hash表的建立和查找
哈希表查找方法原理

哈希表查找方法原理哈希表查找方法什么是哈希表•哈希表是一种常见的数据结构,也被称为散列表。
•它可以提供快速的插入、删除和查找操作,时间复杂度在平均情况下为O(1)。
•哈希表由数组组成,每个数组元素称为桶(bucket)。
•存储数据时,通过哈希函数将数据映射到对应的桶中。
哈希函数的作用•哈希函数是哈希表的核心部分,它将数据转换为哈希值。
•哈希函数应该具备以下特点:–易于计算:计算哈希值的时间复杂度应尽量低。
–均匀分布:哈希函数应能将数据均匀地映射到不同的桶中,以避免桶的过度填充或者空闲。
–独特性:不同的输入应该得到不同的哈希值,以尽量减少冲突。
哈希冲突及解决方法•哈希冲突指两个或多个数据被哈希函数映射到同一个桶的情况。
•常见的解决哈希冲突的方法有以下几种:–链地址法(Chaining):将相同哈希值的数据存储在同一个桶中,通过链表等数据结构来解决冲突。
–开放地址法(Open Addressing):当发生冲突时,通过特定的规则找到下一个可用的桶来存储冲突的数据,如线性探测、二次探测等。
–再哈希法(Rehashing):当发生冲突时,使用另一个哈希函数重新计算哈希值,并将数据存储到新的桶中。
哈希表的查找方法•哈希表的查找方法分为两步:1.根据哈希函数计算数据的哈希值,并得到对应的桶。
2.在桶中查找目标数据,如果找到则返回,否则表示数据不存在。
哈希表的查找性能•在理想情况下,哈希表的查找时间复杂度为O(1)。
•然而,由于哈希冲突的存在,查找时间可能会稍微增加。
•如果哈希函数设计得不好,导致冲突较多,可能会使查找时间复杂度接近O(n)。
•因此,选择合适的哈希函数和解决冲突的方法对于提高哈希表的查找性能非常重要。
总结•哈希表是一种高效的数据结构,适用于快速插入、删除和查找操作的场景。
•哈希函数的设计和解决冲突的方法直接影响哈希表的性能。
•在实际应用中,需要根据数据特点选择合适的哈希函数和解决冲突的方法,以提高哈希表的查找性能。
哈希表的用法

哈希表的用法
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。
也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表的主要用法包括:
1.插入元素:向哈希表中添加新的元素。
这通常涉及到使用哈希函数来计算元素的关键码值对应的存储位置,并将元素存储在该位置。
2.查找元素:在哈希表中查找特定的元素。
这同样需要使用哈希函数来计算元素的关键码值对应的存储位置,然后检查该位置是否有相应的元素。
3.删除元素:从哈希表中移除指定的元素。
这涉及到找到元素的存储位置,并将其从表中删除。
哈希表的时间复杂度通常是O(1),这意味着无论哈希表中有多少元素,插入、查找和删除操作都可以在常数时间内完成。
然而,这取决于哈希函数的选择和冲突解决策略。
如果哈希函数设
计得不好或者冲突解决策略不合适,可能会导致性能下降。
此外,哈希表还有一些其他的应用,例如用于实现关联数组、缓存系统、去重处理等等。
c语言中哈希表用法

c语言中哈希表用法在C语言中,哈希表(hash table)是一种数据结构,用于存储键值对(key-value pairs)。
它利用哈希函数(hash function)将键映射到一个特定的索引,然后将该索引用于在数组中存储或查找相应的值。
使用哈希表可以实现高效的数据查找和插入操作。
下面是哈希表的基本用法:1.定义哈希表的结构体:```ctypedef struct {int key;int value;} hash_table_entry;typedef struct {int size;hash_table_entry **buckets;} hash_table;```2.初始化哈希表:```chash_table *create_hash_table(int size) {hash_table *ht = (hash_table*)malloc(sizeof(hash_table));ht->size = size;ht->buckets = (hash_table_entry**)calloc(size,sizeof(hash_table_entry*));return ht;}```在初始化时,需要定义哈希表的大小(桶的数量)。
3.计算哈希值:```cint hash_function(int key, int size) {//根据具体需求实现哈希函数,例如对key取余操作return key % size;}```哈希函数将key映射到哈希表的索引位置。
4.插入键值对:```cvoid insert(hash_table *ht, int key, int value) { //计算哈希值int index = hash_function(key, ht->size);//创建新的哈希表节点hash_table_entry *entry =(hash_table_entry*)malloc(sizeof(hash_table_entry));entry->key = key;entry->value = value;//将节点插入到相应的桶中if (ht->buckets[index] == NULL) {ht->buckets[index] = entry;} else {//处理哈希冲突,例如使用链表或开放定址法解决冲突//这里使用链表来处理冲突hash_table_entry *current = ht->buckets[index];while (current->next != NULL) {current = current->next;current->next = entry;}}```5.查找值:```cint get(hash_table *ht, int key) {int index = hash_function(key, ht->size);hash_table_entry *current = ht->buckets[index]; //在相应的桶中查找相应的值while (current != NULL) {if (current->key == key) {return current->value;current = current->next;}return -1; //未找到对应的值}```哈希表的优点是它具有快速的查找和插入操作,平均情况下的查找和插入时间复杂度为O(1)。
c++的hash表使用方法

c++的hash表使用方法摘要:1.C++中Hash 表的概念和作用2.Hash 表的构造函数和成员函数3.插入元素的方法4.查找元素的方法5.删除元素的方法6.应用示例正文:C++的Hash 表是一种基于哈希函数的容器,它可以在O(1) 时间复杂度内完成插入、查找和删除操作。
Hash 表在数据结构和算法中具有广泛的应用,例如在字典、集合、地图等场景中。
Hash 表的构造函数和成员函数如下:1.构造函数:Hash 表通过一个模板参数来指定哈希函数的类型。
可以使用默认的哈希函数,也可以自定义哈希函数。
```cpptemplate<class Key, class HashFcn = Hash<Key> >class HashTable {public:HashTable() {}// 其他成员函数};```2.成员函数:Hash 表提供了插入、查找和删除元素的方法。
- 插入元素:使用`insert`成员函数插入元素。
```cppvoid insert(const Key& key, const Value& value) { // 使用哈希函数计算元素的位置size_t pos = HashFcn::hash(key) % HashTable::size;// 插入元素data[pos] = std::make_pair(key, value);}```- 查找元素:使用`find`成员函数查找元素。
```cppIterator find(const Key& key) {// 使用哈希函数计算元素的位置size_t pos = HashFcn::hash(key) % HashTable::size;// 查找元素return data[pos].second;}```- 删除元素:使用`erase`成员函数删除元素。
```cppvoid erase(const Key& key) {// 使用哈希函数计算元素的位置size_t pos = HashFcn::hash(key) % HashTable::size;// 删除元素data[pos].second = nullptr;}```应用示例:```cpp#include <iostream>#include <hash 表>#include <string>using namespace std;int main() {HashTable<string, int> ht;ht.insert("apple", 1);ht.insert("orange", 2);ht.insert("banana", 3);cout << "查找元素:" << ht.find("apple") << endl; // 输出1 cout << "删除元素:apple" << endl;ht.erase("apple");return 0;}```通过上述示例,我们可以看到如何使用C++的Hash 表进行插入、查找和删除元素。
哈希表的创建

哈希表的创建
哈希表的创建主要包括以下步骤:
1.确定哈希表的规模:哈希表的规模决定了哈希表的大小和性能。
通常情况下,可以根据需要存储的元素数量和内存空间来选择合适的规模。
2.确定哈希函数:哈希函数用于将元素的关键字转换为哈希表的索引。
选择一个好的哈希函数可以提高哈希表的性能和碰撞处理能力。
3.处理哈希冲突:当两个或多个元素的关键字通过哈希函数计算得出相同的索引时,就会发生哈希冲突。
常见的处理冲突的方法有链地址法和开放地址法。
4.创建和初始化哈希表:根据选择的规模和冲突处理方法,创建和初始化哈希表。
在初始化过程中,需要为哈希表分配内存空间,并设置初始值。
5.向哈希表中插入元素:按照哈希表的规则,将元素插入到合适的索引位置。
插入时需要计算元素的关键字,并根据冲突处理方法处理可能的冲突。
6.删除元素:如果需要从哈希表中删除某个元素,需要找到该元素在哈希表中的位置,并将其从链表中移除或覆盖该位置的元素。
7.查找元素:根据元素的关键字,通过哈希函数计算出其在哈希表中的索引位置,并返回对应的值或指针。
需要注意的是,在实际应用中,还需要考虑哈希表的动态扩容和缩容等问题,以适应数据量的变化和提高哈希表的性能。
c实现的hash表-概述说明以及解释

c实现的hash表-概述说明以及解释1.引言1.1 概述在计算机科学中,哈希表(Hash Table),又被称为散列表,是一种常用的数据结构。
它能够以常数时间复杂度(O(1))来实现插入、删除和查找等操作,因此具有高效的特性。
哈希表通过哈希函数将键(key)映射到一个固定大小的数组(通常称为哈希表)。
通过这种映射关系,我们可以在数组中快速访问到对应的值(value)。
常见的应用场景包括缓存系统、数据库索引、编译器符号表等。
相对于其他数据结构,哈希表具有以下优点:1. 高效的插入、删除和查找操作:哈希表在插入、删除和查找数据时以常数时间复杂度进行操作,无论数据量大小,都能快速地完成操作。
2. 高效的存储和检索:通过哈希函数的映射关系,哈希表能够将键值对存储在数组中,可以通过键快速地找到对应的值。
3. 空间效率高:哈希表通过哈希函数将键映射到数组下标,能够充分利用存储空间,避免冗余的存储。
然而,哈希表也存在一些局限性:1. 冲突问题:由于哈希函数的映射关系是将多个键映射到同一个数组下标上,可能会导致冲突。
解决冲突问题的常见方法包括链地址法(Chaining)和开放定址法(Open Addressing)等。
2. 内存消耗:由于哈希表需要维护额外的空间来存储映射关系,所以相比于其他数据结构来说,可能会占用较多的内存。
本篇长文将重点介绍C语言实现哈希表的方法。
我们将首先讨论哈希表的定义和实现原理,然后详细介绍在C语言中如何实现一个高效的哈希表。
最后,我们将总结哈希表的优势,对比其他数据结构,并展望哈希表在未来的发展前景。
通过本文的学习,读者将能够深入理解哈希表的底层实现原理,并学会如何在C语言中利用哈希表解决实际问题。
1.2 文章结构本文将围绕C语言实现的hash表展开讨论,并按照以下结构进行组织。
引言部分将对hash表进行概述,介绍hash表的基本概念、作用以及其在实际应用中的重要性。
同时,引言部分还会阐述本文的目的,即通过C语言实现的hash表,来探讨其实现原理、方法以及与其他数据结构的对比。
c语言哈希表的字符串建立与查找

c语言哈希表的字符串建立与查找C语言中的哈希表是一种高效的数据结构,用于存储和查找数据。
它将键(key)映射到值(value),并且可以通过键快速定位到对应的值。
哈希表的建立过程主要包括以下几个步骤:1. 定义哈希表的结构:首先,我们需要定义一个哈希表的结构,该结构包括一个数组和一个用于存储数组大小的变量。
数组的大小应该是一个素数,以减少冲突的可能性。
```c#define SIZE 10000typedef struct {char* key;int value;} HashNode;typedef struct {HashNode** array;int size;} HashMap;```2. 初始化哈希表:在使用哈希表之前,我们需要初始化它。
这包括创建一个数组,并将所有元素设置为NULL。
```cHashMap* createHashMap() {HashMap* hashMap =(HashMap*)malloc(sizeof(HashMap));hashMap->array = (HashNode**)calloc(SIZE,sizeof(HashNode*));hashMap->size = SIZE;return hashMap;}```3. 哈希函数:哈希函数用于将键映射到数组的索引。
一个好的哈希函数应该尽量减少冲突,即不同的键映射到相同的索引。
在字符串建立哈希表时,我们可以使用一种简单的哈希函数,将字符串中的每个字符的ASCII码相加,并取余数组大小。
```cint hash(char* key, int size) {int sum = 0;for (int i = 0; key[i] != '\0'; i++) {sum += key[i];}return sum % size;}```4. 插入键值对:要向哈希表中插入一个键值对,我们首先需要计算键的哈希值,然后将值存储在对应的索引处。
c语言hash用法

c语言hash用法一、概述Hash是一种常用的数据结构,用于将任意长度的数据映射到固定长度的数据中。
在C语言中,可以使用hash来实现数据的快速查找和插入操作。
Hash算法的原理是将数据通过一系列函数映射到一个固定长度的哈希值,从而实现对数据的快速查找和插入。
二、hash的实现方式在C语言中,常用的hash实现方式有线性探测和平方探测等。
线性探测是指在查找失败时,顺序地检查已存在的哈希链中的下一个元素,直到找到空位或者遍历完整个哈希链。
平方探测是指当哈希值碰撞时,检查该碰撞点后面的位置,如果没有冲突则直接插入,否则进行链式存储。
三、hash的使用步骤1. 定义哈希表结构体和哈希函数首先需要定义哈希表结构体,包括存储数据的数组和哈希函数等。
哈希函数的作用是将输入的数据映射到哈希表中存储的位置。
常用的哈希函数有直接平方取余法、除法取余法等。
2. 初始化哈希表在使用hash之前,需要将哈希表进行初始化,即创建一个空的数组并分配相应的内存空间。
3. 插入数据将需要插入的数据通过哈希函数映射到哈希表中存储的位置,并将数据存储在该位置。
如果该位置已经存在数据,则需要根据具体的哈希算法进行处理,例如进行链式存储等。
4. 查找数据根据需要查找的数据通过哈希函数映射到哈希表中存储的位置,并检查该位置是否存储了需要查找的数据。
如果找到了需要查找的数据,则返回该数据的指针;否则返回空指针。
5. 删除数据根据需要删除的数据通过哈希函数映射到哈希表中存储的位置,并执行相应的删除操作。
四、hash的优缺点Hash的优点包括:1. 插入和查找速度快:由于哈希表使用的是数组结构,因此可以在O(1)时间内完成插入和查找操作。
2. 空间利用率高:哈希表使用链式存储时,可以有效地利用空间,避免出现数据重叠的情况。
然而,Hash也存在一些缺点:1. 冲突概率:由于哈希函数的不确定性,可能会出现数据碰撞的情况。
如果碰撞过多,则需要使用链式存储等方法进行处理。
哈 希 查 找

哈希查找
一、哈希表的基本概念 二、构造哈希函数的方法 三、处理冲突的方法 四、哈希表的查找及分析
一、哈希表的基本概念
哈希(Hash)函数:如果在关键字与数据元素的存储位置之间建立某种 对应关系H,根据这种对应关系就能很快地计算出与该关键字key对应的 存储位置的值H(key),我们将关键字与存储位置之间的这种对应关系称 为哈希(Hash)函数。 把关键字为key的元素直接存入地址为H(key)的存储单元,当查找关键 字为key的元素时,利用哈希函数计算出该元素的存储位置H(key),从 而达到按关键字直接存取元素的目的。按照这个思想建立的查找表叫 做哈希表,所得到的存储位置称为哈希地址,利用哈希表进行查找的 方法称为哈希查找。
根据增量序列的取值方式的不同,开放定址法又分为以下三种: ① 线性探测再散列:di为1,2,3,…,h-1,即冲突发生时,顺序查 看哈希表中的下一个位置,直到找出一个空位置或查遍整个表为止。
② 二次探测再散列:di为12,-12,2,-22,3,-32,…,k,- k2 (k≤m/2),即冲突发生时,在表的前后位置进行跳跃式探测。
5.除留余数法
除留余数法是指取关键字被某个不大于哈希表表长m的数p除后所得余数 作为哈希地址,即 H(key)=key%p (p≤m) 例如,已知关键字序列为{23,49,70,68,50,90},对于表长 为20的哈希表,选取p=19,计算所得的哈希地址如下表所示。
6.随机数法
选择一个随机函数为哈希函数,取关键字的随机函数值为它的哈希地 址,即H(key)=random(key) 其中,random()为随机函数。 随机数法适用于关键字长度不等的情况。
三、处理冲突的方法
所谓处理冲突是指,当由关键字计算出 的哈希地址出现冲突时,为该关键字对 应的数据元素找到另一个“空”的哈希 地址。
c++的hash表使用方法

c++的hash表使用方法(原创版3篇)目录(篇1)1.C++中 Hash 表的定义与初始化2.Hash 表的插入操作3.Hash 表的查找操作4.Hash 表的删除操作5.示例代码正文(篇1)C++的 Hash 表是一种基于数组实现的数据结构,通过哈希函数将键映射到数组的一个位置,从而实现快速插入、查找和删除操作。
哈希表在编程中应用广泛,例如在字典、集合等数据结构中都有它的身影。
接下来,我们将详细介绍 C++中 Hash 表的使用方法。
1.Hash 表的定义与初始化在 C++中,可以使用数组来定义一个 Hash 表。
首先,需要定义一个哈希函数,用于计算数组下标。
然后,根据哈希函数计算数组大小,并初始化一个数组。
```cpp#include <iostream>#include <cmath>using namespace std;// 哈希函数int hash(int key, int size) {return key % size;}// 初始化 Hash 表void initHash(int* hashTable, int size) {for (int i = 0; i < size; i++) {hashTable[i] = -1;}}```2.Hash 表的插入操作插入操作是 Hash 表的核心操作之一。
在插入元素时,首先计算元素对应的数组下标,然后判断该位置是否为空。
如果为空,则将元素值赋给该位置;如果不为空,说明发生了哈希冲突,需要进行处理。
常见的处理方法有开放寻址法和链地址法。
```cpp// 插入元素void insertHash(int* hashTable, int size, int key, int value) {int index = hash(key, size);if (hashTable[index] == -1) {hashTable[index] = value;} else {// 哈希冲突处理cout << "Hash 冲突,插入失败!" << endl;}}```3.Hash 表的查找操作查找操作是另一个常用的操作。
哈希表的工作原理

哈希表的工作原理哈希表(Hash Table)是一种基于哈希函数(Hash Function)实现的数据结构,用于快速存储和查找数据。
它的工作原理是通过将关键字映射到哈希值,然后将哈希值作为索引在内存中定位存储位置,从而实现快速的数据访问。
一、哈希函数的作用哈希函数是哈希表的核心,它负责将关键字映射为哈希值。
哈希函数应该具备以下几个特点:1. 确定性:对于相同的关键字,哈希函数应该始终得到相同的哈希值。
2. 均匀性:哈希函数应该能够将关键字均匀地映射到不同的哈希值上,以减少冲突的概率。
3. 高效性:哈希函数应该具备高效的计算性能,以尽快地获得哈希值。
二、哈希表的结构哈希表通常由一个固定大小的数组和哈希函数构成。
数组的大小是根据实际需求确定的,一般会根据数据规模的预估进行调整。
每个数组元素都被称为“桶”(Bucket)或“槽”(Slot),用于存储数据项。
三、哈希表的插入过程1. 根据关键字通过哈希函数计算出哈希值。
2. 将哈希值对数组的大小取模,得到在数组中的索引位置。
3. 判断该索引位置是否已经被占用:a. 如果该索引位置为空,则直接将数据项存储在该位置。
b. 如果该索引位置已经被占用,发生了冲突,需要解决冲突。
4. 解决冲突的方法主要有两种:a. 开放寻址法(Open Addressing):通过线性探测、二次探测等方法,在数组中寻找下一个可用的位置。
b. 链地址法(Chaining):在每个索引位置上维护一个链表,不同数据项通过链表连接在一起。
5. 若成功找到可用的位置或链表,在该位置或链表的末尾插入数据项。
四、哈希表的查找过程1. 根据关键字通过哈希函数计算出哈希值。
2. 将哈希值对数组的大小取模,得到在数组中的索引位置。
3. 判断该索引位置的数据项是否与待查找的关键字匹配:a. 如果匹配成功,则返回该数据项。
b. 如果匹配失败,发生了冲突,需要继续在该索引位置上进行查找。
4. 若使用的是链地址法,遍历链表中的每个数据项,逐个与待查找的关键字进行比较,直到找到匹配的数据项或到达链表的末尾。
C语言hash用法

C语言hash用法在C语言中,哈希(Hash)通常用于将数据映射到一个固定大小的索引或键,以便快速检索数据,而不必遍历整个数据集。
C语言本身没有内置的哈希表(hash table)或哈希函数库,但你可以自己实现哈希表和哈希函数,或者使用第三方库来处理哈希操作。
以下是一些在C语言中使用哈希的基本用法:1. 实现哈希函数:首先,你需要编写一个哈希函数,将输入数据(通常是键)映射到一个索引或哈希值。
这个哈希函数应该尽可能均匀地分布数据,以减少哈希冲突的发生。
例如,一个简单的哈希函数可以是将字符串的每个字符的ASCII码相加,并对哈希表大小取模。
2. 创建哈希表:接下来,你需要创建一个哈希表数据结构,用于存储数据。
哈希表通常是一个数组,每个元素是一个指向数据的指针,如果有多个数据映射到同一个哈希值,可以使用链表或其他数据结构解决冲突。
3. 插入数据:将数据插入哈希表时,首先使用哈希函数计算出哈希值,然后将数据存储在对应的哈希表索引中。
如果发生冲突,可以使用链表等方法将数据添加到已存在的索引处。
4. 查找数据:要查找数据,使用哈希函数计算出哈希值,然后在哈希表中查找对应的索引。
如果有冲突,必须遍历冲突链表以找到所需的数据。
5. 删除数据:删除数据的过程与查找类似,首先计算哈希值,然后查找索引并删除数据。
需要小心处理冲突的情况。
请注意,上述是哈希表的基本用法。
在实际应用中,你可能需要处理更复杂的情况,例如动态调整哈希表大小、解决冲突的不同方法(如开放寻址法、链地址法等),以及处理碰撞时的性能优化等。
此外,如果你不想从头实现哈希表,也可以考虑使用第三方C语言库,如Glib中的哈希表功能,以简化哈希表的操作。
构造哈希表

构造哈希表哈希表(HashTable)是一种以哈希函数和拉链法来实现插入、查找和删除元素的数据结构,广泛用于网络安全、网络存储、生物信息学等领域,是一种重要的数据结构。
一般来说,哈希表可以使用一些简单的操作来构造和维护,这样就可以提高查找和插入数据的效率,而且可以大大减少存储空间的使用量。
哈希表的构造很容易,一般地,我们可以使用以下步骤来构造哈希表:1.先,需要设定哈希表的大小,它的大小一般比所需要的元素的数量要大一些,这样可以提高查找的效率。
2.后,需要选定一个哈希函数来将元素映射到哈希表中,这个哈希函数一般是尽可能均匀以及独立地将元素映射到哈希表中。
3.后,选定一种拉链法(拉链法是一种将相同哈希值的元素放在一起的算法),并将所有元素按照哈希值的大小插入到哈希表中。
哈希表的特点在于,它拥有快速查找的特性,无论是插入元素还是删除元素,都可以在常数时间内完成,而且哈希表可以将空间复杂度降低到O(n)。
但是,哈希表也有一些缺点,比如哈希碰撞(hash collision),即两个元素映射到同一个哈希值上,另外,如果哈希表发生过多的哈希碰撞,就会降低查找的效率,所以我们在构造哈希表时要尽量避免发生哈希碰撞。
另外,在构造哈希表的时候,还要注意一些其他的因素,比如当我们需要将某个元素插入到哈希表中的时候,需要考虑是否需要扩充哈希表的大小,这样可以有效地减少哈希碰撞的发生。
总之,哈希表是一种强大的数据结构,有效地解决了存储和查找的问题,它可以在常数时间内插入、查找和删除元素,因此在网络安全、网络存储、生物信息学等领域都有重要的应用。
如果你想使用哈希表,必须要认真地准备构造它,选择合适的哈希函数以及拉链法,然后再慢慢插入数据,更重要的是要牢记哈希表也有缺点,需要注意哈希碰撞的发生。
详解数据结构之散列(哈希)表
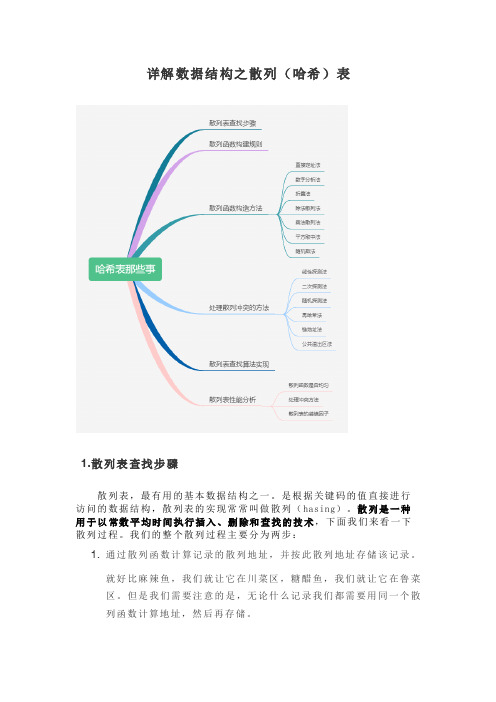
详解数据结构之散列(哈希)表1.散列表查找步骤散列表,最有用的基本数据结构之一。
是根据关键码的值直接进行访问的数据结构,散列表的实现常常叫做散列(hasing)。
散列是一种用于以常数平均时间执行插入、删除和查找的技术,下面我们来看一下散列过程。
我们的整个散列过程主要分为两步:1.通过散列函数计算记录的散列地址,并按此散列地址存储该记录。
就好比麻辣鱼,我们就让它在川菜区,糖醋鱼,我们就让它在鲁菜区。
但是我们需要注意的是,无论什么记录我们都需要用同一个散列函数计算地址,然后再存储。
2.当我们查找时,我们通过同样的散列函数计算记录的散列地址,按此散列地址访问该记录。
因为我们存和取的时候用的都是一个散列函数,因此结果肯定相同。
刚才我们在散列过程中提到了散列函数,那么散列函数是什么呢?我们假设某个函数为f,使得存储位置= f (key) ,那样我们就能通过查找关键字不需要比较就可获得需要的记录的存储位置。
这种存储技术被称为散列技术。
散列技术是在通过记录的存储位置和它的关键字之间建立一个确定的对应关系 f ,使得每个关键字key 都对应一个存储位置f(key)。
见下图这里的 f 就是我们所说的散列函数(哈希)函数。
我们利用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间就是我们本文的主人公------散列(哈希)上图为我们描述了用散列函数将关键字映射到散列表。
但是大家有没有考虑到这种情况,那就是将关键字映射到同一个槽中的情况,即f(k4) = f(k3) 时。
这种情况我们将其称之为冲突,k3 和k4 则被称之为散列函数 f 的同义词,如果产生这种情况,则会让我们查找错误。
幸运的是我们能找到有效的方法解决冲突。
首先我们可以对哈希函数下手,我们可以精心设计哈希函数,让其尽可能少的产生冲突,所以我们创建哈希函数时应遵循以下规则:1.必须是一致的。
假设你输入辣子鸡丁时得到的是在看,那么每次输入辣子鸡丁时,得到的也必须为在看。
哈希表的应用快速查找和去重操作

哈希表的应用快速查找和去重操作哈希表的应用:快速查找和去重操作哈希表(Hash Table)是一种常用的数据结构,它通过散列函数将数据存储在数组中,以实现快速的查找和去重操作。
本文将介绍哈希表的原理和应用,以及如何利用哈希表实现快速查找和去重。
一、哈希表的原理哈希表是由键(Key)和值(Value)组成的键值对(Key-Value)结构。
其核心思想是通过散列函数将键映射为数组的索引,然后将值存储在对应索引的位置上。
这样,在进行查找或者去重操作时,只需计算键的散列值即可定位到对应的存储位置,从而实现常数时间复杂度的操作。
二、哈希表的应用1. 快速查找哈希表在快速查找中发挥了重要的作用。
由于其根据键计算散列值后直接定位到存储位置,所以查找的时间复杂度为O(1)。
这在处理大量数据时,能够显著提高查找效率。
例如,我们可以利用哈希表存储学生的学号和对应的成绩,当要查询某个学生的成绩时,只需通过学号计算散列值,并在哈希表中查找即可,无需遍历整个数组。
2. 去重操作哈希表还可以用于去除重复元素。
在需要对一组数据进行去重时,可以利用哈希表的特性,将元素作为键,将值设为1(或其他常数),并将其存储在哈希表中。
这样,在插入元素时,通过计算散列值即可判断元素是否已存在。
举例来说,假设我们有一个包含大量文章标题的列表,我们希望去除重复的标题。
可以使用哈希表存储已出现过的标题,并在插入新标题时判断是否已存在。
若已存在,则不加入哈希表,从而实现快速、高效的去重操作。
三、哈希表的实现实现哈希表通常需要解决以下几个问题:1. 散列函数的设计散列函数是哈希表实现的核心。
一个好的散列函数能够将键均匀地映射到不同的散列值,以尽量避免冲突。
2. 冲突的处理由于哈希表的存储位置是有限的,不同的键可能会映射到相同的索引位置上,即发生冲突。
常见的解决方法有拉链法(Chaining)和开放地址法(Open Addressing)。
3. 哈希表的动态扩容当哈希表中的元素数量超过存储容量时,需要进行动态扩容,以保证操作的性能。
hash模式的使用

hash模式的使用摘要:一、hash模式简介二、hash模式的使用方法1.创建hash对象2.添加数据3.查询数据4.删除数据5.更新数据三、hash模式的优点与局限性四、实战应用案例正文:hash模式是一种数据存储模式,通过键(key)值(value)对的形式将数据存储在hash对象中。
hash对象可以快速地添加、查询、删除和更新数据,因此在很多场景下都有着广泛的应用。
一、hash模式简介hash模式,又称散列表模式,是一种将数据存储在key-value对中的数据结构。
hash表通过哈希函数将key转换为索引,从而实现快速定位和访问value。
在这种模式下,数据存储和查找的时间复杂度均为O(1)。
二、hash模式的使用方法1.创建hash对象在使用hash模式之前,首先需要创建一个hash对象。
在大多数编程语言中,都有内置的hash对象,如Java中的HashMap,Python中的HashTable等。
以下是一个使用Python创建hash对象的示例:```pythonhash_obj = hashlib.md5()```2.添加数据创建hash对象后,可以使用以下方法向hash对象中添加数据。
在不同的编程语言中,方法可能略有不同。
以下是一个使用Python向hash对象添加数据的示例:```pythondata = "hello, world"hash_obj.update(data.encode("utf-8"))```3.查询数据要查询hash对象中的数据,可以使用以下方法。
以下是一个使用Python 查询hash对象数据的示例:```pythonvalue = hash_obj.hexdigest()```4.删除数据在hash对象中,数据是不可变的,因此无法直接删除。
但可以通过清空hash对象内的所有数据来实现删除效果。
以下是一个使用Python删除hash 对象数据的示例:```pythonhash_obj.clear()```5.更新数据要更新hash对象中的数据,可以将原有数据删除后,再重新添加新数据。
c++的hash表使用方法

c++的hash表使用方法(原创版3篇)篇1 目录1.C++中的哈希表概述2.哈希表的实现原理3.哈希表的常用操作4.哈希表的性能优化篇1正文C++中的哈希表是一种常用的数据结构,它可以在常数时间内实现元素的插入、删除和查找操作。
哈希表通过哈希函数将键映射到一个桶中,每个桶中存储一个链表,从而实现快速的查找操作。
哈希表的实现原理是通过哈希函数将键映射到一个桶中,每个桶中存储一个链表,从而实现快速的查找操作。
在C++中,可以使用标准库中的unordered_map和unordered_set来实现哈希表。
哈希表的常用操作包括插入、删除和查找。
插入操作需要计算键的哈希值,然后将键值对存储到对应的桶中。
删除操作需要计算键的哈希值,找到对应的桶,然后删除对应的元素。
查找操作需要计算键的哈希值,找到对应的桶,然后遍历链表查找元素。
哈希表的性能优化可以通过以下方法实现:使用合适的哈希函数、使用开放地址法解决冲突、使用链表法实现桶的遍历等。
篇2 目录1.C++中的哈希表简介2.哈希表的实现原理3.哈希表的常用操作4.哈希表的优化技巧篇2正文C++中的哈希表是一种常用的数据结构,它可以在O(1)时间内完成查找、插入和删除操作。
哈希表通过哈希函数将键映射到一个桶中,每个桶中存储一个链表,从而实现快速查找。
以下是一些哈希表的常用操作和优化技巧。
1.哈希表的实现原理哈希表的核心是哈希函数,它将键映射到一个桶中。
常见的哈希函数有乘法哈希、平方取模哈希、开放寻址哈希等。
C++标准库中的unordered_map和unordered_set就是使用开放寻址哈希实现的。
2.哈希表的常用操作(1)插入操作:将一个键值对插入到哈希表中。
(2)查找操作:根据键查找对应的值。
(3)删除操作:删除指定的键值对。
(4)清空操作:将哈希表中的所有元素删除。
3.哈希表的优化技巧(1)散列函数的选择:选择一个好的散列函数可以提高哈希表的性能。
哈希表详解

自身函数)。若其中H(key)中已经有值了,就往下一个找,直到H(key)中没有值了,就放进去。
数字分析法: 2.
分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就
会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此
常用方法
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快地定位。 实际工作中需视不同的情况采用不同的哈希函数,通常考虑的因素有: · 计算哈希函数所需时间 · 关键字的长度 · 哈希表的大小 · 关键字的分布情况
· 记录的查找频率
1. 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a·key + b,其中a和b为常数(这种散列函数叫做
原 哈希表详解
2016年05月11日 19:58:10
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个 位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表, 函数f(key)为哈希(Hash) 函数。
1.1. di=1,2,3,…,m-1,称线性探测再散列;
1.2. di=1^2,-1^2,2^2,-2^2,⑶^2,…,±(k)^2,(k<=m/2)称二次探测再散列; 1.3. di=伪随机数序列,称伪随机探测再散列。 2. 再散列法:Hi=RHi(key),i=1,2,…,k RHi均是不同的散列函数,即在同义词产生地址冲突时计算另一个散列函数地址,直到冲突不再发 生,这种方法不易产生“聚集”,但增加了计算时间。 3. 链地址法(拉链法) 4. 建立一个公共溢出区
多级hash 表

多级hash 表摘要:一、多级哈希表概述二、多级哈希表的构建1.初始化哈希表2.插入操作3.查找操作4.删除操作三、多级哈希表的优缺点四、实际应用场景五、总结与展望正文:一、多级哈希表概述多级哈希表是一种高效的数据结构,它通过将数据分散在不同级别的哈希表中来提高查询效率。
多级哈希表的主要特点是查询速度快、空间利用率高,适用于大规模数据的存储和查询。
在实际应用中,多级哈希表常用于数据库、搜索引擎等领域。
二、多级哈希表的构建1.初始化哈希表构建多级哈希表的第一步是初始化哈希表。
根据输入数据的大小和预估的查询频率,选择合适的哈希表大小。
一般情况下,哈希表的大小为2的幂次方。
2.插入操作在多级哈希表中,插入操作分为两步。
第一步是在一级哈希表中进行插入,根据键值对的首字母或前缀字符串来确定位置。
第二步是在二级哈希表中进行插入,如果一级哈希表中找不到匹配的键值对,就将二级哈希表中对应位置的键值对向上移动一位,同时在空位置插入新的键值对。
3.查找操作查找操作同样分为两步。
第一步是在一级哈希表中查找,根据键值对的首字母或前缀字符串来确定位置。
第二步是在二级哈希表中查找,如果一级哈希表中找不到匹配的键值对,就继续在二级哈希表中查找。
4.删除操作删除操作也分为两步。
第一步是在一级哈希表中删除,将不再使用的键值对移动到二级哈希表中。
第二步是在二级哈希表中删除,采用最近最少使用(LRU)算法删除久未使用的键值对。
三、多级哈希表的优缺点多级哈希表的优点主要有以下几点:1.查询速度快:多级哈希表通过将数据分散在不同级别的哈希表中,大大提高了查询速度。
2.空间利用率高:多级哈希表的二级哈希表可以缓存一级哈希表中久未使用的数据,提高了空间利用率。
3.适用于大规模数据:多级哈希表适用于大规模数据的存储和查询,可以在较低的内存消耗下实现高效的数据处理。
缺点:1.插入和删除操作较复杂:多级哈希表的插入和删除操作需要涉及到多个级别的哈希表,因此相对复杂。
hash全表遍历的方法(一)

hash全表遍历的方法(一)Hash全表遍历的方法简介在计算机科学中,散列表(Hash Table)是一种使用哈希函数进行插入或检索的数据结构。
散列表的优势在于可以快速进行查找、插入和删除操作。
然而,当需要遍历整个散列表时,就需要使用hash全表遍历的方法。
方法一:线性探查1.初始化一个游标指向散列表的第一个元素。
2.通过哈希函数计算下一个位置。
3.如果该位置为空,则遍历结束。
4.如果该位置不为空,则进行相应的操作,然后将游标指向下一个位置。
5.重复步骤2-4,直到遍历结束。
方法二:二次探查1.初始化一个游标指向散列表的第一个元素。
2.通过哈希函数计算下一个位置,但是与线性探查不同,每次都会加上一个平方值作为偏移量。
4.如果该位置不为空,则进行相应的操作,然后将游标指向下一个位置。
5.重复步骤2-4,直到遍历结束。
方法三:链表法1.初始化一个游标指向散列表的第一个元素。
2.如果该位置为空,则遍历结束。
3.如果该位置不为空,则进行相应的操作,然后将游标指向链表的下一个元素。
4.如果链表为空,则将游标指向下一个位置。
5.重复步骤2-4,直到遍历结束。
方法四:双散列法1.初始化一个游标指向散列表的第一个元素。
2.通过两个哈希函数计算下一个位置,然后选择其中一个作为偏移量。
3.如果该位置为空,则遍历结束。
4.如果该位置不为空,则进行相应的操作,然后将游标指向下一个位置。
总结通过hash全表遍历的方法,可以遍历散列表中的所有元素。
线性探查、二次探查、链表法和双散列法是常用的四种方法。
选择适合的遍历方法需要考虑散列表的特点和应用场景。
在实际编程中,可以根据需求选择合适的方法进行操作。
以上就是关于hash全表遍历的方法的详细说明。
希望对读者有所帮助!。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
课程设计任务书学生姓名:邓伯华专业班级:计算机0502 指导教师:宋华珠工作单位:计算机科学与技术学院题目: Hash表的建立和查找初始条件:理论:学习了《数据结构》课程,掌握了基本的数据结构和常用的算法;实践:计算机技术系实验室提供计算机及软件开发环境。
要求完成的主要任务:(包括课程设计工作量及其技术要求,以及说明书撰写等具体要求)1、系统应具备的功能:(1)设计哈希函数和哈希表;(2)设计解决冲突的方法;(3)输入一组数据建立哈希表,并实现在哈希表中进行查找。
2、数据结构设计;3、主要算法设计;4、编程及上机实现;5、撰写课程设计报告,包括:(1)设计题目;(2)摘要和关键字;(3)正文,包括引言、需求分析、数据结构设计、算法设计、程序实现及测试、结果分析、设计体会等;(4)结束语;(5)参考文献。
时间安排:2007年7月2日-7日(第18周)7月2日查阅资料7月3日系统设计,数据结构设计,算法设计7月4日-5日编程并上机调试7月6日撰写报告7月7日验收程序,提交设计报告书。
指导教师签名: 2007年7月2日系主任(或责任教师)签名: 2007年7月2日Hash表的建立和查找摘要:本人设计了一个Hash表的建立和查找系统,其主要功能是,用户可以手工输入Hash表元素个数和各个元素的数据内容,系统便相应地建立一个Hash 表,(输入错误时,系统会显示输入错误,并提示重新输入);可对已建立的Hash 表进行多次查找,系统打印查找到的信息,用户可以按提示信息退出系统。
Hash 表采用结构体数组进行存储,Hash函数由除留余数法建立,冲突的解决采用线性探测。
关键字:Hash表,结构体数组,除留余数法,线性探测0.引言随着时代的进步,科技的发展,信息时代已经来临,在这样的时代背景之下,人们迫切需要对信息进行存储和查找,而数据结构成为了信息技术中极为重要的一门学科,发挥着关键作用。
信息资料之多﹑之杂﹑之广,使如何存储和高效查找信息成为了一个很严肃的问题。
本次课程设计中,我设计了一个小程序对用户输入的数据利用Hash表进行存储。
存储完成后,用户可利用Hash表查找数据,速度十分快,可多次查找,也可按提示信息退出。
1.需求分析本次课程设计需要实现Hash表的建立和查找,具体内容如下:1.1 Hash 表的建立建立Hash函数,从而根据用户输入的数据元素个数和各元素的值建立Hash 表,即数据的添加和存储。
如果输入的元素个数超出规定范围,则打印出错信息,并提示重新输入信息。
1.2 Hash 表的查找Hash表建立好之后,用户可以输入想要查找的值,屏幕显示相应信息。
如果存在此值,屏幕显示该值信息;如果不存在,则显示该值不存在;如果想退出系统,则按提示输入命令。
2.数据结构设计2.1定义结构体typedef struct{int key; //定义关键字int cn; //定义查找次数cn}hashtable; //定义哈希表类型2.2定义结构体数组hashtable ht[hm]; //定义哈希表空间3.算法设计3.1 Hash函数该函数利用除留余数法实现“Hash 函数”#define m 19 //不大于表长的最大质数Status h(keytype key){//哈希函数return(key%m); //除留余数法}//h3.2信息查找函数这个函数能查找信息,它既能用于查找所输入信息,又能在建立Hash的时候被建立Hash表的函数调用。
用户可以输入想要查找的值,屏幕显示相应信息。
如果存在此值,屏幕显示该值信息;如果不存在,则显示该值不存在;如果想退出系统,则按提示输入命令。
Status HashSearch(hashtable ht[],keytype key){//哈希表查找函数int d,i;i=0;d=h(key); //求哈希地址ht[d].cn=0; //记录元素被查找的次数while((ht[d].key!=key)&&(ht[d].key!=free)&&(i<hm)){//元素位置冲突时,进行线性探测i++; //寻找下一个单元ht[d].cn++; //寻找次数加1d=(d+i)%m; //线性探测记录的插入位置}if(i>=hm){//Hash表已满,插入失败,返回unsuccessprintf("The hashtable is full!\n");return(unsuccess);}return(d); //若h[d]的关键字等于key说明查找成功}//hashsearch3.3数据输入函数此函数能够对用户输入的数据进行处理,即将输入数据插入Hash表中。
它调用了Hash函数。
如果插入成功,显示插入成功信息;如果插入不成功,则显示插入不成功信息。
Status HashInsert(hashtable ht[],keytype key){//哈希插入函数,插入成功返回success,插入不成功返回unsuccess//查找不成功的时候,将给定关键字key插入哈希表中int d;d=HashSearch(ht,key);if(ht[d].key==free){//插入成功ht[d].key=key;printf("Insert success!\n");return(success);}else{//插入不成功printf("Uneuccess!\n");return(unsuccess);}}//HashInseart3.4建立Hash表函数此函数能够根据用户输入的数据建立Hash表,并将所有数据存入表中。
如果输入数据不和理(即输入的数据长度大于或等于表长,或小于0),屏幕会提示错误信息,并提示用户重新输入正确的数据值;如果输入数据合理(即输入的表长大于等于0,小于表长),用户就可以按提示信息输入表元素,哈希表就会被成功建立。
Hash表的建立也利用了除留余数法,所以该函数调用了哈希表插入运算函数。
void HashCreat(hashtable ht[]){//根据用户输入的信息建立一个哈希表int n;int i;int key1;printf("Input the number of the elements(less than the length of the list %dand no less than 0):\n",hm); //提示输入规定范围内的长度scanf("%d",&n); //输入表长if(n>=20) //输入不合理的表长度printf("Please input a length less than 20:\n");//表长大于等于20 else{if(n<0) printf("Please input a length no less than 0:\n");//表长小于0 }while(n<0||n>=20) //输入表长度合理{scanf("%d",&n);if(n>=20)printf("Please input a length less than 20:\n"); //表长大于等于20 else{if(n<0) printf("Please input a length no less than 0:\n"); //表长小于0 }}for(i=0;i<n;i++){//依次插入用户输入的各个元素的数据printf("Input the key word:\n");scanf("%d",&key1); //输入元素数据HashInsert(ht,key1); //调用哈希表插入运算}}//HashCreat3.5主要界面的设计void jiemian(){//主界面设计hashtable ht0[hm]; //分配Hash表的空间int key0=0; //初始化为0float key1=0; //初始化为0int i;printf("Build the hash list:\n"); //提示建立信息HashCreat(ht0); //建立Hash表printf("Now you can search in the hash list:\n"); //提示用户查找printf("Input the key word of the element required to search\n(If you want to exit ,input a figure bigger than 0 and small than 1.):\n");scanf("%f",&key1); //输入想要查找的数据key0=(int)key1;while((key1-(float)key0)==0){//多次查找输入的数据,系统显示相应结果//按提示退出系统i=HashSearch(ht0,key0);if(ht0[i].key==key0) {//存在该元素时printf("%d exists in the list.\n ",key0); //打印存在信息printf("Its pose is num.%d\n\n",i); //打印元素位置}elseprintf("There is no %d in the list.\n\n",key0);printf("Input the key word of the element required to search\n(If you want toexit ,input a figure bigger than 0 and small than 1.):\n"); //提示用户退出scanf("%f",&key1); //用户继续输入数据key0=(int)key1; //key0是key1的整数部分}}//jiemian3.6其他有关技术讨论我这个程序选用结构体数组为存储结构,实现了Hash表的数据存储。
Hash 表查找给予一种尽可能不通过比较操作而直接得到记录的存储位置的想法而提出的一种特殊查找技术。
它的基本思想是通过记录中关键字的值key为自变量,通过某一种确定的函数h,计算出函数值h(key)作为存储地址,将相应的关键字的记录存储到对应的位置上。