优化算法和梯度下降法
直线拟合的四种方法

直线拟合的四种方法
1、最小二乘法:它是利用正规方程求解线性回归方程的最优解,通过该方法求出最小二乘平方和最小,即最小误差的直线的斜率和截距;
2、梯度下降法:它是一种迭代优化算法,通过不断更新参数使损失函数最小;
3、随机梯度下降法:它是一种迭代优化算法,但比梯度下降法更加高效,它每次只需要使用一小部分的样本数据,依次更新参数使损失函数最小;
4、正则化线性回归:它是一种线性回归方法,该方法通过在损失函数中加入正则化项来抑制参数的极端值,使模型较为简洁,以达到优化参数的目的。
梯度下降法原理

梯度下降法原理
梯度下降法是一种优化算法,主要用于寻找函数的最小值。
它的基本原理是通过不断迭代更新参数,从而逐步接近函数的最小值点。
1. 初始化参数:选择一个初始点作为起始点,即确定函数的初始参数。
2. 计算梯度:在当前参数点处,计算函数的梯度。
梯度是函数在某一点的偏导数,表示函数在该点上升最快的方向。
3. 更新参数:根据梯度的信息,更新参数点。
具体更新方法有多种,最常见的是通过参数点减去学习率乘以梯度的方法进行更新。
4. 判断收敛:判断当前参数点是否满足收敛条件。
可以通过设定一个阈值,当参数的变化小于阈值时停止迭代。
5. 迭代更新:如果参数点不满足收敛条件,则返回步骤2,继续进行梯度的计算和参数的更新,直到满足收敛条件为止。
通过以上步骤,梯度下降法不断迭代更新参数,直到找到函数的最小值点。
需要注意的是,梯度下降法只能保证找到局部最小值,并不一定能找到全局最小值。
此外,学习率是一个重要的超参数,过大或过小的学习率都会影响梯度下降法的性能,因此需要合理选择学习率。
梯度下降法 工作原理

梯度下降法工作原理
梯度下降法是一种优化算法,用于寻找函数的最小值。
其工作原理如下:
1.初始化参数:选择一个起始点作为初始参数,这可以是任意值或随机选择的值。
2.计算损失函数的梯度:计算当前参数点处的损失函数的梯度。
梯度表示损失函数在每个参数维度上的变化率。
3.更新参数:使用梯度信息来更新参数,以使损失函数的值减小。
更新参数的方法是沿着梯度的反方向进行调整。
4.迭代更新:重复步骤2和3,直到满足停止准则(如达到预设的最大迭代次数或损失函数值减小到足够小的值)。
5.输出结果:最终的参数值即为使损失函数最小化的参数值。
梯度下降法通过不断地沿着梯度的反方向移动参数,逐渐找到使损失函数最小化的最优解。
在机器学习和深度学习中,梯度下降法被广泛用于训练模型和优化模型参数。
数学中的优化问题

数学中的优化问题数学是一门研究数量、结构、变化以及空间等概念的学科,优化问题是数学中一个重要的研究领域。
优化问题涉及到如何在给定的约束条件下,找到使目标函数取得最大或最小值的最优解。
在本文中,我们将探讨数学中的优化问题及其应用。
一、最优化问题的定义最优化问题是指在有限资源和给定约束条件下,寻找某一目标函数的最优解。
最优化问题既可以是求最大值,也可以是求最小值。
目标函数即我们需要优化的量,而约束条件则规定了该问题的限制条件。
二、优化问题的分类优化问题可以分为数学规划问题和凸优化问题。
数学规划问题是指在给定约束条件下,寻找目标函数的最优解,其中约束条件可以是线性或非线性的。
凸优化问题是指在给定的凸约束条件下,寻找凸目标函数的最优解。
三、优化问题的应用优化问题在各个领域都有广泛的应用,例如:1. 经济学:优化问题在经济学中被广泛应用,用于求解最优的资源分配方案,最大化利润或最小化成本等。
2. 运筹学:运筹学是研究如何在给定约束条件下,进行最优决策的学科。
优化问题在运筹学中起到了重要的作用,例如在物流规划、生产调度、交通优化等方面的应用。
3. 机器学习:机器学习中的许多问题可以被看作是优化问题,例如参数的最优选择、模型的最优拟合等。
4. 工程学:在工程学中,优化问题可以用于设计最优的结构、最佳的控制策略等。
5. 生物学:在生物学研究中,优化问题被用于模拟和分析生物系统的行为,例如生态系统的最优稳定性等。
四、优化算法为了解决优化问题,人们开发了许多优化算法。
常用的优化算法包括:1. 梯度下降法:梯度下降法是一种迭代的优化算法,通过沿着目标函数的负梯度方向不断更新参数的值,逐步接近最优解。
2. 共轭梯度法:共轭梯度法是一种迭代的优化算法,常用于求解线性规划问题。
3. 遗传算法:遗传算法模拟自然界中的进化过程,通过遗传操作(交叉、变异等)来不断搜索最优解。
4. 粒子群算法:粒子群算法模拟鸟群中鸟的行为,通过模拟每个个体的位置和速度来搜索最优解。
数值优化算法

数值优化算法在现代科学和工程中,数值优化算法被广泛应用于解决各种复杂问题。
数值优化算法是一种寻找函数极值的方法,这些函数可能具有多个自变量和约束条件。
数值优化算法对于在实际问题中找到最佳解决方案至关重要。
本文将介绍几种常见的数值优化算法及其应用。
一、梯度下降法梯度下降法是一种常用的数值优化方法。
它通过寻找损失函数的梯度来更新参数,以在每次迭代中逐步接近极值点。
梯度下降法的优势在于简单易实现,并且在大规模数据集上的表现良好。
这使得它成为许多机器学习算法中参数优化的首选方法。
二、牛顿法牛顿法是一种用于寻找函数极值点的迭代优化算法。
它利用函数的一阶导数和二阶导数信息来逼近极值点。
与梯度下降法相比,牛顿法的收敛速度更快,但它的计算复杂度更高。
牛顿法在求解高维问题或拟合复杂曲线时表现出色。
三、遗传算法遗传算法是一种模拟生物遗传和进化过程的优化算法。
它通过使用选择、交叉和变异等操作,模拟自然界的进化规律,来寻找函数的最优解。
遗传算法适用于复杂问题,能够在搜索空间中找到全局最优解。
在函数不可导或离散问题中,遗传算法能够提供有效的解决方案。
四、模拟退火算法模拟退火算法是一种启发式搜索算法,模拟了金属退火过程中原子随温度变化的行为。
模拟退火算法以一定的概率接受更差的解,并以较低的概率逐渐收敛到全局最优解。
模拟退火算法对局部极小点有一定的免疫能力,并且在大规模离散优化问题中表现出优越性。
五、粒子群算法粒子群算法是一种基于群体行为的优化算法。
它模拟了鸟群觅食的行为,通过迭代寻找问题的最优解。
粒子群算法通过评估适应度函数来引导粒子的移动,从而逐渐靠近最优解。
这种算法适用于多目标优化问题和高维函数优化。
结论数值优化算法在科学和工程领域扮演着至关重要的角色。
梯度下降法、牛顿法、遗传算法、模拟退火算法和粒子群算法是几种常见的数值优化方法。
它们各自具有不同的优势和适用范围,可以根据问题的特点选择合适的优化算法。
通过应用这些优化算法,可以帮助科学家和工程师在实际问题中找到最佳解决方案,推动技术的进步和创新。
梯度下降算法及优化方法

梯度下降算法及优化⽅法序⾔对于y=f(wx+b),如何使⽤神经⽹络来进⾏求解,也就是给定x和y的值,如何让系统⾃动⽣成正确的权重值w和b呢?⼀般情况下,有两种尝试⽅法:1)随机试:纯概率问题,⼏乎不可能实现。
2)梯度下降法:先初始化w和b(可以随机设置,也可以⼈为默认),然后使⽤下降算法来对w和b进⾏更新。
都有哪些⽅法?到底哪种⽅法更好?⽬录⼀、基础知识⼆、SGD三、Momentum四、Adagrad五、Adadelta六、RMSProp七、Adam正⽂⼀、基础知识斜率:在⼀维空间上,斜率就是函数的导数;梯度:在多维空间⾥,函数的导数叫梯度,梯度是偏导数组成的向量;⼆、SGD⼀般情况下,SGD指Mini-batch GD,(GD可分为三种:Batch GD,Stochastic GD,mini-batch GD)SGD就是每次迭代计算mini-batch的梯度,然后对参数进⾏更新:1)gt=∇θt−1f(θt−1)2)Δθt=−η∗gt其中,η是学习率,gt是梯度SGD完全依赖于当前batch的梯度,η可理解为允许当前batch的梯度多⼤程度影响参数更新。
劣势:1、学习率LR选择⽐较困难2、对所有参数都使⽤相同的LR:在数据不均衡的情况下,如稀疏特征希望更新快些,常出现特征出现慢些时,SGD不太满⾜要求。
3、容易收敛到局部最优,有可能被困于鞍点三、Momentum积累之前的动量来替代梯度1)mt=µ∗mt−1+gt2)Δθt=−η∗mt其中,µ是动量因⼦梯度下降前期:使⽤上⼀次参数来更新,下降⽅向⼀致,乘上较⼤的µ能够进⾏很好的加速梯度下降后期,在局部最⼩值来回震荡的时候,gradient→0,µ使得更新幅度增⼤,跳出陷阱梯度⽅向改变时,µ能够减少更新结论:momentum项能够加速SGD,抑制振荡,从⽽加快收敛四、Adagrad对学习率进⾏了约束:nt=nt−1+gt2Δθt=−η/(√nt+ϵ)∗gt此处,对gt从11到tt进⾏⼀个递推形成⼀个约束项regularizer:−1/√(∑r=1t(gr)2+ϵ) ,ϵ⽤来保证分母⾮0特点:前期gt较⼩的时候, regularizer较⼤,能够放⼤梯度后期gt较⼤的时候,regularizer较⼩,能够约束梯度适合处理稀疏梯度缺点:由公式可以看出,仍依赖于⼈⼯设置⼀个全局学习率η设置过⼤的话,会使regularizer过于敏感,对梯度的调节太⼤中后期,分母上梯度平⽅的累加将会越来越⼤,使gradient→0,使得训练提前结束五、Adadelta对Adagrad的扩展,也是对学习率进⾏⾃适应约束,但对计算进⾏了简化。
最优化问题的算法迭代格式

最优化问题的算法迭代格式最优化问题的算法迭代格式最优化问题是指在一定的条件下,寻找使某个目标函数取得极值(最大值或最小值)的变量取值。
解决最优化问题的方法有很多种,其中较为常见的是迭代法。
本文将介绍几种常用的最优化问题迭代算法及其格式。
一、梯度下降法梯度下降法是一种基于负梯度方向进行搜索的迭代算法,它通过不断地沿着目标函数的负梯度方向进行搜索,逐步接近极值点。
该方法具有收敛速度快、易于实现等优点,在许多应用领域中被广泛使用。
1. 算法描述对于目标函数 $f(x)$,初始点 $x_0$ 和学习率 $\alpha$,梯度下降算法可以描述为以下步骤:- 计算当前点 $x_k$ 的梯度 $\nabla f(x_k)$;- 更新当前点 $x_k$ 为 $x_{k+1}=x_k-\alpha\nabla f(x_k)$;- 如果满足停止条件,则输出结果;否则返回第 1 步。
2. 算法特点- 沿着负梯度方向进行搜索,能够快速收敛;- 学习率的选择对算法效果有重要影响;- 可能会陷入局部极小值。
二、共轭梯度法共轭梯度法是一种基于线性方程组求解的迭代算法,它通过不断地搜索与当前搜索方向共轭的新搜索方向,并在该方向上进行一维搜索,逐步接近极值点。
该方法具有收敛速度快、内存占用少等优点,在大规模问题中被广泛使用。
1. 算法描述对于目标函数 $f(x)$,初始点 $x_0$ 和初始搜索方向 $d_0$,共轭梯度算法可以描述为以下步骤:- 计算当前点 $x_k$ 的梯度 $\nabla f(x_k)$;- 如果满足停止条件,则输出结果;否则进行下一步;- 计算当前搜索方向 $d_k$;- 在当前搜索方向上进行一维搜索,得到最优步长 $\alpha_k$;- 更新当前点为 $x_{k+1}=x_k+\alpha_k d_k$;- 计算新的搜索方向 $d_{k+1}$;- 返回第 2 步。
2. 算法特点- 搜索方向与前面所有搜索方向都正交,能够快速收敛;- 需要存储和计算大量中间变量,内存占用较大;- 可以用于非线性问题的求解。
梯度求解方法

梯度求解方法梯度求解方法是一种常用的优化算法,用于求解函数的极值点。
在机器学习和深度学习中,梯度求解方法被广泛应用于模型训练和参数优化过程中。
本文将介绍梯度求解方法的原理和常用的算法,以及其在实际应用中的一些注意事项。
一、梯度的概念在数学中,梯度是一个向量,表示函数在某一点上的变化率最大的方向。
对于多元函数而言,梯度是一个向量,其每个分量分别对应函数在每个自变量上的偏导数。
梯度的方向指向函数在某一点上变化最快的方向,而梯度的模表示函数在该点上的变化率。
二、梯度下降法梯度下降法是一种基于梯度的优化算法,用于求解函数的极小值点。
其基本思想是从一个初始点开始,沿着梯度的反方向迭代更新自变量,直到达到收敛条件或迭代次数达到上限。
具体来说,梯度下降法的更新规则如下:1. 初始化自变量的初始值;2. 计算当前点的梯度;3. 根据梯度的反方向更新自变量;4. 重复步骤2和3,直到达到收敛条件或迭代次数达到上限。
在梯度下降法中,学习率是一个重要的超参数,它控制了自变量在每次迭代中的更新幅度。
学习率过大可能导致震荡或发散,学习率过小可能导致收敛速度过慢。
三、常用的梯度下降算法1. 批量梯度下降法(Batch Gradient Descent,BGD):在每次迭代中,BGD使用全部训练样本计算梯度,并更新自变量。
BGD的优点是每次迭代都朝着全局最优解的方向前进,但计算梯度的代价较高。
2. 随机梯度下降法(Stochastic Gradient Descent,SGD):在每次迭代中,SGD使用一个样本计算梯度,并更新自变量。
SGD的优点是计算梯度的代价较低,但由于每次迭代只使用一个样本,更新方向可能不够准确。
3. 小批量梯度下降法(Mini-batch Gradient Descent):在每次迭代中,Mini-batch GD使用一小批样本计算梯度,并更新自变量。
这种方法综合了BGD和SGD的优点,既可以保证较准确的更新方向,又能降低计算梯度的代价。
各类梯度优化算法的原理

各类梯度优化算法的原理梯度优化算法是求解优化问题中的一类重要算法。
该类算法的目标是通过迭代的方式逐步优化模型的参数,使得模型在训练数据上的损失函数最小化。
常见的梯度优化算法包括梯度下降法、随机梯度下降法、动量法、Nesterov加速梯度法、Adagrad、RMSprop、Adam等。
下面将分别对这些算法的原理进行详细介绍。
梯度下降法是最基本的优化算法之一。
它通过每次迭代更新参数的方式,使得模型在训练数据上的损失函数值逐渐减小。
具体来说,对于每个参数θ,梯度下降法的更新公式如下:θ= θ- α* ∇(Loss(θ))其中∇(Loss(θ))表示损失函数Loss(θ)关于参数θ的梯度,α表示学习率,控制每次迭代更新的步长。
梯度下降法的核心思想是,沿着损失函数的梯度方向更新参数,使得损失函数值逐渐减小。
随机梯度下降法(Stochastic Gradient Descent, SGD)是梯度下降法的一种改进方法。
与梯度下降法每次迭代都要计算所有样本的梯度不同,随机梯度下降法每次迭代只计算一个样本的梯度。
具体来说,对于每个参数θ,随机梯度下降法的更新公式如下:θ= θ- α* ∇(Loss(θ;x_i,y_i))其中(x_i,y_i)表示训练样本,Loss(θ;x_i,y_i)表示损失函数关于样本(x_i,y_i)的值。
相比于梯度下降法,随机梯度下降法的计算开销更小,但是更新方向可能会产生较大的抖动。
动量法(Momentum)是一种基于动量更新参数的优化算法。
它的核心思想是,每次迭代时将当前的更新方向与历史的更新方向进行加权平均,从而增加参数更新的冲力。
具体来说,对于每个参数θ,动量法的更新公式如下:v = β* v - α* ∇(Loss(θ))θ= θ+ v其中v表示历史的更新方向,β表示动量因子,控制历史更新方向的权重。
动量法的好处是可以加快参数更新的速度,并且减小更新方向的抖动,从而更容易逃离局部最优点。
机器学习概念之梯度下降算法(全量梯度下降算法、随机梯度下降算法、批量梯度下降算法)

机器学习概念之梯度下降算法(全量梯度下降算法、随机梯度下降算法、批量梯度下降算法) 不多说,直接上⼲货!回归与梯度下降 回归在数学上来说是给定⼀个点集,能够⽤⼀条曲线去拟合之,如果这个曲线是⼀条直线,那就被称为线性回归,如果曲线是⼀条⼆次曲线,就被称为⼆次回归,回归还有很多的变种,如本地加权回归、逻辑回归,等等。
⽤⼀个很简单的例⼦来说明回归,这个例⼦来⾃很多的地⽅,也在很多的开源软件中看到,⽐如说weka。
⼤概就是,做⼀个房屋价值的评估系统,⼀个房屋的价值来⾃很多地⽅,⽐如说⾯积、房间的数量(⼏室⼏厅)、地段、朝向等等,这些影响房屋价值的变量被称为特征(feature),feature在机器学习中是⼀个很重要的概念,有很多的论⽂专门探讨这个东西。
在此处,为了简单,假设我们的房屋就是⼀个变量影响的,就是房屋的⾯积。
假设有⼀个房屋销售的数据如下: ⾯积(m^2) 销售价钱(万元) 123 250 150 320 87 160 102 220 … … 这个表类似于帝都5环左右的房屋价钱,我们可以做出⼀个图,x轴是房屋的⾯积。
y轴是房屋的售价,如下: 如果来了⼀个新的⾯积,假设在销售价钱的记录中没有的,我们怎么办呢? 我们可以⽤⼀条曲线去尽量准的拟合这些数据,然后如果有新的输⼊过来,我们可以在将曲线上这个点对应的值返回。
如果⽤⼀条直线去拟合,可能是下⾯的样⼦: 绿⾊的点就是我们想要预测的点。
⾸先给出⼀些概念和常⽤的符号,在不同的机器学习书籍中可能有⼀定的差别。
房屋销售记录表 - 训练集(training set)或者训练数据(training data), 是我们流程中的输⼊数据,⼀般称为x 房屋销售价钱 - 输出数据,⼀般称为y 拟合的函数(或者称为假设或者模型),⼀般写做 y = h(x) 训练数据的条⽬数(#training set), ⼀条训练数据是由⼀对输⼊数据和输出数据组成的 输⼊数据的维度(特征的个数,#features),n 下⾯是⼀个典型的机器学习的过程,⾸先给出⼀个输⼊数据,我们的算法会通过⼀系列的过程得到⼀个估计的函数,这个函数有能⼒对没有见过的新数据给出⼀个新的估计,也被称为构建⼀个模型。
数学物理方程的数值解法

数学物理方程的数值解法数学物理方程是自然界和科学中描述物体运动、能量转化和相互作用的基本规律。
我们通常使用数值解法来求解这些方程,以得到近似的解析解。
数值解法既可以用于数学问题,也可以用于物理问题。
本文将介绍几种常见的数学物理方程的数值解法。
一、微分方程的数值解法微分方程是描述物体运动和变化的重要工具。
常见的微分方程有常微分方程和偏微分方程。
常见的数值解法包括:1. 欧拉法(Euler's method)欧拉法是最简单的数值解法之一,通过将微分方程离散化为差分方程,在每个小时间步长上近似计算微分方程的导数。
欧拉法易于实现,但精度相对较低。
2. 龙格-库塔法(Runge-Kutta method)龙格-库塔法是一类常用的数值解法,包括二阶、四阶等不同的步长控制方法。
龙格-库塔法通过计算多个离散点上的导数来近似微分方程,精度较高。
3. 有限差分法(Finite difference method)有限差分法是一种常用的数值解法,将微分方程转化为差分方程并在网格上逼近微分方程的导数。
有限差分法适用于边值问题和初值问题,且精度较高。
二、积分方程的数值解法积分方程描述了给定函数的积分和积分变换之间的关系。
常见的数值解法有:1. 数值积分法数值积分法是通过数值逼近求解积分方程,常用的数值积分法包括梯形法则、辛普森法则等。
数值积分法适用于求解一维和多维积分方程。
2. 蒙特卡洛法(Monte Carlo method)蒙特卡洛法通过随机采样和统计分析的方法,将积分方程转化为概率问题,并通过大量的随机样本来估计积分值。
蒙特卡洛法适用于高维空间和复杂积分方程。
三、优化问题的数值解法优化问题是寻找在给定约束条件下使目标函数取得极值的数学问题。
常见的数值解法有:1. 梯度下降法(Gradient descent method)梯度下降法是一种常用的优化算法,通过迭代和梯度方向来寻找目标函数的局部最优解。
梯度下降法适用于连续可导的优化问题。
matlab 中的优化算法

matlab 中的优化算法MATLAB提供了多种优化算法和技术,用于解决各种不同类型的优化问题。
以下是一些在MATLAB中常用的优化算法:1.梯度下降法:梯度下降法是一种迭代方法,用于找到一个函数的局部最小值。
在MATLAB中,可以使用fminunc函数实现无约束问题的梯度下降优化。
2.牛顿法:牛顿法是一种求解无约束非线性优化问题的算法,它利用泰勒级数的前几项来近似函数。
在MATLAB中,可以使用fminunc 函数实现无约束问题的牛顿优化。
3.约束优化:MATLAB提供了多种约束优化算法,如线性规划、二次规划、非线性规划等。
可以使用fmincon函数来实现带约束的优化问题。
4.最小二乘法:最小二乘法是一种数学优化技术,用于找到一组数据的最佳拟合直线或曲线。
在MATLAB中,可以使用polyfit、lsqcurvefit等函数实现最小二乘法。
5.遗传算法:遗传算法是一种模拟自然选择过程的优化算法,用于求解复杂的优化问题。
在MATLAB中,可以使用ga函数实现遗传算法优化。
6.模拟退火算法:模拟退火算法是一种概率搜索算法,用于在可能的解空间中找到全局最优解。
在MATLAB中,可以使用fminsearchbnd函数实现模拟退火算法优化。
7.粒子群优化算法:粒子群优化算法是一种基于群体智能的优化算法,用于求解非线性优化问题。
在MATLAB中,可以使用particleswarm函数实现粒子群优化算法。
以上是MATLAB中常用的一些优化算法和技术。
具体的实现方法和应用可以根据具体问题的不同而有所不同。
机器学习常见优化算法

机器学习常见优化算法
1. 梯度下降法:梯度下降法是机器学习中最常用的优化算法,它的基本原理是通过计算梯度来更新参数,使得损失函数的值越来越小,从而使得模型的性能越来越好。
2. 随机梯度下降法:随机梯度下降法是梯度下降法的变种,它的基本原理是每次只用一个样本来更新参数,从而使得训练速度更快,但是可能会导致模型的泛化能力变差。
3. 拟牛顿法:拟牛顿法是一种基于牛顿法的优化算法,它的基本原理是通过迭代计算拟牛顿步长来更新参数,从而使得损失函数的值越来越小,从而使得模型的性能越来越好。
4. Adagrad:Adagrad是一种自适应学习率的优化算法,它的基本原理是根据每个参数的梯度大小来调整学习率,从而使得模型的性能越来越好。
5. Adadelta:Adadelta是一种自适应学习率的优化算法,它的基本原理是根据每个参数的更新量来调整学习率,从而使得模型的性能越来越好。
6. Adam:Adam是一种自适应学习率的优化算法,它的基本原理是根据每个参数的梯度和更新量来调整学习率,从而使得模型的性能越来越好。
7.共轭梯度法:共轭梯度法是一种迭代优化算法,它使用一阶导数和共轭梯度来求解最优解。
它的优点是计算速度快,缺点是可能不太稳定。
最优化算法(牛顿、拟牛顿、梯度下降)
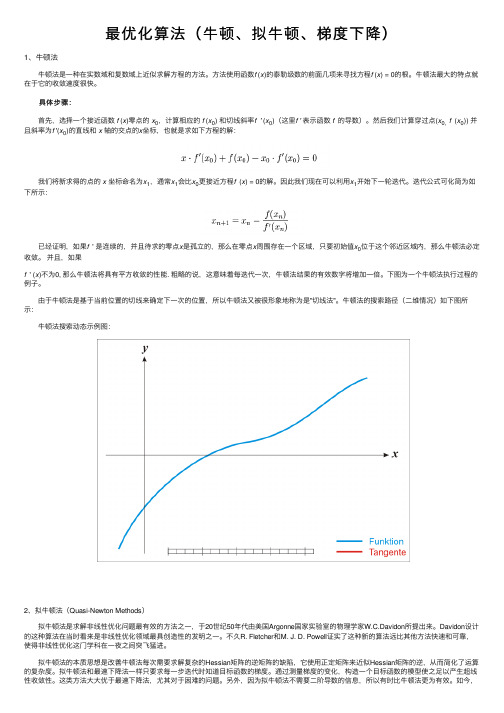
最优化算法(⽜顿、拟⽜顿、梯度下降)1、⽜顿法 ⽜顿法是⼀种在实数域和复数域上近似求解⽅程的⽅法。
⽅法使⽤函数f (x)的泰勒级数的前⾯⼏项来寻找⽅程f (x) = 0的根。
⽜顿法最⼤的特点就在于它的收敛速度很快。
具体步骤: ⾸先,选择⼀个接近函数f (x)零点的x0,计算相应的f (x0) 和切线斜率f ' (x0)(这⾥f ' 表⽰函数f 的导数)。
然后我们计算穿过点(x0, f (x0)) 并且斜率为f '(x0)的直线和x 轴的交点的x坐标,也就是求如下⽅程的解: 我们将新求得的点的x 坐标命名为x1,通常x1会⽐x0更接近⽅程f (x) = 0的解。
因此我们现在可以利⽤x1开始下⼀轮迭代。
迭代公式可化简为如下所⽰: 已经证明,如果f ' 是连续的,并且待求的零点x是孤⽴的,那么在零点x周围存在⼀个区域,只要初始值x0位于这个邻近区域内,那么⽜顿法必定收敛。
并且,如果f ' (x)不为0, 那么⽜顿法将具有平⽅收敛的性能. 粗略的说,这意味着每迭代⼀次,⽜顿法结果的有效数字将增加⼀倍。
下图为⼀个⽜顿法执⾏过程的例⼦。
由于⽜顿法是基于当前位置的切线来确定下⼀次的位置,所以⽜顿法⼜被很形象地称为是"切线法"。
⽜顿法的搜索路径(⼆维情况)如下图所⽰: ⽜顿法搜索动态⽰例图:2、拟⽜顿法(Quasi-Newton Methods) 拟⽜顿法是求解⾮线性优化问题最有效的⽅法之⼀,于20世纪50年代由美国Argonne国家实验室的物理学家W.C.Davidon所提出来。
Davidon设计的这种算法在当时看来是⾮线性优化领域最具创造性的发明之⼀。
不久R. Fletcher和M. J. D. Powell证实了这种新的算法远⽐其他⽅法快速和可靠,使得⾮线性优化这门学科在⼀夜之间突飞猛进。
拟⽜顿法的本质思想是改善⽜顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使⽤正定矩阵来近似Hessian矩阵的逆,从⽽简化了运算的复杂度。
机器学习常见的优化算法

机器学习常见的优化算法1、梯度下降法梯度下降法是最早最简单的,也是最为常⽤的最优化算法。
梯度下降法实现简单,当⽬标函数是凸函数时,梯度下降法的解是全局解。
⼀般情况下,其解不保证是全局最优解,梯度下降法的速度未必是最快的。
梯度下降法的优化思想是⽤当前位置负梯度⽅向作为搜索⽅向,因为该⽅向为当前位置的最快下降⽅向,所以也被称为“最速下降法”。
最速下降法越接近⽬标值,步长越⼩,前进越慢。
在机器学习中,基于基本的梯度下降法发展了两种梯度下降⽅法,分别为随即梯度下降法和批量梯度下降法。
批量梯度下降:最⼩化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最⼩,但是对于⼤规模样本问题效率低下。
随机梯度下降法:最⼩化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优⽅向,但是⼤的整体的⽅向是向着全局最优解,最终的结果往往是在全局最优解附近,使⽤于⼤规模训练样本情况。
2、⽜顿和拟⽜顿法从本质上去看,⽜顿法是⼆阶收敛,梯度下降是⼀阶收敛,所以⽜顿法更快。
如果更通俗得到说的话,⽐如你想找⼀条最短的路径⾛到⼀个盆地的最底部,梯度下降法每次只从你当前的位置选⼀个坡度最⼤的⽅向⾛⼀步,⽜⽜顿法在选择⽅向时,不仅会考虑坡度是否⾜够⼤,还会考虑你⾛了⼀步之后,坡度是否会变得更⼤。
所以,可以说是⽜顿法⽐梯度下降法看的更远⼀点,能更快地⾛到最底部。
优点:⼆阶收敛,收敛速度更快;缺点:⽜顿法是⼀种迭代算法,每⼀步都需要求解⽬标函数的hessian矩阵的逆矩阵,计算⽐较复杂。
拟⽜顿法拟⽜顿法的基本思想是改善⽜顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺点,它使⽤正定矩阵来近似Hessian矩阵的逆,从⽽简化了运算的复杂度。
拟⽜顿法和最速下降法⼀样只要每⼀步迭代时知道⽬标函数的梯度。
通过测量梯度的变化,构造⼀个⽬标函数的模型使之⾜以产⽣超线性收敛性。
这类⽅法⼤⼤优与最速下降法,尤其对于困难的问题,另外,因为拟⽜顿法不需要⼆阶倒数的信息,所以有时⽐⽜顿法更为有效。
凸优化处理方法

凸优化处理方法凸优化是数学中的一种重要方法,广泛应用于工程、经济学、运筹学等领域。
凸优化处理方法是指在解决凸优化问题时所采用的一系列算法和技巧。
本文将介绍几种常用的凸优化处理方法,并分析其特点和适用范围。
一、梯度下降法梯度下降法是一种常用的凸优化处理方法,通过迭代的方式逐步优化目标函数。
其基本思想是沿着目标函数的负梯度方向进行搜索,不断更新参数,直到达到最优解。
梯度下降法具有收敛性好、计算简单等优点,适用于解决大规模的凸优化问题。
二、牛顿法牛顿法是一种基于二阶导数信息的凸优化处理方法。
其核心思想是利用目标函数的二阶导数矩阵信息进行迭代优化,通过求解线性方程组来更新参数。
牛顿法收敛速度较快,适用于解决高维、非线性的凸优化问题。
三、内点法内点法是一种近年来发展起来的凸优化处理方法,通过引入人工内点,将原凸优化问题转化为一系列的线性规划问题。
内点法具有全局收敛性和多项式时间复杂度等优点,适用于解决大规模的凸优化问题。
四、分裂算法分裂算法是一种将原凸优化问题分解为多个子问题进行求解的凸优化处理方法。
其基本思想是将原问题分解为几个较小的子问题,并通过迭代的方式逐步优化子问题,最终得到原问题的解。
分裂算法适用于解决具有一定结构的凸优化问题,能够提高算法的效率和收敛速度。
五、次梯度法次梯度法是一种求解非光滑凸优化问题的处理方法。
在非光滑凸优化问题中,目标函数可能不是处处可微的,此时无法使用传统的梯度下降法等方法。
次梯度法通过引入次梯度的概念,对非光滑点进行处理,从而求解非光滑凸优化问题。
六、对偶法对偶法是一种将原凸优化问题转化为对偶问题进行求解的凸优化处理方法。
通过构造拉格朗日函数和对偶函数,将原问题转化为对偶问题,并通过求解对偶问题来获取原问题的解。
对偶法能够有效地求解具有特殊结构的凸优化问题,提高算法的效率和精度。
七、凸松弛法凸松弛法是一种将原非凸优化问题转化为凸优化问题进行求解的处理方法。
通过对原问题进行适当的松弛,将其转化为一个凸优化问题,并利用凸优化方法来求解。
人工智能中的优化算法比较

人工智能中的优化算法主要用于寻找最优解或最优参数,可以应用于各种问题,如机器学习模型训练、路径规划、资源分配等。
以下是一些常见的优化算法的比较:
1. 梯度下降法:是最基础的优化算法之一,用于找到函数的最小值。
其中的随机梯度下降法(SGD)在处理大规模数据和模型时尤其有效。
2. 牛顿法:是一种寻找函数的零点的优化算法,优点是能快速找到函数的局部最小值,缺点是可能陷入局部最优。
3. 共轭梯度法:是一种在梯度下降法的基础上改进的算法,可以处理具有非凸函数和多个极小值的优化问题,但计算复杂度较高。
4. 遗传算法:是一种模拟自然选择和遗传学机制的优化算法,适用于大规模搜索和多峰概率问题,但可能找不到全局最优解。
5. 模拟退火算法:是一种寻找全局最优的优化算法,通过引入温度参数和退火机制,能够处理具有约束条件的优化问题,但温度参数的选择会影响算法的性能。
6. 蚁群优化算法:是一种受自然界中蚂蚁寻径行为启发的优化算法,适用于大规模搜索问题,但易陷入局部最优解。
这些算法各有优缺点,适用于不同的问题和场景。
在实际应用中,需要根据具体问题选择合适的算法,并进行相应的调整和优化。
同时,也可以将多种算法结合起来使用,以提高搜索效率和精度。
梯度下降法原理

梯度下降法原理梯度下降法(Gradient Descent)是机器学习中常用的优化算法,是一种寻找极小值(局部最小值或全局最小值)的方法。
1、起源和概念梯度下降法在优化算法学科中被称为“负梯度方向”,它的出现主要是为了解决微积分的求解问题,它用于估算函数的最小或最大值。
目标函数和参数的关系是复杂的,由梯度下降法来寻找参数值,使得目标函数收敛到最优值。
2、原理介绍梯度下降法是一种逐步搜索的过程,在机器学习过程中,首先需要定义目标函数,通常把损失函数看作参数中未知量的函数。
损失函数的计算不同,依赖于输入数据和参数值,优化算法计算的过程也不同。
在优化问题中,用可微的函数对参数求偏导,根据偏导值调整参数,使迭代函数逐步收敛到全局最优解(也可能是局部最优解),以此达到损失函数最小化的目的。
梯度下降法其实就是沿着负梯度方向搜索,不断更新参数值,朝着函数值最小的方向。
不断的更新参数值,而经过的路径就是梯度下降的路径。
为了使得损失函数最小化,梯度下降法需要一个参数η(学习速率)来控制更新的步长,一般来说,当η设置得较小时,梯度下降的收敛速度较慢,当η设置得较大时,梯度下降可能会出现收敛不足的情况。
3、特点梯度下降法具有收敛速度快、容易实现等特点,利用梯度下降法可以快速地求出函数的最小或最大值,且具有节省空间的优点。
此外,该算法也可以不断地改进和优化模型参数,使得算法获得最快的性能。
4、应用梯度下降法在机器学习中广泛应用,它可以用于优化损失函数以及估算模型参数。
在线性回归分析中,梯度下降法常用于求解线性回归模型参数;在机器学习领域,梯度下降法可以求解神经网络和深度学习模型参数等。
除此之外,梯度下降法在图像处理、字节码优化和数据挖掘等多个领域都有广泛的应用。
多目标梯度下降算法

多目标梯度下降算法
多目标梯度下降算法是一种优化算法,主要用于解决多目标优化问题。
在多目标优化中,我们试图找到多个目标函数的最优解,而不仅仅是单个目标的最小值或最大值。
梯度下降法是其中的一种常用方法。
具体来说,对于一个目标函数f(x),梯度下降法的核心思想是沿着函数f(x)的负梯度方向进行迭代更新,即每次迭代都沿着当前点的负梯度方向前进一个步长。
这个步长通常被称为学习率。
通过不断地沿着负梯度方向前进,我们可以逐渐逼近函数的最小值点。
对于多目标优化问题,我们通常希望在多个目标之间进行权衡和折中。
这时,可以使用多目标梯度下降法来寻找多个目标之间的最优解。
该方法的基本思想是在每个迭代步骤中,计算每个目标函数的梯度,并根据这些梯度来更新当前点的位置。
通过不断迭代,我们可以逐渐逼近所有目标函数的最优解。
总的来说,多目标梯度下降算法是一种有效的优化方法,特别适用于解决复杂的实际问题,例如机器学习、数据分析等领域的问题。
通过在实践中不断改进和完善算法,可以更好地解决实际问题,并取得更好的效果。
三维空间 最优点 优化算法

三维空间最优点优化算法三维空间最优点优化算法是指在三维空间中寻找最优解的一种数学算法。
在许多实际问题中,需要在三维空间中找到最优点,以便优化某个目标函数的数值。
这种算法在许多领域具有广泛的应用,如机器学习、图像处理、物流优化等。
在三维空间中,最优点指的是使得目标函数取得最大或最小值的点。
这个点可能是一个局部最优点,也可能是全局最优点。
为了找到最优点,我们需要定义一个目标函数,然后通过优化算法来搜索最优点。
常见的三维空间最优点优化算法包括梯度下降法、牛顿法、遗传算法等。
这些算法都有各自的优缺点,适用于不同类型的问题。
下面将介绍其中几种常见的算法。
梯度下降法是一种迭代算法,通过计算目标函数在当前点的梯度信息,不断更新当前点的位置,直到找到最优点。
梯度下降法的优点是简单易实现,但其可能陷入局部最优点,无法找到全局最优点。
牛顿法是一种迭代算法,通过计算目标函数在当前点的一阶导数和二阶导数信息,来更新当前点的位置。
牛顿法的优点是收敛速度快,但其计算复杂度较高,且可能出现不收敛的情况。
遗传算法是一种模拟生物进化的优化算法,通过对种群中个体的遗传操作,不断迭代生成新的个体,直到找到最优点。
遗传算法的优点是能够全局搜索最优点,但其计算复杂度较高,且可能陷入局部最优点。
除了上述算法外,还有许多其他的三维空间最优点优化算法,如模拟退火算法、粒子群优化算法等。
这些算法根据问题的特点和要求,选择合适的算法进行优化。
在实际应用中,三维空间最优点优化算法可以用于解决各种问题。
例如,在机器学习中,可以使用这些算法来优化模型的参数,以提高模型的预测准确性。
在图像处理中,可以使用这些算法来寻找图像中的最优特征点,以实现图像识别和目标跟踪等功能。
在物流优化中,可以使用这些算法来优化路径规划和货物配送,以提高物流效率。
三维空间最优点优化算法是一种重要的数学算法,用于在三维空间中寻找最优解。
通过选择合适的算法和优化方法,可以有效地解决各种实际问题,提高问题的解决效率和准确性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
12 6
局部优化算法之一:梯度下降法
举例:y=x2/2-2x 计算过程: 任给一个初始出发点,设为 x0=-4。 (1) 首先给定两个参数: =1.5,=0.01; (2) 计算导数:dy/dx = x-2 (3) 计算当前导数值:y’=-6 (5) 计算当前导数值:y’=3.0 (4) 修改当前参数: (6) 修改当前参数: x0=-4 x1= x0 - *y’ x1=5.0 x2=5.0 – 1.5*(3.0) =0.5; =-4-1.5*(-6)=5.0;
12 8
局部优化算法之一:梯度下降法
可见,当=1.5时,搜索呈现振荡形式,在极值 点附近反复搜索。可以证明,当<1.0时,搜索 将单调地趋向极值点,不会振荡;当>2.0时, 搜索将围绕极值点逐渐发散,不会收敛到极值点。 为了保证收敛,不应当太大。但如果过小,收敛 速度将十分缓慢。可以采用自适应调节的方法加 快收敛而又不至于发散。 问题:为何当很小时搜索总会成功? 证明:(下页)
局部优化算法之一: 梯度下降法
李金屏 济南大学信息科学与工程学院 2006年9月
优化算法和运筹学
优化算法 许多实际问题利用数学建模的方法得到下面常规的优化形 式: min f(x),s.t. g(x) ≥0, x∈D. 其中,x是一个n维矢量,D是问题的定义域,F可行域。 关于f(x): 当x=(x)时,f(x)是一条曲线; 当x=(x1, x2)时,f(x1, x2)是一个曲面; 当x=(x1, x2, x3)时,f(x1, x2, x3)是一个体密度(或类位势 函数); 当x=(x1, x2, …, xn)时,f(x1, x2, …, xn)是一个超曲面。
12 2
优化算法和运筹学
曲面,自然有许多极大值和极小值,必然各有一 个全局最大值和全局最小值。 超曲面,与上相同。 有些算法,只能在自己的小范围内搜索极大值或 极小值。这些算法称为局部优化算法,常称为经 典优化算法。 另有些算法,可以在整个超曲面取值范围内搜索 最大值或最小值。这些算法称为全局性优化算法, 又称为现代优化算法。
12
10
局部优化算法之一:梯度下降法
可以按照下述方式: x1= - *(dy/dx1), x2= - *(dy/dx2), …, xn= - *(dy/dxn). 其中>0是个小的正数。代入前式,有 f = - *(dy/dx1)*(dy/dx1) - *(dy/dx2)*(dy/dx2) - … - *(dy/dxn)*(dy/dxn) = - *[(dy/dx1)2 + (dy/dx2)2 + (dy/dxn)2] <0 即f<0。这样就可以保证搜索到极小值。 于是获得梯度下降法的搜索策略: x1= - *(dy/dx1), x2= - *(dy/dx2), …, xn= - *(dy/dxn).
12 11
总结和作业
局部优化算法之一:梯度下降法 用于BP神经网络,Hopfield神经网络,模式 分类,求函数极值等。 相关内容:共轭梯度法
12
12
12
9
局部优化算法之一:梯度下降法
y=f (x1, x2, …, xn)。假设只有一个极小点。 假设当前点为(x1, x2, …, xn)。下面修改当前参数: x1x1+x1, x2x2+x2, …, xnxn+xn. 显然问题在于xi (i=1,2,…, n)的确定。 于是,当前函数值为y=f (x1+x1, x2+x2, …, xn+xn). 可以按照泰勒级数展开为: y=f (x1, x2, …, xn) + f 其中f=x1*(dy/dx1)+ x2*(dy/dx2)+ … + xn*(dy/dxn) 如何保证f<0? (搜索极小值)
12 5
dy f ' ( x) dx
局部优化算法之一:梯度下降法
一般情况下分析: y=f (x1, x2, …, xn) 假设只有一个极小点。初始给定参数为 (x10, x20, …, xn0)。问题: 从这个点如何搜索才能找到原函数的极小值点? 方法: 1、首先设定一个较小的正数,; 2、求当前位置处的各个偏导数:dy/dx1, dy/dx2, …, dy/dxn; 3、按照下述方式修改当前函数的参数值: x10x10 dy/dx1, x20x20 dy/dx2, …, xn0xn0 dy/dxn; 4、如果超曲面参数变化量小于,退出;否则返回2。
12 7
局部优化算法之一:梯度下降法
(7) 计算当前导数值: y’=-1.5 (8) 修改当前参数: x2=0.5x3=0.5-1.5*(-1.5) =2.75; (9) 计算当前导数值: y’=0.75 (10) 修改当前参数: x3=2.75 x4 = 2.751.5*(0.75) =1.625; (12) 修改当前参数:x4=1.625 (11) 计算当前导数值: x5 = 1.625-1.5*(-0.375)=2.1875; y’=-0.375 …
12 3
优化算法和运筹学
一个简单 二维曲面
通常的运筹学,就是 经典的局部优化算法。 全局性优化算法通常 是随机性搜索。
12
4
局部优化算法之一:梯度下降法
见右图。局部极小值是C 点(x0)。 梯度,即导数,但是有方 向,是一个矢量。曲线情 况下,表达式为
如果,f’(x)>0,则x增加,y也增加,相当于B点;如果f’(x)<0, 则x增加,y减小,相当于A点。 要搜索极小值C点,在A点必须向x增加方向搜索,此时与A点 梯度方向相反;在B点必须向x减小方向搜索,此时与B点梯度 方向相反。总之,搜索极小值,必须向负梯度方向搜索。