对象,并调用相应的函数,这就引出了动态绑定的概念。
动态绑定是指在运行时确定调用的函数版本。
当通过基类指针或引用调用虚函数时,程序会在运行时根据对象的实际类型来确定调用的函数版本,而不是在编译时就确定。
这种动态绑定的特性使得程序能够更加灵活地处理对象的多态性,从而实现更加复杂的行为和逻辑。
另外,虚函数和动态绑定也涉及到虚函数表的概念。
在包含虚
函数的类的对象中,会有一个指向虚函数表的指针,虚函数表中存
储了该类的虚函数地址。
当调用虚函数时,程序会根据对象的实际
类型找到相应的虚函数表,并调用正确的函数。
这种机制保证了动
态绑定的实现。
总的来说,虚函数和动态绑定是C++中实现多态性的关键机制,它们使得程序能够更加灵活地处理对象的多态性,实现更加复杂的
行为和逻辑。
同时,理解和正确运用虚函数和动态绑定也是面向对
象编程中的重要技能之一。
希望以上总结能够帮助你更好地理解这
两个概念。
2022年太原理工大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)

2022年太原理工大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)一、选择题1、下述文件中适合于磁带存储的是()。
A.顺序文件B.索引文件C.哈希文件D.多关键字文件2、设有一个10阶的对称矩阵A,采用压缩存储方式,以行序为主存储, a11为第一元素,其存储地址为1,每个元素占一个地址空间,则a85的地址为()。
A.13B.33C.18D.403、若线性表最常用的操作是存取第i个元素及其前驱和后继元素的值,为节省时间应采用的存储方式()。
A.单链表B.双向链表C.单循环链表D.顺序表4、已知有向图G=(V,E),其中V={V1,V2,V3,V4,V5,V6,V7}, E={<V1,V2>,<V1,V3>,<V1,V4>,<V2,V5>,<V3,V5>, <V3,V6>,<V4,V6>,<V5,V7>,<V6,V7>},G的拓扑序列是()。
A.V1,V3,V4,V6,V2,V5,V7B.V1,V3,V2,V6,V4,V5,V7C.V1,V3,V5,V2,V6,V7D.V1,V2,V5,V3,V4,V6,V75、向一个栈顶指针为h的带头结点的链栈中插入指针s所指的结点时,应执行()。
A.h->next=sB.s->next=hC.s->next=h;h->next=sD.s->next=h-next;h->next=s6、排序过程中,对尚未确定最终位置的所有元素进行一遍处理称为一趟排序。
下列排序方法中,每一趟排序结束时都至少能够确定一个元素最终位置的方法是()。
Ⅰ.简单选择排序Ⅱ.希尔排序Ⅲ.快速排序Ⅳ.堆排Ⅴ.二路归并排序A.仅Ⅰ、Ⅲ、Ⅳ B.仅Ⅰ、Ⅱ、Ⅲ C.仅Ⅱ、Ⅲ、Ⅳ D.仅Ⅲ、Ⅳ、Ⅴ7、下列叙述中,不符合m阶B树定义要求的是()。
中科曙光c面试题及答案

中科曙光c面试题及答案中科曙光C面试题及答案一、选择题1. C语言中,以下哪个关键字用于定义一个结构体?A. structB. unionC. enumD. typedef答案:A2. 在C语言中,哪个函数用于将整数转换为字符串?A. atoi()B. itoa()C. sprintf()D. strcpy()答案:B二、填空题3. 在C语言中,若要定义一个具有10个整数元素的数组,可以使用以下语法:________。
答案:int array[10];4. 当使用printf()函数输出浮点数时,若要保留两位小数,应使用格式说明符________。
答案:%.2f三、简答题5. 请简述C语言中指针的概念及其重要性。
答案:指针是一种变量,它存储了另一个变量的内存地址。
指针在C语言中非常重要,因为它们允许直接访问和操作内存,从而提高程序的效率和灵活性。
指针广泛应用于数组、函数参数、动态内存分配等方面。
四、编程题6. 编写一个C语言程序,实现计算并输出1到100的整数之和。
```c#include <stdio.h>int main() {int sum = 0, i;for (i = 1; i <= 100; i++) {sum += i;}printf("The sum of integers from 1 to 100 is: %d\n", sum); return 0;}```7. 假设有一个字符串数组,包含若干个单词,请编写一个函数,用于反转数组中的每个单词,但单词之间的位置不变。
```c#include <stdio.h>#include <string.h>void reverseWord(char *str) {int len = strlen(str);for (int i = 0; i < len / 2; i++) {char temp = str[i];str[i] = str[len - i - 1];str[len - i - 1] = temp;}}int main() {char words[] = {"Hello", "World"};for (int i = 0; i < sizeof(words) / sizeof(words[0]); i++) {reverseWord(words[i]);printf("%s ", words[i]);}return 0;}```五、论述题8. 论述C语言中的递归函数及其应用场景。
全国计算机技术与软件专业技术资格(水平)考试模拟题13及答案
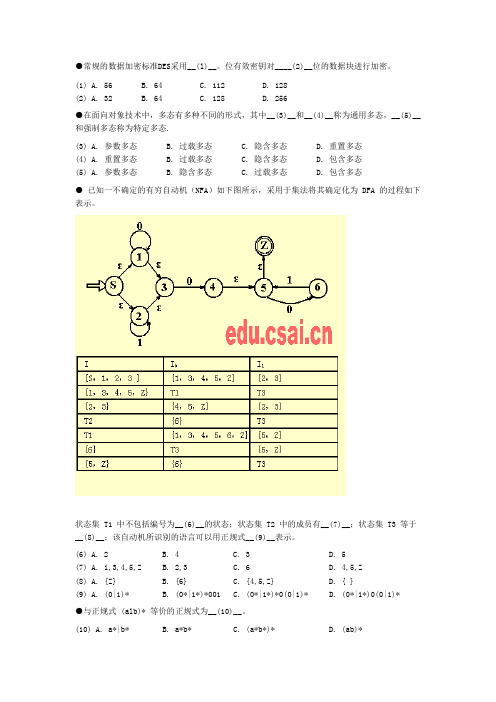
●常规的数据加密标准DES采用__(l)__。
位有效密钥对____(2)__位的数据块进行加密。
(1) A. 56 B. 64 C. 112 D. 128(2) A. 32 B. 64 C. 128 D. 256●在面向对象技术中,多态有多种不同的形式,其中__(3)__和__(4)__称为通用多态,__(5)__和强制多态称为特定多态.(3) A. 参数多态 B. 过载多态 C. 隐含多态 D. 重置多态(4) A. 重置多态 B. 过载多态 C. 隐含多态 D. 包含多态(5) A. 参数多态 B. 隐含多态 C. 过载多态 D. 包含多态●已知一不确定的有穷自动机(NFA)如下图所示,采用于集法将其确定化为 DFA 的过程如下表示。
状态集 T1 中不包括编号为__(6)__的状态;状态集 T2 中的成员有__(7)__;状态集 T3 等于__(8)__;该自动机所识别的语言可以用正规式__(9)__表示。
(6) A. 2 B. 4 C. 3 D. 5(7) A. 1,3,4,5,Z B. 2,3 C. 6 D. 4,5,Z(8) A. {Z} B. {6} C. {4,5,Z} D. { }(9) A. (0|1)* B. (0*|1*)*001 C. (0*|1*)*0(0|1)* D. (0*|1*)0(0|1)*●与正规式 (alb)* 等价的正规式为__(10)__。
(10) A. a*|b* B. a*b* C. (a*b*)* D. (ab)*●算法是对问题求解过程的一类精确描述,算法中描述的操作都是可以通过已经实现的基本操作在限定时间内执行有限次来实现的,这句话说明算法具有__(11)__特性。
(11) A. 正确性 B. 确定性 C. 能行性 D. 健壮性●快速排序算法采用的设计方法是__(12)__。
(12) A. 动态规划法 (Dynamic Programming) B. 分治法 (Divide and Conquer)C. 回溯法 (Backtracking)D. 分枝定界法 (Branch and Bound)●在数据压缩编码的应用中,哈夫曼(Huffman)算法可以用来构造具有__(13)__的二叉树,这是一种采用了__(14)__的算法(13) A. 前缀码 B. 最优前缀码 C. 后缀码 D. 最优后缀码(14) A. 贪心 B. 分治 C. 递推 D. 回溯●用递归算法实现 n 个相异元素构成的有序序列的二分查找,采用一个递归工作栈时,该栈的最小容量应为__(15)__ 。
【小型微型计算机系统】_程序语言_期刊发文热词逐年推荐_20140725

2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
科研热词 自定义谓词 编译优化 数据流程序 并行计算 x10 高性能计算 调试 计算模型 自然语言查询分解 自动定理证明 绿色计算 程序验证 程序分析 查询扩展 推理规则 快照 形状图逻辑 布尔检索 句法树 句法分析 出具证明编译器 内核 云存储 hoare逻辑
推荐指数 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2014年 序号 1 2 3 4 5 6 7 8
科研热词 源到源编译 模型验证 控制流图 存储优化 制导语言 nusmv kripke结构 gpu
推荐指数 1 1 1 1 1 1 1 1
科研热词 软件测试 预设值 需求规约 需求描述与验证 随机测试 访问控制 表达式传播 表单驱动 程序验证 程序分析 程序不变量 移动设备 测试用例 汇编级验证 携带证明代码 并行程序语言 并行性挖掘 并行性分析算法 并发赋值形式 定值引用链 复杂信息系统 图语言 回答集语义 同步 可计算函数语言 动态链状数据结构 到达定值 别名分析 出具证明编译器 共享变量维持 中间件 上下文相关图文法 上下文感知 上下文
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
科研热词 面向方面编程 软件测试 软件安全 缺陷模型 系数规范化 类型系统 式规范 动态横切 前(后)条件 分母消化 出具证明编译器 不尽相异元素 r可重排列 hoare逻辑
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
定义区块链的四种方法

后续会深入的区块链应用领域
把“区块链”作为一个完整技术方案用来管理完全去中心化的分布式账本能够衍生出很多独特的应用,比如管理数字资产或者加密货币。但是我们不会只局限在对一个特殊的使用场景进行深入讨论,从而使你偏离了最核心的概念,因此我们会引入其他的应用场景。但为了让你能够更容易的理解区块链,我们考虑了管理和澄清所有权的一般应用案例,不管所有权管理的具体对象细节。希望能够帮助到你打开思路,理解区块链。
所有权管理
上面的临时性定义并未提及比特币或者对加密数字货币的所有权管理,这看起来会有些奇怪,毕竟大量的文章和数据都把区块链的用途描述为管理数字资产的所有权。事实上,管理加密货币的所有权是一个意义非凡的区块链使用场景,但是绝对不是唯一的使用场景;相反,区块链具有非常广阔且丰富多样的应用场景。
那么为什么如今我们会主要讨论区块链在数字货币资产所有权管理方面的应用呢?主要有两个原因:理解起来最简单,解释起来最容易。这个使用场景会对经济形成巨大影响。所有权及强制执行所有权的权利,这种概念几乎是每个人类社会的核心理念的组成部分,甚至有一些动物都会为捍卫所有权而发生争斗。而在现代社会中,银行,保险公司,保管人,律师,法院,领事馆等日常的大量工作,就是在管理所有权或者确保所有权权利的强制执行。
在一本书中,每一页都包含了存储信息的单词和句子,并且书中所有的信息都被存放在了不同的页中,而不是只放在一个单独的巨大页面里。同时,书中的每一页都通过页码标注来确定其位置,并且与前后页相连接。对于一本书而言,我们可以通过检查其中页码的连续性来判断是否存在内容缺失。同时,这种连续性也意味着每一页上的信息之间也是具有一定顺序的,而信息的顺序是一个被广泛应用的重要细节。
区块链技术的数据结构解读

区块链技术的数据结构解读随着科技的不断进步,区块链技术逐渐成为了人们广泛关注的热点。
作为一种去中心化数字账本技术,它可以在无需信任的情况下实现数据的安全存储和传输。
而要想彻底理解区块链技术,必须了解其背后的数据结构。
本文将从数据结构的角度出发,介绍区块链技术的基本概念和相关数据结构。
一、区块链基础概念区块链是一种分布式的、去中心化的账本技术,其特点是将交易记录保存在由多个节点组成的网络中,而非由单一机构或个人拥有和控制。
在区块链中,所有的参与者都持有账本数据副本,这就保证了数据的可靠性、不可篡改和不可抵赖性。
同时,区块链技术还能够实现一种名为智能合约的自动化合约机制,可以令机器代替人类完成某些特定的业务操作。
区块是区块链中最基本的单位,每个区块中都有一批新的交易记录。
当交易发生时,它将被打包成一个块,并通过加密算法和数字签名的方式被验证和加密。
每个区块的构成包括起始区块的信息、时间戳、交易记录和一定数量的其他信息,这些信息组合在一起构成了一个不可改变的、有时间顺序的链,称为区块链。
二、区块链中的数据结构在区块链技术中,数据结构是至关重要的一部分,它承载着交易记录和账户信息。
区块链中的数据结构主要包括Merkle Tree(默克尔树)、哈希链表(Hashchain)和简单链表(Linked List)等。
下面将详细介绍这些数据结构的特点和应用。
1. 默克尔树Merkle Tree是一种由Ralph Merkle在1979年提出的哈希树结构,它可以有效的验证大量数据的完整性,并提高验证的速度。
在区块链中,Merkle Tree广泛应用于验证交易记录的完整性。
Merkle Tree的核心思想是将大量数据作为叶子节点,然后将它们配对组成一个个哈希值,再对这些哈希值再次配对构成更大的哈希值,一直进行下去,最终形成一棵根节点的哈希树。
在验证时,如果数据中任何一部分被篡改,它的哈希值将发生改变,从而导致整个哈希树的顶层节点发生变化,证明了数据被篡改的事实。
数据结构与算法知到章节答案智慧树2023年中国民用航空飞行学院

数据结构与算法知到章节测试答案智慧树2023年最新中国民用航空飞行学院绪论单元测试1.本课程中需要掌握数据结构的基本概念、基本原理和基本方法。
参考答案:对2.在本课程的学习中还需要掌握算法基本的时间复杂度与空间复杂度的分析方法,能够设计出求解问题的高效算法。
参考答案:对第一章测试1.算法的时间复杂度取决于()。
参考答案:问题的规模2.算法的计算量的大小称为算法的()。
参考答案:复杂度3.算法的时间复杂度与()有关。
参考答案:问题规模4.以下关于数据结构的说法中正确的是()。
参考答案:数据结构的逻辑结构独立于其存储结构5.数据结构研究的内容是()。
参考答案:包括以上三个方面第二章测试1.线性表是具有n个()的有限序列。
参考答案:数据元素2.单链表又称为线性链表,在单链表上实施插入和删除操作()。
参考答案:不需移动结点,只需改变结点指针3.单链表中,增加一个头结点的目的是()。
参考答案:方便运算的实现4.单链表中,要将指针q指向的新结点插入到指针p指向的单链表结点之后,下面的操作序列中()是正确的。
参考答案:q->next=p->next; p->next=q;5.链表不具有的特点是()。
参考答案:可随机访问任一元素第三章测试1.循环队列存储在A[0..m]中,则入队时的操作是()。
参考答案:rear=(rear+1)%(m+1)2.关于循环队列,以下()的说法正确。
参考答案:循环队列不会产生假溢出3.如果循环队列用大小为m的数组表示,队头位置为front、队列元素个数为size,那么队尾元素位置rear为()。
参考答案:(front+size-1)%m4.若顺序栈的栈顶指针指向栈顶元素位置,则压入新元素时,应()。
参考答案:先移动栈顶指针5.设栈S和队列Q的初始状态均为空,元素{1, 2, 3, 4, 5, 6, 7}依次进入栈S。
若每个元素出栈后立即进入队列Q,且7个元素出队的顺序是{2, 5, 6, 4, 7, 3, 1},则栈S的容量至少是:参考答案:46.栈操作数据的原则是()。
数字货币技术的去中心化交易方式

数字货币技术的去中心化交易方式随着数字货币的兴起,去中心化交易成为了一个备受关注的话题。
传统的金融体系中,交易需要经过中心化的机构,例如银行或证券交易所等,但是随着区块链技术的发展,出现了一种新的交易方式——去中心化交易,它不依赖于中心化机构,而是通过智能合约和去中心化交易所实现交易的可靠性和安全性。
本文将从技术原理、优势和发展趋势三个方面对数字货币技术的去中心化交易方式进行探讨。
一、技术原理数字货币的去中心化交易方式主要基于区块链技术。
区块链是一种分布式账本技术,它将参与者的交易记录按照时间顺序组成一个链状的数据结构,并利用密码学算法确保交易数据的可靠性和不可篡改性。
去中心化交易通过智能合约实现了交易方之间的信任和自动化执行。
智能合约是一种以代码形式存在的自动执行合约,其中包含了交易的条件和执行规则,一旦满足条件,交易即会自动执行。
二、优势1. 去中心化交易具有更高的安全性。
传统金融机构往往会面临黑客攻击、内部信息泄露等安全风险,而去中心化交易依赖于区块链技术的去中心化和加密特性,使交易更加安全可靠。
2. 去中心化交易具有更高的透明度。
区块链上的所有交易记录都是公开可见的,任何人都可以查看和验证交易的真实性。
这种透明度有助于减少舞弊和不诚信行为。
3. 去中心化交易具有更高的效率。
传统金融机构的交易通常需要依赖繁琐的中介环节和人工操作,而去中心化交易通过智能合约实现自动化的交易执行,大大提高了交易的效率。
三、发展趋势数字货币技术的去中心化交易方式在近年来得到了迅猛发展,并呈现出以下几个趋势:1. 去中心化交易所的兴起。
传统的中心化交易所存在着风险和监管不足等问题,而去中心化交易所通过智能合约实现交易的安全和自动化执行,受到了越来越多的投资者青睐。
2. 公链与去中心化交易方式的融合。
随着公链技术的不断发展,许多公链项目将去中心化交易作为自己的重要功能,并通过与智能合约的结合,为用户提供更安全、高效的交易体验。
自引用结构体

自引用结构体引言自引用结构体是一种在编程中常见的数据结构,它允许一个结构体类型包含指向同类型的指针。
通过使用自引用结构体,我们可以建立复杂的数据结构,如链表、树等。
本文将探讨自引用结构体的概念、用途以及实现方式。
概念自引用结构体是一个结构体类型,其中至少包含一个指向自身的指针。
这意味着结构体可以引用自己的类型,从而创建一个无限嵌套的数据结构。
自引用结构体在许多编程语言中都有广泛的应用,例如C、C++、Rust等。
用途自引用结构体可以用于构建各种复杂的数据结构。
下面是一些自引用结构体的常见用途:1.链表:链表是最基础的自引用结构体之一。
每个链表节点包含一个值和一个指向下一个节点的指针。
通过将节点的指针指向同类型的结构体,我们可以创建一个具有动态长度的链表。
2.树:树是一种自引用结构体,其中每个节点可以有多个子节点。
通过将子节点的指针指向同类型的结构体,我们可以构建树的层次结构,如二叉树、AVL树等。
3.图:图是一种自引用结构体,其中每个节点可以有多个邻居节点。
通过将邻居节点的指针指向同类型的结构体,我们可以构建图的拓扑结构,并实现图相关的算法,如最短路径、最小生成树等。
实现方式要实现自引用结构体,我们需要注意以下几点:1.结构体声明:在声明自引用结构体时,需要在结构体中包含指向同类型的指针。
例如,要声明一个自引用的链表节点,可以使用以下代码:struct ListNode {int value;struct ListNode* next;};2.内存分配:为了正确地分配内存,我们需要先分配结构体本身的大小,然后再为指针指向的结构体分配内存。
例如,要创建一个新的链表节点,可以使用以下代码:struct ListNode* node = malloc(sizeof(struct ListNode));node->next = malloc(sizeof(struct ListNode));3.内存释放:在使用完自引用结构体后,我们需要注意释放内存以避免内存泄漏。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
小型微型计算机系统Journal o f Chi nese Co m puter Sy stem s2011年7月第7期V o l 132N o .72011收稿日期:2010-04-12 基金项目:国家自然科学基金项目(90718026,60928004)资助. 作者简介:付小朋,男,1983年生,硕士研究生,研究方向为程序分析技术;张 昱,女,1972年生,博士,副教授,CCF 会员,研究方向为程序设计语言理论与实现技术,特别是并行语言设计、编译,并行程序分析和验证等.一种面向动态链状数据结构的指针定值引用链算法付小朋1,2,张 昱1,2,张 伟1,2,汪 晨1,21(中国科学技术大学计算机科学与技术学院,合肥230027)2(中国科学技术大学苏州研究院软件安全实验室,江苏苏州215123)E-m ai:l yuzh ang @ustc .edu .cn摘 要:采用流敏感的方法分析计算过程内操作动态链状数据结构的指针定值引用链.目的是连接对链状数据结构进行定值的语句和引用这些链状数据结构的语句,具体地,每条对链状数据结构进行定值的语句,算法将找出所有引用被该语句定值的链状数据结构的语句的集合.该算法将被整合到我们设计和开发的并行语言m i ni-SPC 中,指导对操作动态链状数据结构的并行程序的正确分析和程序变换.实验表明基于本文的算法能保证操作动态链状数据结构的指针定值引用链的分析精度,提高分析的效率.关键词:定值引用链;到达定值;别名分析;程序分析;动态链状数据结构中图分类号:T P311 文献标识码:A 文章编号:1000-1220(2011)07-1412-06St udy on Definition -use Chai n s A lgorith m in Dyna m ic Pointer -linked Data StructuresFU X iao-peng 1,2,ZHANG Y u 1,2,ZHANG W e i 1,2,W AN G C hen 1,21(Schoo l of C o m pu ter Science &Techn ology,Un i versity o f Science &Techno l ogy o fC h i na,Hefei 230027,Ch i na )2(Soft w a re Secur i ty Lab,Suzhou Institute f o r Ad vanced S t udy,Un iversity of Sci en ce &Technology of Ch ina,Suzhou 215123,C hina )Abstrac t :T his paper presen ts a f l ow -sen sitive a l g or ith m t o com pute i ntrapro cedura l definiti o n-use cha i ns i n dyna m i c po i nter -li nked data struc tures .T he ai m is t o re l a te the sta t em ents t ha t con struc t li nk s o f li nked data struc t ures(.i e .de fi n iti on s)to st a te m ents t ha tm i ght traverse t he struc t ures t hough t he li nks(.i e .uses).Spec ificall y,fo r each sta t em ent S tha t def i nes li nks o f linked da ta structures ,t he a l g or it hm fi nds the se t o f sta t em ents t hat trave rse t he li nk sw h i ch are def i ned by S .O ur m e t hod w ill be i nco rpo ra ted in -to t he pa ra lle l languag e m i ni-SPC designed and dev e l oped by us .It is used to be i n cha rg e o f accurate l y ana l y zing and transfo r m i ng t he para ll e l prog ra m i n dyna m i c po i nter-linked da t a struc tures .Experi m en t a l results illustrate that the propo sed a lgo rith m fo r com pu -ti ng de fi n iti on-use cha i n s co ul d m a i nta i n t he qua lity o f de fi n iti on-use cha i ns fo r dyna m i ca lly a ll o ca ted l o cati o n and i m prov e the a -naly sis c s perfo r m ance effic i entl y.K ey word s :defi n iti on -use cha i n s ;reach i ng -def i nition ;a lias analy sis ;pro gra m ana l y sis ;dyna m i c li nked data struc t ures1 引 言一个变量的定值引用链是连接该变量的定值语句到所有可能流经到的对该定值的引用语句.定值引用链被广泛地应用于优化和并行编译器[1],甚至于软件工程工具中[2].确定含有动态链状数据结构(如链表,二叉链表示的树等)的指针程序中的定值引用链,要比没有动态内存分配的程序复杂得多.这主要因为前者允许通过指针间接访问内存单元以及动态构造链状数据结构,导致程序中存在复杂的别名问题.例如,假设q 指向单链表的节点,p=q 导致p y nex t 和q y nex t 因代表同一个内存单元而互为左值别名,p 和q 因指向同一个内存单元而互为右值别名.由于别名的存在,导致在计算面向动态链状数据结构的指针定值引用链时,往往需要在数据流分析的过程中借助别名分析得到的别名集合(a li a s se ts)或内存形状图SS G s (st o re shape g raphs).在过去的20年里,别名分析问题已经成为程序分析技术研究的重点和难点之一.现有的别名分析研究成果主要是在精度和时空效率之间做取舍.精确的别名分析,可以移除不再有效的到达定值,提高定值引用链的精度,这样这些定值就不会被错误地传播到任何随后的引用.本文设计一种新的面向动态链状数据结构的指针定值引用算法,别名信息的获取是通过正向的数据流分析途径,沿程序执行的所有路径,在每个程序点收集所有能到达这个程序点的定值来识别的,本质上是一个流敏感的别名分析.所谓流敏感就是分析中考虑程序中语句的执行顺序.它的主要特点是:在某个程序点,它并不计算出所有的可能别名集合,而仅仅是识别那些需要知道别名信息的指针变量的可能别名;并且到达定值分析和别名信息的获取是在一个分析遍中完成,而不是先独立的进行别名分析,然后利用别名分析结果再进行到达定值分析.这种方法的优点是:1)避免建立别名集合或内存形状图来概括所有可能的指针型域访问表达式的别名.2)避免利用到达定值和别名分析的别名信息而产生虚假的定值引用链.3)不会产生多级的访问路径表达式,避免多级域访问路径表达式的相等比较.本文利用正向分析的数据流迭代算法,计算过程内的指针到达定值信息;在到达定值信息基础上,推导得到程序的引用定值链和定值引用链.该方法将被整合到我们设计和开发的并行语言m i n-i SPC [3]中,指导对操作动态链状数据结构的并行程序的正确分析和程序转换.2 问题描述2.1 定值引用描述在没有脱引用和取地址操作的程序中,一般指针变量的定值引用链算法和传统的方法[9]相同,本文的算法主要关注指针型域访问表达式的定值引用链.在含有动态链状数据结构的指针程序中,定值引用链可以扩展为:针对每条对链状数据结构的域访问表达式进行定值的语句s ,沿所有可能的程序执行路径,计算引用被语句s 定值的内存位置的所有语句的集合.具体地,如图1(a)所示的程序,假设s i 是对p y f 的定值,s j 中包含对q y f 的引用,s i 是对q y f 的定值,当且仅当:(1)至少有一条程序执行路径从s i 到s j ,这样p y f 的定值能到达s j .(2)p 和q指向同一个内存单元(a) (b)图1 定值引用关系F i g .1 D ef -use asso ciation如图1(b)所示的程序,由于p 和q 右值别名,p y n 和q y n 代表相同的内存单元,这样语句s 2和s 3都是对同一内存单元的赋值,这样可以知道s 4中对p y n 的引用的定值在s 3,而不在s 2.因此在计算定值引用链的时候,需要知道指针变量的右值别名信息,以便确定两个域访问表达式是否代表相同的位置,即是否为左值别名.2.2 语 言为了形式化算法,我们使用了一个简单的语言,如图2所示.语言是强调指针类型的类C 小语言,所有的数据类型type 都是结构体类型,所有声明的变量都是结构体指针变量.语言中有动态的内存分配m a ll o c 和释放free 操作,但是禁止取地址&操作、强制类型转换和指针算术运算.程序中可能的值为指向内存位置的指针或空指针.假设m a ll o c 的每次调用都能成功分配并且所分配空间和尚未释放空间不相交,而free 操作每次释放指针指向的内存单元后将该指针置为空.在动态分配产生的结构体中,每个域保存一个内存位置.多级的域访问表达式,如x y f y f,通过引入临时变量而被规图2 语言的语法F i g.2 T he syntax o f l anguag e范化(no r m a lize)为一级的域访问表达式,如t=x y f,t y f.虽然等式e 1y f =e 2y f 是有效的,但为了简化,表示为t=e 2y f 和e 1y f =,t 即只允许等式的一边出现域访问表达式.从而,在分析程序时只需考虑如下三种指针赋值语句:(1)p=q (别名语句)(2)p=q y f (引用语句)(3)p y f =q (定值语句)前两种语句将引起右值别名,而不会改变链状数据结构中节点之间的连接;而最后一种语句会导致从链状数据结构中移除一个连接(或null),并引入一个新的连接,即指针型域的新的定值.为了抽象具体的内存位置,用H 来表示在程序执行的过程中,变量对应的具体内存,包含变量的栈位置、以及程序执行中产生的所有堆位置.具体的内存抽象是一个二元组Q =(Q v ,Q f ):Q v :V y HQ f :(H @F )y H这样Q v将变量映射到它们的栈位置,range (Q v )表示是栈上的内存位置.假如一个位置h I H 是动态分配的结构体存储位置,则Q f (h,f )表示该结构体的f 域,为了简化起见,表示成h +f .可以知道Q f 的定义域和值域的所有存储位置都是动态分配的.在H 中,对每个内存位置,引入下面几个辅助函数来获得它的属性:函数H entry :H y H,如果某内存位置是由结构体指针变量(如指针p)指向的,则返回结构体指针变量对应的内存位置(Q v (p));由域访问表达式(如p y next)指向的,则返回域访问表达式中结构体指针变量对应的内存位置(Q v (p)).函数H ha sField :H y {true ,false},用来判断某内存位置是否由结构体域访问表达式指向.如果是,则返回true ;否则返回fa lse .函数H field :H y F G {null},如果内存位置是由结构体域访问表达式指向的,则返回其域名,否则返回nul.l3 定值引用算法本节介绍所设计的过程内定值引用链的算法,它首先利14137期付小朋等:一种面向动态链状数据结构的指针定值引用链算法用迭代的数据流分析算法得到到达定值信息;然后利用到达定值分析的结果,得到每条语句的引用定值链;最后根据引用定值链,推导得到定值引用链.3.1 到达定值分析3.1.1 定值抽象每条赋值语句被抽象为一个定值实体,每个定值实体d I D A H @H @L 是一个三元组,用来表示程序中的一个定值点,如3h 1,h 2,l 4,h 1、h 2分别是赋值语句赋值号左、右两边表达式对应的内存抽象,l 是此语句的标号.这样到达定值分析计算的是,在每个程序点,沿所有的程序的执行路径能到达这个程序点的所有可能(m ay)的定值点的集合.在定值抽象D 上定义了一个格,格的底元是X ,表示没有任何定值点;顶元是P ,表示程序的所有定值点都可行.对于任意的d 1,d 2I D ,格的并运算 定义为:d 1 d 2=d 1G d 23.1.2 数据流等式和转换方程数据流方程如图3所示,其中符号"_"表示不关心具体的内存位置或标号,可以为任意的值.p,q 分别表示指针变量p 和q 对应的内存位置,相应地用缩写形式qf 表示域访问表达式q y f 对应的内存位置,下面内容中此形式表示相同的含R kill 和R g en 方程R kill ([p=q]l )={3p,_,_4}R kill ([p =q y f]l)={3p,_,_4}R kill ([p y f=q ]l )={3h +f,_,_4|h I R a lia s (R in (l),p )}R kill ([p=m alloc(t ype)]l)={3p,_,_4}R kill ([free(p)]l)=ÁR kill ([b]l )=ÁR g en ([p =q]l )={3p,h,l 4|h I R a lia s (R in (l),q )}R g en ([p =q y f]l )={3p,h,l 4|h I R alia s (R in (l),q f)}R g en ([p y f=q]l )={3h +f ,h 1,l 4|h 1I R a lia s (R in (l ),q ),h I R a lia s(R in (l),p )}R g en ([p =m all oc(typ e)]l )={3p,nu ll ,l 4}R g en ([free(p )]l )=ÁR g en ([b ]l )=Á数据流方程R i n (l)=Áif l=R in it (S )Gl c I R pre (l)R o ut (l c )o t her w iseR o ut (l)=(R in (l)-R k ill (l))G R gen (l)图3 到达定值分析F i g.3 R eaching-de fi n iti on ana ly sis义.对任一语句s,引入两个程序点,分别代表正好到达该语句的入口位置和正好离开该语句的出口位置.函数R in 和R out 和辅助函数R init 和R pr e 的作用是:函数R in :L y P (D ),计算可到达某语句入口程序点的定值实体的集合.函数R out :L y P (D ),计算可到达某语句出口程序点的定值实体的集合.函数R init :S t m ts y L,用来得到程序段的初始语句标号.函数R pre :L y P (L ),得到某语句在控制流图(容易从控制流语句的语法结构求得)中所有前驱语句的标号的集合.对于赋值语句和条件语句的分析,引入函数R k ill 和R g en 来计算:函数R k ill :S y P (D ),被某语句注销的定值实体的集合,假如语句中对某个内存位置进行了赋值,则这个内存位置的其余定值实体会被注消.函数R gen :S y P (D ),语句中因赋值产生的定值实体的集合,只有赋值语句才产生定值实体.既然每条赋值语句被抽象为一个三元组实体3h 1,h 2,l 4,这样它不但可以用来表示对某个内存位置h 1的定值,而且记录和h 1右值别名的内存位置h 2,它们指向相同的内存单元.如果h 1和h 2互为右值别名,则别名关系可以记作3h 1,h 24.这里我们用等价类[4]来表示指向同一个内存单元的所有指针变量对应的内存位置.这样的话:如果右值别名序对有3h n ,h n-143h n-1,h n -24,3h 2,h 14,则可以用h 1作为它们的等价类表示,这样指向这个内存单元的变量对应的内存位置的右值别名都可以用h 1来表示,即通过传递性,有3h n ,h 143h n-1,h 14,3h 2,h 14.如果某赋值语句抽象的定值实体为d n =3h 3,h 2,l n 4,需要找出和h 2指向同一个内存单元的等价类表示,这里通过辅助函数R alias (如图4)来实现,假如能够到达语句l n 的定值实体集合R in (l n )中有定值实体d n-1=3h 2,h 1,l n -14,则可以知道和h 2右值别名的内存位置为h 1,这样用h 1去替代实体d n 中的h 2,从而得到定值实体3h 3,h 1,l n 4,并向下传递.R a lia s (D se t ,h ){1H set =Á;2if(D s e t ==Á)ret urn {h };3for (each 3h 1,h 2,l 4i n D set ){4 if(H e n try (h )!= H entry (h 1))5 con ti nue;6 els e if(!H ha sF ield (h 1))7 if(H e n try (h 2)!=nu ll &&!H ha sField (h 2)){8 i f(H ha sF ie l d (h ))9 H se t G =R a lia s (D se t ,h 2+H fie ld (h ));10 els e11 H se t G ={h 2};12 }13else i f(H ha sF ie l d (h ))14 if(H fie ld (h )== H field (h 1)&&!H ha s F ie ld (h 2))15 H s e t G ={h 2};16}//end fo r17if(H se t == Á)H se t G ={h }18ret urn H set ;19}图4 辅助函数R a lia s F ig .4 H elper functi o n R a lia s从而在定值实体中所有引用的内存位置都用它们的等价类表示来替代.在数据流方程的R kill 函数中,对于赋值语句等号左边的域访问表达式的指针变量用该指针的等价类表示来替代,而不关心等号右边的表达式;而R g en 函数不但将赋值语句等号左边的域访问表达式的指针变量用该指针的等价类表1414 小 型 微 型 计 算 机 系 统 2011年示来替代,而且对于等号右边的表达式,也将用该表达式的等价类表示来替代.对各种赋值语句和条件语句的函数R kill 和R ge n 的具体操作如图3所示.辅助函数R alias 如图4所示,体现了算法的核心.该函数主要用来找到能够到达某语句的入口程序点并可能(m ay )和参数h 指向同一个位置的等价类表示的内存位置的集合.Progra m R in /R o ut It erator1Iterat or2It erator3[q=x]1R in (1)ÁÁÁR out (1)3q,x,143q,x,143q,x,14[q !=nu ll ]2R in (2)3q,x,143q,x,143q,t 13t 1,xn,443z n,t 1,543xn,z ,643t 2,z ,743q,x,143q,t 13t 1,xn,443t 1,t 1n,443z n,t 1,543xn,z ,643t 1n,z ,643t 2,z,74[z =m all oc (t ype)]3R o ut (2)R in (3)3q,x,143q,x,143q,t 1,843z ,nu ll ,343t 1,xn,443z n,t 1,543xn,z ,643t 2,z ,743q,x,143q,t 1,843z,nu ll ,343t 1,xn,443t 1,t 1n,443z n,t 1,543xn,z ,643t 1n,z ,643t 2,z,74[t 1=q y n]4R o ut (3)R in (4)3q,x,143z,nu ll ,343q,x,143q,t 1,843z ,nu ll ,343t 1,xn,443z n,t 1,543xn,z ,643t 2,z ,743q,x,143q,t 1,843z,nu ll ,343t 1,xn,443t 1,t 1n,443z n,t 1,543xn,z ,643t 1n,z ,643t 2,z,74[z y n =t 1]5R o ut (4)R in (5)3q,x,143z,nu ll ,343t 1,xn,443q,x,143q,t 1,843z ,nu ll ,343t 1,xn,443t 1,t 1n,443zn,t 1,543xn,z,643t 2,z ,743q,x,143q,t 1,843z,nu ll ,343t 1,xn,443t 1,t 1n,443z n,t 1,543xn,z ,643t 1n,z ,643t 2,z,74[q y n=z ]6R o ut (5)R in (6)3q,x,143z,nu ll ,343t 1,xn,443zn,t 1,543q,x,143q,t 1,843z ,nu ll ,343t 1,xn,443t 1,t 1n,443zn,t 1,543xn,z,643t 2,z ,743q,x,143q,t 1,843z,nu ll ,343t 1,xn,443t 1,t 1n,443z n,t 1,543xn,z ,643t 1n,z ,643t 2,z,74[t 2=q y n]7R o ut (6)R in (7)3q,x,143z,nu ll ,343t 1,xn,443zn,t 1,543xn,z ,643q,x,143q,t 1,843z ,nu ll ,343t 1,xn,443t 1,t 1n,443zn,t 1,543xn,z,643t 1n,z ,643t 2,z ,743q,x,143q,t 1,843z,nu ll ,343t 1,xn,443t 1,t 1n,443z n,t 1,543xn,z ,643t 1n,z ,643t 2,z,74[q=t 2y n]8R o ut (7)R in (8)3q,x,143z,nu ll ,343t 1,xn,443zn,t 1,543xn,z ,643t 2,z ,743q,x,143q,t 1,843z ,nu ll ,343t 1,xn,443t 1,t 1n,443zn,t 1,543xn,z,643t 1n,z ,643t 2,z ,743q,x,143q,t 1,843z,nu ll ,343t 1,xn,443t 1,t 1n,443z n,t 1,543xn,z ,643t 1n,z ,643t 2,z,74R o ut (8)3z ,nu ll ,343t 1,xn,443zn,t 1,543xn,z ,643t 2,z ,743q,t 1,843z ,nu ll ,343t 1,xn,443t 1,t 1n,443z n,t 1,543xn,z,643t 1n,z ,643t 2,z ,743q,t 1,843z,nu ll ,343t 1,xn,443t 1,t 1n,443zn,t 1,543xn,z ,643t 1n,z,643t 2,z ,743q,t 1,84图5 单链表程序的到达定值F i g.5 Sing l e linked list c s reaching de fi n iti onR a lias 算法首先初始化一个内存位置集合Hse t<H 为空(第1行),然后判断某语句的入口程序点的到达定值抽象D s e t <D 是否为空,若为空,则退出返回h 本身(第2行);否则循环处理Dset集合中每个元素,假设为3h 1,h 2,l 4,如果H entry (h )和H entry (h 1)不相同,也就是它们的指针变量对应的内存位置不相同,继续处理D s e t 中的下一个元素(第4-5行);否则,如果h 1不是由域访问表达式指向的,有两种情况:(1)h 是域访问表达式指向的,则应该先找出和域访问表达式的指针变量指向相同位置的内存位置,要求H entry (h 2)不为空且H ha sField (h 2)为fa lse ,则h 和h 2指向相同的内存位置.然后再递归找和h 2+H fie ld (h )指向相同位置的内存位置(第6-9行).(2)h 是指针变量指向的,并且H entry (h 2)不为空且H ha s F ield (h 2)为fa lse ,则将h 2加入到H s e t 中(第11行).如果h 和h 1是同一个域访问表达式对应的内存位置,并h 2是由指针变量指向的内存位置,则用h 2替代h,即将h 2加入到H s e t 中(第13-15行).最后在循环结束后判定H se t 是否为空,为空则返回h 本身(第17行).3.1.3 示 例在这里通过下面的程序片段来说明到达定值分析的主要特性.它是对单链表的插入操作,在单链表x 的每个节点后插入节点z .[q =x ]1;while [q !=nu ll]2do {[z =m all oc(type)]3;[t 1=q y n ex t ]4;[z y n ex t =t 1]5;[q y nex t=z]6;[t 2=q y nex t]7;[q=t 2y nex t ]8;}图5表述了到达定值分析利用w o rk list 迭代算法[4]的迭代过程,计算每次迭代中每个程序点的到达定值信息.在Iterato r1中,在语句1中,内存位置q 和x 右值别名,这样出口程序点到达定值中增加(g en)定值实体3q,x,14;到达语句4时,因为q 和x 右值别名,由别名函数可以找到R a lias (R in (4),qn )={xn },即由q 的别名x 替代,增加3t 1,xn,44;到达语句5时,增加3z n,t 1,54;到达语句6时,同理语句4,增加3xn,z,64;到达语句7时,由别名函数可以找到R a lia s (R in (7),qn )={z },故增加3t 2,z ,74;到达语句8时,由别名函数可以找到R alias (R in (8),t 2n )={t 1},由于语句是对q 的定值,将所有到达此程序点对q 的定值注销(kill),而增加3q,t 1,84.14157期 付小朋等:一种面向动态链状数据结构的指针定值引用链算法经过一次迭代计算后,分析没有到达稳定状态,继续迭代计算,从语句1和8到达循环的头部,Ri n (2)=Ro ut(1)G Rout(8),这样q可能(m ay)和x,t1右值别名,同理在定值实体中对q的引用时用x,t1去替代,如到达语句4时,将所有到达此程序点对t1的定值实体注销,而增加定值实体3t1,xn,443t1,t1n,44.经过数次迭代计算后,每个程序点的到达定值没有变化,迭代算法到达稳定的状态,到达定值分析结束,得到如图5中Iterato r3中所示的每个程序点的到达定值信息.3.2引用定值链在到达定值信息的基础上,可以计算引用定值链.引用定值链连接对一个内存位置的引用的语句到所有可能沿某条路径流经到该语句并对该内存位置定值的语句.3.2.1推导方程式函数Rud:L y P(H@L)得到某语句引用的内存位置和所有可能沿某条路径到达该语句并对该内存位置定值的语句的标号之间的序对.对于任一标号为l的语句s,根据语句入口程序点的到达定值信息,有:Rud (l)={3h,l14|h I Rus e s(s l)C3h,_,l14I Rin(l)}(1)其中,函数Ruse s:S y P(H)得到某语句中所有引用的域访问表达式对应的内存位置.对于引用语句,Ruse s函数定义如公式(2),而其它类型的语句的Ruses函数都为空.Ruse s ([p=q y f]l)={h+f|h I Ralia s(Rin(l),q)}(2)3.2.2示例根据图5中每条语句入口程序点已经得到的到达定值信息,利用公式(1)可以求得如图6的Rus e s函数的信息;再利用公式(2),可以求得如图6中的引用定值链.l R uses(l)R ud(l)1ÁÁ2ÁÁ3ÁÁ4xn,t1n3xn,643t1n,645ÁÁ6ÁÁ7xn,t1n3xn,643t1n,648z n3zn,54图6单链表程序的引用定值链F i g.6S i ng l e li nked list c s use-def i n ition cha i ns3.3定值引用链在引用定值链信息的基础上,可以推导得到定值引用链.定值引用链连接对一个内存位置的定值的语句到所有可能沿某条路径流经到对该内存位置引用的语句.3.3.1推导方程式函数Rdu(l):L y P(H@L),得到某语句定值的内存位置和可能沿某条路径到达所有引用该内存位置的语句的标号之间的序对.利用引用定值链,求定值引用链的推导方程式为:P l1,l2I L,h I H,3h,l24I Rud(l1)]3h,l14I Rdu(l2)(3) 3.3.2示例根据图6得到的引用定值链,可以利用公式(3)可以求得程序的定值引用链,如图7所示.l R ud(l)R du(l)1ÁÁ2ÁÁ3ÁÁ43xn,643t1n,64Á5Á3zn,846Á3xn,443xn,743t1n,443t1n,7473xn,643t1n,64Á83z n,54Á图7单链表程序的定值引用链F i g.7S i ng le li nked list c s def i nition-us e cha i ns4实验结果和分析笔者在SU IF[10]框架上,实现了过程内的定值引用算法,并做了相关的测试,详细的程序和数据可见[3],测试用例如表1所示,它们大部分来自O l den[5]中的测试程序.表1测试用例的数据结构T able1D ata struc t ures o f bench m a rk prog ra m s Progra m Descri p tion D at a S tructuresBH N-body si m u lati on Leaf-li nked treeEM3DS i m u l ati on of el ectrom agn eti cw aveB i partitePow er Pow er s yste m op ti m izati on H ierarch i ca l treeT s p T rave li ng s a l es m an p roble m Ba l anced b i n ary-tree T reeadd T ree add it on B i nary t reeIn s ert L ist i n sert L i nked-list选择这些测试用例的原因是它们创建和访问各种类型的动态链状数据结构,如链表、树状结构等.表2给出了经过过表2过程内分析的统计数据T able2S t a tistics after i n trapro cedura l ana l y sis Progra m L i n es Procedures T i m e(s)DEF/U SEDEF/USE[6]BH1977362.9845EM3D352150.1778Pow er772190.4500T s p532140.4115/T reeadd9930.0100In s ert4830.015/程内定值引用链分析的统计数据,分别给出了程序的行数、包含的过程体数量、分析过程中所耗的总时间、经过分析找出的所有定值引用序对的数量和文献[6]中算法给出的定值引用序对的数量.其中符号"/"表示文献[6]中没有对此程序进行测试.可以看到最后两列对应程序的定值引用序对数目并不相1416小型微型计算机系统2011年同.这是因为更精确的别名分析,可以移除虚假的定值引用链.由于本文中采用的算法,分析得到了更精确的别名信息,移除了不再有效的到达定值,提高了定值引用链的精度,所以定值引用序对数量比[6]中的略少,从而也表明本文的算法更优越.5相关工作比较过程内的定值引用链的分析技术,早已众所周知[9],过程间的分析技术也被提出[12],而扩展到带有指针或动态分配数据结构的程序中定值引用链的研究,早期的有文献[6-8].Pande和L andi等[7]首次在一级指针的C语言程序中,提出了一种过程间的定值引用链的算法.算法首先利用别名信息计算过程间的到达定值,然后利用到达定值的信息建立定值引用链,然而该算法忽略了对动态分配的数据结构的分析.A ltucher和L andi[8]运用一种新的命名策略来提高动态分配的内存位置的定值引用信息的精度.它被用来计算动态分配内存位置的扩展的一定别名(ex tended m ust a liases),然后利用此别名信息来提高定值引用链的精度,但是该算法将动态分配的结构体看成是一个整体对象,没有区分结构体中的各个不同域.Hw ang等[6]通过逆向的数据流迭代来计算每条语句向上暴露的引用(upw a rd expo sed uses),然后再计算动态链状数据结构指针程序的过程间的定值引用链.该方法产生多级的域访问路径表达式,为了确定两个多级的域访问路径表达式是否指向同一个内存位置,必须进行访问表达式的比较,算法的时空开销较大.本文采用正向的数据流迭代算法来计算到达定值信息,并在此基础上,推导求得每条语句的引用定值链和定值引用链.笔者受文献[13]的启发,在到达定值的分析过程中,抽象值记录赋值语句等号左,右两边的表达式和语句标号的三元组,不但保存内存位置的定值信息,而且保存了内存位置的右值别名信息.再根据语句入口程序点的到达定值信息,找到和指针变量右值别名的等价类表示,用它去替代指针变量对应的内存位置在定值实体中的位置,并向下传递别名.从而将到达定值分析和别名信息的获取在一个分析过程中完成,大大提高分析的效率.6结束语提出了一种面向动态链状数据结构的过程内指针定值引用链的算法.该算法首先用正向的数据流迭代算法得到动态链状数据结构的每条语句入口和出口程序点的到达定值信息,然后利用语句入口程序点的到达定值信息和别名信息,计算语句的引用定值链;最后根据语句中的引用定值链信息,推导得到定值引用链.本文不足之处在于只处理过程内的定值引用信息,没有完成过程间的定值引用算法.对过程间定值引用链算法的研究将是我们接下来的主要工作内容.R eferences:[1]D uest er w al d E,Gup t a R,Soffa M L.A d e m and-driven an al yzerfor dat a fl ow testi ng at t he i n tegrati on l evel[C].In IEEE In t erna-ti onal Con ference on So ft w areE ngineeri ng,B erli n,G er m any,M arch 1996,575-586.[2]W o lfeM.H i gh perfor m ance com pil ers for parallel com puti ng[M].Add is on-W esley,1995.[3]Z hang Y u.Parallel p rogra mm ing l an guage w it h s h ared res ources pecificati on[EB/OL].U STC-Y al e Joi n t Research C en t er forH igh-Con fi dence So ft w are.h ttp://kyh tcs /pp l srs,2010-11-05.[4]S teen s gaard B.Po i n ts-t o anal y sis i n al m ost li near ti m e[C].Pro-ceed i ng s of t he23rd ACM S y m po si um on the Pri nci p l es o f Pro-gra mm i ng L anguages,S.t Petersburg B each,F l orida,1996.[5]M arti n C C arlisle,Anne Rogers.O l d en:paralleli z i ng progra m sw ith dyna m ic d at a stru ctures on d istri bu t ed-m e m ory m ach i nes[EB/ OL].h tt p://ww w.m arti ncarli s l /o l den.h t m,l1996.[6]Y aun-Sh i n Hw an g,Joel Saltz.In t erprocedura ldefi n ition use chai n sof dyna m i c po i n ter-li nked data stru ctures[M].S ci en ti fic Progra m-m i ng,I O S Press,2003.[7]Pande H D,Land iW A,Ryder B G.In t erprocedura ldef-use associ a-ti ons for c s yste m s w it h si n gle level po i n ters[C].IEEE Transac-ti ons on So ft w are Eng i neeri ng,M ay,1994,20(5):385-402. [8]A lt ucher R,Land iW.An extended for m o fm ust ali as anal y sis fordyna m ic all ocati on[C].Proceedi n gs of the22nd ACM S y m po si um on the Pri nci p les o f Prog ra mm i ng Languages,San Fran ci sco,C al-iforn i a,January1995,74-84.[9]A ho A V,S eth iR,U ll m an J D.C o m p ilers:pri nc i p l es,techn i ques,and too ls[M].Add is on-W esley,1986.[10]W ils on R,French R,W ils on C,eta.l SU I F:an infrast ruct ure for re-search on para ll eliz i ng and opti m i z i ng com p ilers[J].ACM S I G P-LAN N oti ces,Dece m ber,1994,29(12):31-37.[11]N i els on F,N i elson H R,H ank i n C.Princi p l e of progra m anal y sis[M].Spri nger,1999,41-44.[12]H arro l d M J,S offa M L.E ffici en t com putati on o f i n terp rocedurald efi n ition-u se chai n s[C].ACM Transacti ons on Progra mm i ngLan guages and Syste m s,1994,16(2):175-204.[13]H ackettB,Rug i na R.Reg i on-bas ed shape analysis w ith track ed l o-cati on s[C].Proceedi n gs o f t h e32nd ACM Sym pos i um on Pri nc-ip les of Progra mm i ng Languages,Long B each,C aliforn ia,J an uar-y,2005,310-323.[14]Andersen L O.Progra m analysis and s peci alization for t he C pro-gra mm i ng l anguage[D].D I KU,U n i versit y o fC openhagen,1994.14177期付小朋等:一种面向动态链状数据结构的指针定值引用链算法。